Unsupervised Automated Event Detection using an Iterative Clustering based Segmentation Approach
Deepak K. Gupta, Rohit K. Shrivastava, Suhas Phadke, Jeroen, Goudswaard

TL;DR
This paper introduces an unsupervised iterative clustering segmentation method for real-time detection of high-energy, variable-shape events in physics-based imagery, overcoming limitations of supervised models.
Contribution
The paper presents a novel unsupervised iterative clustering approach that detects events in 2D and 3D images without pre-trained models, suitable for physics-based vision problems.
Findings
Effective detection of events in 2D and 3D images demonstrated.
Method operates in real-time with iterative segmentation.
Hyper-parameters tuned via statistical analysis.
Abstract
A class of vision problems, less commonly studied, consists of detecting objects in imagery obtained from physics-based experiments. These objects can span in 4D (x, y, z, t) and are visible as disturbances (caused due to physical phenomena) in the image with background distribution being approximately uniform. Such objects, occasionally referred to as `events', can be considered as high energy blobs in the image. Unlike the images analyzed in conventional vision problems, very limited features are associated with such events, and their shape, size and count can vary significantly. This poses a challenge on the use of pre-trained models obtained from supervised approaches. In this paper, we propose an unsupervised approach involving iterative clustering based segmentation (ICS) which can detect target objects (events) in real-time. In this approach, a test image is analyzed over…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4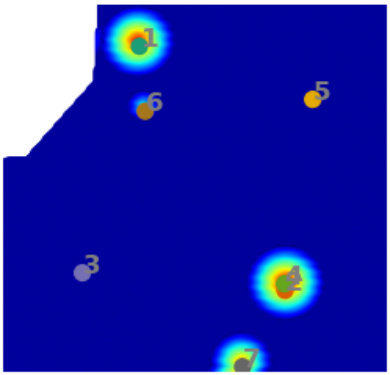 Figure 5
