Deep Semantic Multimodal Hashing Network for Scalable Image-Text and Video-Text Retrievals
Lu Jin, Zechao Li, Jinhui Tang

TL;DR
This paper introduces DSMHN, a deep multimodal hashing network that efficiently enables scalable image-text and video-text retrieval by jointly learning modality-specific hash functions with semantic preservation.
Contribution
The paper presents a novel deep hashing framework that integrates 2D and 3D CNNs with joint learning of hash functions and semantic labels for improved multimodal retrieval.
Findings
DSMHSN outperforms state-of-the-art methods on multiple datasets.
The framework effectively captures spatial and temporal information.
It demonstrates high retrieval accuracy for both image-text and video-text tasks.
Abstract
Hashing has been widely applied to multimodal retrieval on large-scale multimedia data due to its efficiency in computation and storage. In this article, we propose a novel deep semantic multimodal hashing network (DSMHN) for scalable image-text and video-text retrieval. The proposed deep hashing framework leverages 2-D convolutional neural networks (CNN) as the backbone network to capture the spatial information for image-text retrieval, while the 3-D CNN as the backbone network to capture the spatial and temporal information for video-text retrieval. In the DSMHN, two sets of modality-specific hash functions are jointly learned by explicitly preserving both intermodality similarities and intramodality semantic labels. Specifically, with the assumption that the learned hash codes should be optimal for the classification task, two stream networks are jointly trained to learn the hash…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2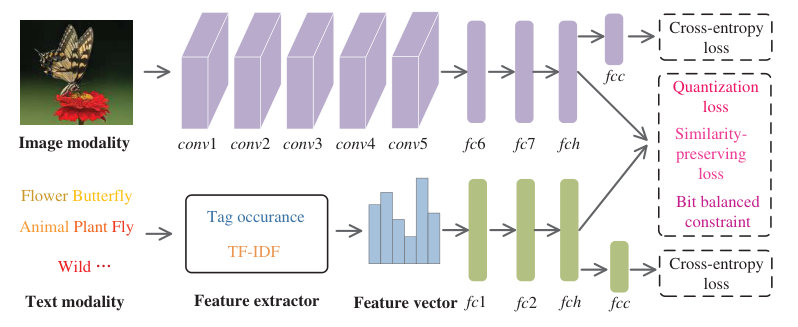 Figure 3
Figure 3 Figure 4
Figure 4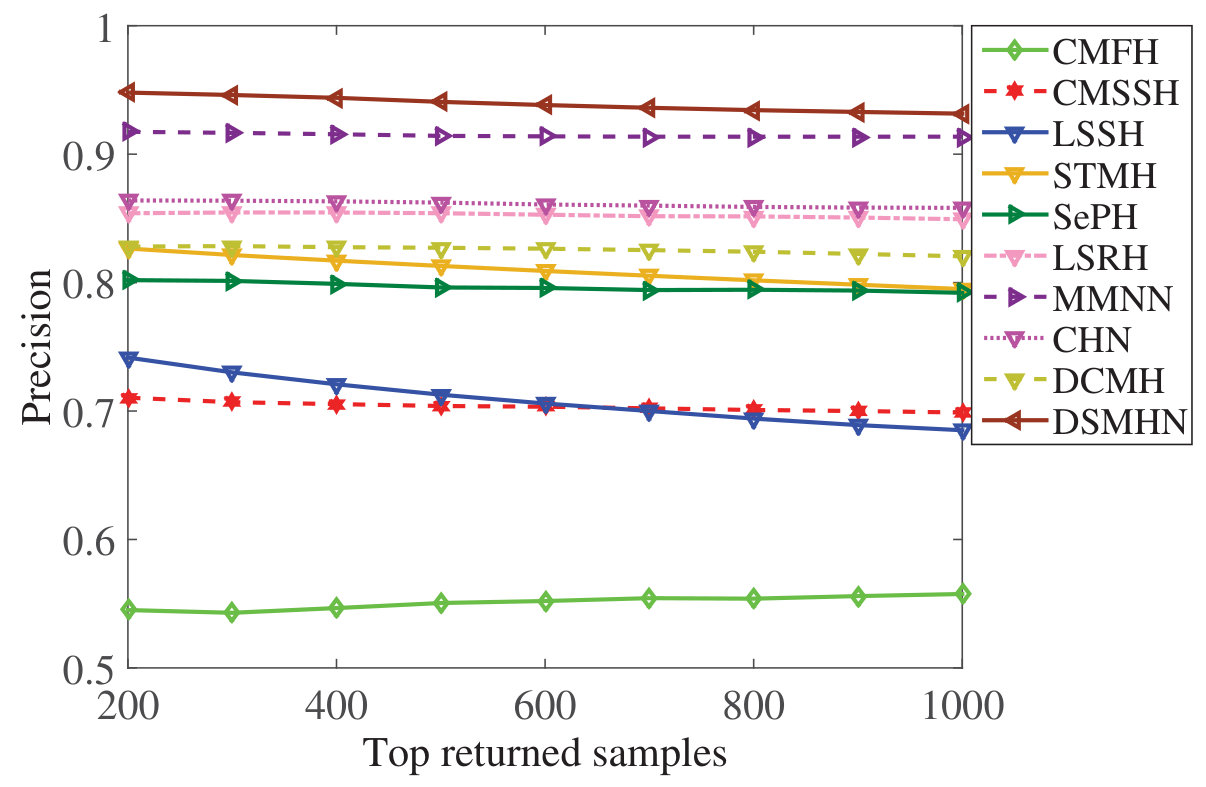 Figure 5
Figure 5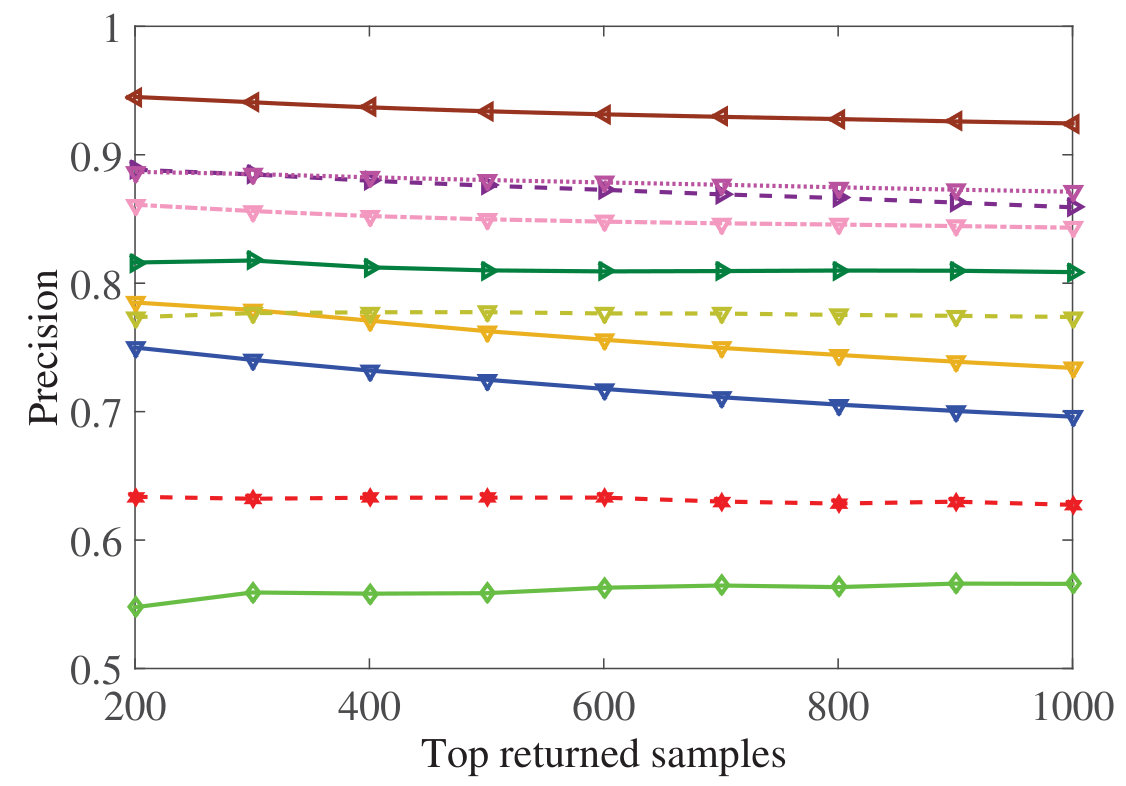 Figure 6
