Spatial Filtering Pipeline Evaluation of Cortically Coupled Computer Vision System for Rapid Serial Visual Presentation
Zhengwei Wang, Graham Healy, Alan F. Smeaton, Tomas E. Ward

TL;DR
This paper introduces a new spatial filtering method called MTWLB for EEG data in RSVP tasks and compares it with existing techniques, demonstrating improved classification performance.
Contribution
The paper proposes the novel MTWLB spatial filtering method and provides a comprehensive comparison of nine pipelines, highlighting the effectiveness of MTWLB and xDAWN.
Findings
MTWLB and xDAWN improve classification accuracy
CSP does not enhance performance in this context
Logistic Regression is effective with discriminative features
Abstract
Rapid Serial Visual Presentation (RSVP) is a paradigm that supports the application of cortically coupled computer vision to rapid image search. In RSVP, images are presented to participants in a rapid serial sequence which can evoke Event-related Potentials (ERPs) detectable in their Electroencephalogram (EEG). The contemporary approach to this problem involves supervised spatial filtering techniques which are applied for the purposes of enhancing the discriminative information in the EEG data. In this paper we make two primary contributions to that field: 1) We propose a novel spatial filtering method which we call the Multiple Time Window LDA Beamformer (MTWLB) method; 2) we provide a comprehensive comparison of nine spatial filtering pipelines using three spatial filtering schemes namely, MTWLB, xDAWN, Common Spatial Pattern (CSP) and three linear classification methods