A binned likelihood for stochastic models
Carlos A. Arg\"uelles, Austin Schneider, Tianlu Yuan

TL;DR
This paper introduces a new analytic likelihood method that incorporates Monte Carlo uncertainties, improving model assessment accuracy in complex systems with limited or large datasets.
Contribution
It presents a novel likelihood formulation that accounts for Monte Carlo uncertainties, enhancing statistical inference in complex stochastic models.
Findings
Performs better than semi-analytic methods
Prevents biased statistical claims
Provides improved coverage properties
Abstract
Metrics of model goodness-of-fit, model comparison, and model parameter estimation are the main categories of statistical problems in science. Bayesian and frequentist methods that address these questions often rely on a likelihood function, which is the key ingredient in order to assess the plausibility of model parameters given observed data. In some complex systems or experimental setups, predicting the outcome of a model cannot be done analytically, and Monte Carlo techniques are used. In this paper, we present a new analytic likelihood that takes into account Monte Carlo uncertainties, appropriate for use in the large and small sample size limits. Our formulation performs better than semi-analytic methods, prevents strong claims on biased statements, and provides improved coverage properties compared to available methods.
Click any figure to enlarge with its caption.
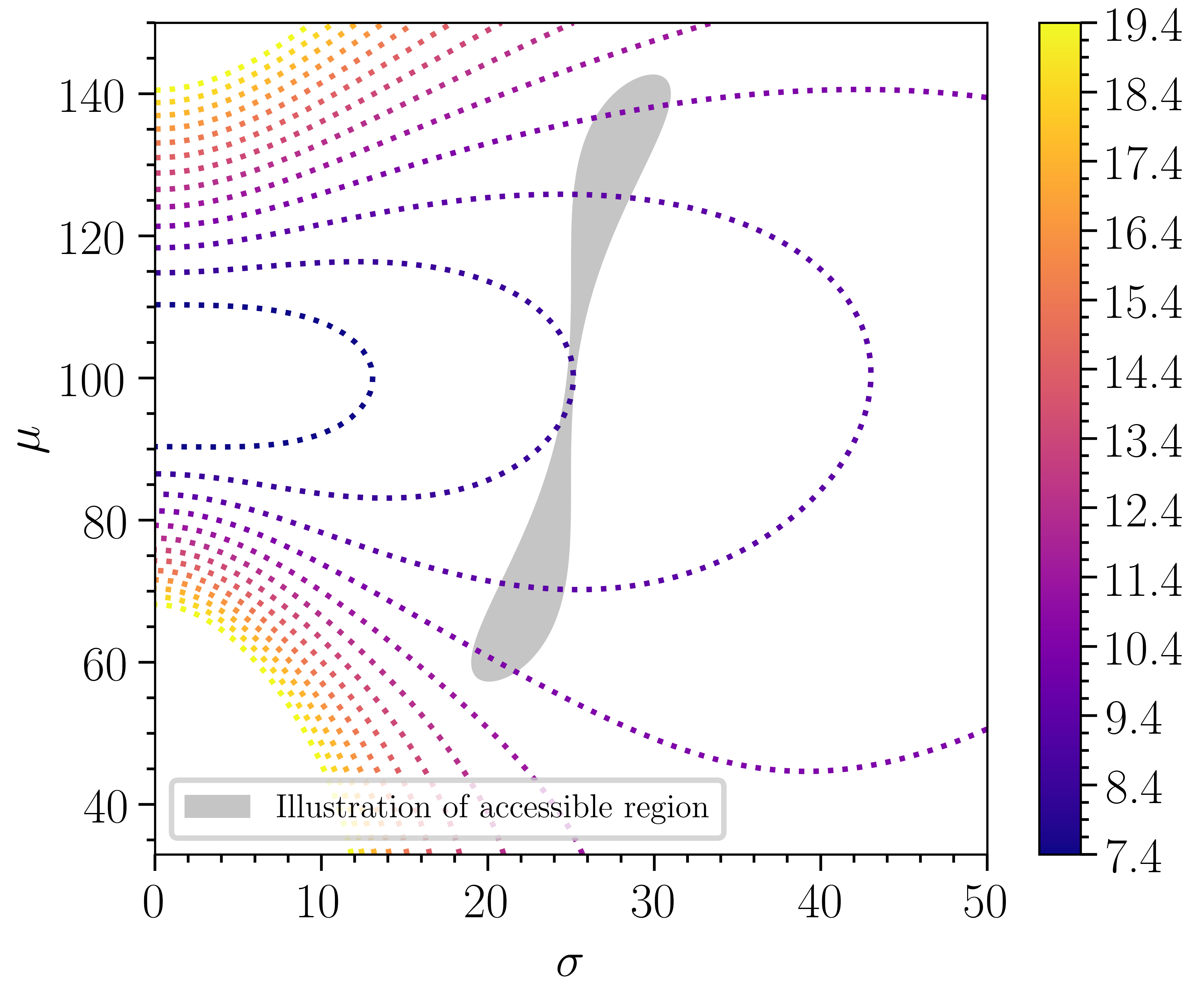 Figure 1
Figure 1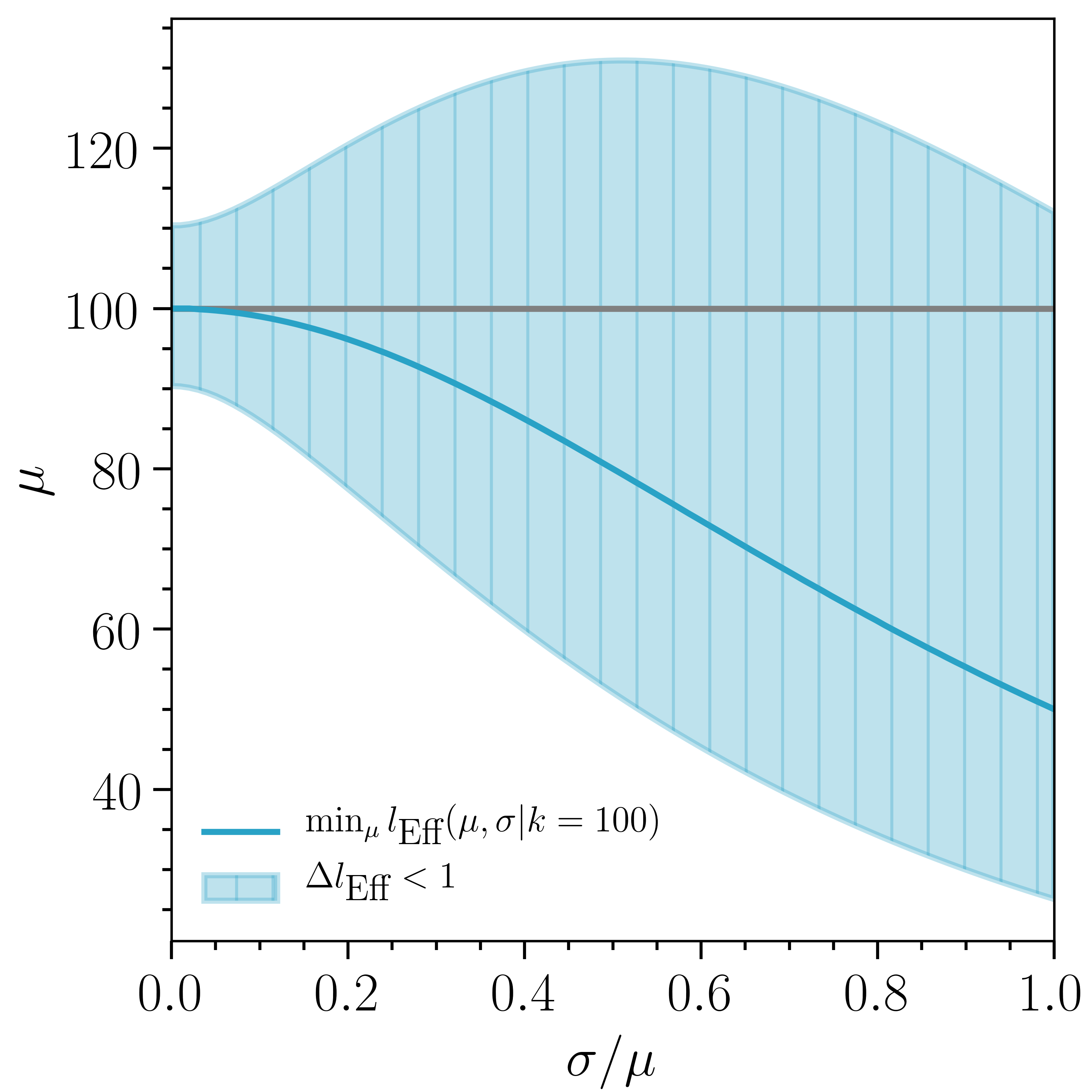 Figure 2
Figure 2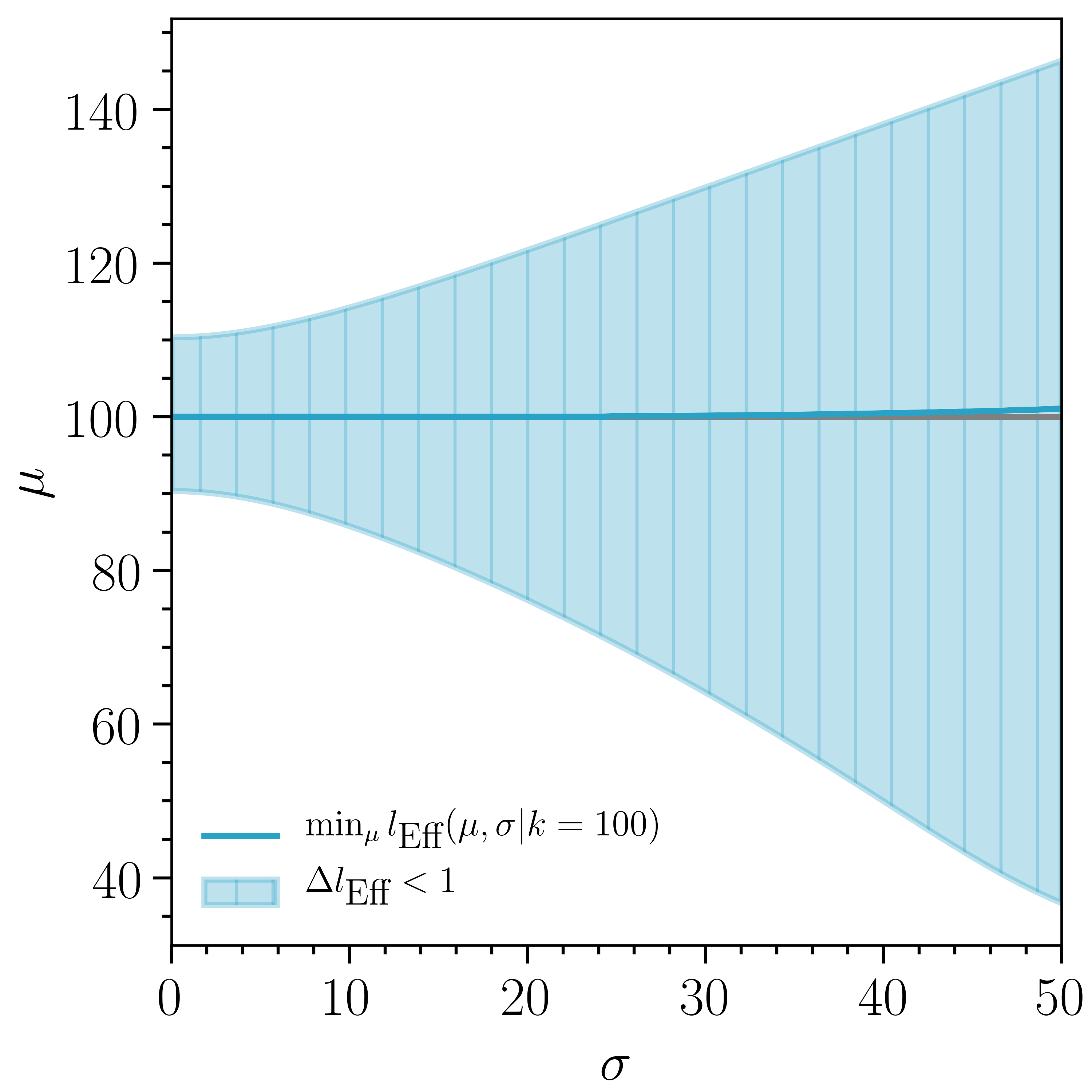 Figure 2
Figure 2 Figure 4
Figure 4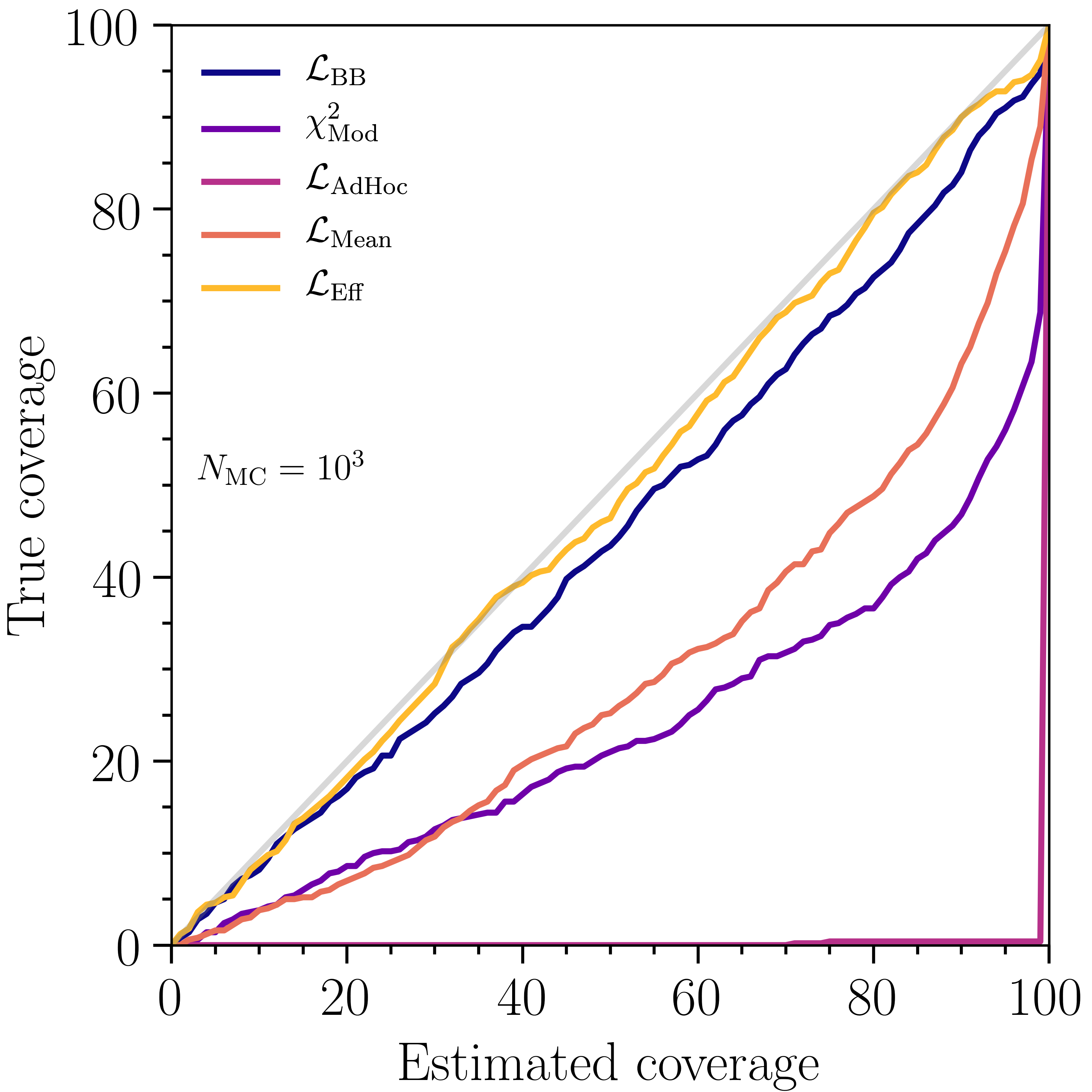 Figure 5
