Multisource Region Attention Network for Fine-Grained Object Recognition in Remote Sensing Imagery
Gencer Sumbul, Ramazan Gokberk Cinbis, Selim Aksoy

TL;DR
This paper introduces a multisource region attention network that learns to align and classify fine-grained objects in remote sensing imagery using deep neural networks, improving accuracy over traditional feature concatenation methods.
Contribution
It proposes a unified deep learning framework that simultaneously learns multisource data alignment and classification for fine-grained remote sensing object recognition.
Findings
Achieved 64.2% accuracy on 18-class street tree classification
Improved accuracy by 13% over feature concatenation approach
Demonstrated effectiveness with RGB, multispectral, and LiDAR data
Abstract
Fine-grained object recognition concerns the identification of the type of an object among a large number of closely related sub-categories. Multisource data analysis, that aims to leverage the complementary spectral, spatial, and structural information embedded in different sources, is a promising direction towards solving the fine-grained recognition problem that involves low between-class variance, small training set sizes for rare classes, and class imbalance. However, the common assumption of co-registered sources may not hold at the pixel level for small objects of interest. We present a novel methodology that aims to simultaneously learn the alignment of multisource data and the classification model in a unified framework. The proposed method involves a multisource region attention network that computes per-source feature representations, assigns attention scores to candidate…
Click any figure to enlarge with its caption.
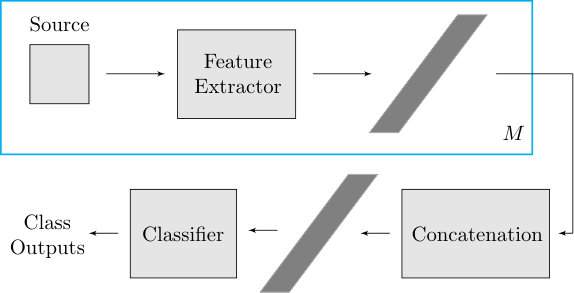 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 1
Figure 1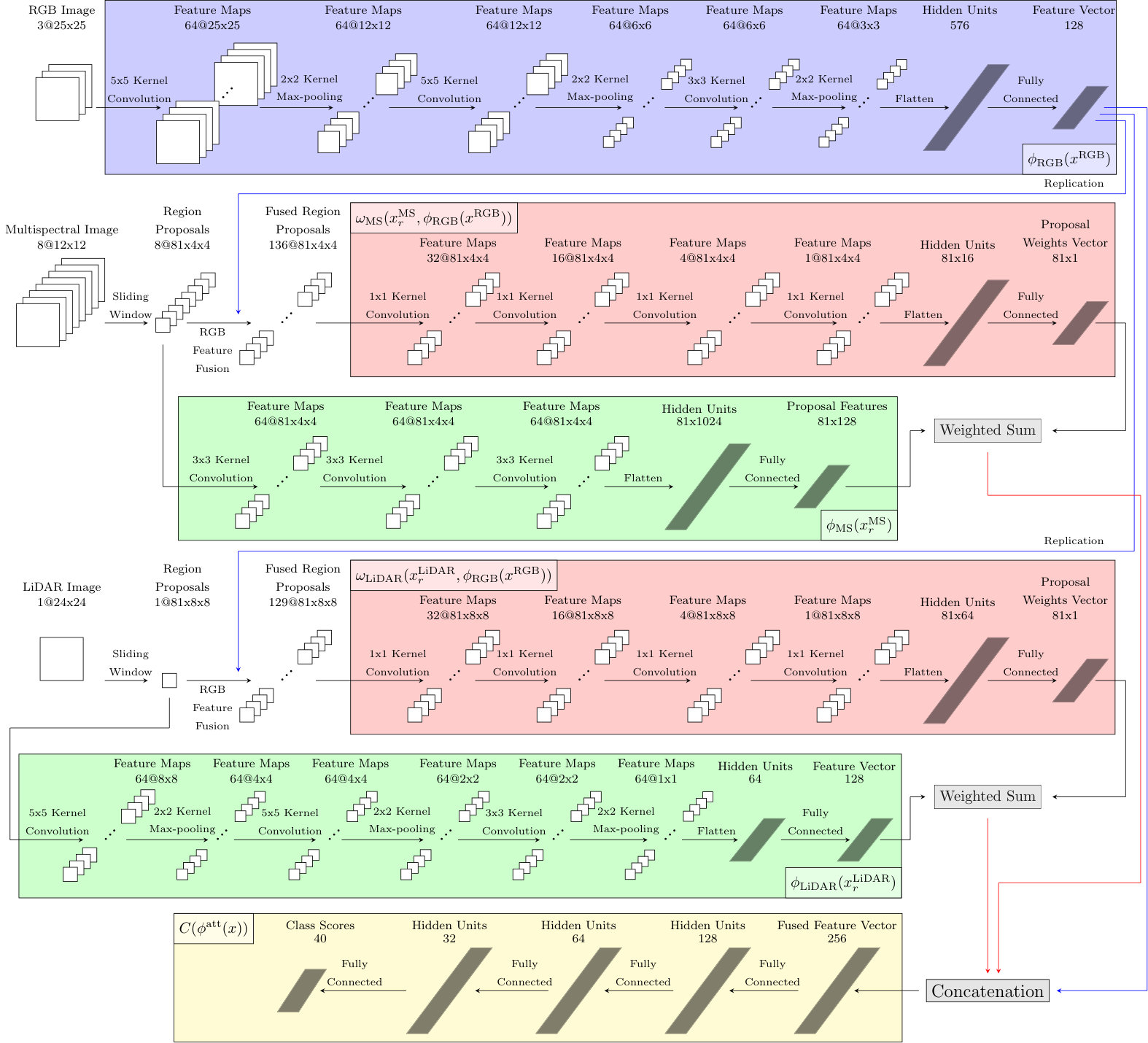 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Image representation | Normalized accuracy |
|---|---|
| Random guess | 6.3 |
| LiDAR patches | 8.0 |
| LiDAR patches | 12.1 |
| RGB patches [3] | 14.3 |
| MS patches | 15.2 |
| MS patches | 16.7 |
| Basic CNN model (RGB & MS) | 15.8 |
| Basic CNN model (RGB, MS & LiDAR) | 17.4 |
| Proposed framework (RGB & MS) | 17.7 |
| Proposed framework (RGB, MS & LiDAR) | 17.0 |
| Image representation | Normalized accuracy |
|---|---|
| Random guess | 6.3 |
| LiDAR patches | 8.0 |
| LiDAR patches | 12.1 |
| RGB patches [3] | 14.3 |
| MS patches | 15.2 |
| MS patches | 16.7 |