Linear…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4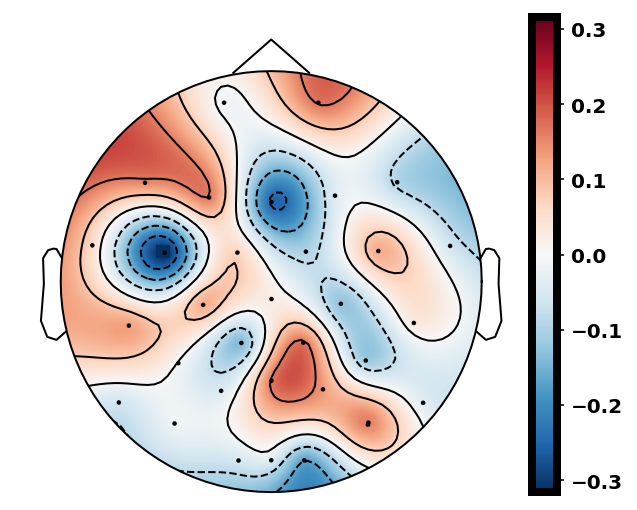 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7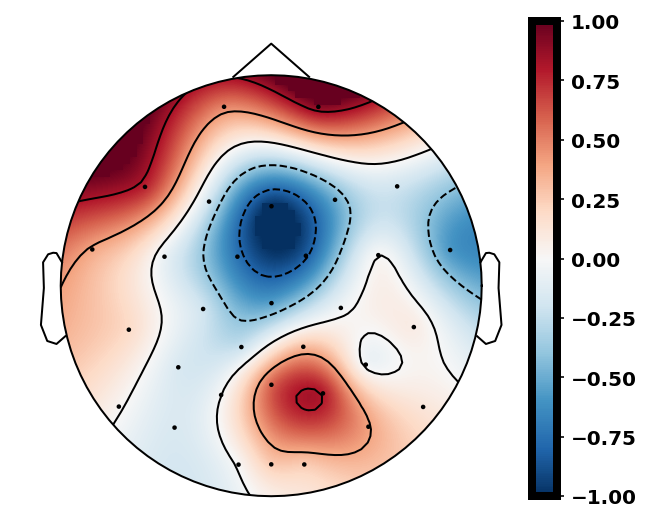 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10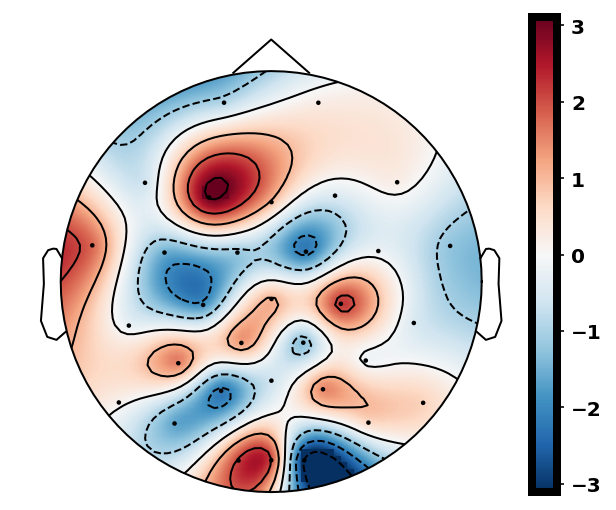 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13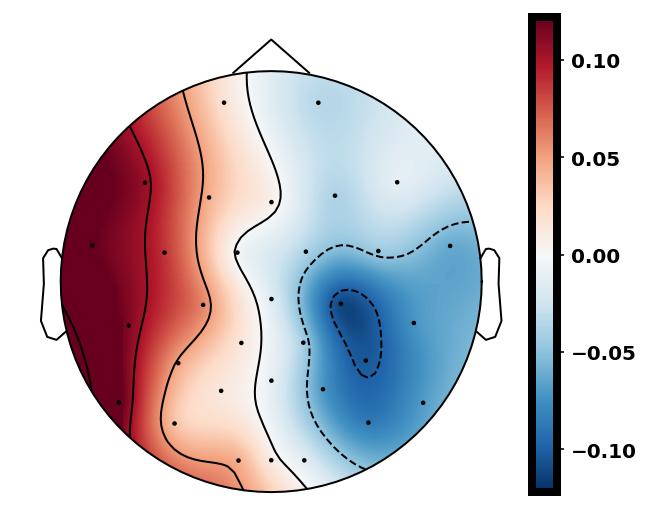 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19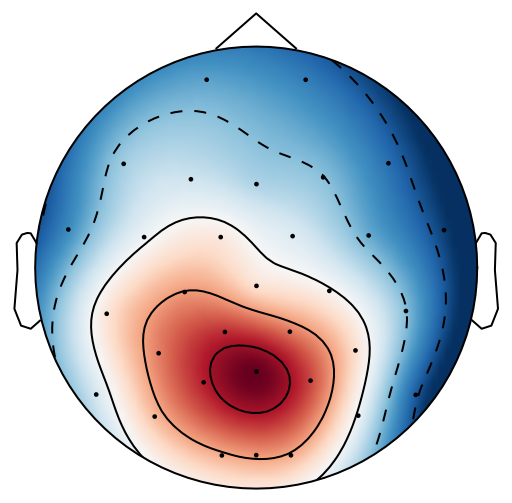 Figure 20
Figure 20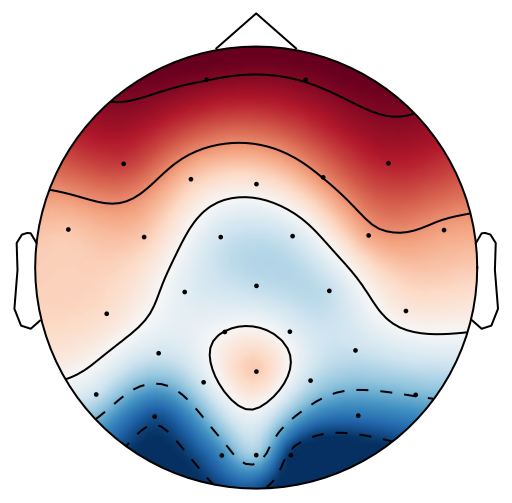 Figure 21
Figure 21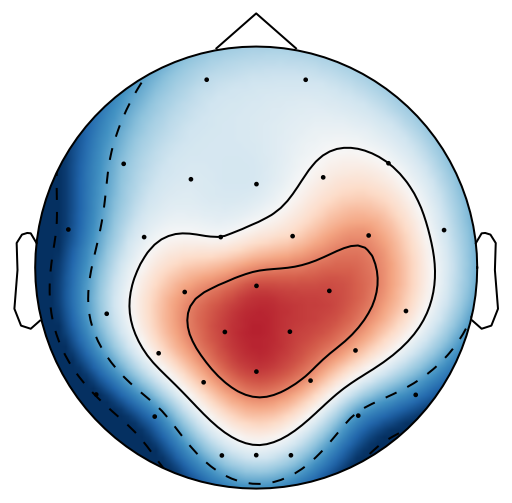 Figure 22
Figure 22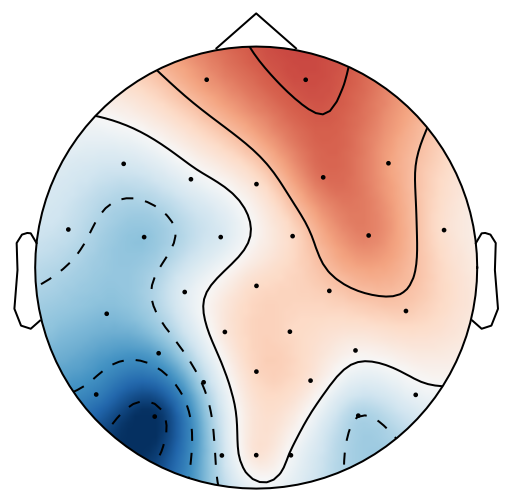 Figure 23
Figure 23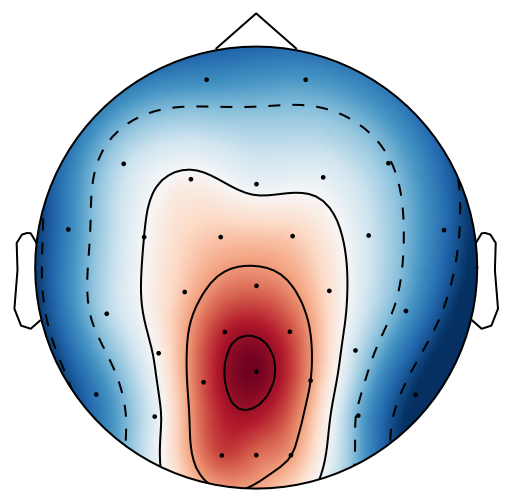 Figure 24
Figure 24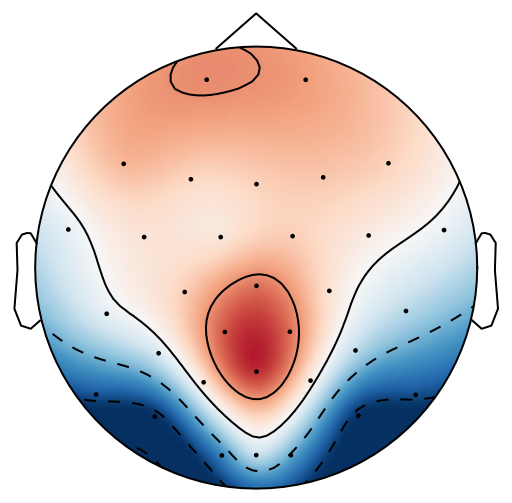 Figure 25
Figure 25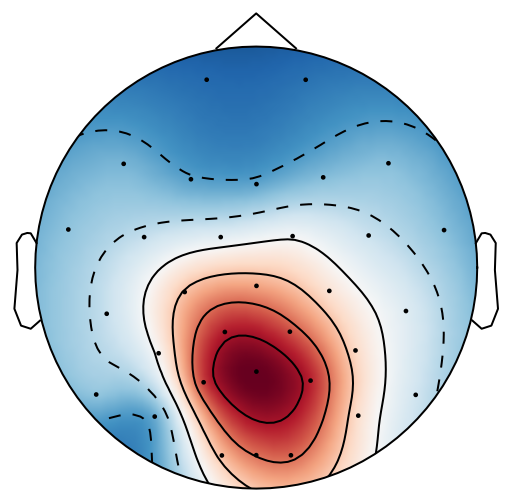 Figure 26
Figure 26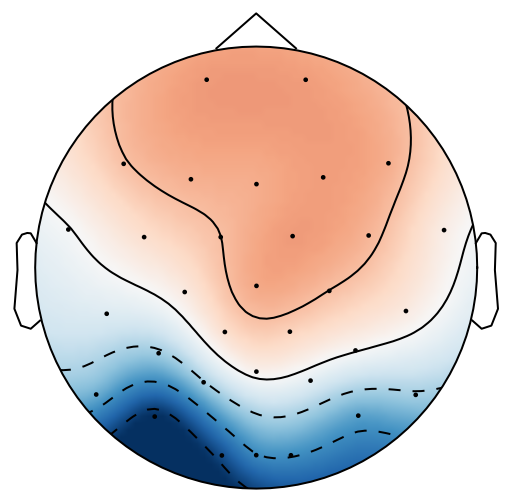 Figure 27
Figure 27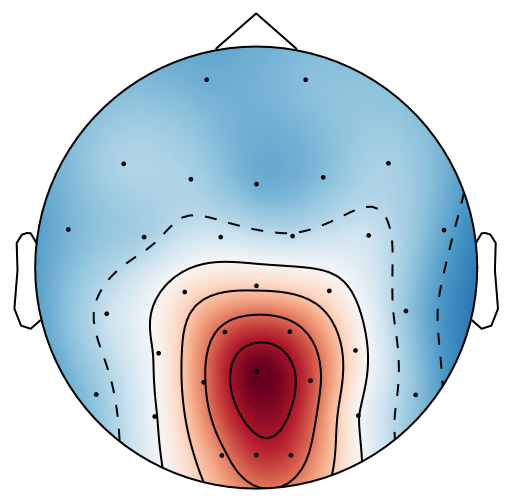 Figure 28
Figure 28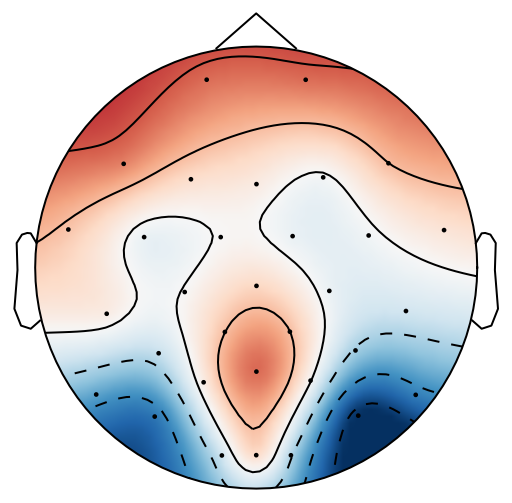 Figure 29
Figure 29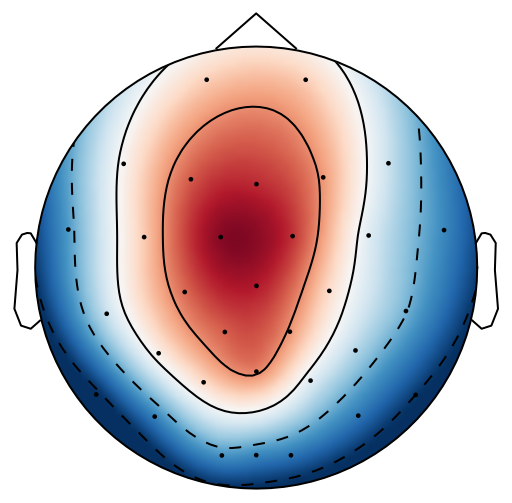 Figure 30
Figure 30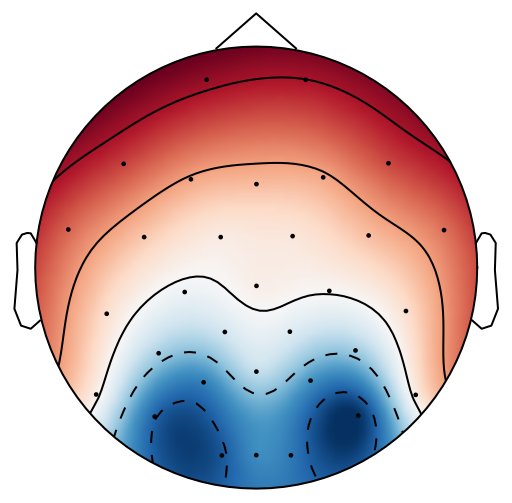 Figure 31
Figure 31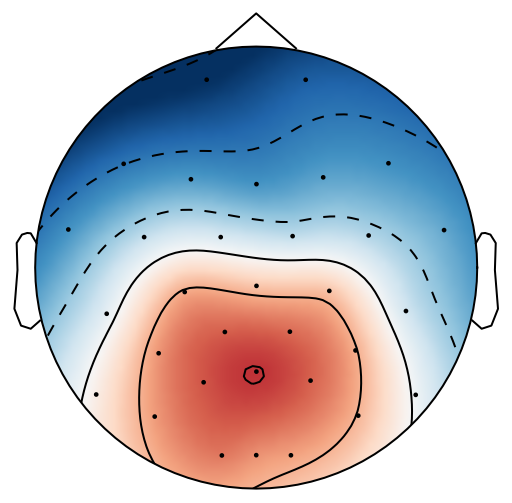 Figure 32
Figure 32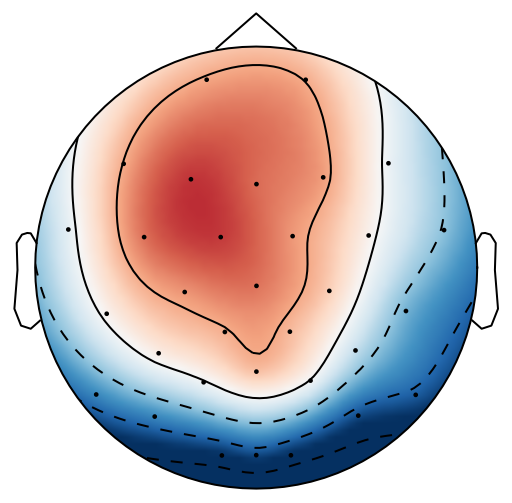 Figure 33
Figure 33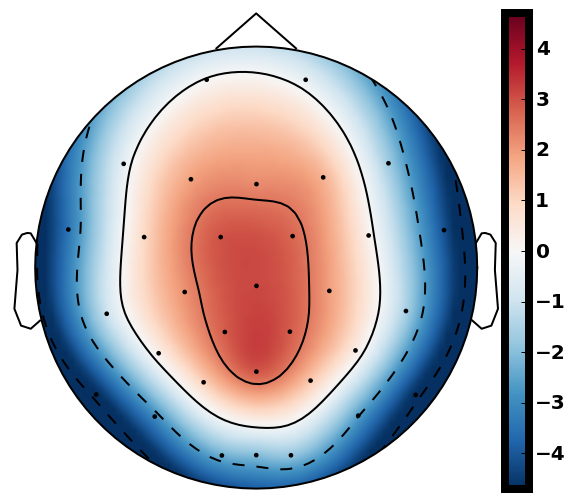 Figure 34
Figure 34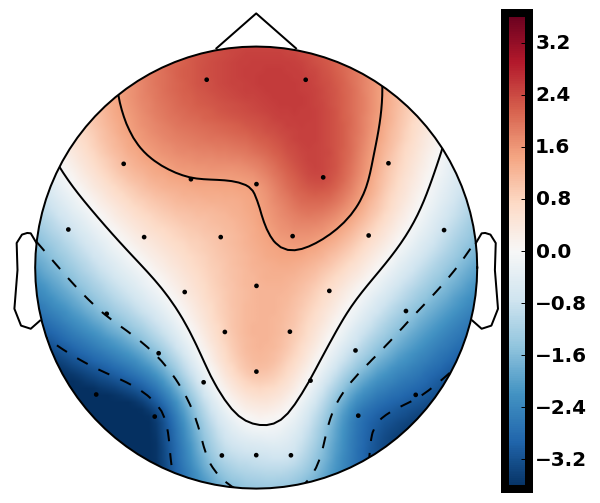 Figure 35
Figure 35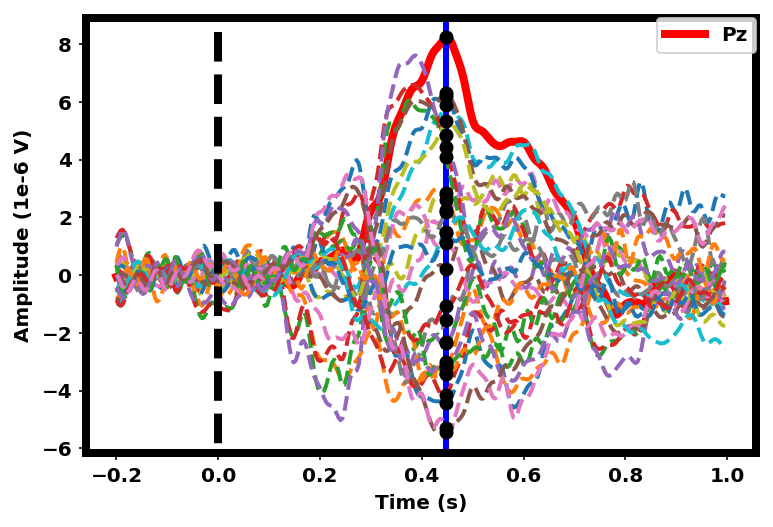 Figure 36
Figure 36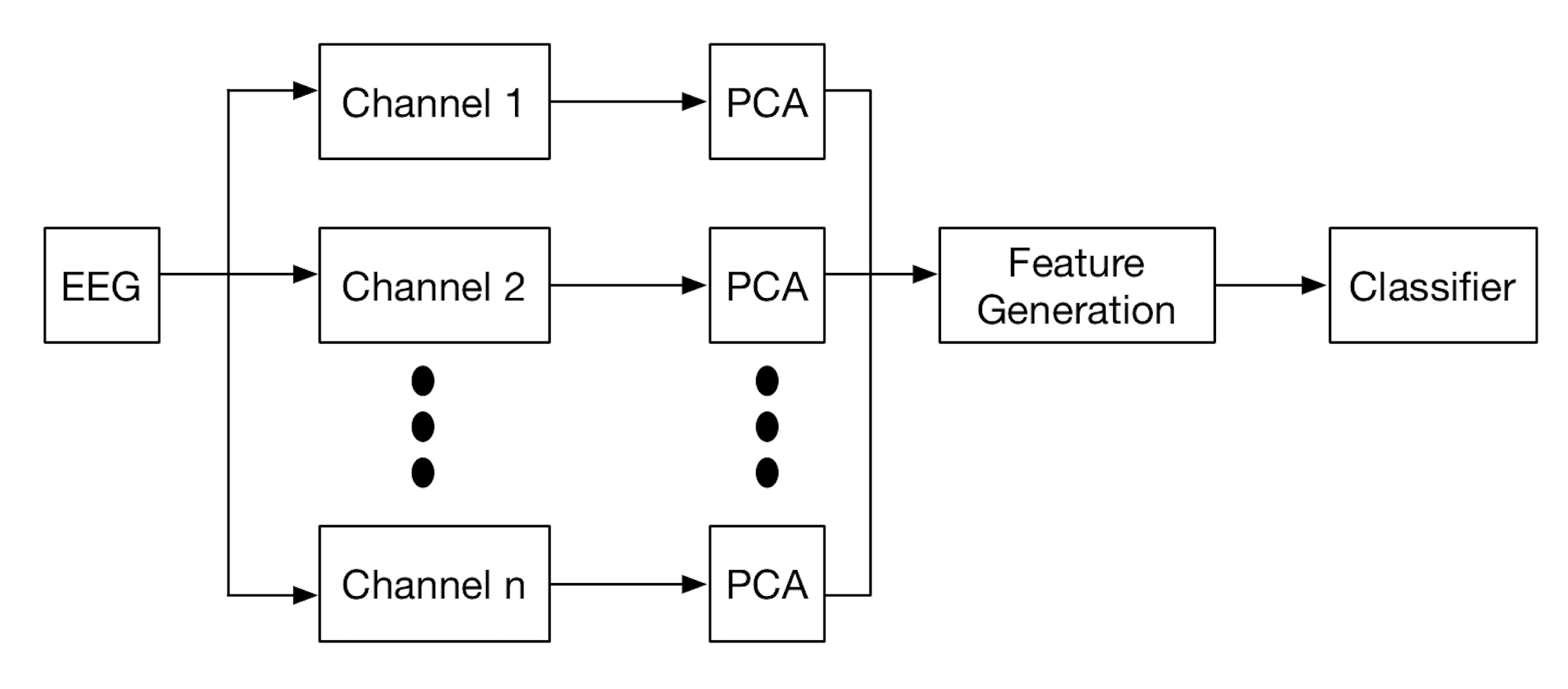 Figure 37
Figure 37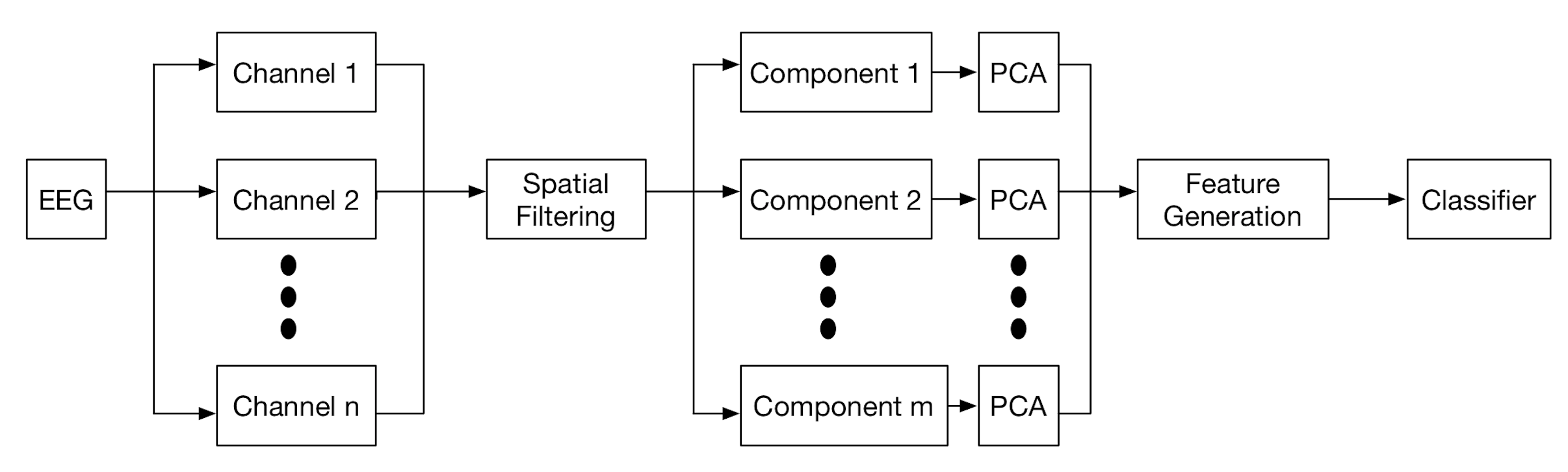 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Pipeline | Hyperparameter |
|---|---|
