
TL;DR
This paper introduces a decision-making model based on adaptive learning with priors aligned with expected utility, revealing similarities to prospect theory and convergence to expected utility with longer learning periods.
Contribution
It presents a novel adaptive learning model for preferences that aligns with expected utility in the long run and resembles prospect theory in finite cases.
Findings
Preferences resemble Kahneman and Tversky's prospect theory
Preferences converge to expected utility as learning period increases
Model bridges prospect theory and expected utility in decision making
Abstract
We consider a model for decision making based on an adaptive, k-period, learning process where the priors are selected according to Von Neumann-Morgenstern expected utility principle. A preference relation between two prospects is introduced, defined by the condition which prospect is selected more often. We show that the new preferences have similarities with the preferences obtained by Kahneman and Tversky (1979) in the context of the prospect theory. Additionally, we establish that in the limit of large learning period, the new preferences coincide with the expected utility principle.
Click any figure to enlarge with its caption.
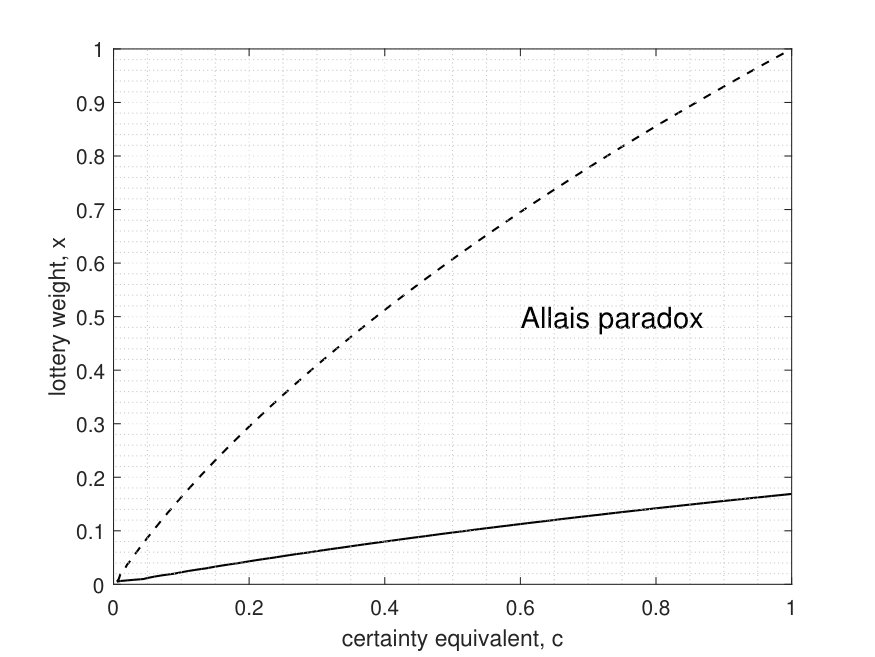 Figure 1
Figure 1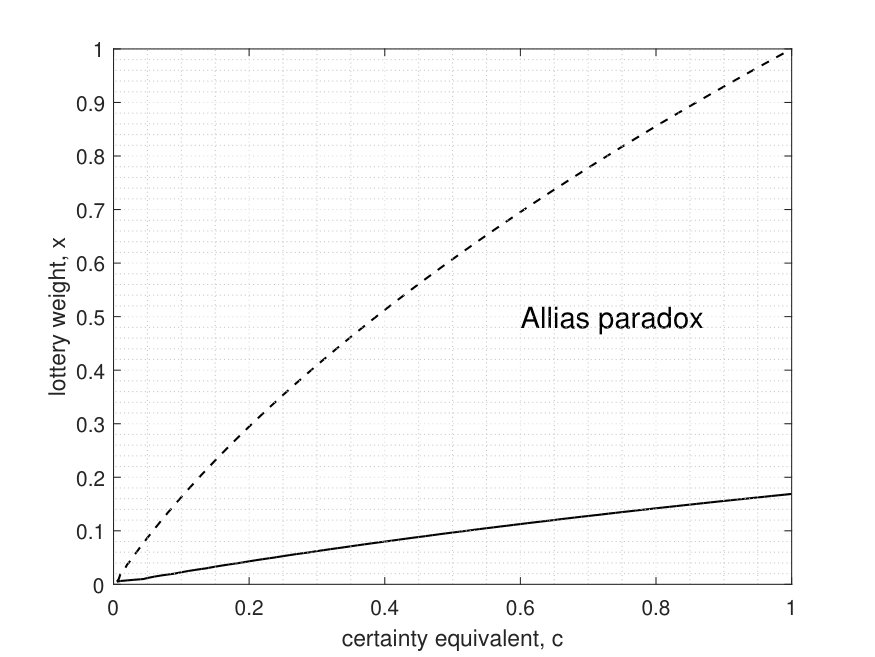 Figure 2
Figure 2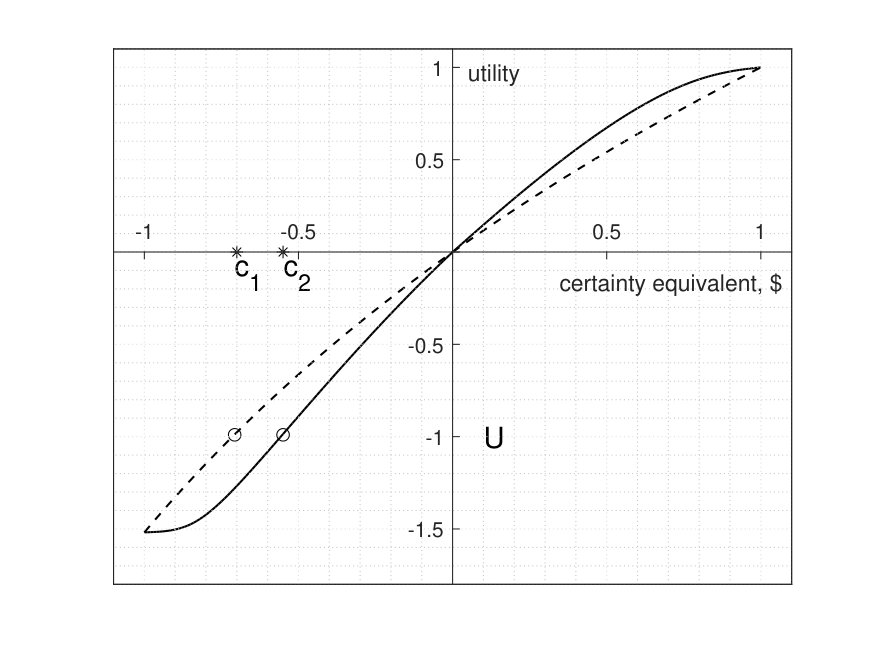 Figure 3
Figure 3 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsChemistry and Stereochemistry Studies
RPS(1) preferences
Misha Perepelitsa
Department of Mathematics
University of Houston
4800 Calhoun Rd.
Houston, TX.
Abstract
