Observability-aware Self-Calibration of Visual and Inertial Sensors for Ego-Motion Estimation
Thomas Schneider, Mingyang Li, Cesar Cadena, Juan Nieto, Roland, Siegwart

TL;DR
This paper introduces an information-theoretic method for self-calibrating visual-inertial sensors by selecting the most informative trajectory segments, enabling efficient calibration on resource-limited systems with comparable accuracy to batch methods.
Contribution
It proposes a novel information-based selection strategy for trajectory segments to improve self-calibration efficiency and robustness in visual-inertial systems.
Findings
Achieves calibration performance comparable to batch methods.
Reduces computational complexity independent of session duration.
Effective in diverse real-world environments.
Abstract
External effects such as shocks and temperature variations affect the calibration of visual-inertial sensor systems and thus they cannot fully rely on factory calibrations. Re-calibrations performed on short user-collected datasets might yield poor performance since the observability of certain parameters is highly dependent on the motion. Additionally, on resource-constrained systems (e.g mobile phones), full-batch approaches over longer sessions quickly become prohibitively expensive. In this paper, we approach the self-calibration problem by introducing information theoretic metrics to assess the information content of trajectory segments, thus allowing to select the most informative parts from a dataset for calibration purposes. With this approach, we are able to build compact calibration datasets either: (a) by selecting segments from a long session with limited exciting motion…
Click any figure to enlarge with its caption.
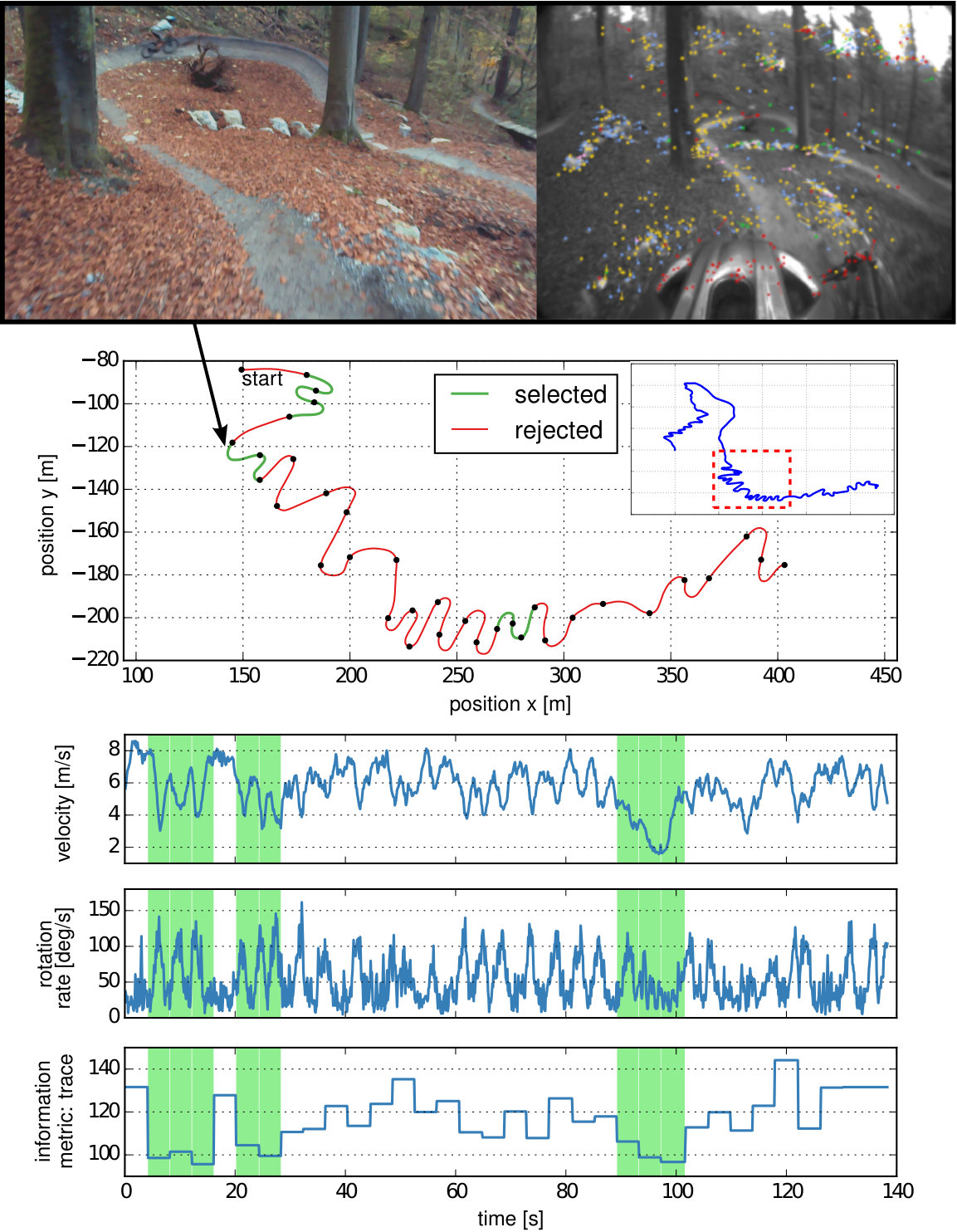 Figure 1
Figure 1 Figure 2
Figure 2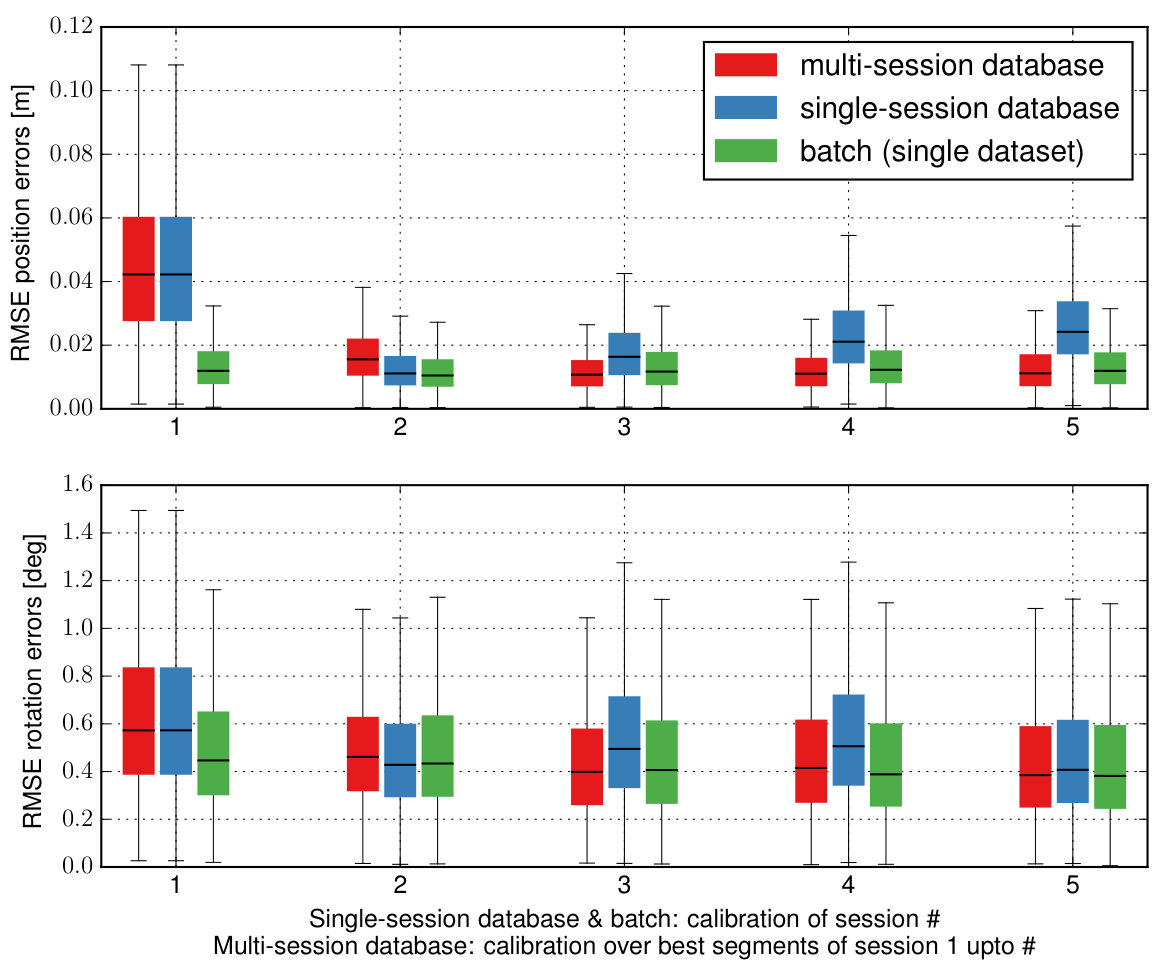 Figure 3
Figure 3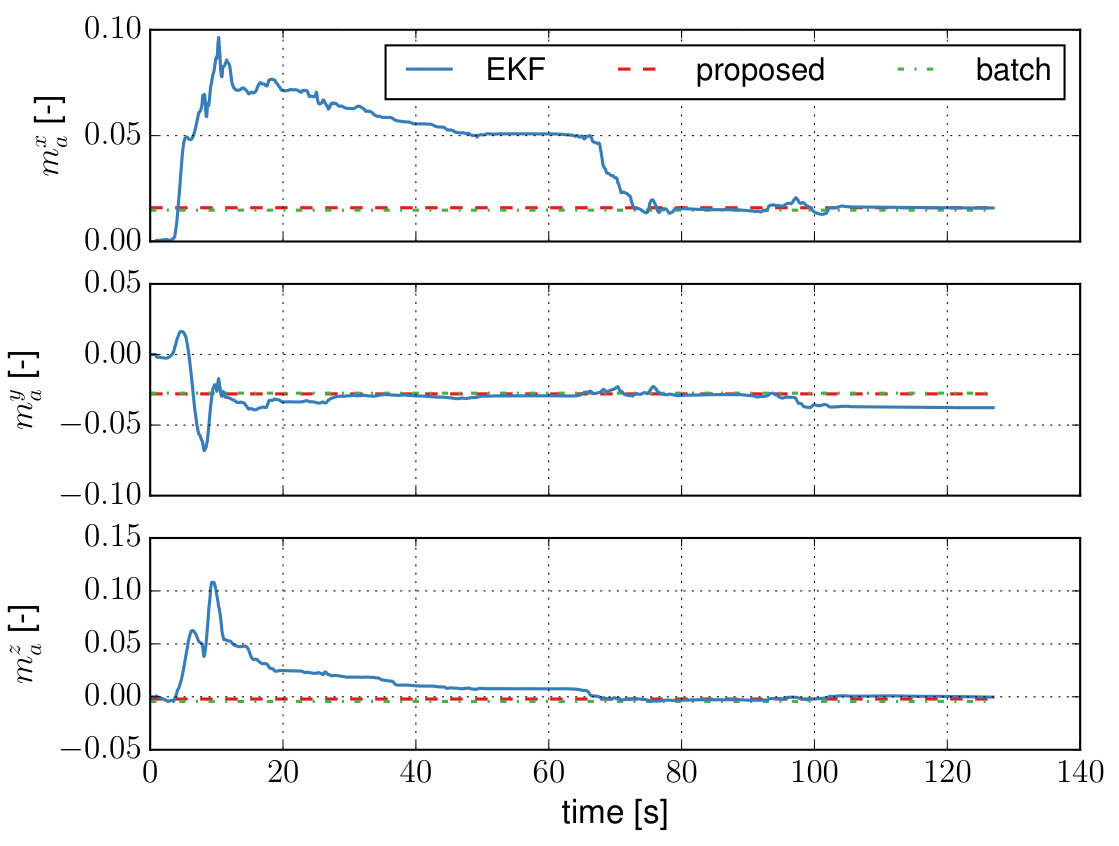 Figure 4
Figure 4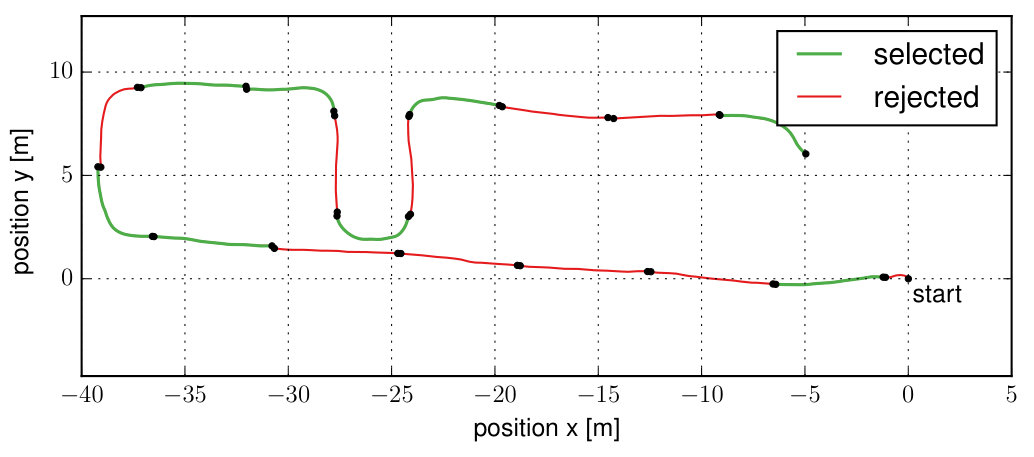 Figure 5
Figure 5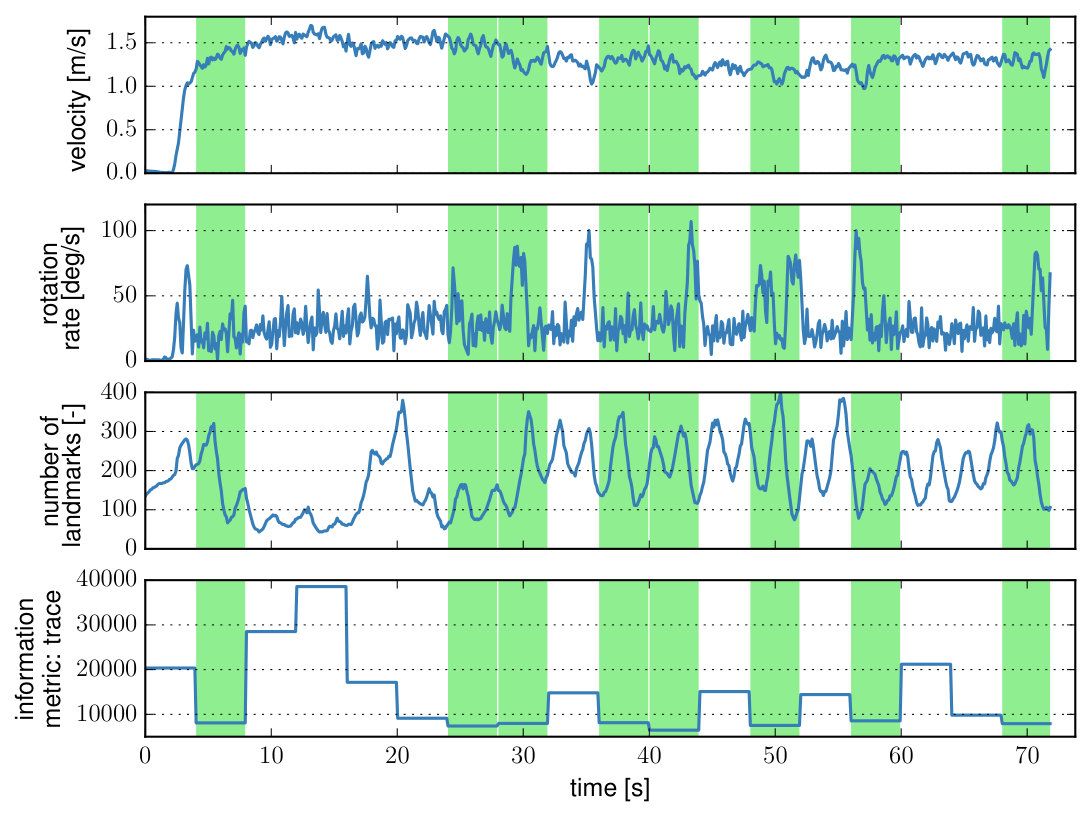 Figure 6
Figure 6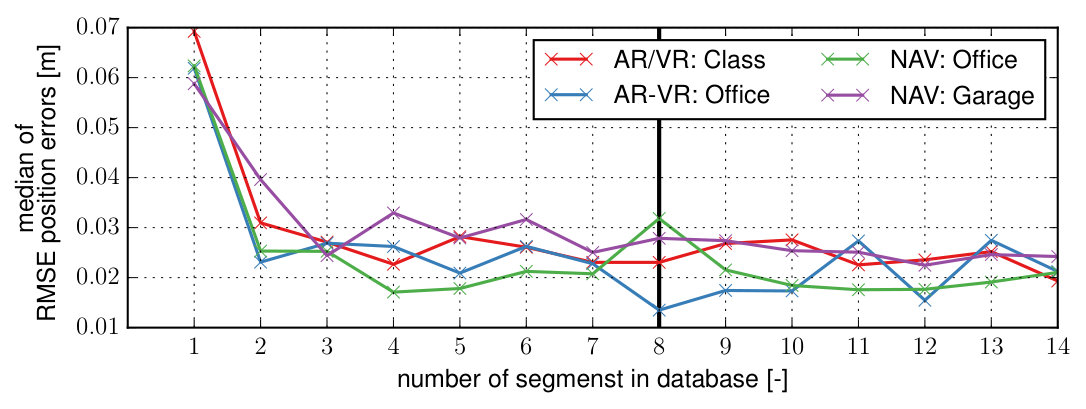 Figure 7
Figure 7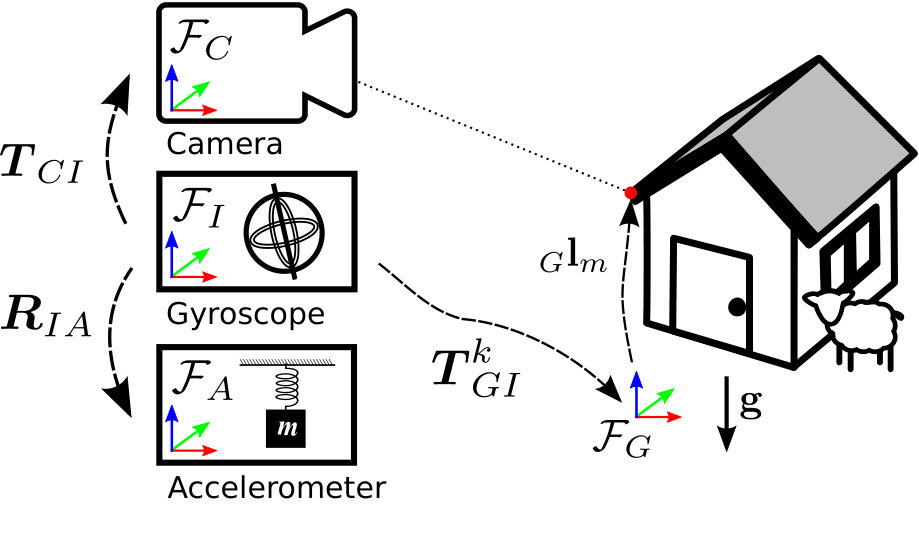 Figure 8
Figure 8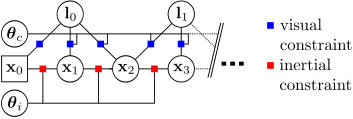 Figure 9
Figure 9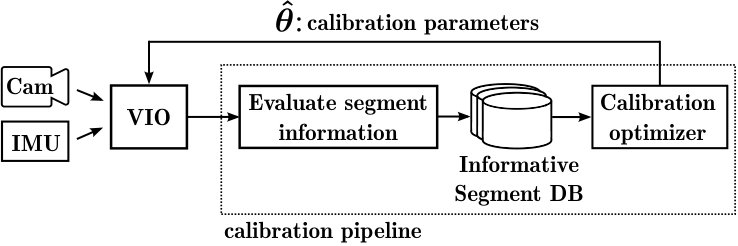 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15| Parameter | Symbol | Dim. | Unit |
| Camera | |||
| focal length | px | ||
| principal point | px | ||
| distortion | - | ||
| IMU | |||
| axis misalignment (gyro, accel.) | , | , | - |
| axis scale (gyro, accel.) | , | , | - |