| Pipeline | Participant | Mean | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| 88.0 | 93.8 | 92.5 | 96.8 | 91.4 | 93.7 | 93.5 | 90.1 | 89.9 | 92.2 | |
| 88.0 | 93.8 | 92.5 | 96.8 | 92.2 | 93.7 | 93.2 | 90.8 | 93.3 | 92.3 | |
| 88.5 | 93.0 | 89.8 | 97.4 | 91.7 | 94.1 | 93.3 | 91.3 | 90.9 | 92.2 | |
| Mean | 88.2 | 93.5 | 91.6 | 97.0 | 91.8 | 93.8 | 93.3 | 90.7 | 91.4 | 92.2 |
| 88.0 | 93.4 | 92.7 | 97.3 | 91.6 | 94.3 | 92.9 | 90.6 | 90.1 | 92.3 | |
| 88.5 | 93.4 | 92.8 | 96.6 | 91.6 | 94.3 | 92.8 | 90.6 | 90.1 | 92.3 | |
| 87.4 | 94.1 | 92.9 | 97.2 | 91.9 | 95.3 | 93.8 | 91.3 | 90.7 | 92.7 | |
| Mean | 88.0 | 93.6 | 92.8 | 97.0 | 91.7 | 94.6 | 93.2 | 90.8 | 90.3 | 92.4 |
| 84.3 | 92.8 | 88.8 | 96.0 | 87.7 | 90.9 | 89.8 | 76.9 | 89.7 | 88.5 | |
| 84.9 | 92.7 | 88.3 | 96.0 | 87.9 | 90.9 | 89.6 | 77.5 | 89.7 | 88.6 | |
| 83.8 | 92.7 | 85.7 | 93.1 | 86.6 | 90.3 | 89.5 | 76.8 | 89.0 | 87.5 | |
| Mean | 94.3 | 92.7 | 87.6 | 95.0 | 87.4 | 90.7 | 89.6 | 77.1 | 89.5 | 88.2 |
| 86.9 | 93.4 | 90.8 | 96.7 | 91.9 | 94.0 | 95.0 | 89.4 | 90.3 | 92.0 | |
| 88.0 | 93.1 | 91.4 | 96.0 | 91.6 | 93.4 | 93.8 | 89.4 | 90.7 | 91.9 | |
| 84.4 | 92.4 | 86.0 | 92.3 | 87.6 | 92.1 | 91.5 | 87.3 | 82.8 | 88.5 | |
| Mean | 86.4 | 93.0 | 89.4 | 95.0 | 90.4 | 93.2 | 93.4 | 88.7 | 87.9 | 90.8 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsLinear Discriminant Analysis · Logistic Regression · Linear Regression
Spatial Filtering Pipeline Evaluation of Cortically Coupled Computer Vision System for Rapid Serial Visual Presentation
\nameZhengwei Wang, Graham Healy, Alan F. Smeaton and Tomas E. Ward This work has been accepted by Brain-Computer Interfaces. DOI:10.1080/2326263X.2019.1568821. Insight Centre for Data Analytics, Dublin City University, Dublin 9, Ireland
