Analytic Performance Modeling and Analysis of Detailed Neuron Simulations
Francesco Cremonesi, Georg Hager, Gerhard Wellein, Felix Sch\"urmann

TL;DR
This paper applies the Execution-Cache-Memory performance model to analyze and predict the runtime of detailed neuron simulations, providing insights into performance bottlenecks and guiding optimization and hardware co-design.
Contribution
It introduces a novel application of the ECM performance model to morphologically detailed neuron simulations, enabling accurate performance predictions and deeper understanding of computational bottlenecks.
Findings
ECM model accurately predicts kernel runtimes
Identifies key performance bottlenecks in neuron simulations
Provides insights for software optimization and hardware co-design
Abstract
Big science initiatives are trying to reconstruct and model the brain by attempting to simulate brain tissue at larger scales and with increasingly more biological detail than previously thought possible. The exponential growth of parallel computer performance has been supporting these developments, and at the same time maintainers of neuroscientific simulation code have strived to optimally and efficiently exploit new hardware features. Current state of the art software for the simulation of biological networks has so far been developed using performance engineering practices, but a thorough analysis and modeling of the computational and performance characteristics, especially in the case of morphologically detailed neuron simulations, is lacking. Other computational sciences have successfully used analytic performance engineering and modeling methods to gain insight on the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1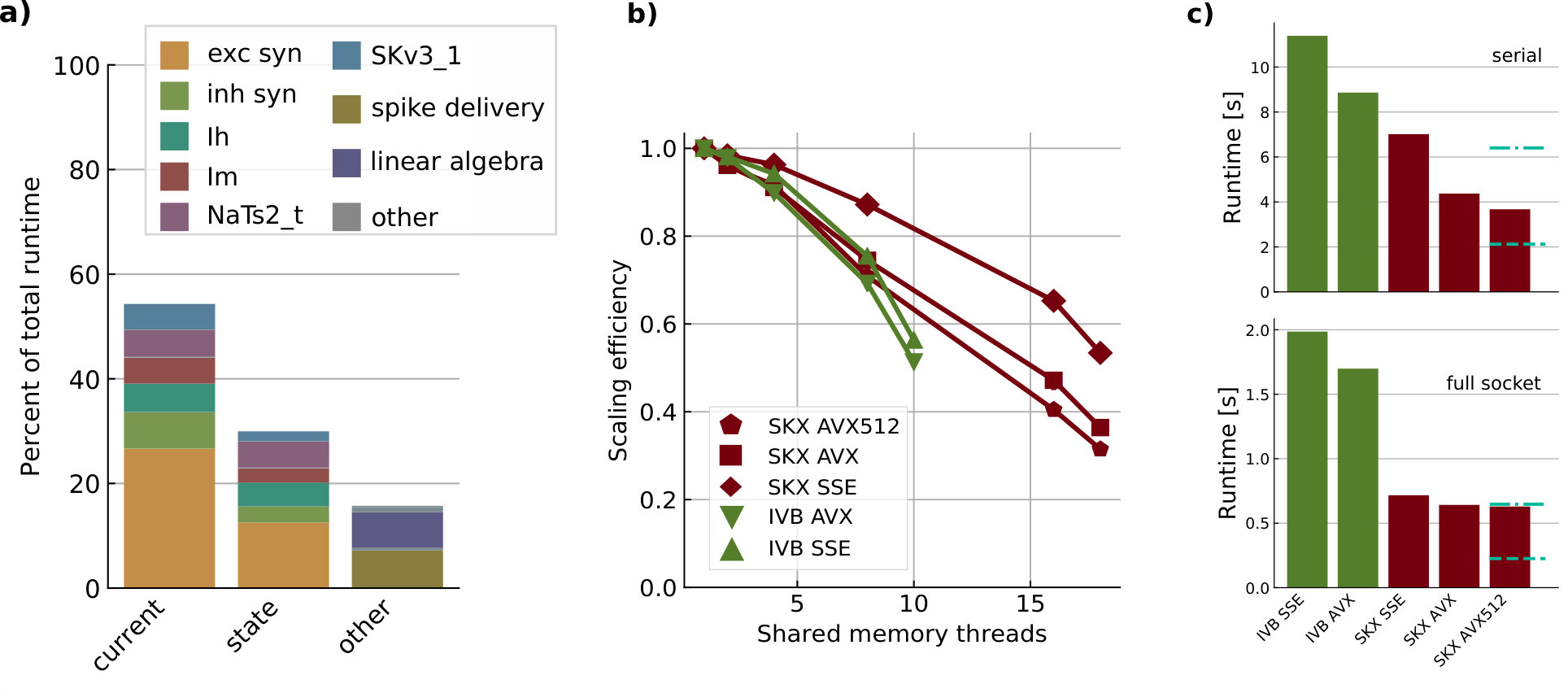 Figure 2
Figure 2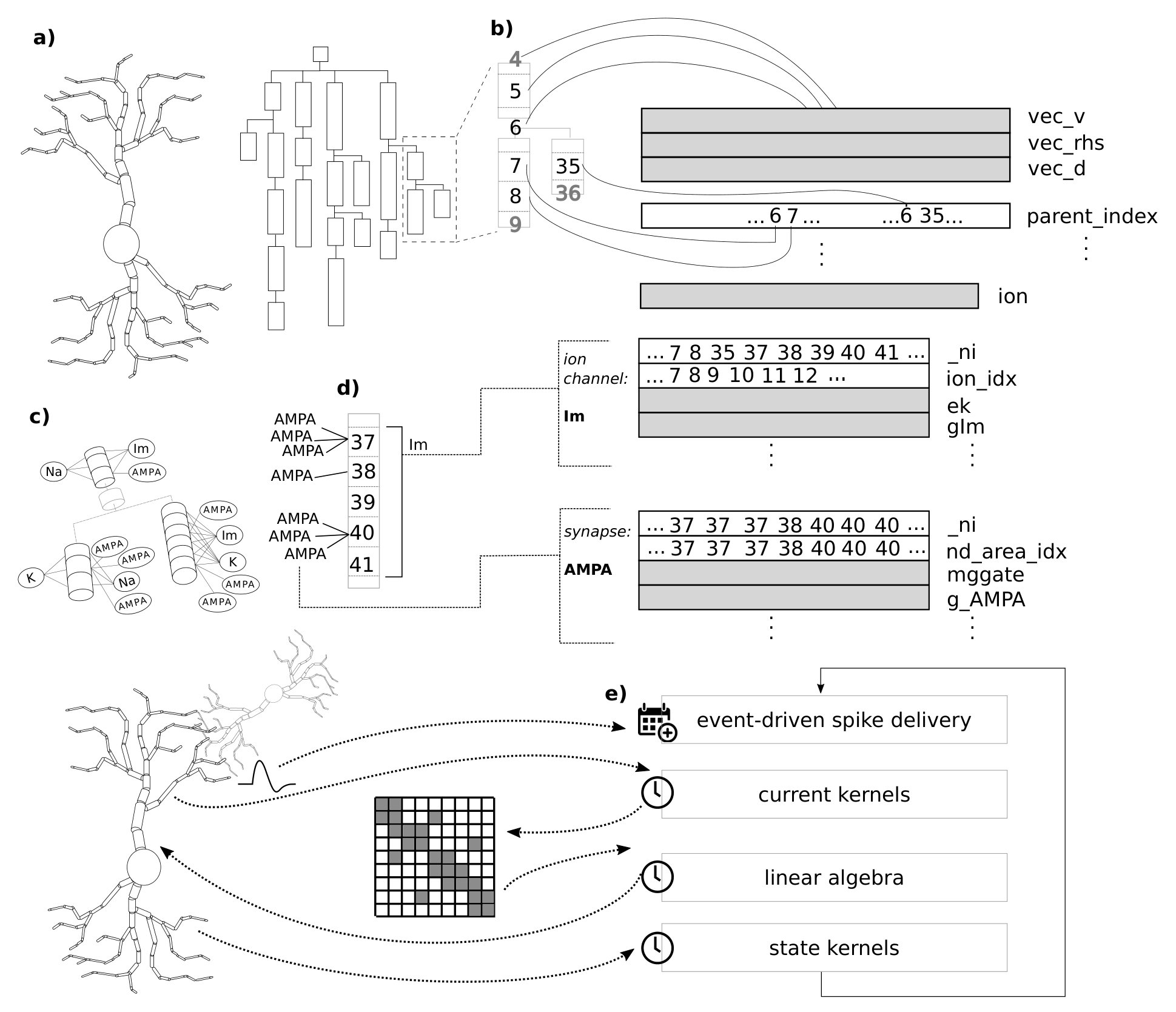 Figure 3
Figure 3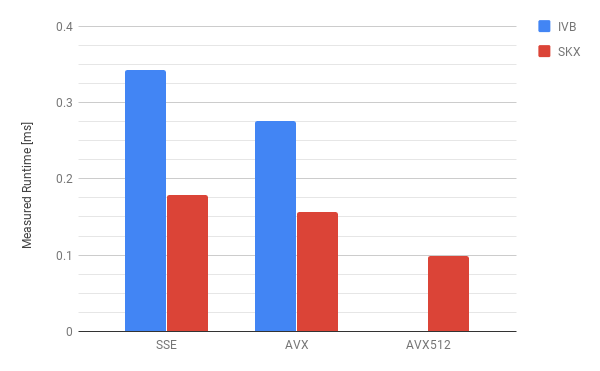 Figure 4
Figure 4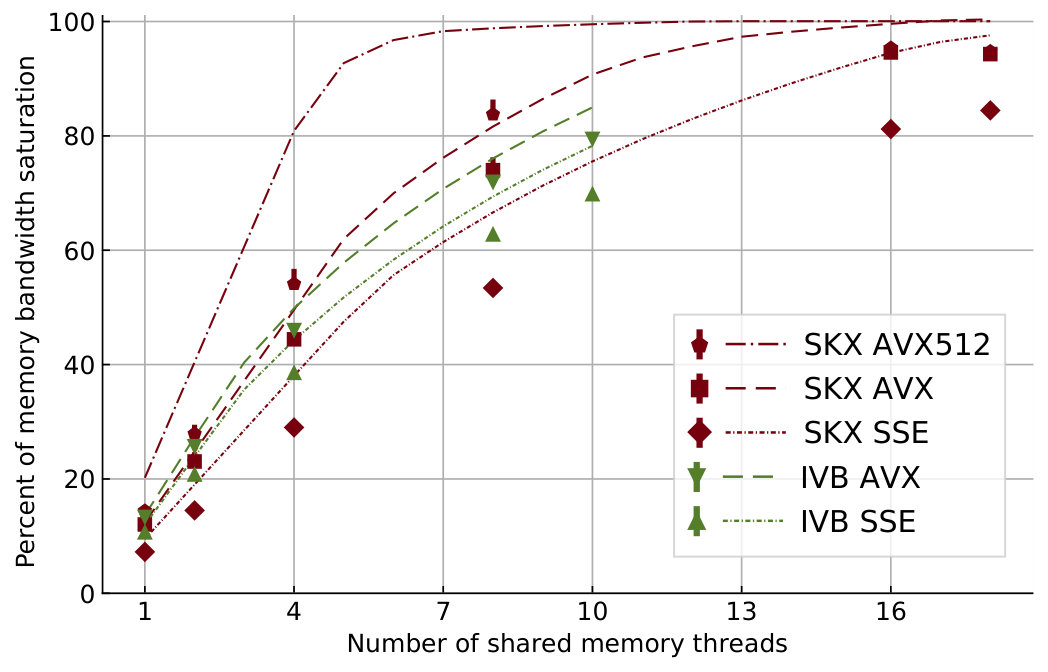 Figure 5
Figure 5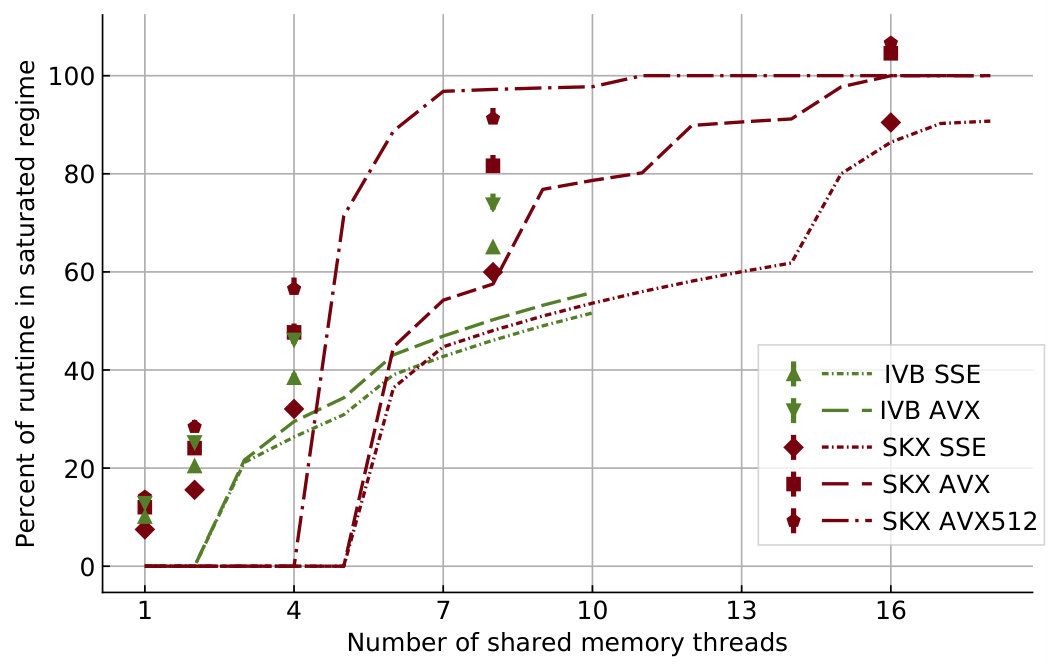 Figure 6
Figure 6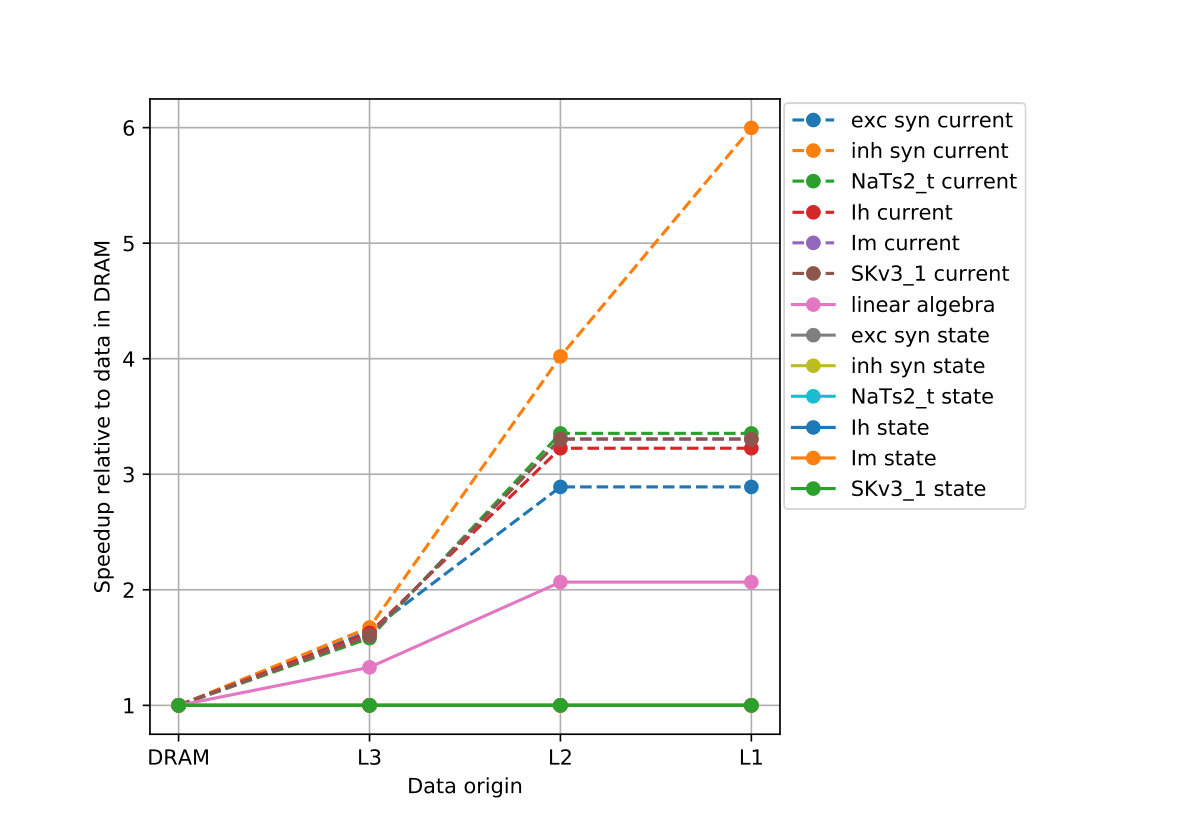 Figure 7
Figure 7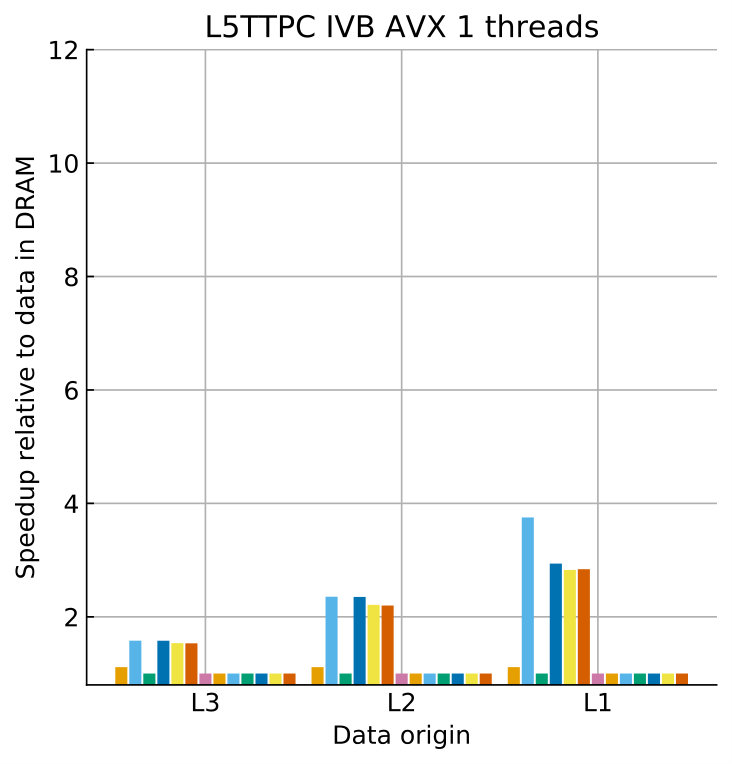 Figure 8
Figure 8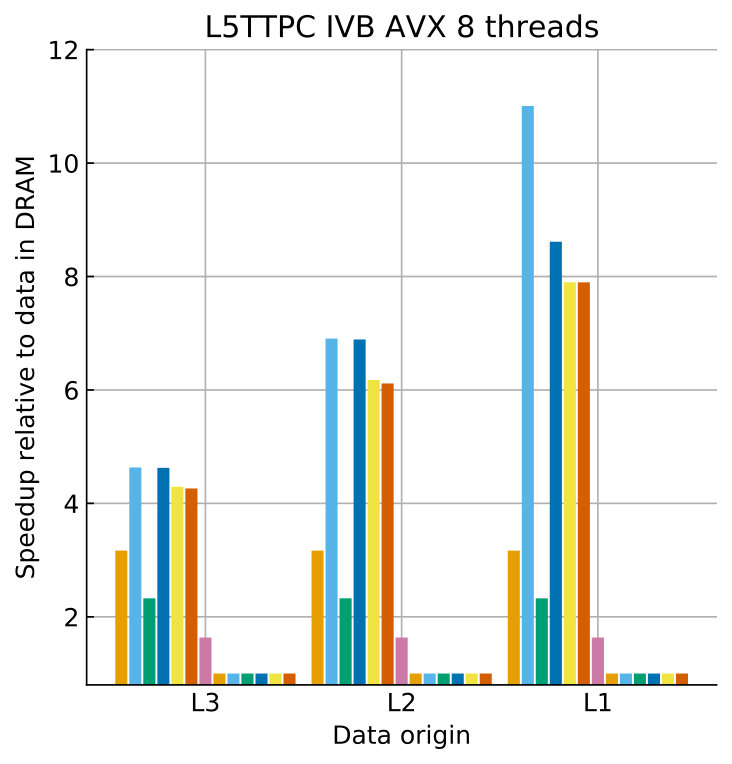 Figure 9
Figure 9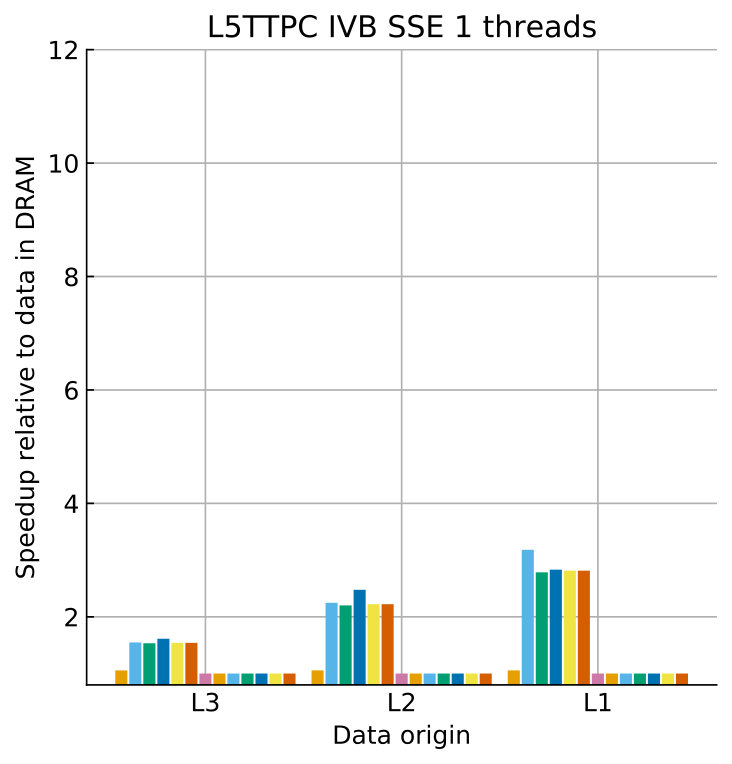 Figure 10
Figure 10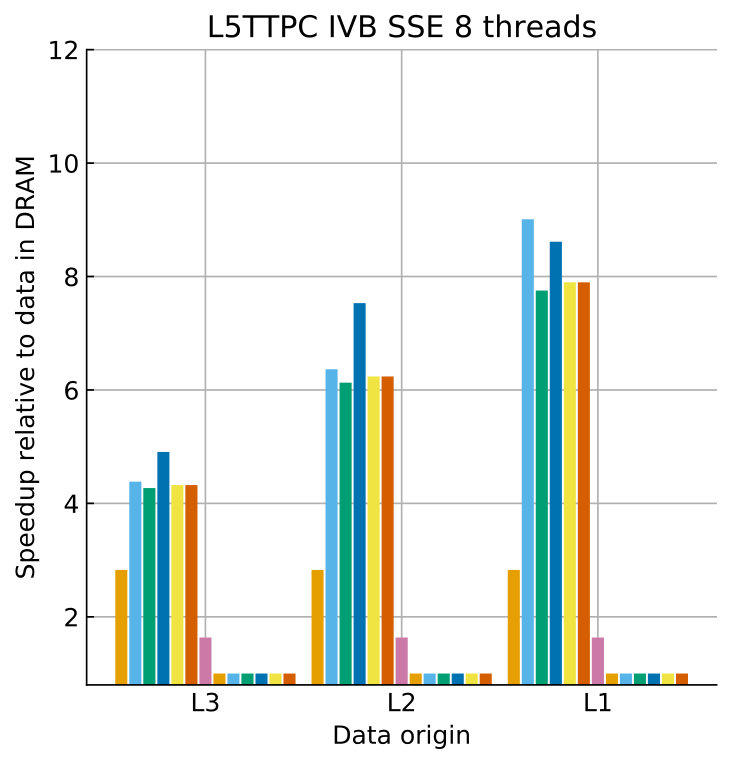 Figure 11
Figure 11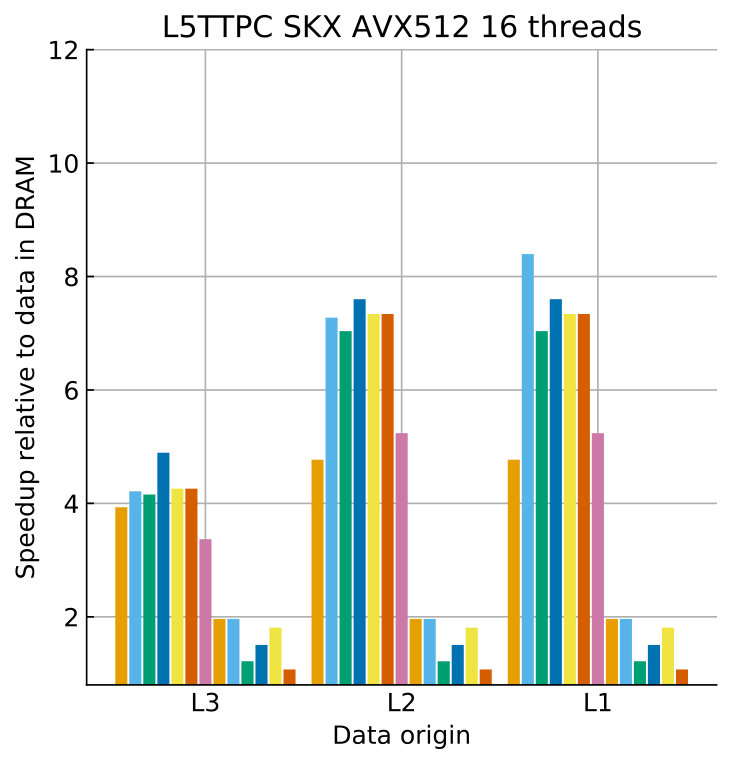 Figure 12
Figure 12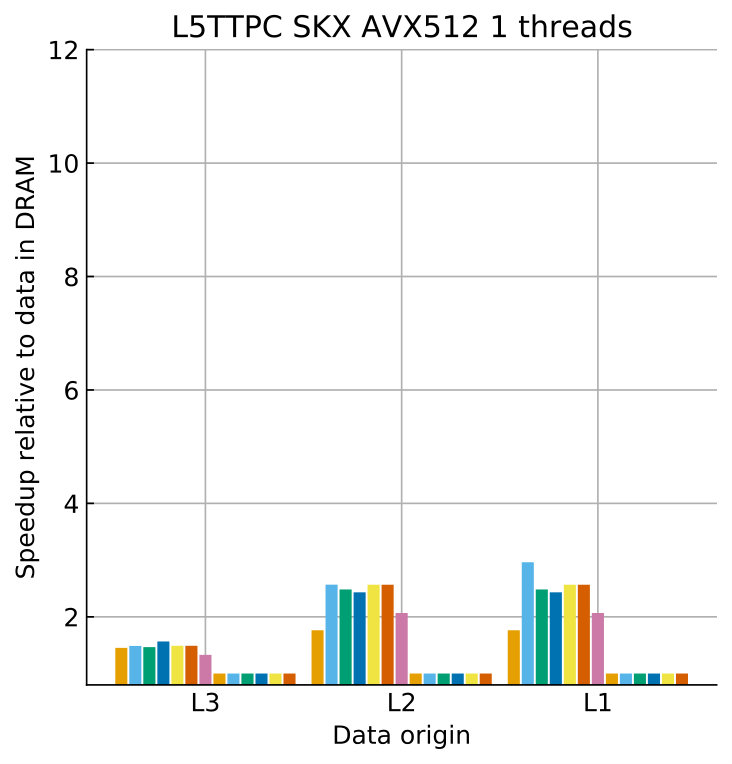 Figure 13
Figure 13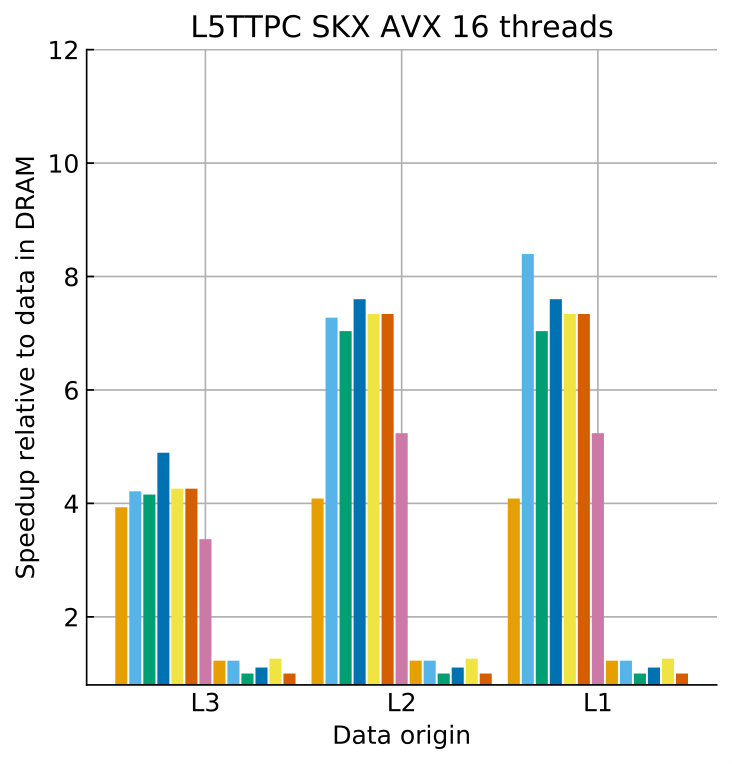 Figure 14
Figure 14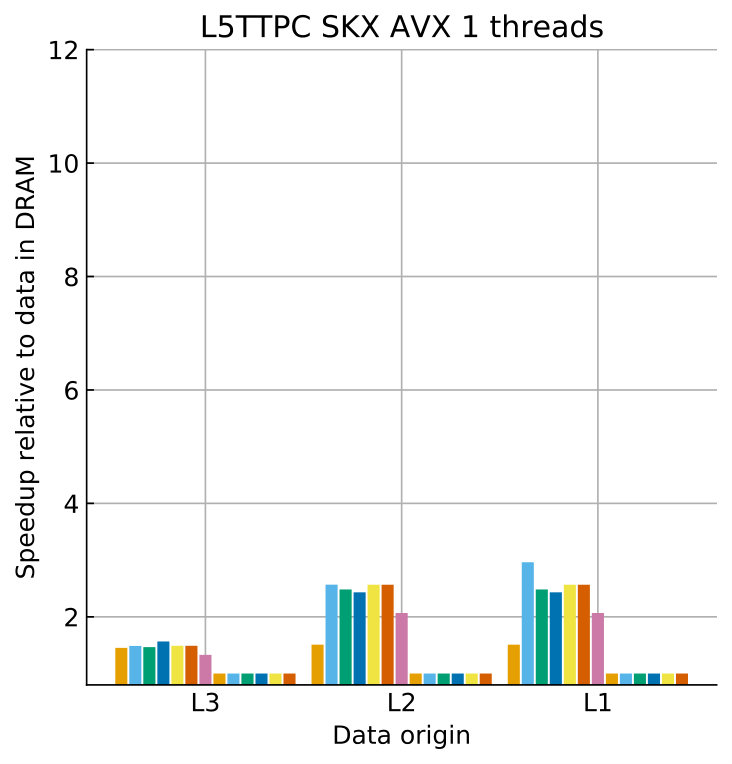 Figure 15
Figure 15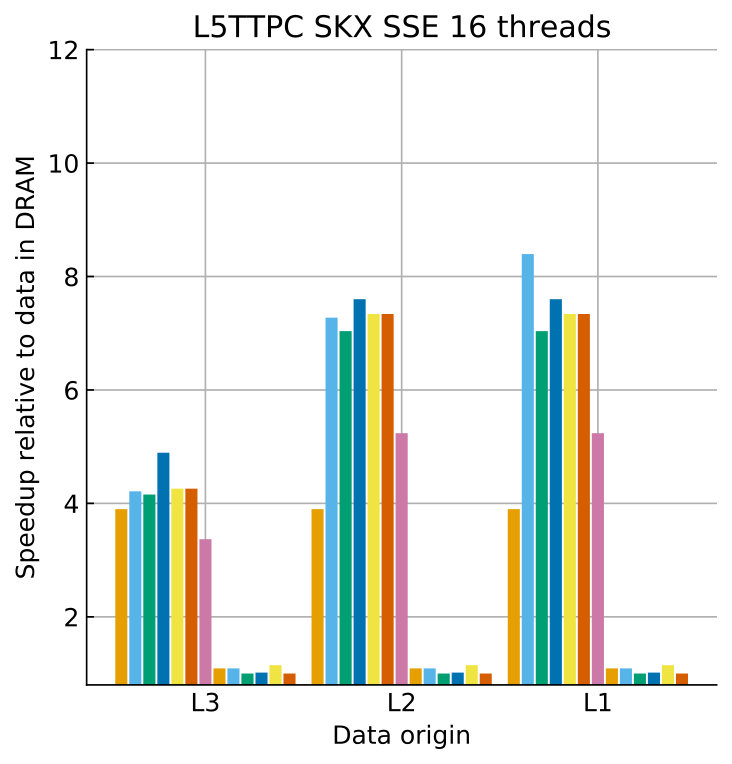 Figure 16
Figure 16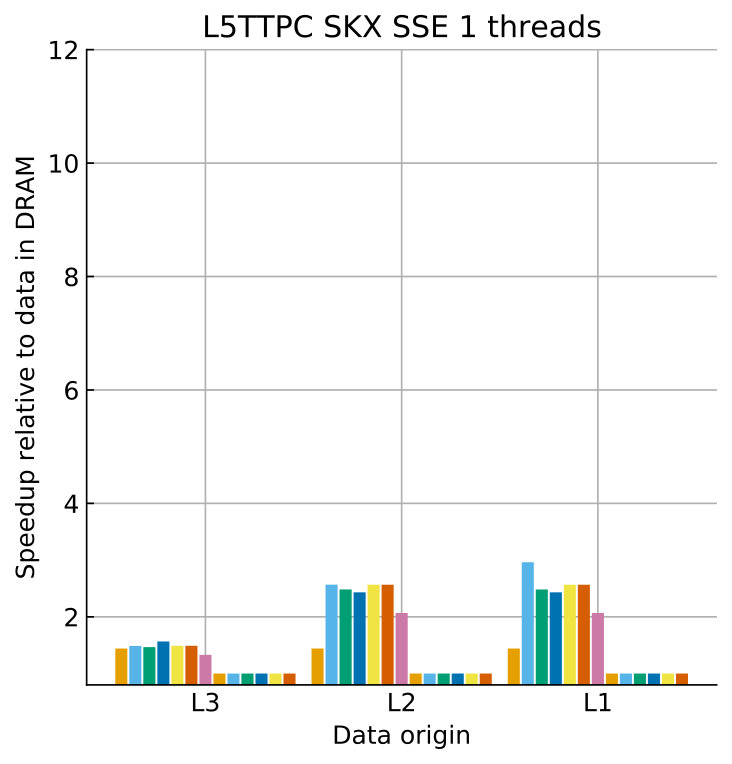 Figure 17
Figure 17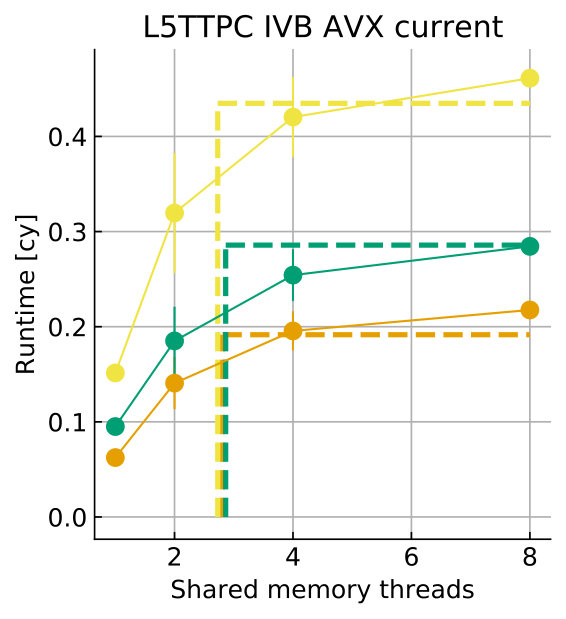 Figure 18
Figure 18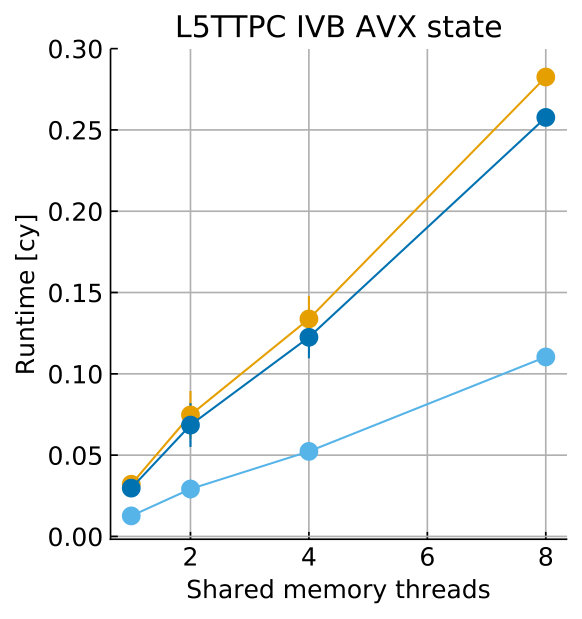 Figure 19
Figure 19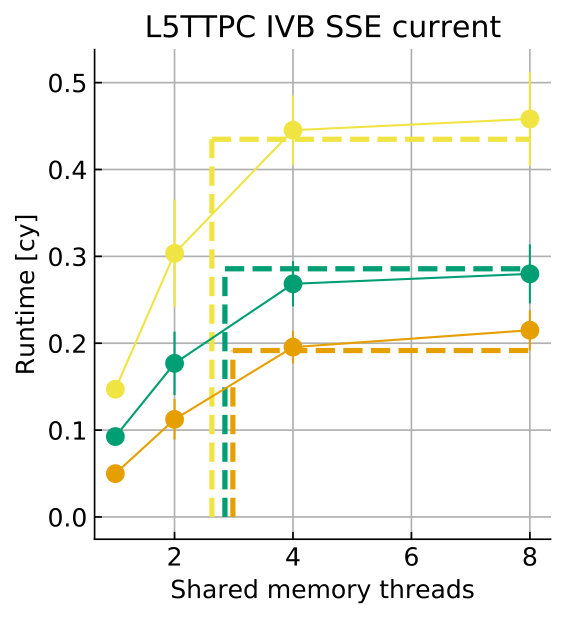 Figure 20
