TrABin: Trustworthy Analyses of Binaries
Andreas Lindner, Roberto Guanciale, Roberto Metere

TL;DR
TrABin is a formal binary analysis platform built on HOL4 that ensures trustworthy translation and analysis of binary code through formal proofs and certificates, enhancing reliability in critical software verification.
Contribution
The paper introduces a formal, proof-producing binary analysis platform that guarantees correctness of translation and analysis, addressing trust issues in existing binary analysis tools.
Findings
Successfully formalized a binary intermediate language in HOL4
Developed proof-producing transpilers for ARMv8 and CortexM0
Benchmarked with an AES encryption implementation
Abstract
Verification of microkernels, device drivers, and crypto routines requires analyses at the binary level. In order to automate these analyses, in the last years several binary analysis platforms have been introduced. These platforms share a common design: the adoption of hardware-independent intermediate representations, a mechanism to translate architecture dependent code to this representation, and a set of architecture independent analyses that process the intermediate representation. The usage of these platforms to verify software introduces the need for trusting both the correctness of the translation from binary code to intermediate language (called transpilation) and the correctness of the analyses. Achieving a high degree of trust is challenging since the transpilation must handle (i) all the side effects of the instructions, (ii) multiple instruction encodings (e.g. ARM Thumb),…
Click any figure to enlarge with its caption.
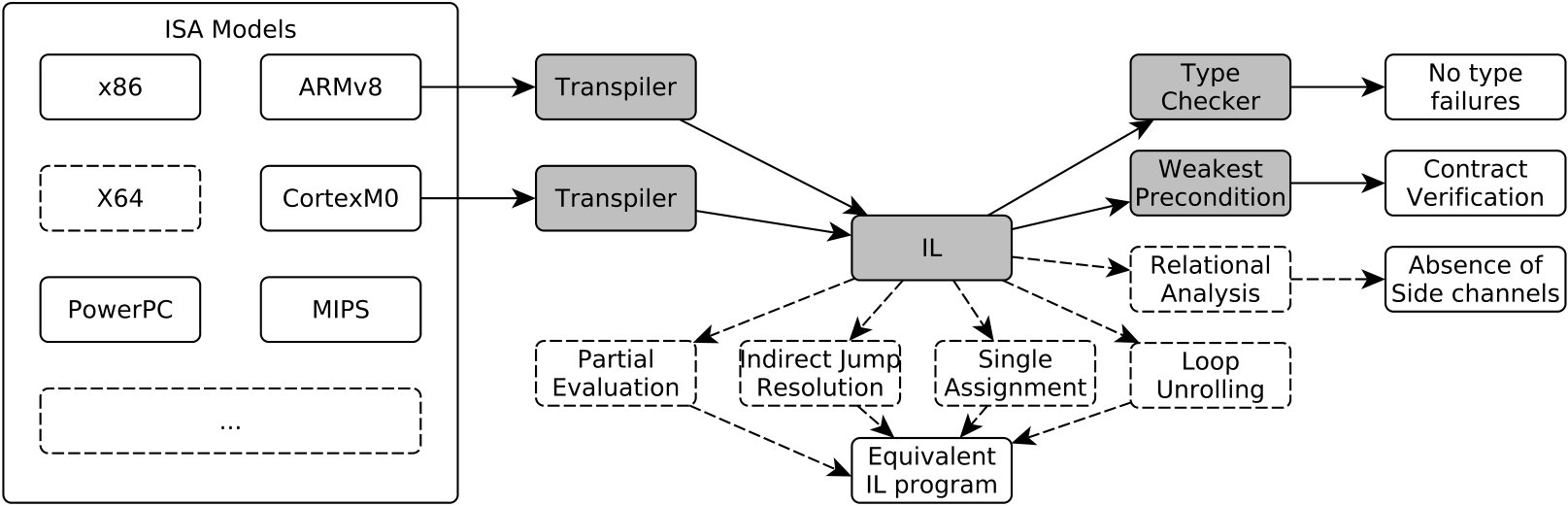 Figure 1
Figure 1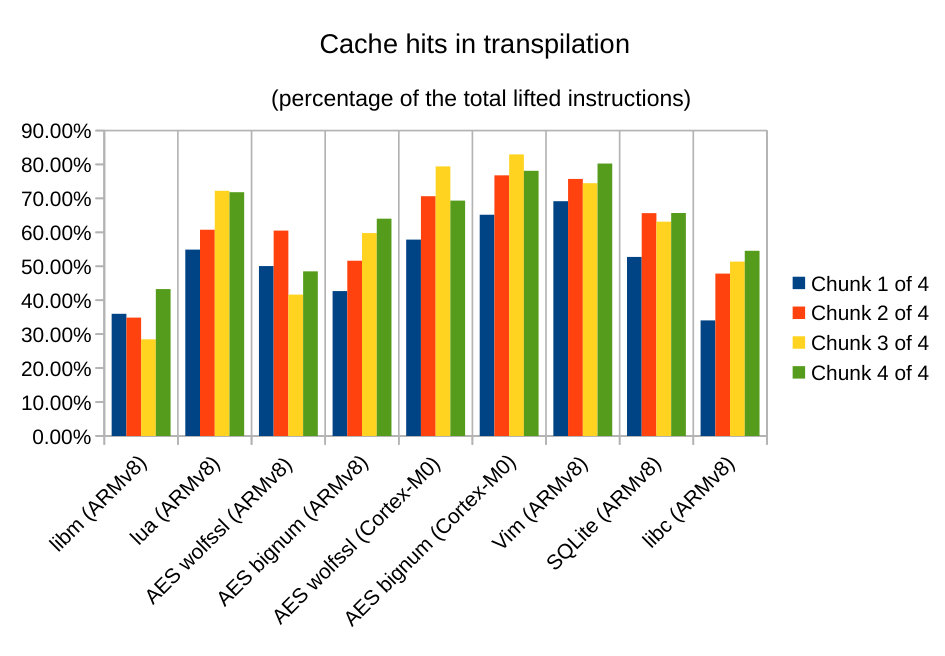 Figure 2
Figure 2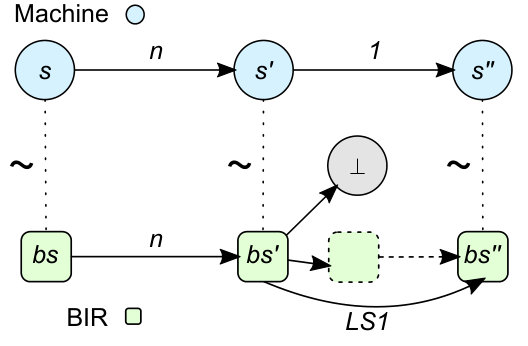 Figure 3
Figure 3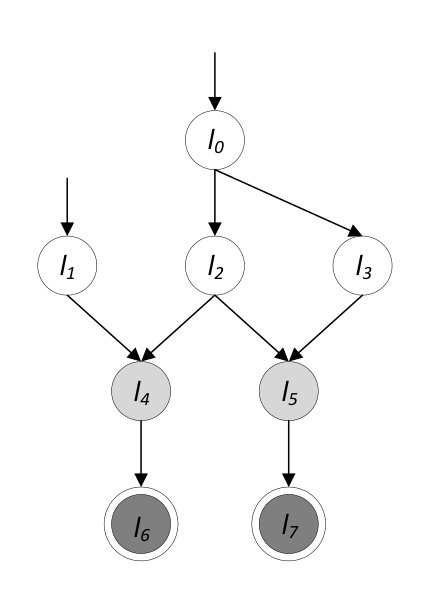 Figure 4
Figure 4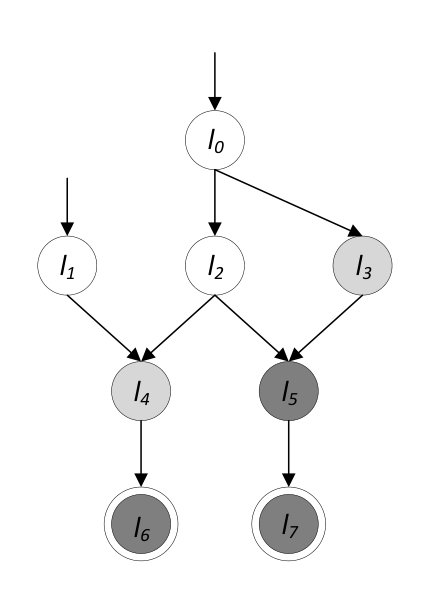 Figure 5
Figure 5| Instructions | Transpiling | Merging | Total | Rate | |
|---|---|---|---|---|---|
| CortexM0 - numlib | 9605 | 684 s | 222 s | 906 s | 10.61 i/s |
| CortexM0 - crypto | 21097 | 1245 s | 1276 s | 2521 s | 8.37 i/s |
| CortexM0 - RTOS | 6292 | 597 s | 118 s | 739 s | 8.51 i/s |
| ARMv8 - numlib | 5737 | 853 s | 131 s | 984 s | 5.83 i/s |
| ARMv8 - crypto | 13149 | 1808 s | 643 s | 2451 s | 5.37 i/s |
| ARMv8 - lua | 37026 | 10917 s | 6614 s | 17531 s | 2.11 i/s |
| ARMv8 - SQLite | 61134 | 23734 s | 16470 s | 40205 s | 1.52 i/s |
| ARMv8 - libc | 23362 | 6264 s | 2425 s | 8690 s | 2.69 i/s |
| ARMv8 - vim | 490398 | 40 h | time out | ||
| J | CJ | S | LB | O | LO | |
|---|---|---|---|---|---|---|
| CortexM0 - numlib | 8538 | 1067 | 33155 | 11 | 121682 | 71 |
| CortexM0 - crypto | 19449 | 1648 | 72396 | 11 | 269499 | 71 |
| CortexM0 - RTOS | 5605 | 654 | 21040 | 11 | 80404 | 71 |
| ARMv8 - numlib | 4972 | 765 | 14337 | 7 | 59284 | 85 |
| ARMv8 - crypto | 11879 | 1270 | 32009 | 7 | 128307 | 85 |
| ARMv8 - lua | 33429 | 3209 | 89840 | 7 | 321726 | 121 |
| ARMv8 - SQLite | 54086 | 6372 | 144367 | 7 | 521370 | 149 |
| ARMv8 - libc | 20069 | 2825 | 56912 | 7 | 226264 | 379 |
| Instructions | Unsupported | Supported | |
|---|---|---|---|
| CortexM0 - numlib | 9605 | 0 | 100.0% |
| CortexM0 - crypto | 21097 | 0 | 100.0% |
| CortexM0 - RTOS | 6292 | 33 | 99.47% |
| ARMv8 - numlib | 5737 | 0 | 100.0% |
| ARMv8 - crypto | 11879 | 0 | 100.0% |
| ARMv8 - lua | 37026 | 1161 | 99.74% |
| ARMv8 - SQLite | 61134 | 2028 | 98.68% |
| ARMv8 - libc | 23362 | 1404 | 98.11% |
| ARMv8 - vim | 490398 | 840 | 99.99% |
| Subset | Cache hits | Percentage of hits |
|---|---|---|
| lua (1/4) | 5084 | 54.92% |
| lua (2/4) | 5626 | 60.77% |
| lua (3/4) | 6688 | 72.24% |
| lua (4/4) | 6647 | 71.82% |
| SQLite (1/4) | 8064 | 52.76% |
| SQLite (2/4) | 10035 | 65.65% |
| SQLite (3/4) | 9651 | 63.14% |
| SQLite (4/4) | 10043 | 65.71% |
| libc (1/4) | 1990 | 34.06% |
| libc (2/4) | 2794 | 47.83% |
| libc (3/4) | 3002 | 51.39% |
| libc (4/4) | 3186 | 54.56% |
| fragments | avg. size | avg. time | max. size | time | |
|---|---|---|---|---|---|
| CortexM0 - AES | 3 | 177 | 372 s | 269 | 568 s |
| CortexM0 - numlib | 189 | 8 | 7 s | 96 | 150 s |
| CortexM0 - crypto | 299 | 10 | 16 s | 131 | 529 s |
| ARMv8 - AES | 2 | 268 | 494 s | 282 | 511 s |
| ARMv8 - numlib | 151 | 10 | 7 s | 106 | 150 s |
| ARMv8 - crypto | 245 | 10 | 8 s | 72 | 109 s |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
TrABin: Trustworthy Analyses of Binaries
Andreas Lindner
Roberto Guanciale
Roberto Metere
KTH Royal Institute of Technology, Sweden
Newcastle University, UK
Abstract
Verification of microkernels, device drivers, and crypto routines requires analyses at the binary level. In order to automate these analyses, in the last years several binary analysis platforms have been introduced. These platforms share a common design: the adoption of hardware-independent intermediate representations, a mechanism to translate architecture dependent code to this representation, and a set of architecture independent analyses that process the intermediate representation.
