Quantum Markovianity as a supervised learning task
Sally Shrapnel, Fabio Costa, Gerard Milburn

TL;DR
This paper explores using supervised learning, specifically Random Forest Regressor, to estimate the dimension of non-Markovian quantum environments from simulated data, opening new avenues in quantum environment characterization.
Contribution
It introduces a novel approach applying supervised learning to quantify quantum environment properties, specifically non-Markovianity, using classical simulation data.
Findings
Random Forest effectively estimates quantum environment dimension
Supervised learning shows promise for quantum environment analysis
Method could be extended to real quantum systems
Abstract
Supervised learning algorithms take as input a set of labelled examples and return as output a predictive model. Such models are used to estimate labels for future, previously unseen examples drawn from the same generating distribution. In this paper we investigate the possibility of using supervised learning to estimate the dimension of a non-Markovian quantum environment. Our approach uses an ensemble learning method, the Random Forest Regressor, applied to classically simulated data sets. Our results indicate this is a promising line of research.
Click any figure to enlarge with its caption.
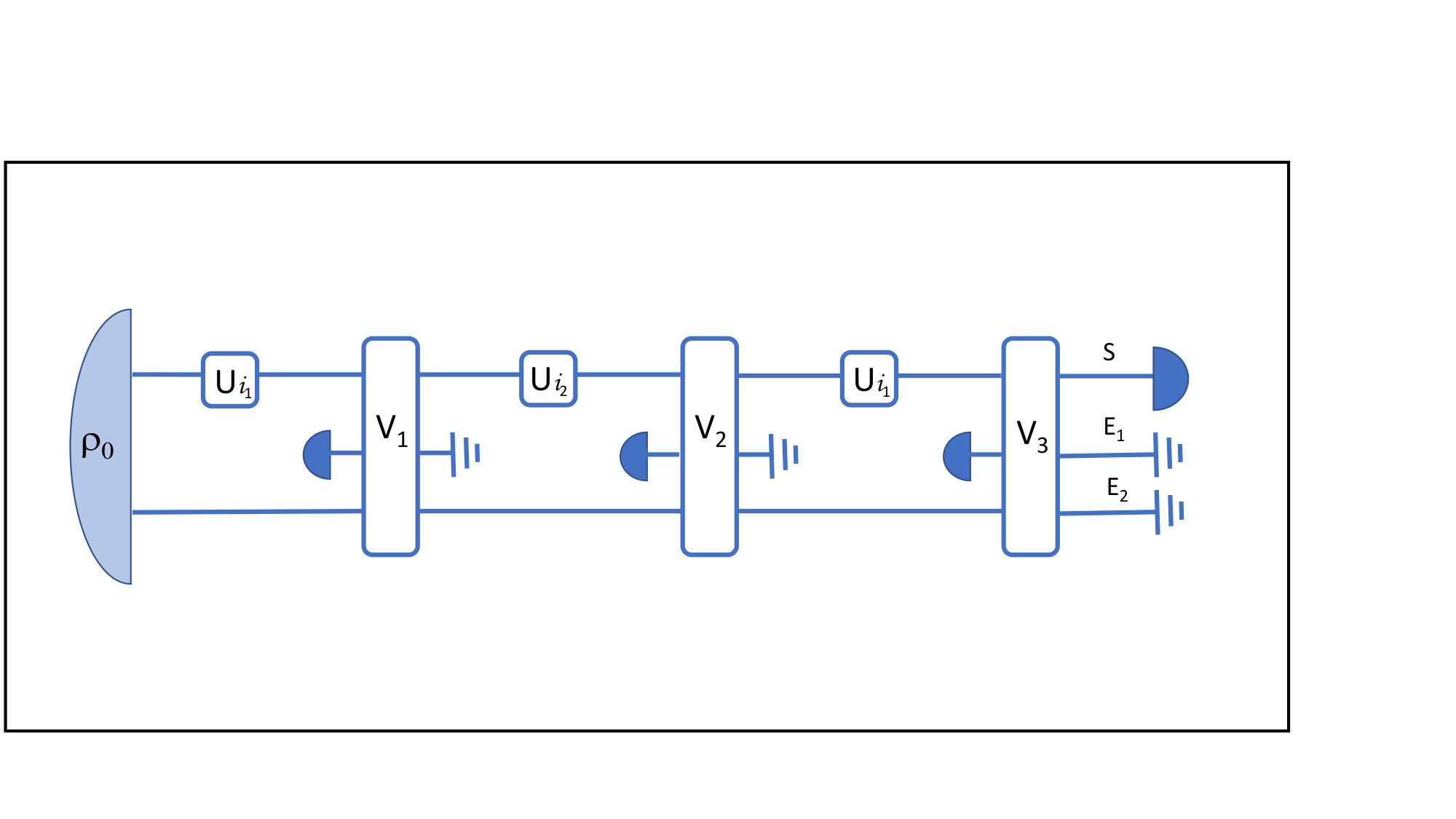 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4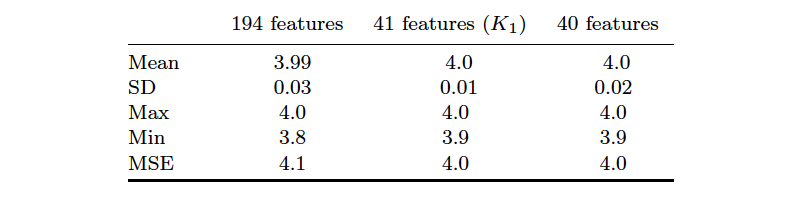 Figure 5
Figure 5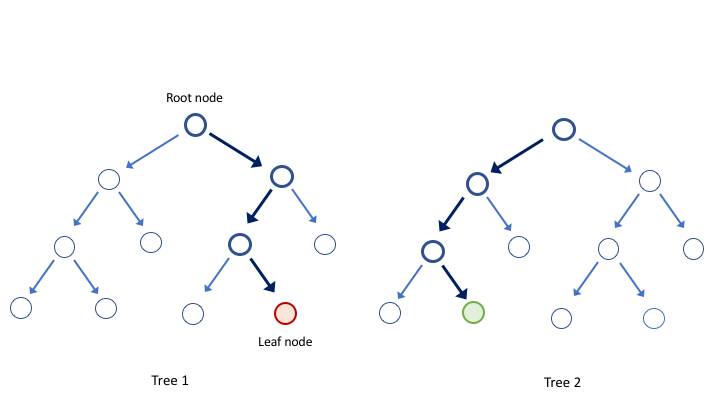 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Quantum Markovianity as a supervised learning task
Sally Shrapnel
Centre for Engineered Quantum Systems, School of Mathematics and Physics, The University of Queensland, St Lucia, QLD 4072, Australia
Fabio Costa
Centre for Engineered Quantum Systems, School of Mathematics and Physics, The University of Queensland, St Lucia, QLD 4072, Australia
Gerard Milburn
