Coherent Transport of Quantum States by Deep Reinforcement Learning
Riccardo Porotti, Dario Tamascelli, Marcello Restelli, Enrico Prati

TL;DR
This paper demonstrates that deep reinforcement learning can autonomously discover superior control sequences for quantum state transport in quantum dots, outperforming traditional ansatz-based methods and adapting to realistic disturbances.
Contribution
It introduces a novel application of deep reinforcement learning to quantum control, surpassing traditional ansatz solutions and adapting to disturbances in quantum dot systems.
Findings
RL discovers control sequences outperforming traditional ansatz.
RL adapts to disturbances, improving speed and fidelity.
Method enables online updates and better system control.
Abstract
Some problems in physics can be handled only after a suitable \textit{ansatz }solution has been guessed. Such method is therefore resilient to generalization, resulting of limited scope. The coherent transport by adiabatic passage of a quantum state through an array of semiconductor quantum dots provides a par excellence example of such approach, where it is necessary to introduce its so called counter-intuitive control gate ansatz pulse sequence. Instead, deep reinforcement learning technique has proven to be able to solve very complex sequential decision-making problems involving competition between short-term and long-term rewards, despite a lack of prior knowledge. We show that in the above problem deep reinforcement learning discovers control sequences outperforming the \textit{ansatz} counter-intuitive sequence. Even more interesting, it discovers novel strategies when realistic…
Click any figure to enlarge with its caption.
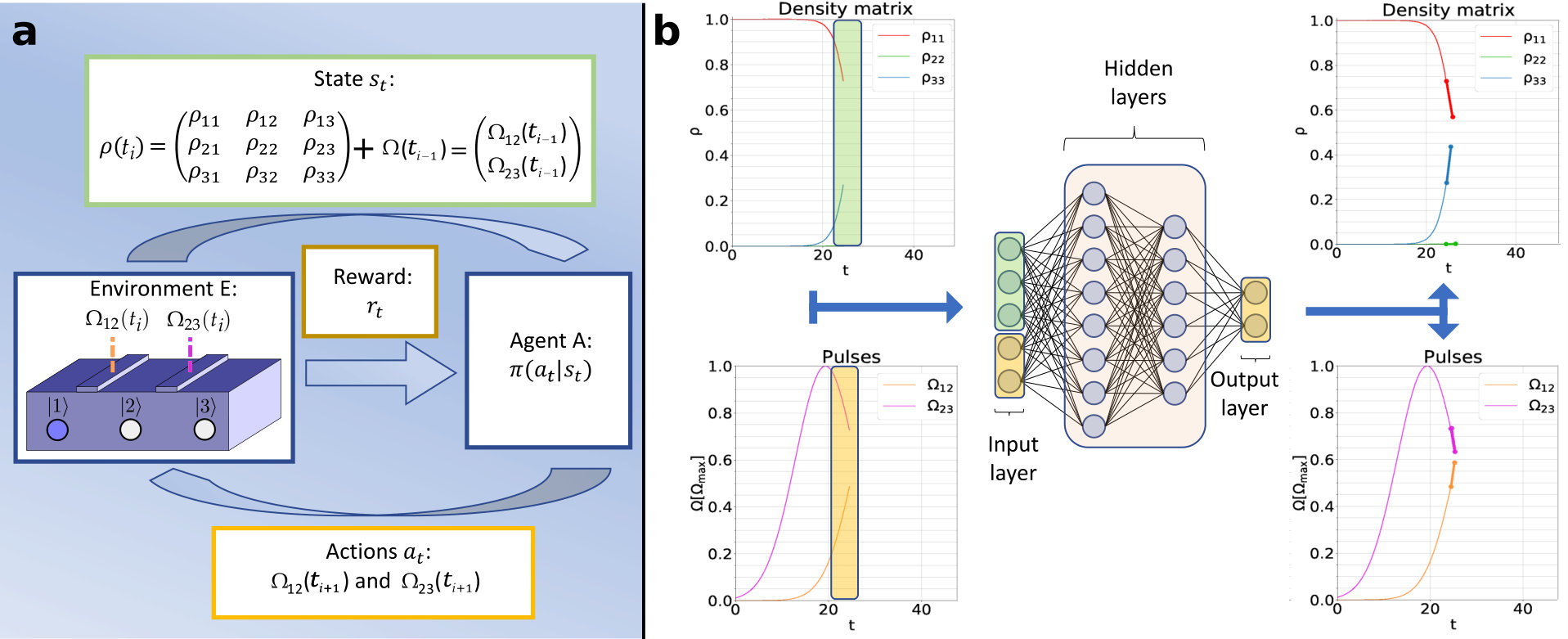 Figure 1
Figure 1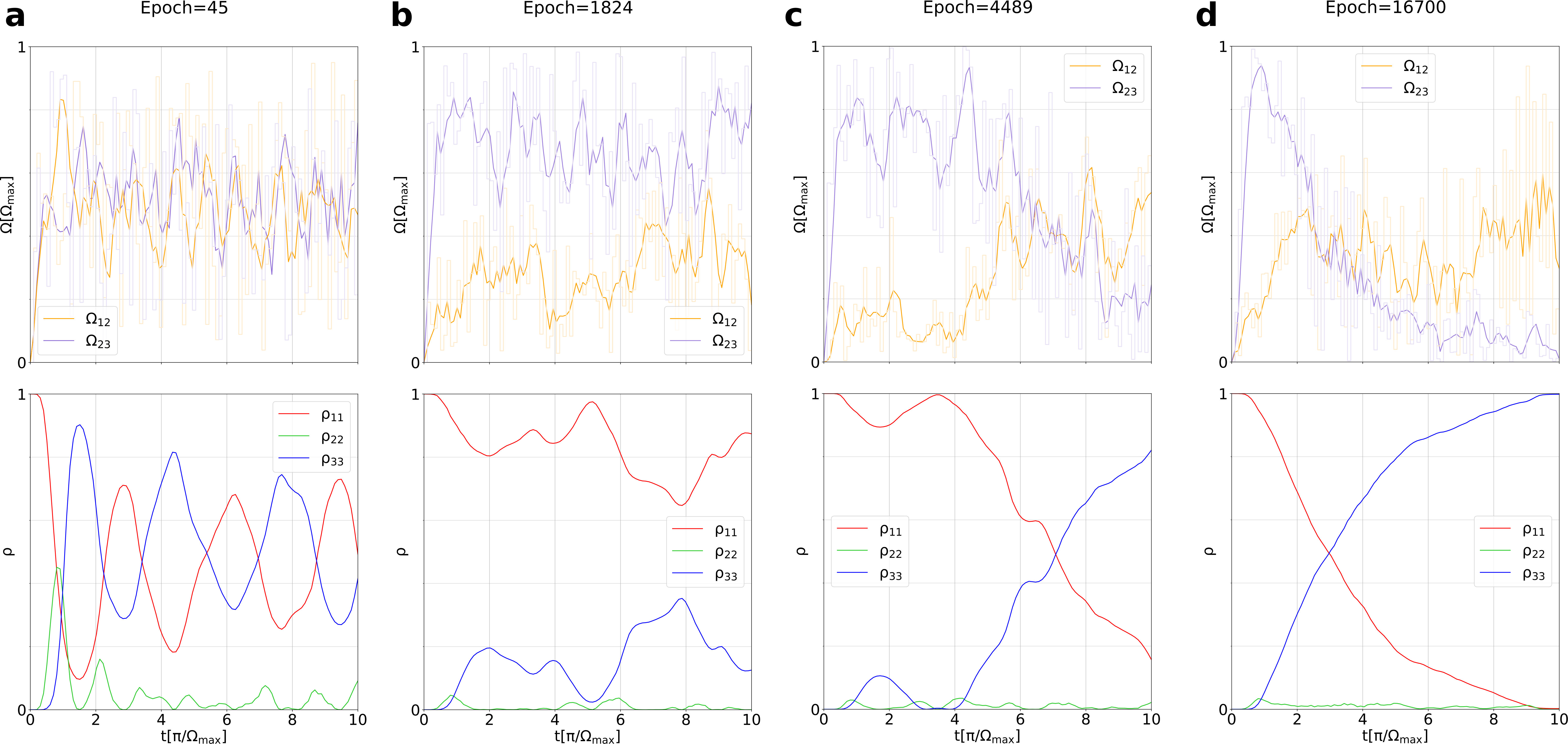 Figure 2
Figure 2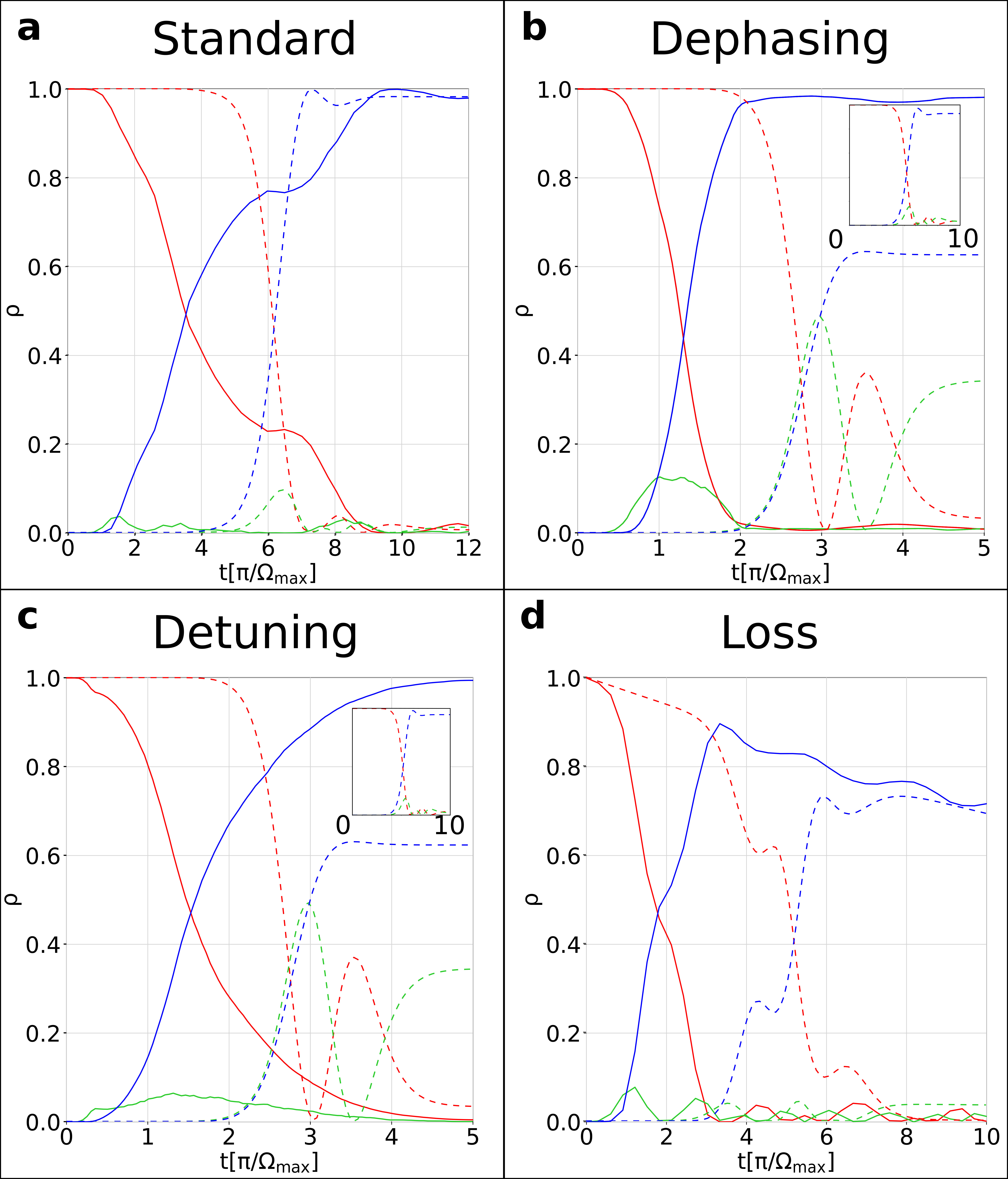 Figure 3
Figure 3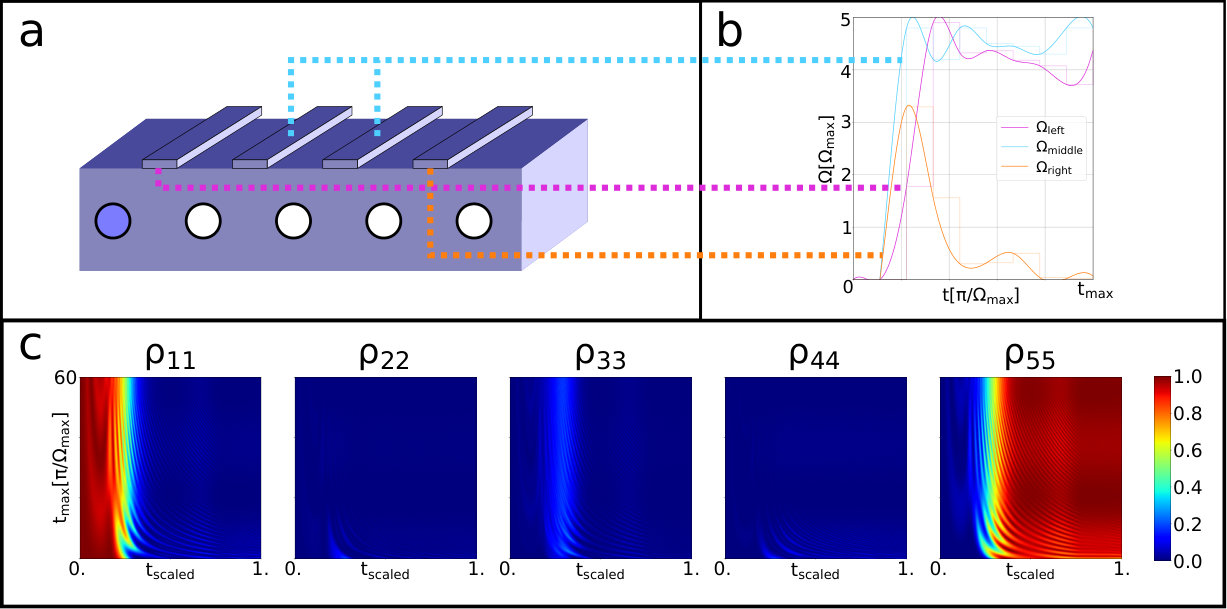 Figure 4
Figure 4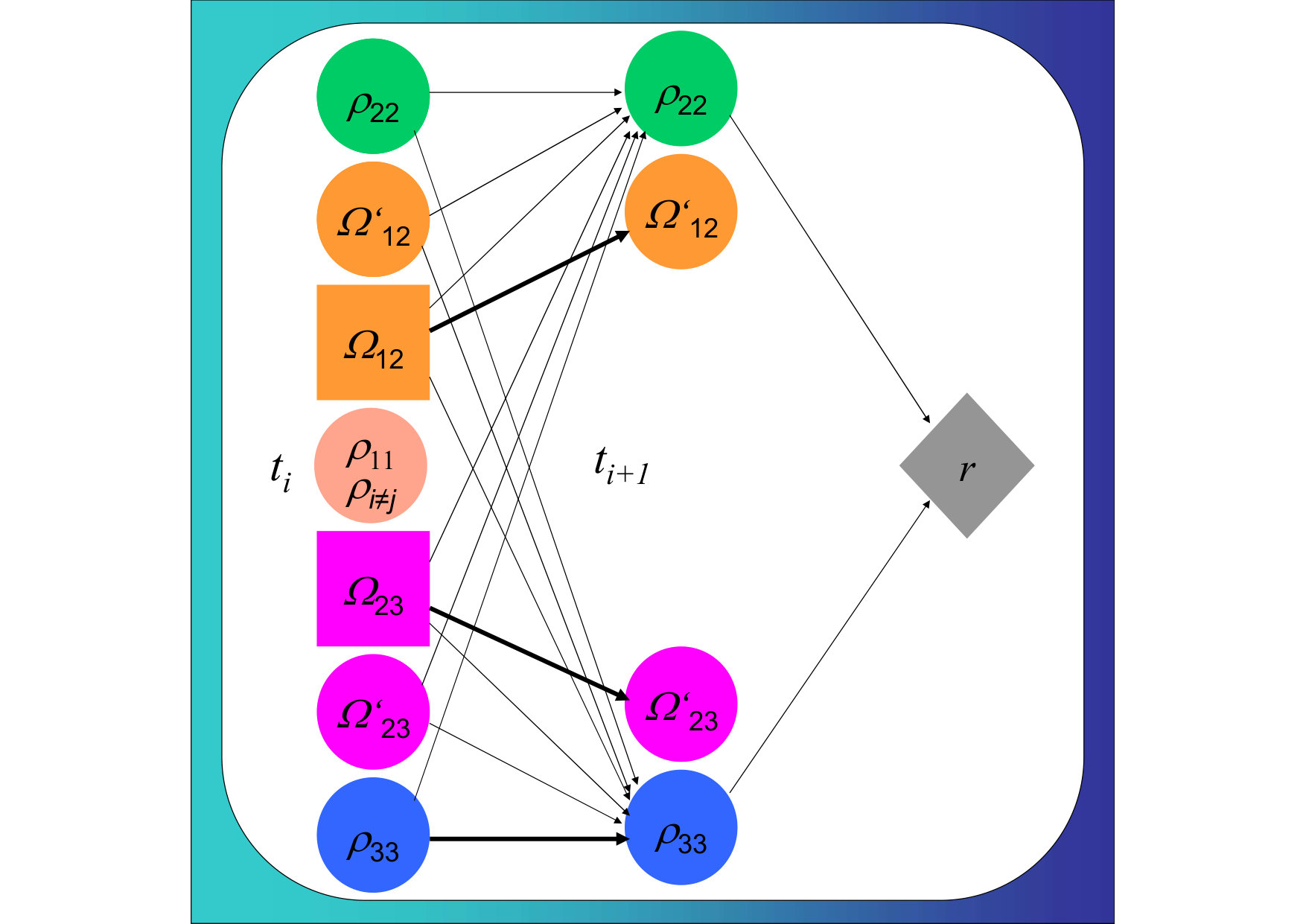 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Coherent Transport of Quantum States
by Deep Reinforcement Learning