| rotation w.r.t. | - | ||
| Extrinsics | |||
| translation w.r.t. | m | ||
| rotation w.r.t. | - |
| avg. length | avg. linear / | ||
|---|---|---|---|
| dataset | duration | angular vel. | description |
| AR/VR use-case: | |||
| office room | 23.8 m | 0.20 m/s | well-lit, good |
| (5 sessions) | 117.3 s | 20.3 deg/s | texture |
| class room | 37.4 m | 0.29 m/s | well-lit, open space, |
| (5 sessions) | 122.9 s | 29.62 deg/s | good texture |
| Navigation use-case: | |||
| parking garage | 168.4 m | 0.57 m/s | dark, low-texture |
| (3 sessions) | 305.0 s | 20.51 deg/s | walls, open space |
| office building | 164.8 m | 0.55 m/s | well-lit, good |
| (3 sessions) | 295.6 s | 23.12 deg/s | texture, corridors |
| Evaluation datasets: | |||
| Vicon room | 59.7 m | 0.49 m/s | motion-capture data, |
| (15 sessions) | 114.1 s | 42.95 deg/s | well-lit |
| RMSE on VIO trajectory vs. motion capture ground-truth (translation [cm] / rotation [deg]) | |||||||||||||||||||||
| initial | no sparsification | sparsified (8 segments, each 4 seconds) | |||||||||||||||||||
| calibration | (batch) | E-optimality | D-optimality | A-optimality | random | joint EKF | |||||||||||||||
| AR/VR: office room | 13.07 | 9.10 cm | 1.50 | 0.89 cm | 1.62 | 0.60 cm | 1.76 | 0.59 cm | 1.79 | 0.62 cm | 3.99 | 2.49 cm | 1.86 | 1.17 cm | |||||||
| 1.18 | 0.60 deg | 0.47 | 0.26 deg | 0.34 | 0.12 deg | 0.37 | 0.13 deg | 0.35 | 0.13 deg | 0.64 | 0.34 deg | 0.49 | 0.27 deg | ||||||||
| AR/VR: class room | 13.09 | 9.13 cm | 1.41 | 1.07 cm | 1.79 | 0.75 cm | 1.28 | 0.54 cm | 1.42 | 0.57 cm | 5.45 | 5.81 cm | 2.44 | 1.71 cm | |||||||
| 1.17 | 0.59 deg | 0.46 | 0.25 deg | 0.35 | 0.12 deg | 0.34 | 0.12 deg | 0.35 | 0.12 deg | 0.77 | 0.54 deg | 0.52 | 0.32 deg | ||||||||
| NAV: parking garage | 13.09 | 9.13 cm | 4.66 | 34.73 cm | 1.65 | 0.56 cm | 2.14 | 1.03 cm | 1.59 | 0.59 cm | 4.97 | 3.56 cm | 3.04 | 1.81 cm | |||||||
| 1.17 | 0.59 deg | 0.57 | 0.62 deg | 0.31 | 0.11 deg | 0.38 | 0.14 deg | 0.31 | 0.11 deg | 0.73 | 0.43 deg | 0.55 | 0.29 deg | ||||||||
| NAV: office building | 13.13 | 9.17 cm | 1.86 | 1.17 cm | 1.68 | 0.62 cm | 1.39 | 0.49 cm | 1.26 | 0.45 cm | 2.32 | 1.18 cm | 2.56 | 1.60 cm | |||||||
| 1.16 | 0.57 deg | 0.51 | 0.27 deg | 0.41 | 0.14 deg | 0.34 | 0.12 deg | 0.35 | 0.12 deg | 0.50 | 0.27 deg | 0.60 | 0.35 deg | ||||||||
| parameter | proposed method | batch | joint EKF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (sparsified) | (complete dataset) | (complete dataset) | |||||||
| [px] | 255.79 | 0.60 | 256.30 | 0.22 | - | ||||
