On the Complexity of Exact Pattern Matching in Graphs: Binary Strings and Bounded Degree
Massimo Equi, Roberto Grossi, Veli M\"akinen

TL;DR
This paper establishes a conditional lower bound on the computational complexity of exact pattern matching in labeled graphs with binary labels, showing it cannot be solved faster than quadratic time unless SETH is false, even in restricted graph classes.
Contribution
The paper provides a direct reduction from SETH to the exact pattern matching problem in graphs, strengthening the understanding of its computational hardness and linking it to well-known complexity hypotheses.
Findings
Exact pattern matching in graphs is conditionally quadratic-time hard.
The problem remains hard even for restricted graph classes like bounded degree and acyclic graphs.
Exact and approximate pattern matching are both quadratic-time hard under SETH.
Abstract
Exact pattern matching in labeled graphs is the problem of searching paths of a graph that spell the same string as the pattern . This basic problem can be found at the heart of more complex operations on variation graphs in computational biology, of query operations in graph databases, and of analysis operations in heterogeneous networks, where the nodes of some paths must match a sequence of labels or types. We describe a simple conditional lower bound that, for any constant , an -time or an -time algorithm for exact pattern matching on graphs, with node labels and patterns drawn from a binary alphabet, cannot be achieved unless the Strong Exponential Time Hypothesis (SETH) is false. The result holds even if restricted to undirected graphs of maximum degree three or directed acyclic graphs of…
Click any figure to enlarge with its caption.
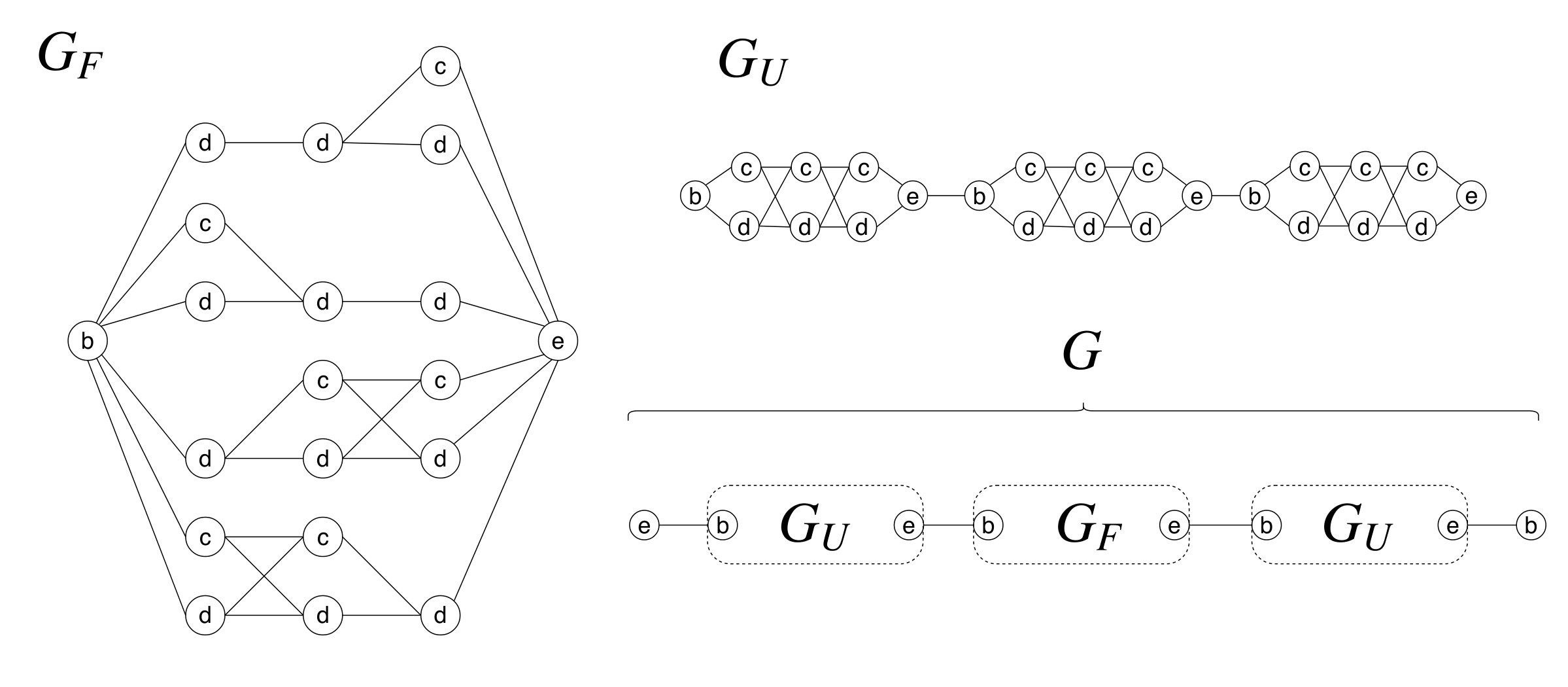 Figure 1
Figure 1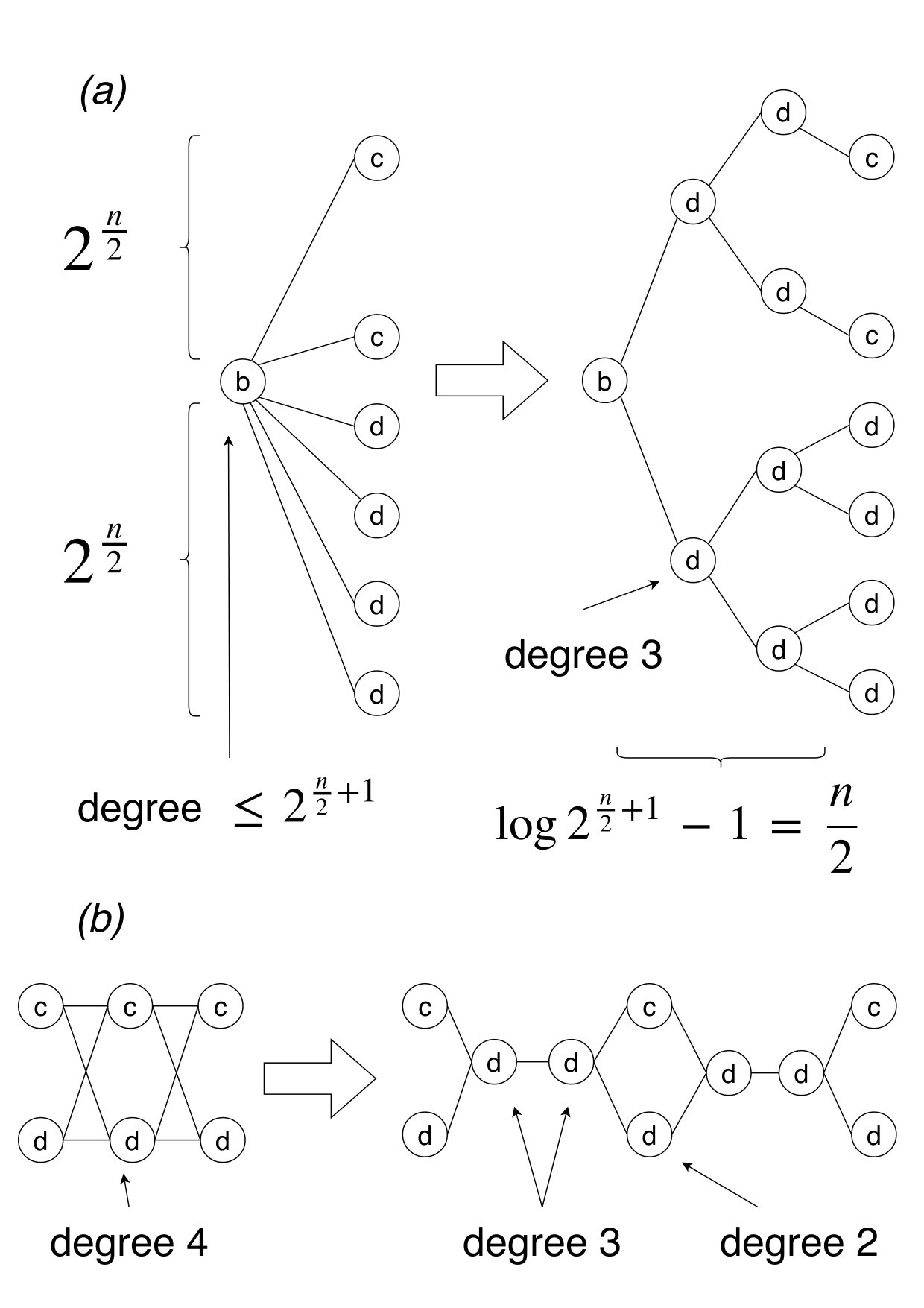 Figure 2
Figure 2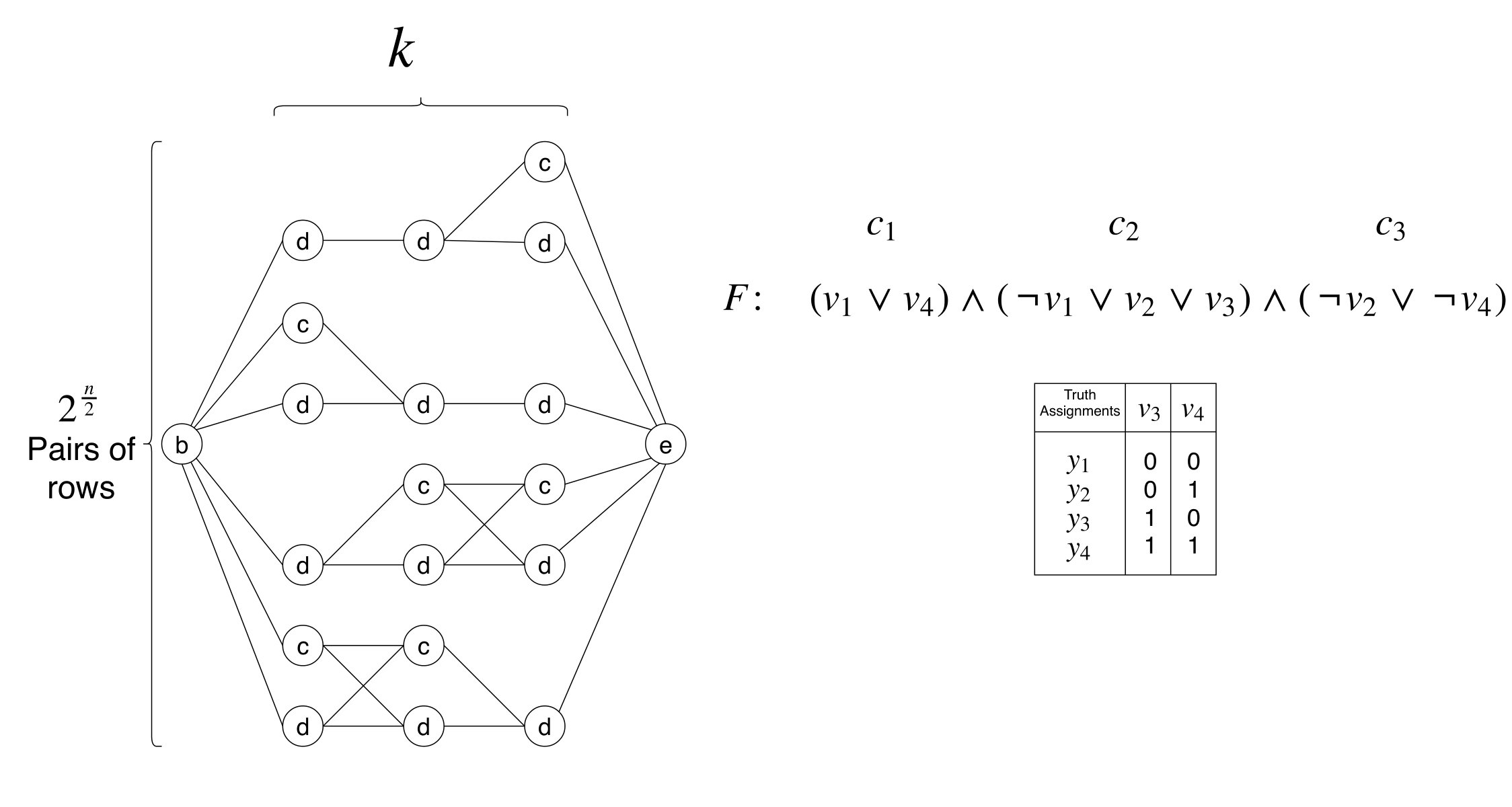 Figure 3
Figure 3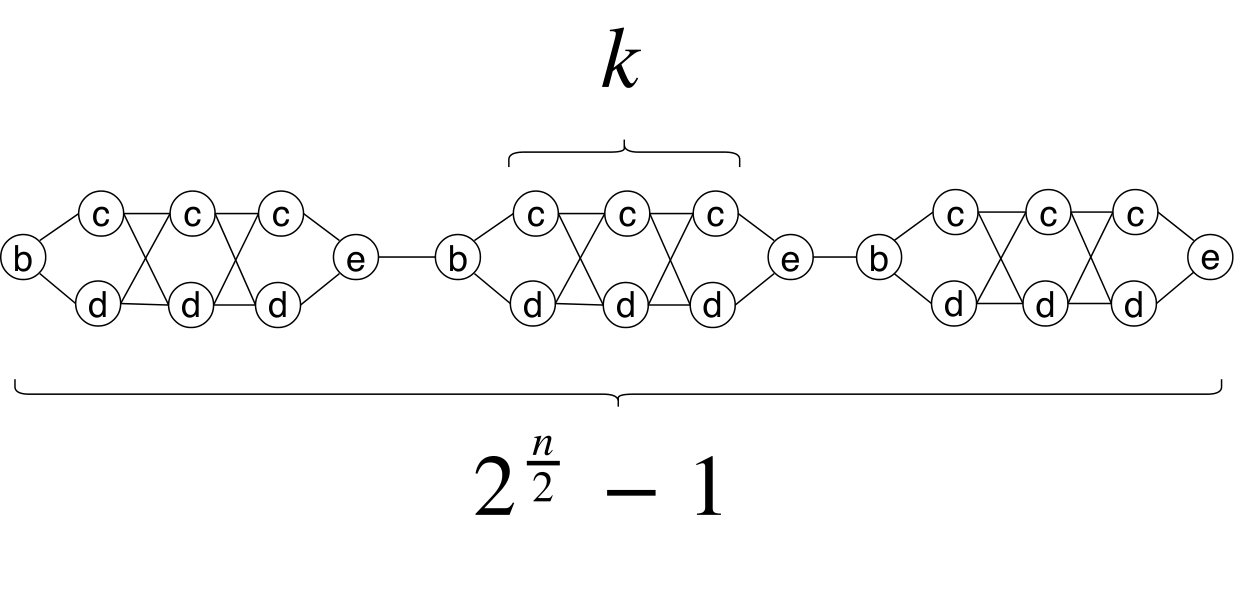 Figure 4
Figure 4 Figure 5
Figure 5| State of the art for PMLG | ||||
|---|---|---|---|---|
| Year | Authors | Graph | Exact/ | Time |
| Approximate | ||||
| 1992 | Manber, Wu [20] | DAG | approximate | |
| 1993 | Akutsu [2] | Tree | exact | |
| 1995 | Park, Kim [22] | DAG | exact | |
| 1997 | Amir et al. [3] | general | exact | |
| 1997 | Amir et al. [3] | general | approximate | NP-Hard |
| 1997 | Amir et al. [3] | general | approximate | |
| 1998 | Navarro [21] | general | approximate | |
| 2017 | Vadaddi et al. [29] | general | approximate | |
| 2017 | Rautiainen, Marschall [24] | general | approximate | |
| 2019 | Jain et al. [18] | general | approximate | NP-Hard on binary alphabet |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\hideLIPIcs
Department of Computer Science, University of Helsinki, [email protected] Dipartimento di Informatica, Università di Pisa, [email protected] Department of Computer Science, University of Helsinki, [email protected]
\CopyrightM. Equi, R. Grossi, V. Mäkinen
\supplement \fundingThis work has been partially supported by Academy of Finland (grant 309048) \EventEditorsXYZ \EventNoEds3 \EventLongTitleXYZ \EventShortTitleXYZ \EventAcronymMFCS \EventYear2018 \EventDateAugust 27–31, 2018 \EventLocationLiverpool, GB \EventLogo \SeriesVolume117 \ArticleNo84
On the Complexity of Exact Pattern Matching in Graphs: Binary Strings and Bounded Degree
Massimo Equi
,
Roberto Grossi
and
Veli Mäkinen
Abstract.
