TL;DR
This paper introduces a spectral method for detecting low-dimensional structures in networks using arbitrary null models, effectively distinguishing meaningful communities from noise in both synthetic and real networks.
Contribution
It presents a novel spectral estimation approach that utilizes generative models to identify significant network structures relative to any chosen null model.
Findings
Effectively detects transitions between random and community structures in synthetic networks.
Identifies noise nodes and community memberships accurately.
Contrasts with traditional methods by showing null model choice impacts conclusions.
Abstract
Discovering low-dimensional structure in real-world networks requires a suitable null model that defines the absence of meaningful structure. Here we introduce a spectral approach for detecting a network's low-dimensional structure, and the nodes that participate in it, using any null model. We use generative models to estimate the expected eigenvalue distribution under a specified null model, and then detect where the data network's eigenspectra exceed the estimated bounds. On synthetic networks, this spectral estimation approach cleanly detects transitions between random and community structure, recovers the number and membership of communities, and removes noise nodes. On real networks spectral estimation finds either a significant fraction of noise nodes or no departure from a null model, in stark contrast to traditional community detection methods. Across all analyses, we find the…
Click any figure to enlarge with its caption.
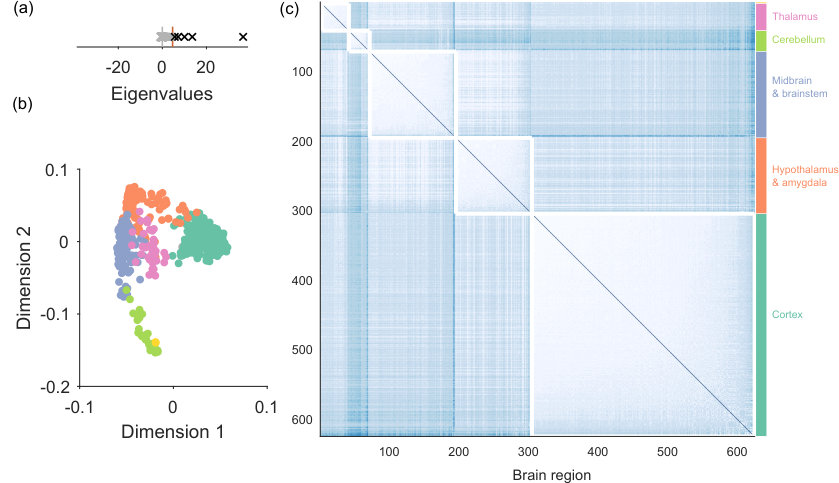 Figure 1
Figure 1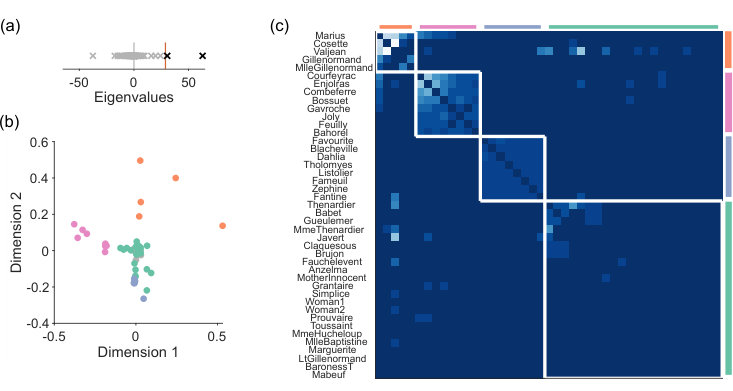 Figure 2
Figure 2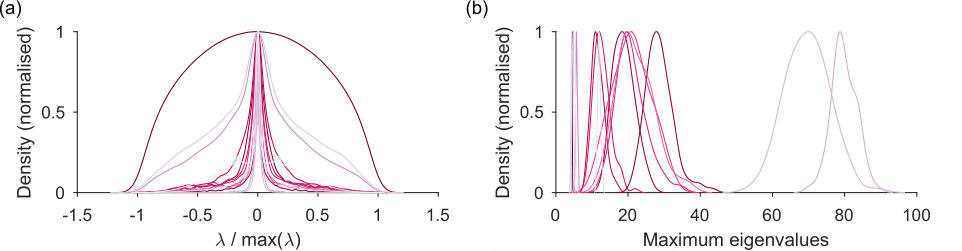 Figure 3
Figure 3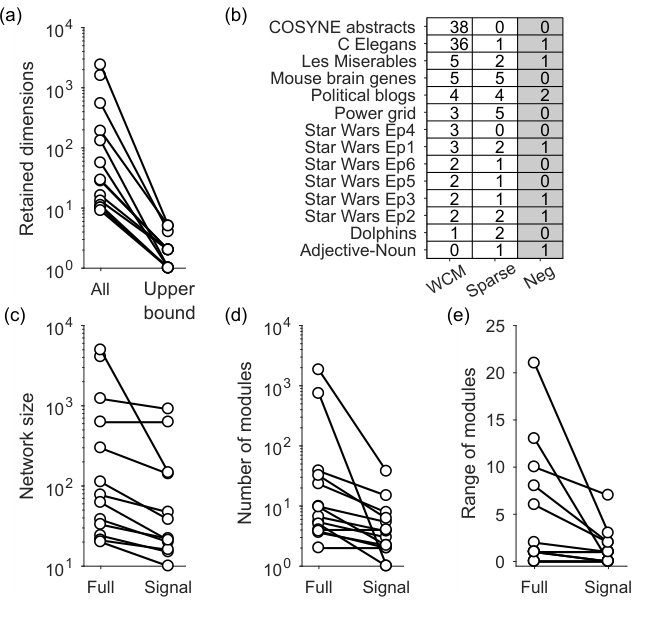 Figure 4
Figure 4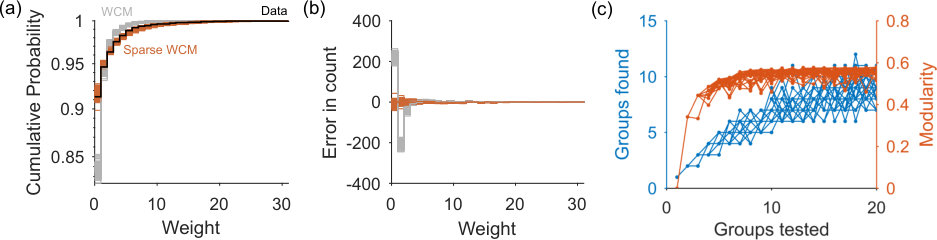 Figure 5
Figure 5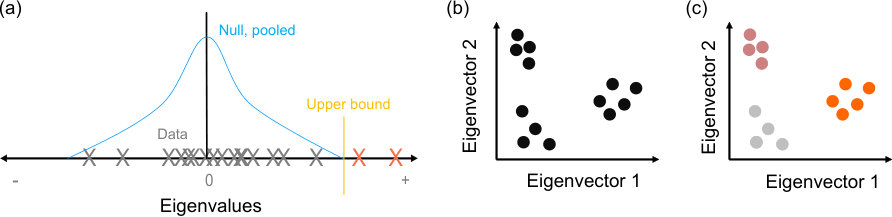 Figure 6
Figure 6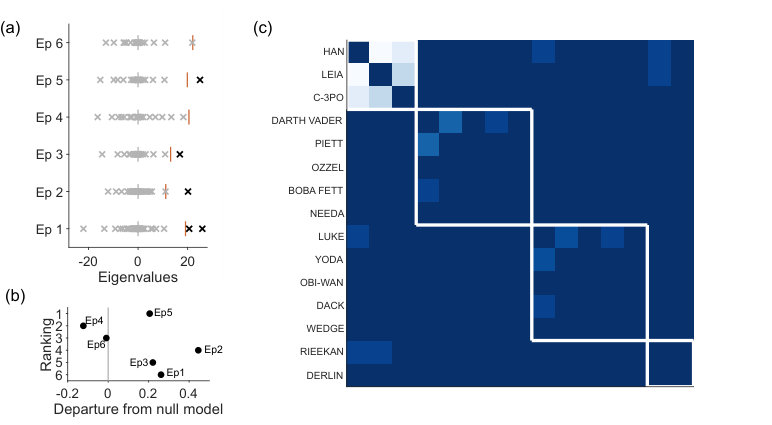 Figure 7
Figure 7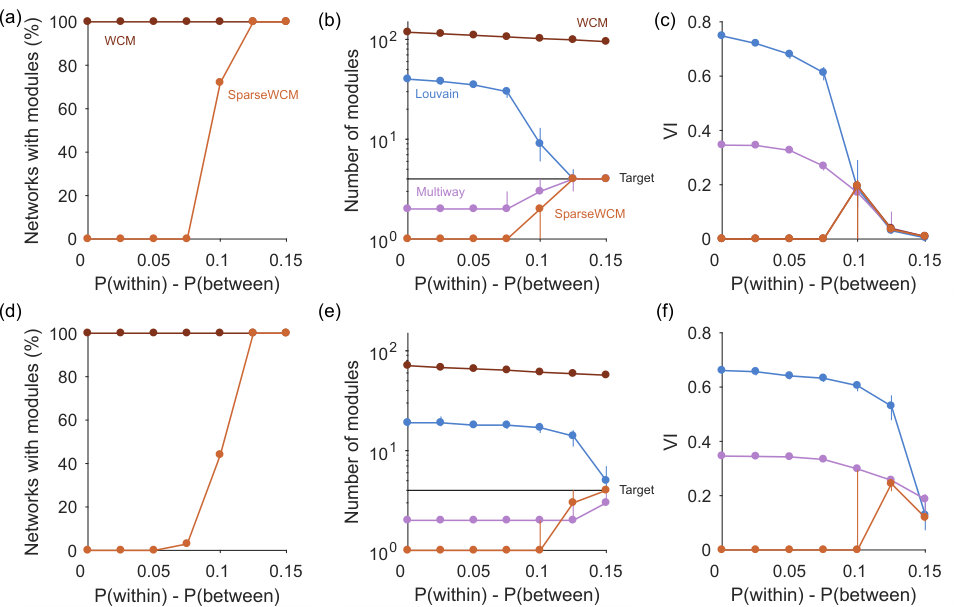 Figure 8
Figure 8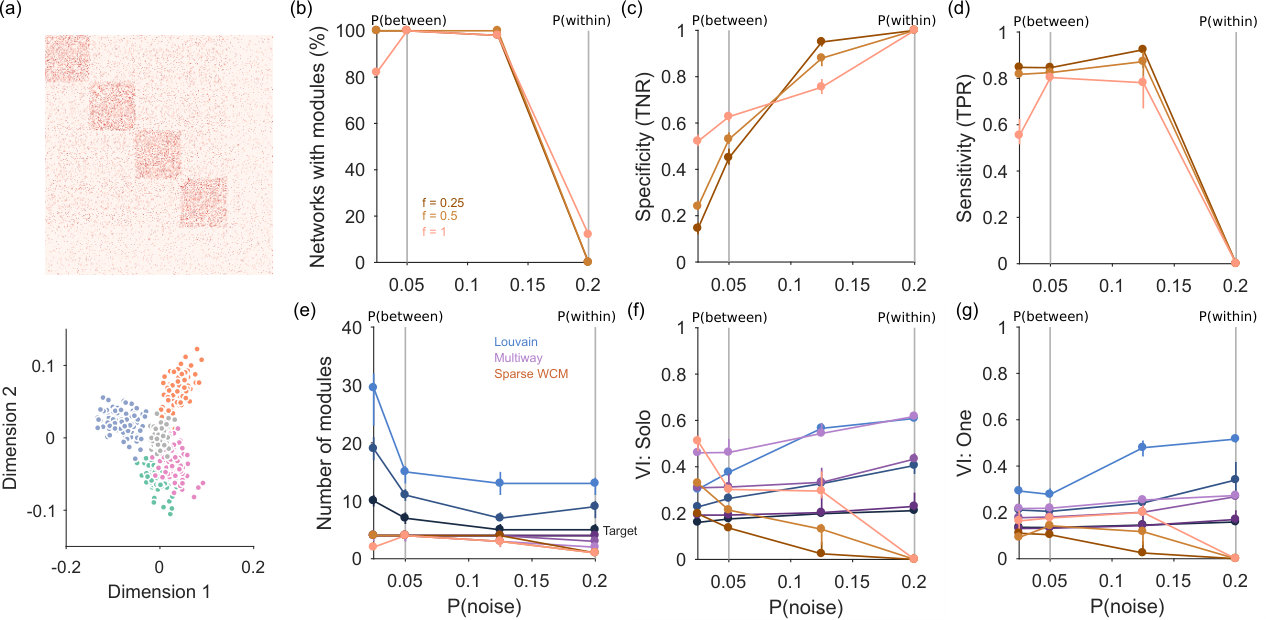 Figure 9
Figure 9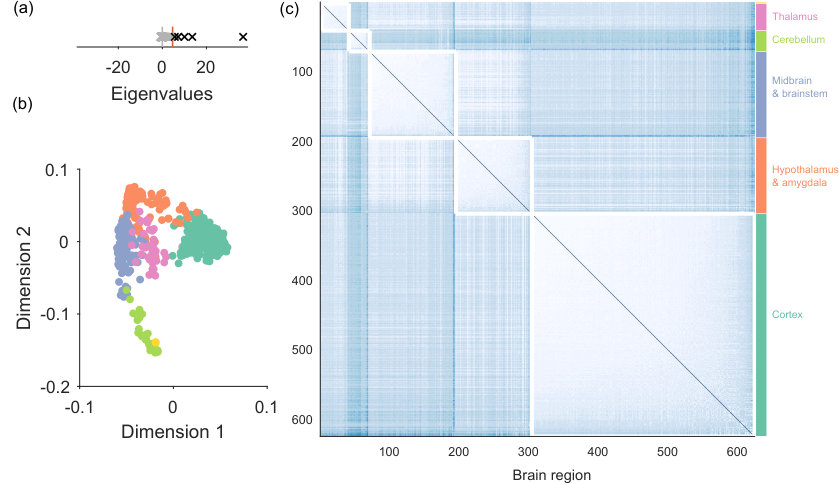 Figure 10
Figure 10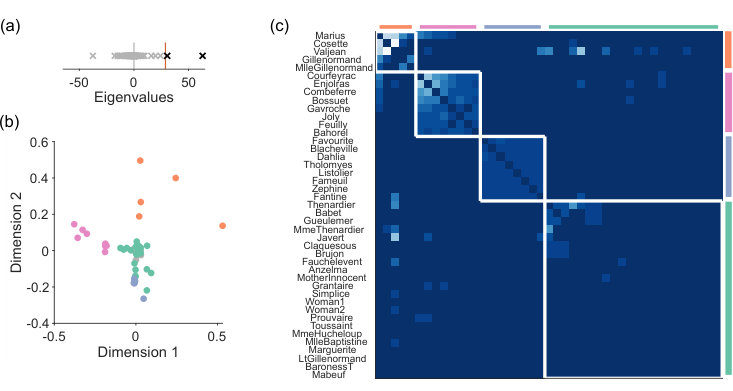 Figure 11
Figure 11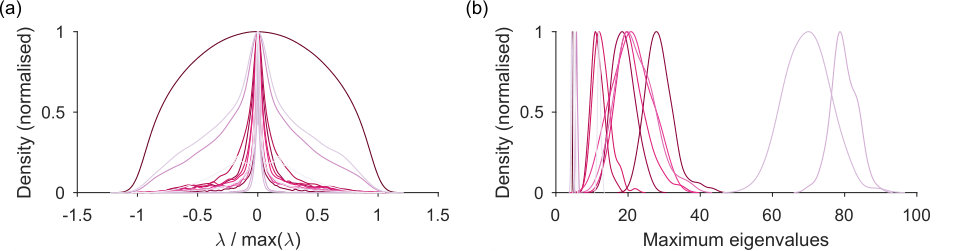 Figure 12
Figure 12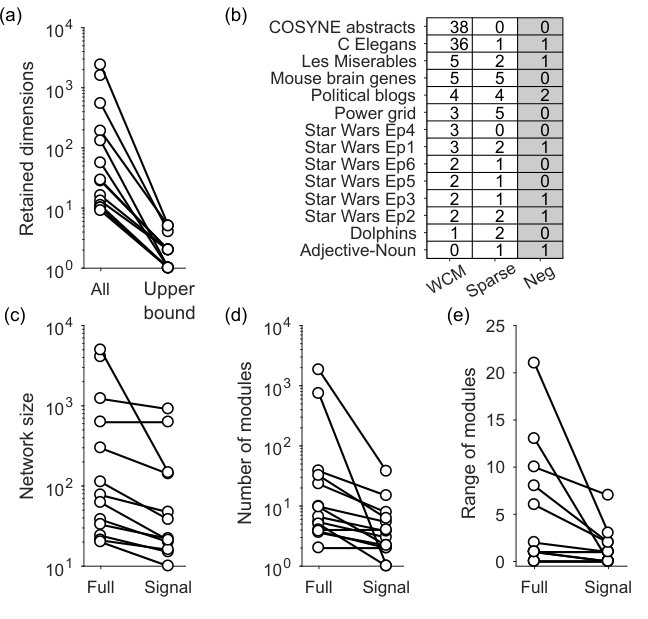 Figure 13
Figure 13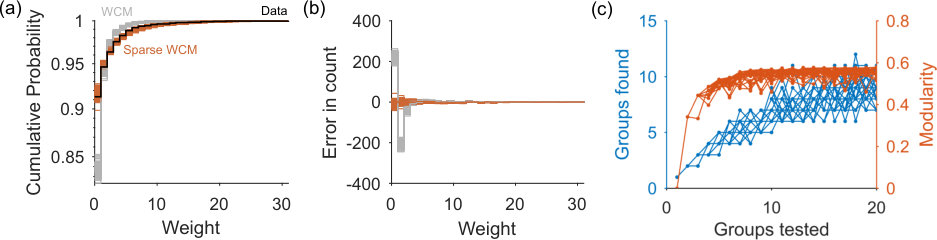 Figure 14
Figure 14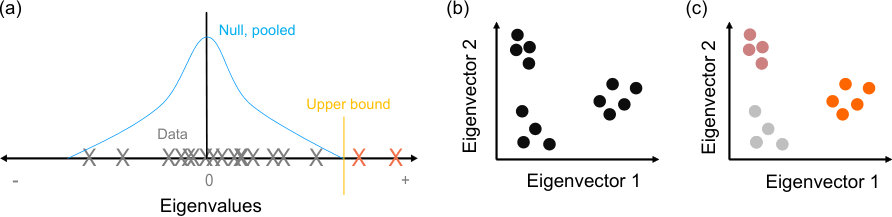 Figure 15
Figure 15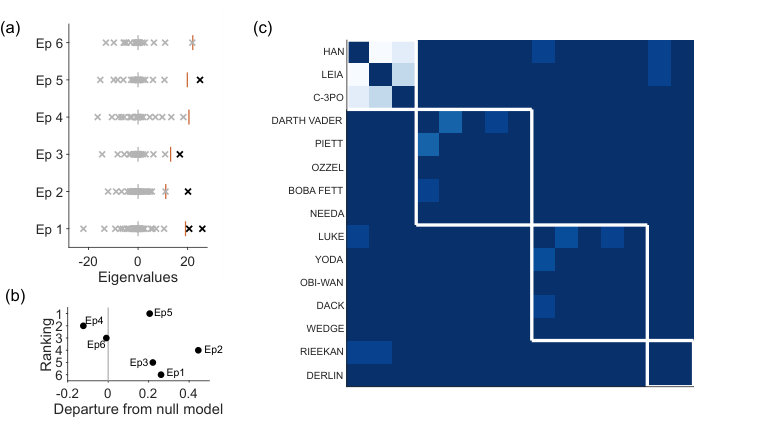 Figure 16
Figure 16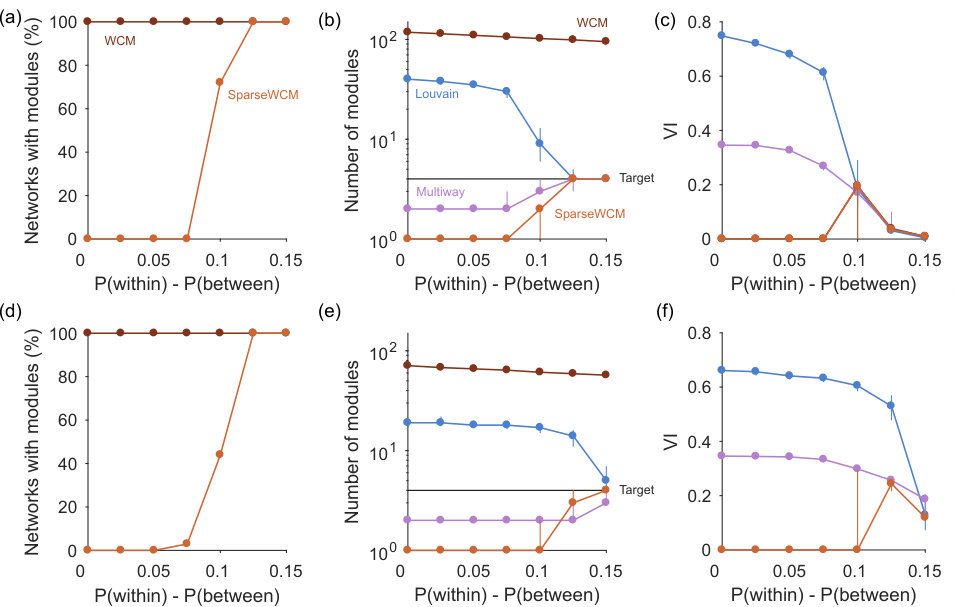 Figure 17
Figure 17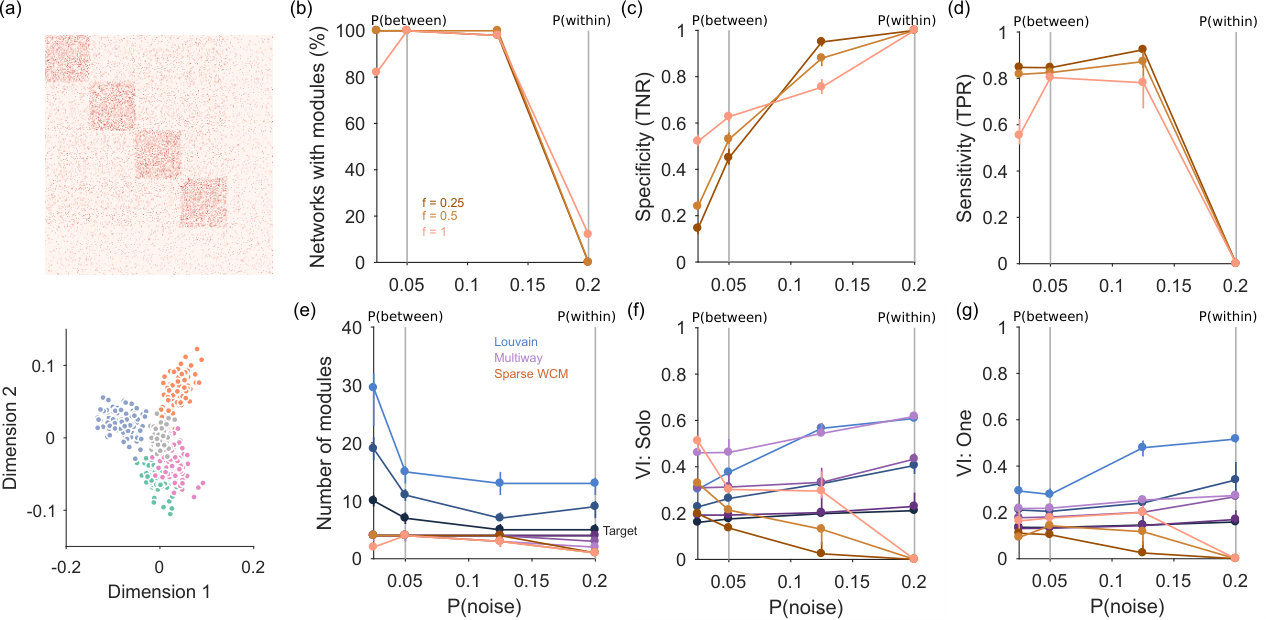 Figure 18
Figure 18 Figure 19
Figure 19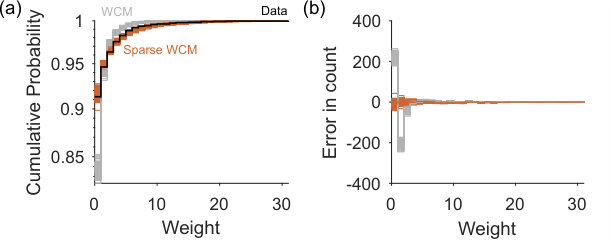 Figure 20
Figure 20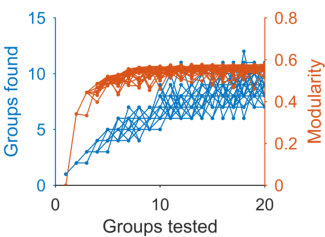 Figure 21
Figure 21 Figure 22