Figure 6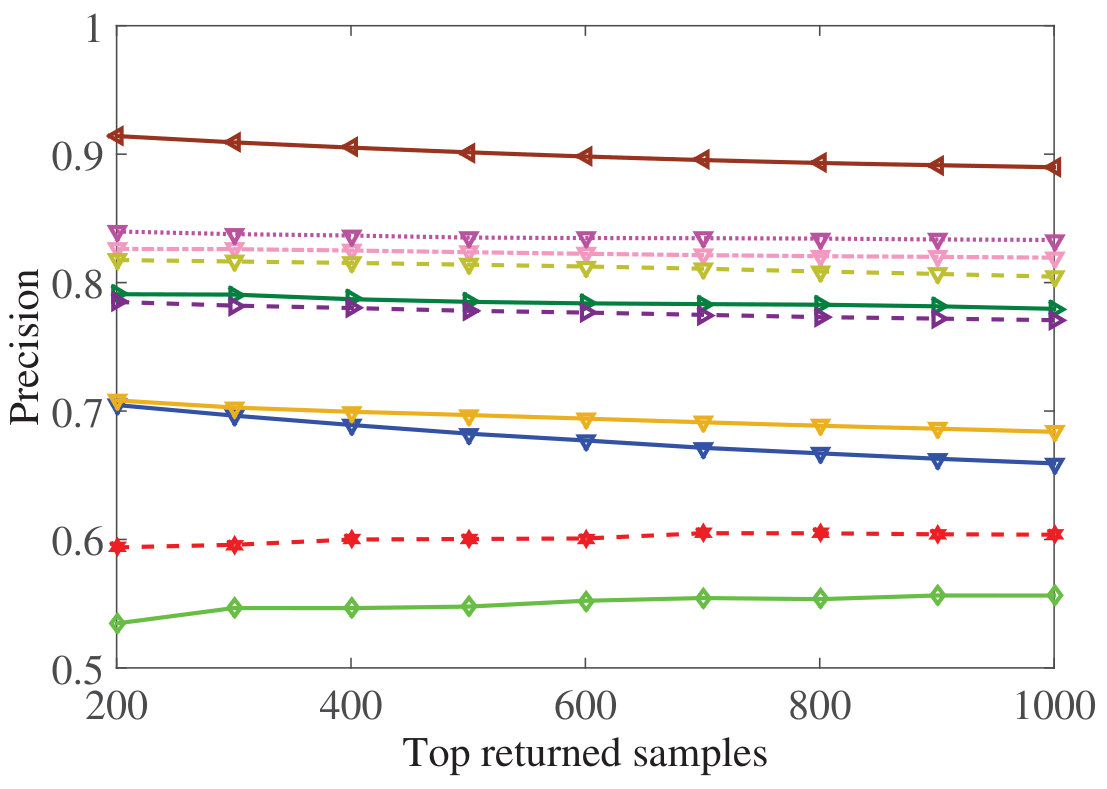 Figure 7
Figure 7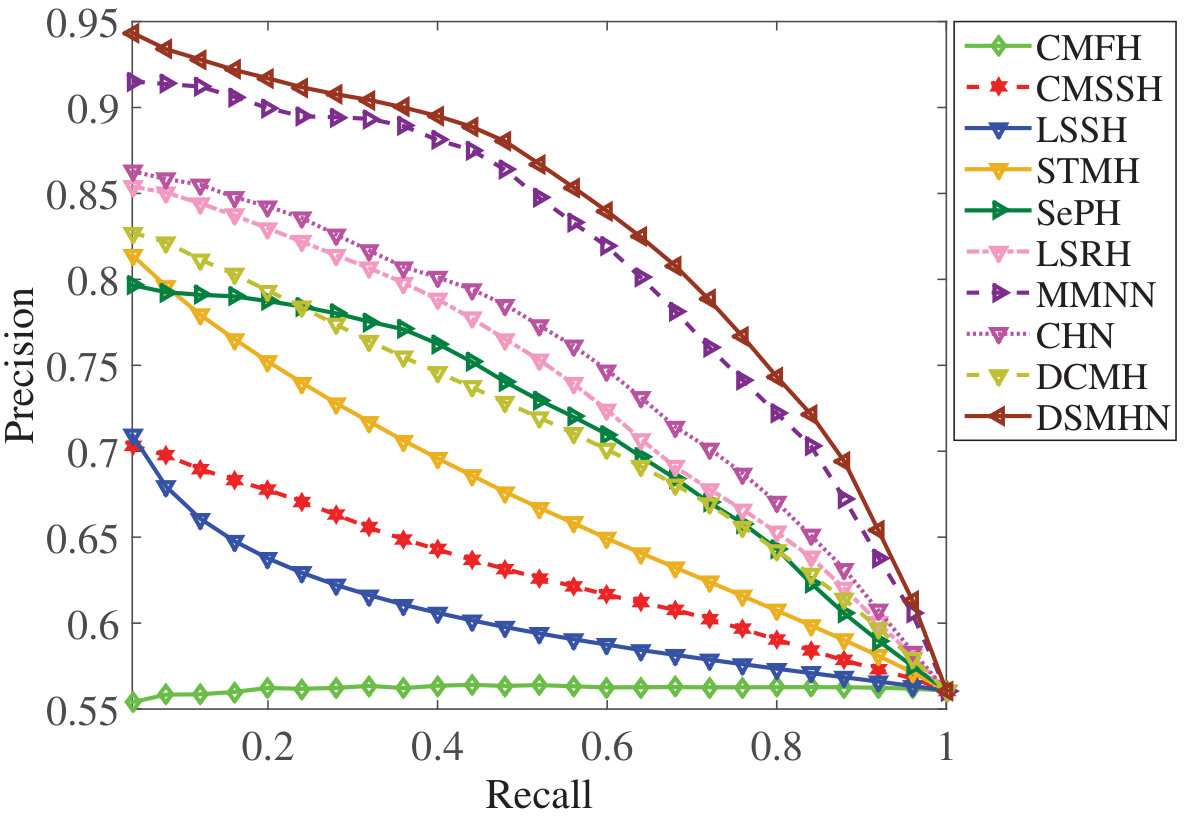 Figure 8
Figure 8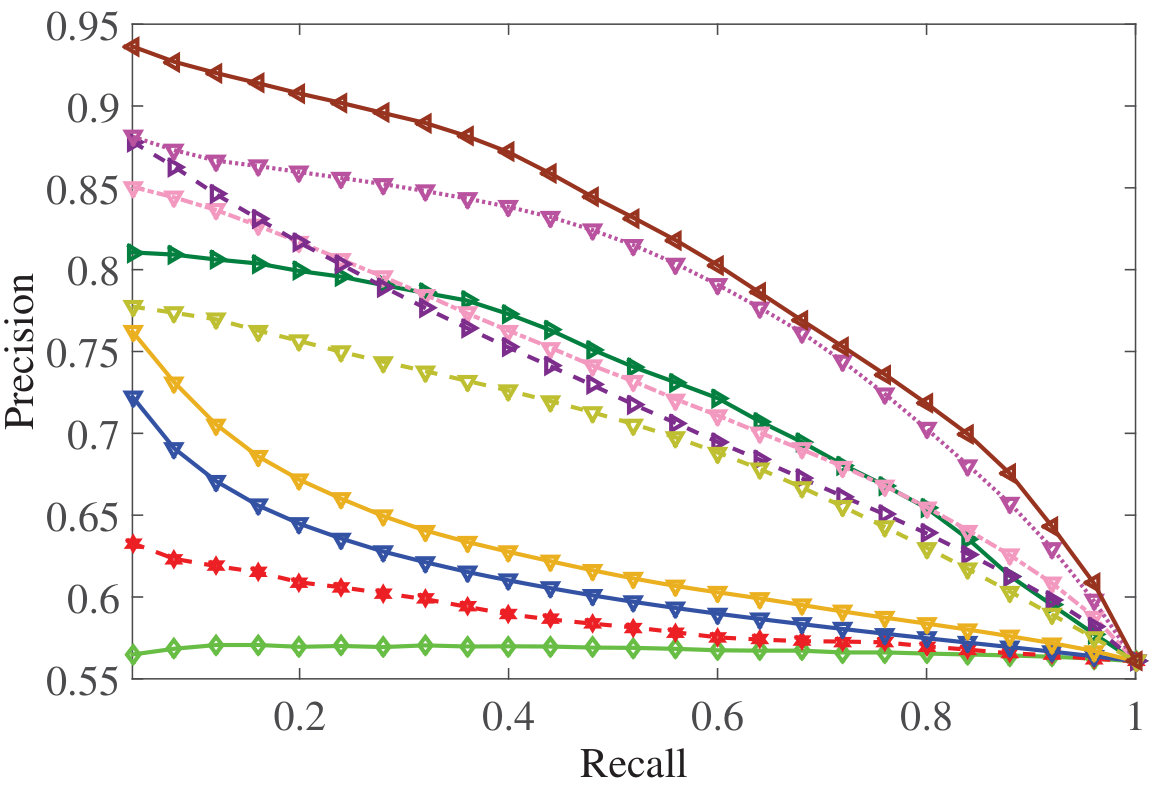 Figure 9
Figure 9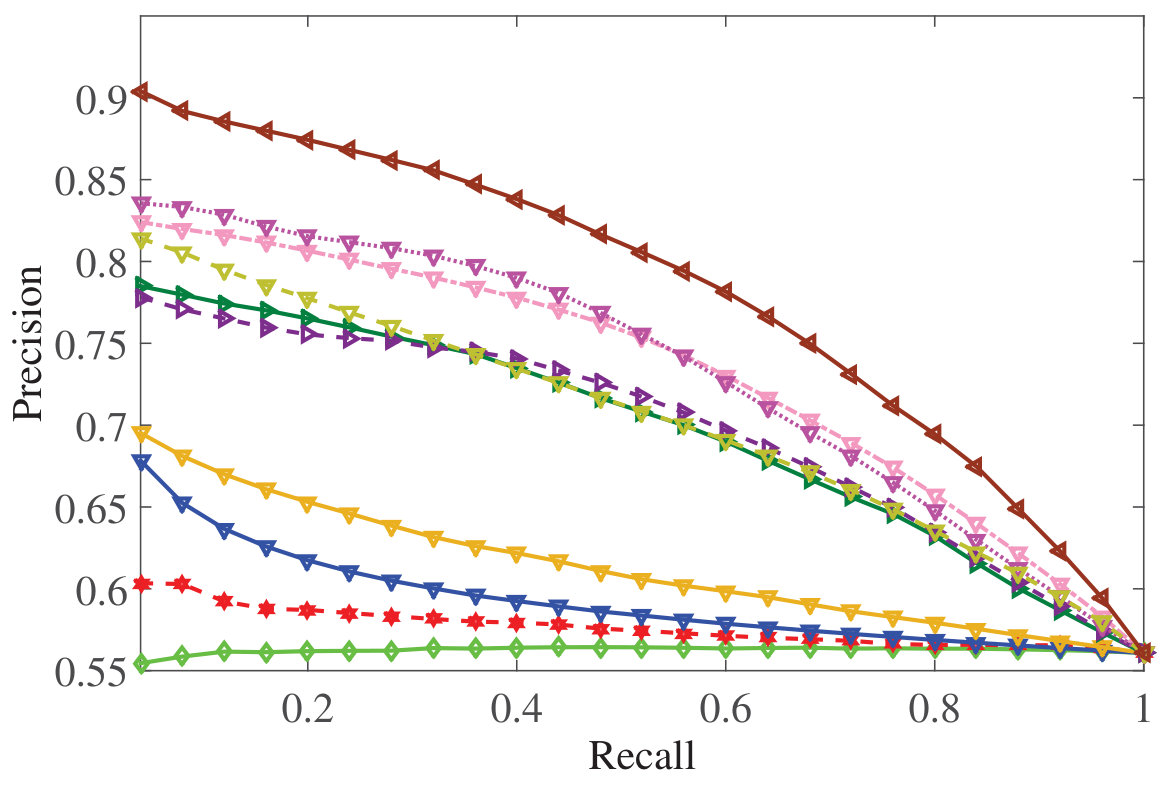 Figure 10
Figure 10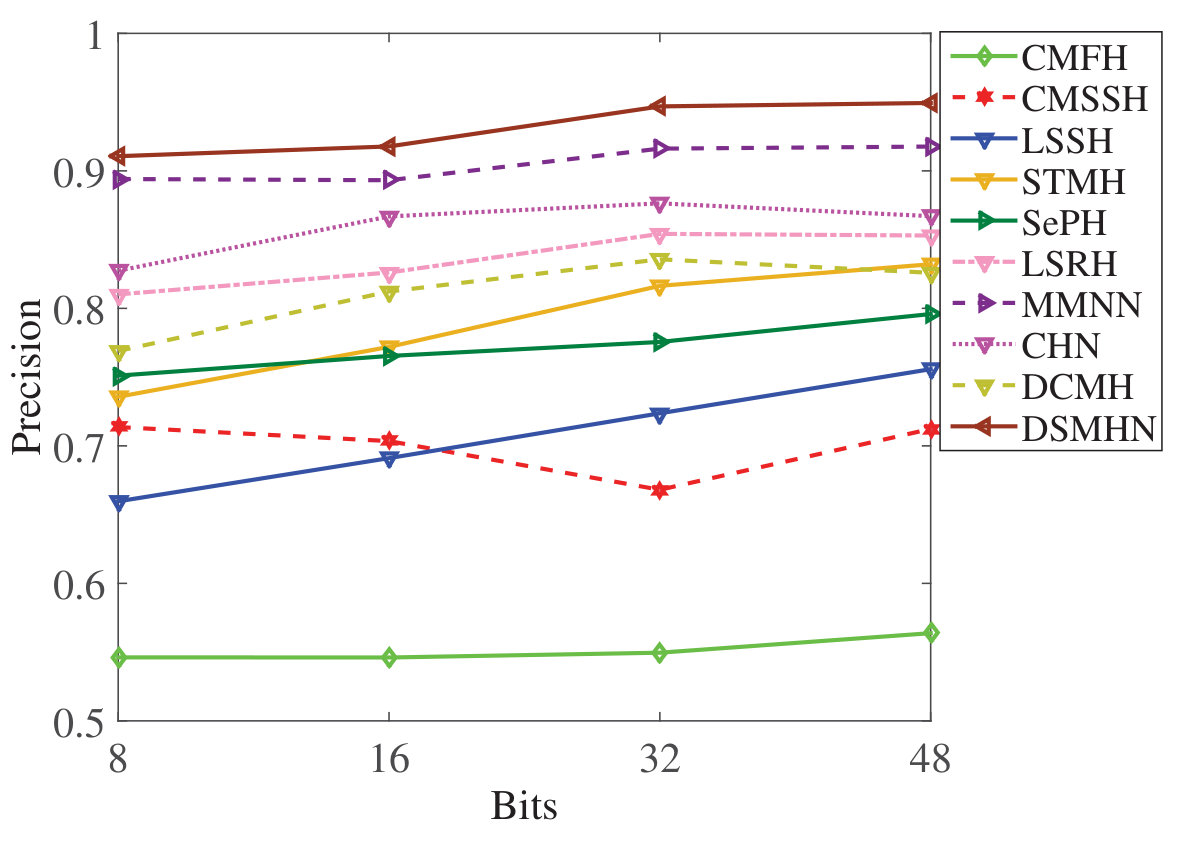 Figure 11
Figure 11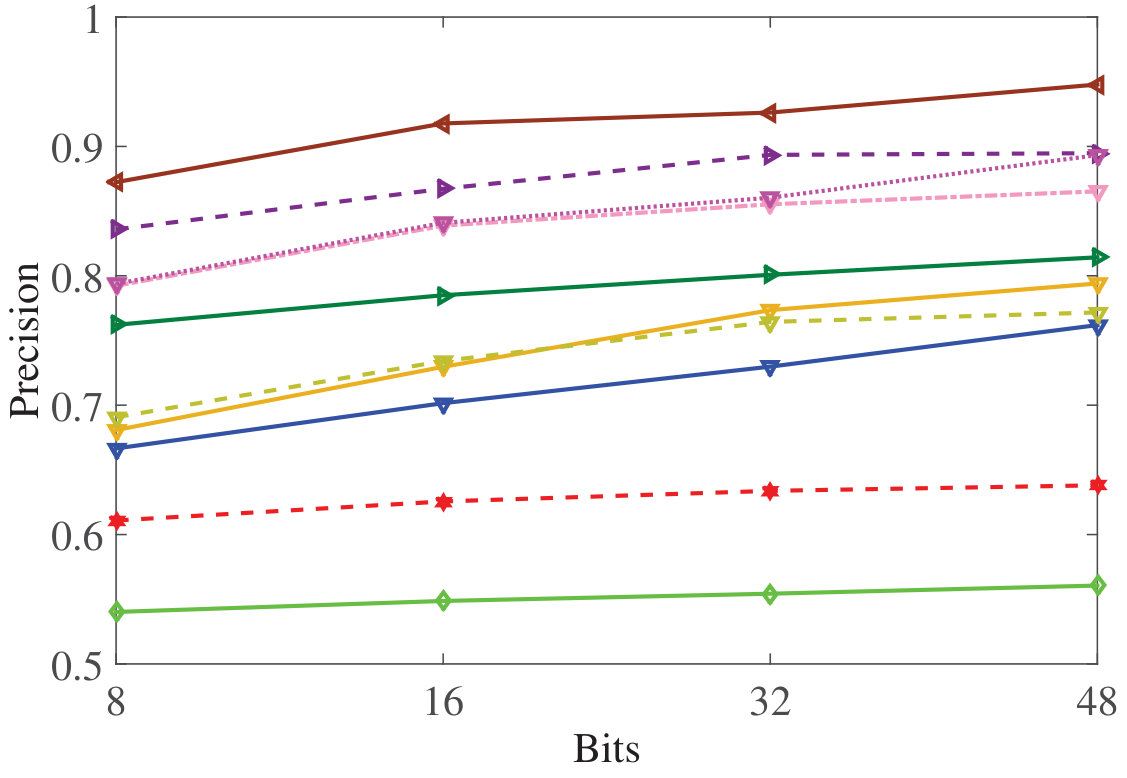 Figure 12
Figure 12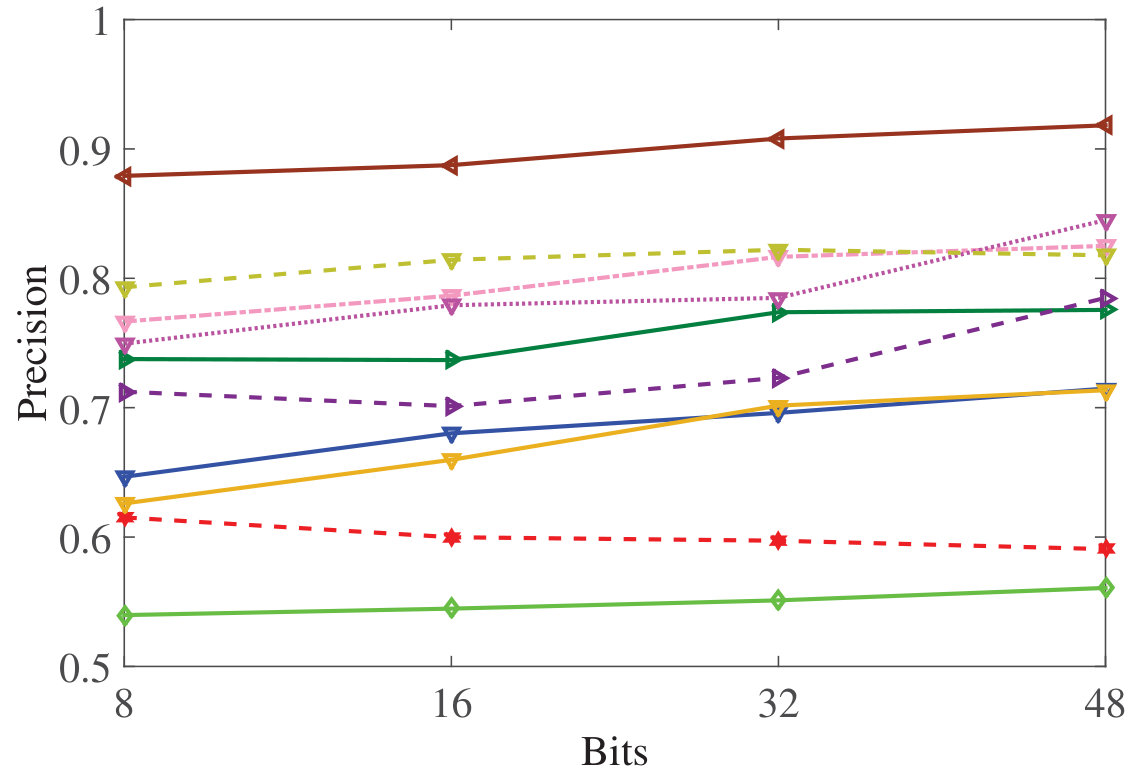 Figure 13
Figure 13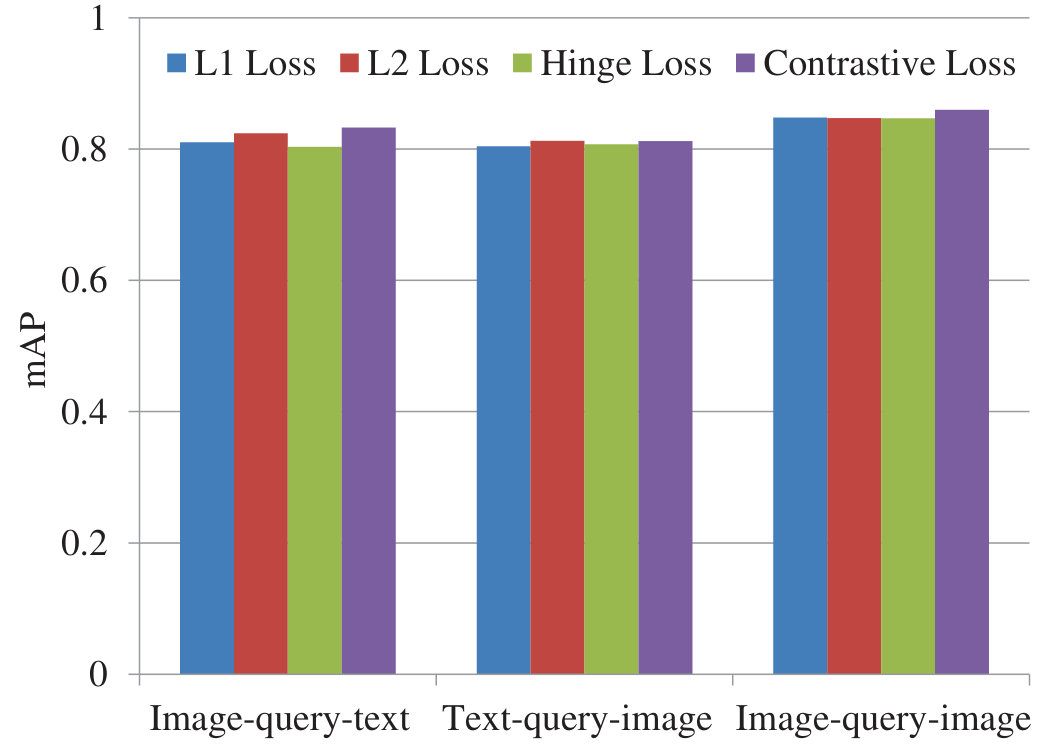 Figure 14
