TL;DR
This paper introduces a novel method using conditional adversarial networks to generate unlimited realistic text sequence images directly from semantic data, enhancing training data for text recognition.
Contribution
It proposes a simple, end-to-end image-to-image translation approach for synthesizing text images without complex pre/post-processing steps.
Findings
Generated images are realistic and diverse.
The method produces high-quality training data.
Evaluation metrics confirm the effectiveness of the generated images.
Abstract
Recently, methods based on deep learning have dominated the field of text recognition. With a large number of training data, most of them can achieve the state-of-the-art performances. However, it is hard to harvest and label sufficient text sequence images from the real scenes. To mitigate this issue, several methods to synthesize text sequence images were proposed, yet they usually need complicated preceding or follow-up steps. In this work, we present a method which is able to generate infinite training data without any auxiliary pre/post-process. We tackle the generation task as an image-to-image translation one and utilize conditional adversarial networks to produce realistic text sequence images in the light of the semantic ones. Some evaluation metrics are involved to assess our method and the results demonstrate that the caliber of the data is satisfactory. The code and dataset…
Click any figure to enlarge with its caption.
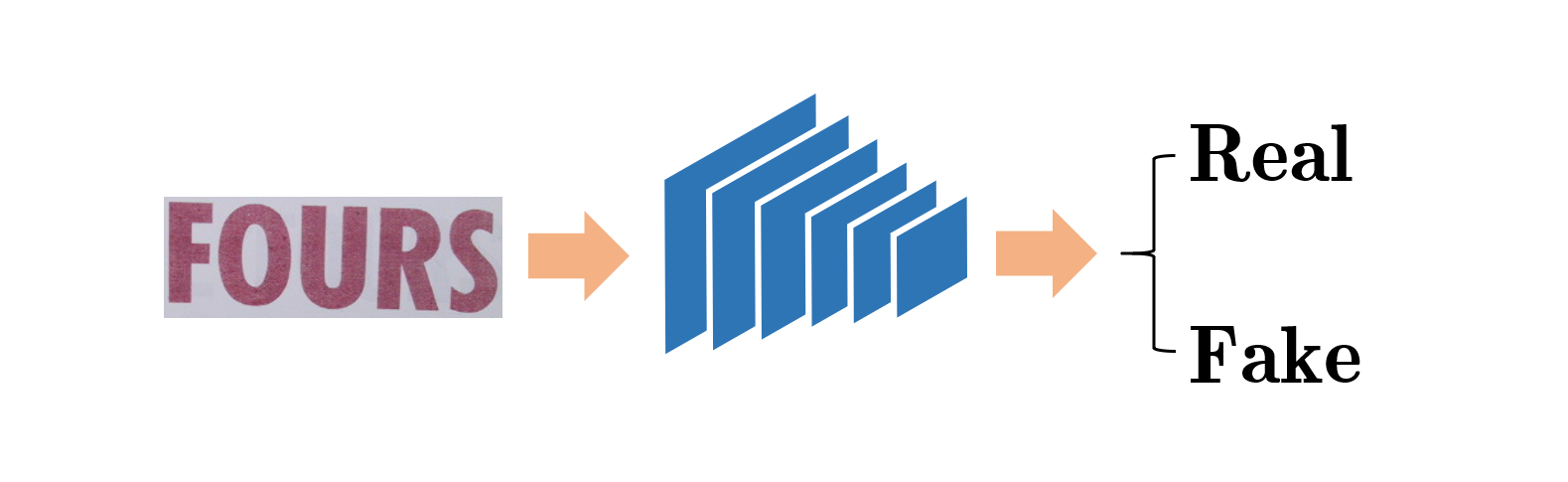 Figure 1
Figure 1 Figure 2
Figure 2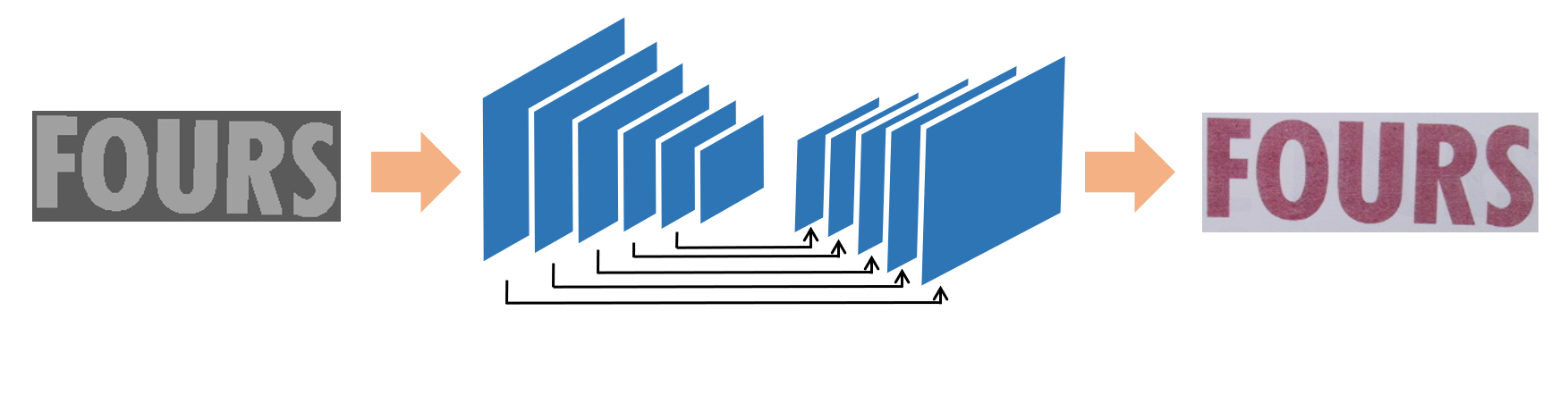 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9| Cascaded Network | Residual Blocks | PReLU | Inception score | FID score | ICDAR2013 | ICDAR2015 | IIIT 5K |
| 3.0020.257 | 51.05 | 70.2 | 43.9 | 68.4 | |||
| ✔ | 2.8770.198 | 48.27 | 72.4 | 45.9 | 71.1 | ||
| ✔ | 2.9980.203 | 45.75 | 75.8 | 47.9 | 73.7 | ||
| ✔ | 3.0860.216 | 51.10 | 75.2 | 47.1 | 75.3 | ||
| ✔ | ✔ | ✔ | 2.8210.174 | 39.44 | 78.7 | 51.0 | 78.0 |
| Dataset | Image number | Inception score | FID score | ICDAR2013 | ICDAR2015 | IIIT 5K |
| Real images | 6k | 3.3630.404 | 25.93 | 12.0 | 1.9 | 5.3 |
| Gupta et al.[6] | 8M | 4.1150.202 | 66.16 | 78.3 | 46.7 | 75.5 |
| Jaderberg et al.[1, 5] | 8M | 2.7470.170 | 51.68 | 78.1 | 52.1 | 77.6 |
| Ours | 8M | 2.8210.174 | 39.44 | 78.7 | 51.0 | 78.0 |
| Gupta et al.[6](colored) | 8M | 4.8480.323 | 72.98 | 78.7 | 48.5 | 74.9 |
| Ours(colored) | 8M | 3.1630.175 | 45.46 | 78.6 | 48.7 | 72.4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Generating Text Sequence Images for Recognition