We consider a model for decision making based on an adaptive, –period, learning process where the priors are selected according to Von Neumann-Morgenstern expected utility principle. A preference relation between two prospects is introduced, depending on which prospect is selected more often. We show that the new preferences have similarities with the preferences obtained by Kahneman and Tversky (1979) in the context of the prospect theory. Additionally, we establish that in the limit of large learning period the new preferences coincide with the expected utility principle.
keywords:
Relative payoff sums , adaptive decision making , expected utility principle
††journal: Theoretical Economics
1 Introduction
The expected utility theory (EUT) was put forward by Von Neumann and Morgenstern (1947) as a mathematical formalization of the way the choices are made between the prospects involving objective, probabilistic outcomes. The theory derives a utility function (VNM utility) which assigns values to the payoffs and is used to rank prospects according to the expectation where is a random variable of payoffs of a given prospect.
As a theory, EUT starts with the set of axioms, called axioms of choice that one has to adhere in assigning the preferences to prospects. They are the completeness, transitivity, continuity and independence (substitution) axioms. The last axioms drew a significant amount of critique from the experimentalists, starting with Allais (1953). Over the years several alternative utility theories were proposed that provide some variants of the expected utility without the independence axiom or with its weaker version. Among them, the generalized expected utility of Machina (1982), weighted utility theory of Chew and MacCrimmon (1979), the regret theory developed independently by Bell (1982), Fishburn (1982), Loomis and Sugden (1982), rank dependent utility theory of Quiggin (1982, 1993), and the dual utility theory by Yaari (1987).