Figure 22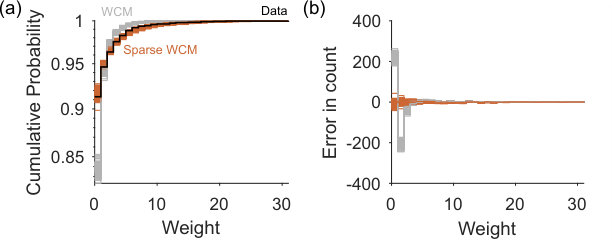 Figure 23
Figure 23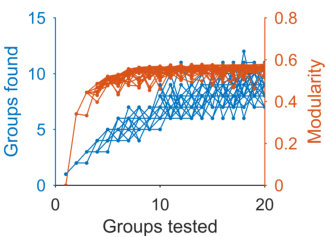 Figure 24
Figure 24| Name | Size | Links | Density | Link weight |
|---|---|---|---|---|
| Dolphins | 62 | 318 | 0.084 | binary |
| Adjective-Noun | 112 | 850 | 0.068 | binary |
| Power grid | 4941 | 13188 | 0.00054 | binary |
| Star Wars Ep1 | 38 | 270 | 0.19 | integer |
| Star Wars Ep2 | 33 | 202 | 0.19 | integer |
| Star Wars Ep3 | 24 | 130 | 0.24 | integer |
| Star Wars Ep4 | 21 | 120 | 0.29 | integer |
| Star Wars Ep5 | 21 | 110 | 0.26 | integer |
| Star Wars Ep6 | 20 | 110 | 0.29 | integer |
| Les Miserables | 77 | 508 | 0.087 | integer |
| C Elegans† | 297 | 4296 | 0.049 | integer |
| COSYNE abstracts | 4063 | 23464 | 0.0014 | integer |
| Political blogs† | 1222 | 33428 | 0.022404 | integer |
| Mouse brain gene expression | 625 | 1 | real |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Spectral estimation for detecting low-dimensional structure in networks using arbitrary null models
Mark D. Humphries1,2*, Javier A. Caballero2,3¶, Mat Evans1,2¶#, Silvia Maggi 1,2¶, Abhinav Singh1¶,
1 School of Psychology, University of Nottingham, UK
2 Faculty of Biology, Medicine, and Health, University of Manchester, UK
3 Department of Psychology, University of Sheffield, UK
Current Address: Department of Automatic Control and Systems Engineering, University of Sheffield, UK.
