Efficient Tsunami Modeling on Adaptive Grids with Graphics Processing Units (GPUs)
Xinsheng Qin, Randall LeVeque, Michael Motley

TL;DR
This paper presents a GPU-accelerated adaptive grid tsunami modeling method that significantly speeds up simulations, enabling faster and more efficient hazard assessment and early warning systems.
Contribution
It introduces a CUDA implementation of GeoClaw combining adaptive mesh refinement and GPU acceleration for efficient tsunami simulation.
Findings
GPU implementation is 3.6 to 6.4 times faster than CPU version.
The method accurately models transoceanic tsunamis with reduced computational time.
Proposed metrics effectively evaluate hardware resource utilization.
Abstract
Solving the shallow water equations efficiently is critical to the study of natural hazards induced by tsunami and storm surge, since it provides more response time in an early warning system and allows more runs to be done for probabilistic assessment where thousands of runs may be required. Using Adaptive Mesh Refinement (AMR) speeds up the process by greatly reducing computational demands, while accelerating the code using the Graphics Processing Unit (GPU) does so through using faster hardware. Combining both, we present an efficient CUDA implementation of GeoClaw, an open source Godunov-type high-resolution finite volume numerical scheme on adaptive grids for shallow water system with varying topography. The use of AMR and spherical coordinates allows modeling transoceanic tsunami simulation. Numerical experiments on several realistic tsunami modeling problems illustrate the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1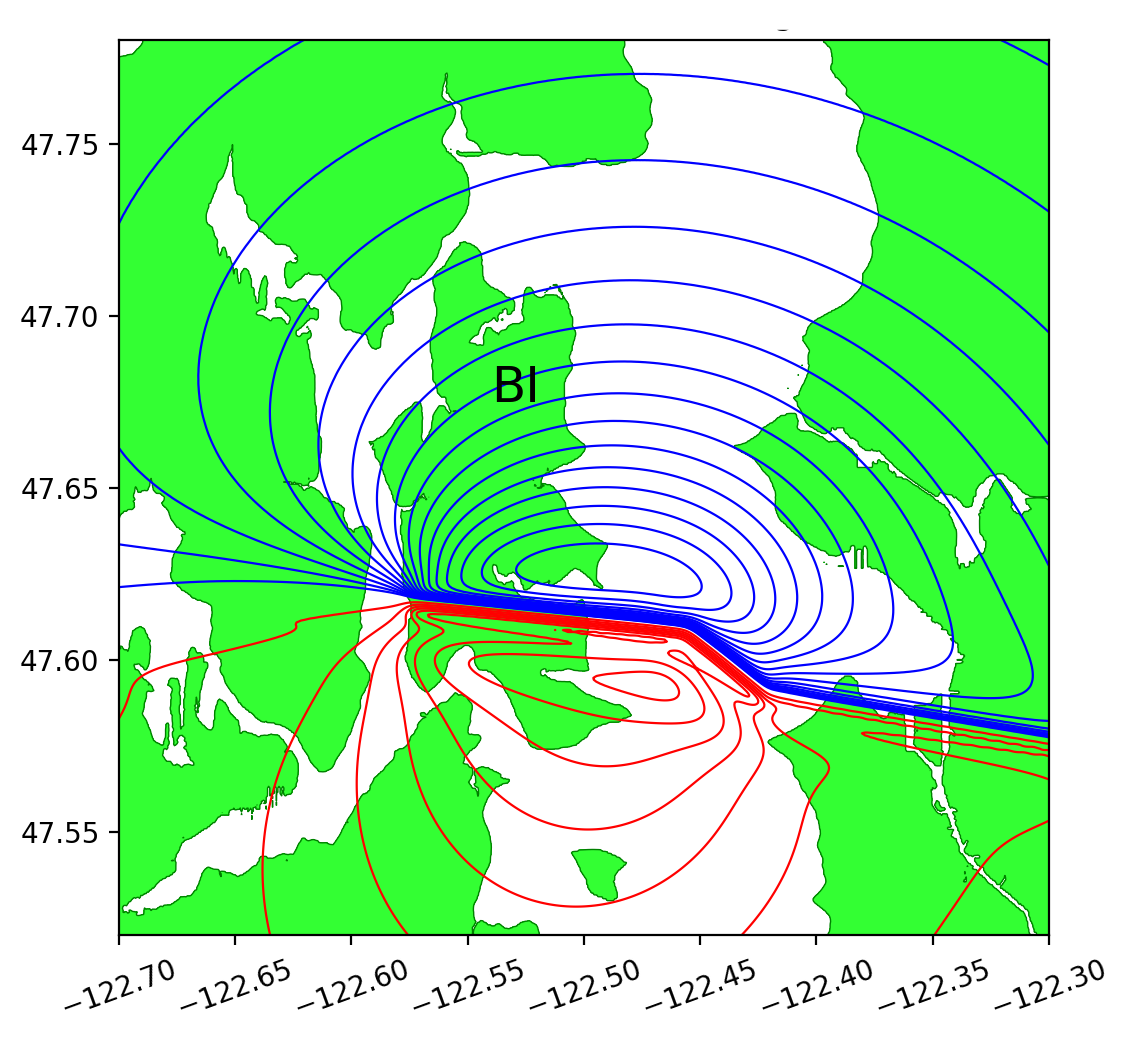 Figure 2
Figure 2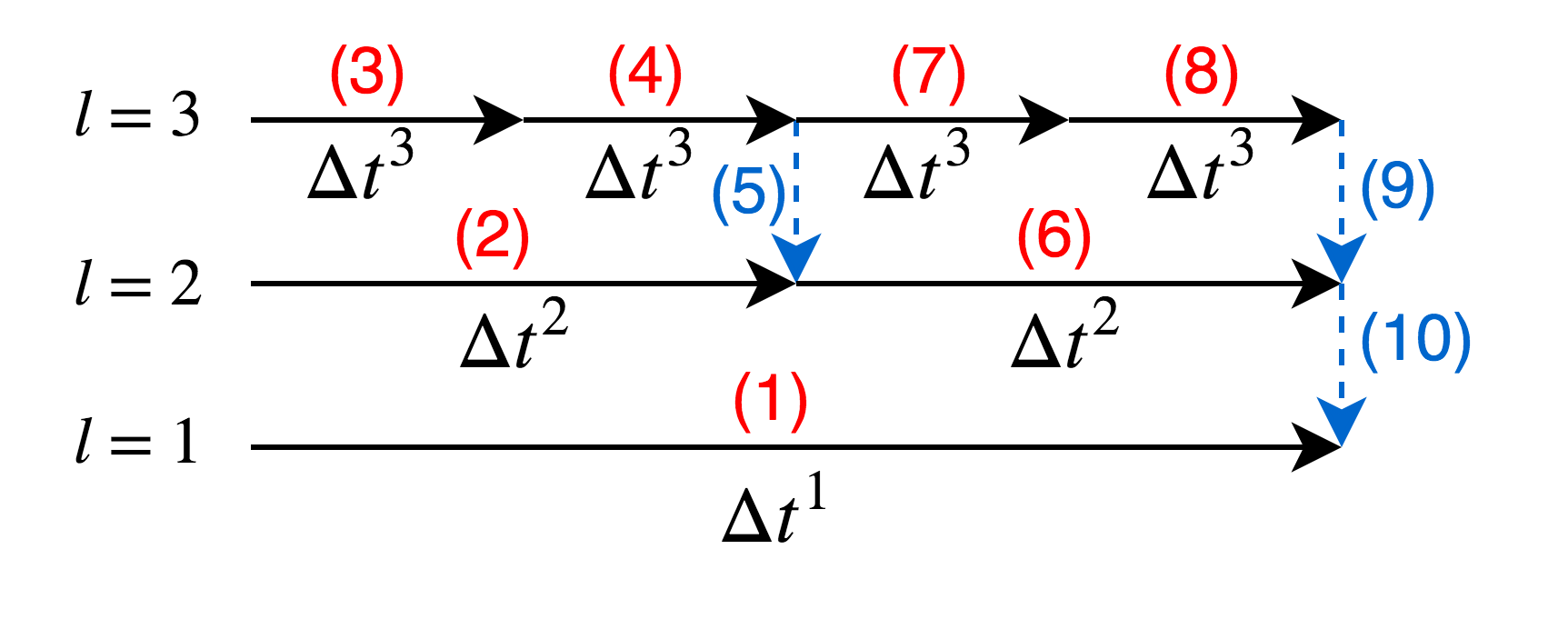 Figure 3
Figure 3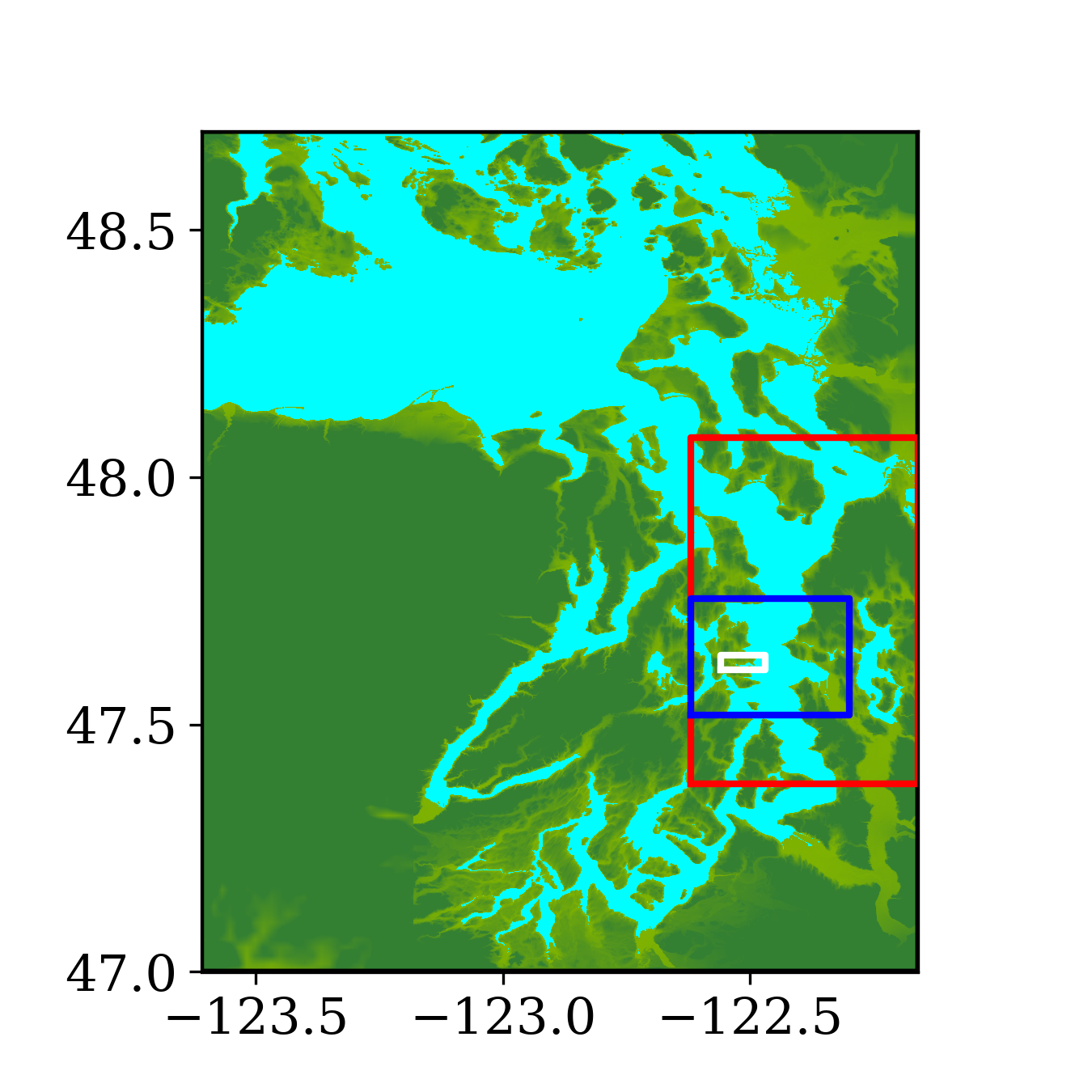 Figure 0
Figure 0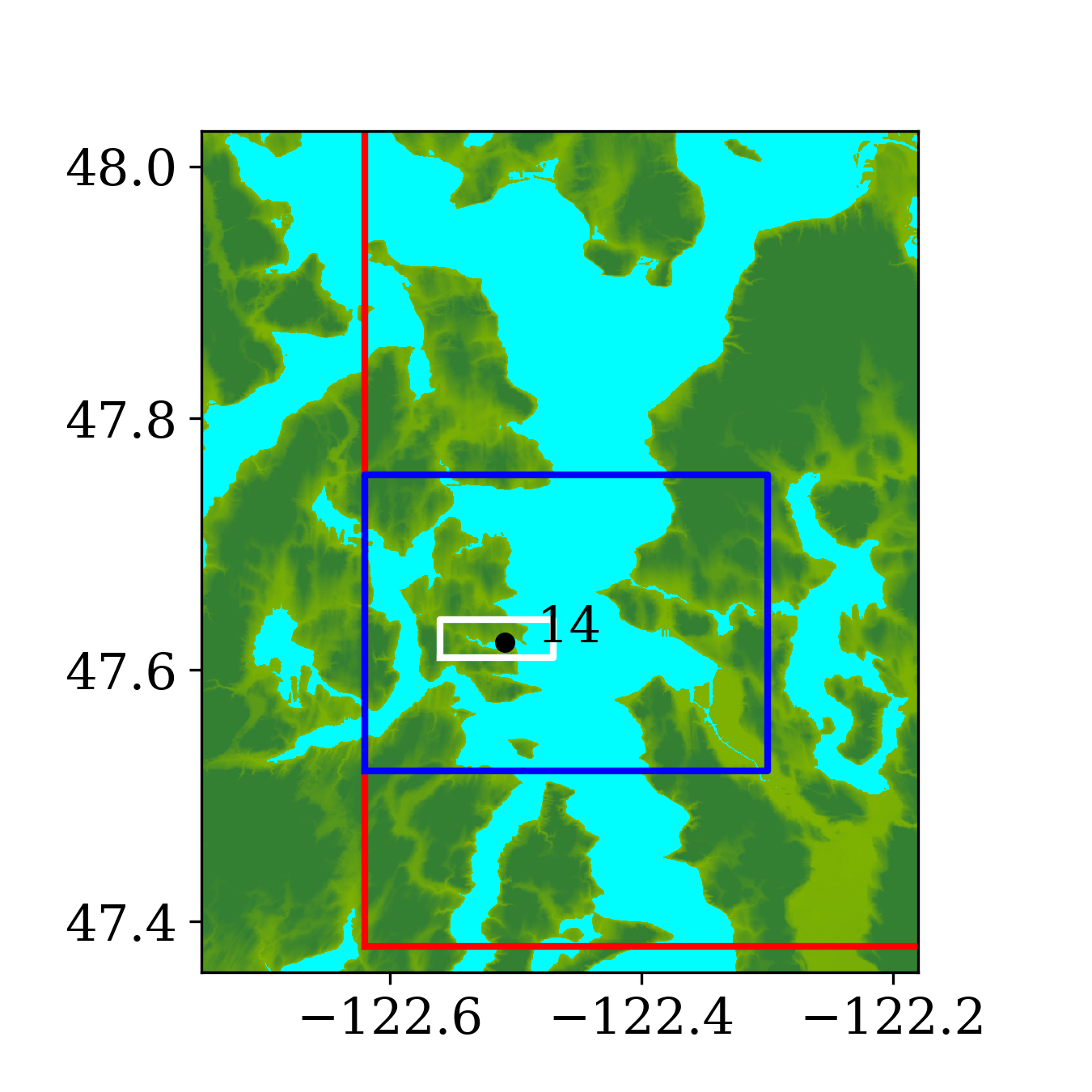 Figure 1
Figure 1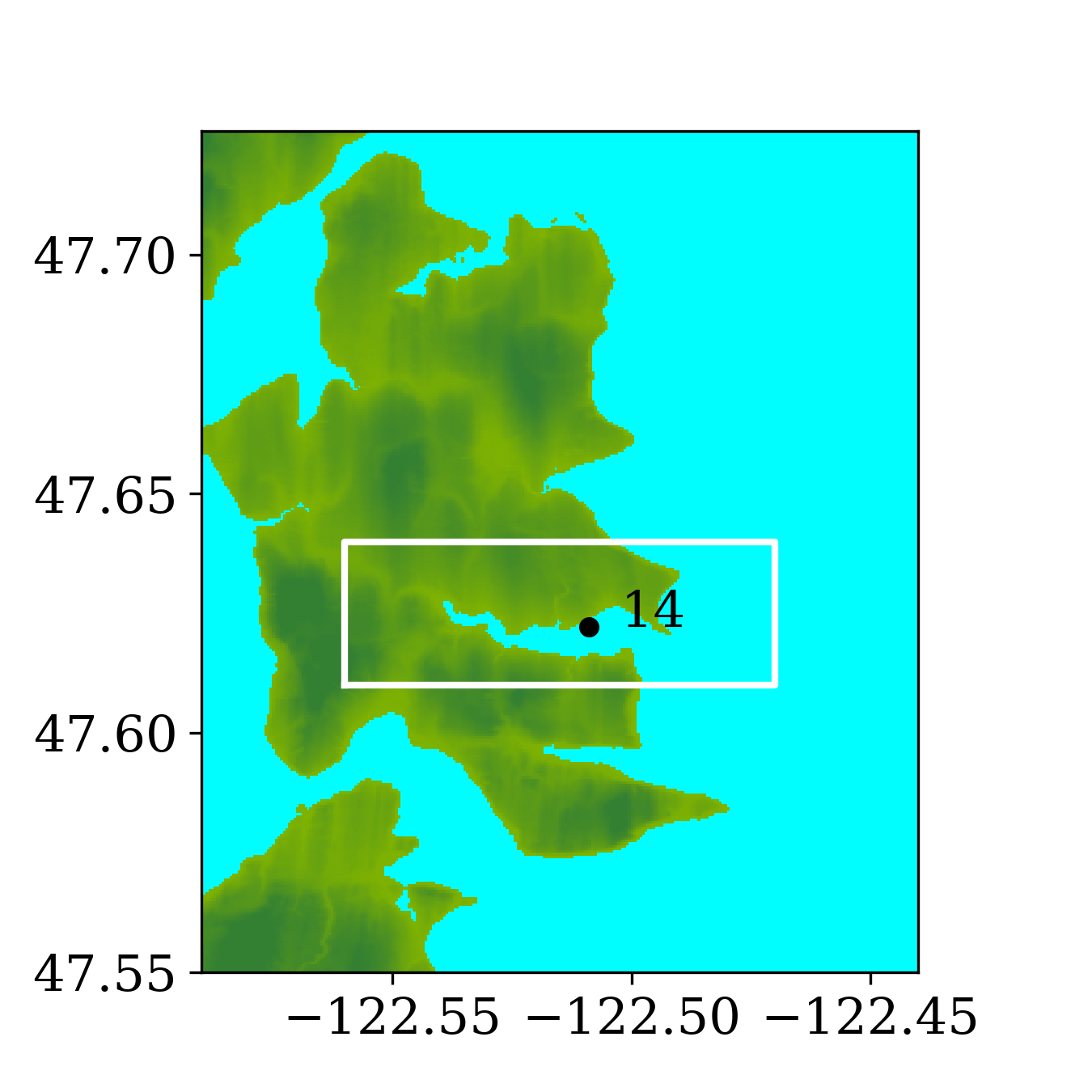 Figure 2
Figure 2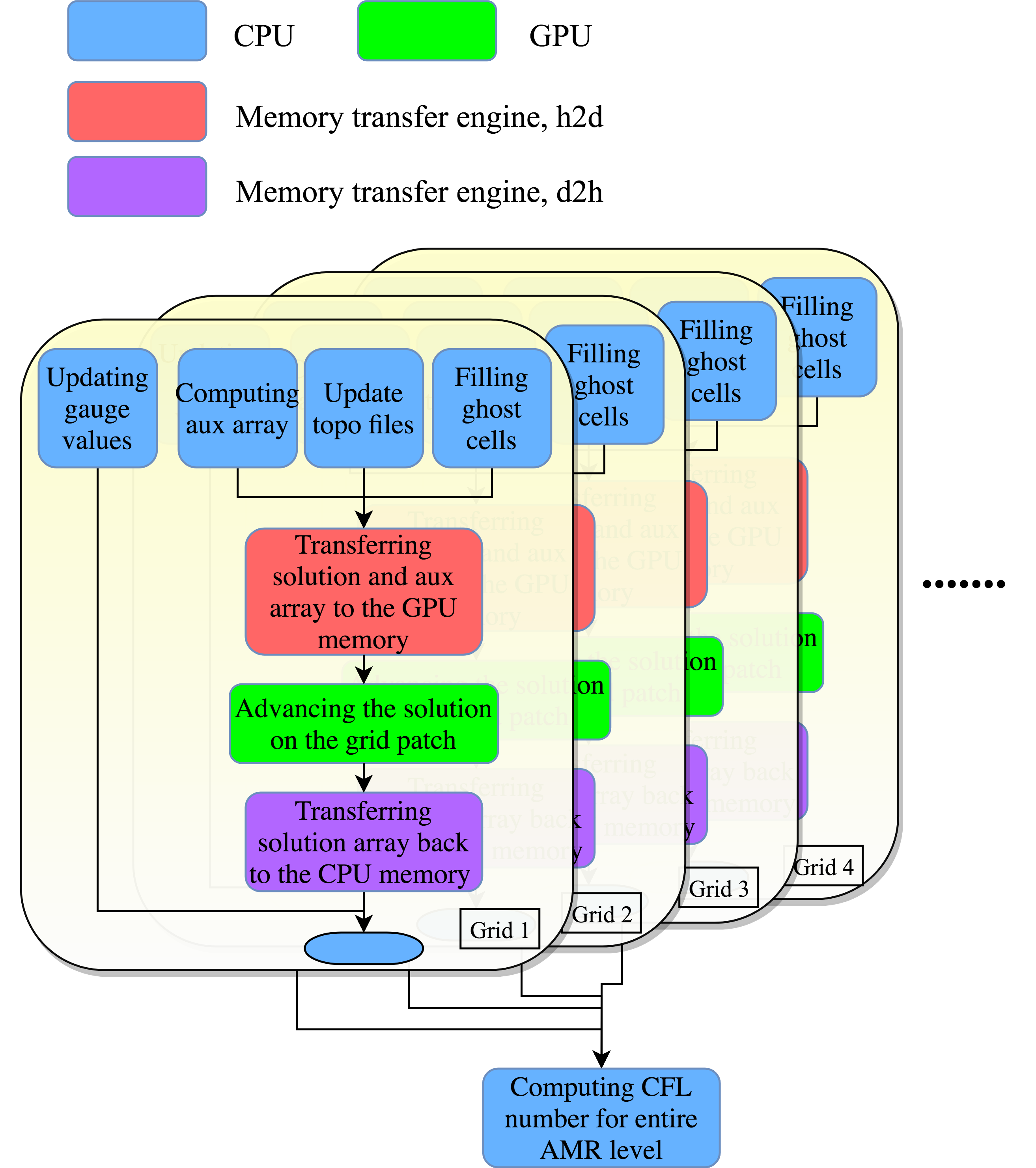 Figure 7
Figure 7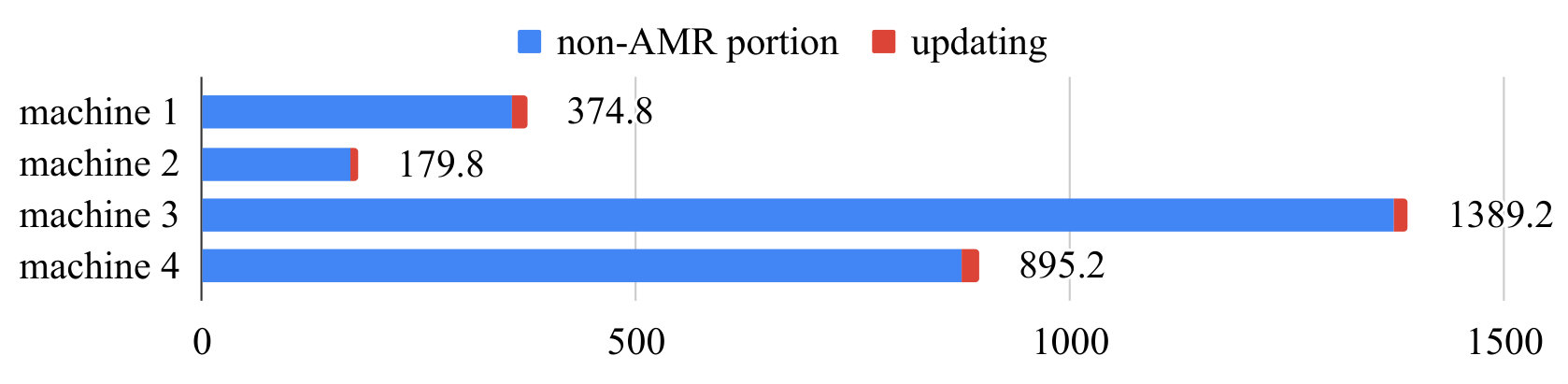 Figure 8
Figure 8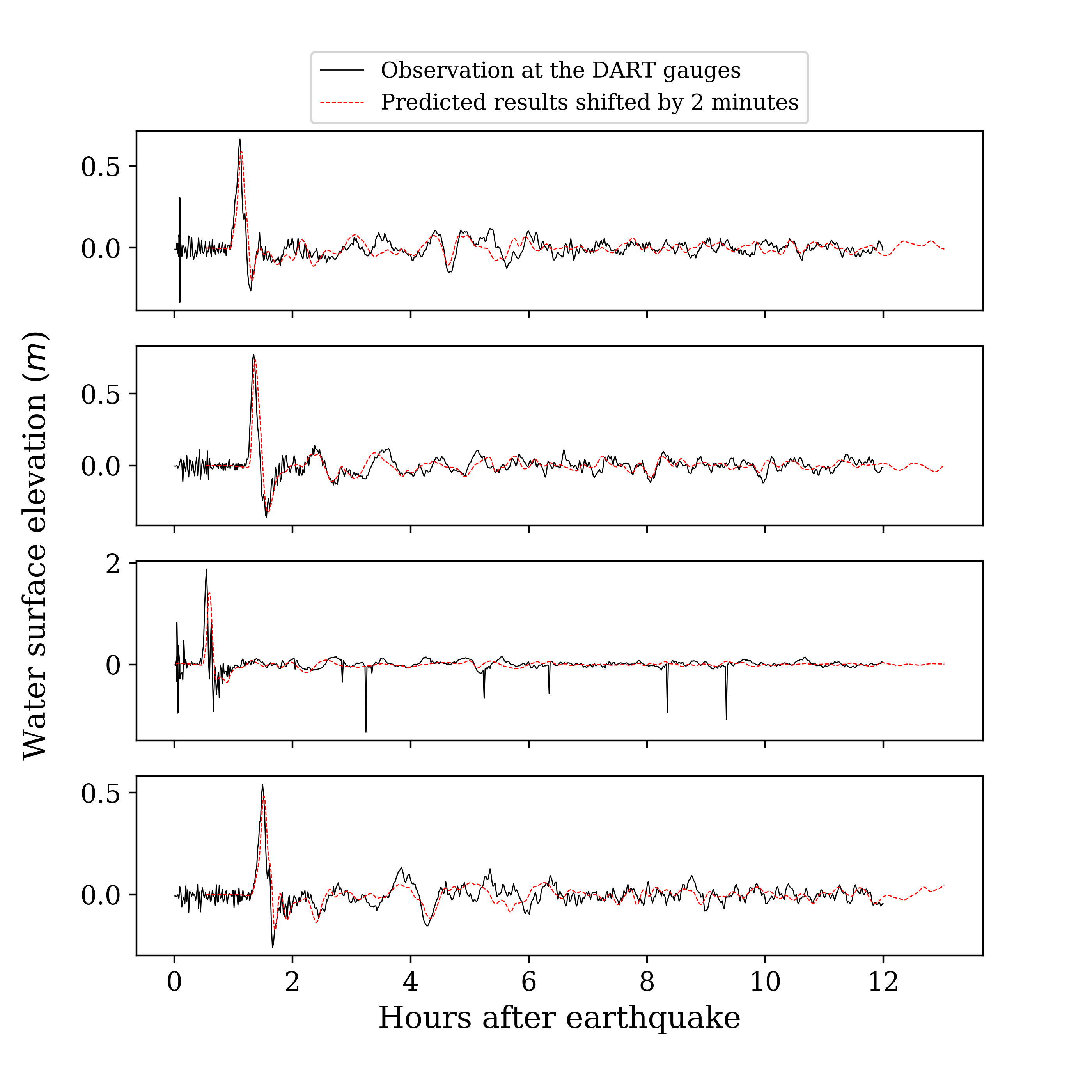 Figure 9
Figure 9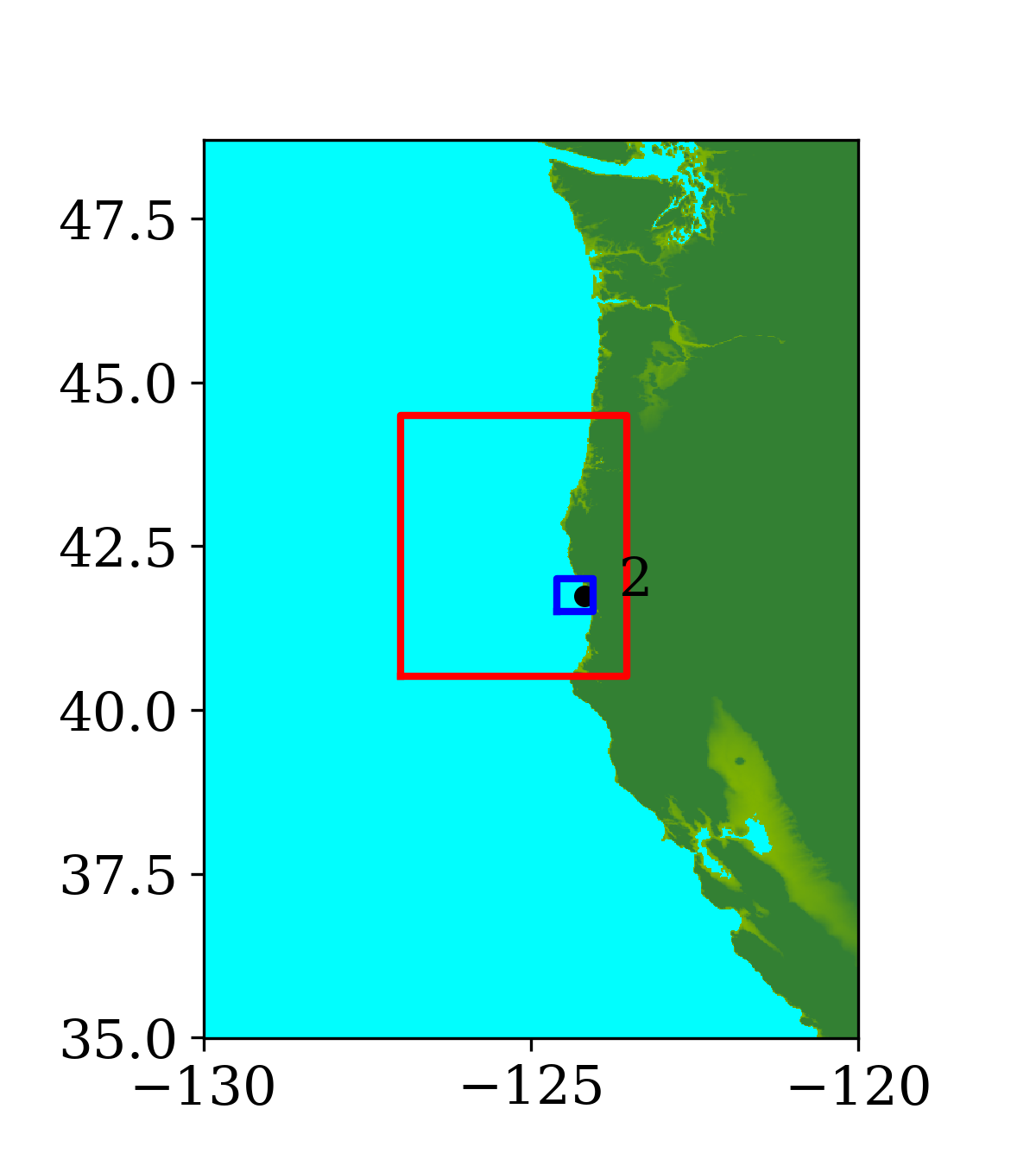 Figure 0
Figure 0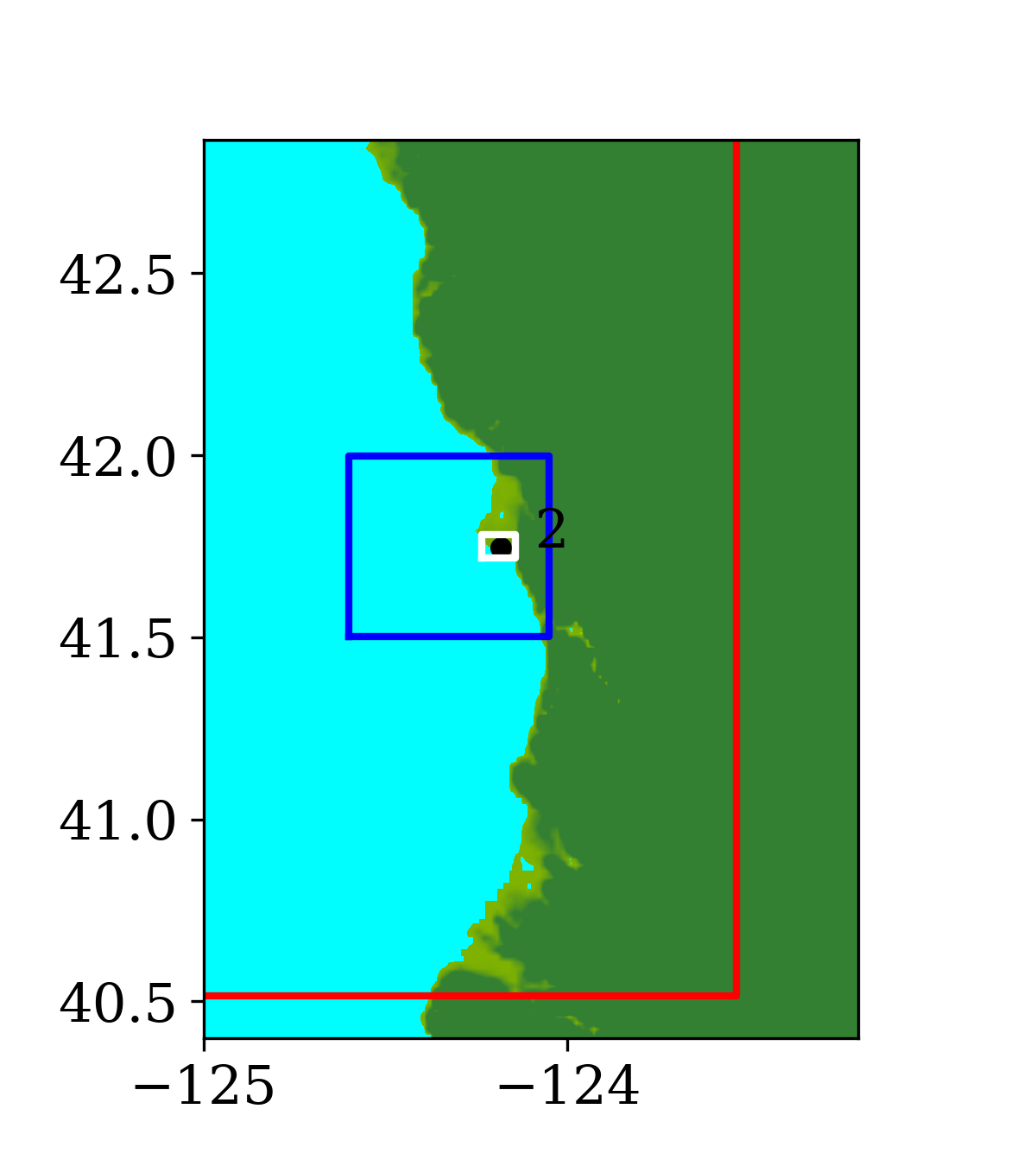 Figure 1
Figure 1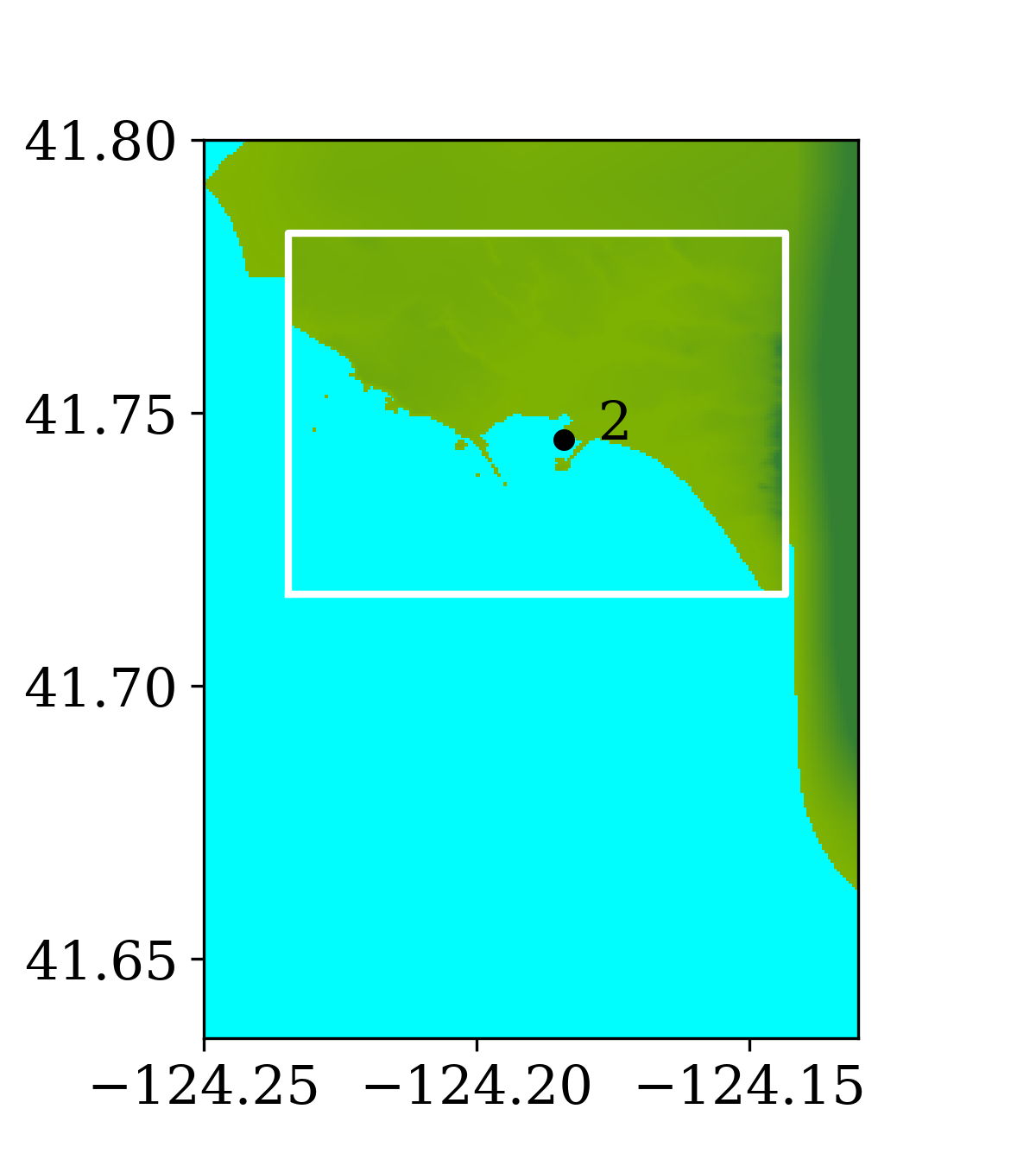 Figure 2
