Fast algorithms for slow moving asteroids: constraints on the distribution of Kuiper Belt Objects
Peter J. Whidden, J. Bryce Kalmbach, Andrew J. Connolly, R. Lynne, Jones, Hayden Smotherman, Dino Bektesevic, Colin Slater, Andrew C. Becker,, \v{Z}eljko Ivezi\'c, Mario Juri\'c, Bryce Bolin, Joachim Moeyens, Francisco, F\"orster, V. Zach Golkhou

TL;DR
This paper presents a GPU-accelerated algorithm capable of rapidly searching for faint moving asteroids in large astronomical datasets, leading to the discovery of new Kuiper Belt Objects and insights into their distribution.
Contribution
The authors develop a massively parallel GPU-based algorithm for efficient asteroid trajectory searches, enabling rapid analysis of large astronomical image stacks and discovery of new Kuiper Belt Objects.
Findings
Discovered 39 new Kuiper Belt Objects in survey data.
Algorithm can search over 10^10 trajectories in under a minute.
Results align with existing models of Kuiper Belt inclination distribution.
Abstract
We introduce a new computational technique for searching for faint moving sources in astronomical images. Starting from a maximum likelihood estimate for the probability of the detection of a source within a series of images, we develop a massively parallel algorithm for searching through candidate asteroid trajectories that utilizes Graphics Processing Units (GPU). This technique can search over 10^10 possible asteroid trajectories in stacks of the order 10-15 4K x 4K images in under a minute using a single