Riccardo Porotti
Istituto di Fotonica e Nanotecnologie, Consiglio Nazionale delle Ricerche, Piazza Leonardo da Vinci 32, I-20133 Milano, Italy
Dipartimento di Fisica “Aldo Pontremoli”, Università degli Studi di Milano, via Celoria 16, I-20133 Milano, Italy
Dario Tamascelli
Quantum Technology Lab, Dipartimento di Fisica “Aldo Pontremoli”, Università degli Studi di Milano, via Celoria 16, I-20133 Milano, Italy
Marcello Restelli
Politecnico di Milano, Piazza Leonardo da Vinci 32, I-20133 Milano, Italy
Enrico Prati
Istituto di Fotonica e Nanotecnologie, Consiglio Nazionale delle Ricerche, Piazza Leonardo da Vinci 32, I-20133 Milano, Italy
Abstract
Some problems in physics can be handled only after a suitable *ansatz *solution has been guessed. Such method is therefore resilient to generalization, resulting of limited scope. The coherent transport by adiabatic passage of a quantum state through an array of semiconductor quantum dots provides a par excellence example of such approach, where it is necessary to introduce its so called counter-intuitive control gate ansatz pulse sequence. Instead, deep reinforcement learning technique has proven to be able to solve very complex sequential decision-making problems involving competition between short-term and long-term rewards, despite a lack of prior knowledge. We show that in the above problem deep reinforcement learning discovers control sequences outperforming the ansatz counter-intuitive sequence. Even more interesting, it discovers novel strategies when realistic disturbances affect the ideal system, with better speed and fidelity when energy detuning between the ground states of quantum dots or dephasing are added to the master equation, also mitigating the effects of losses. This method enables online update of realistic systems as the policy convergence is boosted by exploiting the prior knowledge when available. Deep reinforcement learning proves effective to control dynamics of quantum states, and more generally it applies whenever an ansatz solution is unknown or insufficient to effectively treat the problem.