Kahneman and Tversky (1979, 1984, 1992) introduced framing effects, value functions, and probability weights into the analysis and incorporated them into the prospect theory that was later developed, using the approach of the rank dependent utility theory, into the cumulative prospect theory.
In this paper we will consider the deviations from the EU principle due to response to the current incentives, as modeled by a reinforcement learning mechanism. Rather than postulating axioms of choice we will postulate the type of behavior that directs an agent to a particular choice, and derive the preferences for prospects from that. What we have in mind here is a reactive response to outcomes, as seen, for example, when people are rushing to buy flood insurance just after a historic flood, and then, canceling it in a few years. To an objectivist, who believes in statistical statements like “1 in 100 years flood plan,” this behavior is “irrational.” However if a degree of uncertainty about the future is allowed (weather pattern is changing) the better name for it is “adaptive,” which, when coupled with a learning process that accounts for accumulating experience, represents a ubiquitous behavioral pattern.
The relevance of such behaviors for the problems in Economics has always been acknowledged. A systematic approach has been developed by Cross in the monograph “A theory for adaptive economic behavior” (1983). In that work, the author analyzes stochastic models for the decision making built on the principles of the learning theory laid out by Bush and Mosteller (1951, 1955). Agents actions evolve through a feedback mechanism that updates the choice probabilities. The focus is on the properties of choice and behavior in the transient regime (called disequilibrium), starting at the moment when the exogenous parameters have changed, and prior to the moment the rational equilibrium is reached in the long run.
In this paper we will extend the Cross’ theory to describe the preferences for risky prospects that can be associated with adaptive behavior. This is done by changing the feedback model of Cross to a short-term memory model, when the actions are determined only from few previous experiences. The approach allows us to derive exact expressions for preferences and compare them with the preferences based on the Expected Utility principle.
The new type of preferences will be build upon an agent’s VNM utility function and the expected utilities of prospects, calculated according to EUT. We will assume that the agent does rank prospects according to EU, but the agent’s actions are not determined solely by the expected utilities. They rather depend on the combination of factors expressed by the level of stimulus (propensity) for selecting a prospect. The stimulus for a prospect will be defined as a sum of the “default level of stimulus” (stimulus prior), expressed by its expected utility and the increments, denominated in the units of the utility function, from the most recent payoffs the prospect paid out. At this point, it is best to think of a dynamic (iterated) decision making process, in which the agent constantly updates her attitude toward the prospects. Given the stimuli for prospects, the agent chooses the prospect with a probability, defined as a fraction of the prospect stimuli to the total stimuli of all prospect. The new preference relation between two prospects and is defined by a ranking based on which prospect is selected more often in a long run of choices. We will call such relation RPS (relative payoff sum) preferences, in analogy the learning algorithm, introduced by Harley (1981) in the context of the Game Theory. In that filed, the relation between the reinforcement learning and optimal strategies was studied by Roth and Erev (1995, 1998), Börgers and Sarin (1995, 1997), Erev and Roth (1996), and Fudenberg and Levine (1998).
The new preferences are derived by including adaptation mechanism into decision making. In the view of this, it is particular interesting to see that RPS preferences follow the pattern of violations to the EU theory observed experimentally. Namely, RPS preferences are non-linear, in way similar to the preferences in Allais’ paradox. They are frame dependent, and the risk attitude, in comparison to the EU risk attitude, changes from more risky to more conservative, as payoffs shift from losses to gains.
2 RPS models of decision making
To motivate the new type of the preferences we consider the decision making as a dynamics “learning process”. Given the choice between two prospects (lotteries) and an agent uses her VNM utility function to compute the expected utilities and to compare the prospects. Suppose now that the agent has to select a prospect on a regular basis. Even though the agent has a preference for one, she might be influenced by a variety of other factors (mood, peer-pressure, fashion trends, etc.) to select less preferred prospect at a given instant of time. Those factors are not included in the evaluation of the utility, because, typically, they are too complex to account for and/or unpredictable.