Figure 20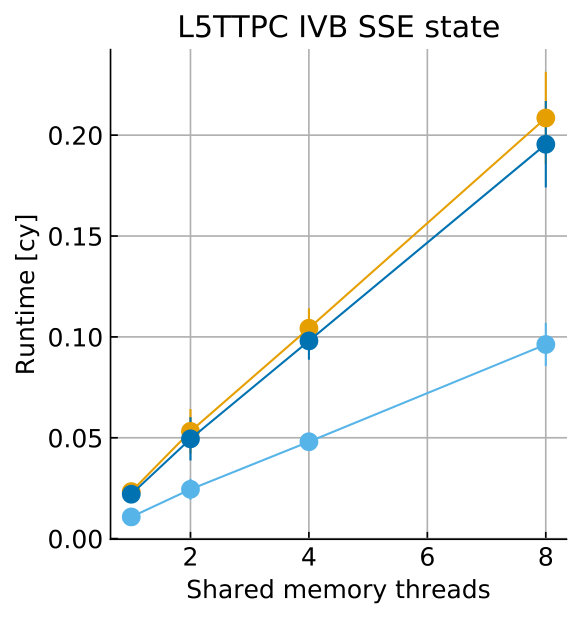 Figure 21
Figure 21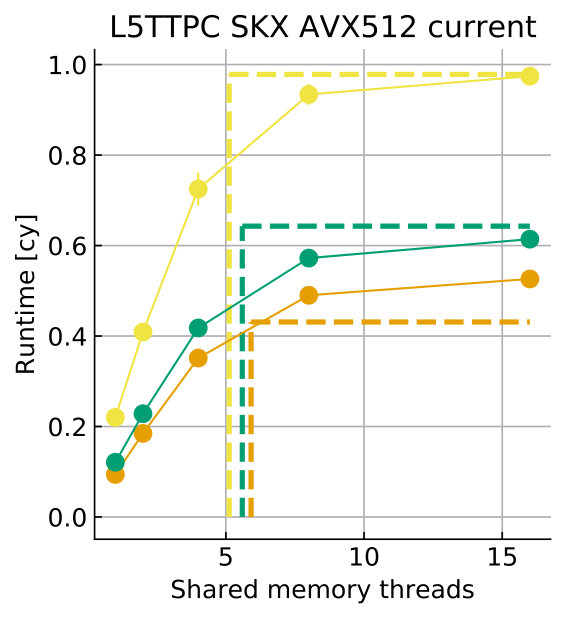 Figure 22
Figure 22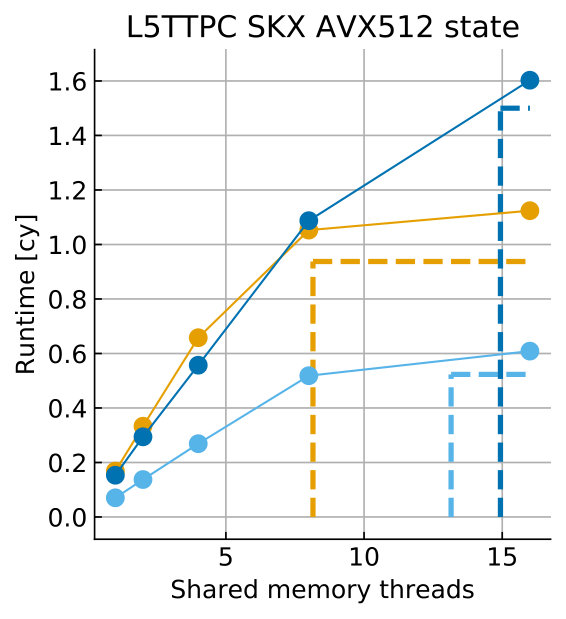 Figure 23
Figure 23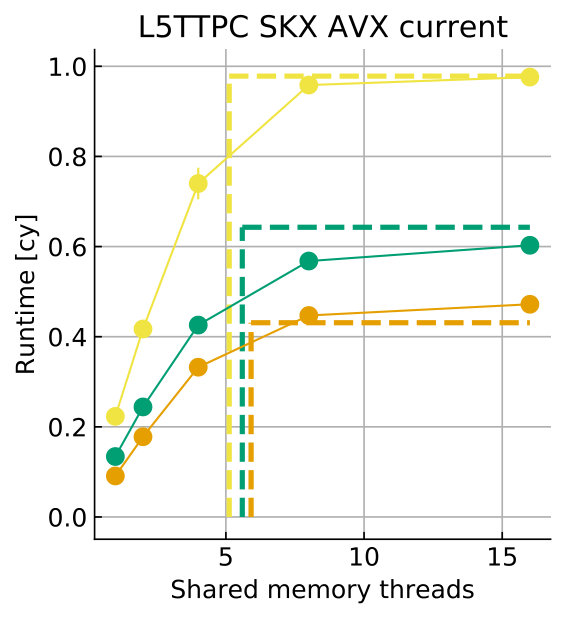 Figure 24
Figure 24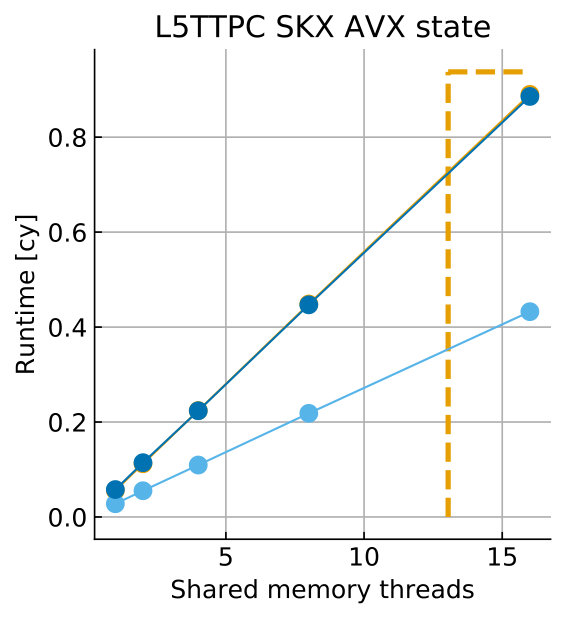 Figure 25
Figure 25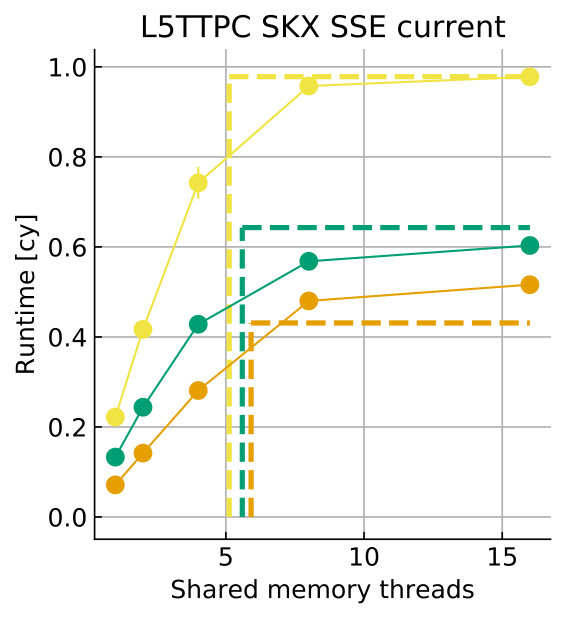 Figure 26
Figure 26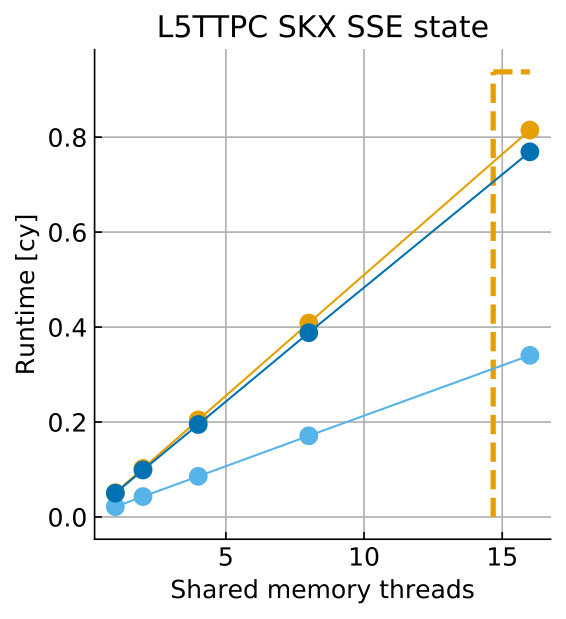 Figure 27
Figure 27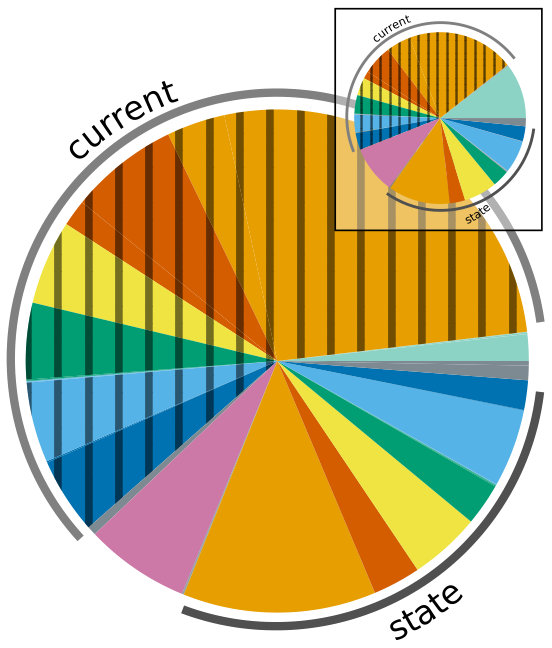 Figure 28
Figure 28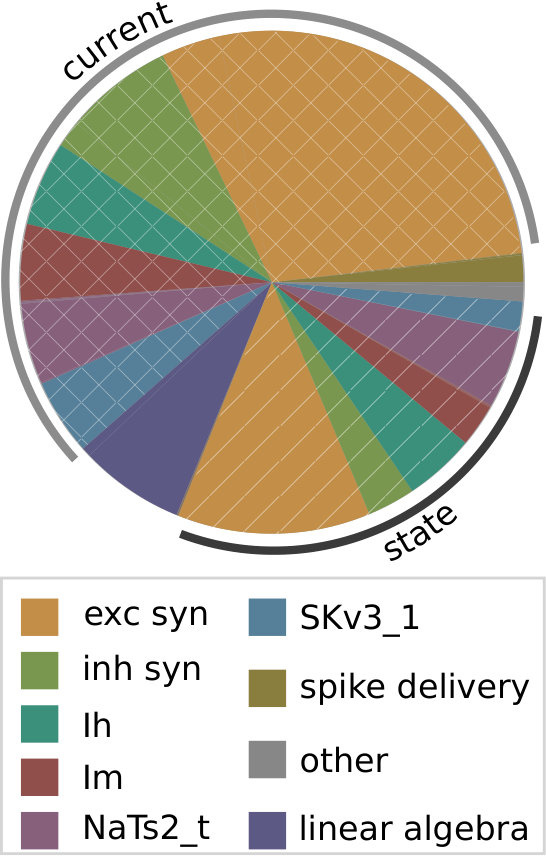 Figure 29
Figure 29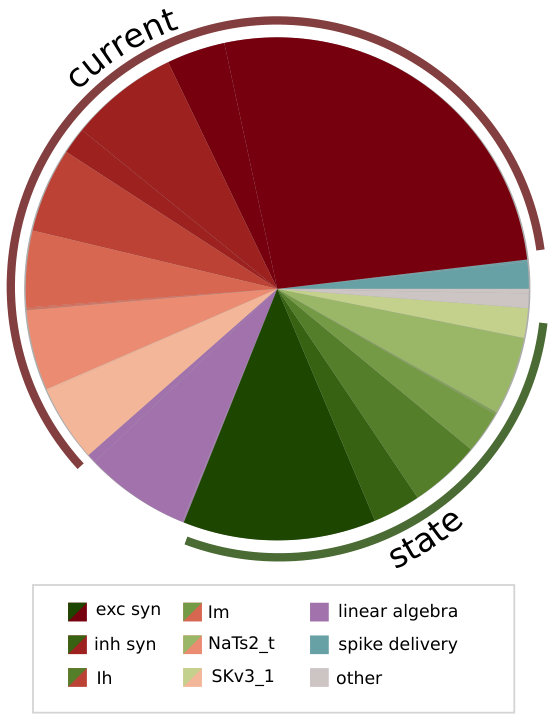 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32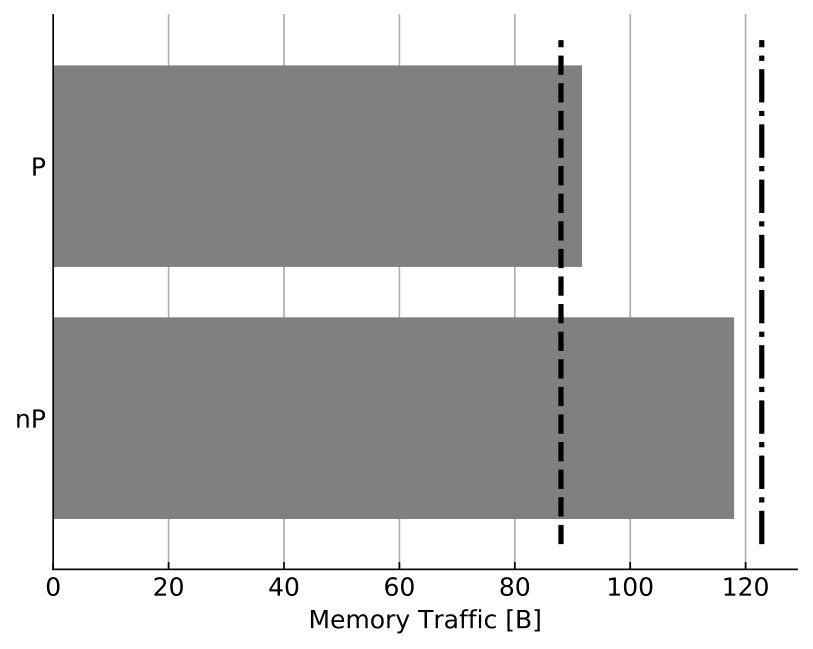 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36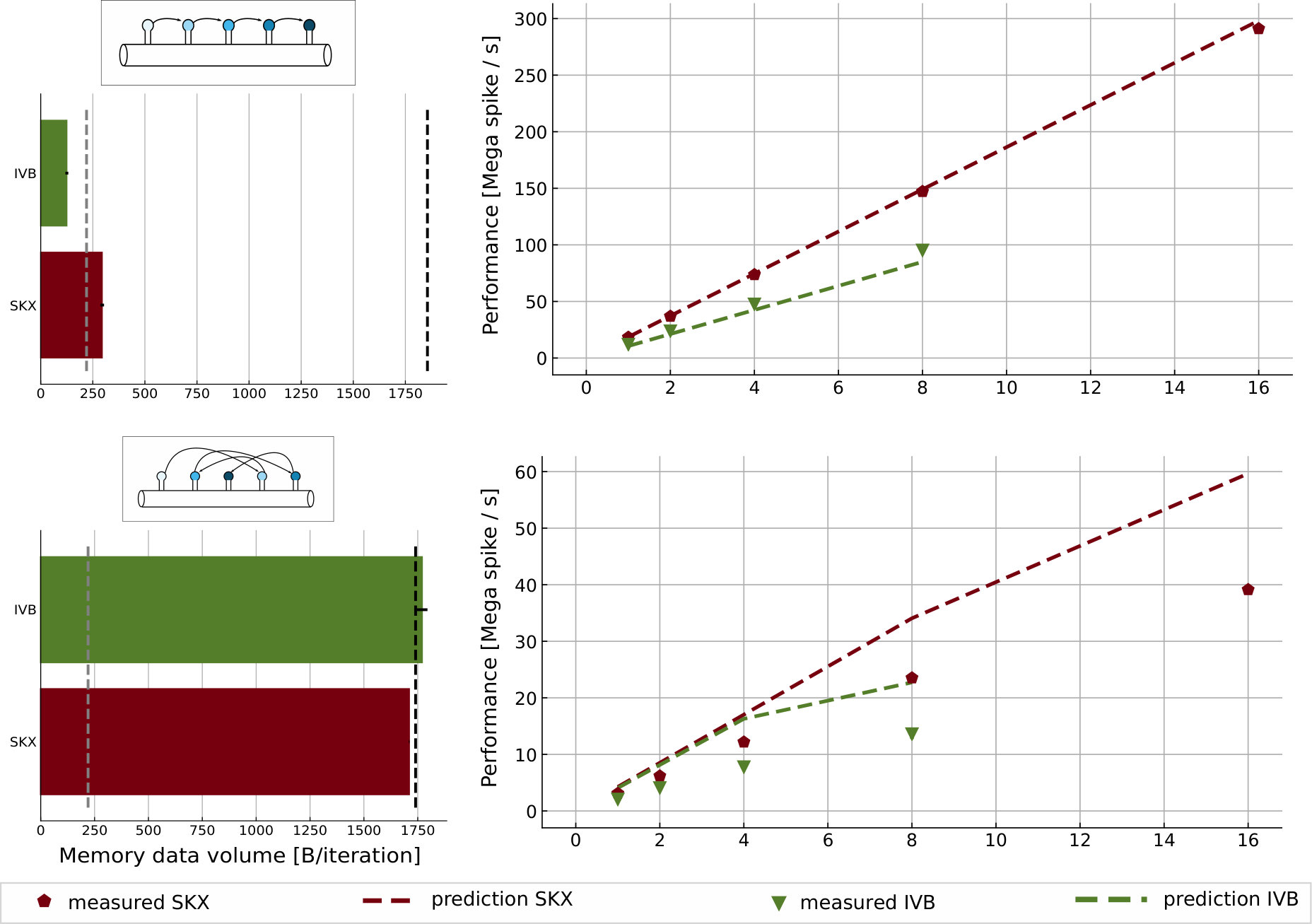 Figure 37
Figure 37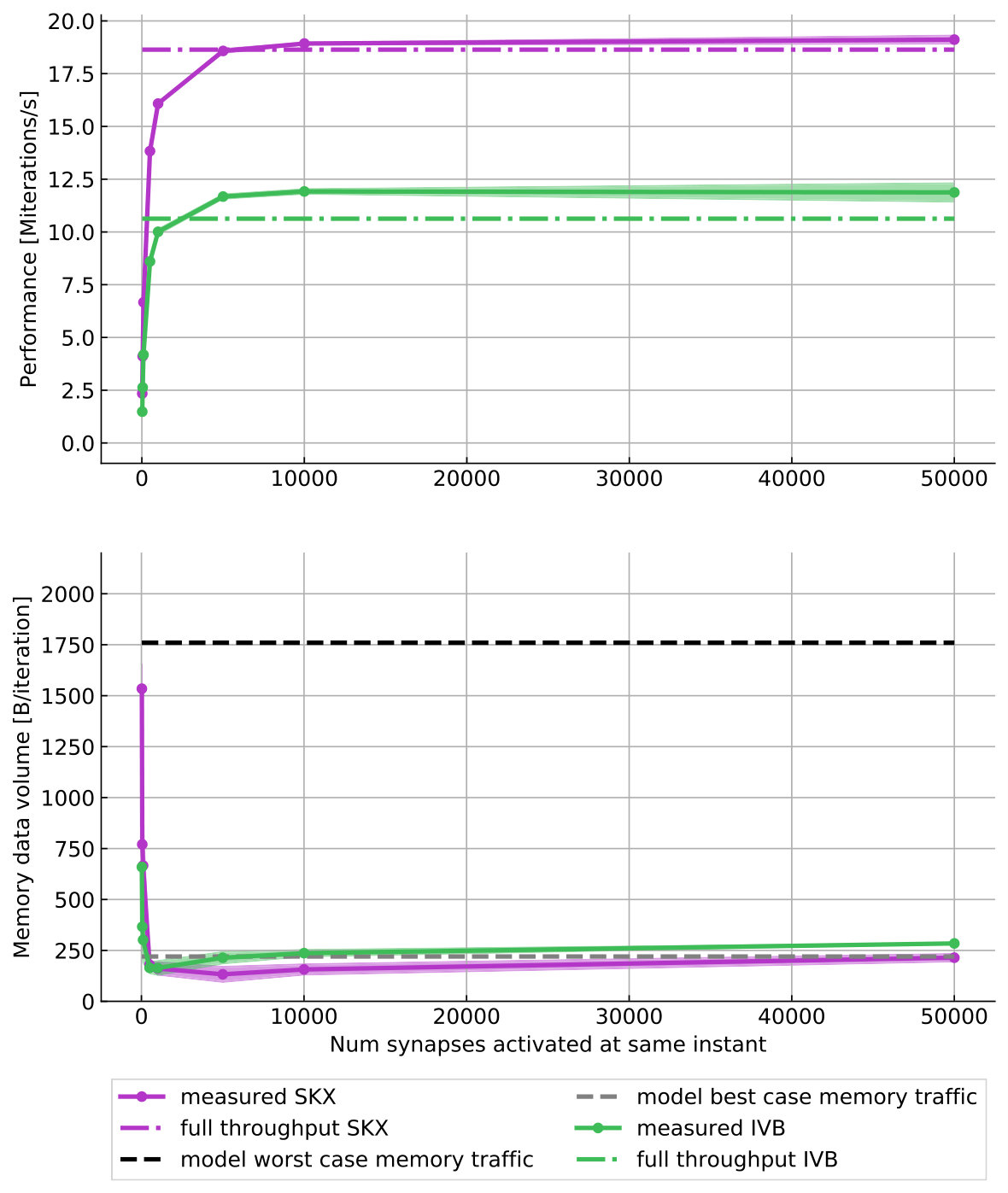 Figure 38
Figure 38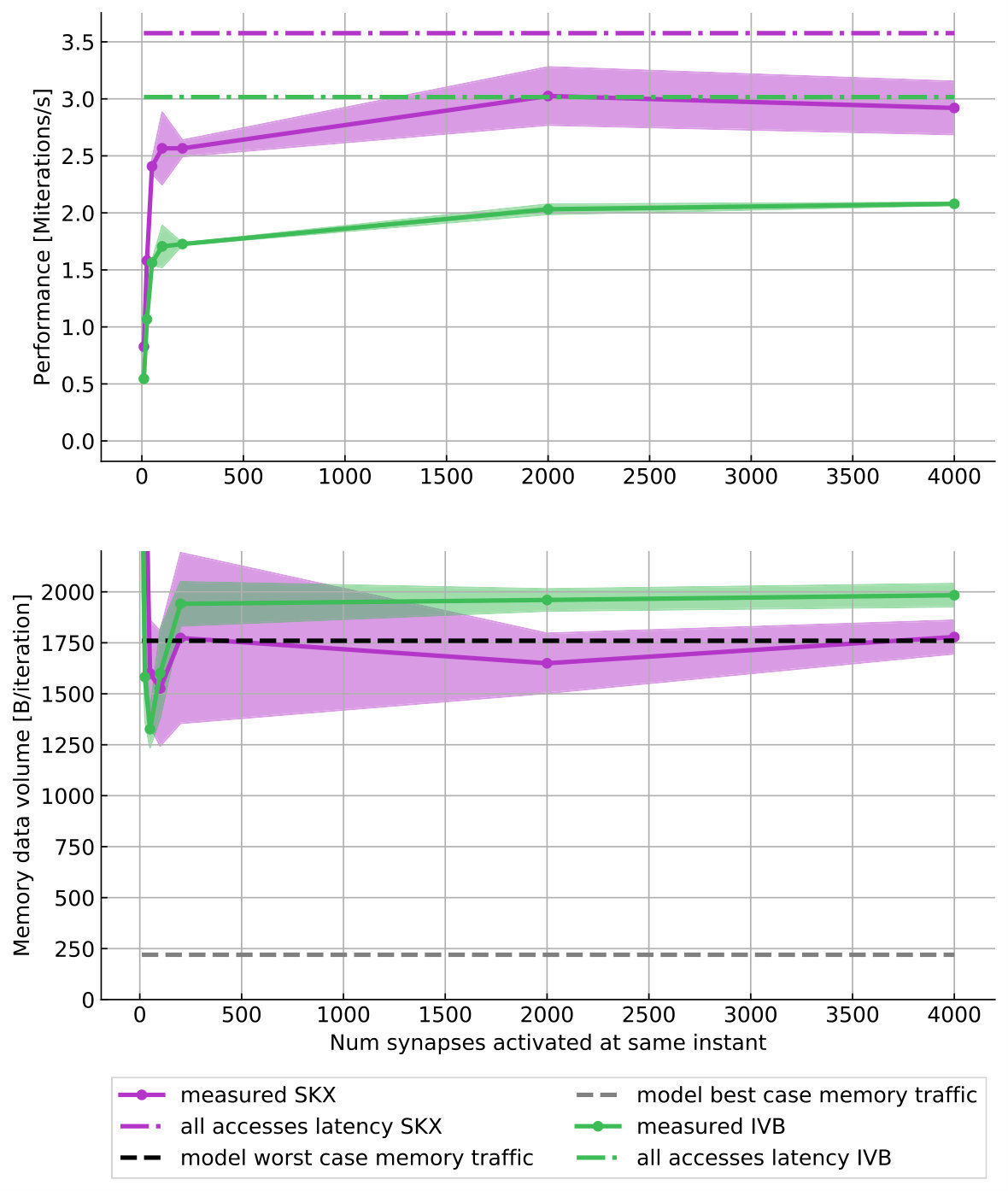 Figure 39
Figure 39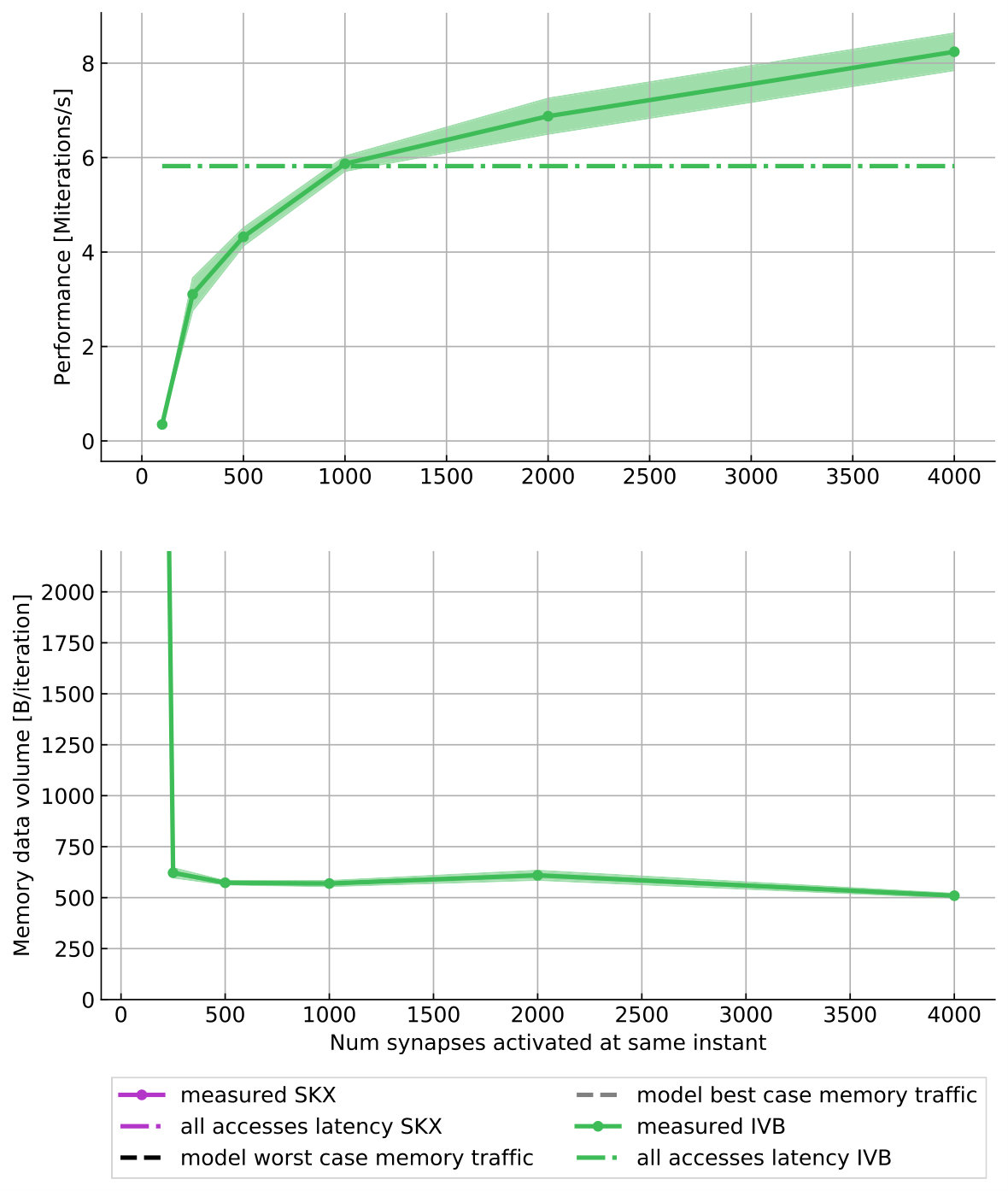 Figure 40
Figure 40| Characteristic | IVB | SKX |
|---|---|---|
| CPU freq [GHz] | ||
| Uncore freq [GHz] | ||
| Mem BW (meas.) [GB/s] | ||
| LD/ST throughput per cy: | ||
| AVX(2), AVX512 | 1 LD, ST | 2 LD, 1 ST |
| SSE, scalar | 2 LD 1 LD, 1 ST | 2 LD, 1 ST |
| AGUs | 2 | 2 + 1 simple |
| Per-core L1-L2 BW [B/cy] | ||
| Per-core L2-L3 BW [B/cy] | ||
| Compiler | Intel 17.0.1 | Intel 18.0.1 |
| IACA version | 2.1 | 3.0 |
| Inverse throughput | IVB | SKX | |||
| for | SSE | AVX | SSE | AVX | AVX512 |
| vector exp() [cy] | 11.5 | 8.0 | 6.7 | 3.5 | 1.5 |
| vector div 11endnote: 1Values taken from Fog (2017) [cy] | 7 | 7 | 2 | 2 | 2 |
| scalar exp() [cy] | 27.8 | 15.1 | |||
| Architecture | formula | DP [Gflop/s] |
|---|---|---|
| IVB 1 core | 17.6 | |
| SKX 1 core | 73.6 | |
| IVB 1 socket | 176 | |
| SKX 1 socket | 1324.8 |
| contributions | predictions | measurements | |
|---|---|---|---|
| IVB SSE | |||
| IVB AVX | |||
| SKX SSE | |||
| SKX AVX | |||
| SKX AVX512 |
| contributions | predictions | measurements | |
|---|---|---|---|
| IVB SSE | |||
| IVB AVX | |||
| SKX SSE | |||
| SKX AVX | |||
| SKX AVX512 |
| contributions | predictions | measurements | |
|---|---|---|---|
| IVB SSE | |||
| IVB AVX | |||
| SKX SSE | |||
| SKX AVX | |||
| SKX AVX512 |
| contributions | predictions | measurements | |
|---|---|---|---|
| IVB SSE | |||
| IVB AVX | |||
| SKX SSE | |||
| SKX AVX | |||
| SKX AVX512 |
| SSE | AVX | |||||||
|---|---|---|---|---|---|---|---|---|
| serial | full socket | serial | full socket | |||||
| kernel | pred | bench | pred | bench | pred | bench | pred | bench |
| exc syn current | 33.9 | 35.20.2 | 11.3 | 11.40.0 | 31.9 | 28.90.9 | 11.3 | 11.40.1 |
| inh syn current | 28.3 | 26.50.2 | 10.0 | 10.10.1 | 27.3 | 26.40.2 | 10.0 | 10.10.1 |
| NaTs2_t current | 23.4 | 21.30.2 | 8.1 | 8.40.2 | 28.0 | 21.00.2 | 8.1 | 8.20.2 |