Figure 5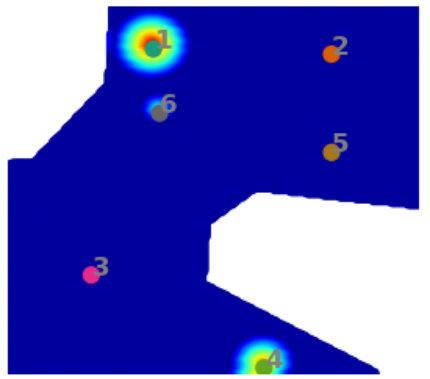 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9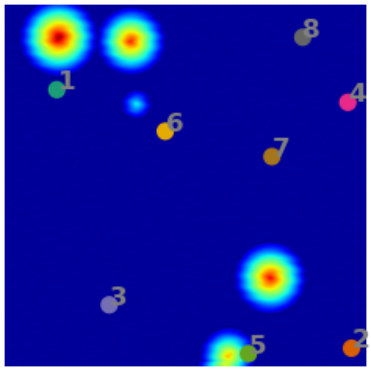 Figure 10
Figure 10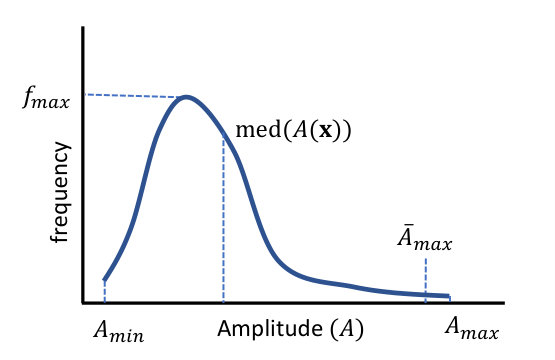 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14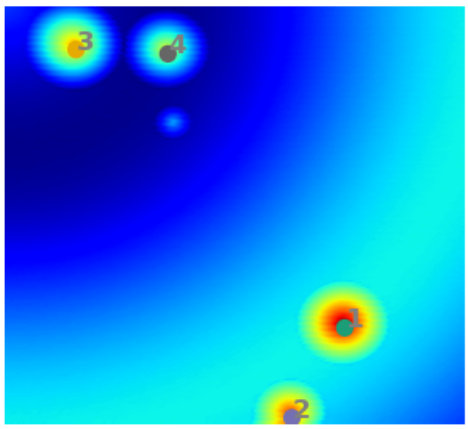 Figure 15
Figure 15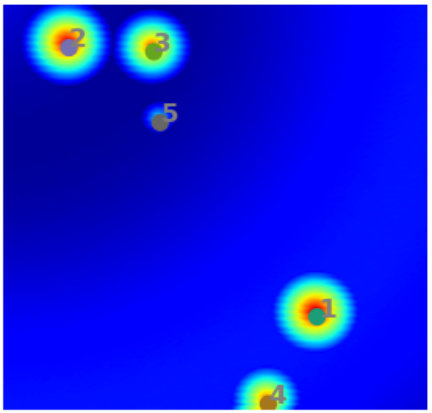 Figure 16
Figure 16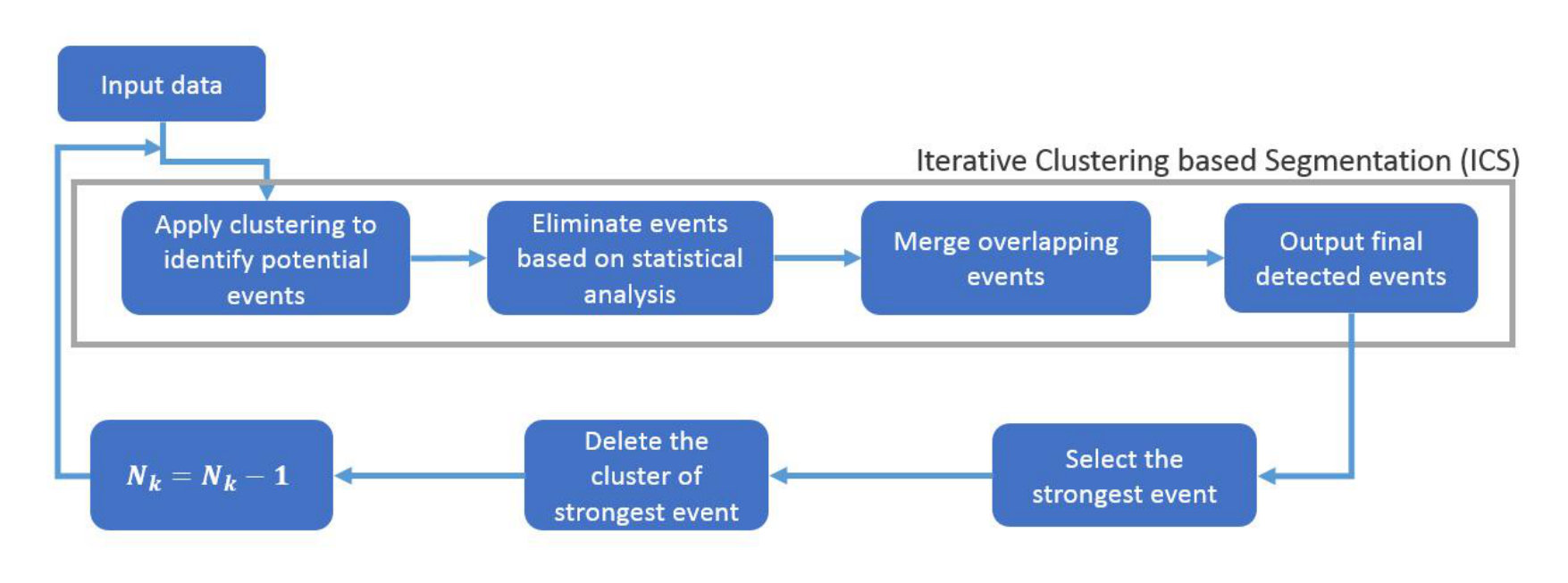 Figure 17
Figure 17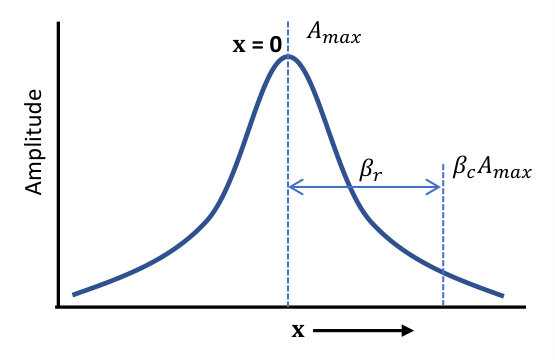 Figure 18
Figure 18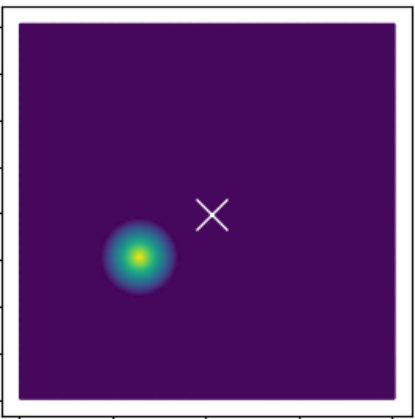 Figure 19
Figure 19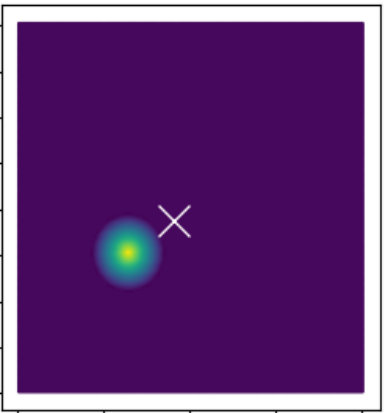 Figure 20
Figure 20 Figure 21
Figure 21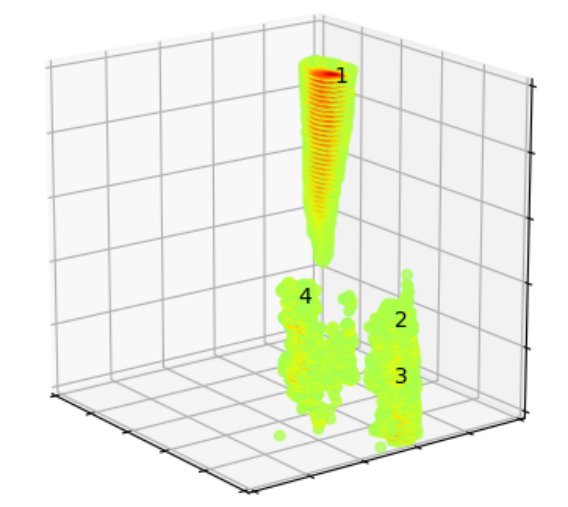 Figure 22
Figure 22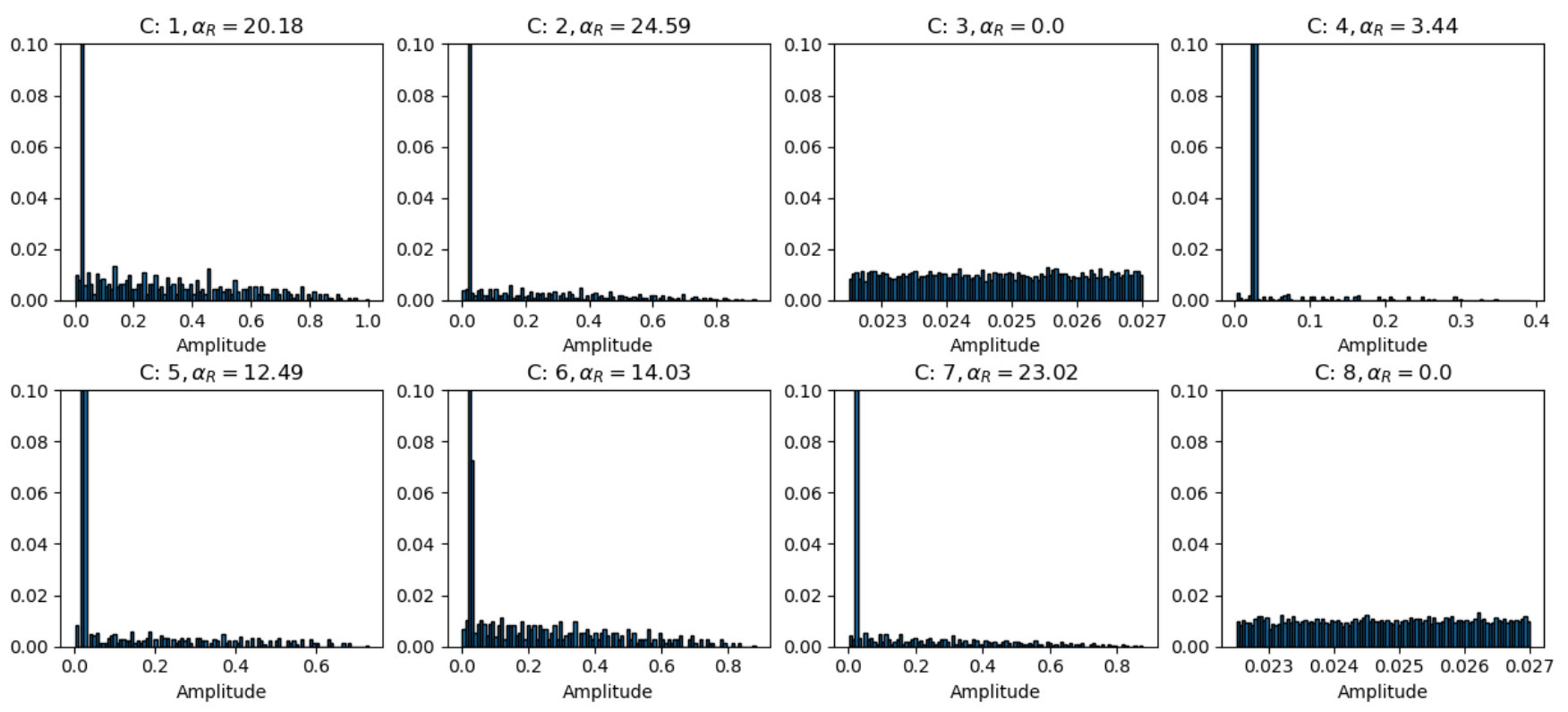 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25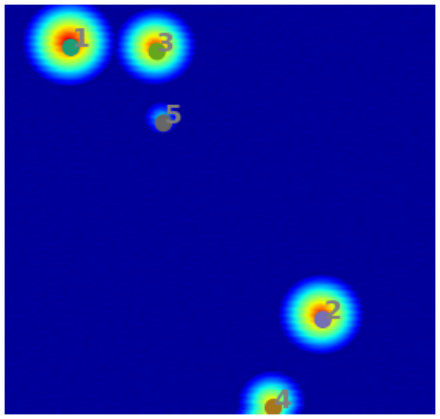 Figure 26
Figure 26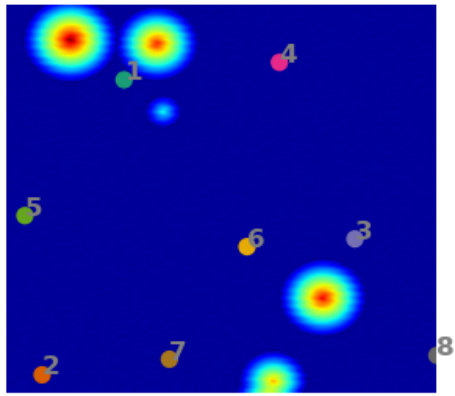 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30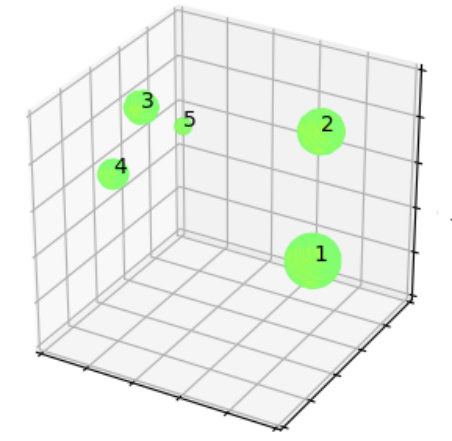 Figure 31
Figure 31Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnomaly Detection Techniques and Applications · Data-Driven Disease Surveillance · Metabolomics and Mass Spectrometry Studies
Methodsk-Means Clustering
Unsupervised Automated Event Detection using an Iterative Clustering based Segmentation Approach
Deepak K. Gupta111Email: [email protected], Rohit K. Shrivastava, Suhas Phadke and Jeroen Goudswaard
Shell Technology Centre, Bengaluru, KA, India
Abstract