Figure 2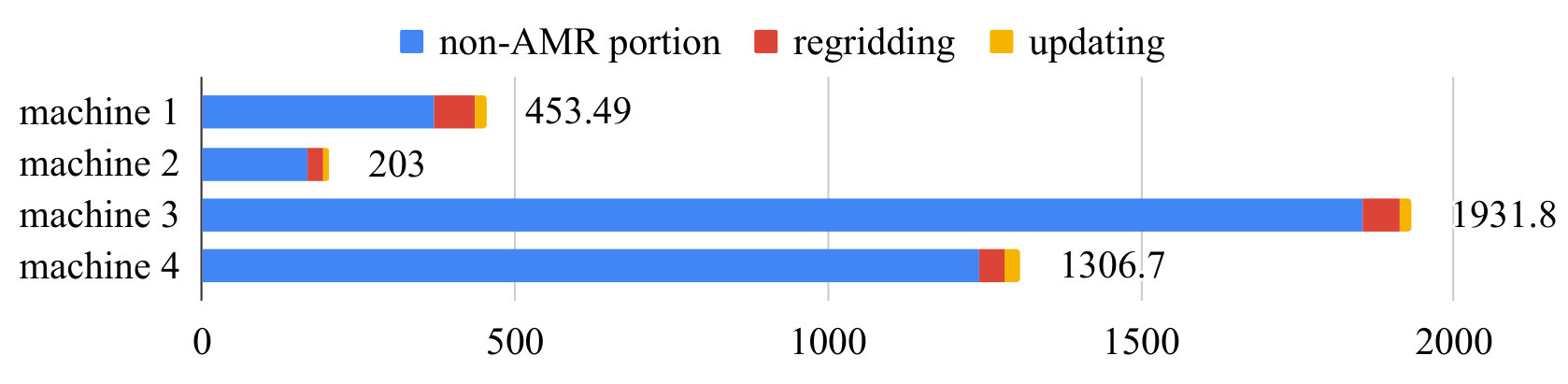 Figure 13
Figure 13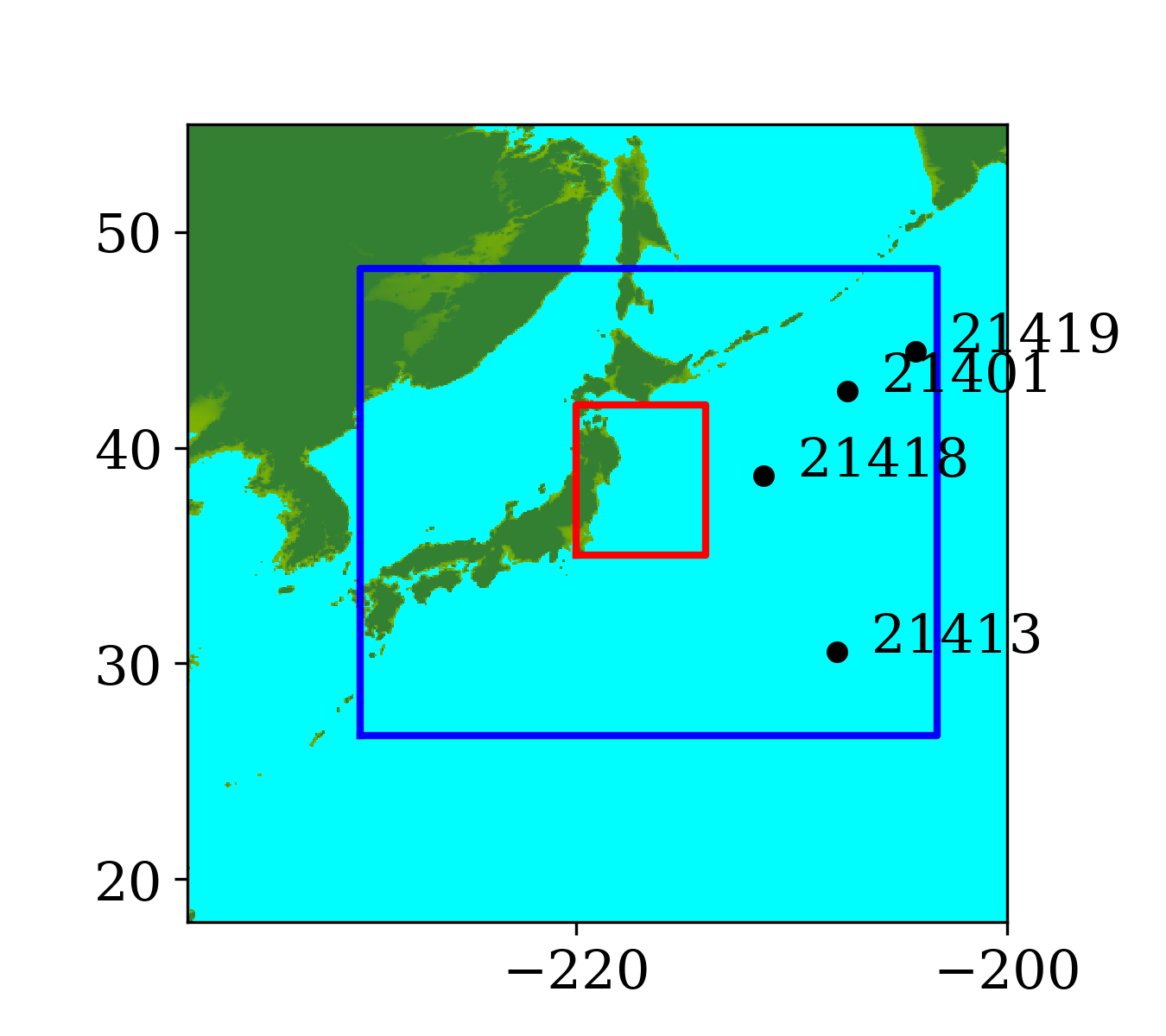 Figure 14
Figure 14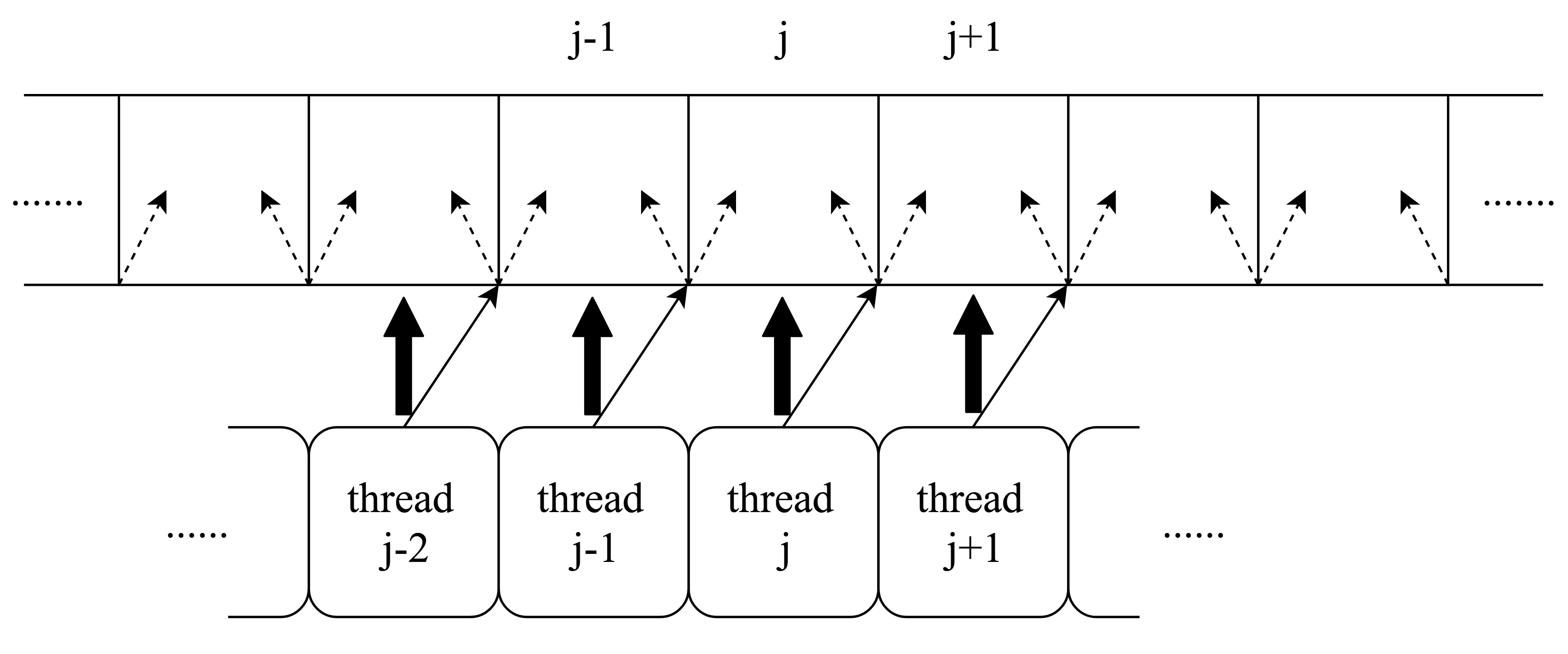 Figure 15
Figure 15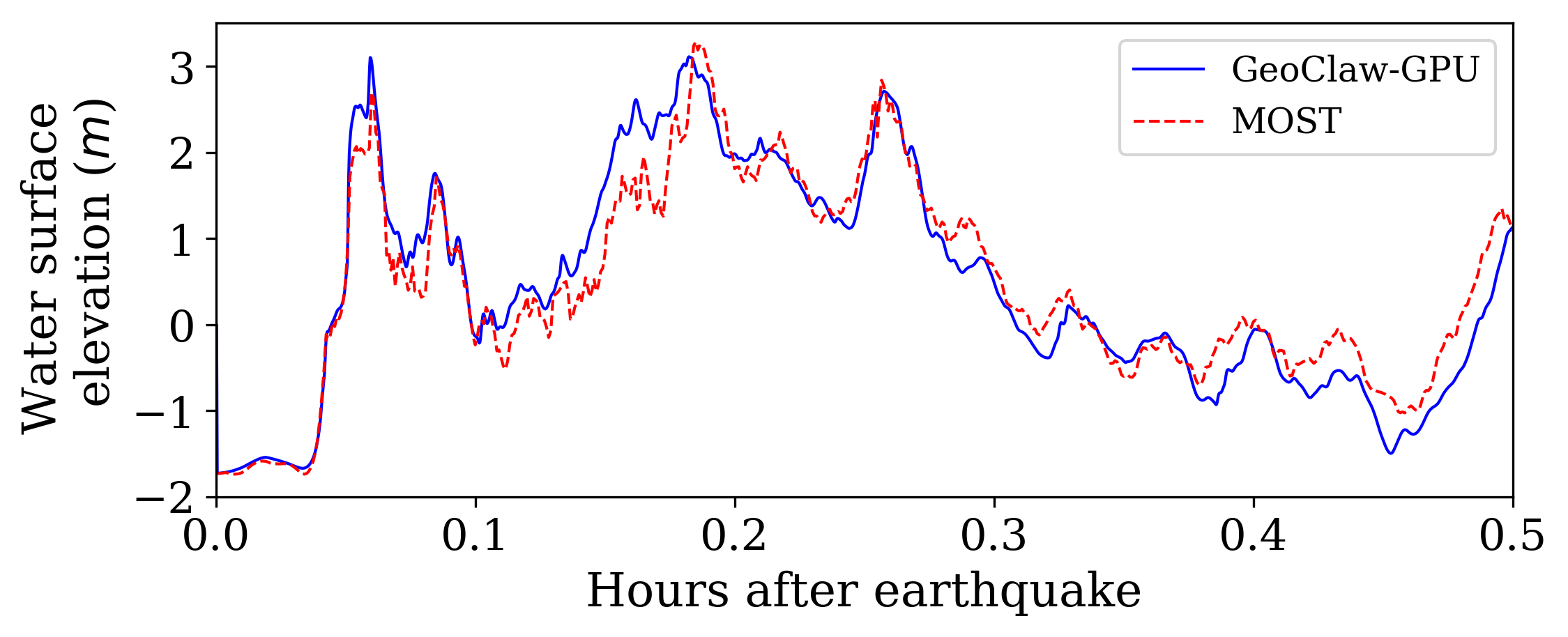 Figure 16
Figure 16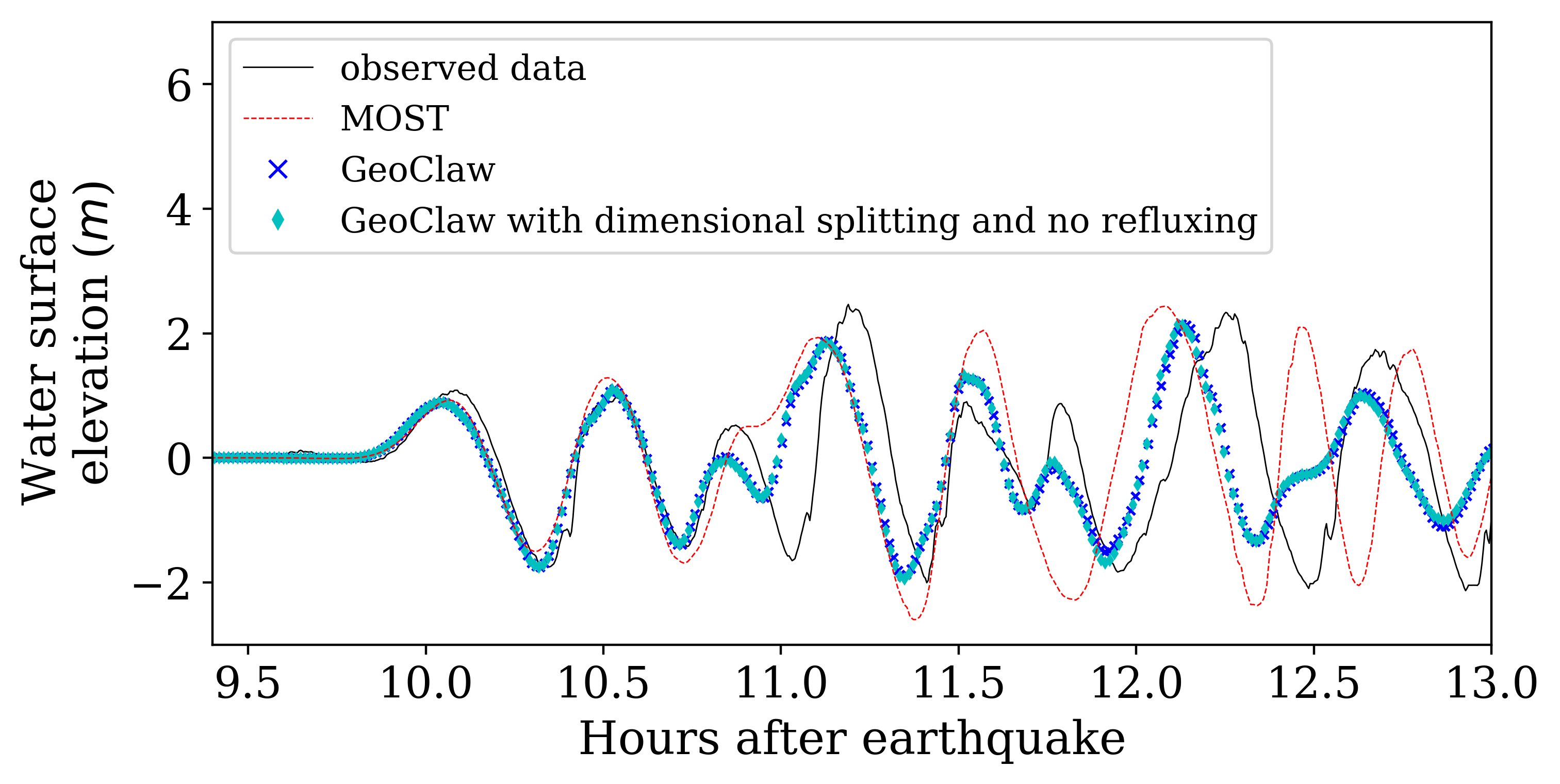 Figure 17
Figure 17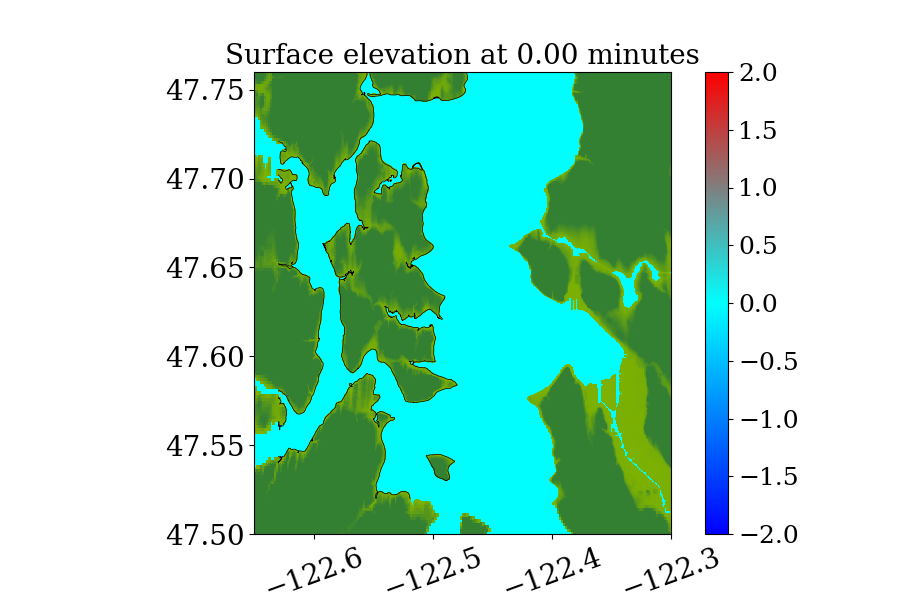 Figure 12
Figure 12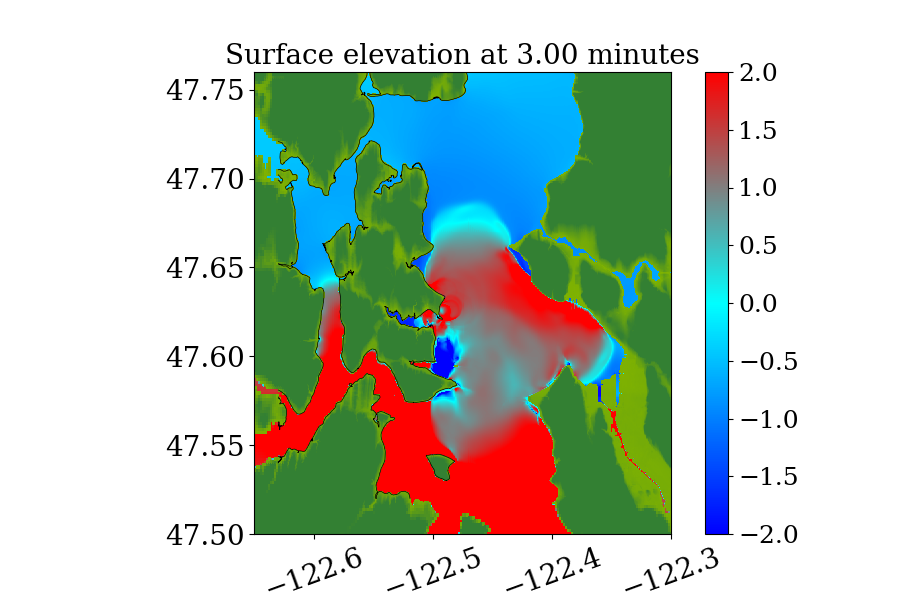 Figure 12
Figure 12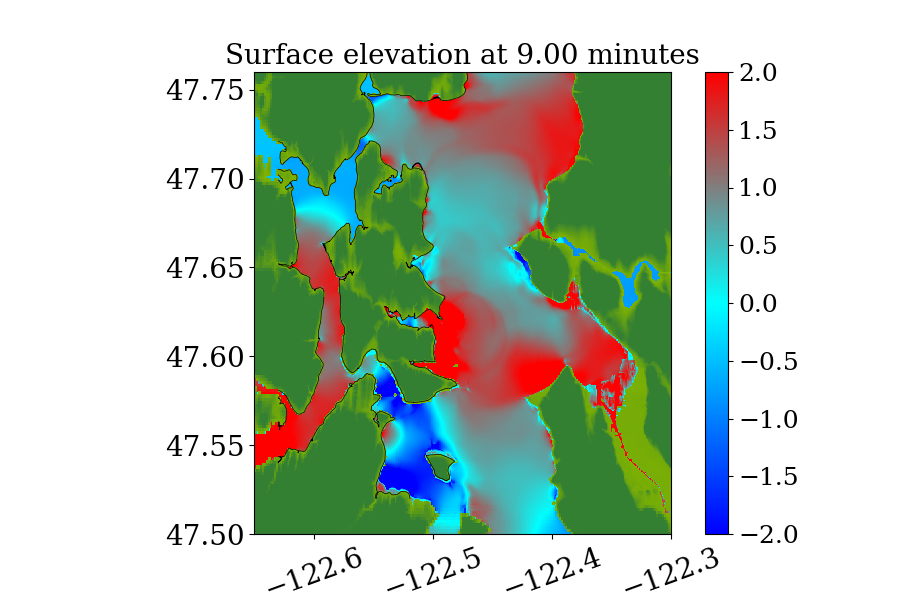 Figure 12
Figure 12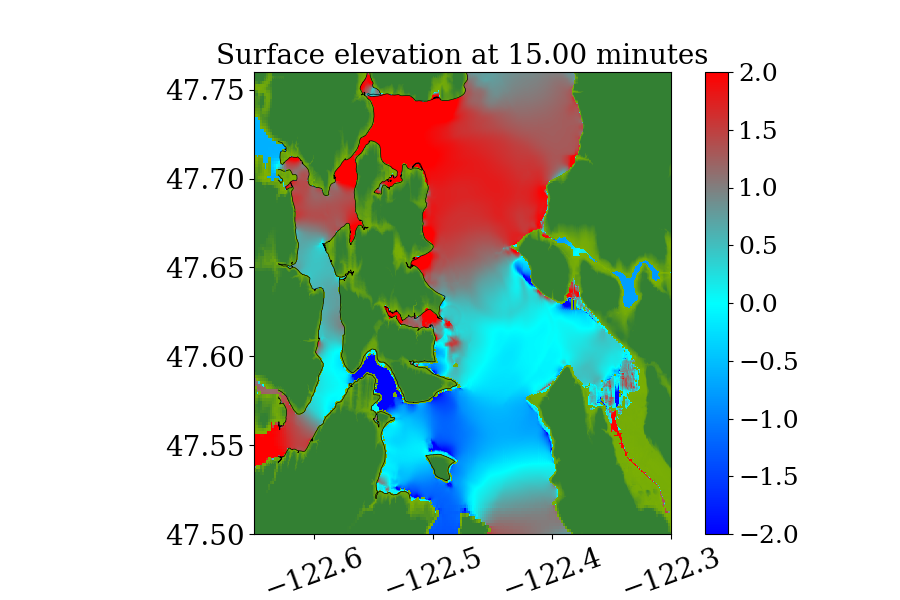 Figure 12
Figure 12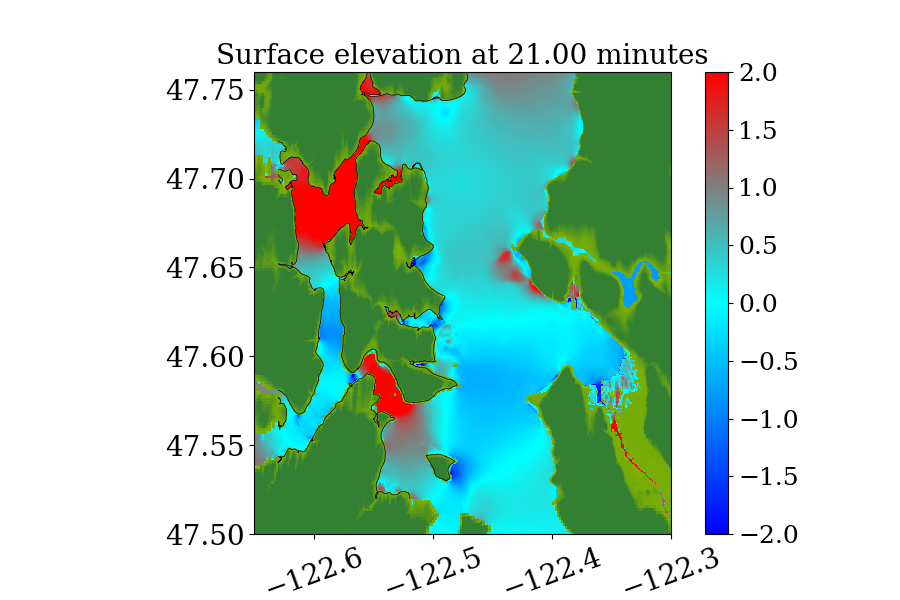 Figure 12
Figure 12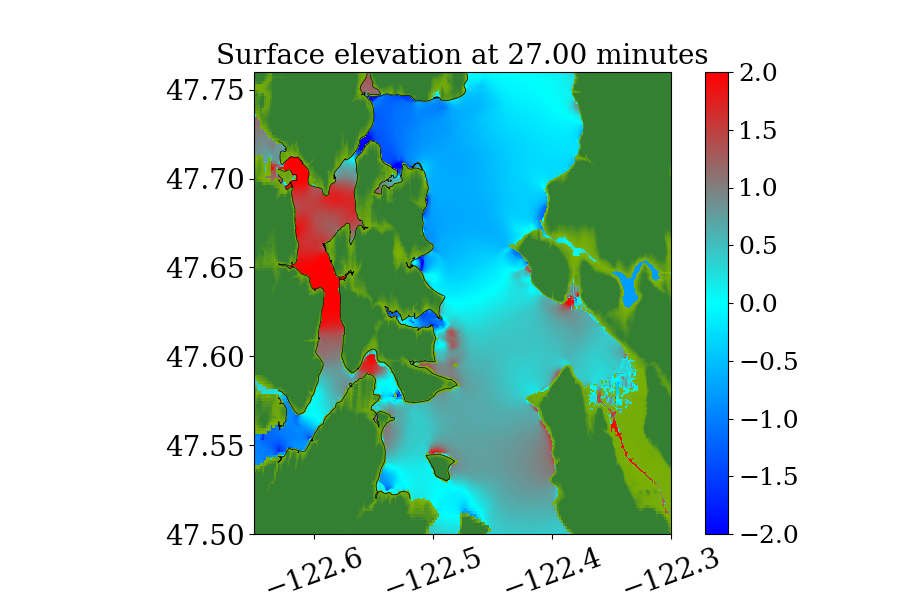 Figure 12
Figure 12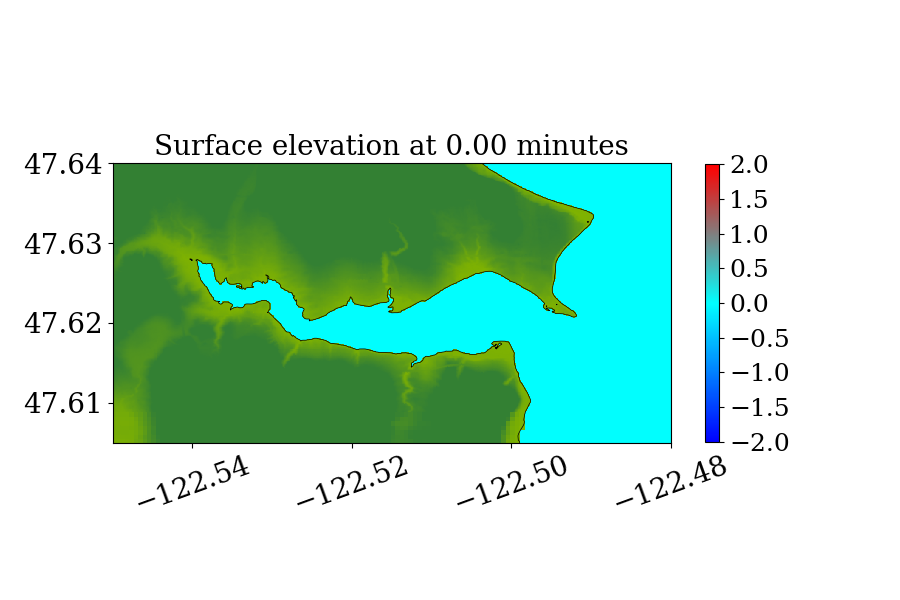 Figure 13
Figure 13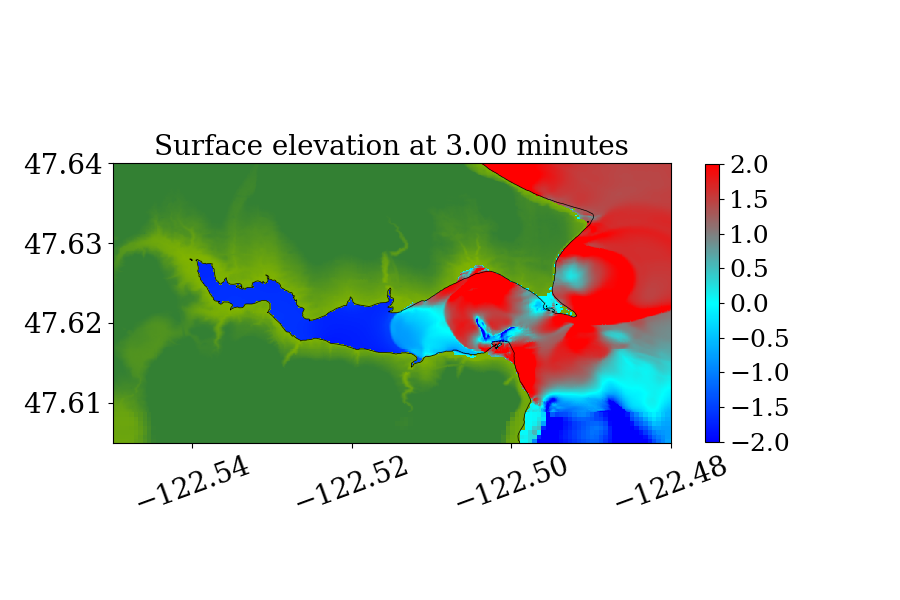 Figure 13
Figure 13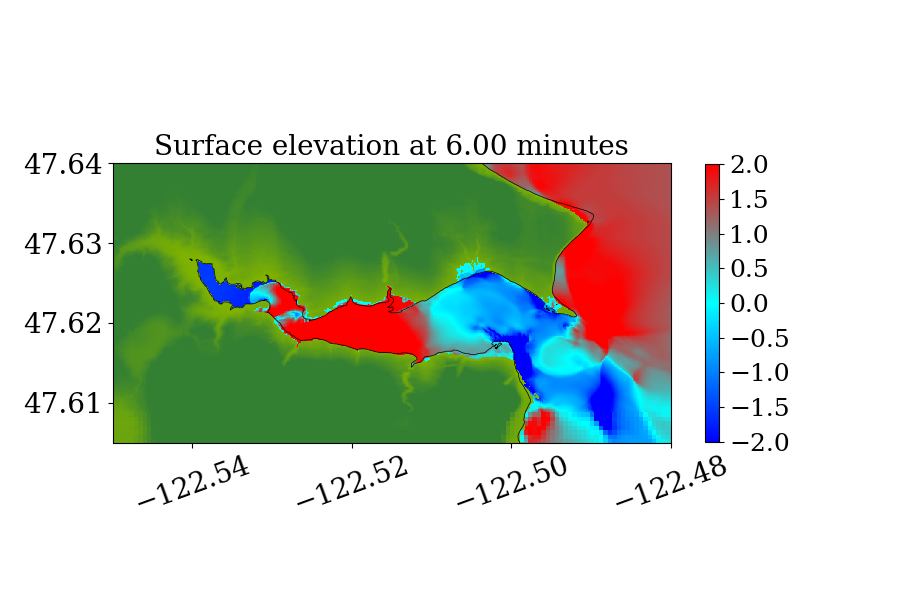 Figure 13
Figure 13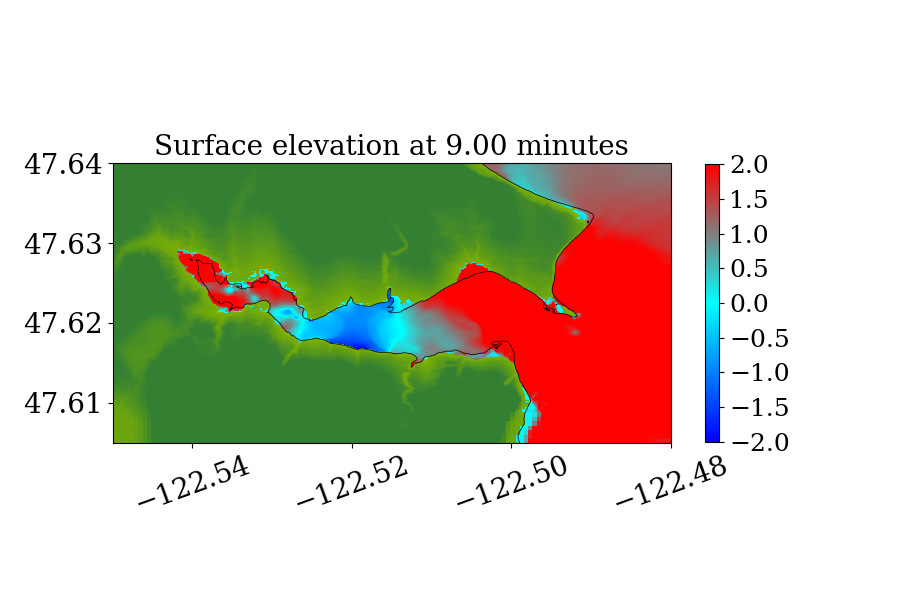 Figure 13
Figure 13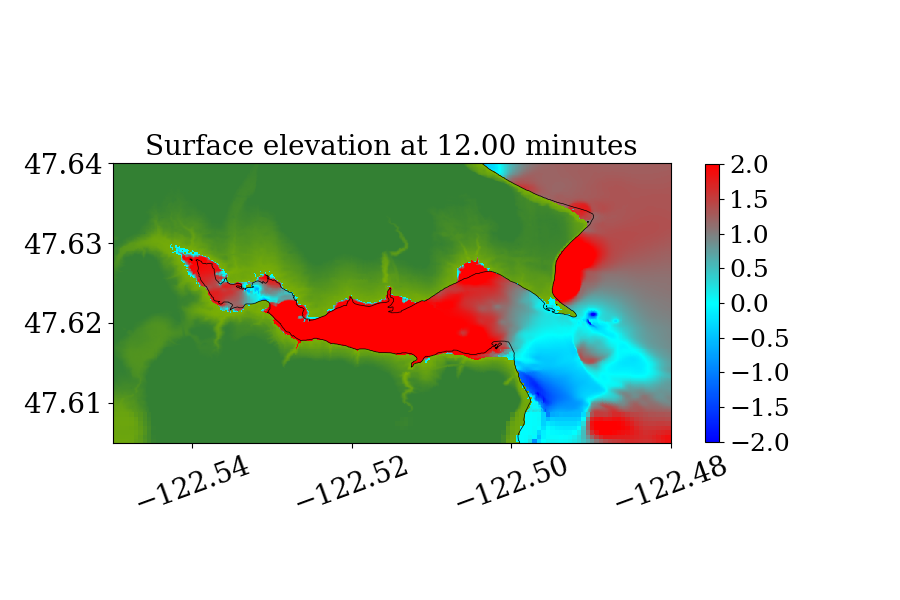 Figure 13
Figure 13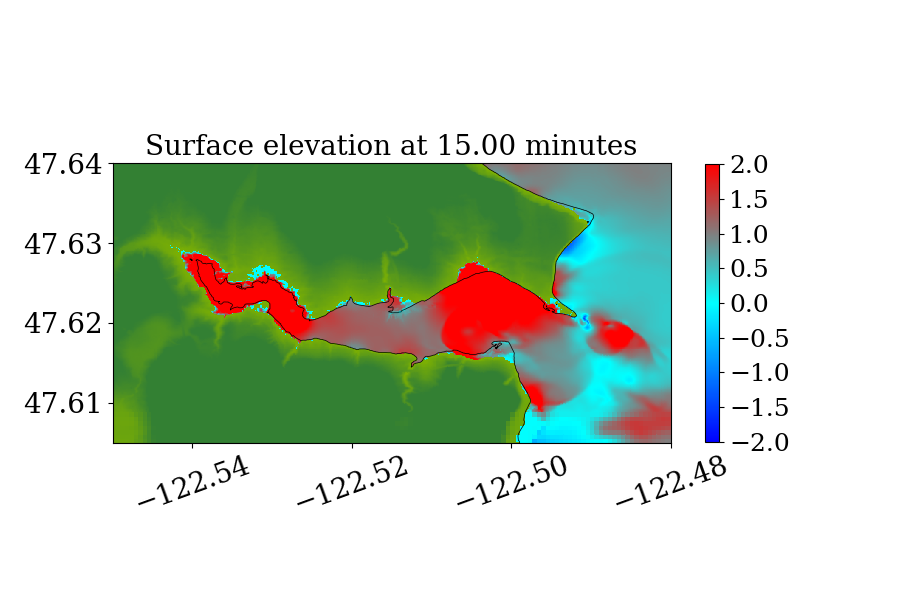 Figure 13
Figure 13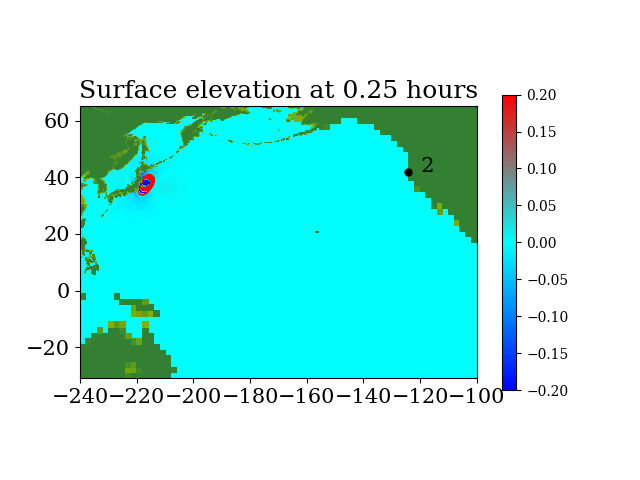 Figure 0
Figure 0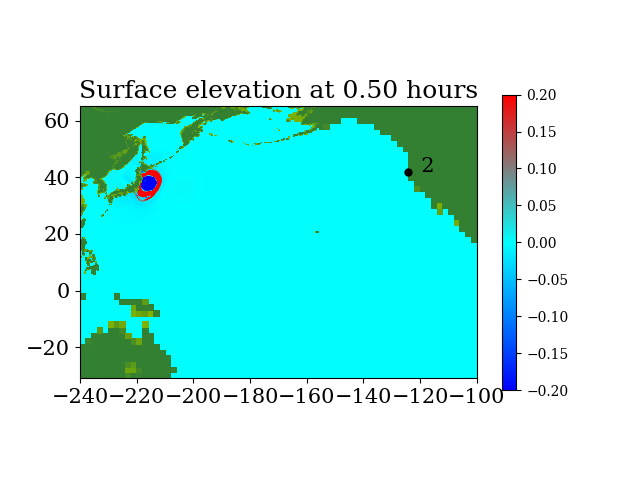 Figure 0
Figure 0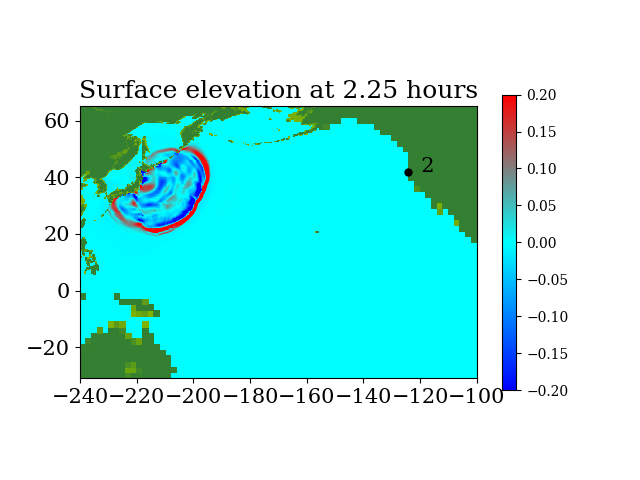 Figure 0