Figure 5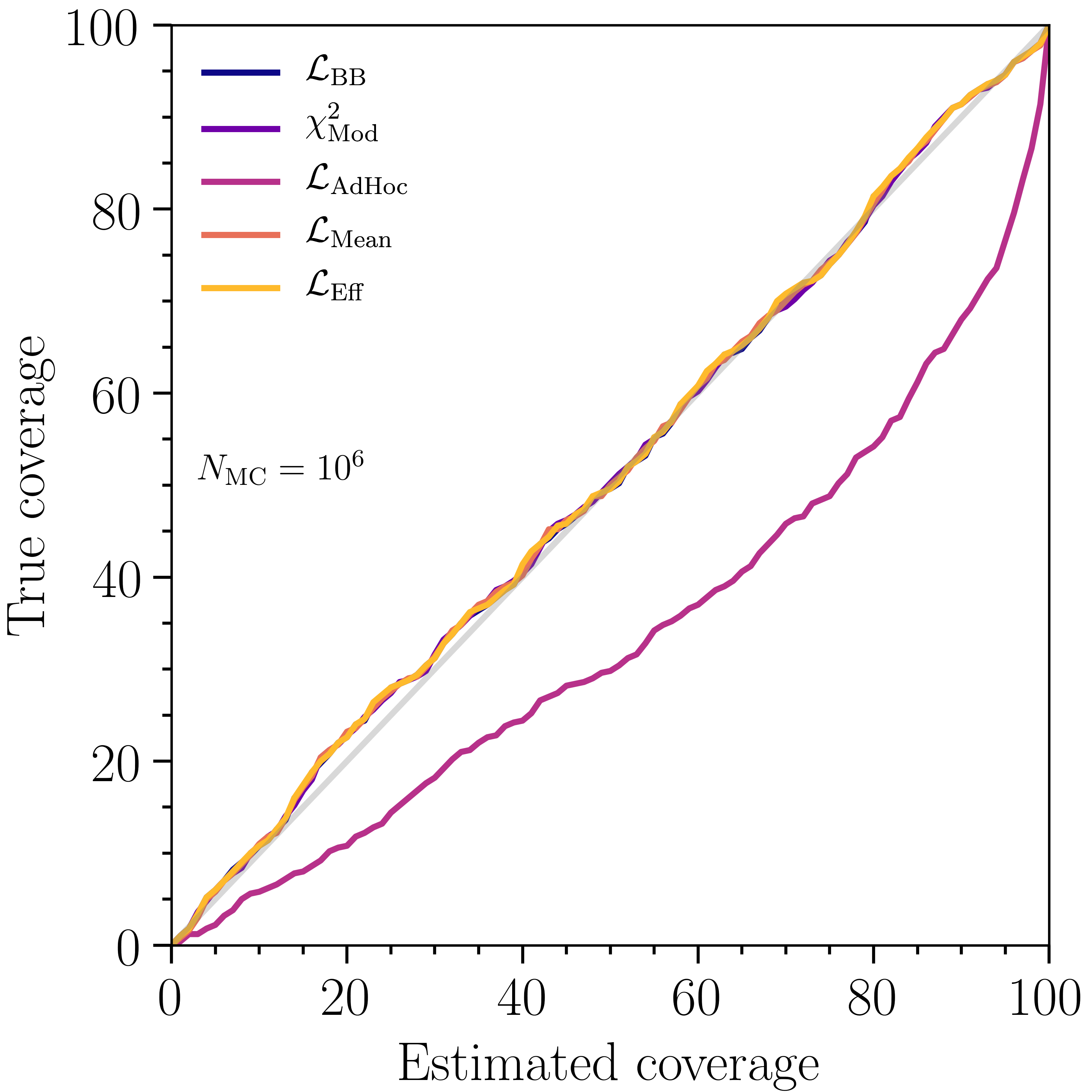 Figure 5
Figure 5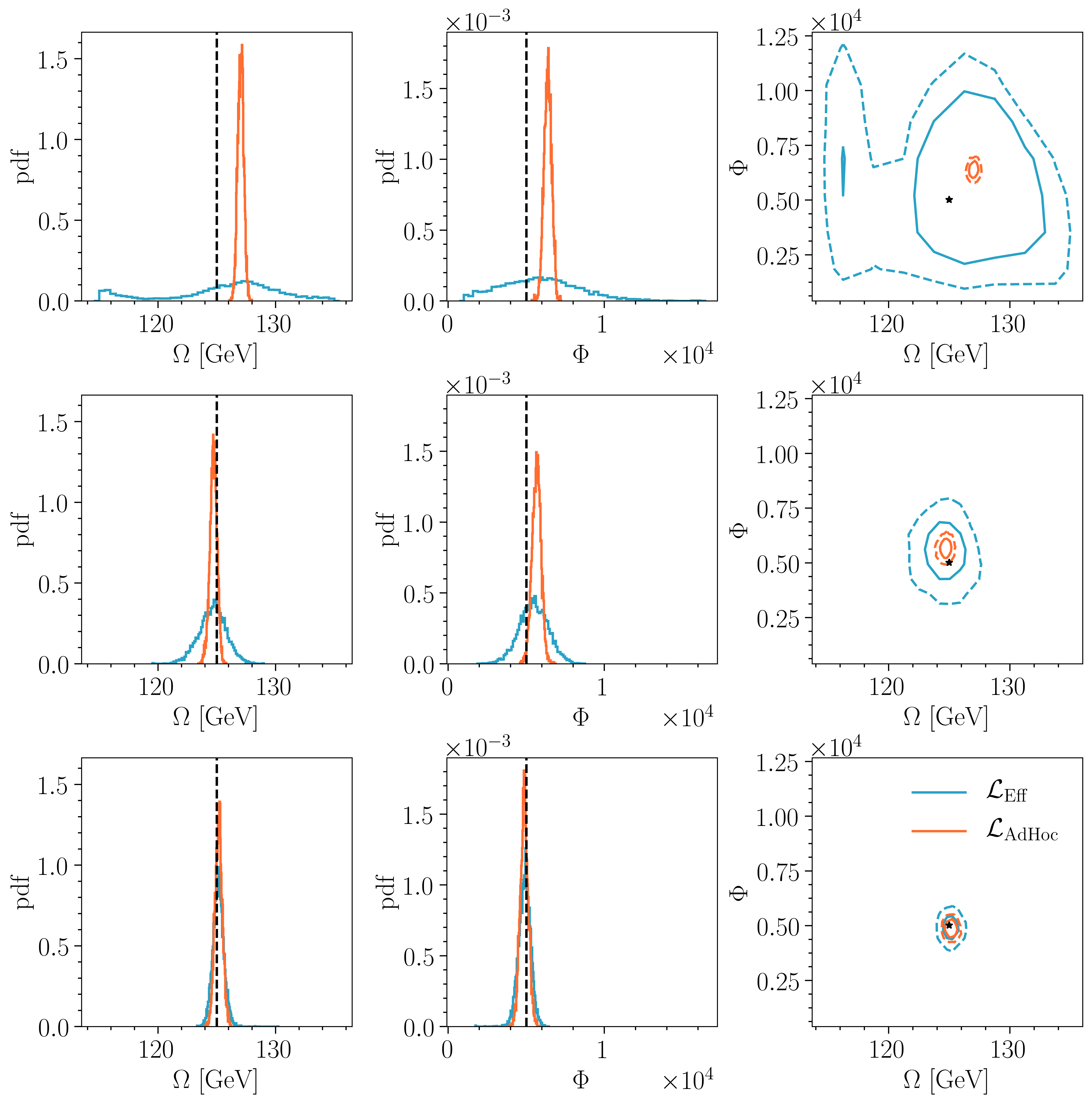 Figure 6
Figure 6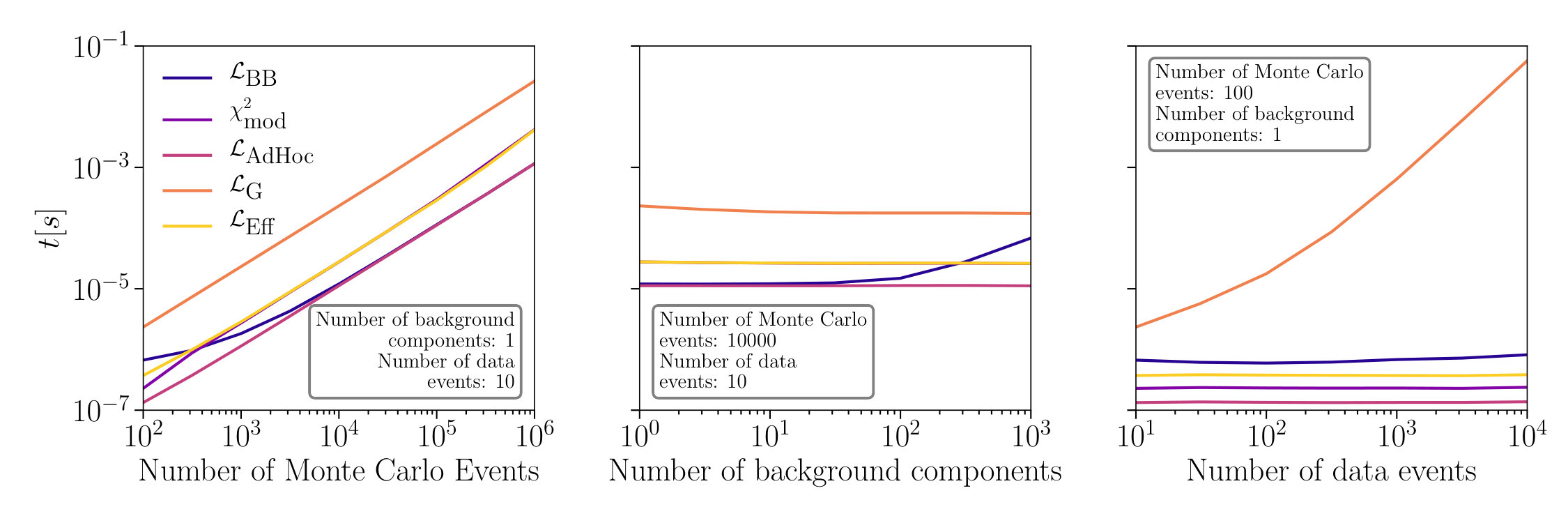 Figure 7
Figure 7| Likelihood | |||
|---|---|---|---|
| Parameters | |
|---|---|
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsForecasting Techniques and Applications · Statistical Methods and Bayesian Inference · Statistical Methods and Inference
\NewEnviron
scaletikzpicturetowidth[1]\BODY
aainstitutetext: Dept. of Physics, Massachusetts Institute of Technology, Cambridge, MA 02139, USA bbinstitutetext: Dept. of Physics and Wisconsin IceCube Particle Astrophysics Center, University of Wisconsin, Madison, WI 53706, USA
A binned likelihood for stochastic models
C.A. Argüelles, 111ORCID: 0000-0003-4186-4182 b,2
A. Schneider, 222ORCID: 0000-0002-0895-3477 b,3
T. Yuan, 333ORCID: 0000-0002-7041-5872
Abstract
Metrics of model goodness-of-fit, model comparison, and model parameter estimation are the main categories of statistical problems in science. Bayesian and frequentist methods that address these questions often rely on a likelihood function, which is the key ingredient in order to assess the plausibility of model parameters given observed data. In some complex systems or experimental setups, predicting the outcome of a model cannot be done analytically, and Monte Carlo techniques are used. In this paper, we present a new analytic likelihood that takes into account Monte Carlo uncertainties, appropriate for use in the large and small sample size limits. Our formulation performs better than semi-analytic methods, prevents strong claims on biased statements, and provides improved coverage properties compared to available methods.
