Fitting ReLUs via SGD and Quantized SGD
Seyed Mohammadreza Mousavi Kalan, Mahdi Soltanolkotabi, and A. Salman, Avestimehr

TL;DR
This paper demonstrates that stochastic gradient descent efficiently finds the optimal ReLU weights in a planted Gaussian model, and introduces a quantized SGD method that reduces communication costs without sacrificing convergence speed.
Contribution
It proves geometric convergence of SGD for ReLU fitting in a planted model and introduces a quantized SGD scheme for distributed training with minimal accuracy loss.
Findings
SGD converges geometrically to the planted model with optimal sample complexity.
Quantized SGD reduces communication costs significantly.
Distributed implementation on Amazon EC2 confirms theoretical results.
Abstract
In this paper we focus on the problem of finding the optimal weights of the shallowest of neural networks consisting of a single Rectified Linear Unit (ReLU). These functions are of the form with denoting the weight vector. We focus on a planted model where the inputs are chosen i.i.d. from a Gaussian distribution and the labels are generated according to a planted weight vector. We first show that mini-batch stochastic gradient descent when suitably initialized, converges at a geometric rate to the planted model with a number of samples that is optimal up to numerical constants. Next we focus on a parallel implementation where in each iteration the mini-batch gradient is calculated in a distributed manner across multiple processors and then broadcast to a master or all other processors. To…
Click any figure to enlarge with its caption.
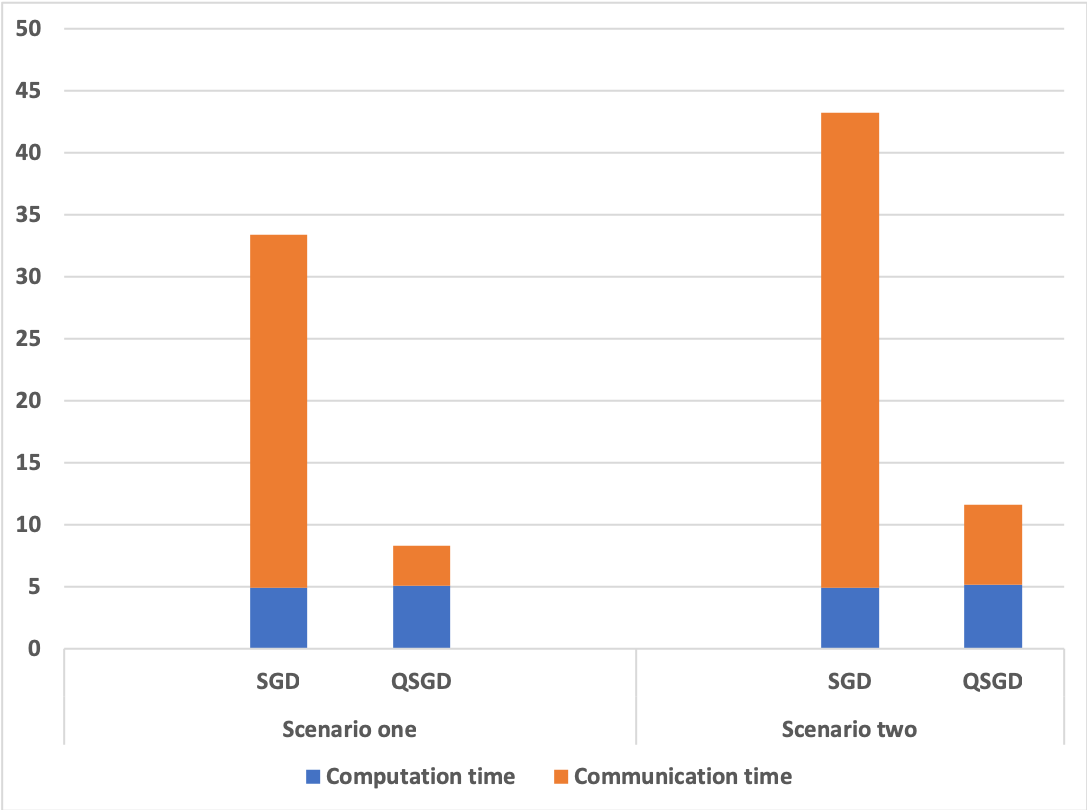 Figure 1
Figure 1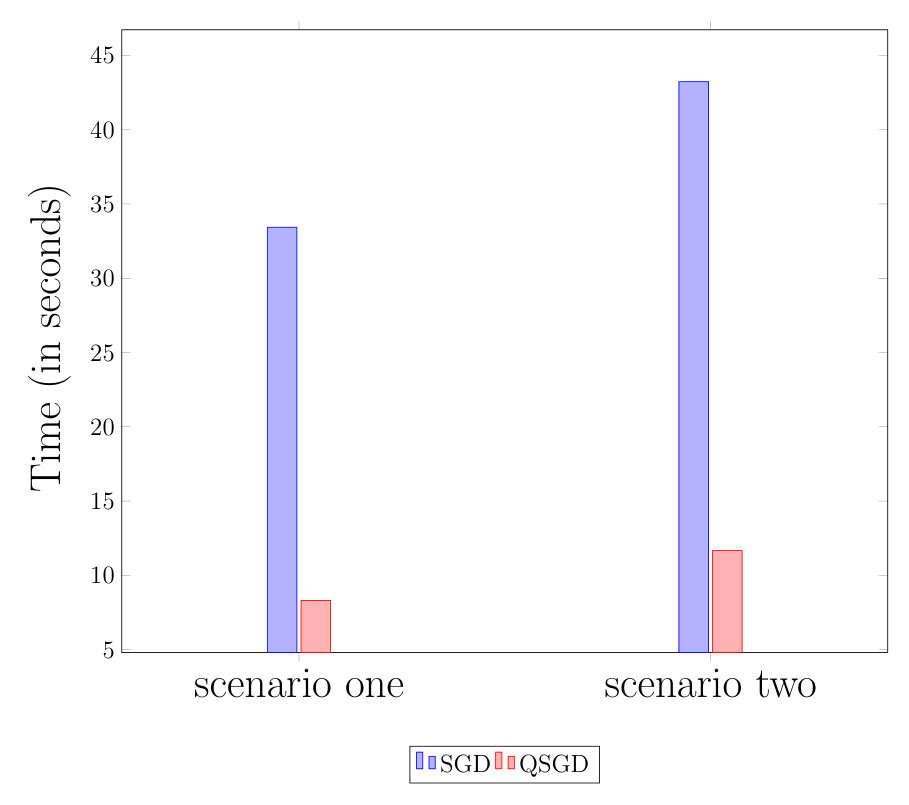 Figure 2