The usage of these platforms to verify software introduces the need for trusting both the correctness of the translation from binary code to intermediate language (called transpilation) and the correctness of the analyses. Achieving a high degree of trust is challenging since the transpilation must handle (i) all the side effects of the instructions, (ii) multiple instruction encodings (e.g. ARM Thumb), and (iii) variable instruction length (e.g. Intel). Similarly, analyses can use complex transformations (e.g. loop unrolling) and simplifications (e.g. partial evaluation) of the artifacts, whose bugs can jeopardize correctness of the results.
We overcome these problems by developing a binary analysis platform on top of the interactive theorem prover HOL4. First, we formally model a binary intermediate language and we prove correctness of several supporting tools (i.e. a type checker). Then, we implement two proof-producing transpilers, which respectively translate ARMv8 and CortexM0 programs to the intermediate language and generate a certificate. This certificate is a HOL4 proof demonstrating correctness of the translation. As demonstrating analysis, we implement a proof-producing weakest precondition generator, which can be used to verify that a given loop-free program fragment satisfies a contract. Finally, we use an AES encryption implementation to benchmark our platform.
keywords:
binary analysis , formal verification , proof producing analysis , theorem proving
††journal: Science of Computer Programming
1 Introduction
Despite the existence of formally verified compilers, the verification of binary code is a critical task to guarantee trustworthiness of systems. This is particularly necessary for software mixing high-level language with assembly (system software), using ad-hoc languages and compilers (specialized software), in presence of instruction set extensions (like for encryption and hashing), and when the source code is not available (binary blobs). This necessity is not only limited to the general-purpose computing scenario but also applies to connected embedded systems, where software bugs can enable a remote attacker to tamper with the security of automobiles, payment services, and smart IoT devices.
The need of semi-automatic analysis techniques for binary code has lead to the development of several tools [1, 2, 3]. To handle the complexity and heterogeneity of modern instruction set architectures (ISA), all these tools follow a common design (see Figure 1): They have introduced a platform independent intermediate representation that allows to implement analysis independently of (i) names and number of registers, (ii) instruction decoding, (iii) endianness of memory access, and (iv) instruction side-effects (like updating conditional flags or the stack pointer). This intermediate representation is often a dialect of the Valgrind’s IR [4].
Even if the existing binary analysis platforms have been proved successful thanks to the automation they provide, their usage for verifying software introduces the need of trusting both the transpiler (i.e. the tool translating from machine code to intermediate language) and the analysis. Soundness of the transpiler should not be foregone: It may have to handle multiple instruction encodings (e.g. ARM Thumb), variable instruction length (e.g. Intel), and complex side effects of instructions (e.g. ARM branch with link and conditional executions). Clearly, a transpiler bug jeopardizes the soundness of all analyses done on the intermediate representation. Similarly, complex analyses involve program transformations (e.g. loop unrolling and resolution of indirect jumps) and simplifications (e.g. partial evaluation) that are difficult to implement correctly.
To handle these issues we implement a binary analysis tookit whose results are machine checkable proofs. The prototype tookit consists of four components: (i) formal models of the Instruction Set Architectures (ISAs), (ii) the formal model of the intermediate language, called Binary Intermediate Representation (BIR), (iii) a proof-producing transpiler, and (iv) proof-producing analysis tools. As verification platform, we selected the interactive theorem prover HOL4, due to the existing availability of formal models of commodity ISAs [6, 7]. Here, we chose ARMv8 [8] and CortexM0 [9] as demonstrating ISAs. For the target language, we implemented a deep embedding of a machine independent language, which can represent effects to registers, flags, and memory of common architectures and it is relatively simple to analyse. Verification of the transpilation is done via two HOL4 proof producing procedures, which translate respectively ARMv8 and CortexM0 programs to IL programs, and yield the HOL4 proof that demonstrates the correctness of the result. The theorem establishes a simulation between the input binary program and the generated IL program, showing that the two programs have the same behavior. Our contribution enables a verifier to prove properties of the generated IL program (i.e. by directly using the theorem prover or proof-producing analysis techniques) and to transfer them to the original binary program using the generated simulation theorems. As demonstrating analysis, we implement a proof-producing weakest precondition propagator, which can be used to verify that a given loop-free program fragment satisfies a contract.