Email: [email protected], @dcu.ie
Abstract
Rapid Serial Visual Presentation (RSVP) is a paradigm that supports the application of cortically coupled computer vision to rapid image search. In RSVP, images are presented to participants in a rapid serial sequence which can evoke Event-related Potentials (ERPs) detectable in their Electroencephalogram (EEG). The contemporary approach to this problem involves supervised spatial filtering techniques which are applied for the purposes of enhancing the discriminative information in the EEG data. In this paper we make two primary contributions to that field: 1) We propose a novel spatial filtering method which we call the Multiple Time Window LDA Beamformer (MTWLB) method; 2) we provide a comprehensive comparison of nine spatial filtering pipelines using three spatial filtering schemes namely, MTWLB, xDAWN, Common Spatial Pattern (CSP) and three linear classification methods Linear Discriminant Analysis (LDA), Bayesian Linear Regression (BLR) and Logistic Regression (LR). Three pipelines without spatial filtering are used as baseline comparison. The Area Under Curve (AUC) is used as an evaluation metric in this paper. The results reveal that MTWLB and xDAWN spatial filtering techniques enhance the classification performance of the pipeline but CSP does not. The results also support the conclusion that LR can be effective for RSVP based BCI if discriminative features are available.
keywords:
Rapid serial visual presentation (RSVP), cortically coupled computer vision, electroencephalography (EEG), event-related potentials (ERPs), spatial filtering.