Figure 2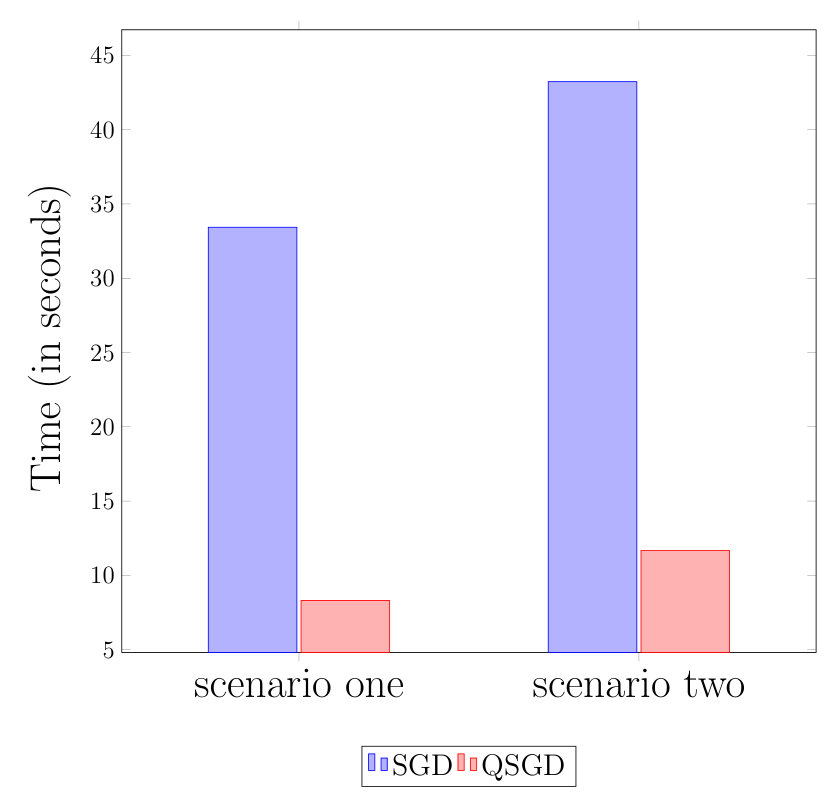 Figure 3
Figure 3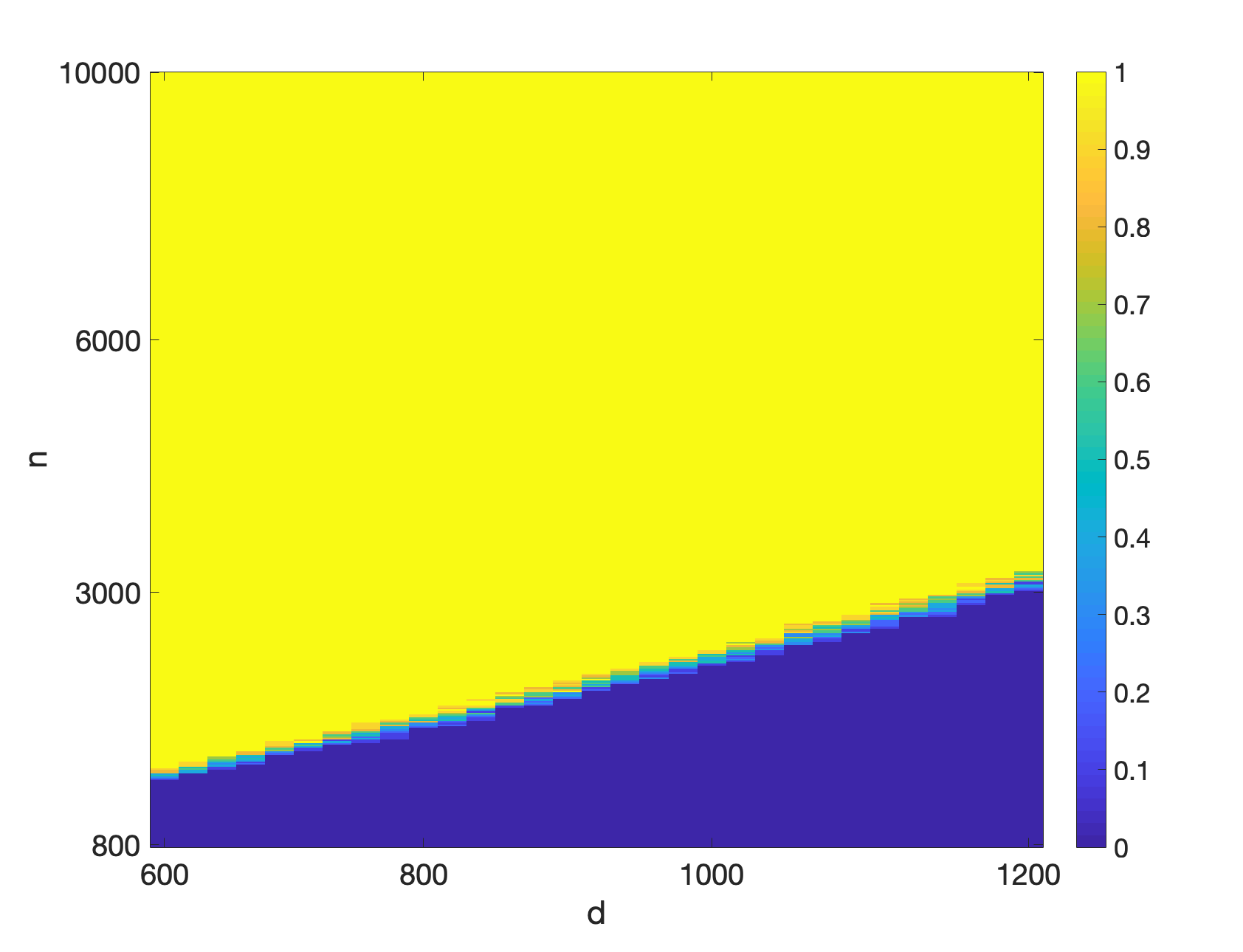 Figure 4
Figure 4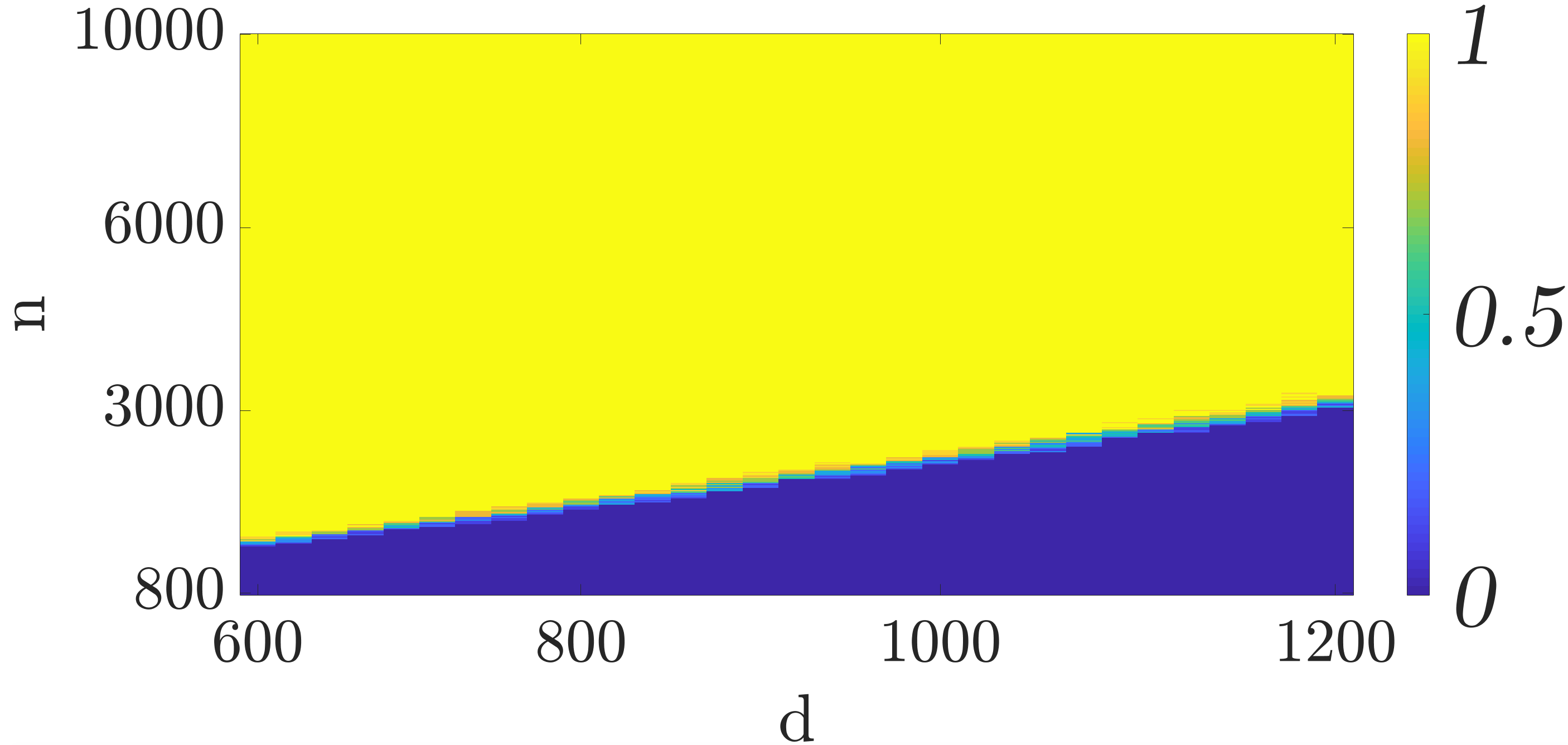 Figure 5
Figure 5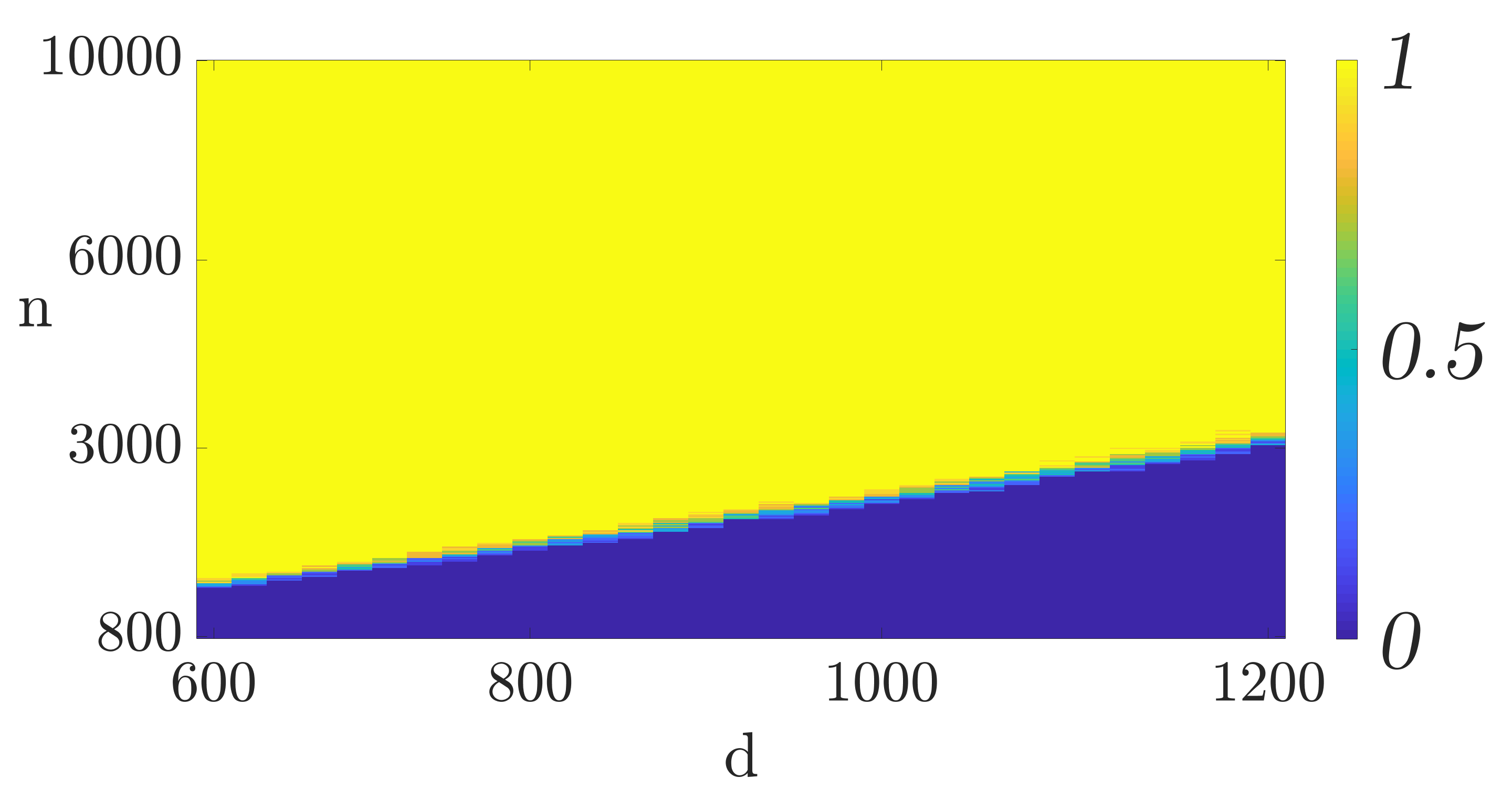 Figure 6
Figure 6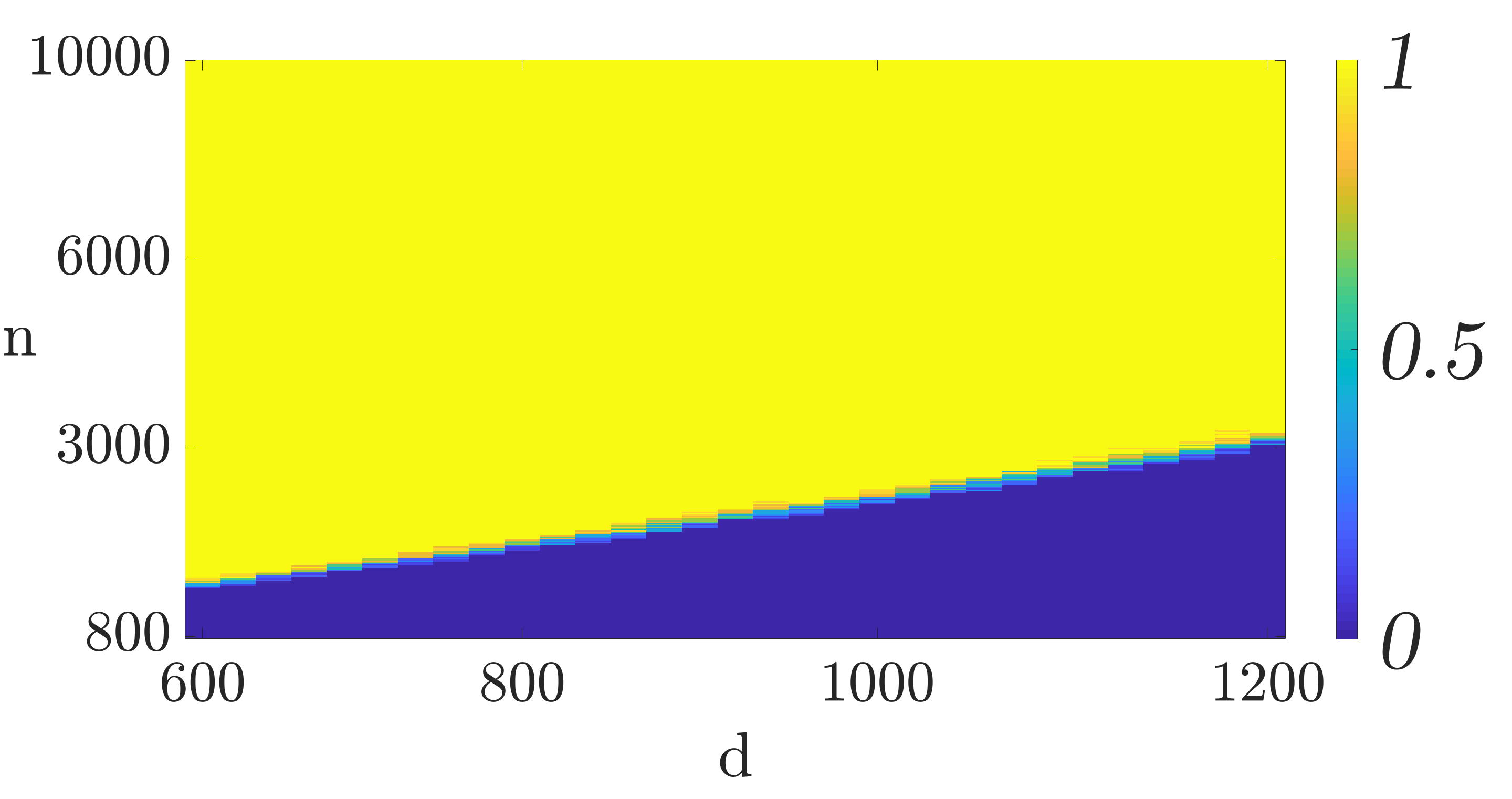 Figure 7
Figure 7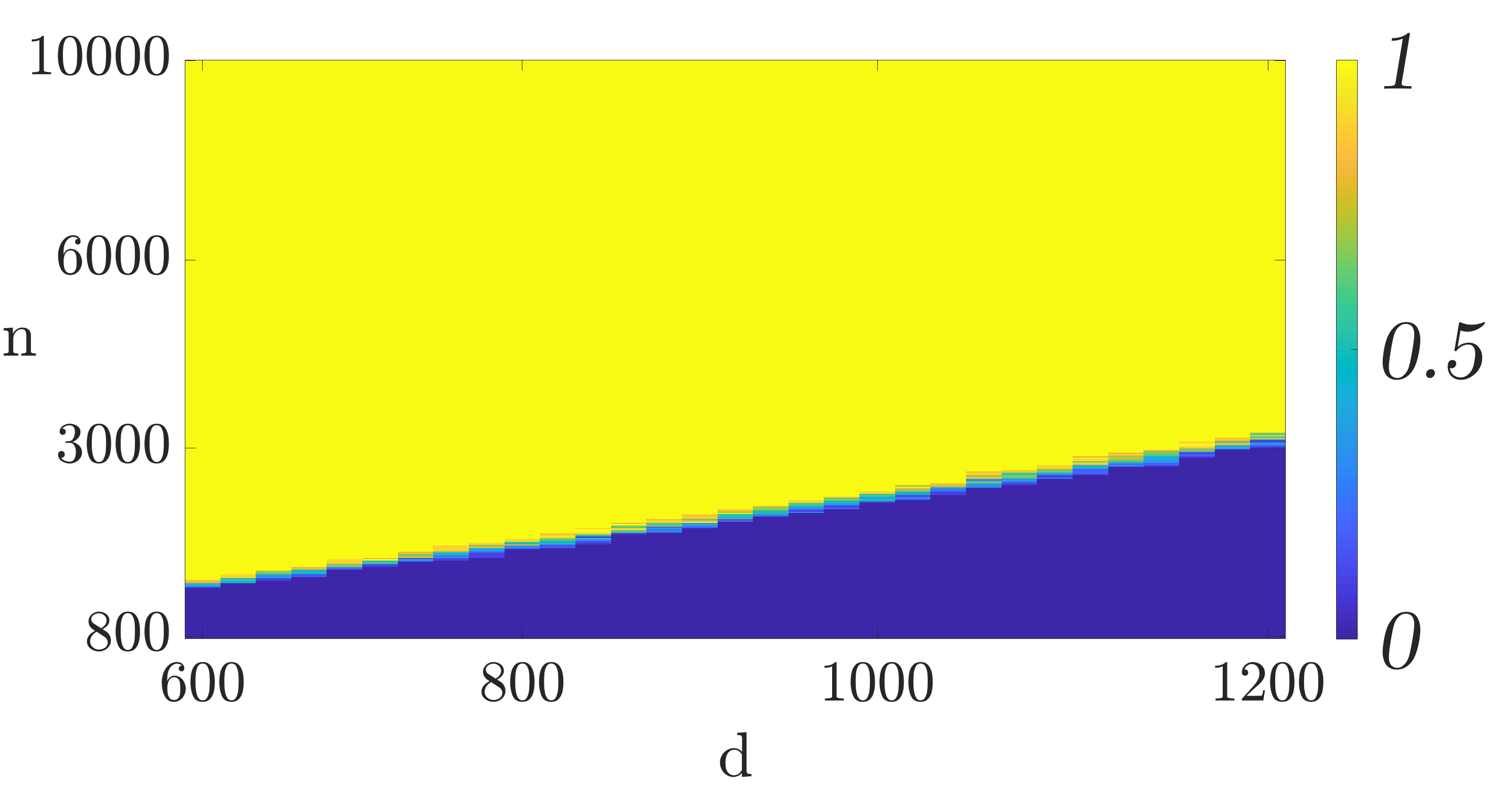 Figure 8
Figure 8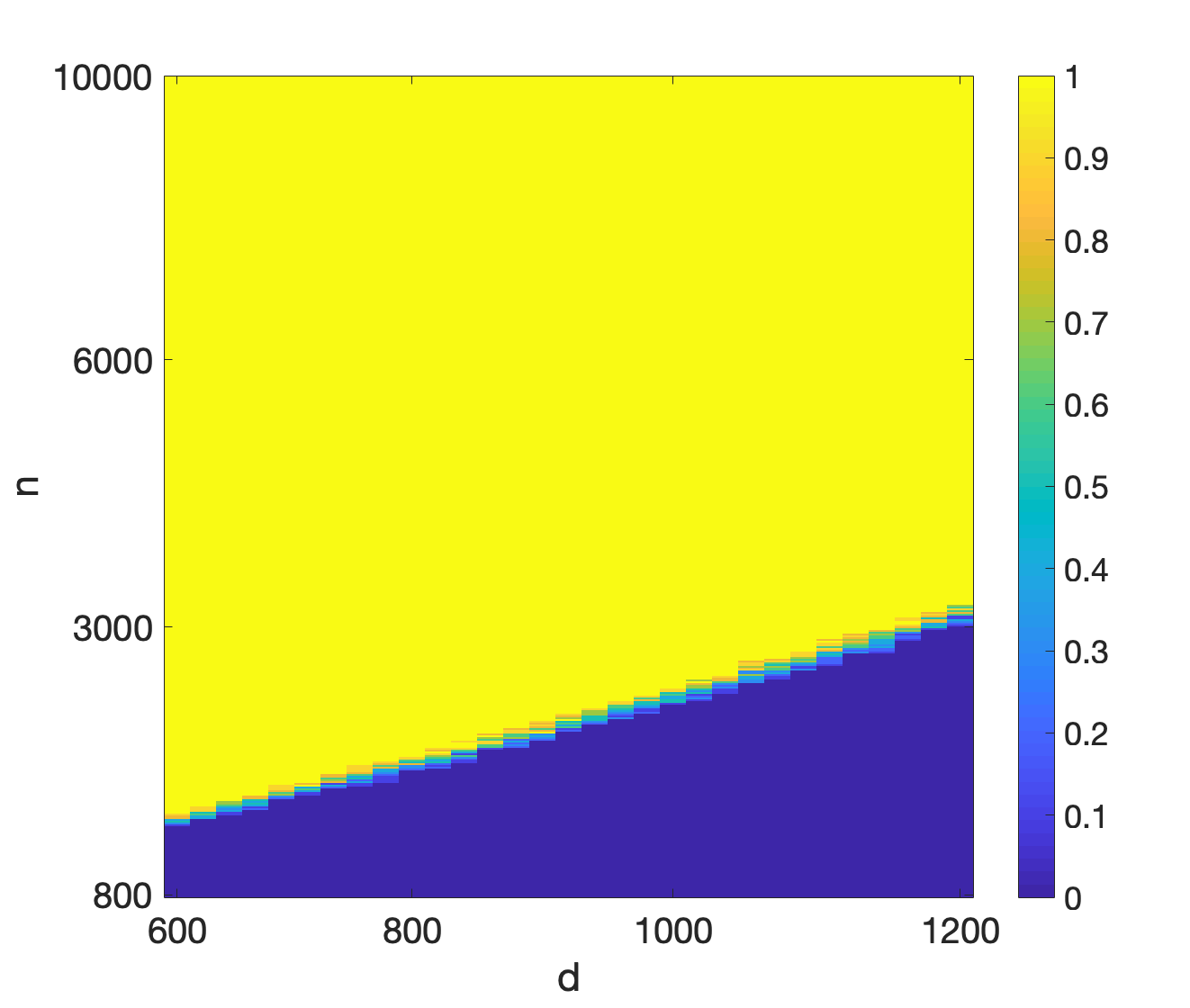 Figure 9
Figure 9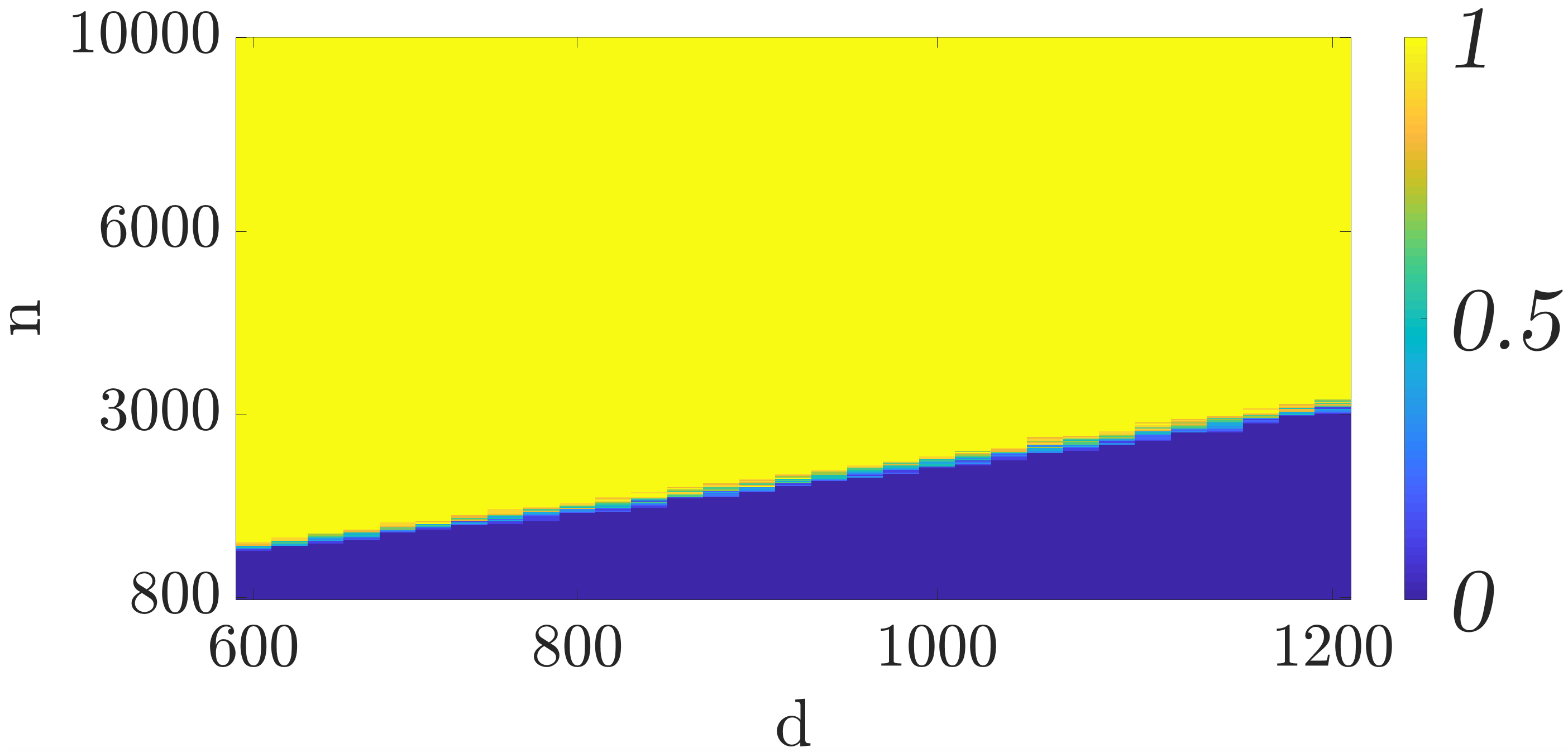 Figure 10
Figure 10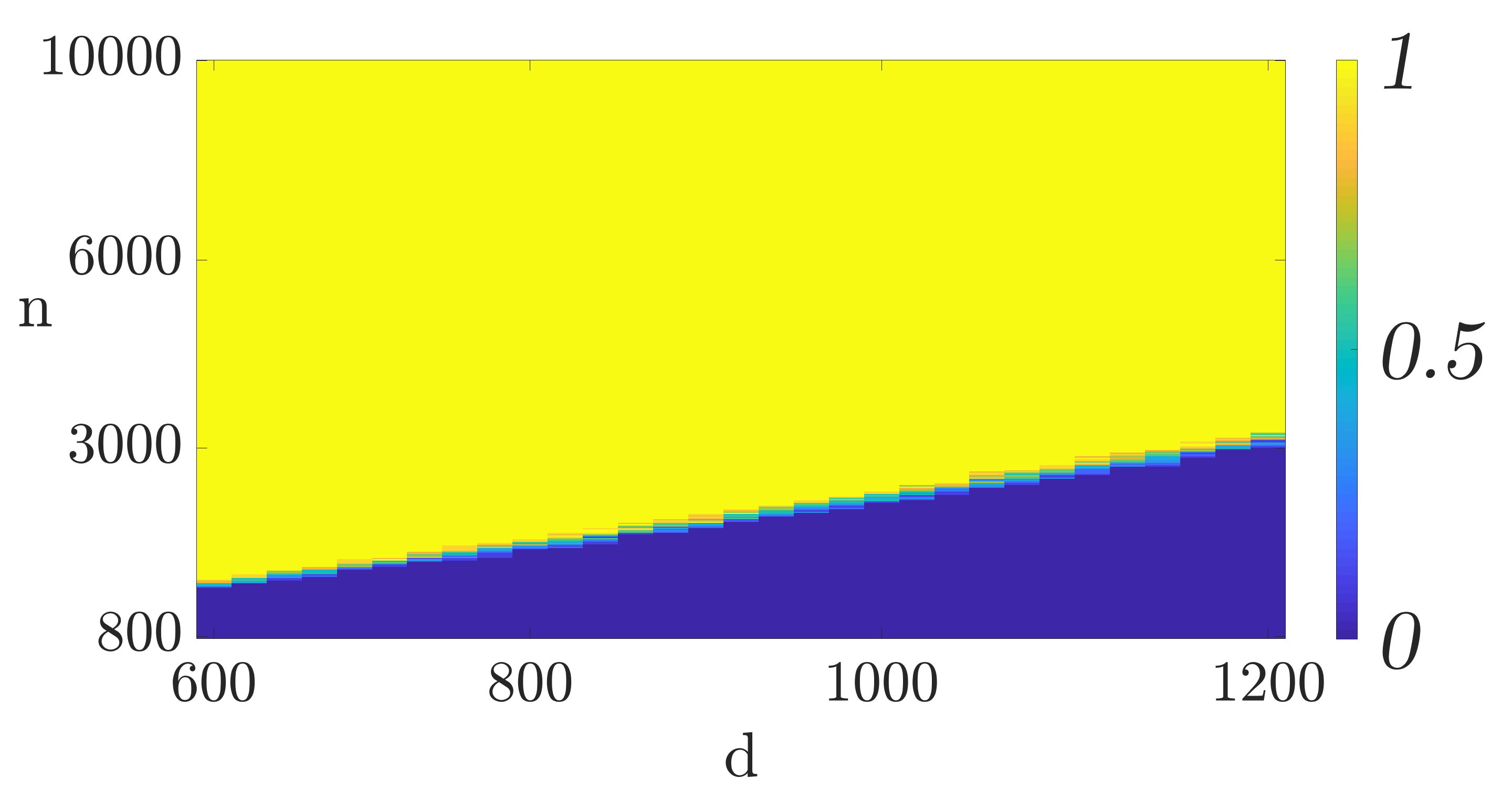 Figure 11
Figure 11| scenario index | # of workers () | # of data points () | feature dimension () |
| 1 | 40 | 20000 | 4000 |
| 2 | 50 | 25000 | 4000 |
| schemes | scenario index | comm. time | comp. time | total time |
|---|---|---|---|---|
| SGD | 1 | 28.5100 s | 4.921 s | 33.431 s |
| QSGD | 1 | 3.2470 s | 5.056 s | 8.303 s |
| SGD | 2 | 38.2910 s | 4.94 s | 43.231 s |
| QSGD | 2 | 6.5010 s | 5.169 s | 11.67 s |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsStochastic Gradient Descent
Fitting ReLUs via SGD and Quantized SGD
Seyed Mohammadreza Mousavi Kalan, Mahdi Soltanolkotabi, and A. Salman Avestimehr
Ming Hsieh Department of Electrical Engineering, University of Southern California
Email: [email protected], [email protected], [email protected]
Abstract
In this paper we focus on the problem of finding the optimal weights of the shallowest of neural networks consisting of a single Rectified Linear Unit (ReLU). These functions are of the form with denoting the weight vector. We focus on a planted model where the inputs are chosen i.i.d. from a Gaussian distribution and the labels are generated according to a planted weight vector. We first show that mini-batch stochastic gradient descent