Outline
We present the state of the art and the previous works relating to our contribution in Section 2. Section 3 introduces the HOL4 formal models of the ISAs and the BIR language. Section 4 and Section 5 present the two proof-producing tools: the certifying transpiler and the weakest precondition generation. We demonstrate that the theorems produced by the proof producing tools can be used to transfer verification conditions in Section 6. In Section 7, we test and evaluate our tool. We give concluding remarks in Section 8.
New contributions
We briefly describe the new contributions of this paper with respect to [10]. The weakest precondition generation and the corresponding optimization is a new proof producing tool. Therefore Section 5 was not present in [10]. Technically, the BIR model and the transpiler have been heavily re-engineered, for this reason Sections 3.2 and 4 have been adapted to introduce some of the new concepts (e.g. the weak transition relation) and tools (e.g. the type checker, the pre-verified theorems that speed up the transpilation). Also, Section 7 has been rewritten, since it evaluates the new transpiler and the weakest precondition procedure. Finally, the transpiler has been extended to support CortexM0. This allows us to demonstrate that the transpiler can be easily adapted to support new architectures and the requirements for specific proofs for the transpiler are limited.
2 Related work
Recent work has shown that formal techniques are ready to achieve detailed verification of real software, making it possible to provide low-level platforms with unprecedented security guarantees [11, 12, 13]. For such system software, limiting the verification to the source code level is undesirable. A modern compiler (e.g. GCC) consists of several millions of lines of code, in contrast to micro-kernels that consist of few thousand lines of code, making it difficult to trust the compiler output even when optimization is disabled111An example of a bug found in GCC: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=80180.
To overcome this limitation, formally verified compilers [14, 15, 16] and proof/producing compilers [17] have been developed. Similarly to our work, these compilers use detailed models of the underlying ISA to show the correctness of their output. This usually involves a simulation theorem, which demonstrates that the behavior of the produced binary code resembles the one specified by the semantics of the high level language (e.g. C or ML). These theorems permit properties verified at the source-level to be automatically transferred to the binary-level. For instance, CompCert has been used in [18] to verify security of OpenSSL HMAC by transferring functional correctness of the source code to the produced binary.
Even if formally verified compilers obviate the need for trusting their output, they do not fulfill all the needs of verified system software. Some of these compilers target languages that are unsuitable for developing system software (e.g. ML cannot be used to develop a microkernel due to its garbage collector). Also, they do not support mixing the high-level language with assembly code, which is necessary for storing and restoring the CPU context or for managing the page table. Some of the effects of these operations can break the assumptions made to define a precise semantics of the high level language (e.g. a memory write can alter the page table which in turn affects the virtual memory layout). Also, some properties (e.g. absence of side channels created by non-secure accesses to the caches) cannot be verified at the source code level; the analysis must be aware of the exact sequence of memory accesses performed by the software. Finally, binary blob analysis is imperative for verifying memory safety of binary code whose source code is not available (e.g. the power management of ARM trusted firmware).
Unfortunately, detailed formal specifications of machine languages (e.g. the ones used to verify compiler correctness [19]) consist of thousands of lines of definitions. The complexity of these models makes them unusable to directly verify any binary code that is not a toy example. Moreover, the target verification tools, usually interactive theorem provers, provide little or no support for either automatic reasoning or reuse of algorithms among different hardware models. To make machine-code verification proofs reusable by different architectures, Myreen et al. [20] developed a proof-producing decompilation procedure. Those tools have been implemented in the HOL4 system and have been used by the seL4 project to check that the binary code produced by the compiler is correct, permitting to transfer properties verified at the source code level to the actual binary code executed by the CPU [21]. The same framework has been used to verify a bignum integer library [22]. However, the automation provided by this framework is still far from what is provided by today’s binary analysis platforms (e.g. [1, 2, 3]). These provide tools to compute and analyze control-flow graphs, to perform abstract interpretation and symbolic execution, to verify contracts, to verify information flow properties [23], and to analyze side channels [24]. On the other hand, their usage requires to trust both the transpiler and the implementation of the analysis. Due to the complexity of writing a transpiler for each architecture, recent work has been done to synthesize the transpiler from compiler backends [25]. However, this requires to trust both: the synthesis procedure and the compiler backend.
Regarding trustworthy weakest precondition generation, which is our demonstrating analisys, Vogels et al. [26] verified the soundness of an algorithm for a simple imperative while language in Coq. However, their work does not fit the needs of a trustworthy verification condition generator for a verification toolkit, since the target language is not designed to handle unstructured binary programs.
3 Formal Models
3.1 The ARMv8 and CortexM0 models
In our work, we use the ARMv8 and CortexM0 models developed by Fox [6], which are constructed from the pseudocode described in the ARM specifications [8, 9]. These models provide detailed HOL4 formalization of the effects of the instructions, taking into account the different execution modes, flags, and other characteristics of the processor behavior.
We start describing the ARMv8 model. The system state is modeled as a tuple . Here, represents a sequence of 64-bit general purpose registers. We identify the -th register with . The tuple contains the special registers representing the program counter, the stack pointer, and the link register respectively. The tuple represents the current processor state and contains the arithmetical flags. The 64-bit addressable memory is modeled as the function . Finally, the system behavior is represented by the deterministic transition relation , describing how the ARMv8 state reaches the state by executing a single instruction. The transition relation models the behavior of standard ARMv8 ISA, including fetching four bytes from memory, decoding the instruction, and applying its effects to registers, flags, and memory. Hereafter, we use . to access tuple fields (e.g. states for the program counter of the state ) and to represent all possible states.
The CortexM0 model has a similar flavour, with main differences consisting of the general purpose registers being 32-bit and the memory being 32-bit addressable memory. Also, CortexM0 has variable encoding, allowing each instruction to use either two or four bytes. Hereafter, when needed, we use subscripts and to respectively identify ARMv8 and CortexM0 models, i.e. is the transition relation of the CortexM0 model.
The HOL4 machine models consist of hundreds of definitions and their complexity makes it difficult to analyze large programs. To simplify the analyses, the models are equipped with a mechanism to statically compute the effects of a single instruction via the function. Let be the binary encoding of an instruction and be the address where the instruction is stored, then the function returns a list of step theorems . Each theorem has the following structure:
[TABLE]
where is a function that reads the instruction from the memory. Intuitively, each step theorem describes one of the possible behaviors of the instruction and consists of the guard condition that enables the transition and the function that transforms the starting state into the next state. We use three examples from the ARMv8 model to illustrate this mechanism.
Let the instruction stored at the address 0x1000000c be the addition of the registers and into the register (whose encoding is 0x8b000020), the step function produces the following step theorem:
[TABLE]
(where updates the register of the state with ). In this case, only one theorem is generated, and there is no guard condition (i.e. is a tautology).
Some machine instructions (i.e. conditional branches) can have different behavior according to the value of some state components. In these cases, the step function produces as many theorems as the number of possible execution cases. For example, the output of the step function for the Signed Greater Than branch instruction consists of the following two theorems:
[TABLE]
[TABLE]
That is, if the test succeeds (i.e. holds) then the jump is taken (in this case jumping back in a loop to the address ), otherwise (i.e. holds) the jump is not taken (the program counter is updated to point to the next instruction). Notice that for every state the condition hold.
Finally, some instructions (i.e. memory stores) can have unsound behavior if some conditions are not met. In these cases, the step function generates the step theorems only for the correct behaviors; for a given instruction, let be the generated theorems and the corresponding guards, the behavior of the instruction is soundly deduced by the step function for every state such that holds and can not be deduced otherwise. For example, the output of the step function for a memory store consists of the theorem:
[TABLE]
Intuitively, the step function can predict the behavior only for states having the target address (i.e. ) aligned.
3.2 The BIR model
Our platform uses the machine independent Binary Intermediate Representation (BIR). In this representation, a statement has only explicit state changes, i.e. there are no implicit side effects, and it can only affect one variable.
BIR’s syntax is depicted in Table 1. A program is a list of blocks, each one consisting of a uniquely identifying label (i.e. a string or an integer), a list of block statements, and one control flow statement. In the following we assume that all programs are well defined, i.e. they have no duplicate block labels. A statement can affect the state by (i) assigning the evaluation of an expression to a variable, (ii) terminating the system in a failure state if an assertion does not hold. A control flow statement can (conditionally or unconditionally) modify the control flow. As usual, labels are used to refer to the specific locations in the program and can be the target of jump statements.