††articletype: Original Research
1 Introduction
There is growing interest in using Electroencephalography (EEG) signals to help in searching images [1, 2, 3]. This is based on estimating image content by examining participants’ neural signals in response to image presentation. The concept of Rapid Serial Visual Presentation (RSVP) can be introduced using a familiar example, that of rapidly riffling through the pages of a book in order to locate a needed image [4]. In RSVP, a rapid succession of target and standard (non-target) images are presented to a participant on a display at a rate of 5 - 12 . The location of target images within the high-speed presentation is not known in advance by users and hence requires them to actively look out for targets i.e. to attend to target images. This paradigm where users are instructed to attend to target images amongst a larger proportion of standard images is known as an oddball paradigm and is commonly used to elicit Event-related Potentials (ERPs) such as the P300, a positive voltage deflection that typically occurs between 300 - 600 after the appearance of a rare visual target within a sequence of frequent irrelevant stimuli [5]. Since participants do not know when target images will appear in the presentation sequence, their occurrence causes an attentional-orientation response that is characterized by the presence of a P300 ERP.
Using modern signal processing and machine learning techniques, RSVP can be coupled with single-trial ERP detection to enable image search BCI applications [6, 7]. Single-trial ERPs detection for an RSVP paradigm presents the following challenges:
Challenge 1. Low Signal-to-noise Ratio (SNR): ERP component amplitudes are often much smaller than those of spontaneous EEG components and task-related ERP components are typically overwhelmed by strong ongoing EEG background activity in single trials and so cannot be normally visually recognized in the raw EEG trace [8]. Traditional methods analyze ERPs by averaging across several task-related trials in order to reduce or eliminate spontaneous EEG components [9].
Challenge 2. Curse of dimensionality: RSVP-based ERP data can have high dimensionality spanning both space and time. Moreover, ERPs vary greatly across participants and experimental task [9]. In order to capture the ERPs, it is necessary to choose a time window large enough for epoching which involves the time region in which ERPs might appear. Moreover the training sets available for machine learning purposes are typically modest in size and worse, contain relatively few instances of the responses evoked by the infrequent (by design) target image class.
Challenge 3. Overlapping epochs: The strength of the RSVP paradigm is that the rate of the stimulus sequence increases the upper limit of potential information transfer rates in BCI applications. However, a relatively large time window has to be set for epoching in order to capture the ERPs. Therefore, there is substantial overlap between adjacent target epochs and standard epochs because of the short Interstimulus Interval (ISI) used in the RSVP paradigm.
In this work, we consider a pipeline combining spatial filtering and linear classification as this is the most widely used pipeline in RSVP-EEG based BCI.
There are several potential signal pre-processing techniques that may increase the efficiency of detecting single-trial ERPs including time-frequency feature extraction and hierarchical discriminant component analysis (HDCA) [10, 11]. However, spatial filtering techniques are more efficient when a full EEG cap dataset is available. In this paper, we focus on spatial filtering for signal pre-processing as this is the predominant approach used in RSVP-based BCI because we are using a full EEG cap recording dataset. Spatial filtering focuses on enhancing task-related information contained in the EEG signal. It plays an important role in BCI research because it can enhance the discriminative information present in the EEG signal whilst reducing the overall data dimensionality. Spatial filtering has been shown to enhance detection accuracy with a P300 speller paradigm [12]. However, classification pipelines without spatial filtering have been proposed for single-trial ERP detection. These methods include widely used linear classifiers such as Linear Discriminant Analysis (LDA) [10], Logistic Regression (LR) [13] and Bayesian Linear Regression (BLR) [14].
Investigation of spatial filtering in RSVP-based EEG has been explored previously in the literature [15, 16, 17]. What is unclear from these studies is how to determine the optimal number of spatial filters i.e. this detail has been omitted in previous studies and yet this is an important consideration so is included in this investigation. The primary objective of this paper is to explore the performance of pipelines that combine different spatial filtering approaches and classifiers where their respective hyperparameters are explored through random search cross validation. A pipeline in this paper comprises spatial filtering, feature dimensionality reduction and classification steps. Three spatial filtering approaches are explored in this paper, namely xDAWN [12], multiple time window LDA beamformers (MTWLB) which is an extension of LDA beamformer [18] and common spatial pattern (CSP) [19]. Principal component analysis (PCA) is utilized for feature dimensionality reduction. Three linear classification methods are explored, namely LDA, BLR and LR respectively. There are nine pipelines in total including spatial filtering and classification combinations. Three pipelines that only apply the three classification methods without applying any spatial filtering are used for comparing performance. This paper should provide neurotechnologists seeking to apply a RSVP paradigm to EEG with a comprehensive assessment of the comparative performance of both commonly used spatial filtering pipelines and a new method all assessed using a new publicly available benchmark dataset.
This paper is organized as follows. Firstly, we describe the methodology which includes pipeline and performance evaluation metrics used in this paper. Secondly, we clarify the experimental RSVP-based EEG dataset used in this paper. Finally, results and discussion are presented in the last two sections.
2 Methodology
2.1 Pipeline Description
This paper explores nine pipelines comprising spatial filtering, feature dimensionality reduction and classification respectively along with three pipelines containing feature dimensionality reduction and classification as comparisons. Fig. 1 illustrates the two pipeline architectures under consideration in this study. With spatial filtering applied, an channel EEG epoch is transformed to source components (). Before the feature generation step, we apply PCA for each individual channel (pipelines without spatial filtering) and individual component (pipelines with spatial filtering) on the temporal axis for dimensionality reduction following the work [20], where is the number of epochs. The reason why we apply PCA individually is because EEG power in each channel and each component is not consistent and this step ensures that discriminative information is not lost. We leave out the PCA components which contain less than 1% ratio of the variance. The feature generation step concatenates components or channel EEG to a feature vector before feeding to the classifier.
2.2 Supervised Spatial Filtering
Before introducing the supervised spatial filtering approaches we clarify the notations which will be used. is the number of channels, is the number of time samples in an epoch, is the number of selected spatial filters and is the number of epochs.
Spatial filtering creates a weighted combination of each EEG channel input in order to enhance a particular subset of information which is contained in the original EEG epoch. Spatial filtering reduces the number of features because the number of spatial filters selected is smaller than the number of channels . The problem of spatial filtering is to find projection vectors (spatial weights for each channel) to project to a subspace, where is calculated by different optimization criterion.
[TABLE]
Several approaches have been presented in the literature for generating spatial filters in equation (1) in the area of BCI research. Independent component analysis (ICA) is a blind source separation technique which can be used to find a linear representation of non-Gaussian data so that the components are statistically independent, or as independent as possible [21]. Such a representation is capable of capturing the inherent structure of data in many applications, and hence has application to feature extraction [22, 2] and removing artifacts from EEG signals [23]. Specifically, ICA finds a component ‘unmixing’ matrix () that, when multiplied by the original data (), yields the matrix () of independent component (IC) time courses [24]. Therefore, the main purpose of ICA is blind source separation instead of discriminating EEG in two experimental tasks. PCA is another statistical technique that uses eigenvalue decomposition to convert a set of correlated variables into a set of linearly uncorrelated variables. PCA has been applied to EEG signals for dimensionality reduction [25] and generating spatial filters [26]. Similar to ICA, PCA operates without knowledge of stimulus types hence it is an unsupervised approach. In this work, we consider supervised spatial filtering methods that aim to enhance the difference between target and standard image stimuli. Three spatial filtering methods are considered in this paper, namely MTWLB, xDAWN and CSP. MTWLB is an extension of the LDA beamformer method which aims to maximize the signal-to-noise ratio (SNR) in each individual time window. xDAWN and CSP are based on Rayleigh quotients where xDAWN maximizes the signal to signal plus noise ratio (SSNR) whereas CSP maximizes the difference of the variance between two classes. In the following paragraphs, we describe the operation of these three spatial filters generation techniques, i.e. The LDA beamformer with our window extensions, xDAWN and CSP.