| Ih current | 13.3 | 12.00.0 | 5.1 | 5.00.1 | 13.8 | 11.90.0 | 5.1 | 4.90.1 |
| Im current | 21.5 | 19.00.2 | 7.5 | 7.90.1 | 21.6 | 19.00.1 | 7.5 | 7.70.1 |
| SKv3_1 current | 22.0 | 19.90.1 | 7.7 | 7.90.2 | 22.1 | 19.70.1 | 7.7 | 7.70.0 |
| exc syn state | 75.0 | 75.40.0 | 7.5 | 9.50.0 | 60.0 | 55.90.0 | 6.0 | 7.10.0 |
| inh syn state | 75.0 | 73.50.1 | 7.5 | 9.30.0 | 60.0 | 51.70.0 | 6.0 | 6.50.0 |
| NaTs2_t state | 220.5 | 162.72.1 | 22.0 | 20.40.0 | 196.0 | 142.50.3 | 19.6 | 17.90.0 |
| Ih state | 90.5 | 85.60.0 | 9.1 | 10.80.0 | 80.0 | 65.50.0 | 8.0 | 8.40.0 |
| Im state | 88.0 | 84.10.2 | 8.8 | 11.20.0 | 74.0 | 59.60.6 | 7.4 | 7.60.1 |
| SKv3_1 state | 83.5 | 79.80.0 | 8.3 | 9.90.0 | 73.0 | 60.70.1 | 7.3 | 7.50.0 |
| SSE | AVX | AVX512 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| serial | full socket | serial | full socket | serial | full socket | |||||||
| kernel | pred | bench | pred | bench | pred | bench | pred | bench | pred | bench | pred | bench |
| exc syn current | 25.9 | 28.60.0 | 4.5 | 4.50.1 | 23.0 | 20.42.3 | 4.5 | 4.50.1 | 19.5 | 22.31.7 | 4.5 | 4.40.1 |
| inh syn current | 21.6 | 22.53.0 | 4.0 | 4.80.0 | 19.8 | 22.52.0 | 4.0 | 4.80.1 | 16.6 | 23.40.6 | 4.0 | 4.70.1 |
| NaTs2_t current | 17.8 | 16.51.1 | 3.2 | 4.10.1 | 17.2 | 16.21.1 | 3.2 | 4.00.1 | 14.9 | 16.80.7 | 3.2 | 4.00.1 |
| Ih current | 9.7 | 9.30.4 | 2.0 | 2.40.1 | 10.5 | 9.20.4 | 2.0 | 2.40.1 | 9.0 | 9.40.4 | 2.0 | 2.40.0 |
| Im current | 16.1 | 15.60.8 | 3.0 | 3.80.1 | 15.4 | 15.30.8 | 3.0 | 3.90.1 | 13.6 | 17.00.6 | 3.0 | 3.80.1 |
| SKv3_1 current | 16.5 | 14.90.7 | 3.1 | 3.80.1 | 16.8 | 14.70.8 | 3.1 | 3.90.1 | 14.0 | 15.40.4 | 3.1 | 3.80.1 |
| exc syn state | 34.8 | 39.90.0 | 2.1 | 2.60.1 | 22.0 | 18.10.1 | 2.1 | 2.10.1 | 9.7 | 12.20.2 | 2.1 | 2.10.0 |
| inh syn state | 34.8 | 40.20.0 | 2.1 | 2.60.0 | 22.0 | 18.00.0 | 2.1 | 2.10.1 | 9.7 | 12.20.3 | 2.1 | 2.10.1 |
| NaTs2_t state | 86.7 | 94.50.0 | 4.8 | 6.00.0 | 64.5 | 51.10.0 | 3.8 | 4.00.1 | 25.3 | 29.00.1 | 3.8 | 3.80.1 |
| Ih state | 36.1 | 46.50.0 | 2.0 | 3.00.0 | 26.4 | 25.60.0 | 2.0 | 2.00.0 | 12.1 | 16.90.1 | 2.0 | 2.00.0 |
| Im state | 38.6 | 44.30.1 | 2.1 | 2.90.0 | 25.9 | 22.70.1 | 2.0 | 2.20.0 | 12.6 | 15.10.3 | 2.0 | 2.10.0 |
| SKv3_1 state | 34.0 | 40.80.0 | 1.9 | 2.70.0 | 24.5 | 21.70.0 | 1.4 | 1.60.0 | 16.1 | 13.30.1 | 1.3 | 1.50.0 |
| kernel | pred [B] | IVB meas [B] | SKX meas [B] |
|---|---|---|---|
| exc syn current | 205.3 | 205.22.8 | 207.12.1 |
| inh syn current | 181.3 | 183.35.2 | 204.08.4 |
| NaTs2_t current | 148.0 | 144.38.2 | 139.411.0 |
| Ih current | 92.0 | 79.24.3 | 80.29.2 |
| Im current | 136.0 | 128.95.8 | 133.410.8 |
| SKv3_1 current | 140.0 | 128.88.0 | 128.113.3 |
| exc syn state | 96.0 | 95.61.9 | 94.31.3 |
| inh syn state | 96.0 | 91.35.3 | 88.64.6 |
| NaTs2_t state | 172.0 | 197.41.9 | 166.22.2 |