Exact pattern matching in labeled graphs is the problem of searching paths of a graph that spell the same string as the pattern . This basic problem can be found at the heart of more complex operations on variation graphs in computational biology, of query operations in graph databases, and of analysis operations in heterogeneous networks, where the nodes of some paths must match a sequence of labels or types. We describe a simple conditional lower bound that, for any constant , an -time or an -time algorithm for exact pattern matching on graphs, with node labels and patterns drawn from a binary alphabet, cannot be achieved unless the Strong Exponential Time Hypothesis (seth) is false. The result holds even if restricted to undirected graphs of maximum degree three or directed acyclic graphs of maximum sum of indegree and outdegree three. Although a conditional lower bound of this kind can be somehow derived from previous results (Backurs and Indyk, FOCS’16), we give a direct reduction from seth for dissemination purposes, as the result might interest researchers from several areas, such as computational biology, graph database, and graph mining, as mentioned before. Indeed, as approximate pattern matching on graphs can be solved in time, exact and approximate matching are thus equally hard (quadratic time) on graphs under the seth assumption. In comparison, the same problems restricted to strings have linear time vs quadratic time solutions, respectively, where the latter ones have a matching seth lower bound on computing the edit distance of two strings (Backurs and Indyk, STOC’15).
Key words and phrases:
exact pattern matching, graph query, graph search, heterogeneous networks, labeled graphs, string matching, string search, strong exponential time hypothesis, variation graphs
1991 Mathematics Subject Classification:
\ccsdesc[500]Mathematics of computing Graph algorithms \ccsdesc[500]Theory of computation Problems, reductions and completeness \ccsdesc[500]Theory of computation Pattern matching
category:
\relatedversion
1. Introduction
Large-scale labeled graphs are becoming ubiquitous in several areas, such as computational biology, graph databases, and graph mining. Applications require sophisticated operations on these graphs, and often rely on primitives that locate paths whose nodes have labels or types matching a pattern given at query time.
In graph databases, query languages provide the user with the ability to select paths based on the labels of their nodes or edges, where the edge labels are called properties. In this way, graph databases explicitly lay out the dependencies between the nodes of data, whereas these dependencies are implicit in classical relational databases [4]. Although a standard query language has not been yet universally adopted (as it occurred for SQL in relational databases), popular query languages such as Cypher [13], Gremlin [25], and SPARQL [23] offer the possibility of specifying paths by matching the labels of their nodes.
In graph mining and machine learning for network analysis, heterogeneous networks specify the type of each node [27]. For example, in the DBLP network [30], the nodes for authors can be marked with letter ’A’, and the nodes for papers can be marked with letter ’P’, where edges connect authors to their papers. For example, coauthors can be identified by the pattern ’APA’ when it matches two different nodes with ’A’. The strings generated by the labels on the paths have several applications in heterogeneous networks, such as graph kernels [16] or node similarity [10], where a basic tool is retrieving the paths for a string.
In genome research, the very first step of many standard analysis pipelines of high-throughput sequencing data has been to align the sequenced fragments of DNA (called reads) on a reference genome of a species. Further analysis reveals a set of positions where the sequenced individual differs from the reference genome. After years of these kind of studies, there is now a growing dataset of frequently observed differences between individuals and the reference. A natural representation of this gained knowledge is a variation graph where the reference sequence is the backbone and variations are encoded as alternative paths [26]. Aligning reads (pattern matching) on this labeled graph gives the basis for the new paradigm called computational pan-genomics [9]. There are already tools that use such ideas, e.g. [15].
Although there is a growing need to perform pattern matching on graphs in several situations described above, the idea of extending the problem of string searching in sequences to pattern matching in graphs was studied over 25 years ago as a search problem in hypertext [20]. The history of key contributions is given in Table 1, where the two best known results for exact and approximate pattern matching, both taking quadratic time in the worst case, are highlighted. Note that errors in the graphs makes the problem NP-hard [3], so we consider errors in the pattern only.
A common feature of the bounds reported in Table 1 is the appearance of the quadratic term (except for the special cases of trees and the general NP-hard approximate version). Here is the length of the pattern string and is the set of edges of the graph. The quadratic cost of the approximate matching on graphs by Rautiainen and Marschall [24] are asymptotical optimal under the Strong Exponential Time Hypothesis [17] (seth) as (i) they solve the approximate string matching as a special case, since a graph consisting of just one path of nodes and edges is a text string of length , and (ii) it has been recently proved that the edit distance of two strings of length cannot be computed in time, for any constant , unless seth is false [5]. Hence this conditional lower bound explains why the barrier has been difficult to cross.
We can only explain the complexity on approximate pattern matching on graphs, but nothing is known on exact pattern matching on graphs. Indeed, the classical exact pattern matching with a pattern and a text string can be solved in linear time [19], so one could expect the corresponding problem on graphs to be easier than approximate pattern matching.
In this paper we end up with a slightly surprising observation that exact and approximate pattern matching are equally hard on graphs. Namely, we show the conditional lower bound that an -time or an -time algorithm for exact pattern matching on graphs cannot be achieved unless seth is false. This result explains why it has been difficult to find indexing schemes for graphs with other than best case or average case guarantees for fast exact pattern matching [28, 14].
Before going on to give the overview and details of the reduction, let us now fix the problem definition and seth formulation.