Centre for Engineered Quantum Systems, School of Mathematics and Physics, The University of Queensland, St Lucia, QLD 4072, Australia
(19th March 2024)
Abstract
Supervised learning algorithms take as input a set of labelled examples and return as output a predictive model. Such models are used to estimate labels for future, previously unseen examples drawn from the same generating distribution. In this paper we investigate the possibility of using supervised learning to estimate the dimension of a non-Markovian quantum environment. Our approach uses an ensemble learning method, the Random Forest Regressor, applied to classically simulated data sets. Our results indicate this is a promising line of research.
I Introduction
Predicting particular aspects of future phenomena is a task central to science. Medical practitioners gather physiological data to make predictions about the likelihood of future pathology. Meteorologists accumulate and analyse environmental data to make predictions about tomorrow’s weather. In almost all fields of human endeavour, one faces the task of predicting the value of a future variable, based on observations about a range of past variables.
Traditionally, scientists have approached such tasks from the perspective of models and theoretical constructs particular to their own field. More recently, an alternative approach has emerged. Developments in computer hardware, computer science and artificial intelligence have led to the possibility of machines that can learn to predict future phenomena with impressive accuracy and efficiency. Early machine learning approaches involved hand-crafted solutions, tailored to perform optimally on specific tasks. Recent techniques more often adopt a ‘black box’ approach, where ‘off-the-shelf’ architectures leverage the high computing power of today’s technology. Similar algorithms are now able to solve a large variety of scientifically dissimilar tasks, with the algorithm remaining ignorant of any domain-specific theoretical suppositions.
