Multivariate mixed membership modeling: Inferring domain-specific risk profiles
Massimiliano Russo, Burton H. Singer, David B. Dunson

TL;DR
This paper introduces a multivariate mixed membership model that improves interpretability and fit by accounting for domain-specific variable blocks and cross-domain correlations, demonstrated through a malaria risk study.
Contribution
The paper proposes a novel multivariate mixed membership model that explicitly models domain-based variable blocks and correlations, enhancing interpretability and fit over standard models.
Findings
Fewer profiles are needed for good data fit.
The model captures cross-domain correlations effectively.
Applied successfully to malaria risk data.
Abstract
Characterizing the shared memberships of individuals in a classification scheme poses severe interpretability issues, even when using a moderate number of classes (say 4). Mixed membership models quantify this phenomenon, but they typically focus on goodness-of-fit more than on interpretable inference. To achieve a good numerical fit, these models may in fact require many extreme profiles, making the results difficult to interpret. We introduce a new class of multivariate mixed membership models that, when variables can be partitioned into subject-matter based domains, can provide a good fit to the data using fewer profiles than standard formulations. The proposed model explicitly accounts for the blocks of variables corresponding to the distinct domains along with a cross-domain correlation structure, which provides new information about shared membership of individuals in a complex…
Click any figure to enlarge with its caption.
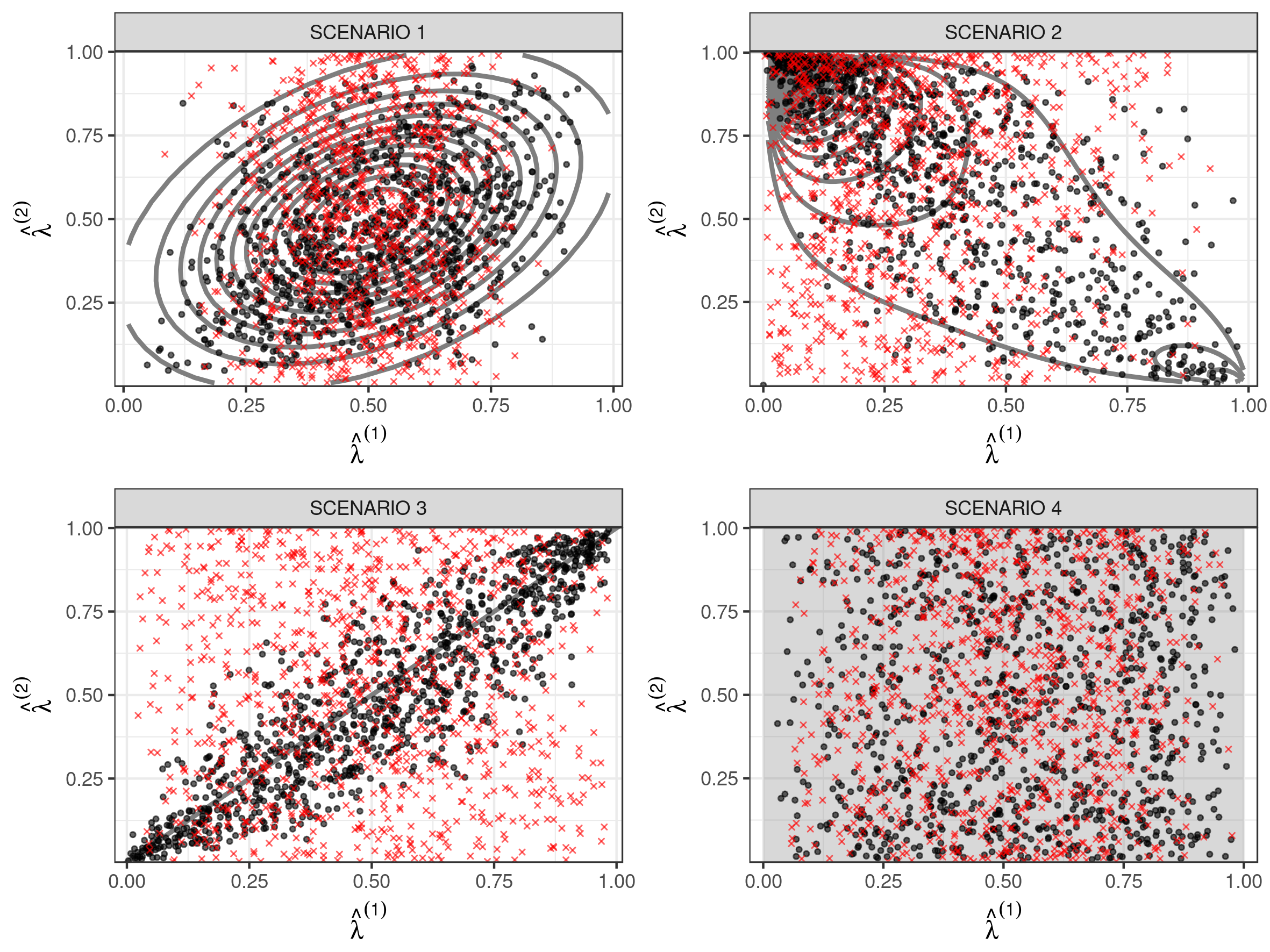 Figure 1
Figure 1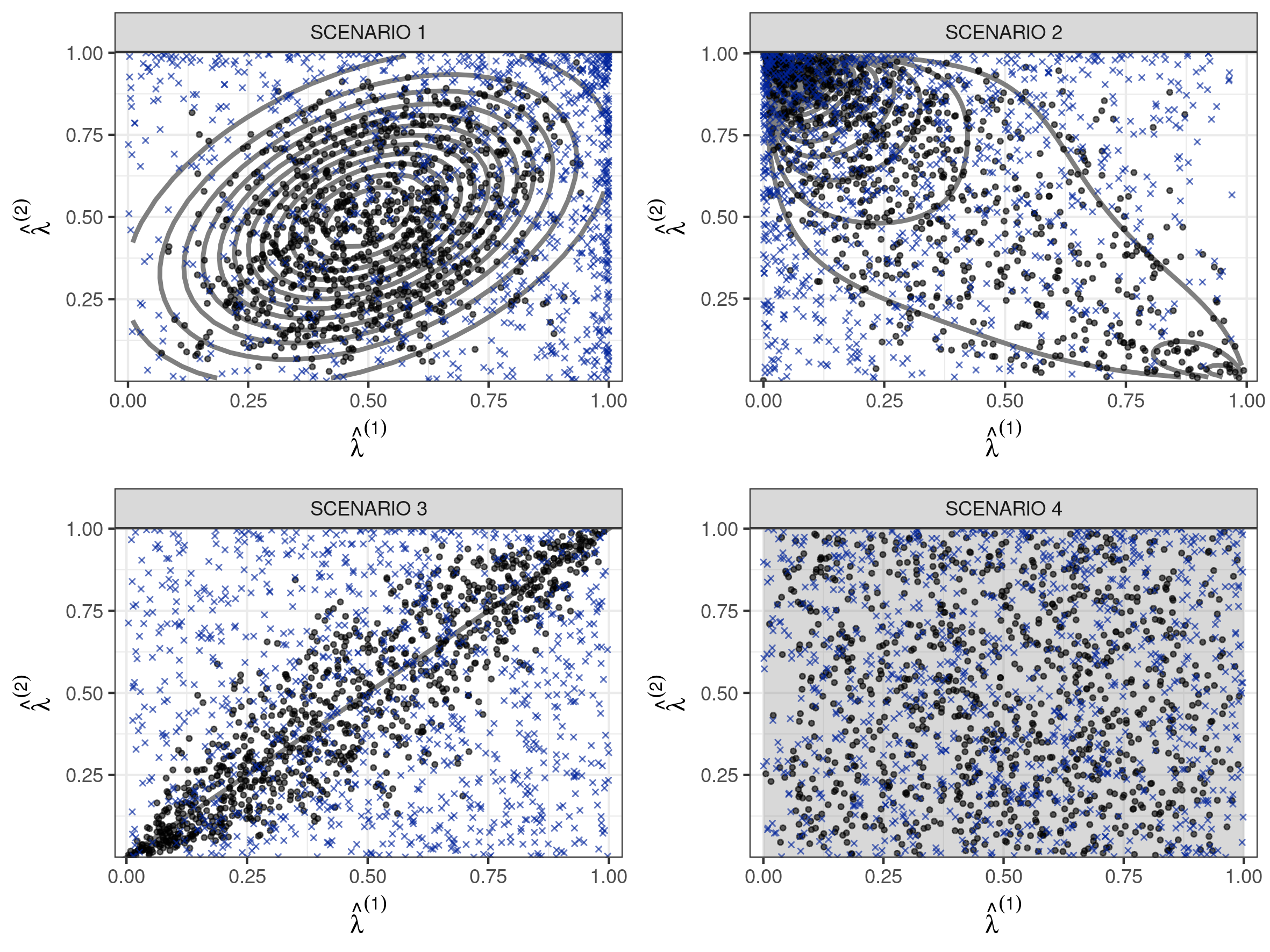 Figure 2
Figure 2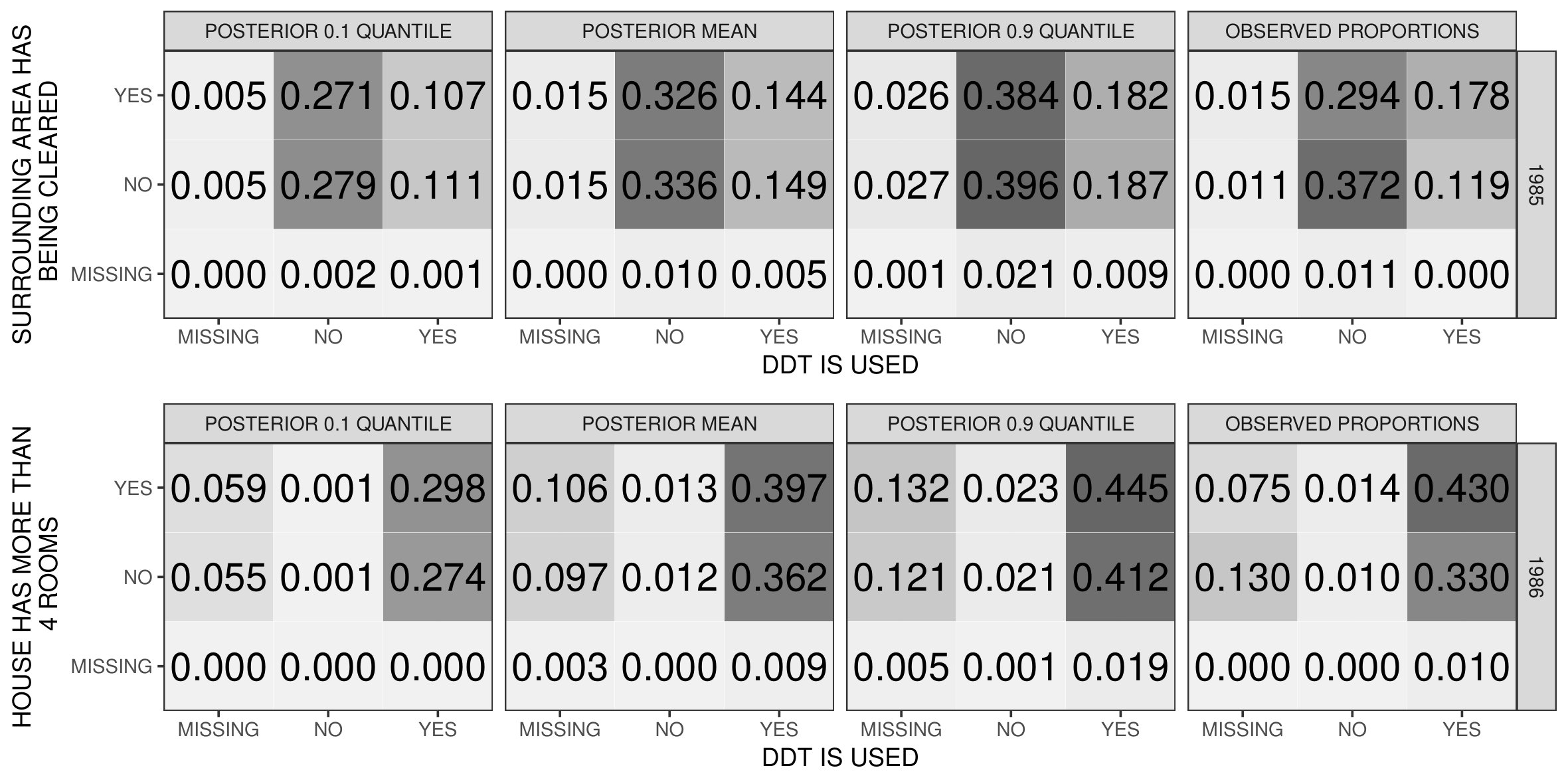 Figure 3
Figure 3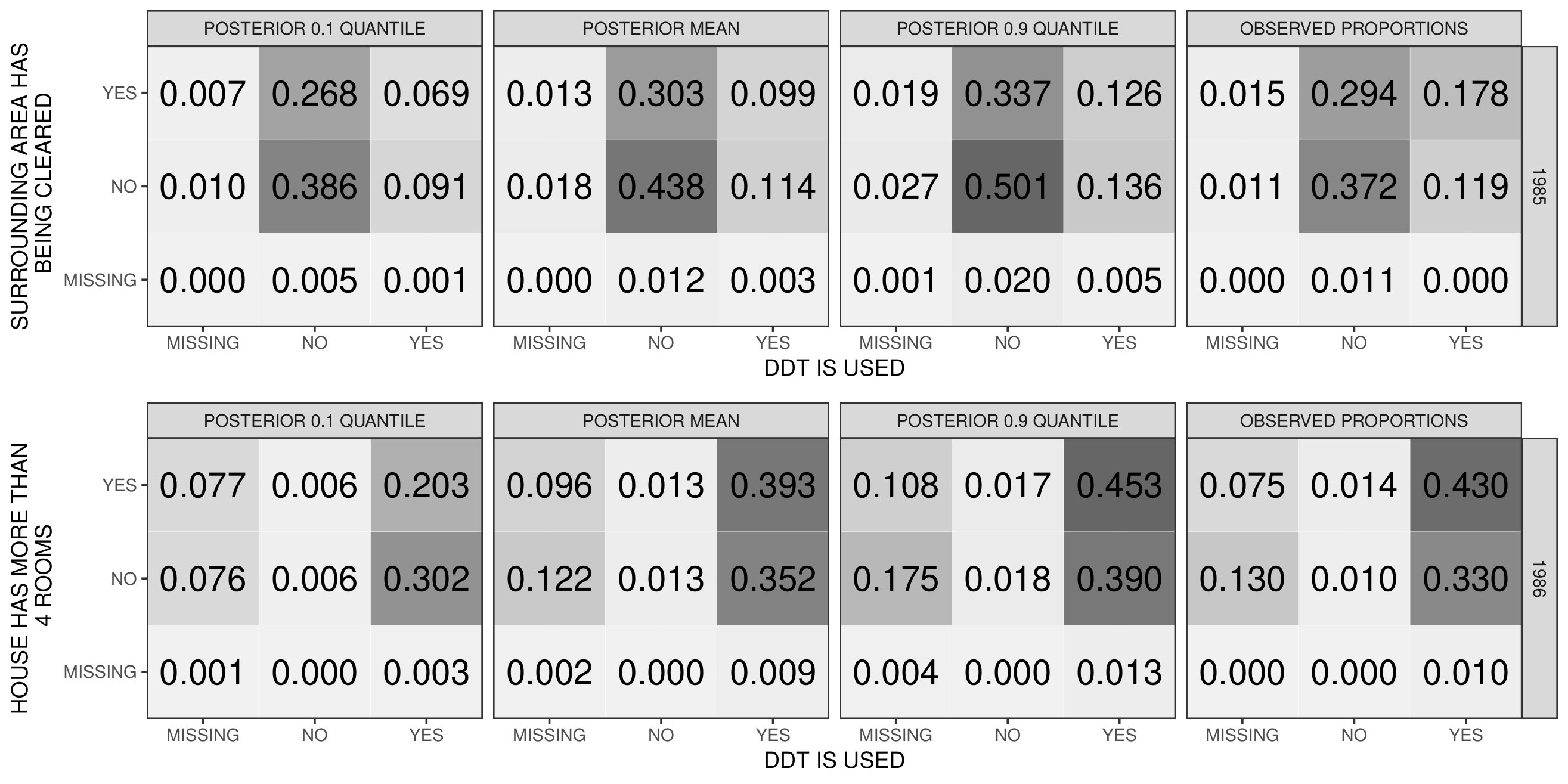 Figure 4
Figure 4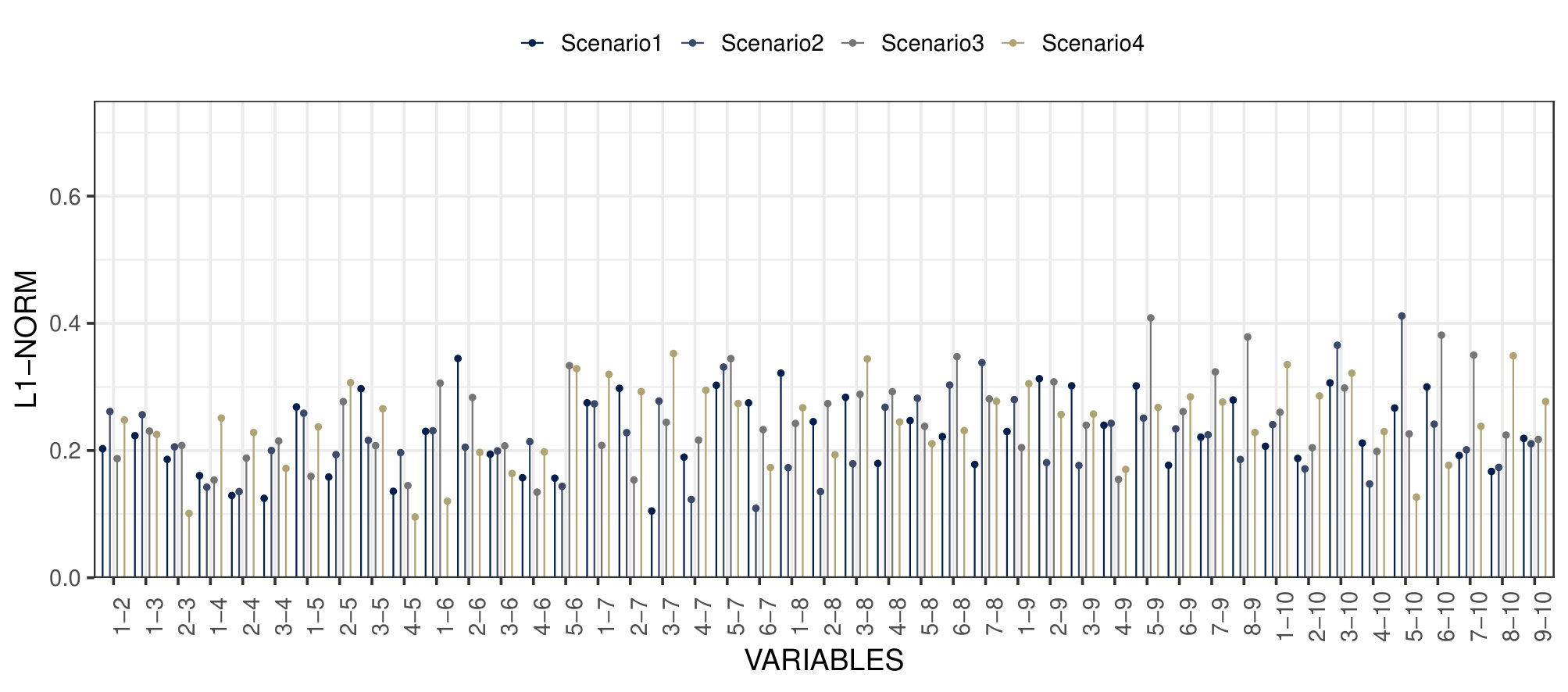 Figure 5
Figure 5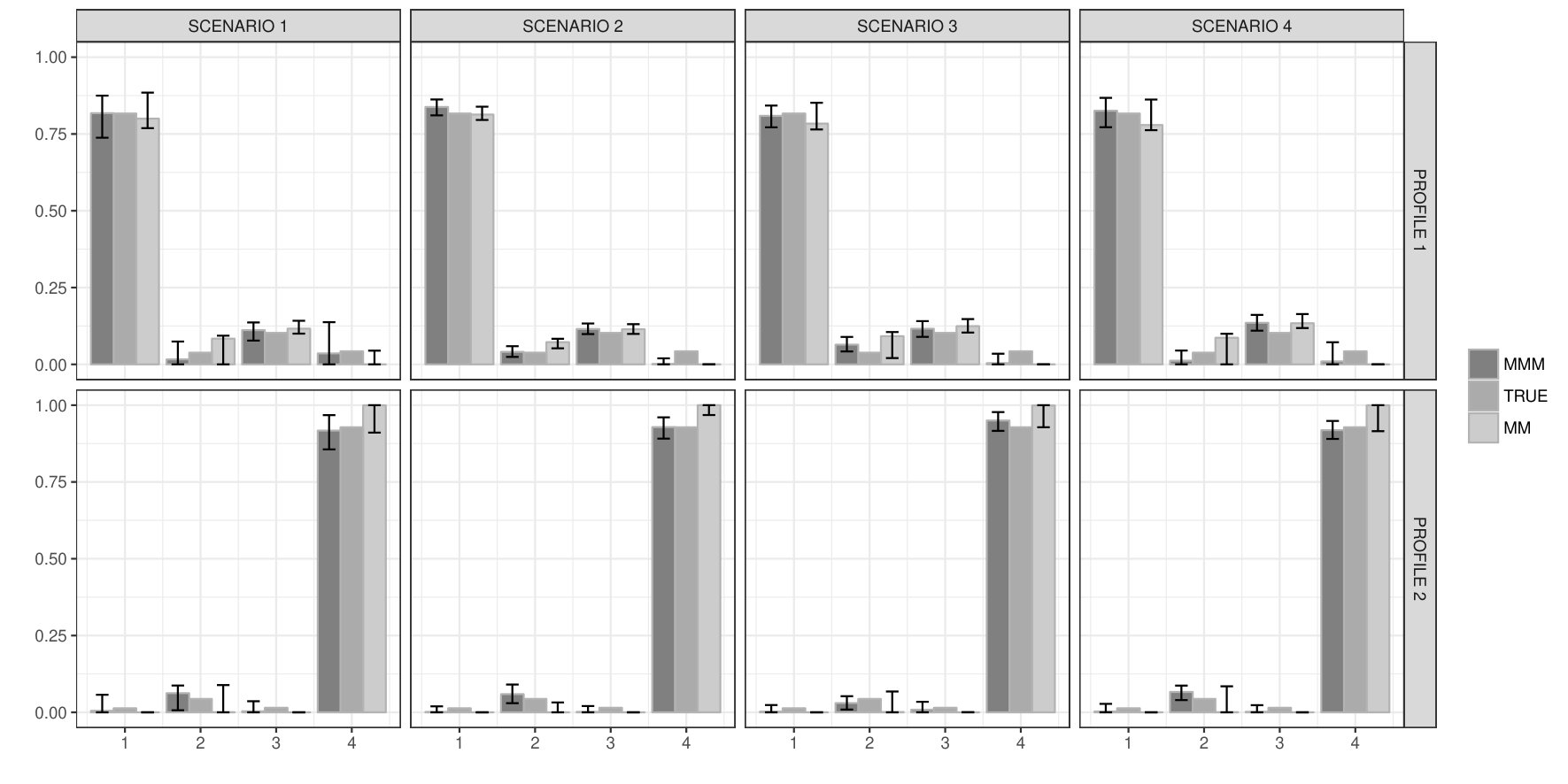 Figure 6
Figure 6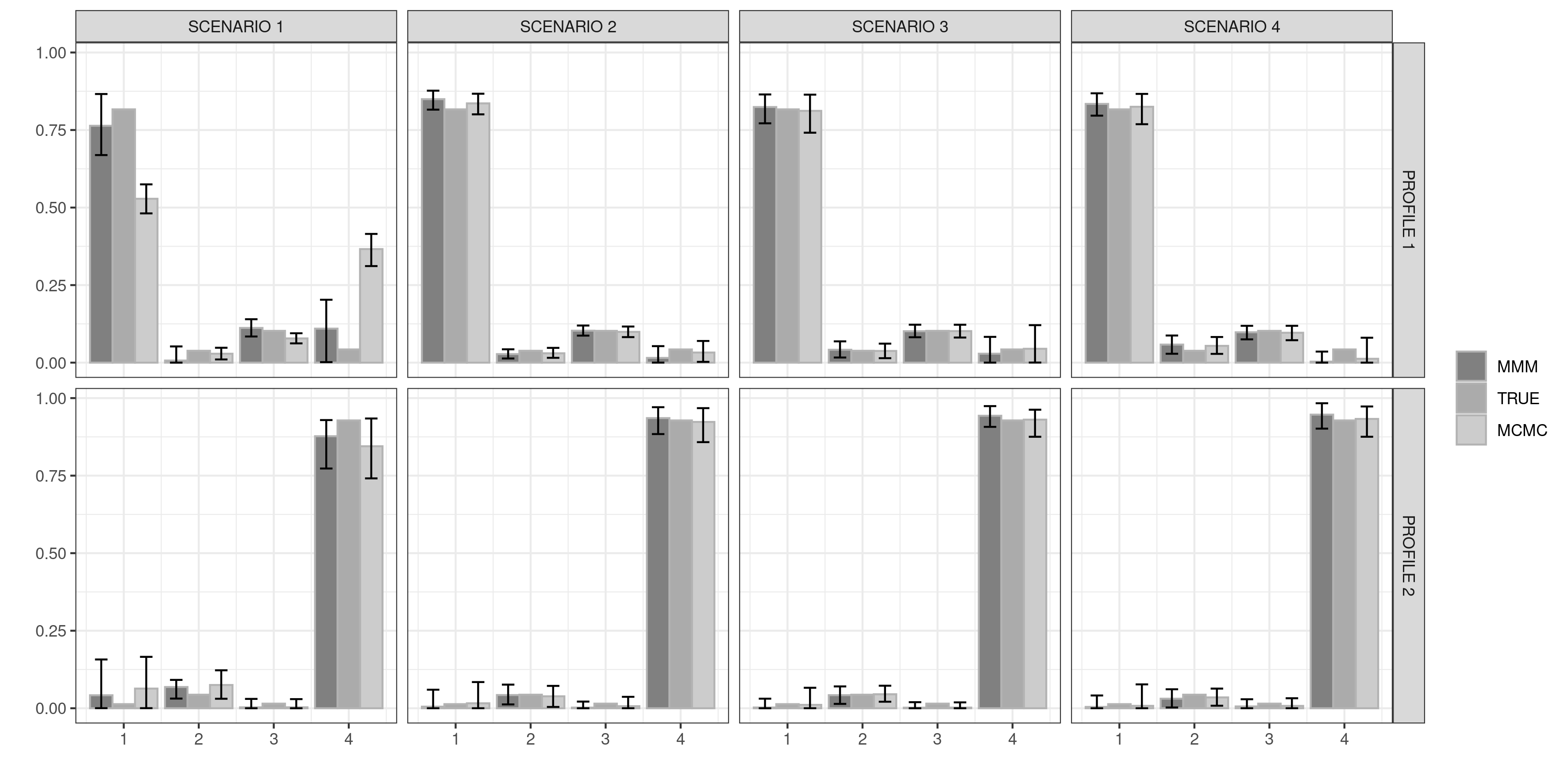 Figure 7
Figure 7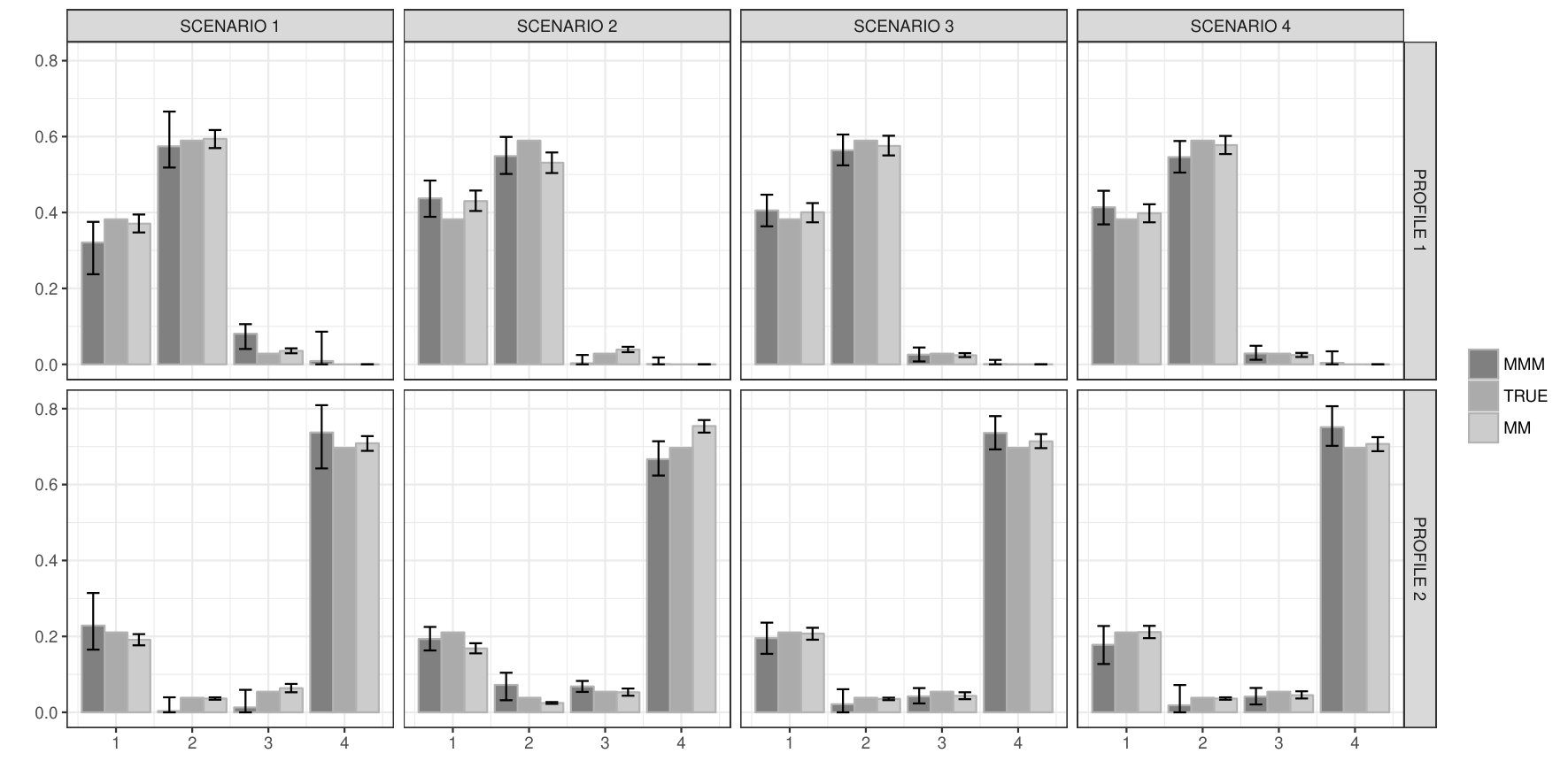 Figure 8
Figure 8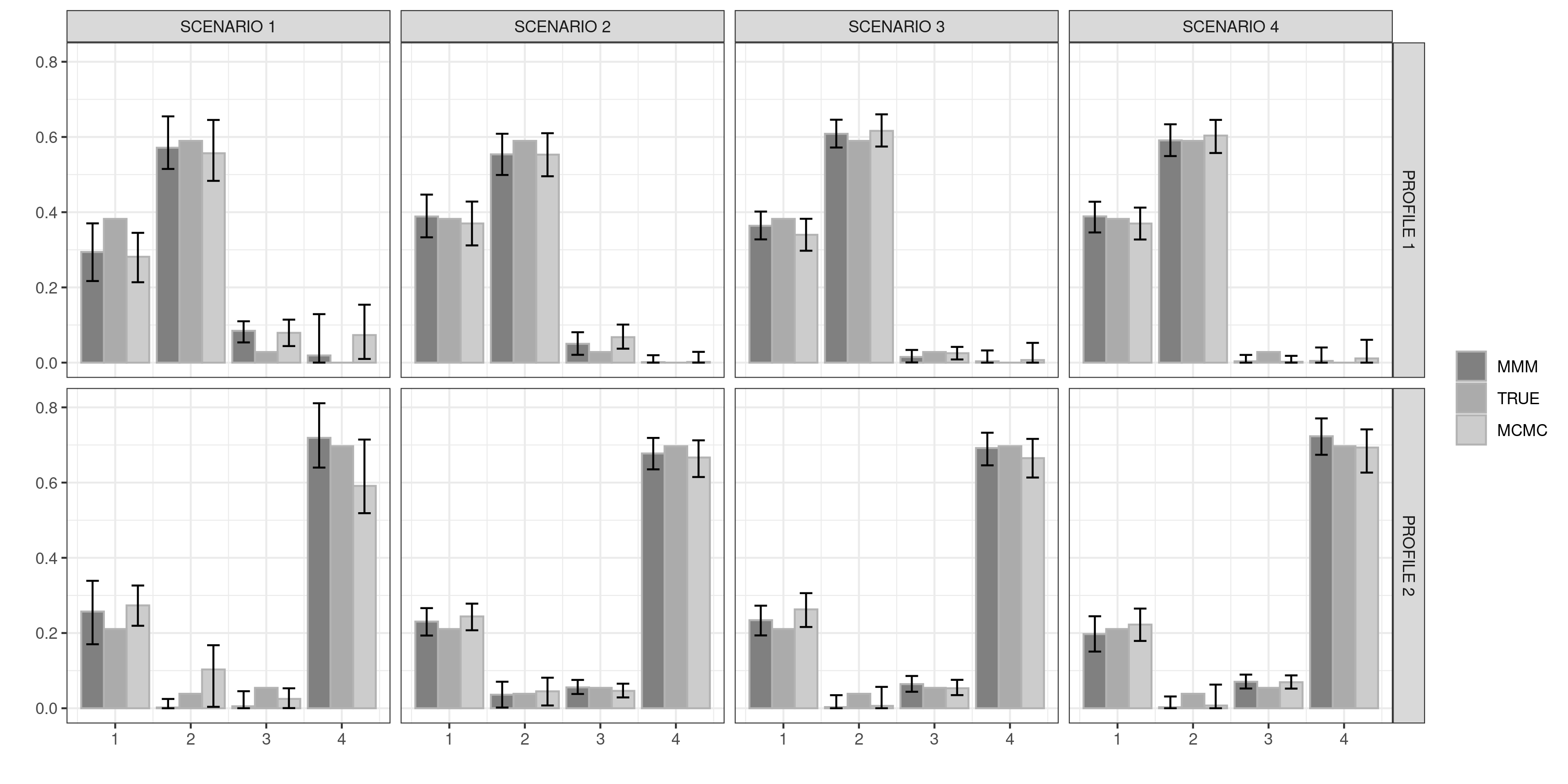 Figure 9
Figure 9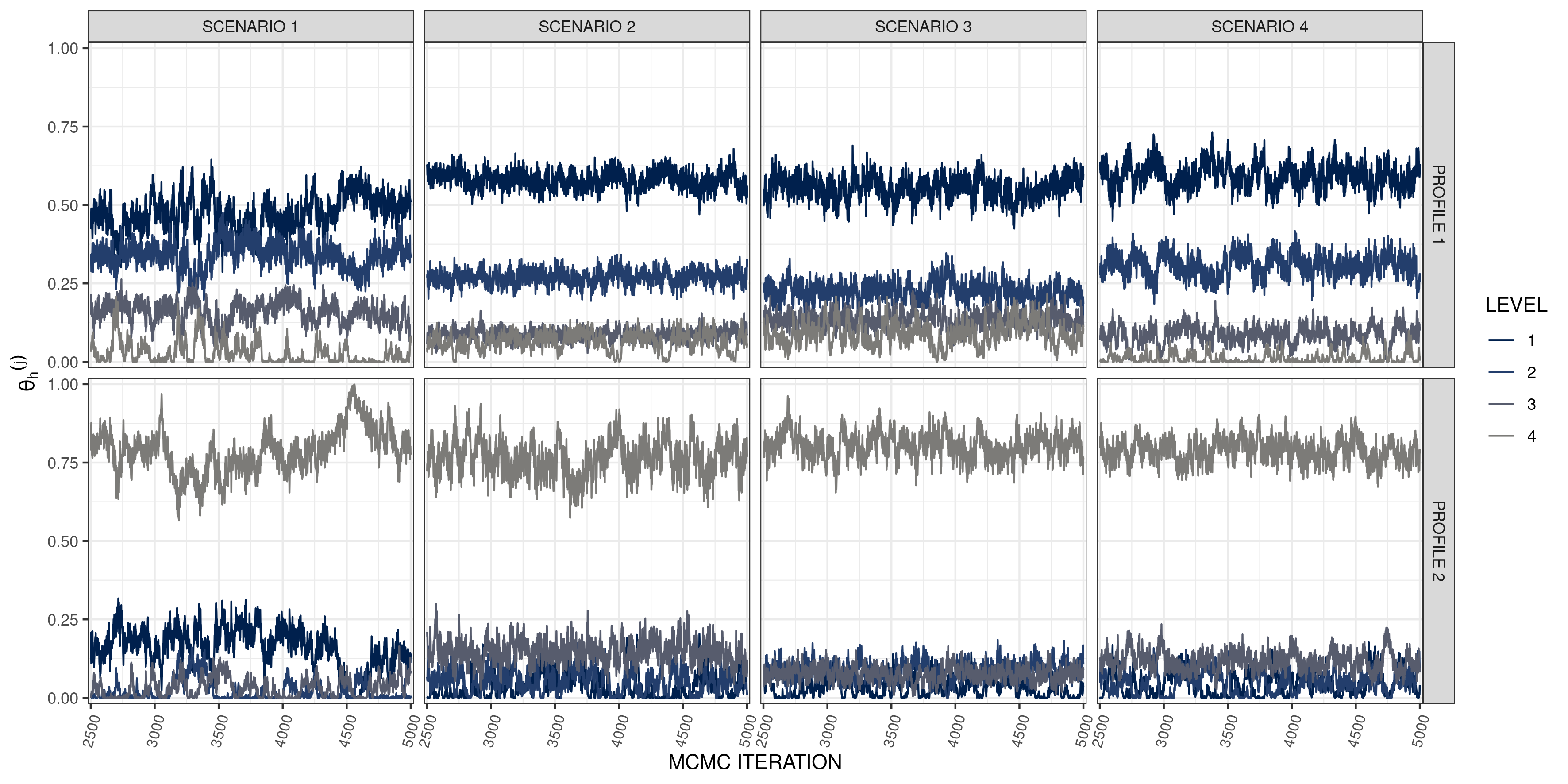 Figure 10
Figure 10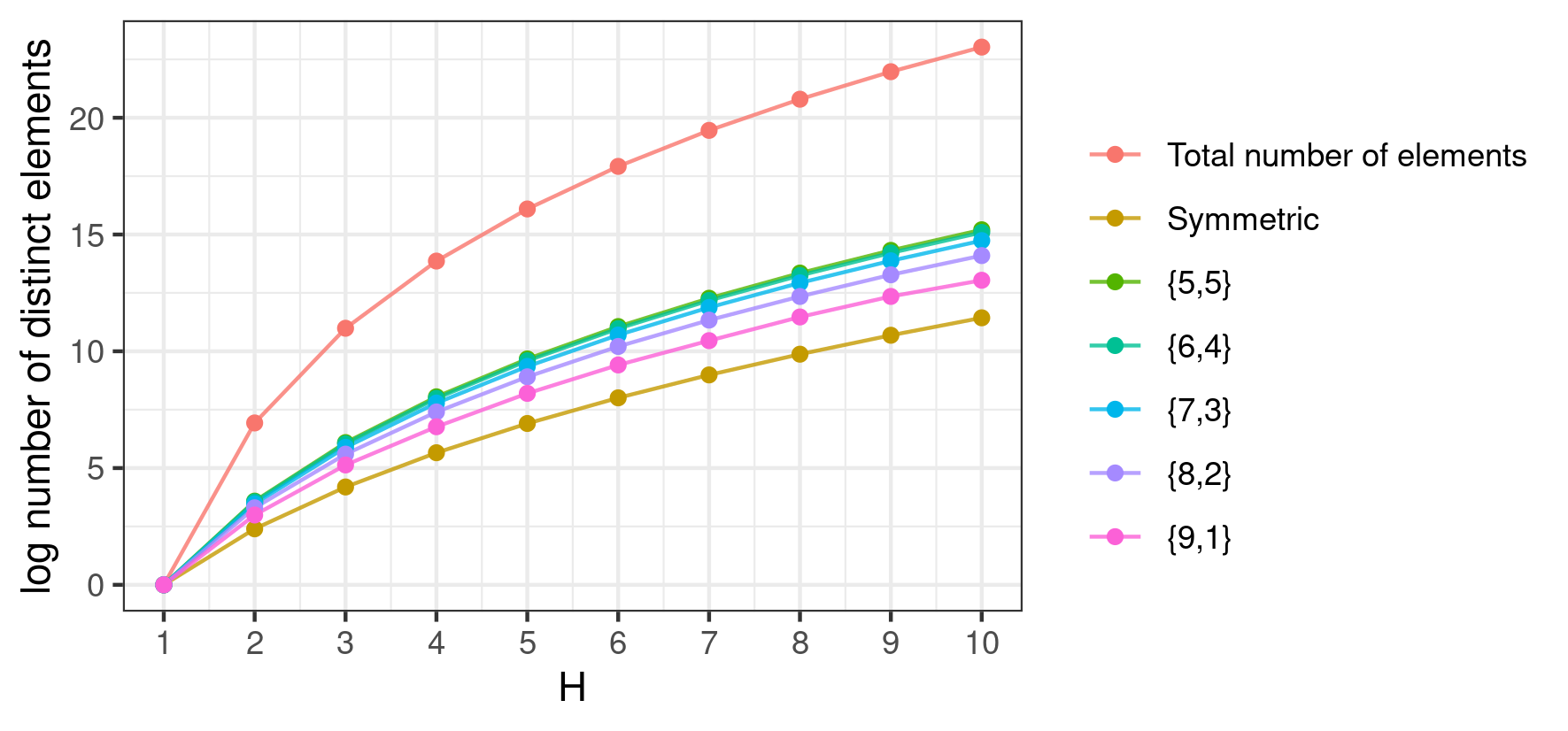 Figure 11
Figure 11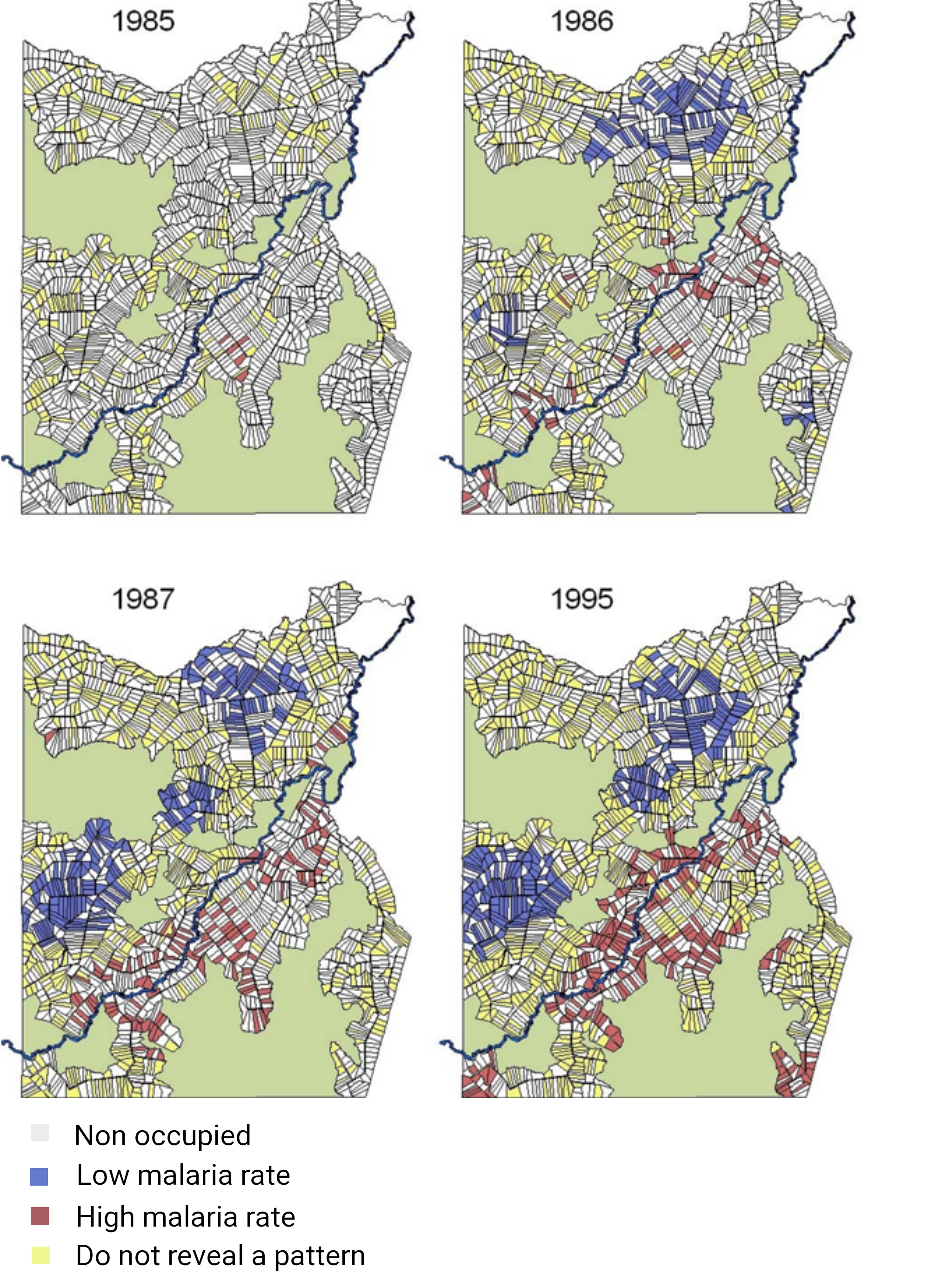 Figure 12
Figure 12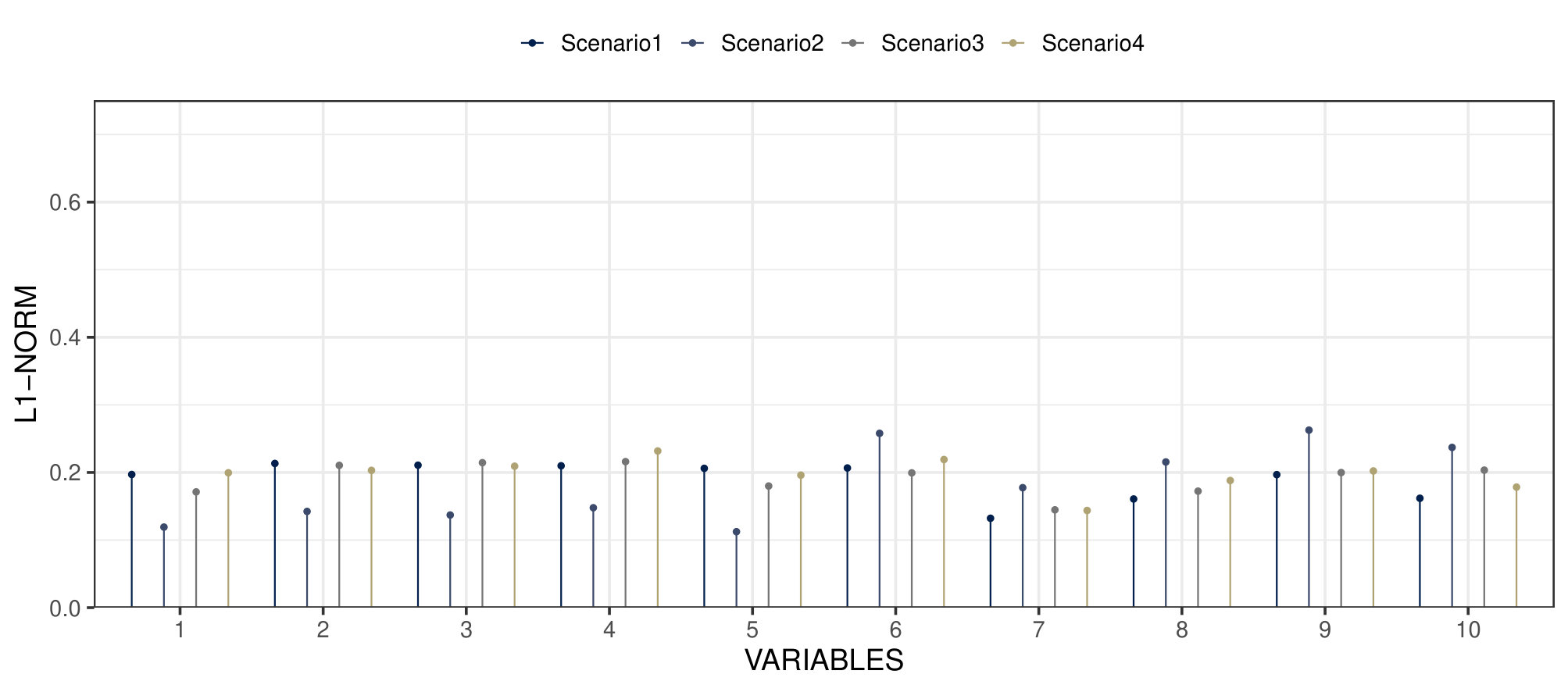 Figure 13
Figure 13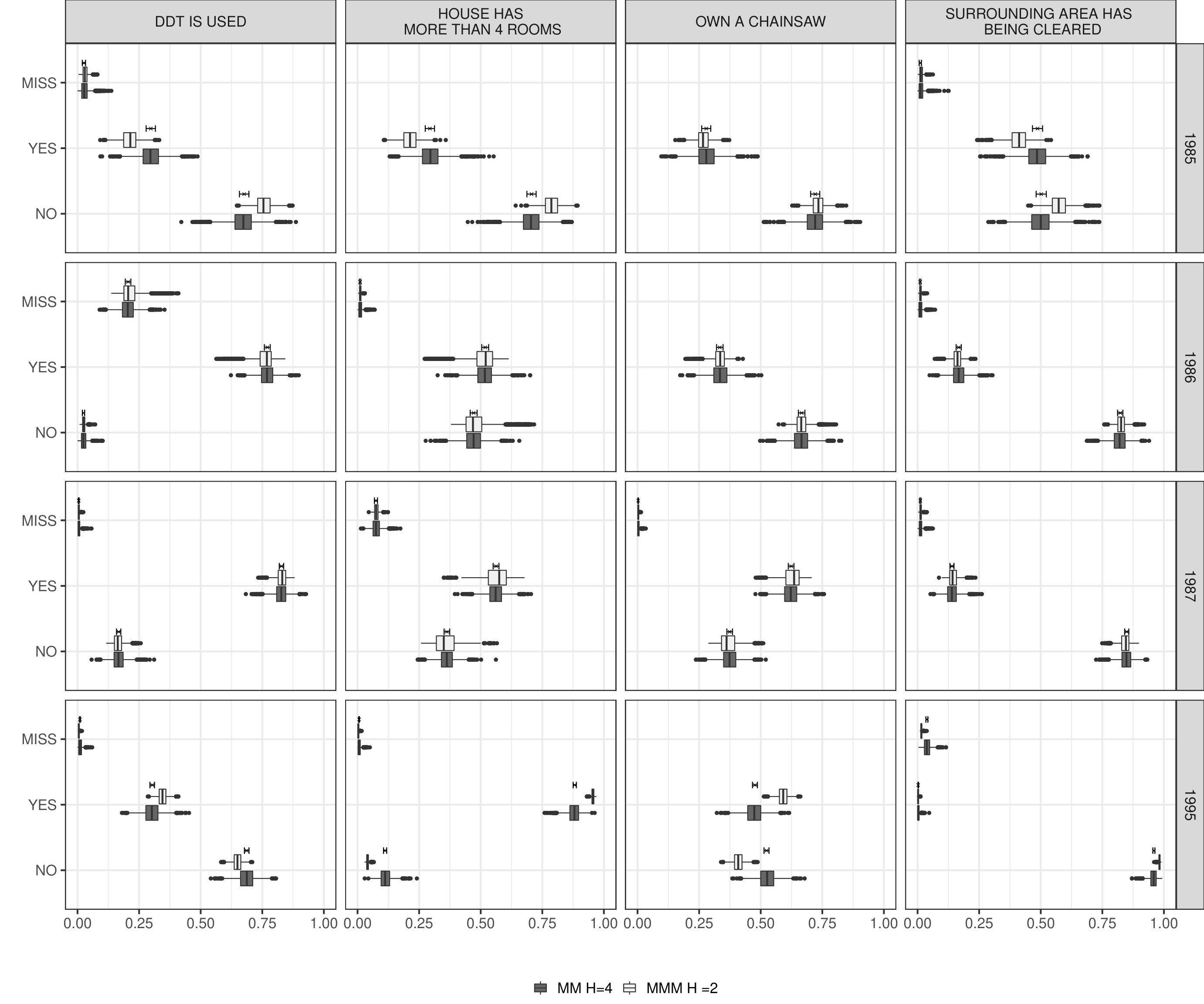 Figure 14
Figure 14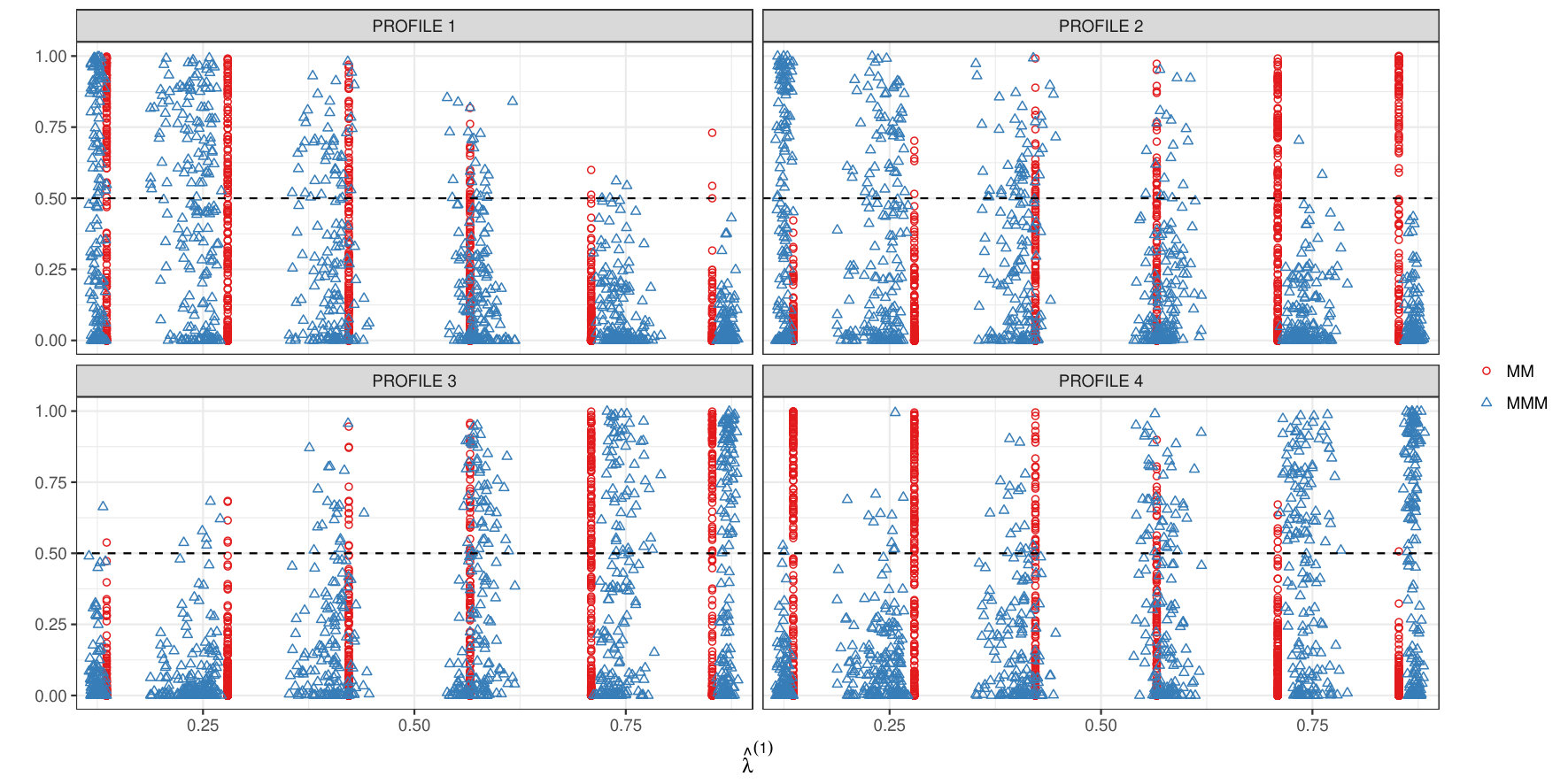 Figure 15
Figure 15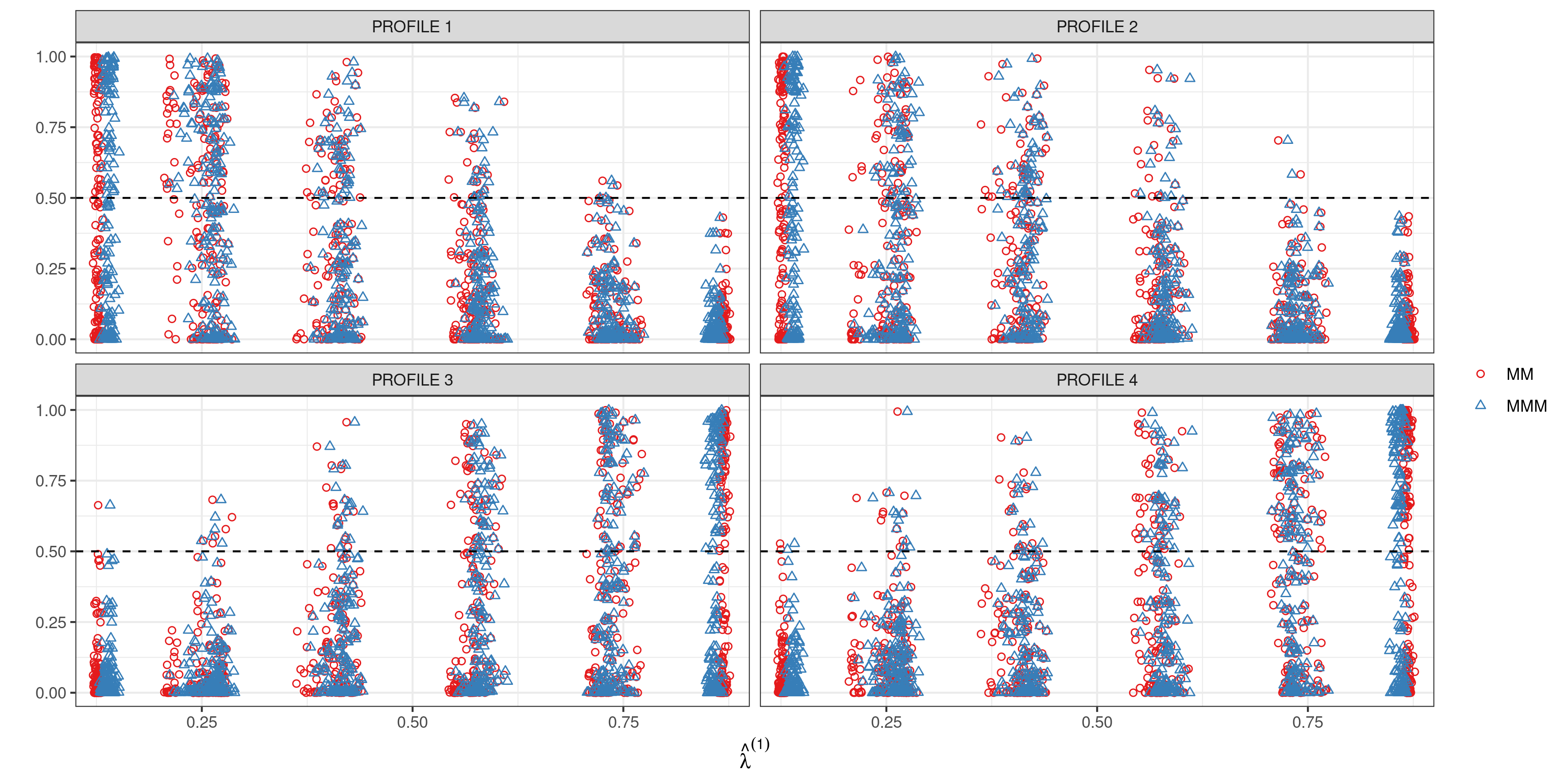 Figure 16
Figure 16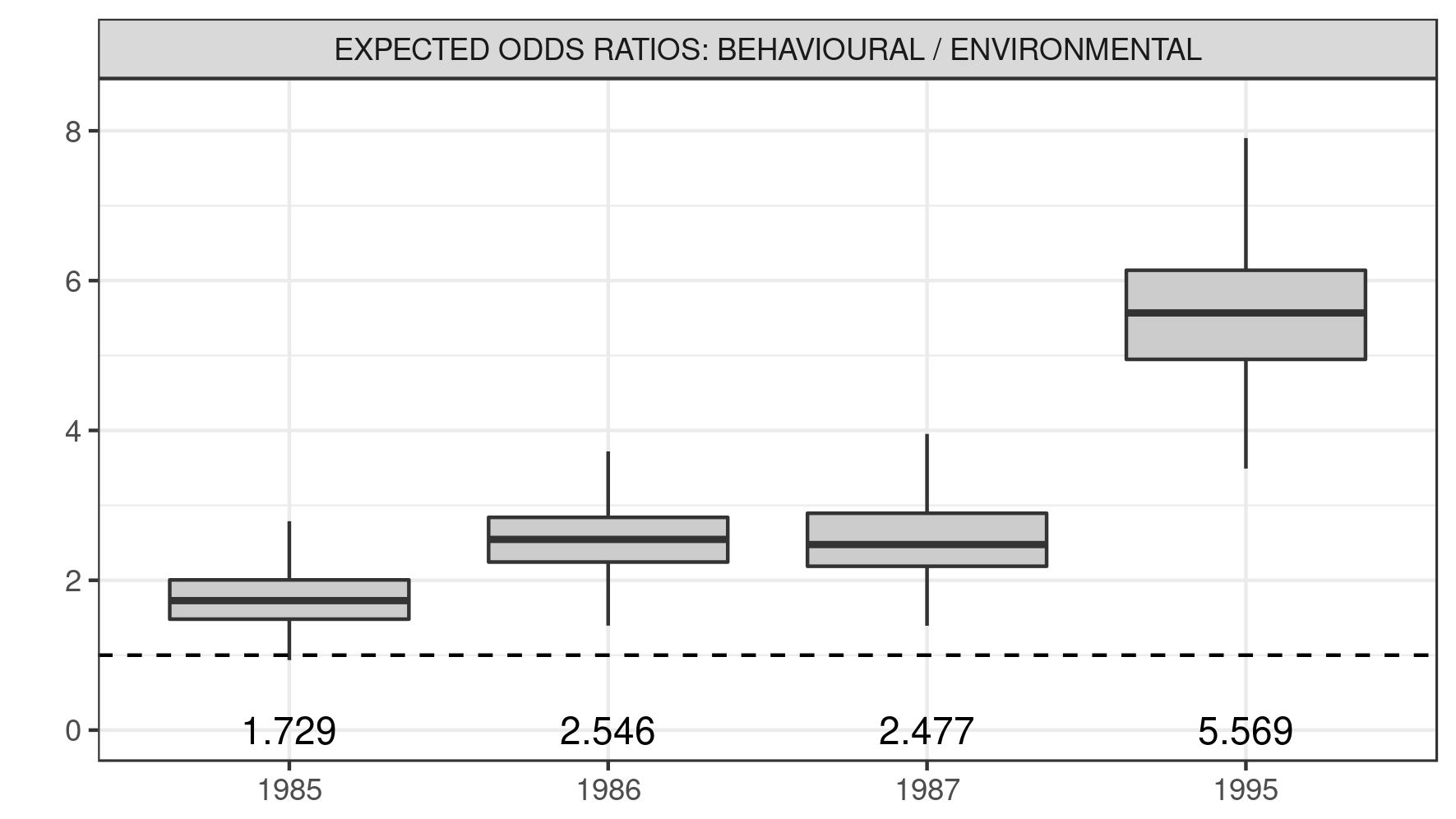 Figure 17
Figure 17 Figure 18
Figure 18| SCENARIO 1 | SCENARIO 2 | SCENARIO 3 | SCENARIO 4 | |
|---|---|---|---|---|
| MMM g = 1 | 0.132(0.096) | 0.126(0.097) | 0.122(0.090) | 0.162(0.106) |
| MMM g = 2 | 0.130(0.094) | 0.134(0.103) | 0.117(0.095) | 0.138(0.105) |
| mixedMem g = 1 | 0.139(0.096) | 0.148(0.110) | 0.174(0.113) | 0.174(0.113) |
| mixedMem g = 2 | 0.140(0.104) | 0.162(0.119) | 0.147(0.108) | 0.141(0.103) |
| LEVEL 1 | LEVEL 2 | LEVEL 3 | LEVEL 4 | |
|---|---|---|---|---|
| MMM | 0.487(0.453;0.521) | 0.491(0.458;0.523) | 0.008(0.000;0.024) | 0.013(0.000;0.037) |
| 0.450 | 0.450 | 0.050 | 0.050 | |
| mixedMem | 0.504 | 0.000 | 0.000 | 0.496 |
| 0.450 | 0.050 | 0.050 | 0.450 | |
| MMM | 0.026(0.000;0.059) | 0.011(0.000;0.032) | 0.449(0.412;0.484) | 0.515(0.478;0.550) |
| 0.050 | 0.050 | 0.450 | 0.450 | |
| mixedMem | 0.000 | 0.533 | 0.467 | 0.000 |
| 00450 | 0.450 | 0.450 | 0.050 |
| Year | # Subjects | # Behavioral variables | # Environmental variables | # Variables |
|---|---|---|---|---|
| 1985 | 269 | 14 | 28 | 42 |
| 1986 | 575 | 16 | 24 | 40 |
| 1987 | 802 | 14 | 29 | 33 |
| 1995 | 1108 | 19 | 36 | 55 |
| Total | 2754 | 63 | 117 | 180 |
| Survey years | ||||||||
| Conditions | ’85 | ’86 | ’87 | ’95 | ||||
| Risk Profiles | ||||||||
| Low | High | Low | High | Low | High | Low | High | |
| House Characteristics | ||||||||
| # rooms 4 | + | - | + | - | + | - | + | * |
| Good quality walls | + | - | + | - | + | - | * | * |
| Good quality roof | + | - | + | - | * | - | * | * |
| Good quality sealing | + | * | * | * | + | * | + | * |
| Land Clearance & Water | ||||||||
| Prior land clearance | * | + | - | + | * | * | * | * |
| 100 m from forest | + | - | + | - | * | * | * | * |
| Good water source available | + | - | + | - | * | - | * | * |
| Good bathing available | * | * | + | * | * | * | * | * |
| Near big pasture area | * | * | + | * | * | * | + | * |
| Code: | stated condition is admissible | |||||||
| stated condition is not admissible | ||||||||
| no level of the condition is admissible | ||||||||
| Note: Additional levels for some other variables are admissible, as indicated in Tables S5–S8 of Acknowledgements. | ||||||||
| 1985 | ||||
|---|---|---|---|---|
| Low B | Med B | High B | ||
| Low E | 0.000(0.000;0.000) | 0.045(0.000;0.197) | —– | 0.000(0.000;0.000) |
| Med E | 0.067(0.000;0.310) | 0.101(0.050;0.143) | 0.115(0.000;0.250) | 0.106(0.067;0.129) |
| High E | —– | 0.115(0.000;0.356) | 0.117(0.100;0.125) | 0.117(0.100;0.125) |
| 0.000(0.000;0.000) | 0.091(0.050;0.125) | 0.117(0.100;0.125) |
| SCENARIO 1 | SCENARIO 2 | SCENARIO 3 | SCENARIO 4 | |
|---|---|---|---|---|
| MMM g = 1 | 0.132(0.096) | 0.126(0.097) | 0.122(0.090) | 0.162(0.106) |
| MMM g = 2 | 0.130(0.094) | 0.134(0.103) | 0.117(0.095) | 0.138(0.105) |
| MM-MCMC g = 1 | 0.233(0.150) | 0.131(0.106) | 0.156(0.111) | 0.157(0.110) |
| MM-MCMC g = 2 | 0.153(0.111) | 0.147(0.118) | 0.147(0.117) | 0.139(0.109) |
| PROFILE 1 | PROFILE 2 | PROFILE 3 | PROFILE 4 | |
|---|---|---|---|---|
| 0.450 | 0.450 | 0.050 | 0.050 | |
| MMM | 0.487(0.453;0.521) | 0.491(0.458;0.523) | 0.008(0.000;0.024) | 0.013(0.000;0.037) |
| MM-MCMC | 0.486 (0.448;0.522) | 0.493 (0.459;0.527) | 0.008 (0.000;0.024) | 0.013 (0.000;0.036) |
| 0.050 | 0.050 | 0.450 | 0.450 | |
| MMM | 0.026(0.000;0.059) | 0.011(0.000;0.032) | 0.449(0.412;0.484) | 0.515(0.478;0.550) |
| MM-MCMC | 0.030 (0.001;0.062) | 0.009 (0.000;0.028) | 0.449 (0.415;0.484) | 0.512 (0.474;0.548) |
| 1985 | 1st tertile | 2nd tertile | 3rd tertile |
|---|---|---|---|
| Score 1 | 0.000 (0.000; 0.685) | 0.100 (0.000; 0.628) | 0.046 (0.000; 0.333) |
| Score 2 | 0.111 (0.000; 0.430) | 0.069 (0.000; 0.571) | 0.271 (0.000; 0.867) |
| Score 3 | 0.100 (0.000; 0.338) | 0.079 (0.000; 0.642) | 0.111 (0.000; 0.333) |
| Score 4 | 0.167 (0.000; 0.862) | 0.074 (0.000; 0.500) | 0.085 (0.000; 0.543) |
| 1986 | 1st tertile | 2nd tertile | 3rd tertile |
| Score 1 | 0.204 (0.000; 0.667) | 0.257 (0.000; 0.750) | 0.198 (0.000; 0.763) |
| Score 2 | 0.292 (0.000; 0.762) | 0.250 (0.000; 0.750) | 0.212 (0.005; 0.768) |
| Score 3 | 0.250 (0.000; 0.691) | 0.250 (0.000; 0.759) | 0.167 (0.000; 0.605) |
| Score 4 | 0.216 (0.026; 0.713) | 0.250 (0.000; 0.750) | 0.231 (0.000; 0.703) |