Keywords:
Likelihood, Monte Carlo, Poisson distribution
1 Introduction
The use of Monte Carlo (MC) techniques to calculate nontrivial theoretical quantities and expectations in complex experimental settings is common practice in particle physics. A MC event is a single representation of what can be detected in data and is typically generated from a single realization of the underlying physics parameters, . These events are often binned in some observable space and compared with the data. Since the generation process is stochastic, a particular used for generating the MC can lead to different outputs. This stochasticity introduces an uncertainty in the MC distributions. Furthermore, as production of large MC is often time-consuming, reweighting is used to move from one hypothesis to another. In reweighting, each MC event is assigned a new weight, that accounts for the difference between the generation parameters and the hypothesis parameters Gainer:2014bta . It follows that MC uncertainties will be hypothesis dependent; thus, to do hypothesis testing, it is important to account for them. This is especially important for small-signal searches, performed in the small sample limit, where a modified- may not be suitable Lyons:1986em . A Poisson likelihood is a more appropriate statistical description of event counts poisson1837recherches , but in that case a proper treatment of MC statistical uncertainties is less straightforward. Solutions to this problem have been discussed in the literature in the context of frequentist statistics by adding nuisance parameters Barlow:1993dm ; Cranmer:2012sba ; Chirkin:2013lya , as well as detailed probabilistic treatment of MC weights Glusenkamp:2017rlp . However, Barlow:1993dm ; Chirkin:2013lya ; Glusenkamp:2017rlp add additional time complexity, and Cranmer:2012sba does not provide a full exposition on how to incorporate weighted MC. We present a new treatment that is valid in the large and small limit of the data sample size, suited for frequentist and Bayesian analyses, based on the Poisson likelihood. Our likelihood accounts for statistical uncertainties due to MC, allows for arbitrary event-by-event reweighting, and is computationally efficient. A test statistic based on the proposed likelihood is found to follow a distribution closer to the asymptotic form expected from Wilks’ theorem. An implementation of the likelihood described in this work can be found in MCLLH .
This paper is organized as follows. In Sec. 2 we briefly review two common treatments available in the literature to account for MC statistical uncertainty. In Sec. 3 we define and discuss our new likelihood. In Sec. 4 we study the performance of the likelihood through an example and compare it to other likelihoods in the literature. In Sec. 5 we provide our conclusions. A summary of the likelihoods discussed in the paper, including our main result, is given in Appendix A.
2 The Poisson likelihood and previous work
In order to compare MC with data, events are often binned into distributions across a set of observables. For simplicity we focus on a single bin. In the absence of cross-bin-correlated systematic uncertainties the generalization to multiple bins is simply a product over the likelihood in all bins. This is assumed for the remainder of the paper. It is well known that the count of independent, rare natural processes can be described by the Poisson likelihood, given by
[TABLE]
where is the expected bin count for a hypothesis and is the number of observed data events. Equation (1) requires exact knowledge of the expected bin count, . In the case of complex experiments it is often not possible to obtain exactly and MC techniques are used to estimate the expected distributions. For weighted MC, often a direct substitution of by is used, where are the weights of each of the MC events in the bin. Then Eq. (1) can be approximated as
[TABLE]
This ad hoc treatment assumes that the MC estimate of the expected bin counts exactly matches the true expectation rate of the model, neglecting the stohastic nature of MC. In the case of large MC, Eq. (2) converges to Eq. (1) for the hypothesis given by .
2.1 The Barlow-Beeston likelihood
To treat MC statistical uncertainties in the small sample limit, a modification of the Poisson likelihood was introduced in Barlow:1993dm , which is briefly covered below. First, note that the expectation in a single bin is given by contributions from different physical processes, which we index by . Then, the number of expected events can be written as
[TABLE]
where is the expected number of MC events from process that fall in the bin and is the total number of relevant processes. Substituting Eq. (3) into Eq. (1) gives the Poisson likelihood for observing data events. For stochastic models, is unknown. Instead, the MC outcome can be modeled as having drawn events from a random process that simulates the physical process. When MC generation is expensive, we can approximate as being drawn from a Poisson process with mean 444The MC generation is a binomial process where we generate a fixed number of events for each process, , and accept them into the bin of interest with probability , such that . In the limit of both of rare processes () and large number of generated events (), the total number of observed events can be approximated as Poisson distributed with mean .. Profiling on the true number of MC events per process in the bin results in the Barlow-Beeston (BB) likelihood, given by Barlow:1993dm
[TABLE]
where is given by Eq. (3), and are the estimated and true MC counts in the bin respectively, and denotes the nuisance parameters we have profiled over.
