Ranking and Cooperation in Real-World Complex Networks
Mohsen Shahriari, Ralf Klamma, Matthias Jarke

TL;DR
This paper explores how ranking algorithms and game theory models like the prisoner dilemma can predict cooperation levels among individuals in online social networks, aiding in identifying potential experts and their willingness to collaborate.
Contribution
It introduces a combined approach using classical ranking algorithms and the prisoner dilemma to analyze cooperation and defection in complex networks.
Findings
Correlations between node rank and cooperativity were identified.
Neighborhood-based strategies provide insights into local cooperation patterns.
Ranking values can predict individuals' propensity to cooperate.
Abstract
People participate and activate in online social networks and thus tremendous amount of network data is generated; data regarding their interactions, interests and activities. Some people search for specific questions through online social platforms such as forums and they may receive a suitable response via experts. To categorize people as experts and to evaluate their willingness to cooperate, one can use ranking and cooperation problems from complex networks. In this paper, we investigate classical ranking algorithms besides the prisoner dilemma game to simulate cooperation and defection of agents. We compute the correlation among the node rank and node cooperativity via three strategies. The first strategy is involved in node level; however, other strategies are calculated regarding neighborhood of nodes. We find out correlations among specific ranking algorithms and cooperativtiy…
Click any figure to enlarge with its caption.
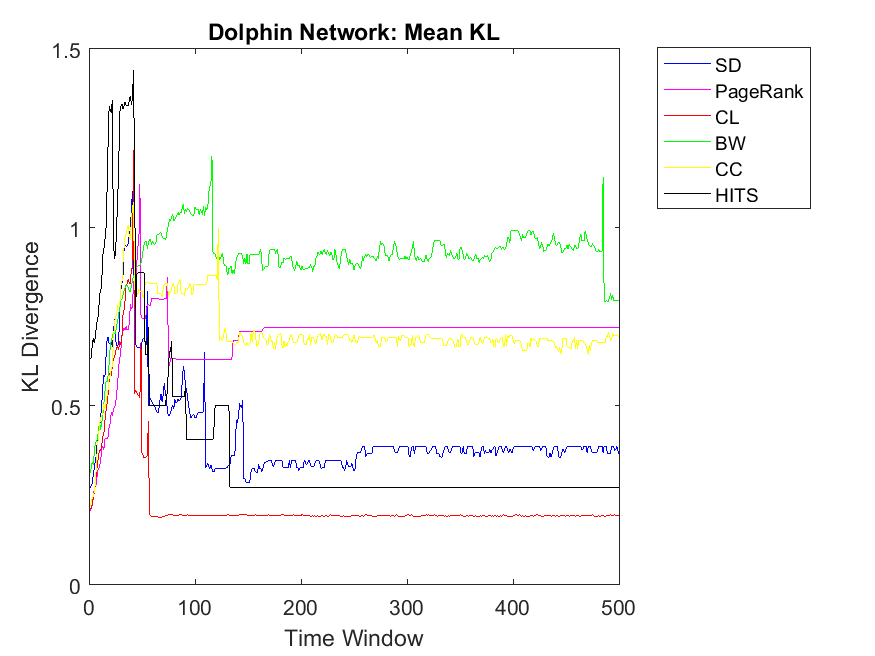 Figure 1
Figure 1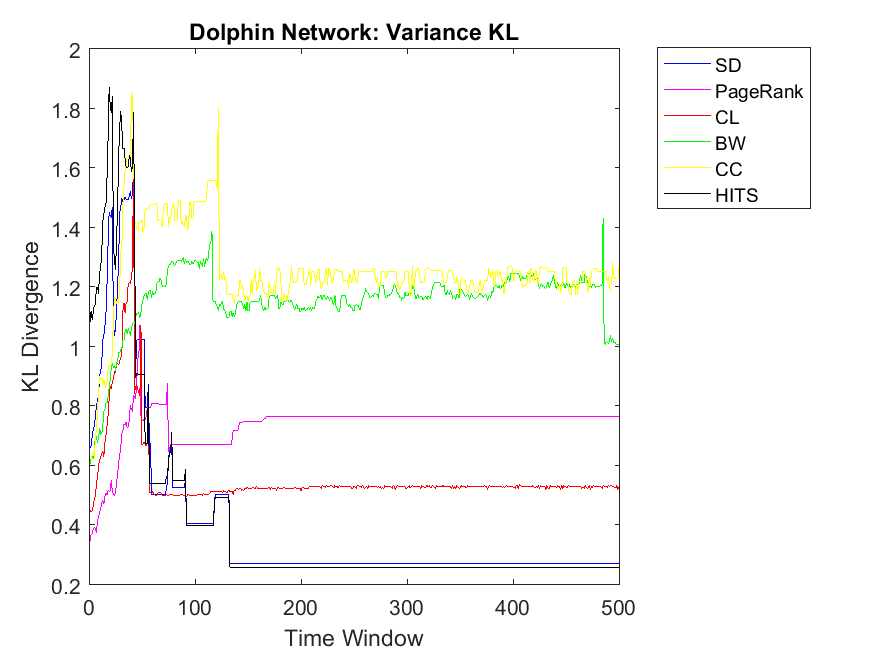 Figure 2
Figure 2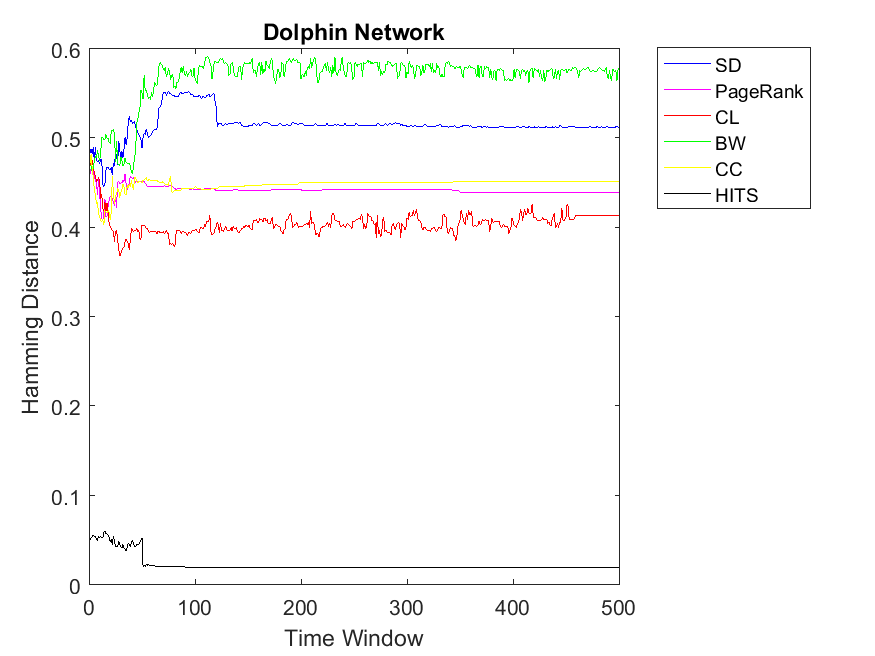 Figure 3
Figure 3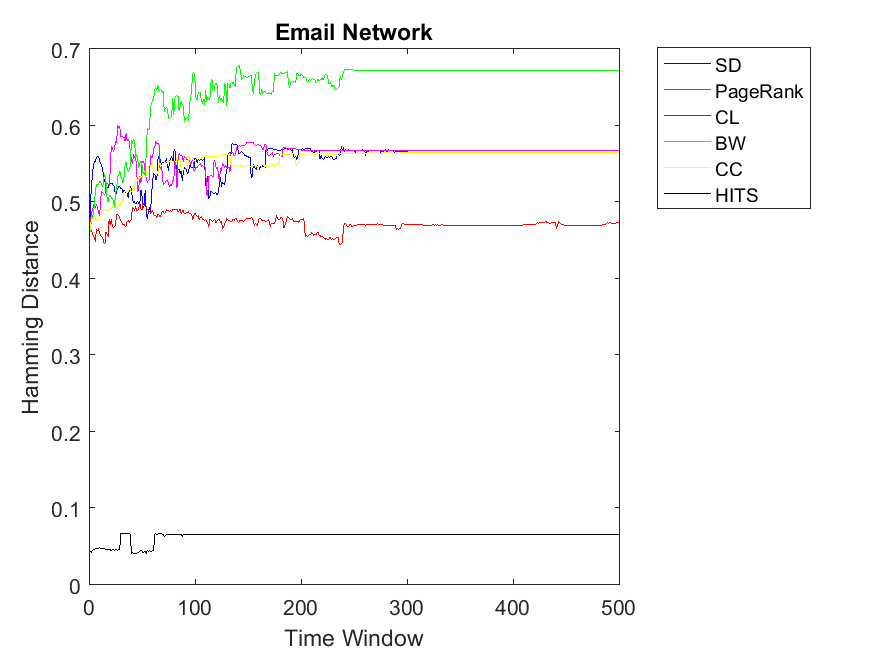 Figure 4