| 1987 | 1st tertile | 2nd tertile | 3rd tertile |
| Score 1 | 0.167 (0.029; 0.592) | 0.182 (0.000; 0.596) | 0.200 (0.000; 0.606) |
| Score 2 | 0.171 (0.000; 0.598) | 0.194 (0.000; 0.600) | 0.143 (0.000; 0.323) |
| Score 3 | 0.175 (0.012; 0.550) | 0.183 (0.000; 0.600) | 0.181 (0.019; 0.624) |
| Score 4 | 0.167 (0.000; 0.594) | 0.200 (0.000; 0.596) | 0.158 (0.004; 0.671) |
| 1995 | 1st tertile | 2nd tertile | 3rd tertile |
| Score 1 | 0.042 (0.000; 0.206) | 0.028 (0.000; 0.169) | 0.031 (0.000; 0.163) |
| Score 2 | 0.028 (0.000; 0.167) | 0.030 (0.000; 0.180) | 0.032 (0.000; 0.180) |
| Score 3 | 0.028 (0.000; 0.226) | 0.030 (0.000; 0.167) | 0.030 (0.000; 0.209) |
| Score 4 | 0.028 (0.000; 0.180) | 0.030 (0.000; 0.167) | 0.033 (0.000; 0.239) |
| 1985 | ||||||
|---|---|---|---|---|---|---|
| 0000 0.071 (0.014; 0.254) | ||||||
| 1000 0.046 (0.000; 0.410) | 0100 0.134 (0.000; 0.535) | 0010 0.000 (0.000; 0.479) | 0001 0.040 (0.000; 0.808) | |||
| 1100 0.133 (0.000; 0.463) | 1010 0.141 (0.000; 0.654) | 0110 0.081 (0.000; 0.724) | 1001 0.000 ( 0.000; 0.331) | 0101 0.111 (0.000; 0.622) | 0011 0.159 (000; 0751) | |
| 1110 0.100 (0.100; 0.100) | 1101 — | 1011 0.250 (0.050; 0.450) | 0111 0.000 (0.000, 0.000) | |||
| 1111 — |
| Behavioral | ||
|---|---|---|
| Plant Cassava: NO | 0.042(0.006;0.107) | 0.990(0.965;0.999) |
| Plant Cassava: YES | 0.933(0.869;0.972) | 0.003(0.000;0.025) |
| Plant Cassava: MISSING | 0.021(0.004;0.045) | 0.003(0.000;0.017) |
| Lavoura branca: NO | 0.105(0.042;0.178) | 0.993(0.977;0.999) |
| Lavoura branca: YES | 0.888(0.814;0.950) | 0.002(0.000;0.014) |
| Lavoura branca: MISSING | 0.005(0.000;0.021) | 0.002(0.000;0.013) |
| DDT is used: NO | 0.296(0.211;0.383) | 0.952(0.910;0.976) |
| DDT is used: YES | 0.687(0.598;0.774) | 0.007(0.000;0.049) |
| DDT is used: MISSING | 0.013(0.002;0.040) | 0.035(0.016;0.060) |
| Plan to build a new house within a year: NO | 0.562(0.470;0.658) | 0.006(0.000;0.040) |
| Plan to build a new house within a year: YES | 0.343(0.246;0.439) | 0.976(0.936;0.997) |
| Plan to build a new house within a year: MISSING | 0.092(0.052;0.141) | 0.011(0.000;0.038) |
| Arrived in Machadino before 1985: NO | 0.655(0.564;0.745) | 0.034(0.003;0.093) |
| Arrived in Machadino before 1985: YES | 0.345(0.255;0.436) | 0.966(0.907;0.997) |
| Own a planter: NO | 0.138(0.059;0.230) | 0.743(0.674;0.810) |
| Own a planter: YES | 0.862(0.770;0.941) | 0.257(0.190;0.326) |
| Do you own other proprieties: NO | 0.316(0.213;0.411) | 0.761(0.694;0.827) |
| Do you own other proprieties: YES | 0.684(0.589;0.787) | 0.239(0.173;0.306) |
| Lived in current house for more that 1m: NO | 0.580(0.502;0.653) | 0.986(0.963;0.997) |
| Lived in current house for more that 1m: YES | 0.412(0.339;0.488) | 0.002(0.000;0.020) |
| Lived in current house for more that 1m: MISSING | 0.003(0.000;0.024) | 0.009(0.001;0.024) |
| Knowledge of malaria vector: NO | 0.726(0.627;0.819) | 0.330(0.261;0.401) |
| Knowledge of malaria vector: YES | 0.231(0.147;0.330) | 0.495(0.425;0.569) |
| Knowledge of malaria vector: MISSING | 0.029(0.000;0.096) | 0.172(0.125;0.223) |
| Plant cocoa: NO | 0.636(0.559;0.702) | 0.998(0.987;1.000) |
| Plant cocoa: YES | 0.364(0.298;0.441) | 0.002(0.000;0.013) |
| Own more the 4 goods: NO | 0.153(0.072;0.242) | 0.514(0.445;0.589) |
| Own more the 4 goods: YES | 0.847(0.758;0.928) | 0.486(0.411;0.555) |
| Plant coffee: NO | 0.662(0.585;0.728) | 0.993(0.979;0.999) |
| Plant coffee: YES | 0.332(0.267;0.407) | 0.001(0.000;0.009) |
| Plant coffee: MISSING | 0.002(0.000;0.017) | 0.004(0.000;0.014) |
| Do you often go to surrounding cities: NO | 0.003(0.000;0.035) | 0.328(0.274;0.383) |
| Do you often go to surrounding cities: YES | 0.975(0.940;0.992) | 0.669(0.613;0.723) |
| Do you often go to surrounding cities: MISSING | 0.017(0.004;0.038) | 0.001(0.000;0.009) |
| HH has high level of education: NO | 0.682(0.581;0.784) | 0.411(0.338;0.487) |
| HH has high level of education: YES | 0.302(0.199;0.403) | 0.558(0.480;0.630) |
| HH has high level of education: MISSING | 0.010(0.000;0.042) | 0.029(0.010;0.053) |
| Own chickens and/or porks: NO | 0.681(0.590;0.765) | 0.929(0.876;0.981) |
| Own chickens and/or porks: YES | 0.311(0.227;0.401) | 0.067(0.015;0.120) |
| Own chickens and/or porks: MISSING | 0.005(0.000;0.021) | 0.002(0.000;0.012) |
| HH wife has high level of education: 4 yr | 0.551(0.451;0.655) | 0.452(0.380;0.524) |
| HH wife has high level of education: 4 yr | 0.279(0.190;0.375) | 0.476(0.407;0.549) |
| HH wife has high level of education: NO-WIFE | 0.013(0.000;0.062) | 0.036(0.006;0.065) |
| HH wife has high level of education: MISSING | 0.141(0.075;0.208) | 0.028(0.000;0.078) |
| More than 4 people in the house: NO | 0.652(0.545;0.753) | 0.418(0.344;0.491) |
| More than 4 people in the house: YES | 0.348(0.247;0.455) | 0.582(0.509;0.656) |
| Spray insecticide: NO | 0.647(0.553;0.738) | 0.841(0.779;0.897) |
| Spray insecticide: YES | 0.353(0.262;0.447) | 0.159(0.103;0.221) |
| Get malaria from dirty water: NO | 0.333(0.240;0.430) | 0.472(0.399;0.546) |
| Get malaria from dirty water: YES | 0.590(0.496;0.689) | 0.427(0.351;0.497) |
| Get malaria from dirty water: MISSING | 0.070(0.031;0.124) | 0.100(0.064;0.143) |
| Use plant to cure malaria: NO | 0.700(0.604;0.794) | 0.634(0.564;0.705) |
| Use plant to cure malaria: YES | 0.088(0.013;0.171) | 0.235(0.175;0.302) |
| Use plant to cure malaria: MISSING | 0.206(0.138;0.287) | 0.127(0.081;0.180) |
| Own a chainsaw: NO | 0.650(0.558;0.736) | 0.770(0.705;0.828) |
| Own a chainsaw: YES | 0.350(0.264;0.442) | 0.230(0.172;0.295) |
| Use a bednet: NO | 0.847(0.758;0.934) | 0.762(0.695;0.823) |
| Use a bednet: YES | 0.136(0.048;0.222) | 0.220(0.162;0.286) |
| Use a bednet: MISSING | 0.014(0.000;0.044) | 0.015(0.001;0.034) |
| Use repellent: NO | 0.984(0.940;0.999) | 0.862(0.820;0.900) |
| Use repellent: YES | 0.016(0.001;0.060) | 0.138(0.100;0.180) |
| Part of family did not come: NO | 0.653(0.561;0.752) | 0.640(0.568;0.711) |
| Part of family did not come: YES | 0.317(0.222;0.409) | 0.351(0.280;0.422) |
| Part of family did not come: MISSING | 0.026(0.002;0.055) | 0.004(0.000;0.027) |
| Do you ever go to urban area?: NO | 0.003(0.000;0.027) | 0.090(0.062;0.124) |
| Do you ever go to urban area?: YES | 0.979(0.949;0.995) | 0.905(0.869;0.934) |
| Do you ever go to urban area?: MISSING | 0.013(0.001;0.034) | 0.002(0.000;0.015) |
| Arrived in Rondonia before 1985: NO | 0.943(0.897;0.984) | 0.975(0.940;0.994) |
| Arrived in Rondonia before 1985: YES | 0.002(0.000;0.013) | 0.005(0.000;0.016) |
| Arrived in Rondonia before 1985: MISSING | 0.053(0.013;0.097) | 0.017(0.001;0.051) |
| Before coming was your occupation rural: NO | 0.001(0.000;0.008) | 0.001(0.000;0.006) |
| Before coming was your occupation rural: YES | 0.994(0.975;1.000) | 0.982(0.963;0.994) |