In the above formalism we have produced the MC at the natural rate, but this is not the case for weighted MC. The prescription is given by replacing Eq. (3) with
[TABLE]
where is a scale factor for process that accounts for the differences in the MC generation and the target hypothesis of interest. In this case, the likelihood definition is still given by Eq. (4); an explicit formula for is given in the appendix. However, for arbitrary weight distributions per physical process may not be appropriate as it neglects the variance from a sum of weights Barlow:1993dm . It remains valid only in the case where the distribution of weights for each process is narrow.
2.2 Uncertainties in the large-sample limit
In the large-sample regime, the Gaussian distribution is an appropriate description of the observed data. In this limit, the use of Pearson’s as a test-statistic Pearson:1900 is common practice. For a single analysis bin, Pearson’s is defined as
[TABLE]
where we continue to use the approximation and are the weights of each of the MC events. The form of Pearson’s arises from the fact that the Gaussian distribution of is the large-sample limit of a Poisson distribution for which the expected statistical variance of the observation is given by . Systematic uncertainties, under the assumption that they follow a Gaussian distribution and are independent between bins, can be included as
[TABLE]
However, this method of incorporating systematic uncertainties tends to overestimate them in shape-only analyses; see Cogswell:2018auu for a recent discussion in the context of reactor neutrino anomalies. Similarly, one can include uncertainties to account for statistical fluctuations of the MC in the test-statistic. In doing so, the Gaussian behavior is implicit and the modified reads
[TABLE]
where is the MC statistical uncertainty in the bin given by
[TABLE]
Note that this test-statistic definition is not appropriate in the small-sample regime, as the data is no longer well described by a Gaussian distribution. If one uses a test-statistic in the small-sample regime, one ought to calculate the test-statistic distribution properly to achieve appropriate coverage cowan1998statistical .
3 Generalization of the Poisson likelihood
Ideally we would like to obtain the expected event count for any hypothesis, , however we are considering problems where this relationship is not known and is instead estimated by MC. The key difference here is that instead of using exact knowledge of we want to perform Bayesian inference to obtain using the MC available. Assuming the weights are functions of , we have
[TABLE]
where the distribution of , , is inferred from the MC. The likelihood, , in Eq. (2) is recovered when , but clearly this is an unrealistic assumption as it presumes perfect knowledge of the parameter from a finite number of realizations. Instead, it is more appropriate to construct based on the MC realization. This is given by
[TABLE]
where is a prior on that must be chosen appropriately and is the likelihood of given . This is similar to Barlow:1993dm ; Cranmer:2012sba , but instead of fitting as a nuisance parameter as in in Eq. (4), we marginalize over it in Eq. (10) as informed by the MC weights. When is used under a frequentist approach, the marginalization over implies a hybrid Bayesian-frequentist construction, similar to the treatment of nuisance parameters described in Cousins:1991qz and employed in Abe:2017vif ; Abe:2018wpn .
This section is organized as follows. We first derive assuming identical weights in Sec. 3.1, then extend it to arbitrary weights in Sec. 3.2. With this in hand, we calculate an analytic expression for Eq. (10) using Eq. (11) under a uniform in Sec. 3.3. In Sec. 3.4 we briefly discuss a family of distributions as possible alternative priors. In Sec. 3.5 we show that our effective likelihood converges to Eq. (2) in the limit of large MC size. Finally, in Sec. 3.6 we provide some intuition on the behavior of our generalized likelihood. Equation (25), along with the definitions of and given in Eq. (12), constitute the primary result of this work.
3.1 Derivation of for identical weights
In this section we derive for identical weights. We will show that can be written in terms of two quantities
[TABLE]
for a bin with MC events.
For identical weights, , the following equalities hold:
[TABLE]
Assume that is the outcome of sampling a Poisson-distributed random variable with probability mass function
[TABLE]
where is the mean of the distribution. Further, assume that the expected number of data events so that . Substituting back into Eq. (14), we can interpret as a likelihood function of
[TABLE]
as and fully specify for identical weights.
3.2 Extension to arbitrary weights
The derivation above assumed identical weights. For arbitrary weights, is an outcome sampled from a compound Poisson distribution (CPD), which can be approximated by a scaled Poisson distribution (SPD) by matching the first and second moments of the two distributions Bohm:2013gla . In order to make the connection, first rewrite and as
[TABLE]
where is the effective number of MC events and the effective weight. From Eq. (13) these are given by: and . Next, assume and
[TABLE]
where again is the expected number of events in data. Equation (17) can be written as a likelihood function of ,
[TABLE]
which is identical to Eq. (15) except the denominator is now a gamma function instead of a factorial. However, since the denominator does not depend on it cancels out in Eq. (11).
To understand this approximation, note that the maximum likelihood in Eq. (17) occurs when . The first and second moments of the SPD random variable , where , are given by
[TABLE]
and
[TABLE]
This shows that the SPD, under the maximum likelihood solution for the given MC realization, has first and second moments that match the sample mean, , and variance, , respectively. These are equal to the first and second moments of the CPD as described in Bohm:2013gla . By assuming that is drawn from a SPD, we can treat and as outcomes that fix the likelihood function of the underlying scaled expectation , analogous to the case of identical weights. Because both the first and second moments are matched, this approximation accounts for the variance of the CPD unlike , which only accounts for the mean. Thus, while is valid only for the case of narrow weight distributions, our approximation remains valid for broader distributions.
3.3 The effective likelihood
Now that we have an expression for from the MC, we can proceed to compute Eq. (10) under a uniform . To simplify the notation, let
[TABLE]
Then, assuming a uniform and substituting Eq. (18) for in Eq. (11) we obtain
[TABLE]
where is the gamma function and the gamma distribution with shape parameter and inverse-scale parameter . Note that in going from Eq. (18) to Eq. (3.3) and go from random variates for a particular to parameters that govern the probability density of . With this choice of and , we can rewrite from Eq. (10) as
[TABLE]
where and depend on through .
3.4 A family of likelihoods
It is possible to generalize the choice of and in Eq. (21) by choosing a particular form of . Since the distribution of interest is a Poisson distribution, a well-motivated choice of is a gamma distribution (the conjugate prior of the Poisson distribution) Fink97acompendium ; also see Glusenkamp:2017rlp for a recent discussion. Thus we set , where and are the shape and inverse-scale parameters of the gamma distribution, respectively. These hyper-parameters dictate the distribution of the Poisson parameter bernardo2009bayesian . In line with our previous discussion, the gamma distribution prior implies that Eq. (21) becomes
[TABLE]
The rest of the likelihood derivation remains the same. This allows the choice of specific values for and to satisfy certain properties. Equation (21) is obtained with and , corresponding to the uniform prior discussed above. Another interesting choice is to require that the mean and variance of match and , respectively. This can be achieved by setting , and we refer to this parameter assignment as . In the case of identical weights, is equivalent to Eq. (20) in Glusenkamp:2017rlp . Both choices are improper priors, as technically they are limiting cases of the gamma distribution. However, we can use them to obtain proper distributions.