| 255.68 | 0.67 | 256.31 | 0.27 | - | |||||
| [px] | 313.63 | 0.67 | 313.19 | 0.63 | - | ||||
| 241.62 | 1.17 | 243.16 | 0.18 | - | |||||
| [-] | 0.9203 | 0.0009 | 0.9208 | 0.0008 | - | ||||
| [-] | -2.82e-03 | 1.32e-03 | -2.11e-03 | 2.27e-04 | 2.39e-03 | 2.06e-03 | |||
| 4.33e-03 | 4.83e-03 | 4.02e-03 | 2.70e-04 | 7.71e-03 | 3.08e-03 | ||||
| -1.21e-03 | 5.18e-04 | -1.54e-03 | 4.18e-04 | 2.61e-03 | 3.90e-03 | ||||
| [-] | -9.70e-03 | 1.50e-02 | -1.85e-02 | 3.07e-03 | -1.64e-02 | 6.54e-03 | |||
| -1.16e-02 | 1.17e-02 | -1.65e-02 | 1.19e-03 | -1.24e-02 | 5.59e-03 | ||||
| -1.95e-02 | 7.38e-03 | -1.86e-02 | 1.48e-03 | -1.34e-02 | 2.43e-03 | ||||
| [-] | -3.22e-04 | 1.69e-03 | 7.36e-04 | 6.56e-04 | 1.03e-03 | 8.78e-04 | |||
| 2.37e-03 | 1.95e-03 | 3.96e-04 | 2.30e-04 | -7.36e-04 | 1.32e-03 | ||||
| -6.78e-04 | 1.60e-03 | -4.95e-05 | 1.17e-03 | -9.82e-04 | 1.77e-03 | ||||
| [deg] | 1.897 | 0.428 | 1.504 | 0.010 | 1.368 | 0.150 | |||
| [-] | 2.11e-02 | 1.11e-02 | 1.35e-02 | 1.54e-03 | 1.68e-02 | 5.05e-03 | |||
| -3.68e-02 | 1.11e-02 | -2.78e-02 | 2.59e-03 | -2.76e-02 | 6.78e-03 | ||||
| -7.93e-03 | 9.30e-03 | -3.19e-03 | 1.21e-03 | -7.92e-04 | 2.99e-03 | ||||
| [m] | 1.06e-03 | 4.01e-03 | 4.93e-03 | 2.33e-03 | 5.43e-03 | 3.68e-03 | |||
| 4.62e-03 | 1.86e-02 | 7.05e-04 | 2.17e-03 | 4.09e-04 | 2.85e-03 | ||||
| -1.48e-02 | 1.12e-02 | -6.09e-03 | 4.08e-03 | -1.19e-02 | 6.77e-03 | ||||
| [deg] | 1.174 | 0.133 | 1.065 | 0.071 | 0.753 | 0.069 | |||
|
batch |
|
|||||
|---|---|---|---|---|---|---|---|
| VIO (each image) | 0.003 s | - | 0.003 s | ||||
| Data selection (each segment) | 0.156 s | - | - | ||||
| Calibration (each dataset) | 12.050 s | 27.028 s | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
2D two-dimensional 3D three-dimensional DoF degree of freedom IMU inertial measurement unit EKF extended Kalman filter SLAM simultaneous localization and mapping VI visual-inertial VIO visual-inertial odometry MEMS Micro Electro-Mechanical Systems RMSE root-mean-square error MAV Micro Aerial Vehicle UAV Unmanned Aerial Vehicle ML maximum-likelihood SfM structure from motion
Observability-aware Self-Calibration of Visual and Inertial Sensors for Ego-Motion Estimation
Thomas Schneider, Mingyang Li, Cesar Cadena, Juan Nieto, and Roland Siegwart T. Schneider, C. Cadena, J. Nieto and R. Siegwart are with the Autonomous Systems Lab, ETH Zürich, Zürich, CH-8092, Switzerland (e-mail: {schneith,cesarc,nietoj,rsiegwart}@ethz.ch).M. Li is with the Alibaba Group, Hangzhou, China (e-mail: [email protected]).