| Before coming was your occupation rural: MISSING | 0.003(0.000;0.020) | 0.016(0.005;0.034) |
| Are there rubber tree: NO | 0.982(0.960;0.995) | 0.998(0.988;1.000) |
| Are there rubber tree: YES | 0.018(0.005;0.040) | 0.002(0.000;0.012) |
| Behavioral | ||
|---|---|---|
| Plant coffee: NO | 0.115(0.068;0.161) | 0.957(0.915;0.977) |
| Plant coffee: YES | 0.882(0.837;0.930) | 0.005(0.000;0.052) |
| Plant coffee: MISSING | 0.001(0.000;0.006) | 0.031(0.017;0.050) |
| Cultivate rice: NO | 0.007(0.000;0.041) | 0.743(0.661;0.835) |
| Cultivate rice: YES | 0.988(0.956;0.999) | 0.213(0.115;0.294) |
| Cultivate rice: MISSING | 0.001(0.000;0.009) | 0.044(0.026;0.068) |
| Own a planter: NO | 0.060(0.008;0.111) | 0.710(0.624;0.805) |
| Own a planter: YES | 0.940(0.889;0.992) | 0.290(0.195;0.376) |
| Own chickens and/or porks: NO | 0.001(0.000;0.012) | 0.566(0.498;0.635) |
| Own chickens and/or porks: YES | 0.997(0.985;1.000) | 0.408(0.338;0.479) |
| Own chickens and/or porks: MISSING | 0.001(0.000;0.006) | 0.023(0.011;0.041) |
| DDT is used: NO | 0.024(0.005;0.042) | 0.022(0.001;0.061) |
| DDT is used: YES | 0.969(0.948;0.991) | 0.399(0.321;0.467) |
| DDT is used: MISSING | 0.003(0.000;0.020) | 0.574(0.508;0.650) |
| More than 4 people in the house: NO | 0.723(0.671;0.772) | 0.148(0.062;0.239) |
| More than 4 people in the house: YES | 0.277(0.228;0.329) | 0.852(0.761;0.938) |
| Own more the 4 goods: NO | 0.032(0.002;0.078) | 0.601(0.522;0.693) |
| Own more the 4 goods: YES | 0.968(0.922;0.998) | 0.399(0.307;0.478) |
| Plant cocoa: NO | 0.424(0.379;0.468) | 0.971(0.930;0.989) |
| Plant cocoa: YES | 0.573(0.529;0.619) | 0.006(0.000;0.052) |
| Plant cocoa: MISSING | 0.001(0.000;0.007) | 0.017(0.006;0.033) |
| Are there rubber tree: NO | 0.528(0.485;0.570) | 0.980(0.960;0.993) |
| Are there rubber tree: YES | 0.469(0.428;0.512) | 0.001(0.000;0.015) |
| Are there rubber tree: MISSING | 0.001(0.000;0.008) | 0.016(0.005;0.031) |
| Before coming was your occupation rural: NO | 0.820(0.770;0.871) | 0.364(0.283;0.449) |
| Before coming was your occupation rural: YES | 0.176(0.127;0.227) | 0.633(0.548;0.714) |
| Before coming was your occupation rural: MISSING | 0.002(0.000;0.007) | 0.001(0.000;0.008) |
| Do you own other proprieties: NO | 0.401(0.350;0.455) | 0.851(0.773;0.926) |
| Do you own other proprieties: YES | 0.599(0.545;0.650) | 0.149(0.074;0.227) |
| Lived in current house for more that 1m: NO | 0.524(0.478;0.571) | 0.931(0.863;0.964) |
| Lived in current house for more that 1m: YES | 0.473(0.427;0.519) | 0.024(0.000;0.095) |
| Lived in current house for more that 1m: MISSING | 0.001(0.000;0.007) | 0.041(0.025;0.063) |
| Plan to build a new house within a year: NO | 0.689(0.635;0.740) | 0.267(0.183;0.354) |
| Plan to build a new house within a year: YES | 0.268(0.219;0.320) | 0.627(0.540;0.716) |
| Plan to build a new house within a year: MISSING | 0.041(0.010;0.074) | 0.103(0.053;0.162) |
| HH wife has high level of education: 4 yr | 0.525(0.474;0.575) | 0.235(0.150;0.316) |
| HH wife has high level of education: 4 yr | 0.454(0.405;0.506) | 0.348(0.264;0.429) |
| HH wife has high level of education: NO-WIFE | 0.010(0.000;0.022) | 0.008(0.000;0.034) |
| HH wife has high level of education: MISSING | 0.003(0.000;0.029) | 0.406(0.343;0.471) |
| Working in the plot from more than 1 month: NO | 0.001(0.000;0.014) | 0.392(0.335;0.453) |
| Working in the plot from more than 1 month: YES | 0.966(0.945;0.983) | 0.568(0.504;0.630) |
| Working in the plot from more than 1 month: MISSING | 0.030(0.014;0.048) | 0.037(0.012;0.072) |
| Part of family did not come: NO | 0.750(0.698;0.799) | 0.348(0.265;0.432) |
| Part of family did not come: YES | 0.247(0.199;0.299) | 0.570(0.487;0.654) |
| Part of family did not come: MISSING | 0.001(0.000;0.007) | 0.081(0.057;0.109) |
| Own a chainsaw: NO | 0.540(0.488;0.594) | 0.888(0.813;0.963) |
| Own a chainsaw: YES | 0.460(0.406;0.512) | 0.112(0.037;0.187) |
| Spray insecticide: NO | 0.549(0.496;0.601) | 0.795(0.709;0.874) |
| Spray insecticide: YES | 0.444(0.391;0.496) | 0.192(0.109;0.279) |
| Spray insecticide: MISSING | 0.007(0.000;0.017) | 0.011(0.001;0.029) |
| Knowledge of malaria vector: NO | 0.472(0.421;0.523) | 0.386(0.305;0.469) |
| Knowledge of malaria vector: YES | 0.298(0.251;0.346) | 0.406(0.329;0.488) |
| Knowledge of malaria vector: MISSING | 0.229(0.186;0.273) | 0.206(0.140;0.275) |
| Arrived in Machadino before 1985: NO | 0.228(0.191;0.270) | 0.085(0.032;0.147) |
| Arrived in Machadino before 1985: YES | 0.772(0.730;0.809) | 0.915(0.853;0.968) |
| Get malaria from dirty water: NO | 0.417(0.369;0.467) | 0.332(0.252;0.409) |
| Get malaria from dirty water: YES | 0.535(0.486;0.583) | 0.639(0.562;0.721) |
| Get malaria from dirty water: MISSING | 0.047(0.027;0.068) | 0.025(0.001;0.058) |
| Arrived in Rondonia before 1985: NO | 0.860(0.833;0.889) | 0.884(0.838;0.918) |
| Arrived in Rondonia before 1985: YES | 0.001(0.000;0.006) | 0.096(0.070;0.128) |
| Arrived in Rondonia before 1985: MISSING | 0.137(0.110;0.165) | 0.014(0.000;0.057) |
| Use plant to cure malaria: NO | 0.814(0.770;0.858) | 0.918(0.847;0.989) |
| Use plant to cure malaria: YES | 0.177(0.134;0.219) | 0.076(0.006;0.147) |
| Use plant to cure malaria: MISSING | 0.009(0.002;0.017) | 0.002(0.000;0.015) |
| HH has high level of education: NO | 0.522(0.472;0.570) | 0.428(0.350;0.505) |
| HH has high level of education: YES | 0.473(0.424;0.523) | 0.559(0.481;0.636) |
| HH has high level of education: MISSING | 0.003(0.000;0.014) | 0.011(0.000;0.028) |
| Behavioral | ||
|---|---|---|
| Plant coffee: NO | 0.002(0.000;0.014) | 0.883(0.799;0.936) |
| Plant coffee: YES | 0.994(0.981;0.999) | 0.043(0.001;0.132) |
| Plant coffee: MISSING | 0.002(0.000;0.009) | 0.068(0.042;0.099) |
| Plant banana: NO | 0.001(0.000;0.008) | 0.664(0.588;0.756) |
| Plant banana: YES | 0.998(0.990;1.000) | 0.248(0.145;0.328) |
| Plant banana: MISSING | 0.000(0.000;0.004) | 0.088(0.062;0.121) |
| Own more the 4 goods: NO | 0.002(0.000;0.012) | 0.750(0.669;0.833) |
| Own more the 4 goods: YES | 0.998(0.988;1.000) | 0.250(0.167;0.331) |
| Own a chainsaw: NO | 0.206(0.174;0.242) | 0.944(0.833;0.995) |
| Own a chainsaw: YES | 0.792(0.756;0.824) | 0.051(0.001;0.161) |
| Own a chainsaw: MISSING | 0.002(0.000;0.006) | 0.003(0.000;0.015) |
| More than 4 people in the house: NO | 0.621(0.590;0.652) | 0.004(0.000;0.041) |
| More than 4 people in the house: YES | 0.298(0.267;0.331) | 0.990(0.953;0.999) |
| More than 4 people in the house: MISSING | 0.080(0.066;0.095) | 0.001(0.000;0.014) |
| Plan to build a new house within a year: NO | 0.822(0.787;0.858) | 0.219(0.115;0.324) |
| Plan to build a new house within a year: YES | 0.172(0.136;0.208) | 0.740(0.634;0.843) |
| Plan to build a new house within a year: MISSING | 0.004(0.000;0.014) | 0.042(0.014;0.071) |
| Own chickens and/or porks: NO | 0.001(0.000;0.005) | 0.413(0.351;0.478) |