Figure 14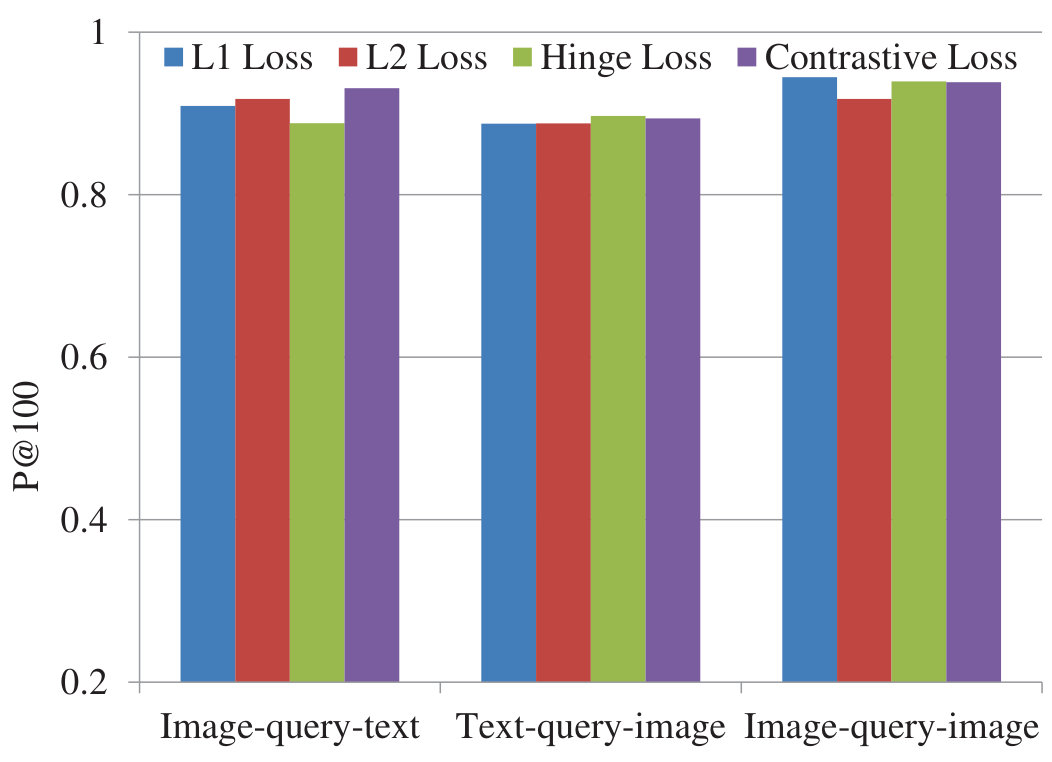 Figure 15
Figure 15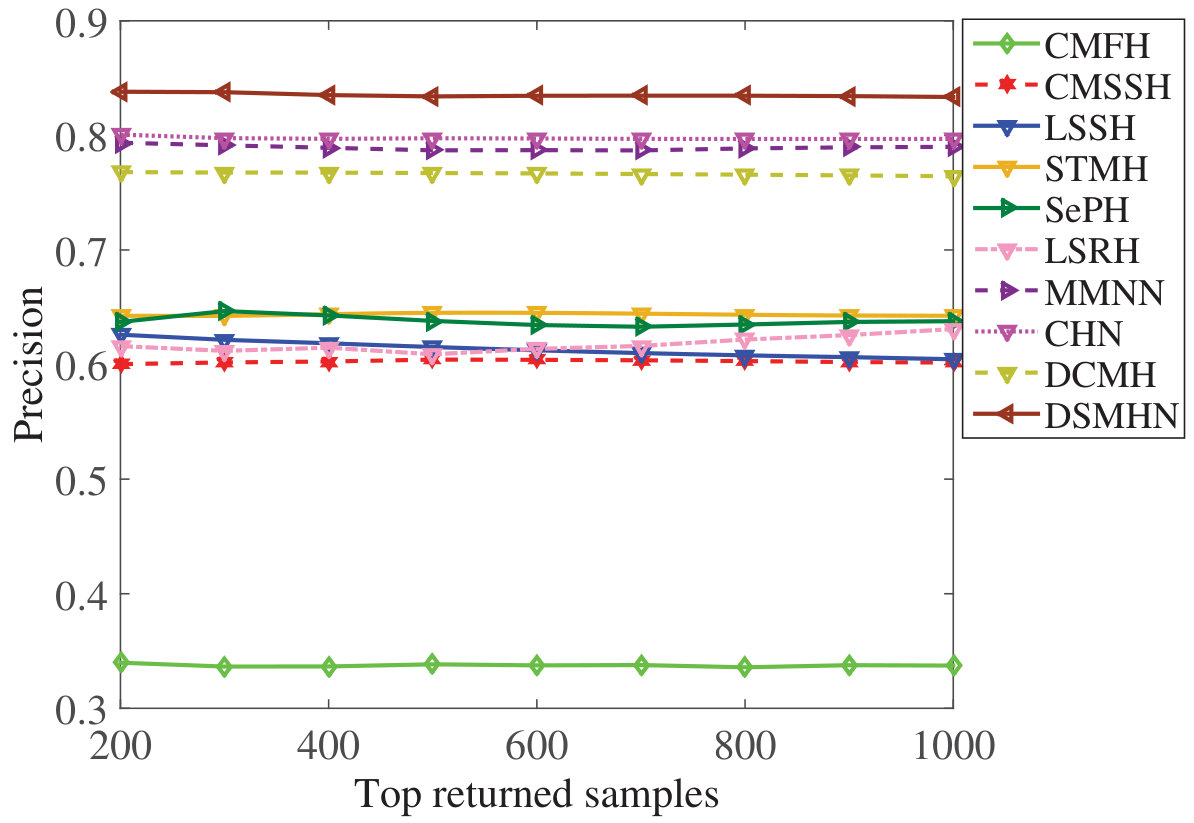 Figure 16
Figure 16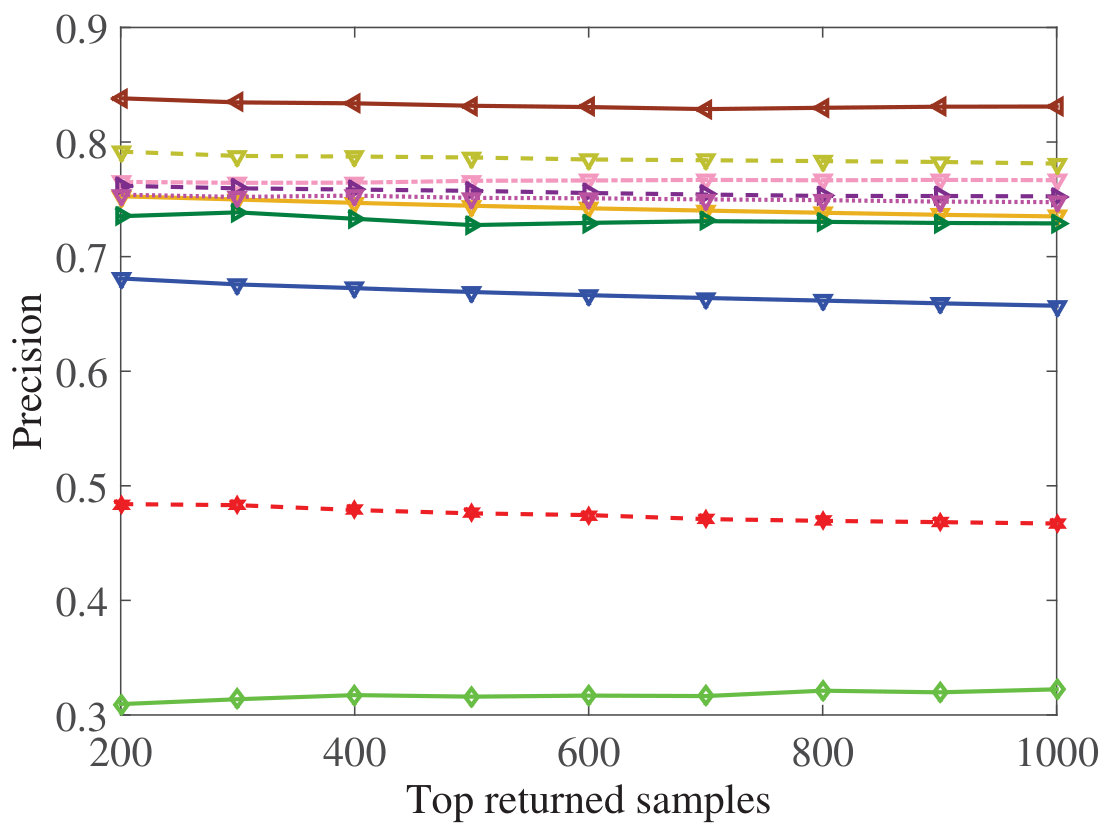 Figure 17
Figure 17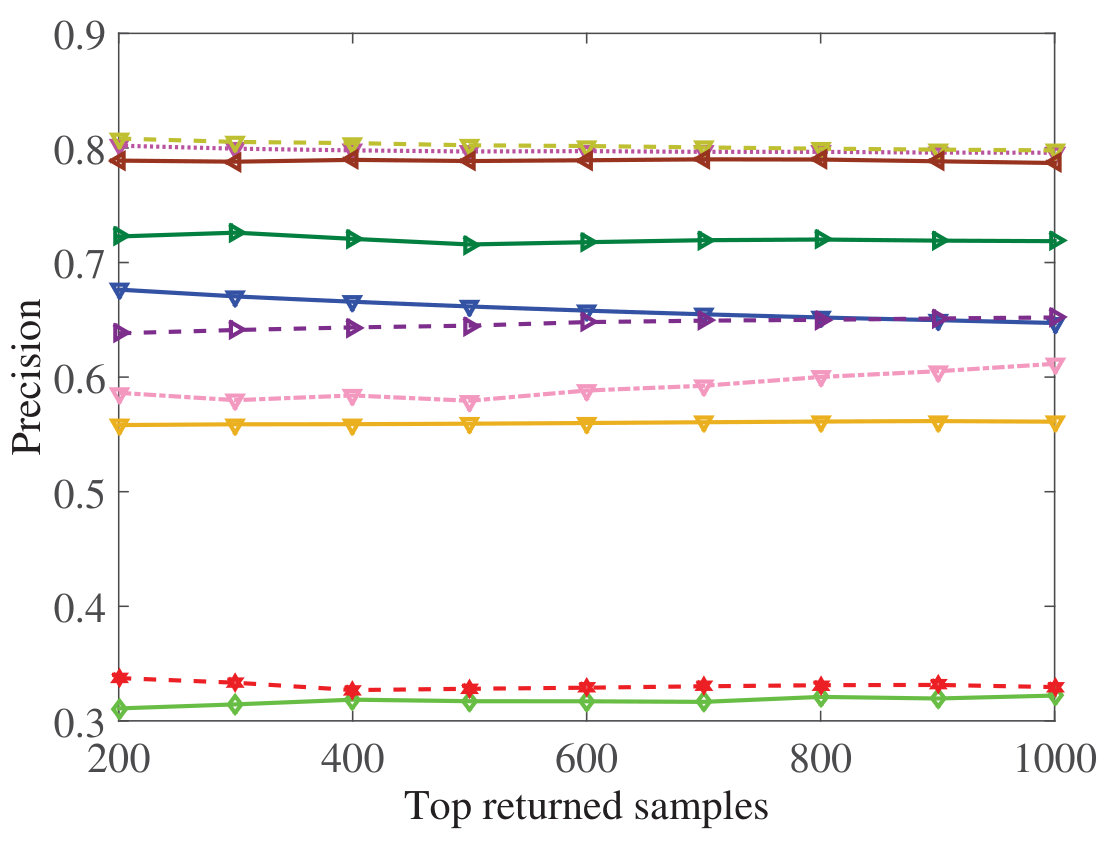 Figure 18
Figure 18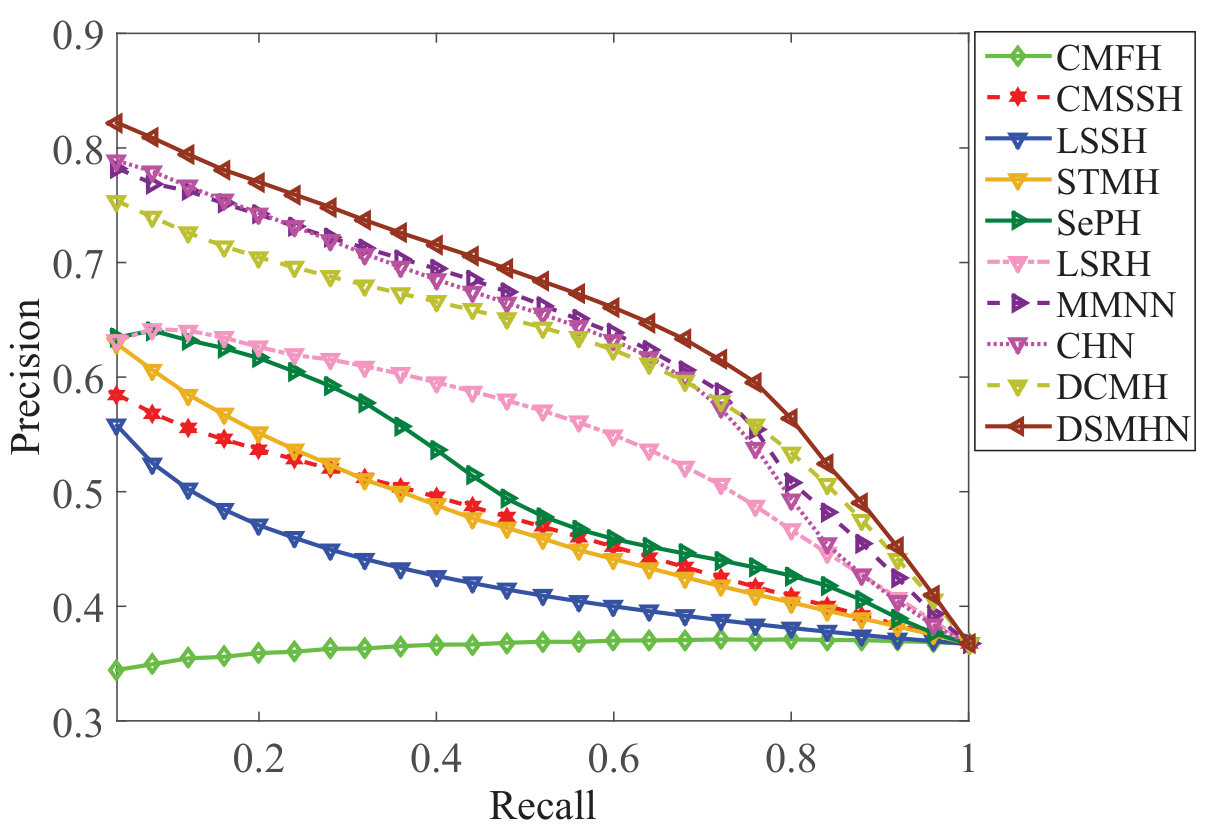 Figure 19
Figure 19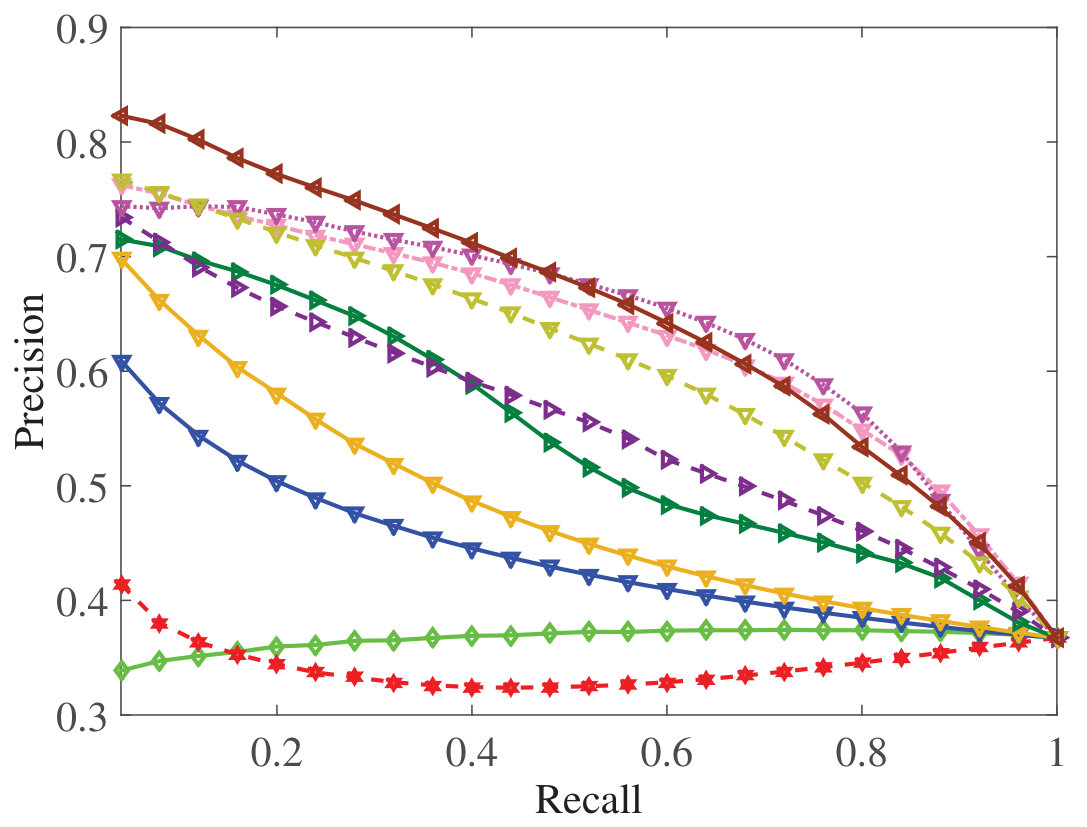 Figure 20
Figure 20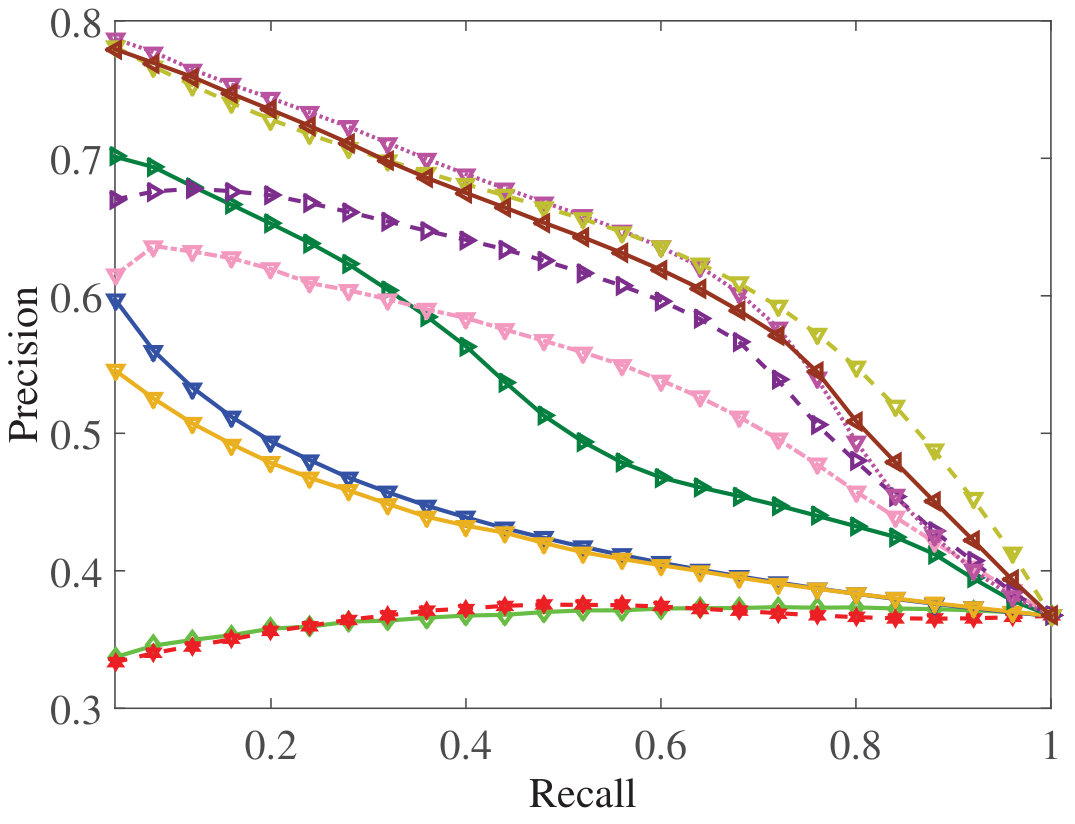 Figure 21
Figure 21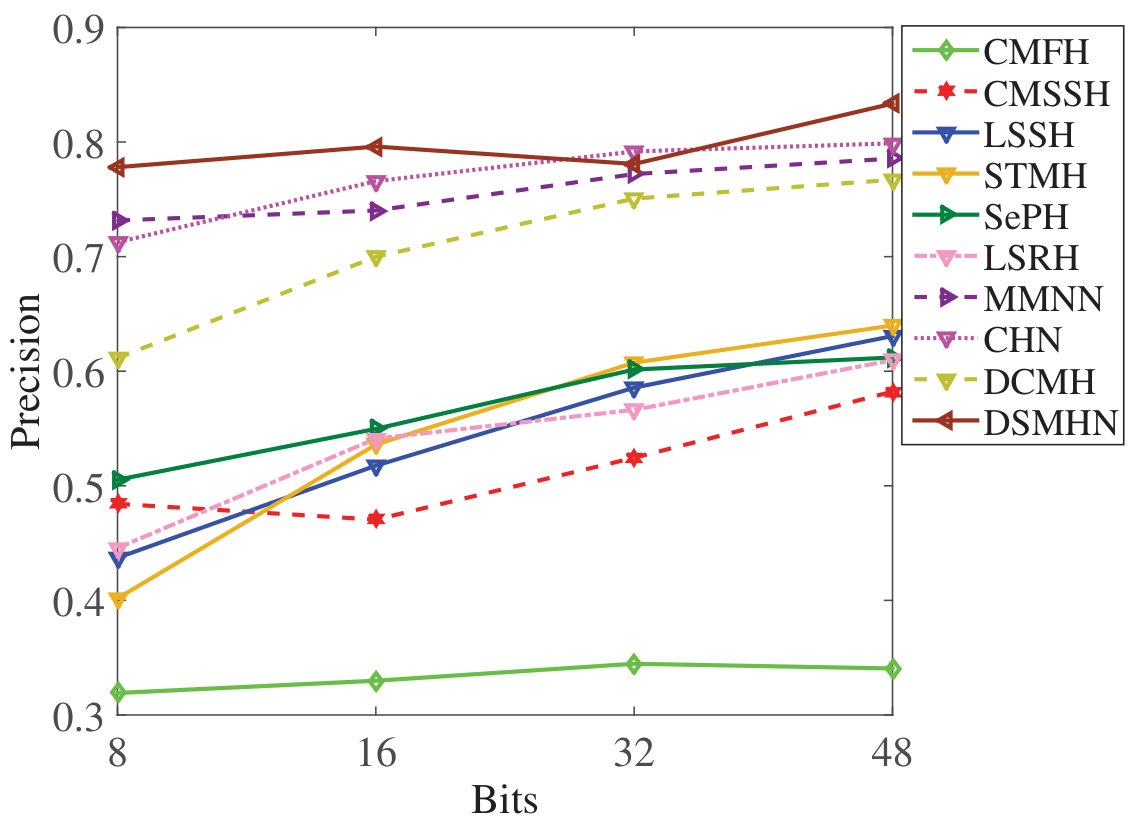 Figure 22