Abstract
External effects such as shocks and temperature variations affect the calibration of visual-inertial sensor systems and thus they cannot fully rely on factory calibrations. Re-calibrations performed on short user-collected datasets might yield poor performance since the observability of certain parameters is highly dependent on the motion. Additionally, on resource-constrained systems (e.g mobile phones), full-batch approaches over longer sessions quickly become prohibitively expensive.
In this paper, we approach the self-calibration problem by introducing information theoretic metrics to assess the information content of trajectory segments, thus allowing to select the most informative parts from a dataset for calibration purposes. With this approach, we are able to build compact calibration datasets either: (a) by selecting segments from a long session with limited exciting motion or (b) from multiple short sessions where a single sessions does not necessarily excite all modes sufficiently. Real-world experiments in four different environments show that the proposed method achieves comparable performance to a batch calibration approach, yet, at a constant computational complexity which is independent of the duration of the session.
Index Terms:
observability-aware, life-long, marker-less, self-calibration, camera and IMU calibration, visual-inertial calibration
††An earlier version of this paper was presented at the 2017 IEEE International Conference on Robotics and Automation (ICRA) and was published in its Proceedings.
I Introduction
In this work, we present a sensor self-calibration method for visual-inertial ego-motion estimation frameworks i.e. systems that fuse visual information from one or multiple cameras with an inertial measurement unit (IMU) to track the pose (position and orientation) of the sensors over time. Over the last years, visual-inertial tracking has become an increasingly popular method and is being deployed into a big variety of products including AR/VR headsets, mobile devices, and robotic platforms. Large-scale projects, such as Microsoft’s HoloLens, make these complex systems available as part of mass-consumer devices operated by non-experts over the entire life-span of the product. This transition from the traditional lab environment to the consumer market poses new technical challenges to keep the calibration of the sensors up-to-date.
††1Figures in this paper are best viewed in color.
Traditionally, visual-inertial sensors are calibrated in a laborious manual process by an expert often using specialized tools and external markers such as checkerboard patterns (e.g. [1]). Aside from a lack of equipment, the lack of knowledge on how to properly excite all modes usually renders these methods infeasible for consumers as specific motion is required to obtain a consistent calibration. However, it can be used at the factory to provide an initial calibration for the device. Due to varying conditions (e.g. temperature, shocks, etc.) such calibrations degrade over time and periodic re-calibrations become necessary. A straightforward approach to this problem would be to run a calibration over a long dataset, hoping it is rich enough to excite all modes of the system. Yet, the large computational requirement of such a batch method might render this approach infeasible on constrained platforms without careful data selection.
This work exploits that information is usually not distributed uniformly along the trajectory of most visual-inertial datasets, as illustrated in Fig. 1 for a mountain-bike dataset. trajectory segments with higher excitation provide more information for sensor calibration whereas segments with weak excitation can lead to a non-consistent or even wrong calibration. Consequently, we propose a calibration architecture that evaluates the information content of trajectory segments in a background process alongside an existing visual-inertial estimation framework. A database maintains the most informative segments that have been observed either in a single-session or over multiple sessions to accumulate relevant calibration data over time. Subsequently, the collected segments are used to update the calibration parameters using a segment-based calibration formulation.
By only including the most informative portion of the trajectory, we are able to reduce the size of the calibration dataset considerably. Further, we can collect exciting motion in a background process assuming such motion occurs eventually and thus take the burden from the users to perform them consciously (which might be hard for non-experts). With this approach we can automate the traditional tedious calibration task and perform a re-calibration without any user intervention e.g. while playing an AR/VR video game or while navigating a car through the city. Additionally, our method facilitates the use of more advanced sensor models (e.g. IMU intrinsics) with potentially weakly observable modes that require specific motion for a consistent calibration.
This article is an extension of our previous work [2] where we presented the following:
- •
an efficient information-theoretic metric to identify informative segments for calibration,
- •
a segment-based self-calibration method for the intrinsic and extrinsic parameters of a visual-inertial system, and
- •
evaluations of the calibration parameter repeatability showing comparable performance to a batch approach.
In this work, we extend with the following contributions:
- •
a comprehensive review of the state-of-the-art on visual and inertial sensor calibration,
- •
a study of three different metrics for the selection of informative segments,
- •
an evaluation of the motion estimation accuracy on motion-capture ground-truth, and
- •
a comparison against an extended Kalman filter (EKF) approach that jointly estimates motion and calibration parameters.
II Literature Review
Over the past two decades, visual-inertial state estimation has been studied extensively by the research community and many methods and frameworks have been presented. For example, the work of Leutenegger et al. [3] fuses the information of both sensor modalities in a fixed-lag-smoother estimation framework and demonstrates metric pose tracking with an accuracy in the sub-percent range of distance traveled. Many applications on resource-constrained platforms, such as mobile phones, however, use filtering-based approaches which offer pose tracking with similar accuracy at a lower computational cost. An early method of this form is the one from Mourikis and Roumeliotis [4], and more recently also from Bloesch et al. [5], that directly minimizes a photometric error on image patches instead of a geometric re-projection error on point-features. Newer frameworks e.g. from Qin et al. [6] or Schneider et al. [7] also incorporate online localization/loop-closures to further reduce the drift or in certain cases even eliminate it completely.
All these methods require an accurate and up-to-date calibration of all sensor models to achieve good estimation performance. For this reason, a multitude of methods have been developed to calibrate models for the camera, IMU and relative pose between the two sensors. An overview of early methods that calibrate each model independently can be found in [8, 9, 10]. In the remaining of this section we, first, provide an overview of the state of the art in self-calibration of visual-inertial sensor systems and, second, discuss the most relevant observability-aware calibration approaches. And finally, we review methods that perform information-theoretic data selection for calibration purposes; which are most related to our approach.
II-A Marker-based Calibration
The work on self-calibration of visual and inertial sensors is still limited and therefore, we first discuss approaches that rely on external markers such as checkerboard patterns. An approach based on an EKF is presented in [11] that uses a checkerboard pattern as a reference to jointly estimate the relative pose between an IMU and a camera with the pose, velocity, and biases. Zachariah and Jansson [12] additionally estimate the scale error and misalignment of the inertial axis using a sigma-point Kalman filter.