| Basic CNN model (RGB & MS) | 15.8 |
| Basic CNN model (RGB, MS & LiDAR) | 17.4 |
| Proposed framework (RGB & MS) | 17.7 |
| Proposed framework (RGB, MS & LiDAR) | 17.0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Multisource Region Attention Network
for Fine-Grained Object Recognition
in Remote Sensing Imagery††thanks: This work was supported in part by the TUBITAK Grant 116E445, BAGEP Award of the Science Academy, and METU Research Fund Project 2744.
Gencer Sumbul, , Ramazan Gokberk Cinbis, and Selim Aksoy G. Sumbul and S. Aksoy are with the Department of Computer Engineering, Bilkent University, Ankara, 06800, Turkey. After this work has been done, the affiliation of Gencer Sumbul has changed to TU Berlin. Email: [email protected], [email protected]. G. Cinbis is with the Department of Computer Engineering, METU, Ankara, 06800, Turkey. Email: [email protected].© 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Abstract
Fine-grained object recognition concerns the identification of the type of an object among a large number of closely related sub-categories. Multisource data analysis, that aims to leverage the complementary spectral, spatial, and structural information embedded in different sources, is a promising direction towards solving the fine-grained recognition problem that involves low between-class variance, small training set sizes for rare classes, and class imbalance. However, the common assumption of co-registered sources may not hold at the pixel level for small objects of interest. We present a novel methodology that aims to simultaneously learn the alignment of multisource data and the classification model in a unified framework. The proposed method involves a multisource region attention network that computes per-source feature representations, assigns attention scores to candidate regions sampled around the expected object locations by using these representations, and classifies the objects by using an attention-driven multisource representation that combines the feature representations and the attention scores from all sources. All components of the model are realized using deep neural networks and are learned in an end-to-end fashion. Experiments using RGB, multispectral, and LiDAR elevation data for classification of street trees showed that our approach achieved and accuracies for the -class and -class settings, respectively, which correspond to and improvement relative to the commonly used feature concatenation approach from multiple sources.