BIR expressions are built using constants (i.e. strings and integers), conditionals (i.e. ), standard binary and unary operators (ranged over by and respectively) for finite integer arithmetic and casting, and accessing variables of the environment (i.e. ). Additionally, two types of expressions can operate on memories. The expression reads bytes from the memory starting from the address . The expression returns a new memory in which all the locations have the same values as the initial memory except the addresses where that contain the chunks of . Figure 2 provides an example of a BIR program.
Hereafter, we use to represent the set of all possible strings. These can be used to identify both labels and variable names. We use to range over BIR data types; let , the type for words of -bits is denoted by and the type for memories addressed using -bits is denoted by . We use and to represent the set of all BIR types and values respectively.
A BIR environment maps variable names (given as strings) to pairs of type and value; . Types of variables are immutable and any wrongly typed operation produces a run-time failure. The semantics of BIR expressions is modeled by the evaluation function : It takes an expression and an environment and yields either a value having a type in or . The evaluation intuitively follows the semantics of operations by recursively evaluating the sub-expressions given as operands. The value results when operators and types are incompatible, thus modeling a type error.
A BIR state is a pair of an environment and a program counter . While executing a program, the program counter is and is the label of the executing block. In the cases of either type mismatch or failed assertion, the execution terminates setting the program counter to either (type mismatch) or (failed assertion). Notice that the program is not part of the state, disallowing run-time changes to the program.
The system behavior is modeled by the deterministic transition relation , which describes the execution of one BIR block. In HOL4, this relation is modeled by the execution function , which defines the small step semantics of an entire block. Hereafter, we use when the program counter of the resulting states represents one of the possible errors. The relation is defined on top of two other functions: models the environment effects of a single block statement , and models the program counter resulting by executing a single control flow statement . Both functions can return and in case of violated assertions and type errors respectively.
The execution of assigns the evaluation of the expression to the variable . Let and be the type of , the value of the variable is updated in the context (). The statement fails in case of a type mismatch: or . The statement has no effects if the expression evaluates to true (i.e. ) and terminates in an error state otherwise.
The execution of jumps to the referenced block, by setting the program counter to . If the type of is neither string nor integer then the statement fails. The statement changes the control flow based on the condition . The statement fails if the type of the condition is not or the targets (i.e. or ) are not valid labels. Notice that the targets of the jump are evaluated using the current context, allowing BIR to express indirect jumps that are resolved at run-time.
The HOL4 model is equipped with several supporting tools and definitions, which simplify the development of the transpiler and analyses. A weak transition relation is defined to hide some executions steps. Let be a set of labels, is a partial function built on top of the single-block small step semantics, which yields the first reachable state that is an error state or that has the program counter in . The function is undefined if no error and no label in are reachable. A formally verified type checker permits to rule out run-time type errors. Well typed programs cannot have wrongly typed expressions (i.e. arguments of binary operators must have the same type, values to store in memory must match the specified type, etc.), use only one type per variable name, use expressions with correct types in statements (i.e. conditions in assertions and conditional jumps must be boolean expressions). A pair consisting of a program and an environment is well typed if the program is well typed and if for every variable the type of variable in the environment matches the usage of the variable in the program. Well typed program fragments that start from well typed environments cannot cause type errors and can only reach well typed environments.
4 Certifying Transpiler
The translation procedure uses a mapping of HOL4 machine states to BIR states. Every machine state field must be mapped to a BIR variable or to the program counter. Our framework provides one default mapping for each supported architecture: ARMv8 and CortexM0. In both cases, the i-th register is mapped to the variable (i.e. represents the register number zero), the variable represents the system memory, the BIR program counter reflects the machine’s program counter, and every flag is mapped to a proper variable. This mapping induces a simulation relation that relates BIR states to machine states.
To transform a program to the corresponding BIR fragment, we need to capture all possible effects of the program execution in terms of affected registers, flags and memory locations. The generated BIR fragment should emulate the behaviour of the instructions executed on the machine. This goal is accomplished by reusing the function and the following two HOL4 certifying procedures.
A procedure to translate HOL4 word terms (i.e. those having type , , etc.) to BIR expressions. This procedure is used to convert the guards of the step theorems and the expressions contained in the transformation functions.
- 2.
A procedure to translate a single instruction to the corresponding BIR fragment. This procedure computes the possible effects of an instruction using the transformation functions of the step theorems.
To phrase the theorem produced by the transpiler we introduce the following notations. A binary program is represented by a finite set of pairs , where each pair represents that the instruction is located at the address . The predicate states that the program is stored in the memory of the state (formally, ). A single machine instruction can be transpiled to multiple blocks. The transpiler uses a naming convention to distinguish the label of the first block produced for an instruction from the labels of the other blocks. Hereafter, we use to identify the set of labels that represents the entry point of instructions. We denote transitions of machine states with and transitions of BIR visiting with . The translation procedure generates a theorem that resembles compiler correctness222The ISA and BIR transition systems are deterministic, thus the transition relations are functions. For this reason we omit quantifiers over the states on the right hand side of transitions, since they are unique.:
Theorem 1**.**
Let be the entry point of the program . For every state and BIR state , if , , and , then
for every if then
, and 2. 2.
*for every if then *
.
The meaning of the transpiler theorem is depicted in Figure 3. Each machine instruction is translated to multiple blocks, the first one having a label in , and each block consisting of multiple statements. Assuming that the program is stored in machine memory, the state is configured to start the execution from the entry point of the program, and the initial HOL4 machine state resembles the initial BIR state, then (1) for every state reachable by the ISA model, there is an execution of the BIR program that results (after visiting blocks whose labels are in ) in either an error state () or in a state that resembles , and (2) for every state reachable by the BIR program after reaching the first block of an instruction, there is an execution of the machine that re-establishes the simulation relation.
Error states permit to identify if an initial configuration can cause a program to reach a state that cannot be handled by the transpiler (e.g. self-modifying programs or programs containing instructions whose behavior cannot be predicted by the step function). It is worth noticing that these cases cannot be identified statically without knowing the program preconditions (e.g. misaligned memory accesses can be caused by the initial content of the stack where pointers are stored) and must be ruled out when verifying the program.
4.1 Translation of expressions
In order to build the transpiler on top of the step function, the HOL4 expressions occurring in the guards and the transformation functions must be converted to BIR expressions. For example, while translating the binary instruction 0x54fffe8c of Section 3.1 to a conditional jump, the expressions and must be expressed in BIR to generate the condition and the target of the jump respectively.
Let be a HOL4 expression, the output of the transpiler is the theorem , stating that, if the environment satisfies the assumption , then the evaluation of is . These assumptions usually constrain the values of the variables in the environment to match the free variables of the HOL4 expressions. For instance, for the expression the transpiler generates the theorem .
If a HOL4 operator has no direct correspondence in BIR, the transpiler uses a set of manually verified theorems to justify the emulation of the operator via a composition of the primitive BIR operators. This is the case for expressions involving bit extractions (i.e. most significant bit, least significant bit, etc), alignment, reversing endianness, and rotation.
For several ISA models, special care must be taken to convert expressions involved in updating status flags. For instance, both ARMv8 and CortexM0 use so called NZCV status flags for conditional execution, where
Negative is set if the result of a data processing instruction was negative
- 2.
Zero is set if the result is zero
- 3.
Carry is set if is set if an addition, subtraction or compare causes a result bigger than word size
- 4.
oVerflow is set if an addition, subtraction or compare produces a signed result bigger than 31/63 bit (for CortexM0 and ARMv8 respectively), i.e. the largest representable positive number
The expressions produced by the ISA models for these flags involve conversion of words to natural numbers and arithmetic operations with arbitrary precision. For example, following the pseudocode of the ARMv8 reference manual [8], the carry flag in 64-bit additions is computed by the expression , where and is their interpretation as natural numbers. Both the inequality and the addition cannot be directly converted as BIR expression, because BIR can only handle finite arithmetics333This design choice simplifies the development of analyses for BIR and the integration of external tools, like SMT solvers supporting bitvectors. For the carry flag the transpiler uses the theorem , where and are complement and unsigned comparison of bitvectors respectively.
4.2 Translation of single instructions
The transpilation of a single instruction takes three arguments: the binary code of the instruction, the address of the instruction in memory, and a set of memory address ranges . The latter argument identifies which memory addresses should not be modified by the instruction and is used to guarantee that the program is not self-modifying. In fact, a self-modifying program cannot be transformed to equivalent BIR programs (due to BIR following the Harvard architecture). If an instruction modifies the program code then the translated BIR program must terminate in an error state. The addresses in are used to instrument the instruction transpiler with the information about where the program code is stored. Hereafter we use to represent that the transpiler produces the program fragment (sequence of blocks) . Also, we use to represent that a program contains the fragment .