| Ih state | 92.0 | 88.00.3 | 87.71.2 |
| Im state | 92.0 | 118.05.8 | 89.12.0 |
| SKv3_1 state | 60.0 | 92.58.3 | 56.62.1 |
| linear algebra | 88.0 | 90.67.6 | 90.74.2 |
| contributions | measured | ||
|---|---|---|---|
| IVB | 28.0 | ||
| SKX | 13.3 |
| contributions | CP | ||
|---|---|---|---|
| IVB | 85.1 | 207.0 | |
| SKX | 57.8 | 123.4 |
| Runtime IVB [cy] | Runtime SKX [cy] | |||
|---|---|---|---|---|
| pred | meas | pred | meas | |
| BC-S | 207.0 | 123.4 | ||
| WC-S | 540.0 | 540.0 | ||
| BC-P | 25.9 | 7.7 | ||
| WC-P | 96.8 | 45.0 | ||
| prediction is … | data-bound kernel | core-bound kernel |
|---|---|---|
| optimistic | memory latency | critical path |
| pessimistic | data locality | OoO engine |
| CPU @ 2.3 GHz | CPU @ 3.5 GHz | |
|---|---|---|
| SKX SSE | 16 | 11 |
| SKX AVX | 12 | 8 |
| SKX AVX512 | 6 | 4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\corrauth
Felix Schürman, Campus Biotech, B1 4 282.040 Ch. des Mines 9, CH-1202 Genève
Analytic Performance Modeling and Analysis of Detailed Neuron Simulations
Francesco Cremonesi11affiliationmark:
Georg Hager22affiliationmark:
Gerhard Wellein33affiliationmark: and Felix Schürmann11affiliationmark:
11affiliationmark: Blue Brain Project, Brain Mind Institute, École polytechnique fédérale de Lausanne
22affiliationmark: Erlangen Regional Computing Center, Friedrich-Alexander Universität Erlangen-Nürnberg
33affiliationmark: Department of Computer Science, Friedrich-Alexander Universität Erlangen-Nürnberg
Abstract
Big science initiatives are trying to reconstruct and model the brain by attempting to simulate brain tissue at larger scales and with increasingly more biological detail than previously thought possible. The exponential growth of parallel computer performance has been supporting these developments, and at the same time maintainers of neuroscientific simulation code have strived to optimally and efficiently exploit new hardware features. Current state of the art software for the simulation of biological networks has so far been developed using performance engineering practices, but a thorough analysis and modeling of the computational and performance characteristics, especially in the case of morphologically detailed neuron simulations, is lacking. Other computational sciences have successfully used analytic performance engineering and modeling methods to gain insight on the computational properties of simulation kernels, aid developers in performance optimizations and eventually drive co-design efforts, but to our knowledge a model-based performance analysis of neuron simulations has not yet been conducted.