consumer grade GPU. We apply this algorithm to data from the 2015 campaign of the High Cadence Transient Survey (HiTS) obtained with the Dark Energy Camera (DECam). We find 39 previously unknown Kuiper Belt Objects in the 150 square degrees of the survey. Comparing these asteroids to an existing model for the inclination distribution of the Kuiper Belt we demonstrate that we recover…
Click any figure to enlarge with its caption.
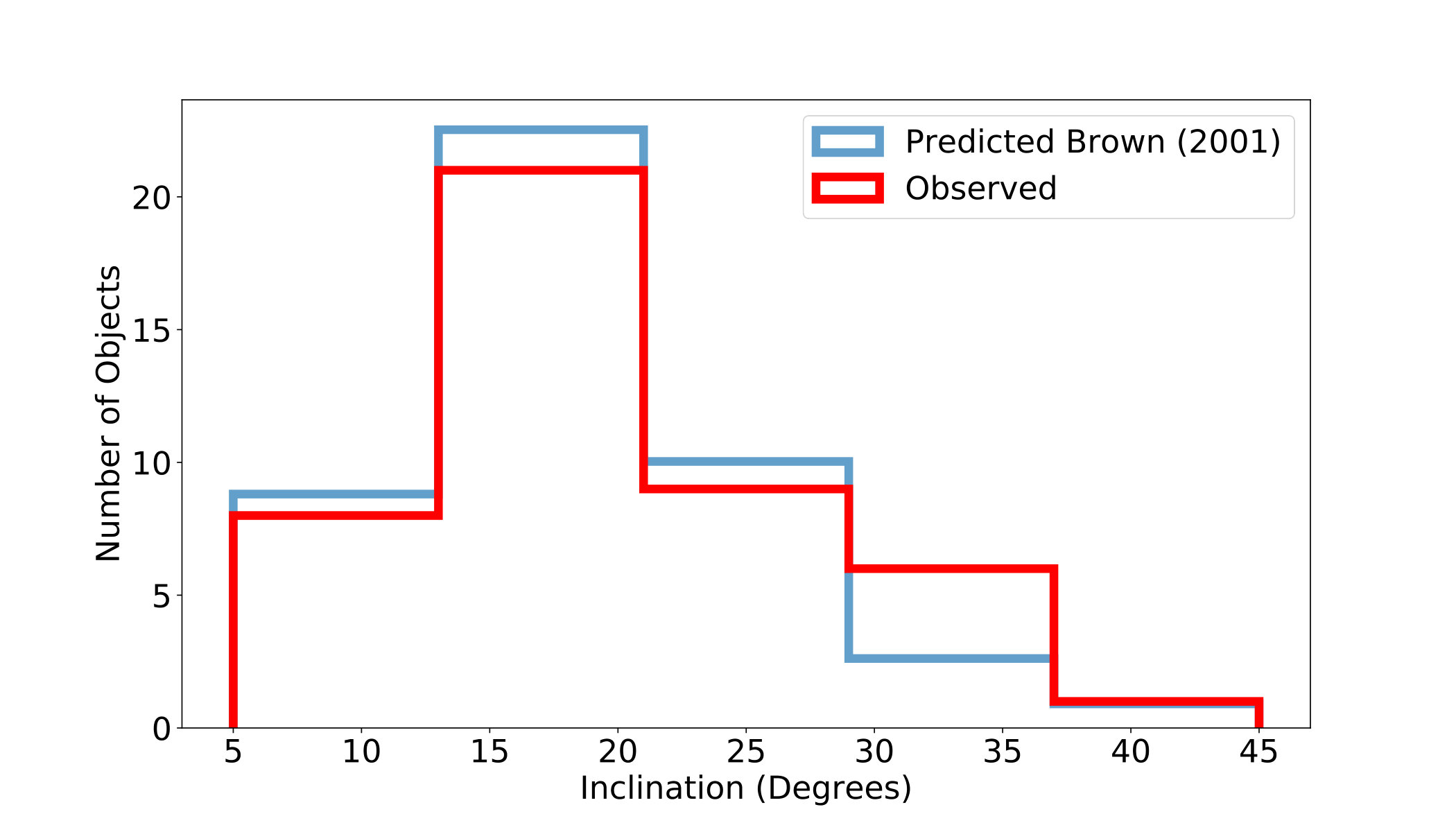 Figure 1
Figure 1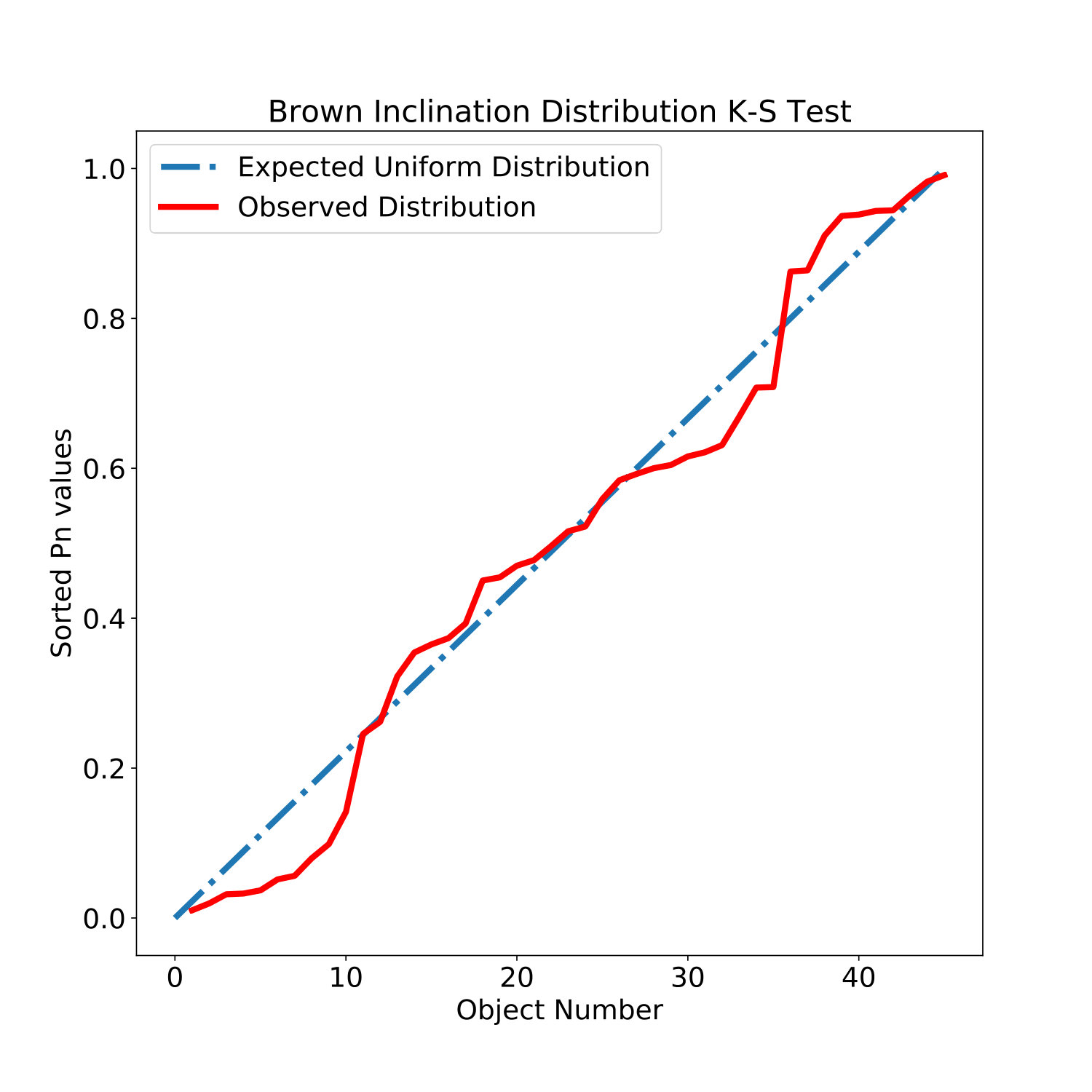 Figure 2
Figure 2 Figure 3
Figure 3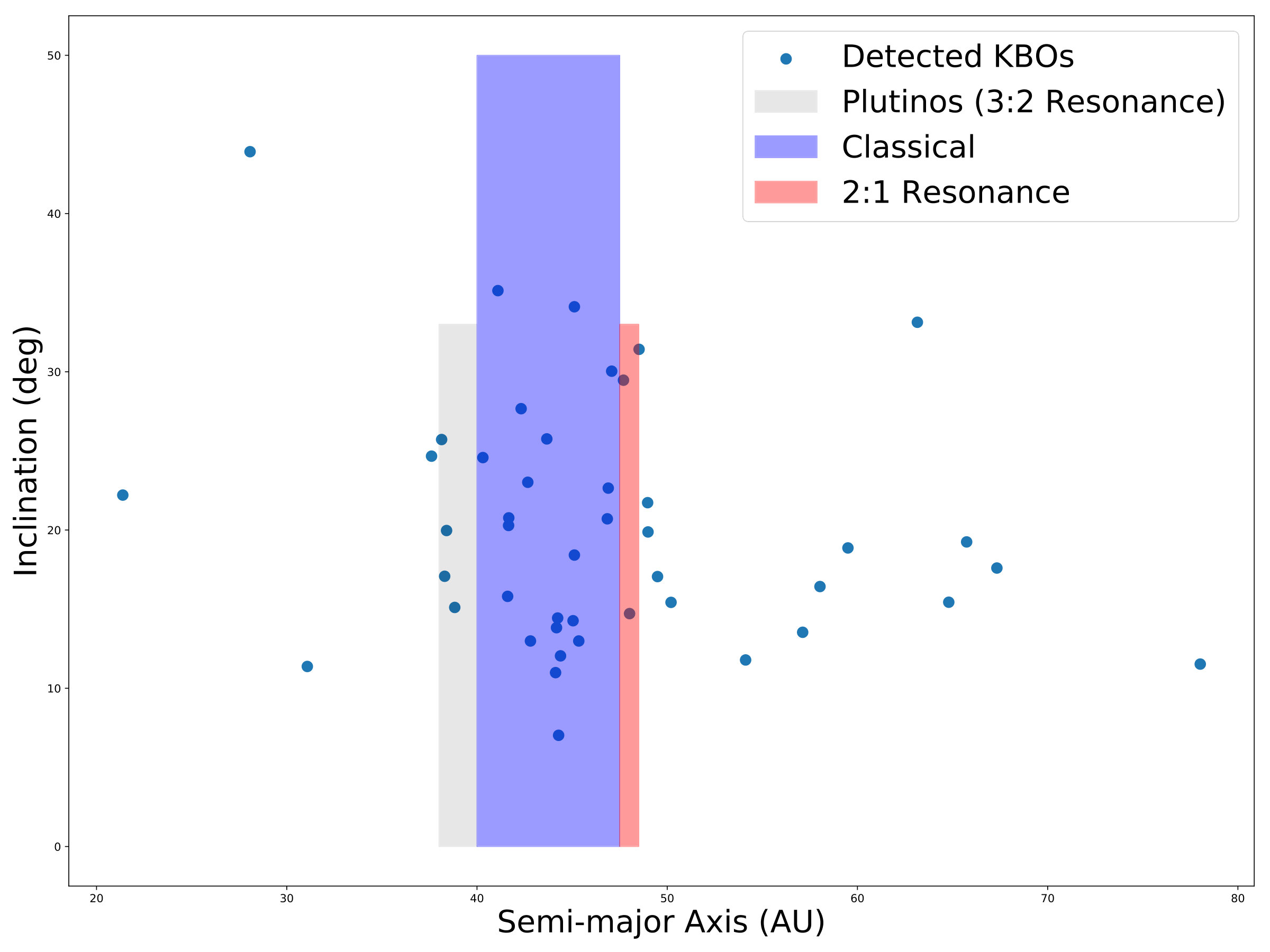 Figure 4
