TL;DR
This survey reviews current methodologies for application placement in Fog computing, highlighting algorithms, prototypes, and challenges to optimize data processing across distributed IoT and cloud resources.
Contribution
It provides a comprehensive classification of existing models, algorithms, and open challenges in application placement within Fog computing environments.
Findings
Overview of employed algorithms and open-source prototypes
Classification based on application and infrastructure characteristics
Identification of open challenges in application placement
Abstract
Fog computing aims at extending the Cloud towards the IoT so to achieve improved QoS and to empower latency-sensitive and bandwidth-hungry applications. The Fog calls for novel models and algorithms to distribute multi-service applications in such a way that data processing occurs wherever it is best-placed, based on both functional and non-functional requirements. This survey reviews the existing methodologies to solve the application placement problem in the Fog, while pursuing three main objectives. First, it offers a comprehensive overview on the currently employed algorithms, on the availability of open-source prototypes, and on the size of test use cases. Second, it classifies the literature based on the application and Fog infrastructure characteristics that are captured by available models, with a focus on the considered constraints and the optimised metrics. Finally, it…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2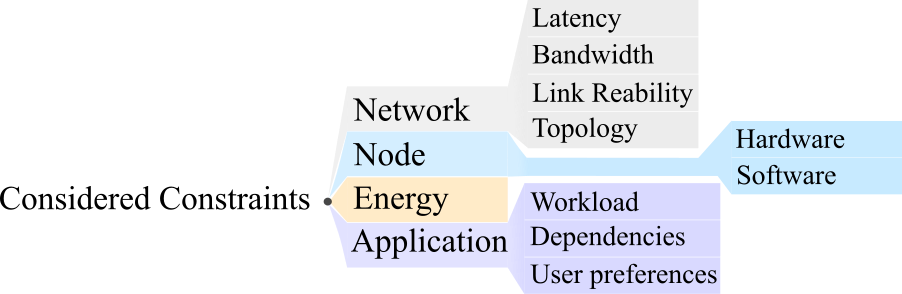 Figure 3
Figure 3 Figure 4
Figure 4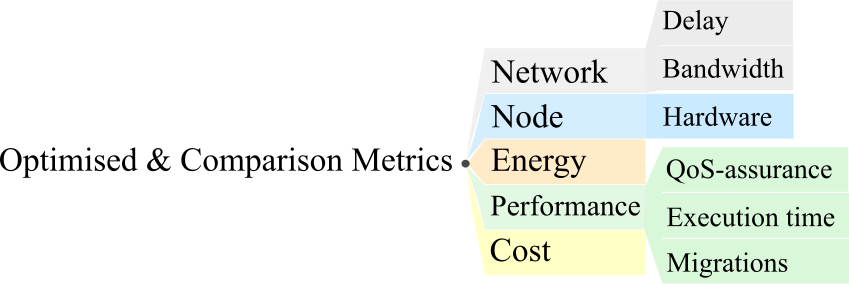 Figure 5
Figure 5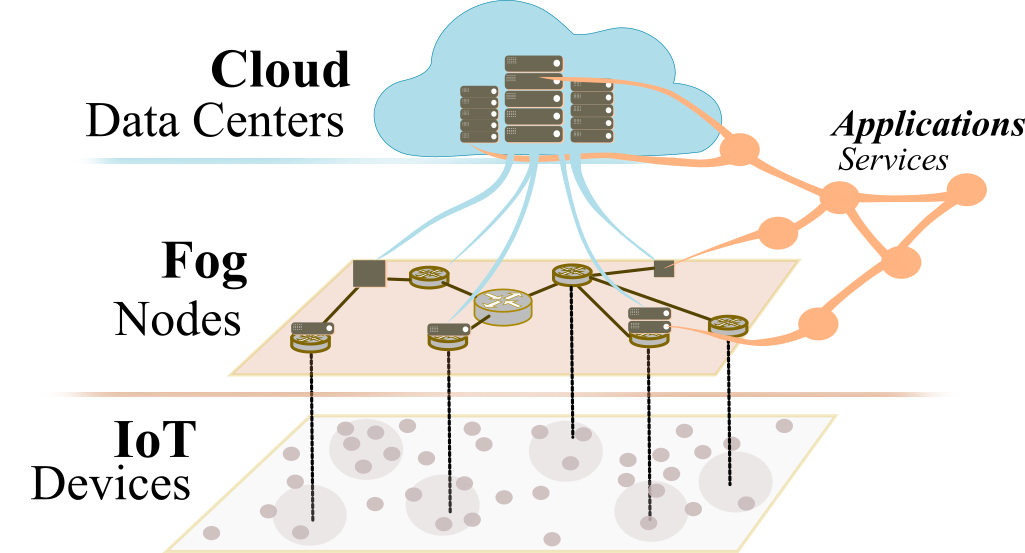 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8| Ref. | Alg.222Algorithm: S Search; MP Mathematical Programming; BI Bio-inspired; GT Game Theory; DL Deep Learning; DP Dynamic Programming; CN Complex Networks | Strengths | Weaknesses | Open |
|---|---|---|---|---|
| Proto. | ||||
| 2425 | S | Heuristic search. Modelling of IoT, Fog and Cloud. Extension to a well-known Cloud simulator. Medium-scale experiments (up to 80 Fog nodes). | Static tree-based infrastructures and DAG applications only. No complexity analysis. | \checkmark |
| 26 | S | First-fit service placement and distributed a posteriori optimisation of delays and idle resource usage. | Static tree-based infrastructures and DAG applications only. Lack of details on possible real-world implementation. Small-scale example (up to 30 Fog nodes). | |
| 27 | S | Distributed placement strategy based on local data of each node. Validated on a real application topology. Improved network usage with respect to users demand. | Static tree-based infrastructures and DAG applications only. Increased number of service migrations. Small-scale experiments (up to 25 Fog nodes). | |
| 28 | S | Heuristic search for best placement and migration plan. Uncertainty in user mobility and data rates is considered. Large-scale example (up to 1000 Fog nodes). | Use of simple prediction mechanisms. Cubic-time complexity. | |
| 29 | S | Heuristic search. Arbitrary application and infrastructure topologies, modelling of IoT and asymmetric network QoS. Complexity proofs. | Static infrastructure conditions. Small-scale example (5 Cloud and Fog nodes). Worst-case exp-time. | \checkmark |
| 30 | S | Exhaustive search. Dynamic network QoS through Monte Carlo simulations. Possibility to perform what-if analyses. | Small-scale example (5 Cloud and Fog nodes). Exp-time complexity. | \checkmark |
| 3132 | S | Parallel exhaustive search. Cost model considering operational IoT, Fog and Cloud costs. Possibility to perform what-if analyses. Medium-scale examples (up to 80 Fog nodes). | Exp-time complexity (tamed by multi-thread implementation). | \checkmark |
| 33 | S | Heuristic search. Arbitrary application and infrastructure topologies. High scalability and large-scale experiments (up to nodes). Comparison with exhaustive and first-fit. | Static infrastructure conditions. No codebase released. | |
| 34 | S | Exhaustive search. Medium-scale experiments (50 nodes). Hints for a distributed extension to the approach. | Linear application chains and static tree-based infrastructure only. Quadratic-time complexity. | |
| 35 | S | Heuristic search. Online implementation with Kubernetes. Linearithmic-time complexity. Real laboratory testbed. | Only considers generic device capacity. Does not consider infrastructure topology nor network QoS. Small-scale experiments (5 Fog nodes). | |
| 36 | S | Heuristic search. Linearithmic time complexity. Preliminary hints for a benchmark. | Static tree-based infrastructures and DAG applications only. Small-scale example (up to 13 Fog nodes). | |
| 37 | MP | Detailed framework and architectural proposal for solving FAPP with ILP. | No implementation nor evaluation is available. | |
| 38 | MP | MINLP and linearisation into MILP. Joint solution of FAPP and task distribution to minimise operational costs. Medium-scale experiments (up to 100 Fog nodes). | Data trace of the experiments are not provided. Static infrastructure conditions. | |
| 39 | MP | ILP and problem relaxation. Workload variations according to users mobility. Data migration costs. Small-scale example (20 nodes), comparison with GA and classical ILP. | Cubic-time complexity. Static tree-based infrastructures and DAG applications only. | |
| 40 | MP | MINLP and linearisation into MILP. Joint solution of FAPP and task distribution to minimise response times. Medium-scale example (up to nodes). | No complexity analysis provided. Complex formulation. | |
| 41 | MP | MINLP and linearisation into MILP. Comparison with greedy strategy. | No complexity analysis provided. Static infrastructure conditions. Small-scale example ( nodes). Not very detailed experimental settings. | |
| 42 | MP | ILP. Optimising latency for resource allocation. | Only models two application types and generic device capacity. Small-case example (6 Fog nodes). | |
| 43 | MP | Mixed-cast Flow Problem. Joint solution of FAPP and requests routing to minimise operational costs. Mock data traces used for experiments. | Not very detailed experimental settings. | |
| 44 | MP | ILP. QoE-placement, aware of (fuzzy) user expectations. Comparison with other 3 heuristic algorithms. | Static tree-based infrastructures and DAG applications only. No complexity analysis provided. | |
| 45, 46 | MP | ILP. Distributed management of Fog colonies (infrastructure portions). Modelling of IoT, Fog and Cloud nodes. | Static tree-based infrastructures. Simplistic linear cost model. Small-scale example. | |
| 47 | GA | GA. Distributed management of Fog colonies (infrastructure portions). Modelling of IoT, Fog and Cloud nodes. Poly-time complexity. Comparison with first-fit and ILP strategies. | Static tree-based infrastructures. Fitness function based on constraints satisfaction instead of optimisation metrics. Small-scale example (10 Fog nodes). | |
| 48 | MP | ILP. Heuristic to solve an equivalent problem. Considering communication energy consumption. Complexity proof. Large-scale experiments (1000 Fog nodes). | Experiments focus only on energy results. | |
| 49 | MP | LP. Decomposition of the primal problem into sub-problems to optimise the power consumption-delay tradeoff. | Static infrastructure conditions. Small-scale example (8 nodes). | |