Some problems in physics are solved thanks to the discovery of an ansatz solution, namely a successful test guess, but unfortunately there is no general method to generate one. Recently, machine learning has increasingly proved to be a viable tool to model hidden features and effective rules in complex systems. Among the classes of machine learning algorithms, deep reinforcement learning (DRL) sutton1998reinforcement is providing some of the most spectacular results for its ability to identify strategies for achieving a goal in a complex space of solutions without prior knowledge mnih2015human . Contrary to supervised learning, which has already been applied to quantum systems, such as the determination of high fidelity gates and to the optimization of quantum memories by dynamic decoupling, DRL has been proposed only very recently to maintain a physical system in its equilibrium condition fosel2018reinforcement . To show the power of DRL, we apply it to the problem of coherent transport by adiabatic passage (CTAP) of a quantum state encoded by an electron through an array of quantum dots, whose ansatz solution is notoriously called *counterintuitive *because of its not-obvious barrier control gate pulse sequence. During the coherent adiabatic passage, the electron spends no time in the central quantum dot by the simultaneous modulation of the coupling between the dots which suitably drive the trajectory through the Hilbert space greentree2004coherent ; cole2008spatial ; greentree2014darkstate ; menchon2016spatial . The system moves from an initial equilibrium condition to a different one represented by populating the last dot of the array. By exploiting such ansatz solution of pulsing the barrier control gates between the dots in a "reversed order" with respect of what intuition would naturally suggest, the process displays truly quantum mechanical behavior, provided that the array consists of an odd number of dots. We already explored separately silicon-based quantum information processing architectures rotta2016maximum ; rotta2017quantum , including the coherent transport by adiabatic passage of multiple-spin qubits into double quantum dots ferraro2015coherent , and heuristic search methods, such as genetic algorithms, to find a universal set of quantum logic gates ferraro2014effective ; michielis2015universal , and separately the application of deep reinforcement learning to classical systems bonarini2008batch ; tognetti2009batch ; castelletti2013multiobjective . Here we demonstrate that DRL implemented in a compact neural network can, first of all, autonomously discover the analogue of the counter-intuitive gate pulse sequence without any prior knowledge, therefore finding a control path in a problem whose solution is far from the equilibrium of the initial conditions. More importantly, such a method allows to outperform the analytical solutions proposed in the past in terms of process speed and when the system deviates from ideal conditions because of detuning between the quantum dots, dephasing and losses. Under such conditions, no analytical approach does exist, to the best of our knowledge. Here we exploit the Trust Region Policy Optimization (TRPO) schulman2015trust to handle the CTAP problem. First, we compare the results discovered by the artificial intelligence algorithm with the *ansatz *solution know from the literature. Next, we apply the method to solve the system when the ground states of the quantum dots are detuned, and when the system is perturbed by the interaction with the uncontrollable degrees of freedom of the surrounding environment, resulting in dephasing and loss terms in the master equation describing the system, for which there is no analytical method. Like for the case of the artificial intelligence learning in the classical Atari environment mnih2015human , agent here interacts with a QuTIP johansson2012qutip simulation providing the environment of the CTAP by implementing the master equation of the system, and exploiting the information retrieved from the feedback in terms of the temporal evolution of the population of the dots. The use of a pre-trained neural network as a starting point to identify the solution of a modified master equation may further reduce the computation time by one order of magnitude. As a further advantages of such approach, a 2-step temporal Bayesian network analysis allows to identify which parameters of the system are more influencing the process. Our investigation indicates that a key factor is the appropriate definition of the reward function that deters the system from occupying the central quantum dot and rewards the occupation of the last quantum dot.
I Steering a quantum system far from final equilibrium state
Reinforcement learning (RL) is a set of techniques used to learn how to behave in sequential decision-making problems when no prior knowledge about the system dynamics is available, or the control problem is too complex for classical optimal-control algorithms. RL methods can be roughly classified into three main categories: value-based, policy-based, and actor-critic methods sutton1998reinforcement . Recently, actor-critic methods have proven to be successful in solving complex continuous control problems duan2016benchmarking .
The idea behind actor-critic methods is to use two parametric models (e.g., neural networks) to represent both the policy (actor) and the value function (critic). The actor decides in each state of the system which action to execute, while the critic learns the value (utility) of taking each action in each state. Following the critic’s advice, the actor modifies the parameters of its policy to improve the performance. Among the many actor-critic methods available in the literature, we selected Trust Region Policy Optimization algorithm (TRPO) schulman2015trust to find an optimal policy of control pulses to achieve CTAP in a linear array of quantum dots. The choice of TRPO is motivated both by its excellent performance on a wide variety of tasks and by the relative simplicity of tuning its hyper-parameters schulman2015trust (see S.I.).
The coherent transport by adiabatic passage is the solid state version of a method developed for Stimulated Raman Adiabatic Passage (STIRAP)vitanov2001laser ; menchon2016spatial , relevant for instance in those quantum information processing architectures that require to shuttle a qubit from one location to another by paying attention to minimize the information loss during transport. In solid-state quantum devices based on either silicon maurand2016cmos or gallium arsenide bluhm2011dephasing , the qubit can be encoded, for instance, into spin states of either excess electron(s) or hole(s) in quantum dots rotta2017quantum . CTAP was originally developed for single-electron states in single-occupied quantum dots, but it can be also extended to more complex spin states, such as for hybrid qubits based on triplets of spin.ferraro2015coherent If one imagines to employ, for instance, an array of dopants in silicon prati2012anderson , a reasonable inter-dopant spacing is of the order of about 20 nm and hopping time of 100 ps hollenberg2006two . The adiabatic passage needs control pulses with a lower bandwidth of an order of magnitude or two with respect to the hopping time, which can be managed by conventional electronics homulle2017reconfigurable . To demonstrate the exploitation of deep reinforcement learning, we start by the simplest case of CTAP across a chain of three identical quantum dots. The deep reinforcement learning architecture is depicted in Figure 1a. The simulation of the physical system that supports the CTAP consists in the environment E that receives as input the updated values of the parameters (in our case the coupling terms with between the adjacent dots ith and (i+1)th) that reflect the action on the control gates as calculated by the agent A according to the policy . In turn, the environment E computes the new system state (here expressed in terms of the density matrix of the triple quantum dot device) and provides feedback to agent A. Agent A calculates the next input parameters after evaluating the effects of the previous input according to a reward function , which is expressed in terms of the system state.
