Reducing state updates via Gaussian-gated LSTMs
Matthew Thornton, Jithendar Anumula, Shih-Chii Liu

TL;DR
This paper introduces the Gaussian-gated LSTM (g-LSTM), a novel RNN architecture that improves long-term dependency learning, reduces computation, and accelerates convergence through timing gates and curriculum learning.
Contribution
The paper proposes a timing-gated LSTM model with learnable Gaussian time gates that enhance long-term memory, reduce computation, and improve training efficiency over standard LSTMs.
Findings
g-LSTM captures long-term dependencies better than LSTM
The model reduces computation by at least 10x
Curriculum learning accelerates convergence on long sequences
Abstract
Recurrent neural networks can be difficult to train on long sequence data due to the well-known vanishing gradient problem. Some architectures incorporate methods to reduce RNN state updates, therefore allowing the network to preserve memory over long temporal intervals. To address these problems of convergence, this paper proposes a timing-gated LSTM RNN model, called the Gaussian-gated LSTM (g-LSTM). The time gate controls when a neuron can be updated during training, enabling longer memory persistence and better error-gradient flow. This model captures long-temporal dependencies better than an LSTM and the time gate parameters can be learned even from non-optimal initialization values. Because the time gate limits the updates of the neuron state, the number of computes needed for the network update is also reduced. By adding a computational budget term to the training loss, we can…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1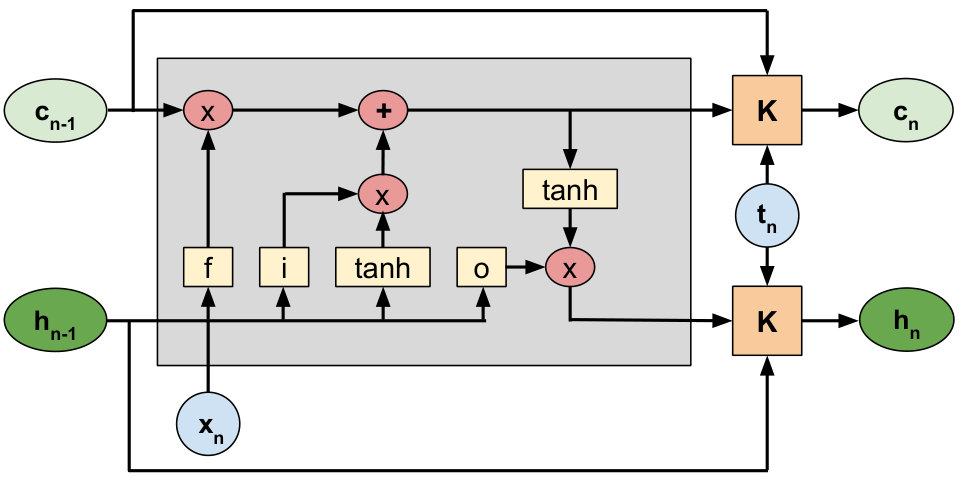 Figure 2
Figure 2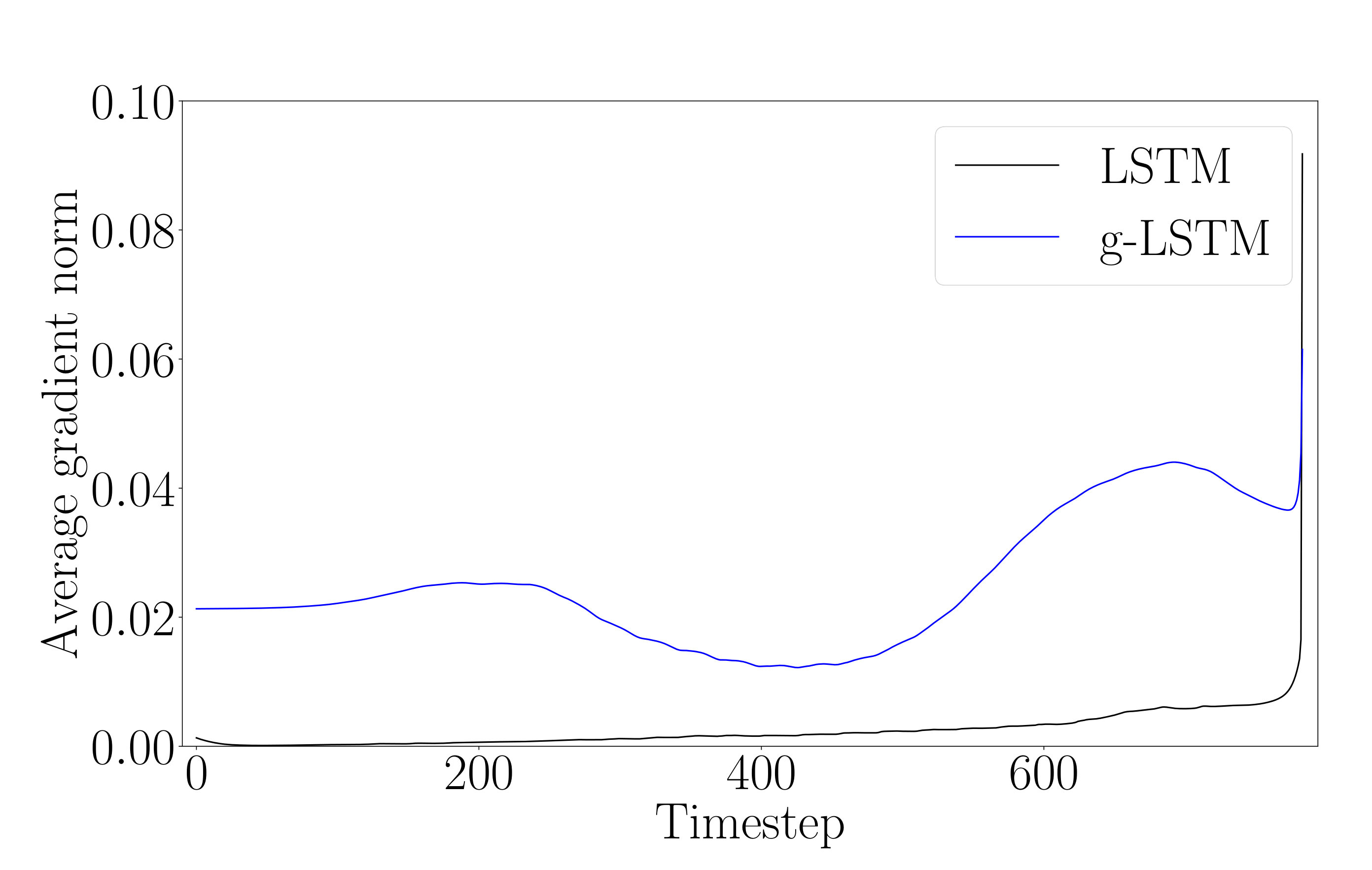 Figure 3
Figure 3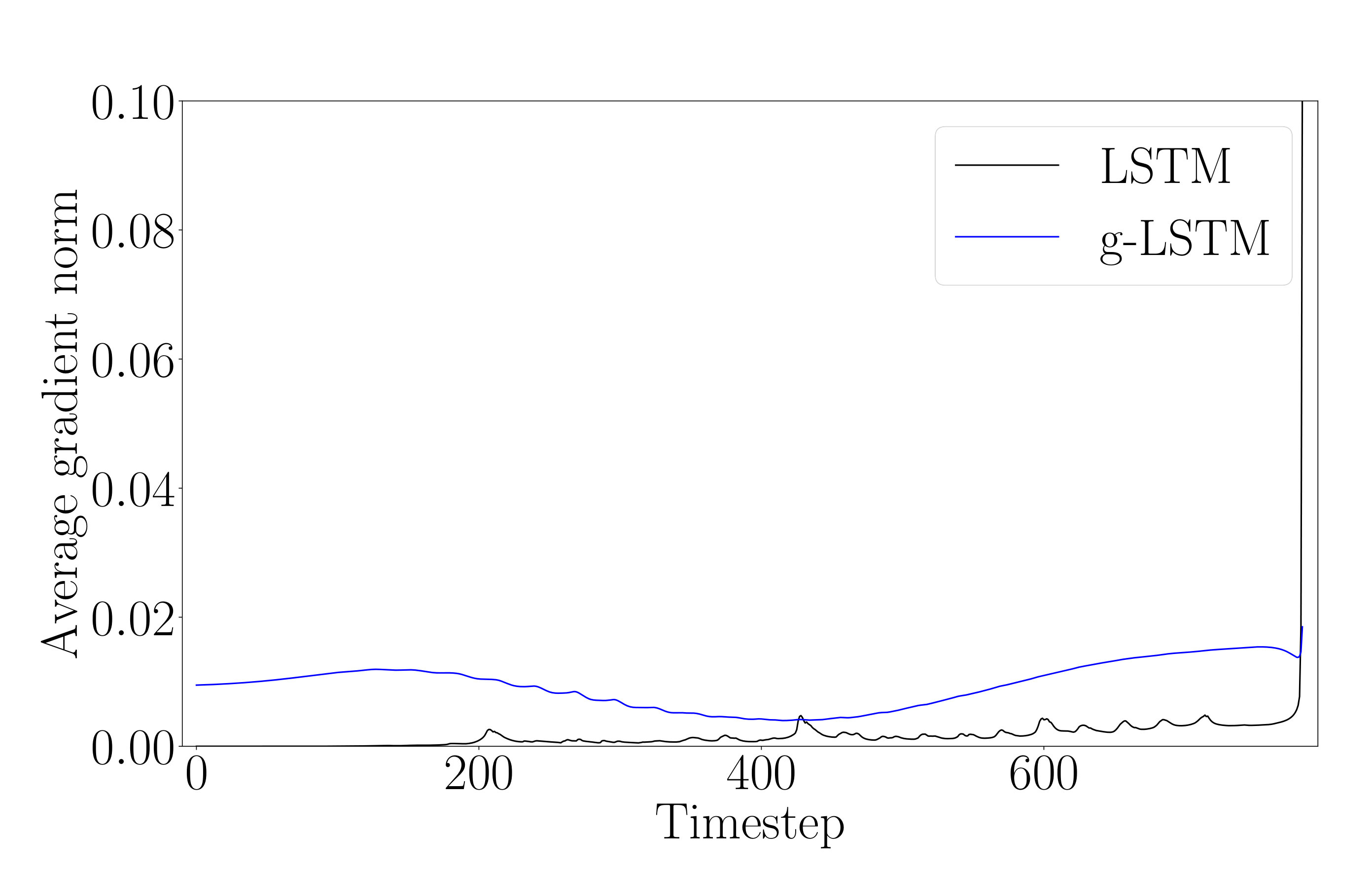 Figure 4
Figure 4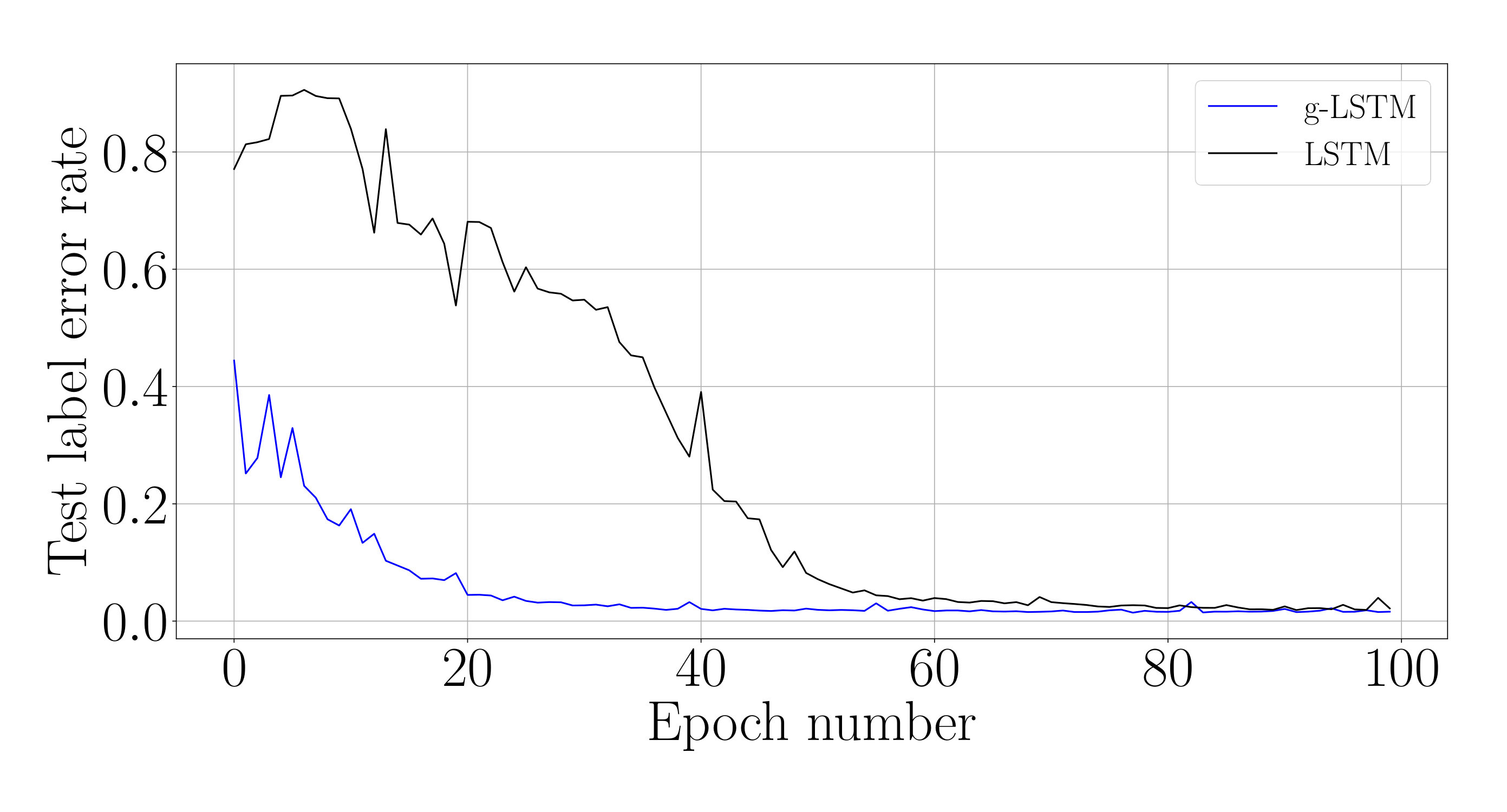 Figure 5
Figure 5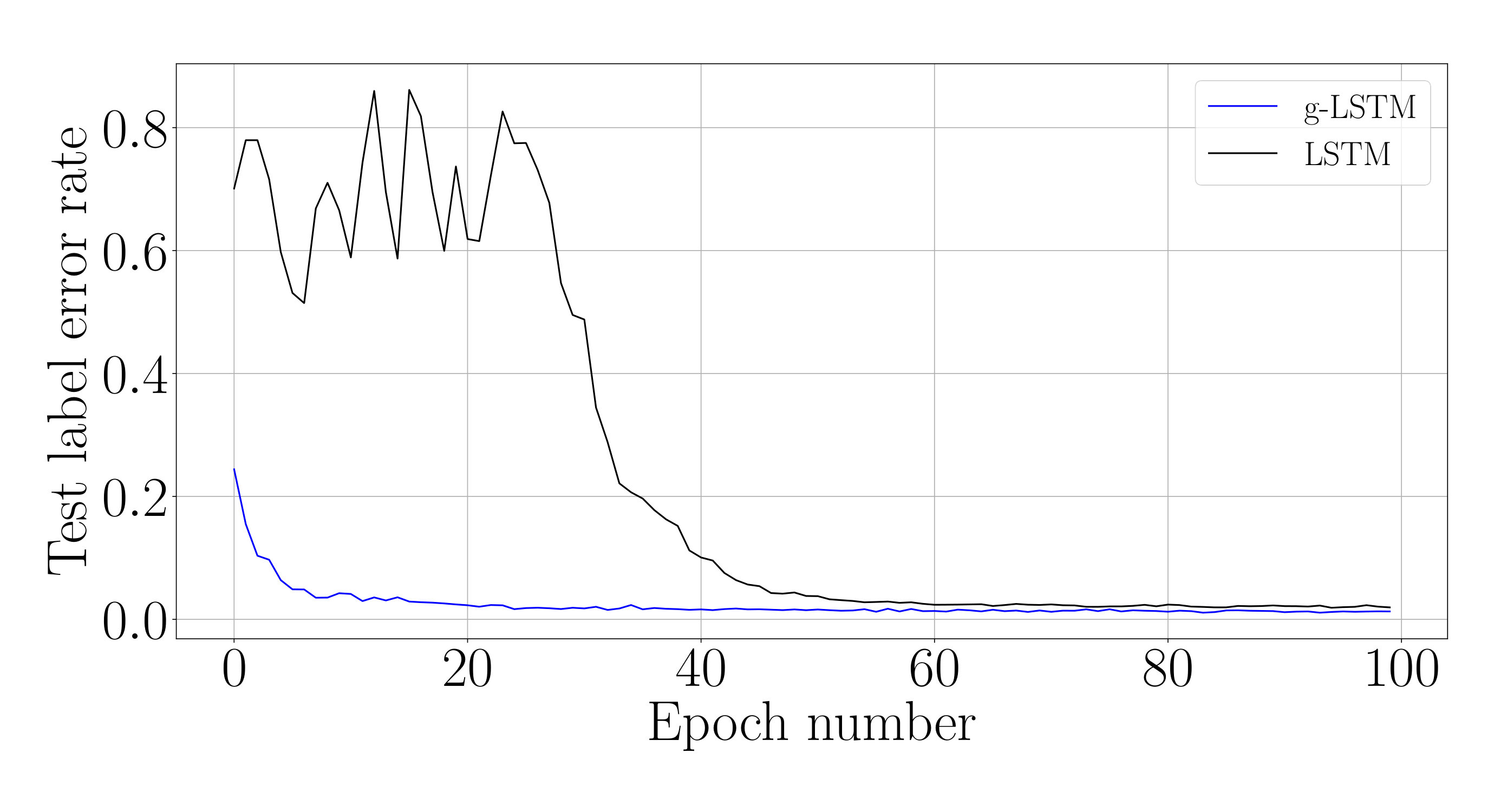 Figure 6
Figure 6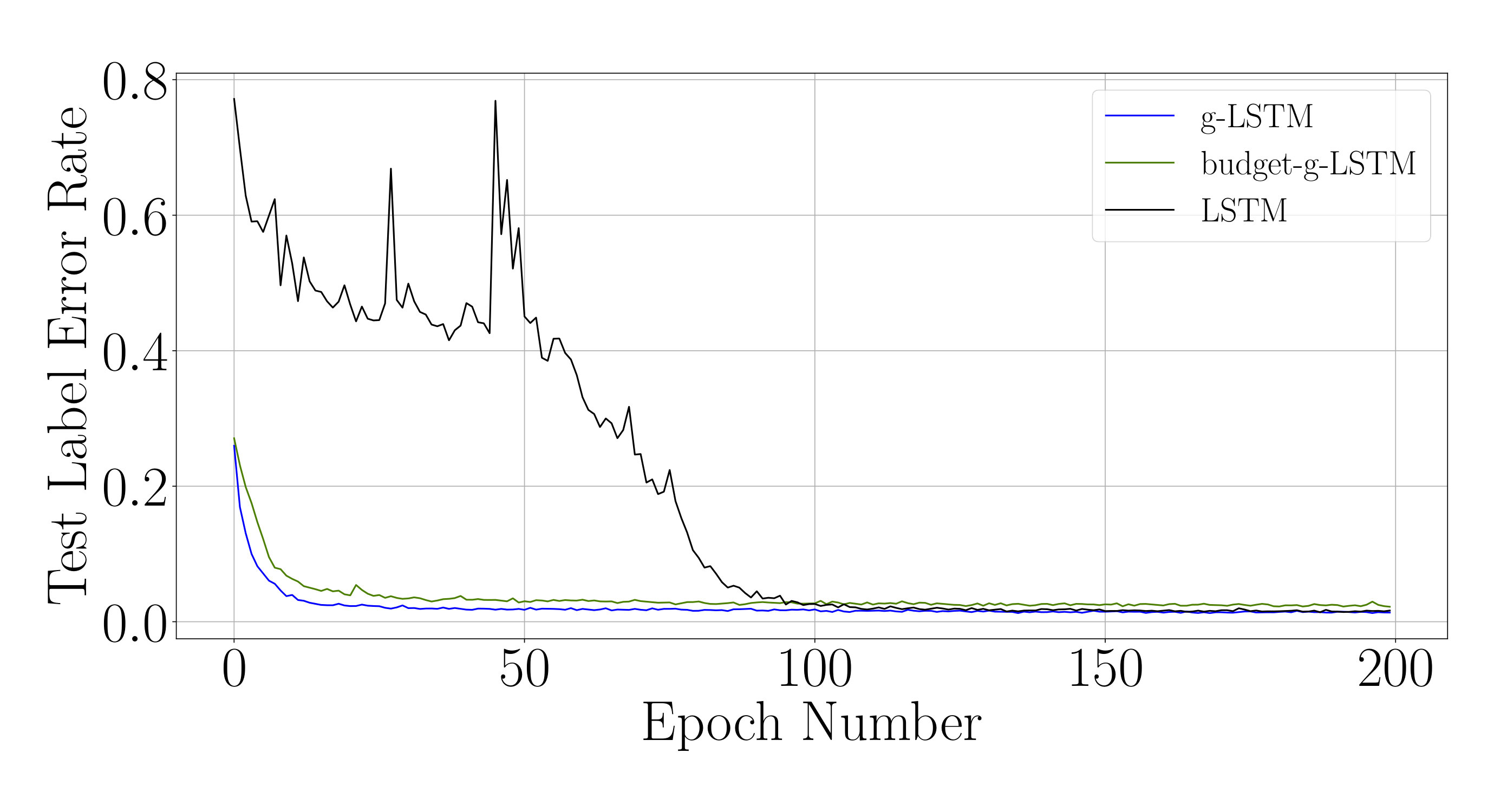 Figure 7
Figure 7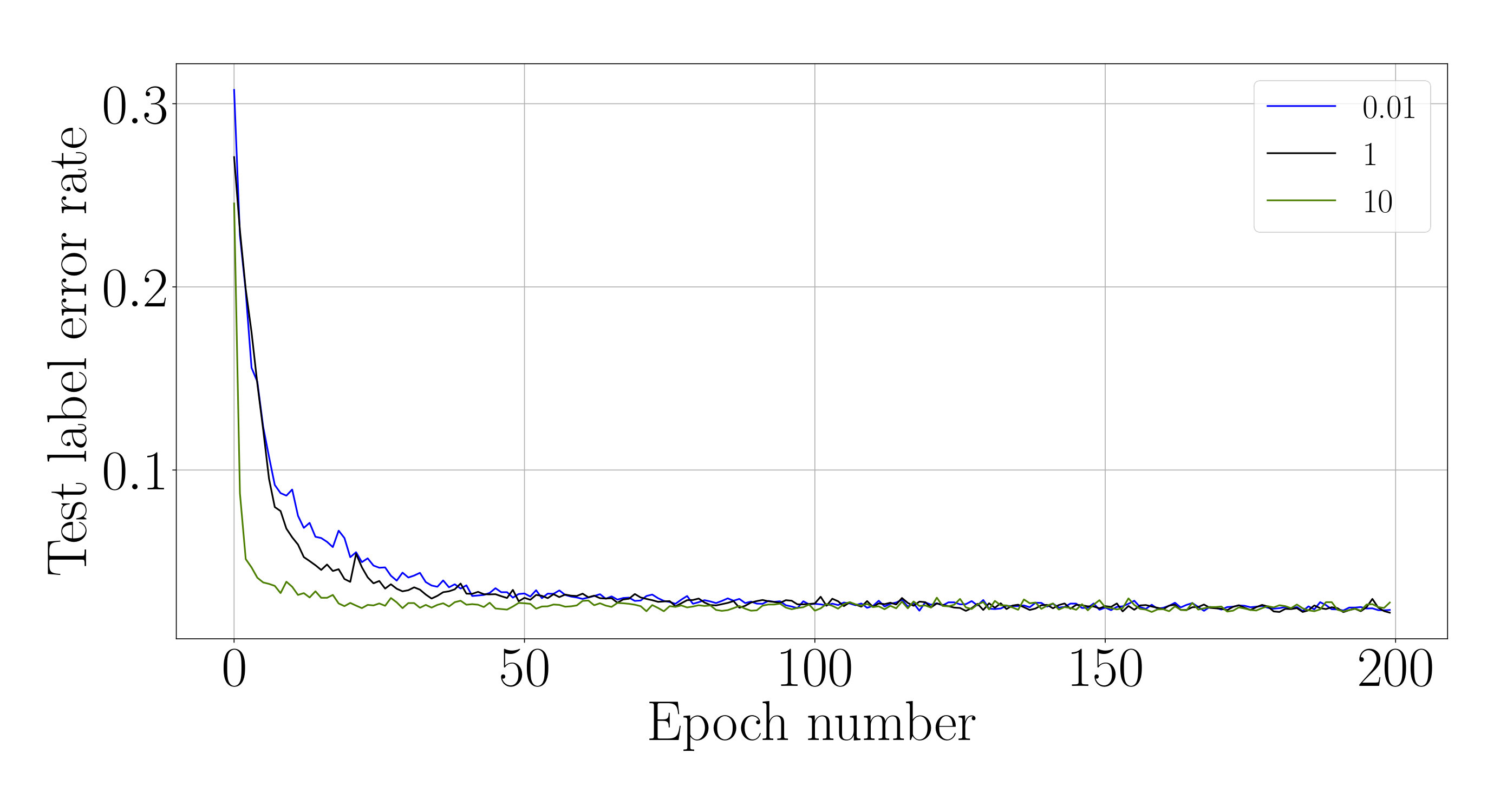 Figure 8
Figure 8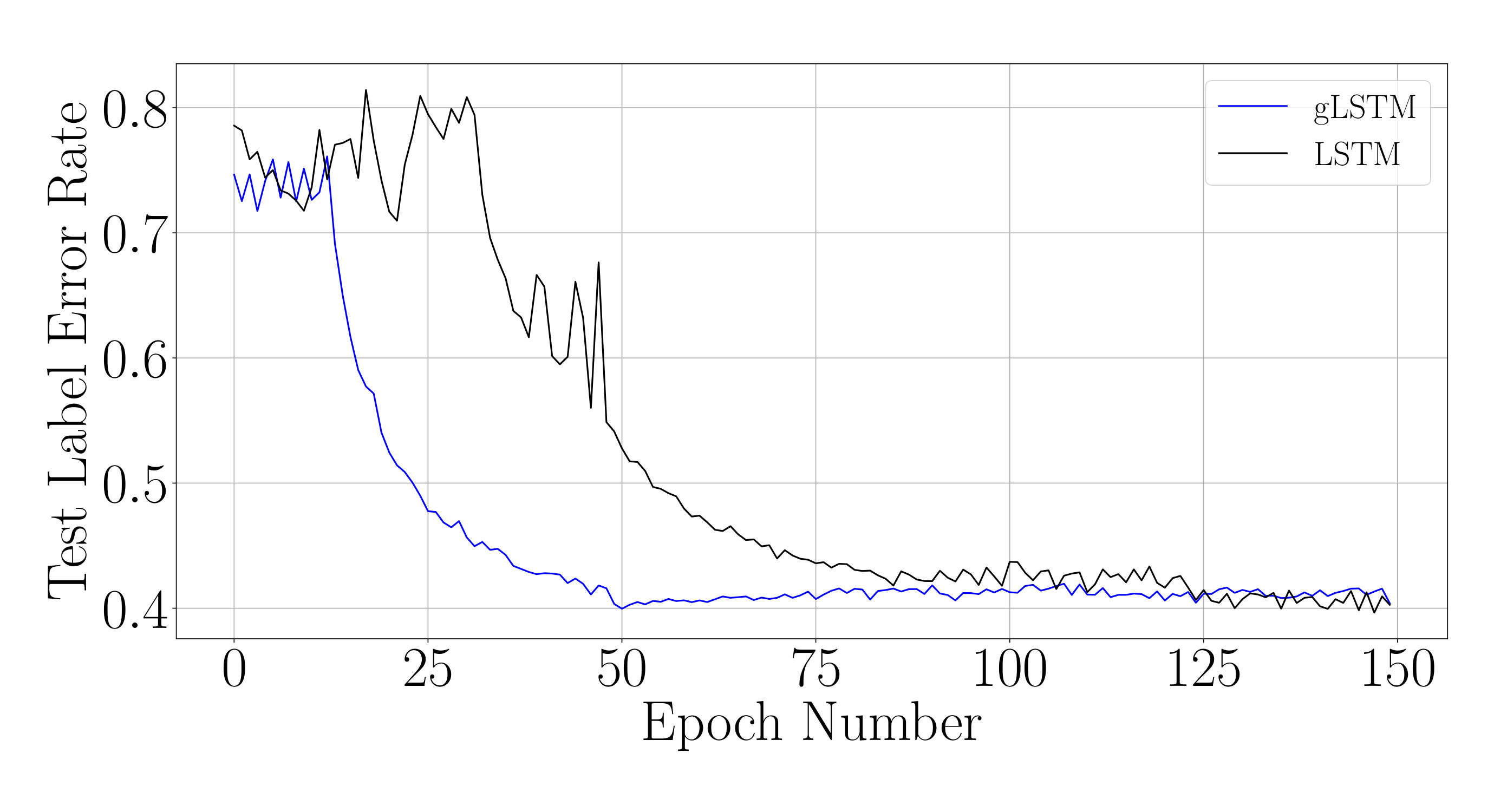 Figure 9
Figure 9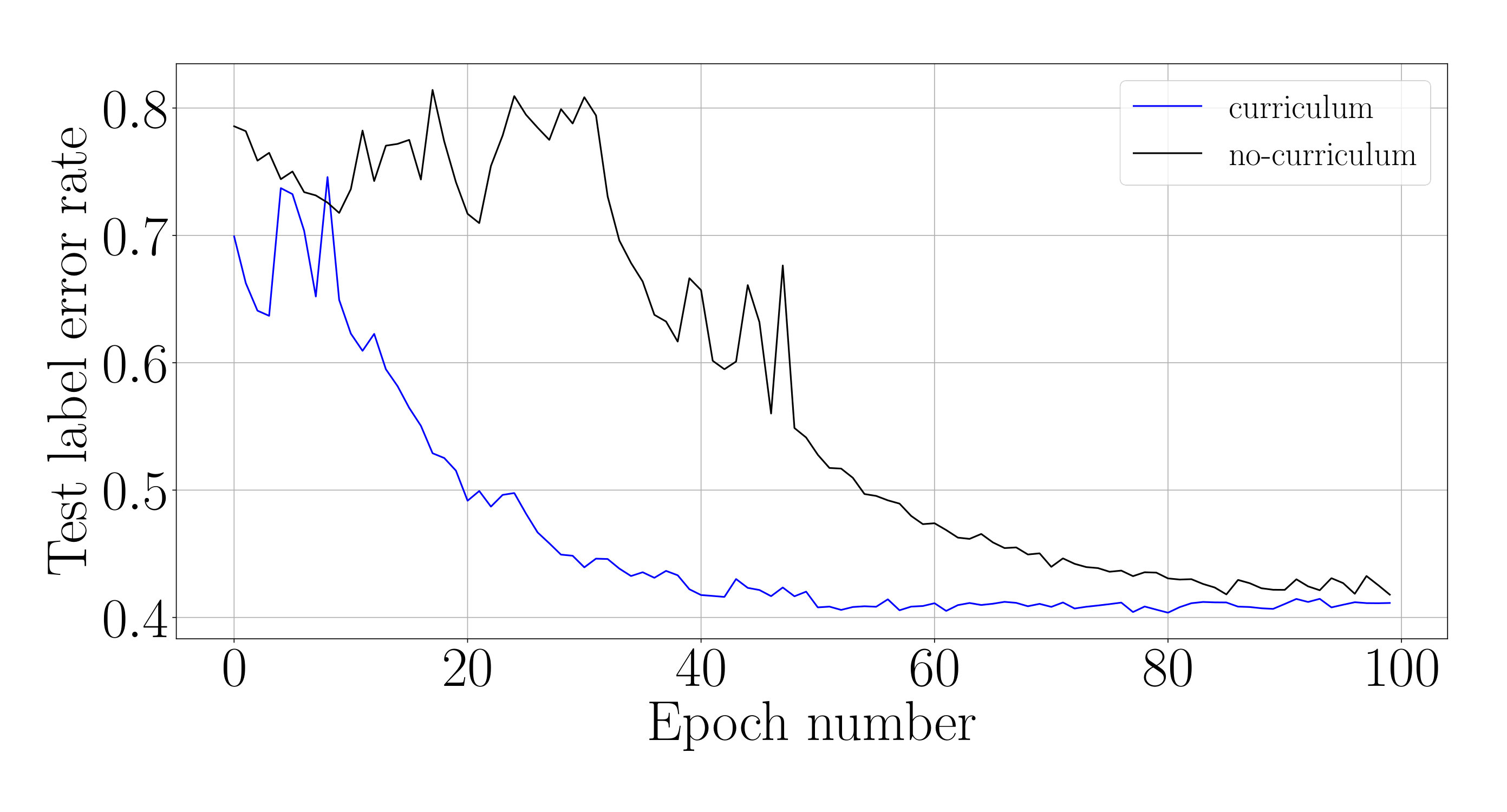 Figure 10
Figure 10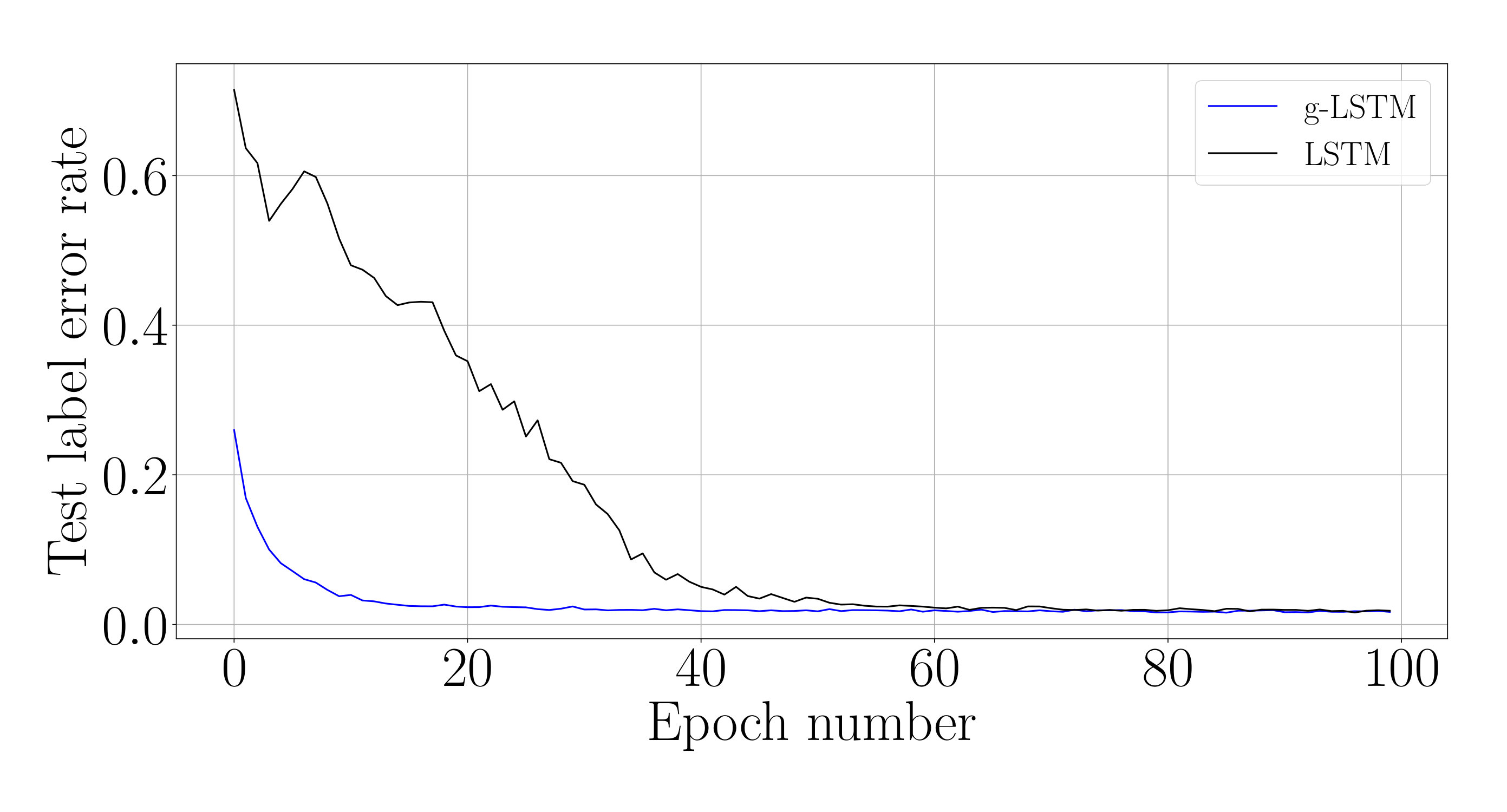 Figure 11
Figure 11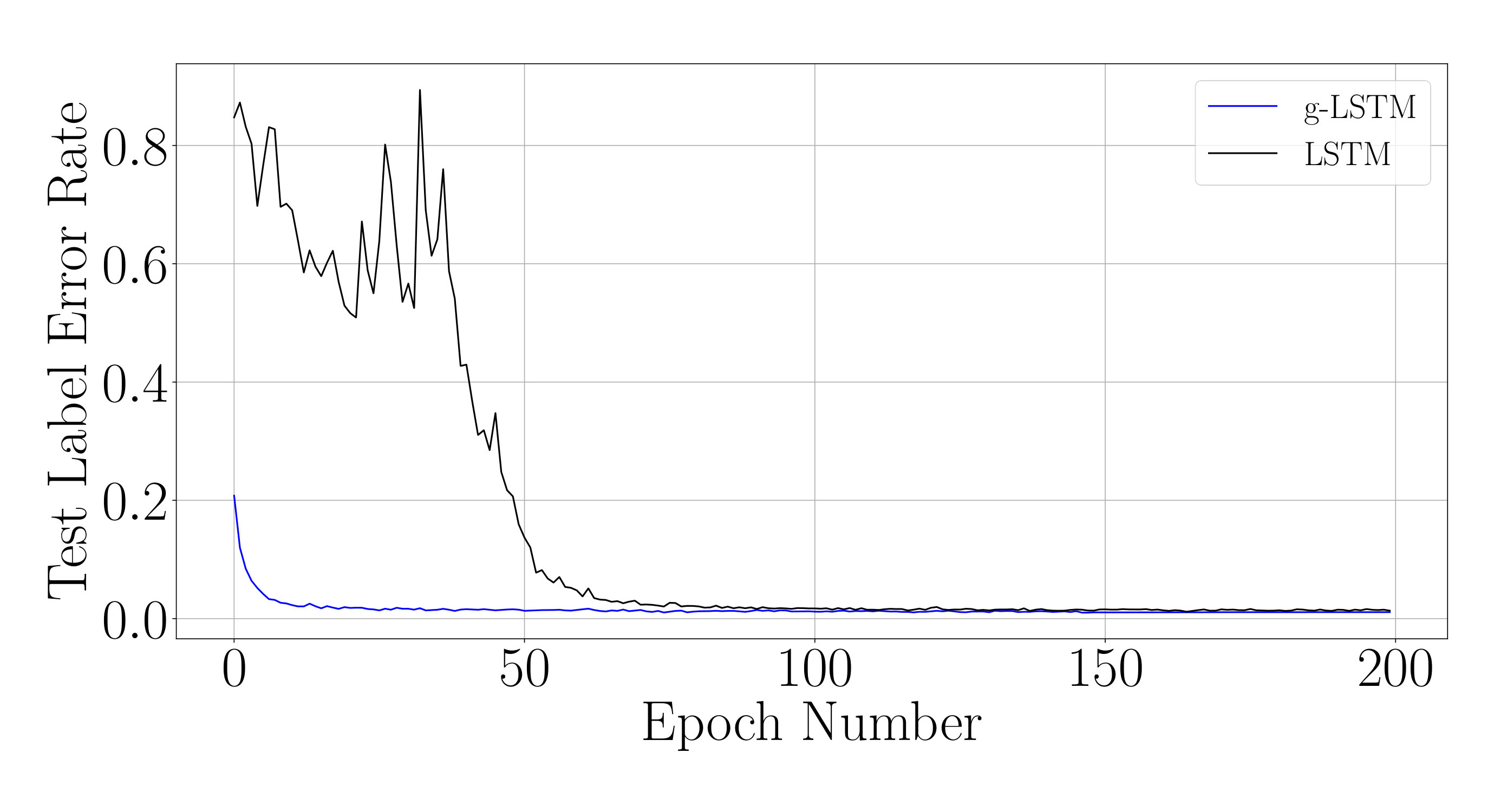 Figure 12
Figure 12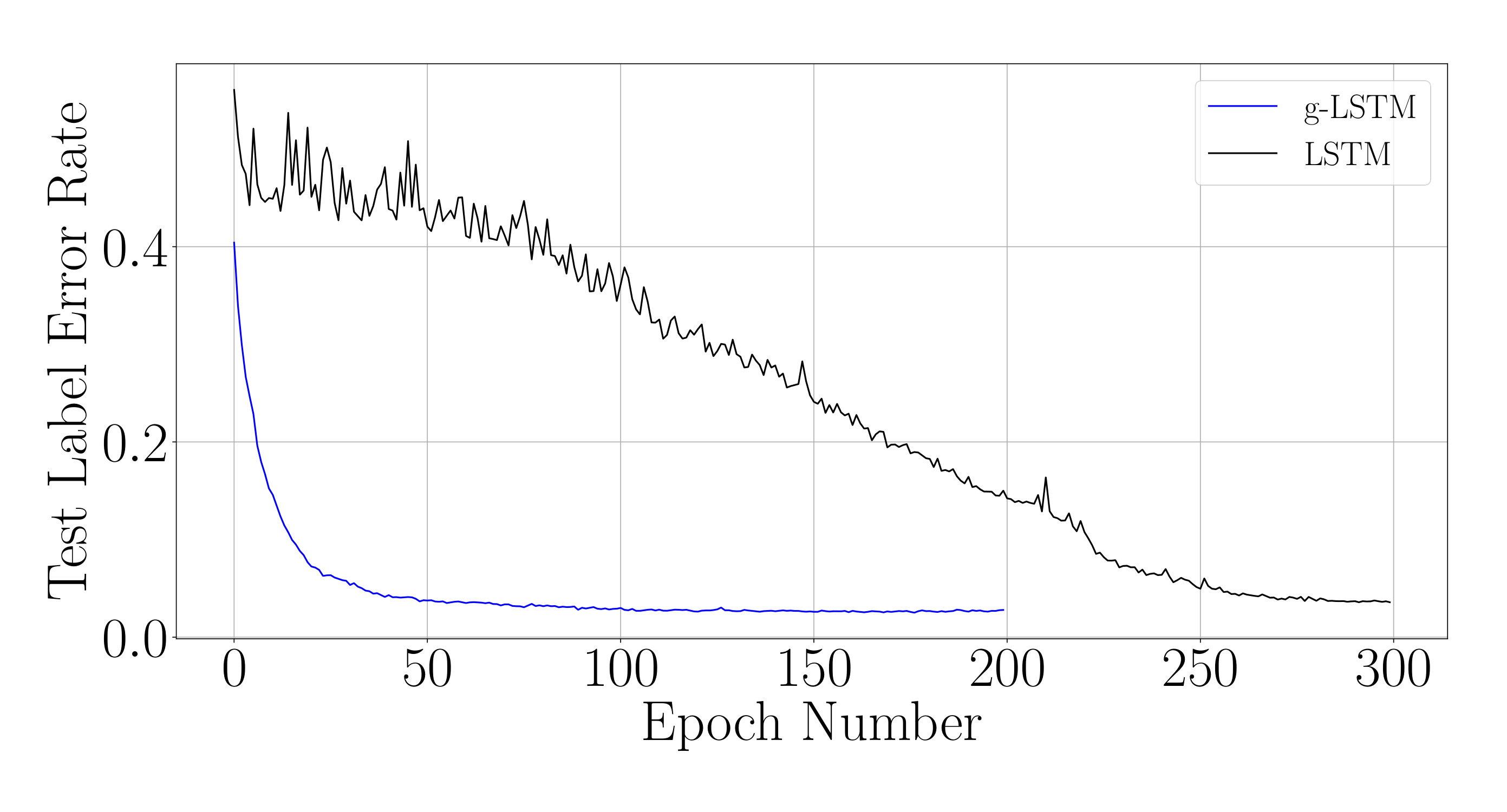 Figure 13
Figure 13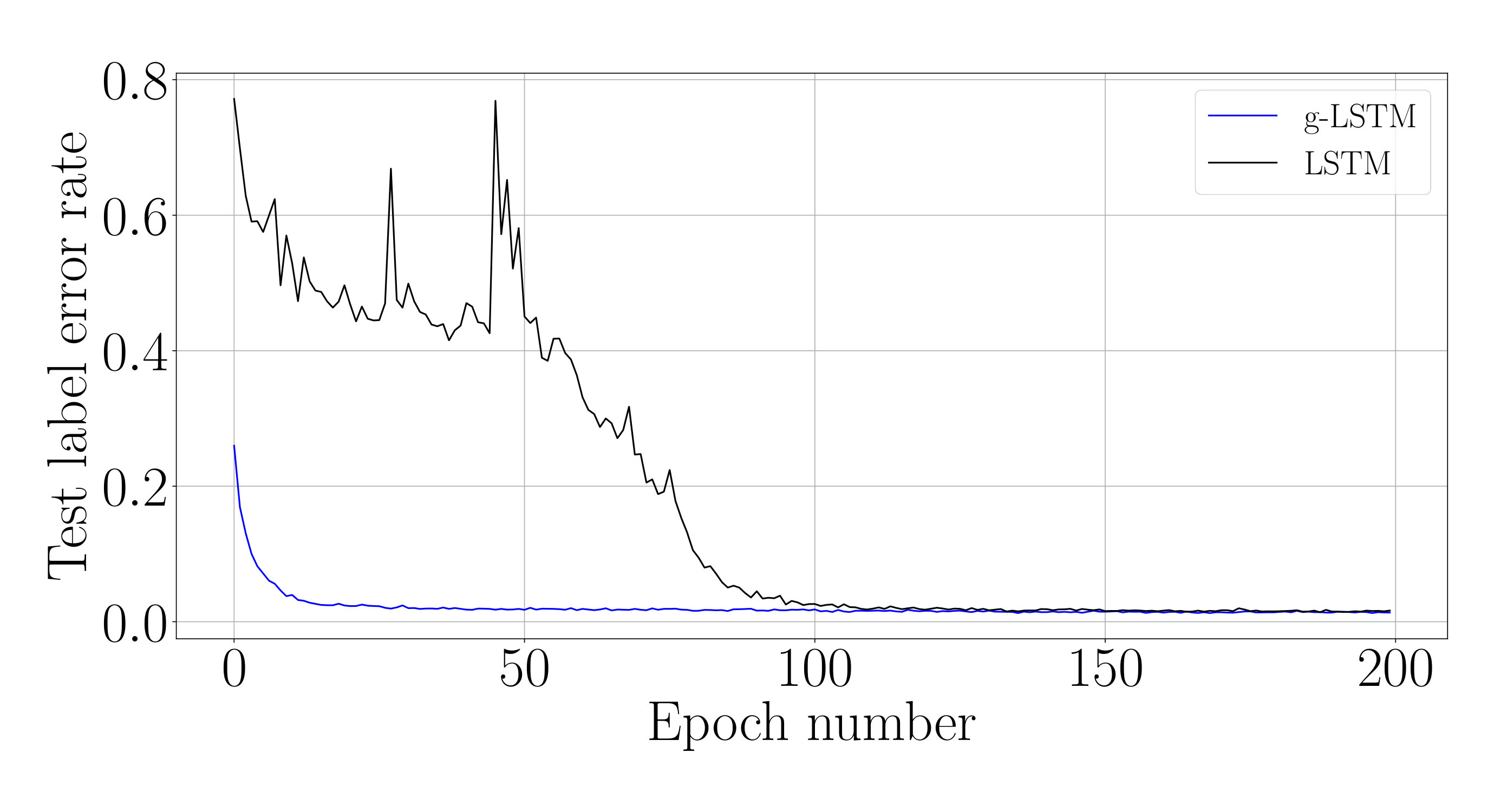 Figure 14
Figure 14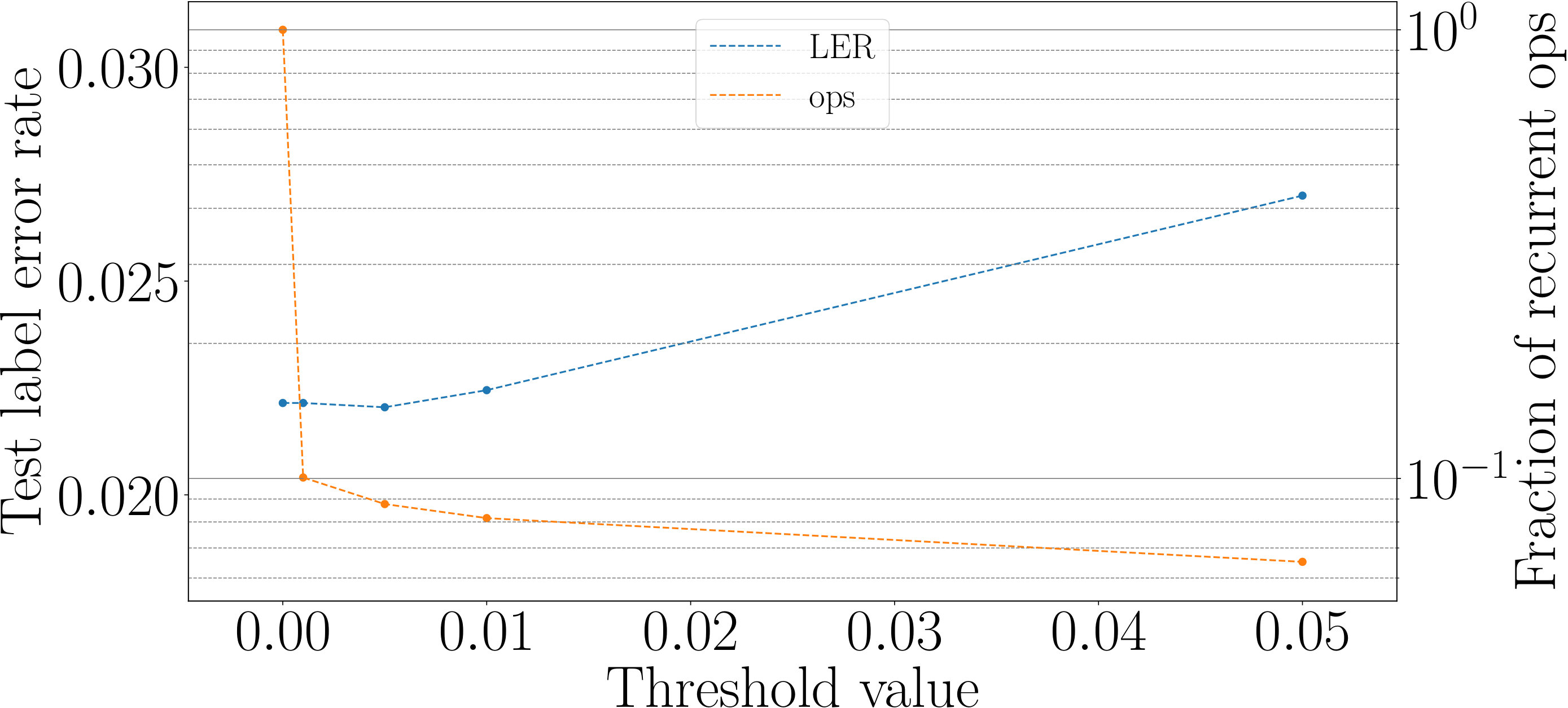 Figure 15
Figure 15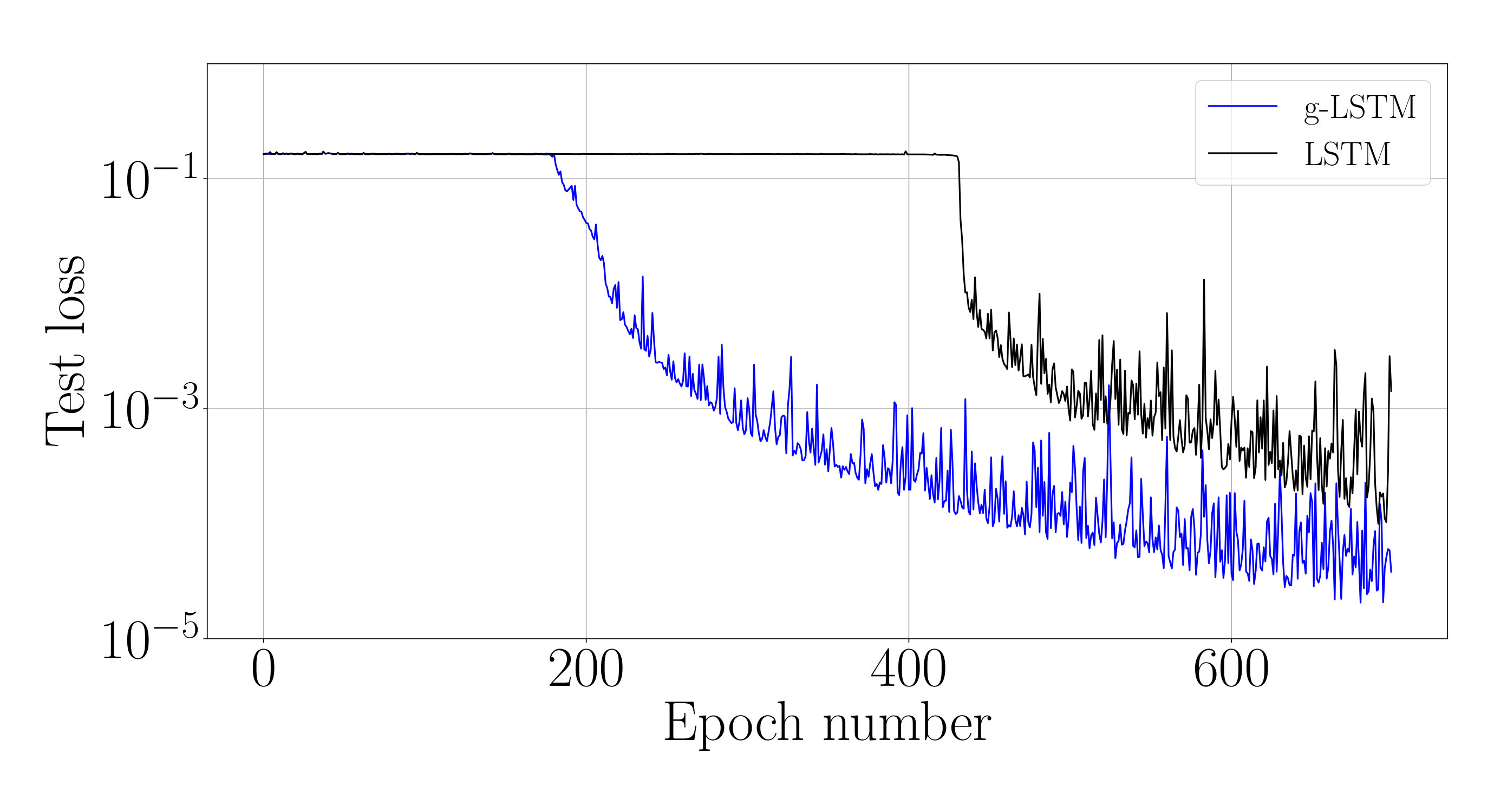 Figure 16
Figure 16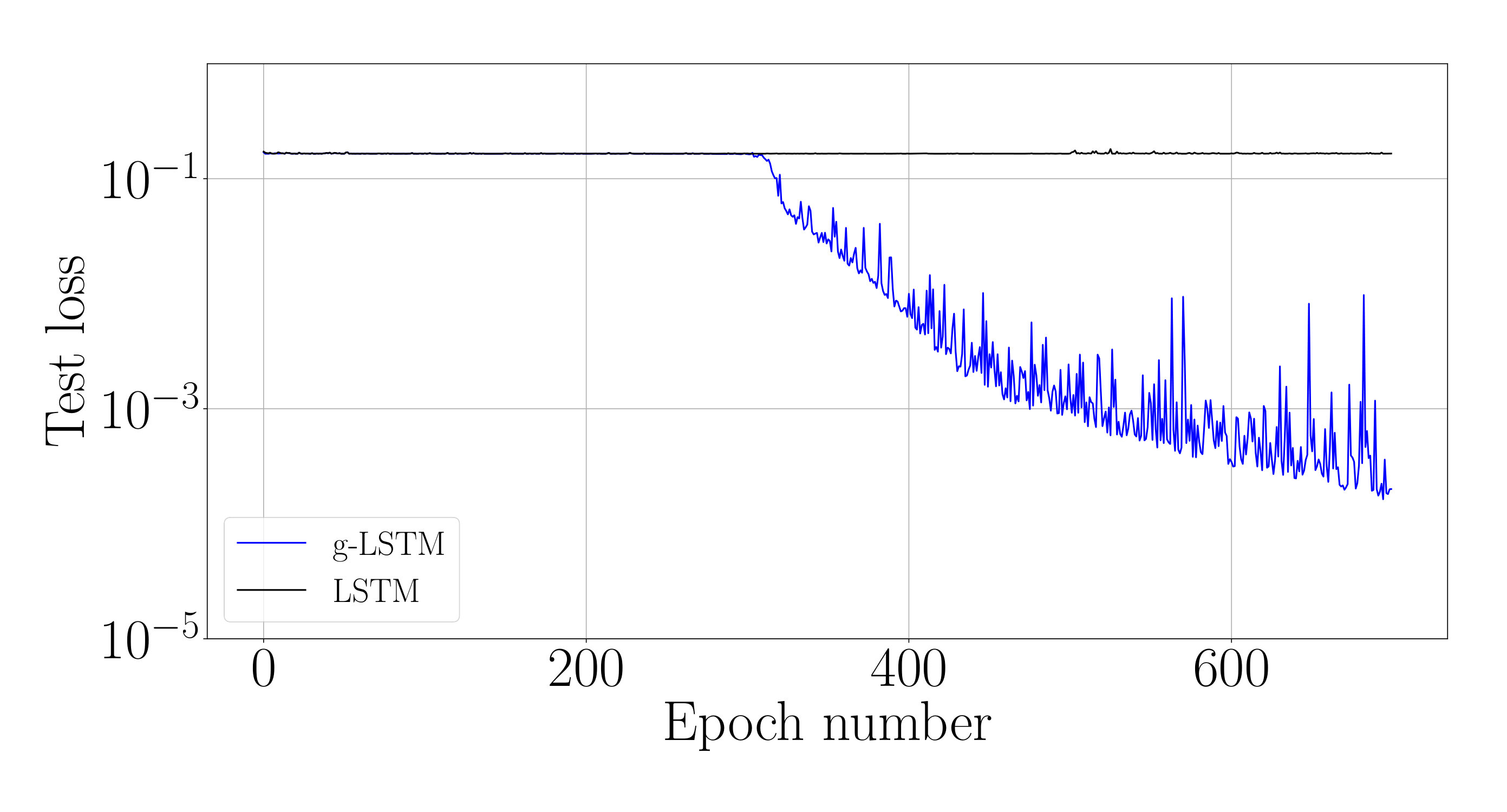 Figure 17
Figure 17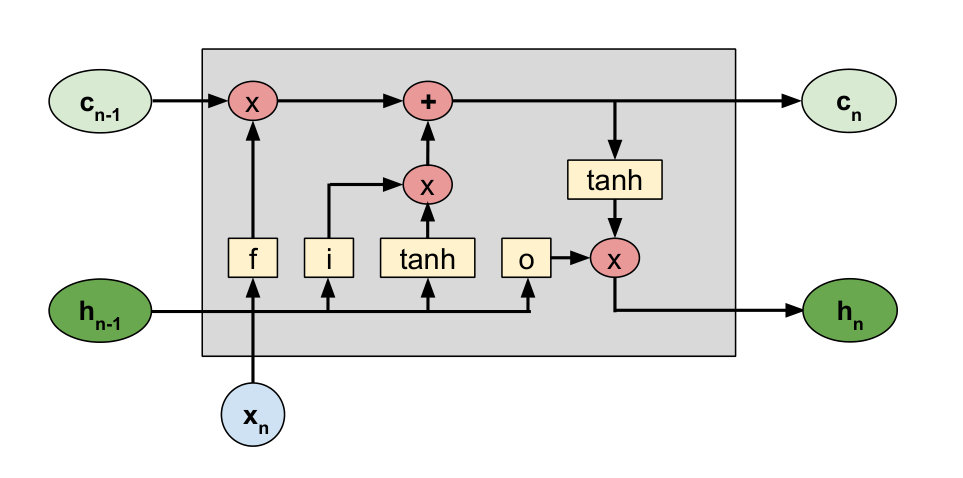 Figure 18