Figure 4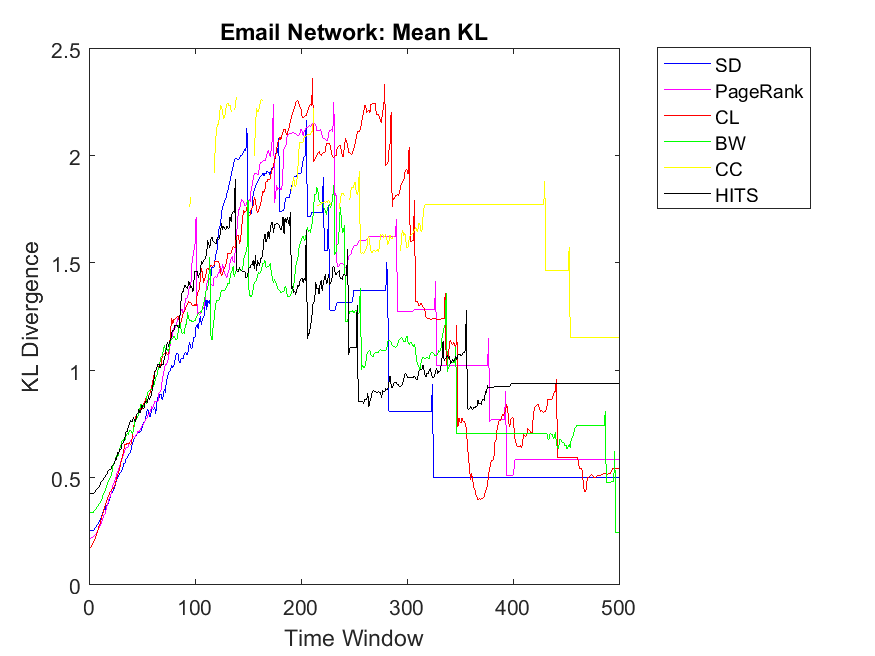 Figure 5
Figure 5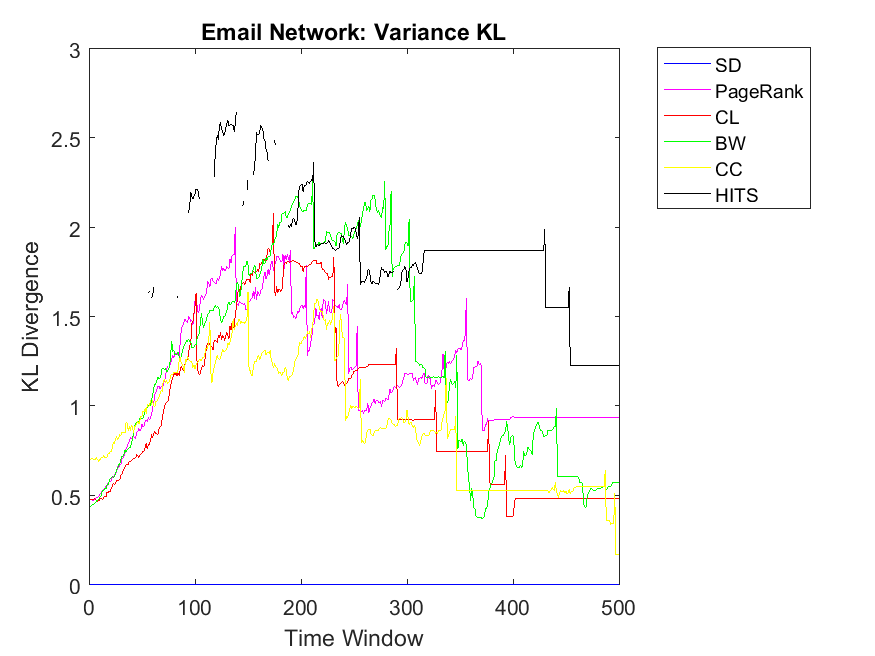 Figure 6
Figure 6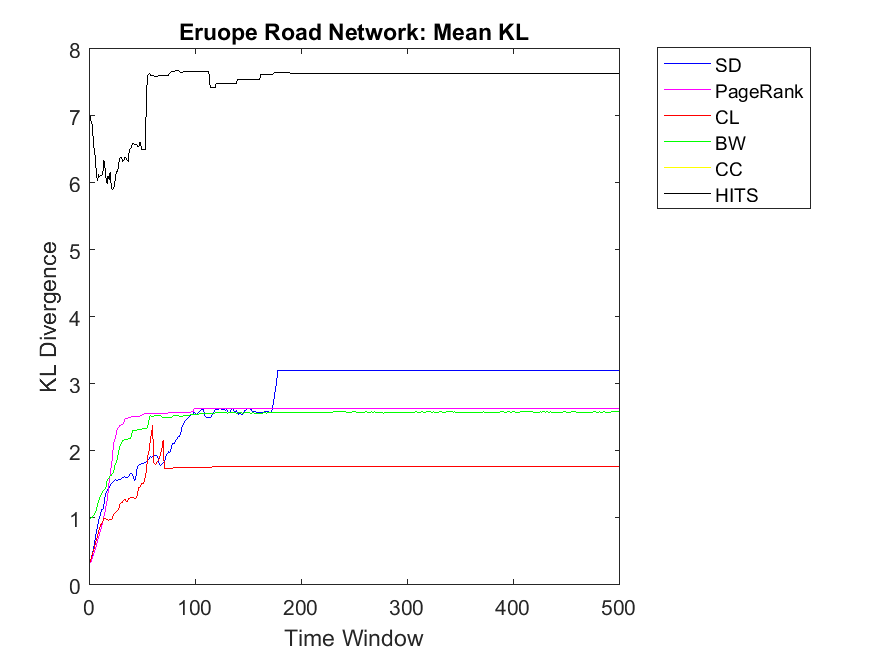 Figure 7
Figure 7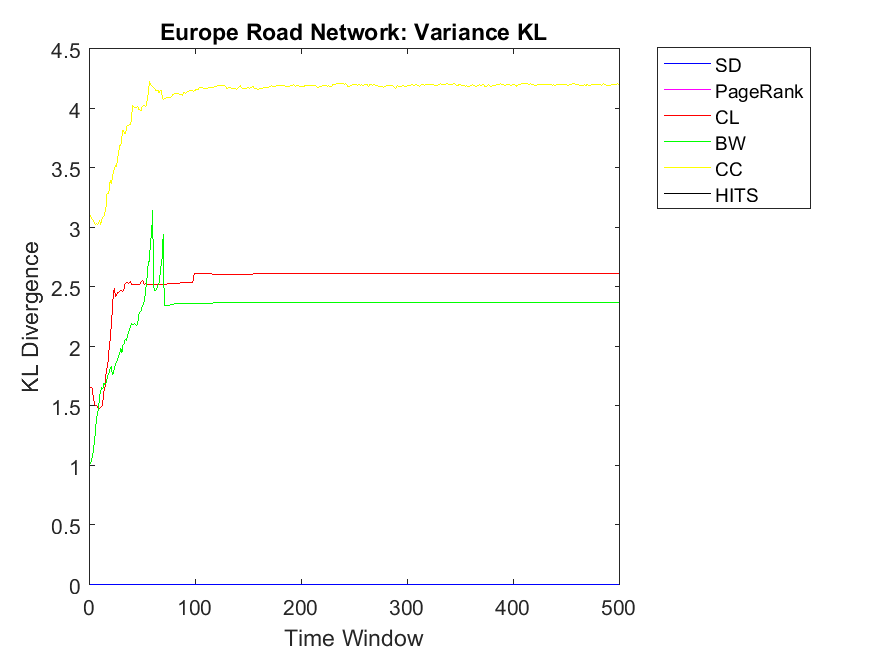 Figure 8
Figure 8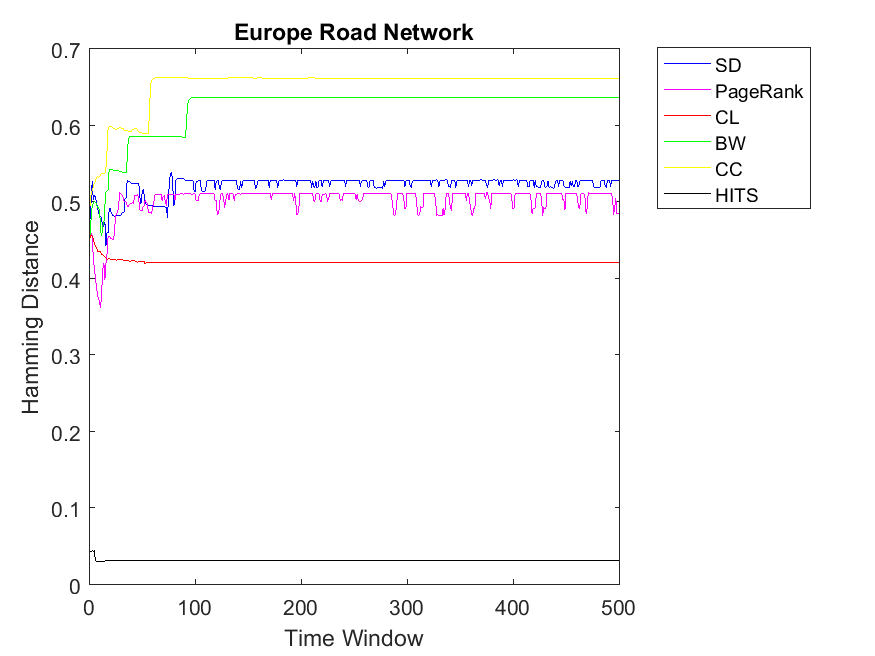 Figure 9
Figure 9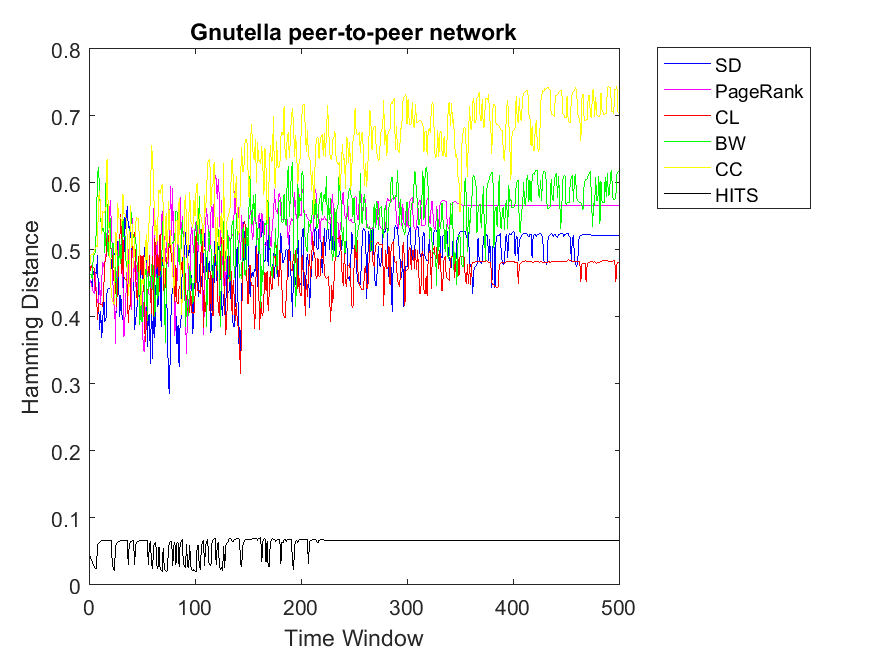 Figure 10
Figure 10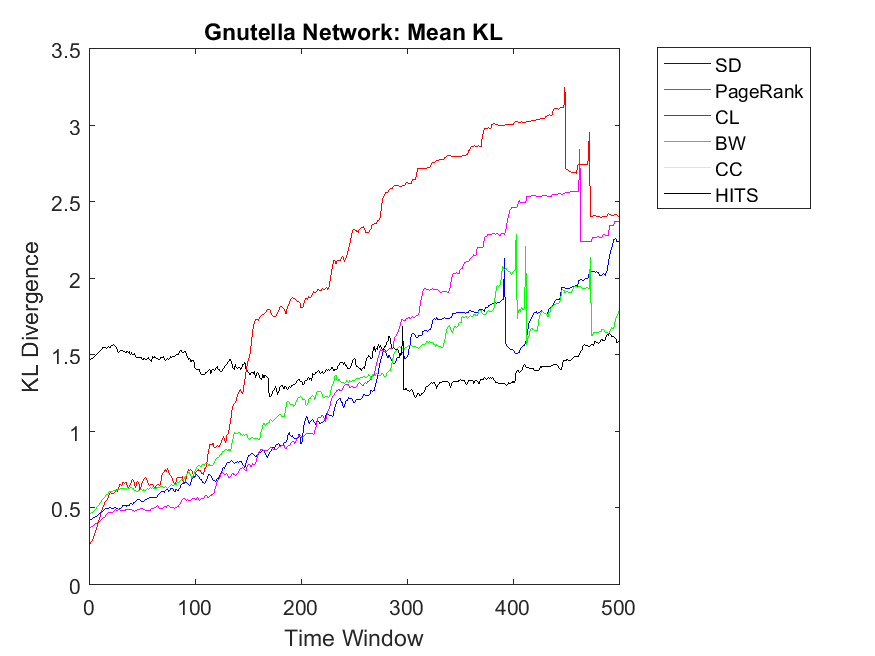 Figure 11
Figure 11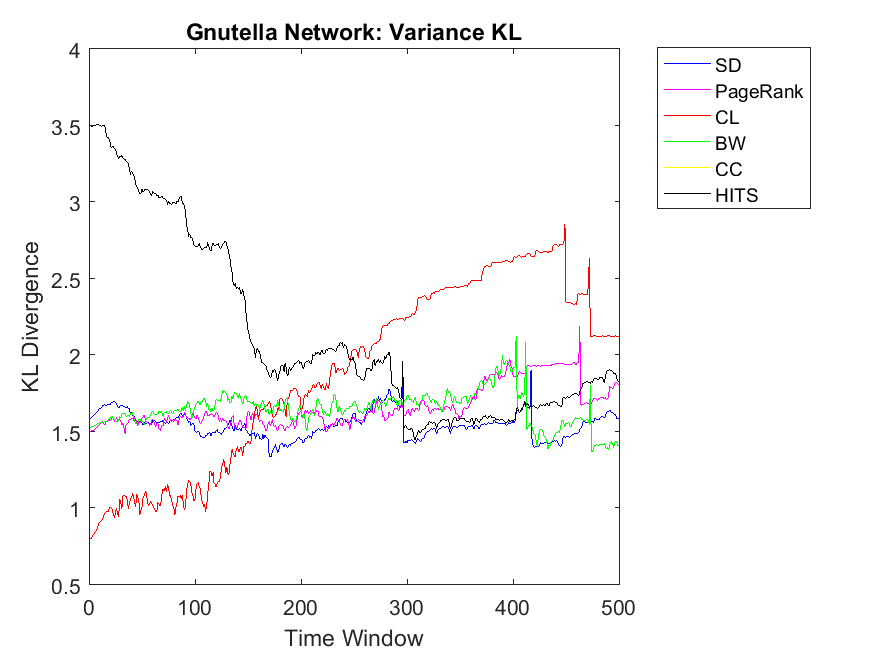 Figure 12
Figure 12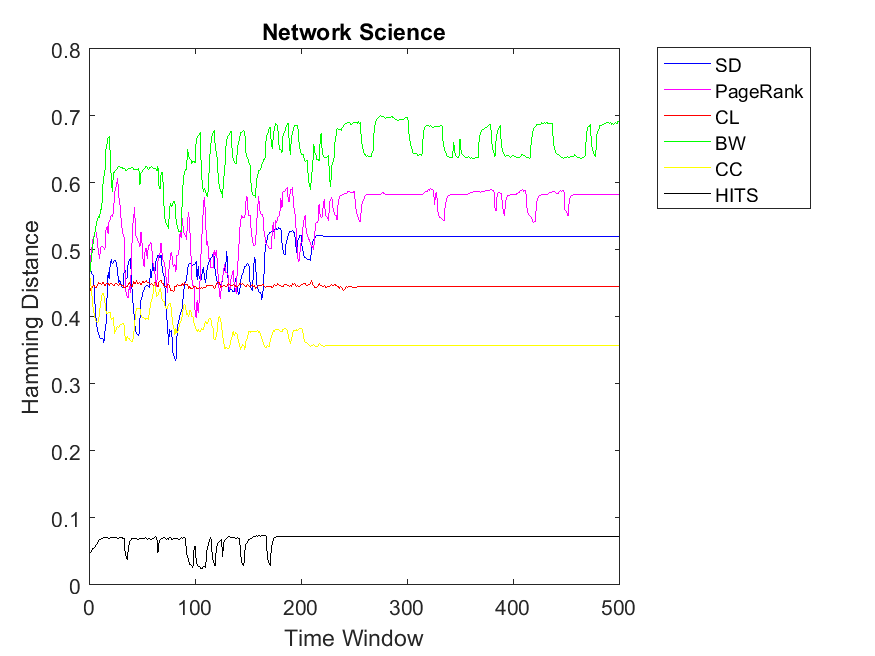 Figure 13
Figure 13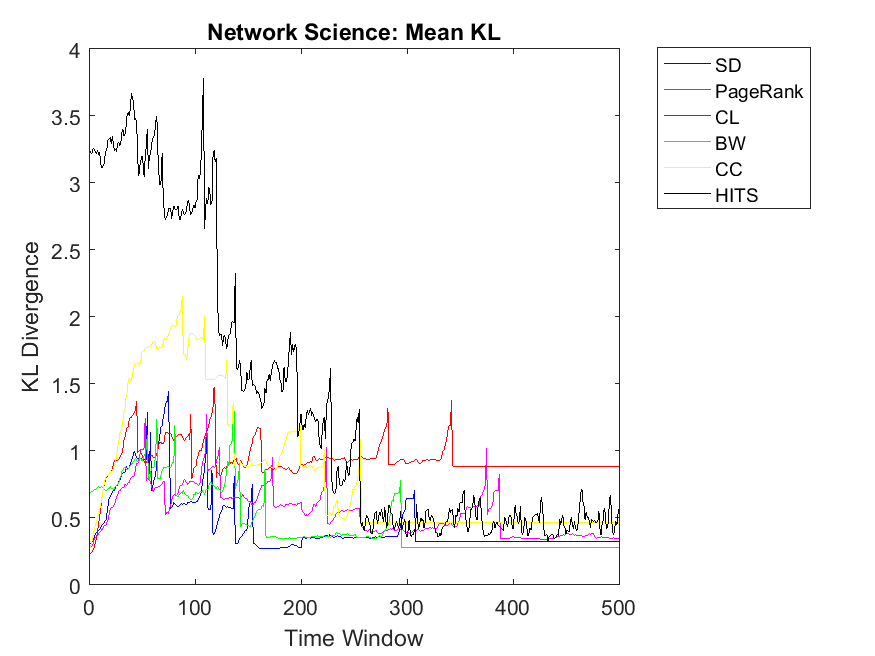 Figure 14
Figure 14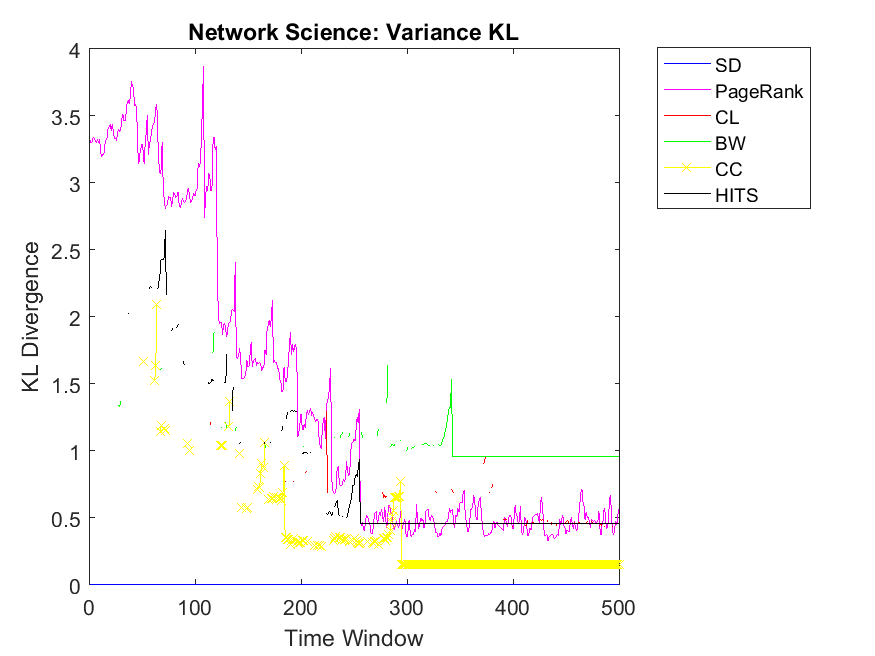 Figure 15
Figure 15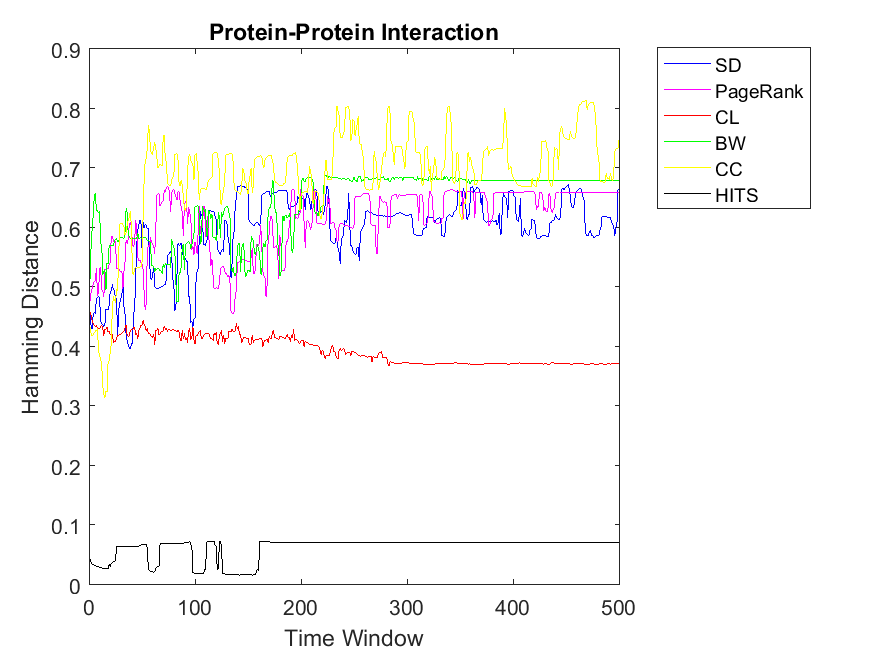 Figure 16
Figure 16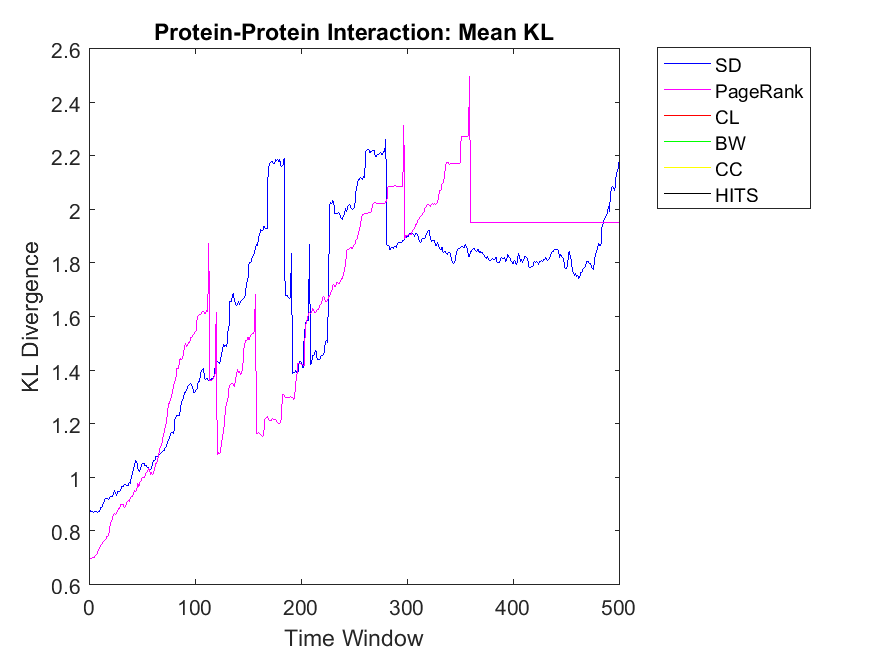 Figure 17
Figure 17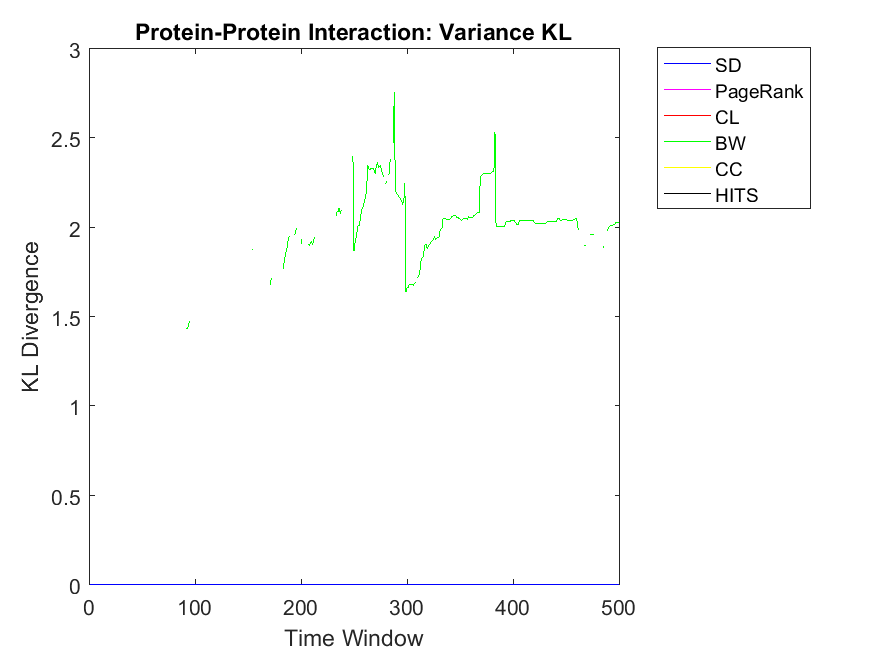 Figure 18
Figure 18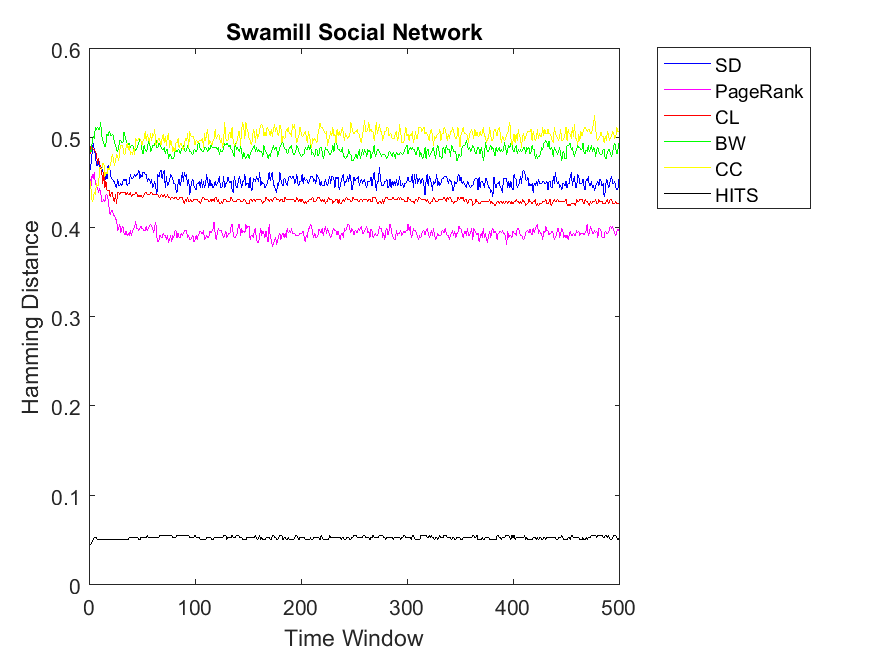 Figure 19
Figure 19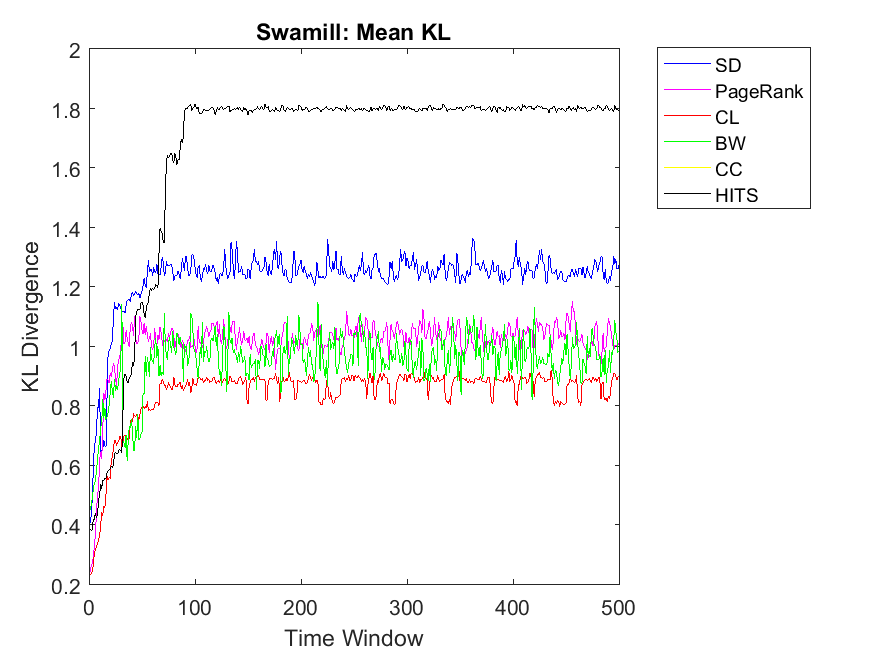 Figure 20
Figure 20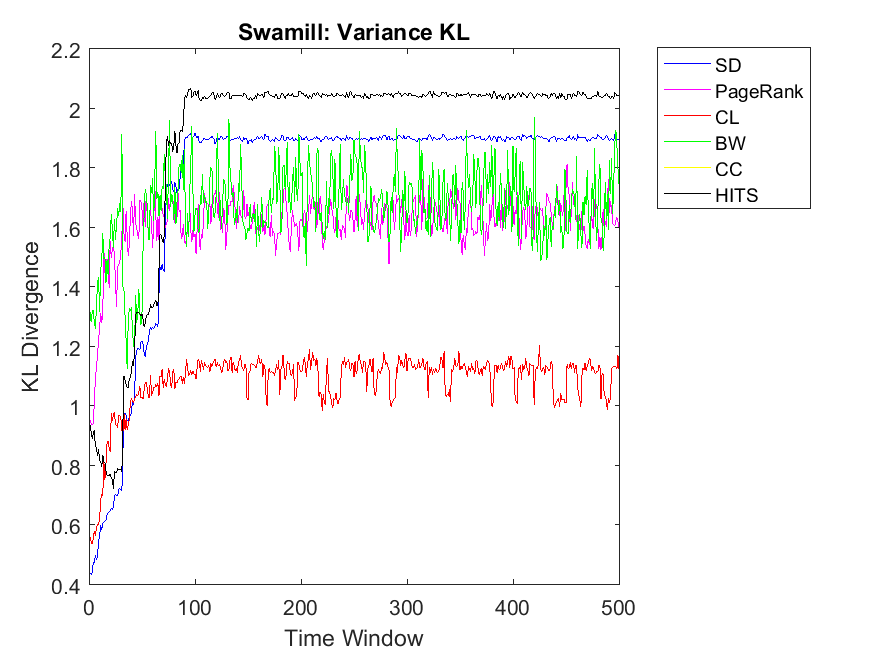 Figure 21
Figure 21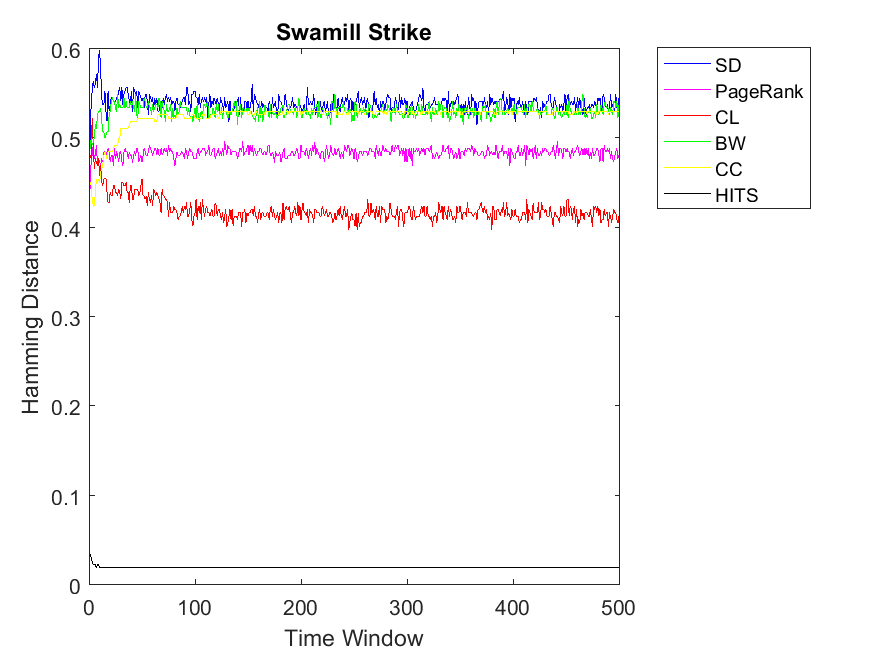 Figure 22
Figure 22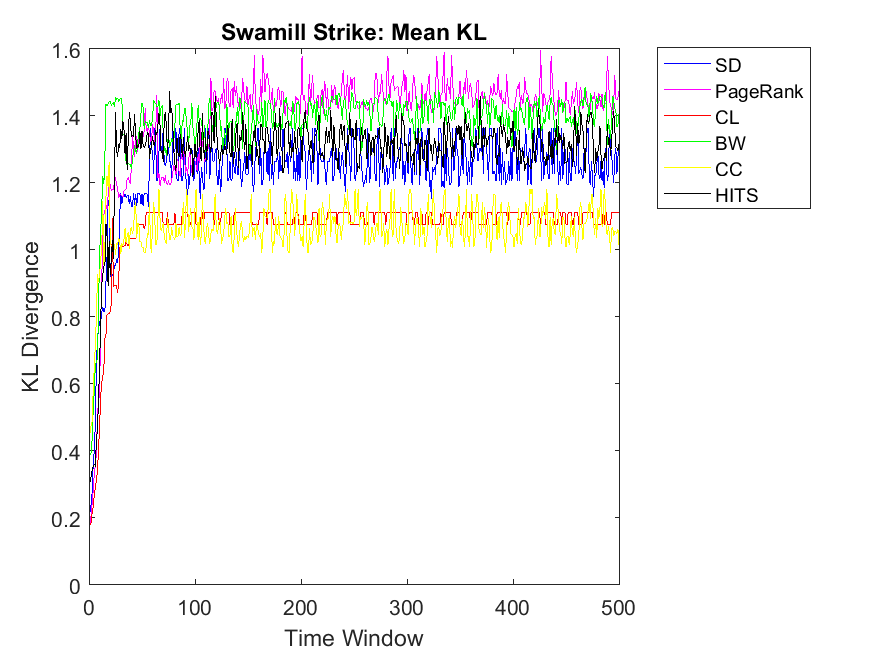 Figure 23
Figure 23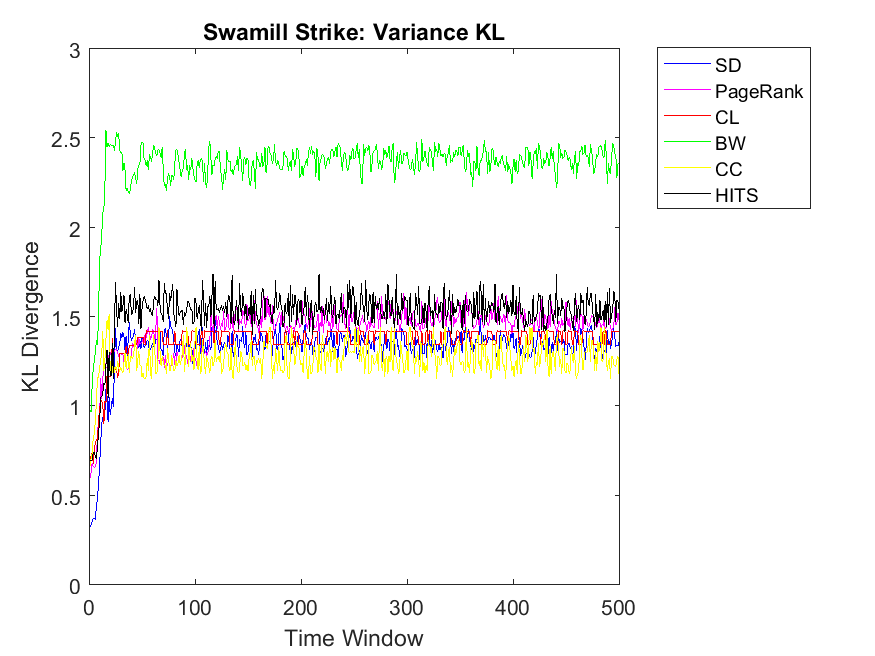 Figure 24
Figure 24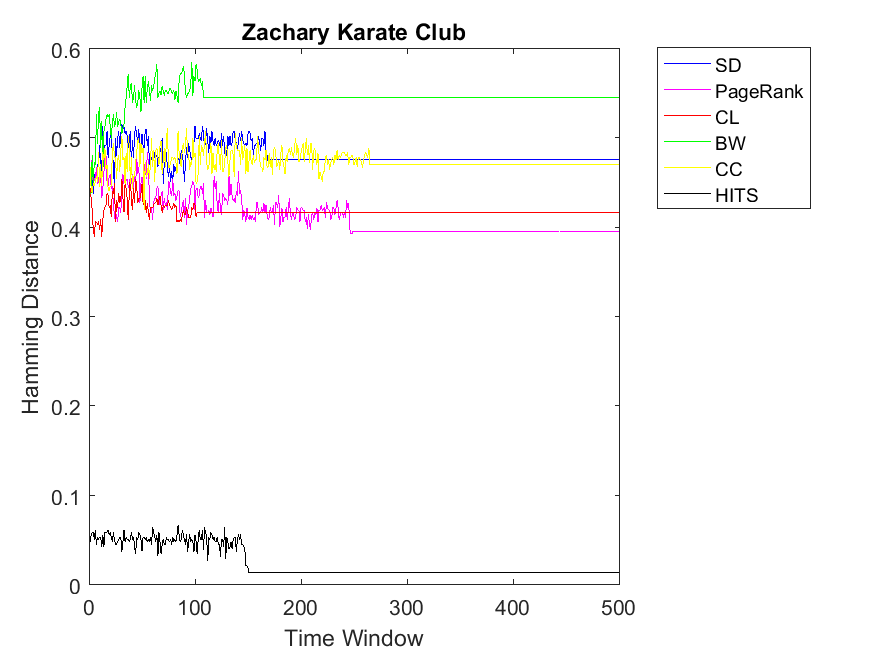 Figure 25
Figure 25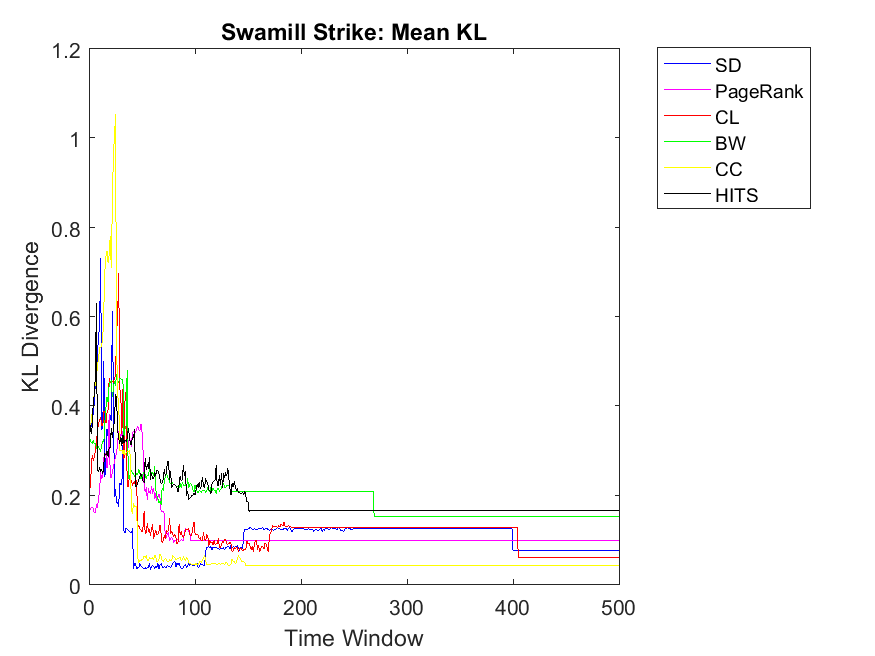 Figure 26
Figure 26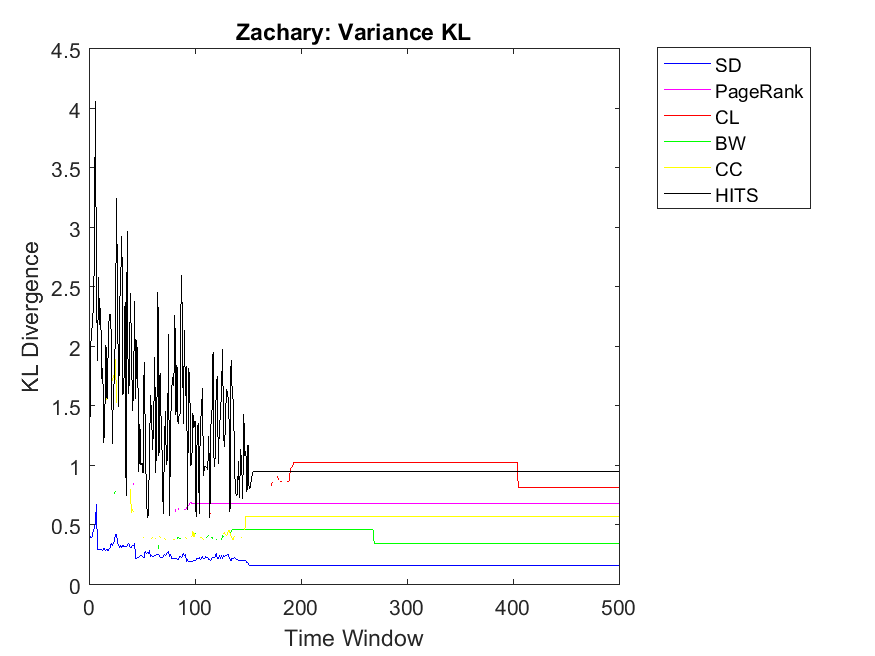 Figure 27
Figure 27 Figure 28
Figure 28| C | D | |
| C | (R;R) | (S;T) |
| D | (T;S) | (P;P) |
| Data set | # nodes | # edges | avg | std | CC | Type |
| Zachary | 34 | 156 | 4.59 | 15.04 | 0.31 | Social |
| Swamill | 36 | 124 | 3.44 | 4.77 | 0.31 | Social |
| Swamill Strike | 24 | 76 | 3.17 | 1.88 | 0.4421 | Social |
| Dolphin | 62 | 318 | 5.13 | 8.74 | 0.26 | Animal |
| Gnutella | 6301 | 41554 | 6.6 | 72.94 | 0.01 | Technological |
| 1133 | 10903 | 9.62 | 87.28 | 0.22 | Communication | |