| 50 | MP | ILP. Management of Fog colonies (infrastructure portions). Extensive comparison of Cloud-only, Fog-only and Fog-to-Cloud placements. Real smart-city scenario. | Static tree-based infrastructures. Small-scale experiments (1 Cloud, 1 Fog node). | |
| 515253 | MP | ILP. Heuristic QoS-aware extension of Apache Storm distributed framework. Real small testbed (8 nodes). Medium-scale simulation (up to 100 Fog nodes). Complexity proof. | Worst-case exp-time. Placement policy might deteriorate application availability when many operators are involved. | \checkmark |
| 54 | BI | GA. Perspective and future directions in FAPP with a focus on GA and their parallel implementation. | Preliminary work. Simple case study. | |
| 55 | BI | GA. Distributed strategy for handling application replicas and guaranteeing reliability against probabilistic infrastructure failures. Comparison with ILP. | Limited scalability. Small-scale example (5 Fog nodes). | |
| 56 | GT | Stackelberg games. FAPP modelled as sub-problems of pairing subscribers to needed resources, and of deciding resource prices. | No dynamic conditions considered. Small-scale example (20 Fog nodes). | |
| 57 | GT | Stackelberg games. Pricing analysis using Stackelberg game in a three-tiered network model (student-project allocation algorithm). | No dynamic conditions considered. Some details missing on experimental settings. | |
| 58 | DL | Q-learning. Service migration and user mobility are considered. Medium-scale experiments (70 nodes) with real-world driver traces. | Complex formulation. Cubic-time complexity. Parameter tuning not very clear. | |
| 59 | DP | 0-1 Knapsack. Load and energy adaptive strategy according to the resource availability. | No algorithmic details. Small-scale example (9 nodes). | |
| 60 | DP | Knapsack problem. Exploratory work in symbiotic search. Comparison with FCFS policy and traditional solvers. | Very small-scale example. | |
| 61 | CN | Network science. Mobility of users is considered. Extension to a well-known Cloud simulator. | Static tree-based infrastructures. Medium-scale example (80 Fog nodes). |
| Considered Constraints | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Network | Nodes | Energy | Application | |||||||
| Ref. |
Latency |
Bandwidth |
Link Reliability |
Topology |
Hardware |
Software |
Energy |
Workload |
Dependencies |
User preferences |
| 24 25 | \checkmark | \checkmark | \checkmark | \checkmark | ||||||
| 26 | \checkmark | \checkmark | \checkmark | |||||||
| 27 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||||
| 28 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||||
| 29 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||||
| 30 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||||
| 31 32 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||||
| 33 | \checkmark | \checkmark | ||||||||
| 34 | \checkmark | \checkmark | \checkmark | \checkmark | ||||||
| 35 | \checkmark | |||||||||
| 37 | ||||||||||
| 38 | \checkmark | \checkmark | \checkmark | \checkmark | ||||||
| 39 | \checkmark | \checkmark | \checkmark | \checkmark | ||||||
| 40 | \checkmark | |||||||||
| 41 | \checkmark | \checkmark | ||||||||
| 42 | \checkmark | \checkmark | ||||||||
| 43 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | ||||
| 44 | \checkmark | \checkmark | ||||||||
| 45 | \checkmark | \checkmark | \checkmark | |||||||
| 47 | \checkmark | \checkmark | \checkmark | |||||||
| 46 | \checkmark | |||||||||
| 48 | \checkmark | |||||||||
| 49 | \checkmark | |||||||||
| 50 | \checkmark | \checkmark | \checkmark | |||||||
| 5152 | \checkmark | |||||||||
| 54 | ||||||||||
| 55 | \checkmark | \checkmark | \checkmark | |||||||
| 56 | \checkmark | |||||||||
| 57 | \checkmark | |||||||||
| 58 | \checkmark | \checkmark | \checkmark | \checkmark | ||||||
| 59 | \checkmark | \checkmark | \checkmark | |||||||
| 60 | \checkmark | \checkmark | ||||||||
| Optimised & Comparison Metric(s) | ||||||||
| Network | Nodes | Energy | Performance | Cost | ||||
| Ref. |
Delay |
Bandwidth |
Hardware |
Energy |
QoS-assurance |
Execution time |
Migrations |
Cost |
| 2425 | \checkmark | \checkmark | \checkmark | \checkmark | ||||
| 26 | \checkmark | |||||||
| 27 | \checkmark | |||||||
| 28 | \checkmark | \checkmark | \checkmark | |||||
| 29 | \checkmark | \checkmark | ||||||
| 30 | \checkmark | \checkmark | ||||||
| 31 32 | \checkmark | \checkmark | \checkmark | |||||
| 33 | \checkmark | \checkmark | ||||||
| 34 | \checkmark | |||||||
| 35 | \checkmark | \checkmark | ||||||
| 37 | \checkmark | \checkmark | ||||||
| 38 | \checkmark | |||||||
| 39 | \checkmark | \checkmark | \checkmark | \checkmark | ||||
| 40 | \checkmark | |||||||
| 41 | \checkmark | \checkmark | ||||||
| 42 | \checkmark | |||||||
| 43 | \checkmark | |||||||
| 44 | \checkmark | |||||||
| 45 | \checkmark | \checkmark | ||||||
| 47 | \checkmark | \checkmark | ||||||
| 46 | \checkmark | \checkmark | \checkmark | |||||
| 48 | \checkmark | |||||||
| 49 | \checkmark | \checkmark | \checkmark | |||||
| 50 | \checkmark | |||||||
| 5152 | \checkmark | |||||||
| 54 | \checkmark | |||||||
| 55 | \checkmark | \checkmark | ||||||
| 56 | \checkmark | |||||||
| 57 | \checkmark | |||||||
| 58 | \checkmark | \checkmark | \checkmark | \checkmark | ||||
| 59 | \checkmark | \checkmark | \checkmark | \checkmark | \checkmark | |||
| 60 | \checkmark | \checkmark | \checkmark | \checkmark | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\authormark
BROGI, FORTI, GUERRERO and LERA
\corres
Stefano Forti,
\fundingInfo
University of Pisa project “DECLWARE: Declarative methodologies of application design and deployment" (PRA_2018_66) and by the Spanish Government (Agencia Estatal de Investigación) and the European Commission (Fondo Europeo de Desarrollo Regional), Grant Number: TIN2017-88547-P (MINECO/AEI/FEDER, UE)
Authors Contribution: The authors are ordered alphabetically. All the authors contributed equally to this work.
How to Place Your Apps in the Fog
State of the Art and Open Challenges
Antonio Brogi
Stefano Forti
Carlos Guerrero
Isaac Lera
\orgdivDepartment of Computer Science, \orgnameUniversity of Pisa, \orgaddress\statePisa, \countryItaly
\orgdivDepartment of Computer Science, \orgnameUniversity of the Balearic Islands, \orgaddress\stateBalearic Islands, \countrySpain
A. Brogi
S. Forti
C. Guerrero
I. Lera
(27 July 2018; 27 July 2019; 12 September 2019)
Abstract
[Summary]Fog computing aims at extending the Cloud towards the IoT so to achieve improved QoS and to empower latency-sensitive and bandwidth-hungry applications. The Fog calls for novel models and algorithms to distribute multi-service applications in such a way that data processing occurs wherever it is best-placed, based on both functional and non-functional requirements.
This survey reviews the existing methodologies to solve the application placement problem in the Fog, while pursuing three main objectives. First, it offers a comprehensive overview on the currently employed algorithms, on the availability of open-source prototypes, and on the size of test use cases. Second, it classifies the literature based on the application and Fog infrastructure characteristics that are captured by available models, with a focus on the considered constraints and the optimised metrics. Finally, it identifies some open challenges in application placement in the Fog.