Index Terms:
Multisource classification, fine-grained classification, object recognition, image alignment, deep learning
I Introduction
New generation sensors used for remote sensing has allowed the acquisition of images at very high spatial resolution with rich spectral information. A challenging problem that has been enabled by such advances in sensor technology is fine-grained object recognition that involves the identification of the type of an object in the domain of a large number of closely related sub-categories. This problem differs from the traditional object recognition and classification tasks predominantly studied in the remote sensing literature in at least three main ways: (i) differentiating among many similar categories can be much more difficult due to low between-class variance, (ii) difficulty of accumulating examples for a large number of similar categories can greatly limit the training set sizes for some classes, (iii) class imbalance can cause the conventional supervised learning formulations to overfit to more frequent classes and ignore the ones with limited number of samples. Such major differences lead to an uncertainty in the applicability of existing approaches developed based on traditional settings. Thus, the development of methods and benchmark data sets for fine-grained classification is an open research problem, whose importance is likely to increase over time.
Fine-grained object recognition has received very little attention in the remote sensing literature. Oliveau and Sahbi [1] proposed an alternating optimization procedure that iteratively learned a dictionary-based attribute representation and a support vector machine (SVM) classifier based on these attributes for classification of image patches into 12 ship categories. Branson et al. [2] jointly used aerial images and street-view panoramas for fine-grained classification of street trees. They concatenated the feature representations computed by deep networks independently trained for the aerial and ground views, and fed these features to a linear SVM for classification of 40 tree species. In [3], we studied the more extreme zero-shot learning scenario where no training example exists for some of the classes. First, a compatibility function between image features extracted from a convolutional neural network (CNN) and auxiliary information about the semantics of the classes of interest was learned by using samples from the seen classes. Then, recognition was done by maximizing this function for the unseen classes. Experiments were done by using an RGB image data set of 40 street tree categories.
New approaches that aim to learn classifiers under the presence of low between-class variance, small sample sizes for rare classes, and class imbalance can overcome these problems by enriching the data sets so that increased spectral and spatial content provides potentially more identifying information that can be exploited for discriminating instances of fine-grained classes. However, these two types of information do not necessarily come together in the same data source. Thus, multisource remote sensing is a promising research direction for fine-grained recognition. For example, very high spatial resolution RGB data provides texture information, whereas multi- and hyperspectral images contain richer spectral content. Furthermore, LiDAR-based elevation models can provide complementary information about the heights and other structural characteristics of the objects.
Multisource image analysis [4] has been a popular problem in remote sensing with a wide range of solutions including dependence trees [5], kernel-based methods [6], copula-based multivariate statistical model [7], active learning [8], and manifold alignment [9, 10]. Combining information from multiple data sources has also been the focus of data fusion contests [11, 12, 13, 14] for land cover/use classification. Similar to their popularity in general classification tasks, deep learning-based approaches also received interest in multisource analysis. Deep networks have typically been used in the classification stage where raw optical bands and LiDAR-based digital surface models (DSM) [15, 16] as well as handcrafted features from hyperspectral and LiDAR data [17] were concatenated and given as input to a CNN classifier, or in the feature extraction stage where independently learned deep feature representations from hyperspectral and SAR data [18] or hyperspectral and LiDAR data [19] were concatenated to form the input of a separate classifier. The output of a fully convolutional network trained on optical data and a logistic regression classifier trained on LiDAR data were also used in decision-level fusion by using a conditional random field [20].
A common assumption in all of these approaches is that the data sources are georeferenced or co-registered so that concatenation can be used for pixel-wise classification. Potential registration errors may not cause a problem during learning if one considers a small number of relatively distinct classes with many samples, or during testing where evaluation is done by pixels sampled from the inside of large regions labeled by land cover/use classes. Even though various approaches have been proposed for the registration of multisensor images [21, 22], finding pixel-level correspondences between images acquired from different sensors with different spatial and spectral resolution may not be error-free due to differences in the imaging conditions, viewing geometry, topographic effects, and geometric distortions [23]. Furthermore, errors at the level of a few pixels may not matter when the goal is to classify pixels sampled from land cover/use classes such as road, building, vegetation, soil, water, but can be very significant for fine-grained object recognition when the objects of interest, e.g., individual trees as in this paper, can appear as small as a few pixels even in very high spatial resolution images.