In Glusenkamp:2017rlp , a convolutional approach is suggested for handling arbitrary weights. We refer to this likelihood as . Each weighted MC event has , corresponding to the prior , such that . The likelihood is a good analytic approximation of the more computationally expensive calculation given in Glusenkamp:2017rlp for . The latter has time complexity where and are the number of data and MC events in the bin respectively. When assuming uniform priors, the convolutional approach does not recover Eq. (3.3) for identical weights, so it cannot be used as a generalization of .
3.5 Convergence of the effective likelihood
In this section we will show that, if the relative uncertainty of the bin content vanishes as MC size increases, and both converge to .
For positive weights , the relative uncertainty is bounded between zero and one. Uncertainty as large as the estimated quantity, , occurs if and only if . In the limit that goes to zero, Eq. (3.3) converges to and and both go to . We can see this by noting that the shape parameter, , goes to infinity as the MC relative uncertainty goes to zero, turning the gamma distribution into a Gaussian distribution of mean and variance . This Gaussian converges to in the limit of vanishing . Substituting into Eq. (10), we recover Eq. (2), which converges to Eq. (1) in the large MC limit.
It remains to be shown that the relative uncertainty of the bin content vanishes as MC size increases. For identical weights,
[TABLE]
For arbitrary weights, the limit can be written in terms of the running average of and as
[TABLE]
where is the average over and the average over for . This shows that as long as does not grow much faster than , the limit will converge to zero. For weight distributions with positive support and finite, non-zero mean, this should be the case.
3.6 Behavior of the effective likelihood
It is instructive to examine the behavior of for a single bin. It is standard to work with the log-likelihood and we do so here. Figure 1 shows the contour lines for . Since and are both dependent on the same underlying parameters, , a minimization over can be thought of as a constrained minimization over and . This is visualized as the gray region in Fig. 1, which indicates where and are allowed to vary for some physics model555A general bound for positive weights is which can be seen from their definitions.. Similarly, we can also visualize the standard Poisson log-likelihood, , which is simply constrained along the line .
To further illustrate the effect of the accessible region, we minimize over for two possible constraints: fixed and fixed . In terms of Eq. (12), a sufficient but not necessary condition for constant with varying is equal weights, and a necessary but not sufficient condition for constant with varying is . For a standard Poisson likelihood, . Figure 2 shows as well as the region where for fixed (left) and fixed (right). Note that the shaded regions for fixed are calculated without requiring that , which would be the case for Eq. (12). As goes to zero, the Poisson best-fit and Wilks’ interval are recovered. As or increases, the shaded region becomes wider, as expected. For fixed , does not deviate much from , while for fixed , deviates from as increases. The shaded regions correspond to the interval assuming the approximation from Wilks’ theorem and give a sense of the shape of projected onto one-dimensional slices.
4 Example and performance
In practice, likelihoods such as those discussed above are used to estimate physical parameters from data. As discussed in Sec. 1, weighted MC is often used to compute the likelihood of a particular physical scenario given the observed data. Statements are then made about the physical scenarios either by maximizing the likelihood or by examining the posterior distribution assuming some priors. We examine a toy experiment where we measure the mode, , and normalization, , of a Gaussian-distributed signal against a steeply falling inverse power-law background. The performance of is evaluated and compared against other likelihoods.
For our toy experiment, we generate the true energies, , of synthetic data events from a background falling as , where , and a Gaussian signal centered at GeV with width of GeV and normalization for a fixed number of expected events. Our imaginary detector is sensitive in the 100–160 GeV range. To simulate the effect of a real detector, the true energy, , is smeared by 5% for background and 3% for signal to obtain event-by-event reconstructed energies, . We generate a total number of MC events, , split evenly between the components. Generation is performed assuming inverse power-law distributions of for signal and for background. We choose and . Reweighting of the MC can then be performed as a function of and forward-folded onto distributions in over which the events are histogrammed and likelihoods evaluated. A diagram of the steps described above is shown in Fig. 3. For all toy experiments, the background component, , and the signal width, , are kept fixed to their true values. Only the signal mean, , and normalization, , are treated as free parameters.
4.1 Point estimation
Figure 4 shows the expectation in as well as the data and best-fit distributions in . The leftmost panel shows the expectation for both signal and background assuming no smearing in . The three other panels show the smeared, , distribution for data (black) and the best-fit result from for three different MC datasets (orange) of varying MC size. The smeared shape of the signal peak is clearly visible in data, but not in the smallest size MC. As the MC increases in size, the best-fit MC can be seen to converge to data.
The best-fit values for the example shown in Fig. 4 are given in Table 1 for and . As point estimators, both likelihoods return similar values. This is driven by the fact that the same underlying MC distribution is used to fit to the data. The effect of convoluting mostly serves to broaden the likelihood space, while preserving the maximum within the constraints described in Sec. 3.6. In the large MC limit, both likelihoods can be used for unbiased point estimation, provided that the likelihood space is smooth enough for standard minimization techniques to probe the global minimum.
4.2 Coverage
Due to the higher computational cost of computing frequentist confidence intervals by generating pseudodata to estimate the test-statistic () distribution, it is common to use the approximation given by Wilks’ theorem for the cases where the underlying hypotheses hold. In the case of small MC, a likelihood description that neglects MC uncertainties may lead to undercoverage even for a large data sample. In this section, we will use , where and correspond to the true and best-fit , respectively. We evaluate the coverage properties, computed using the asymptotic approximation given by Wilks’ theorem, of the two-dimensional fit over for several likelihood constructions. These include the modified-, , , , and . These five test-statistics were chosen on the basis of their computation speed and as tests of different approaches towards the treatment of weighted MC. Note that using Wilks’ theorem is an approximation and in general we encourage the reader to perform coverage tests for their own particular setup.
Several configurations were tested, all under the assumptions of the toy experiment described in Sec. 4.1. The MC was generated for two different settings of the total number of events: and . For each setting, 500 toy experiments were generated, their best-fits found, and their evaluated. Each toy experiment was classified as covering at a specified level if , where is the inverse of the cumulative density function and indicates the number of degrees of freedom.