Figure 18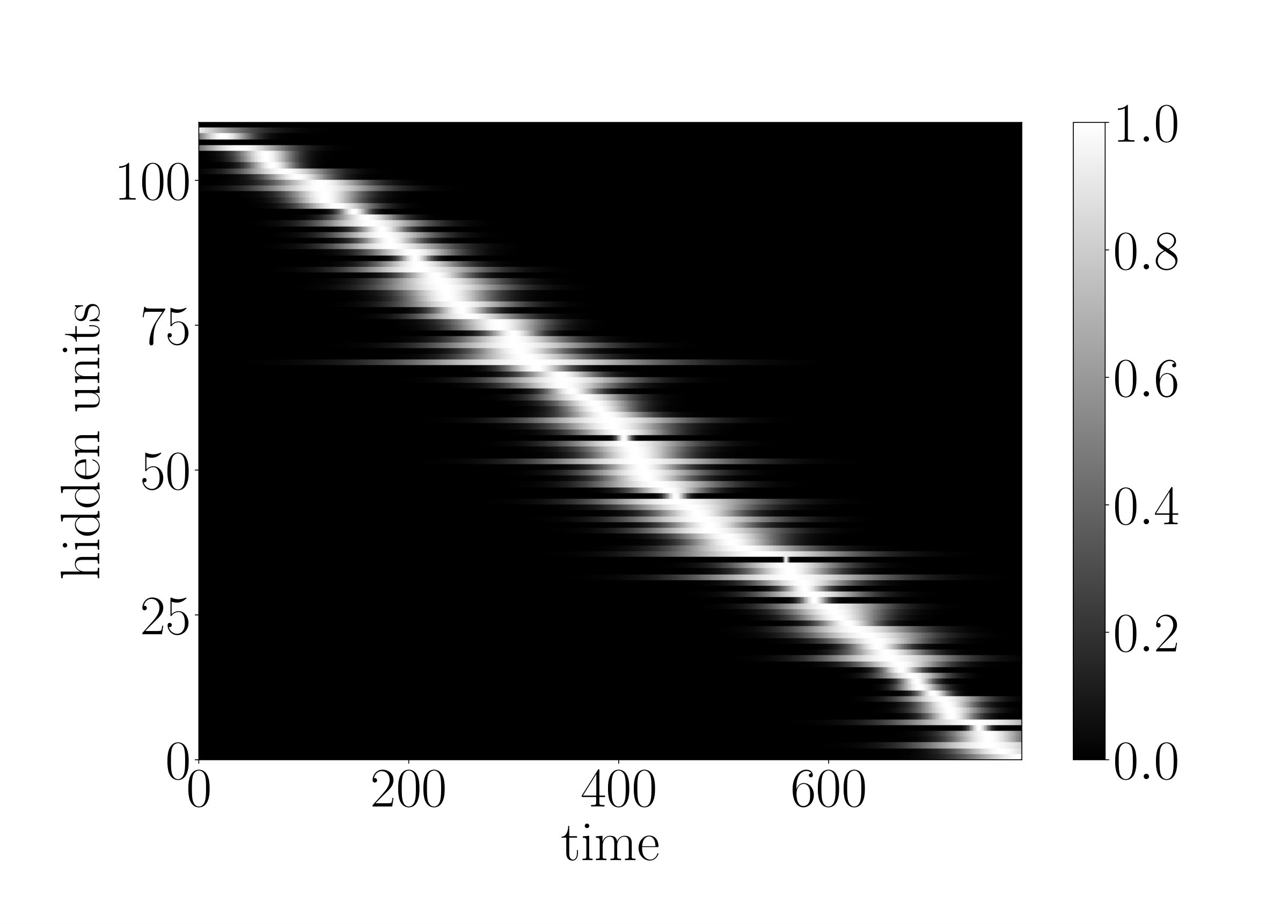 Figure 19
Figure 19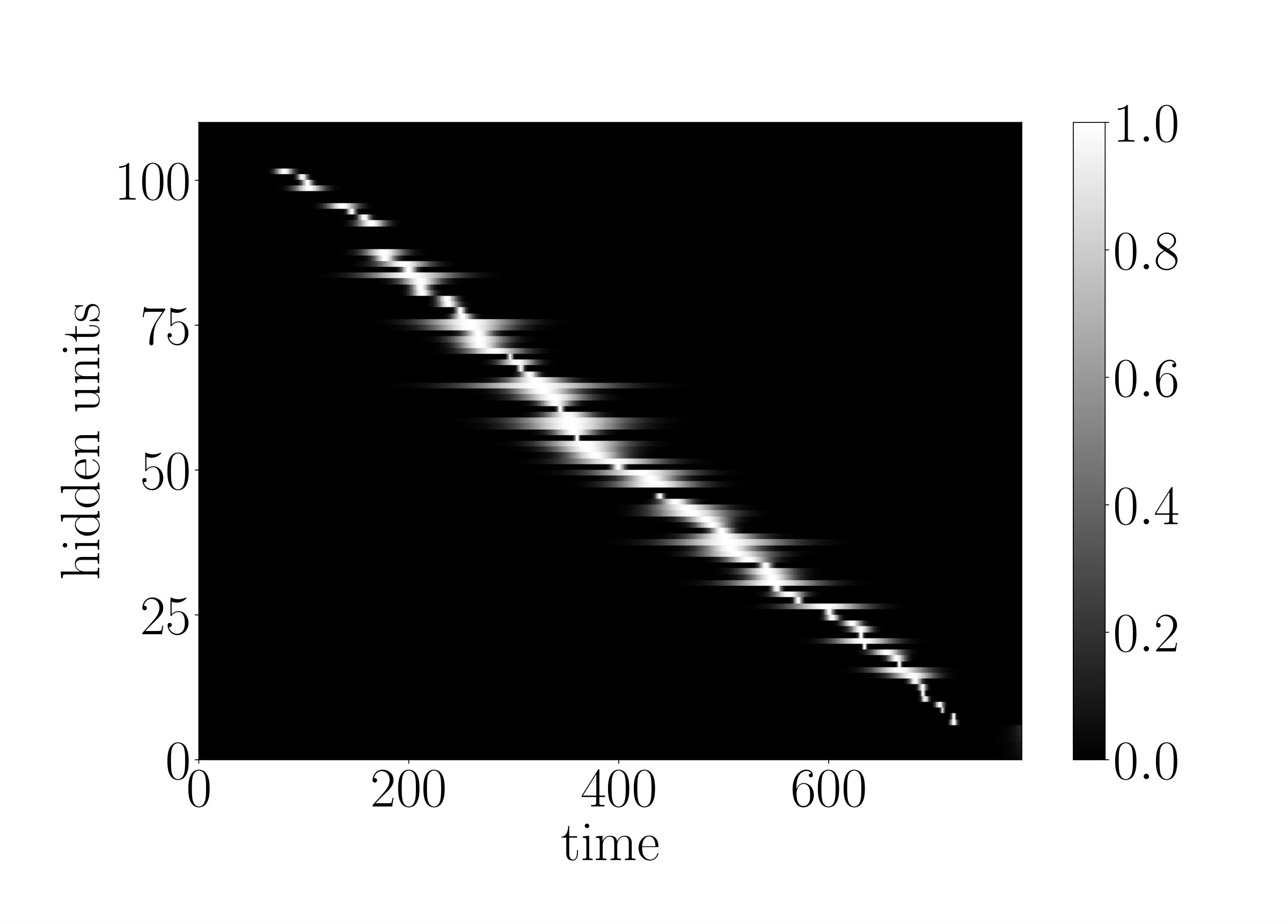 Figure 20
Figure 20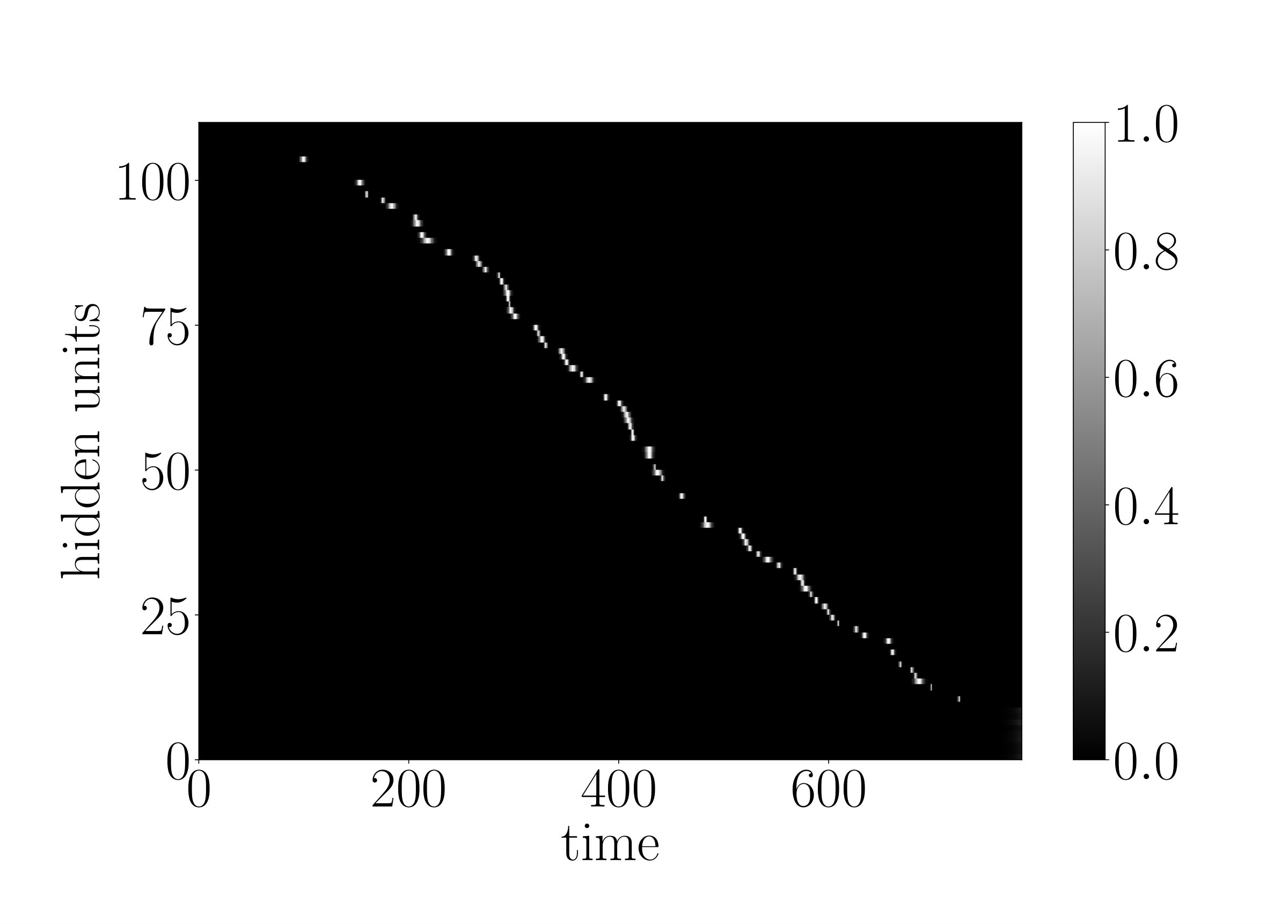 Figure 21
Figure 21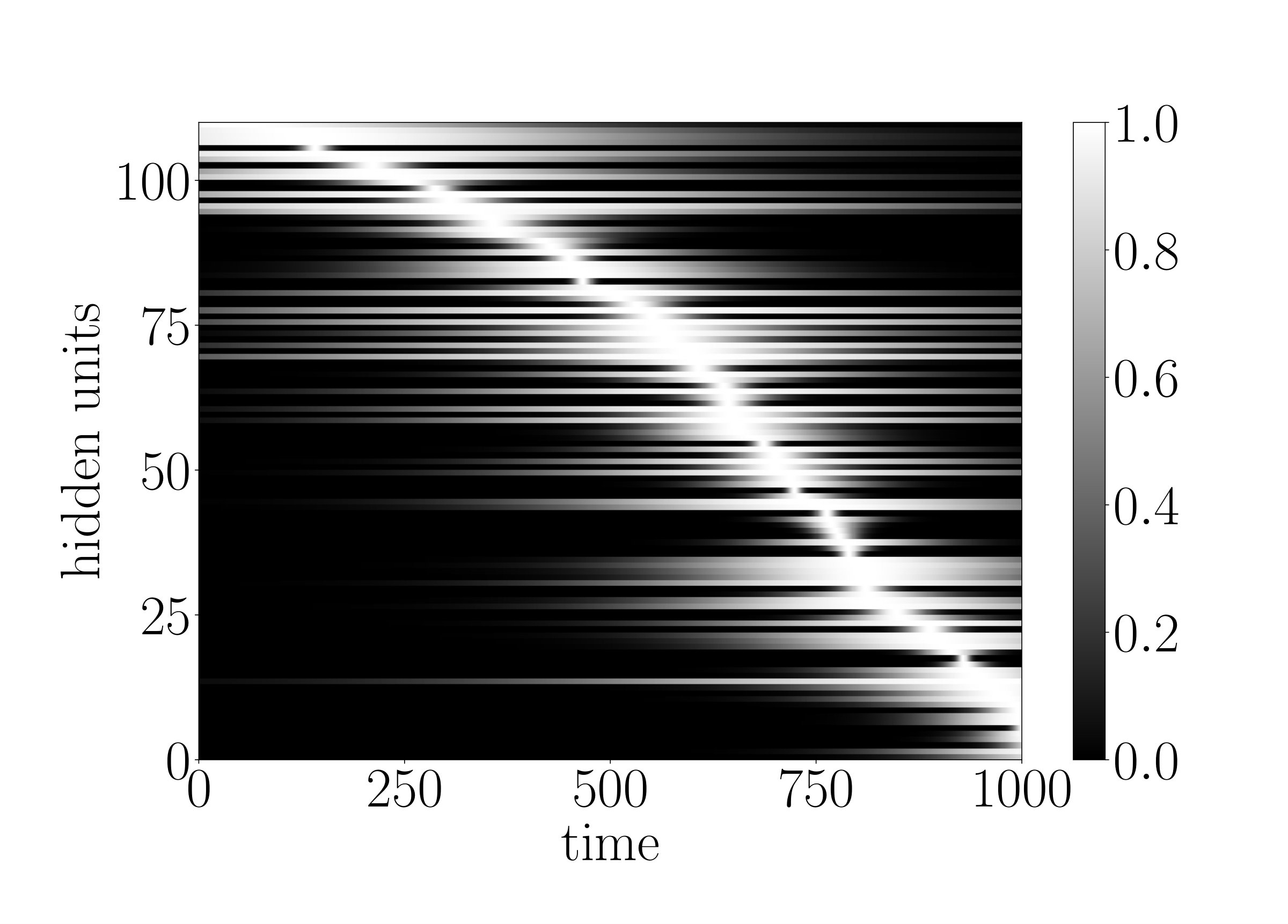 Figure 22
Figure 22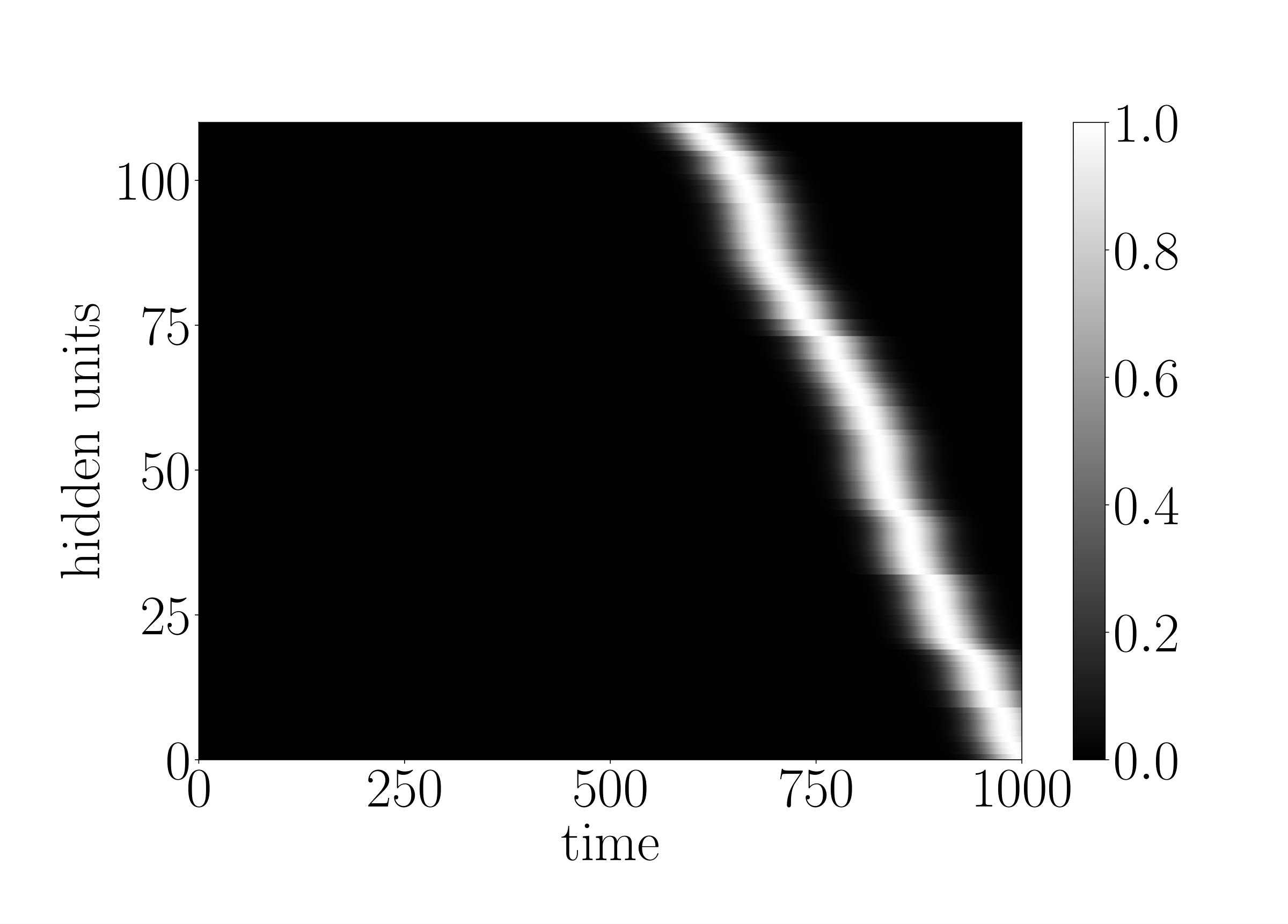 Figure 23
Figure 23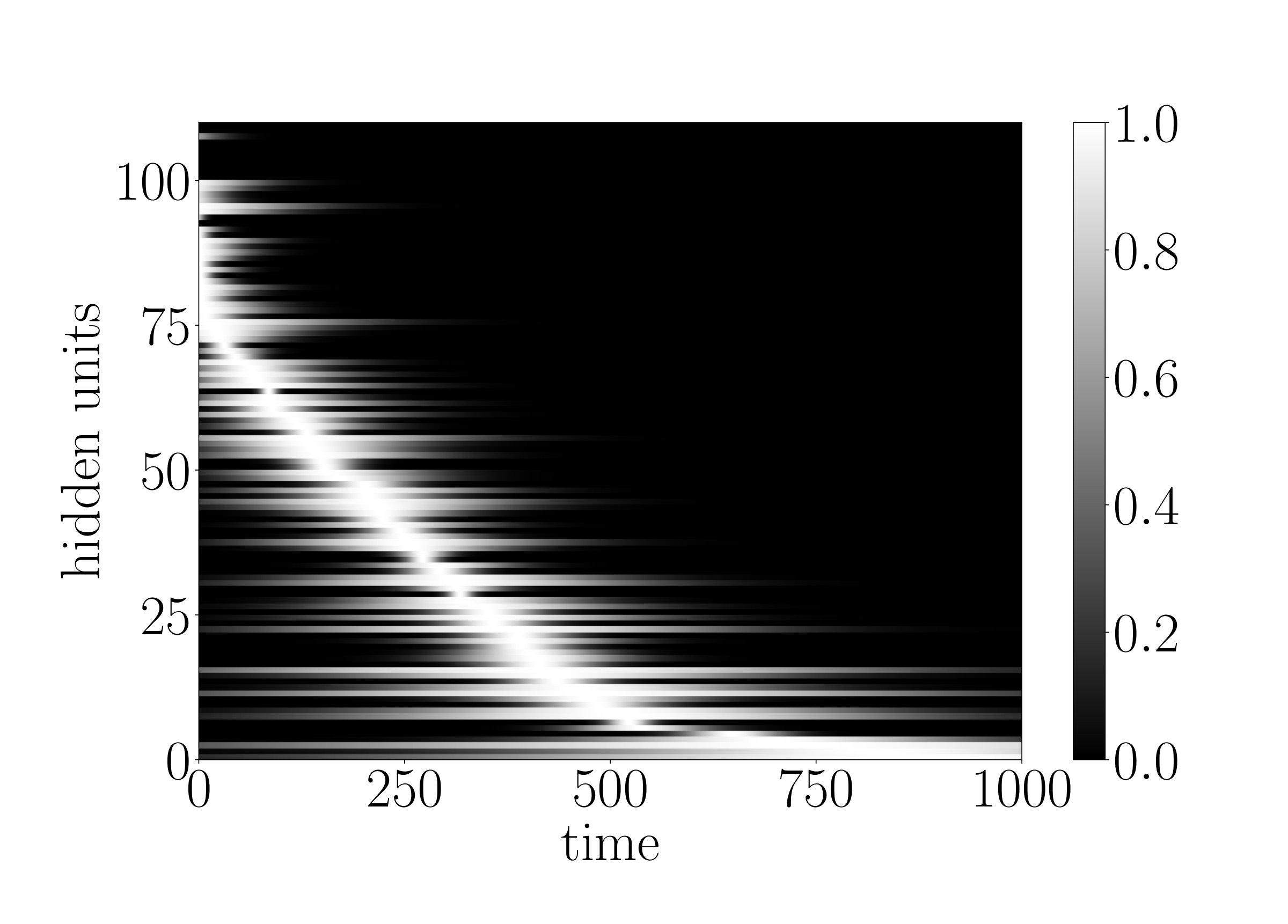 Figure 24
Figure 24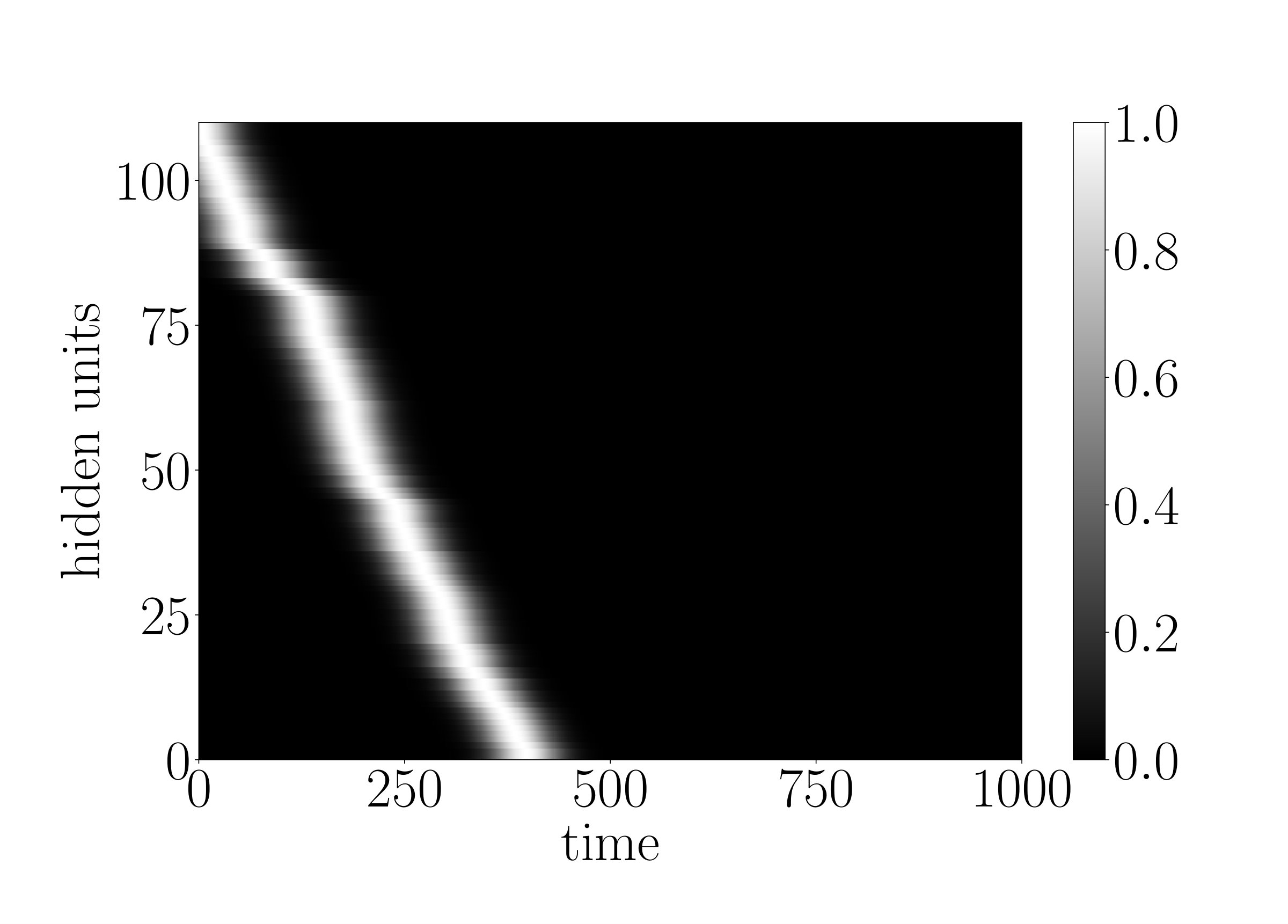 Figure 25
Figure 25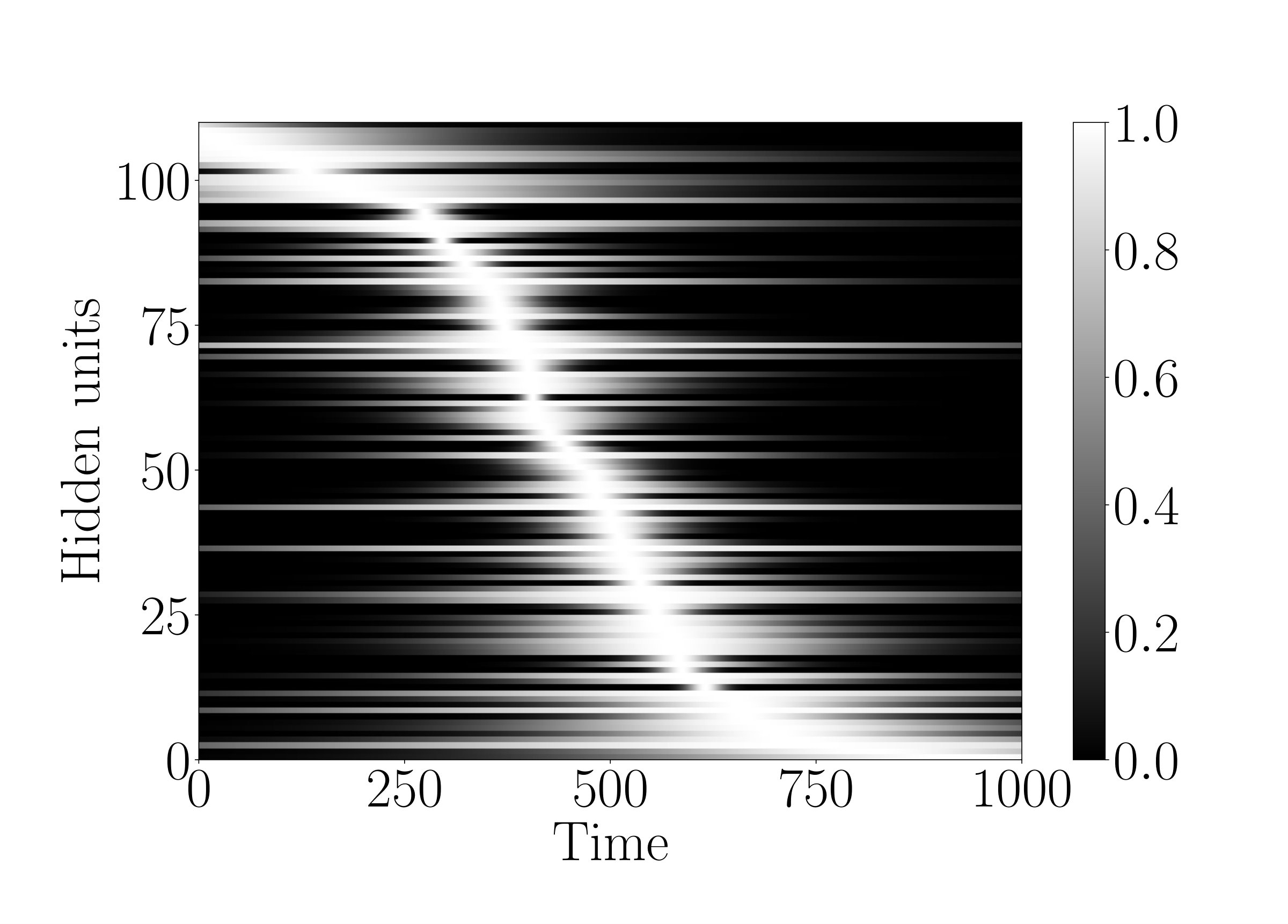 Figure 26
Figure 26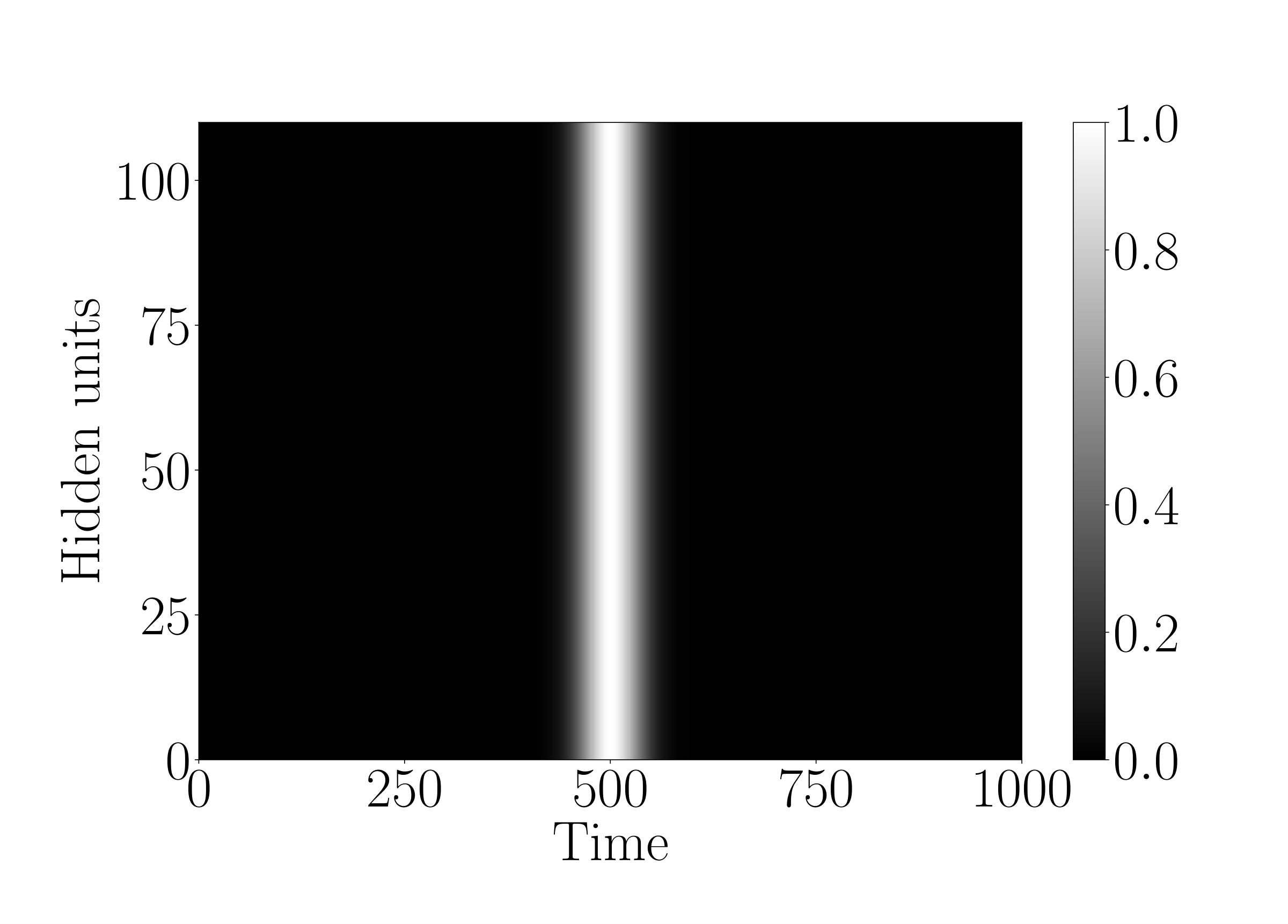 Figure 27
Figure 27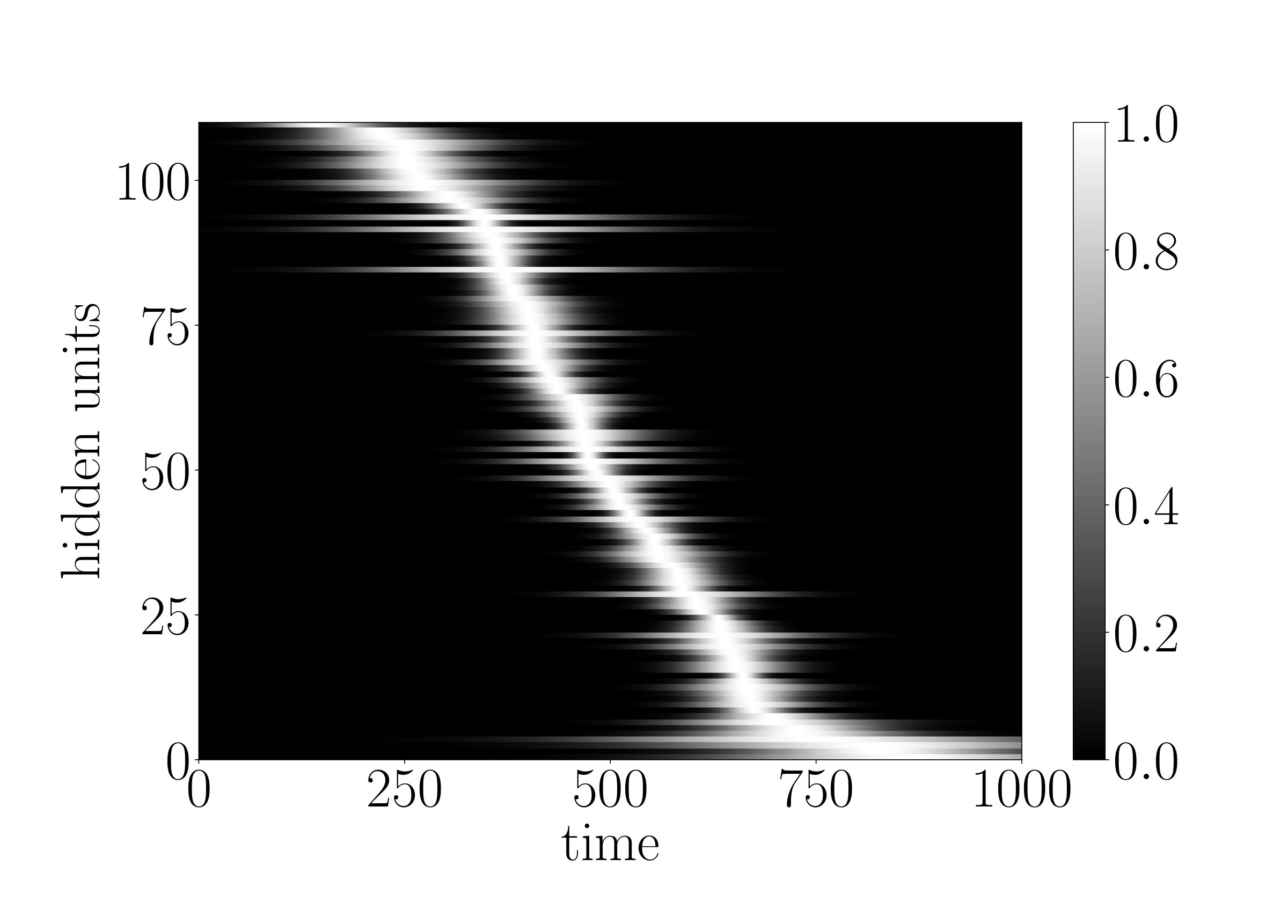 Figure 28
Figure 28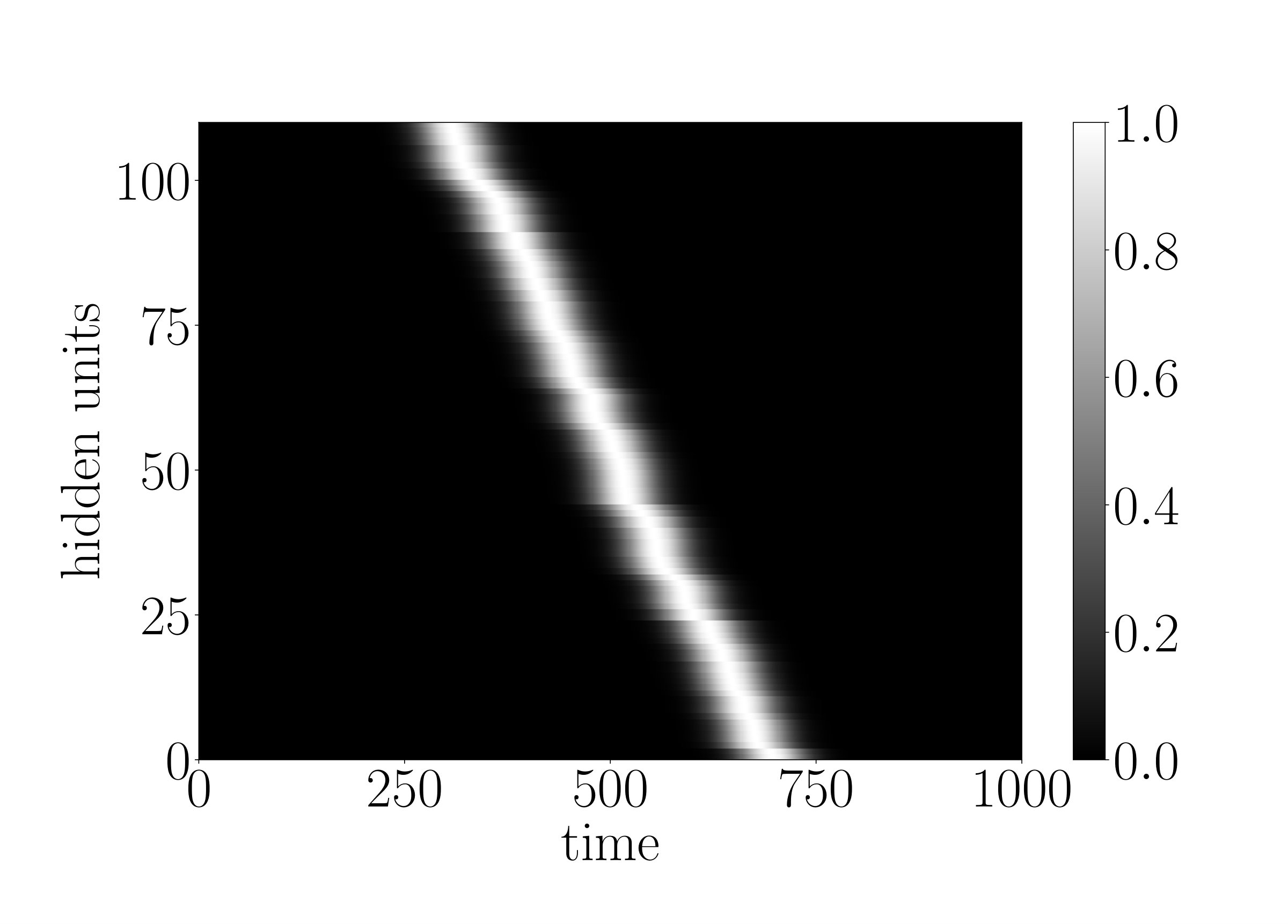 Figure 29
Figure 29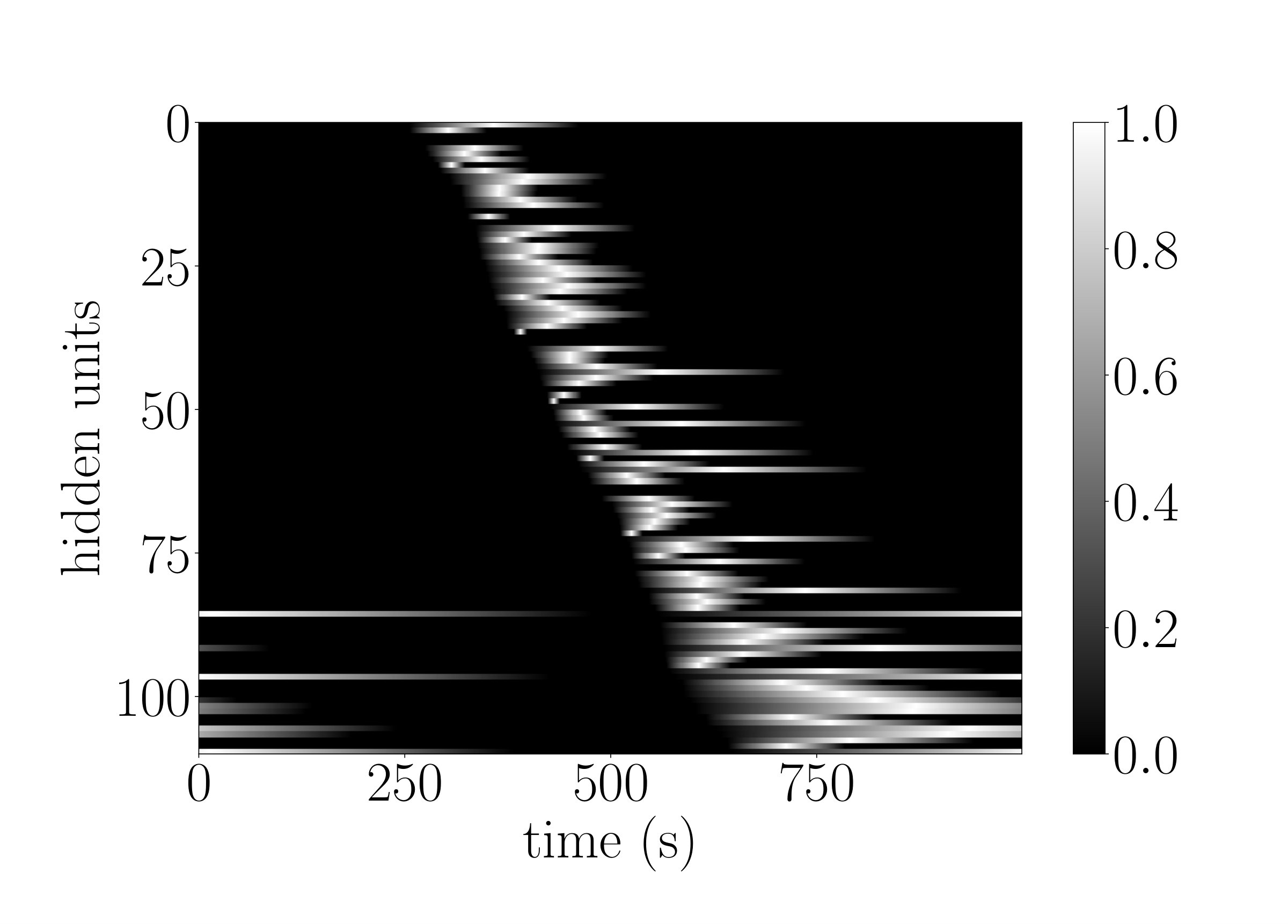 Figure 30
Figure 30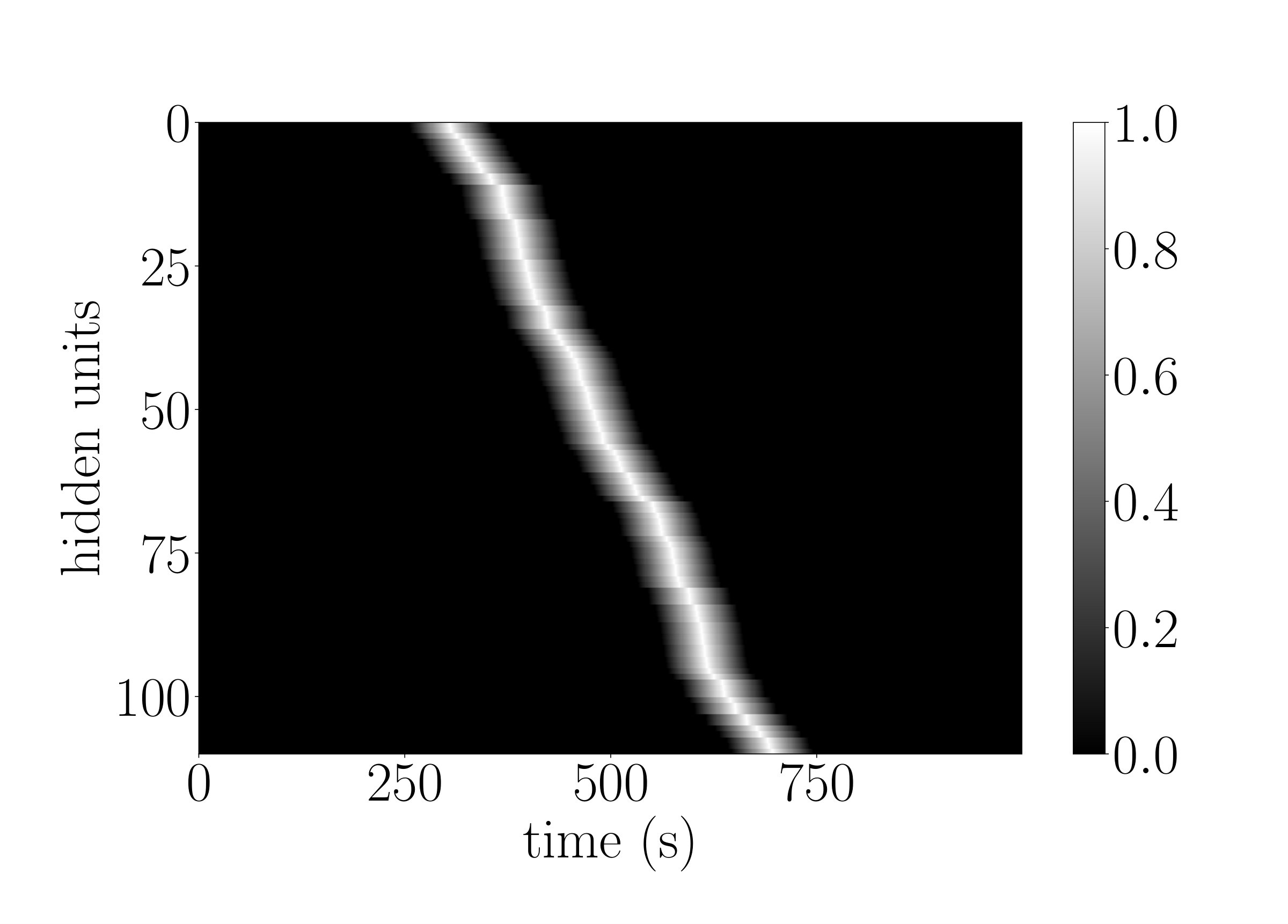 Figure 31
Figure 31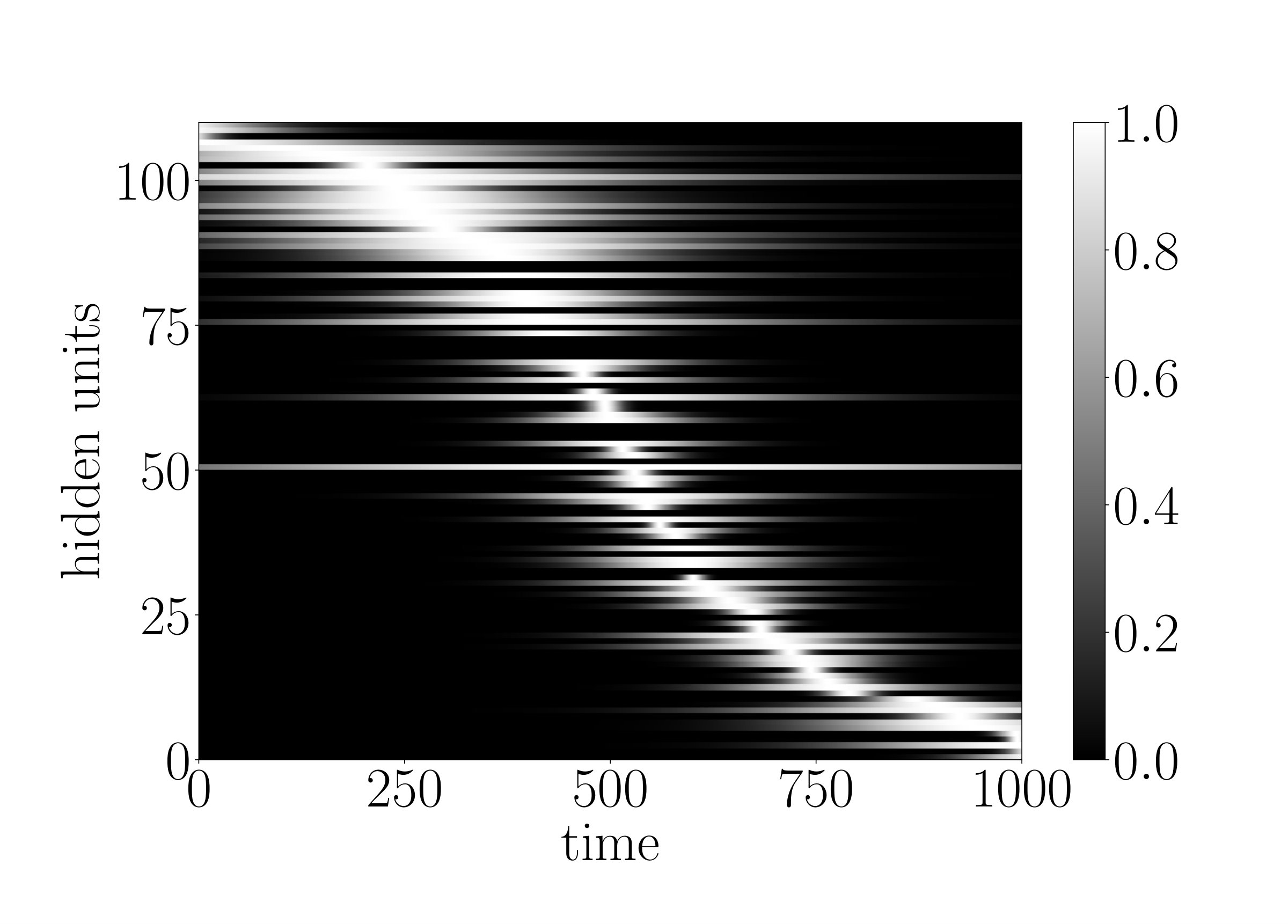 Figure 32
Figure 32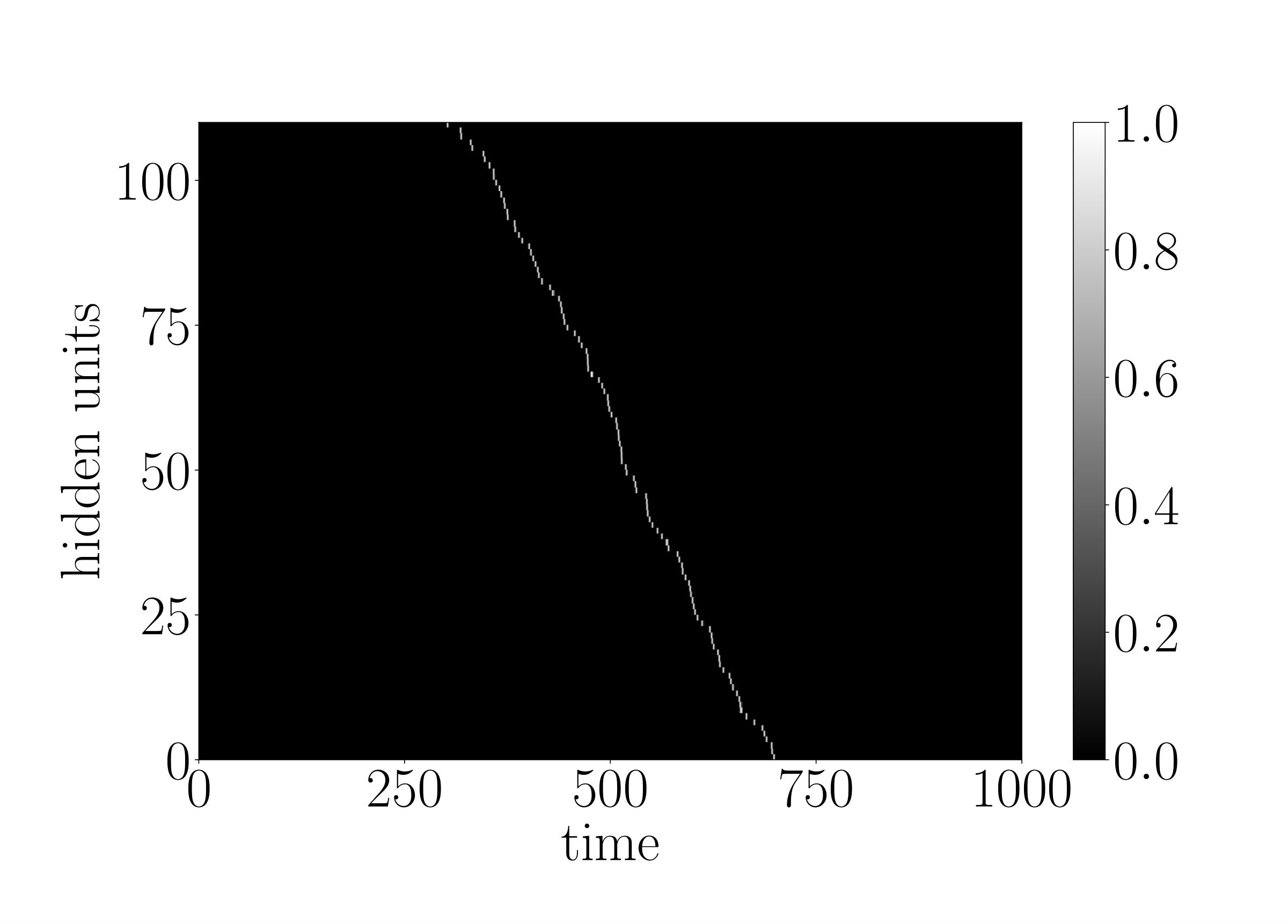 Figure 33
Figure 33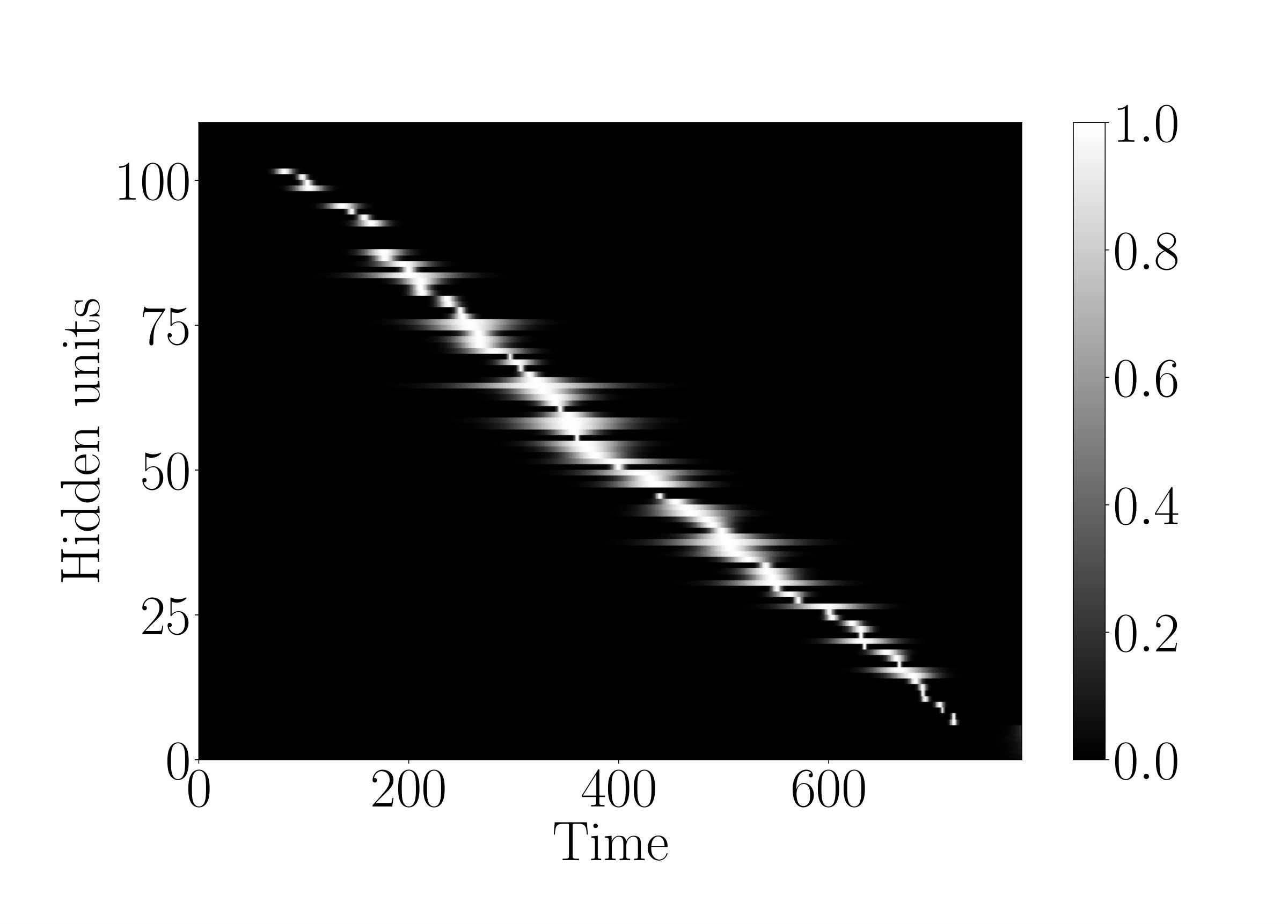 Figure 34
Figure 34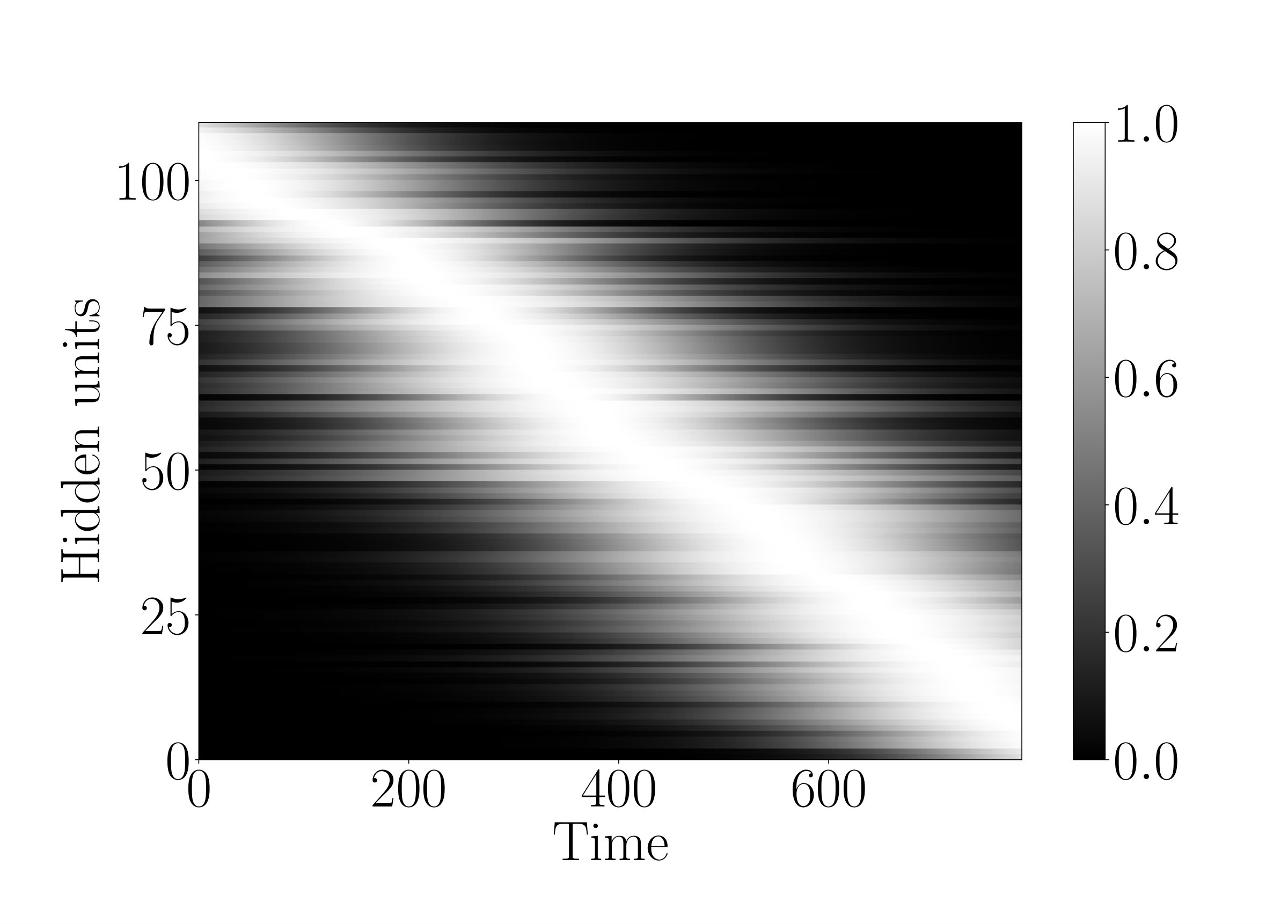 Figure 35
Figure 35 Figure 36
Figure 36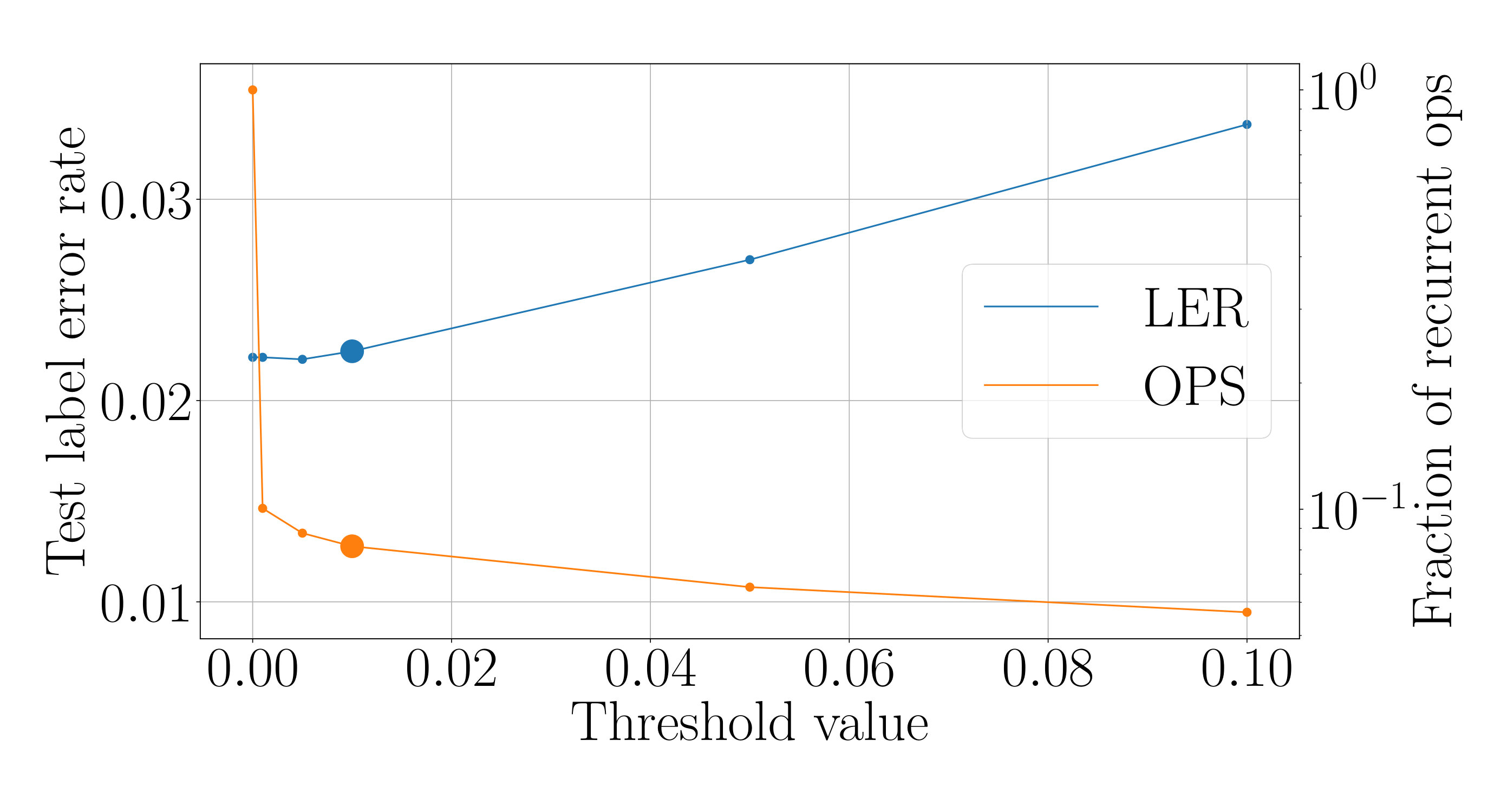 Figure 37
Figure 37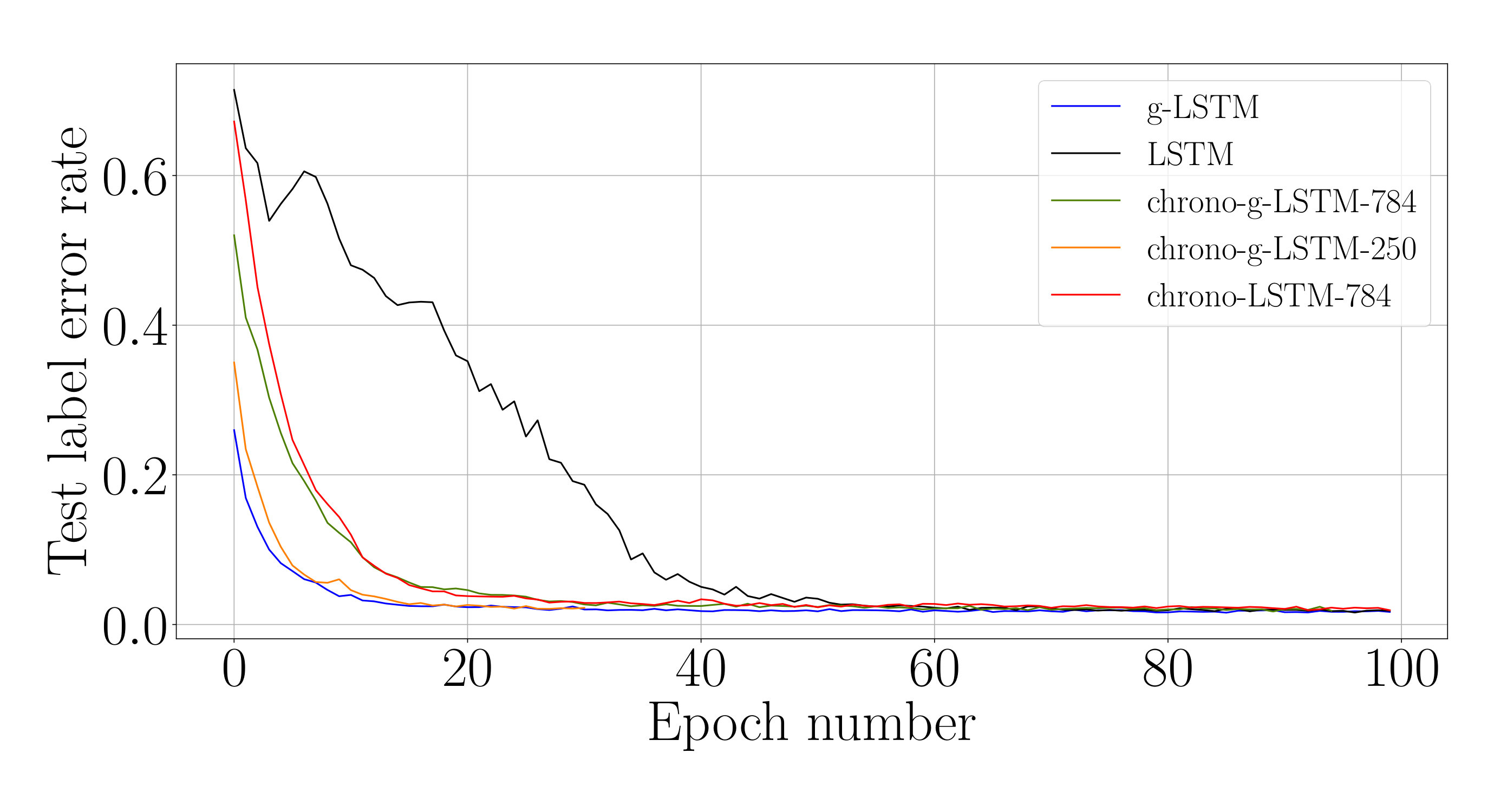 Figure 38
Figure 38| Initialization | Performance | ||||
|---|---|---|---|---|---|
| Dataset | # units | g-LSTM | LSTM | ||
| Adding (N=1000) | 110 | 40 | |||
| Adding (N=2000) | 110 | 40 | |||