| Netscience | 1589 | 5485 | 3.45 | 12.04 | 0.64 | Coauthorship |
| Protein | 1706 | 6346 | 3.74 | 48.83 | 0.0059 | Biological |
| Euro Roads | 1174 | 2834 | 2.41 | 1.41 | 0.02 | Infrastructure |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOpinion Dynamics and Social Influence · Evolutionary Game Theory and Cooperation · Complex Network Analysis Techniques
11institutetext: Mohsen Shahriari 22institutetext: Information Systems and Databases Chair, RWTH Aachen University; 22email: [email protected] 33institutetext: Ralf Klamma 44institutetext: Information Systems and Databases Chair, RWTH Aachen University; 44email: [email protected] 55institutetext: Matthias Jarke 66institutetext: Information Systems and Databases Chair, RWTH Aachen University; 66email: [email protected]
Ranking and Cooperation in Real-World Complex Networks
Mohsen Shahriari
Ralf Klamma
Matthias Jarke
Abstract
People participate and activate in online social networks and thus tremendous amount of network data is generated; data regarding their interactions, interests and activities. Some people search for specific questions through online social platforms such as forums and they may receive a suitable response via experts. To categorize people as experts and to evaluate their willingness to cooperate, one can use ranking and cooperation problems from complex networks. In this paper, we investigate classical ranking algorithms besides the prisoner dilemma game to simulate cooperation and defection of agents. We compute the correlation among the node rank and node cooperativity via three strategies. The first strategy is involved in node level; however, other strategies are calculated regarding neighborhood of nodes. We find out correlations among specific ranking algorithms and cooperativtiy of nodes. Our observations may be applied to estimate the propensity of people (experts) to cooperate in future based on their ranking values.