A parametric method is proposed in [13] describing a batch estimator in continuous-time that represents the pose and bias trajectories using B-splines. Krebs [14] extends this work by compensating additional sensing errors in the IMU model; namely measurement scale, axis misalignment, cross-axis sensitivity, the effect of linear accelerations on gyroscope measurements and the orientation between the gyroscope and the accelerometer. A similar model is calibrated by Nikolic et al. [15] where they make use of a non-parametric batch formulation and thus avoid the selection of a basis function for the pose and bias trajectories which might depend on the dynamics of the motion (e.g. over the knot density). The non-parametric and parametric formulation are compared in real-world experiments with the conclusion that the accuracy and precision of both methods are similar [15].
II-B Marker-less Calibration
In contrast to target-based, self-calibration methods solely rely on natural features to calibrate the sensor models without the need for external markers such as checkerboards. Early work of this from was presented by Kelly and Sukhatme [16] and uses an unscented Kalman filter to jointly estimate pose, bias, velocity, IMU-to-camera relative pose and also the local scene structure. Their real-world experiments demonstrate that the relative pose between a camera and an IMU can be accurately estimated with similar quality to target-based methods. The work of Patron-Perez et al. [17] additionally calibrates the camera intrinsics and uses a continuous-time formulation with a B-splines parameterization. Li et al. [18] go one step further and also include the following calibration parameters into the (non-parametric) EKF-based estimator: time offset between camera and IMU, scale errors and axis misalignment of all inertial axis, linear acceleration effect on the gyroscope measurements (g-sensitivity), camera intrinsics including lens distortion and the rolling-shutter line-delay. A simulation study and real-world experiments indicate that all these quantities can indeed be estimated online solely-based on natural features [18].
II-C Observability of Model Parameters
All of the discussed calibration methods so far, both target-based and self-calibration methods, rely on sufficient excitation of all sensor models to yield an accurate calibration. Mirzaei and Roumeliotis [11] formally prove that the IMU-to-camera extrinsics are observable in a target-based calibration setting where the observability only depends on sufficient rotational motion. The analysis of Kelly and Sukhatme [16] shows that the IMU-to-camera extrinsics remains observable also for a self-calibration formulation. Further, Li and Mourikis [19] derive the necessary condition for the identifiability of a constant time offset between the IMU and camera measurements.
So far, no observability analysis has been performed for the full joint self-calibration problem that includes the intrinsics of the IMU and camera and also the relative pose between the two sensors. Our experience, however, indicates that ‘rich’ exciting motion is required to render all parameters observable and usually such calibration datasets are collected by expert intuition. Often, this knowledge is missing when simultaneous localization and mapping (SLAM) systems are deployed to consumer-market products. For this reason, the (re-)calibration dataset collection process must be automated for true life-long autonomy.
II-D Active Observability-aware Calibration
Active calibration methods automate the dataset collection by planning and executing trajectories which ensure the observability of the calibration parameters wrt. a specified metric. An early work in this direction for target-based camera calibration is [20]. They present an interactive method that suggests the next view of the target that should be captured such that the quality of the model improves incrementally.
Another active calibration method is presented by Bähnemann et al. [21] to plan informative trajectories using a sampling-based planner to calibrate Micro Aerial Vehicle (MAV) models. The informativeness of a candidate trajectory segment within the planner is approximated by the determinant of the covariance of the calibration parameters which is propagated using an EKF. In a similar setting, Hausman et al. [22] plan informative trajectories to calibrate the model of an Unmanned Aerial Vehicle (UAV) using the local observability Gramian as an information measure. An extension to this work is presented by Preiss et al. [23] where they additionally consider free-space information and dynamic constraints of the vehicle within the planner. The condition number of the Expanded Empirical Local Observability Gramian (E2LOG) is proposed as an information metric. The columns of E2LOG are scaled using empirical data to balance the contribution of multiple states. A simulation study shows that the method outperforms random motion and also the well-known heuristic, such as the figure-8 or star motion pattern. Further, the study indicates that trajectories minimizing the E2LOG perform slightly better compared to the minimization of the trace of the covariance matrix but in general yield comparable performance.
II-E Passive Observability-aware Calibration – Calibration on Informative Segments
In contrast to the class of active calibration methods, passive methods cannot influence the motion and instead identify and collect informative trajectory segments to build a complete calibration dataset over time. The framework of Maye et al. [24] selects a set of the most informative segments using an information gain measure to consequently perform a calibration on the selected data. A truncated-QR solver is used to limit updates to the observable subspace. The generality of this method makes it suitable for a wide range of problems. Unfortunately, the expensive information metric and optimization algorithm prevent its use on resource-constrained platforms. Similarly, Keivan and Sibley [25] maintain a database of the most informative images to calibrate the intrinsic parameters of a camera but use a more efficient entropy-based information metric for the selection. Nobre et al. [26] extend the same framework to calibrate multiple sensors and more recently Nobre et al. [27] also include the relative pose between an IMU and a camera.
In our work, we take a similar approach to [24, 25] but also consider inertial measurements and consequently collect informative segments instead of images. In contrast to the general method of [24], we use an approximation for the visual-inertial use-case and neglect any cross-terms between segments when evaluating their information content. This approximation increases the efficiency at the cost that no loop-closure constraints can be considered. Compared to [27], we assume the calibration parameters to be constant over a single session but additionally calibrate the intrinsic parameters of the IMU using a model similar to [14, 28].
III Visual and Inertial System
The visual-inertial sensor system considered in this work consists of a global-shutter camera and an IMU. For better readability, the formulation is presented only for a single camera, however, the method has been tested for multiple cameras as well. All sensors are assumed to be rigidly attached to the sensor system. The IMU itself consists of a 3-axis accelerometer and a 3-axis gyroscope. In this work, we assume an accurate temporal synchronization of the IMU and camera measurements and exclude the estimation of the clock offset and skew. However, online estimation of these clock parameters is feasible as shown in [19].
The following subsections introduce the sensor models for the camera and IMU. An overview of all model parameters is shown in Table I and all relevant coordinate frames of the visual and inertial system in Fig. 2.
III-A Notation and Definitions
A transformation matrix takes a vector expressed in the frame of reference into the coordinates of the frame and can be further partitioned into a rotation matrix and a translation vector as follows:
[TABLE]
The unit quaternion represents the rotation corresponding to as defined in [29]. The operator is defined to transform a vector in from to the frame of reference as according to Eq. (1).
III-B Camera Model
A function models the perspective projection and lens distortion effects of the camera. It maps the -th 3d landmark onto the image plane of the camera to yield the 2d image point as:
[TABLE]
where denotes the model parameters of the perspective projection function (which we want to calibrate).
In our evaluation setup, we use high-field-of-view cameras as they typically yield more accurate motion estimates [30]. As a consequence the camera records a heavily distorted image of the world. To account for these effects, we augment the pinhole camera model with the field-of-view (FOV) distortion model [31] to obtain the following perspective projection function:
[TABLE]
where denotes the focal length, the principal point and the 2d projection of a 3d landmark in normalized image coordinates as:
[TABLE]
The function models the (symmetric) distortion effects as a function of the radial distance to the optical center as:
[TABLE]
with being the single parameter of the FOV distortion model.
The measurement model for landmark observations expressed in the global frame (see Fig. 2) can be written as:
[TABLE]
where denotes the projection of the landmark onto the image plane of the keyframe , the pose of the sensor system, the relative pose of the camera w.r.t. the IMU and a white Gaussian noise process with zero mean and standard deviation as . The full calibration state of the camera model can be summarized as:
[TABLE]
where the camera-IMU relative pose is split into its rotation part and its translation part , is the focal length, the principal point and the distortion parameter of the lens distortion model.
III-C Inertial Model
The IMU considered in this work consists of a (low-cost) MEMS 3-axis accelerometer and a 3-axis gyroscope. As in the work of [28, 14, 15], we include the alignment of the non-orthogonal sensing axis and a correction of the measurement scale into our sensor model. Further, we assume the translation between the accelerometer and gyroscope to be small (single-chip IMU) and only model a rotation between the two sensors (as shown in Fig. 2).
Considering these effects, we can write the model for the gyroscope measurements as:
[TABLE]
where denotes the true angular velocity of the system, a correction matrix accounting for the scale and misalignment of the individual sensor axis (see Eq. (15)), is a random walk process as:
[TABLE]
with the zero-mean white noise Gaussian processes being defined as
[TABLE]
Similarly, the specific force measurements of the accelerometer are modeled as:
[TABLE]
where is the true acceleration of the sensor system w.r.t. to the inertial frame , the relative orientation between the gyroscope and accelerometer frame, the orientation of the IMU w.r.t. the inertial frame , is a correction matrix for the scale and misalignment (see Eq. (15)), the gravity acceleration expressed in the inertial frame . The bias process is defined as a random walk process as:
[TABLE]
with the zero-mean white noise Gaussian processes being defined as:
[TABLE]
The noise characteristics of the IMU are assumed to have been identified beforehand at nominal operating conditions e.g. using the method described in [32]. The correction matrix and accounting for the scale and misalignment errors is defined identically for the gyroscope and accelerometer and is partitioned as:
[TABLE]
where denotes the collection of all misalignment and all scale factors as:
[TABLE]
The full calibration state of the inertial model can then be summarized as:
[TABLE]
where describes the rotation of gyroscope frame w.r.t. to the accelerometer frame (with the IMU frame being defined as the gyroscope frame ).