The modern field of machine learning now provides a large suite of tools that can be applied to a wide variety of learning tasks. Although there are a wealth of past theoretical computer science results relating to the performance of these methods, advances are currently driven largely by direct experimental application. As techniques are applied to new domains, a richer understanding of both the relevant search space and the limitations of particular approaches is gained. Utilising classical machine learning techniques to better understand the structure of quantum data is likely no exception. The application of machine learning to the quantum domain has only recently begun to receive attention biamonte2017 ; dunjko2017 , and it is likely the benefits and pitfalls of specific approaches will become clearer with time.
In this paper we apply an ensemble supervised classification technique, Random Forest Regression, to address a specific quantum information problem: classifying an unknown environment, interacting with a quantum system, as either Markovian or non-Markovian. We also consider, in the case of a non-Markovian environment, the task of estimating its dimension. Our definitions of Markovianity and non-Markovianity follow recent work on quantum Markovian processes Costa2016 ; giarmatzi2018quantum ; Pollock2018 ; Pollock2018a ; milz2016reconstructing . These approaches use a process matrix approach to define conditions for Markovianity, and have been shown to unify previous approaches.
For many quantum-technology applications the presence of non-Markovian noise is difficult to characterise. The complexity grows with the dimension of the environment that needs to be modelled: reliable and efficient methods to detect and measure non-Markovianity would certainly be of use. Current approaches require full tomography of a multi-time process, necessitating multiple non-destructive measurements on the system Costa2016 ; Pollock2018a ; giarmatzi2018quantum . Here we consider the possibility of characterising non-Markovianity in a more practically accessible scenario to explore the possibility of learning information about the environment when one does not have access to tomographically complete information. Specifically, we consider a situation where the system of interest is subjected to a sequence of controlled unitary transformations, and a single measurement is performed at the end.
Our results demonstrate that it is indeed possible to train a learning model to provide a good estimate of the dimension of a non-Markovian environment from the statistics of the final measurement. Our approach represents first steps towards finding a practical solution to the problem of estimating non-Markovian noise, and suggests machine learning techniques may well prove useful in this context.
The structure of the paper is as follows: in Section 2 we introduce the problem and clarify the nature of the particular learning task we wish to solve. In Section 3, we introduce the reader to machine learning and detail the main technique used, Random Forest Regression. In Section 4 we present the specific methods used and in Section 5 we present our results. We finish with a discussion.
II Quantum non-Markovianity
We consider the following scenario: an experimentalist attempts to control and manipulate a system , which can interact with some inaccessible environment . For concreteness, we take to be a two-level system, while can in principle have arbitrary dimension. The experimentalist can perform operations on the system at some prescribed times . The operation at time is restricted to be a projective measurement on one of the states
[TABLE]
At the times , the experimentalist can apply one of the unitary transformations
[TABLE]
(We assume that the time it takes to perform unitaries and measurements is short with respect to any other relevant dynamics, so each operation can effectively be considered as instantaneous.) The experimenter thus collects statistics in the form of probabilities
[TABLE]
Although can be coupled with an arbitrarily large environment, a subsystem of dimension is sufficient to reproduce an arbitrary multi-time expression such as Eq. (3) Gutoski2006 ; Chiribella2009 ; we shall identify the environment with such a subsystem without loss of generality. The observed probabilities (3) can be obtained by alternatively evolving an initial system-environment state, possibly correlated, with the controlled unitaries and some joint system-environment unitary evolution. This can be hard to model in general, both theoretically and computationally, given the exponential scaling of the relevant environment’s dimension. The task of the experimenter is thus to estimate whether a simplification is possible, i.e., if it is possible to reproduce the observed statistics with a lower-dimensional effective environment.