Figure 0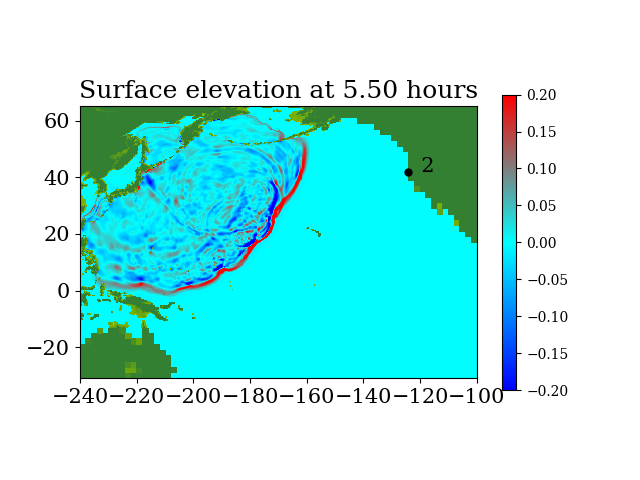 Figure 0
Figure 0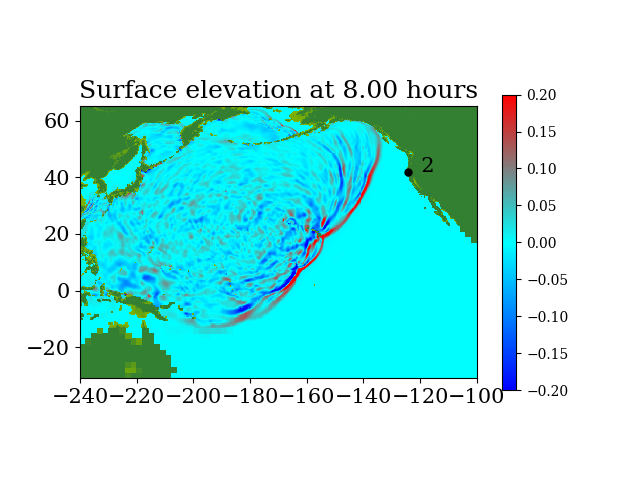 Figure 0
Figure 0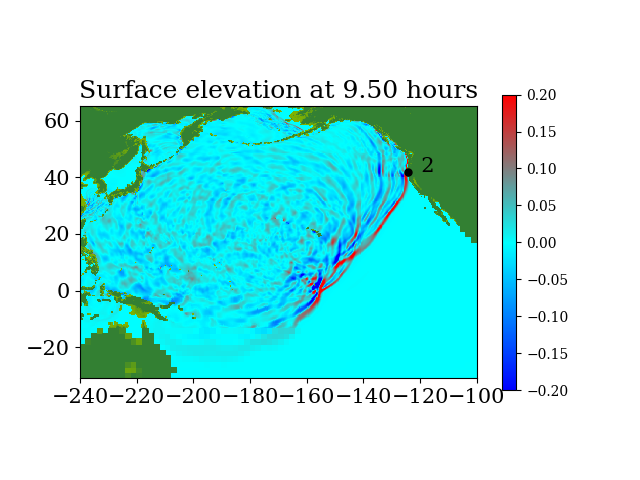 Figure 0
Figure 0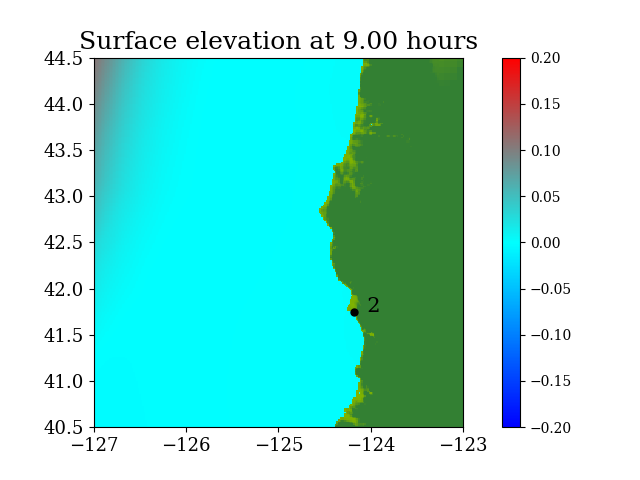 Figure 1
Figure 1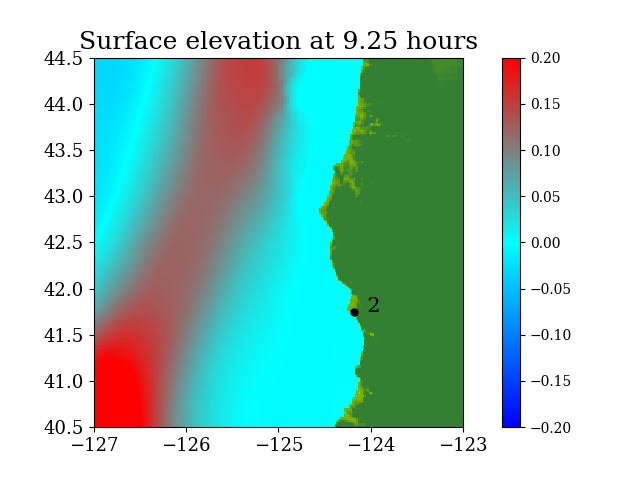 Figure 1
Figure 1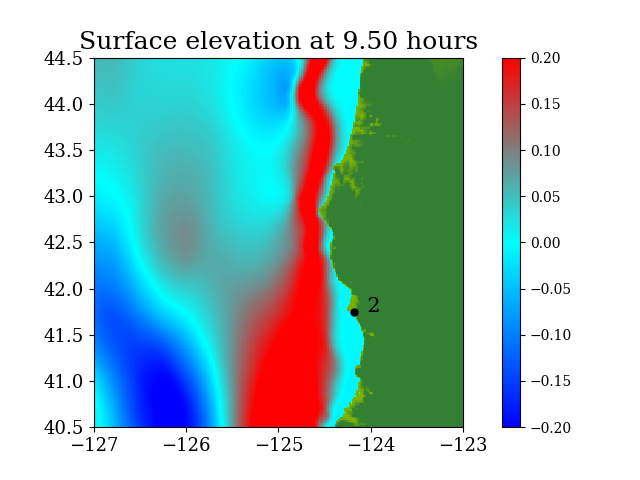 Figure 1
Figure 1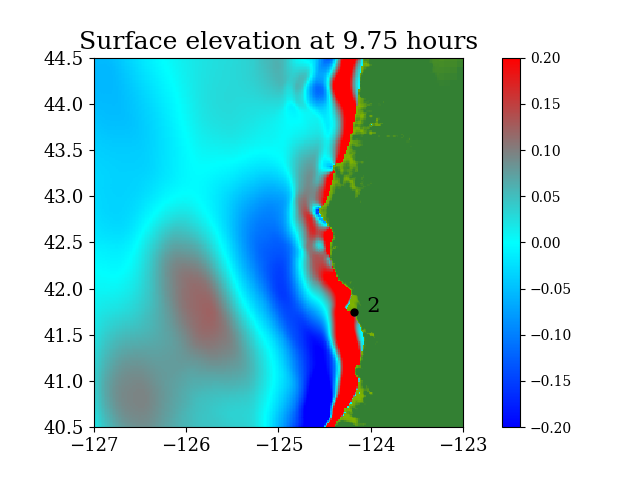 Figure 1
Figure 1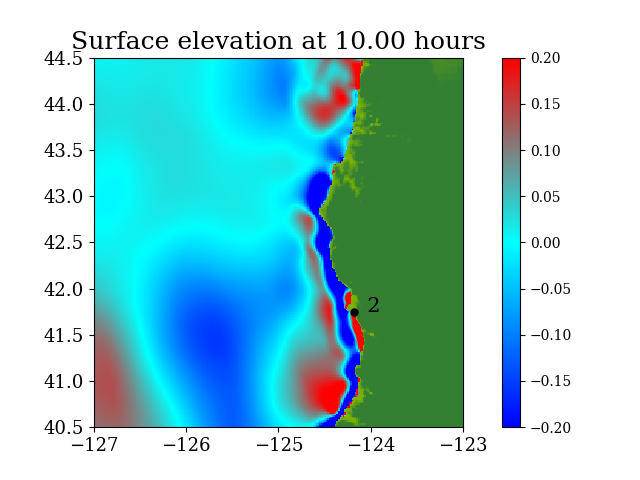 Figure 1
Figure 1| machine 1 | machine 2 | |
|---|---|---|
| 46.92% | 64.20% | |
| 84.50% | 79.30% | |
| 3.98% | 2.90% |
| machine 1 | machine 2 | |
|---|---|---|
| 60.76% | 57.39% | |
| 84.80% | 84.60% | |
| 6.87% | 1.77% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMethane Hydrates and Related Phenomena · Meteorological Phenomena and Simulations · earthquake and tectonic studies
Efficient Tsunami Modeling on Adaptive Grids with Graphics Processing Units (GPUs)
Abstract
Solving the shallow water equations efficiently is critical to the study of natural hazards induced by tsunami and storm surge, since it provides more response time in an early warning system and allows more runs to be done for probabilistic assessment where thousands of runs may be required. Using Adaptive Mesh Refinement (AMR) speeds up the process by greatly reducing computational demands, while accelerating the code using the Graphics Processing Unit (GPU) does so through using faster hardware. Combining both, we present an efficient CUDA implementation of GeoClaw, an open source Godunov-type high-resolution finite volume numerical scheme on adaptive grids for shallow water system with varying topography. The use of AMR and spherical coordinates allows modeling transoceanic tsunami simulation. Numerical experiments on several realistic tsunami modeling problems illustrate the correctness and efficiency of the code, which implements a simplified dimensionally-split version of the algorithms. This implementation is shown to be accurate and faster than the original when using CPUs alone. The GPU implementation, when running on a single GPU, is observed to be to times faster than the original model running in parallel on a 16-core CPU. Three metrics are proposed to evaluate relative performance of the model, which shows efficient usage of hardware resources.