Yanxiang Gong1, Linjie Deng1, Zheng Ma and Mei Xie* The authors are with the School of Information and Communication Engineering, University of Electronic Science and Technology of China, Chengdu 611731, Sichuan, China.1 These authors contributed equally to this work.*Mei Xie is the corresponding author(e-mail:[email protected]).
Abstract
Recently, methods based on deep learning have dominated the field of text recognition. With a large number of training data, most of them can achieve the state-of-the-art performances. However, it is hard to harvest and label sufficient text sequence images from the real scenes. To mitigate this issue, several methods to synthesize text sequence images were proposed, yet they usually need complicated preceding or follow-up steps. In this work, we present a method which is able to generate infinite training data without any auxiliary pre/post-process. We tackle the generation task as an image-to-image translation one and utilize conditional adversarial networks to produce realistic text sequence images in the light of the semantic ones. Some evaluation metrics are involved to assess our method and the results demonstrate that the caliber of the data is satisfactory. The code and dataset will be publicly available soon.
Index Terms:
Image Generation, Text Sequence Images, Training Data, Text Recognition
I Introduction
Text recognition plays an important role in the field of computer vision. With the advent of deep learning, text recognition methods have made great progresses[1, 2, 3, 4]. But they cannot achieve a satisfactory performance for insufficient training data which causes over-fitting problems. Owing that to collect and label real text images is a time-consuming work, methods to synthesize text images were proposed in order to alleviate the deficit in training data. The method put forward by Jaderberg et al.[1, 5] is based on a font catalogue. Coloring and projective distortion are applied on word images synthesized by font, border and shadow rendering, and then the processed images are added to background scene images with some noises. Gupta et al.[6] proposed to apply the semantic segmentation on the scene image at first. Then the processed word images are pasted on a contiguous region of it, which guarantees that the word will not appear on objects of different distances. Based on [6], Zhan et al.[7] presents a method which realizes semantic coherent synthesis. By leveraging the semantic annotations of objects and image regions created in the prior semantic segmentation research, semantic coherence between the text and the background has been reached while synthesizing text images. These methods are effective, but usually need complicated preceding or follow-up steps such as collecting background images, coloring the words and adding noises for improving the robustness, which requires more manual engineering.