The transpiler uses the function to compute the behavior of the input instruction and to generate the step theorems , where is . Hereafter we assume that the function generates two theorems (i.e. ), which is the case for conditional instructions in CortexM0 and branches in ARMv8. We will comment on the other cases at the end of this section.
A single machine instruction can be translated to multiple BIR blocks, following the template of Figure 4. The label of the first block is equal to the address of the instruction and is the only block having an integer label. The other two blocks have string labels and represent the effects of the two step theorems.
The behavior of the instruction can be soundly deduced by the step function only if one of the predicates holds (see Section 3.1). The transpiler simplifies the disjunction of the guards demonstrating (where is a HOL4 predicate) and translates it to a BIR expression (demonstrating ). The BIR statement is generated as first statement of the first block. Intuitively, if a machine state does not satisfy any guard, then every similar BIR state does not satisfy the assertion, causing the BIR program to terminate in a error state. On the other hand, if the BIR state satisfies the assertion, then every similar machine state satisfies at least one of the guards, thus the instruction’s behavior can be deduced by the step function.
The second task is to redirect the BIR control flow to the proper internal block according to the guards of the step theorems. The procedure translates to a BIR expression ( demonstrating ) and is generated as last statement of the first block. Intuitively, a BIR state executes if and only if the similar machine state satisfies .
The third task is to translate the effects of the instruction on every field of the machine state for every step theorem . Let be one field of the machine state (e.g. is the register zero) and let be the corresponding variable of BIR according to the relation . The transpiler computes the new value of the field (and demonstrates ). If then the machine state’s field is not affected by the instruction and the corresponding variable should not be modified by the generated BIR block, otherwise the variable must be updated accordingly. The expression is translated to obtain the theorem and the BIR statement is generated. The need of a temporary variable is due to the presence of instructions that can affect several variables, and whose resulting values depend on each other (i.e. imagine an instruction swapping registers zero and one, where ). After all field values have been computed and stored into the temporary variables, these are copied into the original variables via the statement .
Special care is needed for memory updates (i.e. ). The BIR program should fail if the original program updates a memory location in . The transpiler inspects the expression to identify the addresses that can be changed by the instruction and extracts the corresponding set of expressions (in CortexM0 and ARMv8 a single instruction can store multiple registers). The expression (which guarantees that no modified address belongs to the reserved memory region) is translated to obtain the theorem and the BIR statement is added as preamble of the block. If the machine instruction modifies an address in , then the corresponding BIR state does not satisfy the assertion, causing the BIR program to terminate in an error state.
Finally, the program counter field is used to generate statements that update the control flow. The expression is translated to and is appended to the BIR fragment. If possible, is first simplified to be a constant, which reduces the number of indirect jumps in the BIR program.
This procedure is generalized to handle arbitrary number of step theorems, using one block per theorem. Moreover, the transpiler optimizes some common cases. If the transformation function modifies only the program counter (i.e. a conditional instruction, which behaves as NOP if the instruction condition is not met) then is not generated and the translation of is used in place of ”ad-j” in . If there is only one step theorem, then the is merged with and the conditional jump is removed. If an updated state field is not used to compute the value of other fields then the temporary variable is not used.
A large part of the HOL4 implementation focuses on optimizing the verification that the generated fragment resembles the original machine instruction. This is done by preproved theorems about the template-blocks (i.e. ), which enable the transpiler to use the intermediate theorems generated for expressions and the step theorems to establish the instruction-theorem. The preproved theorems for the template-blocks also ensure that these are well-typed, statically guaranteeing that a generated fragment cannot cause a type error.
Theorem 2**.**
Let . For every machine state , BIR state , and BIR program if , , , and , then
** 2. 2.
*if and *444We remark that is deterministic and left total, and is deterministic * then *
**
The theorem shows (1) the BIR program either fails or reaches the first block of an instruction starting from the first block of the translated one (i.e. the internal blocks do not introduce loops), and (2) if the complete execution of the generated blocks succeeds then the BIR program behaves equivalently to the machine instruction and memory in is not modified.
4.3 Transpiling programs
The theorems generated for every instruction are composed to verify Theorem 1. Property (1) is verified by induction over , using predicate . This ensures that the program is in memory after the execution of each instruction, thus allowing to make the assumption of the translation theorem (i.e. ) an invariant.
Property (2) is verified by induction over . Since then the program counter of points to the one of the produced by the transpiler. Therefore we can use the corresponding instruction-theorem to show that exists. This and the fact that the ISA transition relation is total enable part (2) of the instruction-theorem, showing that the machine instruction behaves equivalently to the BIR block.
4.4 Support for more architectures
In the following, we review the modifications of the certifying procedures needed to support other common computer architectures, like MIPS, x86 and ARMv7-A. The transpiler has three main dependencies: A formal model of the architecture, a function producing step theorems, and the definitions of a simulation relation. There exist HOL4 models for x86, x64, ARMv7-A, RISC-V, and MIPS, which are equipped with the corresponding step function. The simulation relation can differ for each architecture since it maps machine state fields to BIR variables. In fact, the name, the number, and the type of registers can be very different among unrelated architectures. However, defining the simulation relation is straightforward, since it simply requires to map machine state fields to BIR variables.
The expression translation has to handle the expressions of guard conditions and transformation functions that are present in the step theorems. Since these use HOL4 number and word theories, independently of the architecture, big parts of the translation of Section 4.1 can be reused. There are two exceptions: One is the possible usage of different word lengths, and the other is the need of proving helper theorems to justify the emulation of operators that have no direct correspondence in BIR (e.g. for the computation of the carry flag in CortexM0 and ARMv8, or to support specialized instructions for encryption).
Defining the simulation relation and extending the expression translation enable the transpilation of single instructions of Section 4.2 to support a new architecture, without requiring further modifications. In fact, the structure of the produced BIR blocks is architecture independent and is ready to support some peculiarities of MIPS and x64.
4.4.1 Delay slots
On the MIPS architecture, jump and branch instructions have a “delay slot”. This means that the instruction after the jump is executed before the jump is executed. The HOL4 model for MIPS handles delay slots using the shadow registers BranchDelay (), which can be either unset or the address of an instruction. This register can be mapped to BIR using a boolean variable (), which holds if the shadow register is set, and a word variable (), which represents the register value.
Let be a MIPS state, the transition relation is undefined if is set and the instruction makes a jump (i.e. jumps are not allowed after jumps). Otherwise it yields a state where
if is set, otherwise
- 2.
is the target of jump if the instruction modifies the control flow, otherwise is unset
The step theorems can be accordingly generated. Let be the step theorem’s guards of an instruction and let be the condition that causes the instruction to modify the control flow (i.e. is always false if the current instruction is neither a jump nor a branch), holds if is unset or does not hold. Following the template of Figure 4, the transpiler will produce the assertion , where . Non-jump and non-branch instructions need multiple step theorems to model delay slots. These instructions could be translated via two BIR blocks: one executed when holds and that jumps to ; and one that jumps to the next instruction when BD_SET does not hold. Finally, the variables and can be update like all other register variables.
4.4.2 Different calling conventions
Intel x86 and x64 architectures have different calling conventions. In fact, in x64 a limited number of parameters can be passed via registers. It is worth noticing that the transpiler does not make any assumption on the calling convention used. In fact, the transpiler procedure does not need to know symbols and can handle programs that violate standard calling convention. In practice, different calling conventions will result in different assembly instructions, whose behavior is captured by the step theorems.
5 Weakest preconditon generation
Contract based verification is a convenient approach for compositionally verifying properties of systems. Due to the unstructured nature of binary code, a binary program (and therefore the corresponding BIR program) can have multiple entry and exit points. For this reason we adapt the common notion of Hoare triples. Hereafter we assume programs and environments to be well typed. Let and be two partial functions mapping labels to BIR boolean expressions, we say that a BIR program satisfies the contract , if the execution of the program starting from an entry point and a state satisfying the precondition establishes the postcondition whenever it reaches an exit point , formally
Definition 1** (BIR triple).**
* holds iff for every , , if , then and . *
There are well known semi-automatic techniques to verify contracts for program fragments that are loop free and whose control flow can be statically identified. A common approach is using precondition propagation, which computes a precondition from a program and a postcondition . Hence, the algorithm must ensure that the triple holds. Also, if for every the precondition is the weakest condition ensuring that is met, then the algorithm is called weakest precondition propagation. The desired contract holds if for every the precondition implies the computed precondition . Therefore, the overall workflow is: specify a desired contract, automatically compute the weakest precondition, and prove the implication condition.