In this paper, we propose a multisource fine-grained object recognition methodology that aims to simultaneously learn the alignment of the images acquired from different sources and the classification model in a unified framework. We illustrate this framework in the fine-grained categorization of 40 different types of street trees using data from RGB, multispectral (MS) and LiDAR sensors. Classification of urban tree species provides a suitable test bed for this challenging fine-grained recognition problem because of the difficulty of finding field examples for training data, fine-scale spatial variation, and high species diversity [24]. Furthermore, appearance variations with respect to scale and spectral values, the difficulty of co-registration of small objects of interest in multiple sources, and rareness of certain species resemble the typical problems in fine-grained object recognition [25]. Consequently, differentiating the sub-categories can be a very difficult task even with visual inspection using very high spatial resolution imagery. Classification of tree species has been previously studied in the remote sensing literature by using specialized approaches via fusion of hyperspectral and LiDAR data with linear discriminant [26], nearest neighbor [27], SVM [28], or random forest [29, 28, 24] classifiers. However, all of these approaches were specialized to tree classification, and none of them considered the alignment problem.
Our main contributions in this paper are as follows. The first contribution is a novel multisource region attention network that simultaneously learns to attend regions of source images that are likely to contain the object of interest and to classify the objects by using an attention-driven multisource deep feature representation. The problem flow is illustrated in Figure 1. We assume that the objects exist in all sources but their exact positions are unknown except one particular source, the reference, that is verified with respect to the ground truth. The proposed network learns to (i) compute per-source deep feature representations, (ii) assign attention scores to candidate regions sampled around the expected object locations in remaining sources by relating them to the reference, and (iii) classify objects by using an attention-driven multisource representation that combines the feature representations and the attention scores from all sources. A deep neural network architecture is presented to realize the components of this framework, and learn them in an end-to-end fashion. The second contribution is the detailed evaluation of this framework by using different combinations of source images from RGB, MS, and LiDAR sensors in fine-grained categorization of different types of tree species. To the best of our knowledge, the proposed methodology is the first example for a generic unified framework for fine-grained object recognition by using any number of sources with different spatial and spectral resolutions via simultaneous learning of alignment and classification models.
The rest of the paper is organized as follows. Section II introduces the fine-grained data set. Section III describes the details of the methodology. Section IV presents the experiments. Section V provides the conclusions.
II Data set
The data set in [3] contained instances of street trees belonging to categories. Each instance was represented by an aerial RGB image patch of pixels at foot spatial resolution, centered at points provided in the point GIS data. The names of the classes and the number of samples can be found in [3]. We use both an -class subset (named the supervised set in [3]) and the full set of classes here.
This work extends that data set with an -band WorldView-2 MS image and a LiDAR-based DSM with meter and foot spatial resolution, respectively. Consequently, each tree instance corresponds to a pixel patch in the MS data, and an pixel patch in the LiDAR data. Since the RGB image has the highest spatial resolution and the corresponding annotations were verified by visual inspection in [3], we consider it as the reference source. Even though each source image was previously georeferenced, precise pixel-level alignments among these sources were not possible as shown in Figure 1. Thus, the proposed methodology in the following section aims to find the true, yet unknown, matching patch of pixels in the neighboring region of pixels in the MS data, and the corresponding patch of pixels within a pixel region in the LiDAR data. The neighborhood sizes are selected empirically using validation data. Using larger neighborhoods risks the inclusion of other trees that can confuse the attention mechanism, and smaller neighborhoods may not contain sufficient number of candidates.
III Methodology
In this section, we first introduce the multisource object recognition problem and present a baseline scheme for it. Then, we explain our Multisource Region Attention Network approach, followed by the details of the network architecture.
III-A Multisource object recognition problem
In the multisource object recognition problem, we assume that there exists different source domains, where the space of samples from the -th domain is represented by . Our goal is to learn a classification function that maps a given object represented by a tuple of input instances from the source domains to one of the classes where is the set of all classes.
In this work, we focus on the problem of object recognition from multiple source images, where each source corresponds to a particular sensor, such as RGB, MS, LiDAR, etc. We are particularly interested in the utilization of overhead imagery, where the samples are typically collected from cameras with different viewpoints, elevations, resolutions, dates and time of day. Such differences in imaging conditions across the data sources make the precise spatial alignment of the images very difficult. The image contents may also differ due to changes in the area over time and occlusions in the scene.
In the next section, we first present a simple baseline approach towards utilizing such multiple sources, and then, we explain our approach for addressing these challenges in a much more rigorous way.