Figure 22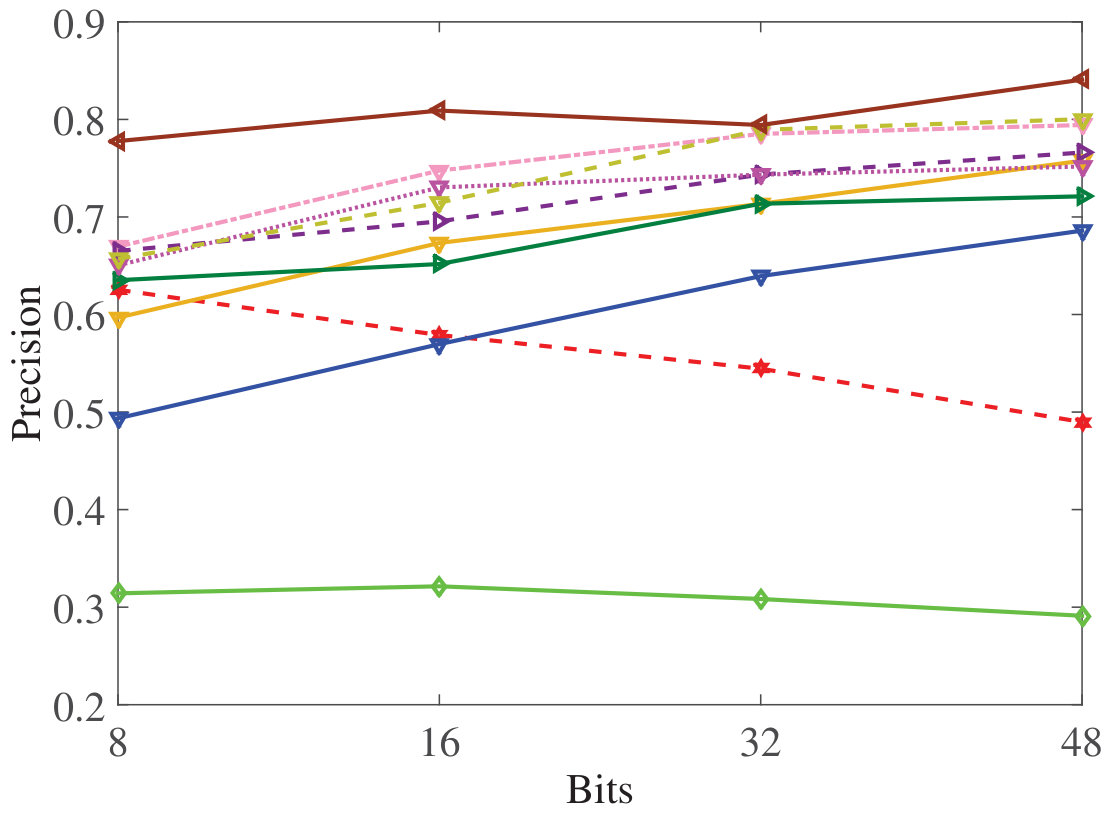 Figure 23
Figure 23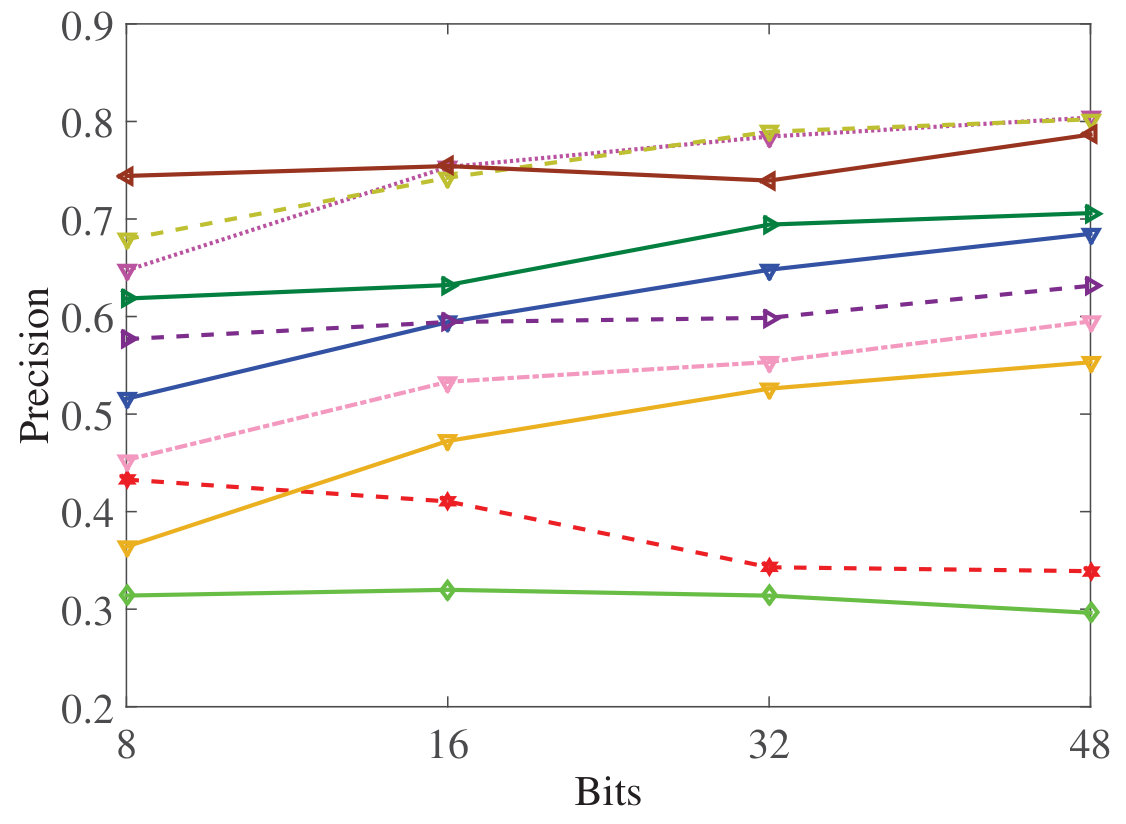 Figure 24
Figure 24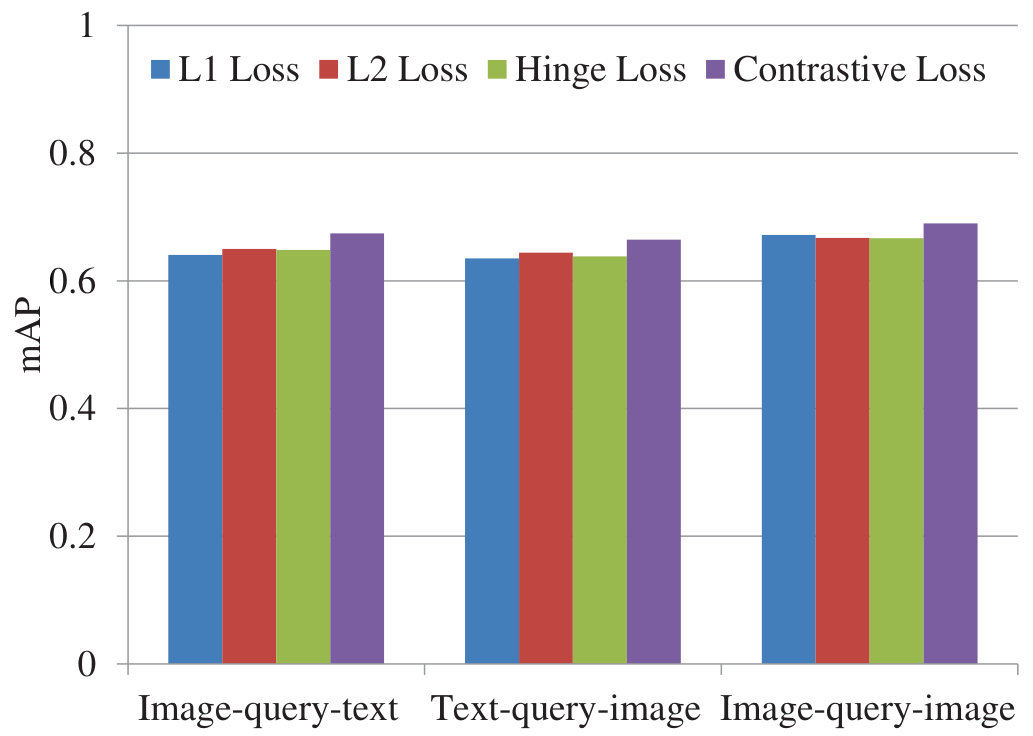 Figure 25
Figure 25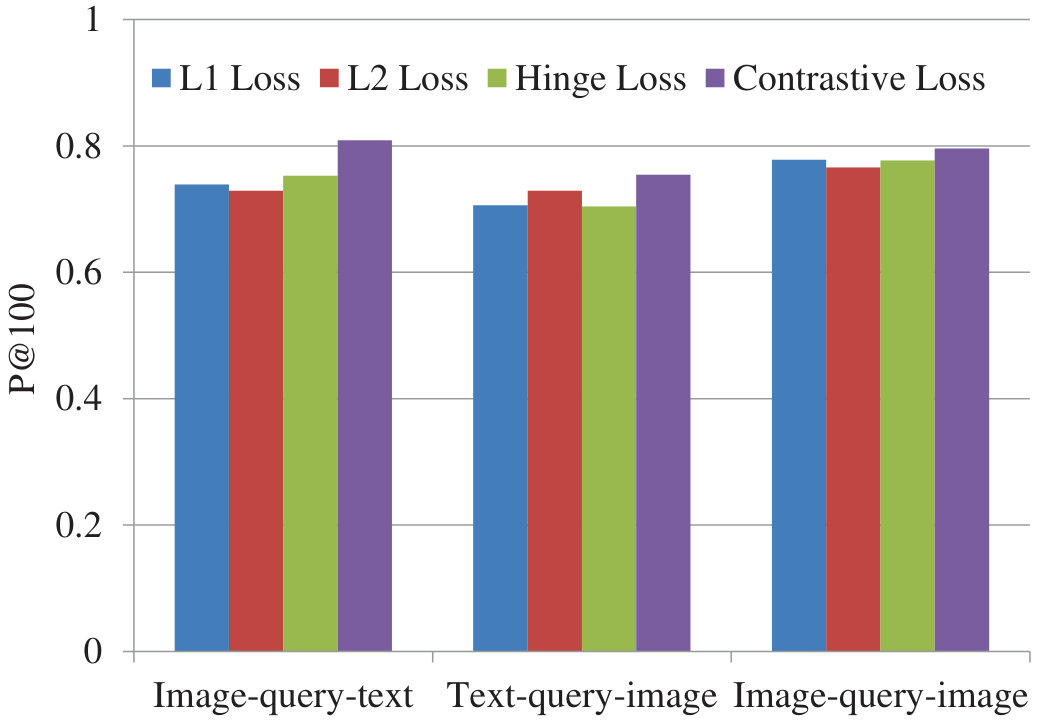 Figure 26
Figure 26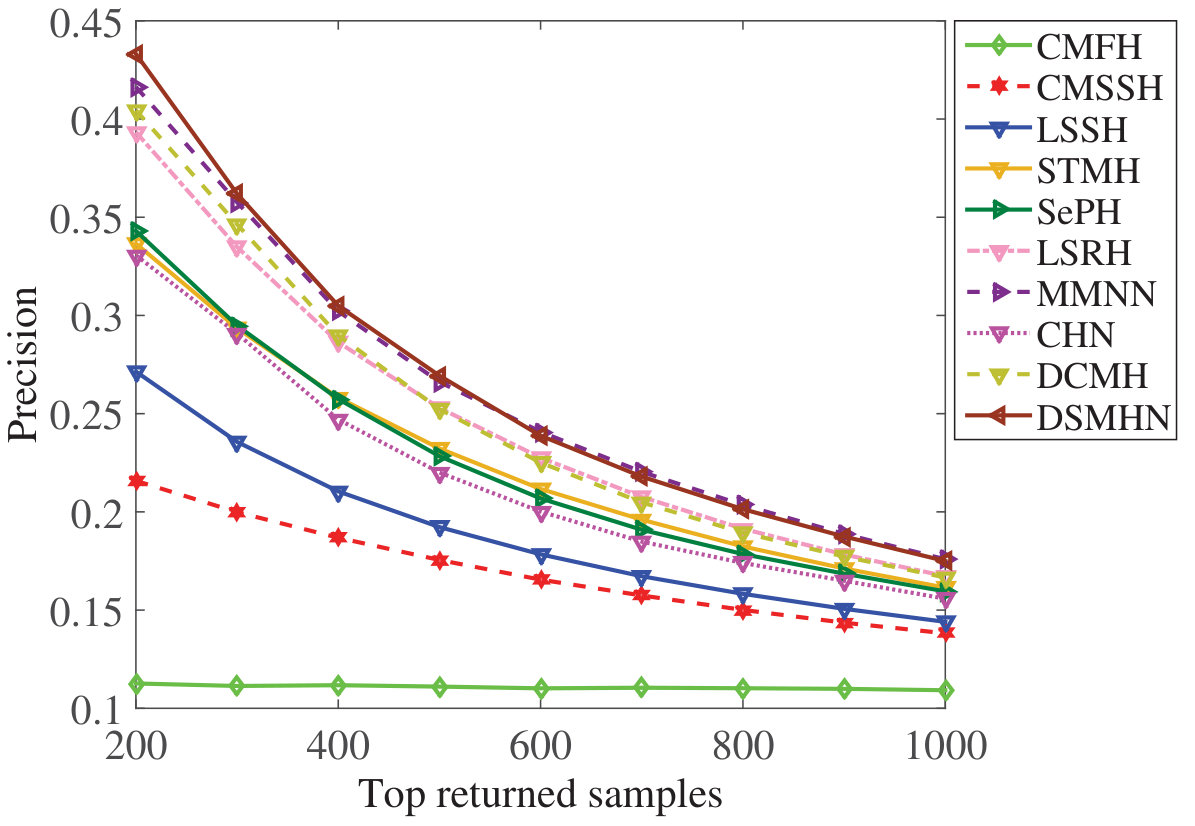 Figure 27
Figure 27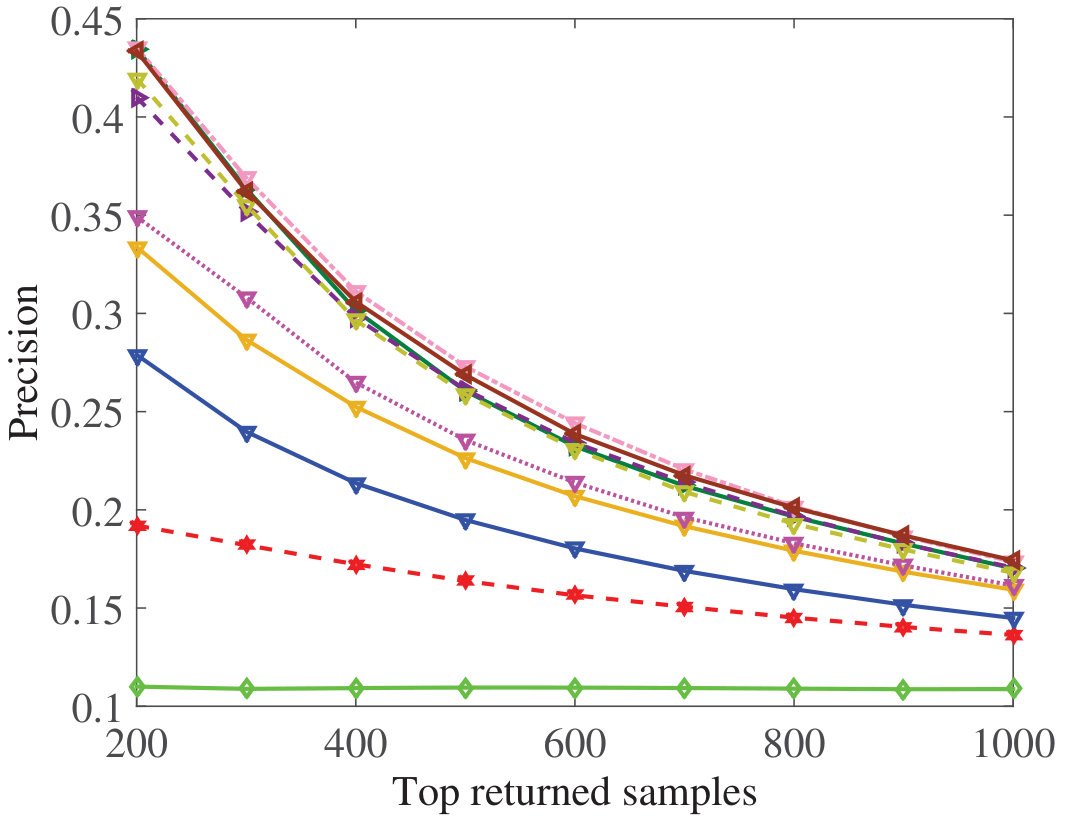 Figure 28
Figure 28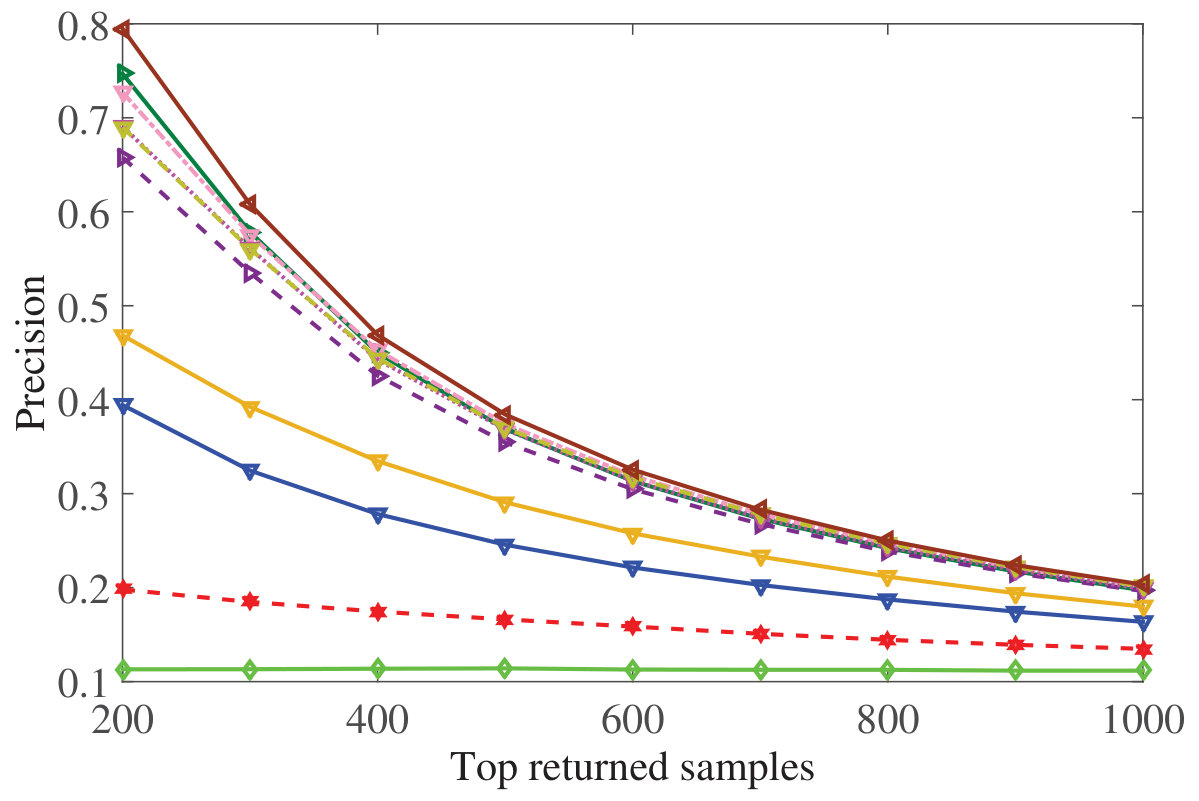 Figure 29
Figure 29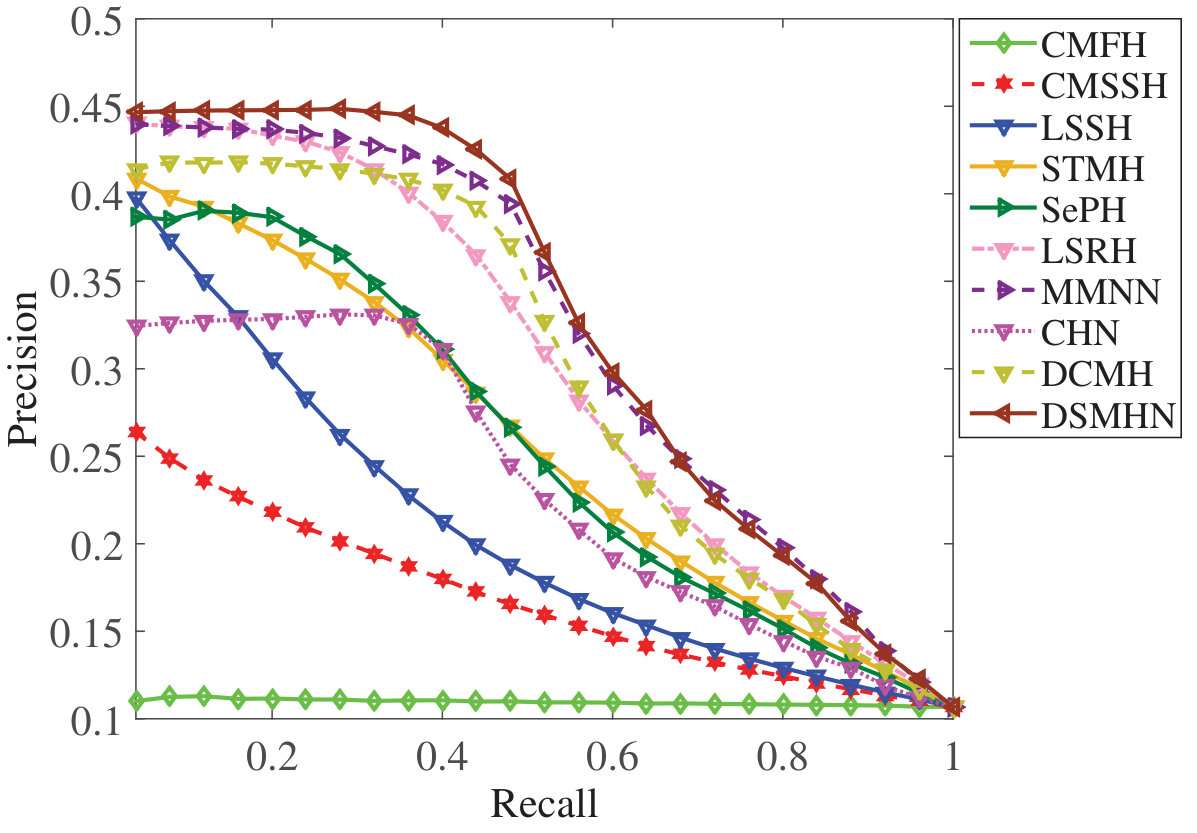 Figure 30