Definition 1.1**.**
Given an alphabet , a labeled graph is a triplet where is a directed or undirected graph and is a function that defines which string over is assigned to each node.
Definition 1.2**.**
Let be a path in graph and be a pattern. Also, and denote the suffix of starting at position and the prefix of ending at position , respectively. We say that is a match for in with offset if the concatenation of the strings equals , for some .
The Pattern Matching in Labeled Graphs (pmlg) problem is then defined as:
**: **
input: a labeled graph and a pattern over an alphabet .
**: **
output: all the matches for in .
For example, in Fig. 1 pattern \mathtt{c}$$\mathtt{d}$$\mathtt{e} has two occurrences but pattern \mathtt{b}$$\mathtt{c}$$\mathtt{c}$$\mathtt{c}$$\mathtt{e} does not occur. For our purpose it would be enough to exploit a decision version of the problem, namely, to be able to determine whether or not there exists at least one match for in , without reporting all of them. Note that the matching path for can go through the same nodes multiples times in as otherwise pmlg is trying to solve the NP-hard Hamiltonian path problem.
We now recall what is seth, namely, the Strong Exponential Time Hypothesis [17]. This is a conjecture which is commonly used as a basis of reductions in the scientific community, even though its weaker version eth is more widely accepted.
Definition 1.3** ([17]).**
Let q-sat be an instance of sat with at most q literals per clause. Given , seth claims that .
In other words, it is hard to find an -time algorithm for general sat for a constant . We use seth in the the following result, given that the best known algorithm for pmlg, devised 20 years ago [3], has an time complexity.
Theorem 1.4**.**
For any constant , the Pattern Matching in Labeled Graphs (pmlg) problem for an alphabet of at least symbols cannot be solved in either or time unless seth is false.
We can further strengthen the statement of this theorem by proving the following corollaries.
Corollary 1.5**.**
The conditional lower bound stated in Theorem 1.4 holds even if it is restricted to graphs with binary alphabet for the labels, where each node has degree at most three.
Corollary 1.6**.**
The conditional lower bound stated in Theorem 1.4 holds even if it is restricted to labeled directed acyclic graphs (DAGs) with binary alphabet for the labels, where each node has the sum of indegree and outdegree at most three.
In order to achieve these results we break down our reasoning process in some intermediate steps. Since this is a conditional lower bound we will reduce sat to pmlg. Then we will show that having a truly subquadratic algorithm for pmlg would cause to solve sat in time with . Our reduction costs time for a sat formula with variables and clauses, where is the shorthand for ignoring polynomial factors in , e.g. . Hence the main steps can be synthesized as follows.
- •
Find a reduction from sat to pmlg.
- •
Ensure that this reduction costs time.
- •
Show that having a or a time algorithm for pmlg gives a solution for sat that makes seth fail.
Our reduction shares some similarities with those for string problems in [5, 8, 1, 6, 7] as it uses seth. The closest connection is with [6], where regular expression matching is studied (graph in Section 2.2 is analogous to the NFA derived from the regular expression matching of type in [6]). At presentation level, the difference to earlier work is that we reduce directly from seth, while the earlier work uses an intermediate problem, orthogonal vectors, as a tool; our reduction can also be presented via the orthogonal vectors problem, but we preferred to work with seth directly since sat is more familiar to researcher from various research areas. On a more conceptual level, the new reduction has some interesting features of independent interest. Given a sat formula, our reduction builds a pattern and a graph, using some special characters in the pattern to match bridges in the graph that can be traversed in one direction only (even if the graph is undirected). Also, obtaining the reduction for a binary alphabet requires a suitable variable-length encoding of the characters to avoid certain paths in the graph.
An earlier version of this reduction can be found in the Master’s thesis of the first author [11] (supervised by the two last authors).
2. Conditional lower bound for PMLG on undirected graphs
Consider a sat formula with variables and set of clauses.111 In this paper we discuss the interesting case where .
We show how to generate a corresponding instance of pmlg. We build a pattern of suitable length and a labeled graph , where and is the node labeling with strings from , such that matches in if and only if is satisfied by some truth assignment of its variables. Recall that a truth assignment is a tuple , where is the truth value assigned to each variable . We write to indicate that there exists at least one literal satisfied by (i.e. either and , or and ).
Our reduction builds a pattern with symbols from a binary alphabet along with an undirected graph whose nodes are labeled with single symbols from (i.e. ). This graph has nodes and edges, and maximum degree three. The reduction can be modified so that the graph is directed with maximum sum of indegree and outdegree at least three.
For presentation’s sake, we begin with a pattern using an alphabet of four symbols, , whose interpretation is to label nodes according to their implicit functionality: egin (synchronization token), nd (synchronization token), lause (marker), ummy (don’t care); moreover, the resulting undirected graph has unbounded degree; after that, we will show how to get the minimal degree configuration for and how to achieve a binary alphabet, as depicted above.
We assume that is an even number, without loss of generality, and denote by the set of possible assignments for the first variables, and by those for the last variables, that is,
[TABLE]
We call elements of and half-assignments and interpret notation accordingly. For example, if and only if there is a literal satisfied by the half-assignment (i.e. either and , or and , for some ).
The reduction components to follow will be interpreted as follows. The pattern encodes by position, placing a symbol to indicate which clauses cannot be satisfied by a half-assignment ; the other clauses are marked by as they are already satisfied by alone; symbols and are employed to sync the half-assignments from with portions of the graph, called gadgets.