Keywords:
Ranking Algorithms; Prisoner Dilemma; Cooperation and Defection; Complex Networks; Online Social Networks
1 Introduction
Network science has received much attention recently. Advanced computational technologies and machine learning algorithms have created vast opportunities of research in this domain. Moreover, the easy available data sets for network analysis has expanded this area. Ranking algorithms Klei99 Page99 , cooperation and defection problem Nowa06 , link prediction LiKl04 , overlapping community detection PDI*05 are lucrative trends in the direction of network analysis. Extracting informative patterns and properties from networks contributes to understand the dynamics behind their formation and evolution. Moreover, one can support and create online applications out of the found dynamics. One can mention scale-free degree distribution Watt99b , small-world-ness WaSt98d , densification LeKF07 , community structures Newm04 and motifs MSI*02 as properties of complex networks.
One key challenge in complex networks is to rank the nodes. In other words, we may require to reliably sort the nodes based on their reputation or other criteria. Ranking algorithms are employed in search engines Page99 , in addition, they can support some online applications such as expert identification ShPK15 . Lary Page proposed PageRank that has been used in Google search engine Page99 . In PageRank, a walker surfs the network based on stochastic random processes. Other ranking algorithms such as HITS and SALSA consider hub and authority vectors to compute rank values of the nodes Klei99 LeMo01 . Ranking algorithms are employed to identify experts when people look for such people in question/answer forums. Experts are members of social networks that have higher level of knowledge in certain domains. They help novices to