In this paper, we propose a method based on Generative Adversarial Networks(GANs)[8] which can generate infinite realistic text sequence images without any extra pre/post-process. The inspiration comes from the procedure of drawing pictures. While painting something in the real world, generally we will sketch the contours of it at first, and then use pigments to color the draft to finish the drawing. Following this procedure, we cope with the generation task from a new perspective as an image-to-image translation one, and utilize conditional adversarial networks to yield text sequence images on the basis of semantic ones. This work is based on a modified conditional Generative Adversarial Networks[9] model named pix2pix[10] which aims to translate semantic images to realistic ones. Some evaluation metrics will be utilized to assess our method and confirm the effectiveness. There are two main contributions in this work:
1.Unlike previous approaches, our method needs no extra preceding and follow-up step for generation. Besides, infinite images can be produced without any redundant operations.
2.The data generated by our method achieves a satisfactory performance on various evaluation metrics, and the code and dataset will be publicly available soon.
II Method
Recently, works based on Generative Adversarial Networks(GANs)[8, 9, 10] has made great achievements in the field of image generation. The initial GANs[8] are models which learn a mapping from random noise vector to output image , . By contrast, the subsequently proposed condition Generative Adversarial Networks(cGAN)[9] are models that learn a mapping from an image and random noise vector to output image , . We will introduce the details of our methods in the following parts.
II-A Network Architectures
First let us recall the architecture of pix2pix network[10]. It uses modules of the form Convolution-BatchNorm-ReLU[11] in both the generator and the discriminator. And inspired by U-Net[12], some skip connections are added to an encoder-decoder network[13] as the generator. The architectures of the generator and the discriminator of the pix2pix model[10] are shown respectively in Fig. 2(a) and Fig. 2(b). The objective can be expressed as
[TABLE]
where represents the objective of condition GANs and represents the L1 distance. The parameter is set to 100 in the original work. We make some adaptations on the network in order to make it more appropriate for text images. Each component will be listed in the following part, and ablation experiments which can confirm that they are effective will be described in next chapter. The pipelines of pix2pix[10] and our work are shown in Fig. 1.
II-A1 Cascaded generators
Enlightened by StackGAN[14] who decomposes the text-to-image generative process into two stages, where the first GANs model aims to generate images with a small size and the second one tries to improve the resolution, we cascade two generators to make the generator to possess its own focus. The first generator is designed to generate the text area and its surroundings which are defined as the foreground area obtained through dilation operation on the masks of the text sequence images. The second generator aims to supplement the background area to produce realistic scene images. The architecture of the two generators are the same, while they are optimized respectively. As the generators do not need to generate too many areas, they can concentrate on their own work. Restrict by the hardware, only two generators are utilized though more generators are available. The procedure is depicted in Fig.2(c).
II-A2 Residual Blocks
Residual Networks(ResNets)[15] solves the degradation problem in the process of training a deeper network through employing some residual blocks. The mapping of a residual block can be expressed as
[TABLE]
which let the layers fit a residual mapping rather than a desired underlying mapping to mitigate the vanishing gradient problem. In order that our model can be optimized better, some residual blocks are added to the generator. As shown in Fig 3(c), after each convolutional layer except the last one of the encoder, a residual block with two convolutional layers which is depicted in Fig. 2(d) will be added.
II-A3 Activation Function
For better abilities to extract the features, we change the activation function of the encoder from leaky Rectified Linear Unit(leaky ReLU) to Parametric Rectified Linear Unit (PReLU)[16].
[TABLE]
The parameter are set to 0.25 at first, and it will be updated automatically while training. In contrast, the parameter of leaky ReLU should be set up by ourselves, while to search for the best fitted parameter will take lots of time without satisfactory effects. Because there are only a few parameters added to the network, the computation and risks of over-fitting will not increase too much.
II-B Synthesizing Semantic Images
Gupta et al.[6] proposed a method to synthesize text sequence images through morphology ways, which gives us inspiration about synthesizing semantic images. Taking this approach as basis, first we acquire suitable text samples from Newsgroup20 dataset[17] in words, lines and paragraphs. Then the text sample is rendered with a randomly selected font and transformed randomly. Finally the text is blended into a black background image using Poisson image editing[18].
III Experiments
In the following part, we will describe the implementation details of our method. We also utilize some evaluation metrics and run a number of ablations to analyze the effectiveness of the proposed component.
III-A Training
In training stage, we collect some data from ICDAR 2013 training dataset[19] which contains 229 images and KAIST scene text database[20] which contains 1,498 images. It is worth noting that no testing dataset is involved into the training process. There are totally 6,715 word images while we discard those who only contain punctuations and those whose height is longer than the width, and we relabel them for better adaptability of our model. In the training stage, the optimizer of the network is Adam[21], the batch size is set to 64, and the learning rate is 0.0002. All images will be resized to . The network is trained for 200 epochs which consumes about 2 hours. The proposed method is implemented by PyTorch[22]. All experiments are carried out on a standard PC with Intel i7-8700 CPU and a single NVIDIA TITAN Xp GPU.