IV Visual-Inertial Self-Calibration
In this section, we formulate the self-calibration problem for visual and inertial sensor systems using the sensor models introduced in the previous section. The derived maximum-likelihood (ML) estimator makes use of all images and inertial measurements within the dataset to yield a full-batch solution. The motion of the sensor system and the (sparse) scene structure are jointly estimated with the model parameters to achieve self-calibration without the need for a known calibration target (e.g. a chessboard pattern). The batch estimator will serve as a base to introduce the segment-based calibration which only considers the most informative segments of a trajectory (see Section V).
IV-A System State and Measurements
The self-calibration formulation jointly estimates all keyframe states , all point landmarks , the calibration parameters of the camera and the IMU with the keyframe state being defined as:
[TABLE]
where and define the pose of the sensor system at timestep , the velocity of the system and the bias of the gyroscope and accelerometer.
To simplify further notations, we collect all states of the problem in the following vectors:
[TABLE]
where is the total number of keyframes and the number of landmarks. Additionally, the vector stacks all estimated states as:
[TABLE]
Further, we define the collection to contain all IMU measurements and all 2d landmark observations of the camera as:
[TABLE]
where is the set of all accelerometer and gyroscope measurements between the keyframes and and the 2d measurement of the -th landmark seen from the -th keyframe and and denote the number of keyframes and landmarks respectively.
IV-B State Initialization using VIO
A vision front-end tracks sparse point features between consecutive images and rejects potential outliers based on geometrical consistency using a perspective-n-point algorithm in a RANSAC scheme. The resulting feature tracks and the IMU measurements are processed by an EKF which is loosely based on the formulation of [4, 18] but with various extension to increase robustness and accuracy. The filter recursively estimates all keyframe states and landmark positions . The calibration states are not estimated by this filter except for the camera-to-IMU relative pose (camera extrinsics). However, for the initialization of the calibration problem, we only use the keyframe states (pose, velocity, biases) and the most recent estimate of the camera-to-IMU extrinsics. The landmark states are initialized by triangulation using the poses estimated by the EKF filter.
It is important to note that the filter needs sufficiently good calibration parameters in order to run properly and provide accurate initial estimates. In our experience, it is sufficient for most single-chip IMUs to initialize their intrinsic calibration to a nominal value (unit scale, no misalignment). However, a complete self-calibration may be difficult if no priors are available for the camera intrinsics. In this case, a specialized calibration method should be used beforehand e.g. [1, 33].
IV-C ML-based Self-Calibration Problem
We use the framework of ML estimation to jointly infer the state of all keyframes , landmarks and calibration parameters using all available measurements of the IMU and the 2d measurements of the point landmarks extracted from the camera images.
A factor graph representation of the visual-inertial self-calibration formulation is shown in Fig. 3. The problem contains two types of factor: the visual factor models the projection of the landmark onto the image plane of the keyframe and the inertial factor forms a differential constraint between two consecutive keyframe states and (pose, velocity, bias). The ML estimate is obtained by a maximization of the corresponding likelihood function . When assuming Gaussian noise for all sensor models (see Section III), the ML solution can be approximated by solving the (non-linear) least-squares problem with the following objective function :
[TABLE]
where denotes the number of keyframes, the set of landmarks off from keyframe , the reprojection error of the -th point landmark of observed from the -th keyframe and denotes the inertial constraint error between two consecutive keyframe states and as a function of integrated IMU measurements. The terms and denote the inverse of the error covariance matrices: keypoint measurement and the integrated IMU measurement covariance respectively. The reprojection error is defined as:
[TABLE]
where is the 2d measurement of the projection of the landmark into camera and its prediction as defined in Eq. (6). The inertial error is obtained by integrating the continuous equations of motion using the sensor models described in Section III-C and is based on the method described in [18]. The non-linear objective function is minimized using numerical optimization methods. In our implementation, we use the Levenberg-Marquardt implementation of the Ceres framework [34].
V Self-Calibration using Informative Motion Segments
In this section, we propose a method to identify informative segments in a calibration dataset and a modified formulation for estimating calibration parameters based on a set of segments. First, the method can be used to sparsify a dataset and consequently reduce the complexity of the optimization problem. And second, a complete calibration dataset can be built over time by accumulating informative segments from multiple sessions, thus enabling the calibration of even weakly observable parameters by collecting exciting motion that occurs eventually. It is important to note that the proposed method is presented on the use-case of visual-inertial calibration but it can be applied to arbitrary calibration problems.
V-A Architecture
A high-level overview of the modules and data-flows is shown in Fig. 4. The proposed method is intended to be run in parallel to an existing visual-inertial motion estimation system. The VIO implementation used in this work is described in Section IV-B but it is important to note that the method is not tied to a particular motion estimation framework. The keyframe and landmarks states estimated by the VIO module are partitioned into segments. In a next step, the information content of each segment w.r.t. the calibration parameters is evaluated using an efficient information theoretic metric. A database maintains the most informative segments of the trajectory and a calibration is triggered once enough data has been collected. This algorithm is summarized in Alg. 1 and explained in more details in the following sections.
V-B Evaluating Information Content of Segments
The continuous stream of keyframe (pose, velocity, bias) and landmark states , estimated by the VIO, is partitioned into motion segments. The -th segment is made up by the consecutive keyframes and the set of landmarks observed from this segment.
We propose to use information metrics that only consider the constraints within each segment to evaluate the information content w.r.t. the calibration parameters . Using such an information metric which is independent of all other segments makes its evaluation very efficient at the cost of neglecting cross-terms coming from other segments such as loop-closure constraints. However, the neglected constraints can be re-introduced and considered during the calibration. Thus, this assumption only affects the selection of informative segments and potentially leads to a conservative estimate of the actual information but should not bias the calibration results.
To quantify the information content of the -th segment , we recover the marginal covariance of the calibration parameters given all the constraints within the segment. For this, we first approximate the covariance over all segment states using the Fisher Information Matrix as:
[TABLE]
The matrix represents the stacked Jacobians of all error terms and the stacked error covariances corresponding to the errors terms as:
[TABLE]
where denotes the collection of all states within the segment and the number of errors terms within the segment . Further, the state ordering is chosen such that the rightmost columns of correspond to the states of the calibration parameters .
A rank-revealing QR decomposition is used to obtain with being the Cholesky decomposition of the error covariance matrix. The Eq. (24) can then be rewritten as
[TABLE]
As is an upper-triangular matrix, we can obtain the marginal covariance efficiently by back-substitution.
In a next step, we normalize the marginal covariance to account for different scales of the calibration parameters with:
[TABLE]
where is the expected standard deviation that has been obtained empirically from a set of segments from various datasets. It is important to note, that depends on the sensor setup (e.g. focal length, dimensions, etc.) and should either be re-evaluated for each setup or a normalization based on nominal calibration parameters should be performed.
We can now define different information metrics based on the normalized marginal covariance . These metrics will be used to compare segments based on their information content w.r.t. the calibration parameters . They are defined such that a lower value corresponds to more information. In this work, we will investigate the three most common information-theoretic metrics from optimal design theory:
V-B1 A-Optimality
This criterion seeks to minimize the trace of the covariance matrix which results in a minimization of the mean variance of the calibration parameters. The corresponding information metric is defined as:
[TABLE]
V-B2 D-Optimality
Minimizes the determinant of the covariance matrix which results in a maximization of the differential Shannon information of the calibration parameters.
[TABLE]
It is interesting to note that this criterion is equivalent to the minimization of the differential entropy which for Gaussian distributions is defined as:
[TABLE]
where is the normalized normal distribution of and the dimension of this distribution.
V-B3 E-Optimality
This design seeks to minimize the maximal eigenvalue of the covariance matrix with the metric being defined as:
[TABLE]
V-C Collection of Informative Segments
We want to maximize the information contained within a fixed-sized budget of segments. For this reason, we maintain a database with a maximum capacity of segments retaining only the most informative segments of the trajectory. The information metric will be used to decide which segments are retained and which are rejected such that the sum over the information metric of all segments in the database is minimized. Such a decision scheme will ensure that the accumulated information on the calibration parameter is increasing over time while the number of segments remains constant. Therefore, an upper bound on the calibration problem complexity can be guaranteed. However, it is important to note that the sum of information metrics is only a conservative approximation of the total information content for two reasons: First, the information metric is only a scalar and therefore no directional information is available. Second, the information metrics neglect any cross-terms to other segments and thus underestimates the true information.