| Own chickens and/or porks: YES | 0.999(0.994;1.000) | 0.399(0.323;0.471) |
| Own chickens and/or porks: MISSING | 0.000(0.000;0.002) | 0.187(0.147;0.231) |
| HH wife has high level of education: 4 yr | 0.570(0.533;0.607) | 0.088(0.002;0.190) |
| HH wife has high level of education: 4 yr | 0.398(0.365;0.434) | 0.309(0.217;0.398) |
| HH wife has high level of education: NO-WIFE | 0.001(0.000;0.008) | 0.051(0.027;0.077) |
| HH wife has high level of education: MISSING | 0.027(0.003;0.054) | 0.547(0.462;0.629) |
| Plant cocoa: NO | 0.452(0.421;0.483) | 0.942(0.914;0.962) |
| Plant cocoa: YES | 0.547(0.516;0.577) | 0.002(0.000;0.015) |
| Plant cocoa: MISSING | 0.000(0.000;0.004) | 0.053(0.034;0.078) |
| Do you go often to urban area: NO | 0.429(0.393;0.468) | 0.802(0.695;0.892) |
| Do you go often to urban area: YES | 0.535(0.496;0.573) | 0.108(0.009;0.215) |
| Do you go often to urban area: MISSING | 0.035(0.021;0.050) | 0.090(0.048;0.138) |
| Do you own other proprieties: NO | 0.487(0.453;0.523) | 0.887(0.798;0.971) |
| Do you own other proprieties: YES | 0.513(0.477;0.547) | 0.113(0.029;0.202) |
| Arrived in Rondonia before 1985: NO | 0.956(0.934;0.976) | 0.574(0.496;0.656) |
| Arrived in Rondonia before 1985: YES | 0.023(0.006;0.044) | 0.369(0.293;0.451) |
| Arrived in Rondonia before 1985: MISSING | 0.020(0.009;0.032) | 0.053(0.019;0.094) |
| DDT is used: NO | 0.091(0.066;0.119) | 0.419(0.335;0.508) |
| DDT is used: YES | 0.907(0.880;0.933) | 0.560(0.471;0.646) |
| DDT is used: MISSING | 0.000(0.000;0.004) | 0.019(0.006;0.036) |
| Before coming was your occupation rural: NO | 0.800(0.765;0.836) | 0.452(0.354;0.555) |
| Before coming was your occupation rural: YES | 0.200(0.164;0.235) | 0.548(0.445;0.646) |
| Use plant to cure malaria: NO | 0.448(0.410;0.485) | 0.782(0.676;0.884) |
| Use plant to cure malaria: YES | 0.538(0.499;0.576) | 0.198(0.099;0.307) |
| Use plant to cure malaria: MISSING | 0.015(0.005;0.024) | 0.011(0.000;0.049) |
| Use protective clothes: NO | 0.855(0.823;0.884) | 0.514(0.412;0.603) |
| Use protective clothes: YES | 0.137(0.108;0.167) | 0.294(0.211;0.392) |
| Use protective clothes: MISSING | 0.005(0.000;0.021) | 0.190(0.137;0.245) |
| Spray insecticide: NO | 0.603(0.569;0.640) | 0.917(0.815;0.991) |
| Spray insecticide: YES | 0.397(0.360;0.431) | 0.083(0.009;0.185) |
| Are there rubber tree: NO | 0.693(0.667;0.719) | 0.942(0.913;0.963) |
| Are there rubber tree: YES | 0.306(0.280;0.331) | 0.001(0.000;0.013) |
| Are there rubber tree: MISSING | 0.000(0.000;0.004) | 0.054(0.035;0.079) |
| Part of family did not come: NO | 0.639(0.603;0.674) | 0.359(0.260;0.458) |
| Part of family did not come: YES | 0.358(0.324;0.394) | 0.612(0.515;0.711) |
| Part of family did not come: MISSING | 0.001(0.000;0.006) | 0.027(0.013;0.048) |
| Use a bednet: NO | 0.789(0.755;0.822) | 0.559(0.462;0.657) |
| Use a bednet: YES | 0.204(0.172;0.238) | 0.250(0.151;0.342) |
| Use a bednet: MISSING | 0.004(0.000;0.018) | 0.192(0.140;0.243) |
| Plant guarana: NO | 0.769(0.745;0.792) | 0.916(0.886;0.941) |
| Plant guarana: YES | 0.229(0.206;0.253) | 0.001(0.000;0.011) |
| Plant guarana: MISSING | 0.000(0.000;0.004) | 0.081(0.056;0.110) |
| HH has high level of education: NO | 0.631(0.596;0.667) | 0.415(0.313;0.513) |
| HH has high level of education: YES | 0.365(0.329;0.400) | 0.524(0.428;0.626) |
| HH has high level of education: MISSING | 0.002(0.000;0.012) | 0.059(0.029;0.091) |
| Get malaria from dirty water: NO | 0.467(0.429;0.503) | 0.289(0.189;0.393) |
| Get malaria from dirty water: YES | 0.497(0.460;0.536) | 0.655(0.548;0.755) |
| Get malaria from dirty water: MISSING | 0.035(0.021;0.051) | 0.054(0.014;0.102) |
| Do you ever go to city through BR364: NO | 0.576(0.538;0.612) | 0.602(0.503;0.698) |
| Do you ever go to city through BR364: YES | 0.407(0.370;0.444) | 0.287(0.187;0.380) |
| Do you ever go to city through BR364: MISSING | 0.017(0.003;0.032) | 0.110(0.065;0.168) |
| Arrived in Machadino before 1985: NO | 0.168(0.144;0.191) | 0.025(0.002;0.084) |
| Arrived in Machadino before 1985: YES | 0.832(0.809;0.856) | 0.975(0.916;0.998) |
| Knowledge of malaria vector: NO | 0.504(0.466;0.540) | 0.452(0.348;0.550) |
| Knowledge of malaria vector: YES | 0.327(0.292;0.360) | 0.332(0.243;0.430) |
| Knowledge of malaria vector: MISSING | 0.169(0.141;0.197) | 0.215(0.139;0.294) |
| Worked in rural area for more tha 1 year: NO | 0.032(0.006;0.049) | 0.059(0.011;0.141) |
| Worked in rural area for more tha 1 year: YES | 0.967(0.950;0.993) | 0.892(0.807;0.942) |
| Worked in rural area for more tha 1 year: MISSING | 0.000(0.000;0.003) | 0.047(0.029;0.071) |
| Lived in rural area for more than 1 year: NO | 0.028(0.003;0.045) | 0.046(0.001;0.129) |
| Lived in rural area for more than 1 year: YES | 0.972(0.954;0.997) | 0.902(0.819;0.953) |
| Lived in rural area for more than 1 year: MISSING | 0.000(0.000;0.002) | 0.049(0.030;0.074) |
| Own a planter: NO | 0.656(0.619;0.691) | 0.698(0.596;0.799) |
| Own a planter: YES | 0.343(0.308;0.380) | 0.297(0.198;0.397) |
| Own a planter: MISSING | 0.000(0.000;0.003) | 0.004(0.000;0.014) |
| Behavioral | ||
|---|---|---|
| Planted Corn: NO | 0.969(0.949;0.980) | 0.041(0.003;0.087) |
| Planted Corn: YES | 0.002(0.000;0.018) | 0.958(0.912;0.996) |
| Planted Corn: MISSING | 0.027(0.018;0.038) | 0.000(0.000;0.002) |
| Plant Cassava: NO | 0.951(0.932;0.967) | 0.090(0.046;0.137) |
| Plant Cassava: YES | 0.001(0.000;0.012) | 0.906(0.859;0.951) |
| Plant Cassava: MISSING | 0.045(0.030;0.062) | 0.002(0.000;0.010) |
| Plant banana: NO | 0.942(0.876;0.966) | 0.187(0.147;0.232) |
| Plant banana: YES | 0.015(0.000;0.085) | 0.812(0.767;0.852) |
| Plant banana: MISSING | 0.038(0.027;0.052) | 0.000(0.000;0.003) |
| Cultivate rice: NO | 0.740(0.670;0.823) | 0.001(0.000;0.005) |
| Cultivate rice: YES | 0.231(0.144;0.304) | 0.999(0.994;1.000) |
| Cultivate rice: MISSING | 0.027(0.018;0.040) | 0.000(0.000;0.002) |
| Planted Bean: NO | 0.967(0.951;0.978) | 0.330(0.287;0.370) |
| Planted Bean: YES | 0.001(0.000;0.009) | 0.669(0.629;0.711) |
| Planted Bean: MISSING | 0.030(0.020;0.044) | 0.001(0.000;0.004) |
| Own a chainsaw: NO | 0.947(0.869;0.998) | 0.298(0.250;0.346) |
| Own a chainsaw: YES | 0.053(0.002;0.131) | 0.702(0.654;0.750) |
| Active in community organization: NO | 0.990(0.965;0.998) | 0.401(0.359;0.438) |
| Active in community organization: YES | 0.005(0.000;0.030) | 0.597(0.561;0.640) |
| Active in community organization: MISSING | 0.003(0.000;0.009) | 0.001(0.000;0.004) |
| More than 4 people in the house: NO | 0.167(0.091;0.249) | 0.681(0.634;0.730) |
| More than 4 people in the house: YES | 0.833(0.751;0.909) | 0.319(0.270;0.366) |
| Own a planter: NO | 0.461(0.410;0.517) | 0.001(0.000;0.007) |
| Own a planter: YES | 0.539(0.483;0.590) | 0.999(0.993;1.000) |
| Plant coffee: NO | 0.403(0.355;0.457) | 0.001(0.000;0.006) |