The gadgets encode which clauses are satisfied by the half-assignments of , encoding each such clause with a distinct node labeled with : when a symbol in the pattern matches a node with label in the graph, the corresponding clause is now covered by a half-assignment , while it was not yet covered by half-assignment . If all the symbols for are matched by the nodes of the gadget corresponding to , then assignment satisfyes the sat formula ; also the other direction holds.
Parallel nodes labeled with are introduced to deal with the cases when the pattern indicates that the corresponding clause is already satisfied by a half-assignment in . Nodes labeled with or are used to match a half-assignment with a half-assignment of . Details follow below.
2.1. Building the pattern
Pattern is defined over the alphabet using the half-assignments in and the set of clauses of sat formula . Specifically, it is built as the concatenation of strings where and, for , the th symbol of string is defined as
[TABLE]
We will prove that is satisfiable if and only if we can find a match for this pattern in our graph, where the latter is made up of gadgets as specified below.
2.2. Graph gadgets for SAT formulas
Our gadget is an undirected graph , illustrated in Figure 1 and defined as follows using the half-assignments in and the set of clauses of sat formula .
In the set of nodes, we have a clause node for every possible pair such that , and a dummy node for every possible pair . Set also contains two special nodes, a begin node and an end node ,
[TABLE]
Labeling is consequently defined, where a symbol in the pattern that matches a node labeled with in the graph will represent the fact a clause not satisfied by a certain half-assignment in is actually satisfied by a certain half-assignment in . The symbols are sort of “don’t care”, and and symbols synchronize the whole.
[TABLE]
As shown in Fig. 1, the edges in the set connect to every and , and connect every and to , for . Moreover, there is an edge for every pair of nodes that share the same and are consecutive in terms of coordinate (e.g. ), for and .
[TABLE]
We observe that pattern occurrences in have some combinatorial properties.222Gadget is analogous to the main component of the seth reduction to regular expression matching of type in [6].
Lemma 2.1**.**
If subpattern matches in then all the nodes matching share the same coordinate and have distinct and consecutive coordinates (i.e. either or for ).
Proof 2.2**.**
Gadget contains a single node with label and a single node with label . Morever, the shortest path from to contains nodes ( and included). As contains symbols, its matching path in must traverse all distinct nodes by construction. Suppose by contradiction that at least one node in has different coordinate. This means that two consecutive nodes and in have coordinates and , with . Node is actually either or , whereas is either or . By inspection of these four possible cases, we observe that our construction of does not provide any edge connecting and . Indeed, there is no edge that allows a node to change the coordinate in the middle of a path. Hence we reach a contradiction. Finally, if one of the matching nodes were not consecutive in terms of coordinate, by construction we know that we would not be following the shortest path to hence it would not be possible to complete the match.
Lemma 2.3**.**
Subpattern matches in if and only if there is such that the truth assignment satisfies (i.e. ).
Proof 2.4**.**
By Lemma 2.1, we can focus on the distinct nodes matching , sharing the same coordinate . We handle the two implications of the statement individually.
() Consider the partial assignment . From the structure of the pattern we know that satisfies all the clauses for which . Since has a match in , consider the assignment where exists by Lemma 2.1, as observed above. We observe that by construction satisfies those clauses that cannot satisfy, namely those for which . Hence we have found a truth assignment that satisfies .
() Consider a truth assignment that satisfies , that is, all clauses for sat formula are true. Consider now the nodes with coordinate in . For , if then and matching node exits in by its definition. If then it must be : thus and a matching node exists in by its construction. The definition of the edges of ensures that all the above nodes and , as we need, are properly linked to form a path of distinct nodes (for increasing values of ); it is so because they all share the same coordinate. This implies that matches in .
While the previous gadget is useful to check whether a half-assignment satisfies using a given subpattern , we need another “jolly” gadget that matches all subpatterns in (this is useful when does not satisfy ). We concatenate instances of the latter gadget, thus obtaining the graph illustrated in Figure 2, whose definition is clear from the picture. The th copy of the gadget substructure has a node followed by nodes , and then node , with and . The labels are , , and (we may think about nodes and as disposed along two parallel lines). We place the edges for connecting the beginning and ending nodes of each gadget with its inner part. We connect nodes and with the edges . We concatenate our gadgets one after the other using the edges , for .
2.3. Putting all together
Armed with gadgets and , we obtain the graph from the sat formula by combining them as illustrated in Figure 3. We take one instance of and two instances of , say and , and two new nodes and , where their label is respectively and . Then has node set , preserving the node labels. The edge set is the union of the previous edge sets plus four edges: one connects the “last” node labeled with in with the node labeled with in ; the other connects the node labeled with in with the “first” node labeled with in , plus is connected to the first node labeled with in , and the last node labeled with in is connected to .
Remark 2.5**.**
Each edge connecting a node labeled with to a node labeled with is a bridge in (i.e. its removal disconnect ). As we shall see, the purpose of these bridges is dual since, within a matching path, the th occurrence of \mathtt{e}$$\mathtt{b} in the pattern matches the th bridge with labels and at its endpoints: (i) they synchronize the distinct subpatterns with the distinct (portions of the) gadgets, and (ii) they guarantee that the pattern matches a path of distinct nodes rather than a walk.
We now prove that the reduction is correct, first focusing on subpatterns of .
Lemma 2.6**.**
Pattern matches in if and only if a subpattern of matches in .
Proof 2.7**.**
For the implication, the bridges with endpoints labeled with and can only be traversed once in this direction, as contains the sequence \mathtt{e}$$\mathtt{b} but does not contain \mathtt{b}$$\mathtt{e}. Moreover, each occurrence of must begin with one such bridge and end with another such bridge. For this reason each distinct subpattern matches a path from either a distinct portion of ()) or . Recall that and can match at most subpatterns of each, while has of them. Hence one subpattern is forced to have a match in in order to have a full match for .