when suitably initialized, converges at a geometric rate to the planted model with a number of samples that is optimal up to numerical constants. Next we focus on a parallel implementation where in each iteration the mini-batch gradient is calculated in a distributed manner across multiple processors and then broadcast to a master or all other processors. To reduce the communication cost in this setting we utilize a Quanitzed Stochastic Gradient Scheme (QSGD) where the partial gradients are quantized. Perhaps unexpectedly, we show that QSGD maintains the fast convergence of SGD to a globally optimal model while significantly reducing the communication cost. We further corroborate our numerical findings via various experiments including distributed implementations over Amazon EC2.
1 Introduction
Many modern learning tasks involve fitting nonlinear models to data. Given training data consisting of pairs of input features and desired outputs we wish to infer a function that best explains the training data. A prominent example is neural network models which have enabled impressive empirical success in applications spanning natural language processing to robotics. Guaranteed training of nonlinear data models however remain elusive. The main challenge is that fitting such nonlinear models requires solving highly nonconvex optimization problems and it is not clear why local search methods such as stochastic gradient descent converge to globally optimal solutions without getting stuck in spurious local optima and saddles.
In this paper we focus on fitting Rectified Linear Units (ReLUs) to the data which are functions of the form . We study a nonlinear least-squares formulation of the form
[TABLE]