| Plant coffee: YES | 0.566(0.511;0.617) | 0.999(0.993;1.000) |
| Plant coffee: MISSING | 0.029(0.019;0.042) | 0.000(0.000;0.002) |
| HH wife has high level of education: 4 yr | 0.148(0.077;0.210) | 0.468(0.428;0.505) |
| HH wife has high level of education: 4 yr | 0.503(0.438;0.572) | 0.502(0.462;0.540) |
| HH wife has high level of education: NO-WIFE | 0.008(0.001;0.016) | 0.001(0.000;0.005) |
| HH wife has high level of education: MISSING | 0.343(0.279;0.407) | 0.027(0.000;0.061) |
| Own more the 4 goods: NO | 0.340(0.300;0.385) | 0.001(0.000;0.008) |
| Own more the 4 goods: YES | 0.660(0.615;0.700) | 0.999(0.992;1.000) |
| Plant cocoa: NO | 0.965(0.946;0.977) | 0.660(0.630;0.688) |
| Plant cocoa: YES | 0.002(0.000;0.017) | 0.339(0.312;0.370) |
| Plant cocoa: MISSING | 0.030(0.021;0.043) | 0.000(0.000;0.002) |
| Are there rubber tree: NO | 0.975(0.959;0.985) | 0.680(0.652;0.707) |
| Are there rubber tree: YES | 0.002(0.000;0.016) | 0.319(0.293;0.348) |
| Are there rubber tree: MISSING | 0.020(0.012;0.031) | 0.000(0.000;0.002) |
| Arrived in Rondonia before 1985: NO | 0.543(0.476;0.605) | 0.839(0.803;0.876) |
| Arrived in Rondonia before 1985: YES | 0.396(0.334;0.461) | 0.150(0.117;0.184) |
| Arrived in Rondonia before 1985: MISSING | 0.063(0.034;0.089) | 0.009(0.000;0.026) |
| Use plant to cure malaria: NO | 0.853(0.795;0.918) | 0.577(0.536;0.617) |
| Use plant to cure malaria: YES | 0.145(0.080;0.203) | 0.422(0.382;0.463) |
| Use plant to cure malaria: MISSING | 0.001(0.000;0.006) | 0.001(0.000;0.003) |
| Plant guarana: NO | 0.979(0.942;0.998) | 0.737(0.709;0.766) |
| Plant guarana: YES | 0.021(0.002;0.058) | 0.263(0.234;0.291) |
| DDT is used: NO | 0.822(0.758;0.881) | 0.613(0.575;0.652) |
| DDT is used: YES | 0.149(0.092;0.215) | 0.386(0.347;0.424) |
| DDT is used: MISSING | 0.027(0.017;0.040) | 0.000(0.000;0.003) |
| Do you own other proprieties: NO | 0.784(0.712;0.851) | 0.565(0.522;0.611) |
| Do you own other proprieties: YES | 0.216(0.149;0.288) | 0.435(0.389;0.478) |
| Got a loan for pasture: NO | 0.963(0.947;0.974) | 0.788(0.765;0.809) |
| Got a loan for pasture: YES | 0.001(0.000;0.009) | 0.211(0.189;0.234) |
| Got a loan for pasture: MISSING | 0.034(0.024;0.049) | 0.000(0.000;0.003) |
| Planted Nut: NO | 0.947(0.920;0.964) | 0.801(0.776;0.824) |
| Planted Nut: YES | 0.003(0.000;0.026) | 0.197(0.174;0.221) |
| Planted Nut: MISSING | 0.046(0.032;0.063) | 0.001(0.000;0.006) |
| Own chickens and/or porks: NO | 0.188(0.158;0.221) | 0.001(0.000;0.003) |
| Own chickens and/or porks: YES | 0.812(0.779;0.842) | 0.999(0.997;1.000) |
| Knowledge of malaria vector: NO | 0.310(0.240;0.379) | 0.461(0.419;0.504) |
| Knowledge of malaria vector: YES | 0.573(0.504;0.645) | 0.474(0.430;0.516) |
| Knowledge of malaria vector: MISSING | 0.117(0.072;0.163) | 0.064(0.041;0.091) |
| Planted Pepper: NO | 0.975(0.962;0.984) | 0.842(0.822;0.861) |
| Planted Pepper: YES | 0.001(0.000;0.008) | 0.157(0.138;0.178) |
| Planted Pepper: MISSING | 0.022(0.014;0.033) | 0.000(0.000;0.002) |
| Get malaria from dirty water: NO | 0.507(0.433;0.582) | 0.379(0.335;0.421) |
| Get malaria from dirty water: YES | 0.462(0.388;0.535) | 0.602(0.560;0.645) |
| Get malaria from dirty water: MISSING | 0.028(0.007;0.055) | 0.020(0.006;0.033) |
| Got a loan for agriculture: NO | 0.963(0.948;0.975) | 0.855(0.835;0.872) |
| Got a loan for agriculture: YES | 0.001(0.000;0.006) | 0.144(0.127;0.164) |
| Got a loan for agriculture: MISSING | 0.034(0.023;0.049) | 0.000(0.000;0.003) |
| Spray insecticide: NO | 0.850(0.789;0.909) | 0.712(0.674;0.749) |
| Spray insecticide: YES | 0.148(0.089;0.210) | 0.286(0.250;0.324) |
| Spray insecticide: MISSING | 0.001(0.000;0.005) | 0.001(0.000;0.003) |
| Do you go often to urban area: NO | 0.492(0.405;0.580) | 0.618(0.567;0.666) |
| Do you go often to urban area: YES | 0.497(0.409;0.582) | 0.380(0.332;0.431) |
| Do you go often to urban area: MISSING | 0.010(0.003;0.019) | 0.001(0.000;0.006) |
| Lived in rural area for more than 1 year: NO | 0.140(0.101;0.191) | 0.038(0.013;0.059) |
| Lived in rural area for more than 1 year: YES | 0.847(0.797;0.888) | 0.960(0.939;0.986) |
| Lived in rural area for more than 1 year: MISSING | 0.011(0.004;0.021) | 0.000(0.000;0.004) |
| Arrived in Machadino before 1985: NO | 0.001(0.000;0.013) | 0.096(0.081;0.112) |
| Arrived in Machadino before 1985: YES | 0.968(0.943;0.991) | 0.891(0.870;0.910) |
| Arrived in Machadino before 1985: MISSING | 0.028(0.007;0.051) | 0.012(0.001;0.026) |
| Use a bednet: NO | 0.880(0.835;0.920) | 0.963(0.941;0.984) |
| Use a bednet: YES | 0.104(0.068;0.146) | 0.029(0.008;0.048) |
| Use a bednet: MISSING | 0.014(0.001;0.033) | 0.008(0.000;0.018) |
| Have another rural plot: NO | 0.839(0.779;0.898) | 0.763(0.727;0.800) |
| Have another rural plot: YES | 0.159(0.100;0.218) | 0.236(0.200;0.272) |
| Have another rural plot: MISSING | 0.001(0.000;0.006) | 0.001(0.000;0.003) |
| HH has high level of education: NO | 0.392(0.313;0.462) | 0.441(0.401;0.486) |
| HH has high level of education: YES | 0.597(0.527;0.675) | 0.557(0.513;0.597) |
| HH has high level of education: MISSING | 0.010(0.003;0.020) | 0.001(0.000;0.005) |
| Go to main urban area from treatment: NO | 0.199(0.131;0.277) | 0.165(0.122;0.206) |
| Go to main urban area from treatment: YES | 0.790(0.711;0.859) | 0.834(0.794;0.877) |
| Go to main urban area from treatment: MISSING | 0.010(0.004;0.017) | 0.000(0.000;0.002) |
| Go to secondary urban area from treatment: NO | 0.829(0.753;0.898) | 0.829(0.789;0.871) |
| Go to secondary urban area from treatment: YES | 0.158(0.089;0.233) | 0.170(0.129;0.211) |
| Go to secondary urban area from treatment: MISSING | 0.013(0.006;0.022) | 0.000(0.000;0.002) |
| Got a loan for equipment: NO | 0.963(0.949;0.975) | 0.981(0.973;0.987) |
| Got a loan for equipment: YES | 0.000(0.000;0.005) | 0.018(0.012;0.025) |
| Got a loan for equipment: MISSING | 0.036(0.024;0.049) | 0.000(0.000;0.003) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Statistical Methods and Bayesian Inference · Bayesian Methods and Mixture Models
Multivariate mixed membership modeling: Inferring domain-specific risk profiles
Massimiliano Russolabel=e1][email protected] [
Burton H. Singerlabel=e2][email protected] [
David B. Dunson label=e3][email protected] label=u1 [[
Harvard Medical School, and Dana-Farber Cancer Institute\thanksmarkt1, University of Florida\thanksmarkt2 and Duke University\thanksmarkt3
Massimiliano Russo
Harvard-MIT Center for Regulatory Science,
Harvard Medical School,
and Department of Data Science,
Dana-Farber Cancer Institute,
Boston, MA 02115
Burton H. Singer
Emerging Pathogens Institute
and Department of Mathematics
University of Florida
Gainesville, FL 32610
David B. Dunson
Department of Statistical Science
Duke University
214 Old Chemistry Bldg, Box 90251
Durham, NC 27708-0251