find their intended content online. Classical ranking algorithms and their variations have been employed to identify experts. Their idea is to construct a network among askers and answerers and apply HITS Klei99 JuAg07 JuAg07b and PageRank Page99 . Jurczyk and Agichtein constructed a multigraph and connected edges from asker to the question and from question to the answers and from answers to the answerer. However, they omitted the vertices which are questions and answers JuAg07 ; JuAg07b , afterwards, HITS is applied on the resultant graph. Similarly, Zhou et al. assimilate link analysis and topical similarity and extend PageRank to identify experts ZLLZ12 . They apply Latent Drichlet Allocation (LDA) for topical analysis and extract interesting topics of users. Additionally, a topical PageRank algorithm is employed on the resultant graph. ZCX*14 ZCX*11 combine information from various data sources and employ the information from target and relevant categories. They apply random surfer model to rank experts. Although expert identification has been investigated especially with ranking algorithms, task management and cooperativity of experts is still a challenging problem in this regard. Although the expert identification models recommend experts to a certain user, she might not be cooperative and willing to help the user. In this paper, we investigate this challenge via connecting ranking algorithms with cooperation/defection challenge in complex networks.
Cooperation and defection problem has been studied in different domains such as biological, social and animal networks Nowa06 MaPr73 Henr06 . If you pay attention to your daily interaction with people, you figure out that cooperation and defection is a keystone of human societies OHLN06 RAB*14 . Even in other networks, we can observe cooperation in different levels. For instance, cells cooperate to form