- Corresponding author: [email protected] (MDH)
¶These authors contributed equally to this work, and are listed alphabetically.
Abstract
Discovering low-dimensional structure in real-world networks requires a suitable null model that defines the absence of meaningful structure. Here we introduce a spectral approach for detecting a network’s low-dimensional structure, and the nodes that participate in it, using any null model. We use generative models to estimate the expected eigenvalue distribution under a specified null model, and then detect where the data network’s eigenspectra exceed the estimated bounds. On synthetic networks, this spectral estimation approach cleanly detects transitions between random and community structure, recovers the number and membership of communities, and removes noise nodes. On real networks spectral estimation finds either a significant fraction of noise nodes or no departure from a null model, in stark contrast to traditional community detection methods. Across all analyses, we find the choice of null model can strongly alter conclusions about the presence of network structure. Our spectral estimation approach is therefore a promising basis for detecting low-dimensional structure in real-world networks, or lack thereof.
Introduction
Network science has given us a powerful toolbox with which to describe real-world systems, encapsulating a system’s entities as nodes and the interactions between them as links. But the number of nodes is typically between and [1, 2], so networks are inherently high-dimensional objects. For a deeper understanding of a network constructed from data, we’d like to know if that network has some simpler underlying principles, some kind of low-dimensional structure. Two questions arise: what is that low-dimensional structure, and which nodes are participating in it? We propose here a spectral approach to answer both questions.
One way of detecting low-dimensional structure is to specify a null model for the absence of that structure, then detect the extent to which the data network departs from that null model. The problem of community detection is a prime example of this approach, where we seek to determine whether a network contains groups of nodes that are densely interconnected [3, 4, 5, 6, 7]. To give some examples [8, 9, 6]: in social networks, these communities may be groups of friends, of collaborating scientists, or of people with similar interests; in biological networks these groups may be interacting brain regions, interacting proteins, or interacting species in a food web; more abstractly, these groups may be webpages on the same topic, or words commonly found together in English. Finding such a community structure in a data network requires a null model against which to assess the relative density of connections in the data. We use community detection as our prime application here as it illustrates both the key challenges we want to address.
First, community detection algorithms overwhelmingly use the same null model, the expectation of the configuration model [4, 6], which then often determines the form of the algorithm itself. Moreover, typically community detection algorithms are unable to detect the absence of community structure. We’d like the freedom to choose a null model for how we want to define a community structure, or its absence, not least different variants of the configuration model itself [10]. This is an example of the more general problem of detecting low-dimensional structure in a network, for which we would like to able to use any suitable null model for that structure.
Second, community detection algorithms rarely consider the problem of nodes that do not belong to any community [11, 12]. In any network constructed from data, such “noise” nodes may be present due to sampling error [11], or to sparse sampling of the true network (as in networks of connections between neurons). Or they may be generated by some random process marginally related to the construction of the main network, such as minor characters in narrative texts. However they arise, ideally we would be able to detect such noise nodes by defining them against the same null model for the absence of communities. This is a special case of the more general problem of detecting nodes that are not participating in the low-dimensional structure of a network.
Our proposed solution to these challenges is a simple sampling approach. We frame the departure between data and model as a comparison between the eigenspectrum of a real-world network and that predicted by the specified null model, an approach motivated by current spectral approaches to community detection [4, 13, 14, 15, 16, 17]. We give an algorithm that samples networks from a generative null model to determine the expected bounds on the data network’s eigenspectra if it was a sample from that generative model. The upper bound is used to construct a low-dimensional projection of the data network from its excess eigenvectors; we then use this projection to reject nodes that do not contribute to these dimensions, extracting a “signal” network. All code for this framework is provided at https://github.com/mdhumphries/NetworkNoiseRejection.
Applying our spectral estimation approach to synthetic networks with planted communities, we show that the low-dimensional projection recovers the correct number of planted communities, and successfully rejects noise nodes around the planted communities. On real-world networks, we show significant advantages over community detection alone, which finds community structure in every tested network. For example, our spectral approach reports no community structure in the large co-author network of the Computational and Systems Neuroscience (COSYNE) conference, pointing to a lack of disciplinary boundaries in this research field. We also demonstrate that spectral estimation can recover -partite structure in a sub-set of real networks. Finally, we show that the choice of null model can strongly alter conclusions about the low-dimensional structure in both synthetic and data networks. Our spectral estimation approach is a starting point for developing richer comparisons of real-world networks with suitable generative models.
Results
Our goal is to compare a weighted, undirected data network to some chosen null model that specifies the absence of a particular low-dimensional structure. A simple way to compare data and null models is , where the matrix is the expected weights under some null model. For example, if we choose to be the classic configuration model, then is the modularity matrix [4]; as we are framing this as a general problem, we thus here term the comparison matrix. Our idea is to test whether the data network is consistent with being a realisation of the generative process whose expectation is , namely that .
To do so, we generate a set of sample null model networks from the generative model whose expectation is . We then compute each sample’s comparison matrix , and the eigenspectra of . Combining the sampled eigenspectra thus estimates the expected eigenspectrum of due solely to variations in the null model, illustrated schematically in Fig 1a. Here we focus on estimating its upper bound: finding eigenvalues of the data network’s comparison matrix exceeding that bound is then evidence of some low-dimensional structure in the data that departs from the null model. Moreover, the number of eigenvalues exceeding the upper bound gives us an estimate of the number of dimensions of that low-dimensional structure.
We can then obtain a low-dimensional projection of the data network (Fig 1b), by using the eigenvectors of corresponding to the eigenvalues that exceed the limits predicted by the model. In that low-dimensional projection, we can do two things: first, test if individual nodes exceed the predictions of the null model, and reject them if not (Fig 1c, grey circles); second, cluster the remaining nodes (Fig 1c, coloured circles). Full details of this spectral estimation process are given in the Methods.
The choice of null model network is limited only to those which can be captured in a generative process, for we need to sample networks. For some null models, like the classic configuration model, we know explicitly; if not, we can simply estimate as the expectation over the sampled networks. We use two null models here. One is the weighted version of the classic configuration model (WCM) [18]. For the second we introduce a sparse variant (sparse WCM) that more accurately captures the distribution of weights in the data network, as we illustrate for a real network in the S1 Appendix–Fig 1. As we show below, the choice of null model is crucial.
Spectral estimation detects transitions to community structure
We first ask if our spectral estimation approach is able to correctly detect networks with no low-dimensional structure. As our application here is community detection, we construct synthetic weighted networks with planted communities. Each synthetic network has nodes divided into equal-sized groups, and its adjacency matrix is constructed by creating links between groups with probability and within groups with probability . The corresponding weight matrix is then constructed by assigning sampled weights to those links (see Methods). By increasing the difference from zero, we move from a random weighted network to a strongly modular weighted network.