III-B Multisource feature concatenation
A simple and commonly used scheme for utilizing multiple images in classification is to extract features independently across the images and then concatenating them later, which is often called early fusion. More precisely, for each source , we assume that there exists a feature extractor which maps the input to a -dimensional feature vector. In this approach, it is presumed that each multisource tuple consists of the images of the same object from all sources, and these images are spatially registered. Then, the multisource representation is obtained by concatenating per-source feature vectors:
[TABLE]
Once the multisource representation is obtained, the final object class prediction is given by a classification function. This approach is illustrated using plate notation111The plate notation represents the variables that repeat in the model where the number of repetitions is given by the number on the bottom-right corner of the corresponding rectangle enclosing these variables. in Figure 2.
The main assumption of the simple feature concatenation approach is that the representation obtained independently from each source successfully captures the characteristics of the object within the target region. However, registration across the sources is usually imprecise, which requires choosing relatively large regions to ensure that all images within a tuple contain the same object instance. In this case, however, the features extracted from these relatively large regions are likely to be dominated by background information, which can greatly degrade the accuracy of the final classification model.
This problem is tackled by the proposed Multisource Region Attention Network, explained in the following section.
III-C Multisource Region Attention Network (MRAN)
A central problem in multisource remote sensing is the difficulty of registration of source images, as discussed above. To address this problem, we propose a deep neural network that learns to attend regions of source images such that the resulting multisource representation is most informative for recognition purposes. We refer to this approach as Multisource Region Attention Network (MRAN).
In our approach, we presume that there is (at least) one source for which feature extraction is reliable, i.e., the representation for this source is not dominated by noise and/or background information. We refer to this source as the reference. Since the reference source typically has a higher spatial resolution, it is often possible to annotate objects in it with high spatial fidelity, either by geo-registering it with some form of ground truth or by visually inspecting the images.
Our goal is to enhance recognition by leveraging additional sources. While we presume that all images within a tuple contain the same object instance, we do not expect a precise spatial alignment among them, i.e., the exact position of an object is locally unknown in the sources other than the reference. In addition, the images of additional sources may potentially contain other object instances belonging to different classes. In this realistic setting, therefore, extracting features independently at each source is likely to perform poorly.
In our approach, we aim to overcome these difficulties via a deep network including a conditional attention mechanism that selectively assigns importance scores to regions in each one of the sources, i.e., in those other than the reference. Without loss of generality, we assume that the reference source is the very first one, and there are candidate regions in each one of the other source images, denoted by where . In our experiments, we obtain these candidate regions (proposals) by regularly sampling overlapping patches of fixed size within a larger neighborhood around the expected position of the object obtained by a simple transformation from the reference source (see Section IV for details).
To formalize the proposed conditional attention mechanism, we define the region attention estimator , which takes the -th candidate region from the -th source and the feature representation of the corresponding reference image, and maps to a non-negative attention score. The attention score represents the confidence that the region contains (a part of) the object of interest.
We then leverage these scores to obtain a multisource representation that focuses on the regions containing the object of interest within each source. For this purpose, we define the attention-driven source representation , as a weighted sum of per-region representations:
[TABLE]
where is the region-level feature extractor, and the weighting term is the normalized attention score of the region:
[TABLE]
Our final attention-driven multisource representation is obtained by concatenation of attention-driven source representations:
[TABLE]
The resulting attention-driven multisource representation can be fed to a classifier to recognize the object of interest:
[TABLE]
where is the classifier function that outputs a confidence score for each of the classes. An illustration of our MRAN framework can be found in Figure 2.
In the next section, we present the proposed deep architecture that implements the complete MRAN model by realizing the region-level feature extractors , the per-source conditional attention estimators , and the classifier by using deep neural networks, and explain how we jointly learn these networks in an end-to-end fashion.
III-D MRAN architecture details
We utilize a deep neural network in order to realize our MRAN framework. Our goal here is to (i) jointly process spatial and spectral information in the source images, (ii) implement an effective conditional region attention mechanism, and, (iii) learn the whole recognition pipeline in an end-to-end fashion. While the proposed architecture can easily be adapted to various combinations of sources, we assume that the reference source is RGB imagery, and the additional sources are obtained using MS and LiDAR sensors in this presentation.