A popular approach to solving problems of this kind is via Stochastic Gradient Descent (SGD). Indeed, SGD due to its manageable memory and footprint and highly parallelizable nature has become a mainstay of modern learning systems. Despite its wide use however, due to the nonconvex nature of the loss it is completely unclear why SGD converges to a globally optimal model. Fitting ReLUs via SGD poses new challenges: When are the iterates able to converge to global optima? How many samples are required? What is the convergence rate and is it possible to insure a fast, geometric rate of convergence? How do the answers to above change based on the mini-batch size?
Yet, another challenge that arises when implementing SGD in a distributed framework is the high communication overhead required for transferring gradient updates between processors. A recent remedy is the use of quantized gradient updates such as Quantized SGD (QSGD) to reduce communication overhead. However, there is little understanding of how such quantization schemes perform on nonlinear learning tasks. Do quantized updates converge to the same solution as unquantized variants? If so, how is the convergence rate affected? How many quantization levels or bits are required to achieve good accuracy?
In this paper we wish to address the above challenges. Our main contributions are as follows:
- •
We study the problem of fitting ReLUs and show that SGD converges at a fast linear rate to a globally optimal solution. This holds with a near minimal number of data observations. We also characterize the convergence rate as a function of the SGD mini-batch sizes.
- •
We show that the QSGD approach of [1] also converges at a linear rate to a globally optimal solutions. This holds even when the number of quantization levels grows only Logarithmically in problem dimension. We also characterize the various tradeoffs between communication and computational resources when using such low-precision algorithms.
- •
We provide experimental results corroborating our theoretical findings.
2 Algorithms: SGD and QSGD
In this section we discuss the details of the algorithms we plan to study. We begin by discussing the specifics of the SGD iterates we will use. We then discuss how to use quantization techniques in order to reduce the communication overhead in a distributed implementation.
2.1 Stochastic Gradient Descent (SGD) for fitting ReLUs
To solve the optimization problem (1) we use a mini-batch SGD scheme. While, the loss function (1) is not differentiable, one can still use an update akin to SGD by defining a generalized notion of gradients for non-differentiable points as a limit of gradients of points converging to the non-differentiable point [2]. Then, in each iteration we sample the indices uniformly with replacement from and apply updates of the form
[TABLE]
Here, denotes the generalized gradient of the loss and is equal to
[TABLE]
2.2 Reducing the communication overhead via Quantized SGD
One of the major advantages of SGD is that it is highly scalable to massive amounts of data. SGD can be easily implemented in a distributed platform where each processor calculates a portion of the mini-batch based on the available local data. Then the partial gradients are sent back to a master node or the other processors to calculate the full mini-batch gradient and update the next iteration. The latter case for example is common in modern deep learning implementations [1]. Both distributed approaches however, suffer from a major bottleneck due to the cost of transmitting the gradients to the master or between the processors.
A recent remedy for reducing this cost is utilizing lossy compression to quantize the gradients prior to transmission/broadcast. In particular, a recent paper [1] proposes the quantized SGD (QSGD) algorithm based on a randomized quantization function with denoting the number of quantization levels. Specifically, for a vector the th entry of the quantization function is given by
[TABLE]
where ’s are independent random variables defined as
[TABLE]
Here, is an integer such that and we follow the convention that .
To see how this quantization scheme can be used in a distributed setting consider a master-worker distributed platform consisting of worker processors numbered and a master processor. To run SGD on this platform we partition the training data points into batches of size with each worker processor storing one of the batches. In each iteration, the master broadcasts the latest model to all the workers. Each worker then chooses points from local available data points randomly and computes a partial gradient based on the selected data points using the latest model received from the master and quantizes the resulting partial gradient. The workers then send the quantized stochastic gradients to the master. The master waits for all the quantized partial stochastic gradients from the workers and then updates the model using their average. As a result the aggregate effect of QSGD leads to updates of the form
[TABLE]
Since only the quantized partial gradients are transimitted between the processors, QSGD significantly reduces the number of communicated bits.