More specifically, here we are interested in estimating how much of the environment carries memory of the system. We can formalise this question by decomposing into two subsystems at each time step: of dimension (the Markovian environment) and of dimension (the non-Markovian environment). After each time , , the Markovian environment is discarded and replaced with some fiducial state . Then the experimentally-controlled unitary is applied on the system , after which system and environment (both Markovian and non-Markovian) evolve through a joint unitary . Since the Markovian environment is discarded after each time step, we only need to explicitly keep track of the evolution of the system and the non-Markovian environment. The state just before each time is then given by the recursive mapping
[TABLE]
where in Eq. (4) the unitary is implicitly extended to act as identity on , the superscripts on the right-hand-side of Eq. (5) denote the subsystems on which the corresponding operators are defined, denotes the partial trace over a subsystem , and is some initial joint state of system and non-Markovian environment, possibly correlated. The observed probabilities are finally given by
[TABLE]
where the dependence on the unitaries on the right-hand-side is implicit in the state (Fig 1).
If , the whole process can be described by a sequence of trace-preserving maps acting on the system alone, concatenated with the experimentally-controlled operations. We say in this case the process is Markovian. A simple task is to estimate whether or not a system is Markovian, i.e., to verify whether is sufficiently close to within some confidence interval. This can be useful, for example, in a context where some protocol is only guaranteed to work in the presence of Markovian noise. More generally, the experimenter might be interested in estimating for a non-Markovian environment. This could be useful to evaluate the resources required to reproduce or simulate a process of interest, or to bound the space of processes to use for the analysis and optimisation of the experiment. Recall, in the most general case the dimension of the non-Markovian environment can be exponentially large in the number of time steps, (see also Gross , particularly figure 5). Thus, finding a small can dramatically reduce the cost of modelling the process.
Therefore, the task we consider here for the experimenter is to estimate the smallest value of that correctly reproduces all possible observations on the system. Note that, for a given value of , the amount of non-Markovian noise imparted on the system will vary depending on the strength of the interaction. Here we assume that such a strength, or the type of interaction, is not known by the experimenter, who attempts to deduce from the observed statistics only. We will assume that the strength and type of interaction with the environment is constant over time; we will come back to the details of the model in Section IV.1.
The process described above, where an environment retains memory of a system that can be probed at multiple times, is known as a channel with memory Kretschmann2005 , and it has also been studied in the context of quantum strategies Gutoski2006 and quantum networks Chiribella2008 . The corresponding notion of Markovianity we adopt agrees with that of quantum stochastic processes ACCARDI1978226 ; lindblad1979 ; Pollock2018 and quantum causal modelling Costa2016 ; Allen2016 . Note that, although different definitions of Markovianity exist in the literature li2017concepts , approaches that characterise open dynamics in terms of a (time-dependent) map from an initial to a final state of the system Rivas2014 fall short of describing a scenario where multiple interventions at different times are possible within a single experimental run (as is the case for the situation we describe here).
One possible method to estimate would be to fully reconstruct the multi-time process (i.e., the channel with memory) through tomography; this would however require performing measurements, and not just unitary transformations, at each time step Costa2016 ; Pollock2018a ; giarmatzi2018quantum . Therefore, one would expect that having access only to the probabilities (6) would not be sufficient to determine in general, because they range over settings that are not tomographically complete milz2016reconstructing . However, it remains unknown whether alternative methods exist that might permit one to estimate with a high probability of success for a broad range of physical situations.
Our approach is to cast this problem as a supervised learning task. We generate training data according to our knowledge of interacting quantum systems, where we label each data example by the values of the parameters used to generate that particular example. Specifically, our aim is to train the learning model to estimate the value of with low error on both training, validation and test set data.
III Random Forests
Understanding any machine learning application requires familiarity with some standard terminology. A computer program may be considered to ‘learn’ from an “experience with respect to some class of tasks and performance measure , if its performance in tasks in , as measured by , improves with experience " mitchell97 . Tasks are typically described according to how the learning system should process an example, which is a collection of features: quantitative values measured from the system of interest. Each example is represented as a vector , where each vector entry corresponds to a specific feature. The learning experience is usually a dataset formed by a collection of independently and identically distributed examples (alternatively data points).