| sMNIST | 110 | 250 | |||
| sCIFAR-10 | 128 | 650 | |||
| Initialization | |||
|---|---|---|---|
| Experiment ID | Final MSE Loss | ||
| A1 | 1 | ||
| A2 | 40 | ||
| A3 | 40 | ||
| Network | Initialization | Final MSE Loss |
|---|---|---|
| g-LSTM | , | |
| PLSTM | , , |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Advanced Neural Network Applications · Neural Networks and Applications
MethodsSigmoid Activation · Tanh Activation · Long Short-Term Memory
Reducing state updates via Gaussian-gated LSTMs
Matthew Thornton, Jithendar Anumula, and Shih-Chii Liu
Institute of Neuroinformatics
University of Zurich and ETH Zurich
Zurich, Switzerland
[email protected], [email protected], [email protected]
Abstract
Recurrent neural networks can be difficult to train on long sequence data due to the well-known vanishing gradient problem. Some architectures incorporate methods to reduce RNN state updates, thereby allowing the network to preserve memory over long temporal intervals. We propose a timing-gated LSTM RNN model, called the Gaussian-gated LSTM (g-LSTM) for reducing state updates. The time gate controls when a neuron can be updated during training, enabling longer memory persistence and better error-gradient flow. This model captures long temporal dependencies better than an LSTM on very long sequence tasks and the time gate