cellular organism and genes cooperate in genomes Nowa06 . In online social networks cooperation happens in different layers. For instance, if one considers the example of an online learning forum, the cooperation happens between a knowledgeable person (expert) and a person seeking for the information. Additionally, Open Source Software (OSS) development also benefits from volunteer developers in this regard. Nowak mentions five rules for the evolution of cooperation: kin selection, direct reciprocity, indirect reciprocity, network reciprocity and group selection Nowa06 . In case of OSS, indirect reciprocity through gaining reputation and experience motivates developers to contribute and join OSS projects. In other words, the obtained reputation from one side and the gained experience from the other side inspire developers to join OSS projects
Cooperation and defection has been majorly studied through Prisoner Dilemma (PD) game in which two players can play an evolutionary game through time. In this game theoretic perspective, each player pays a cost in return for a benefit. The payoffs are considered as with fitness measure NoMa92 . There have been some variations to the original PD game such as Tit for Tat, Joss, Friedman and random strategies. In Tit for Tat strategy, an agent cooperates in the first round of the game, afterwards, replicates the behavior of the other player. Joss strategy is based on Tit for Tat; however, it is combined with some random defection in between. Friedman strategy is a bit different and the players usually do not defect at the start of the game but would start not to cooperate as soon as the opponent start defection. Then the player continues defection until the end of the game. In random strategy, each player has a random probability of cooperation and defection which usually is considered equal for the players KiNa07 Axel84 .