5.1 WP generation
Since the BIR transition relation models the complete execution of one block, we consider a block the unit for which the algorithm operate. The weakest precondition is propagated by following the control flow graph (CFG) backwards. The CFG is a directed acyclic graph (due to absence of loops) with multiple entry points and multiple exit points. For instance, Figure 5a depicts the CFG of a program with blocks having labels through , two entry points (i.e. and ) and two exit points ( and ).
Our approach is to iteratively extend a partial function , which initially equals the postcondition partial function . This function maps labels to their respective weakest precondition or postcondition in the case of exit points. Formally, the procedure preserves the invariant and (where is the restriction of a function to the domain and is set complement). Once includes all entry points of the program, the weakest precondition is obtained by the restriction . For each iteration, the algorithm uses the following rule:
It (1) selects the label of a BIR block for which the domain of contains the labels of all successors (i.e. the weakest precondition of the successors have already been computed); (2) computes the weakest precondition for the label , demonstrating ; (3) extends as . Figure 5 depicts an example of this procedure. The partial function is defined for labels of dark gray nodes, and light gray nodes represent nodes that can be selected by (1). Figure 5a shows the initial state where only the exit nodes are mapped and Figure 5b shows the results of the first iteration if is selected. The algorithm extends with the weakest precondition for , making available for selection in the next iteration. Notice that after the first iteration, we cannot directly compute the weakest precondition of , since we do not know the weakest precondition of the child node labeled .
To compute the weakest precondition of a block compositionally, the definition of triples is lift to smaller elements of BIR, i.e. the execution of single blocks and single statements:
Definition 2**.**
Let be a block having label , be a statement, and be a control flow statement:
* holds iff for every if and then *
- 2.
* holds iff for every if and then and *
- 3.
* holds iff for every if and then and *
To compute the weakest precondition for the label (i.e. ) the proof producing procedure uses the following rules:
Assuming that is defined for every child of and that the program block having label is , the weakest precondition of can be computed by propagating the preconditions through the block, by computing the weakest precondition of the execution of (i.e. ). As usual for sequential composition, the block precondition is computed by propagating the postcondition backwards.
Notice that, differently than blocks and control flow statements, internal block statements always have one successor, therefore their postcondition is a boolean expression instead of a partial function. The rules for the block statements and are standard (we use to represent the substitution of every occurrence of the variable name in with the expression ):
[TABLE]
The rules for the control flow statements and are standard for unstructured programs. Both rules access for the successor labels, which requires to identify the CFG of the program statically (e.g. the program fragment is free of indirect jumps), and to have already computed the preconditions for the successor labels (, , and ).
[TABLE]
Steps (2) and (3) of the weakest precondition procedure have been formally verified, by demonstrating soundness of the rules. Step (1) is a proof producing procedure, which dynamically demonstrates for each iteration that the selection of is correct (i.e. that contains all successors of ). This frees us from verifying that the algorithm to select and compute the CFG graph is correct, enabling to integrate heuristics to handle indirect jumps, which can be incomplete and difficult to verify. Also, our procedure only demonstrates soundness of the generated precondition, but does not prove that it is the weakest one. This task requires to dynamically build a counterexample showing that any weaker condition is not a precondition. The lack of this proof does not affect the usage of the tools, since it is not needed for contract based verification.
5.2 Optimization
Weakest precondition propagation has two well known scalability issues. Firstly, branches in the CFG can cause an exponential blowup. For instance, in Figure 5 the precondition of node is propagated twice (via and ) and occurs twice as sub-expression of the precondition of the branch node . There exist approaches [27] to handle this problem, however they generate preconditions that are difficult to handle with SMT solvers, which can preclude their usage for practical contract verification. The second problem, which Section 7 demonstrates to be critical for our scenario, is that expression substitutions introduced by assignments can exponentially increase the size of preconditions. Consider the following program fragment:
[TABLE]
The weakest precondition of is . This equals when external substitutions are expanded. This behavior is common in BIR programs that model binary programs, due to the presence of indirect loads and stores. For example, in the following fragment
[TABLE]
both and are loaded from , leading the expression modeling the new value of the variable to contain three occurrences of .
A solution to this issue is using single dynamic assignment and passification. The program is transformed into an “equivalent” one, which ensures that each variable is only assigned once for every possible execution path. Then a second transformation generates a program that has assumptions in place of assignment. However, this approach requires proof-producing transformers and additional machinery to transfer properties from the the passified program to the original one.
For the scope of contract based verification, we can obtain the same conditions without applying these transformations. Our goal is to generate a precondition and to check that for every BIR state this is entailed by the contract precondition , i.e. checking that is a tautology (we write this as ). This drives our strategy: (1) we generate a weakest precondition that contains substitutions, but we do not expand them to prevent the exponential growth of ; (2) we take the precondition and we generate a substitution free condition using a proof producing procedure, which ensures that if and only if ; (3) the original contract is verified by checking unsatisfability of .
For step (2) we developed a proof producing procedure that uses a set of preproved inference rules. The rules capture all syntactic forms which can be produced by the weakest precondition generation, i.e. conjunction, implication and substitution. If the precondition is a conjunction, we can recursively transform the two conjuncts under the common premise and combine the transformed preconditions:
If is the implication , we can include in the premise and transform recursively. Then we can restore the original implication form using the transformed predicate :
If is the substitution and is free in , we apply the following rule.
This rule prevents the blowup by avoiding applying the substitution and instead using the fresh variable as an abbreviation for in . Before continuing the application of transformation rules, we have to remove the substitution . This ensures that each application of this transformation rule removes one substitution from . We achieve this by recursively applying the substitution until we reach another substitution . Normally, the application of substitution would require the application of the inner substitution first, which would reintroduce the blowup problem. Instead, we rewrite the expression as follows:
This moves the inner substitution out by individually applying the substitution to every free occurrence of in and . This means that the substitution should not be applied to if .
Notice that the last tautology transformation rule cannot be applied if , since it can introduce type errors. Consider the predicate substitution . Here, the two references to have different types, i.e. integer and boolean. By using this rule and applying all substitutions, we would obtain . However, this equality does not hold, since the left side can be a tautology while the right side cannot, since it is a wrongly typed expression. Practically, if is not free in then the substitution has no effect and can be simply removed:
This simplification procedure can be applied to the previous example, where the weakest precondition of is . Let be a precondition, the simplification prevents the four repeated occurrences of the variable in the final substitution:
[TABLE]
6 Applications
The TrABin’s verification work flow consists of three tasks: (1) transpile a binary program to BIR, (2) proving that the BIR program does not reach error states, (3) proving that the desired properties of the BIR program hold, and (4) using the refinement relation to transfer these properties to the original binary program.
Task (2) can be done following the strategy of Section 5. Let be the partial function whose domain is the program entry points and values are the corresponding preconditions, and let be the partial function whose domain is the exit points of the program which all map to the constant true, error freedom of program can be verified by simply establishing the contract .
For (3) and (4) we show that the transpiler output and BIR contract verification can be used for four common verification tasks: Control Flow Graph (CFG) analysis, contract-based verification, partial correctness refinement, and verification of termination.
Knowing the CFG of a program is essential to many compiler optimizations and static analysis tools. Furthermore, proving control flow integrity ensures resiliency against return-oriented programming [28] and jump-oriented programming attacks [29]. In its simplest form, the CFG consists of a directed connected graph , whose node set is : The graph contains if the program can flow from the address to the address by executing a single instruction; The nodes represent the entry points of the program, which can be multiple due to binary programs being unstructured.
Analyzing the CFG of a binary program requires to deal with indirect jumps. Even if the source program avoids using function pointers, indirect jumps are introduced by the compiler, e.g. to handle function exits and exceptions (for example the ARM link register is used to track the return address of functions and can be pushed to and popped from the stack). For this reason, the correctness of the control flow depends on the integrity of the stack itself. Thus, verifying the CFG of a program requires assuming a precondition for every entry point , which constraints the content of the heap, stack and registers.
Definition 3** (Control flow graph integrity).**
*For every machine state such that , , and , for every , if and then . *
It is straightforward to show that CFG integrity can be verified by using the transpiler theorem, by defining a BIR precondition that corresponds to , and by proving the following verification conditions.
Verification Condition 1** (BIR control flow integrity).**
*For every such that , and for every if , then , , and . *
Verification Condition 2** (Transfer of precondition).**
*For every and such that , if then . *
Contract based verification for a binary program consists of verifying that a program meets the contract , when its executions start at an entry point and end at one of the exit points .