\jnlcitation\cname
, , , and (\cyear2018), \ctitlePlace Your Apps in the Fog. State of the Art and Open Challenges, \cjournalSoftware Practice Experience, \cvol2019;1–22, https://doi.org/10.1002/spe.2766.
keywords:
fog computing, application placement, service placement, application deployment, optimisation algorithms
††articletype: Special issue††© 2019. This manuscript version is made available under the CC-BY-NC-ND 4.0 license (http://creativecommons.org/licenses/by-nc-nd/4.0/). This manuscript is a preprint of the article published in Software Practice and Experience and available at: https://doi.org/10.1002/spe.2766
1 Introduction
CISCO expects more than 50 billion of connected entities (people, machines and connected Things) by 2021, and estimates they will have generated around 850 Zettabytes of information by that time, of which only 10 will be useful to some purpose 1, 2. As a consequence of this trend, enormous amounts of data – the so-called Big Data 3 – are collected by Internet of Things (IoT) sensors and stored in Cloud data centres 4. Once there, data are subsequently analysed to determine reactions to events or to extract analytics or statistics. Whilst data-processing speeds have increased rapidly, bandwidth to carry data to and from data centres has not increased equally fast 5. On one hand, supporting the transfer of data from/to billions of IoT devices is becoming hard to accomplish due to the volume and geo-distribution of those devices. On the other hand, the need to reduce latency for time-sensitive applications, to eliminate mandatory connectivity requirements, and to support computation or storage closer to where data is generated 24/7, is evident 6.
In this context, a new utility computing paradigm took off, aiming at connecting the ground (IoT) to the sky (Cloud), and it has been named Fog computing 7. The Fog aims at better supporting time-sensitive and bandwidth hungry IoT applications by selectively pushing their components/services closer to where data is produced and by exploiting a geographically distributed multitude of heterogeneous devices (e.g., personal devices, gateways, micro-data centres, embedded servers) spanning the continuum from the IoT to the Cloud (Fig. 1). In its reference architecture111The OFC reference architecture of Fog computing was also adopted as the IEEE 1934-2018 standard 8., the OpenFog Consortium (OFC) 9, which is fostering academic and industrial research in the field since 2015, gives the following definition of Fog computing:
Fog computing is a system-level horizontal architecture that distributes resources and services of computing, storage, control and networking anywhere along the continuum from Cloud to Things, thereby accelerating the velocity of decision making. Fog-centric architecture serves a specific subset of business problems that cannot be successfully implemented using only traditional cloud-based architectures or solely intelligent edge devices.
The NIST has also recently proposed a conceptual architecture for Fog computing 10. The Fog configures as a powerful enabling complement to the IoT+Edge and to the IoT+Cloud scenarios, featuring a new intermediate layer of cooperating devices that can autonomously run services and complete specific business missions, contiguously with the Cloud and with cyber-physical systems at the edge of the network 11.
Overall, Fog computing should ensure that computation over the collected data happens wherever it is best-placed, based on various application (e.g., hardware, software, QoS) or stakeholders (e.g., cost, business-related) requirements. Since modern software systems are more and more often made from distributed, (numerous) interacting components (e.g., service-oriented and micro-service based architectures), it is challenging to determine where to deploy each of them so to fulfil all set requirements. Fog computing architectures substantially differ from Cloud architectures. Particularly, according to recent literature 12, 13, 14, 15, 16:
- –
Fog nodes feature limited and very heterogeneous resources, whilst data centre nodes feature high (and virtually unbounded) computational, storage and power capabilities,
- –
Fog devices are highly geographically distributed – often mobile – and possibly span wide large-scale networks reaching closer to (human and machine) end-users, whilst Cloud data centres are located in few geographic locations all over the world and connect directly to fibre backbones,
- –
end-to-end latency between Cloud nodes within data centres is usually negligible and bandwidth availability is guaranteed via redundant links, whilst in Fog domains network QoS between nodes can largely vary due to the presence of a plethora of different (wired or wireless) communication and Internet access technologies,
- –
Fog nodes are owned and managed by various service providers (from end-users to Internet Service Providers to Cloud operators) and might also opportunistically include available edge devices (e.g., crowd-computing, ad-hoc networks) whereas largest Cloud data centres are in the hands of a few big players.
Due to these differences, Fog computing calls for new and specific methodologies to optimise the distribution of application functionalities and the usage of the available infrastructure, by suitably dealing with (possibly) limited hardware resources and large-scale deployments, unstable connectivity and platform/operators heterogeneity, and (node or link) failures 17.
Lately, following this line, a significant amount of research has considered the problem of optimally placing application components or services based on different – and sometimes orthogonal – constraints. However, to the best of our knowledge, no comprehensive and systematic survey of these efforts exists in the literature.
This work aims precisely at offering an exhaustive overview of the solutions proposed for the application placement problem in the Fog, by providing the reader with two complementary perspectives on this topic:
- P1.
an algorithmic perspective that reviews state-of-the-art contributions based on the methodologies that they employed to address Fog application placement, along with a study on the available prototypes and experiments, and
- P2.
a modelling perspective that analyses which (functional and non-functional) constraints and which optimisation metrics have been considered in the literature to determine best candidate application placements.
The rest of this paper is organised as follows. After describing the methodology followed to realise this survey (Section 2), a comprehensive analysis of state-of-the-art related to Fog application placement under P1 (Section 3.1) and P2 (Section 3.2) is presented. Finally, based on both P1 and P2, some open problems and future research challenges are pointed out (Section 4).
2 Setting the Stage
This survey includes research articles that deal with Fog application placement with the objective of optimising non-functional requirements of the system. To set the stage, we start by formally defining the considered application placement problem.
Definition – Let be a multi-component (or multi-service) application with a set of requirements and let be a distributed Fog infrastructure. Solutions to the Fog Application Placement Problem (FAPP) are mappings from each component of to some computational node in , meeting all requirements set by and optimising a set of objective metrics used to evaluate their quality. Solution mappings can be many-to-many, i.e. a component can be placed onto one or more nodes and a node can host more than one component.
It is worth noting that FAPP can be solved or adjusted also at runtime (i.e., when is running), in case that some requirements in cannot be met by the current solution mapping or whenever can be further optimised as Fog infrastructure conditions change over time.
The concept of FAPP and the underlying technologies are currently emerging, and the boundary with other technologies is not always clear. In this survey, we include all the articles that deal with the placement of applications that are generally available for the users and that can benefit from the adoption of the Fog computing paradigm. Focussing on existing approaches to solve FAPP, we will exclude those works that only deal with dispatching or scheduling of (user or IoT) requests, as they represent a phase that is subsequent to the placement of the application components. Similarly, we will exclude research in the field of task offloading (i.e., outsourcing of the computation of a given function to get a result back) from one node to a better (e.g., more powerful or reliable, closer) one, which is covered in detail by other recent surveys18, 19.
A problem similar to FAPP has been studied in the context of Software Defined Networking (SDN), and literature on the placement of Virtual Network Functions (VNFs) onto SDN substrates has been already thoroughly analysed in exhaustive recent surveys (e.g. 20, 21, 22, 23). Such a problem is known as VNF embedding and includes the joint placement of virtual function services and the routing of traffic flows between them. FAPP significantly differs from VNF embedding as the latter assumes to have the possibility of programming network flows from a (logically) centralised point of control in the infrastructure. As Fog application deployments will likely span various service providers, these might not always support SDN across their infrastructures, hence the previous assumption might be too stringent when considering Fog scenarios in general. Thus, also to avoid overlapping with existing surveys on SDN and VNF placements, in what follows we will exclude results in those areas.
Finally, research in the field of mobile offloading, shifting the processing and execution from mobile terminals to network capabilities or edges nodes, will be also excluded.
To the best of our knowledge, this is the first survey that covers the state of the art for FAPP. Our search criteria were formed by the following terms: (Fog computing (service application) (placement deployment)). The search was carried out, with the help of Google Scholar, in the following libraries: IEEE Xplore Digital Library, Wiley Online Library, ACM Digital Library and Web of Science. To fully capture the advances in the field, both journal and conference articles were collected during the search phase. Additionally, the references in selected articles were also analysed to find more related work in the FAPP domain. At the end of this first step, the 110 articles we collected were carefully screened. After a more accurate and deeper selection process, where references in the field of offloading, dispatching, scheduling and VNF embedding were removed, we selected 38 articles to be further analysed.
Table 1 offers a complete bird’s-eye view of the set of the analysed papers highlighting their main strengths and weaknesses, and the availability of an open-source prototype implementation. Focussing the definition of FAPP from an optimisation point of view, the common elements in any optimisation process are the following:
Decision variables – They are the items whose values need to be determined during the optimisation process. In the case of the FAPP, they can be the binary decision variables (or, equivalently, the mapping functions) that indicate if a component of is allocated (or not) to a Cloud or Fog node of . All the articles that we have included in our study, rely on similar decision variables.