A customary approach to model this situation is to assume that the agent follows a mixed strategy, by selecting one prospect or another with a certain probability, which, in the view of the given conditions, can be set to be the proportion of utilities, i.e. the probability to select prospect is determined by the ratio
[TABLE]
In this way both prospects are being repeatedly selected. The important property of such dynamic decision process is its consistency with the EU principle: the prospect that is selected most often is the prospect with the higher expected utility.
To model the deviations from the EU principle, we will assume that the agent adjusts the probability (1) from one decision to another depending on the history of realized payoffs. The adjustment is modeled by a positive/negative reinforcement mechanism.
First, we consider the reinforcement model determined only by the last payoff.
2.1 RPS(1) preferences
To simplify the presentation, we consider lotteries with non-negative payoffs first, and relax this condition in subsequent sections.
Let be the payoffs from lotteries and at epoch The reinforcement mechanism is defined through the stimuli (propensities) to select and at the next epoch They are set to be proportional to the utilities of the last payoff:
[TABLE]
where, we set expression or to zero if the lottery is not selected. are the default levels of the stimuli. At the next epoch the agent executes a mixed strategy by selecting lottery with the decision probability
[TABLE]
Once the lottery is selected, the payoff is determined by a random sampling of lottery or
We will call rule (2)–(4) the relative payoff sum (or RPS(1)) decision making model, following the nomenclature introduced by Harley (1981). Note that this model is a short memory model, unlike most of the learning models considered in the literature cited in the Introduction.
In the course of repeated choices the agent will keep switching between two lotteries. A statistically minded agent however, will notice that one lottery is being selected more often than the other. With more choices made, this observation gets re-confirmed.
It leads to a preference relation, defined by the rule that lottery is selected, in the long run, more often than when the decisions are made according to the rule (2)–(4).
As shown in Appendix, the mathematical equivalent of this definition is inequality
[TABLE]
where is a random payoff corresponding to lottery and is that of We call this relation RPS(1) preferences. These preferences can also be interpreted as “expected decision probability” principle, according to formula (9) from Appendix.
In terms of the agent’s cognition, new preferences correspond to the following mental math calculations: “To select between and I will compare my average willingness to repeat the same choice next time if I selected each lottery now and observed its payoff.”
Here, by “willingness” we understand the decision probability (4) calculated from the ratio of stimuli. Clearly, this rule is not restricted to the iterated decision making scenario described above, but can be deliberated even when one-time decisions are made.
RPS(1) preferences differ form the corresponding EU preferences. This, and other properties, are discussed below, but a quick example can help to illustrate it. Consider a lottery that pays out 0 and U(x)=x,$ then she is indifferent between two lotteries in EU preferences, but according to RPS(1)-rule (5), the sure bet is more attractive to her.
We list below the properties of RPS(1) preferences that follow directly from the definition, with explanations provided in Appendix.
- a.
RPS(1) preferences are not invariant under the shifts of the utility function from to They exhibit the framing effect. This property is considered in more details in section 2.3. 2. b.
Given the priors and RPS(1) preferences depend on wealth increments, not the total accumulated wealth. 3. c.
RPS(1) preferences are not transitive. 4. d.
RPS(1) preferences violate the independence axiom. 5. e.
RPS(1) preferences verify first order stochastic dominance (FSD) principle.
2.2 Independence Axiom and Allais experiment
We illustrate the failure of the independence axiom on the following numerical example. Consider a concave VNM utility normalized so that Denote by the lottery that pays L_{x}0 with probability and x.L_{c}L_{x}by RPS(1)-rule. The result is represented graphically in figure [1](#S2.F1). The dashed line divides the unit square into two parts: below the line, the certain bet\hat{L}{c}\succ L{x},L_{x}\succ\hat{L}_{c},$ and the line itself is the indifference curve (certainty equivalent curve).