A class of vision problems, less commonly studied, consists of detecting objects in imagery obtained from physics-based experiments. These objects can span in 4D and are visible as disturbances (caused due to physical phenomena) in the image with background distribution being approximately uniform. Such objects, occasionally referred to as ‘events’, can be considered as high energy blobs in the image. Unlike the images analyzed in conventional vision problems, very limited features are associated with such events, and their shape, size and count can vary significantly. This poses a challenge on the use of pre-trained models obtained from supervised approaches.
In this paper, we propose an unsupervised approach involving iterative clustering based segmentation (ICS) which can detect target objects (events) in real-time. In this approach, a test image is analyzed over several cycles, and one event is identified per cycle. Each cycle consists of the following steps: (1) image segmentation using a modified -means clustering method, (2) elimination of empty (with no events) segments based on statistical analysis of each segment, (3) merging segments that overlap (correspond to same event), and (4) selecting the strongest event. These four steps are repeated until all the events have been identified. The ICS approach consists of a few hyper-parameters that have been chosen based on statistical study performed over a set of test images. The applicability of ICS method is demonstrated on several 2D and 3D test examples.
1 Introduction
Machine learning can be used to detect ‘irregularities’ in a provided dataset, and this process has been referred in the literature as anomaly detection [14]. In the context of real-time monitoring, an anomaly, referred to as ‘event’, would be a disturbance observed in space and time for measurements done as a part of a certain experiment. Examples of automated event detection