Quantile Tracking in Dynamically Varying Data Streams Using a Generalized Exponentially Weighted Average of Observations
Hugo Lewi Hammer, Anis Yazidi, H{\aa}vard Rue

TL;DR
This paper introduces a novel, lightweight quantile estimator based on a generalized exponentially weighted average, capable of efficiently tracking quantiles in dynamic data streams with proven convergence and superior adaptivity.
Contribution
It presents the first generalized EWA-based quantile estimator with online adjustment, proven convergence, and demonstrated superior performance in synthetic and real-world data.
Findings
Outperforms existing quantile estimators in dynamic environments
Achieves faster adaptation to changing data distributions
Effectively used for online climate control and concept drift detection
Abstract
The Exponentially Weighted Average (EWA) of observations is known to be state-of-art estimator for tracking expectations of dynamically varying data stream distributions. However, how to devise an EWA estimator to rather track quantiles of data stream distributions is not obvious. In this paper, we present a lightweight quantile estimator using a generalized form of the EWA. To the best of our knowledge, this work represents the first reported quantile estimator of this form in the literature. An appealing property of the estimator is that the update step size is adjusted online proportionally to the difference between current observation and the current quantile estimate. Thus, if the estimator is off-track compared to the data stream, large steps will be taken to promptly get the estimator back on-track. The convergence of the estimator to the true quantile is proven using the theory…
Click any figure to enlarge with its caption.
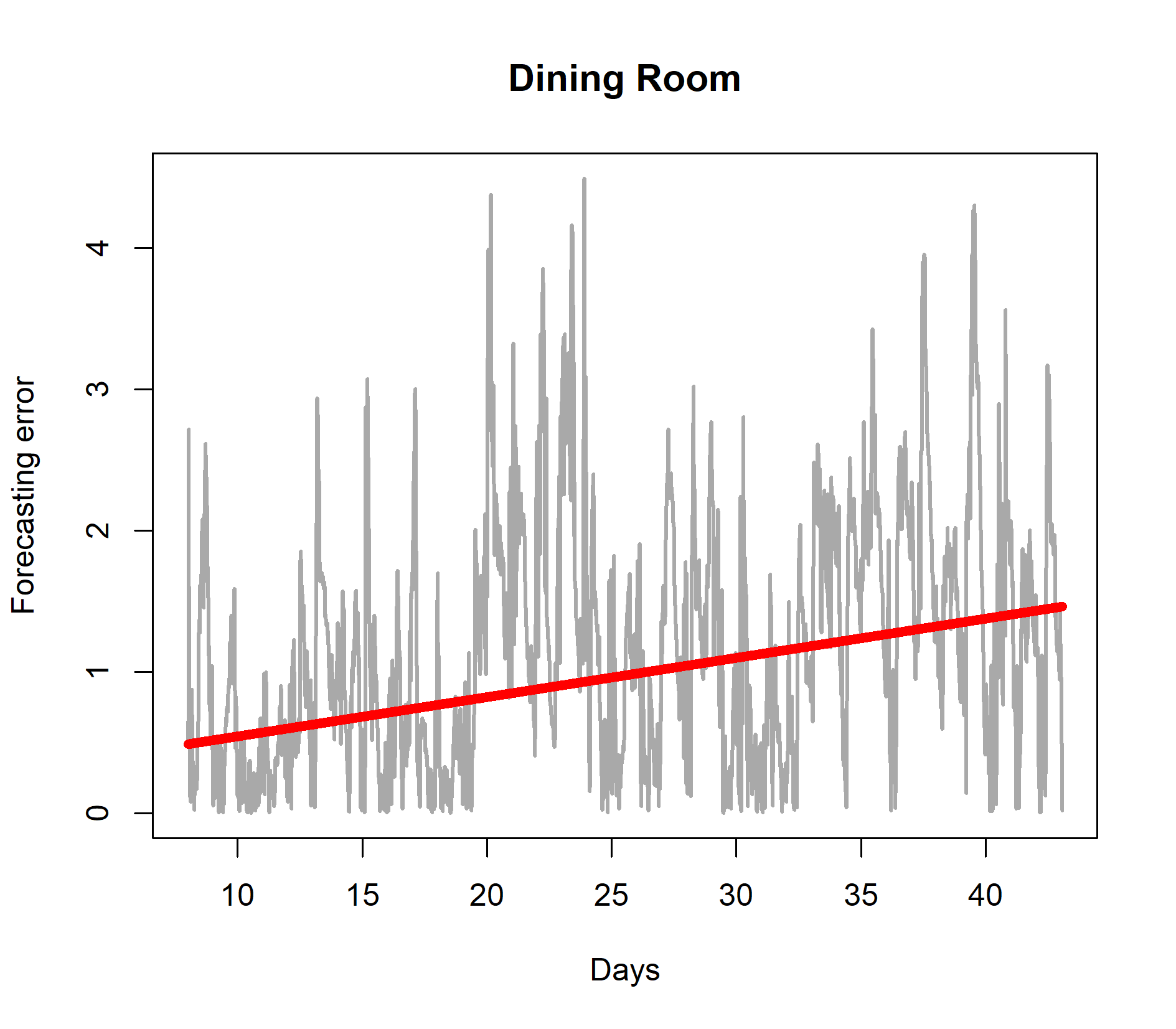 Figure 1
Figure 1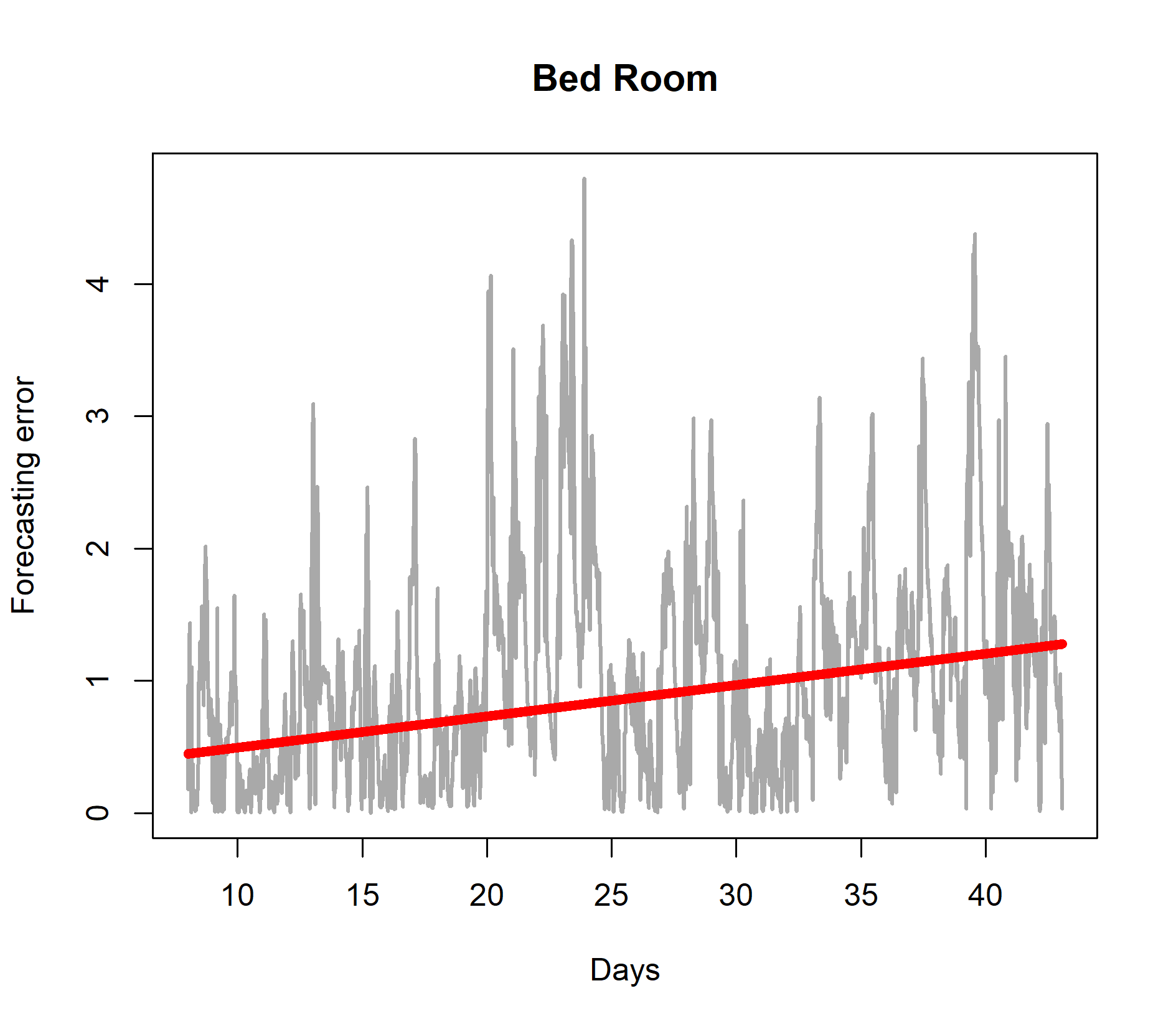 Figure 2
Figure 2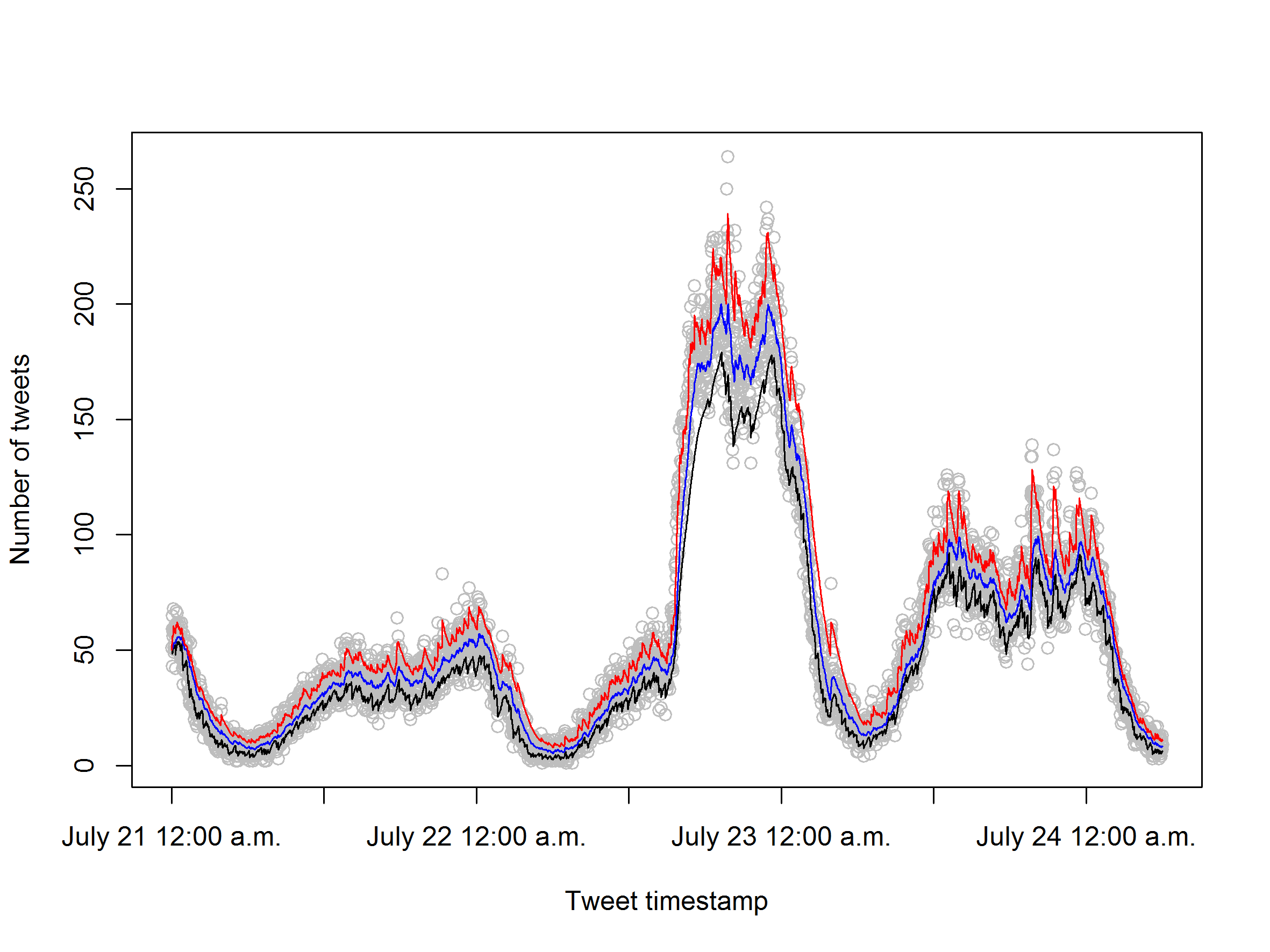 Figure 3
Figure 3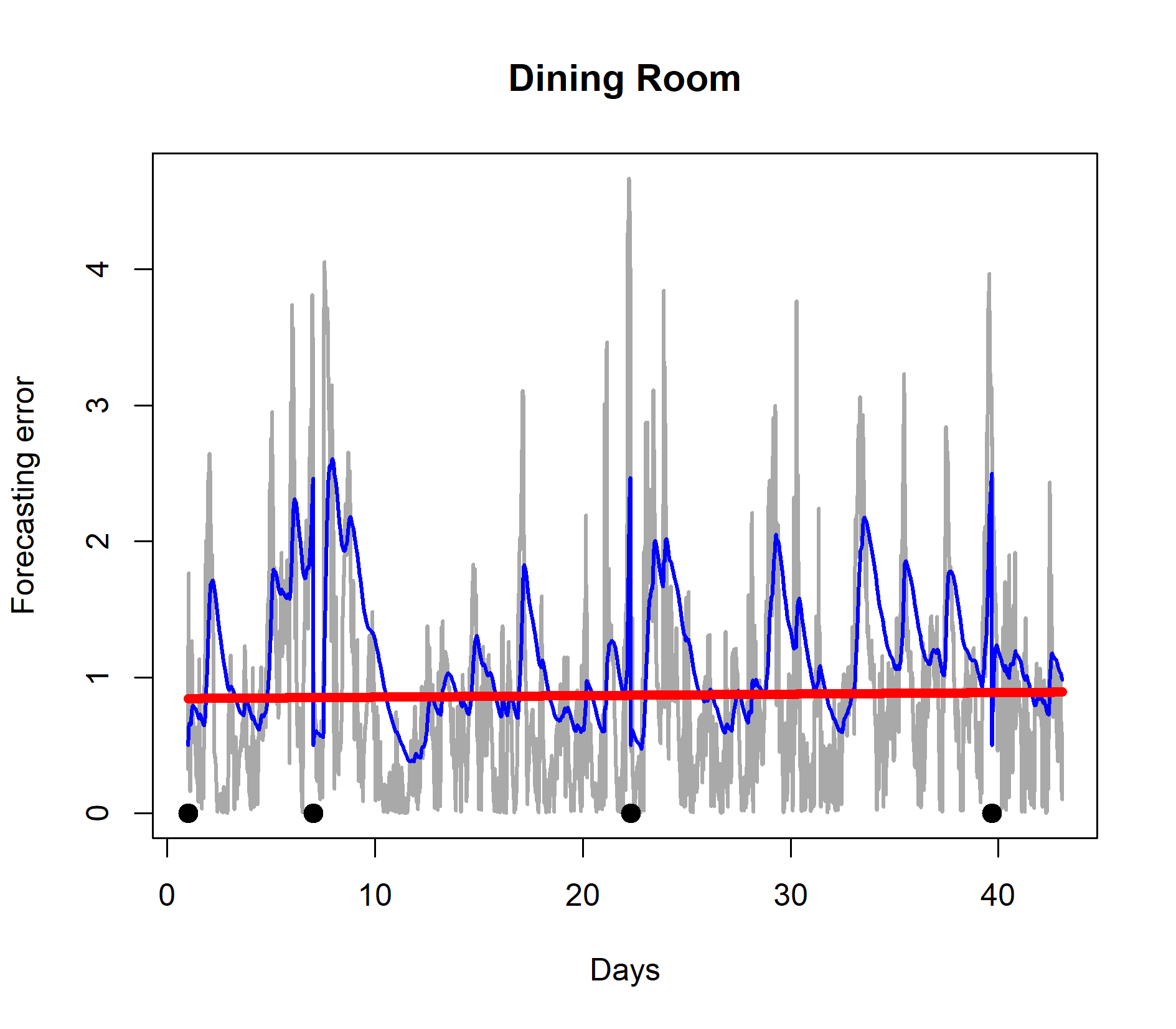 Figure 4
Figure 4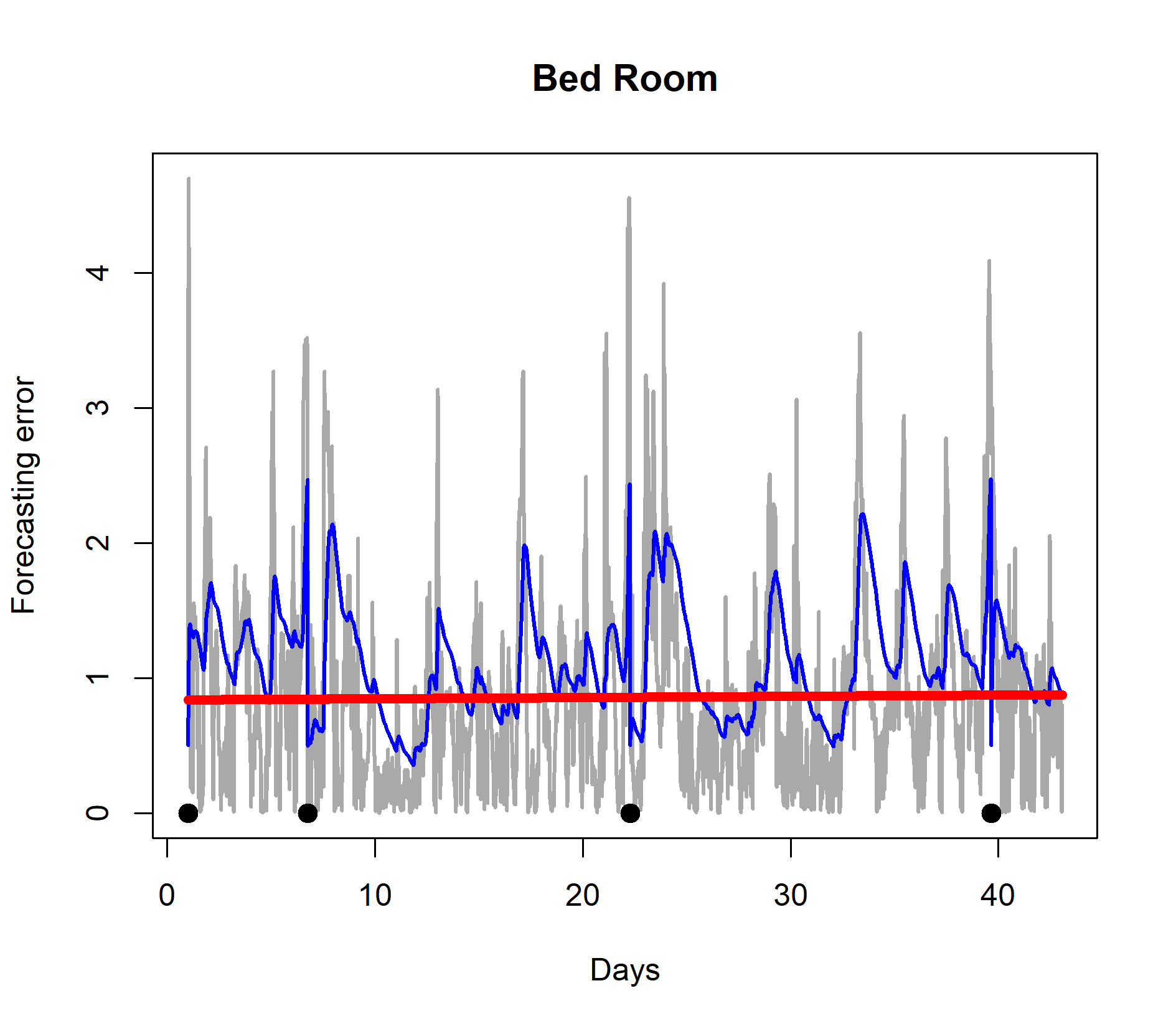 Figure 5
Figure 5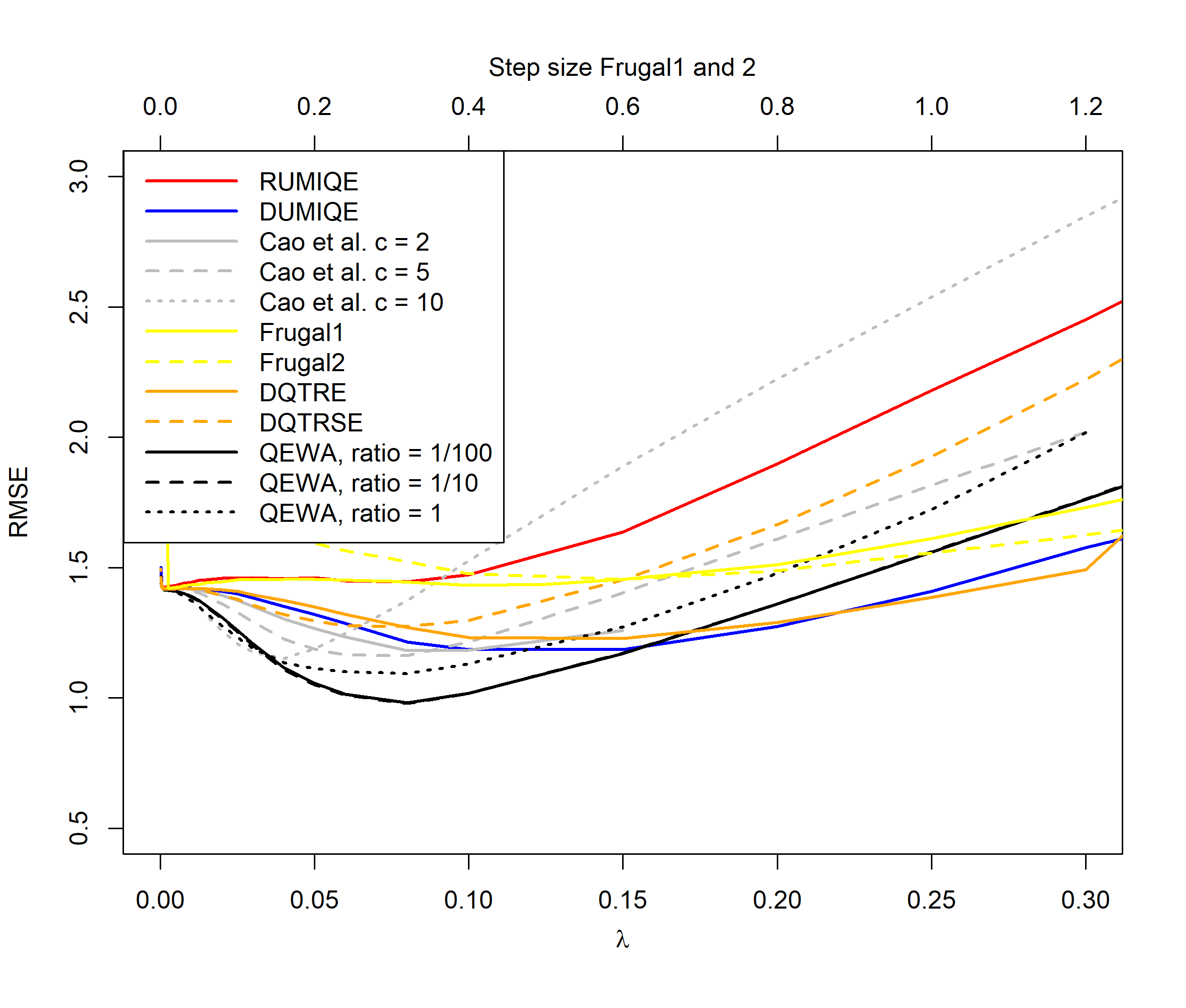 Figure 6
Figure 6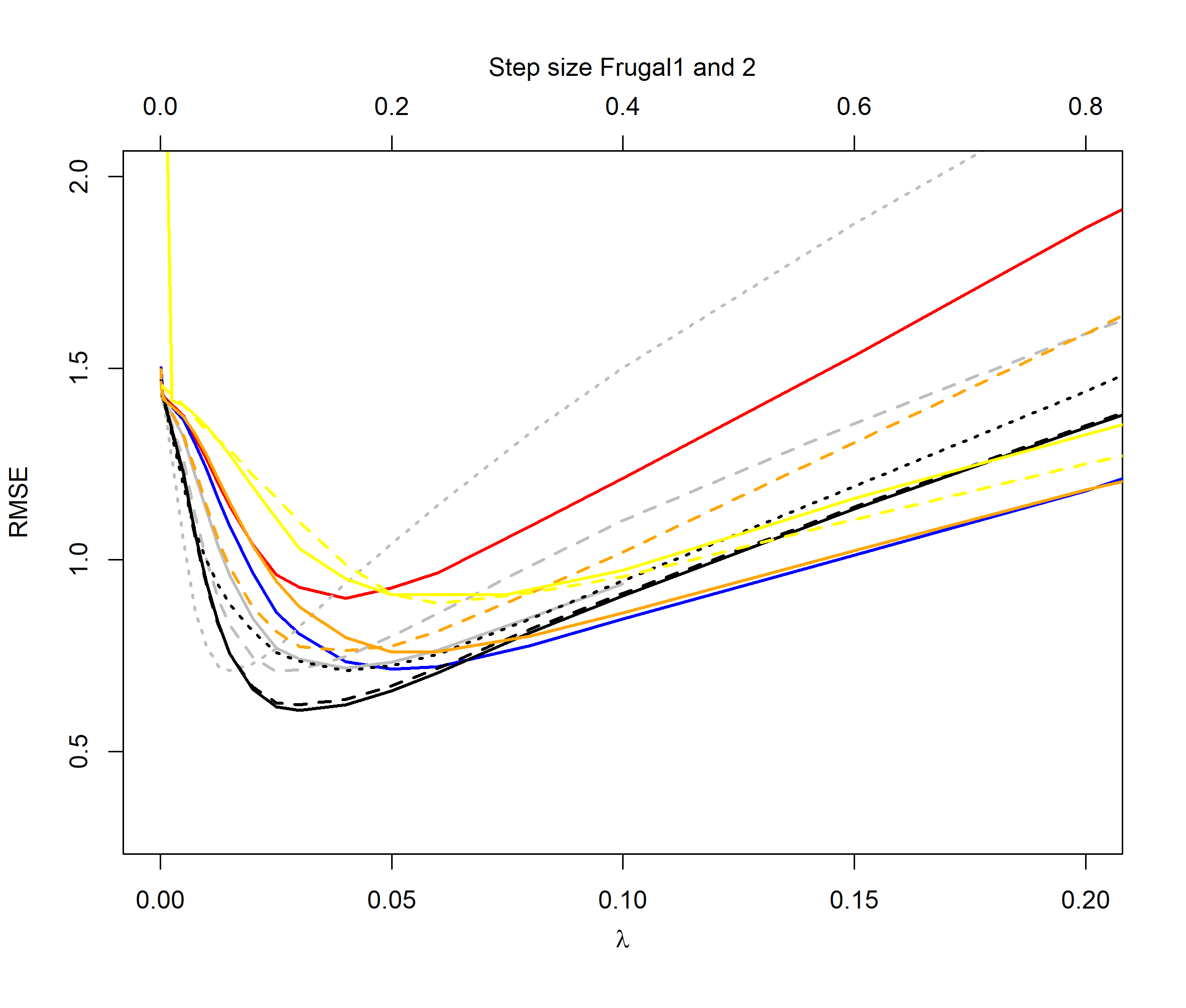 Figure 7
Figure 7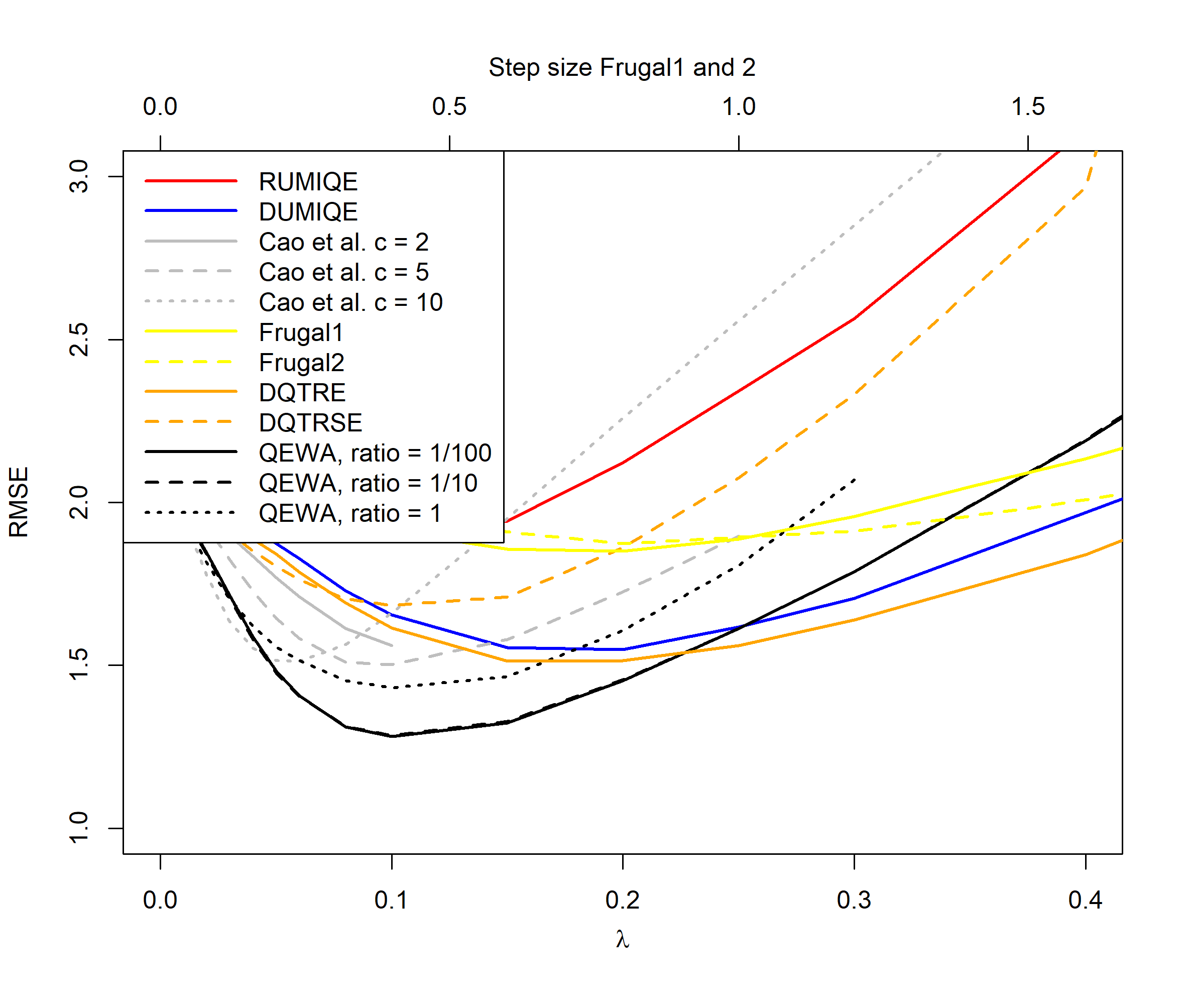 Figure 8
Figure 8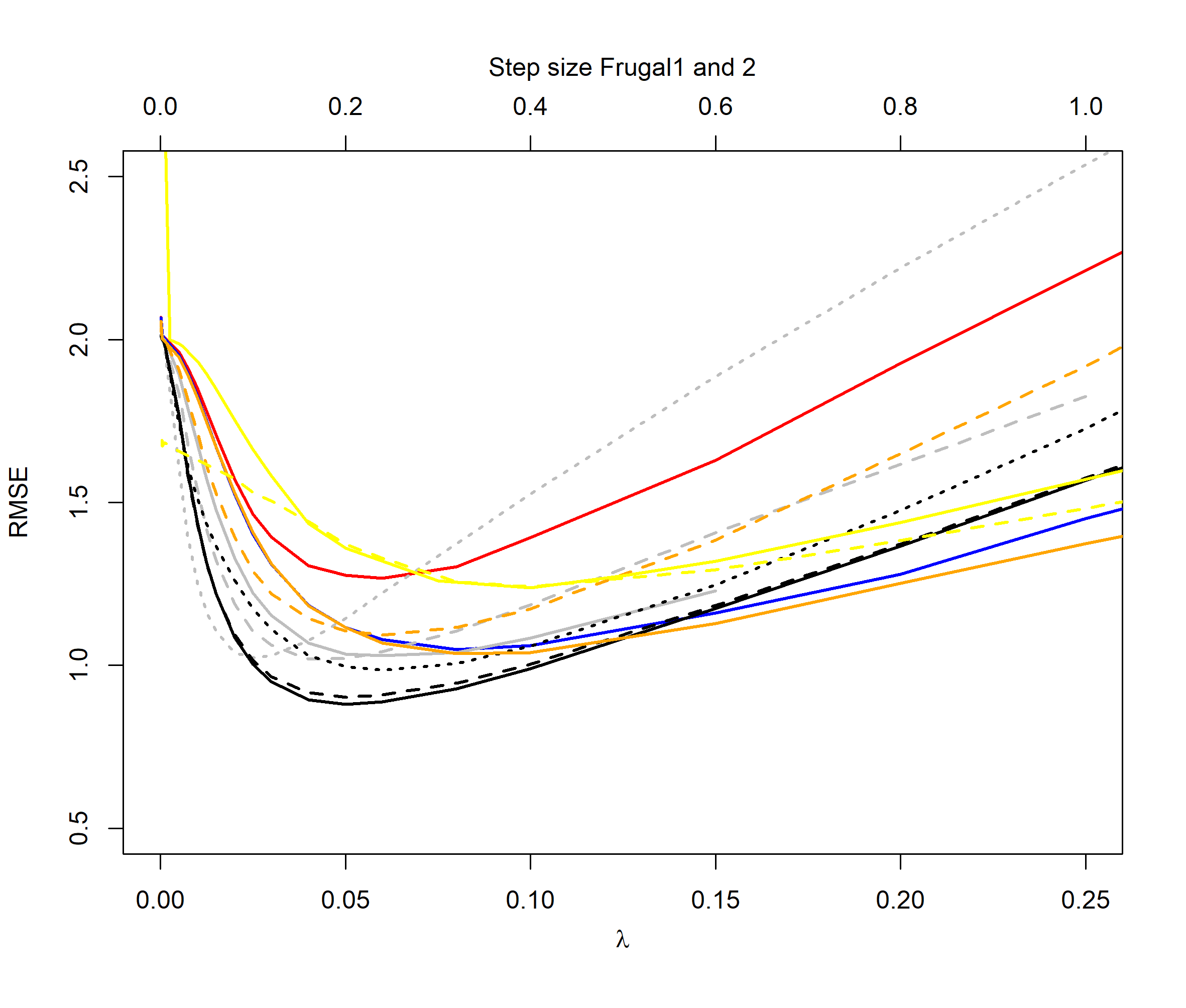 Figure 9
Figure 9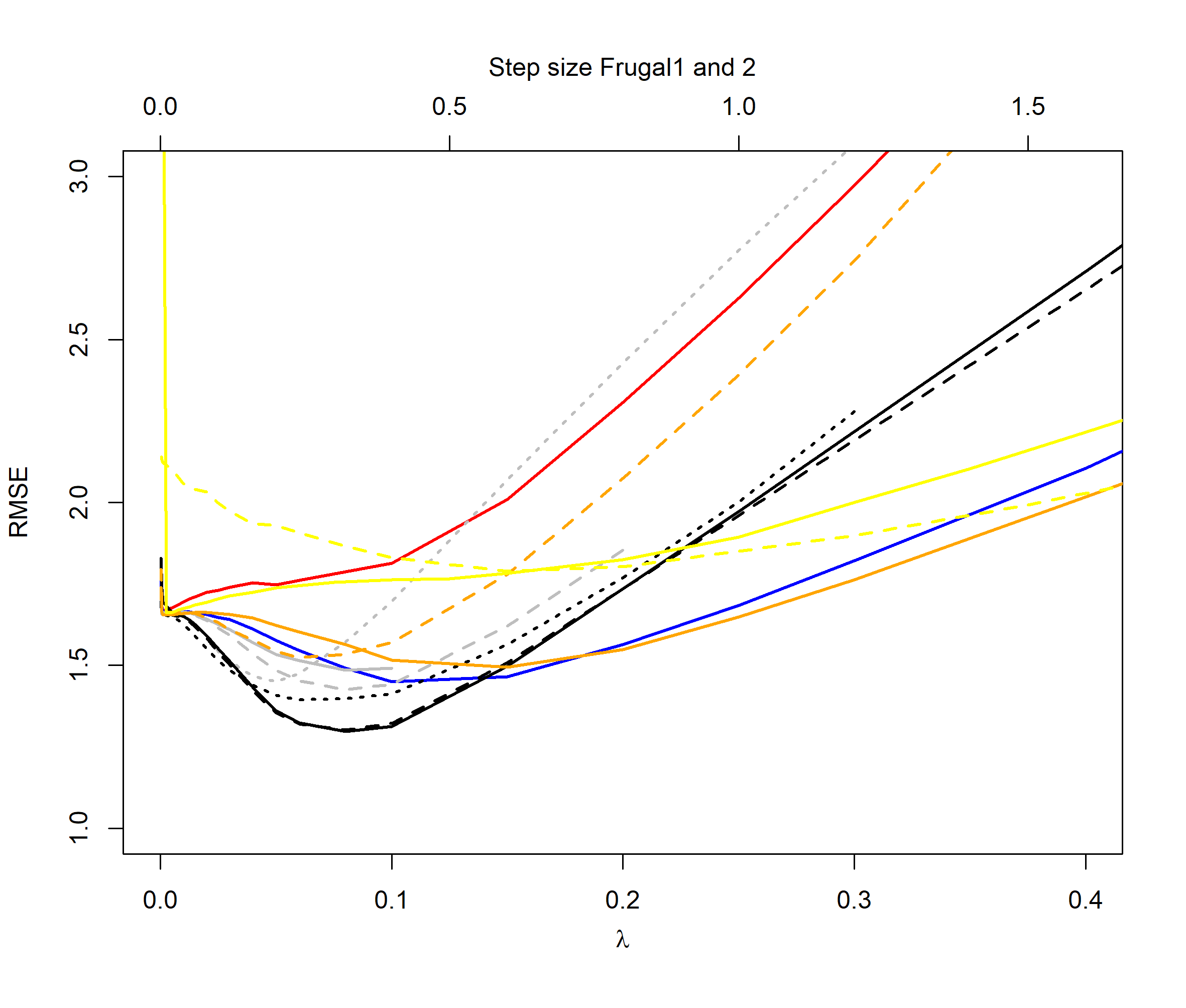 Figure 10
Figure 10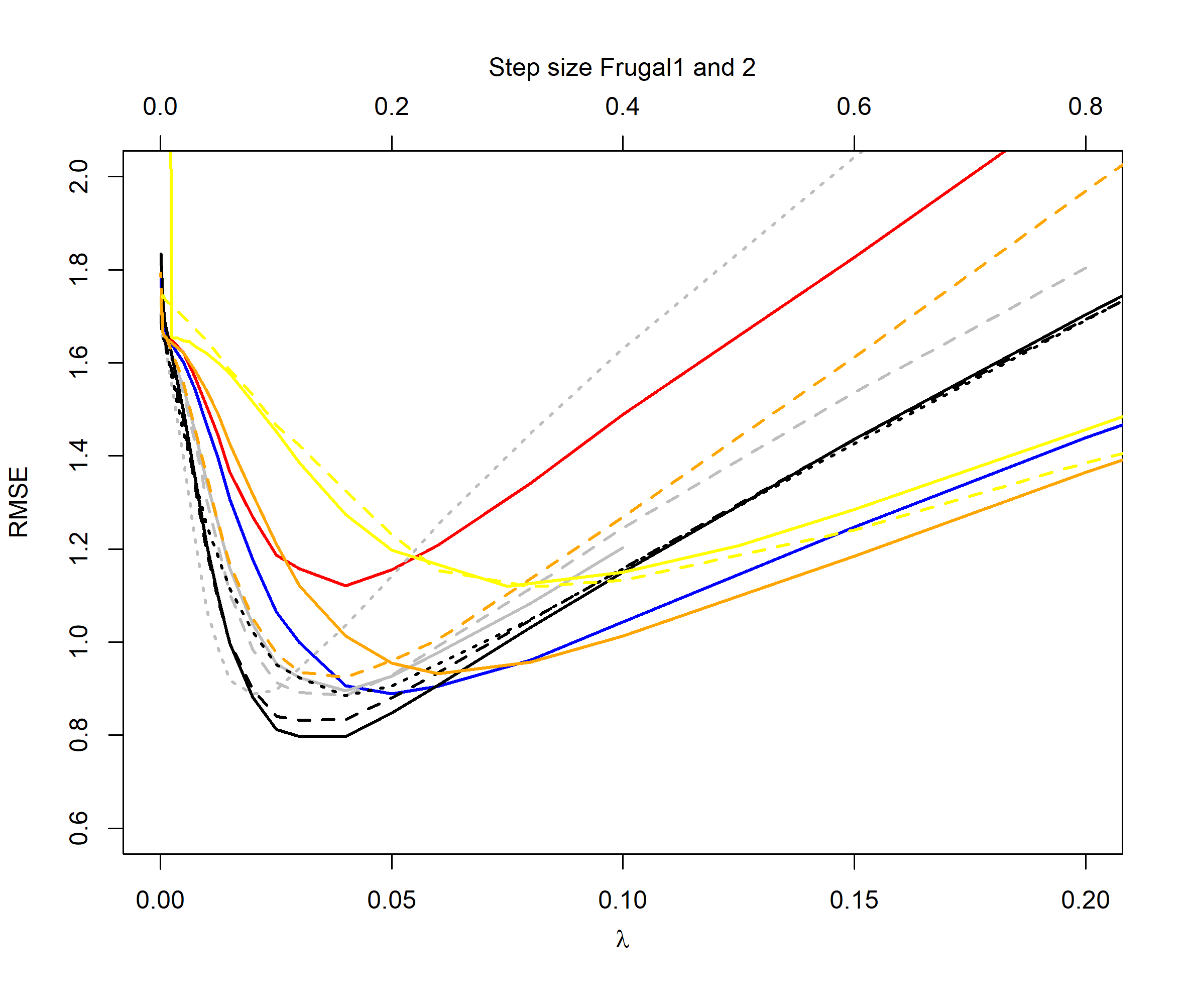 Figure 11
Figure 11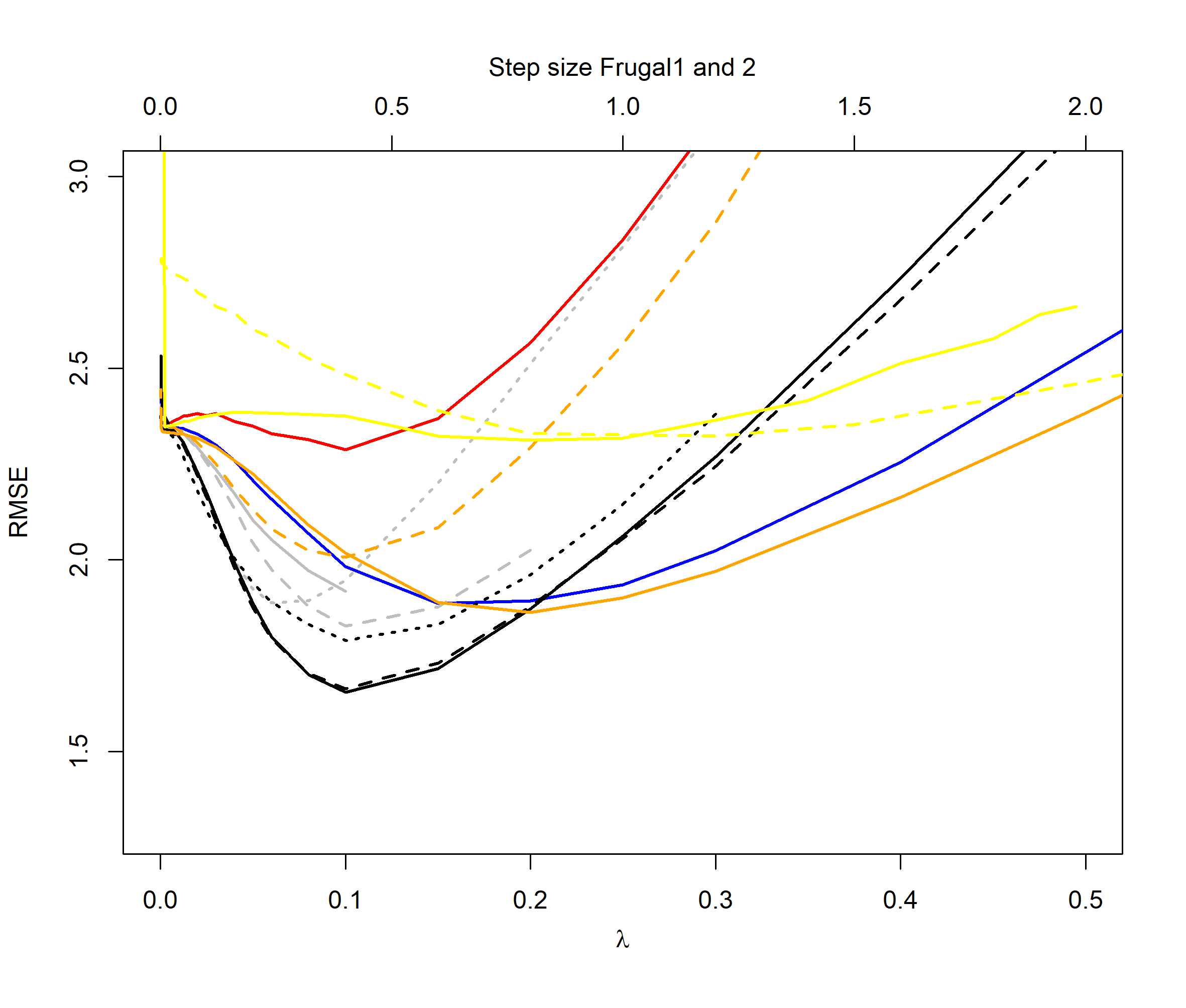 Figure 12
Figure 12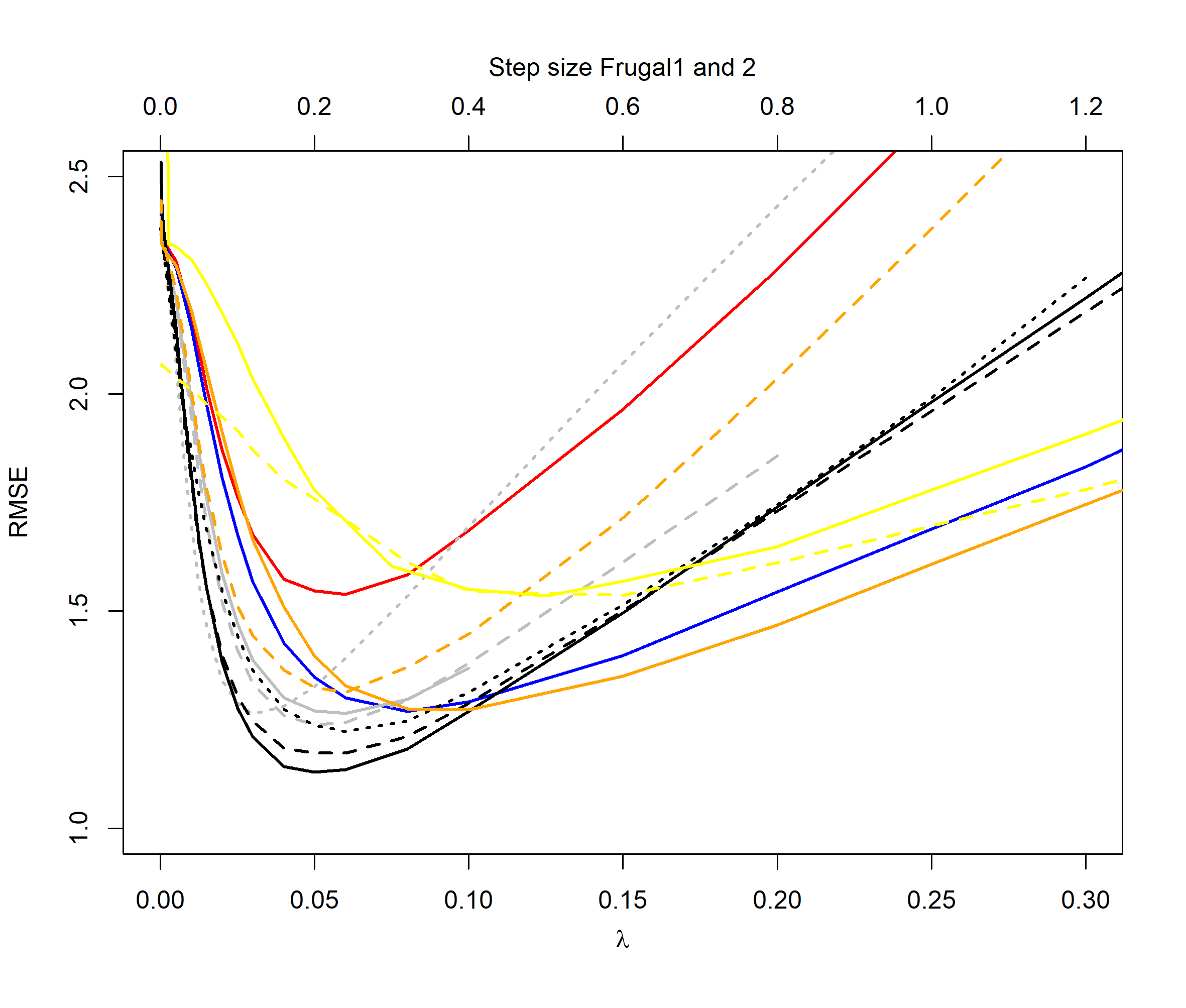 Figure 13
Figure 13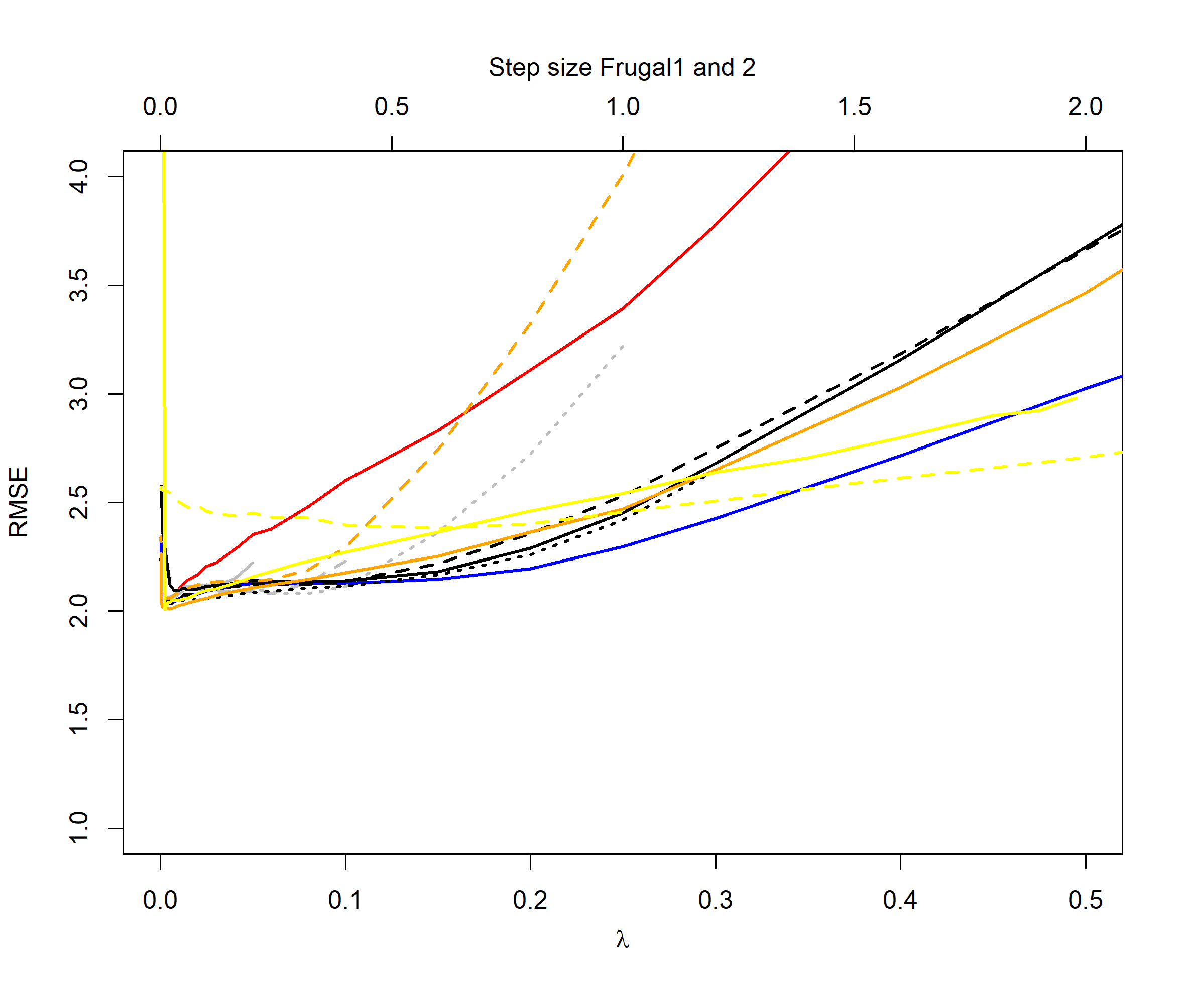 Figure 14
Figure 14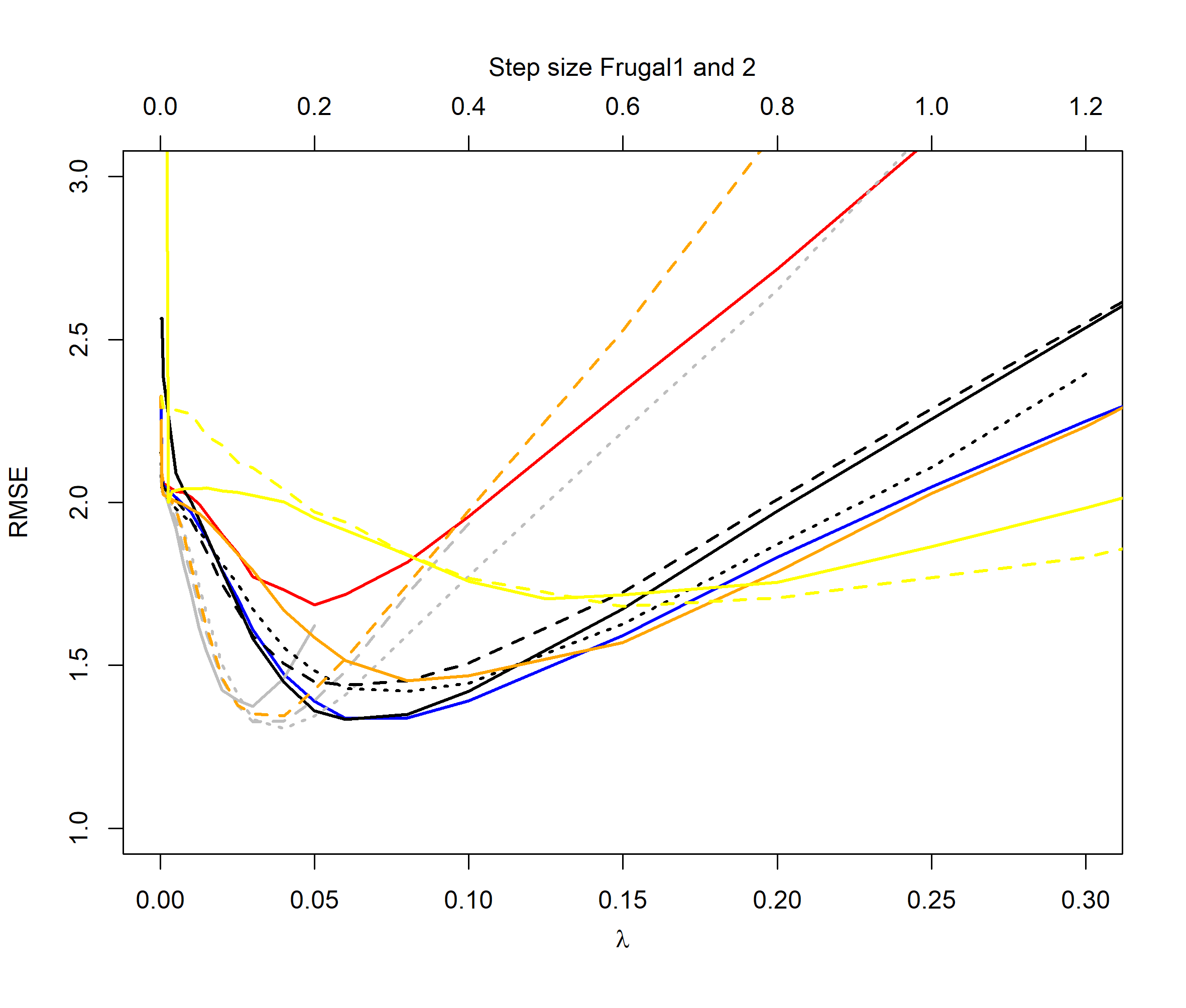 Figure 15