Figure 30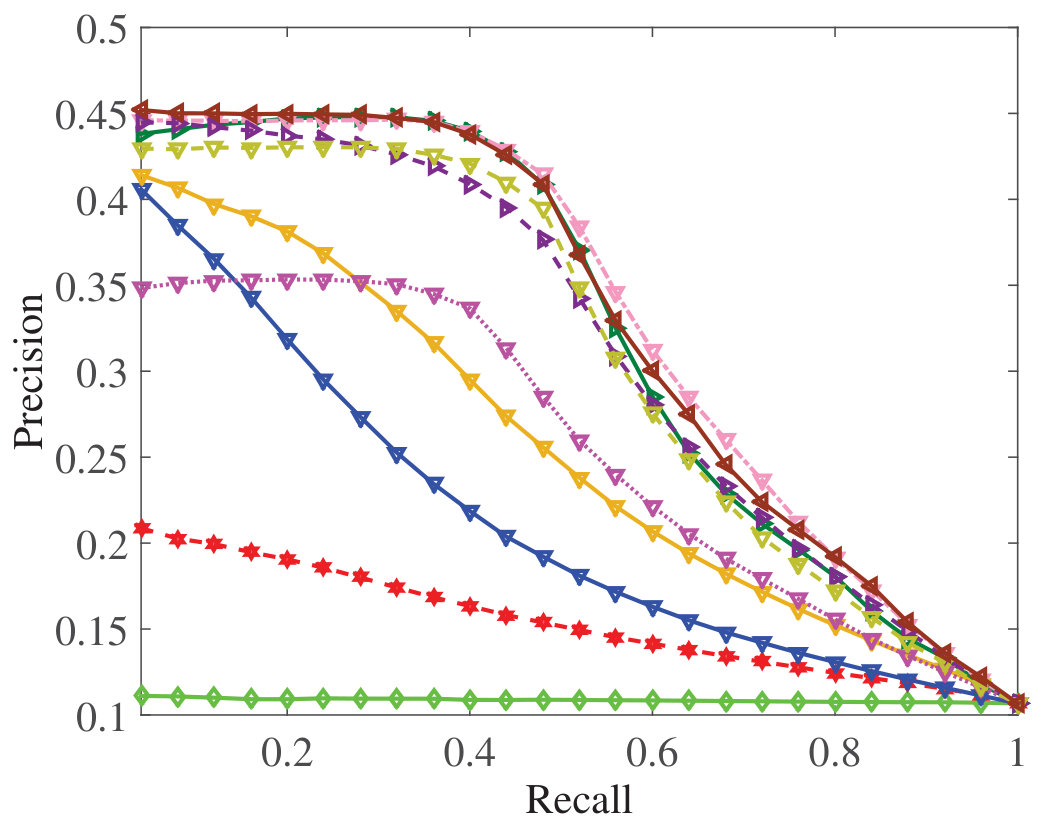 Figure 31
Figure 31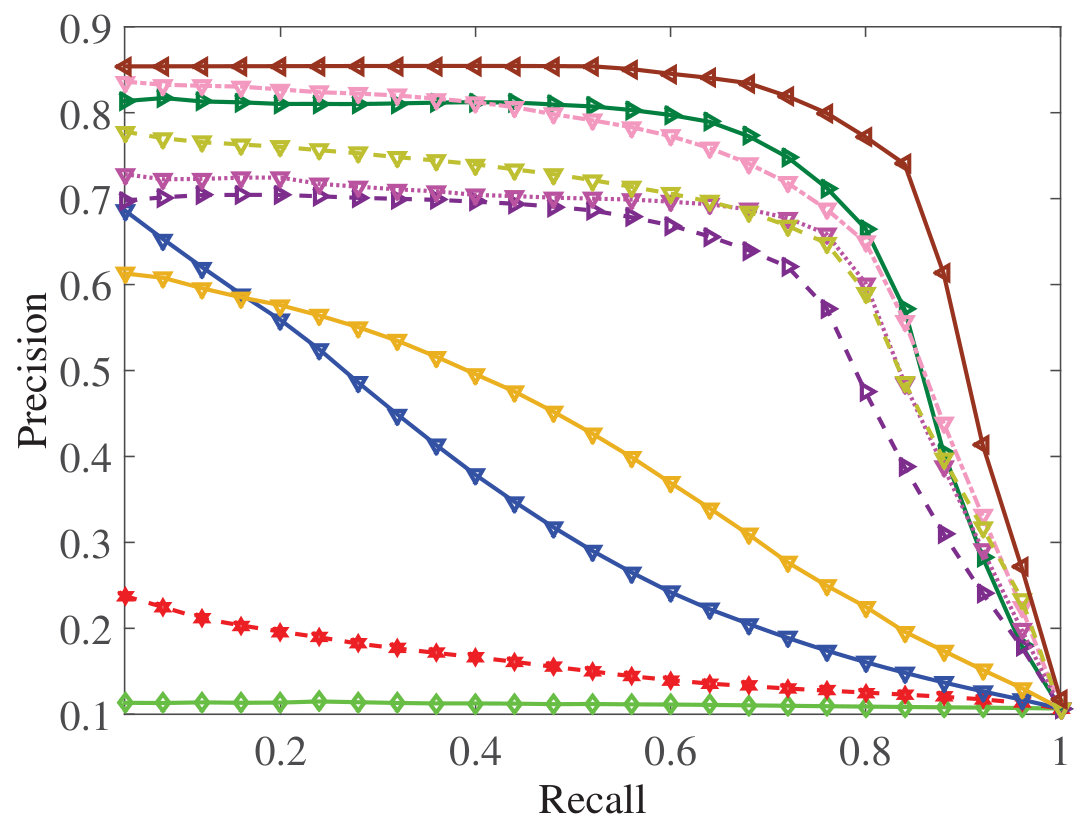 Figure 32
Figure 32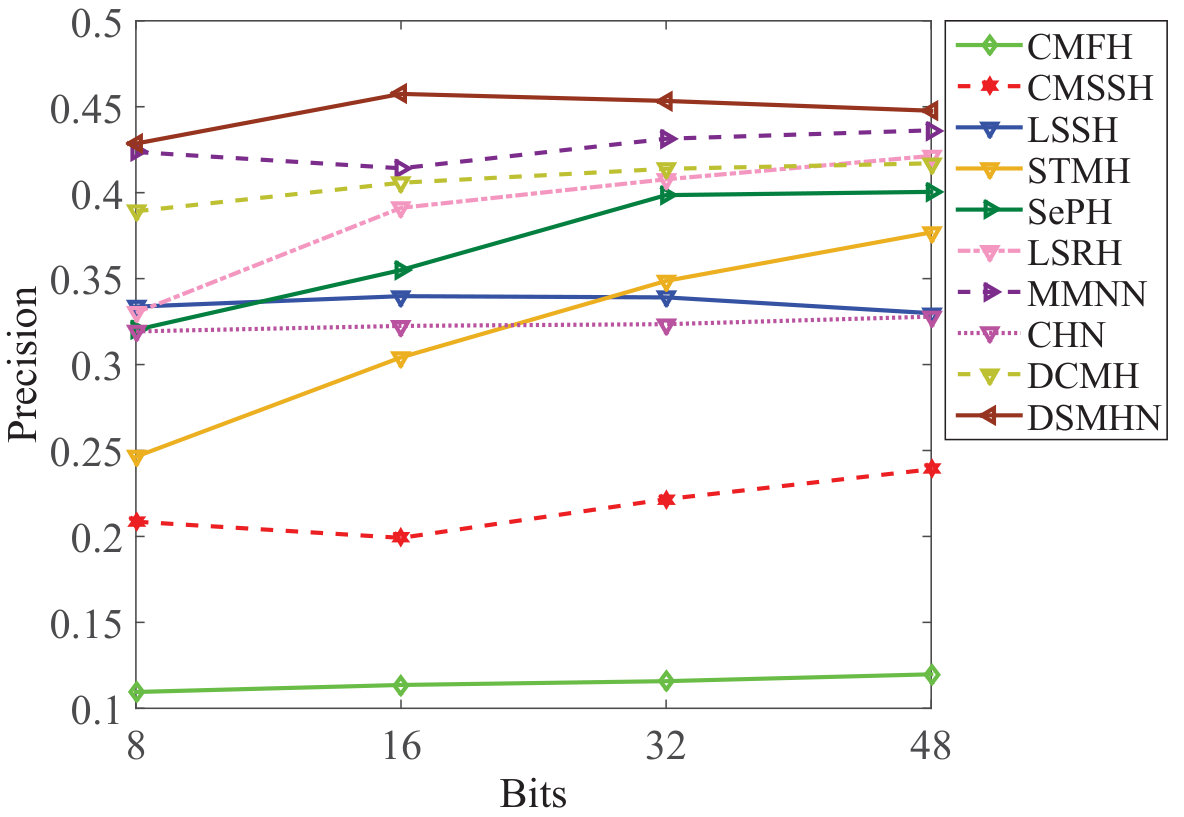 Figure 33
Figure 33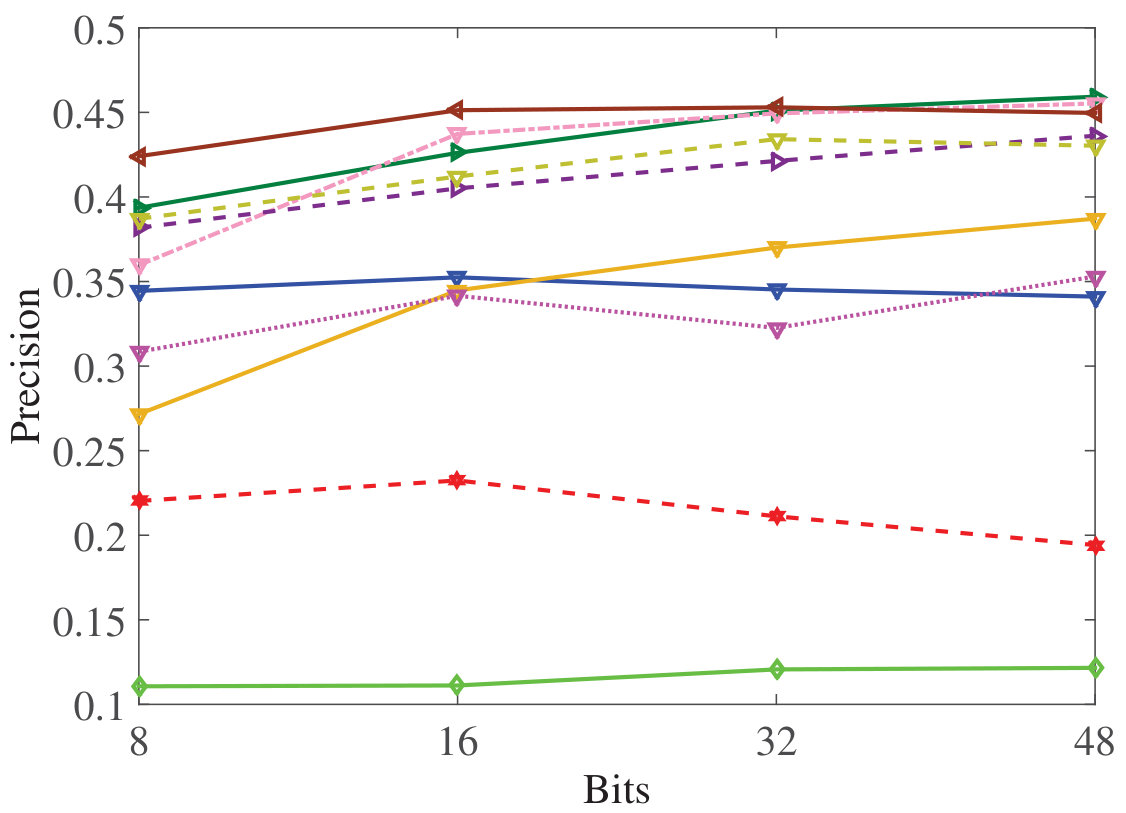 Figure 34
Figure 34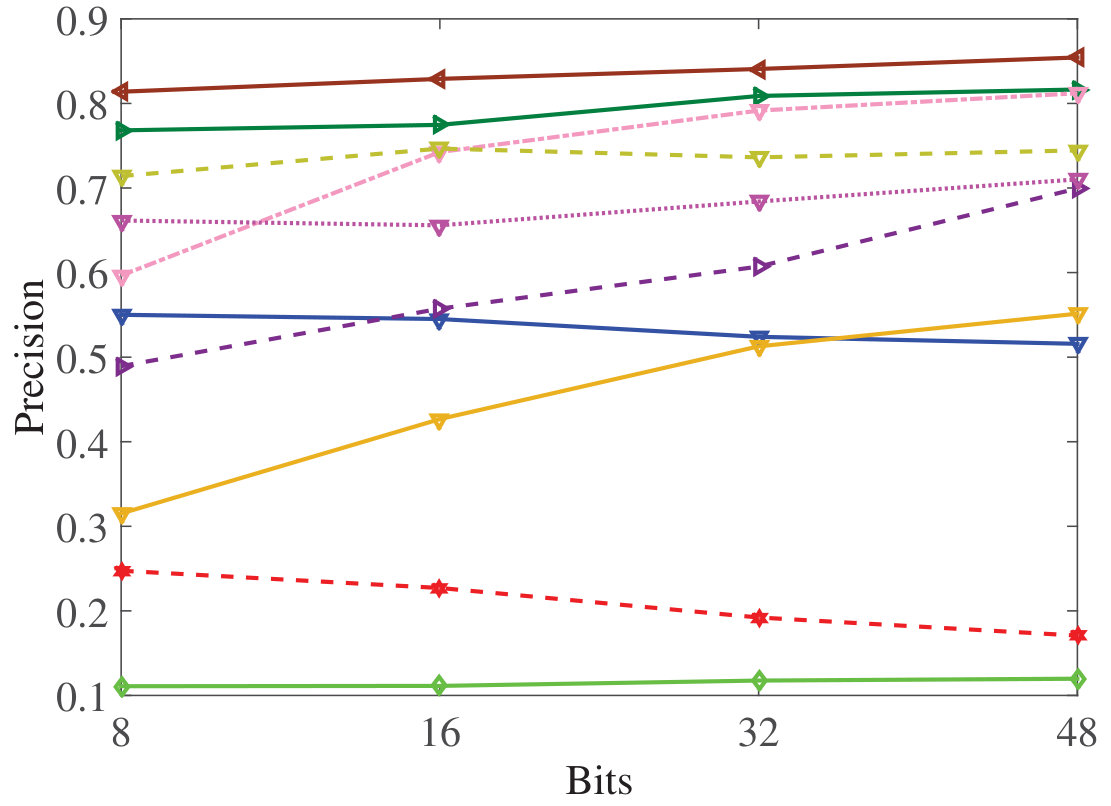 Figure 35
Figure 35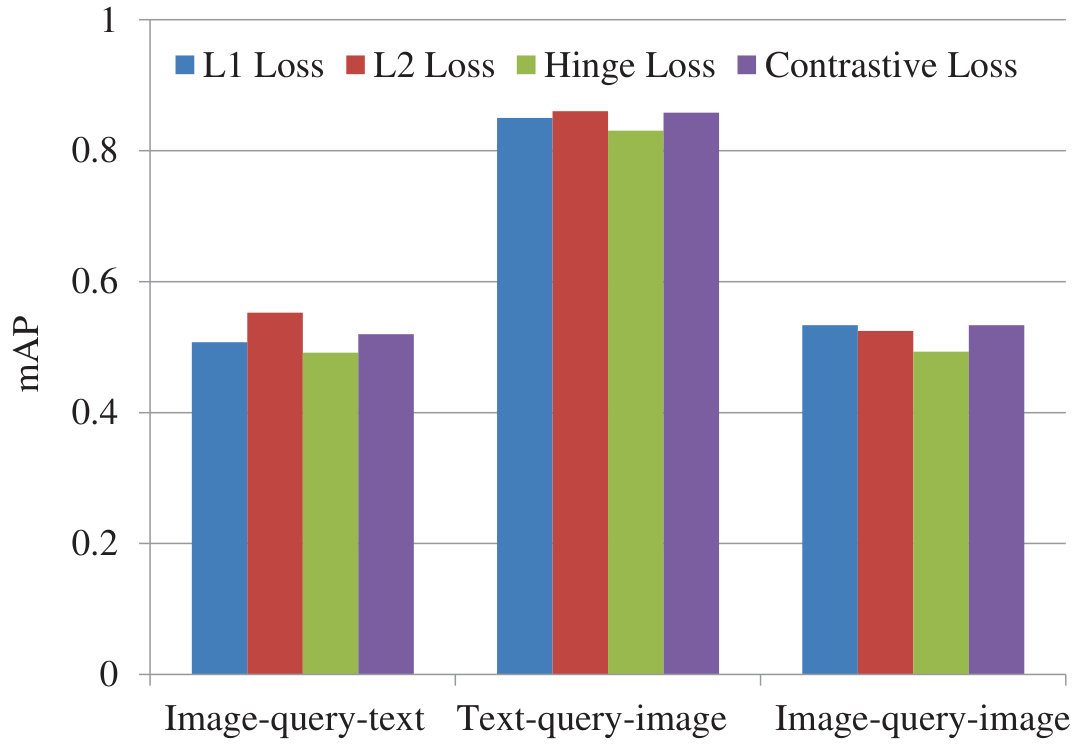 Figure 36
Figure 36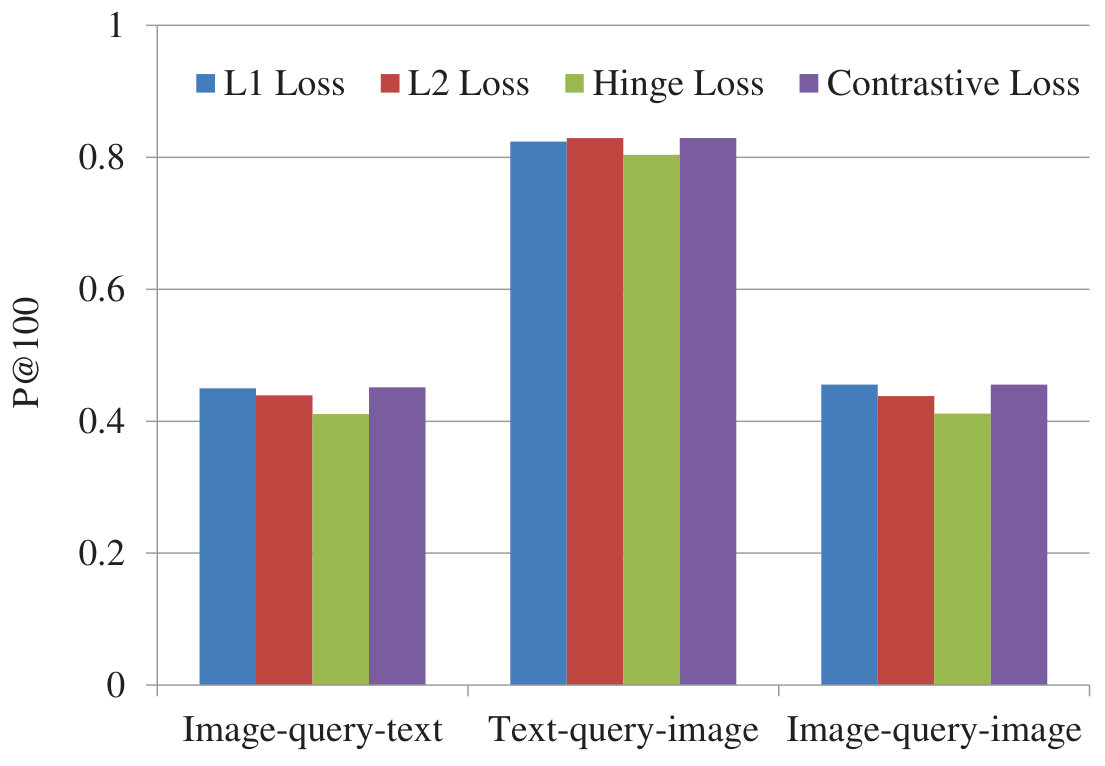 Figure 37
Figure 37 Figure 38
Figure 38Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.