Cooperation and defection problem has been applied to study correlation among motif frequencies and cooperativity level of motifs SaRJ10 . A similar problem is to compute the correlation among rank of nodes and their cooperativity level in complex networks. This investigation can be applied in several domains. For instance, it is important to evaluate and predict cooperativity of experts in learning environments or to estimate the probability of joining a developer to a OSS project based on its rank; however, we require a reliable approach to rank the objects in complex networks. To investigate the correlation of cooperativity of nodes and ranking of nodes, we implemented the PD game adopted from Nowak and May NoMa92 SaRJ10 . Furthermore, we implemented classical centrality and rank strategies including PageRank, HITS, BetWeen-ness (BW), CLoseness (CL), Clustering Coefficients (CC) and Simple Degree (SD). Afterwards, three strategies are employed to evaluate the amount of correlation between cooperation and rank problem. First of all, we investigated the correlation of node ranks with cooperativity levels of nodes through Hamming Distance. In other words, each assigned rank value is mapped to a binary value and then compared with the binary cooperativity value obtained through PD game. In the second strategy, we considered the neighborhood of each node and computed the average real rank values of the node neighbors. Moreover, average cooperativity of the node neighborhood is also calculated. Afterwards, these two vectors for the nodes are correlated through relative entropy. Finally, we did the same experiment on the neighborhood of nodes; however, variance of rank values are correlated with variance of cooperativity levels of the neighborhoods.
Through simulations, we could figure out tangible correlations among several ranking algorithms and the cooperation of nodes through PD game. HITS algorithm indicates the highest cooperativity level in comparison to other algorithms in the node level strategy (first strategy). Other algorithms show less correlations and this was observed in almost all the data sets. Regarding the second strategy (mean neighbor rank versus mean neighbor cooperativity), we could observe high correlations regarding the algorithms including SD, CC and CL in most of data sets especially small networks; however, the analysis are more complex and it may require to investigate internal structure of each network. For instance, we only observed tangible correlation when the clustering coefficient of the network is very low. Regarding the third strategy (variance of neighbor rank versus variance of cooperativity rank), we could also identify SD algorithm with the highest correlation among its competitors. In several experiments, we could also observe high correlations for CC and CL centrality metrics.
The rest of this article is organized as follows. In section 2, we introduce the basic cooperation and defection game through Prisoner Dilemma and the basic game adopted from Nowak NoMa92 . In section 3, classical ranking algorithms are explained in details. In section 4, we discuss and mention simulation protocols and employed parameters for the experiments. Next, data sets and evaluation results are explained in section 4.4. Finally, we conclude the paper in section 5.
2 Cooperation and Defection
Network researchers have been interested to understand the dynamics of cooperation and selfish behaviors of individuals and groups. One may not separate interests and benefits of groups from individuals and vice verse. In other words, cooperation of one person with others has reciprocal effects that needs to be studied. In fact, pursuit of selfish agents’ behavior might be detrimental for the whole community. These issues have been modeled with game theory approaches such as Prisoner’s Dilemma (PD) RAB*14 RBH*14 . Merrill M. Flood and Melvin Dresher developed this game in around 1950’s that has been under much discussion in computational social and computer sciences. There are some variations to this game; however, the original game which is rampant is a two player game that each agent can take two strategies; either cooperation or non-cooperation. Non-cooperation is also known as defection. The basic mindset behind this problem is that cooperation of both agents leads to higher lucrative outcomes while defection increases individual benefits SaPa05 .
The original PD game is the story of two persons imprisoned in which the prosecutor can not convict them based on the existing evidence. Here the court specifies a bonus for the pairs and they can behave as follows: both prisoners would serve one year in jail if both stay silent. If one of them betrays, he will be free and the other must serve three years in jail and vice versa. Finally, if both of them betray (defect), they require to serve two years in jail. Rationally speaking, pairwise cooperation serves more beneficial outcomes to both players and nonreciprocal defection is only useful for each of them EaKl10 .
To simulate the problem, we consider the PD game with a more formal definition. We investigate an evolutionary game played on a network of interactions among individuals or players. Each player can take a set of rational behaviors; named strategies. Here, we mention Cooperation(C) and Defection (D) as possible ones. Based on the selected strategy, she will obtain a payoff; higher payoff values are preferred. Payoff is denoted by a matrix which is shown in the Table 1. Elements of the payoff matrix are defined as follows:
- •
If both players cooperate then they both receive a payoff .
- •
If one cooperates and the other defects then the later receives a and the former obtains .
- •
If both players defect then is granted to both.
Each individual plays with its neighbors in the network and receives the corresponding payoff (fitness). With , the non-cooperation dynamic prevails and reaches a Nash Equilibrium. In contrast, reciprocal cooperation of individuals prevails unilateral cooperation and thus mutual cooperation generates higher payoff Gint09 .
3 Ranking Approaches
To calculate significance and centrality of nodes in a network, we require to apply ranking algorithms. Ranking methods are applied in different application domains such as search engines, recommendation systems and expert identification algorithms. If we denote a graph with in which is the set of nodes and is the set of connections between these nodes then a ranking algorithm computes a value assigned to each node. For each node , we denote the set of its neighbors with which stems from the word degree. Moreover, in-neighbors (in-degrees) and out-neighbors (out-degrees) are denoted via and , respectively. Correspondingly, we employ sign to show magnitude of the sets, for instance, means number of neighbors of node . In addition, we consider number of nodes as and number of connections as . Based on the connection context, these rank values can be interpreted as reputation, expertise and social rank; we denote the rank value for node as . Researchers have designed several ranking algorithms that we investigate them in the following.
3.1 Simple Degree
Simple degree measure is a classical metric with easy understanding and low computational complexity (O(N)). Simply, we count the number of neighbors of each node (). Simple degree, which is also called prestige, had good performance in several studies EaKl10 .
3.2 PageRank
In 1990s, Larry Page proposed PageRank which is the most widely discussed ranking algorithm. If we denote PageRank value of each node with then it is updated as follows:
[TABLE]
Here, is the teleporting parameter showing the probability of starting a new walk by the random surfer Page99 .
3.3 Hyperlink-Induced Topic Search
Hyperlink-Induced Topic Search (HITS) algorithm is proposed by Kleinberg in around 1999 and it was employed to extract useful information from World Wide Web. HITS consists of two vectors named hubs and authorities. Hubs are nodes which refer to other nodes and authorities receive links from other nodes in the network. We initialize the hub and authority vectors with value and apply the equation 2 and 3, as follows:
[TABLE]
and
[TABLE]
where and show authority-ness and hub-ness of node . We let the algorithm run until convergence condition is met. Convergent vector is considered as the rank vector ().
3.4 Closeness Centrality
Closeness Centrality (CL) shows whether a node is middle of the things EaKl10 . CL can be defined based on the average shortest distance of a node to all other nodes. It can be written as follows:
[TABLE]
This value can be normalized with and the vector is consider as the vector.
3.5 Betweenness Centrality
BetWeenness Centrality (BW) is a measure which shows how many of nodes should go through you to reach other nodes EaKl10 . It can be defined as follows:
[TABLE]
where is the number of shortest paths between node and and is the number of these paths going through . Similarly, we consider vector as the vector .
3.6 Clustering Coefficient
Clustering Coefficient (CC) shows local connectivity and local information exchange in the network. We adopted the definition of CC from Watts and Strogatz HuGu08 and computed clustering based on the following formula:
[TABLE]
where is the number of edges between neighbors of node . Here, we consider vector equal to vector.
4 Simulation Protocol
Our goal is to compute the correlation among cooperativity level of nodes and neighbors and their corresponding rank values.
4.1 Evolutionary Cooperation Process
In general, cooperative level of an evolutionary game on a network of agents interacting through PD game is the final number of cooperative agents. As we want to calculate the correlation between node cooperativity and its rank, we require to know cooperation status of each agent. In this regard, we assign a binary variable as the cooperation status of an agent; 1 denotes cooperation and 0 shows defection. We start the game with equal number of cooperators and defectors. Afterwards in each evolutionary step of the PD game, each agent plays with its neighbors and its payoff value is updated based on the payoff matrix introduced in the Table 1. We adopt the parameters for the payoff matrix proposed by Nowak and May and thus we consider in which is the propensity to defect NoMa92 . Synchronously, players update their payoffs; however, through the evolutionary steps of the game, players change their strategies. In other words, each player randomly looks at one of its neighbors and change its strategy with a probability given in the equation 7 only if its payoff is less than of its neighbor. In fact, regarding node , it compares its payOff with one random neighbor and changes its strategy with the following probability:
[TABLE]
To simulate the evolutionary process, we run the PD game for a . To obtain more stable results, we iterate the PD game 10 times and average over their output. The pseudo code better shows the process.
4.2 Node Rank and Cooperativitiy
To compute the cooperativity level of each node, we consider binary values for each of the ranking algorithms introduced in section 3. After normalizing each ranking vector to a real value between 0 and 1, it is mapped to binary values by considering a threshold value equal to mean value of the rank vector . For each of the time windows, we correlate the binary rank vector with binary cooperation vector . The correlation is simply the Hamming Distance which is the number of binary elements that needs to be changed in order to reach from binary rank vector to cooperation vector .
4.3 Neighbor Rank and Cooperativitiy
To observe how cooperativity of a node is related to its rank value, we consider the nodes’ neighbors. In other words for node , we compute the average of rank values of neighbors of node as follows:
[TABLE]
where is the average rank value of node . Similarly variance of rank values of neighbors of node can be computed as follows:
[TABLE]
where is the variance rank values of neighbors of node . Similarly the cooperativity level of neighbors of node can be calculated as the average of cooperation strategies of nodes . we denote average cooperativity level of neighbors of node with . It is calculated as follows:
[TABLE]
Finally, we correlate and vectors with vector based on relative entropy or kullback-leibler divergence (KL divergence). KL divergence is usually applied to compute dissimilarities of two random variables. KL divergence can be computed as follows:
[TABLE]
in which and are two vectors that we need to compute their relative information. divergence can be rewritten by entropy terms as follows:
[TABLE]
where is named the cross entropy. One can show that when exactly then equals zero and always Murp12 . Here in the evaluations, we compute relative entropy of average and variance neighbor rank and cooperation.