More explicitly, the ground state of each quantum dot is tuned with respect to the others by external top metal gates (not shown for simplicity in the sketch of the environment E in Figure 1a),while the coupling between two neighboring quantum dots is in turn controlled by additional barrier control gates. The idealized physical system is prepared so that the ground states of the three quantum dots have the same energy. As the reference energy is arbitrary, we can without any loss of generality set . The Hamiltonian therefore reads:
[TABLE]
One of the three eigenstates is special in that it is expressed as a function of the state of the first and third dots only and reads
[TABLE]
where ). A suitable time evolution of the values of the coupling terms and between the dots allows to transform from at to at . If the Hamiltonian is prepared in at , it will remain in the same eigenstate if the adiabaticity criterion is met, that is where eigenstates are explicitly expressed in the S.I.. The effectiveness of the pulse sequence of the barrier control gate, which is reflected on the coupling terms , is addressed by taking as the fidelity and by maximizing it while the population is kept constant at zero. Time evolution is governed by a master equation that involves the density matrix , namely . Notoriously a suitable shaping of and as Gaussian pulses can achieve a coherent transport with high fidelity, if . The remarking fact is that the two pulses must be applied in the so-called counter-intuitive sequence, with the meaning that the first gate controlling is operated as second in time, while the second gate acting on as first. Such pulse sequence drives the occupation of the first dot to zero and that of the last dot to 1, while maintaining the central dot empty () greentree2004coherent . It is worth mentioning that recently a different *ansatz *combination of pulse shapes has been proposed to speed up such process ban2018fast . Generally speaking, there is no analytical method to optimize the pulses, so further improvements are based only on still undiscovered ideas. Here is where the power of the deep reinforcement learning comes into play. Thanks to a robust definition of the *reward function *that allows the agent to judge its performance, the neural network evolves in order to obtain the best temporal evolution of the coupling parameters , so to ensure that the wanted effects on the electron population across the device evolved over time. The definition of the best reward function is certainly the most delicate choice in the whole model. The key features of the reward can be summarized by two properties, namely its generality, so it should not contain specific information on the characteristics of the two pulses, and its expression as a function of the desired final state, which in our case consists of maximizing \rho_{33}\at the end of the temporal evolution. The rewards functions used in this research are fully accounted for in the S.I.. The reward function used in most simulations is
[TABLE]
with . The sum of the first three terms is non-positive at each time step, so the agent will try to bring it to 0 by minimizing and by maximizing . Subtracting (e.g., punishing electronic occupation in the site 2) improves the convergence of the learning. Furthermore, in some specific cases, we stop the agent at an intermediate episode if is greater than an arbitrary threshold for a certain number of time step. This choice can help to find fast pulses that achieve high-fidelity quantum information transport, at the cost of a higher with respect to the analytic pulses (more details are given in S.I.).
Figure 3 shows the best results achieved by the agent at various epochs. As the agent is left free of spanning the whole coupling range at each step, we smoothed the output values and we run the simulation for the smoothed values, with negligible differences from the simulation calculated by using the original output values. The smoothing is done to obtain a more regular shape of the pulses by a spline interpolation. The three occupations , shown in Figure 3 refer to the smoothed pulse sequences. At the very beginning, the untrained agent tries random values with apparently small success, as the occupation oscillates between the first and the last dot during time. It is worth noting that despite such fluctuation, the agent, thanks to the reward function, learns very quickly after only 45 epochs to keep the occupation of the central dot always below 0.5. After about 2000 epochs, the agent learns to stabilize the occupation of the first and last dot, while keeping the central dot empty. After about twice the time, the reversing of the population of the first and last dot happens, even if they do not yet achieve the extremal values. Finally, after about four times more, the agent achieves a high-fidelity CTAP. Notice that the pulse sequence reminds the ansatz Gaussian counterintuitive pulse sequence as the second gate acting on is operated first, but the shape of the two pulses differs. It is remarkable that the reward function implicitly asks to achieve the result as quickly as possible, resulting in a pulse sequence that is significantly faster than the analytical Gaussian case, and comparable to the recent proposal of Ref. ban2018fast . The high point is that the agent achieves such results irrespectively on the actual terms of the Hamiltonian contributing to the master equation. Therefore, DRL can be applied straightforward to more complex cases for which there is no generalization of the ansatz solutions found for the ideal case, to which we devote the next section.
II Deep reinforcement learning to overcome disturbances
We turn now the attention to the behavior of our learning strategy applied to the non-ideal scenario in which the realistic conditions typical of semiconductor quantum dots are considered. In particular, we discuss the results produced by DRL when the dot array is affected by detuning between the energy gap of the dots, dephasing and losses. Such three effects do exist, to different degrees, in any practical attempt to implement CTAP of the electron spin in quantum dots: the first one is typically due to manufacturing defects jehl2011mass , while the last two emerge from the interaction of the dots with the surrounding environment breuer02 ; clement2010one involving charge and spin fluctuations pierre2009background ; kuhlmann2013charge and noise on the magnetic field prati2013quantum . Under such kind of disturbances, neither analytical nor *ansatz *solutions are available. On the other side, the robustness and generality of the reinforcement-learning approach can be exploited naturally as, from the point of view of the algorithm, it does not differ from the ideal case discussed above. As we could determine the pulse sequence only by adding a second hidden layer H2 of the neural network, we refer from now on to deep reinforcement learning.
Let us consider a system of quantum dots with different energy . We indicate by , so that the Hamiltonian (1) can be written, without loss of generality, as
[TABLE]
Figure 3b refers to the particular choice (a full 2D scan of both and is shown in the S. I.). In this case DRL finds a solution that induces a significantly faster transfer than the one obtained with standard counter-intuitive Gaussian pulses. Moreover, the latters are not even able to achieve an acceptable fidelity. As shown in the S. I., such speed is a typical feature of the pulse sequences determined by DRL.