Objective function – The objective function measures the suitability of a solution (a specific value assigned to the decision variables) within the optimisation process. The optimisation can be addressed to maximise or minimise the value of the objective function. In a more general way, the objective function represents the concerns of the optimisation and defines the metrics that are optimised by fixing the values of the decision variables. In our case, the objective functions measure the metrics of candidate solutions to FAPP.
Constraints over the decision variables – They define the requirements that must be satisfied by each specific case of the decision variables. Solutions (values of the decision variables) that do not satisfy the constraints are rejected as possible solutions to FAPP.
Domain variables or parameters – Commonly, they are the fixed values which are known previously to the optimisation process. We also include in this category other variables, metrics or items related to the optimisation that are not constraints neither optimisation objectives.
Algorithms – They are the algorithms proposed to find the values of the decision variables that optimise the objective function value, while satisfying all set constraints. The problem of finding solution mappings between application components in and Fog/Cloud nodes in , whilst minimising/maximising the values of the objectives functions and satisfying the constraints in , is NP-hard. Moreover, when several opposite optimisation objectives are considered, it is necessary to determine a trade-off between the objectives because some of them may increase when the other decrease. Indeed, FAPP needs to be solved by evaluating – at worst – all possible solutions, i.e., assuming the application is made of modules and the infrastructure is composed of nodes, different candidate solutions. Such complexity can be tamed by using heuristics which permit to find sub-optimal solutions. It is also important to consider that Fog computing is a large-scale and dynamic domain, where real implementations have to deal with huge quantities of Fog nodes and applications.
Overall, we have organised the description and presentation of the articles from the point of view of the elements of the optimisation process: algorithms (Section 3.1), constraints and parameters (Section 3.2.1), and objective functions (Section 3.2.2). Table 1 (and Fig. 3), Table 2, and Table 3 give an overview of the characteristics of the analysed articles according to such three elements, respectively:
Algorithms view point – The analysis of the selected articles has shown that various algorithmic approaches have been proposed to optimise FAPP (Fig. 2). We have grouped and analysed the articles in Section 3.1 by those optimisation algorithms resulting in two main groups, with the highest number of articles proposing search-based and mathematical programming solutions to FAPP. Other types of algorithms – i.e., bio-inspired, game theoretical, deep learning, dynamic programming, and complex networks algorithms – have been only studied in a more limited number of works.
Constraints view point – In the case of the constraints, we analysed the articles and classified the constraints into a two-level taxonomy (Fig. 4). In a first level, we considered constraints related to the main elements of Fog architectures, i.e. network constraints, characteristics of the available Fog nodes, energy constraints, and application requirements. By further analysing the articles, we detected that network constraints related to the available Fog network topology (e.g. availability of IoT devices, existing communication links), to the experienced end-to-end latency (or communication time) among nodes, to bandwidth availability, and to link reliability. We also sub-divided node-related constraints relating them to the availability of hardware resources (e.g., RAM, CPU, storage) and of particular software frameworks (e.g., libraries, OSs). Similarly, application constraints are related with the type and number of requests that are generated in the systems (workload), to the organisation and interrelation between application components or services (dependencies), and to the possibility for the users to set conditions in the application placement or to choose between a set of alternative placements (user preferences). Lastly, energy constraints are only related to the power consumption and a second classification was not considered for them.
Objective functions view point – From the analysis of the optimisation objectives, we observed that the articles could be again described by a two-level taxonomy (Fig. 5). Particularly, optimising network usage was a common objective, attempting to reduce communication delay (often including processing times) and network bandwidth consumption. Similarly, many approaches attempted an optimisation on the amount of hardware resources allocated to application deployment and to energy objectives, related to the power consumption that the execution of applications generates in the Fog layer. With respect to system performance, the optimisation focus was on overall QoS-assurance (e.g., measured as the number of requests executed before a specific deadline or as the likelihood to satisfy certain constraints on QoS requirements), on the execution time of the application requests, or on the overhead due to migrations of application components or services from different Fog or Cloud nodes. Finally, operational cost (due to hardware, software and bandwidth purchase) for keeping an application deployment up and running was often considered among the optimisation objectives.
3 Analysis of the State of the Art
3.1 Algorithms
In this section, all reviewed approaches are analysed according to the algorithms or methodologies that they use for solving FAPP. As aforementioned, we identified three main classes of algorithms which have been exploited in the literature (Figure 2). Namely:
- •
search-based algorithms, such as (heuristic) backtracking search, or first- and best-fit application placement,
- •
mathematical programming algorithms, such as integer or mixed integer linear programming,
- •
other algorithms like game theoretical or deep learning.
Figure 3 graphically depicts the classification of the surveyed algorithms in Table 1 from such an algorithmic perspective. The rest of this section is organised according to this classification with the goal of providing the reader with a complete overview of the state of the art related to frameworks used for solving FAPP (Sections 3.1.1 to 3.1.3). For each reviewed approach, we indicate the availability of open source research prototypes and the size of the experiment used for assessing or testing it. Strengths and weaknesses of each work are also summarised in Table 1.
3.1.1 Search-based Algorithms
Being FAPP an NP-hard problem, the first solutions which have been exploited to solve it are traditional search algorithms along with greedy or heuristic behaviour 62.
Among the first proposals investigating this direction, Gupta et al.24 and Mahmud et al.25 proposed a Fog-to-Cloud search algorithm as a first way to determine an eligible (composite) application placement of a given (Directed-Acyclic) IoT application to a (tree-structured) Fog infrastructure. The search algorithm proceeds Edge-ward, i.e. it attempts the placement of components Fog-to-Cloud by considering hardware capacity only, and allows merging homologous components from different application deployments. An open-source tool – iFogSim – implementing such strategy has been released and used to compare it with Cloud-only application placement over two quite large use cases from VR gaming (3 application components scaled up to 66, 1 Cloud, up to 80 Fog nodes) and video-surveillance (4 application components, scaled up to 19, 1 Cloud, up to 17 Fog nodes). Building on top of iFogSim, Mahmud et al.26 refined the Edge-ward algorithm with an a posteriori management policy to guarantee the specified application service delivery deadlines and to optimise Fog resource exploitation. They illustrated their proposal at work on two small-scale motivating examples (up to Fog nodes).
Recently, exploiting iFogSim, Guerrero et al.27 proposed a distributed search strategy to find the best service placement in the Fog, which minimises the distance between the clients and the most requested services. Each Fog node takes local decision to optimise the application placement, based on request rates and freely available resources. The SocksShop 63 application (9 components) is used to evaluate the proposed decentralised solution against the Edge-ward policy of iFogSim –varying the replication factor in the range and the number of Fog nodes in the range . The results showed a substantial improvement in network usage and service latency for the most frequently requested services. Also, Ottenwalder et al.28 proposed a distributed solution – MigCEP – both to FAPP and to runtime migration. Such proposal reduces the network usage in Fog environments and ensures end-to-end latency constraints by searching for the best migration, based on probabilistic mobility of application users. The OMNeT++ 64 simulator was used to show how MigCEP improves live migration against a static and a greedy strategy over a dynamic large-scale infrastructure (i.e., 1000 emulated connected cars). No codebase was released for either the works of Guerrero et al.27 or Ottenwalder et al.28.
In this context, Brogi and Forti29 proposed both an exhaustive and a greedy backtracking algorithm to solve FAPP based on the (hardware, software, IoT and QoS) requirements of multi-component applications. The greedy heuristic attempts the placement of components sorted in ascending order on the number compatible nodes (i.e., fail-first), considering candidate nodes one by one sorted in decreasing order on the available resources (i.e., fail-last). The devised approach works on arbitrary application and infrastructure graph topologies. Later on, Brogi et al. extended their initial model and algorithms probabilistically so to estimate QoS-assurance, resource consumption in the Fog layer 30 and monthly deployment cost 31 of eligible placements. QoS-assurance is estimated by means of Monte Carlo simulations so to consider variations in the QoS of end-to-end communication links and to predict how likely each application placement is to comply with the desired network QoS 30. An open-source prototype – FogTorch – implementing the whole methodology has been released and used on different simple use cases (i.e., 3 application components, 2 Clouds, 3 Fog nodes) from smart agriculture and smart building scenarios. Despite exploiting worst-case exponential-time algorithms, the prototype was shown to scale 32 also on the larger VR game example proposed by Gupta et al.24. FogTorch was also modularly extended by other researchers to simulate mobile task offloading in Edge computing 65.