include identifying unusual human actions in a video [17], detection of intrusion in internet traffic [26] and automated picking of events in time-series seismic data [21]. Several algorithms exist in the literature that can be used to detect such anomalies. For an overview of such methods, see the review works presented in [6, 14].
In event detection problems, the event itself can be considered as an anomaly compared to the rest of the data. For example, earthquakes are seismic events that show up as anomalous points on the seismogram [12]. These seismograms can be converted to 4D images () of the subsurface, and machine learning can provide real-time information of these earthquakes from the images. Fig. 1 shows two examples of synthetic 2D images containing 5 and 4 events. The events are characterized as high amplitude zones, and the background has low amplitudes. The goal of this paper is to develop an automated approach to efficiently pick these events.
The problem of event detection as described above can be categorized under anomaly detection techniques dealing with images [4, 28]. Thus, we interchangeably use ‘anomaly’ and ‘event’ to refer to the class of problems described in this paper. The problem of event detection has been studied in the past using supervised as well as unsupervised methods [6]. The primary challenge with supervised learning approaches is to prepare the extensive training data that can make the trained model robust enough. Unsupervised methods partition the data into event and non-event classes. However, events in general are rare compared to the normal data, and due to this imbalance, the traditional unsupervised approaches suffer from high false alarm rates [6].