For this purpose, we define an architecture that is formed by the combination of five deep convolutional neural network branches and a block of fully-connected (FC) layers as shown in Figure 3. The first branch extracts the image feature representation of the reference RGB data. We adopt this architecture from our previous work [3]. The second and fourth branches take the region proposals of the images from the additional sources, and append the feature vector of the reference source to the end of each pixels’ input channels via replication. Four convolutional layers with dimensional filters and an FC layer estimates the attention scores of region proposals. The third branch in which the feature representation is computed for each region proposal in the MS data differs from the first branch for the RGB data by using smaller filters and not using max-pooling because of the difference in spatial resolution. The fifth branch is the feature extractor for the LiDAR data and is similar to the first branch. Finally, the concatenation of attention-driven source representations and the reference source representation goes to the last branch in which four FC layers implement the classifier that gives the final class scores. Stride for all convolutional layers is set at to prevent information loss. We use zero-padding to avoid reduction in the spatial dimensions over convolutional layers.
The number of filters for each convolutional layer in the first, third and fifth branches is selected as in order to find a balance between model capacity and preventing overfitting. However, for the attention score estimator branches, we prefer to use decreasing number of filters from to in order to have correct number of scores at the end. Finally, although we have experimented with deeper and wider models, we reached the best performance with the presented network.
The particular instantiation of the network in Figure 3 uses the RGB data as the reference and MS and LiDAR data as the additional sources. Note that the region attention estimator branches (red boxes) are the same for all sources, and the feature extractor branches (blue and green boxes) differ only slightly in terms of the number of layers according to the spatial resolutions of the sources and the sizes of the region proposals. The design in Section III-C and the abstraction in Figure 2 are generic so that any number of reference and additional sources with any spatial and spectral resolution can be handled in the proposed framework by selecting an appropriate feature extractor model for each source.
Training the model is carried out over the classes by employing the cross-entropy loss, corresponding to the maximization of label log-likelihood in the training set. For enhancement of training, we benefited from dropout regularization and batch normalization. Additional training details and a comparison of our model are provided in Section IV.
IV Experiments
In this section, we present the experimental setup, results when the sources are used individually and in different combinations, and comparisons with the baseline approach.
IV-A Experimental setup
We follow the same class split in [3] and evaluate our method using both and classes. For both cases, we split images from all sources into train (), validation () and test () subsets. Based on our previous observations, we add perturbations to training images by shifting each one randomly with an amount ranging from zero to of height/width.
For all experiments, training is carried out on the train set by using stochastic gradient descent with the Adam method [31] where the hyper-parameters are tuned on the validation set. All network parameters are initialized randomly and are learned in an end-to-end fashion. The initial learning rate of Adam, mini-batch size, and -regularization weight are set to , , and , respectively, as in [3].
We use normalized accuracy as the performance metric where the per-class accuracy ratios are averaged to avoid biases towards classes with a large number of examples.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Q. Oliveau and H. Sahbi, “Learning Attribute Representations for Remote Sensing Ship Category Classification,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. , vol. 10, no. 6, pp. 2830–2840, June 2017.
- 2[2] S. Branson, J. D. Wegner, D. Hall, N. Lang, K. Schindler, and P. Perona, “From Google Maps to a fine-grained catalog of street trees,” ISPRS J. Photogram. Remote Sens. , vol. 135, pp. 13–30, January 2018.
- 3[3] G. Sumbul, R. G. Cinbis, and S. Aksoy, “Fine-grained object recognition and zero-shot learning in remote sensing imagery,” IEEE Trans. Geosci. Remote Sens. , vol. 56, no. 2, pp. 770–779, February 2018.
- 4[4] L. Gomez-Chova, D. Tuia, G. Moser, and G. Camps-Valls, “Multimodal classification of remote sensing images: A review and future directions,” Proc. IEEE , vol. 103, no. 9, pp. 1560–1584, September 2015.
- 5[5] M. Datcu, F. Melgani, A. Piardi, and S. B. Serpico, “Multisource data classification with dependence trees,” IEEE Trans. Geosci. Remote Sens. , vol. 40, no. 3, pp. 609–617, March 2002.
- 6[6] G. Camps-Valls et al., “Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection,” IEEE Trans. Geosci. Remote Sens. , vol. 46, no. 6, pp. 1822–1835, June 2008.
- 7[7] A. Voisin, V. A. Krylov, G. Moser, S. B. Serpico, and J. Zerubia, “Supervised classification of multisensor and multiresolution remote sensing images with a hierarchical copula-based approach,” IEEE Trans. Geosci. Remote Sens. , vol. 52, no. 6, pp. 3346–3358, June 2014.
- 8[8] Y. Zhang, H. L. Yang, S. Prasad, E. Pasolli, J. Jung, and M. Crawford, “Ensemble multiple kernel active learning for classification of multisource remote sensing data,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. , vol. 8, no. 2, pp. 845–858, February 2015.