V-D Segment Calibration Problem
The segment-based calibration differs from the batch estimator introduced in Section IV in that it only contains the most informative segments of a (multi-session) dataset. The removal of trajectory segments from the original problem leads to two main challenges.
First, the time difference between two (temporally neighboring) keyframes could become arbitrarily large when non-informative keyframes have been removed in-between. An illustration of such a dataset with a temporal gap due to the keyframe removal is shown in Fig. 5 (between keyframe 6/10 and 12/16). In this case, we only constrain the bias evolution between the two neighboring keyframes using a random walk model described in Section III-C and no constraints are introduced for the remaining keyframe states (pose, velocity).
Second, the removal of non-informative trajectory segments often creates partitions of keyframes that are neither constrained to other partitions through (sufficient) shared landmark observations nor through inertial constraints. Each of these partitions can be seen as a (nearly) independent calibration problem that only shares the calibration states with other partitions. Assuming non-degenerate motion and sufficient visual constraints, each of these partitions contains the 2 structurally unobservable modes of the visual-inertial optimization problem namely the rotation around the gravity vector (yaw in global frame) and the global position. These modes are eliminated from the optimization by keeping them constant for exactly one keyframe in each of the partitions to achieve efficient convergence of the iterative solvers.
We identify the partitions based on the co-visibility of landmarks and the connectivity through inertial constraints. An overview of the algorithm is shown in Alg. 2. In a first step, all segments that are direct temporal neighbors, and thus connected through inertial constraints, are joined into larger segments (e.g. segment 1 and 2). In a next step, we use a union-find data structure to iteratively partition the joined segments into disjoint sets (partitions) such that the number of co-observed landmarks between the partitions lies below a certain threshold. At this point, all keyframes within a partition are either constrained through inertial measurements or through sufficient landmark co-observations w.r.t. each other. It is important to note that degenerate landmark configurations are still possible using such a heuristic metric. However, an error will only influence the convergence rate of the incremental optimization but should not bias the calibration results.
VI Experimental Setup
This section introduces the experiments, datasets, and hardware used to evaluate the proposed method. The results are discussed in the next section.
VI-A Single-/Multi Session Database
We evaluate the proposed method using two different strategies to maintain informative segments in the database. Each strategy is investigated using a set of multi-session datasets and discussed along a suitable use-case:
VI-A1 Single-session Database: Observability-aware Sparsification of Calibration Datasets
Each session starts with an empty segment database and the most informative segments from this single session are kept. After each session, a segment-based calibration is performed using all the segments in the database and the calibration parameters are updated for use in the next session. This strategy can be seen as an observability-aware sparsification method for calibration datasets. It is well suited for infrequent and long sessions (e.g. navigation use-case with lots of still phases) where batch calibration over the entire dataset would be too expensive and data selection is necessary.
VI-A2 Multi-session Database: Accumulation of Information over Time
The multi-session strategy does not reset the database between sessions and the most informative segments are collected from multiple consecutive sessions. In contrast to the single-session strategy, it is particularly suited for frequent and short sessions; for example in an AR/VR use-case where a user performs many short session over a short period of time. It accumulates information from multiple sessions and thus enables the calibration of weakly observable modes which might not be sufficiently excited in a single session.
VI-B Datasets and Hardware
All datasets were recorded using a Google Tango tablet as shown in Fig. 6. This device uses a high-field-of-view global shutter camera (10 Hz) and a single-chip MEMS IMU (100 Hz). The measurements of both sensors are time-stamped in hardware on a single clock for an accurate synchronization. Additionally, the sensor rig is equipped with markers for external tracking by a Vicon motion capture system. All datasets were recorded on the same device, in a short period of time and while trying to keep the environmental factors constant (e.g. temperature) to minimize potential variations of the calibration parameters across the datasets and sessions.
We have collected datasets representative for each of the two use-cases introduced in the previous section in different environments (office, class room, and garage). These datasets consist of multiple sessions that will be used to obtain a calibration using the proposed method. Right after recording the calibration datasets, we have collected a batch of evaluation datasets with motion capture ground-truth. These datasets are used to evaluate the motion estimation accuracy that can be achieved using the obtained calibration parameters. An overview of all datasets and their characteristics is shown in Table II and Fig. 7.
While recording the calibration datasets, we tried to achieve the following characteristics representative for the two use-cases:
VI-B1 AR/VR use-case
We collected datasets that mimic an AR/VR use-case to evaluate whether we can accumulate information from multiple-sessions (multi-session database strategy). Characteristic of this use-case, the datasets consists of multiple short sessions restricted to a small indoor space (single room), containing mostly fast rotations, only slow and minor translation and stationary phases. Two datasets have been recorded in a class and office room each containing sessions that are min long.
VI-B2 Navigation use-case
In contrast to the AR/VR use-case, the navigation sessions contain mostly translation over an area of multiple rooms and only slow rotations but also contain stationary and rotation-only phases. Datasets have been recorded in two locations: garage and office - each contains sessions with a duration of min. These datasets will be used to evaluate the observability-aware sparsification (single-session database strategy).
VI-C Evaluation Method
For performance evaluation, we calibrate the sensor models on each session of the dataset in temporal order where we use the calibration parameters obtained from the previous session as initial values. The first session uses a nominal calibration consisting of a relative pose between camera and IMU from CAD values, nominal values for the IMU intrinsics (unit scale factors, no axis misalignment) and camera intrinsics.
This calibration scheme is performed for all datasets and for both of the database strategies to obtain a set of calibration parameters for each session. The quality of the obtained calibration parameters is then evaluated using the following methods:
VI-C1 Motion estimation performance
As the main objective of our work is to calibrate the sensor system for ego-motion estimation, we use the accuracy of the motion estimation (based on our calibrations) as the main evaluation metric. We run all evaluation datasets for each set of calibration parameters and evaluate the accuracy of the estimated trajectory against the ground-truth from the motion-capture system.
The motion estimation error is obtained by first performing a spatio-temporal alignment of the estimated and the ground-truth trajectory. Second, a relative pose error is computed at each time-step between the two trajectories. To compare different runs, we use the root-mean-square error (RMSE) calculated over all the relative pose errors.
VI-C2 Parameter repeatability
We only evaluate the parameter repeatability over different calibrations of the same device as no ground-truth for the calibration parameters is available. We have recorded all dataset close in time while keeping the environmental conditions (e.g. temperature) similar and avoiding any shocks to minimize potential variations of the calibration parameters between the datasets.
VII Results and Discussion
In this section, we discuss the results of our experiments (Section VI) along the following questions:
- •
Section VII-A: How accurate are motion estimates based on calibrations derived only from informative segments? How does it compare to the non-sparsified (batch) calibration?
- •
Section VII-B: Does the sparsified calibration yield similar calibration parameters to the (full) batch problem?
- •
Section VII-D: Can we accumulate informative segments from multiple sessions and perform a calibration where the individual session would not provide enough excitation for a reliable calibration?
- •
Section VII-E: How does the proposed method compare against an EKF approach that jointly estimates motion and calibration parameters?
- •
Section VII-C: How do the three different information metrics compare? Can we outperform random selection of segments?
- •
Section VII-F: What segments are being selected as informative? What are their properties?
- •
Section VII-G: How do we select the number of segments to retain in the database?
VII-A Motion Estimation Performance using the Observability-aware Sparsification (Single-session Database)
In this experiment, we use a database of segments ( seconds each) which leads to a reduction of the sessions size by around % in the AR/VR use-case and % in the navigation use-case. To evaluate the observability-aware sparsification, we select the most informative segments for all sessions of a dataset independently. A segment-based calibration is then run over the selected segments to obtain an updated set of calibration parameters for each session. Finally, the VIO motion estimation accuracy is evaluated for each calibration on all of the evaluation datasets as described in Section VI-C1. The resulting statistics of the RMSE are shown in Table III for each dataset. The mean of rotation states corresponds to the rotation angle of the averaged quaternion as described in [35] and the standard deviation is derived from rotation angles between the samples and the averaged quaternion. For comparison, the same evaluations have been performed for the initial and batch calibration (no sparsification).
The calibrations obtained with the sparsified dataset yield very similar motion estimation performance when compared to full batch calibrations. This indicates that the proposed method can indeed sparsify the calibration problem while retaining the relevant portion of the dataset and still provide a calibration with motion estimation performance close to the non-sparsified problem. It is interesting to note, that the sparsification to a fixed number of segments keeps the calibration problem complexity bounded while the complexity of the batch problem is (potentially) unbounded when used on large datasets with redundant and non-informative sections.