\draftfalse\journalname
Journal of Advances in Modeling Earth Systems (JAMES)
Department of Civil and Environmental Engineering, University of Washington Department of Applied Mathematics, University of Washington
\correspondingauthor
Xinsheng [email protected]
{keypoints}
A fast, accurate and GPU-based tsunami model on patched-based AMR is presented.
The model shows good relative performance with speed-ups of to .
Absolute performance evaluation shows efficient usage of hardware resources.
1 Introduction
Tsunamis are among the most dangerous natural disasters and have recently resulted in hundreds of thousands of fatalities and significant infrastructure damage (e.g. the 2004 Indian Ocean tsunami, the 2010 Chile tsunami, the 2011 Japan tsunami, and more recently the 2018 Indonesia tsunami). A wide range of research has been conducted to simulate tsunami phenomena. These studies are essential for evacuation planning (e.g., Scheer \BOthers., \APACyear2012; Lämmel \BOthers., \APACyear2010), designing vertical evacuation structures (e.g., Ash, \APACyear2015; González \BOthers., \APACyear2013), risk assessment (e.g., González \BOthers., \APACyear2013; L\BPBIM. Adams \BOthers., \APACyear2017; Geist \BBA Parsons, \APACyear2006; González \BOthers., \APACyear2009; Annaka \BOthers., \APACyear2007) and early warning systems (e.g., Taubenböck \BOthers., \APACyear2009; Liu \BOthers., \APACyear2009). The later two, in particular, can benefit from fast simulators. For instance, Probabilistic Tsunami Hazard Assessment (PTHA) often requires thousands of simulations to generate tsunami hazard curves and maps, and some early warning systems depend on rapid simulation results to allow longer evacuation time.
The numerical modeling of tsunamis often includes modeling multiple phases in very different scales, including tsunami generation from the source (e.g., Nosov, \APACyear2014; Okada, \APACyear1985), long-distance propagation (e.g., George \BBA LeVeque, \APACyear2006; Choi \BOthers., \APACyear2003; V\BPBIV. Titov \BBA Gonzalez, \APACyear1997), local inundation of coastal regions (e.g., Park \BOthers., \APACyear2013; Qin \BOthers., \APACyear2017; Qin, Motley, LeVeque\BCBL \BOthers., \APACyear2018) and its interaction with coastal structures (e.g., Motley \BOthers., \APACyear2015; Qin, Motley\BCBL \BBA Marafi, \APACyear2018; Winter \BOthers., \APACyear2017). Some computer codes use separate models for different phases of tsunamis, while some integrate the modeling of multiple phases into a single simulation (e.g., V\BPBIV. Titov \BBA Gonzalez, \APACyear1997; Y\BPBIJ. Zhang \BBA Baptista, \APACyear2008; Macías \BOthers., \APACyear2016), facing the computational challenges induced by very different scales (from thousands of kilometers to tens of meters) in the problem.
The simulation speed can be increased by either reducing computational cost, using more powerful machines, or both. Since being proposed by Berger \BBA Oliger (\APACyear1984), the Adaptive Mesh Refinement (AMR) algorithm has been shown to effectively reduce computational cost in the numerical simulation of multi-scale problems. It can track features much smaller than the overall scale of the problem and adjust the computational grid during the simulation. The algorithm has been implemented and developed into several frameworks and can be categorized into three major variants. The first one is often referred to as patch-based or structured AMR (Berger \BBA Colella, \APACyear1989). It allows rectangular grid patches of arbitrary size and any integer refinement ratios between two level of grid patches (e.g., Hornung \BBA Kohn, \APACyear2002; Bryan \BOthers., \APACyear2014; Clawpack Development Team, \APACyear2017; W. Zhang \BOthers., \APACyear2016; M. Adams \BOthers., \APACyear2015). Another variant is the cell-based AMR, which refines individual cells and often uses a quadtree or octree data structure to store the grid patch information. The last variant is a combination of the first two, often referred to as block-based AMR. Unlike the patch-based AMR, which stores the multi-resolution grid hierarchy as overlapping and nested grid patches, this approach stores the grid hierarchy as non-overlapping fixed-size grid patches, each of which is stored as a leaf in a forest of quadtrees or octrees (e.g., Burstedde \BOthers., \APACyear2014, \APACyear2011; Fryxell \BOthers., \APACyear2000; MacNeice \BOthers., \APACyear2000). In the past two decades, the AMR algorithm has been extensively applied for geophysical applications (e.g., Leng \BBA Zhong, \APACyear2011; Burstedde \BOthers., \APACyear2013; LeVeque \BOthers., \APACyear2011). In particular, tsunami models that simulate both large scale transoceanic tsunami propagation and inundation of small-scale coastal regions save several orders of computational cost by using AMR.
Another approach to increasing tsunami simulation speed is to use faster hardware and/or a greater degree of parallelism to take advantage of modern architectures. Several codes parallelize tsunami modeling on multi-core CPUs (e.g., Pophet \BOthers., \APACyear2011), and GeoClaw takes this approach via OpenMP. ForestClaw (Burstedde \BOthers., \APACyear2014), on the other hand, can simulate a tsunami on distributed-memory machines with MPI parallelism. Recently, use of the Graphics Processing Units (GPUs), which are even accessible on general desktop PCs, have become increasingly popular in the scientific computing community. Many researchers have reported decent speed-ups in simulating tsunamis by using the GPUs. However, most of these earlier studies involved implementing the PDE solvers on grids with constant spatial resolution, including those of Acuña \BBA Aoki (\APACyear2009), Lastra \BOthers. (\APACyear2009), De La Asunción \BOthers. (\APACyear2011), Brodtkorb \BOthers. (\APACyear2012), de la Asunción \BOthers. (\APACyear2013), Smith \BBA Liang (\APACyear2013), and De La Asunción \BOthers. (\APACyear2016). This approach may suffer from too much computational cost when modeling transoceanic tsunami propagation, since no AMR is used. The complexity of the AMR algorithm and data structure add challenges to the implementation of tsunami simulation model on the GPUs. There have been some implementation of AMR algorithms on the GPUs with application to astrophysics (e.g., Wang \BOthers., \APACyear2010; Schive \BOthers., \APACyear2010). However, very few models for simulating tsunami with AMR on the GPU have been developed. Relevant work includes simulation of landslide-generated tsunamis by de la Asunción \BBA Castro (\APACyear2017) for example.
In this paper, a CUDA (Nickolls \BOthers., \APACyear2008) implementation of the patched-based AMR algorithm is developed and used to simulate tsunamis on the GPU. The Godunov-type wave-propagation scheme with 2nd-order limiters is implemented to solve the nonlinear shallow water system with varying topography. Both canonical Cartesian grid coordinates for modeling tsunamis in small regions and spherical coordinates for transoceanic tsunami propagation are supported. The use of AMR adds challenges to the implementation, including dynamic memory structure creation and manipulation, balanced distribution of computing loads between the CPU and the GPU, and optimizations to minimize global memory access and maximize arithmetic efficiency in the GPU kernel. Numerical experiments on several realistic tsunami modeling problems are conducted to illustrate the correctness and efficiency of the implementation, showing speed-ups from 3.6 to 6.4 when compared to the original model running in parallel on 16-core CPU.
The paper is structured as follows. Section 2 gives an overview of the shallow water equations and numerical schemes implemented to solve them. Section 3 briefly reviews the AMR algorithm and how it is combined with the numerical scheme described in Section 2. Section 4 describes the implementation details. Section 5 shows the simulation results and performance statistics from several tsunami cases. Finally the results are summarized in Section 6.
2 Shallow Water Equation and Numerical Scheme
2.1 Shallow Water Equation with Variable Topography
The shallow water equations (SWEs) have been used broadly by many researchers in modeling of tsunamis, storm surge, and flooding. It can be written in the form of a nonlinear system of hyperbolic conservation laws for water depth and momentum:
[TABLE]
where and are the depth-averaged velocities in the two horizontal directions, is the bathymetry/topography, and is the drag coefficient. The subscript represents a time derivative, while the subscripts and represent spatial derivatives in the two horizontal directions. The value of is positive for topography above sea level and negative for bathymetry. Coriolis terms can also be added to the momentum equations but is generally negligible for tsunami problems and is not used here. The drag coefficient used in the current implementation is
[TABLE]
where is the Manning coefficient and depends on the roughness of the ground. A constant value of is often used for tsunami modeling, and this value is used for all benchmark problems in this study.
2.2 Finite Volume Methods and Wave Propagation Algorithm
A one-dimensional homogeneous system of hyperbolic equations in non-conservative form can be written as:
[TABLE]
For non-conservative form, the wave propagation algorithm (LeVeque, \APACyear1997, \APACyear2002) can be used to update the solution:
[TABLE]
where is the net effect of all right-going waves propagating into cell from its left boundary, and is the net effect of all left-going waves propagating into cell from its right boundary. Namely,
[TABLE]
where is total number of waves, is the th wave from the Riemann problem, is wave speed of the th wave, and
[TABLE]
The notations here are motivated by the linear case where . In such a case, the waves are simply decomposition of the initial jumps into basis form by the eigenvectors of the coefficient matrix , propagating at the speed of eigenvalues:
[TABLE]
where and are right and left states of the Riemann problem, is the th eigenvector of matrix , and is coordinate in the direction of .
The wave propagation form of Godunov’s method (equation 4) is only first-order accurate and introduces a great amount of numerical diffusion into the solution. This often smears out the steep gradients in the solution which are common in surface elevation near shoreline in tsunami simulation. To obtain second-order resolution and maintain steep gradients, additional terms are added to equation 4:
[TABLE]
The second-order correction terms are computed as
[TABLE]
where the time step index is dropped and the superscript refers to the wave family. The wave is a limited version of the original wave , where is a scalar that measures the strength of wave relative to waves in the same wave family arising from a neighboring Riemann problem:
[TABLE]
where the index represents the interface on the upwind side of interface
[TABLE]
is a limiter function that gives values near 1 where solution is smooth and is close to 0 near discontinuities. Such property of a limiter function preserves second-order accuracy in region where the solution is smooth while avoiding non-physical oscillations arising near the discontinuities. Note that computing limited waves adds complexity to the parallel algorithm implemented on the GPU since limited waves at one interface cannot be computed until its neighboring waves are solved. This is detailed in section 4.
A two-dimensional hyperbolic system in non-conservative form
[TABLE]
is a general extension of the one-dimensional hyperbolic system (equation 3) in two-dimensional space. The Godunov-type finite volume algorithms discussed above can be naturally extended to two-dimensional space by dimensional splitting, which splits the two-dimensional problem into a sequence of one-dimensional problems. The wave propagation algorithm now becomes
[TABLE]
[TABLE]
where and are net effect of all waves propagating into cell from its left and right edges, while and are 2nd-order correction fluxes through its left an right edges. Similarly, and are net effect of all waves propagating into cell from bottom and top edges, while and are 2nd-order correction fluxes through its bottom and top edges.
In GeoClaw, the shallow water equation is written in non-conservative form, which augments the system by introducing equations for topography and momentum flux (LeVeque \BOthers., \APACyear2011). An approximate Riemann solver has been implemented by George (\APACyear2008) to solve the Riemann problems at each cell interface for this augmented system. This Riemann solver has some nice properties for tsunami modeling, including the capability of preserving steady state of the ocean, handling dry states in the Riemann problem, and maintaining non-negative depth in the solution.
The time step size for time integration must be chosen and adapted carefully at each time step if variable time step is used, which is typical for tsunami modeling. The Courant, Friedrichs and Lewy (CFL) condition implies that the time step size for a certain AMR level must satisfy
[TABLE]
where is the CFL number and is the maximum wave speed seen at the AMR level.
3 Adaptive Mesh Refinement
The block-structured adaptive mesh refinement algorithm implemented in Clawpack is described in numerous papers, including Berger \BBA Oliger (\APACyear1984) and Berger \BBA Colella (\APACyear1989), and is only briefly summarized here.
A collection of rectangular grid patches are used to store the solution. Grid patches at different levels have different cell sizes. The coarsest grid patches (level 1) cover the entire domain. Grids patches at level +1 are finer than coarser level grid patches by integer refinement ratios and in the two spatial directions, , and cover sub-region of level grid patches. In this study, the refinement ratios in the two spatial directions are always taken to be equal, . Typically, the time step size is also refined the same factor for level +1 grid patches, , with .
The high level grid patches are regenerated every time steps such that they move with features in the solution. When level +1 grid patches need to be regenerated, some cells at level are flagged for refinement based on some criterion (in GeoClaw, typically where the amplitude of the wave is above some specified tolerance, or in specified regions where higher refinement is required, for example near the target coastal location, or where the wave will affect the solution in destination during time interval of interest as indicated by the backward adjoint solution(Davis \BBA LeVeque, \APACyear2016)). The flagged cells are then clustered into new rectangular grid patches, which usually include some cells that are not flagged as well, using an algorithm proposed by Berger \BBA Rigoutsos (\APACyear1991). The algorithm tries to keep a balance between minimizing the number of grid patches and minimizing the number of unflagged cells that are included in the resulting rectangular grid patches. The newly generated level +1 grid patches get their initial solution from either copying data from existing old level +1 grid patches or, if no such grid patch exists, interpolating from level grid patches. We say the level +1 patch cells are “on top” of some level cells that cover the same spatial region. Note that the algorithm described below integrates the underlying level grid patches before the level patches. After updating the finer patches, any level cells under level cells have their values updated to the average of level cell values. After each regridding step, the new level patches need not cover the same level cells as previously.