III-B Evaluation Metrics
III-B1 Inception score
To calculate Inception score[23] of the generated dataset is a way to evaluate its quality. Images that contain meaningful objects should have a conditional label distribution with low entropy. And the marginal should have high entropy owing that we expect the model to generate varied images.
III-B2 FID score
Fréchet Inception Distance(FID) score[24] is also an indicator of the performance of a model of GANs because it represents the similarity between two datasets. A lower FID score means two datasets are more similar with each other. As we expect the distribution of the generated images to be close to real ones, FID scores between the generated data and ICDAR 2013 testing dataset[19] are utilized to evaluate our model.
III-B3 Recognition Task
Actually, the initial intention is to generate training data for recognition models. A higher accuracy of a trained model will prove that the data has a better quality. Therefore, an end-to-end recognition network named CRNN(Convolutional Recurrent Neural Network)[3] is applied to test our model. The text sequence images and the contents of them will be fed into the training stage. For fair comparisons, we generate 8M images and transform them to gray ones to match the data from Jaderberg et al.[1, 5]. In addition, we also test the model through using colored images. In the training process, the batch size is set to 64 and the learning rate is 0.00005 with the SGD optimizer. The network is trained for 3 epochs which consumes about 6 hours carried on our hardware. The trained models will be evaluated on some public benchmarks such as ICDAR 2013[19], ICDAR 2015[25] and IIIT 5K[26].
III-C Ablation Experiments
First, we evaluate the effectiveness of the proposed components and compare them with our baseline models, which is extended straightly from the pix2pix[10] framework. The comparison results are listed in Table I. From the table, we can observe that each component achieves a progress of the performance compared with the baseline model. We integrate them and get a further promotion of each evaluation metric, which demonstrate the proposed components are effective for the generation task.
Second, we make some comparisons with other methods including Jaderberg et al.[1, 5] and Gupta et al.[6]. The numbers of images generated by each method are the same. Some samples of each dataset are shown in Fig. 3. Specially, we involve the training data of our GANs model into the comparisons. The results are shown in Table II. Naturally, the training images of our GANs model achieve the best FID score because they are sampled from the same distribution of ICDAR 2013 testing dataset. But they cannot achieve a good performance for in the recognition task cause there is a huge over-fitting problem within only 6k training images. In the inception scores, Jaderberg et al. reaches the best owing that the images contains less background information. The colored images are not as good as gray ones because a colored background contains more contents. In the FID scores, our method get the first place in the three producing methods. In recognition task, we achieve the highest accuracy on ICDAR 2013 and IIIT 5K. On ICDAR 2015, our data cannot achieve the best accuracy. We consider that it is because ICDAR 2015 contains plenty of images whose text is vague or distorted, and our generated images are too clear. In addition, the colored images are also evaluated but there is no obvious promotion. We argue that the CRNN network[3] is not sensitive about the color mode of inputs. Finally, it is worth noting that each of the recognition model are only trained with 8M data, but our method is able to generate infinite images without any extra process.
IV Conclusion and Future Work
We have proposed a method to generate realistic text sequence images for training recognition models. The method is able to produce infinite images with high quality, which exceeds general morphology methods. As more complicated networks can be used to synthesize high resolution images, in the future, our goal is to design an end-to-end system that can detect and recognize text in an image with high resolution while given a font catalogue and a lexicon finally.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman, “Synthetic data and artificial neural networks for natural scene text recognition,” ar Xiv preprint ar Xiv:1406.2227 , 2014.
- 2[2] C.-Y. Lee and S. Osindero, “Recursive recurrent nets with attention modeling for ocr in the wild,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2016, pp. 2231–2239.
- 3[3] B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,” IEEE transactions on pattern analysis and machine intelligence , vol. 39, no. 11, pp. 2298–2304, 2017.
- 4[4] F. Bai, Z. Cheng, Y. Niu, S. Pu, and S. Zhou, “Edit probability for scene text recognition,” ar Xiv preprint ar Xiv:1805.03384 , 2018.
- 5[5] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman, “Reading text in the wild with convolutional neural networks,” ar Xiv preprint ar Xiv:1412.1842 , 2014.
- 6[6] A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic data for text localisation in natural images,” in IEEE Conference on Computer Vision and Pattern Recognition , 2016.
- 7[7] F. Zhan, S. Lu, and C. Xue, “Verisimilar image synthesis for accurate detection and recognition of texts in scenes,” in European Conference on Computer Vision . Springer, 2018, pp. 257–273.
- 8[8] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems , 2014, pp. 2672–2680.