3 Main results
3.1 SGD for fitting ReLUs
In this section we discuss our results for convergence of the SGD iterates.
Theorem 3.1
Let be a fixed weight vector, and the feature vectors be i.i.d. Gaussian random vectors distributed as with the corresponding labels given by . Furthermore, assume
- (I)
the number of samples obey for a fixed numerical constant .
- (II)
the initial estimate obeys for some .
Then, the Stochastic Gradient Descent (SGD) updates in (2.1) with mini-batch size and learning rate obey
[TABLE]
with probability at least . Furthermore, if for , then
[TABLE]
holds with probability at least .
Remark 3.2
We note that Theorem 3.1 requires the initial estimate to be sufficiently close to the planted model (i.e. ). Such an initial estimate can be easy obtained by using one full gradient descent step at zero [3]. The required sample complexity for this initialization to be effective is on the order of for a fixed numerical constant. For the purposes of this result we will use a small constant so that on the order of samples are sufficient for this initialization.
Remark 3.3
Theorem 3.1 shows that the SGD iterates (2.1) converge to a globally optimal solution at a geometric rate. Furthermore, the required number of samples for this convergence to occur is nearly minimal and is on the order of the number of parameters .
Remark 3.4
Theorem 3.1 also characterizes the influence of mini-batch size on the convergence rate, illustrating the trade-off between the computational load and the convergence speed.
Remark 3.5
In Theorem 3.1, the probability of success depends on the distance of initial point to the optimal solution. As we detail in the appendix we can use an ensemble algorithm to reduce the failure probability arbitrarily small without the need to start from an initial point that is very close to the optimal solution.
Remark 3.6
We note that for , the updates in (2.1) reduce to full gradient descent and the guarantee (3.1) takes the form . In this special case our result recovers that of [3] up to a constant factor.
3.7 Quantized SGD
We next focus on providing gurantees for QSGD.
Theorem 3.2
Consider the same setting and assumptions as Theorem 3.1. Furthermore, consider a parallel setting with worker processors and a master per Section 2.2 and assume that each worker computes partial gradients in each iteration (i.e. ). We run QSGD over these processors via the iterative updates in (2.2). Then
[TABLE]
holds with probability at least . Furthermore, if for then
[TABLE]
with probability at least .
Remark 3.8
As mentioned in Remark 3.2 of Theorem 3.1, in order to address the initialization issue we can use one full Gradient Descent pass from zero to find an initializaiton obeying the conditions of this theorem.
Remark 3.9
Similar to the results of Theorem 3.1, Theorem 3.2 shows geometric convergence of the QSGD iterates (2.2) with a near minimal number of samples (). Furthermore, it characterizes the effect of both mini-batch size and quantization levels on the convergence rate. Specifically, by increasing the quantization levels, the iterates (2.1) converge faster. Perhaps unexpected, by choosing the number of the bits to be on the order of the iterates (2.1) and (2.2) converge with the same rate up to a constant factor. This allows QSGD to significantly reduce the communication load while maintaining a computational effort comparable to SGD.
4 Numerical results and experiments on Amazon EC2
In this section we wish to investigate the results of Theorems 3.1 and 3.2 using numerical simulations and experiments on Amazon EC2. We first wish to investigate how the rate of convergence of mini-batch SGD and QSGD iterates depends on the different parameters. To this aim, we generate the planted weight vector with with entries distributed i.i.d. . In addition, we generate feature vectors i.i.d. and set the corresponding output labels . To estimate , we start from a random initial point and run SGD and QSGD with learning rates and , where is the number of bits required for quantization.
In Figure 1(a) we focus on corroborating our convergence analysis for SGD. To this aim we vary the mini-batch size and plot the relative error () as a function of the iterations. This figure demonstates that the convergence rate is indeed linear and increasing the batch size results in a faster convergence.
In Figure 1(b) we focus on understanding the effect of the number of bits on the convergence behavior of QSGD. To this aim we fix the mini-batch size at and vary the number of bits . This plot confirms that QSGD maintains a linear convergence rate comparable to SGD (especially when ).
To understand the required sample complexity of the algorithms, we plot phase transition curves depicting the empirical probability that gradient descent converges to for different data set sizes () and feature dimensions (). For each value of and we perform trials with the data generated according to the model discussed above. In each trial we run the algorithm for iterations. If the relative error after iterations is less than we consider the trial a success otherwise a failure. Figures 2(a) and 2(b) depict the phase transition for mini-batch SGD and QSGD with bits, respectively. As it can be seen, the figures corroborate the linear relationship of the required sample complexity with the feature dimensions. Furthermore, these figures demonstrate that quantization does not substantially change the required sample complexity.
In order to understand the effectiveness of QSGD at reducing the communication overhead, we provide experiments on Amazon EC2 clusters and compare the performance of QSGD with SGD. We utilize a master-worker architecture and make use of t2.micro instances. We use Python for implementing two algorithms and use MPI4py [4] for message passing across the instances. Before starting the iterative updates each worker receives its portion of the training data. In each iteration , after the workers receive the latest model from the master, they compute the stochastic gradients at based on the local data and then send it back to the master. In SGD and QSGD we use float64 and int8 for sending gradients, respectively. Additionally, we use isend() and irecv() for sending and receiving, respectively, and Time.time() to measure the running time.
We compare the performances of these two algorithms in the following two scenarios.
- •
Scenario one: We use 41 t2.micro instances, with one master and workers. We have data points with feature dimension . We partition and distribute the data into equal batches of size with each worker performing updates based its own batch.
- •
Scenario two: We use 51 t2.micro instances, with one master and workers. In this scenario we use and , and again distribute the data evenly among the workers.
Table 1 summarizes the experiment scenarios. In both cases we run SGD and QSGD algorithms for iterations. Figure 3 depicts the total running times. Table 2 also shows the breakdowns of the run-times. These experiments indicate that the total running time of QSGD is 5 times less than that of SGD. Since both algorithms have similar convergence rate and hence computational time, this clearly demonstrates that the communication time for QSGD is significantly smaller.
5 Related work
The problem of fitting non-linear models to data has a rich history in statistics and learning theory using a variety of algorithms [5, 6, 7, 8]. In the context of training deep models such nonlinear learning problems have lead to major breakthroughs in various applications [9, 10]. Despite these theoretical and empirical advances, rigorous understanding of local search heuristics such as stochastic gradient descent which are arguably the most widely used techniques in practice, have remained elusive.
Recently, there has been a surge of activity surrounding nonlinear data fitting via local search. Focusing on ReLU nonlinearities [3] shows that in generic instances full gradient descent converges to a globally optimal model at a geometric rate. See also [11, 12, 13, 14, 15, 16, 17, 18] for a variety of related theoretical and empirical work for fitting ReLUs and shallow neural networks via local search heuristics. In contrast to the above, which require full gradient updates in this paper we focus on fitting ReLU nonlinearities via mini-batch SGD and QSGD. Finally, we would like to mention another recent result which studies a stochastic method for fitting ReLUs [19] via a First order Perturbed Stochastic Gradient Descent. This approach differs from ours in a variety of ways including the update strategy and required sample complexity. In particular, this approach is based on stochastic methods with random search strategies which only use function evaluations. Furthermore, this result requires samples and provides a polynomial converge guarantee where as is this paper we have established a geometric rate of convergence to the global optima with a near minimal number of samples that scales linearly in the problem dimension (i.e. ).