Fig 2a shows that spectral estimation can consistently identify the absence of modular structure in synthetic networks when none is present, and transitions sharply to consistently detecting modular structure as the synthetic networks depart from random. Crucially, correct performance depends on the choice of null model: using the sparse weighted configuration model gives the transition, but using the classic, full weighted configuration model always detects modular structure even when none is present (Fig 2a).
When modular structure is detected by the sparse WCM model, the number of eigenvalues above the null model’s estimated upper limit is a good guide to the number of planted communities (Fig 2b). By contrast, using the full configuration model dramatically over-estimates the number of planted communities.
To further illustrate that spectral estimation’s ability to distinguish structure is non-trivial, we test examples of standard unsupervised community detection algorithms – Louvain and multi-way spectral clustering – on the same synthetic networks. Both these algorithms always found groups even when the network had no modular structure (Fig 2b). Correspondingly, the accuracy of their community assignment was poor until the synthetic networks were clearly modular (Fig 2c). These results remind us that standard algorithms can give no indication of when a network has no internal structure. We are not claiming spectral estimation to be unique in this regard: other approaches to community detection can also detect transitions between structure and its absence in these simple block models, for example those using the non-backtracking matrix [15] or using significance testing on sampled partitions [20, 21].
When network structure is detected, we have the option of using the -dimensional space defined by spectral estimation to find groups using simple clustering (see Methods). This approach always performed as well or better than the community detection methods in recovering the planted modules (Fig 2c).
In more densely connected synthetic networks, we find spectral estimation performs similarly in detecting structure, jumping rapidly between rejecting all and accepting all networks as containing modules (Fig 2d). Comparing detection in the sparse (Fig 2a) and dense (Fig 2d) synthetic networks hints that the detectability limit for spectral estimation is constant for the magnitude difference ; future work could explore the robustness of this constant limit to changes in the network’s parameters, especially size, strength distribution, and number and size of modules. Notably, on these denser networks spectral estimation is always better than community detection alone in detecting both the number of groups (Fig 2e), and in the accuracy of recovering the planted modules (Fig 2f). Spectral estimation can thus successfully both detect low-dimensional structure and its absence at the level of the whole network; we thus next turn to the level of individual nodes.
Node rejection recovers planted communities among noise
A difficult and rarely tackled problem in analysing networks is the recovery of structure from within noise. Such noise may manifest as extraneous nodes in the network due to sampling only part of the system, or because there really are only a sub-set of nodes contributing to a given structure (e.g. communities). Here we show that our proposed solution of using a low-dimensional space defined by spectral estimation can recover planted network structure from within noise.
We test this by adding a halo of extraneous “noise” nodes to the planted communities in our synthetic networks (Fig 3a). Each synthetic network has community nodes with planted communities defined by and , to which we add additional nodes. The probability of links to, from and between these noise nodes is defined by . By tuning relative to , we can thus move from a strongly modular network when to a noise-dominated network when .
Fig 3a shows an example such network, with four modules embedded in a set of extraneous nodes, here sparsely connected. We detect these “noise” nodes by projecting all nodes into the -dimensional space defined by the eigenvalues above the null model’s predicted upper limit. As illustrated at the bottom of Fig 3a, nodes not contributing to the low-dimensional structure of the network will cluster close to the origin of this space. We find them by predicting the projection of each node from the set of sampled null model networks, and retaining only those nodes whose data projection exceeds the prediction (see Methods). We term this network of retained nodes the “signal” network.
In practice, the combination of spectral estimation and node rejection works well on noisy synthetic networks. The spectral estimation algorithm consistently detects the embedded modular structure when , and correctly detects the absence of embedded structure when (Fig 3b; panel e plots the number of detected modules).
When the embedded network structure is detected, node rejection does well at detecting the noise nodes (Fig 3c), always detecting some noise nodes and thus performing better than without this step. Maximum accuracy at rejection appears to occur at intermediate probabilities of links to and within noise nodes. At the same time, the rejection procedure does well at not rejecting nodes within the embedded modules (Fig 3d).
Again, we can further illustrate the utility of node rejection by looking at the performance of standard community detection algorithms on these synthetic networks with noise. The Louvain algorithm almost always finds too many modules, and both Louvain and multi-way spectral clustering find modules when none exist at (Fig 3e). By contrast, spectral estimation almost always detects the correct number of modules when they are clearly distinguished from the noise nodes (i.e. , Fig 3e).
To assess the accuracy of community detection, we measure performance against two alternative ground-truths: one where each noise node is placed in its own group; and one where all noise nodes are placed in a single, fifth group. We again also test our simple clustering in the -dimensional space, using the retained nodes; we thus compare to a ground-truth of just the retained nodes. For either ground-truth, the Louvain algorithm performs poorly, and increasingly so as the fraction of noise nodes is increased (Fig 3f,g). Multi-way spectral clustering performance is similar to our simple clustering for sparsely connected noise nodes (low ); with more densely-connected noise nodes, simple clustering in the -dimensional space outperforms the other algorithms at all sizes of the embedding noise (Fig 3f,g). The combination of spectral estimation and node rejection thus allows the extraction of embedded community structure in networks.
Detecting low-dimensional structure in real networks
We now turn to examining what the spectral estimation approach can tell us about real networks, and how our choice of null model affects the conclusions we can draw. To this end, we apply spectral estimation and node rejection to a set of 14 real networks (Table 1), covering all cases of possible weight values (binary, integer, and real-valued).
In Fig 4 we show the null model eigenspectra for this set of networks: the distributions of the eigenvalues of predicted by the sparse WCM model. Most have a symmetric, narrow-peaked, and heavy-tailed distribution; three are more broadly distributed (Fig 4a). The variation of distribution shape shows the usefulness of the explicit generative approach to estimating the distribution. The distribution of predicted maximum eigenvalues is also approximately symmetric about its mean for most networks (Fig 4b). Setting the upper bound for the real network’s eigenvalues as the mean of this distribution is thus a reasonable first approximation.
Setting this upper bound has a dramatic effect on the estimated dimensionality of the real network. One may wonder if it’s worth the extra computational effort of estimating the eigenvalues bounds predicted by the null model. Spectral algorithms for community detection typically use the eigenspectra of , using only the expectation of the null model; consequently, all positive eigenvalues of are possible dimensions in the network [4, 14]. Fig 5a shows this to be a poor assumption: establishing an upper bound on the expected eigenvalue distribution reduces the estimated dimensionality of the real network (and hence the estimated number of communities) by orders of magnitude (Fig 5a).
The choice of null model to establish the upper bound can strikingly change our conclusions about a given real network. We find the full and sparse WCM models disagree strongly about the dimensionality of some real networks (Fig 5b): notably there are two networks in this data-set where the full WCM model finds more than 35 dimensions, and the sparse WCM model finds at most one. The sparse WCM model mostly estimates fewer dimensions, consistent with its closer estimates of the real network’s sparseness, and its more accurate performance on synthetic data (Fig 2). Most striking is that we are able to reject the existence of low-dimensional community structure for a handful of the real networks (0’s in Fig 5b), but the null models do not agree on which networks have no structure (no real network has 0’s for both null models in Fig 5b). These results underline how the choice of null model is critical when testing the structure of a network.
Node rejection stabilises analysis of real networks
When we then test for node rejection using the sparse WCM model, all real networks with low-dimensional structure have nodes rejected. The resulting signal network is up to an order of magnitude smaller than the original network (Fig 5c).
This offers some straightforward but nonetheless useful advantages. As we demonstrate below, one advantage is that the signal network can simplify interpretation of the network’s structure. Another advantage is that it reduces the variability of unsupervised analyses of the network. To demonstrate this, we apply the Louvain algorithm to the full and signal versions of each real network. As expected, the number of modules detected in the signal networks is usually – but not always – smaller than in the full network (Fig 5d). Over repeated runs of the Louvain algorithm, the range of detected modules can vary considerably in the full real networks, but this variation is markedly reduced for the signal versions of the same network (Fig 5e).
Hidden -partite structure in real networks
Throughout this paper we estimate the upper bound of the eigenvalue spectrum predicted by the null model; but we could equally well estimate the lower bound, and check if the data network at hand has eigenvalues that fall below this lower bound. Real networks with eigenvalues of below the lower bound indicate -partite structure [4]. In the simplest case, one eigenvalue below the lower bound is evidence of bipartite structure (), with two groups of nodes that have more connections between the groups and fewer within each group than predicted by the null model.