Figure 15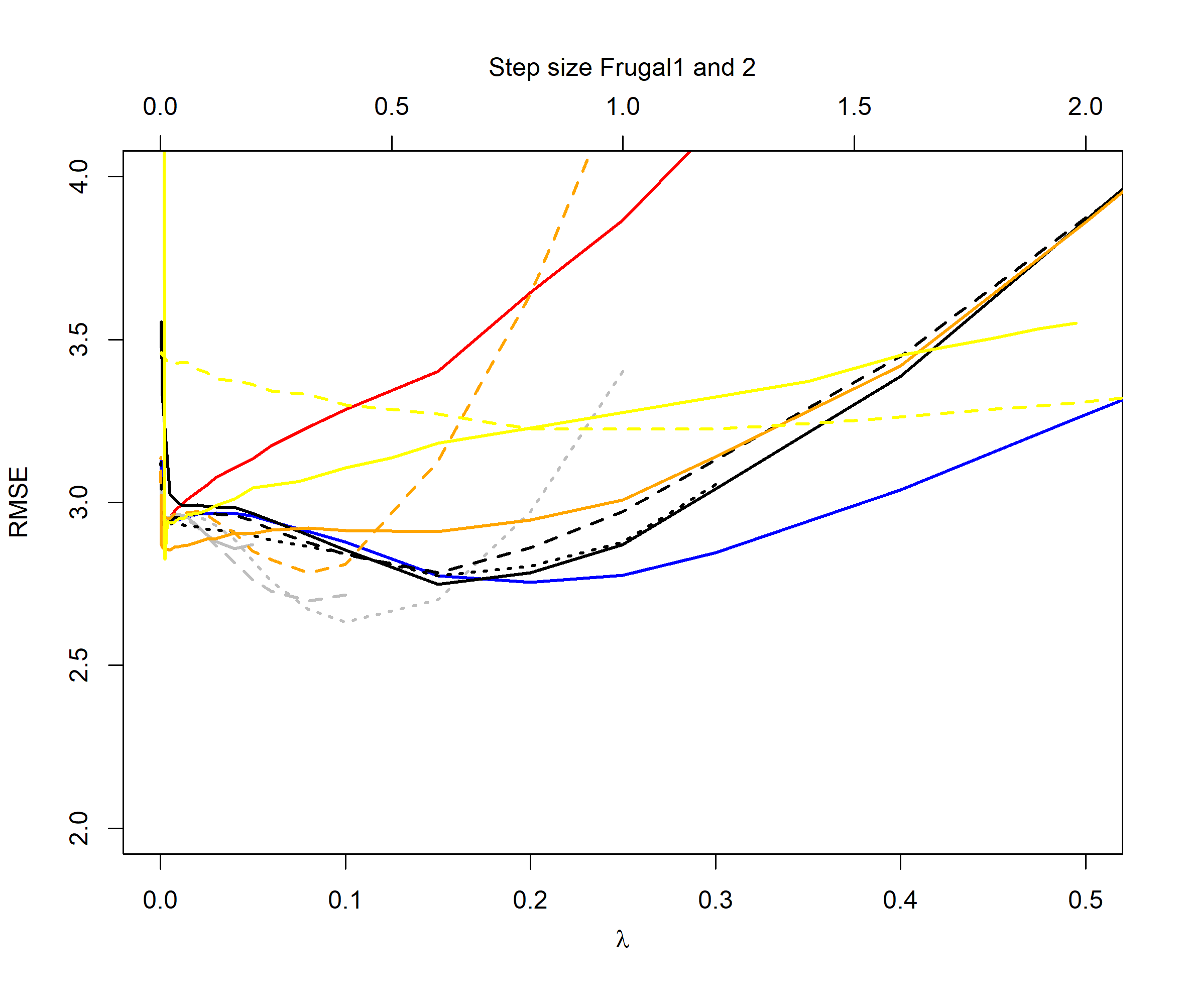 Figure 16
Figure 16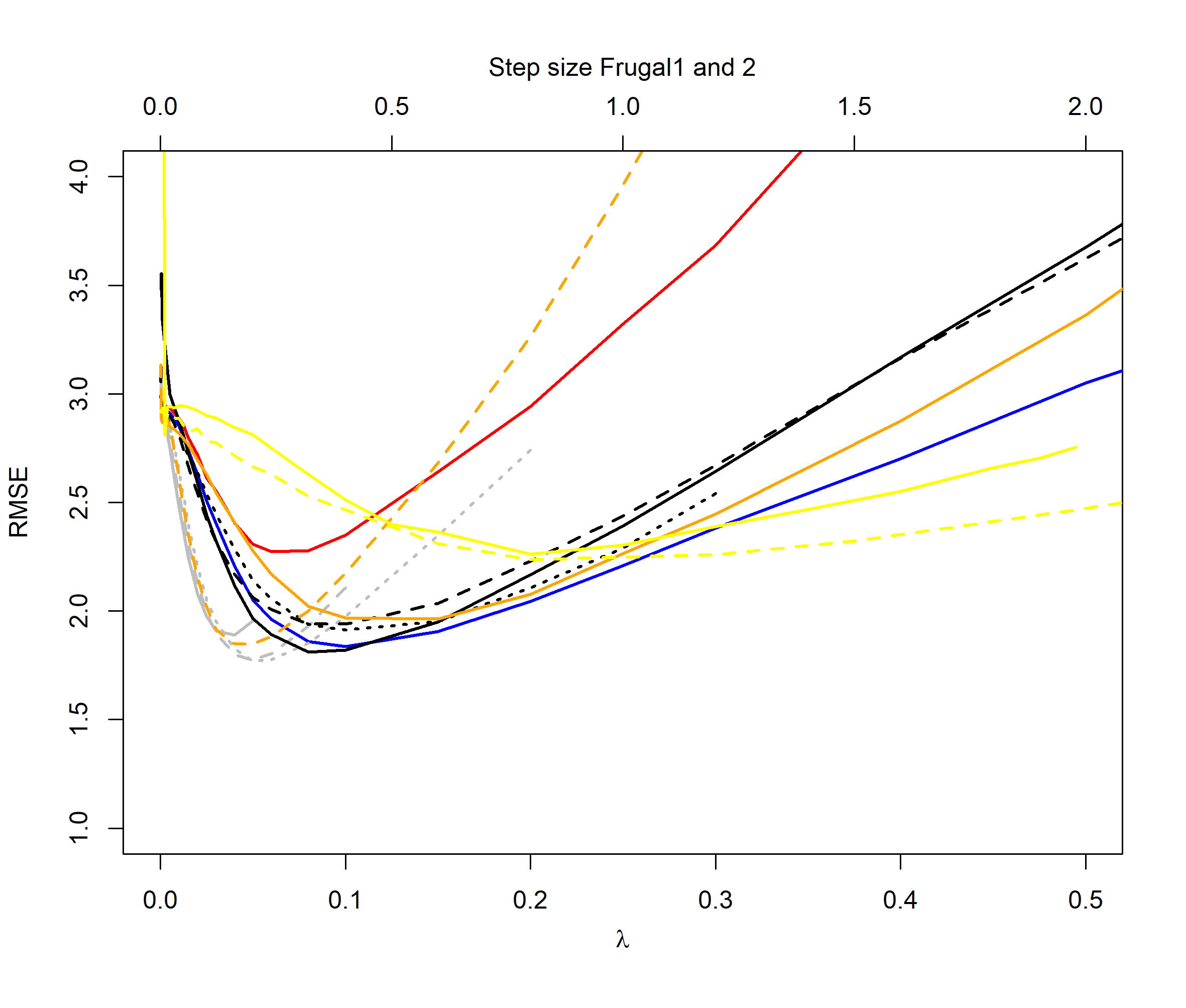 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| 1.4278 | 1.5279 | 1.7646 | |
| 1.4233 | 1.5433 | 1.7342 |
| 2.0541 | 2.3171 | 2.5479 | |
| 2.0947 | 2.3489 | 2.5427 |
| 1.4441 | 1.7423 | 2.4316 | |
| 1.4386 | 1.7273 | 2.6951 |
| 2.0367 | 2.3913 | 3.3717 | |
| 2.0462 | 2.4137 | 3.1166 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Stream Mining Techniques · Advanced Bandit Algorithms Research · Distributed Sensor Networks and Detection Algorithms
Quantile Tracking in Dynamically Varying Data Streams Using a Generalized Exponentially Weighted Average of Observations
Hugo Lewi Hammer222OsloMet – Oslo Metropolitan University444Corresponding author. Email: [email protected], Anis Yazidi22footnotemark: 2 and Håvard Rue555King Abdullah University of Science & Technology
Abstract
The Exponentially Weighted Average (EWA) of observations is known to be state-of-art estimator for tracking expectations of dynamically varying data stream distributions. However, how to devise an EWA estimator to rather track quantiles of data stream distributions is not obvious. In this paper, we present a lightweight quantile estimator using a generalized form of the EWA. To the