Besides energy detuning between the quantum dots, in a real implementation, the dots interact with the surrounding environment. Since the microscopic details of such interaction are unknown, its effects are taken into account through an effective master equation. A master equation of Lindblad type with time-independent rates is adopted to grant sufficient generality while keeping a simple expression. To show the ability of the DRL to mitigate disturbances, we consider, in particular, two major environmental effects consisting of decoherence and losses respectively. The first corresponds to a randomization of relative phases of the electron states in the quantum dots, which results in a cancellation of the coherence terms, i.e., the off-diagonal elements of the density matrix in the position basis. The losses, instead, model the erasure of the quantum information carried by the electron/hole moving along the dots. In fact, while the carrier itself cannot be reabsorbed, the quantum information, here encoded as a spin state, can be changed by the interaction with some surrounding spin or by the noise on the magnetic field. In the presence of dephasing and losses, the system’s master equation is of Lindblad type. Its general form is
[TABLE]
where are the Lindblad operators, the associated rates, and is the anticommutator.
We first considered each single dot affected by dephasing and assumed equal the dephasing rate for each dot. The master equation can be rewritten as
[TABLE]
Figure 3c shows an example of the pulses determined by DRL and the corresponding dynamics for the choice . The CTAP is achieved with Gaussian pulses in a time at the cost of a significant occupation of the central dot (inset). The advantage brought by the DRL agent with respect to Gaussian pulses is manifest: DRL (solid lines) realizes the population transfer in about half of the time required when the analytic pulses (dashed lines) are employed. The occupation of the central dot is less than the one achieved by Gaussian pulses.
We now consider the inclusion of a loss term in the master equation. The loss refers to the information carried by the electron encoded by the spin. While the loss of an electron is a very rare event in quantum dots, requiring the sudden capture of a slow trap prati2008giant ; prati2010measuring , the presence of any random magnetic field and spin fluctuation around the quantum dots can modify the state of the transferred spin. Losses are described by the operators , where is the loss rate, modeling the transfer of the amplitude from the -th dot to an auxiliary vacuum state . Figure 3d shows the superior performance of DRL versus analytic Gaussian pulses. Because of the reward function, DRL minimizes transfer time as to minimize the effect of losses. As a further generalization, we applied DRL to the passage through more than one intervening dot, an extension called straddling CTAP scheme (or SCTAP) as from Refs. malinovsky1997simple ; greentree2004coherent . To exemplify a generalization to odd , we set according to the sketch depicted in Figure 4a, and no disturbance is considered for simplicity. For 5-state transfer, like 3-state and for any other odd number of quantum dots, there is one state at zero energy. The realization of the straddling tunneling sequence is achieved by augmenting the original pulse sequence by the straddling pulses, identical for all intervening tunneling rates . The straddling pulse involves the second and third control gates, as shown in Figure 4a. The pulse sequence discovered by DRL (Figure 4b) is significantly different from the known sequence based on Gaussian pulses (Figure 4a, right) and it operates the population transfer in about one third of the time by displaying only some occupation in the central dot. It is remarkable that the reward function (see S.I.) achieves such a successful transfer without any requirement on the occupation of the intermediate dots with (i=2,3,4) as it only rewards occupation of the last dot.
III Analysis of relevant variables within the deep reinforcement learning framework
The advantages of employing DRL with respect of an ansatz solution to solve the physical problem is further increased by the chance of determine which factors are more relevant to the effectiveness of the final solution by the analysis of the neural network. In fact, the employment of DRL algorithm enables the analysis of which state variables are actually relevant to solve the control problems, like that discussed above. To select the variables needed to solve an MDP, we follow the approach presented in peters2008natural ; peters2010relative ; castelletti2011tree . The idea is that a state variable is useful if it helps to explain either the reward function or the dynamics of the state variables that in turn are necessary to explain the reward function. Otherwise, the state variable is useless and it can be discarded without affecting the final solution. To represent the dependencies between the variables of an MDP, we use a 2-Step Temporal Bayesian Network (2TBN) koller2009probabilistic . In the graph of Figure 5, there are three types of nodes: the Grey diamond node represents the reward function, the circle nodes represent state variables and the squares represent action variables. The nodes are arranged on three vertical layers: the first layer on the left includes the variables at time , the second layer the state variables at time , and the third layer the node that represents the reward function. If a variable affects the value of another variable, we obtain a direct edge that connects the former to the latter. The weights are quantified in the S.I.. Figure 5 shows the 2TBN estimated from a dataset of 100,000 samples obtained from the standard case of the ideal CTAP. As expected from Eq. 3, the reward function depends only on the values of variables and . From the 2TBN, it emerges that the dynamics of these two state variables can be fully explained by knowing their value at the previous step, the values of the two action variables and and the actions taken in the previous time step (stored in the variables and ). All other state variables do not appear and therefore could be ignored for the computation of the optimal control policy. Such finding matches the expectation from the constraints of the physical model that the coherences are not directly involved in the dynamics and that is linearly dependent from and as the trace of the density matrix is constant. To confirm this finding, the agent has been successfully trained in the standard case of the ideal CTAP by using only the input values (, , , ). Furthermore, the size of the hidden layer H1 could be reduced in this case from 64 to 4 with the same convergence of the total reward as a function of the episodes, or even faster by reducing the batch size from 20 to 10 (see S.I.). In the detuning and dephasing cases, the corresponding 2TBNs are more complex since the dynamics of and are affected also by the values of the other elements of the matrix . This fact is also corresponding to the changes carried by the Hamiltonian, as trace is not constant when loss are present and because of the direct action on the coherence for the dephasing.