When we use the sparse WCM to estimate the predicted lower bound of the real networks here, we find seven have eigenvalues below that lower bound. All but one of those networks have just one eigenvalue, and so are bipartite (third column in Fig 5b). Applying node rejection to the corresponding eigenvector rejects a considerable proportion of nodes, indicating that the -partite structure is embedded within the network; we show examples in section 2 of the S1 Appendix. Thus, spectral estimation using the lower bound can reveal hidden -partite structure in larger networks.
Insights into specific networks
We now look in more detail at examples from the data-set of real networks to illustrate the new insights brought by spectral estimation (of the upper bound). Any interpretation of global structure in real networks faces the problem that meta-data about network nodes can be a poor guide to ground-truth [22] – and indeed that there need exist no “ground-truth”. Thus here we use domain knowledge to aid interpretation of the results. We first look at networks derived from a narrative structure in order to compare the recovered signal network and its modules to the narrative.
Les Miserables narrative
The Les Miserables network encapsulates the book’s narrative by assigning characters to nodes and a weighted link between a pair of nodes according to the number of scenes in which that pair of characters appear together. Spectral estimation detects a departure from the sparse WCM model (Fig 6a), and hence a low-dimensional structure to the narrative (Fig 6b). Node rejection in this two dimensional space removes 30 nodes, yet retains all major characters (for example, Valjean, Marius, Fantine, and Javert), considerably simplifying the identification of the main narrative structure.
We use unsupervised consensus clustering on the low-dimensional projection of the signal network in order to identify small modules potentially below the resolution limit. This recovers four modules, corresponding to major narrative groups, including Les Amis de l’ABC (the “Barricade Boys”: Enjoiras and company), and the student friends of Fantine (Fig 6c). Thus for the Les Miserables network, spectral estimation can correctly identify the major characters, and identifies key narrative groups.
Star Wars dialogue structure
The networks of dialogue structure in Star Wars Episodes 1 to 6 illustrate how we can detect qualitative differences in narratives using spectral estimation. In each of these six networks, each node is a character in that film, and the weight of each link between nodes is the number of scenes in which that pair of characters share dialogue.
Applying spectral estimation to each film’s network reveals that only four of the six have a low-dimensional structure beyond that predicted by the sparse WCM model (Fig 7a). Character interactions in Episode 4 (A New Hope) and Episode 6 (Return of the Jedi) do not depart from the null model. From this we might conclude that the complexity of dialogue structure is no predictor of the quality of Star Wars films. Plotting the strength of departure from null model against a respected critic’s ranking of the films’ quality supports this conclusion (Fig 7b).
Nonetheless, when there is low-dimensional structure, consensus clustering of the signal network recovers modules that correspond to narrative arcs in each film. In Fig 7c we illustrate this for Episode 5 (The Empire Strikes Back), where the clustering recovers the separate arcs of the fleeing Millennium Falcon, Luke on Dagobah, and the Empire and its associates.
Notably, Star Wars Episodes 1-3 are also the only ones to have a bipartite structure (see section 2 of the S1 Appendix), indicating an overly-structured narrative in which there exists both well-defined groups of characters that converse, and well-defined groups that do not interact at all.
Co-author network of the COSYNE conference
Networks of scientific fields are useful surrogates for social networks as we can bring considerable domain knowledge to bear on their interpretation. As an example of this, here we take a look at the network of co-authors at the annual, selective Computational and Systems Neuroscience (COSYNE) conference. This network’s nodes are authors of accepted abstracts in the years 2004-2015, and the weight of links between authors is the number of co-authored abstracts in this period. The full network has 4806 nodes, from which we analyse the largest component containing 4063 nodes.
As shown in Fig 5b, using the full configuration model as the null model for spectral estimation predicts 38 dimensions in this network. If we run the Louvain algorithm on the full network, it finds 728 modules. This order-of-magnitude discrepancy in the predicted dimensions and detected modules is reminiscent of the poor performance in estimating modules that we observed in Fig 2b for synthetic networks without modular structure.
Indeed, when we instead use the sparse WCM as the null model for spectral estimation, no low-dimensional structure is found. And this is useful, as it suggests this particular null model captures much of the structure of the real network. Here the sparse WCM model suggests that the collaborative structure in the COSYNE conference is no different to a model where, once a pair of authors have begun working together, then the number of co-authored abstracts by that pair is simply proportional to their total output. The consequent absence of low-dimensional structure suggests there is no rigid subject-based division (into e.g. vision and audition; or cortex and hippocampus) of this conference network.
Gene co-expression in the mouse brain
Our final detailed example demonstrates the use of spectral estimation on a general clustering problem. The Allen Mouse Brain Atlas [23] is a database of the expression of 2654 genes in 625 identified regions of the entire mouse brain. From this database, we construct a network where each node is a brain region, and the weight of each link is the Pearson’s correlation coefficient between gene-expression profiles in those two regions. One goal of clustering such gene co-expression data is to detect correspondences between gene expression and brain anatomy [24].
An advantage of using spectral estimation on such a clustering problem is the unsupervised detection of the dimensionality of any clusters. Using sparse WCM as the null model, we find the gene co-expression network has five eigenvalues above the expected upper limit (Fig 8a). Projection of the nodes onto the first two of the five retained dimensions indicates a clear group structure (Fig 8b). Reassuringly, no nodes are rejected from this network. (For if we found rejected nodes here, it would mean either that small brain regions existed with profiles of gene expression that bore no resemblance to others, which would be difficult to reconcile with known patterns of brain development; or that there was a considerable error in those regions’ gene expression profiling).
Fig 8c plots the partition with maximum modularity that we found by clustering in this five-dimensional space (consensus clustering gives us 26 groups, which are subdivisions of these groups). As shown on the figure, the detected modules correspond remarkably well to highly distinct broad divisions of the mammalian brain.
Discussion
Detecting low-dimensional structure in a network requires a null model for the absence of structure. The choice of null model in turn will define the type of structure that can be detected. Here we introduced a spectral approach to detecting low-dimensional structure using a chosen generative null model. We have shown that this spectral approach allows rejection and detection of structure at the level of the whole network and of individual nodes.
Our results emphasised that the choice of null model can strongly change conclusions about network structure. Here we contrasted the classic configuration model with a sparse variant that accounted for the problem that using the classic configuration model as a generative model creates networks that are denser than the data network at hand. Indeed, for the synthetic networks, using the classic configuration model consistently predicts a vastly more complex structure than actually exists. By contrast, using the sparse variant correctly detects the absence of structure in synthetic networks, and sharply transitions to detecting community structure when present. It also reveals the absence of community structure in a set of real networks. Using analysis of network structure to do scientific inference will thus need careful choice of an appropriate null model.
Indeed there are now a wide range of null model networks to choose from. Variations of the configuration model abound [10, 12], including versions for correlation matrices [25], and simplical models [26]. Other options include permutation null models, derived directly from data networks by the permutation of links [27], and specific generative models for network neuroscience applications [28]. Exploring the insights of these null models in our spectral estimation approach could be a fruitful path.
We illustrated the advantages of using spectral estimation over naive community detection, using the Louvain algorithm and multi-way spectral clustering as examples of unsupervised agglomerative and divisive approaches. In particular, we demonstrated that “noise” nodes without community assignment are dealt with by spectral estimation, but invisible to standard algorithms, which can result in them performing poorly in finding the number and membership of true communities. This raises questions over the accuracy of standard algorithms’ results on real network data, in which the prevalence of “noise” nodes is rarely assessed. Indeed, our analysis of real-world data suggests all but one data network we tested contains a substantial fraction of noise nodes – and the one that did not was a network of gene expression correlations across brain regions, for which finding “noise” nodes would have indicated an error in our approach.
Once we have derived the signal network using spectral estimation, we can apply any unsupervised community detection algorithm to it, including the Louvain and multi-way spectral clustering. And indeed for multi-way spectral clustering, we can specify the number of groups to find directly from the number of dimensions found by the spectral estimation algorithm. Of course, this does not change the limitation that any community detection algorithm that maximises modularity contends with the twin problems of the resolution limit [29], and the degeneracy of high values for modularity [30]. For our analyses of real networks, we supplemented our community detection with consensus clustering to address these issues.
Our work here continues a considerable body of work using spectral approaches to detecting the number of communities in a network [4, 13, 31, 32]. A recent breakthrough has been the idea of non-backtracking walks on a network, as the eigenvalues of the corresponding matrix can detect community structure in synthetic sparse networks down to the theoretical limit [15, 16, 17]. Our work complements this prior work by allowing a choice of null models to define structure at the network level, and goes beyond them by creating an approach for rejecting nodes.