best of our knowledge, this work represents the first reported quantile estimator of this form in the literature. An appealing property of the estimator is that the update step size is adjusted online proportionally to the difference between current observation and the current quantile estimate. Thus, if the estimator is off-track compared to the data stream, large steps will be taken to promptly get the estimator back on-track. The convergence of the estimator to the true quantile is proven using the theory of stochastic learning.
Extensive experimental results using both synthetic and real-life data show that our estimator clearly outperforms legacy state-of-the-art quantile tracking estimators and achieves faster adaptivity in dynamic environments. The quantile estimator was further tested on real-life data where the objective is efficient online control of indoor climate. We show that the estimator can be incorporated into a concept drift detector for efficiently decide when a machine learning model used to predict future indoor temperature should be retrained/updated.
1 Introduction
In this paper we consider the problem of tracking quantiles when data arrive sequentially (data stream). The problem has been considered for many applications like portfolio risk measurement in the stock market [14, 1], fraud detection [36], signal processing and filtering [30], climate change monitoring [37], SLA violation monitoring [28, 29] and back-bone network monitoring [9].
Suppose that we are interested in estimating the quantile related to some probability . The most natural estimator is to use the quantile of the sample distribution. Unfortunately, such a quantile estimator has clear disadvantages for data streams as computation time and memory requirement are linear to the number of samples received so far from the data stream. Such methods thus are infeasible for large data streams.
Several algorithms have been proposed to deal with those challenges. Most of the proposed methods fall under to the category of what can be called histogram or batch based methods. The methods are based on efficiently maintaining a histogram estimate of the data stream distribution such that only a small storage footprint is required. A thorough review of state-of-the-art histogram and batch methods is given in the related work section (Section 2).
Another ally of methods are the so-called incremental update methods. The latter methods are based on performing small updates of the quantile estimate every time a new sample is received from the data stream. Generally, the current estimate is a convex combination of the estimate at the previous time step and a quantity depending on the current observation. One of the first and prominent examples of this family of methods is the algorithm attributed to Tierney (1983) [31] which is based on the stochastic learning theory. A few modifications of the Tierney method have been suggested, see e.g. [8, 4, 5, 7].
In data stream applications, a common situation is that the distribution of the samples from the data stream varies with time. Such system or environment is referred to as a dynamical system in the literature. Given a dynamical system, two main problems are considered in the literature namely to i) dynamically update estimates of quantiles of all data received from the stream so far or ii) estimate quantiles of the current distribution of the data stream (tracking). Despite the importance of efficient tracking of statistical properties, the tracking problem ii) has been far less studied in the literature than problem i). Incremental methods are well suited to address the tracking problem ii) while histogram and batch methods mainly have been used to address problem i). Histogram and batch based methods are not well suited for the tracking problem ii) and incremental methods typically are the only viable lightweight alternatives [5].