Significantly inspired by Brogi and Forti29, Xia et al.33 proposed a backtracking solution to FAPP to minimise the average response time of deployed IoT applications. Two new heuristics were devised. The first one sorts the nodes considered for deploying each component in ascending order with respect to the (average) latency between each node and the IoT devices required by the component. The second one considers a component that caused backtracking as the first one to be mapped in the next search step. A motivating IoT application 66 (i.e., 6 application components replicated up to 800 times) was used to assess the algorithms on very large random infrastructures (i.e., 1 Cloud, up to 20000 Fog nodes). The exhaustive search handled at most 150 nodes, whilst the first-fit and the heuristic strategy scaled up to 20000 nodes, the latter showing a 40% improvement on the response time with respect to first-fit. Prototype implementations were not released.
Limiting their work to linear application graphs and tree-like infrastructure topologies, Wang et al.34 described an algorithm for optimal online placement of application components, with respect to load balancing. The algorithm searches for cycle-free solutions to FAPP, and shows quadratic complexity in the number of considered computational nodes. An approximate extension handling tree-like application is also proposed, which considers placing each (linear) branch of the application separately and shows increased time complexity. The approach is simulated on 100 applications to be placed featuring 3 to 10 components each and infrastructures with 2 to 50 nodes. Finally, the achieved performance is compared against the Vineyard algorithm 67 and a greedy search minimising resource usage.
Hong et al.35 proposed a (linearithmic) heuristic algorithm that attempts deployments by prioritising the placement of smaller applications to devices with less free resources. A face detection application made from 3 components is used to evaluate the algorithm on a small real testbed (1 server acting as Cloud, 5 Fog nodes). Taneja and Davy36 proposed a similar search algorithm that assigns application components to the node with the lowest capacity that can satisfy application requirements, also featuring linearithmic time complexity in the number of considered nodes. Binary search on the candidate nodes is exploited as a heuristic to find the best placement for each component, by attempting deployment to Fog nodes first (i.e., Fog-to-Cloud). The medium-scale experiments (i.e., 6 application components, 1 Cloud, up to 13 Fog nodes) were carried in iFogSim, but the code to run them has not been made publicly available.
3.1.2 Mathematical Programming
Mathematical programming 68 is often exploited to solve optimisation problems by systematically exploring the domain of an objective function with the goal of maximising (or minimising) its value, i.e., identifying a best candidate solution. Many of the reviewed approaches tackled FAPP with such a mathematical framework, by relying on Integer Linear Programming (ILP), Mixed-Integer Linear Programming (MILP) or Mixed-Integer Non-Linear Programming (MINLP).
Velasquez et at.37 proposed a framework and an architecture for application placement in Fog computing. An ILP implementation is suggested but it is not realised nor evaluated by the authors. On the other hand, Arkian et al.38, in addition to proposing a Fog architectural framework, formulated FAPP as a MINLP problem, where application components (i.e., VMs) are to be deployed to Fog nodes so to satisfy end-to-end delay constraints. The problem is then solved (along with the problem of task dispatching) by linearisation into a MILP and the solution is evaluated on data traces from IoT service demands (from 10-100 thousand devices) in the province of Teheran, Iran. The results of the experiment showed that the Fog promises to improve latency, energy consumption and costs for routing and storage. Similarly, Yang et al.39 tackled both FAPP and its cost-aware extension with the problem of balancing request dispatching. The proposed methodology attempts optimising the trade-off between access latency, resource usage, and (data) migrations (costs). It accounts for constraints on the available resources as well as for workload variations depending on users’ service accessing patterns. A novel greedy heuristic (solving a relaxed LP problem and approximating a solution for the full-fledged ones) is shown to outperform other benchmark algorithms (i.e., classic ILP and GA) both in terms of obtained results and algorithm execution time over an example with 20 Fog nodes and 30 services to be placed.
Alike to these proposals, Zeng et al.40, 41 solved FAPP along with task scheduling, converting a MINLP into a MILP, solved with the commercial tool Gurobi 69. A simulation and comparison is provided against server-greedy (i.e., Cloud-ward) and client-greedy (i.e., Edge-ward) placement strategies, showing good improvements on response time when using the proposed approach in a small (i.e., 15 to 25 application images, 11 Fog/Cloud servers41) and medium (i.e., 45 to 80 Fog nodes40) sized use case. Still relying on Gurobi (together with PuLP 70), Souza et al.42 solved FAPP as an ILP problem, aimed at optimising latency/delay needed for resource allocation. Resources are modelled uniformly as available slots at different nodes. Out of the services to be deployed, few of them were considered to require large amounts of resources (i.e., elephants, 10%) and many more required instead few resources (i.e., mice, 90%). In the small-scale experimental settings (90 applications, 1 Cloud, 6 Fog nodes) both sequential and parallel resource allocation were considered and the benefit of Fog computing was shown in terms of reduced delays in service access.
Alternatively, Barcelo et al.43 combined FAPP with the routing of requests across an IoT-Cloud (i.e., Fog) infrastructure. They modelled FAPP as a minimum (energy) cost mixed-cast flow problem, considering unicast downstream and multicast upstream, typical of IoT. A solution to FAPP is then provided by means of known poly-time algorithms, which are simulated via the LP solver Xpress-MP 71 on mock data traces from three use cases (i.e., smart city, smart building, smart mobility). The experiments simulated tens of devices and showed some performance improvements (as per latency, energy, reliability) with respect to traditional IoT deployments that do not rely on Fog nodes. Mahmud et al.44 proposed instead a QoE extension of iFogSim – based on an ILP modelling of users expectation – which exploited fuzzy logic and achieved improvements in network conditions and service quality.
Skarlat et al. designed a hierarchical modelling of Fog infrastructures, consisting of a centralised management system to control Fog nodes organised per colonies45, 47, 46. Particularly, Skarlat et al.45 adopted an ILP formulation of the problem of allocating computation to Fog nodes in order to optimise (user-defined) time deadlines on application execution, considering IoT devices needed to properly run the application. A simple linear model for Cloud costs is also taken into account. The proposed approach is compared via simulation to first-fit and Cloud-only deployment strategies, showing good margins for improvement, on a small-scale use case (i.e., up to 80 services, 1 Cloud, 11 Fog nodes).
Some of the methodologies proposed in the literature combine ILP with other optimisation techniques. Huang et al.48, for instance, modelled the problem of mapping IoT services to Edge/Fog devices as a quadratic programming problem, afterwards simplified into an ILP and into a Maximum Weighted Independent Set (MWIS) problem. The services are described as a co-location graph, and heuristics are used to find a solution that minimises energy consumption. A (promising) evaluation is performed over large-scale simulation settings (i.e., 50 services, 100 to 1000 Fog nodes).
Similarly, Deng et al.49 followed a hybrid approach to model FAPP and to determine the best trade-off between power consumption and network delays (exploiting Markov models to describe network capabilities). After decomposing FAPP into three sub-problems (power-delay vs Fog communication, power-delay vs Cloud communication, and minimising WAN delay) balanced workload solutions are looked for exploiting different optimisation methods (i.e., convex optimisation, generalised Benders’ decomposition and Hungarian method). A quite large simulation setup in MATLAB 72 was used to evaluate the proposed approach (i.e, from 30000 to 60000 nodes).
Unfortunately, none of the approaches previously discussed in this section released the code to run the experiments. Conversely, based on the hierarchical model of Skarlat et al. 47, Venticinque and Amato 50 proposed a software platform to support optimal application placement in the Fog, within the framework of the CoSSMic European Project 73. Envisioning resource, bandwidth and response time constraints, their approach permits to choose among a Cloud-only, a Fog-only or a Cloud-to-Fog deployment policy, which were evaluated in a small testbed (i.e., 1 Cloud, 1 Fog node) where a composite application (8 components) from Smart Energy scenarios 74 was deployed and run over emulated IoT data traces.
Finally, Cardellini et al.51, 52, 53 discussed and released Distributed Storm (formerly S-ODP), an open-source extension of Apache Storm that solves FAPP by means of the CPLEX 75 optimiser with the goal of minimising end-to-end application latency and availability of stream-based applications. Extensive experiments (i.e., up to 50 application components and up to 100 Fog nodes) showed the scalability of their ILP approach (with respect to a traffic-aware extension of Storm 76), which can be easily extended to include bandwidth constraints and a network-related objective function considering network usage, traffic and elastic energy computation.
3.1.3 Other Algorithms
Bio-inspired Algorithms
Genetic algorithms (GAs) implement meta-heuristics to solve optimisation and search problems based on bio-inspired operators such as mutation, crossover and selection 77. Naturally, some of the reviewed works exploited such bio-inspired search algorithms to explore the solution space of FAPP, and to solve it. Wen et al.54 surveyed Fog orchestration-related issues and offered a first description of the applicability of GAs and parallel GAs to FAPP.