Similar to Allais experiment, we mix each lottery, and with 80% chance of lottery which pays 0 for sure. In violation of the independence axiom, the preference change: the solid line in figure [1](#S2.F1) is the new indifference curve. In the region between the two lines \hat{L}{c}\succ L{x},0.2L_{x}+0.8L_{0}\succ 0.2\hat{L}{c}+0.8L{0}.$
2.3 Losses and Gains
Consider now the situation when the wealth increments are framed as losses (negative) or gains (positive). The decision rule (4) must be re-defined for expression (4) to be meaningful. An approach adopted in learning literature cited in the Introduction is to use a positive, non-decreasing function, for example, , and set
[TABLE]
The preferences, that we still call RPS(1) preferences, are defined by inequality
[TABLE]
when
In this setting we are going to look at the problem of determining the certainty equivalent for probabilistic lotteries involving positive or negative payoffs.
As an example, we take logarithmic utility normalized so that First we consider lottery that pays 1-x1 with probability For each such lottery we find its certainty equivalent c according to RPS(1)-preferences. Figure [2](#S2.F2) shows, by the solid line, the corresponding indifference curve, in the first quadrant. Then, we consider lotteries L_{x}0 with probability and with probability The solid line in the third quadrant is the indifference curve for losses. For comparison we draw on the same figure the certainty equivalent curve (dashed) according to the EU principle, which is simply the graph of
As seen from that figure, the indifference curve for RPS(1)-preferences lies above in the region of gains, and below it, for losses. Thus, an agent is more risk averse, compared to the expected utility preferences, in gains, and more risk tolerant in losses. It should be noted that the situation in figure 2 applies only to two-valued lotteries described there. Since RPS(1) is not an expected utility no conclusions about other types of lotteries can be drawn from the graph of the certainty equivalents of such lotteries. In particular, the type of convexity of the certainty equivalent curve can not be used to characterize RPS(1) preferences in the relation to the attitude toward risk.
However, as shown in Appendix, the following property is generic.
Lemma 1**.**
Suppose that VNM utility is risk-neutral, and let be any lottery, described by a payoff random variable Then, if the RPS(1) certainty equivalent of is less than the expected utility If the RPS(1) certainty equivalent of is greater than the expected utility
2.4 RPS(k)-preferences
A direct extension of the decision model (2)–(4) is a model in which an agent accounts for the last payoffs. The stimuli change, for example, by the average:
[TABLE]
where is the number of times lottery has been selected during the last rounds, and similarly for Again, we are using the convention that if () was not chosen at round then (). The decision between lotteries is made randomly with decision probability (4).
We define the preference relation if is selected more often in a long series of decision making, and refer to such preferences as RPS(k)-rule.
It is possible to develop a mathematical formalism similar to (5), however it is outside of the scope of this work. Here, we would like to use RPS(k)-preferences to a establish a connections between the adaptive decision making and the expected utility theory.
Consider RPS(k)-preferences with the memory extending to utmost past, that is, In the limit, the average payoffs in (7), (8) become the expected utilities and respectively. In this case, the lottery most often played is the one with the highest expected utility. Thus, the adaptive decision making in the long memory limit takes agents’ adaptive RPS-preferences to the expected utility preferences.
The relation of the EU preferences and long-run learning is by no means original. It has been expressed by many authors, including Cross (1983) and Plott (1996).
2.5 Discussion
We live in changing environments. Some environments are fairly stationary and predictable, like changes of seasons. In the course of the human history we developed certain rules that regulate our decisions about such processes, like the decision to sow in spring and reap in fall, with little variations. Even the occurrence of an unprecedentedly warm winter followed by a cold summer won’t moves us to act contrary to the rule and we won’t invest our effort in planting seeds in the fall.
Other processes, like the changes in the financial markets, have a great deal of uncertainty in future outcomes. If a large drop in a stock price is observed today, should it be considered as a random fluke, an outlier of a probabilistic model one uses, or is it an indication that it is time to adjust the means, deviations and other parameters in the model, or even to sell all the stocks immediately? Most likely, if we lost a significant sum of money due to this drop, our first reaction will be to sell to avoid further losses, and we have to analyze more information and do some non-trivial mental work to find arguments for not doing so, or to confirm our initial impulse.
Reaction to the current stimuli, as the one just described, is a part of our biological adaptive response. It has been developed in the course of the Evolution to let us quickly react once the environment has changed, increasing our chances for survival. To a higher degree, it manifests itself during the critical events, such as market crashes or social upheavals, when old rules of behavior become irrelevant and people pursue minute gains, resulting in a state of chaos, until new rules are learned or enforced.