Definition 4** (Contract verification).**
*For every and such that , and , if and then . *
This property can be verified using the theorem produced by the transpiler, by identifying BIR predicates for every , establishing the BIR contract , and by proving the following verification condition:
Verification Condition 3** (Transfer of contracts).**
*For every , , , , such that and , if then and if then . *
Partial correctness is proved as a refinement of an abstract specification and by using contract verification. With composability of specifications in mind, we assume that the specification is phrased such that domain and codomain are the same. Let be a functional specification with the signature .
Definition 5** (Partial correctness - refinement).**
*For every , , such that , , , if , and then . *
Notice, that the refinement relation implicitly contains the mapping from to and an invariant that permits to preserve the refinement. Starting from and we can derive a verification condition suitable for contract-based verification. The precondition is the invariant of the refinement relation; the postcondition incorporates the functional specification with respect to the mapping of .
Total correctness (or functional correctness) additionally requires termination:
Definition 6** (Termination verification).**
*For every such that , and , exists such that and . *
To prove this property, we use the theorem produced by the transpiler (i.e. the second clause of Theorem 1), identify an appropriate BIR precondition , and prove Condition 2 and the following one:
Verification Condition 4** (BIR termination verification).**
*For every such that and exists such that and . *
7 Evaluation
Our contribution counts 33000 lines of HOL4 code: 3000 lines for the model and semantics of BIR; 2000 lines for supporting tools, which includes the static type checker; 10000 lines for helper theorems, which includes validation of emulation of bitvector operators using primitive BIR operators and support for the weak transition relation; 10000 lines for the transpiler, which includes preproved theorems for computing the effects of template-blocks and compose them; 2000 lines of architecture-dependent proofs to handle peculiarities of CortexM0 and ARMv8; 2000 lines for the weakest precondition predicate transformer; and 5000 lines for the precondition simplifier.
7.1 Transpiler benchmarks
A large part of the proof engineering efforts focused on proving the architecture independent transpiler theorems which enable to reduce the run-time cost of establishing the instruction-theorem. This permits to translate (on a modern mobile Intel CPU) in average three instructions per seconds.
We experimented with various unmodified binary programs produced by standard compilers and using standard optimizations:
An embedded SSL library WolfSSL for both ARMv8 and CortexM0:
- (a)
The numlib used to implement asymmetric encryption
- (b)
The modules for md5, sha, hmac, pkcs7, elliptic curve, des3, AES, RSA, and their dependencies
- 2.
The run-time of the embedded real-time operating system FreeRTOS for CortexM0
- 3.
Several binaries extracted from Ubuntu 18.04 for ARMv8
- (a)
The embedded database SQLite
- (b)
The interpreter of the high level language lua
- (c)
The libc part of the standard run-time
- (d)
The general purpose application vim
The transpilation consists of two steps: the transpiling step that translates each instruction independently and produces code and certificates; the merging step that composes the certificates to derive a single theorem for the entire program. The performance of the transpiler is reported in Table 2.
The merging procedure is designed to translate single procedures and to enable their modular analysis. For this reason, it is not optimized to handle monolithic large binary blobs and the percentage of time spent in the merging step increases with the number of instructions. Despite this, the merging can handle binary blobs consisting of more than 50000 instructions. On the other hand, the time needed to transpile single instructions is independent of the size of the program. In Table 3 we report metrics regarding resulting BIR programs.
The transpiler relies on the external HOL4 model of the architecture. Therefore, it does not translate instructions that are not supported by the external model. For ARMv8, the model does not support floating point operations. Frequency of these instructions are reported in Table 4.
In order to optimize transpilation, instruction theorems are cached. This permits to reduce the time needed for re-transpiling instructions. Clearly large programs benefit more from the caching mechanism. Table 5 reports cache hit for three programs. We split the data for each program in four fragments of equal size, in order to show that the frequency of cache hits increases while cache is filled with more instructions. It is worth noticing that cache hits are always less then 75%. This is connected with the fact that even if instructions are repeated, they occur with different arguments. For example both add x1, x1, #0x9d8 and add x1, x1, #0x9f8 add a constant to the same register (e.g. to set two different offsets on the stack), but these two instructions have different encoding (since the encoding includes the constants): 0x91276021 and 0x9127E021. The design of the transpiler is oblivious to the decoding of a particular ISA. This prevents us to detect that these two instructions represent the same operation with different constants. On the other hand, this design allows the tool to be easily extended to support new architectures, since it delegates the inspection of the binary code to the step theorem of the external model.
7.2 Weakest Precondition benchmarks
For evaluating the weakest precondition procedures, we used a selection of the binaries transpiled: the numlib and the crypto library for both CortexM0 and ARMv8. The weakest precondition procedure is automatic only for loop-free programs, for this reason we extracted loop free fragments using an automatic procedure. Due to the time needed to execute the weakest precondition procedure, we limit the size of the extracted fragments to 150 blocks. We also report the benchmarks for the complete implementation of AES, which is part of the crypto library and is considerably larger than the limit imposed to the automatic extractor.
For our experiments we use the postcondition: . Even if minimal, establishing it is not trivial, since the weakest precondition entails all intermediate assertions generated by the transpiler: i.e. there is no memory error that can lead to code injection and all memory accesses are correctly aligned (which is required to compute the step theorems). Therefore, establishing the postcondition rules out the error states from transpilation theorems. Table 6 reports the number of fragments extracted, their average number of BIR blocks, the size of the largest block, and the time (average and maximum) to compute the weakest precondition. The average time to propagate a weakest precondition for one block is 1.2 seconds. This time refers to the first phase of the procedure, and does not include application of the optimization procedure and the substitutions.
Comparing the optimization procedure with respect to the naive expansion of the substitution is possible only for relatively small fragments, because the time required by the naive approach increases quickly.
We compared the two approaches for the last 70 instructions of the AES encryption procedure. In this case, the weakest precondition consists of 1170 BIR operators and includes 70 substitutions for ARMv8; and 1576 BIR operators and 133 substitutions for CortexM0. Naively applying the substitutions for the ARMv8 expression requires 49.0 minutes and produces a weakest precondition consisting of 7 million BIR operators. For CortexM0, the same approach requires 7.5 hours and produces an expression of 25 million BIR operators. The execution of our optimization procedure requires 1.7 minutes and produces an expression with 1377 BIR operators for ARMv8. For CortexM0 this takes 2.3 minutes and produces an expression with 1335 BIR operators.
Once the weakest precondition is computed, it can be verified to be entailed by the program precondition. In the case of the AES encryption procedure, the precondition constraints the stack to be separated from the program memory, and the function argument (i.e. the content of the stack containing the pointers to the the block to be encrypted and the encryption key) to not overlap with the stack and the program memory. The validity of the tautology is checked using the external SMT solver Z3. We could not use the existing HOL4 Z3 export that provides proof reconstruction, since it cannot handle the theory of arrays, which is necessary for modeling memory loads and stores. For this reason, we developed a small untrusted export that supports the BIR operators.
8 Concluding remarks
We presented the main building blocks of TrABin, a platform for trustworthy analyses of binary code. These consist of the HOL4 formal model of the intermediate language BIR, the implementation of a transpiler for binary programs, and a weakest precondition predicate transformer. TrABin overcomes two of the main barriers in adopting binary analysis platforms to formally verifying binary code: the need for trusting translation soundness and the lack of a formal ground for correctness of the analyses.
We demonstrated the proof producing transpiler for two common architectures: ARMv8 and CortexM0. To handle other machine architectures (e.g. x86, x64, ARMv7, MIPS, RISC-V), new transpilers must be developed. Fortunately, among 12000 lines of the transpiler, only 2000 are architecture specific, which permits to easily adapt the translation to support existing (and upcoming) HOL4 ISA models that are equipped with the step function.
The proof producing tool to generate weakest preconditions demonstrates that the platform can be used to create trustworthy analyses and is a key component for a trustworthy semi-automatic verification tool based on pre/post conditions for binary code. Such tools can be developed by developing a sound satisfiability solver for bitvectors to check if the precondition entails the weakest precondition. Böhme et al. [30] demonstrated HOL4 proof reconstruction for Z3 [31] capable of handling the theory of fixed-size bit-vectors. However, the current implementation lacks support for arrays, which are needed to handle memory loads and stores. Also, to make the use of the verification tool practical, some supporting analyses are needed, like loop unrolling and heuristics for indirect jump resolution. Fortunately, these analyses can be build on top of contract based verification, which allows us to reuse the existing infrastructure to prove correctness of their results.
An ongoing research activity is extending the BIR language and the supporting tools to handle non-functional aspects of hardware architectures, for instance to represent cache accesses performed by a binary program. This can enable the development of trustworthy static analysis of side channels, including timing and power consumption, in the style of CacheAudit [24].