3.1 Time Integration
Each grid patch in the AMR grid hierarchy, despite different resolution, can be integrated in time with the wave-propagation form of Godunov’s method described in the previous section. Specifically, the following steps are applied recursively, starting from the coarsest grid patches at level , as illustrated in a simple case in Figure 1.
Advance the solution in all level grid patches at by one step of length to get solution at . 2. 2.
Fill the ghost cells for all level grid patches, by either copying cell values from adjacent level grid patches if any exists, or interpolating in space and time from the cell values at level at and if no adjacent level grid patch exists. Note that interpolation in time is generally required because the finer grids are integrated with smaller time steps. 3. 3.
Advance the solution at level for time steps such that solution at level is at the same time as solution at level . Each time level is advanced, this entire algorithm (step 1–5) is applied recursively to the next finer level (with replaced by in these steps) if additional level(s) exist. 4. 4.
For any grid cell at level that is covered by level grid cells, the solution in that cell is replaced with an appropriate weighted average of the values from the level cells on top. This is referred to below as the updating process. 5. 5.
For any grid cell at level that is adjacent to level grid cells, the solution in that cell is adjusted to replace the value originally computed using fluxes found on level with the potentially more accurate value obtained by using level fluxes on the side of this cell adjacent to the level patch. This step also preserves conservation for certain problems and is referred to below as the refluxing process. (This step is dropped in our implementation, see below.)
Step 5 is important for some problems where exact conservation is expected, e.g., of a conserved tracer or for strong shock waves in nonlinear problems, and is necessary in this case to avoid the use of different numerical fluxes at the same interface on the side of the fine patch and the side where it abuts a coarser grid. However, this step requires storing additional flux information at every time step and communicating this information between levels and was found to have a large negative effect on the ability to speed up the code on the GPU. We also found that this refluxing step has very little effect on the numerical results obtained for tsunami modeling (as shown in Section 5.1). In this application we do not expect conservation of momentum at any rate (due to the topographic and friction source terms) and even conservation of mass is sacrificed when AMR is applied to a cell near the coast (as described in LeVeque \BOthers. (\APACyear2011)). For these reasons we omit Step 5 in the GPU implementation. This greatly helps to optimize the logistics of the code and achieve very impressive performance in the benchmark problems, while only introducing negligible changes to the solution.
3.2 Regridding
Every time a level is advanced by time steps, regridding based on this level is conducted (except on the finest allowed level). Typically, is chosen as 2–4 in tsunami modeling. A larger results in less frequent regridding, which reduces time spent on the regridding process. However, in order to ensure the waves in the solution do not propagate beyond the refined region before the next regridding process, when cells are flagged for refinement, usually an extra layer of cells surrounding the original flagged cells are flagged. This makes each grid patch cells wider in each of the two horizontal dimensions and thus introduces more cells, which increases the computational time of time integration.
In the regridding process, cells must be flagged before they are clustered into new grid patches. A variety of different flagging criteria have been implemented, including flagging based on the slope of the sea surface, sea surface elevation, or adjoint methods. For all the benchmarks in this study, the sea surface elevation is used for flagging. In addition to this, some spatio-temporal regions might also be specified to enforce flagging in these regions, which is very useful for problems where both the transoceanic propagation and local inundation of a tsunami must be modeled, and thus require grid cells that are finer than the coarsest resolution in some near shore regions like a harbor or bay.
During regridding, if a newly generated grid cell cannot copy values from old cells at the same level, its initial value must be interpolated from coarser levels. In the updating process, coarse cell values get updated with the appropriate averaged value of fine grid cells on top. An important requirement for both the interpolation and averaging strategies in tsunami modeling is to maintain the steady state of the ocean at rest, since refinement generally occurs before the tsunami waves arrive in an undisturbed area of the ocean. For areas far from shoreline, the interpolation strategy can be simple linear interpolation and the averaging strategy used is averaging the surface elevation in fine cell values arithmetically and then compute depth in each cell based on the topography and surface elevation. However, near the shoreline where one or more cells is dry, it is impossible to maintain conservation of mass and also preserve the flat sea surface during the interpolation or averaging in some circumstances. Details of the strategies can be found in LeVeque \BOthers. (\APACyear2011).
4 A Hybrid CPU/GPU Implementation
One very basic question to answer in designing a GPU implementation of some code is which part of the program should be done by the CPU and which part should be done by the GPU. In the current implementation we have put the Riemann solvers, wave limiter and CFL reduction on the GPU while letting the CPU take care of the rest, including the updating process, regridding process, filling ghost cells, and updating gauge values (finding the best grid patch to sample quantities of interest from, interpolating from cell values, and output), etc. Since the GPU and the CPU considered in the study have separate physical memory, this design requires the transfer of solution data on each grid patch back and forth between the GPU and CPU memory through a PCI express 2.0 interface, which has relatively low bandwidth compared to the main memory of the CPU and the GPU. However, as we show later in the benchmark results, the extra time introduced by such data transfer takes less than of the total running time, since these operations can be carefully hidden by performing other operations concurrently.
If we instead put all procedures on the GPU, although it might save time by eliminating much of the data transfer, the code might suffer from having tiny GPU kernels that add significant overhead to the running time, and running inefficient GPU kernels that can be even slower than the CPU counterpart. One example is filling ghost cells on the GPU. Each GPU kernel that fills ghost cells for a two-dimensional grid patch of by cells can have parallelism of at most ( ghost cells to fill on each side), which is much less than the parallelism exposed in time integration of the same grid patch, which has parallelism of and often involves much more computation. The overhead of launching a GPU kernel is almost a fixed amount of time regardless of the actual execution time of the kernel. This overhead is often much longer than the execution time of a tiny GPU kernel like the GPU kernel that would be needed for filling ghost cells. As a result, the total cost (including kernel launching overhead and kernel execution) of doing such operations on the GPU can be even higher than the cost of doing so on the CPU in some cases. In addition to the consideration from kernel launching overhead, code that puts all procedures on the GPU wastes CPU computational resources. Since a typical machine considered in this study consists of a multi-core CPU and a GPU, ideally the work load of the entire program would be distributed between the two as evenly as possible, such that the CPU stays busy as much as possible during the entire execution and so does the GPU. In Section 5, two metrics are proposed to measure such characteristics of a code in numerical experiments.
4.1 Procedure Dependencies and Concurrent Execution
Figure 2 shows the major procedures of the code that are hearafter referred to as the non-AMR portion of the code. (Omitted are the regridding process and updating process, essential components of AMR.) An arrow from procedure to procedure indicates that procedure must be finished before procedure can start. The color indicates the type of hardware resource a procedure needs. 4 colors represent 4 major types of hardware resource involved in the execution of the code. A blue block uses one CPU core, a green block uses the GPU Streaming Multiprocessors, a red block uses the memory transfer engine that transfers the data from the CPU memory to the GPU memory, and a purple block uses the memory transfer engine that transfers data in the opposite way. Note that these are separate transfer engines but there is only one of each. Any two procedures without dependency can be done concurrently as long as relevant hardware resources are available. The dependencies in the current implementation are enforced through a combination of rearrangement of CPU procedures and GPU kernel launches, use of OpenMP directives and CUDA streams, and proper synchronization between CPU threads and between the CPU and the GPU.
Figure 3 shows an example of these procedures being processed concurrently by four types of hardware on a machine with a three-core CPU. Procedures follow the dependency specified in figure 2. Procedures that use the same hardware resource must wait in queue for the hardware to become available. Note that procedures that needs CPU cores can use any available CPU core so those processed by different CPU cores can be executed concurrently.
In figure 3, during the entire time period when the red block for grid patch 12 is processed by one of the two memory transfer engines, the GPU Streaming Multiprocessors are processing the green block for grid patch 14. In this case, transferring the solution data of grid patch 12 from the CPU memory to the GPU memory does not induce any extra cost. During some middle time period of the red block for grid 14, however, no GPU computation is conducted so the GPU Streaming Multiprocessors are idle, which can be caused by unavailability of data on the GPU, for instance. This time segment does induce extra cost due to transferring data between the CPU memory and the GPU memory. Later in section 5, such extra cost will be quantified to reveal the influence of transferring data between the CPU memory and the GPU memory on performance of the code. Two additional metrics will also be defined and measured later in section 5, the proportion of time during which the CPU has some work to do instead of waiting for the GPU to finish, and the proportion of time during which GPU Streaming Multiprocessors are doing computations.
4.2 Memory Pool
During regridding, new grid patches are generated and old ones are destroyed. New memory must be allocated on both the CPU and the GPU for storing solution data and auxiliary data for the new grid patches, while old memory for removed grid patches must be freed. The total overhead of calling the CUDA runtime library to conduct these frequent memory operations cannot be neglected, and can even dominate execution of the code sometimes when grid patches are so small that the overhead is expensive relative to the time spent advancing the solution on grid patches. To save the cost of such frequent memory operations, a memory pool is implemented, which requests a huge chunk of memory from the system by calling the CUDA runtime library at the initial time, keeping it until the end of execution, and getting more chunks when needed. All memory allocation and deallocation requests from the code are then through this memory pool at much less cost, with no need to actually allocate/free system memory.
4.3 Efficient Design of the Solver Kernels
4.3.1 The CUDA Programming Model
The current implementation is based on the CUDA programming model and targeted Nvidia GPUs. The architecture of Nvidia GPUs as well as explanation of the CUDA programming model are detailed in the Nvidia CUDA C programming guide (NVIDIA, \APACyear2018). Here only a brief review is given to provide sufficient knowledge for understanding the implementation details introduced in this section.
In the CUDA programming model, each function that is written to run on the GPU is called a CUDA kernel (or GPU kernel). The code in a CUDA kernel specifies a set of instructions to be executed by multiple CUDA threads in parallel. The code can specify that some of the instructions should be executed by a certain group of threads but not the others. All threads assigned to execute a CUDA kernel are grouped into CUDA blocks. All such CUDA blocks then form a CUDA grid. CUDA blocks are independent of each other, can be sent to different Streaming Multiprocessors, and run concurrently. During the execution of a CUDA kernel, each thread is provided with information regarding which CUDA block and which thread within that block it is. Based on this information, each thread can perform its own set of instructions on a specific portion of the data.
The GPU has many different types of hardware for data storage. The three relevant types here are registers, shared memory and main memory. The registers are the fastest storage and have very low access latency but each Streaming Multiprocessor has a very limited number of registers. Each thread is assigned its own registers and thus can only access its own registers (unless special instructions are used).
The shared memory has relatively slower bandwidth and longer access latency than the registers but its bandwidth is still much faster than that of the main memory and access latency is also much shorter than that of the main memory. Each CUDA block is assigned a specified amount of shared memory, which is accessible by all CUDA threads in the CUDA block. The quantity of registers and shared memory in the Streaming Multiprocessor is limited and fixed. As a result, number of CUDA blocks that can reside in a Streaming Multiprocessor at the same time is limited by total number of registers and the amount of shared memory these CUDA blocks request. If too few CUDA blocks can reside in a Streaming Multiprocessor at the same time, the Streaming Multiprocessor has low occupancy and thus runs the CUDA kernel less efficiently. For this reason, it is important to minimize the number of registers used by each thread and the amount of shared memory used by each CUDA block when the CUDA kernel is designed.
The main memory is located the farthest from the chip and thus has the lowest bandwidth and the longest access latency. In principle, a CUDA kernel should have a minimal number of read and writes to main memory, especially given the fact that stencil computations for partial differential equations are often memory bandwidth bound. A simple idea in CUDA kernel design is to load all data as efficiently as possible from the main memory to the shared memory, conduct all computations using the shared memory as a buffer to avoid unnecessary accesses of main memory, and then write new data back to the main memory. However, this often causes too much shared memory usage for each CUDA block and results in very inefficient execution of the CUDA kernel.
4.3.2 Data Layout
Every 32 threads within a CUDA block are grouped as a warp, which executes the same instruction at the same time, including memory load and write operations. The hardware can execute memory request from all threads in a warp most efficiently if they access a contiguous piece of memory. This is called a coalesced access. Such characteristic of the GPU hardware makes Structures-of-Arrays (SoA) preferable over Arrays-of-Structures (AoS). With SoA layout, the same state variables, e.g. water depth , on the entire grid patch are stored contiguously in memory, whereas with AoS format, all state variables within the same grid cell are stored contiguously in memory. Such a data layout results in strided access of the GPU memory. Namely, consecutive CUDA threads will access memory locations that are not consecutive. This can greatly reduce effective memory bandwidth since memory accesses cannot be coalesced.
The current implementation contributes to the Clawpack eco-system (Mandli \BOthers., \APACyear2016), which uses an AoS layout since Fortran arrays are dimensioned so that is the th component (depth or momenta) in the grid cell. However, many applications within the Clawpack eco-system will be affected if the AoS data layout is changed. Thus we continue to use the AoS layout in the current implementation. In the first half of the dimensional splitting method, the CUDA kernel that solves the equation in the direction reads in data in AoS but writes intermediate solution data in SoA, which is coalesced. The CUDA kernel that solves the equation in the direction then reads in data in SoA layout in a coalesced manner and writes new solution back in AoS layout.
4.3.3 CUDA Kernel Implementations
In designing a CUDA kernel, one essential goal is to assign computational tasks to each thread. To perform time integration on gird patches with Godunov-type wave-propagation methods, the goal is to decide how to distribute to each thread the tasks of solving the Riemann problems at each cell edge, limiting waves, and updating cell values.
Figure 4 shows a one-dimensional slice of a grid patch along the direction when the first step of the dimensional splitting method is conducted to get the intermediate state . Updating cell depends on the two sets of waves at cell edges and . When waves are limited, the waves at cell edge depends on waves at cell edges and , while the waves at cell edge depends on waves at cell edges and . Any of these waves depends on the two cell values around them, respectively. As a result, the solution at cell depends on four neighboring sets of waves, which depend on the 5 cell values around cell (including itself).
If each CUDA thread is assigned to update a cell in this one-dimensional slice, it needs to solve the four Riemann problems the cell depends on. Redundant work is performed since some Riemann problems are solved and some waves are limited by neighboring CUDA threads as well. On the other hand, if each thread is assigned to solve a Riemann problem at one cell edge in this one-dimensional slice, limit the waves, and then update the two neighboring cells with left- and right-going waves, the code must carefully avoid data racing since each cell is updated by two CUDA threads. This typically involves the usage of a synchronization mechanism called lock, which decreases the execution efficiency of the CUDA kernel.
In the current implementation, a combination of the two ideas above is implemented. Figure 5 shows how CUDA threads are first assigned to cell edges for solving Riemann problems and limiting waves, and then re-assigned to grid cells for updating the solution. Each solid arrow denotes assigning one CUDA thread on a cell edge. The thin arrows show the initial assignment to edges, while the thick arrows show the final assignment to cells.
In the first stage, each CUDA thread is assigned to a cell edge to solve the Riemann problem there. The left and right state for the Riemann problem for a thread is loaded from the main memory, while resulting waves from the Riemann problem are written into the shared memory. In the second stage, each CUDA thread limits its waves to get correction fluxes at the cell edge it is assigned to. This requires reading waves from the two neighboring edges, which were produced by the two neighboring CUDA threads and stored in the shared memory. Each thread then writes the limited waves (correction fluxes) back to the shared memory.
In the last stage, each CUDA thread is assigned to update a cell (thick arrows). At this time, each thread already has left-going waves and correction fluxes at the right edge of its cell in its registers, which can be directly applied to update the cell value. The right-going waves and correction fluxes at the left edge of the same cell was produced by its left neighboring thread, and were stored in the shared memory in the last stage. Thus each thread needs to read in these waves and fluxes from the shared memory and apply them to update the cell it is assigned to. Each thread then writes the updated value back to the main memory. A similar kernel is then conducted for the second step of dimensional splitting method to get new state .
This implementation requires a kernel to read solution data from the main memory only once at the beginning of the kernel execution and write the updated solution back to the main memory only once at the end of the kernel execution. This is done by using only a reasonable number of GPU registers for each thread and a reasonable amount of shared memory for each CUDA block. The usage of GPU registers for each CUDA thread only includes storing the state variables for left and right states of one Riemann problem, waves and wave speeds from one Riemann problem, plus any extra intermediate variables created during solving the Riemann problem, while the usage of shared memory only includes waves from one Riemann problem per thread in a CUDA block.
5 Numerical Results
This section is focused on evaluating the performance of current GPU implementation. Two machines for benchmarking the original CPU implementation and two machines for benchmarking the current GPU implementation are listed as below.
a single Nvidia Kepler K20x GPU with a 16-core AMD Opteron 6274 CPU running at 2.2 GHz as the host; 2. 2.
a single Nvidia TITAN X (Pascal) GPU with a 20-core Intel E5-2698 CPU running at 2.2 GHz as the host (but only 16 CPU threads are used for fair comparison with others); 3. 3.
a single 16-core AMD Opteron 6274 CPU running at 2.2 GHz; 4. 4.
a single 16-core Intel Xeon E-2650 CPU running at 2.0 GHz;
As shown in the previous sections, the GPU implementation consists of jobs that are done by the CPU and jobs that are done by the GPU. In the benchmarks, the CPU implementation always runs in parallel with 16 OpenMP threads, using 16 CPU cores. The CPU part of the GPU implementation are also always processed in parallel by 16 OpenMP threads, using 16 CPU cores. The GPU implementation solves the benchmark problems on machine 1 and 2 while the CPU implementation solves the same benchmark problem on machine 3 and 4. Note that machine 1 and machine 3 have the same AMD CPU while machine 2 and machine 4 have similar Intel CPU. Thus in this section, all speed-ups will be computed by comparing results on machine 1 to results on machine 3 and comparing results on machine 2 to results on machine 4.