Among the various unsupervised methods, clustering has widely been used to detect anomalous features in an image [25]. Without the need of any prior training, clustering methods group similar instances into groups, separating the non-event data from the events. For problems involving point or conceptual anomalies, clustering can easily identify the events [6]. However, for the type of problems considered in this paper, although a certain data point might not be an anomaly, a collection of data points lying together in () can constitute an event in the context of background values. Along this line, the traditional clustering algorithms can separate high amplitude points from the background (non-event) parts, however, the events themselves cannot be identified uniquely. Moreover, several other inherent drawbacks of these methods make them unsuited for the class of event detection problems dealt in this paper.
We propose an iterative clustering based segmentation approach for the efficient identification of events in images. The unsupervised ICS approach decomposes an event detection problem into sub-problems: (1) image segmentation and (2) statistical interpretation of each segment. For segmentation purpose, clustering methodology is employed. We present a modified -means clustering approach tailored to our image segmentation problem. Further, the amplitude distribution within each cluster is analyzed to decide whether a segment corresponds to an event or not. Details related to the proposed ICS methodology are discussed in Sections 3.1 and 3.2. The applicability of ICS method is demonstrated on 2D and 3D synthetic test images. Further, ICS is used to identify earthquake-events from a real 3D dataset. Related results are presented in Section 4, and a brief discussion on ICS method is presented in Section 5.
2 Related Work
Event (anomaly) detection problems, in general, have widely been studied in the field of computer vision. For an overview of the methods used to handle this problem, see the surveys presented in [14, 6]. These can primarily be divided into two categories: supervised methods and unsupervised methods. In the context of image processing, methods have been presented to identify events distributed in space and time., e.g. satellite imagery [4], spectroscopy [7] and mammographic image analysis [27]. Some of the earliest methods used for automated event detection are mixture of models [27], regression methods [7], Bayesian networks [11], support vector machines [10], neural networks [4], clustering [25] and nearest neighbor based techniques [23]. Recently, several deep learning methods have also been proposed that can be used for detection (e.g. [29, 9, 22]).
In general, the supervised algorithms can outperform the unsupervised algorithms in terms of speed, however, they are fragile to event detection problems [15]. There exist several semi-supervised algorithms that can help to circumvent this issue, but, the unsupervised methods are still preferred due to their generalizability in identifying a wide-variety of events. Several unsupervised methods have been used in the past for event detection (e.g. [8, 1]). Based on the methodology employed, these can be categorized into divisions: nearest-neighbor based [24], clustering based [16], statistical [2], subspace based [19] and classifier based [13].
The nearest-neighbor algorithms such as -NN approach perform well for classification problems, however, these are not very robust for an unsupervised setting [14]. Local variants such as local outlier factor (LOF) and local outlier probability (LoOP) approaches present a relative measure where the distance to -nearest neighbors is compared to a reference value obtained for the entire data [5, 18]. However, most of these algorithms suffer from the setback of choosing [14]. Cluster-based detection algorithms such as CBLOF [16] and CMGOS use clustering to identify dense areas in the data, and in the next step, outliers are identified based on density estimates obtained for each cluster. However, for problems studied in this paper, data points are distributed almost uniformly, and the traditional clustering approach cannot be deployed to identify the events.
Overall, to the best of our knowledge, the existing anomaly detection methods are not directly applicable to our event detection problems, and a tailored approach has been missing. In this work, we propose an iterative clustering based segmentation (ICS) approach to deal with these problems.
3 Iterative clustering based segmentation
3.1 Description
The iterative clustering based segmentation (ICS) method analyzes the data over several cycles, and identifies one event per cycle. Fig. 2 provides a schematic description of the ICS approach. During every cycle, ICS employs spatial clustering schemes with tailored assignment function, followed by statistical analysis of the data contained within each cluster. The statistical distribution within every cluster is studied and the cluster containing the strongest event is identified. The associated event is selected and the data related to this cluster is deleted. The whole process of event search is then repeated to find the next event. This process is continued till no more event can be identified in the remaining dataset.
For the purpose of clustering, a variant of the traditional -means clustering has been used [20], and cluster centroids are initialized using the -means++ algorithm [3]. Fig. 3 shows an example of a synthetic 2D test case, where the initial cluster centroids (obtained using -means++) as well as their optimized locations are shown. The hyper-dimensions for clustering comprise spatial (as well as temporal dimensions in 4D) and the amplitude feature weighted by a power term . Including the effect of amplitudes in clustering forces the centroids to lie close to centers of the events in the optimized segmentation, and ths impact is controlled by . An example of event-centers and the associated partitions for a 2D problem is shown in Fig. 4. More details on this aspect as well as the mathematical formulation are presented in Section 3.2.