Massimiliano Russolabel=e1][email protected] [
Burton H. Singerlabel=e2][email protected] [
David B. Dunson label=e3][email protected] label=u1 [[
Harvard Medical School, and Dana-Farber Cancer Institute\thanksmarkt1, University of Florida\thanksmarkt2 and Duke University\thanksmarkt3
Supplementary Material for “Multivariate mixed membership modeling: Inferring domain-specific risk profiles”
Massimiliano Russolabel=e1][email protected] [
Burton H. Singerlabel=e2][email protected] [
David B. Dunson label=e3][email protected] label=u1 [[
Harvard Medical School, and Dana-Farber Cancer Institute\thanksmarkt1, University of Florida\thanksmarkt2 and Duke University\thanksmarkt3
Massimiliano Russo
Harvard-MIT Center for Regulatory Science,
Harvard Medical School,
and Department of Data Science,
Dana-Farber Cancer Institute,
Boston, MA 02115
Burton H. Singer
Emerging Pathogens Institute
and Department of Mathematics
University of Florida
Gainesville, FL 32610
David B. Dunson
Department of Statistical Science
Duke University
214 Old Chemistry Bldg, Box 90251
Durham, NC 27708-0251
Massimiliano Russolabel=e1][email protected] [
Burton H. Singerlabel=e2][email protected] [
David B. Dunson label=e3][email protected] label=u1 [[
Harvard Medical School, and Dana-Farber Cancer Institute\thanksmarkt1, University of Florida\thanksmarkt2 and Duke University\thanksmarkt3
Abstract
Characterizing the shared memberships of individuals in a classification scheme poses severe interpretability issues, even when using a moderate number of classes (say 4). Mixed membership models quantify this phenomenon, but they typically focus on goodness-of-fit more than on interpretable inference. To achieve a good numerical fit, these models may in fact require many extreme profiles, making the results difficult to interpret. We introduce a new class of multivariate mixed membership models that, when variables can be partitioned into subject-matter based domains, can provide a good fit to the data using fewer profiles than standard formulations. The proposed model explicitly accounts for the blocks of variables corresponding to the distinct domains along with a cross-domain correlation structure, which provides new information about shared membership of individuals in a complex classification scheme. We specify a multivariate logistic normal distribution for the membership vectors, which allows easy introduction of auxiliary information leveraging a latent multivariate logistic regression. A Bayesian approach to inference, relying on Pólya gamma data augmentation, facilitates efficient posterior computation via Markov Chain Monte Carlo. We apply this methodology to a spatially explicit study of malaria risk over time on the Brazilian Amazon frontier.
Admixture model,
Contingency table,
Latent Dirichlet allocation,
Multivariate categorical data,
Multivariate logistic normal distribution,
keywords:
\thanksmarkt1 [email protected]
\arxiv\startlocaldefs\endlocaldefs
,
and
1 Introduction
Mixed membership (MM) modeling began in response to difficulties in achieving crisp classification of individuals on the basis of assessments of many characteristics about them (Woodbury, Clive and Garson, 1978). MM also proved useful for identifying the driving forces of a specific outcome when they are expressed by multiple potentially influencing features, no combination of which occurred with high frequency in the overall population (Berkman, Singer and Manton, 1989). More recently MM has been used in a variety of contexts including text analysis (Blei, Ng and Jordan, 2003), medicine (Erosheva, Fienberg and Joutard, 2007), and several studies of social interactions (e.g., Airoldi et al., 2005, 2008; Kao, Smith and Airoldi, 2018), among many others. An extensive review on this class of models can be found Airoldi et al. (2014).
Algorithms for MM analyses usually begin by fitting a set of pure, or ideal, types summarizing high dimensional discrete-valued data, and assigning probabilities for levels of each variable to be members of each pure type. With a set of pure types at hand, it is useful to think of them as vertices of a unit simplex. Then each individual’s response vector is associated with a point inside or on the boundary of the simplex. Each point is given a set of degree of similarity scores, the score vector, , such that and , that represent location in the simplex. If an individual has, for example, 5 non-zero elements in the score vector, each representing relative proximity to a different pure type, then the individual shares characteristics with 5 pure-types. If all individuals in a population have response vectors that are assigned a score of 1, relative to some pure type, then crisp classification has occurred, with the pure types associated with one or more individuals being the categories in a classification scheme. When individuals have more than one component of their score vector positive, they share conditions represented by each of the pure types to which they have some similarity, which is particularly appealing when an exact grouping is difficult if not impossible to obtain, as for example in identification of disease risks (e.g., Chuit et al., 2001; Castro et al., 2006) or political ideology (e.g., Gross and Manrique-Vallier, 2014).
If many individuals have score vectors with or more non-zero components, then it becomes difficult, in almost any application, to write a coherent sentence describing what this complex set of shared memberships actually means. This is a reflection of the intrinsic limitations on human capacity for understanding many distinct ideas simultaneously (Miller, 1956), particularly when these are not easily summarized in a plot or a table. When most individuals only have two non-zero components in their score vectors—i.e. they are located on an edge in the unit simplex with pure types defined as the vertices—then they share conditions with a particular pair of pure types, and interpretable description tends to be straightforward. To-date many published MM analyses have a number of pure types ranging from (e.g., Erosheva and Fienberg, 2005) to several hundreds (e.g., Griffiths and Steyvers, 2004). Curiously, considerations on interpretability have mostly been avoided by there being almost no discussion of the sets of shared memberships. Most of the emphasis has gone to descriptions of the pure types; a notable exception is Erosheva, Fienberg and Lafferty (2004). From our perspective, this is avoiding one of the most informative, and even motivating, features of MM representations. Hence, it is desirable to employ a small number of profiles, e.g. . In epidemiology applications, we frequently use , with the two profiles corresponding to high and low risk. The weight vector then corresponds to values in summarizing the degree of risk to which individual is exposed.