VII-B Repeatability of Estimated Calibration Parameter
As we have no ground-truth for the calibration parameters, we can only evaluate their repeatability across multiple calibrations of the same device. The statistics over all calibration parameters obtained with all sessions of the class room datasets are shown in Table IV. We used the same sparsification parameters as in Section VII-A ( segments, each seconds).
The experiments show that the deviation between the full-batch and sparsified solution remain insignificant in mean and standard deviation even though % of the trajectory has been removed. This is a good indication that the sparsified calibration problem is a good approximation to the complete problem.
VII-C Comparison of Information Metrics
In Section V-B, we have proposed three different information metrics to compare trajectory segments for their information w.r.t. to the calibration parameters. The same evaluation performed for the sparsification use-case (Section VII-A) has been repeated for each of the proposed metrics and, as a baseline, also for calibrations based on randomly selected segments. The motion estimation errors based on these calibration is reported in Table III.
The motion estimation error is around - times larger when randomly selecting the same amount of data indicating that the proposed metrics successfully identify informative segments for calibration. It is important to note, that this comparison heavily depends on the ratio of informative / non-informative motion in the dataset and therefore this error might be larger when there is less excitation in a given dataset. In general, all three metrics show comparable performance, however, the A-optimality criteria performed slightly better on the navigation and the D-optimality on the AR/VR use-case.
VII-D Accumulation of Information over Time: Single- vs Multi-session Database
In this section, we evaluate whether the proposed method can accumulate informative segments from multiple consecutive sessions to obtain a better and more consistent calibration than the individual session would yield. This is especially important in scenarios where a single session often would not provide enough excitation for a reliable calibration. The evaluations were performed on the AR/VR use-case datasets which consist of multiple short sessions. We use the A-optimality criteria to select the most informative segments of each sessions and maintain them in the database ( segments, seconds). In contrast to the sparsification use-case from Section VII-A, the database is not reset between the sessions. In other words, the database will collect the most informative segments from the first up to the current session. After each session, a calibration is triggered using all segments of the database. These calibrations are then used to evaluate the motion estimation error on all evaluation datasets. The results are shown in Fig. 8 for the class room dataset.
The evaluation shows that the motion estimation error decreases as the number of sessions increases (from which informative segments have been selected). Further, the motion estimation error is smaller when compared to calibrations based on the most informative segments from individual sessions. After around sessions the estimation performance is close to what would be achieved using a batch calibration. This indicates that the proposed method can accumulate information from multiple sessions while the number of segments in the database remains constant. It can therefore provide a reliable calibration when a single session would not provide enough excitation.
VII-E Comparison vs. joint EKF
In this section, we compare the proposed method against an EKF filter that jointly estimates the motion, scene structure and the calibration parameters (similar to [18]). In our implementation, we only estimate the IMU intrinsics and the relative pose between the camera and IMU. The camera intrinsics are not estimated and set to parameters obtained with a batch calibration on the same dataset.
We evaluated the motion estimation errors on all datasets and report the results in Table III. The resulting calibration parameters are compared to the proposed method and batch solution in Table IV. The evaluations show a position error that is up to times larger compared to calibrations obtained with the proposed method or a batch calibration. When looking at the state evolution of e.g. the misalignment factors, as shown in Fig. 9 for one of the datasets, it can be seen that it converges roughly to the batch estimate but does not remain stable over time. We see this as an indication that the local scope of the EKF is not able to infer weakly observable states properly and thus a segment-based (sliding-window) approach is beneficial in providing a stable and consistent solution over time.
VII-F Selected Informative Segments
In this section, we investigate the motion that is being selected as informative by the proposed method. Fig. 10 shows the most informative segments that have been selected in one of the session of the navigation use-case. We only show the first minute of the session as otherwise the trajectory would start to overlap. It can be seen that the information metric correlates with changes in linear and rotational velocity and therefore mostly segments containing turns have been selected while straight segments have been found to be less informative. This experiment seems to confirm the intuition that segments with larger accelerations and rotational velocities are more informative for calibration.
VII-G Influence of Database Size on the Calibration Quality
In this experiment, we investigate the effect of the database size on the calibration quality to find the minimum amount of data required for a reliable calibration. We sparsify all sessions of all datasets repeatably to retain to of the most informative segments. A segment-based calibration is then run on each of the sparsified datasets and the motion estimation error is evaluated on all evaluation datasets. The segment duration was chosen as seconds from geometrical considerations such that segments span a sufficiently large distance for landmark triangulation with the assumption that the system moves at a steady walking speed. The median of the RMSE over all evaluation datasets is shown in Fig. 11.
The motion estimation error seems to stabilize when using more than segments. Based on these experiments, we have selected a database size of segments as a reasonable trade-off between calibration complexity and quality and used this value for all the evaluations in this work. It is important to note, that the amount of data required for a reliable calibration depends on the sensor models, the expected motion and the environment and a re-evaluation might become necessary if these parameters change. In future work, we plan to investigate methods to determine the information content of the database directly to avoid a selection of this parameter.
VII-H Run-time
Table V reports the measured run-times of the proposed method and the batch calibration for the experiments of Section VII-A. Both optimizations use the same number of steps and the same initial conditions.
It is important to note, that the complexity and thus run-time of the batch method is unbounded when the duration of the sessions increase. The run-time of the proposed method, however, remains constant as we only include a constant amount of informative data. This property makes the proposed method well-suited for systems performing long sessions.
VIII Conclusion
We have proposed an efficient self-calibration method for visual and inertial sensors which runs in parallel to an existing motion estimation framework. In a background process, an information-theoretic metric is used to quantify the information content of motion segments and a fixed number of the most informative are maintained in a database. Once enough data has been collected, a segment-based calibration is triggered to update the calibration parameters. With this method, we are able to collect exciting motion in a background process and provide reliable calibration with the assumption that such motion occurs eventually - making this method well-suited for consumer devices where the users often do not know how to excite the system properly.
An evaluation on motion capture ground-truth shows that the calibrations obtained with the proposed method achieve comparable motion estimation performance to full batch calibrations. However, we can limit the computational complexity by only considering the most informative part of a dataset and thus enable calibration even on long sessions and resource-constrained platforms where a full-batch calibration would be unfeasible. Further, our evaluations show that we can not only sparsify single-session datasets but also accumulate information from multiple sessions and thus perform reliable calibrations when a single-session would not provide enough excitation. The comparison of three information metrics indicates that A-optimality could be selected for navigation purposes while D-optimality looks like a good compromise for AR/VR applications.
In future work, we would like to investigate methods to dynamically determine the segment boundaries instead of using a fixed segment length and also account for temporal variations in the calibration parameters by detecting and removing outdated segments from a database.
Acknowledgements
We would like to thank Konstantine Tsotsos, Michael Burri and Igor Gilitschenski for the valuable discussions and inputs. This work was partially funded by Google’s Project Tango.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Rehder et al. [2016] J. Rehder, J. Nikolic, T. Schneider, T. Hinzmann, and R. Siegwart, “Extending kalibr: Calibrating the extrinsics of multiple imus and of individual axes,” in IEEE International Conference on Robotics and Automation (ICRA) , 2016, pp. 4304–4311.
- 2Schneider et al. [2017] T. Schneider, M. Li, M. Burri, J. Nieto, R. Siegwart, and I. Gilitschenski, “Visual-inertial self-calibration on informative motion segments,” in IEEE International Conference on Robotics and Automation (ICRA) , 2017, pp. 6487–6494.
- 3Leutenegger et al. [2015] S. Leutenegger, S. Lynen, M. Bosse, R. Siegwart, and P. Furgale, “Keyframe-based visual–inertial odometry using nonlinear optimization,” The International Journal of Robotics Research , vol. 34, no. 3, pp. 314–334, 2015.
- 4Mourikis and Roumeliotis [2007] A. I. Mourikis and S. I. Roumeliotis, “A multi-state constraint kalman filter for vision-aided inertial navigation,” in Proceedings 2007 IEEE International Conference on Robotics and Automation , 2007, pp. 3565–3572.
- 5Bloesch et al. [2015] M. Bloesch, S. Omari, M. Hutter, and R. Siegwart, “Robust visual inertial odometry using a direct ekf-based approach,” in Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on . IEEE, 2015, pp. 298–304.
- 6Qin et al. [2018] T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics , vol. 34, no. 4, pp. 1004–1020, 2018.
- 7Schneider et al. [2018] T. Schneider, M. T. Dymczyk, M. Fehr, K. Egger, S. Lynen, I. Gilitschenski, and R. Siegwart, “maplab: An open framework for research in visual-inertial mapping and localization,” IEEE Robotics and Automation Letters , 2018.
- 8Hartley and Zisserman [2003] R. Hartley and A. Zisserman, Multiple view geometry in computer vision . Cambridge university press, 2003.