After the data domain has been divided into a number of segments, there exist certain segments having cluster-centroids (approximately) aligned with the event-centers, and other segments with no events. As a next step, the segments which do not encompass an event, need to be discarded. For this purpose, the statistical distribution of amplitudes is studied within every segment, and based on a certain mathematical criterion defined by , the respective segment is accepted or discarded. Fig. 6(a) shows the distribution of amplitudes for the various segments shown in Fig. 4. Here, it is straightforward to identify the partitions that correspond to an event (Clusters 4 and 7) and the partitions which are empty (3 and 8). However, for noisy data, isolating the empty clusters is not easy (Fig. 6(b)). More details associated with the elimination criterion are discussed in Section 3.2.
Next, the remaining segments are studied to identify whether there are partitions that correspond to the same event. Fig. 5 shows the segments that are left after elimination of empty clusters in Fig. 6(a). It can be seen that there are two clusters which are formed around the same event, and these need to be merged. This is done by analyzing the ‘span’ of each event, where span refers to the space in which the disturbance in amplitude has been created by the event. If the center of one event lies within the span of another one, both the events are merged as a single event. Thus, in Fig. 5, clusters 2 and 7 get merged.
The process from clustering to merging the common partitions constitutes one cycle of ICS process. Among the identified events, the strongest event is selected, and the data corresponding to its segment is deleted from the data domain. For the events identified in Fig. 5, Segment 1 is identified to be containing the strongest event. Thus, the data for this segment is removed from the domain, and the second cycle of ICS is executed to identify the next event. Fig. 7 shows the identified events and segments obtained from clustering during Cycle 2 of ICS. In this manner, the ICS process is repeated over several cycles, till no more event can be identified. From Cycle 2, every new event selected at the completion of the ICS process, is checked with the already selected events for possible overlap.
3.2 Method
The process of iteratively identifying the events can be broken down into 4 steps, and these have briefly been discussed in Section 3.1. Below, we discuss the details related to each of these steps.
Modified -means clustering. During every cycle of ICS methodology, the domain is segmented using a clustering approach. Since only circular (spherical) events are studied in this paper, a modified form of -means clustering has been implemented. The choice of here depends on a priori knowledge of the problem that we are dealing with. However, we have observed that the algorithm itself is not very sensitive to the choice of . As a rule of thumb, we choose to be approximately 2-3 times the maximum number of events that can generally be expected to occur in the domain. This can be further lower for data where the amplitude of background noise is significantly lower than that of the event. For example, for the synthetic test cases shown in Fig. 3, even is found to be sufficient. A brief discussion on the initial choice of is presented in Section 5.
For the modified -means clustering, the locations of the initial centroids are chosen using the -means++ approach [3]. Let the amplitude distribution be represented by a set of data points , where refers to dimensions of the data. In the -means++ approach, the cluster centroid is chosen uniformly at random from . The centroids are then iteratively chosen, and for every next centroid , any point can be chosen with probability . Here, denotes the distance of data point to the nearest amongst cluster centroids . The process is continued until all the cluster-centroids have been chosen.
Based on -means++, gets partitioned into segments denoted as . Next, a variant of the traditional -means clustering method is applied to optimize the cluster-centroids . This involves solving a zeroth order optimization problem which is stated as
[TABLE]
where denotes an amplitude functional and denotes amplitude-value of data point . Each iteration of the clustering method involves two updates which are as follows:
Assignment step: Each data point needs to be mapped to one of the clusters in to obtain a new set of partitions . Mathematically, data point is mapped to partition , where . 2. 2.
Update step: After each data point has been assigned to one of the partitions in , the locations of centroids in are updated as
[TABLE]
These two steps are repeated until the value of objective goes below a certain minimum threshold, or some other stopping criterion is reached. Note that unlike the initial assignment done using -means++, the amplitude of data points has been taken into account during the assignment as well as update steps of ICS.
A better understanding on the role of can be obtained from Fig. 8. For simplicity let us assume that , where is a power term used to adjust the weight on amplitude values. For this example, . In Fig. 8, we have one event in a 2D image, and the goal of ICS approach is to identify the event-center. The data points are assumed to be uniformly distributed in the domain. With , the clustering approach is independent of amplitude-values, due to which the cluster centroid is identified at approximately the geometric center of the image. With , amplitudes are provided certain weight, due to which the cluster centroid shifts towards the event. Adding more weight with , the cluster centroid overlaps with the event. Thus, when is chosen properly, the modified clustering approach can detect the event.
However, the formulation for mentioned above will be sensitive to the values of , and we formulate it differently for our problems to make it more robust. The amplitudes are normalized between 0 and 1, and , where is a exponential scaling term. For the examples shown in this paper, is set to 16 based on observations from a set of numerical experiments.