While we have focussed here on community detection, in principle the type of structure we can detect depends on the choice of null model. For example, we could fit a stochastic block model to our data network [33, 34, 35], and use this fitted model to generate our sample null model networks . The spectral estimation algorithm would then test the extent of the departure between the data network and the fitted block model. Similarly, one could use fitted core-periphery models [36] as the generative null model, and test departures from this structure in the data.
While our approach allows the use of any null model, this also brings the inherent limitation that we must explicitly generate a sample of null model networks. The computational cost scales with both the number and size of the generated networks. However, as we discuss in detail in the Methods, there are a number of approaches to ameliorate the computation time; indeed, the primary bottleneck in our code implementation is not computation time but memory for storage of all generated networks (see Methods section “Practical computation of the sampled null models” for details). For scaling our approach to networks of , future development of more efficient memory usage is a priority.
Of the other possible developments of our spectral estimation approach, two stand out. One is that we could construct a de-noised comparison matrix from the outer product of the eigenvectors retained by spectral estimation. This approach has been successfully applied to analyses of both financial [37, 38] and neural activity [39, 40] time-series, where de-noised matrices of time-series correlation allow for more accurate inference of structure. Another is to further develop node rejection. Here we tested an initial idea of comparing projections between the data and null models, which performed reasonably well, with clear scope for improved performance with more rigorous approaches. These and other potential developments suggest that our spectral estimation approach is a promising basis for richer comparisons of real-world networks with suitable generative models.
Methods
We develop our spectral algorithm for weighted, undirected networks. For a given network of nodes, we will make use of both its adjacency matrix , whose entry defines the existence or absence of links between nodes and , and the corresponding weight matrix , whose entry defines the weight of the link between nodes and . Weights can real valued or integer valued; in the latter case the weights are equivalent to the number of links between and . For binary networks .
Detecting the existence of low-dimensional structure in networks requires that we compare the data network with some null model for the absence of that low-dimensional structure. A simple comparison is
[TABLE]
where is an expectation of the link weights over the ensemble of possible networks consistent with the chosen null model. The comparison matrix thus encodes the departure of the data network from the null model. If we choose the classic configuration model as the null model, then is the well-known modularity matrix [4]. But we’d like the freedom to choose the most appropriate null model, according to the structural hypothesis we want to test.
In seeking to detect low-dimensional structure, it is particularly useful that the eigenvalue spectrum of contains much information about the structure of the network [4]. In general, the separation of a few eigenvalues from the bulk of the spectrum indicates low-dimensional structure in a matrix [37, 39, 40, 38]; for networks, this can indicate the number of communities within it, and form the basis of a low dimensional projection of the network [4, 13, 14]. So our goal is to estimate the spectrum of predicted by a given class of null model, and compare it to the spectrum of for the data network; a departure between the predicted and data spectra then indicates the presence of meaningful structure in the network. It also gives us additional information about the data network, as we detail below.
Our general approach then is to sample null model networks from a generative model with expectation , and so sample the expected variation in solely due to the ensemble of networks consistent with the null model. We then use these samples to estimate the eigenspectrum of due solely to variations in the networks consistent with the null model. In particular, we estimate its upper bound: if any of the data network’s eigenvalues exceed that bound, we have evidence of low-dimensional structure in the data network that is not captured by the ensemble of null model networks. Moreover, data eigenvalues that exceed the limits predicted by the model provide us with additional information about the structure of the data network; and, as we show below, a basis for testing node-level membership of a network too.
The spectral estimation algorithm
Our spectral estimation algorithm proceeds as follows. Given some chosen generative null model, we:
generate sample null model networks . 2. 2.
from each we can then compute the sampled network’s comparison matrix , for , 3. 3.
and the comparison matrices’ corresponding set of eigenvalues , for the th sampled network. 4. 4.
These sets of eigenvalues are then samples from the eigenspectrum of the population of null model networks whose expectation is . In practice here we make use of the upper and lower bounds, and so estimate them directly. We denote the maximum eigenvalue from each of the sampled networks as . The upper bound of the eigenspectrum predicted by the null model is estimated as the expectation over those maximum eigenvalues. Similarly, the lower bound is estimated as over the set of minimum eigenvalues.
For comparison, we compute the data’s comparison matrix , and its eigenvalues . How we compute will depend on the null model at hand: for some, is known analytically; for others we can estimate it as the expectation over .
With these to hand, we then test our null model (Fig 1a). If any data eigenvalues exceed the expected upper bound , then we have evidence that the data network contains low-dimensional structure not captured by the null model. If not, then we cannot discount that the data network is a realisation of the null model .
(Note that we treat this process here as an estimation problem: in section 3 of the S1 Appendix, we outline how the same process can be cast in a null hypothesis significance testing framework, to test the rejection of each data eigenvalue at some defined -value).
For a data network that departs from the null model, we will have eigenvalues of the data network greater than , labelled , which estimate the dimensionality of the data network with respect to the null model. The corresponding eigenvectors define a -dimensional space into which we can project the data network’s comparison matrix (Fig 1b): we can then use this projection to infer properties of the structure of (detailed below for community detection), and perform a rejection test per node.
Node rejection
Each node will have a projection in this -dimensional space. Nodes that are weakly contributing to the structure of the network captured by this space (e.g. nodes that are not in any community) will have small values in each eigenvector, and so have short projections that remain close to the origin (Fig 1c). We can thus reject individual nodes by defining a boundary on “close”.
Here we do this by comparing the data network’s projections to those predicted by the sampled null model networks. For node , we compute its L2 norm from the -dimensional projection of : . We also compute the L2 norm for the th node in the -dimensional projection of each obtained from the sampled networks, giving the distribution over all sampled networks. From that distribution, we compute the expected projection for that node. A node is then rejected if , which defines here our boundary on “close” to the origin; otherwise the node is retained. Again we frame this here as an estimation problem; interesting extensions of this work would be to test node rejections based on confidence intervals or hypothesis tests that make use of the null model distribution of projections .
We call the retained nodes the “signal” network. Rejecting nodes from a sparse network may fragment it; it may also leave isolated leaf nodes with a single link to the rest of the network. Consequently, in practice, we strip the leaf nodes and retain the remaining largest component as the “signal” network.
Generative null models
Key to our algorithm is the use of a generative null model for sampling networks. We use two generative models here, based on the classic configuration model.
Weighted configuration model
We start with the weighted version of the classic configuration model [18, 14, 10]. In this model, the strength sequence of the network is preserved, and the expectation is , where are the strength of nodes and , and is the sum total of unique weights in the network. (We also tested the computation of as the expectation over the sampled networks, for consistency with how we computed it for the sparse model below; we obtained identical results).
Sparse weighted configuration model
The classic weighted configuration model is dense, as the expectation has an entry for every pair of nodes. However, real networks are predominantly sparse [1, 2]. Consequently each sampled network using the weighted configuration model is also likely more densely connected than its corresponding data network. This difference is amplified in weighted networks because the comparatively denser connections in the sample network means the weights are spread over more links than in the data network, creating a potentially large difference in the distribution of weights. We show this large disagreement for an example real network in Fig 1 of the S1 Appendix.
To better take into account the distribution of link weights and sparseness, we use a sparse weighted configuration model (sparse WCM). This model generates a sample network in two steps. We first create the sampled adjacency matrix using the probability of connecting two nodes , where is the degree of node , and is the total number of unique links in the data adjacency matrix . We then create the sampled sparse weight matrix by assigning weights only to links that exist in , as detailed below. This is repeated times. In the absence of an analytical form for , we compute it as the expectation over the generated networks, with elements .
Poisson generation of links
When weights between nodes are binary or integer valued, then an exact way of generating a sample network from these null models is by stub-matching, where node is assigned stubs, and stubs are linked between nodes at random until all stubs are matched. Stub-matching in the sparse model would be restricted to the linked nodes in the sampled adjacency matrix . While we provide code for building these models using stub-matching, generative procedures using stub matching can be prohibitively slow with many links, many nodes, or real-valued weights converted to integers – all of which we have here.
We thus use a Poisson model for drawing the link weight between any pair of nodes (the use of the Poisson model is motivated by the fact that all networks we deal with have, or are converted to, integer weights – see below). We draw the weight between nodes and from a Poisson distribution with
[TABLE]
where is the probability of placing a single link between nodes and , and is the total number of links to place in the null model network .
For both classic and sparse weighted configuration models, it follows from the stub-matching model that the probability of placing a link between a pair of nodes is:
[TABLE]
In the classic configuration model all pairs of nodes are linked in , so the sum in the denominator of Eq 3 is over all pairs of nodes; the total number of links to place is then .
In the sparse model, only a subset of nodes in are linked, so the sum in the denominator of Eq 3 is over just those linked nodes. We then generate by drawing weights only for those pairs of linked nodes, with the total number of links to place being , where is the number of unique links already in .