IV Conclusions
Neural networks can discover control sequences of a tuneable quantum system starting its time evolution far from its final equilibrium, without any prior knowledge. Contrary to the employment of special ansatz solutions, deep reinforcement learning discovers novel sequences of control operations to achieve a target state, regardless possible deviations from the ideal conditions. Such method is irrespective from having previously discovered *ansatz *solutions and it applies when they are unknown. To apply to a practical quantum system known for its counter-intuitiveness, we adopted quantum state transport across arrays of quantum dots, including sources of disturbances such as energy level detuning, dephasing, and loss. In all cases, the solutions found by the agent outperform the known solution in terms of either speed or fidelity or both. Both pre-training of the network and 2TBN analysis - by reducing the computational effort - contribute to speed up the learning process. In general, we have shown that neural-network based deep reinforcement learning provides a general tool for controlling physical systems by circumventing the issue of finding ansatz solutions when neither a straightforward method nor a brute force approach are possible.
V Acknowledgements
E. Prati gratefully acknowledges the support of NVIDIA Corporation for the donation of the Titan Xp GPU used for this research.
VI Methods
VI.1 Master equation for Hamiltonian including pure dephasing
Pure dephasing Taylor2008 is the simplest model that accounts for environment interaction of an otherwise closed system. The corresponding Lindblad operators are diagonal and their form is:
[TABLE]
In the case , the master equation becomes:
[TABLE]
If the Hamiltonian is time-independent, then
[TABLE]
for every , so the electronic population remains unchanged in presence of pure dephasing. This implies Tempel that the energy of the system remains unchanged during the evolution, since the environment cannot change it.
VI.2 Neural network
The neural network consists of a multi-layered feed-forward network of neurons, where , as it includes the nine elements of the density matrix and the two coupling terms , are the two updated values of the coupling terms spanning a continuous range between 0 and an arbitrary value chosen according to experimental considerations, and the number of neurons of the hidden layer.
Different setups for the neural network have been employed. Nonethless, all the neural networks were feed-forward and fully connected, with ReLU activation function for the neurons. For the implementation of the neural networks and their training, Tensorforce schaarschmidt2017tensorforce has been employed. Being the RL algorithm adopted for this work Trust Region Policy Optimization (TRPO), the hyperparameters have been set as summarized in S.I.. Optimal number of neurons of the hidden layer is peaked around (see S.I.).
VI.3 Reward functions
Various kinds of reward function have been implemented and compared. In general, higher cumulative reward values should correspond to better approximation of an ideal coherent transfer.
The difficulty of defining the reward in our case arises from the fact that ideally one wants to keep the maximum value of small while the maximum value of (which defines the fidelity) reaches 1.
Among those tested, the most effective reward functions have, in general, two characteristics:
- •
A punishing term , so that this subtractive term is [math] if , , and is maximum if , , so an agent will try to minimize the difference between and 1 and the difference between and 0.
- •
A punishing term proportional to , where . This term exponentially punishes increments of . Typical values for are of the order of units.
Note that such two terms are both non-positive, so a "perfect" simulation can have a maximum of cumulative reward equal to [math]. The two terms are also differentiable, and this can help the agent to converge to a global maximum, because the algorithm used in this work involves derivatives of the reward function.
The reward functions used for each case are reported in S.I.. In the case of the SCTAP across an array of quantum dots, the reward function used in Figure 4 of the main text is:
[TABLE]
Despite its simplicity, the agent was able to keep and close to zero during most of the population transfer.
VI.4 Software
The QuTIP routine has been run in parallel by using GNU Parallel.tange2011gnu
VII Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
VIII Competing interest
The authors declare that there are no competing interests
IX Author contributions
R. P. developed the simulation and implemented the algorithms, D. T. elaborated on the Hamiltonian framework and the master equation formalism, M. R. operated the reinforcement learning analysis, E. P. conceived the simulated experiment and coordinated the research. All the Authors discussed and contributed to the writing of the manuscript.
X Figures
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) R. S. Sutton, A. G. Barto, et al. , Reinforcement learning: An introduction . MIT press, 1998.
- 2(2) V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. , “Human-level control through deep reinforcement learning,” Nature , vol. 518, no. 7540, p. 529, 2015.
- 3(3) T. Fösel, P. Tighineanu, T. Weiss, and F. Marquardt, “Reinforcement learning with neural networks for quantum feedback,” ar Xiv preprint ar Xiv:1802.05267 , 2018.
- 4(4) A. D. Greentree, J. H. Cole, A. Hamilton, and L. C. Hollenberg, “Coherent electronic transfer in quantum dot systems using adiabatic passage,” Physical Review B , vol. 70, no. 23, p. 235317, 2004.
- 5(5) J. H. Cole, A. D. Greentree, L. Hollenberg, and S. D. Sarma, “Spatial adiabatic passage in a realistic triple well structure,” Physical Review B , vol. 77, no. 23, p. 235418, 2008.
- 6(6) A. D. Greentree and B. Koiller, “Dark-state adiabatic passage with spin-one particles,” Phys. Rev. A , vol. 90, p. 012319., 2014.
- 7(7) R. Menchon-Enrich, A. Benseny, V. Ahufinger, A. D. Greentree, T. Busch, and J. Mompart, “Spatial adiabatic passage: a review of recent progress,” Reports on Progress in Physics , vol. 79, no. 7, p. 074401, 2016.
- 8(8) D. Rotta, M. D. Michielis, E. Ferraro, M. Fanciulli, and E. Prati, “Maximum density of quantum information in a scalable CMOS implementation of the hybrid qubit architecture,” Quantum Information Processing , vol. 1425, pp. 1–22, 2016.