Elimination of empty clusters. After the data has been divided into partitions , the empty partitions need to be separated from those that contain the events. As stated earlier in Section 3.1, this is achieved by analyzing the statistical distribution of amplitude-values inside every partition, and comparing them against a certain threshold. Unlike the traditional approach of choosing a certain value of for thresholding, functional is analyzed.
Fig. 9 shows a schematic histogram plot for the amplitude values observed in a certain partition . Ideally, for an event characterized by a Gaussian distribution of amplitudes or a linear decay away from the event-center, the distribution of amplitudes is expected to resemble a right skewed distribution with very low values of frequency at the right tail. To decide whether the distribution shown in Fig. 9 corresponds to an event or not, the rejection factor needs to be defined. Mathematically, this term is defined as
[TABLE]
where, superscript is an index term used to refer to partition , denotes the maximum value of frequency for the distribution of amplitudes discretized into 100 bins, and denotes the median functional. Further, calculates the maximum value of amplitude in by setting statistical significance level at 0.999, which means 0.1% of the values at the right tail of the distribution in Fig. 9 are ignored.
To understand the motivation for choosing the expression in Eq. 3, we refer back to Fig. 9. Here, the maximum value of amplitude () plays role in deciding whether the distribution corresponds to an event or not (as in Fig. 6(a)). For partitions which do not contain an event, is expected to be equal to the maximum noise-level in the data, and for partitions with event, it corresponds to that of the event. There is a possibility that random noise-spikes are contained in the data whose amplitudes are higher than the event amplitude itself. To avoid capturing these spikes as event, 0.1% of the data on the right tail side of the distribution is categorized as statistically insignificant, and is replaced by . Here, characterizes the strength of the event, and ranks it against other events in the iterative selection criterion. In this sense, it can be considered as a global criterion for event detection.
For weak events, is low, which reduces for that partition. For such partitions, helps to differentiate an event from background noise. Unlike an actual event, the amplitudes in background noise are uniformly distributed over a range of values, due to which its is expected to be lower than that of an event. A better understanding of this can be obtained from Fig. 6(b). This figure shows the histogram plots for partitions obtained using ICS for one of the examples shown in Fig. 3, but with added Gaussian noise (). Among the 4 clusters shown in Fig. 6(b), Clusters 5 and 6 correspond to partitions containing events, thus clearly have higher values of . Also, for partitions in that contain an event (e.g. Clusters 5 and 6), median of the distribution will be shifted more towards left compared to that in partitions that contain only background noise. In this manner, together with defines which is further used to eliminate the empty partitions.
Partition is then rejected if , where refers to a cut-off threshold. The value of is chosen based on numerical experiments, and in this paper, it is set to 0.1. Further discussion on the sensitivity of this parameter as well as on how to choose it, is presented in Section 5. With the partitions left after eliminating the empty ones, the next step is to merge the overlapping partitions.
Merge overlapping clusters. Partitions which share the same event need to be identified. For this purpose, the distribution of amplitudes in space (for 2D and 3D) and time (for 4D) needs to be studied and the extent of overlap has to be identified. Fig. 10 shows the schematic representation of amplitude distribution for 1D space, and an approximate Gaussian distribution is assumed. Next, we define the term span radius , which denotes the distance from the center of an event up to which the event is considered to span. Here, is a fractional term used to control the span. For example, to assume that the event is significant up to the point where decays to 40% of its maximum, . Thus, in simple terms, can be defined as the distance from the center of an event, where decays to fraction of .
Although from Fig. 10, it seems very straightforward to compute , the distributions are not perfectly Gaussian and frequently contain noise. Thus, there will be multiple values of that satisfy the requirement. Moreover, for robustness, we need to search for values within the range rather than . Here, is a parameter that defines an amplitude interval for calculating the span, and in this study, it has been set to 0.01. More discussions on choosing and follow in Section 5. Thus, for the partition, is defined as
[TABLE]
Once has been calculated for all the partitions, partition is merged to partition , if:
[TABLE]
Accordingly, and . Further, is updated based on the new set of data points in .
Select the strongest event. After the overlapping partitions have been merged, each of the partitions is expected to contain an event. As defined earlier, our ICS methodology selects only one event per cycle. To understand the motivation for doing so, we look at Eq. 1. Since the objective functional here depends on as well, there would be a preference to form clusters around the stronger events. In this scenario, if there is an outlier event which is far stronger than the rest of the events, most of the partitions will be clustered around it, and the weaker events of the data will be shadowed.
The iterative scheme in ICS selects the strongest event during the first cycle, and the corresponding partition is then removed from for the next ICS cycle. This facilitates improved clustering around the weaker events during the later cycles. Eventually, most of the events can be identified over a series of cycles. Let denote the partition selected during the cycle. Assuming that the stopping criterion has been reached after cycles of ICS, the centroids corresponding to partitions correspond to the identified events.