We present a detailed study of the shared-memory performance of morphologically detailed neuron simulations based on the Execution-Cache-Memory (ECM) performance model. We demonstrate that this model can deliver accurate predictions of the runtime of almost all the kernels that constitute the neuron models under investigation. The gained insight is used to identify the main governing mechanisms underlying performance bottlenecks in the simulation. The implications of this analysis on the optimization of neural simulation software and eventually co-design of future hardware architectures are discussed. In this sense, our work represents a valuable conceptual and quantitative contribution to understanding the performance properties of biological networks simulations.
keywords:
Analytic performance modeling, execution-cache-memory model, biological neural networks, morphologically detailed neuron models
1 Introduction and related work
1.1 Neuron simulations
Understanding the biological and theoretical principles underlying the brain’s physiological and cognitive functions is a great challenge for modern science. Exploiting the greater availability of data and resources, new computational approaches based on mathematical modeling and simulations have been developed to bridge the gap between the observed structural and functional complexity of the brain and the rather sparse experimental data, such as the works of Izhikevich and Edelman (2008); Potjans and Diesmann (2012); Markram et al. (2015) and Schuecker et al. (2017).
Simulations of biological neurons are characterized by demanding performance and memory requirements: a neuron can have up to 10,000 connections and must track separate states and events for each one; the model for a single neuron can be very detailed itself and contain up to 20,000 differential equations; neurons are very dense, and a small piece of tissue of roughly 1 mm3 can contain up to 100,000 neurons; finally, very fast axonal connections and current transients can limit the simulation timestep to 0.1 ms or even lower. Therefore, developers have gone to great lengths optimizing the memory requirements of the connectivity infrastructure in Jordan et al. (2018), the efficiency of the parallel communication algorithm in Hines et al. (2011) and Ananthanarayanan and Modha (2007), the scalability of data distribution in Kozloski and Wagner (2011) and even the parallel assembly of the neural network in Ippen et al. (2017). While these efforts improve the performance of the distributed simulations, little is still known about the intrinsic single-core and shared memory performance properties of neuron simulations. On the other hand, the work of Zenke and Gerstner (2014) studied the performance of shared-memory simulations of biological neurons. However their analysis is mainly based on empirical performance analysis and is centered on current-based point neuron simulations, a formalism that discards information about a neuron’s arborization.