Retaking the ILP model of Skarlat et al.45 based on Fog colonies and hierarchical control nodes, Skarlat et al.47 also proposed a GA solution implemented in iFogSim and compared to a greedy (first-fit) heuristic and to an exact optimisation obtained with CPLEX, over a small example (i.e., 5 application components, 10 Fog nodes). Whilst the first-fit strategy does not manage to guarantee user-defined application deadlines, both the exact solution and the GA do. On average, the GA solutions are 40% more costly than the optimal ones, despite guaranteeing lower deployment delays.
Mennes et al.55 required the user to provide a minimum reliability measure and a maximum number of replicas for each (multi-component) application to be deployed. They employed a distributed GA, by using Biased Random-Key arrays to represent solutions (instead of binary arrays). The placement ratio (placed/required) is used to evaluate the proposed algorithm, which showed near-optimal results against a small example (i.e., 10 applications, 5 Fog nodes) and faster execution time with respect to ILP solvers. Regrettably, open-source implementations are not provided for any of the works exploiting GA.
Game Theory
Game theoretical models 78 – which describe well multi-agent systems where each agent aims at maximising its profit whilst minimising its loss – were fruitfully applied to solve FAPP in 56 and 57.
Zhang et al.56 modelled FAPP as Stackelberg games between data service subscribers and data service providers, the latter owning Fog nodes. A first game is used to determine the number of computing resource blocks that users should purchase (based on latency requirements, block prices and utility). A second game is used to help providers set their prices so to maximise revenues. A matching game is used to map providers to Fog nodes based on their preferences. And, finally, matching between Fog nodes and subscribers is refined in order to be stable. The proposal was tested in a simulated MATLAB environment considering 120 service subscribers, 4 data providers, and 20 Fog nodes.
Similarly, Zhang et al.57 describe a game among service providers, Fog nodes and service subscribers. The mapping between the Fog resources and service subscribers is determined to solve a student-to-project allocation problem. During the game, subscribers consider revenues, data transmission costs, providers’ costs and latency to evaluate possible assignments. On the other hand, providers consider revenue from subscribers minus the cost of service delay.
Deep Learning
Reinforcement learning trains software agents (with reward mechanisms) so that they learn policies determining how to react properly under different conditions 79. To the best of our knowledge, only Tang et al.58 exploited recent reinforcement learning techniques to solve FAPP. After defining a multi-dimensional Markov Decision Process to minimise communication delay, power consumption and migration costs, a (deep) Q-learning algorithm is proposed to support migration of application components hosted in containers or VMs. The proposal took into account user mobility and was evaluated over a medium-sized infrastructure (i.e., 70 nodes) using real data about users mobility taken from San Francisco taxi traces.
Dynamic Programming
Differently from the others, Souza et al.59 modelled FAPP as a 0-1 multidimensional knapsack problem 80 with the objective of minimising a given objective function. Limited simulation results on a medium-sized example (40 application components, 6 Fog nodes, 3 Clouds) are provided by the authors. However, no details are given on how the solution is computed, and the code to run the experiments is not available.
Also Rahbari et al.60 modelled FAPP as a knapsack problem, by considering the allocation of application modules to running VMs in a Fog infrastructure. iFogSim was used to simulate the proposed symbiotic organisms search algorithm, showing some improvements in energy consumption and network usage with respect to a First Come First Served allocation policy and traditional knapsack solvers.
Complex networks
To the best of our knowledge, only Filiposka et al.61 relied on network science theory to model and study FAPP, employing on a community detection method to partition the available Fog nodes into a hierarchical dendogram81. The dendrogram was then used to analyse different community partitions so to find the most suitable set of nodes to support the VMs that encapsulate the applications. The proposal was validated with CloudSim 82 over a medium-scale use case (i.e., 80 Fog nodes, and from 150 to 250 application components). The proposed community-based extension to CloudSim is, however, not available.
3.2 Modelling
In this section, all reviewed approaches are analysed according to a modelling perspective that accounts for both the considered problem constraints (Section 3.2.1) and optimisation metrics (Section 3.2.2).
3.2.1 Considered Constraints
During the analysis of the modelling of FAPP, we first studied the features of the problem that were taken as constraints to solve it in the surveyed literature. As a result, we obtained the taxonomy of Figure 4 which permits to classify the articles as shown in Table 2. As aforementioned, the two-level taxonomy of FAPP constraints considers four main types of characteristics, i.e. network features, Fog and Cloud nodes resources, energy consumption and application requirements.
We defined four features for the second level of the network constraints. Latency is the network feature related with the transmission time of the requests and responses through the network links. This has an important influence on Fog environments since one of the objectives of these domains is to reduce the response time of Cloud-based applications. Consequently, latency is commonly included in the optimisation works targeting FAPP. Similarly, the bandwidth – i.e. quantity of data that the network link is able to transmit per unit of time – is also important to achieve this objective of reducing the user-perceived response time. In the field of communication networks, the availability and the influence of failures in the transmission is also important, and we additionally included the link reliability in our analysis. Finally, topology information was also included as a criterion so to highlight those articles that considered the distribution and organisation of Fog devices, the influence of the region of the network where the applications are deployed (or users are connected), as well as the presence of IoT devices (i.e., sensors or actuators) that might influence the deployment of application services.
The constraints related to Fog nodes are categorised into hardware and software ones. In the first case, the constraints refer to different types of resources (e.g., processors, memory, storage) or to a generic resource capacity that can represent any considered resource type. In the second case, the constraints are related to software dependencies that should be available at the node hosting a component (e.g., OS, libraries/frameworks, language support).
Energy constraints, commonly related to the power consumption of the hardware elements, are important in Fog domain for two main reasons. The first one is a constraint inherited from Cloud domains. Both Cloud and Fog need a high level of power consumption to give service to the users. Small improvements in power consumption can result on important energy savings. Additionally, in the case of Fog infrastructures, mobile and battery-powered devices are also involved, making energy considerations even more important in the optimisation of FAPP.
Concerning application constraints, we classified the articles by analysing the number of user request (workload), the interrelation between the modules of the applications (dependencies), and the possibility to express user-defined conditions or preferences related to the application placement (user preferences).
Network Constraints
The first set of constraints and decision variables are related to the network. The most common metric in this set is the network latency, but others such as the bandwidth and the topology are also quite usual. On the contrary, link reliability is seldom considered in the analysed research works. Various works solely considered latency among the metrics related with the network26, 42, 49, 56, 57, 59, often but not always along with bandwidth24, 28, 29, 30, 31, 32, 43, 58. Bandwidth was also considered in 36, 38, along with hardware constraints. On the contrary, the studies that included link reliability also included other network constraints, such as bandwidth34, 55, latency and topology53, or latency, bandwidth and topology43.
Topology is the most diverse metric from the ones of the networks as many different proposals exist and have been surveyed in our analyses. Several works deal with the application placement by considering that exist statically defined Fog colonies45, 47, 46, or sets of devices that are managed by a controller node. Thus, a twofold placement based on those colonies was proposed, with a previous mapping of applications in colonies and a second phase of mapping applications to the devices inside a colony. Venticinque and Amato50 also considered Fog colonies, and they additionally included the network bandwidth constraint.
Alternatively, Yang et al.39 considered that the devices with the capacity to place services are organised in cloudlets, and those cloudlets are assigned to cover a region of the network. A cloudlet is defined as an abstraction tier between the user and the Cloud that provides processing capabilities. It can be a static infrastructure connected to the wireless access network, or augmented routers and switches in the wireless access network. Consequently, the use of a cloudlet would depend on the gateways where the users are connected to and in the topology of the network (reflected in the coverage definition). In this work, the authors also considered the latency of the network as a constraint.
Ottenwalder et al. 28 defined a federation of hierarchy brokers implemented with a combination of Cloud data centres and Fog devices. They also studied the mobility pattern of the users and how they are connected to different nodes in the network topology. The study of the mobility of the users across different parts of the topology of the network is also included in the studies of Tang et al.58 and Filiposka et al.61. Additionally, the latter study used the topological structure of the network as the method to determine the mapping among applications and nodes. We have also considered that the number of node elements between the users and the applications or between nodes allocating modules of the same application is also a feature related to the topology of the network. Under these conditions, several works24, 27, 48 took into account the hop distances of the Fog nodes as input variables of the optimisation process.
Finally, there is a small set of papers that also considered the interactions between applications and IoT devices24, 30, 31, i.e., if the application modules need to be executed in devices with specific hardware requirements or with sensor or actuator elements. We have classified those works into the topology feature since the application placement depends on the characteristics of the network components (nodes).
Node Constraints
The analysis of Table 2, clearly identified that most of the articles considered constraints about the hardware of the devices. On the contrary, software constraints are only included in a very small number of the surveyed articles on FAPP.