The algorithm is classed as supervised when the experience includes a dataset where each example is also associated with a label or target (assumed to be provided with perfect accuracy by an expert “supervisor"). The underlying assumption is that the output target variable does not take its value at random, but rather a relationship exists between the examples and their labels. Roughly speaking, the task of the model is to learn a function that maps examples to labels; a good approximation of the mapping function will permit accurate prediction of the value of an unseen output label, given the value of its input example. The performance measure is to some extent determined by the learning task: when one wishes to estimate the value of a categorical variable, e.g. “has disease/does not have disease", the performance is judged according to the proportion of examples for which the model produces the correct output (the accuracy). For regression tasks, where one wishes to estimate the value of a real variable, e.g. “sale price", the performance is often judged by mean squared error (the error decreases as the Euclidean distance between model predictions and targets decreases).
The ultimate aim of machine learning is to perform optimally on new, previously unseen examples. Clearly, it is no good to perform perfectly on the data used to train the model (the ‘training data set’ ), and perform poorly on unobserved examples. The ability for models to perform well on unseen data is called generalisation. Common to all machine learning tasks is the problem of over-fitting, where one fits the training data very well, but at the cost of generalisation. It is possible to estimate the generalisation error of a model by measuring the performance on a test set of previously unseen examples. Thus the overall aim of machine learning is to not only minimise the training error, but to also minimise the difference between the training and test error.
Random Forests (RFs) are a popular supervised learning method that require very few statistical assumptions about the underlying data, are easy to use, and have been applied with success in many domains Breiman2001 ; biau2016random ; louppe2014 . They provide an opportunity for parallel computation, have very few hyper-parameters to tune, and perform well on both high and low dimensional learning tasksCaruana08 . Consequently, Random Forests have enjoyed widespread use in a variety of scientific and industry related domains.
RFs are an example of ensemble learning - a class of algorithms that generate multiple classification or regression models and then aggregate their results.111There are a number of alternative ensemble methods that perform similarly to RFs across a variety of learning tasks. AdaBoost, Gradient Boosting Trees and XGBoost are all likely to provide models with similar success, though some studies show RFs have a slight advantage for data sets of high dimension Caruana08 . The basic unit is the decision tree, a non-parametric model that is built by recursively partitioning the data space according to thresholding decisions (e.g. “is the value of this feature above or below 0.5?", see fig. 2). Each tree takes a randomly chosen subset of feature values as input, and returns a label prediction as output. For the data set we study in this paper there are in total 192 features, thus each decision tree will take as input values from a random subset of the 192 features. Following partitioning of the input data via splitting decisions, each individual tree will return a predicted value for k2.
Each tree in the RF ensemble is built directly from a ‘bootstrap sample’ – data drawn at random from the training set, with each drawn example replaced prior to the subsequent selection. Therefore, individual examples can be represented more than once in the boot-strapped set. The final set contains the same number of examples as the original data set: typically one ends up sampling roughly two thirds of the original examples (due to the repeated selection of some examples). Examples not included in the boot-strapped data set used to fit a particular decision tree are called “out-of-bag" samples for that particular tree.
Following training, the trees can be used to predict labels for unseen examples of the same data type. Individual decision trees alone tend to over-fit training data and do not generalise well. RFs solve this problem by fitting many trees on random sub-samples of the data (the “boot-strapped"data) and then aggregating the results. By introducing randomness into the construction of each tree, a diverse set of models is produced, with the prediction of the entire ensemble given as the average of the predictions of the individual trees.
RFs can be used for both classification and regression tasks; here we will only be interested in regression. In particular, for our task we use ‘Extremely Randomized Trees’, where the choice of threshold for splitting is randomised, and the best of these randomly chosen thresholds is used, rather than choosing the optimal threshold for splitting directly (as is the case for the standard approach, Random Forest Regressors). Extremely Randomised Trees are an example of “weak" learners: although each individual tree may not fit the data very well, the averaged ensemble provides a good fit to the data that is likely to generalise.
The entire ensemble of decision trees is optimised according to a given metric. The most common optimality criterion for RF regression is the mean squared error (MSE), which we use here. Mean squared error loss penalises large discrepancies between predicted labels and true labels more than small ones:
[TABLE]
where is the true label of the -th example, is the label predicted by the model and is the number of examples in the training data set.