The assumptions underlying brain simulations are very diverse, leading to a wide range of models across several orders of magnitude of spatial and time scales and thus to a complex landscape of simulation strategies, as summarized in the reviews by Brette et al. (2007) and Tikidji-Hamburyan et al. (2017). In this work we focus on the simulation of morphologically detailed neurons based on the popular neuroscientific software NEURON presented in Carnevale and Hines (2006), which implements a modeling paradigm that includes details about a neuron’s individual morphology as well as its connectivity and allows to easily introduce custom models in the system. Our purpose is to extract the fundamental computational properties of the simulations of detailed biological networks and understand their relationship with modern microprocessor architectures.
1.2 The need for analytic performance modeling
An analytic performance model is a simplified description of the interactions between software and hardware together with a recipe for generating predictions of execution time. Such a model must be simple to be tractable but also elaborate enough to produce useful predictions.
Purely analytic (a.k.a. first-principles or white-box) models are based on known technical details of the hardware and some assumptions about how the software executes. The textbook example of a white-box model is the Roofline model by Williams et al. (2009) for loop performance prediction. The accuracy of such predictions depends crucially on the reliability of low-level details. A lack of predictive power challenges the underlying assumptions and, once corrected, often leads to better insight.
Black-box models, on the other hand, are ideally unaware of code and hardware specifics; measured data is used to identify crucial influence factors for the metrics to be modeled (see. e.g., Calotoiu et al. (2013)). One can then predict properties of arbitrary code, or play with parameters to explore design spaces. Black-box models have a wider range of applicability: Even if low-level hardware information is lacking they still provide predictive power. Wrong predictions, however, may be rooted in inappropriate fitting procedures and do not directly lead to better insight.
In this work we choose the analytic approach combined with some phenomenological input, which makes the model a gray-box model. Analytic modeling has several decisive advantages that make it more suitable for delivering the insight we are looking for. First, it allows for universality identification, which means that some behavior in hardware-software interaction is valid for a wide range of microarchitectures of some kind. Second, it enables the identification of governing mechanisms: Since the model pinpoints the actual performance bottlenecks in the hardware, classes of codes with similar behavior are readily identified. This insight directly leads to possible co-design approaches. And third, analytic models provide insight via model failure, as described above.
1.3 The ECM performance model for multicore processors
The Execution-Cache-Memory (ECM) model takes into account predictions of single-threaded in-core execution time and data transfers through the complete cache hierarchy for steady-state loops. These predictions can be put together in different ways, depending on the CPU architecture. One starts with “optimistic” transfer times through the memory hierarchy:
[TABLE]
where is the bandwidth of data path and is the data volume transferred over it for some definite unit of work (e.g., one iteration of a loop). For convenience we use a compact notation for such predictions, e.g.:
[TABLE]
While the are machine properties, the must be obtained by analysis, i.e., using knowledge about how data flows through the system (see, e.g., Hager et al. (2018)).
As for code execution in the core, one has to set up a model for the execution time of the loop, which may be as simple as assuming maximum throughput for all instructions, or as complex as considering the full critical path. Tools such as IACA, the Architecture Code Analyzer by Intel (2017) can help with this task.
On all recent Intel server microarchitectures it turns out that the single-core model yields the best predictions if one assumes no (temporal) overlap of data transfers through the cache hierarchy and between the L1 cache and registers, while in-core execution (such as arithmetic) shows full overlap. For a dataset with a considerable amount of memory transfers, the model thus predicts:
[TABLE]
Here, is the part of the in-core execution that is unrelated to data transfers, such as arithmetic, while is the time (cycles) required to retire load instructions. For runtime predictions we use the following shorthand notation, to be distinguished from (2) by the use of as delimiter:
[TABLE]
where denotes the runtime prediction if data comes from the level of the memory hierarchy. For presenting measurements we substitute the curly braces by parentheses or omit them altogether.
Scalability is assumed to be perfect until a bandwidth bottleneck is hit. Since the memory interface is the only multi-core bandwidth bottleneck on Intel processors, the predicted execution time is for cores is
[TABLE]
The bandwidth saturation point, i.e., the number of cores required for saturation, is readily obtained from this expression:
[TABLE]
A full account of the ECM model would exceed the scope of this paper, so we refer to Stengel et al. (2015) and Hofmann et al. (2017) for a recent discussion.
1.4 Contributions and organization of this paper
In this work we make the following contributions:
- •
We demonstrate that the analytic ECM performance model can be applied successfully to nontrivial loop kernels with a wide range of different performance features. Although there are considerable error margins in some cases, a very good qualitative understanding can be achieved. We also identify cases where the model needs corrections or cannot be applied sensibly: Strong latency components in the data transfers and long critical paths in the core execution. While the former is beyond the applicability of the model in its current form, the latter does not hinder the derivation of useful conclusions.
- •
We apply the ECM model for the first time to the Intel Skylake-X processor architecture, whose cache hierarchy is different from earlier Intel designs.
- •
We give clear guidelines for co-designing an “ideal” processor architecture for neuron simulations. In particular, we spot wide SIMD capabilities as a crucial ingredient in achieving memory bandwidth saturation. A low core count part with a high clock speed and wide SIMD units (such as AVX-512) will present the most cost-effective hardware platform. Cache size is inconsequential for most kernels.
- •
As a consequence we can also predict if linear algebra and spike delivery kernels may become bottlenecks if a very large degree of parallelism could be exposed, and what hardware features would be required to avoid this.
This paper is organized as follows: In Section 2 we give details on the software and hardware environment under investigation, including preliminary performance observations. In Section 3 we construct and validate ECM performance models for the important kernel classes in NEURON. In Section 4 we summarize and discuss the findings in order to pinpoint the pivotal components of processor architectures in terms of neuron simulation performance, and give an outlook to future work.
We provide a reproducibility appendix as a downloadable release file at Cremonesi et al. (2019), which should enable the interested reader to re-run our experiments and reproduce the relevant performance data.
2 Application and simulation environment
2.1 Target architectures and programming environment
We apply the ECM model introduced by Treibig and Hager (2010) and refined by Stengel et al. (2015) on two Intel processors with different micro-architectures: the Ivy Bridge (IVB) Intel(R) Xeon(R) E5-2660v2 and the Skylake (SKX) Intel(R) Xeon(R) Gold 6140 (with Sub-NUMA clustering turned off). The ECM model for the IVB architecture has been extensively studied by Hofmann et al. (2017) and Hammer et al. (2017).
The ECM model for the SKX architecture has not been fully developed to date, but a preliminary formulation based on (5) that takes into account the victim cache architecture of the L3 was published in Hager et al. (2018). The heuristics governing cache replacement policies are not disclosed by Intel, but we have found that the following assumptions usually lead to good model predictions:
- •
Read traffic from DRAM goes straight to L2.
- •
All evicted cache lines from L2, both clean and dirty, are moved to L3.
- •
The data path between the L2 and the L3 cache can be assumed to provide a bandwidth of 16 B/cy in both directions (i.e., full duplex).
The most relevant hardware features for the modeling of both architectures are presented in Tables 1 and 2. The Intel IACA tool was used for estimating in-core execution times of loop kernels. Although IACA supports both architectures, its support for critical path (CP) prediction was recently dropped. The IACA outputs for all kernels are available in the reproducibility appendix.
We illustrate the application of the ECM model to SKX with the STREAM triad kernel developed by McCalpin (1995):
[TABLE]
Considering only AVX vectorization as an example, this kernel has the following properties per scalar iteration:
- •
AGU-bound inverse throughput prediction of cy/it
- •
Two loads and one store, so cy/it
- •
B/it (including write-allocate)
- •
cy/it
- •
Due to the victim L3 cache, we have to distinguish in-memory and in-L3 datasets.
- –
L3: B/it (read + write)
- –
Memory: B/it (write-only)
- •
The transfer times between L2 and L3 are the same in this particular case because reads and writes to L3 can overlap:
- –
L3: cy/it
- –
Memory: cy/it (write-only)
- •
B/it (read-only traffic)
- •
cy/it
- •
B/it (write-only traffic)
- •
cy/it
So the ECM model contributions for the STREAM triad kernel in (7) on SKX-AVX would be:
[TABLE]
[TABLE]
with corresponding predictions according to the non-overlapping machine model of . For validation we compared these predictions to benchmark measurements and obtained , which is in reasonable agreement with the model. The deviation in memory could be fixed by introducing a latency penalty (see Hofmann et al. (2017)), but since the memory contribution is rather small for most of the kernels studied here we opted for a simpler model. In this simple example we have assumed a “perfect” machine code with the minimum number of instructions per scalar iteration. For the modeling of more complex kernels we use the actual, unmodified assembly code as generated by the compiler.
To roughly compare the two architectures a common approach is to use the peak performance as a metric, measured in single-precision or double-precision Gflop/s. The IVB chip supports AVX vectorization and can retire one multiply and one add instruction per cycle, while the SKX chip supports AVX512 vectorization and can retire two fused multiply-add instructions per cycle. This leads to the peak performance numbers shown in Table 3.
The naive Roofline model uses the peak performance of the chip as the core-bound limit, but often other limitations apply, such as the load or store throughput between registers and the L1 cache, or pipeline stalls due to a long critical path or loop-carried dependencies. The ECM model takes this into account via the and runtime contributions, which are based on an analysis of the actual loop code.
On IVB we used the Intel 17.0.1 compiler with options -xSSE4.2 and -xAVX for SSE and AVX code, respectively. On SKX we used the Intel 18.0.1 compiler with options -xSSE4.2, -xAVX2 and -xCORE-AVX512 -qopt-zmm-usage=high for SSE, AVX and AVX512 code, respectively. On both machines we employed #pragma ivdep, #pragma vector aligned and #pragma omp simd simdlen(N) directives where appropriate to ensure vectorization. The compiler option -qopt-streaming-stores never was used to disable the generation of nontemporal stores by the compiler.
To measure relevant performance metrics such as data transfer through the memory hierarchy we used the likwid-perfctr tool from the well-established LIKWID framework presented by Treibig et al. (2010); Gruber et al. (2018). We instrumented the code using markers and inserted a barrier before the execution of each kernel to ensure that measurements would be minimally affected by load imbalance. On both architectures we employed the CACHES performance group and pinned the OpenMP threads to the physical cores of a socket. In order to guarantee reproducible benchmark runs, we employed the likwid-setFrequencies tool to set the clock speed of the cores (and the Uncore in case of SKX) to the base values indicated in Table 1. In spite of this, we observed the well-known kernel-specific clock frequency throttling on the SKX architecture at all vectorization levels: the average clock frequency never exceeded the limits in Table 1 but in some kernels it was observed to be lower, although never less than 2.1 GHz. In the course of our analysis, we scale our performance predictions by the measured clock frequency whenever required.
2.2 Simulation of morphologically detailed neurons
A common approach to modeling morphologically detailed neurons is the so-called conductance-based (COBA) compartmental model as formalized in the reviews by Brette et al. (2007); Bhalla (2012) and Gerstner et al. (2014). In this abstraction the arborization of dendrites and axons is represented as a tree of sections, where a section corresponds to an unbranched portion of the neuron. Each section is then divided into compartments that represent discretization units for the numerical approximation. Quantities of interest such as membrane potential or channel gating variables are typically only well defined at compartment centers and branching points.
In the compartmental model each compartment is considered analogous to an RC circuit where the resistance (or rather, the conductance) term can be nonlinearly dependent on the membrane potential itself. Due to their stability, implicit methods are a common choice for time integration of the differential equations arising from this representation, thus the solution of a linear system of equations is required at each time step. In the presence of branching points, this leads to a quasi-tridiagonal system that can be solved in linear time using the algorithm proposed in Hines (1984).
In the COBA model, the membrane conductance is determined by aggregating several contributions from ion channels, which are special cross-membrane proteins that allow an ionic current to flow into or out of the cell. Thus in the COBA compartmental model, when using an implicit time integrator, three algorithmic phases are required to advance a neuron in time: first one must compute the contributions to the linear system (the ion channel and synapses currents); then one must solve the linear system; finally, one must update the states of individual ion channel and synapse instances based on the recently-computed compartment potentials (see Figure 1).
Neurons also have the ability to communicate with other neurons using synapses: points of contact between different neurons that are triggered when an action potential is elicited in the presynaptic cell and, at the onset of this event, determine a change in the membrane potential of the postynaptic cell. Therefore the simulation algorithm is composed of two parts: a clock-driven portion that advances the state of a neuron from a timestep to the next; and an event-driven part that is only executed when a synaptic event is received. Figure 1 presents a summary of the main algorithm phases and data layout.
The compartmental modeling of neurons using COBA formalism is implemented in the widely-adopted software for neuroscientific simulations NEURON. The NEURON software is a long-lasting project that includes an interpreter for a custom scripting language (HOC), a domain specific language tool to expand the models of ion channels and synapses, a GUI and a domain specific language (NMODL) to expand the repertoire of available models. To reduce the complexity and concentrate on the fundamental computational properties of the simulation kernels, in this work we utilize instead CoreNEURON, a lean version of NEURON’s simulation engine based on the work by Kumbhar et al. (2016). CoreNEURON implements several optimizations over NEURON, including improved memory requirements and vectorization, at the cost of functionality. In particular, NEURON is usually still required to define a model and a simulation setup before CoreNEURON executes the simulation. The NEURON/CoreNEURON software allows neuroscientists to specify custom ion channel and synapse models using the domain specific language NMODL introduced in Hines and Carnevale (2000), which is then automatically translated into C code and compiled in a dynamic library.
The CoreNEURON data layout is shown in Figure 1. First the neuron is modeled logically as a tree of unbranched sections, whose topology is represented by a vector of parent indices. Other relevant quantities such as the membrane potential and the tridiagonal sparse matrix are are represented by double precision arrays with length equal to the number of compartments. More details about the matrix representation are given in Section 3.6. Additionally, ion channel-specific and synapse-specific quantities are held in separate data structures consisting of arrays of double precision values in Structure-of-Arrays layout (SoA), indices to the corresponding compartments and, if needed, pointers to other internal data structures.
2.3 Preliminary performance observations and motivation
Given that the simulation algorithm is composed of many phases with different characteristics, the first step in performance analysis is a search for the time-consuming hot spots. In the shared-memory parallel execution, current and state kernels are usually dominant, representing roughly 80% of the total execution time, while the event-driven spike delivery and linear algebra kernels account for 10–20% (see Figure 2a). In the serial execution we observe that the relative importance of spike delivery increases slightly, however, the state and current kernels still dominate. This serial performance profile was also observed in Kumbhar et al. (2016) and is a peculiar feature of compartmental COBA models, whereas current-based point neuron models are typically dominated in serial execution by event-driven spike delivery and event bookkeeping, as shown in the work by Peyser and Schenck (2015). Unfortunately, these results are tightly linked to the benchmark setup, and it is unknown whether this is a general property of COBA models or not.
We have chosen two Intel architectures that were introduced about five years apart in order to be able to identify the speedup from architectural improvements. Judging by the peak performance numbers in Table 3 one would expect a per-socket speedup of about 7.5. On the other hand, comparing memory bandwidth (see Table 1), which is the other lowest-order bottleneck of code execution, a factor of 2.6 could be estimated. As shown in Figure 2c, we observe a factor of roughly 3 between the best IVB and SKX versions. Although it is satisfying that the measurement lies between the two estimates, detailed performance modeling is required to explain the actual value.
One of the main in-core features of modern architectures is the possibility to expose data parallelism using vectorized (SIMD) instructions on wide registers. We investigated the benefits of vectorization at different levels of thread-parallelism. In the serial execution (see Figure 2c) we found that the Skylake architecture had in general better performance than Ivy Bridge, and that using wider registers improved the performance, even though the acceleration was not ideal (i.e., not in line with the larger register width). At full socket we found that the difference between architectures was exacerbated, while we saw only minor improvements from vectorization (see Figure 2c). We also investigated the strong-scaling efficiency of the simulation code on different architectures (Figure 2b) and found that, as expected, the efficiency decreases as the level of parallelism grows. This indicates a tradeoff in terms of chip and software design: further analysis is required to understand whether it is worth investing in SIMD or shared-memory parallelism, optimize for instruction level parallelism, out of order execution or a combination of all of these.