The most common feature related to the hardware was the resource capacity of the Fog devices as a constraint element for the number of services that can be placed into them. The resource capacity is usually modelled as a vector (or set) of elements, one for each of the hardware elements considered in the Fog devices or the network. Examples of those vectors for the case of the Fog devices are: considering CPU24, 58; considering CPU and storage38; CPU, RAM and storage30, 31, 40, 47; considering only storage39, 41, 45. Examples of resource capacity vectors both for Fog nodes and network are: considering CPU, RAM and network bandwidth36, 55; considering CPU, RAM, storage and network bandwidth33, 50; considering processing and transmission capacities43.
Other papers defined a general resource model and they did not focus on the specific resource components26, 29, 61. Mahmud et al.44 also considered a general resource value, but they additionally defined the service demand and device capacity in terms of the expected and offered processing times. On the contrary, this model was sometimes simplified to a scalar value which represents a general capacity unit27, 35, 51, 52, 53, or with general resources slots42, 59. Finally, some other papers defined the hardware resources of the Fog computing nodes, but they did not include this constraint in the optimisation process to simplify it34.
In other papers, the hardware is considered as variables of a fitness function. The fitness function is used to measure the suitability of a device to place the application modules. Rahbari et al.60 included the CPU and network usages in the fitness function. For example, Skarlat et al.45 defined the type of service that determines the additional hardware that the device needs to include to be allocated in.
As we previously mentioned, constraints related to the software features of the Fog computing nodes are just considered in a small number of studies. For instance, Brogi and Forti29 and Brogi et al.30, 31, 32 also characterised Fog devices (and application requirements) with software capabilities (e.g., operating system, platforms, frameworks).
Energy Constraints
Energy is also considered as an input variable or constraint in some of the analysed works. For example, Barcelo et al.43 characterised the Fog devices with their energy resources, such as power grid, battery, or energy costs, and the network links with, also, the energy costs. The limitations of devices powered with batteries are taken into account to guarantee lifetime requirements. Souza et al.59 proposed the concept of energy cells to measure the energy consumed by the underlying devices, and the optimisation took into account the number of available energy cells for the mapping of applications and devices. The objective was to minimise the excessive energy consumption in the most energy constrained devices.
Application Constraints
Three types of application constraints have been considered for the classification of the papers in the survey: constraints related to the dependencies between the modules or services of the applications, to the workload generated over the applications, and if the users are able to define any kind of preference in the deployment of the application services.
These constraints were not usually considered together in the papers of the survey. There were only four papers27, 28, 38, 39 that included more than one of those application constraints, more concretely, the workload and dependency constraints. Guerrero et al.27 considered both the request rate of the applications to prioritise the placement of some application and the interrelation between the services. They considered that the interrelated services of an application should be allocated in devices within the network shortest path between the user and the Cloud provider, and the placement order was determined by the topological order of the services, placing the initial services closer to the users. Yang et al.39 analysed the workload generated from each region of the Fog domain and the dependencies between the application modules. Ottenwalder et al.28 defined the dependencies of the applications as an operator graph and also considered the load over the system to find a migration plan for the operators (services) across the devices. Arkian et al.38 considered the request rates of the applications between the Fog devices and the association between the consumers and the data. Mahmud et al.44 defined the user expectation metric that includes metrics such as the service access rate, demanded resources, and expected processing time, and this metrics is used to prioritise the placement of the applications. Additionally, the interrelation of the devices was also included in the status metric (proximity, resource availability and processing speed).
The constraint about the dependency of the application models is the most common one. In the work of Skarlat et al.47, the interactions between the application services were considered to calculate the theoretical response time of applications. Since they organised the devices in colonies, if two interrelated services are allocated in different colonies, the response time would be increased. Consequently, the optimisation algorithm should co-locate the services of an application in the same colony. Zeng et al.41 considered the interrelation between the storage (data placement) and the execution (scheduling) of the applications to minimise the application completion time by optimising the influence of the I/O time and the task completion time. Wang et al.34 proposed two algorithms which were defined by considering the interrelations between the modules of the applications, represented by a graph. The first algorithm was defined for linear-like applications and the second one for tree-like applications. Other application shapes were not considered. Rahbari et al.60 considered a symbiotic organisms search that used the relationships between the virtual machines (VM) to decide the allocation of the services on those VMs. Mahmud et al.26 presented a decentralized policy for the inter-dependent application modules that simultaneously considered the service access delay, service delivery time and device communication delays.
User preferences were only included in few modelling efforts. Brogi and Forti29 and Brogi et al.30, 31, 32 created an algorithm that suggests to the user several alternatives for the deployment among a set of eligible candidates, and that permits whitelisting those nodes that should be considered for the placement of certain services, according to user defined business policies. But they left to the users to choose how to trade-off the QoS metrics and the Fog resources consumptions, or even taking into account other types of considerations. In the work of Skarlat et al.45, the users are allowed to define a deadline for the applications to warranty a level of QoS. Finally, Cardellini et al.53 stated that their solution could easily include user-related constraints, such as service co-location, bandwidth limitation, even tag-based constraints, but they did not implement them.
3.2.2 Optimised & Comparison Metrics
The ultimate objective of the FAPP is to optimise one or several metrics of the Fog domain. Usually, in a complex system such as a Fog architecture, some of the most common optimisation objectives are contrasting, i.e., they cannot be both optimised and a trade-off between them needs to be determined. For example, if resource usage is optimised, probably the QoS of the application would be damaged. Some of the papers also studied the influence of their proposals in additional metrics to the ones of their optimisation metrics. By this, a general view of the effects of the FAPP proposal in the system is provided. In this section, in addition to the optimised metrics, we have included all those metrics that have been studied, evaluated, and analysed in the results of the papers in the survey.
From the analysis of the papers, we defined a taxonomy of eight elements to classify the articles in terms of the considered optimisation metrics (Figure 5). Table 3 gives an overview of the papers classified according to this criterion. Despite this, the papers are presented in only six groups to avoid repetition of references. In some cases, these groups are created by the union of related metrics, such as the network delay and the node execution time, that are commonly studied together. For other metrics, such as the network bandwidth and the hardware of the nodes, they resulted in not being always related to the same other metrics, and the papers that included them were already explained in other groups of metrics. If we had created a group for bandwidth or node hardware, it would have resulted in repeating the articles in several groups.
Network Delay and Execution Time
Probably, the most important contribution of the Fog computing paradigm is to reduce the latency of Cloud-based applications by placing them closer to the users. This latency includes the communication time and the node execution time.
In a first set, we present the articles that included both communication and node execution time. Skarlat et al.46 obtained a decrease of the network delay and the execution time up to 39% with regard to a baseline policy. Zeng et al.41 also considered both network and execution times. But for the latter, they studied the computation and input/output operations separately. Cardellini et al.53 also studied other metrics, such as availability or network traffic, apart from the network delay and service time. The work proposed by Xia et al.33 minimised the application response time to improve the number of requests that are served before a fixed application deadline. Gupta et al.24 and Mahmud et al.25 presented some baseline policies to validate their Fog simulator, and they studied the total execution time of the user requests together with the network usages and the power consumption. They compared their policies with the case of requesting services only from the Cloud provider.
In the second set, we present the papers including the network delay but that did not consider the node execution time. There are two papers that solely considered the network delay40, 42. Souza et al.42 reduced the execution time of the application service by measuring the allocated time slots, and the results proved the reduction of the high delays of requesting the services to the Cloud provider. In some other cases, the network latency is not measured directly, and indicators such as the hop count are considered37. Guerrero et al.27 also minimised the hop count between the users and the placement of the services with the objective to reduce the application latency, and the network usage. The number of migrations was also included in the metrics evaluated in the experimental phase.
Finally, the number of papers considering the execution time but without including the network delay is very reduced. For example, Wen et al.54 solely considered the execution time, showing improvement around the 30%. Additionally, Mennes et al.55 had the objective of maximising the number of applications deployed on Fog devices, but they also measured the execution time of the application in the results of their experiments.
QoS-assurance
Some approaches, instead of minimising network or execution times, aimed at increasing the Quality of Service (QoS) satisfaction. QoS is directly related to those times, but its improvement does not necessarily result in a reduction of the times. For example, the QoS can be measured as the percentage of requests that are executed before a time deadline. The improvement of the QoS involves then to keep the execution times below this threshold, but the minimisation of the times is not required.
Brogi and Forti29 and Brogi et al.30, 31, 32 studied the QoS in terms of latency and network bandwidth. They also considered resource consumption of the Fog devices and they proposed a novel cost model for Fog devices. In the work of Mahmud et al.26, the objective of the optimisation was to reduce the number of active Fog devices. But this optimisation was constrained with the warranty of satisfying the QoS level, i.e., shorter execution times than the application deadlines. Consequently, results about the percentage of deadline satisfaction were presented, showing important improvements. Skarlat et al.45, 47 maximised the resource usage of the Fog devices to maximise the number of applications deployed on the Fog layer, while the latency and QoS are not damaged. The results showed that the Fog landscape was used for the 70% of the services, reducing 30% of the execution cost, without affecting the QoS.