4.4 Evaluation Results and Discussion
To observe the correlation among rank values of nodes and their cooperativity level, we employ a couple of real-world data sets as listed in the Table 2. All of the data sets can be found on the Web. Some information regarding number of nodes, number of edges, average degree, standard deviation of node degrees and clustering coefficients of these networks are provided in the corresponding table.
We apply the three strategies on a couple of data sets and plot the correlation versus the time window of the PD game. For the first strategy, we plot the Hamming Distance of the binary rank vectors and the binary cooperation vector versus number of iterations in the PD game which is set to 500. Ranking algorithms include Simple Degree (SD), PageRank, Closeness Centrality (CL), BetWeenness centrality (BW), Clustering Coefficient (CC) and HITS. One can observe legends of each algorithm besides its figure.
Figures 1 and 2 indicate the correlation among node ranks and cooperitivity level of each node using Hamming Distance. As it can be observed, the distance is normalized between 0 and 1. Here the higher value indicates less correlation and lower values indicate more similar vectors. As for Dolphin network, for almost for all the ranking algorithms the correlation values have a smooth horizontal line. This indicates that after a few iterations the PD game on the network convergences to a steady state with a fixed cooperativity level. Moreover, we can observe the highest correlation for HITS algorithm regarding cooperativity. In other words, rank values obtained by HITS have the highest similarity with cooperativity of nodes; mostly less than 0.1 value. In comparison to HITS, other ranking strategies including CL, PageRank, CC, SD and BW obtain less similarity, respectively; however, their difference is not high. In this regard, BW, SD and CC obtain similar distance values of rank and cooperativity. Similar to Dolphin network, we observe the same pattern as for Zachary; HITS showing the highest correlation between node rank and cooperativity. Regarding other ranking algorithms, the patterns might be a bit different; SD has the highest Hamming Distance and BW has the lowest. Additionally, CL, CC and PageRank retain similar correlations. As for Swamill social network, we approximately observe a similar pattern in which HITS shows the highest similarity and others show the least. Regarding Swamill, these correlation values remain between 0.4 and 0.55.
Now we observe bigger networks with higher complexities. Although one can observe some fluctuations, the pattern is still kept the same for network Science data in which HITS has the highest correlation of node rank and cooperativitiy. In this data set, CC and CL have higher similarity values in comparison to the rest and BW produces least correlation values. Regarding the Europe road and email networks, the pattern is smooth and almost the same with HITS reaching the highest similarity of rank and cooperation for nodes. Moreover, other ranking strategies obtain less correlations in the range of 0.4 to 0.75. As for Protein-Protein interaction and Gnutella peer-to-peer networks, the correlations show more fluctuations due to variations of some nodes between cooperation and defection strategies. However, the pattern is kept similar to the previous simulations with HITS obtaining the highest correlation between rank and cooperation.
To extend our observations, we also apply neighbor mean and variance correlation strategies on these data sets. Figures 3, 4 and 5 show KL divergence of the mean strategy on the left and KL divergence of the variance on the right. We might notice that KL divergence is a value bigger than zero and can be up to infinite values, therefore, correlations which are very high values are omitted for plotting. When KL divergence approaches zero, it means the neighbor rank and neighbor cooperativity have the highest correlation; this is true for both average and variance values in this regard. Let us first observe smaller data sets, for example Figure 3. Regarding Dolphin network and the mean strategy, the highest correlation can be observed for CL and CC followed by SD, HITS, PageRank and BW, respectively. In other words, if one intends to evaluate the cooperativity level of a node’s neighbor with the average rank of the node’s neighbor, CL and CC show the highest correlations. As for Swamill and the Mean strategy, HITS and SD have the highest correlations followed by CL, PageRank, BW, therefore the pattern is a bit different. Regarding Swamill Strike, CL, CC and SD obtain the highest correlation values near to zero which indicates the similarity of mean neighbor rank and mean neighbor cooperation strategies. Here again CC and CL are among highest correlations and also SD is added to previous set. Still looking in to small data sets, Swamill Strike shows the highest correlation for CC followed by CL and SD. Here HITS, BW and PageRank has lower correlations; however, CC and CL were among the top correlation values.
To extend our observation regarding the correlation of mean neighbor rank and mean neighbor cooperation, we investigate bigger data sets to check whether CL, CC and SD show the same correlation patterns. Regarding Network science data set, more or less, we can observe that BW and SD obtain the highest similarity followed by CL, HITS, PageRank and CC. As for Europe road network, we can observe almost similar correlations for all the algorithms except HITS with lower similarities. Regarding Email network, the pattern is similar to Europe road network and HITS also shows close similarities like other algorithms. Although HITS showed the highest correlation in node level, it has the lowest correlation for the neighborhood strategy. As for Gnutella network the correlation values are somehow increasing in which it depends on the internal structure of the network. Here BW and HITS have the highest correlation values followed by SD, PageRank, BW and CL. Finally, regarding the Protein network, some correlations were too low that are not plotted in this diagram and the highest correlation can be observed for CL and SD. Overall, we can observe that CL, SD and CC show the highest mean neighbor rank and mean neighbor cooperation correlations; this is also true for big data sets such as Email network and Network science. By investigating Table 2, we figure out that Europe road and Science networks and the small data sets such as Swamill, Swamill Strike and Dolphin have approximately low variance degrees; however, data sets such as Gnutella, Email and Protein-Protein interactions have high variance degrees in which their ranking might be different with different strategies. All the data sets have approximately similar average degree for the nodes but the variance degrees can be observed quite differently in which indicates different internal structures.
Regarding neighbor variance strategy, we intend to observe whether CC, CL and SD are among the highest correlation values. As for Dolphin network, SD, HITS and CL have the highest similarities among others. Regarding Swamill, the pattern is a bit different and the highest correlation can be observed for CL followed by PageRank and BW. Here Dolphin has double variance degree in comparison to Swamill which leads into different correlation values. Regarding Zachary, the pattern is smooth and SD, BW and CC obtain the highest correlations among others. Here Zachary has high variance degree in comparison to other data sets. As for Swamill Strike, one can observe CC, SD, CL, PageRank and HITS among algorithms with high correlation values. Swamill Strike has low variance degree and approximately high clustering coefficient of 0.44 in this regard. As for Europe road network, SD neighbor variance rank vector is completely similar to cooperation neighbor variance vector which is followed by BW. In this regard, the variance degree for Europe road is quite low. As for Email network, we observe the highest variance correlation for SD, CL and CC followed by PageRank, HITS and BW. Correspondingly, Email network has approximately high variance degree of 87.28.
As for Protein, Email, Science and Europe networks, we observe SD as the KL divergence of near to zero which shows that variance simple degree of neighbors of a node has a high correlation with variance of neighbors’ cooperativity. Regarding Protein network, the pattern is a bit different and all other algorithms have no correlation with the cooperativity of the neighbors with the variance strategy. This might be because of the low clustering coefficients observed in the protein networks with 0.0059 value. Regarding Gnutella with high variance degree, the correlations values are a bit unstable but reaching to a steady state with PageRank, SD and CL as the highest correlations.
To sum up, HITS showed the highest correlation in the node level strategy; however, centrality metrics such as SD, CL and CC indicated higher correlation among node neighborhood rank and node neighborhood cooperation strategies. Regarding neighborhood strategies, results were more scattered which may require more investigation of internal properties of real-world networks through analyzing overlapping community structures and internal network/community motifs. In addition, we performed the experiments on networks with several thousands of nodes and edges; however, our simulation protocol can be extended on large scale complex networks with millions of nodes and edges. Furthermore, results and the methodology can be applied on different domains such as learning and open source software development environments to estimate the propensity of users (experts) to cooperate through their ranks. Other research domains such as recommender systems and link prediction algorithms may be improved through the joint contribution of rank and cooperativity problems.
5 Conclusion
Cooperation and Defection (CD) is one of the basic phenomenon observed in human interactions. Other network types and biological systems evolve and benefit from this inherent property of complex systems. One can also observe the cooperation in different levels of an online media; in an online question answer forum or an open source software developer community. Nodes in complex networks can be described and categorize by ranking algorithms and our knowledge regarding the cooperativity of a node and its rank value is imperceptible. In this regard, we implemented different ranking algorithms and the basic prisoner dilemma game and applied three strategies to evaluate such correlations. First strategy is related to correlation of the node rank and its cooperativity level. Second and third ones are related to correlation of node neighborhood rank and node neighborhood cooperation. Our results indicate correlation of specific ranking algorithms of each strategy. HITS had high correlation with cooperativity of nodes in the node level strategy. For mean neighborhood strategy the results were more scattered and depends on the network and its internal structure; however, we could mention SD, CC and CL as the ranking metrics with the highest correlations for the second and third strategies. These findings can be applied on expert identification systems for task management and estimating the cooperativity of users through their ranking values.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Axelrod, R. M. The evolution of cooperation . Basic Books, New York, 1984.
- 2(2) David, E., and Jon, K. Networks, Crowds, and Markets: Reasoning About a Highly Connected World . Cambridge University Press, New York, NY, USA, 2010.
- 3(3) Duncan J. Watts . Small Worlds: The Dynamics of Networks Between Order and Randomness . Princeton University Press, 1999.
- 4(4) Duncan J. Watts, and Steven H. Strogatz . Collective dynamics of small-world networks. Nature 393 (1998), 440–442.
- 5(5) Gintis, H. Game theory evolving : a problem-centered introduction to modeling strategic interaction . Princeton University Press, 2009.
- 6(6) Henrich, J. Cooperation, Punishment, and the Evolution of Human Institutions. Science 312 , 5770 (Apr. 2006), 60–61.
- 7(7) Humphries, M. D., and Gurney, K. Network ‘small-world-ness’: A quantitative method for determining canonical network equivalence. P Lo S ONE 3 , 4 (2008), e 0002051.
- 8(8) Jurczyk, P., and Agichtein, E. Discovering authorities in question answer communities by using link analysis. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management (New York and NY and USA, 2007), CIKM ’07, ACM, pp. 919–922.