We exploit performance modeling techniques in order to gain insight into the interaction between the CoreNEURON simulation code and modern hardware architectures. This will allow us to answer the open performance questions above as well as to generalize to different architectures for future co-design efforts.
3 Performance Modeling of Detailed Simulations of Neurons
3.1 Ion channels current kernels
Ion channel current kernels are used in the simulation algorithm to update the matrix representing the voltage equation by computing contributions from the ionic current of different chemical species. We consider in this work four ion channel types that are among the most representative: Ih, Im, NaTs2_t, SKv3_1. In Listing 1 we show the code for the Im current kernel as an example; other kernels share similar memory access patterns and arithmetic operations with only minor changes.
Current kernels are typically characterized by two main features: low arithmetic intensity and scattered loads/stores. The latter can present a modeling problem, but in practice we can obtain good accuracy using a few heuristics based on domain-specific knowledge. In particular, as a first approximation one can treat the indices in _ni and ion_idx as perfectly contiguous (see Figure 1 as a justification). In total, the kernel reads from four double and two integer arrays, and writes to six double arrays, leading to 136 B of overall data traffic per scalar iteration through the complete memory hierarchy (this includes write-allocate transfers on store misses).
Combining the data volume estimates with in-core predictions from IACA (using the full throughput assumption) we can generate the ECM model predictions in cycles per scalar iteration as shown in Table 4. The compiler is able to employ scatter/gather instructions for this kernel on SKX (these are not supported on IVB). As expected, the model predicts that the performance of this strongly data-bound kernel will degrade as the data resides farther from the core. Vectorization is not beneficial at all except for AVX512 with data in L1, which can be attributed to the required scalar load instructions when gather/scatter instructions are missing. To validate the predictions we designed a serial benchmark that allowed fine-grained control over the dataset size by removing all ion channels and synapses except Im from our dataset, but still executing the complete application loop. The resulting dataset size was roughly 50 kB and 200 kB for the L2 benchmarks and 6 MB and 7 MB for the L3 benchmarks on the IVB and SKX architectures, respectively. Due to overheads, it was impossible to construct a benchmark for the L1 cache on either machine.
On IVB the measurements remained within 10% of the predictions for all levels of the memory hierarchy, while on SKX the ECM predictions were a little more off, especially for data in the cache. This might be caused by our simplifying model assumptions about the data transfers between L2 and L3, for which no official documentation exists. Still the ECM model gave accurate predictions in almost all of our benchmarks and provided insight into the computational properties of this kernel.
We conclude that the Im current kernel, and all current kernels in general, are data-bound and limited solely by data transfer capabilities of the system across the memory hierarchy. Even for an in-memory dataset, wider data paths between the caches would thus benefit the performance of the kernel. The clock frequency will have a significant but weaker than linear impact on the performance because memory transfer rates are only weakly dependent on it (especially on the more modern architectures like SKX). The analysis also predicts strong memory bandwidth saturation with a few (4–5) cores, so the memory bandwidth starts to play a decisive role once bandwidth saturation is achieved.
3.2 Synaptic current kernels
Synapses are arguably the pivotal component of neuron simulations. Synaptic current kernels are particularly important for performance as shown in Figure 2, and pose a modeling challenge because of their complex chain of intra-loop dependencies, memory accesses and presence of transcendental functions. There are two types of synapses in this dataset: excitatory AMPA/NMDA synapses and inhibitory GABAAB synapses. As an example, the source code for the excitatory AMPA/NMDA synapse current is shown in Listing 2.
The expensive exponentials and divides in this code are balanced by large data requirements. The kernel reads one element each from eight double and two integer arrays, and writes one element each to nine double arrays, which would amount to a traffic of 216 B per iteration. However, as shown in Figure 1, the typical structure of the _ni and nd_area_idx arrays is different from that of the indexing arrays in ion channel kernels. In particular, as a direct consequence of multiple synapse instances being able to coexist within the same compartment, the _ni and nd_area_idx arrays often exhibit sequences of repeated elements. This means that subsequent iterations of the kernel can exploit some temporal locality in accessing the vec_v and _nd_area arrays. To account for this we reduce the expected traffic from these arrays by a weighting factor equal to the average length of a sequence of repeated elements in _ni and nd_area_idx, which is about 3 in our case. Thus the updated data traffic estimate is 205 B through the complete memory hierarchy. To compute the inverse throughput of the vectorized exponential operation from Table 2 must be added to the kernel runtime reported by IACA, and is derived from the retired load instructions as usual. We then obtain the ECM predictions per scalar iteration in Table 5.
The analysis reveals a complex situation. Both code versions on IVB and the SSE code on SKX are predicted to be core bound as long as the data fits into any cache. The AVX and AVX512 code on SKX, however, become data bound already in the L3 cache.
Again we used a benchmark dataset containing only synapses to validate the model, with a size of roughly 80 kB and 500 kB for the L2 benchmarks and 1.5 MB and 11 MB for the L3 benchmark on the IVB and SKX architectures, respectively. On both CPUs the model predictions are optimistic compared to measurements by a 10–50% margin. Interestingly, within each architecture the model becomes more accurate as the SIMD width increases. Even though the predictions are not all within a small accuracy window, the model still allows us to correctly categorize the relevant bottlenecks, and is especially effective in capturing the fact that on SKX with AVX512 the kernel is rather strongly data bound. Given the complex inter-dependencies between operations in the kernel, we speculate that a critical path might be invalidating the full-throughput assumption of the ECM model, although this would not be sufficient to explain why the DRAM measurements are larger than the L2 and L3 measurements.
As a result from the analysis we conclude that, for an in-memory dataset, the performance of the serial excitatory synapse current kernel would improve significantly only if in-core execution and data transfers were enhanced at the same time. Still the model predicts bandwidth saturation for all code variants, once run in parallel, at 4–6 cores.
3.3 Ion channels state kernels
During the execution of a state kernel, the internal state variables of an instance of an ion channel or a synapse are integrated in time and advanced to the next timestep. Figure 2a shows that state kernels represent a significant portion of the overall runtime, although their relative importance is largest in the single-thread execution and decreases with shared-memory parallelism.
State kernels are characterized by a very large overlapping contribution due to exponential functions and division operations, combined with low data requirements. This gives reason to expect a clearly core-bound situation. As an example, we show the code for the Ih state kernel in Listing 3.
In analogy with the previous ion channel example, we treat the indices in _ni as contiguous. Therefore this kernel requires reading one element each from one double and one integer array, and writing one element each to three double arrays, amounting to a traffic of 60 B per iteration. On the other hand, the kernel needs three exponential function evaluations and eight divides, of which some might be eliminated by compiler optimizations (common subexpression elimination and substitution of multiple divides by the same denominator for a reciprocal and several multiplications).
Again combining the IACA prediction with measured throughput data for exp() (see Table 2) and the data delay we arrive at the ECM predictions per scalar iteration in Table 6. State kernels can be considered as the polar opposite of current kernels in terms of their computational profile, and the model predicts that their performance will be independent of the location of the working set in the memory hierarchy. This also leads to the expectation that vectorization should yield massive improvements, but the ECM model says otherwise. According to the performance model these kernels are dominated by the throughput of the exp function and the eight divides, by comparable amounts; for instance, the SKX-AVX version spends 16 cy in divides and another 10.4 cy in exp(). No optimizations concerning the divides are done by the compiler, although the number of divides may be reduced to three by the methods mentioned above.
Both architectures show only moderate speedup from SSE to AVX (13% on IVB and 37% on SKX, respectively). On IVB this can be partly attributed to the mere 44% speedup for the exp() function (see Table 2), but the main cause on both CPUs is the constant throughput per divide operation, independent of the SIMD width. This is a well-known design tradeoff in Intel architectures: putting a large number of low-throughput units on a core does not pay off on a general-purpose CPU.
AVX512, on the other hand, exhibits a large speedup that cannot be explained by the above analysis. Inspection of the assembly code reveals that the compiler did not generate any divide instructions at all. Instead, it uses vrcp14d instructions together with Newton-Raphson steps for better throughput on SKX (see Intel (2018)).
We validated our predictions with dataset sizes of 124 kB and 500 kB for the L2 benchmarks on IVB and SKX respectively, and a dataset size of 5 MB for the L3 benchmarks on both architectures. Except for the AVX kernels, for which the accuracy is more than satisfying, the predictions are optimistic by between 15% and 35%. It must be stressed that when a loop is strongly core bound and has a long critical path, the automatic out-of-order execution engine in the hardware may have a hard time overlapping successive loop iterations. Since the ECM model has no concept of this issue, predictions may be qualitative.
Despite all inaccuracies, the conclusion from the analysis is clear: Faster exponential functions, wider SIMD execution for divide instructions and a higher clock frequency would immediately (and proportionally) boost the performance of the serial Ih state kernel. Memory bandwidth saturation is not expected on IVB, but on SKX the AVX and AVX512 versions will be able to hit the memory bandwidth limit, albeit at a larger number of cores than with the more data-bound kernels. Hence, boosting parallel performance is achieved by different means on the two chips.
3.4 Synaptic state kernels
Synapse state kernels have computational properties similar to ion channel state kernels, i.e., a dominating in-core overlapping contribution due to exponentials and divides, coupled with low data requirements. As an example, we show the code for the excitatory AMPA/NMDA synapse in Listing 4. This kernel reads one element each from four double arrays and updates one element each from four other double arrays, thus totaling 96 B of data volume per iteration.
The ECM predictions per scalar iteration are listed in Table 7. An important observation to be made here is that using the AVX2 instruction set was crucial to obtaining good performance on Skylake-X. Indeed the exp function invoked by the AVX instruction set has a much worse throughput (despite having the same vector width) and thus would significantly degrade the performance of this kernel. As expected, all other observations and conclusions are the same as for the ion channel state kernels in the previous section. All predictions are optimistic by 20–30%.
3.5 Validation for all state and current kernels
To assess the validity of our performance and conclusions about bandwidth saturation on a real-world use case we designed a representative dataset based on the L5_TTPC1_cADpyr232_1 neuron, which can be downloaded from the Blue Brain NMC portal introduced in Ramaswamy et al. (2015). Since L5 pyramidal cells are among the cell types with the largest computational load in the reconstruction of the rat neocortex by Markram et al. (2015), this constitutes a highly representative subset of a full cortical column reconstruction. Commonly studied network arrangements are composed of a large number of neurons to be able to capture macroscopic effects, and even in the case of distributed simulations this usually amounts to a few hundred or even thousands of neurons per node. Given that the average detailed neuron among those in the Blue Brain NMC portal requires roughly 2 MB of data, this means that one can usually assume that data must be fetched from main memory each time. We used a sufficiently large dataset consisting of 500 copies of the neuron mentioned above (for a total of 850 MB) as a building block for our benchmarks, eventually duplicating it according to the type of scaling scenario under analysis to avoid load imbalance issues.
Tables 8 and 9 show the predicted and measured runtimes of current and state kernels for the two architectures, all vectorization levels and serial vs. full-socket parallel execution, while Figure 3 presents the performance scaling of these kernels across the cores of a chip. Overall we observe a good match between the predicted and observed runtimes: excluding a few exceptions our predictions always fall within 15% of the observations, and we are able to correctly capture the previously observed phenomenon that current kernels have a strongly saturating behavior, while state kernels need more cores to saturate or do not saturate at all (such as on IVB, and on SKX with SSE code). This corroborates our statements about optimization and co-design strategies: Boost in-core performance via reducing expensive operations (divides and exponentials), using wide SIMD cores and high clock speed for state, and look for a fast memory hierarchy to reduce the data delay of current kernels. As the runtime of state and current kernels decreases, we expect the relative importance of spike delivery and linear algebra to increase. We will cover these two kernels in Sections 3.6 and 3.7.
In the rest of this section, we address some of the largest deviations between measurements and predictions by providing a tentative explanation for the failure of our performance model. As stated in the state kernel Sections 3.3 and 3.4, a long critical path in the loop kernel code could be weakening the accuracy of our predictions due to a failure of the full throughput assumption. We believe that, in order to improve our predictions, a cycle-accurate simulation of the execution and in particular of the OoO engine would be needed, thus invalidating our requirement for a simple analytical model. At large thread counts the predictions for current kernels are always within a reasonable error bound, while those for state kernels can be off by as much as 30%. The state kernels’ performance is often in a transitional phase between saturation and core-boundedness even at large thread counts, where the ECM model in the form we use it here is known to perform poorly as shown in Stengel et al. (2015). We do not plan to employ the adaptive latency penalty method as described in Hofmann et al. (2018) to correct for this discrepancy, because it is not only a modification of the machine model but also requires a parameter fit for every individual loop kernel. We believe that this is an undesirable trait in an analytic model.
3.6 Special kernels: linear algebra
The most common approach for time integration of morphologically detailed neurons is to use an implicit method (typically backward-Euler or Crank-Nicolson) in order to take advantage of its stability properties for stiff problems. In Hines (1984) a linear-complexity algorithm based on Thomas (1949) was introduced to solve the quasi-tridiagonal system arising from the branched morphologies of neurons. This algorithm is based on a sparse representation of the matrix using three arrays of values (vec_a,vec_b,vec_d representing the upper, lower and diagonal of the matrix, respectively) and one array of indices (parent_index). It is structured in two main phases: triangularization and a backward substitution. The code is shown in Listing 5. The boundary loop in the middle is executed but its trip count is so short in practice that we can ignore it in the analysis.
To construct a performance model for this kernel we must tackle a few challenges: Indirect accesses make it difficult to estimate the data traffic, and dependencies between loop iterations could break the full-throughput hypothesis. Moreover, a yet-unpublished optimized variant of the algorithm proposed in Hines (1984) that exploits a permutation of node indices to maximize data locality is executed by default by the simulation engine22endnote: 2See the open-source code at https://github.com/BlueBrain/CoreNeuron. This permutation of node indices can be disabled with the command line argument --cell-permute 0.. For reasons of brevity of exposition we restrict our analysis to this optimized variant of the solver. Additionally we will ignore the solve boundaries loop in our analysis because its impact on the overall performance is always neglectable, for two reasons: the number of cells is always much smaller than the number of compartments so this loop makes very few iterations compared to the others, and there are no data dependencies so this loop can be trivially vectorized.
In order to give a runtime estimate we examine two corner-case scenarios. The first, optimistic scenario assumes that indirect accesses can exploit spatial data locality in caches and thus do not generate any additional memory traffic. The combined data traffic requirements of triangularization and back-substitution then amount to reading one element each from four double arrays and two integer arrays, and writing one element each to three double arrays, i.e., 88 B per iteration. Considering the opposite extreme, it might happen that at every branching point the value of parent_index[i] is so much smaller than i that this generates an additional cache line of data traffic through the full memory hierarchy. We call this the worst-case branching hypothesis, in which we adjust the memory traffic predictions by assuming that every section boundary, i.e., the location of a potential discontinuity in the parent_index array, requires a full cache line transfer of which only one variable will constitute useful data.
Even though the dependencies between loop iterations could potentially break the full-throughput hypothesis, considering that compartment indices are by default internally rearranged to optimize data locality we still use the full throughput as a basis for our predictions. It should be noted that indirect addressing and potential loop dependencies hinder vectorization. IACA reports that the combined inverse throughput of triangularization and back substitution amounts to 28 cy/it for IVB and 8.12 cy/it for SKX, while cy/it for both architectures. This leads to the runtime predictions in Table 11.
We measured the performance of the linear algebra kernel on a specially designed dataset with a very large number of cells and neither ion channels nor synapses, thus ensuring that the only data locality effects are intrinsic to the algorithm and not a consequence of a small dataset. Our predictions based on the full-throughput hypothesis are validated by measurements of both the performance (see Figure 4) and the memory traffic (last row in Table 10). This kernel highlights very strongly an important difference between the two architectures: SKX has a much better divide unit, which is able to deliver one result every four cycles, whereas IVB’s divider needs 14. This ratio is almost exactly reflected in the prediction, although the triangularization kernel on SKX is actually load bound by a small margin. This large difference in causes different single-core bottlenecks: While the execution on IVB clearly core bound, it is strongly data bound on SKX. The single-core medians are a little higher than predicted but also prone to some statistical variation; the best measured value is very close to the model. Saturation is predicted at six cores on IVB and seven cores on SKX. Starting from the newer architecture, the only way to boost performance would be to enhance the performance of the memory hierarchy (in serial mode) or the memory bandwidth (in parallel). Having more than ten cores per chip would be a waste of transistors.