Recently there has been a lot of exciting activity surrounding SGD analysis. Classic SGD convergence analysis shows that the distance to the global optima (in loss or parameter value) decreases polynomially in the number of iterations (e.g. after iterations). More recent results demonstrate that in certain cases, a significantly faster and geometric rate of convergence (i.e. with ) is possible [20, 21]. For instance, [22] showed that randomized Kaczmarz algorithm converges to the solution of a consistent linear system of equations at a geometric rate. More recently, [23] showed that under some assumptions such as smoothness, strong convexity, and perfect interpolation, SGD achieves a geometric rate of convergence. In this paper we add to this growing literature and demonstrate that such a fast geometric rate of convergence to a globally optimal solution is also possible despite the nonlinear and nonconvex nature of fitting ReLUs.
Reducing communication overhead by compressing the gradients has become increasing popular in recent literature [24, 25, 26]. Most notably [27] empirically demonstrated that one-bit quantization of gradients is highly effective for scalable training of deep models. The QSGD paper [1] develops convergence gurantees for convex losses as well convergence of gradient to zero for nonconvex losses. Related [28] also shows that under the assumption of smoothness and bounded variance a quantized SGD procedure converges to a stationary point of a general non-convex function with a polynomial convergence rate. In contrast in this paper we focus on geometric convergence to the global optima but for the specific problem of fitting a ReLU nonlinearity.
6 Proofs
6.1 Convergence analysis for fitting ReLUs via SGD (Proof of Theorem 3.1)
To show
[TABLE]
we begin with a useful definition. In particular, we denote the mini-batch empirical loss as , where is the set of indices chosen at iteration . Therefore, we can rewrite the mini-batch SGD updates as
[TABLE]
To upper bound in terms of , we expand in the form
[TABLE]
To draw the desired conclusion of the theorem (i.e. (6.1)), it suffices to upper bound the second expectation which consists of two terms . To upper bound the first term, We apply the expectation to the inner product to conclude that
[TABLE]
To lower bound the inner product we utilize the following lemma proved in [3].
Lemma 6.1
For the loss function defined in (1), we have
[TABLE]
holding for all and with probability at least . Specifically for and , we obtain
[TABLE]
Using Lemma 6.1 we have
[TABLE]
for all with . By choosing we can conclude that
[TABLE]
holds with probability at least .
Thus, by combining (6.2), (6.3), and (6.5) we can conclude that
[TABLE]
Next, in order to upper bound the second term in the right hand side of (6.6), we use following lemma proven in Section 6.1.1.
Lemma 6.2
The following inequality
[TABLE]
holds with probability at least .
Hence, by (6.6) and (6.7) with we arrive at
[TABLE]
This holds with probability at least . We note however, that the proof is not yet complete. We have not shown that all subsequent iterations will also lie in the local neighborhood dictated by Lemma 6.1. We have only shown that on average they belong to this neighborhood. To overcome this challenge we utilize some techniques from stochastic processes to obtain a conditional convergence. Our argument heavily borrows from [29] with some parts directly adapted.
Conditional linear convergence. In order to make our notations compatible with typical notations used in stochastic processes theory, we denote as the random vector of estimated solution at iteration and as a realization of that random vector. Using these conventions the result we have proven so far can be rewritten as
[TABLE]
Let denote the -algebra generated by indices chosen in the steps from to . Also let be the region consisting of all points which are in where . Finally, assume an initial estimate which is fixed obeying and . Now define a stopping time as . For each , and , we have
[TABLE]
Hence
[TABLE]
Therefore, we obtain
[TABLE]
To show that the probability of leaving this neighborhood is low we bound . We begin by showing that is a supermartingale.
[TABLE]
Using the fact that is a supermartingale we have
[TABLE]
Now By the definition of stopping time,
[TABLE]
and using , we arrive at
[TABLE]
This in turn implies that . Thus,
[TABLE]
Whence,
[TABLE]
Hence we conclude that . Thus
[TABLE]
By (6.9) we have
[TABLE]
Thus, using Markov’s inequality we conclude that
[TABLE]
which is bounded by .
6.1.1 Proof of Lemma 6.2
We use the following identity shown in [23].
[TABLE]
To upper bound the first term, using (6.4) with we conclude that
[TABLE]
holds with probability at least .
In order to upper bound the second term on the right hand side of (6.10) we use the following chain of inequalities
[TABLE]
This holds with probability at least . In (a) we used the fact that a high-dimensional Gaussian random vector is well-concentrated on the sphere ofradius with high probability and in the last inequality we used a well-known upper bound on the spectral norm of the sample covariance matrix which holds with high probability.
6.2 Convergence of Quantized SGD (Theorem 3.2)
The proof of this theorem is similar to its counter part in Theorem 3.1. We begin by defining . We can repeat the argument of the proof of Theorem 3.1 and rewrite (6.2) using the updates (2.2). We begin by taking expectations with respect to the randomness in the quanitzation procedure (denoted by ). This allows us to conclude that
[TABLE]
To continue we use a Lemma from [1] which shows the stochastic gradient is unbiased and bounds its variance.
Lemma 6.3
*For any vector ,
(i) .
(ii) .*
Using Lemma 6.3, we conclude that
[TABLE]
and
[TABLE]
Therefore,
[TABLE]
Whence,
[TABLE]
The remainder of the proof is exactly the same as that of Theorem 3.1.
7 Acknowledgements
M. Soltanolkotabi is supported by the Packard Fellowship in Science and Engineering, a Sloan Research Fellowship in Mathematics, an NSF-CAREER under award #1846369, the Air Force Office of Scientific Research Young Investigator Program (AFOSR-YIP) under award #FA9550-18-1-0078, an NSF-CIF award #1813877, and a Google faculty research award.
8 Appendix
In the statement of the two Theorems, the probability of success depends on the proximity of the initial estimate to the solution. To alleviate this dependency we directly adapt the Ensemble Algorithm used in [29]. See Algorithm 1 for details of this approach.
We now state a result regarding the performance of the ensemble method. We note that the proof of this lemma is essentially identical to its counterpart in [29] and requires only minor modifications.
Proposition 8.1
(Guarantees for ensemble methods). Consider the setup and assumptions of Theorem 3.1. Furthermore assume that . Then, for any there is an absolute constant such that if then the estimate obtained via Algorithm 1 satisfies .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. Vojnovic, “Qsgd: Communication-efficient sgd via gradient quantization and encoding,” in Advances in Neural Information Processing Systems 30 , I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds. Curran Associates, Inc., 2017, pp. 1709–1720.
- 2[2] F. H. Clark, “Optimization and nonsmooth analysis,” SIAM .
- 3[3] M. Soltanolkotabi, “Learning relus via gradient descent,” in Advances in Neural Information Processing Systems 30 . Curran Associates, Inc., 2017, pp. 2007–2017.
- 4[4] L. D. Dalcin, R. R. Paz, P. A. Kler, and A. Cosimo, “Parallel distributed computing using python,” Advances in Water Resources , vol. 34, no. 9, pp. 1124–1139, 2011.
- 5[5] A. T. Kalai and R. Sastry, “The isotron algorithm: High-dimensional isotonic regression.” in COLT , 2009.
- 6[6] S. Goel, V. Kanade, A. R. Klivans, and J. Thaler, “Reliably learning the relu in polynomial time,” Co RR , vol. abs/1611.10258, 2016.
- 7[7] J. Horowitz and W. Härdle, “Direct semiparametric estimation of single-index models with discrete covariates,” Journal of the American Statistical Association , vol. 91, no. 436, pp. 1632–1640, 12 1996.
- 8[8] H. Ichimura, “Semiparametric least squares (sls) and weighted sls estimation of single- index models,” Minnesota - Center for Economic Research, Working Papers, 1991.