2.2.1 LDA Beamformer
The LDA beamformer has been successfully applied for recovering N2 and P3 sources in an auditory experiment [18]. Considering the epoch , let column vectors and be the spatial pattern of a specific component in two different experimental conditions. We denote the difference pattern as and the covariance matrix . The optimization problem of the LDA beamformer can be stated as
[TABLE]
where is the spatial filter. Consequently, the solution to the optimization problem maximizes the signal-to-noise ratio (SNR) of the desired signal and the optimal spatial filter is given by
[TABLE]
The spatial pattern for the LDA beamformer is directly estimated from the difference between ERP peaks in an oddball experiment [18]. As seen in Fig. 2, the bold red line is the ERP difference at the Pz channel and the blue line represents the peak value timestamp of difference ERPs at the Pz channel. The different ERP values across all channels at that timestamp can then be estimated as spatial patterns.
Due to the substantial overlap between adjacent target epochs and non-target epochs, along with inherent variability in ERP latencies and topographies between participants, we extend the LDA beamformer to MTWLB. The MTWLB implementation can be seen in Algorithm 1. The key idea of MTWLB is to train multiple LDA beamformer models over non-overlapping successive time windows i.e. to train a single LDA beamformer for each time window that is adaptive to the local spatio-temporal features characterizing target-related ERP activity at that time point.
Spatial pattern estimation for MTWLB
In contrast with the LDA beamformer method, we estimate the spatial pattern and calculate the equation (3) separately for each time window rather than whole time series. Therefore, there are sets of estimated spatial patterns while each set has 32 individual spatial patterns. The reason why we do this is the substantial overlap between adjacent target epochs and non-target epochs, along with inherent variability in ERP latencies and topographies between participants in RSVP-based EEG.
Covariance matrix estimation for MTWLB
MTWLB uses the specified time window coinciding with ERP activity to estimate the covariance matrix instead of using the whole EEG epoch that is utilized by LDA beamformer [18]. We firstly concatenate trial EEG epochs through time and trials (i.e. the concatenated data , where ) and then normalize the concatenated data through columns. The covariance matrix can be calculated from the normalized concatenated data. After using artifact rejection or other EEG pre-processing methods, the covariance matrix is singular. We used shrinkage algorithms to regularize the covariance matrix in order to make it invertible [27].
As a result, MTWLB is able to generate a set of spatial filters corresponding to ERP differences in each specified time window where the number of time windows can be selected using cross-validation.
2.2.2 xDAWN
The xDAWN algorithm has been applied in BCI for ERP detection in the P300 speller paradigm [28, 12] and the RSVP paradigm [15]. It considers the model of the recorded signals as follows:
[TABLE]
where ( is the number of temporal samples of the ERP response) is the Toeplitz matrix whose first column elements are set to zero except for those corresponding to a target onset, which are set to one, is the matrix of ERPs. Hence, in (4) represents the ERP response corresponding to the synchronous response with target stimuli. is the on-going brain activity, also known as EEG background noise.
The goal of xDAWN is to apply spatial filters to enhance the SSNR of the ERP response corresponding to the target stimulus. The optimization problem for xDAWN can be defined as
[TABLE]
where is the least squares estimation of [12]. Thus, a number of spatial filters corresponding to different evoked responses can be obtained through the Rayleigh quotient optimzation problem [29]. The number of spatial filters are often chosen through cross-validation.
2.2.3 Common Spatial Pattern
CSP is one of the most popular spatial filtering approaches for motor imagery based BCIs, where the task involves two different states of brain activity (e.g. imagery of the movement of the left or right hand) [19, 30]. CSP aims to maximize the variance of one class and minimize the variance of another class. The optimization problem for CSP can also be estimated and interpreted as Rayleigh quotient [29].
First, let and be the th event locked ERP epoch and two covariance matrices and are calculated as follows (subscript “0” for standard condition and “1” for target condition)
[TABLE]
The solution for CSP can be determined through Raleigh quotients by solving a generalized eigenvalue problem
[TABLE]
Similar to the previous two approaches, CSP is able to generate a set of spatial filters. However, spatial filters in CSP appear pair-by-pair because CSP maximizes variance in one class and minimize variance in the other class. From Cecotti’s work, four spatial filters were chosen as ( is the number of electrodes) [15]. This work chooses a pair of spatial filters via cross-validation.
At this point, we have highlighted how the three methods under consideration here can generate spatial filters . All three spatial filters generated serve the same objective of reducing computation complexity but the optimization target are different. MTWLB generates spatial filters based on maximizing the SNR in individual time windows. xDAWN, in contrast generates spatial filters based on maximizing the signal-to-signal plus noise ratio (SSNR) for the whole EEG epoch. Finally the method of CSP generates spatial filters through maximizing the variance difference between two classes.
2.3 Feature Generation
The spatial filter generated serves to transform the original EEG epoch to the feature space
[TABLE]
where . The projected subspace can be represented as spatial-filtered EEG signals involving different discriminative information corresponding to the criteria used in their filter generation. PCA can then be applied to each row in for feature reduction and generating a new set of time series which are linearly uncorrelated. In this work, principal components whose explained variance ratio is greater than 1% are selected and concatenated as the feature vector which will be used as input to the classification step.
2.4 Linear Classifiers
Linear classifiers are widely used for RSVP-based BCI due to their good performance, often simple implementation and low computational complexity [2, 10, 1, 11]. In this paper, we focus on three widely used linear classifiers in RSVP-based BCI research, namely LDA, LLR and BLR.
2.4.1 Linear Discriminant Analysis
LDA is a supervised subspace learning method which is based on the Fisher criterion and it is equivalent to least squares regression (LSR) if the regression targets are set to for samples from class 1 and for samples from class 2 (where is total number of training samples, is the number of samples from class 1 and is the number of samples from class 2) [31]. It aims to find an optimal linear transformation that maps to a subspace in which the between-class scatter is maximized while the within-class scatter is minimized in that subspace. The optimization problem for LDA is to maximize the cost function as below
[TABLE]
where represents the cost to be minimized, is the between-class scatter, is the within-class scatter, is the transpose matrix to the . Regularization is often applied in order to avoid the singular matrix problem of [32]. LDA enables the best separation between two classes on the subspace . LDA has relatively low computational complexity which makes it suitable for online BCI systems. As mentioned earlier, classification of RSVP-based EEG data suffers from the imbalanced data set problem. In Xue’s work [33], he showed that there is no reliable empirical evidence to support that an imbalanced data set has a negative effect on the performance of LDA for generating the linear transformation vector. Consequently, LDA is suitable and has been successfully used in RSVP-based BCI [2, 10].
2.4.2 Bayesian Linear Regression
Bayesian linear discriminant analysis (BLDA), can be seen as an extension of LDA or LSR. In BLR, regularization for parameters is used to prevent overfitting caused by high dimensional and noisy data. BLR assumes the parameter distribution and target distribution are both Gaussian [31]. We introduce LSR as a starting point for the description of BLR. The solution for LSR can be stated as
[TABLE]
Note that for class 1 and for class 2 here (threshold can be determined by adding a column with all one as the first column in ). LSR does not consider the parameter distribution in this case and it maximizes the likelihood. For BLR, it considers the parameter distribution and maximizes the posterior. Given the prior target distribution and parameter distribution (where and are the inverse variance), BLR gives the optimized estimation for the parameter
[TABLE]
The optimization problem of BLR can be concluded as the maximum a posterior (MAP) estimation [34], which lies in the assumption of an appropriate prior distribution of the parameter to be estimated. Hence, the optimization depends on the hyperparameters and . In real-world applications, the hyperparameters can be tuned using cross validation or the maximum likelihood solution with an iterative algorithm [31, 35]. BLR has been shown to outperform LDA in BCI research [14, 16].
2.4.3 Logistic Regression
LR models the conditional probability as a linear regression of feature inputs. The logistic model can be constructed as
[TABLE]
The optimization problem of an LR can be constructed by minimizing the cost function as below:
[TABLE]
where , is the sample number of two classes and is the regularization parameter ().