If we are to accurately represent the dependence structure in most epidemiological data, usually more than two profiles are needed, since goodness-of-fit and interpretability are conflicting factors. A possible way to improve interpretability is to block variables into distinct domains—e.g. human behavioral, physical environmental, and climatic in infectious disease epidemiological studies, and then carry out standard MM analyses on each domain separately for the same set of individuals, with the number of pure types forced to be or . The use of the same individuals across models induces a correlation structures in the score vectors, yielding new information about the phenomena under investigation that is not at all transparent from conventional MM specifications (e.g., Chuit et al., 2001; Singer and Castro, 2014). To-date no formalization of this kind of correlation structure exists.
The main aims of this paper are to: (1) specify a new class of Multivariate Mixed Membership (MMM) models that explicitly include the classification of blocks of variables corresponding to distinct subject matter domains and the cross-domain correlation structure; (2) apply the MMM framework to the problem of characterizing malaria risk on the Brazilian Amazon frontier. This problem has been studied previously (Castro et al., 2006; Castro, Sawyer and Singer, 2007), but with less sophisticated tools.
We address (1) by linking group-specific MM models through dependence in the membership scores. We show that this model require fewer profiles to characterize the joint probability mass function underlying the data, relaxing the constraints of the standard mixed membership model formulation. Additionally, we propose a novel joint distribution defined on a product space composed of simplices, leading to an easy-to-implement Gibbs sampler for posterior computation, based on Pólya gamma data augmentation (Polson, Scott and Windle, 2013). The proposed framework allows simple inclusion of subject and group-specific covariates leveraging multiple latent logistic regression.
The paper is structured as follows. In Section 2 we present a brief review of mixed membership models and their connection with tensor decompositions. In Section 3 we introduce our MMM generalization of such models and describe some of their key properties. Section 4 introduces a multivariate distribution defined on a product space of simplices. In Section 5 we provide technical details on posterior computation. In Section 6 we study the performance of our model under different simulation scenarios, and in Section 7 we apply the model to the problem of characterizing malaria risk over time at a colonization project on the Brazilian Amazon frontier.
2 Mixed membership models and tensor decompositions
Given a collection of categorical random variables for and such that , a mixed membership model can be defined as follows:
[TABLE]
where , for and , while is the distribution of the membership score vector associated with each observation . Popular choices for the distribution include Dirichlet (Blei, Ng and Jordan, 2003) and logistic normal (Lafferty and Blei, 2006). From model (2.1) we can notice that there is a population level assumption, i.e. the population is composed of subpopulations, and an individual level assumption, for which each subject has a degree of similarity with the type expressed by .
The kernel probabilities express the probability of observing the -th category for the -th profile, while the vector represents subject and quantitatively describes the individual’s degree of similarity to each of the subpopulations. Geometrically, it locates individual in a unit simplex whose vertices are identified with the subpopulations. Leveraging the local independence assumption in model (2.1) the probability distribution for the generic subject can be expressed, integrating out the latent variable , as
[TABLE]
which is a product of conditionally independent mixture models. The population model can be retrieved integrating out with respect to its distribution
[TABLE]
where is the expectation of the product of the score vector elements over . Depending on the choice of , the expectation may or may not have a closed form expression.
Equation (2.3) is an instance of a Tucker tensor decomposition (e.g., Kolda and Bader, 2009), and is a flexible representation for the probability mass function of unordered categorical random variables, since there always exists an such that any probability mass function can be characterized as in (2.3). Additionally, representation (2.3) typically requires a smaller than a standard discrete mixture model representation (see for example Bhattacharya and Dunson, 2012).
Moreover, equation (2.3) can be interpreted as a constrained discrete mixture model with latent components. In fact, the core tensor is specified to be a cubic symmetric tensor. A cubic tensor is a tensor having all modes with the same dimension, while a symmetric tensor, sometime referred to as super symmetric, is the direct generalization of a symmetric matrix in tensor algebra. Formally, given a vector of indices and defining to be the space of all permutation of , we have that for all . This definition implies that just elements out of the are distinct, where is the rising factorial. It is easy to see that in -dimensional space the previous definition reduces to the usual symmetric matrix (i.e. equal to its transpose) and that .
Such constraints derive from the exchangeability assumption for the profile probabilities in (2.1) (e.g., Erosheva, Fienberg and Joutard, 2007). When compared to an unconstrained discrete mixture model, the effect of such constraints is to increase the value of needed to fully characterize the probability distribution underlying the data. Independent of applications and issues of subject-matter interpretability, which are not mathematical concerns, increasing as needed poses no particular problem. However, if is constrained a priori, our representation can lead to an unsatisfactory approximation of the probability mass function. To deal with this issue, we propose a generalization of the above approach relaxing the constraints imposed on the latent part of the model.
3 A multivariate mixed membership model
We assume, a priori, that variables can be divided into distinct groups which, in applications, are identified with different subject-matter domains. Let be an indicator vector for groups of variables, where for . Each subject is endowed with membership score vectors such that for . Note that the sum of the membership scores for the different domains is not equal to , i.e. , for .
The proposed model can be expressed in the following hierarchical form:
[TABLE]
As in model (2.1), representation (3.1) relies on conditional independence of the observed variables given the profile labels; in fact, the latent variables are conditionally independent given the mixed membership scores :
[TABLE]
Integrating out the scores from equation (3.2), we obtain the population level model:
[TABLE]
Although equation (3.3) seems identical to equation (2.3), the elements of the core tensors are different, as are the imposed constraints. The core tensor is not a symmetric tensor, but it has some equality constraints on the elements. To describe these constraints, we can define a group preserving permutation space; specifically, given the vector of indices , and a group indicator vector , the group preserving permutation space is such that the effect of is to permute the elements of a vector within the groups, leaving the group structure unchanged. It immediately follows that is a well defined group since it is closed under composition, while also respecting associativity, identity and invertibility properties (e.g., Artin, 1991).
The core tensor can be defined as a group symmetric tensor, meaning that given a multivariate index we have , for all . A symmetric tensor can be viewed as group symmetric with only one group, or can be defined such that it is group symmetric for any possible group configuration . Following the same logic, model (3.1) can be seen as a sub-model of (3.2) having just one group () or the score vectors for all .
The number of distinct elements in is given by , which is considerably larger than in the symmetric tensor case, as can be seen from Figure 1. Moreover, as a consequence of Lemma 3.1, for any fixed , equation (3.3) is never worse than equation (2.3) in approximating the ‘true’ probability mass function generating the data.
Lemma 3.1**.**
Let be a probability tensor of dimension , and be, respectively, the best group symmetric and symmetric multi-rank approximations of . Then , where denotes the Frobenius norm.
The proof immediately follows after noticing that by definition minimizes under the constraint for all , and that can be obtained by solving the same problem with additional equality constraints on the element of such that, if for a . ∎
Lemma 3.1 implies that incorporating group-specific membership scores leads to a population level model (3.3) with less replicated elements in the core tensor compared to (2.3), for any fixed . Hence, if we fix or to ensure interpretability of shared membership score vectors, we will tend to produce a better fit to the data by using group-specific scores than in modeling a single global score vector. Note that Lemma 3.1 does not imply that the MMM specification requires less parameters than MM to characterize the p.m.f., because of the additional group-specific membership parameters. To complete a specification of the MMM model, it remains for us to choose an appropriate distribution .
4 The multivariate logistic normal distribution
Letting denote the probability simplex, we aim to define a joint distribution on the product space . To achieve this goal, we start from a distribution on , mapping to via an appropriate transformation. Potentially any continuous multivariate distribution can be used, but we focus on the multivariate Gaussian distribution to retain simplicity and flexibility. Let be a multivariate normal distribution of dimension with mean vector , where , and covariance matrix . We consider the transformed vector , whose elements can be defined as for and , with .
It is easy to show that and that the Jacobian matrix of the transformation is block diagonal having determinant given by . The probability density function of the resulting distribution is
[TABLE]
where . Each of the group marginals has a logistic normal distribution with parameters and , where is the block of the matrix corresponding to the -th group. We refer to (4.1) as the Multivariate Logistic Normal Distribution (MLND), as it is a multivariate generalization of the logistic normal used in Lafferty and Blei (2006).
Distribution (4.1) can be alternatively derived as a compound distribution from a collection of independent logistic normal distributions and a multivariate normal for the mean vectors, as stated in Proposition 4.1.
Proposition 4.1**.**
Let such that independently for , and let . Then , where .
Following Aitchison and Shen (1980), we consider a class of distribution preserving transformations, useful to maintain some invariance properties of the induced distribution. According to our problem, we additionally restrict our attention to the sub-class of group preserving transformations (e.g., group permutation defined in Section 3).
Proposition 4.2**.**
Let and a block diagonal matrix, having diagonal blocks of dimension for , then the dimensional vector whose elements are defined as
[TABLE]
for and , has distribution .
The diagonal block structure of matrix in Proposition 4.2 ensures that the transformation preserves the same group structure of the original vector; for a general matrix , is still distributed as an MLDN, but categories in different groups can be merged. Proposition 4.2 implies that the MLDN distribution is invariant with respect to permutations of the labels, and allows easy computation of the joint distribution of the vector when some categories are merged.
The proposed MLND distribution has finite moments, but these moments in general do not have an analytic form. However, we can obtain simple expressions for moments related to log-odds and odds ratios both between and across the groups. For example, letting
[TABLE]
we have
[TABLE]
where with an abuse of notation we indicate with the element in position of the non diagonal block of corresponding to the groups and . Higher order moments can also be computed relying on normal and log-normal distribution properties.
From equations (4.2) we can notice that the log-odds of the elements in different groups are linearly related. Moreover, when applied to multivariate mixed membership models with , log-odds and odds ratios give important insights on which group is more important in characterizing high and low risk conditions. Additionally, the elements of , or of the corresponding correlation matrix , can be used to assess if membership scores are independent across domains, or if a single MM model is sufficient to describe the latent structure. In fact if , the model reduces to independent MM models for the domains and .
For , this hypothesis can be checked by choosing a hyperprior for and inspecting the credible interval for , or for a specified credible level; if the credible interval includes [math], separate MM models can be a viable alternative to a full MMM. Similarly, if the posterior correlation concentrates near or , a single vector for the membership scores is sufficient to describe the considered data.
5 Posterior computation
We propose an algorithm to simulate from the posterior of model (3.1), with defined in (4.1). We focus on the special case where for . Generalization to more pure types can be obtained by iterating the proposed Polya gamma data augmentation on all the conditional log-odds (Polson and Scott, 2011), or alternatively relying on the stick breaking parameterization of the multinomial likelihood of Linderman, Johnson and Adams (2015).
We begin by specifying conjugate prior distributions for all the parameters in the model. For the kernel probabilities we set , for the hyperparameter and for the covariance matrix . Parameters can be updated by iterating the steps in Algorithm 1. In step we update the mean vector of a multivariate Gaussian distribution: at this step we can substitute a multivariate regression to account for covariate effects.
Potentially for our MMM model, as in other MM models and more broadly for mixture models, we may encounter label switching. This occurs when the extreme profiles change their meaning across MCMC iterations. Although including information on variable partitions can reduce identifiability issues (e.g., Xu, 2017), the invariance with respect to group transformations of the MLND distribution (Proposition 4.2) makes labels exchangeable. When label switching occurs, post processing should be used to appropriately align the MCMC samples (see for example Stephens, 2002). However, such post processing was not applied in any of the simulated data we report below, as trace plots showed no evidence of label switching in the MCMC samples (refer to Figure S1 in Acknowledgements for an example).
6 Simulation study
We analyze different simulation scenarios in evaluating the performance of our approach. We consider different probability distribution functions for the membership scores , relying on hierarchical representation (3.1) to generate the data. The goal in defining these scenarios is to assess whether the proposed model can characterize generative mechanisms having broadly different properties. We compare our results with the standard admixture formulation implemented in the R package mixedMem, using separate models for each group. This package relies on a Variational EM algorithm, approximating the posterior distribution of the latent memberships and selecting hyperparameters through a pseudo MLE procedure (refer to Wang and Erosheva, 2015, for more details). We quantified uncertainty in the estimates using the bootstrap procedure in Chen, Wang and Erosheva (2018). Additional comparisons with an MCMC implementation of the same model are provided in Acknowledgements.
We initially assume that is the ‘true’ number of extreme profiles, presenting four different scenarios, while in a second Section we consider the misspecified case . The code to reproduce our simulations, together with broader implementation of Algorithm 1, can be found at https://github.com/rMassimiliano/MMM-tutorial.
6.1 Number of profiles correctly specified
We consider groups, subjects, categorical variables, having levels and profiles for . We simulate data from categorical distributions, whose probabilities are drawn from a Dirichlet distribution with parameters having values , , and . In the first simulation scenario, we let the probability density function for the joint distribution of the score vectors be a bivariate normal distribution truncated over the unit square, having parameter and . This formulation induces positive dependence between the two scores with their distribution having ellipsoid contours truncated at the borders. In the second simulation scenario, we consider the distribution proposed in Section 4 with and . In the third scenario, we rely on the generative mechanism (2.1), having profile distribution shared by all variables; we generate this profile from a uniform distribution. Finally, in the fourth simulation scenario, we consider to be the product of two independent uniforms, forcing independence in the variables belonging to different groups, which translates into the case in which two separate models for the groups represents the correctly specified model.
We perform posterior inference under the proposed model (3.1) with priors defined in Section 5, setting for , we consider , , and . We maintained these default hyperparameters in all our simulation cases, collecting Gibbs samples from Algorithm 1. Trace plots suggest convergence is reached by a burn-in of .
Figure 2 shows the estimated profile distribution for all simulated scenarios, comparing results with the use of two separate MM models. Despite the challenging scenarios and the misspecification of the profile distribution, our proposed approach is able to reconstruct the latent mechanism underlying the profiles in a satisfactory way.
In evaluating subject-specific estimates of the scores we rely on the mean L1 distance relative to the ‘true’ values. We obtain good results in retrieving the ‘true’ membership vectors in all simulation scenarios (Table 1) as the proposed approach always produces better or comparative results to the standard mixed membership model implemented in the package mixedMem.
Figures S4 and S5 show posterior estimates and credible intervals for the kernel parameters for selected variables in both scenarios. We notice that our proposed approach robustly estimates kernels in the considered scenarios. Contrarily in some cases, the MM model underestimates variability. This behavior is evident in the lower part of Figures S4 where MM produces confidence intervals for , , collapsing to [math] inappropriately. This underestimation of the kernel parameters variability is probably due to the variational approximation of their posterior distribution. In fact, when using MCMC to approximate the posterior of two separate MM models, we do not observe a collapse in the variability. Instead, this variability tends to be overestimated in comparison with our proposed MMM model (see Figures S4 and S5 in Acknowledgements).
The proposed MMM model also presents a good fit to the data with L1-norm between the estimated and empirical proportions close to 0.2 for all marginal and bivariate distributions (see Figure S1 in Acknowledgements).
6.2 Misspecification: more than two pure types
In this Section we consider a scenario in which generative model (3.1) has more than types, while retaining the proposed inference model with for . The key idea is to understand how the model is able to approximate the profiles in a lower dimensional space, and compare this approximation with that for the standard MM model. Specifically, we consider as generative mechanism a group model with . Kernels for the first group are fixed as , , and , while membership scores . For the second group we consider instead the same mechanism used in scenario 4 with , enforcing no dependence in the scores distribution. This scenario is constructed to favour the use of two separate MM models, having no dependence across the groups and a Dirichlet distribution for the profiles.
Figure 5 shows the relations between each component of the ‘true’ unknown and the estimated scores , from our proposed approach and the MM model. As expected, the scores are strongly correlated with more ‘true’ profiles, for both considered models. Some individual variability is lost in the process as we are projecting a 3-dimensional space to a 1-dimensional one. This dimensionality reduction leads to ‘mixed’ pure types that can be considered as averages of the ‘true’ ones. For example, MMM model profile 2 is composed of subjects with high values of and , and low values of and , while in the MM model profile 2 is composed of high values of and and low values of and . This can be assessed by looking at the estimated kernels for a representative variable in group 1 (see Table S2).
To additionally evaluate model performance, we compute the Frobenius norm between the ‘true’ probability tensor , and and , denoting the estimates from the MMM and MM model, respectively. Leveraging equations (2.3) and (3.3), for MM we have a closed form expression of the core tensor, while for MMM we use Monte Carlo replicates for the estimation. To estimate uncertainty in the MM case, we rely on 1000 bootstrap replicates. We obtain a posterior mean of for with a standard deviation of , and a bootstrap mean for with standard deviation . As expected, in this scenario having independent scores vectors, separate MM and MMM models share very similar performances in characterizing . For comparison, we also estimate the Frobenius norm considering a correctly specified model with profiles for group 1, leading to a bootstrap mean of with standard deviation of . This slight improvement in estimation accuracy does not justify the greater complexity of interpretation in using the larger value.
7 Application to malaria risk assessment
7.1 Background
Starting from 1981, the World Bank sponsored Polonoroeste Development Project (World Bank, 1992), which included funding for human settlements in previously forested areas (Wade, 2011). In these sponsored settlements we find the Machadinho project, in the state of Rondônia, where the primary goal was in promoting agricultural development and elevation of living standards by distributing pre-specified plots of land, and favoring migration from outside the area. Land clearance practices at the plots created new areas of partial shade—from cut but not cleared large trees—redefined the boundaries of forest fringe, and led to establishment of new pools of water of relatively high pH. These are precisely the ideal larval development conditions for A. Darlingi mosquitoes, the primary transmitter of malaria in the Brazilian Amazon region (Castro et al., 2006).
As part of a field study of the dynamics of the settlement process at Machadinho, a set of household surveys was conducted in , , , and at plots with relatively stable occupancy. The surveys were administered to settlers living on of what were regarded as occupied plots in and of such plots in , , and . An occupied plot is one in which settlers cleared some of their land and at least lived part-time in Machadinho. The surveys had as one objective the identification of drivers of malaria risk among the settlers, including some who were ascertained shortly after arrival in Machadinho and others who engaged in early out-migration, largely as a result of difficulties in establishing a productive agricultural site and illness, much of it being due to malaria.
Factors that a priori were anticipated to influence exposure of settlers to Anopheles mosquitoes were complex physical environmental conditions and human behavioral conditions. It is natural to focus on extreme risk categories/profiles as “High” and “Low”. Thus each occupied plot would have a numerical degree of similarity score, , with value in the unit interval. Values close to can be associated with proximity to the high risk profile, while values close to [math] can be associated with low risk conditions. Using these variables in a standard MM analysis for each year, we obtain best fitting models with selected number of profiles ranging between and . Since the selected are greater than , an interpretability problem arises for scoring risk in the unit interval between two extreme profiles. If we force , as in prior analyses (Castro et al., 2006), we are directly trading off model goodness-of-fit for interpretability in the scoring of malaria risk. Goodness-of-fit can be improved increasing and use domain knowledge to map the resulting membership scores into behavioral and environmental risks, in this case, we have a mixture of environmental and behavioral variables in each profile; hence, it requires some interpretive effort to decide which of the domains is most contributory at particular survey dates (Castro et al., 2006). We use an MM model with as a competitor of the proposed MMM, refer to Section 2 of Acknowledgements for the details on this model.