4 Applications
To demonstrate the applicability of ICS, we consider examples of 2D and 3D images. For 2D cases, a total of 140 synthetic images (noisefree as well as containing certain noise) have been considered, and average accuracies are reported in Fig. 13 for several values of . An example application of ICS on 2D noisefree images has been demonstrated in Fig. 4.
Fig. 11 further demonstrates the potential of ICS under different noise levels for uniform random, uniform normal and periodic noises. Details related to types and levels of the added noise are described in the caption of Fig. 11. For all the cases, it is observed that ICS can resolve all the major events observed in the images. However, for high levels of noise (as in Figs 11e), one of the weak events cannot be identified. For rest of the cases, we observe that a correct number of events have been identified. At low noise-levels, the identified event locations are correct. However, for the cases of Gaussian noise considered here (Figs. 11 c and d), the identified locations of Event 5 seem to deviate from the actual value. This happens primarily because for any partition, we assume the point with highest amplitude value to be the event centroid. However, in the presence of noise, this assumption might not be true, and a direction of improvement would be to correctly identify the event location within the active partition.
Further, two 3D test cases have been considered as shown in Fig. 12, and here, only amplitude values above have been displayed. The synthetic image shown in Fig. 12(a) consists of 5 events with no added noise. Using ICS method, all the 5 events could been identified successfully. Fig. 12(b) shows the application of ICS method on a real dataset of earthquake-events. Based on manual interpretation, 3 events had been identified in the past for this case. Using ICS, we identified 4 events, and further manual analysis confirmed that the additional event identified by ICS is indeed a real event. Clearly, in 3D or higher, human interpretations are limited due to visual constraints, and this numerical example demonstrates that such a limitation can be overcome using ICS.
5 Discussions
There are a few parameters that control the performance of the proposed ICS methodology. These include initial number of clusters , amplitude power , rejection factor , decay factor and . These parameters have been chosen statistically, and their optimal values have been chosen through a number of simulations on 2D datasets. Due to constraint on the length of this paper, we discuss only one of these parameters.
Fig. 13 shows the affect of , where refers to number of events in the simulated data. A total of 20 test cases of 2D synthetic images were used, each containing between 3 and 6 events of varying strength. Each of these images was duplicated 6 times with different noise types and levels to generate 120 noisy cases. Further, for every case, 10 simulations have been run, and the average ICS accuracies are reported in Fig. 13. A general observation is that sufficiently good accuracies are obtained for values in between 2 and 3. For higher values, the domain is analyzed using too many partitions, which leads to insufficient information being contained in every partition, and this leads to loss in accuracy.
Similar tests have been carried out for other parameters, and here we only report the optimal choices observed. For amplitude power , a value between 13 and 17 works well. Similarly for , and , the recommended values are 0.05-0.15, 0.3-0.5, 0.1-0.2, respectively. While the other two parameters are not so important, is very critical since it plays an important role in deciding whether a partition contains an event or not. To some extent, its value depends on the noise level in the data, and in future we aim to look into this aspect.
6 Conclusion and Future work
In this paper, we presented ICS, an iterative clustering based segmentation approach for the detection of events in image data. Over a sequence of cycles, ICS partitions an image and analyzes whether each partition contains an event or not. Aiming at automated real time detection of events in continuously streaming data, the applicability of ICS has been demonstrated on 2D and 3D datasets.
In the future work, we aim at exploring the application for higher dimensions. Further, we look forward to using ICS on microseismic data for the automated real time detection of earthquakes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. C. Aggarwal. Outlier analysis . Springer-Verlag, New York, 2013.
- 2[2] M. Amer, M. Goldstein, and S. Abdennadher. Enhancing one-class support vector machines for unsupervised anomaly detection. In Proc. ACM SIGKDD workshop ODD’13 , pages 8–15, 2013.
- 3[3] D. Arthur and S. Vassilvitskii. k-means++: the advantages of careful seeding. In SODA ’07 Proc. Eighteenth Annual ACM-SIAM symposium on Discrete algorithms , pages 1027–1035, 2007.
- 4[4] M. Augusteijn and B. Folkert. Neural network classification and novelty detection. International Journal of Remote Sensing , 23(14):2891–2902, 2002.
- 5[5] M. M. Breunig, H. P. Kriegel, R. T. Ng, and J. Sander. Identifying density-based local outliers. In Proc. ACM SIGMOD International Conference on Management of Data , pages 93–104, 2000.
- 6[6] V. Chandola, A. Banerjee, and V. Kumar. Anomaly detection: A survey. ACM Computing Surveys , 41(3):1–58, 2009.
- 7[7] D. Chen, X. Shao, B. Hu, and Q. Su. Simultaneous wavelength selection and outlier detection in multivariate regression of near-infrared spectra. Analytical Sciences , 21(2):161–167, 2005.
- 8[8] P. Chhabra, C. Scott, E. D. Kolaczyk, and M. Crovella. Distributed spatial anomaly detection. In INFOCOM , 2008.