LR is part of a broader family of generalized linear models (GLMs), where the conditional distribution of the response falls in some parametric family, and the parameters are set by the linear predictor. LR is the case where the response (i.e. in equation (13)) is binomial and it can give the prediction of the conditional probability estimation. LR is easily implemented and has been successfully applied to RSVP based BCI research [36, 13].
2.5 Evaluation
The evaluation described in this work seeks to assess the relative performance when combining three spatial filtering approaches with three linear classification methods, thus there are nine pipelines (spatial filtering feature generation classification) in total that are discussed in this paper. For comparison, the original EEG epochs without spatial filtering and only using PCA, are fed to three linear classifiers. Performance of the different pipelines are evaluated through the area under the curve (AUC) based on true positive rate (TPR) and false positive rate (FPR)
It should be noted that the pipeline described in this paper contains a number of hyperparameters. Three spatial filtering approaches contain a number of spatial filters as the hyperparameter. BLR contains data distribution variance () and parameter distribution variance () while LR has the regularization term () as hyperparameters. Only LDA does not require a hyperparameter. Table 1 summarizes the hyperparameters used in each pipeline. We apply a random search [37] for 100 hyperparameter combinations in each pipeline and select these for evaluation on a test set using 10-fold cross validation. The optimal model is then applied to the testing data to calculate the AUC score.
3 Data acquisition and pre-processing
The EEG datasets used in this work is from the Neurally Augmented Image Labelling Strategies (NAILS) task as part of an open data challenge carried out in 2017 [38]. EEG data from up to 9 participants in NAILS was used in this work. Data collection was carried out with approval from Dublin City University’s Research Ethics Committee (DCU REC/2016/099). EEG was recorded along with timestamping information for image presentation (via a photodiode and hardware trigger) to allow for precise epoching of the EEG signals for each trial [39]. Each participant completed 6 different tasks (INSTR, WIND1, WIND2, UAV1, UAV2 and BIRD). For each task, participants were asked to search for specific target images from the presented images (i.e. an airplane has the role of target in UAV1 and UAV2 tasks, a keyboard instrument is the target for the INSTR task, while a windfarm is the target in the WIND1 and WIND2 tasks, parrot being the target in the BIRD task, see Fig. 4). Each task was divided into 9 blocks, where each block contained 180 images (9 targets/171 standards) thus there were 486 target and 9,234 standard images available for each participant. Images were presented to participants at a 6 Hz presentation rate. EEG data was recorded using a 32 channel BrainVision actiCHamp at 1000 sampling frequency, using electrode locations as defined by the 10-20 system.
Pre-processing of some kind is generally a required step before any meaningful interpretation or use of any EEG data can be realized. Pre-processing typically involves re-referencing, filtering the signal (by applying a bandpass filter to remove environmental noise or to remove activity in non-relevant frequencies), epoching (extracting a time epoch typically surrounding the stimulus onset) and trial/channel rejection (to remove those containing artifacts) [9]. In this work, a common average reference (CAR) was utilized and a bandpass filter (e.g. 0.1-30 ) was applied to the dataset. EEG data was then resampled at 250 and the analysis of a behavior response is considered between 0 and 1 after the presentation of a stimulus. Trial rejection based on HEOG and VEOG channels was applied for all participants. The dataset was split into a training/testing set of 66%/33% respectively, by selecting 3 blocks from each search task to act as a withheld test set in the evaluation.
4 Results
4.1 Impact of Number of Spatial Filters
The P300 is not the only ERP that is commonly encountered when using an RSVP target search paradigm. Earlier ERPs (notably the N200) are often present alongside the P3 [40] and can be useful in providing discriminative information for classification. Fig. 3 shows the discriminant ERPs for 9 participants in two different time regions and it can be seen that both early time regions and later time regions generate discriminative ERP-related activity across participants. It can be noted also that the specific latencies and topographies vary across participants, hence may vary across participants for capturing target-related ERP phenomena in the RSVP paradigm.
From previous work [15], has been set to 4 for both xDAWN and CSP methods. It is difficult to determine the optimal , thus we leave it as a searching hyperparameter in our pipeline. Even selection of the number of spatial filters has been stated in the area of the motor imagery BCI [41], we have more hyperparameters in this work. In this case, we search for the optimal number of spatial filters with other parameters together in each model, which has been specified in the Evaluation Section. It is worth reiterating again that this has not been explicitly reported upon previously in the area of RSVP. Fig. 5 shows an example of 10 spatial patterns and filters estimated with three spatial filtering approaches. It can be seen that spatial patterns estimated with the same approach are different from each other which indicates target-related ERPs span broadly over both time and space in an RSVP paradigm. Hence, a search for an optimal value of is required for best performance
4.2 Performance Evaluation
This work evaluated 9 different pipelines, composed of three classifiers with three spatial filtering methods. We used whole original EEG epochs for training three classifiers as measuring metrics for comparison. The AUC for each pipeline across nine participants are presented in Table 2.
4.2.1 Performance of spatial filtering
For the performance of three spatial filtering methods, all three classifiers with CSP pre-processing generate lower AUC score compared to those which do not use spatial filtering. This indicates that CSP is a wholly unsuitable spatial filtering approach for RSVP-BCI. Unlike CSP, all three classifiers with MTWLB and xDAWN spatial filtering pre-processing perform better than those without spatial filtering which show the efficacy of MTWLB and xDAWN pre-processing. This result demonstrates that it is critical to select carefully the precise spatial filtering method in RSVP-BCI and an ‘improper’ spatial filtering method may have deleterious effects and degenerate performance to the level of not using any spatial filtering.
CSP aims to maximize the EEG variance difference between two classes. However, the single-trial ERPs variance difference is very small in RSVP paradigm between two classes and the challenge for single-trial ERPs detection is its low SNR. Here we define the ‘proper’ spatial filtering approach for RSVP-based EEG as those methods which improve the SNR for the EEG signals. Both MTWLB and xDAWN optimize for maximized SNR and as a result both perform better than the inappropriately applied CSP method. A proper spatial filtering method can not only improve the quality of the EEG data but also reduce the computational complexity since spatial filtering can reduce the EEG dimensionality.
4.2.2 Performance of classifier
As mentioned before, CSP is not able to extract discriminant features for ERPs generated in an RSVP paradigm. Therefore, features generated by CSP have negative effects on all three classifiers compared to the EEG data without spatial filtering. From results generated by LR across MTWLB and xDAWN and without spatial fitering, it can be seen that the performance of LR improved significantly when using non-CSP spatial filtering methods (i.e. 92.2% for MTWLB and 92.7% for xDAWN versus 87.5% and 88.5% without spatial filtering). This indicates that the quality of features has large impact on LR. For another two classifiers, spatial filtering improves the performance of LDA and BLR slightly. This indicates that LDA and BLR are more robust to the quality of features compared to LR. However, LR shows good performance if good features can be extracted by pre-processing (i.e. highest AUC score for LR with xDAWN).
5 Discussion
In this paper, we addressed two main issues: 1) the impact of choice of spatial filtering method on the performance of an RSVP-based BCI single trial classification task and 2) the sensitivity of different classifier’s performance to the feature types produced in a typical RSVP-BCI pipeline.
Regarding the first issue, we have shown that the performance of our novel MTWLB method and the popular xDAWN method both improve classifier performance. However, the performance generated by pipelines involving CSP is worse than those without using spatial fitering. This indicates that the choice of spatial filtering method is critical for single-trial detection of ERPs in an RSVP paradigm. In the literature, we find some work which uses CSP for RSVP-based EEG [42, 43] which illustrates that CSP is considered by at least some researchers as being a suitable method for RSVP-BCI. Our results however reveal that this is not an optimal choice. By comparing the optimization criterion of each spatial filtering approach, it should be noted that MTWLB and xDAWN both use ERPs for calculating the spatial filters (i.e. ERPs difference and estimated ERP response are used for calculating equation (3) and (5)).