parameters can be learned even from a non-optimal initialization. Because the time gate limits the updates of the neuron state, the number of computes needed for the network update is also reduced. By adding a computational budget term to the training loss, we obtain a network which further reduces the number of computes by at least . Finally, we propose a temporal curriculum learning schedule for the g-LSTM that helps speed up the convergence time of the equivalent LSTM on long sequences.
1 Introduction
Numerous methods and architectures have been proposed to mitigate the vanishing gradient problem in RNNs, with LSTMs (Hochreiter & Schmidhuber, 1997) as one of the first prominent solutions doing so by including gating structures in the computation. Although the LSTM has excelled at handling many tasks (Schmidhuber, 2015; Lipton, 2015), it still has difficulties in learning complex and long time dependencies (Neil et al., 2016; Chang et al., 2017; Trinh et al., 2018).
In the last few years, various methods which reduce the state updates of an RNN (LSTM) have been explored to better learn long time dependencies from data. Clockwork RNNs (Koutnik et al., 2014) group the hidden units of the RNN into “modules,” where each module is executed at pre-specified time steps thereby skipping time steps which helps learn longer time dependencies. Recently, various other methods have been proposed which can be characterized by the use of additional “time gates,” , that control the information flow from one time step to the next (Krueger et al., 2016; Campos et al., 2017). Phased LSTM (PLSTM) (Neil et al., 2016) learns a parameterized function, , from the the time input of the current state and was proven to be successful at learning over long sequences.
The PLSTM time gate, parameterized by period, phase, and ratio parameters for each hidden unit, is defined through a modulo function with an ill-defined gradient. Furthermore, with periodic functions being hard to learn using gradient-based methods (Shamir, 2016) and with being periodic, the PLSTM was unable to learn the time gate parameters and hence relied on careful initialization. In order to offset these difficulties, this work proposes a new LSTM variant called the Gaussian-gated LSTM (g-LSTM). Similar to the PLSTM, it is an LSTM model with a parameterized but with only two parameters per hidden unit. Unlike the PLSTM which uses a periodic formulation for , the g-LSTM uses a Gaussian function.
We show in this work that the g-LSTM can provide a number of possible advantages over the LSTM, in particular, on long sequence tasks that pose convergence problems during training:
- •
The g-LSTM network can process very long sequences by reducing the time over which the neurons can be updated. It converges faster than the LSTM, especially on sequences that are over 500 steps.
- •
The “openness” of the neuron for an update can be adapted according to the task during training, even for extreme, non-optimal initializations of the time gate parameters.
- •
By introducing a computational budget term into the loss function during training, the “openness” of the neuron can be optimized for a reduced computational budget. This reduction can be achieved with little or no degradation to the network performance and is useful for network pruning.
- •
A “temporal curriculum” training schedule can be set up for the g-LSTM so that it helps to speed up the convergence of a normal LSTM.
The paper is structured as follows: In section 2, we discuss briefly the related work. Then, in section 3, we present the formulation of the g-LSTM, the datasets used in this work and details about the experimental hyperparameters. In section 4, we present experiments demonstrating the usefulness of the g-LSTM with respect to the four claims listed above. We provide gradient analysis in section 5 to further explain the faster convergence results of the g-LSTM. Finally in section 6, we conclude with a brief discussion of the results.