Interpretability issues can be alleviated with an MMM analysis where is the number of subject matter domains and for , relying directly on the domain knowledge to partition variables. At Machadinho, the environmental conditions included quality of a house and its proximity to standing water; cut but not cleared trees changing the definition of the forest fringe and producing partial shade; site of initiation of farming near standing water and the forest fringe. Behavioral conditions included wearing of protective clothing, ownership of a chain saw and planter to facilitate land clearance and initiation of crop production, and farming close to the forest fringe. A core of variables remained common to all the years, while some other questions were gradually added over time. Household spatial locations are also available and will be considered in the analysis. Although the survey was carefully administrated, the composition of the resulting data is highly heterogeneous across time and includes many missing data, which were considered informative for this application; hence we defined a missing category for each variable so that the missingness pattern can inform the analysis results.
The full set of variables in the surveys is displayed in the first column of Tables S5–S8 of Acknowledgements, while Table 3 shows, at a summary level, the number of subjects and variables included in the analysis by survey year and domain of variables.
A fundamental challenge for identifying the drivers of malaria risk is the fact that there are many environmental and behavioral conditions that contribute to exposure to A. Darlingi, but there is no individual or small combination of such conditions that occurs at high frequency and stands out as a major influence on malaria episodes experienced. This is precisely where MMM can be used to an advantage.
7.2 Model specification
Malaria behavioural and environmental risk scores can present distinct time and space evolutions, since we consider data that goes from the beginning of a settlement project to 10 years later. To characterize such evolution we leverage the multivariate Gaussian model in step of Algorithm 1. Different multivariate spatio-temporal models can be considered (see for example Banerjee, Carlin and Gelfand, 2014), and we rely on a separable model for time and space, assuming no interactions. This assumption leads to a simple and computationally efficient latent model, while accommodating non regular observations in space and time. Indicating with and the behavioral and environmental risk score for subject , space-time dependence can be included in distribution (4.1) letting
[TABLE]
where , and , are respectively a time indicator and the observed longitude and latitude corresponding to the household of subject .
We account for time dependence through a multivariate Gaussian hierarchical model with common hyperprior. Specifically, , and . This model does not impose a rigid time evolution, allowing borrowing of information across different years.
For the spatial effect we specify a bivariate spatial model. A simple possibility would be to rely on a separable structure for the spatial cross covariance of the process (e.g., Banerjee, Gelfand and Polasek, 2000). However, this model would imply the same spatial effect for both the environmental and behavioral domain. We expect that behavioral and environmental scores can have a very different spatial evolution, and for this reason we rely on a conditional Gaussian process for the components of . Specifically we consider , where is a lower triangular matrix obtained through Cholesky decomposition, and we let and . This formulation enforces no dependence across time and space for the spatial effects.
Since we are considering standardized data, we parameterize the Gaussian processes in terms of correlation functions , obtained by normalizing the square exponential form , where are length scale parameters, is the Euclidean distance and is a nugget effect to limit numerical instability. The considered prior induces independent spatial effects for each domain and time, while leading to a computationally efficient model, since small matrices are involved in the Gaussian process computation.
The model can be easily implemented adapting Gibbs sampler Algorithm 1, with updating of the length scale parameters relying on a Metropolis step.
7.3 Model checking
We assess goodness-of-fit of the proposed model to the observed data. We are particularly interested in whether the assumption of leads to significant lack of fit.
One possibility is to compute posterior distributions for some statistics of the considered data and compare them with the corresponding empirical quantities (e.g., Gelman et al., 2013). We consider as statistics the marginal and bivariate distributions, that can be obtained as:
[TABLE]
for and , and where and .
Figure 7 shows estimated marginal distributions from Gibbs samples for 4 representative variables across the years, for the proposed model and the MM described in Section 2 of Acknowledgements, together with the sample proportion with the level Wald type confidence interval. Both models produce estimated marginals that are compatible with the observed ones. We additionally estimated the posterior mean of the L1-norm between the empirical frequencies and the estimated ones obtained by averaging 2500 MCMC samples of the expression in (7.2). The L1-norm has expression . Considering all the variables, we have an average L1-norm of about , and and quantiles of , for the proposed model, and for the MM with profiles. These quantities also suggest a strong adherence of the estimated marginals with the empirical ones.
Figure 8 shows posterior distributions and quantiles for 2 bivariate distributions (for the MM model refer to Figure S7 in Acknowledgements). Also in this case we observe a satisfactory adherence of the estimated quantities and the empirical ones.
As with the marginals we compute the L1-norm between the empirical bivariate distributions and the estimated ones. We focus on pairs of variables in the same year. We obtain good results also in this case with a mean of and and 0.9 quantiles of , for the proposed MMM model, and for the MM model.
In the MMM model as a general tendency, we observed that variables that are sensibly different across the estimated profiles are generally better reconstructed. These are also the most interesting from an interpretation point of view since they characterize the profiles.
The agreement between empirical and estimated quantities suggests that the considered interpretable model with and , for , is sufficiently precise to analyze the profile structure more in depth. The additional latent parameters in the MM model with provide a small benefit in terms of fit to the data, but they make the latent profiles less straightforward to interpret in terms of malaria risk (refer to Section 2 of Acknowledgements). If the MMM model had presented a poor fit to the observed data, we should either have increased , or defined a finer partition of variables. Both solutions are viable and, as a consequence of Lemma (3.1), might lead to an equally accurate approximation of the underlying probability mass function. Note also that the posterior mean (and standard deviation) of the correlation for the environmental and behavioral score vectors are , , , and , for and respectively. These values suggest that two separate MM models would ignore a high correlation structure, while a single MM model with (posterior correlation =1) may be insufficient to characterize the score distribution.
7.4 The structure and evolution of risk profiles
All variables that can enter risk profiles take on a discrete set of possible values/levels. Each level of a variable represents what we will refer to as a condition. The conditions that occur in a profile with substantially greater frequency than in the overall population can be considered as the most relevant to describe the profiles, and will be referred to as admissible (see Singer, 1989, for a detailed discussion).
To make this precise we say that condition for variable in vertex is called admissible if either
[TABLE]
where , and are the marginal empirical frequencies.
Inequality (7.3a) is appropriate for —i.e. relatively infrequent conditions. Inequality (7.3b) is particularly important in the present survey data, as quite a few conditions occur with high frequency—e.g. —in the overall population.
The set of conditions is defined to be an admissible profile. Admissible profiles are described by logical AND statements for the set of admissible conditions. In the proposed Bayesian framework we can compute the posterior probability of (7.3a) and (7.3b), and define as admissible the conditions having posterior probability exceeding . These conditions are reported in light gray in Tables S5–S8 of Acknowledgements. Further categorizing sets of conditions especially relevant for exposure to A. Darlingi mosquitoes in, for example, the environmental profiles, leads to a clear display of the change in such conditions over time as the highly dynamic plot occupancy process evolves (see Figure 6).
Admissible environmental conditions labeled in a high risk profile, summarized in Table 4, correspond to situations that facilitate exposure to A. Darlingi mosquitoes (e.g. poor quality of wall and sealing). These high environmental risk conditions, operable during the first three years of the settlement process, disappear by when diverse improvements at occupied plots have been incorporated. Such a tendency is clearly highlighted by an increasing trend in the distribution of expected odds ratios of the risk scores shown in Figure S8 in Acknowledgements.
These results are in accordance with current literature on malaria risk, in Amazon areas, reporting that the risk is initially driven by favorable environmental conditions for malaria vectors to proliferate (e.g., Castro et al., 2006). Soon after human settlement, there is a phase lasting for about 8 or 10 years, in which environmental risk is high but human behavior is starting to gradually become the predominant risk factor. In the last stage, called the endemic phase, the risk is far more related to behavioral causes. From a spatial perspective, we can study the changes in behavioral and environmental risks by considering the posterior predictive distribution of the defined in equation (7.1). Maps evaluating this distribution over a regular grid of points are available in Acknowledgements (Figure S9), showing that the behavioral risk distribution is constant across time and space; hence the spatial variability is driven by environmental conditions. Environmental risk zones can be mostly explained in term of geographical characteristics of the area; in fact higher risk zones correspond to the forest fringe and the Machadinho river path.
7.5 Malaria rates and risk profiles
To assess the relationship between malaria rates and the estimated profiles, for each MCMC sample in each year, we assign households/plots into low, moderate, and high behavioral and environmental risk groups using tertile cut points. We compute the average malaria rate for each of the groups. Posterior median and quantiles of the malaria rate distribution for the considered clusters are shown in Table 5. A similar strategy using tertiles of separate MM models has been used to determine risk profiles for Chagas disease in northern Argentina (Chuit et al., 2001). We expect the obtained distribution to be ordered in such a way that higher malaria rates correspond to high environmental and behavioral risk clusters. Formally considering a table such as Table 5, having low risk clusters in the upper left corner, we expect the resulting table to be a double-gradient table, meaning that each row should be non-decreasing from left-to-right and each column should be non-decreasing from top-to-bottom.
From Table 5 we notice that in defining groups with either environmental or behavioral scores we obtain groups sharing almost the same malaria rate. However, a more detailed classification can be obtained leveraging both domains at the same time. In general, we observe higher malaria median rates in high behavioral and environmental risk zones, with only two violations of the expected double gradient assumption if we consider the median; in both cases, however, upper quantiles are still increasing as expected. We provide a similar analysis for the MM model in Section 2 of Acknowledgements. Although the two models share similar performances in terms of goodness-of-fit, the direct use of domain knowledge in the MMM model lead to results which are simpler to interpret in term of malaria risk.
8 Discussion
We introduced a new family of multivariate mixed membership models (MMM) that facilitate the representation of interpretable shared memberships in classification schemes in settings where good-fitting conventional MM models pose severe interpretation problems. The crux of this issue is that it is virtually impossible to write a coherent sentence describing shared membership among, say, profiles. However, if a large set of variables can be meaningfully partitioned into separate subject matter domains, for each of which there is a small number (ideally ) of domain-specific profiles, then experience to-date indicates that interpretable descriptions of the patterns of shared membership are possible. Further, cross-domain comparisons of shared membership reveal new information that cannot be extracted with MM models that typically incorporate a large number of profiles. This is shown at a most basic level via Table 5 in our analysis of malaria risk on the Amazon frontier.
In the considered application there is a clear partition of variables into subject matter domains, which simplifies model specification and interpretation of results. Similar sharp partitions of variables can be found in many applications; for example, in testing student language skills we can have questions related to several tasks (i.e., reading, writing, listening, etc.). In other settings, the number and compositions of domains can be just partially known, or unknown. In these cases, it can be useful to let the data inform on the subject matter domains, generalizing model (3.1) with an additional prior on variable groups. Informative priors on the space of partitions can be included adapting recent proposals in Paganin et al. (2020) and Smith and Allenby (2020). However, additional latent layers make interpretation and computation challenging, inducing a further trade-off between model complexity and interpretability.
The MMM framework that we put forth is quite general and should be applicable in a wide variety of scientific contexts. In the interest of focusing attention on MMM per se, we provided a first top-level illustration of what can be done with this technology that is not feasible with other extant methods. More nuanced spatially explicit analyses that integrate evidence from the surveys used here with satellite imagery and ethnographic appraisal would be a next step for utilization of MMM. An initial pass at this kind of complex data integration in a study of malaria in the Brazilian Amazon region is presented in Castro et al. (2006), but the methodology introduced here has the potential to carry this case study much further.
Acknowledgements
Data for this study were extracted from the project “Land Use and Health” funded by the International Development Research Centre (IDRC), grant #94-0206-00, awarded to Centro de Desenvolvimento e Planejamento Regional, CEDEPLAR (Belo Horizonte, MG, Brazil), PI: Diana O. Sawyer. Data was cleaned and treated by Marcia C. Castro, and originally used in (Castro et al., 2006)(www.pnas.org/cgi/doi/10.1073/pnas.0510576103). The work was partially supported by funding from grants R01ES027498 and R01ES028804 from the United States National Institute of Environmental Health Sciences and grant N00014-16-1-2147 from the Office of Naval Research.
{supplement}\sname
Supplement A \stitleMalaria risk conditions \slink[url]url \sdescriptionThe file includes additional simulations and tables showing posterior medians, 0.1 and 0.9 quantiles of the kernels for behavioral and environmental variables for all the survey years. It also includes details of an MM model with profiles applied to the Machadino data, a plot of the expected odds ratios between environmental and behavioral risk scores, and one on spatial risk predictions for the Machadinho area, with some comments.
,
and
1 Simulation details
The code to reproduce all the tables and plots in Section 6 is available at https://github.com/rMassimiliano/MMM-tutorial, which includes step-by-step description on how to generate and analyze data from the considered simulation scenarios. To initialize the Variational EM algorithm in the mixedMem package, we used the simulation truth (in Section 6.2 we used true values from the first two profiles). In our MMM model we found no significant difference in the initialization of the parameters. We consider also an MCMC implementation of the MM models as the one proposed in Erosheva, Fienberg and Joutard (2007), using the software NIMBLE (de Valpine et al., 2020); the code is available in the script MM_nimble.R. In this implementation we set , , and , with mean and variance ; with these hyperparameters the score vector components are centered at , with a variance of approximately .
2 Mixed Membership model for malaria data
As a competitor to the MMM model described in Section 7.2, we consider an MM model with pure types. This model does not directly incorporate domain knowledge on environmental and behavioral variables, but can potentially represent the same risk structure: high (low) risk for just one domain and low (high) risk for the other, or high (low) risk for both. We incorporate space and time information via the following model:
[TABLE]
where and are, respectively, a time indicator and the observed longitude and latitude corresponding to the household of subject .
We account for time dependence through a multivariate Gaussian hierarchical model with common hyperprior. Specifically, , and . Note that , while . For the spatial effect we specify independent Gaussian processes for each profile with the covariance structure described in Section 7.2. This model uses more parameters than our proposed MMM specification, which leverages domain-knowledge to parsimoniously characterize space and time variability, using domain-specific parameters in place of profile-specific ones.
We consider here the relation between malaria rates and risk profiles, similarly to what was presented in Section 7.5 for the MMM model. From table S3, we can notice that all profiles give similar results in terms of malaria rates, and none of them present an increasing (or decreasing) pattern.
We also consider a summary of the malaria risk, grouping subjects into ‘low/high’ risk for each of the four profiles using the median of the scores for each profile. In this way, we divide households into 16 groups. Similarly to Table 5, we would expect malaria rates to be non-increasing (or decreasing) reading the tables from top-to-bottom. This does not seem to occur in Table S4 at this simple level of analysis.
3 Time and space domain evolution
Figure S8 shows boxplots of the distribution of the expected odds ratios of being high risk in behavioral and environmental domains. Such distributions can be computed relying on equation (4.2). Specifically, for each iteration of the MCMC algorithm, we can compute the quantity , where are the elements of the covariance matrix in equation (7.1).
We notice an increasing trend in the odds ratios across the years; specifically, in environmental and behavioral risks coexist, while starting from behavioral risk starts to gain more and more importance, as is evident from the fact that the posterior odds ratio is not significantly above one in and then it gradually increases. These results are in accordance with current literature on malaria risk, in Amazon areas, reporting that the risk is initially driven by favorable environmental conditions for malaria vectors to proliferate (e.g. Castro et al., 2006). Soon after human settlement, there is a phase lasting for about 8 or 10 years, in which environmental risk is high but human behavior is starting to gradually become the predominant risk factor. In the last stage, called the endemic phase, the risk is far more related to behavioral causes.
From a spatial perspective, we can consider the posterior predictive distribution of evaluated over a regular grid of values (Figure S9). We notice that the behavioral risk distribution is constant across time and space; hence, from the considered survey data, it appears that the spatial variability is driven by environmental conditions. Environmental risk zones can be mostly explained in terms of geographical characteristics of the area; in fact higher risk zones correspond to the forest fringe and the Machadinho river path.
4 Malaria risk conditions
Tables S5, S6, S7 and S8 includes posterior medians and 0.1 and 0.9 quantiles of the kernels for all behavioral and environmental variables considered in the analysis, computed using posterior samples. Light gray values in the table highlight admissible conditions as defined in (7.3a) or (7.3b).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Airoldi et al. (2005) {barticle} [author] \bauthor \bsnm Airoldi, \bfnm Edoardo \binits E., \bauthor \bsnm Blei, \bfnm David \binits D., \bauthor \bsnm Xing, \bfnm Eric \binits E. and \bauthor \bsnm Fienberg, \bfnm Stephen \binits S. ( \byear 2005). \btitle A Latent Mixed Membership Model for Relational Data. \bjournal Proceedings of the 3rd International Workshop on Link Discovery(Link KDD ’05). New York, NY, USA: ACM \bpages 82–89. \endbibitem
- 2Airoldi et al. (2008) {barticle} [author] \bauthor \bsnm Airoldi, \bfnm Edoardo M \binits E. M., \bauthor \bsnm Blei, \bfnm David M \binits D. M., \bauthor \bsnm Fienberg, \bfnm Stephen E \binits S. E. and \bauthor \bsnm Xing, \bfnm Eric P \binits E. P. ( \byear 2008). \btitle Mixed membership stochastic blockmodels. \bjournal Journal of Machine Learning Research \bvolume 9 \bpages 1981–2014. \endbibitem
- 3Airoldi et al. (2014) {bbook} [author] \bauthor \bsnm Airoldi, \bfnm Edoardo M \binits E. M., \bauthor \bsnm Blei, \bfnm David \binits D., \bauthor \bsnm Erosheva, \bfnm Elena A \binits E. A. and \bauthor \bsnm Fienberg, \bfnm Stephen E \binits S. E. ( \byear 2014). \btitle Handbook of Mixed Membership Models and their Applications. \bpublisher New York: Chapman and Hall/CRC. \endbibitem
- 4Aitchison and Shen (1980) {barticle} [author] \bauthor \bsnm Aitchison, \bfnm J. \binits J. and \bauthor \bsnm Shen, \bfnm S. M. \binits S. M. ( \byear 1980). \btitle Logistic-Normal Distributions: Some Properties and Uses. \bjournal Biometrika \bvolume 67 \bpages 261–272. \endbibitem
- 5Artin (1991) {bbook} [author] \bauthor \bsnm Artin, \bfnm Michael \binits M. ( \byear 1991). \btitle Algebra. \bpublisher Prentice Hall. \endbibitem
- 6Banerjee, Carlin and Gelfand (2014) {bbook} [author] \bauthor \bsnm Banerjee, \bfnm Sudipto \binits S., \bauthor \bsnm Carlin, \bfnm Bradley P \binits B. P. and \bauthor \bsnm Gelfand, \bfnm Alan E \binits A. E. ( \byear 2014). \btitle Hierarchical modeling and analysis for spatial data. \bpublisher New York: Chapman and Hall/CRC. \endbibitem
- 7Banerjee, Gelfand and Polasek (2000) {barticle} [author] \bauthor \bsnm Banerjee, \bfnm Sudipto \binits S., \bauthor \bsnm Gelfand, \bfnm Alan E. \binits A. E. and \bauthor \bsnm Polasek, \bfnm Wolfgang \binits W. ( \byear 2000). \btitle Geostatistical modelling for spatial interaction data with application to postal service performance. \bjournal Journal of Statistical Planning and Inference \bvolume 90 \bpages 87 - 105. \bdoi https://doi.org/10.1016/S 0378-3758(00)00111-7 \end
- 8World Bank (1992) {barticle} [author] \bauthor \bsnm World Bank ( \byear 1992). \btitle World Bank Approaches to the Environment in Brazil, Vol. V: The Polonoroeste Program. \bjournal OECD Report 10039, Sec M 92 - 64. \endbibitem