Motivated by the lack of research on the tracking problem ii), the authors of this paper introduced the deterministic multiplicative incremental quantile estimator (DUMIQE) [34] given by
[TABLE]
The intuition behind the estimator is simple. If the received sample has a value below the current quantile estimate, the estimate is decreased. Alternatively, whenever the received sample has a value above the current quantile estimate, the estimate is increased. The “weights” and are included to ensure convergence to the true quantile. Even though the estimator is really simple, it can document state-of-the-art tracking performance [34]. However, as Eq. (1) reveals, the estimator do not use the values of the received samples directly to update the estimate, but only whether the value of the samples are above or below some varying threshold. Intuitively, this seems like a waste of information received from the data stream. In this paper, we thus present an estimator that uses the values of the received samples directly. The estimator is such that the update step size is proportional to the distance between the current estimate and the value of the sample. Thus if the current estimate is off-track compared to the data stream, the estimator will perform large jumps to rapidly get back on-track. A theoretical proof is provided to document the convergence properties of the estimator in addition to extensive simulation experiments. The experiments show that the estimator outperforms DUMQUE and several other legacy state-of-the-art quantile estimators.
The EWA of observations is known to be state-of-the-art estimator to track expectations of dynamically varying data streams [13]. Interestingly, we will show that the suggested quantile estimator in this paper is in fact an instance of a generalized EWA such that quantiles and not expectations are tracked. To the best of our knowledge, this is the first EWA based quantile estimator found in the literature.
The paper is organized as follows. In Section 3 we present the novel quantile estimator using an EWA of observations. In Section 4, we present a quantile estimation algorithms based on the estimator in Section 3. In Section 5, we perform extensive experiments that document the superiority of the suggested algorithm. Finally, in Section 6 we apply the quantile estimator on real-life data related to the problem of efficient online control of indoor climate. More specifically the estimator is used to detect when a machine learning model should be retrained/updated which is commonly referred to as concept drift detection [12].
2 Related Work
In this Section, we shall review some of the related work on estimating quantiles from data streams. However, as we will explain later, these related works require some memory restrictions which renders our work radically distinct from them. In fact, our approach requires storing only one sample value in order to update the estimate. The most representative work for this type of “streaming” quantile estimator is due to the seminal work of Munro and Paterson [23]. In [23], Munro and Paterson described a -pass algorithm for selection using space for any . Cormode and Muthukrishnan [10] proposed a more space-efficient data structure, called the Count-Min sketch, which is inspired by Bloom filters, where one estimates the quantiles of a stream as the quantiles of a random sample of the input. The key idea is to maintain a random sample of an appropriate size to estimate the quantile, where the premise is to select a subset of elements whose quantile approximates the true quantile. From this perspective, the latter body of research requires a certain amount of memory that increases as the required accuracy of the estimator increases [33]. Furthermore, in the case where the underlying distribution changes over time, those methods suffer from large bias in the summary information since the stored data might be stale [8]. Examples of these works include [3, 33, 23, 15, 16]. Guha and McGregor [16] advocate the use of random-order data models in contrast to adversarial-order models. They show that computing the median requires exponential number of passes in adversarial model while requiring in random order model.
In [8, 4, 5, 7], the authors proposed modifications of the stochastic approximation algorithm [31]. While Tierney [31] uses a sample mean update from previous quantile estimates, [8, 4, 5, 7] propose an exponential decay in the usage of old estiamtes. This modification is particularly helpful to track quantiles of non-stationary data stream distributions. Indeed, a “weighted” update scheme is applied to incrementally build local approximations of the distribution function in the neighborhood of the quantiles. More recent approaches in this direction is the Frugal algorithm by Ma et al. [22], which is an additive alternative to the multiplicative estimator in Eq. (1), and the DQTRE and DQTRSE algorithms by Tiwari and Pandey [32]. A nice property of the DUMIQE in Eq. (1) and the estimator suggested in this paper is that the update size is automatically adjusted dependent on the scale/range of the data. This makes the estimators robust to substantial changes in the data stream. The DQTRE and DQTRSE aims to achieve the same by estimating the range of the data using peak and valley detectors. However, a disadvantage with these algorithms is that several tuning parameters are required to estimate the range making the algorithms challenging to tune.
In many network monitoring applications, quantiles are key indicators for monitoring the performance of the system. For instance, system administrators are interested in monitoring the quantile of the response time of a web-server so that to hold it under a certain threshold. Quantile tracking is also useful for detecting abnormal events and in intrusion detection systems in general. However, the immense traffic volume of high speed networks impose some computational challenges: little storage and the fact that the computation needs to be “one pass” on the data. It is worth mentioning that the seminal paper of Robbins and Monro [26] which established the field of research called “stochastic approximation” [20] have included an incremental quantile estimator as a proof of concept of the vast applications of the theory of stochastic approximation. An extension of the latter quantile estimator which first appeared as example in [26] was further developed in [18] in order to handle the case of “extreme quantiles”. Moreover, the estimator provided by Tierney [31] falls under the same umbrella of the example given in [26], and thus can be seen as an extension of it.
As Arandjelovic remarks [2], most quantile estimation algorithms are not single-pass algorithms and thus are not applicable for streaming data. On the other hand, the single pass algorithms are concerned with the exact computation of the quantile and thus require a storage space of the order of the size of the data which is clearly an unfeasible condition in the context of big data stream.
Thus, we submit that all work on quantile estimation using more than one pass, or storage of the same order of the size of the observations seen so far is not relevant in the context of this paper.
When it comes to memory efficient methods that require a small storage footprint, histogram based methods form an important class. A representative work in this perspective is due to Schmeiser and Deutsch [27]. In fact, they proposed to use equidistant bins where the boundaries are adjusted online. Arandjelovic et al. [2] use a different idea than equidistant bins by attempting to maintain bins in a manner that maximizes the entropy of the corresponding estimate of the historical data distribution. Thus, the bin boundaries are adjusted in an online manner. Nevertheless, histogram based methods have problems addressing the problem of tracking quantiles of the current data stream distribution[5] and are mainly used to recursively update quantiles for all data received so far.
In [24], the authors propose a memory efficient method for simultaneous estimation of several quantiles using interpolation methods and a grid structure where each internal grid point is updated upon receiving an observation. The application of this approach is limited for stationary data. The approximation of the quantiles relies on using linear and parabolic interpolations, while the tails of the distribution are approximated using exponential curves. It is worth mentioning that the latter algorithm is based on the algorithm [17].
In [17], Jain et al. resort to five markers so that to track the quantile, where the markers correspond to different quantiles and the min and max of the observations. Their concept is similar to the notion of histograms, where each marker has two measurements, its height and its position. By definition, each marker has some ideal position, where some adjustments are made to keep it in its ideal position by counting the number of samples exceeding the marker. In simple terms, for example, if the marker corresponds to the quantile, its ideal position will be around the point corresponding to of the data points below the marker. However, such approach does not handle the case of non-stationary quantile estimation as the position of the markers will be affected by stale data points. Then based on the position of the markers, quantiles are computed by supposing that the curve passing through three adjacent markers is parabolic and by using a piecewise parabolic prediction function.
It is worth mentioning that an important research direction that has received little attention in the literature revolves around updating the quantile estimates under the assumption that portions of the data are deleted. Such assumption is realistic in many real life settings where data needs to be deleted due to the occurrence of errors, or because the data samples are merely out-of-date and thus should be replaced. The deletion triggers a re-computation of the quantile [6], which is considered a complex operation. Note that the case of deleted data is more challenging than the case of insertion of new data. In fact, the insertion can be handled easily using either sequential or batch updates, while quantile update upon deletion requires more complex forms of updates.
Finally, Lou et al. [21] perform extensive experiments to compare several of the algorithms described above.
3 Quantile Estimator Using a Generalized Exponentially Weighted Average of Observations
Let denote a stochastic variable representing the possible outcomes from a data stream at time and let denote a random sample (realization) of . We assume that is distributed according to some distribution that varies dynamically over time . We denote the cumulative distribution of with , i.e. . Further, let denote the quantile associated with probability , i.e .
A weakness of the state-of-the-art DUMIQE in Eq. (1) is that the update step size is independent of the amount of the current error in the quantile estimate. We now propose an incremental quantile estimator where the update step size is proportional to the distance between the received sample and current estimate. Thus, if the current estimate is off-track compared to the data stream, the estimator will initiate large jumps to rapidly get back on-track. The suggested estimator is described formally as follows
[TABLE]
where and . Naturally, the conditional expectations satisfy the inequality
[TABLE]
such that and . The factors and are included to ensure that the estimator converges to the true quantile value.
The constants can be any sequence of positive and bounded values. The estimator performed well when the fractions in Eq. (2) were “normalizied” as follows
[TABLE]
Substituting Eq. (3) into Eq. (2) we get
[TABLE]
where
[TABLE]
Please note that since and we have that . By factoring out and we get
[TABLE]
which can be written as
[TABLE]
where and the indicator function returning one (zero) if is true (false).
Now we will present a theorem that catalogs the properties of the estimator for a stationary data stream, i.e. .
Theorem 1**.**
Let be the true quantile to be estimated. Applying the updating rule in Eq. (6), we obtain:
[TABLE]
The proof of the theorem can be found in Appendix A. Although the quantile estimator given in Eq. (6) is designed to estimate quantiles for dynamic environments, it is an important requirement that the estimator converges to the true quantile for static data streams as verified by Theorem 1.
We end this section with a remark.
Remark 1: If the conditional expectations are symmetrically positioned on each side of the quantile estimate, then and which is equal to DUMIQE. In other words, we can interpret that and ensure that the update rules take into account the asymmetries of the data stream distribution on each side of the quantile.
3.1 Connection to the EWA
A simple and intuitive approach to track the expectation of a data stream distribution, i.e. , is the weighted moving average
[TABLE]
where . Using and the other weights equal to zero, Eq. (7) reduces to the standard moving average. Intuitively, it seems more reasonable to use weights with decreasing values. The decrease should be more rapid than the standard sample mean to be able to track the changes in the data stream.
Consider the following recursive update scheme
[TABLE]
where the current estimate is a convex combination of the estimate at the previous time step and the observation. By substitution, we get
[TABLE]
Interestingly, from Eq. (10) we see that Eq. (8) to Eq. (9) can be interpreted as an EWA of observations. The estimator is highly popular and known to be the state-of-the-art approach to track expectations of dynamically varying data streams. Inspecting the incremental update form of our quantile estimator in Eq. (6), we see that it is identical to the update form of Eq. (9), except that the varies with time. Thus by keeping the weights constant as in Eq. (9), the estimator will track the expectation of the data stream distribution, while using the weights in Eq. (6), the estimator will track a quantile of the distribution.
4 Quantile Estimation Algorithm
The interpretation of the update rule in Eq. (6) as an EWA of observations (recall Section 3.1) and Theorem 1 constitute some intriguing theoretical results on the link between EMA and quantile estimation. However, the update rule in Eq. (6) cannot be used directly since the conditional expectations, and , are unknown and need to be estimated. Probably the most natural approach is to track conditional expectations using an EWA of observations as given in in Eq. (8) to Eq. (9). This results in the following update rules:
[TABLE]
In each of the equations (12) to (15), the part is included to ensure that the conditional expectation estimates are relative to the current quantile estimate . Thus Eq. (11) tracks the overall trends of the dynamical data stream while Eq. (12) to Eq. (15) are responsible for estimating the conditional expectations relative to the quantile estimate. Thus, for most dynamic data streams it is reasonable to use a value of the EWA tuning parameter, , that is on a smaller scale than [19]. This is verified in our experiments. In the rest of the paper, we denote this EWA quantile estimator approach for QEWA. We end this section with a remark.
Remark1: We evaluated a second approach based on estimating the streaming distribution, , and computing the unknown conditional expectations from the estimated distribution. The streaming distribution where estimated by tracking several quantiles and a linear spline were interpolated between the quantile estimates. However experiments showed that the QEWA approach performed better than this spline approach. The spline approach therefore is not followed any further in the paper.