We remark that it remains unclear whether the node permutation optimization is applicable in all cases or suffers from some constraints, and that our full-throughput predictions heavily rely on it. Therefore it may happen that, in some cases where it is impossible to reorder the nodes effectively, our predictions would only provide an optimistic upper bound on performance.
3.7 Special kernels: spike delivery
Accounting for network connectivity and event-driven spike exchange between neurons is, in terms of algorithm design, the most distinguishing feature of neural tissue simulations. In terms of performance, however, spike delivery plays a marginal role in the simulation of morphologically detailed neurons, rarely exceeding 10% of the total runtime (see Figure 2a).
The source code for the spike delivery kernel of AMPA/NMDA excitatory synapses is shown in Listing 6. For benchmarking purposes we executed this kernel as the body of a loop iterating over a vector of spike events, which was previously populated by popping a priority queue33endnote: 3See branch perf_eng_binq_bench of https://github.com/sharkovsky/CoreNeuron.git. This only represents a small deviation from the original implementation in CoreNEURON, where the kernel is directly called at every pop of the priority queue. However, it was necessary to implement this in order to separate the performance of the kernels from the performance of the queue operations.
This kernel is characterized by erratic memory accesses indexed by i, as well as several compute-intensive operations such as divisions and exponentials, thus making it challenging to model. In terms of memory traffic we consider two scenarios: a best-case one in which all synapses are activated in memory-contiguous order and a worst-case scenario in which synapses are activated in random order. In the best-case scenario we assume the execution engine will be able to fully pipeline the execution and hide all latencies. Thus we base our performance predictions on either the full-throughput hypothesis or a critical path. Given that this kernel requires a read-only transfer on seven double arrays, three integer arrays and one pointer array, and an update or write/write-allocate transfer on nine double arrays, we estimate a (best-case) memory traffic of 220 B per iteration. From IACA we learn that the inverse throughput of this kernel is 29.5 cy/it on IVB and 27.6 cy/it on SKX, while is 19.5 cy/it on both architectures, and as with the linear algebra kernel the indirect accesses prevent vectorization. Under the full-throughput assumption, this leads to the single-thread predictions per iteration shown in Table 13.
Given the complex chain of interdependencies in the kernel, we suspect that a CP effect could also be present. For the IVB architecture we can directly use IACA with the -analysis LATENCY option, while for SKX we resorted to using the estimate for the Haswell architecture (HSW) from IACA v2.1, because latency analysis is no longer supported in IACA v3.0. The CP values are also reported in Table 13.
In the worst-case scenario we assume that a full cache line of data needs to be brought in from memory for every data access. Assuming that the variables spike_event.target and spike_event.weight_index can still be read contiguously, the kernel requires 27 noncontiguous data accesses plus reading from one pointer and one integer array, which amounts to a predicted memory traffic of 1740 B per iteration. Estimating the runtime is more complex: On the one hand, it seems clear that the memory requests to arbitrary locations should have an effect on performance. On the other hand, this kernel does not have the typical latency-bound structure in which an iteration requires the full completion of the previous one before being executed. Indeed, multiplying the number of memory accesses by the memory latency leads to a prediction that is more than ten times too pessimistic. Instead, we created a synthetic stream-copy benchmark with a similar number of memory accesses and the same access pattern and determined the average latency per memory access to be around cycles for both architectures. To obtain a runtime prediction for the serial execution we then multiply this average latency by the number of memory accesses, yielding a prediction of 540 cy/it. To extend this to the multi-threaded case, we assume that either the bandwidth is saturated (and thus our performance prediction corresponds to the Roofline model) or the performance scales linearly with the number of threads.
The validation of the model is shown in Figure 5 and Table 13. In the serial best-case scenario the measured runtime is so close to the CP-assumption that we can safely discard the full-throughput hypothesis and assume that under ideal memory access conditions this kernel is bounded by the dependencies within one loop iteration. In the worst-case scenario, while the data volume predictions are quite correct, the runtime predictions are off by factors from 50% up to 100% (see also Table 13). A reason for this could be that a CP estimate should be added to the memory access latency. Unfortunately this does not give a sufficiently convincing improvement in the estimates: On IVB, IACA computes a CP of 79 cy/it to which we should add twice the latency of a scalar exponential, benchmarked to be around 64 cy. This leads to an adjusted prediction of 747 cy/it, which is still far from the measured 1087 cy/it. Considering that only a strikingly correct prediction would justify an adjustment to our model, we prefer to keep the old but simpler estimate. One should add that the worst-case scenario is beyond the applicability of the ECM model, so our analysis stretches the model very far.
4 Discussion
Using the ECM performance model we have analyzed the performance profile of the simulation algorithm of morphologically detailed neurons as implemented in the CoreNEURON package. Within its design space, the ECM model yielded accurate predictions for the runtime of 13 kernels on real-world datasets. It must be stressed that some of these kernels are rather intricate, with hundreds of machine instructions and many parallel data streams. This confirms that analytic modeling is good for more than simple, educational benchmark cases. We have also, for the first time, set up the ECM model for the Intel Skylake-X architecture, whose cache hierarchy differs considerably from earlier Intel server CPUs. Our analysis shows that the non-overlapping assumption applies there as well, including all data paths between main memory, the L2 cache and the victim L3. Note that a reproducibility appendix is available at Cremonesi et al. (2019).
As expected, the modeling error was larger in situations where the bottleneck was neither streaming data access nor in-core instruction throughput. By making a few simplifying assumptions we were still able to predict with good accuracy the performance of a kernel with a complex memory access pattern and dependencies between loop iterations such as the tridiagonal Hines solver Hines (1984).
On the other hand, if the bottleneck is the memory latency, which is the case with the spike delivery kernel, the ECM model could only provide upper and lower bounds. In this case where the deviation from the measurement was especially large, we could at least pinpoint possible causes for the failure. It is left to future work on the foundations of the ECM model to extend its validity in those settings.
In conclusion, the ECM model was always able to correctly identify the computational characteristics and thus the bottlenecks of the 14 kernels under investigation, thus providing valuable insight to the performance-aware developers and modelers. In the following we use these crucial insights to give clear guidelines for both the optimization of simulation code and the co-design of an “ideal” processor architecture for neuron simulations. We mostly concentrate on the Skylake-X architecture since it is the most recent one, and only discuss results for Ivy Bridge where necessary.
4.1 Small networks (in cache)
Serial performance properties of small networks
One of the main insights offered by the ECM model is the possibility to identify and quantify the performance bottleneck of each kernel. In the simulation of morphologically detailed neurons, we found that ion channel current kernels are data bound while all state kernels are core bound for all cache levels, all SIMD levels and both architectures considered. The case of excitatory synapse current kernel was special in that on both SKX and IVB, the kernel was core bound as long as the dataset fits in the caches, but switched to data-bound when the data comes from memory. This effect was most prominent on SKX-AVX512. In the extreme strong scaling scenario where data fits in the cache, this points to two optimizations: optimize expensive operations such as div and exp for all state kernels and the excitatory synapse current kernel, and minimize data movement for the ion channel current kernels. In terms of co-design, high-frequency cores with high-throughput instructions are ideal for all state kernels while fast data-paths within the cache hierarchy would optimize ion channel current kernels.
SIMD parallelism and small networks
The possibility to execute high-throughput SIMD vector instructions can potentially provide great returns in terms of speedup at a low hardware and programming cost. In this analysis we observed that wider SIMD units were indeed capable of providing benefits in terms of reduced runtime, but we also failed to observe the ideal speedup factor. Moreover, Skylake-X showed diminishing returns as the SIMD units grew wider. Applying the ECM model to the scenario where data comes from cache we discovered that all state kernels show significant speedups from vectorization, and would benefit even more from even wider SIMD units. The synapse current kernels benefit from SIMD instructions at least for data in the L1 or L2 cache. Ion channel current kernels show only small speedups from vectorization because their performance is solely determined by the speed of the data transfer, even when the working set fits into a cache.
The importance of high-throughput exp and div functions cannot be overrated, which is punctuated by the large performance gain from Ivy Bridge to Skylake-X for kernels where these functions contribute significantly to the runtime. We have observed that the compiler was sometimes not able to eliminate expensive divide operations, although this was possible and allowed by the optimization flags.
4.2 Large networks (out of cache)
Memory bandwidth saturation of large networks
At constant memory bandwidth, a sufficient number of cores and/or high enough clock speed will render almost every code memory bound. One of the key insights delivered by the ECM model is how many cores are required to achieve saturation of the memory bandwidth during shared-memory execution, and what factors this number depends on. We applied saturation analysis to the full simulation loop by predicting the memory bandwidth of each kernel for different numbers of cores and compared it to the ratio of measured memory bandwidth to theoretical maximum bandwidth, weighted by the runtime of each kernel. Figure 6 shows the results, highlighting the remarkable power of the AVX512 technology on SKX, which is able to almost fully saturate the memory bandwidth using only seven cores. Since in-core features come essentially for free but more cores are more expensive, this means that in the max-filling scenario where the number of neurons being simulated is large and the data fits in main memory, the most cost-effective hardware platform for this code among the architectures considered is one with AVX512 support, high clock speed and a moderate core count. To further quantify the tradeoff between clock speed and saturation on SKX-AVX512 we computed the saturation point, which we define as the number of threads required to utilize at least 90% of the theoretical memory bandwidth, at different clock frequencies for the SKX architecture (assuming no clock frequency reduction). The results in Table 15 highlight once again that, as long as the working set is in main memory, vectorization pushes the bottleneck towards the memory bandwidth in the shared memory execution. We have to allow some room for error in the measurements of the memory bandwidth and the over-optimistic ECM model near the saturation point as shown in Stengel et al. (2015), but the model indicates clearly that cores can be traded for clock speed, which provides a convenient price-performance optimization space.
Wide SIMD and large networks
For in-memory data sets, wide SIMD execution helps to push the saturation point to a smaller number of cores, as shown in Table 15 and Figure 6, but it will certainly not increase the saturated performance. Hypothetical hardware with even wider SIMD units would thus have to be supported by a larger memory bandwidth to be fully effective. Moreover, as clearly shown by the ECM model analysis, wider SIMD execution would ultimately make even the state kernels data bound. In the mid-term future it would hence be advisable to put more emphasis on fast clock speeds and better memory bandwidth than on pushing towards wider SIMD units, at least for the workloads discussed in this work.
When choosing the most fitting cluster architecture one is thus left with the decision between a larger number of high-frequency chips with moderate memory bandwidth and a smaller amount of lower-frequency chips with large memory bandwidth and more cores. Roughly speaking, larger bandwidth is more expensive than faster clock speed, but the decision has to be made according to the market and pricing situation at hand, which unfortunately tends to be rather volatile.
Memory hierarchy for large networks
There is practically no temporal locality in the data access patterns of almost all kernels. This means that cache size is insignificant for determining the performance of large networks of detailed neuron simulations. Unfortunately, cache size is not a hardware parameter that one is free to choose when procuring clusters of off-the-shelf CPUs. Moreover, using the decomposition of the runtime by the ECM model we observe that contributions from different levels of the memory hierarchy are rather evenly distributed. Hence, the runtime of data-bound kernels could best be improved by reducing the data volume. A common programming technique to solve this problem is loop fusion, by which two or more back-to-back kernels that read or write some common data structures are cast into a single loop in order to leverage temporal locality and thus increase the arithmetic intensity. The structure of the NEURON code does not easily allow this.
5 Conclusions
In this work we have demonstrated the applicability of the ECM analytic performance model to analyze and predict the bottlenecks and runtime of simulations of biological neural networks. The need for such modeling is demonstrated by the ongoing development efforts to optimize simulation code for current state of the art HPC platforms, coupled with demands for simulators able to handle faster and larger datasets on present and future architectures. Using the performance model we identified high-frequency cores capable of high-throughput div and exp operations and wide cache data paths as the most desirable features for real-time simulations of small neuron networks, while high memory bandwidth, few cores with moderate to high SIMD parallelism and a shallow memory hierarchy are the ideal hardware characteristics for simulations of large networks. No attempts have been made so far towards porting NEURON kernels to traditional vector processors (which have again become available recently), and porting to GPGPUs is still in an exploratory phase, but at least for large networks, where abundant parallelism is available, the characteristics we have identified let us expect speedups according to the memory bandwidth difference to standard multicore CPUs: a device with 1 TB/s of memory bandwidth, such as the SX-Aurora “Tsubasa” by NEC (2018), should outperform one Skylake-X socket by a factor of 9–10.
In the reconstruction and simulation of brain tissue, performance engineering and modeling is now a pressing issue limiting the scale and speed at which computational neuroscientists can run in silico experiments. We believe that our work represents an important contribution in understanding the fundamental performance properties of brain simulations and preparing the community for the next generation of hardware architectures.
Future work
Two shortcomings hinder the comprehensive applicability of the ECM model for all the kernels in CoreNEURON: the inability to correctly describe latency-bound data accesses, and long critical paths in the loop body. Both shortcomings may be addressed by refining the model, i.e., endowing it with more information about the processor architecture. This data, however, is not readily available (and it might never be). In case of critical path analysis, the Open Source Architecture Code Analyzer (OSACA) by Laukemann et al. (2018) is planned to become a versatile substitute for IACA, which does not provide critical path prediction for modern Intel CPUs. Data latency support would require a fundamental modification of the model, and work is ongoing in this direction.
From the point of view of the simulation algorithm and implementation, given the delayed nature of the dependencies between neuron connections, a potentially very effective optimization could be made by looping through the time steps within a minimum network delay for each neuron, nested within a loop over all neurons, thus potentially allowing the algorithm to exploit temporal locality of data. This optimization is already implemented in CoreNEURON but requires to generate many datasets comprising at most a few neurons instead of a single dataset with many neurons, so it was not considered in this study. The ECM model provides a way to assess the tradeoffs of this approach but its validation is still a work in progress.
Acknowledgments
This work has been funded by the EPFL Blue Brain Project (funded by the Swiss ETH board). The authors would like to thank Johannes Hofmann for fruitful discussions about low-level benchmarking and Thomas Gruber for his contributions to the LIKWID framework. We are also indebted to the Blue Brain HPC team for helpful support and discussion regarding CoreNEURON.
Notes
- 1 Values taken from Fog (2017)
- 2 See the open-source code at https://github.com/BlueBrain/CoreNeuron. This permutation of node indices can be disabled with the command line argument --cell-permute 0.
- 3 See branch perf_eng_binq_bench of https://github.com/sharkovsky/CoreNeuron.git
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ananthanarayanan and Modha (2007) Ananthanarayanan R and Modha DS (2007) Anatomy of a cortical simulator. In: Proceedings of the 2007 ACM/IEEE conference on Supercomputing . ACM, p. 3.
- 2Bhalla (2012) Bhalla US (2012) Multi-compartmental models of neurons. In: Computational Systems Neurobiology . Springer, pp. 193–225.
- 3Brette et al. (2007) Brette R, Rudolph M, Carnevale T, Hines M, Beeman D, Bower JM, Diesmann M, Morrison A, Goodman PH, Harris Jr FC et al. (2007) Simulation of networks of spiking neurons: a review of tools and strategies. Journal of computational neuroscience 23(3): 349–398.
- 4Calotoiu et al. (2013) Calotoiu A, Hoefler T, Poke M and Wolf F (2013) Using automated performance modeling to find scalability bugs in complex codes. In: Proc. of the ACM/IEEE Conference on Supercomputing (SC 13), Denver, CO, USA . ACM, pp. 1–12. 10.1145/2503210.2503277 . · doi ↗
- 5Carnevale and Hines (2006) Carnevale NT and Hines ML (2006) The NEURON book . Cambridge University Press.
- 6Cremonesi et al. (2019) Cremonesi F et al. (2019) Reproducibility appendix for paper on modeling Blue Brain Project kernels with ECM. URL https://github.com/RRZE-HPC/BBP-ECM-RA/releases/tag/2019-01-16 .
- 7Fog (2017) Fog A (2017) Instruction tables: Lists of instruction latencies, throughputs and micro-operation breakdowns for intel, amd and via cpus. technical university of denmark.
- 8Gerstner et al. (2014) Gerstner W, Kistler WM, Naud R and Paninski L (2014) Neuronal dynamics: From single neurons to networks and models of cognition . Cambridge University Press.