TrABin artifacts
The source code of the analysis platform, including the BIR model, the transpiler, the weakest precondition generator, and the binaries used for benchmarking, are available at https://github.com/andreaslindner/HolBA.
Acknowledgments
We warmly thank Thomas Tuerk for his key contributions to build up the foundation of the binary analysis platform reported in this paper. This work has been supported by the TrustFull project financed by the Swedish Foundation for Strategic Research and by the KTH CERCES Center for Resilient Critical Infrastructures financed by the Swedish Civil Contingencies Agency.
References
- [1]
D. Song, D. Brumley, H. Yin, J. Caballero, I. Jager, M. G. Kang, Z. Liang, J. Newsome, P. Poosankam, P. Saxena, BitBlaze: A new approach to computer security via binary analysis, in: International Conference on Information Systems Security, Springer, 2008, pp. 1–25.
- [2]
D. Brumley, I. Jager, T. Avgerinos, E. J. Schwartz, BAP: A Binary Analysis Platform, in: Computer Aided Verification, Springer, 2011, pp. 463–469.
- [3]
Y. Shoshitaishvili, R. Wang, C. Salls, N. Stephens, M. Polino, A. Dutcher, J. Grosen, S. Feng, C. Hauser, C. Krügel, G. Vigna, SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis, in: Symposium on Security and Privacy, IEEE, 2016, pp. 138–157.
- [4]
N. Nethercote, J. Seward, Valgrind: A program supervision framework, Electronic notes in theoretical computer science 89 (2) (2003) 44–66.
- [5]
K. Y. Rozier, M. Y. Vardi, LTL satisfiability checking, International journal on software tools for technology transfer 12 (2) (2010) 123–137.
- [6]
A. Fox, L3: A Specification Language for Instruction Set Architectures (Retrieved on 2015).
URL http://www.cl.cam.ac.uk/~acjf3/l3/
- [7]
A. Fox, Directions in ISA Specification, in: Interactive Theorem Proving, Springer, 2012, pp. 338–344.
- [8]
A. Ltd., ARM Architecture Reference Manual (ARMv8, for ARMv8-A architecture profile) (2013).
URL http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0487a.h/index.html
- [9]
A. Ltd., ARMv6-M Architecture Reference Manual (2017).
URL http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0419c/index.html
- [10]
R. Metere, A. Lindner, R. Guanciale, Sound transpilation from binary to machine-independent code, in: Brazilian Symposium on Formal Methods, Springer, 2017, pp. 197–214.
- [11]
G. Klein, K. Elphinstone, G. Heiser, J. Andronick, D. Cock, P. Derrin, D. Elkaduwe, K. Engelhardt, R. Kolanski, M. Norrish, et al., seL4: Formal verification of an OS kernel, in: Operating systems principles, ACM, 2009, pp. 207–220.
- [12]
E. Alkassar, M. A. Hillebrand, D. Leinenbach, N. W. Schirmer, A. Starostin, The Verisoft approach to systems verification, in: Verified Software: Theories, Tools, and Experiments, Springer, 2008, pp. 209–224.
- [13]
M. Dam, R. Guanciale, H. Nemati, Machine code verification of a tiny ARM hypervisor, in: Workshop on Trustworthy Embedded Devices, Co-located with CCS, ACM, 2013, pp. 3–12.
- [14]
X. Leroy, Formal verification of a realistic compiler, Communications of the ACM 52 (7) (2009) 107–115.
- [15]
S. Boldo, J. Jourdan, X. Leroy, G. Melquiond, A Formally-Verified C Compiler Supporting Floating-Point Arithmetic, in: Symposium on Computer Arithmetic, IEEE, 2013, pp. 107–115.
- [16]
R. Kumar, M. O. Myreen, M. Norrish, S. Owens, CakeML: a verified implementation of ML, in: SIGPLAN Notices, Vol. 49, ACM, 2014, pp. 179–191.
- [17]
G. Li, S. Owens, K. Slind, Structure of a proof-producing compiler for a subset of higher order logic, in: European Symposium on Programming, Springer, 2007, pp. 205–219.
- [18]
L. Beringer, A. Petcher, Q. Y. Katherine, A. W. Appel, Verified Correctness and Security of OpenSSL HMAC., in: USENIX Security Symposium, 2015, pp. 207–221.
- [19]
A. C. Fox, M. J. Gordon, M. O. Myreen, Specification and verification of ARM hardware and software, in: Design and verification of microprocessor systems for high-assurance applications, Springer, 2010, pp. 221–247.
- [20]
M. O. Myreen, M. J. C. Gordon, K. Slind, Machine-Code Verification for Multiple Architectures - An Application of Decompilation into Logic, in: Formal Methods in Computer-Aided Design, IEEE Press, 2008, pp. 1–8.
- [21]
T. A. L. Sewell, M. O. Myreen, G. Klein, Translation validation for a verified OS kernel, in: SIGPLAN Conference on Programming Language Design and Implementation, ACM, 2013, pp. 471–482.
- [22]
M. O. Myreen, G. Curello, Proof Pearl: A Verified Bignum Implementation in x86-64 Machine Code, in: Certified Programs and Proofs - Third International Conference, Springer, 2013, pp. 66–81.
- [23]
M. Balliu, M. Dam, R. Guanciale, Automating information flow analysis of low level code, in: SIGSAC Conference on Computer and Communications Security, ACM, 2014, pp. 1080–1091.
- [24]
G. Doychev, B. Köpf, L. Mauborgne, J. Reineke, Cacheaudit: A tool for the static analysis of cache side channels, ACM Transactions on Information and System Security (TISSEC) 18 (1) (2015) 4.
- [25]
N. Hasabnis, R. Sekar, Lifting Assembly to Intermediate Representation: A Novel Approach Leveraging Compilers, ACM SIGOPS Operating Systems Review 50 (2) (2016) 311–324.
- [26]
F. Vogels, B. Jacobs, F. Piessens, A machine-checked soundness proof for an efficient verification condition generator, in: Symposium on Applied Computing, ACM, 2010, pp. 2517–2522.
- [27]
K. R. M. Leino, Efficient weakest preconditions, Information Processing Letters 93 (6) (2005) 281–288.
- [28]
H. Shacham, The Geometry of Innocent Flesh on the Bone: Return-into-libc Without Function Calls (on the x86), in: Conference on Computer and Communications Security, ACM, 2007, pp. 552–561.
- [29]
T. Bletsch, X. Jiang, V. W. Freeh, Z. Liang, Jump-oriented programming: a new class of code-reuse attack, in: Symposium on Information, Computer and Communications Security, ACM, 2011, pp. 30–40.
- [30]
S. Böhme, A. C. Fox, T. Sewell, T. Weber, Reconstruction of Z3’s Bit-Vector Proofs in HOL4 and Isabelle/HOL., in: Certified Programs and Proofs: First International Conference, Springer, 2011, pp. 183–198.
- [31]
L. M. de Moura, N. Bjørner, Z3: An Efficient SMT Solver, in: Tools and Algorithms for the Construction and Analysis of Systems, Springer, 2008, pp. 337–340.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. Song, D. Brumley, H. Yin, J. Caballero, I. Jager, M. G. Kang, Z. Liang, J. Newsome, P. Poosankam, P. Saxena, Bit Blaze: A new approach to computer security via binary analysis, in: International Conference on Information Systems Security, Springer, 2008, pp. 1–25.
- 2[2] D. Brumley, I. Jager, T. Avgerinos, E. J. Schwartz, BAP: A Binary Analysis Platform, in: Computer Aided Verification, Springer, 2011, pp. 463–469.
- 3[3] Y. Shoshitaishvili, R. Wang, C. Salls, N. Stephens, M. Polino, A. Dutcher, J. Grosen, S. Feng, C. Hauser, C. Krügel, G. Vigna, SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis, in: Symposium on Security and Privacy, IEEE, 2016, pp. 138–157.
- 4[4] N. Nethercote, J. Seward, Valgrind: A program supervision framework, Electronic notes in theoretical computer science 89 (2) (2003) 44–66.
- 5[5] K. Y. Rozier, M. Y. Vardi, LTL satisfiability checking, International journal on software tools for technology transfer 12 (2) (2010) 123–137.
- 6[6] A. Fox, L 3: A Specification Language for Instruction Set Architectures (Retrieved on 2015). URL http://www.cl.cam.ac.uk/~acjf 3/l 3/
- 7[7] A. Fox, Directions in ISA Specification, in: Interactive Theorem Proving, Springer, 2012, pp. 338–344.
- 8[8] A. Ltd., ARM Architecture Reference Manual (AR Mv 8, for AR Mv 8-A architecture profile) (2013). URL http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi 0487 a.h/index.html