Including the possibility of boot-strapping enables a measure of an ‘out-of-bag’ (OOB) error. If each new tree is fit from a boot-strap sample of the training examples, , then the OOB error is the average error for each calculated using predictions from those trees that do not use in their boot-strap sample. One can either manually compare OOB error rates for particular choices of hyper-parameters, or perform an automated ‘grid-search’ (which usually enables one to cover a larger range of hyper-parameters). Out-of-bag estimates are generally considered to provide accurate estimates of the generalisation error of the ensemble, often producing statistics that are even more precise, and computationally efficient than K-fold cross-validation estimates Wolpert1999 .
The final, trained ensemble model itself is evaluated by the score, a metric which gives an indication of how well future examples are likely to be predicted by the model. For a predicted value of on the -th example, with a true value of , the score over samples is:
[TABLE]
where is the mean: .
The best possible score is (arbitrarily close to) 1, and for extremely bad models can also be negative: models can be arbitrarily worse than simply estimating the mean. A model that is constant and always predicts the expected value of the labels, regardless of the training data, will have an of [math] (the second term on the right-hand side of Eq 8 simplifies to 1). In general one will measure the score for the training set, the validation set and the out-of-bag samples, in order to assess the overall quality of the model. A model with a high score for the training set, but a poor validation or OOB will be likely to generalise poorly. Ultimately, one aims for an OOB score as close to 1 as possible. The main advantage of analysing the performance of the model on the validation set is to provide an opportunity to improve the model via hyper-parameter tuning, prior to final testing. Tuning the model runs the risk of over-fitting to the validation set, hence the need for a final test, or "hold out" set of data with which to measure the model’s performance.
One faces a number of choices when implementing this kind of model. The number of trees, the maximum depth of each tree (how many splitting decisions are included), the minimum leaf number and the maximum features included in the root node will all contribute to the performance of the model.
A final advantage of RFs is the possibility of assessing feature importance. Individual features are ranked according to their contribution to the final model, providing an opportunity to prune redundant features and improve the computational efficiency of the final model. Feature importance is evaluated after the Random Forest has been trained: one randomly permutes all the example entries corresponding to a particular feature, and runs these altered examples through the model to generate a new set of predictions. The new predictions are then compared to the true labels to generate a new set of scores which can then be compared to those calculated prior to the random permutation. Any consequent reduction in score can be attributed to the particular feature being evaluated and all features can be ranked according to this measure.
IV Methods
IV.1 Data generation
Our aim was to simulate a system of fixed dimension () and total number of time steps (). Furthermore, we restrict our attention only to time-translation invariant processes. Therefore all the unitaries describing the joint system-environment evolution at different times are equal: . This is a relatively natural assumption in many situations, where one does not expect a systematic change in the environment within each experimental run.
In several scenarios of practical interest, one would not expect the joint system-environment evolution to be completely arbitrary. In particular, for several quantum-technology applications one would attempt to have the system evolving as little as possible, aside from the chosen, controlled transformations. We therefore introduce a parameter that describes how far from identity the unitary is. The latter is sampled in the following way: first a set of numbers , is sampled independently and uniformly from the interval . The diagonal matrix is generated. Then, a -dimensional unitary is sampled from the Haar measure, and finally is calculated (we use Mezzadri’s algorithm to sample unitary matrices from the Haar measure mezzadri2006generate ). For , this method only generates the identity matrix, while for it corresponds to sampling from the Haar measure. For intermediate values, applies random phases of at most to the states of a randomly-chosen basis. We call the evolution parameter. The initial joint state of system and non-Markovian environment is a -dimensional density matrix sampled from the ‘Ginibre’ ensemble BRUZDA2009320 .
A single example corresponds to a list of probabilities , which is generated through formulas (4), (5), and (6). A set of values for the indices , denotes a single feature. The value of the last index , denotes the basis of the final measurement, while the values of , , denote the unitary performed at time . In our scenario, with , the indices can vary in the range for and . For , this amounts to features. For example, the feature corresponds to the identity being applied at each time except the last, when the state is measured. The full set of features also include the values of , the ‘Markovian dimension’, and the evolution parameter , giving a total of features. We generate examples for a range of parameter values (; ; and ). For each parameter combination a total of examples is generated, giving a total of examples.
The data set was shuffled and retained for training the RFs, with retained for hyper-parameter tuning. The final was retained for testing the tuned model. The value of was chosen as the target feature for the network to learn.