Figure 5 shows the percentage of times the true parameters were within the confidence intervals at level as a function of the estimated coverage percentile for that level. First note that, as expected, the true coverage is highly dependent on MC size, with higher MC size leading towards improved agreement. In the case of , , , modified-, and all undercover to varying degrees of severeness. For , still undercovers, which is not surprising as it presumes zero MC uncertainty, but the other likelihoods exhibit good agreement. In this benchmark test, exhibits the best coverage properties. However, note that using Wilks’ theorem in order to evaluate confidence intervals implies an asymptotic approximation. In general, this approximation does not necessarily have to hold and we encourage the reader to always perform their own coverage tests suitable for their particular experimental setup.
4.3 Posterior distributions
It is also possible to use in a Bayesian approach. Using Bayes’ theorem, the posterior
[TABLE]
where is a prior on the parameters. As evaluation of the normalization factor can by challenging, can be approximated using a Markov Chain Monte Carlo (MCMC). For our toy example, we used emcee ForemanMackey:2012ig to sample under a uniform box prior for two different likelihood functions: and . The sampling was performed using the data and MC sets described in Sec. 4.1.
Figure 6 shows the posterior distributions of and . For each comparison, (blue) and (orange) were sampled using the same underlying data and MC. We used 20 walkers with 300 burn-in steps followed by 1000 steps as settings for emcee. The left and center column show the marginal posterior distribution for the mass, , and normalization, , respectively. The true value is indicated by the dashed, vertical line. The rightmost column shows the joint posterior distribution with 68% (solid) and 95% (dashed) contours. The true values are indicated by the star. With , the true value of the parameter is highly improbable for the lower MC-size cases of the top and middle rows. In contrast, the posterior evaluated using has increased width due to the reduced MC size. Even for (bottom row), the shape of the posterior evaluated using is narrower than that using . Credible regions estimated using would bias the result.
4.4 Performance
In this section we compare our performance with other treatments available in the literature in terms of the runtime cost per likelihood evaluation for a single bin. We perform our tests using a single Intel® Core™ i5-8350U CPU @ 1.70GHz running code compiled with clang version 6.0.0-1ubuntu2. We compute the likelihood CPU-evaluation time for the following likelihoods: , modified-, Glusenkamp:2017rlp , Barlow:1993dm , and . For each of them we consider increasing number of MC events from to , increasing number of background components from to , and increasing counts of data events from to . Figure 7 shows the behavior of the runtime with respect to these quantities. All likelihoods have runtime that increases with the number of MC events, as seen in the leftmost panel of Fig. 7, as each likelihood must compute the sum of event weights which incurs an cost, where is the number of MC events in the bin. Additionally at low MC sample sizes the modified- is faster than since requires the evaluation of more expensive special functions, however at larger MC sample sizes this additional cost is negligible compared to that of summing the MC weights. In the middle panel of Fig. 7 it can be seen that all likelihoods except are constant with respect to the number of background components as they only depend on summary statistics of the weight distribution. The Barlow-Beeston likelihood, , incurs an cost for solving a single root finding problem per physical component, where is the number of background components and is the number of digits of precision, and therefore is not constant in runtime with respect to the number of components. However, one key difference between and is that must compute two summations (the sum of the weights and sum of the square weights), while needs only to compute a single summation of the MC weights. The rightmost panel of Fig. 7 shows the runtime as a function of the number of data events; for most likelihoods the number of data events, , enters only in the evaluation of some special functions which for all practical applications are approximately constant in runtime. evaluates a special function which for these purposes can only be computed in time, resulting in the dependence on the number of data events. The treatment is always the fastest, but it does not incorporate MC statistical uncertainties in any way.
5 Conclusion
The use of MC to estimate expected outcomes of physical processes is nowadays standard practice. By construction, MC distributions are sample observations and subject to statistical fluctuations. MC events are also typically weighted to a particular physics model, and these weights may not be uniform across all events in an observable bin. A direct comparison of MC distributions to data is typically performed using or , where the expectation from MC is computed as a sum over weights in a particular observable bin. Such likelihoods neglect the intrinsic MC fluctuations and may lead to vastly underestimated parameter uncertainties in the case of low MC size. A better approach is to use a likelihood that accounts for MC statistical uncertainties.
Along with the definitions of and in Eq. (12), the main result of this work is given in Eq. (25). This new is motivated by treating the MC realization as an observation of a Poisson random variate, computing the likelihood of the expectation using the MC and marginalizing the Poisson probability of observed data over all possible expectations. It is an analytic extension of the Poisson likelihood that accounts for MC statistical uncertainty under a uniform prior, . By assuming that the number of MC events per bin is the outcome of sampling a Poisson-distributed random variable, and that the SPD is a good approximation of the CPD for arbitrary weights, can be written in terms of and as shown in Eq. (18). This allows us to calculate , given in Eq. (25), and can be directly substituted in favor of . Our construction is computationally efficient, exhibits proper limiting behavior, and has excellent coverage properties. In our tests, it outperforms other treatments of MC statistical uncertainty.
Acknowledgements
We thank Thorsten Glüsenkamp for useful discussions and Jean DeMerit for proofreading an early draft. CAA is supported by U.S. National Science Foundation (NSF) grant PHY-1505858. AS and TY are supported in part by NSF grant PHY-1607644 and by the University of Wisconsin Research Committee with funds granted by the Wisconsin Alumni Research Foundation.
Appendix A Summary of likelihood formulas
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) J. S. Gainer, J. Lykken, K. T. Matchev, S. Mrenna and M. Park, Exploring Theory Space with Monte Carlo Reweighting , JHEP 10 (2014) 078 [ 1404.7129 ]. · doi ↗
- 2(2) L. Lyons, STATISTICS FOR NUCLEAR AND PARTICLE PHYSICISTS . 1986.
- 3(3) S. D. Poisson, Recherches sur la probabilité des jugements en matière criminelle et en matière civile precédées des règles générales du calcul des probabilités . Bachelier, 1837.
- 4(4) R. J. Barlow and C. Beeston, Fitting using finite Monte Carlo samples , Comput. Phys. Commun. 77 (1993) 219 . · doi ↗
- 5(5) K. Cranmer, G. Lewis, L. Moneta, A. Shibata and W. Verkerke, Hist Factory: A tool for creating statistical models for use with Roo Fit and Roo Stats , .
- 6(6) D. Chirkin, Likelihood description for comparing data with simulation of limited statistics , 1304.0735 .
- 7(7) T. Glüsenkamp, Probabilistic treatment of the uncertainty from the finite size of weighted Monte Carlo data , Eur. Phys. J. Plus 133 (2018) 218 [ 1712.01293 ]. · doi ↗
- 8(8) C. Argüelles, A. Schneider and T. Yuan, “ MCLLH .” https://github.com/austinschneider/MCLLH , 2019.