The implication is trivial. In fact, if has a match in then we can match in and in by construction, and have a full match for in .
The main result proves the correctness of our reduction.
Theorem 2.8**.**
Pattern matches in if and only if the sat formula is satisfiable.
Proof 2.9**.**
By Lemma 2.6, matches in if and only if a subpattern matches in . By Lemma 2.3 this holds if and only if the truth assignment satisfies , hence is satisfiable.
2.4. Cost of the reduction
We analyze the cost of building the pattern and the graph from the sat formula .
Lemma 2.10**.**
Given a sat formula with variables, the corresponding pattern and graph can be built in time and space.
Proof 2.11**.**
Checking if an assignment satisfies a clause takes time which, for our goals, is negligible when compared to . Recalling that the number of clauses is polynomially bounded in , we observe that each in has symbols that can be either or plus symbols and . Since has sub-patterns , summing everything up we get a length of symbols. As for , it has gadgets each one having nodes labeled with , nodes labeled with , and nodes and . Hence there are total nodes. Each node has a constant number of incident edges (at most ) thus their size is as well. As for , it has nodes labeled with and the same amount of nodes labeled with plus those with and . In this case, each node has a constant number of edges but for and . Nevertheless, and have edges each, therefore the total amount of edges is again . For connecting to the two instances of we are adding just edges. Since the pattern and the graph have size , we conclude that the cost of our reduction is indeed .
2.5. Implications on SETH
The last step in our proof of Theorem 1.4 is showing that any -time or -time algorithm for pmlg unavoidably leads to a failure of seth. To this aim, assume that we have such an algorithm, say . Given a sat formula we perform our reduction stated in Theorem 2.8 obtaining pattern and graph in time by Lemma 2.10, observing that and . At this point, no matter whether has or time complexity, we will end up with an algorithm deciding if is satisfiable in time. Since we conclude that this implies to be able to solve sat in time with , making seth false.
3. From undirected graphs to DAGs, with binary alphabets
In this section we show that the graph obtained from the reduction described in Section 2 can be transformed so that each node has degree at most three and label chosen from an alphabet of two symbols .
We describe how to modify the proof of Theorem 1.4 so that it holds for any graph of degree at least three. We observe that the graph built in the reduction in Section 2 has degree . To obtain degree at most three, we first modify gadgets and to meet such requirement, and then adjust pattern consequently. Finally, we obtain a binary alphabet for the labels, thus proving Corollary 1.5.
After that we prove Corollary 1.6, showing that the undirected graph can be easily transformed into a directed acyclic graph (DAG).
3.1. Maximum degree three
Revised gadget
As depicted in Figure 4(a), consider the edges connecting node with nodes and in . We replace them by a binary tree structure whose nodes are new dummy nodes with labels for . As for node , we proceed along the same way and replace the edges connecting nodes and to by a binary tree structure (this case is not shown in the figure). The internal nodes of these trees have degree at most three.
This is not enough to guarantee degree at most three for each node in as nodes and could have degree four. For example, with some nodes and , nodes and could exists. Then both and would have degree four. This can be fixed as shown in Figure 4(b), adding two pairs of dummy nodes with label to lower the degree to three.333One pair is placed between nodes and nodes via edges and . The other pair of dummy nodes is placed between nodes and nodes via edges and .
At this point, we added dummy nodes for the binary tree, and pairs of nodes . Moreover, the new edges for the binary tree are as many as the nodes while for the other modifications we add one edge for each pair of dummy nodes. The overall time complexity to build the transformed does not increase significantly.
Revised gadget
Gadget has to be consistent with . We add dummy nodes with label between every node and the nodes and following it. We also add dummy nodes with label between every node and the previous nodes and . We are adding new nodes and one new edge per node, thus the overall time complexity will not be affected. The need for this step will be clearer when we will modify pattern , as it has to match either or , so the same format of is required in both types of gadgets.
We have another issue to handle. As in , there could be nodes and of degree four. In that case, we add pairs of dummy nodes with label following the same schema presented for and illustrated in Figure 4(b). In this way we are introducing new nodes and one edge for each pair of dummy nodes which do not change the time complexity of the reduction.
Revised pattern
Pattern is modified so as to match and when needed. We add symbols after each occurrence of and before each occurrence of . Moreover, we insert symbols inside the subpatterns , where , to obtain the new subpatterns . Therefore, the new pattern to match will be
[TABLE]
It is worth noting that in this way. The number of new symbols added before and after the subpatterns is while the ones inserted inside them are . The time cost of the reduction does not increase significantly.
3.2. Binary alphabet
The last step consists in defining a binary encoding of the symbols , namely,
[TABLE]
Given any string , we define its binary encoding . The following useful synchronizing property holds, recalling that each edge connecting a node with label to a node with label is a bridge in (transformed) .
Lemma 3.1**.**
For any string , its binary encoding contains \mathtt{0}$$\mathtt{1}$$\mathtt{1}$$\mathtt{0} if and only if contains \mathtt{e}$$\mathtt{b}.
Proof 3.2**.**
We observe that and are encoded by two bits each, while and are enconed by four bits each. Hence, \mathtt{0}$$\mathtt{1}$$\mathtt{1}$$\mathtt{0} can appear by concatenating the binary encoding of two or three symbols. On the other hand, \mathtt{e}$$\mathtt{b} occurs in if and only if it occurs in a substring of length 3 of . Consequently, it suffices to check the claim by inspection of all the 64 substrings of of length 3, \mathtt{c}$$\mathtt{c}$$\mathtt{c}, …, \mathtt{e}$$\mathtt{e}$$\mathtt{e}, and their encodings to see that the property holds.