Venticinque and Amato 50 considered the QoS in terms of the number of request and transactions processed per unit of time. The authors also included the results of the execution time and the resource usages of the devices. Cardellini et al.51, 52 also studied the QoS measured with data obtained from each node, such as utilisation, availability, and network metrics. All the nodes are informed of the QoS of other nodes with the use of a gossip-based dissemination schema. The authors presented the experiment results in terms of application availability, application latency, network traffic and node utilization.
Mahmud et al.44 defined three metrics to study the QoS of their proposal: network relaxation ratio, processing time reduction ratio and resource gain. Additionally, they also presented results about deadlines, costs and packet losses. Finally, Zhang et al.57 optimised the QoS by providing a suitable utilization of the nodes. The algorithm ensures an optimal amount of hardware resources for the allocated applications.
Migrations
An important consequence of bringing the applications near to the users is the increase of the network traffic due to the application migrations. Consequently, some of the studies have dealt with the minimization of the number of migrations or their effects on the system.
Apart from the already cited work of Velasquez et al.37, where the number of migrations was minimised along with the network delay, migrations were also optimised by Ottenwalder et al.28, by minimising the network utilization without damaging the network latency, and by Yang et al.39, where the migration was reduced along with the latency, the resource usage, and the provider cost.
Finally, Filiposka et al.61 studied the cost of migrations to just migrate the applications if the obtained benefits were greater than the overhead generated in the system by the movement of the application between nodes. They also studied the network latency in terms of hop counts.
Cost
Cost is a common minimisation objective in resource management proposals in computation-as-a-service domains. In Fog domain the evaluation of the cost is still in a very initial phase, but there are some preliminary works dealing with its optimisation.
In addition to the already cited works31, 32, 46, there are other four papers that included the cost in their evaluation and optimisation. Zhang et al.56 studied the cost of the transmission delay and the service execution. Arkian et al.38 optimised the overall cost of the deployment of the applications, while the QoS is guaranteed, by allocating them in the devices with the smallest costs. They additionally studied the power consumption and the service latency. Wang et al.34 addressed the minimisation of the cost of each physical node and link, ensuring that the devices would not be overloaded.
Finally, Hong et al.35 optimised the cost of the application deployment by selection of the provider from a federated pool of Cloud providers. Additionally, other three objectives were also minimised: the available resources on the devices, the network distance between the users and the services, and between the nodes which allocate interrelated services.
Energy
The energy and the power consumption are also one of the most important concerns among the authors of the analysed papers. The energy optimisation has been addressed from different point of views. For example, Barcelo et al.43 defined a linear characterised function of the energy cost, and they minimised it. Their proposal was able to reduce the overall power consumption by more than an 80%.
Huang et al.48 were more focused on the reduction of the communication energy cost, by placing in the same device interrelated services and, consequently, reducing the number of communications between devices and their hop count. The experiments showed an improvement of 10% energy savings. In other cases, the energy was optimised along with other metrics: (a) the trade-off between energy consumption and end-user delay49, (b) optimisation of the energy consumption with the network usage and the execution cost60, resulting in improvements of 18% for the energy consumption, 1.17% for the network usage and 15% for the execution cost, (c) balancing the energy consumption and the resource usage in the Fog devices59, (d) or reducing the application execution time, the power consumption of the devices, and the cost of the services migrations58.
In a few cases, the energy was not the optimisation objective, but it was analysed to validate the benefits of the proposals. For example, Taneja et al.36 mainly addressed the minimisation of the application execution time, but they also analysed other common metrics such as network usage and energy consumption.
4 Conclusions: Open Problems and Research Challenges
In this section, we conclude by pointing to some open challenges and future directions that can be explored to better approach FAPP.
First of all, whilst search and mathematical programming have been thoroughly investigated in the literature, more modern techniques are to be applied to FAPP. Particularly, based on the first promising results they obtained on FAPP, it would be interesting to study further the applicability of other genetic or evolutionary algorithms, swarm optimisation techniques, deep learning, network science and game theoretical approaches to FAPP. Additionally, very few approaches available nowadays are distributed, whilst those solutions might scale better and show stronger resilience in highly dynamic Fog infrastructures. In these regards, devising decentralised algorithms to be applied to solve FAPP online and without relying on control nodes would be important and crucial to the success of the Fog.
Naturally, whilst exploring new proposals, it is important to compare them to the related state-of-the-art techniques with respect to the execution time (utterly important in Fog scenarios) and – possibly – to the achieved results (in terms of a standard set of common metrics). To this end, the design of a set of benchmark examples (based on established standards like TOSCA Yaml 83) would make it possible to systematically compare and contrast different approaches to FAPP as well as to quantify performance improvements or degradation. Such examples should possibly consider all the attributes that have been modelled in the literature (e.g., hardware, software, IoT, QoS, energy) and should come with an optimal candidate solution, determined by exhaustive techniques. Another possibility towards this direction is to exploit the solid theory of complex networks both to generate test topologies and to analyse the obtained results.
From a modelling perspective, none of the surveyed studies considered security aspects when determining optimal application placements. Security will play a crucial role in the success of the Fog paradigm and it represents a concern that should be addressed by-design at all architectural levels 9. Therefore, there is a clear need to (quantitatively) evaluate whether an application will have its security requirements fulfilled by the (Cloud and Fog) nodes chosen for the deployment of its components. Furthermore, due to the mission-critical nature of many Fog applications (e.g., e-health, disaster recovery), it is important that the techniques employed to perform security analyses to solve FAPP are well-founded and, possibly, explainable.
Similarly, mobility of Fog and IoT nodes was considered in very few of the reviewed works, even though it is a parameter that cannot be neglected in Fog scenarios. Indeed, many Fog verticals (e.g., autonomous vehicles, flying drones) include nodes that move, and that continuously and opportunistically connect/disconnect from other devices. In general, few authors considered infrastructure variations due for instance to changing topologies (i.e., available nodes), network traffic (i.e., latency, bandwidth), or workload conditions (i.e., available node hardware). Future research in the field of FAPP should, therefore, devise and tweak novel models that account for these typical traits of Fog computing, so to understand how application placement can be adaptively adjusted to this phenomenon.
Analogously, Fog computing exists in continuity with both the IoT and the Cloud. Hence, more effort should be made to consider the integration and simultaneous management of these three entities which was neglected in many works. Particularly, QoS attributes that define the reachability of IoT and Cloud nodes from different Fogs showed to be key in leading the search towards better placements. In line with this effort of considering the Cloud to Things continuum as a unique system, the possibility of some application components to be deployed in different flavours depending on the resources of target deployment nodes (like in Osmotic Computing 84) is to be studied yet. Overall, understanding how the proposed methodologies could be exploited to work with production-ready tools for Fog application management (e.g., CISCO FogDirector 85) would be surely of interest.
To conclude, most of the experiments were carried out in small to medium scale simulated environments, often without disclosing the codebase to repeat them. Future research in this field should prototype more versatile and well-documented simulators that can be used to experiment with different strategies or algorithms and that permit evaluating proposals over large-scale, lifelike, examples. Last but not least, real Fog testbeds could be realised with the help of those industries that are currently shaping Fog computing, so to actually test and assess the proposed solution strategies.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 11 CISCO . Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are https://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/computing-overview.pdf [Online; accessed 27-July-2018]; 2015.
- 22 CISCO . Cisco Global Cloud Index: Forecast and Methodology, 20162021 https://www.cisco.com/c/en/us/solutions/collateral/service-provider/global-cloud-index-gci/white-paper-c 11-738085.html [Online; accessed 27-July-2018]; 2018.
- 33 Manyika James, Chui Michael, Brown Brad, et al. Big data: The next frontier for innovation, competition, and productivity. 2014.
- 44 Hashem Ibrahim Abaker Targio, Yaqoob Ibrar, Anuar Nor Badrul, Mokhtar Salimah, Gani Abdullah, Khan Samee Ullah. The rise of Big Data on cloud computing: Review and open research issues. Information Systems. 2015;47:98–115.
- 55 Shi Weisong, Dustdar Schahram. The Promise of Edge Computing. Computer. 2016;49(5):78–81.
- 66 Dastjerdi A. V., Buyya R.. Fog Computing: Helping the Internet of Things Realize Its Potential. Computer. 2016;49(8):112-116.
- 77 Bonomi Flavio, Milito Rodolfo A., Natarajan Preethi, Zhu Jiang. Fog Computing: A Platform for Internet of Things and Analytics.. in Big Data and Internet of Things (Bessis Nik, Dobre Ciprian, eds.) Studies in Computational Intelligence, vol. 546: Springer 2014 (pp. 169-186).
- 88 IEEE . IEEE 1934-2018 - IEEE Standard for Adoption of Open Fog Reference Architecture for Fog Computing http://standards.ieee.org/findstds/standard/1934-2018.html [Online; accessed 27-July-2018]; 2018.