2 Related Work
There have been a multitude of proposed methods to improve the training of RNNs, especially for long sequences. Apart from incorporating additional gating structures, for example the LSTM and the GRU (Cho et al., 2014), more recently various techniques were proposed to further increase the capabilities of recurrent networks to learn on sequences of length over 1000. Proposed initialization techniques such as the orthogonal initialization of kernel matrices (Cooijmans et al., 2016), chrono initialization of the biases (Tallec & Ollivier, 2018), and diagonal recurrent kernel matrices (e.g. Li et al. (2018)) have demonstrated success. Trinh et al. (2018) propose using truncated backpropagation with an additional auxiliary loss to reconstruct previous events.
Methods that enable more efficient learning on long temporal sequences use solutions that preserve memory over longer timescales. Such solutions were first explored by Koutnik et al. (2014) in the Clockwork RNN (CW-RNN). This network skips state updates by allowing different neurons to be “activated” on different, modulated clock cycles. More recently proposed models for skipping updates include the Phased LSTM (PLSTM) (Neil et al., 2016) which uses a modulo-periodic timing gate to limit state updates; the Zoneout network (Krueger et al., 2016) which skips state updates in a random manner; and the Skip RNN (Campos et al., 2017) which learns a state skipping scheme from the data to shorten the effective sequence length for the task. Additionally, the LSTM-Jump (Yu et al., 2017) uses a reinforcement learning algorithm to learn when to skip state updates, showing a method to more quickly process (long) sequential data with an RNN while maintaining an accuracy comparable to a baseline LSTM.
It has been suggested but not yet demonstrated in the literature that the parameters of the CW-RNN clock cycle and PLSTM timing gate could be learned in training. Currently, the implementation of these networks requires a careful initialization of these parameters. With the Gaussian-gated LSTM (g-LSTM) in this work we present a time gated RNN network that converges on long sequence tasks and also has the ability to learn its time gate parameters even when initialized in a non-optimal way.
3 Methods
3.1 g-LSTM
The g-LSTM is an LSTM model with an additional time gate (Fig. 1). This time gate is used to regulate the information flow in time. Equations 1 - 3 describe the update equations for the hidden and cell states of the LSTM. Equations 4 and 5 describe the gating mechanism of the time gate, .
[TABLE]
In a standard LSTM, the gating functions , , , represent the input, forget, and output gates respectively at sequence index . is the cell activation vector, and and represent the input feature vector and the hidden output vector, respectively. The cell state is updated with a fraction of the previous cell state that is controlled by , and a new input state created from the element-wise (Hadamard) product, denoted by , of and the candidate cell activation as in Eq. 2.
In the g-LSTM, we further control the cell state and the output hidden state through the gate which is independent of the input data and hidden states, and is purely dependent on the time input corresponding to the sequence index . The use of the Hadamard product ensures that each hidden unit is independently controlled by the corresponding time gate unit, thus enabling the different units in the layer to process the input at different time scales.
The time gate is defined based on a Gaussian function as: where the mean parameter, , defines the time when the hidden unit is “open” and the standard deviation, , controls the openness of the time gate for each unit around its corresponding . The time inputs for the sequence can correspond to the physical notion of time at the respective sequence input. In the absence of a standard notion of time, we use the sequence indices as the time input, i.e. . In this work, we assume this notion of time by default. The “openness” of for a neuron is defined by the parameterization of its Gaussian function.
3.2 Back Propagation for g-LSTM
An important characteristic of the g-LSTM is reduced gradient flow in back propagation training methods. By having the gating structure as in Eqs. 4 and 5 there are fewer gradient product terms, which reduces the likelihood of vanishing or exploding gradients. In a gradient descent learning scheme for a given loss function, , when training the recurrent parameters, (from Eqs. 1 - 3), the gradient as in Eq. 6 is used.
[TABLE]
By the chain rule expands for all time steps of the sequence, . Because each output state is gated by the time gate, , the gradient terms in the expansion of are scaled by . When the time gate is open less often, i.e. with a small value, then there are fewer influential gradient terms. More details are given in Appendix A.
3.3 Datasets
The experiments described in the paper are carried out on the adding task and two standard long sequence datasets: the sequential MNIST and the sequential CIFAR-10 datasets.
Adding task: In order to test the long sequence learning capability of the g-LSTM, we use the adding task (Hochreiter & Schmidhuber, 1997). In this task, the network is presented with two sequences of length , , ) and . The sequence m has exactly two values of and the remaining values of the sequence are [math]. The indices of the “1” values are chosen at random. For each pair in the sequence , the associated label value, , is the sum of the two values in x corresponding to the “1” values of m. The objective of this task is to minimize the mean squared error between the predicted sum from the network, , and the labeled sum, . A new training set of 5000 sequence samples is presented in every epoch during training in order to avoid overfitting. The test set consists of a separate 5000 samples. For , it is known that LSTMs have difficulty learning the task and hence we focus on values of in this work.
sMNIST: The sequential MNIST dataset is widely used to analyze the performance of a recurrent model. This dataset consists of 60,000 training samples and 10,000 test samples, each a single vector sequence of length 784 corresponding to the 28 28 pixel images in the MNIST dataset (LeCun et al., 1998). We also use permuted MNIST (pMNIST), a permuted variant of the sMNIST dataset where the sequences are processed with a fixed random permutation, making the task harder.
sCIFAR-10: The sequential CIFAR-10 dataset is another long sequence dataset based on CIFAR-10 (Krizhevsky et al., 2014) with 10 classes. The RGB pixel images are reshaped into sequences of length with 3 dimensional features corresponding the RGB channels at every time step. Like in the sMNIST dataset, the dataset consists of 60,000 training samples and 10,000 test samples.
3.4 Experimental Hyperparameters
For the adding task, a mean squared error (MSE) loss was used with the Adam optimizer (Kingma & Ba, 2014) with a learning rate of . The g-LSTM time gate parameters were trained using a learning rate of . For both sMNIST and sCIFAR-10 datasets, the cross-entropy loss function was used along with the RMSProp optimizer (Tieleman & Hinton, 2012) with a learning rate of . Decay parameters of and were used for sMNIST and sCIFAR-10, respectively. The bias of the forget gate is initialized to following (Jozefowicz et al., 2015).
4 Results
Section 4.1 presents results that demonstrate the faster convergence properties of the g-LSTM on long sequence tasks. Section 4.2 shows the trainability of the time gate parameters of the g-LSTM even when the parameters are initialized in a non-optimal way. Section 4.3 presents a modified loss function used during training to reduce the number of computes for the network update and Section 4.4 presents a new “temporal curriculum” learning schedule that allows g-LSTMs to help LSTMs converge faster.
4.1 Fast convergence properties of g-LSTM
First, we look at the convergence properties of the g-LSTM on the long-sequence adding task, the sMNIST task and the sCIFAR-10 task. Table 1, above, details the network architectures used in the experiments in this section. Similar to the architecture from Trinh et al. (2018), the recurrent layer of the sCIFAR-10 network is followed by two unit fully-connected (FC) layers, where Drop-Connect (Wan et al. (2013)) () is applied to the second FC layer. The kernel matrices in the LSTM networks were initialized in an orthogonal manner as described in (Cooijmans et al., 2016).
The test performances of these networks during the course of the training on different datasets are shown in Fig. 2, while the corresponding final performance metrics at the end of training are shown in Table 1. From Fig. 2, it is evident that the test loss of the g-LSTM decreases faster in training than the LSTM across all datasets. Further experiments show that this trend is maintained with different training optimizers, LSTM initializations including the bias initialization following Tallec & Ollivier (2018), and network sizes as shown in Appendix D.
Table 2 compares the performance of various networks including the g-LSTM and the baseline LSTM on sMNIST and sCIFAR-10 (from Table 1). The results show that the g-LSTM consistently performs better than the LSTM and has a similar performance to other state-of-the-art networks. Different network sizes were also investigated for the sMNIST task, see Appendix D.
4.2 Trainability of the time gate parameters of g-LSTM
To demonstrate that the g-LSTM can be trained even with non-optimal initializations, we look at the performance of the g-LSTM on the adding task with different time gate parameter initializations. We concern ourselves with sequences of length that are difficult for the LSTM. The time gate parameters are initialized in a way to temporally constrain the network so that it can only process for a short period of time. For example, a network with time gate parameters initialized with and as in Figure 3 (a) can only process a short period of time around the middle of sequence. It follows that the network would be unable to learn with these parameters because in the adding task the input data is distributed equally across the sequence length (). Therefore, in order to learn the task from this initialization, the time gate parameters must learn a distribution such that the gates over all hidden units are open across the entirety of the sequence.
We observe that the time gate parameters do learn, as shown in Figure 3 (b), thereby enabling the network to solve the task. Independent of various time gate initializations, the network reaches an MSE of around at the end of 700 epochs; details of which could be found in Appendix B. The ability of the network to learn the time gate parameters necessary to cover the entire sequence is especially significant because it shows that even with this narrow time window initialization that requires learning of the time gates, the g-LSTM learns the task, whereas the PLSTM does not learn the task as well. An example of this is shown in Appendix C.
4.3 Reduction in computation
Although the formulation of the g-LSTM appears to require more computes, it offers substantial speedup as a large proportion of the neurons can be skipped in a timestep at runtime. We can set a threshold on the time gate so that we skip all corresponding computations for time steps where is below this threshold. To further reduce the number of operations, it is preferred that the of the for different neurons should be small but the network performance should not be significantly degraded. To achieve this goal, we included a “computational budget” loss term during the optimization of the gate parameters, and . The loss equation for updating the parameters is given by:
[TABLE]
Similar to the Skip RNN network (Campos et al., 2017), a budget loss term which minimizes the average openness of the time gate over time is applied:
[TABLE]
for every neuron of the g-LSTM. The study was carried out on sMNIST using a network with 110 units, initialized to 50, initialized uniformly at random between 1 to 784, and a value of 1. The network’s performance of LER was comparable to the network’s performance of when no additional budget constraint was imposed. The final range for the budgeted g-LSTM is much smaller compared to that of the g-LSTM as shown in Fig. 4. There is only a slight increase in LER for the budgeted g-LSTM versus the g-LSTM (see Table 2), even though there is a significant decrease in the average time gate openness across all hidden units.
In order to reduce the number of computes, we set a threshold, for so that the update steps are carried out only if , if the previous neuron state can be copied over to the current state. By increasing , the number of computes decreases as shown in Fig. 6. In the case of , only of the time gates are open on average across all hidden units and all time steps. Furthermore, the LER increased only slightly to from .
We give a quantitative estimate for the number of operations (Ops) corresponding to the number of update equations for a g-LSTM. In the estimate, we count a multiply and an add operation as 1 Op and non-linear functions as 5 Ops. For an LSTM, the number of operations is given by
[TABLE]
where is the number of time steps, is the number of hidden units, and is the dimension of the input data. For a g-LSTM, the number of operations is given by
[TABLE]
where is the total number of operations for computing the time gate. The total number of operations for the g-LSTM network on the sMNIST dataset is around 80 MOps for and , after thresholding the budgeted g-LSTM this number is reduced to 7.6 MOps. Additional hyperparameters were also investigated for the sMNIST task, see Appendix D.
4.4 Temporal curriculum training schedule for LSTMs
We demonstrate that it is possible to train an LSTM network to converge faster on a difficult task by using a “temporal curriculum” training schedule for the equivalent g-LSTM network. According to this schedule, the initial values of the g-LSTM network are increased continuously throughout the training period ending up with high values by the end of training. With such high values, the time gates are essentially open, resulting in an LSTM network. At every training epoch, the lowest of the values, in the layer are updated as: .
We analyze the impact of this training schedule for training an LSTM network on sCIFAR-10. For the equivalent g-LSTM network with 110 units, is initialized uniformly at random between 1 and 1024 and is initialized to 50. An value of 1/6 and value of are chosen. To ensure that the time gate is fully open by the end of training, is set to across all units during the last epochs of training. The learning rate of the time gate parameters is set to [math], i.e. and are no longer updated. Figure 6 shows that the temporal curriculum training schedule allows for faster convergence of an LSTM network. The final weights of the trained g-LSTM network can then be copied over to a LSTM network for inference.
5 Gradient flow
We present results regarding backpropagation flow through the LSTM and g-LSTM networks. Following the hypothesis presented in Section 3.2 on the reduced likelihood of vanishing or exploding gradients in the g-LSTM, we investigate the average gradient norms across time steps, similar to the work in (Krueger et al., 2016). We compute the gradient norms of the loss with respect to the hidden activations, the exact definition is given in Appendix E. Comparing the error propagation of the g-LSTM and LSTM networks on the SMNIST task (as in Sec. 4.1), Figure 7 shows the gradient norms at each time step after training for two different epochs.
Interpreting the gradient flow from higher to lower time steps (right to left), the gradients of the g-LSTM shown in Fig. 7 show higher gradient values in earlier time steps than the LSTM. It is possible that one of the reasons the g-LSTM converges more quickly (as in Fig. 2 (c)) is that this back-propagated gradient information is more consistent across time steps and does not vanish at early time steps.
6 Conclusion
This work proposes a novel RNN variant with a time gate which is parameterized by the input in time. The convergence speeds of the g-LSTM and LSTM are similar for short sequence tasks but the g-LSTM shows faster convergence and produces higher accuracies than LSTM networks on long sequence tasks, as demonstrated for adding task sequences which are longer than 1000 timesteps; and on the sMNIST and sCIFAR-10 datasets. We also demonstrate that the time gate parameters of the g-LSTM (unlike those of the PLSTM) are learnable even when the time gates are initialized in an extreme non-optimal manner for the adding task. The time gate of the g-LSTM can reduce the number of computes that is needed for the updates of the LSTM equations and with an additional loss term to reduce the compute budget, the values of the time gate are reduced leading to a decrease in the number of actual computes and with little loss in network accuracy, for the sMNIST dataset. The observation that the budgeted g-LSTM has neurons which are closed by the timing gate suggests that this method can be used to prune a network. We also show that our proposed temporal curriculum training schedule for the g-LSTM can help a corresponding LSTM network to converge during training on long sequence tasks. For future work, it will be of interest to investigate whether these properties carry over to larger or domain-specific datasets.
Appendix A Back propagation in Gaussian-gated RNN
For ease of illustration we analyze the gradient of a plain RNN with a Gaussian time gate (Eqs. 7 and 8).
[TABLE]
[TABLE]
[TABLE]
where .
From Eq. 9 we can deduce some information about the advantages of the Gaussian time gate in gradient flow for two simple cases of the function .
In Case 1 we choose a timing gate openness which corresponds to a very small for the Gaussian gate, i.e. the gate is only open for time step.
[TABLE]
[TABLE]
In Case 2 we choose a timing gate openness which corresponds to a slightly larger for the Gaussian gate, i.e. it is open for time steps.
[TABLE]
[TABLE]
These cases show that there are fewer terms in the gradient for a timing gate that is opened for only a small fraction of the sequence.
Appendix B Comparing various g-LSTM initializations
Appendix C Comparing time gate parameter trainability in g-LSTM and PLSTM
Appendix D Hyperparameter Investigation
We look at the network performance for different hyperparameter values, focusing on the sMNIST task.
Network Initialization and Optimizer
In Fig. 2(c) of Section 4.1, we show that the g-LSTM network converges faster than the LSTM for the sMNIST task using the RMSProp optimizer and with an orthogonal initialization of LSTM kernels of both networks, as in (Cooijmans et al., 2016). In addition to using this initializer and optimizer we include results using the ADAM initializer (learning rate of ) and a random weight initialization, “Xavier” as in (Glorot & Bengio, 2010). Across all of these different training techniques we consistently observe that the g-LSTM converges more quickly than the LSTM.
We ran further experiments to compare the chrono initialization of the LSTM forget and input biases from (Tallec & Ollivier, 2018). The forget and input biases are set as and where for the sMNIST task. The use of the time gate with the g-LSTM shortens the effective sequence length for each unit; to account for this, we also provide the results of using a smaller value for the chrono initialization, . The comparison of both g-LSTM and LSTM with the chrono initialization and with the “constant initialization” () in Fig. 12 shows that the g-LSTM with the constant initialization converges the fastest. We hypothesize that the g-LSTM can converge faster when using the constant initialization over the chrono initialization because the time gate’s effect of sequence-length-shortening reduces the necessity for long memory, for which chrono initialization seeks to provide. We see that when we reduce the maximum temporal dependency for the chrono initialization (to , “chrono-g-LSTM-250”) this g-LSTM network converges more quickly, similar to the g-LSTM with a constant bias initialization. This suggests that these two techniques, chrono initialization and a Gaussian time gate, could be used together to improve convergence in LSTM networks.
Network Size
Aside from the network size of hidden units, we investigated the training convergence for two additional network sizes: and hidden units. Note that the LSTM for network size is trained for additional epochs until convergence was observed. Across all different network sizes the g-LSTM converges much faster than the LSTM network. With fewer hidden units, as seen in Fig. 13 (a), an even more dramatic speed-up in convergence is seen for the g-LSTM compared with the LSTM. The final LERs (g-LSTM, LSTM) for each network size are: 25 units (, ), 110 units (, ) , 220 units (, ).
Budgeted g-LSTM
We provide additional results of the budgeted network (subsection 4.3) for 2 additional values, and , comparing with the original result, for . The final LERs: (), (), (). The number of computes used by the network trained with is significantly lower than the network that was trained for both and .
Appendix E Average Gradient Norm Definition
The average gradient norm in Section 5 is defined as:
[TABLE]
where is the number of time steps of the sequence (for SMNIST, ).
[TABLE]
summing over all samples of the training set and all hidden units.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Campos et al. (2017) Victor Campos, Brendan Jou, Xavier Giro i Nieto, Jordi Torres, and Shih-Fu Chang. Skip RNN: learning to skip state updates in recurrent neural networks. Co RR , abs/1708.06834, 2017. URL http://arxiv.org/abs/1708.06834 .
- 2Chang et al. (2017) Shiyu Chang, Yang Zhang, Wei Han, Mo Yu, Xiaoxiao Guo, Wei Tan, Xiaodong Cui, Michael J. Witbrock, Mark Hasegawa-Johnson, and Thomas S. Huang. Dilated recurrent neural networks. Co RR , abs/1710.02224, 2017. URL http://arxiv.org/abs/1710.02224 .
- 3Cho et al. (2014) Kyunghyun Cho, Bart van Merriënboer, Çağlar Gülçehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN Encoder–Decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. 1724–1734, Doha, Qatar, October 2014. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/D 14-1179 .
- 4Cooijmans et al. (2016) Tim Cooijmans, Nicolas Ballas, Cesar Laurent, and Aaron C. Courville. Recurrent batch normalization. Co RR , abs/1603.09025, 2016. URL http://arxiv.org/abs/1603.09025 .
- 5Glorot & Bengio (2010) Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Yee Whye Teh and Mike Titterington (eds.), Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , volume 9 of Proceedings of Machine Learning Research , pp. 249–256, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010. PMLR. URL http://proceedings.mlr.press/v 9/glorot 10a.html .
- 6Hochreiter & Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Comput. , 9(8):1735–1780, November 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735 . URL http://dx.doi.org/10.1162/neco.1997.9.8.1735 . · doi ↗
- 7Jozefowicz et al. (2015) Rafal Jozefowicz, Wojciech Zaremba, and Ilya Sutskever. An empirical exploration of recurrent network architectures. In International Conference on Machine Learning , pp. 2342–2350, 2015.
- 8Kingma & Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. Co RR , abs/1412.6980, 2014. URL http://arxiv.org/abs/1412.6980 .