The main difference between MTWLB and xDAWN is selecting the number of spatial filters. In MTWLB, number of spatial filters is selected corresponding to the divided individual time window that means each spatial filter maximizes SNR for ERPs in the selected time window. xDAWN uses generalized eigenvalue decomposition for whole EEG epoch and eigenvectors that correspond to high eigenvalues will be selected. Therefore, the number of spatial filters refers to the number of time windows in MTWLB while it refers to the number of eigenvectors corresponding to the highest eigenvalues in xDAWN. From the classification result, the proposed MTWLB gives similar performance compared to xDAWN. However, this proposed approach can be well-suited for generating spatial filters for those tasks that elicit ERPs in specific time regions. CSP also uses generalized eigenvalue decomposition for optimizing the spatial filter but it uses a single-trial EEG epoch instead of ERPs to calculate the covariance matrix in equation (7). Because RSVP-based EEG has low SNR, this optimization formulation can be effected significantly by low SNR in this case. CSP origins from the motor imagery BCI in which sensor motor rhythm (SMR), a periodic EEG, is elicited in the experiment [44]. The optimization criterion for CSP is maximizing the difference of variance between two classes which coincides with the property of SMR. In an RSVP paradigm, ERPs are elicited alongside the steady-state visual evoked potentials (SSVEP) and there is a very small difference of the variance between target and standard classes. The challenge for single-tiral ERP detection is its low SNR. MTWLB and xDAWN aim to improve the SNR and SSNR respectively for the reconstructed signal which overcomes the low SNR problem. Therefore, MTWLB and xDAWN are very suitable for single-trial ERP detection in an RSVP paradigm. We explored further the performance difference between MTWLB and xDAWN. We used one-way ANOVA on the mean value of three classification methods applied with MTWLB (92.2%) and xDAWN (92.4%) i.e. , which indicates the insignificant difference of the performance between these two spatial filtering methods. This suggests that the performance of these two methods are similar for this dataset. While MTWLB and xDAWN perform similarly, MTWLB still has some advantages. First, the proposed method MTWLB gives an intuition of producing the spatial filter corresponding to the time-line. From the generated spatial filter or the projected subspace , we can see the spatial filter or projected subspace change over time. For example, the spatial filter and spatial pattern change with time in MTWLB from left to right in Fig. 5. It provides a more physiological representation of the spatial pattern and the spatial filter changing with time which the conventional spatial filtering approach is not able to represent. Second, we searched for the appropriate time window for MTWLB due to the inherent variability in ERP latencies between participants in our case. However, MTWLB can be effective for those cases in which the time region for the ERPs are known in advance. Hence, there is no need to search for the time window and the computational complexity is reduced significantly. Third, performance of xDAWN can be affected by the selected epoch length because the optimization of xDAWN is based on the whole epoch. On the contrary, MTWLB estimates the spatial pattern and covariance in the specific time window instead of the whole EEG epoch. So changing epoch length will have no effect on the performance of the MTWLB algorithm.
Regarding the second issue of the effect of features on classifier performance we have shown the performance of three classifiers in different pipelines. It can be noted that LDA and BLR outperform LR in the CSP pipeline and the pipeline without spatial filtering. This indicates that LR is more sensitive to the quality of features compared to LDA and BLR. LR is used for modeling the relationship between independent and categorical dependent variables and variable colinearities may have negative effects on estimation [45]. From the pipeline with proper spatial filtering, three classifiers perform closely to each other with MTWLB and LR outperforming the other two methods in the pipeline when using xDAWN. This indicates that the LR classifier performs well with informative features as input. LDA and BLR have been used more widely compared to LR in the literature since LDA performs well even without feature extraction and is simpler to implement [15, 16, 2, 10]. Here we have shown that LR is able to generate very good performance when informative features are extracted from RSVP-based EEG.
Result in this paper partly supports the result in [15] that spatial filtering can improve the overall performance. In this work, we performed a more comprehensive comparison of the spatial filtering pipeline. First, we included a random search [37] for the set of hyperparameters listed in the Table 1 in order to attain optimal performance. In the experiment, we found that the number of spatial filters can have critical impact on the final classification performance and it varies with different participants. Instead of leaving it as a specific number [15], we suggest to search it as a hyperparameter in the pipeline in order to optimize the performance of spatial filtering. Second, the type of spatial filtering is critical to the classification performance for different types of EEG. For example, CSP has been widely used for motor imagery based BCI [46, 30, 47], where oscillatory EEG activity is elicited in the experiment [48, 49]. However, the classification performance of pipeline with applying CSP spatial filtering is even worse than pipelines without spatial filtering, which supports the results in [15]. These results suggest that improper use of spatial filtering in RSVP-based BCI system can have negative impact on the classification performance and this conclusion can be extended to other types of EEG activity. On the contrary, applying the appropriate spatial filtering technique (i.e. MTWLB, xDAWN for RSVP-based EEG in this work) results in reduced computational complexity and improvement in classification performance. This work demonstrates that it is critical to choose the appropriate type of spatial filtering for the signal processing pipeline in RSVP-based BCI systems.
6 Conclusion
In this work, we present a novel spatial filtering approach (MTWLB) for RSVP-based EEG. Our results demonstrate comparable performance with the leading method of xDAWN although the approach is significantly different. Consequently the method presents a different set of optimization parameters which may make it suitable for particular RSVP-BCI implementations. Even there is no statistical significance between our proposed method and xDAWN, MTWLB presents useful properties that lend themselves to certain RSVP-BCI performance optimizations not available via xDAWN. First, the method is more robust to EEG epoch length compared to the conventional spatial filtering approaches (e.g. xDAWN and CSP) because its optimization relies on the time window instead of whole epochs. Second, MTWLB can be more effective when knowing ERPs time region in advance because there is no need to search for the time window and the computational complexity is reduced significantly. Furthermore this work includes a thorough evaluation of single-trial classification pipelines with a number of spatial filters and classifiers in a comprehensive way using a publicly available dataset. We have shown that the selection of spatial filtering method should correspond to the nature of ERPs elicited in the task paradigm and that naive application of the approach may not produce good performance. Finally we demonstrate that even though LDA and BLR are the most prevalent classification approaches used in RSVP-based BCI research, the LR method can be even more effective for single-trial ERPs detection when good quality features are made available through the spatial filtering methods. In summary this paper should help inform designers of RSVP-BCI of an appropriate spatial filtering / classifie r choice at design time based on results with a publicly available dataset which allows comparative benchmarking of performance.
7 Acknowledgement
This work is funded as part of the Insight Centre for Data Analytics which is supported by Science Foundation Ireland under Grant Number SFI/12/RC/2289.
8 Appendix
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gerson AD, Parra LC, Sajda P. Cortically coupled computer vision for rapid image search. IEEE Transactions on Neural Systems and Rehabilitation Engineering. 2006 June;14(2):174–179.
- 2[2] Bigdely-Shamlo N, Vankov A, Ramirez RR, et al. Brain activity-based image classification from rapid serial visual presentation. IEEE Transactions on Neural Systems and Rehabilitation Engineering. 2008;16(5):432–441.
- 3[3] Healy G, Smeaton AF. Eye fixation related potentials in a target search task. In: Engineering in Medicine and Biology Society, EMBC, 2011 Annual International Conference of the IEEE; IEEE; 2011. p. 4203–4206.
- 4[4] Spence R, Witkowski M. Rapid serial visual presentation: design for cognition. Springer; 2013.
- 5[5] Polich J. Updating P 300: an integrative theory of P 3a and P 3b. Clinical neurophysiology. 2007;118(10):2128–2148.
- 6[6] Lawhern V, Solon A, Waytowich N, et al. Eegnet: a compact convolutional neural network for eeg-based brain–computer interfaces. Journal of neural engineering. 2018;.
- 7[7] Lees S, Dayan N, Cecotti H, et al. A review of rapid serial visual presentation-based brain–computer interfaces. Journal of neural engineering. 2018;15(2):021001.
- 8[8] Teplan M, et al. Fundamentals of EEG measurement. Measurement science review. 2002;2(2):1–11.