We propose three metrics that can be used to measure absolute performance of current GPU implementation, which do not require comparing a GPU implementation to a CPU implementation. We first define some quantities used in the definition of the three metrics. Along the program execution time line , define as the time interval that the th GPU computation event (e.g. one of the green blocks in figure 3) happens. is essentially a set of all moments that the th GPU computation event is happening. Similarly, define , and for the th CPU computation, the th memory transfer from the CPU to the GPU memory and the th memory transfer from the GPU to the CPU memory, respectively. Then, all time intervals during which the GPU is doing computation, , can be represented as , where is the union operation for sets and is total number of GPU computation events. Similarly, we define another three sets of intervals for the other three types of events. All time intervals during which the CPU is doing computation, , can be represented as , where is total number of CPU computation events. All time intervals during which the memory transfer from the CPU memory to the GPU memory is happening, , can be represented as , where is total number of such memory transfers. All timer intervals during which the memory transfer from the GPU memory to the CPU memory is happening, , can be represented as .where is total number of such memory transfers. Lastly, define as the time interval that the entire program runs.
The first metric measures the proportion of time during which the GPU is doing computation, defined as
[TABLE]
where represents size of the set , which essentially computes the total length of all time intervals in in this case. Similarly, the second metric is defined as
[TABLE]
which measures proportion of time during which the CPU is doing computation. The last metric measures the proportion of extra time introduced by transferring data between the CPU memory and the GPU memory
[TABLE]
where is the subtract operation for sets. For two sets and , denotes all elements in but not in .
5.1 2011 Japan Tsunami
5.1.1 Problem Setup
The first benchmark problem is the 2011 Japan tsunami, which was triggered by an earthquake of magnitude 9.0-9.1 off the Pacific coast of Tōhoku, occurred at 14:46 JST (05:46 UTC) on Friday March 11th, 2011. The earthquake source deformation files were obtained from NOAA Pacific Marine Environmental Laboratory (PMEL). They were not on an uniform latitude-longitude grid initially, and were converted to deformation information on uniform grids for use in our implementation.
The computational domain is from longitude to and latitude to 65 in spherical coordinates. Three levels of refinement are set across the ocean and around the source region (before getting close to the destination). Starting from the coarsest level (level 1) that has a resolution of 2 degrees, the refinement ratios are 5 and 6, giving a resolution of 25 minutes on level 2 and 4 minutes on level 3. A refinement tolerance parameter can be specified to guide the mesh refinement. The smaller this parameter is set, the more likely the grid will be refined to the highest level allowed in a particular region. The refinement tolerance parameter is chosen to be the wave amplitude and is set to meter. Thus, if a region is allowed to use any of the choices above (2 degree, 24 minute, 4 minute), the region will be refined up to a maximum of level 3 when the amplitude of a wave is higher than . In addition to specifying a tolerance for flagging individual cells, regions of the domain can be specified so that all cells in the region, over some time interval also specified, will be refined to at least some level and at most some level. In the simulation, the three refinement levels mentioned above are allowed in the entire region, with other constraints in specific sub-regions. In the first 7 hours after the earthquake, a 4-minute resolution (level 3) in the region from longitude to and from latitude 18 to 62 is enforced. This is reverted to the choices of 2 degrees or 24 minutes after 7 hours when the wave amplitudes are below tolerance. Then moving onward toward the destination, a 4-minute resolution in the region from longitude to and from latitude 18 to 62 is enforced starting at 7 hours till the end of the 13-hour simulation. Near Crescent City, the destination we are interested in, three higher higher levels of refinement regions are enforced to resolve for smaller-scale flow features near the coast:
Level 4 with 1-minute resolution is enforced starting from 8 hours after the earthquake, in the region from longitude to and from latitude 40.515 to 44.495. 2. 2.
Level 5 with 12-second resolution is enforced starting from 8 hours after the earthquake, in the region from longitude to and from latitude 41.502 to 41.998. 3. 3.
Level 6 with 2-second resolution is enforced starting from 8.5 hours after the earthquake, in the region from longitude to and from latitude 41.717 to 41.783.
Figure 6 shows the three refinement regions as well as location of gauge 2, where the time series of water surface elevation is recorded.
To ensure solution data on an entire grid patch can fit into the cache of the CPU for data locality, the size of each grid patch is limited to 128 by 128 for both the GPU and CPU cases. The Godunov-type dimensional splitting scheme is used with 2nd order MC limiter applied to the waves. The problem is simulated for a simulation time of hours.
5.1.2 Simulation Results
Figure 7 and Figure 8 show snapshots during the simulation for the entire computational domain and near Crescent city, colored by defined as
[TABLE]
During the tsunami, wave height data were recorded at 4 DART buoys (Deep-ocean Assessment and Reporting of Tsunamis) near the earthquake source, the locations of which are shown in Figure 9. The blue rectangle in the figure indicates the extent of the earthquake source. However, most of the sea floor deformation is inside the red rectangular region, where one-minute topography files are used to make sure the region is well resolved. The wave heights predicted by the current GPU implementation at the 4 DART buoys are shown in figure 10 and compared against observed data. The comparison shows the predicted results agree quite well with observed data at the 4 DART buoys.
Recall that the current implementation uses a dimensional splitting scheme with no refluxing. To show that this simplification gives comparable results to the original GeoClaw code, Figure 11 gives time series of surface elevation recorded at a tide gauge near Crescent City, California, United States, during the 2011 Japan Tsunami. The observation has been detided by subtracting the predicted tide level from it to remove the influence of tide level. Sample result from another well-known tsunami model MOST (V\BPBIV. Titov \BBA Gonzalez, \APACyear1997) have also been included for comparison. The comparison shows that a simplified GeoClaw CPU code that implements such a dimensional splitting scheme with no refluxing gives very close results to those produced by the original GeoClaw and agree well with another model and observed data. The current GPU implementation gives identical results to this simplified version of the original GeoClaw and is not shown in the Figure.
Figure 12 shows total running time and proportion of the three components on 4 machines. The total speed-ups are on machine 1 and on machine 2 for current GPU implementation. Note that since time spent on the non-AMR portion decreases on machine 1 and 2, the cost for regridding and updating take up larger portion of the total run time. However, one could still only gain a very limited additional performance increase if the regridding and updating processes were implemented on the GPU. Amdahl’s law states theoretical speed-up of the execution of a whole program is
[TABLE]
where is theoretical speed-up of the execution of the whole program, is the speed-up of the portion that is accelerated, is proportion of total running time that the accelerated portion takes. Further more, one has , where the equality is achieved when approaches in equation 20. From Amdahl’s law, even if the regridding and updating processes are implemented on the GPU and are accelerated infinitely, the entire program only get roughly speed-up on machine 1 and 2.
Table 1 shows the three metrics for current GPU implementation running on machine 1 and machine 2 when the Japan 2011 tsunami is simulated. The proportion of GPU computation () reaches about on machine 1 and a higher percentage of on machine 2. This could be due to the fact that machine 2 has a newer GPU which has much lower overhead for kernel launch and memory transfer. The proportion of CPU computation () are around for both machines. In other words, during of the total running time, the CPU is idle. , the extra time introduced by transferring data between the CPU and the GPU memory, is less than for both machines. This shows that even if the data can be transferred infinitely fast between the CPU and the GPU memory so the data transfer has no effect on execution time at all, the total running time of the entire program can be reduced by at most . Thus having to transfer data between the CPU and the GPU memory is not a critical issue that affects the performance of the code.
5.2 A local Tsunami Triggered by Near-field Sources
5.2.1 Problem Setup
The second benchmark problem is the modeling of a local tsunami that is triggered by a near-field earthquake, which typically hits the shoreline much earlier than a tsunami triggered by a far-field earthquake. The tsunami is triggered by a hypothetical Mw 7.3 earthquake on the Seattle Fault, which cuts across Puget Sound (through Seattle and Bainbridge Island, see figure 13) and can create a tsunami that can cause significant inundation and high currents in some coastal communities around the Puget Sound. The event was designed to model an earthquake that occurred roughly 1100 years ago, and for which geologic data is available for the uplift or subsidence at several locations. Here, we focused on modeling this local tsunami and predicting its impact on Eagle Harbor at the Bainbridge island, the location of which is shown below in figure 14. The ground deformation file for generating the tsunami is obtained from PMEL, which has been used for recent comparison study of GeoClaw and MOST as part of a tsunami hazard assessment of Bainbridge Island (V. Titov \BOthers., \APACyear2018).
Figure 14 also shows the computational domain, which is from longitude to and latitude 47 to 48.7. Since this is a local tsunami in an enclosed Sound surrounded by land, the tsunami waves soon get reflected by shorelines and spread out to cover the full domain very soon after the earthquake. Thus, instead of using a refinement tolerance parameter, we enforce mesh refinement everywhere in the domain regardless of wave amplitude, and never regenerate new grid patches. Four levels of refinement are used, as denoted by the rectangles in figure 14 that denote regions where refinement is enforced. Starting from the coarsest level (level 1), which has a resolution of 30 minutes, the refinement ratios are 5, 3 and 6, giving a resolution of 6 minutes on level 2, 2 minutes on level 3 and minutes on level 4. Note that for this benchmark problem, a large proportion of the domain is dry land and the shorelines are relatively much longer and more complex. As a result, many branches occur along the execution path of solving Riemann problems of the shallow water system since more different situations arise, e.g. a Riemann problem with one state being dry initially but becoming wet, or staying dry, depending on the flow depth and velocity in the neighboring cell. For the GPU, if the 32 threads in a warp do not take the same execution path, each extra branch will be executed by the entire warp, introducing significant extra execution time. Thus the irregularity of water area in this benchmark problem is challenging for some CUDA kernels to use the GPU hardware efficiently .
5.2.2 Simulation Results
Figures 15 and 16 show snapshots from the simulation at several moments during the simulation in the Puget Sound and near Eagle Harbor, colored by defined in equation 19. The black solid line denotes the original shoreline before the earthquake. At the entry of the harbor, deep inundation occurred at several places as early as only 3 minutes after the earthquake. Even at the very end of the Eagle Harbor, the influence from the tsunami is also significant, causing more than 2-meter deep inundation in several places starting at 9 minutes after the earthquake. One wave gauge is placed inside Eagle Harbor to record the inundation depth during the tsunami. Figure 14 shows the location of the wave gauge. As this is a hypothetical event for modeling an earthquake roughly 1100 year ago, there is no surface elevation observation available for comparison. Hence, the results from current implementation are compared with those from the MOST tsunami model (V\BPBIV. Titov \BBA Gonzalez, \APACyear1997). Additional comparisons of GeoClaw and MOST results can be found in the comparison study recently performed by V. Titov \BOthers. (\APACyear2018). For that study the original CPU version of GeoClaw was used, with the unsplit algorithm and refluxing, but we have confirmed that very similar results are obtained with the GPU code, at least in Eagle Harbor.
Figure 18 shows total running time and proportion of the two components on 4 machines (no regridding process since it is never conducted) The total speed-ups are on machine 1 and on machine 2 for this benchmark problem. For the original CPU implementation, the non-AMR portion takes and of the total computational time, which indicates high potential of benefiting from optimizing the performance of this portion. Although the proportion of the non-AMR portion increases for current implementation on machine 1 and machine 2, it still takes more than of the total computational time, showing great potential for further improvement.
Table 2 shows the three metrics for current GPU implementation running on machine 1 and machine 2 when the Seattle Fault tsunami is simulated. Similar values are obtained for all three metrics, showing consistency and validity of the three metrics on evaluating GPU implementation with different tsunami problems.
6 Conclusions
The shocking fatalities and infrastructure damage caused by tsunamis in the past two decades highlight the importance of developing fast and accurate tsunami models for both forecasting and hazard assessment. This paper presents a fast and accurate GPU-based version of the GeoClaw code using patched-based AMR. Arbitrary levels of refinement and refinement ratios between levels are supported. The surface elevation at DART buoys and wave gauges in benchmark problems show the ability of current tsunami model to produce accurate results in tsunami modeling. With the GPU, the entire tsunami model runs – times faster than an original CPU-based tsunami model for several benchmark problems on different machines. As a result, the Japan 2011 Tōhoku tsunami can be fully simulated for 13 hours in under 3.5 minutes wall-clock time, using a single Nvidia TITAN X GPU. Three metrics for measuring the absolute performance of a GPU-based model are also proposed to evaluate current GPU implementation without comparing to others, which show the ability of current model to efficiently utilize GPU hardware resources. Other hazards such as storm surge (e.g. Mandli \BBA Dawson (\APACyear2014)) and dam failures (e.g. George (\APACyear2010)) can also be modeled with GeoClaw and can similarly benefit from this GPU-enhanced version of GeoClaw.
Acknowledgements.
The first author would like to thank Weiqun Zhang, Max Katz and Ann Almgren for many discussions with them during a summer internship at Lawrence Berkeley National Lab, supported by the AMReX project, which inspired many ideas and design strategies chosen in this work. This work was also supported in part by NSF grant EAR-1331412 and the University of Washington Department of Applied Mathematics.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Acuña \BBA Aoki ( \APA Cyear 2009) \APA Cinsertmetastar acuna 2009 real {APA Crefauthors} Acuña, M. \BCBT \BBA Aoki, T. \APA Cref Year Month Day 2009. \BBOQ \APA Crefatitle Real-time tsunami simulation on multi-node GPU cluster Real-time tsunami simulation on multi-node gpu cluster. \BBCQ \B In \APA Crefbtitle ACM/IEEE conference on supercomputing. Acm/ieee conference on supercomputing. \Print Back Refs \Current Bib
- 2L \BPBI M. Adams \B Others . ( \APA Cyear 2017) \APA Cinsertmetastar Adams 2017 {APA Crefauthors} Adams, L \BPBI M., Leveque, R \BPBI J., Rim, D. \BCBL \BBA González, F \BPBI I. \APA Cref Year Month Day 2017. \APA Crefbtitle Probabilistic Source Selection for the Cascadia Subduction Zone Final Report Probabilistic Source Selection for the Cascadia Subduction Zone Final Report \APA Cb Vol Ed TR \BTR . \APA Caddress Institution University of Washington Department of Applied Mathmatics. \Prin
- 3M. Adams \B Others . ( \APA Cyear 2015) \APA Cinsertmetastar adams 2015 chombo {APA Crefauthors} Adams, M., Schwartz, P \BPBI O., Johansen, H., Colella, P., Ligocki, T \BPBI J., Martin, D. \BDBL others \APA Cref Year Month Day 2015. \APA Crefbtitle Chombo software package for AMR applications-design document Chombo software package for amr applications-design document \APA Cb Vol Ed TR \BTR . \Print Back Refs \Current Bib
- 4Annaka \B Others . ( \APA Cyear 2007) \APA Cinsertmetastar annaka 2007 logic {APA Crefauthors} Annaka, T., Satake, K., Sakakiyama, T., Yanagisawa, K. \BCBL \BBA Shuto, N. \APA Cref Year Month Day 2007. \BBOQ \APA Crefatitle Logic-tree approach for probabilistic tsunami hazard analysis and its applications to the Japanese coasts Logic-tree approach for probabilistic tsunami hazard analysis and its applications to the japanese coasts. \BBCQ \B In \APA Crefbtitle Tsunami and Its Hazards i
- 5Ash ( \APA Cyear 2015) \APA Cinsertmetastar ash 2015 design {APA Crefauthors} Ash, C. \APA Cref Year Month Day 2015. \BBOQ \APA Crefatitle Design of a Tsunami Vertical Evacuation Refuge Structure in Westport, Washington Design of a tsunami vertical evacuation refuge structure in westport, washington. \BBCQ \B In \APA Crefbtitle Structures Congress 2015 Structures congress 2015 ( \BPGS 1530–1537). \Print Back Refs \Current Bib
- 6Berger \BBA Colella ( \APA Cyear 1989) \APA Cinsertmetastar Berger 1989 {APA Crefauthors} Berger, M \BPBI J. \BCBT \BBA Colella, P. \APA Cref Year Month Day 1989. \BBOQ \APA Crefatitle Local adaptive mesh refinement for shock hydrodynamics Local adaptive mesh refinement for shock hydrodynamics. \BBCQ \APA Cjournal Vol Num Pages Journal of Computational Physics 82164–84. {APA Cref DOI} 10.1016/0021-9991(89)90035-1 \Print Back Refs \Current Bib · doi ↗
- 7Berger \BBA Oliger ( \APA Cyear 1984) \APA Cinsertmetastar berger 1984 adaptive {APA Crefauthors} Berger, M \BPBI J. \BCBT \BBA Oliger, J. \APA Cref Year Month Day 1984. \BBOQ \APA Crefatitle Adaptive mesh refinement for hyperbolic partial differential equations Adaptive mesh refinement for hyperbolic partial differential equations. \BBCQ \APA Cjournal Vol Num Pages Journal of computational Physics 533484–512. \Print Back Refs \Current Bib
- 8Berger \BBA Rigoutsos ( \APA Cyear 1991) \APA Cinsertmetastar Berger 1991 {APA Crefauthors} Berger, M \BPBI J. \BCBT \BBA Rigoutsos, I. \APA Cref Year Month Day 1991. \BBOQ \APA Crefatitle An Algorithm for Point Clustering and Grid Generation An Algorithm for Point Clustering and Grid Generation. \BBCQ \APA Cjournal Vol Num Pages IEEE Transactions on Systems, Man and Cybernetics 2151278–1286. {APA Cref DOI} 10.1109/21.120081 \Print Back Refs \Current Bib · doi ↗