It is not unlikely that this response to current stimuli is present in all decisions that we make, but it is balanced against the past experience. We suggest that it is one of the main contributors to the deviations of the experimentally observed behaviors from EU principle. In this paper we considered a simple decision making model for such deviations, called RPS preferences. Moreover, we showed that the EU preferences can be derived from RPS preferences in infinitely long-memory adaptive behavior.
The point of view suggested here is that decision making is a dynamics learning process. When placed in stationary environments, long-memory will lead to the formation of the preferences (rules) that resemble EU preferences. The more advantageous these rules are, the more pronounced they affect the decisions that me make. This seems to be the conventional notion of rationality. However, “the irrational part”, the response to current stimuli, is also always present. It becomes dominating when the environment is changing, and perhaps, is our best choice when the changes are completely unpredictable.
3 Appendix
3.1 Equation (5)
Consider the stochastic decision making process from section 2.4. Let denote the lottery, either or selected by the agent at step It is a Markov chain on the state of two elements Denote by the probability density for the distribution of payoffs in lottery and by the probability density for The matrix of transition probabilities for the Markov chain equals to
[TABLE]
The Markov chain is irreducible and both states are ergodic, see the monograph of Feller (1957). This implies that the distribution of converges to the invariant measure, given by the pair of probabilities solving the matrix equation
[TABLE]
Lottery iff From the above equation we find that it is equivalent to
[TABLE]
which is equivalent to (5). In the view of the definition of the probability in (4), the above inequality says that the expected probability to select provided that was selected last time, is greater than the expected probability to select provided that was selected last time.
3.2 First order stochastic dominance
Suppose that lottery described by random payoff variable stochastically dominates described by random payoff Let be a non-decreasing function. Then,
[TABLE]
and
[TABLE]
From these two inequalities it follows that
[TABLE]
which means that dominates in RPS(1)-preferences.
3.3 Risk tolerance
In this section we show that if VNM utility is a linear function and is a lottery with expected utility then RPS(1) certainty equivalent verifies
[TABLE]
if the lottery offers only positive payoffs, and
[TABLE]
if the lottery offers only negative payoffs. The certainty equivalent is defined by the equation
[TABLE]
Here we using function that determines the stimuli increments in (6). Consider first the gains: Let denote the left-hand side of the equation, and the right-hand side. We have: and Moreover,
[TABLE]
because function is convex for Thus, the point of intersection, of graphs of and is less than
The other inequality is proved analogously, using the fact that is concave for
3.4 RPS(1) preferences are not transitive
Suppose, for simplicity, that VNM utility Consider two lotteries given by random payoffs and that have the same expected utilities and have the same certainty equivalent in RPS(1) preferences. That is,
[TABLE]
and there a $c, such that
[TABLE]
However, if lotteries are not necessarily equivalent, as the value of integral
[TABLE]
can be less, or greater, than that with random payoff
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Allais, M. (1953) Les comportement de l’homme rationnal devant le risque: critique des postulates and axioms de l’ecole americaine. Econometrica, 21.
- 2[2] Börgers, T., and Sarin, R. (1995). Naive reinforcement learning with endogenous aspirations, Mimeo., University College London and Texas A&M University.
- 3[3] Börgers, T, and Sarin, R. (1997). Learning through reinforcement and replicator dynamics. J. Economic Theory, 77, 1, 1-14.
- 4[4] Bush, R.R., and Mosteller, F. (1951). A mathematical model for simple learning. Psychological Review 58, 313–323.
- 5[5] Bush, R.R. and Mosteller, F. (1955). Stochastic models for learning. New York, Wiley.
- 6[6] Cross, J. G. (1983). A theory of adaptive economic behavior. Cambridge University Press.
- 7[7] Erev, I. and Roth, A. E. (1996). On the need of low rationality cognitive game theory: reinforcement learning in experimental games with unique mixed equilibria. Mimeo. University of Pittsburgh.
- 8[8] Erev, I. and Roth, A. E. (1998). Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibrium. American Econ. Review 88, 848–881.