5 Experiments based on Synthetic Data
In this section we perform a thorough comparison of the performance of the suggested algorithm QEWA and other quantile estimators in the literature. Figure 1 shows tracking of the quantile with probability for the suggested algorithm QEWA and DUMIQE. The true quantile is given as the dashed black line. The tuning parameters are adjusted such that the estimation error in the stationary parts after convergence is the same for the two algorithms. We see that the proposed algorithm QEWA tracks the true quantile more efficiently after a switch than the DUMIQE. For the suggested algorithm, the step size is proportional to the difference between the observations and the quantile estimate (recall Eq. (4)). After a switch, these differences are large, and our devised algorithm makes large steps to get back on-track. The DUMIQE, and the other state-of-the art incremental algorithms, use the same step size independent of the these difference, resulting in poorer tracking.
The results below show a more systematic evaluation of the performance of the suggested algorithm against seven state-of-the-art quantile estimators namely the DUMIQE and RUMIQE by Yazidi and Hammer [34], the estimator due to Cao et al. [4], the Frugal approach by Ma et al. [22], the selection algorithm by Guha and McGregor [16] and the DQTRE and DQTRSE algorithms by Tiwari and Pandey [32]. For the DQTRE and DQTRSE algorithms we used values of the tuning parameters recommended in [32], namely and which performed well in our experiments.
The estimator in this paper is designed to perform well for dynamically changing data streams and the experiments will focus on such streams.
We consider four different cases where we assume that the data are outcomes from a normal distribution or from a distribution. For two of the cases we look at both a case where the data stream varies smoothly (periodic) or switches rapidly (switch). For the normal distribution periodic case, we assume that the expectation of the distribution varies with time
[TABLE]
which is the sinus function with period . For the switch case, the expectation jumps between values and .
[TABLE]
We assume that the standard deviation of the normal distribution does not vary with time and is equal to one.
For the distribution periodic case, we assume that the number of degrees of freedom varies with time as follows
[TABLE]
where such that for all . For the switch case, the number of degrees of freedom jumps between values and
[TABLE]
In the experiments we used and .
We estimated quantiles of both the normally and distributed data streams above using two different periods, namely (rapid variation) and (slow variation), i.e. in total eight different data streams. For each data stream we estimated the , and quantiles ending up with a total of different estimation tasks.
To measure estimation error, we used the root mean squares error (RMSE) for each quantile given as:
[TABLE]
where is the total number of samples in the data stream. In the experiments, we used which efficiently removed any Monte Carlo errors in the experimental results. In order to obain a good overview of the performance of the algorithms, we measured the estimation error for a large set of different values of the tuning parameters of the algorithms.
Figures 2 to 5 illustrate the results of our experiments. For the normal distribution period case (Figure 2), we see that the QEWA algorithm outperforms all the algorithms in the literature. In accordance with the analysis in Section 4, the QEWA algorithm performed the best using a small value of the ratio . The Cao et al. algorithm struggled with numerical problems for some choices of the tuning parameters and therefore some of the curves are short.
For the normal distribution switch case (Figure 3), we see that the QEWA algorithm again outperforms all the algorithms in the literature. Again we see that the QEWA performs best using a small value of the ratio .
For the distribution cases we see that the QEWA algorithm also here outperforms the other algorithms. For , the QEWA algorithm documents competitive results to the best performing alternative algorithms. Also here a small value of the ratio is the preferable choice.
Among the alternative algorithms there are no consistency in which algorithm are closest to the performance of the QEWA, but overall the DUMIQE and DQTRE seem to be closes. However, all the alternative algorithms suffer with significantly poorer results than the QEWA for at least some cases. E.g. DQTRE performs poorly when estimating quanties in the tails () and DUMIQE for the switch cases.
Tables 1 to 4 show results for the selection algorithm [16]. The algorithm does not have any tuning parameters and the results thus are presented in tables. We see that QEWA outperforms the selection algorithm with a clear margin for all the different cases.
In summary the QEWA algorithm outperforms all the different state-of-the-art algorithms from the literature. Best performance is achieved using a small value of the ratio .
6 Real-life Data Experiments – Concept Drift Detection
In most challenging data prediction tasks, the relation between input and output data evolves over time. Thus if static relationships are assumed, prediction performance will degrade with time. In the field of machine learning and data mining this phenomenon is referred to as concept drift [12]. Different strategies have been suggested to detect when the performance of the predictive model degrades and thus should be retrained/updated [12]. Current state-of-the-art strategies monitor the average predictive error, but for real-life applications it is often more relevant to control that the prediction error rarely goes above some critical threshold. In this example we demonstrate how to perform concept drift detection and adaptation on such a critical threshold by tracking an upper quantile of the prediction error distribution, e.g. the 80% quantile. As an application domain, we investigate the case of efficient control of indoor climate.
Heating, ventilation and air conditioning (HVAC) systems typically control indoor climate by reacting on the current room conditions such as indoor temperature. However, given the time required for a HVAC system to adjust to changes in the indoor climate, such strategies always will lag behind resulting in poor control of indoor climate and energy usage. This raises the need for building models that forecast future indoor climate temperature and use this as input to the HVAC system. Zamora-Martínez et al. [35] propose to use artificial neural network (ANN) models to forecast future indoor temperature based on a total of 20 features including outdoor climate variables such as temperature and precipitation amounts and indoor climates variables such as CO2 level. Since more observations are received with time and the relation between input and output may evolve with time, the model is retrained in an online manner. The authors however do not take advantage of concept drift detection in order to efficiently decide when to retrain the model.
We now demonstrate how the suggested quantile estimator in this paper can be used for concept drift detection for the online indoor temperature forecasting problem described above. We consider the same dataset as in [35] where new observation of input and output variables is received every 15 minutes. We forecasted indoor temperature 15 minutes into the future using an autoregressive (AR) model of order one. In addition to the current indoor temperature, the current value of the other 20 features were used as input to the forecasting model. Given the large number of features, regularization of the model parameters was required to get a reliable forecasts and we relied on LASSO regularization [11]333This model is a simple and natural forecasting model, but other and more advanced machine learning models that predict on the continuous scale, like ANN models, could also be used..
First, we trained the LASSO AR model based on eight days of observations and used the model to predict 15 minutes into the future each time a new observation was received. The results are shown in Figure 6. The figure demonstrates that if the model is not retrained after day eight, the forecasting error gradually increases with time (the red line). In other words, the data is subject to concept drift and the forecasting model should be retrained as more observations are received. Instead of retraining the model regularly according to a fixed periodicity which is clearly ineffective, a sophisticated approach consists of retraining the model only if concept drift is detected.
We now build a concept drift and model retraining procedure based on quantile tracking. We required that the indoor temperature forecasting error rarely should go above two degrees centigrade. We used the QEWA estimator to track the 80% quantile of the forecasting error data stream (the gray curves in Figure 6). If the quantile estimate went above two degrees centigrade, the model was retrained. We trained the model for the first time after 24 hours of observations. The results are shown in Figure 7. After the initial training after 24 hours of observations, the quantile estimate of the forecasting error distribution went above two degrees three times and each time the model was retrained. The results demonstrates that by a few selected retrainings of the model, the forecasting error is controlled, indicated by a horizontal linear trend (red curves) in Figure 7.
In conclusion, the example demonstrates how the suggested quantile estimator can be useful for concept drift detection and model adaptation.
7 Closing remarks
The exponentially weighted moving average of observations is known to be the state-of-art estimator to track the expectation of dynamically varying data stream distributions. In this paper, we have presented an incremental quantile estimator that is in fact a generalized exponential weighted moving average estimator. To the best of our knowledge, this is the first quantile estimator in the literature that falls within this well-known class of efficient estimators. The experiments show that the estimator outperforms state-of-the-art quantile estimators in the literature.
We demonstrate how tracking of quantiles has application in the field of machine learning. More particularly, we show how the suggested estimator can be used for tracking quantiles of the prediction error distribution in order to detect when a machine learning model should be retrained.
A potential ally for future research is to extend the QEWA estimator to simultaneously track multiple quantiles. One could of course, just run the QEWA estimator for each quantile of interest, but this could potentially lead to a violation of the monotone property of quantiles. The monotone property of quantiles, refers to the requirement that an estimate of a higher quantile should be always bigger than an estimate of a lower quantile e.g. the 50% quantile always be above the 30% quantile.
Appendix A Proof of Theorem 1
We will first present a theorem due to Norman [25] that will be used to prove Theorem 1. Norman [25] studied distance ”diminishing models”. The convergence of to is a consequence of this theorem.
Theorem 2**.**
Let be a stationary Markov process dependent on a constant parameter . Each , where is a subset of the real line. Let . The following are assumed to hold:
I is compact 2. 2.
** 3. 3.
** 4. 4.
* where for and as * 5. 5.
* has a Lipschitz derivative in * 6. 6.
* is Lipschitz .*
If Assumptions 1 to 6 above hold, has a unique root in and \frac{dw}{dy}\bigg{|}_{y=y^{*}}\leq 0 then
* uniformly for all and . For any , the differential equation has a unique solution with and uniformly for all and .* 2. 2.
* has a normal distribution with zero mean and finite variance as and .*
Having presented Theorem 2, we are now ready to prove Theorem 1.
Proof.
We now start by showing that the Markov process based on the updating rules in Eq. (6) and Theorem 1 satisfies the assumptions 1 to 6 in Theorem 2. We start by verifying assumption 2
[TABLE]
where is as given in Eq. (3). We now let , and equal to ”everything” in Eq. (19) except . It is easy to see that assumption 2 in Theorem 2 is satisfied. Further, since and , has a Lipschitz derivative and assumption 5 is satisfied.
Next we turn to assumption 3.
[TABLE]
where and . Further we know that
[TABLE]
By substituting Eq. (19) and Eq. (LABEL:eq:16) into Eq. (21), we see that assumption 3 is satisfied with equal to everything in Eq. (21) except . Since and , is Lipschitz and assumption 6 is also satisfied. Assumption 4 can now be proved in the same manner.
We will use the results of Norman to prove the convergence. It is easy to see that in Eq. (19) admits one unique root .
We now differentiate to get:
[TABLE]
We substitute the unique root for and get
[TABLE]
This gives
[TABLE]
and
[TABLE]
Consequently
[TABLE]
∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Babak Abbasi and Montserrat Guillen. Bootstrap control charts in monitoring value at risk in insurance. Expert Systems with Applications , 40(15):6125–6135, 2013.
- 2[2] Ognjen Arandjelovic, Duc-Son Pham, and Svetha Venkatesh. Two maximum entropy-based algorithms for running quantile estimation in nonstationary data streams. Circuits and Systems for Video Technology, IEEE Transactions on , 25(9):1469–1479, 2015.
- 3[3] Arvind Arasu and Gurmeet Singh Manku. Approximate counts and quantiles over sliding windows. In Proceedings of the twenty-third ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems , pages 286–296. ACM, 2004.
- 4[4] Jin Cao, Li Li, Aiyou Chen, and Tian Bu. Tracking quantiles of network data streams with dynamic operations. In INFOCOM, 2010 Proceedings IEEE , pages 1–5. IEEE, 2010.
- 5[5] Jin Cao, Li Erran Li, Aiyou Chen, and Tian Bu. Incremental tracking of multiple quantiles for network monitoring in cellular networks. In Proceedings of the 1st ACM workshop on Mobile internet through cellular networks , pages 7–12. ACM, 2009.
- 6[6] Jin Cao, Li Erran Li, Aiyou Chen, and Tian Bu. Incremental tracking of multiple quantiles for network monitoring in cellular networks. In Proceedings of the 1st ACM workshop on Mobile internet through cellular networks , pages 7–12. ACM, 2009.
- 7[7] John M Chambers, David A James, Diane Lambert, and Scott Vander Wiel. Monitoring networked applications with incremental quantile estimation. Statistical Science , pages 463–475, 2006.
- 8[8] Fei Chen, Diane Lambert, and José C Pinheiro. Incremental quantile estimation for massive tracking. In Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining , pages 516–522. ACM, 2000.