A further test set, consisting of data generated using parameters outside those used to generate the training data was used to further assess the generalisability of the model. Test set 1: with other parameters in the range ; , with examples for each parameter combination. Test set 2: ; ; .
The data was generated using Mathematica software. The relevant notebooks can be obtained with permission from the authors.
IV.2 Learning algorithm
The learning algorithm was implemented using code from the open-source python library Scikit-learn pedregosa2011scikit , specifically Scikit-learn’s ExtraTreesRegressor (http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesRegressor.html), and also from the open-source pytorch library: fastai (https://github.com/fastai). The full code for the data simulation, pre-processing and model optimisation can be obtained with permission from the authors. Hyper-parameter tuning was initially optimised manually by comparing OOB estimates for a range of possible trial values. Optimal hyper-parameters values were assessed to be 80 trees, with all other values evaluated to agree with the Scikit-learn default values. Further hyper-parameter tuning was undertaken via both RandomCV search and GridSearch methods, although as the performance of the model did not change appreciably the Scikit-learn default values were retained.
The model was trained both including and excluding the parameters and . Prior to training and testing the model, it was not clear to what extent these parameters were relevant to the learning task. This is the advantage of using simulated data to test a learning task: one can ask such questions even though the parameters may not be experimentally accessible. As we will see below, for this particular task, knowledge of the values of these parameters turns out to have little impact on the final accuracy of the trained model.
V Results
In order to provide context, a dummy regression was performed on the training and validation data to calculate a comparative training score. In this way, one has a value of that is determined using a model that is simply calculating a “naive" property of the data, such as the mean of the training labels. This gives a kind of benchmark with which to compare the scores obtained after training. A model designed to always predict the mean of the training set returned an score of , and a model designed to always predict a constant value of 2, independently of the input value, returned an OOB of . In both cases values are approximately 0. This is precisely what one would expect: recall that a model that can predict the expected value of the true labels, but does so independently of the training data, will have an of 0. Thus we expect scores following training and tuning of the Random Forests to be at least greater than 0, and ideally closer to 1.
Following hyper-parameter optimisation, training and validation of our model, feature importance was assessed in order to consider the possibility of training and testing with fewer input features. Model performance was assessed to remain stable until the total feature number reached 41 (out of a possible 194 features). Unsurprisingly, different features were assessed as optimal on different training runs due to the similarity of certain feature subsets. This is expected because each individual sequence of unitaries followed by a measurement should be as informative as any other sequence.
Following feature reduction, the model was trained and validated on the reduced data set containing entries from these 41 features only, one of which was the value (somewhat surprisingly, the feature corresponding to was not ranked high enough to be included in the set of 41 features). Finally, the model was also trained and assessed after removing the feature. The results are contained in Table 1.
Each of the three models was then evaluated using the hold-out set of test data, and the performance was seen to be essentially unchanged (Table 2). The mean squared error of the predicted by the model as compared to the true labels was also evaluated. By taking the square root of the MSE, one can assess the average deviation of the predicted values for from the true values. These errors remained small for each of the three models (Table 2, final column).
The results here indicate that the model would be expected to generalise reasonably well. The scores are a significant improvement over the values obtained from the naive dummy regressors. It is likely the small degree of over-fitting (evidenced by the discrepancy between training and validation scores, and the less-than-perfect OOB ) would be improved by training on larger data sets and with more trees. For many applications the total number of trees numbers in the thousands, where here we only used 80. The drawback of using such large numbers of trees is that training time will increase. For 80 trees training time was on the order of 30 seconds; for 200 trees it was on the order of two minutes with a corresponding improvement in OOB of 0.005. The results indicate a slight improvement (2%) in performance when trained with knowledge of the parameter and no significant difference with adding knowledge of .
Whilst the results suggest the model would generalise well to new data where parameters were consistent with those used to generate the data, further confidence was sought by testing on data generated according to parameters outside those used in simulation. We tested the model predictions for a true of 2 across the full range of and values, including a previously unseen of 0.5. The results can be seen in Table 3 and show that although the model was not trained on examples generated for this particular value of , the model was nonetheless able to provide a reasonably accurate prediction of unseen examples generated using this value of . The mean prediction (bottom row of table) was close to in all three models
We also tested the model on samples generated using a log of 6, and the mean of the predictions was , with standard deviation of . The result of 4.0 is as good as can be expected, given Random Forests can only return values within the training range. The MSE of simply reflects that the model is consistently predicting a value of 4, which is being evaluated against the true value of . These results are summarised in Table 4.