As well as dramatically speeding up computation time, this Poisson approach has two appealing features. First, it gives a model that is closely linked to the generative process of many real-world networks, for which weights are counts of events in time or space (e.g. word co-occurrence; co-authorships; character dialogue). Second, it also closely approximates the multinomial distribution of link weights that results from stub-matching (, for all unique links), becoming arbitrarily close as .
Practical computation of the sampled null models
The Poisson model and stub-matching work for binary or integer weights. To deal with data networks of real-valued weights, we first quantise them to integer values: we scale all weights by a conversion factor and round to get an integer weight. Once all links are placed, we then convert back to real-valued weights by rescaling all weights by . The choice of is strongly determined by the discretisation and distribution of weights. For networks with weights in steps of 0.5, we use ; for networks based on similarity we use (which implies that weights less than 1/100 are not considered links). These scalings are used for all types of generative model in this paper.
Typically we generate null models for each comparison with a data network. The generative model approach is of course more computationally expensive than using just the expectation of the null model in Eq. 1. However, as each generated null model network is an independent draw from the ensemble of possible networks, this process is easily parallelised; all code was run on a 12-core Xeon processor. Moreover, the Poisson model is quick; even our largest weighted network (4096 nodes) took a few seconds to generate each null model network.
Rather, a potential bottleneck for scaling our spectral estimation algorithms is memory (RAM). For example, given a data network of nodes we create a matrix of sampled weight matrices (and the same size matrix of eigenvectors). For a data network of nodes and sampled null models, the sampled weight matrices would require 74.5 GB at the default double-precision float used in our code; an immediate improvement in memory could be had if the data networks used binary or integer weights, and so could be cast to the appropriate data class: using unsigned 8-bit integers for a binary network of that size would require 9.3GB; unsigned 16-bit integers for an integer-weighted network of that size would require 18.6GB. But even then, a data network of nodes, which are common, would require 930GB just to store the 100 generated null models for a binary network. Further improvements to the algorithm’s code implementation could also create more efficient memory usage by, for example, first taking a two step approach of generating only the eigenvalues to do spectral estimation, then generating only the specified number of leading eigenvectors.
Testing the spectral estimation algorithm’s performance
Synthetic networks
We use a version of the weighted stochastic block model to test our spectral estimation algorithm. We specify modules of size . Here each synthetic network has nodes divided into equal-sized groups. Its adjacency matrix is constructed by creating links between groups with probability and within groups with probability . The weight matrix is then constructed by first sampling a strength sequence from a Poisson distribution with parameter ( throughout). We then sample weights from a Poisson distribution: for each link () in , we draw a weight from the Poisson distribution , exactly as for the sparse WCM. Note we deliberately construct the synthetic networks as sparse weighted networks in order to detect any differences in performance between the null models.
To test rejection of nodes not contributing to a network’s low-dimensional structure, we add a noise halo to our stochastic block model. We add noise nodes to the synthetic network, to give nodes in total. To construct , the first nodes have the above modular structure defined by and ; the additional noise nodes are connected to all other nodes, including each other, with probability . The weight matrix is then constructed as above, sampling the strength sequence of all nodes from a Poisson distribution, and the consequent weights conditioned on the links in . Thus, both modular and noise nodes have the same expected strengths, differing only in the distribution of their weights.
Community detection algorithms
As benchmarks for community detection performance we use the standard Louvain algorithm [41] as an example of an agglomerative algorithm, and multi-way vector-partition [42] as an example of a divisive algorithm. We introduce an unsupervised version of this multi-way vector algorithm in section 4 of the S1 Appendix.
As our spectral estimation procedure will be estimating the exact number of communities , we also want a way to do community detection given the -dimensional projection of . We use a simple clustering in this space [14]. We project all nodes using the eigenvectors, and k-means cluster times, given clusters as the target and using Euclidean distance between the nodes. For each partition, node assignment to the communities is encoded in the binary matrix with if node is in community , and otherwise [4]; from this we compute the modularity of each partition as , where Tr is the trace operator, and using the expectation over our chosen null model. We retain the partition that maximises .
For real networks, we address the resolution limit [29] and degeneracy of maximal solutions [30] by also using our unsupervised consensus clustering approach [43], which we extend here to use an explicit null model for consensus matrices. Briefly, given the partitions, we construct a consensus matrix whose entry is the proportion of times nodes and are in the same cluster. We construct the consensus comparison matrix , given a specific null model for consensus clustering (defined below). As the purpose of using the consensus clustering is to explore more and smaller module sizes than can be accessed by maximising alone, we use the number of positive eigenvalues of as the upper limit on the number of modules to check. That is, we project using the top eigenvectors, then use k-means to cluster the projection of times for each between 2 and . From these partitions, we construct a new consensus matrix. The general consensus null model is the proportion of expected co-clusterings of a pair of objects in the absence of cluster structure, with entries: , where the sum is taken over all tested numbers of clusters from some lower bound ( for the initial consensus matrix above; otherwise). We repeat the consensus matrix and clustering steps until has converged on a single partition.
Data networks
All real-world networks were checked for a single component: if not connected, then we used the giant component as for spectral estimation.
The following networks were obtained from Mark Newman’s repository (http://www-personal.umich.edu/~mejn/netdata/): the Les Miserables character co-appearances; the dolphin social network of Doubtful Sound, New Zealand [44]; the adjective-noun co-occurrence network of David Copperfield; the USA 2004 election political blogs network; the C Elegans neuronal network, and the Western USA power grid [45].
Networks of shared character dialogues in Star Wars Episodes I-VI were constructed by Evelina Gabasova [46], and are available at http://doi.org/10.5281/zenodo.1411479.
Data on abstract co-authorship at the annual Computational and Systems Neuroscience (COSYNE) conference were shared with us by Adam Calhoun (personal communication). These data contained all co-authors of abstracts in each of the years 2005 to 2014. From these we constructed a single network, with nodes as authors, and weights between nodes indicating the number of co-authored abstracts in that period.
We obtained the Mouse Brain Atlas of gene co-expression [23] from the Allen Institute for Brain Sciences website (http://mouse.brain-map.org/), using their API. The Brain Atlas is the expression of 2654 genes in 1299 labelled brain regions. However, these regions are arranged in a hierarchy; we used the 625 individual brain regions at the bottom of the hierarchy as the finest granularity contained in the Atlas. We constructed the gene co-expression network by calculating Pearson’s correlation coefficient between the gene expression vectors for all pairs of these 625 brain regions; all correlations were positive.
Data and code availability
MATLAB code implementing the spectral estimation algorithms, synthetic network generation, and scripts for this paper are available under a MIT License at https://github.com/mdhumphries/NetworkNoiseRejection
This repository also contains all data networks we use here, and all results of running our algorithms on those networks.
Acknowledgements
We thank Adam Calhoun for permission to use his collated COSYNE submission data-set. This work was supported by grants to M.H. from the Medical Research Council [grant numbers MR/J008648/1, MR/P005659/1, and MR/S025944/1] and a National Council of Science and Technology (CONACyT) Fellowship to J.C.
Author Contributions
MDH: wrote paper; developed conceptual framework; coded algorithms; developed synthetic network models; ran final analyses; interpreted results
SM: developed null models
ME: generated real networks; ran initial analyses of real networks
AS: synthetic network models; ran initial analyses of synthetic models
JC: developed unsupervised version of multi-way spectral clustering; wrote null hypothesis significance testing
All authors edited the manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 11. Newman MEJ. The structure and function of complex networks. SIAM Review. 2003;45:167–256.
- 22. Humphries MD, Gurney K. Network ’small-world-ness’: A quantitative method for determining canonical network equivalence. P Lo S One. 2008;3:e 0002051.
- 33. Newman ME, Girvan M. Finding and evaluating community structure in networks. Phys Rev E. 2004;69:026113.
- 44. Newman MEJ. Finding community structure in networks using the eigenvectors of matrices. Phys Rev E. 2006;74:036104.
- 55. Reichardt J, Bornholdt S. Statistical mechanics of community detection. Phys Rev E. 2006;74:016110.
- 66. Fortunato S, Hric D. Community detection in networks: A user guide. Physics Reports. 2016;659:1–44.
- 77. Ghasemian A, Hosseinmardi H, Clauset A. Evaluating Overfit and Underfit in Models of Network Community Structure. IEEE Transactions on Knowledge and Data Engineering. 2019; p. 1722–1735. doi:10.1109/tkde.2019.2911585.
- 88. Fortunato S. Community detection in graphs. Physics Reports. 2010;486:75–174. doi:10.1016/j.physrep.2009.11.002.