Any walk matched by the revised pattern crosses the bridges in the direction from to .
Lemma 3.3**.**
For any pattern obtained in the reduction, its binary encoding does not contain .
Proof 3.4**.**
Recalling that , all the possible substrings of length 3 in by construction are of the forms , , , , , and . By inspection of this small number of cases, none contains \mathtt{b}$$\mathtt{e}, and none of their binary encodings contains \mathtt{1}$$\mathtt{0}$$\mathtt{0}$$\mathtt{1}.
An immediate consequence of Lemma 3.1 and 3.3 is that the encodings preserve the occurrences. Let be the transformed graph, and be the revised pattern in the reduction. Let denote the graph obtained from by relabeling its nodes with the binary encoding of their labels.
Lemma 3.5**.**
In the reduction, matches in if and only if matches in .
Proof 3.6**.**
It follows by Lemma 3.1 and 3.3, and the fact that all the edges whose endpoints have one label and the other label are bridges, and they are traversed in the direction from to when matching .
In the encoding above, each node stores two or four bits. By replacing it with a chain of two or four nodes with a single bit as a label, we obtain the proof of Corollary 1.5.
3.3. Directed acyclic graphs
In order to prove Corollary 1.6, we observe that the proof of Theorem 1.4 can be easily modified in order to work also for DAGs.
Considering the definitions of edges and in the proof of Theorem 1.4, and the transformation described so far, we immediately obtain a directed graph that is acyclic. Indeed, because of bridges and occurrences of \mathtt{e}$$\mathtt{b} in the pattern, each pattern match must begin with some bridge, end with a different bridge and lay along a path from the first to the last bridge in the graph. So the edges can be oriented by construction from left (first bridge) to right (last bridge), as it can be checked in Fig. 1–4.
4. Conclusions
We studied the complexity of pattern matching on labeled graphs, giving a seth conditional quadratic lower bound for the exact pattern matching. In strings the exact pattern matching takes linear time whereas the approximate pattern matching takes quadratic time under a matching conditional lower bound. Differently from strings, our result along with the upper bounds in [3, 24] imply that the exact and approximate pattern matching (the latter with errors in the pattern) have the same complexity under the seth conjecture. Our conditional lower bound uses a binary alphabet and holds even if restricted to nodes of maximum degree at most three for undirected graphs, and to nodes of maximum sum of indegree and outdegree at most three for directed acyclic graphs (DAGs).
Two border cases are left if the maximum degree or sum of indegree and outdegree is at most two: a) when the undirected graph is a simple path or a cycle, and pattern matching goes along a walk (so it is a sort of zig-zag string matching), and b) when the graph is a directed cycle. For a), we can convert each edge into a pair of arcs and apply the known quadratic algorithm in [3]. On the other hand, we can extend our reduction to derive a matching seth lower bound for this case [12]. For b), we can adapt any known string matching algorithm (e.g. [19]) to get linear time.
An interesting and natural question for directed graphs is what happens when the graph is deterministic, that is, for each symbol and each node , there is at most one neighbor of labeled with . Unfortunately, this does not make the problem any easier. Although our reduction creates an inherently non-deterministic graph, it is possible to alter the reduction scheme to create a deterministic graph [12].
Acknowledgements
The first two authors are grateful to Alessio Conte and Luca Versari for providing their comments on the reduction. The last author wishes to thank the participants of the annual research group retreat on sparking the idea to study seth reductions in this context. We thank the anonymous reviewers of an earlier version of this paper for useful suggestions for improving the presentation and for pointing out the connection to regular expression matching.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Amir Abboud, Arturs Backurs, and Virginia Vassilevska Williams. Tight hardness results for LCS and other sequence similarity measures. In IEEE 56th Annual Symposium on Foundations of Computer Science, FOCS 2015, Berkeley, CA, USA, 17-20 October, 2015 , pages 59–78, 2015.
- 2[2] Tatsuya Akutsu. A linear time pattern matching algorithm between a string and a tree. In 4th Symposium on Combinatorial Pattern Matching, Padova, Italy , pages 1–10, 1993.
- 3[3] Amihood Amir, Moshe Lewenstein, and Noa Lewenstein. Pattern matching in hypertext. J. Algorithms , 35(1):82–99, 2000.
- 4[4] Renzo Angles and Claudio Gutierrez. Survey of graph database models. ACM Comput. Surv. , 40(1):1:1–1:39, February 2008.
- 5[5] Arturs Backurs and Piotr Indyk. Edit distance cannot be computed in strongly subquadratic time (unless seth is false). In Proceedings of the Forty-seventh Annual ACM Symposium on Theory of Computing , STOC ’15, pages 51–58, New York, NY, USA, 2015. ACM.
- 6[6] Arturs Backurs and Piotr Indyk. Which regular expression patterns are hard to match? In IEEE 57th Annual Symposium on Foundations of Computer Science, FOCS 2016, 9-11 October 2016, Hyatt Regency, New Brunswick, New Jersey, USA , pages 457–466, 2016.
- 7[7] Arturs Backurs and Christos Tzamos. Improving viterbi is hard: Better runtimes imply faster clique algorithms. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 , volume 70, pages 311–321. PMLR, 2017.
- 8[8] Karl Bringmann and Marvin Kunnemann. Quadratic conditional lower bounds for string problems and dynamic time warping. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science (FOCS) , FOCS ’15, pages 79–97, Washington, DC, USA, 2015. IEEE Computer Society.