VI Discussion
Our results provide preliminary evidence that supervised learning techniques may well be useful for identifying features of non-Markovian noise in quantum experiments. Perhaps the most interesting result is that good predictions can still be made even when one considers tomographically incomplete data.
There are some obvious limitations of our approach. We are restricted to considering cases of fixed dimension and number of time-steps, and although it would be straightforward to extend the simulations to include variations of these parameters, clearly implementing the simulations will become increasingly onerous. An important question, in this respect, regards the scalability of the learning approach. A direct generalisation of our settings choices ( unitaries per time step) would result in a total number of features (and thus of experimental settings) that grows exponentially with the number of time steps (similarly to tomographic methods giarmatzi2018quantum ). However, we have seen that there is a good amount of redundancy in the data, since retaining only of the features is sufficient to attain good accuracy. The question then is how the number of relevant features scales with the total number of time steps, and whether a less-than-exponential number would be sufficient. An independent question is whether a different choice of settings would be more efficient: here we used Pauli gates as a simple and natural choice but other choices might turn out to be more suitable, possibly depending on the class of processes under consideration.
There are many possibilities for future research, including testing alternative supervised learning methodologies. Deep neural networks, for example, may perform better on this particular regression task than the Random Forest technique we use here. It is impossible to know which kind of model architecture would perform best on this kind of data without directly comparing the performance of various architectures. Larger simulation sets, with more varied parameters, would also increase the likelihood that subsequently trained models would generalise beyond the limited setting we consider here. Most importantly, however, future research should be directed towards assessing to what degree these kinds of models can generalise to real world data. That is, data that has been generated experimentally rather than via simulation. Without further work, it is not possible to claim that our results would apply to real quantum experiments. Experimental platforms where one can accurately model Markovian and non-Markovian environments of specific dimensions would help validate the particular approach we take here.
Acknowledgments
We are grateful to Josh Combes and Peter Wittek for helpful discussions. This work was supported by an Australian Research Council Centre of Excellence for Quantum Engineered Systems grant (CE 110001013). F.C. acknowledges support through an Australian Research Council Discovery Early Career Researcher Award (DE170100712). This publication was made possible through the support of a grant from the John Templeton Foundation. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the John Templeton Foundation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, “Quantum machine learning,” Nature 549 , 195 (2017).
- 2(2) V. Dunjko and H. J. Briegel, “Machine learning & artificial intelligence in the quantum domain,” ar Xiv:1709.02779 [quant-ph] .
- 3(3) F. Costa and S. Shrapnel, “Quantum causal modelling,” New Journal of Physics 18 , 063032 (2016) . · doi ↗
- 4(4) C. Giarmatzi and F. Costa, “A quantum causal discovery algorithm,” npj Quantum Information 4 , 17 (2018) . · doi ↗
- 5(5) F. A. Pollock, C. Rodríguez-Rosario, T. Frauenheim, M. Paternostro, and K. Modi, “Operational Markov Condition for Quantum Processes,” Phys. Rev. Lett. 120 , 040405 (2018) . · doi ↗
- 6(6) F. A. Pollock, C. Rodríguez-Rosario, T. Frauenheim, M. Paternostro, and K. Modi, “Non-Markovian quantum processes: Complete framework and efficient characterization,” Phys. Rev. A 97 , 012127 (2018) . · doi ↗
- 7(7) S. Milz, F. A. Pollock, and K. Modi, “Reconstructing non-Markovian quantum dynamics with limited control,” Phys. Rev. A 98 , 012108 (2018) . https://link.aps.org/doi/10.1103/Phys Rev A.98.012108 . · doi ↗
- 8(8) G. Gutoski and J. Watrous, “Toward a general theory of quantum games,” in In Proceedings of 39th ACM STOC , pp. 565–574. 2006. quant-ph/0611234 .