Figure 4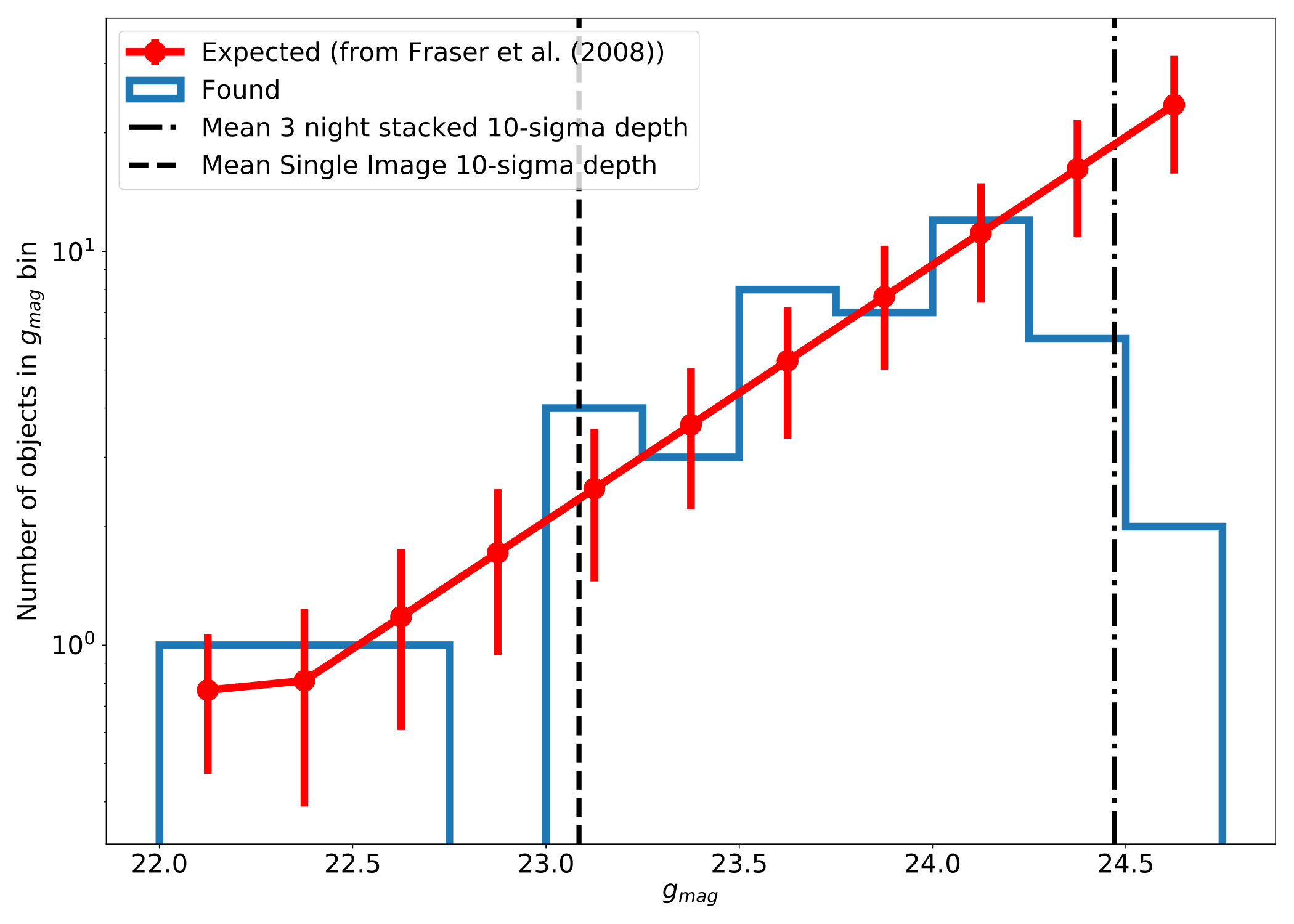 Figure 5
Figure 5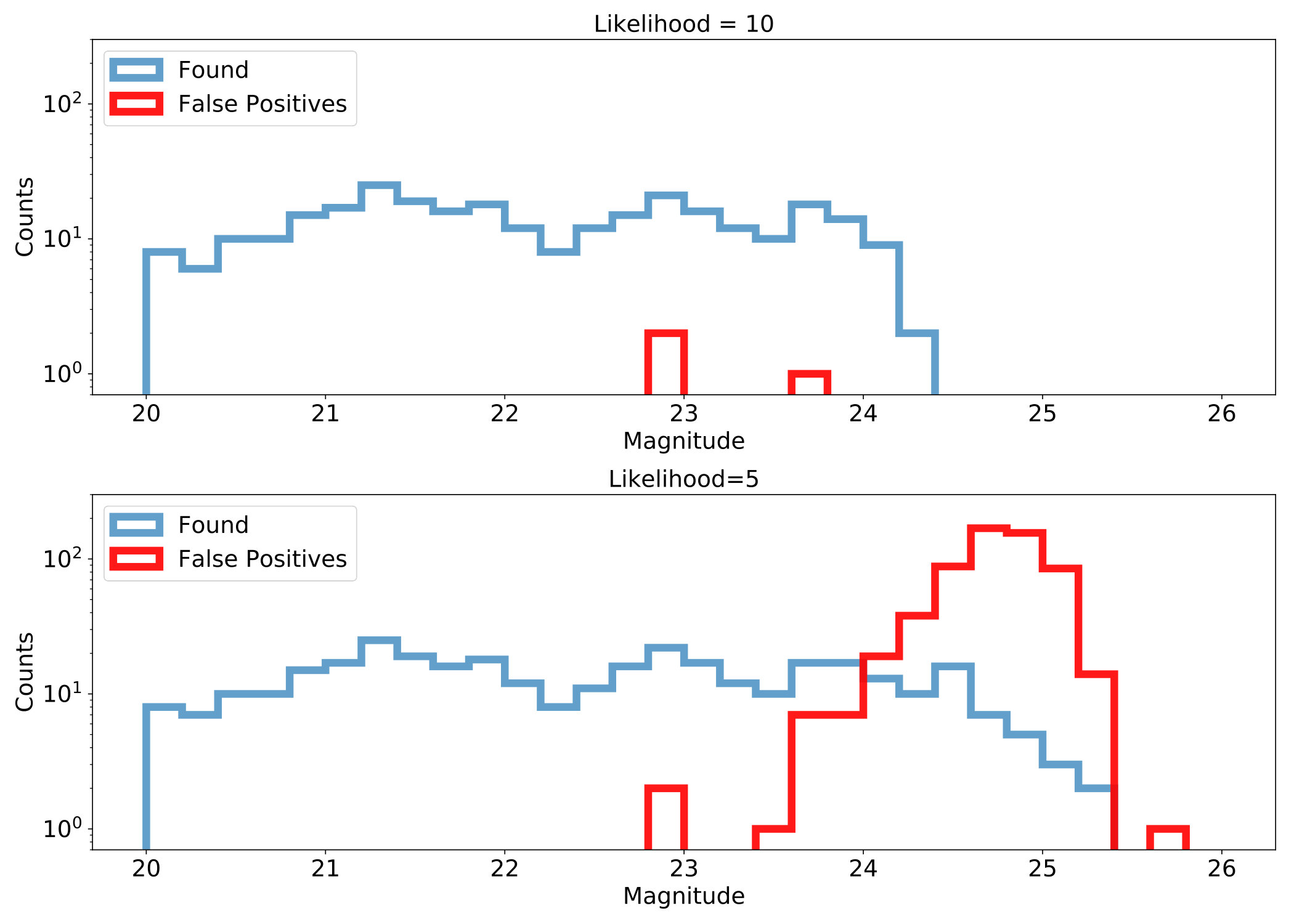 Figure 6
Figure 6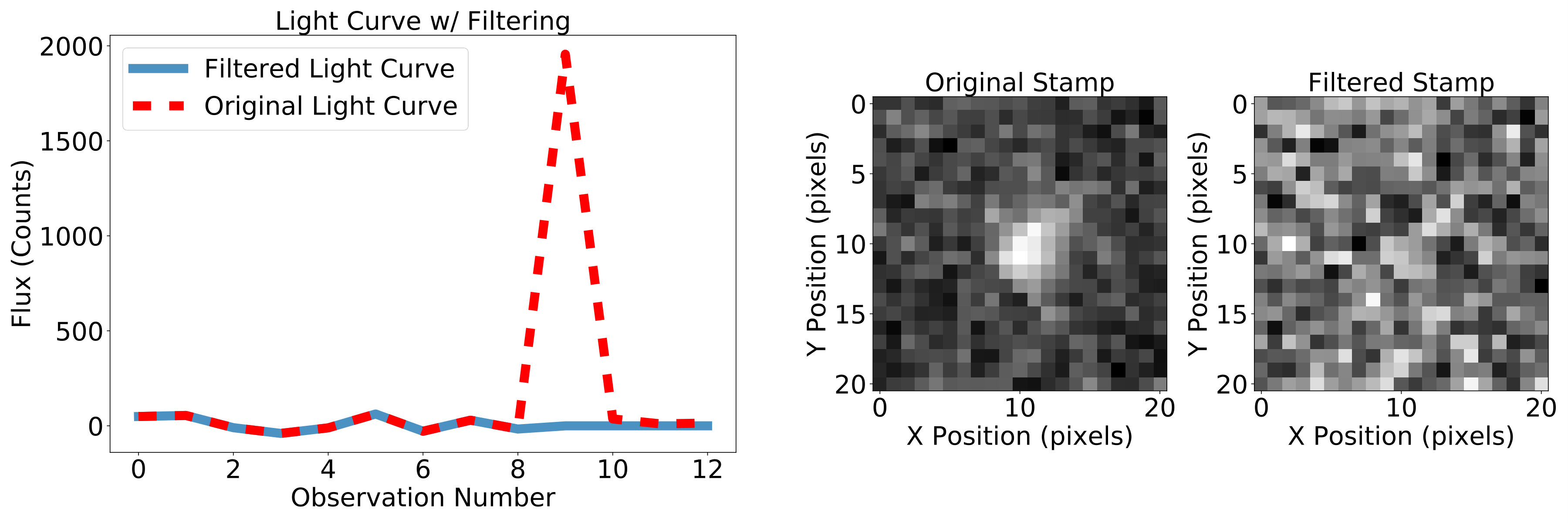 Figure 7
Figure 7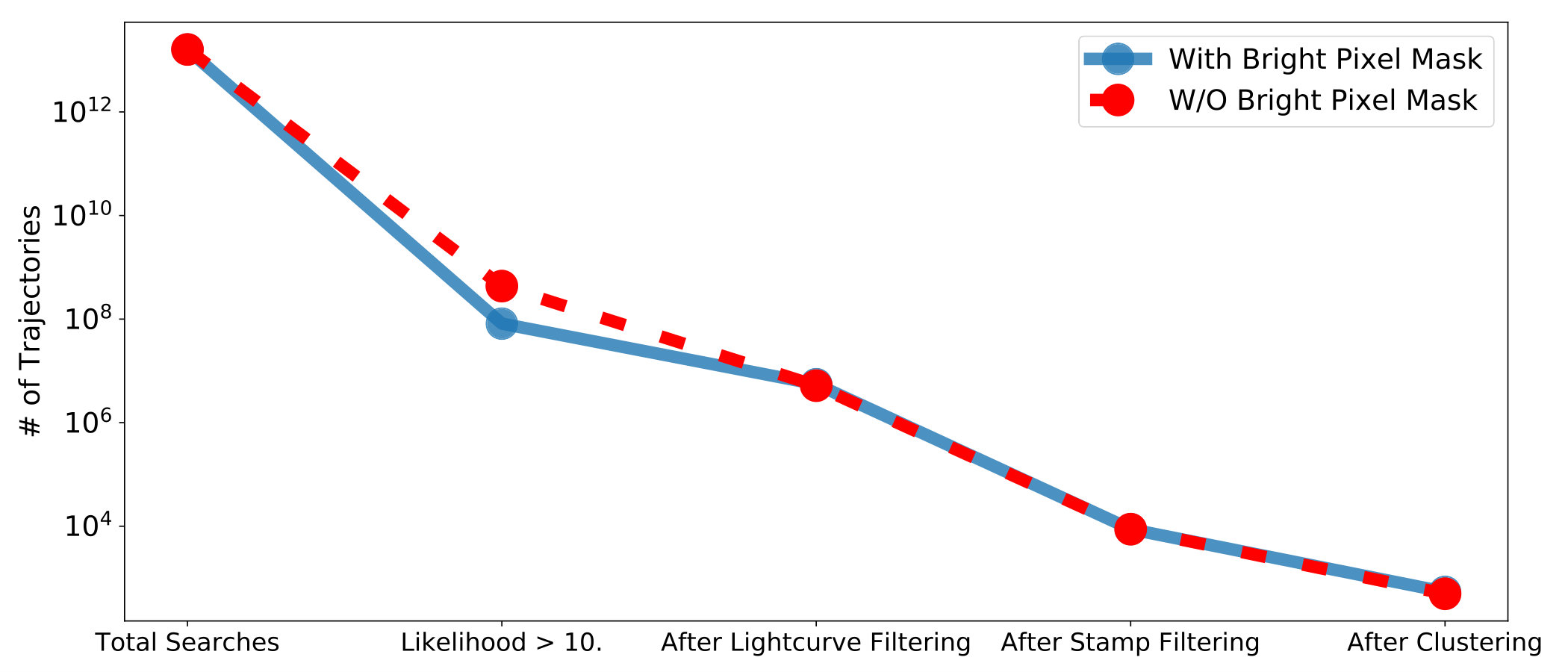 Figure 8
Figure 8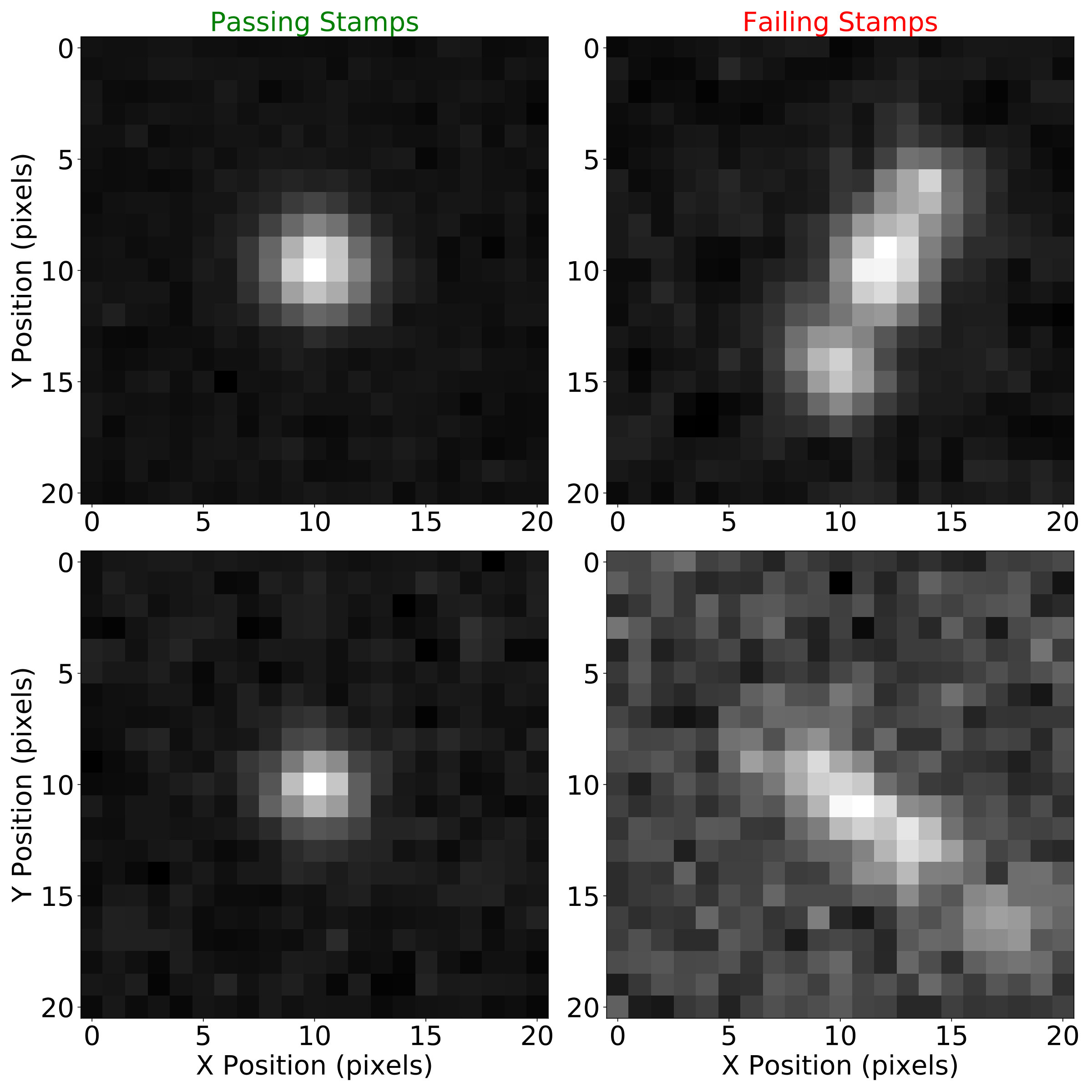 Figure 9
Figure 9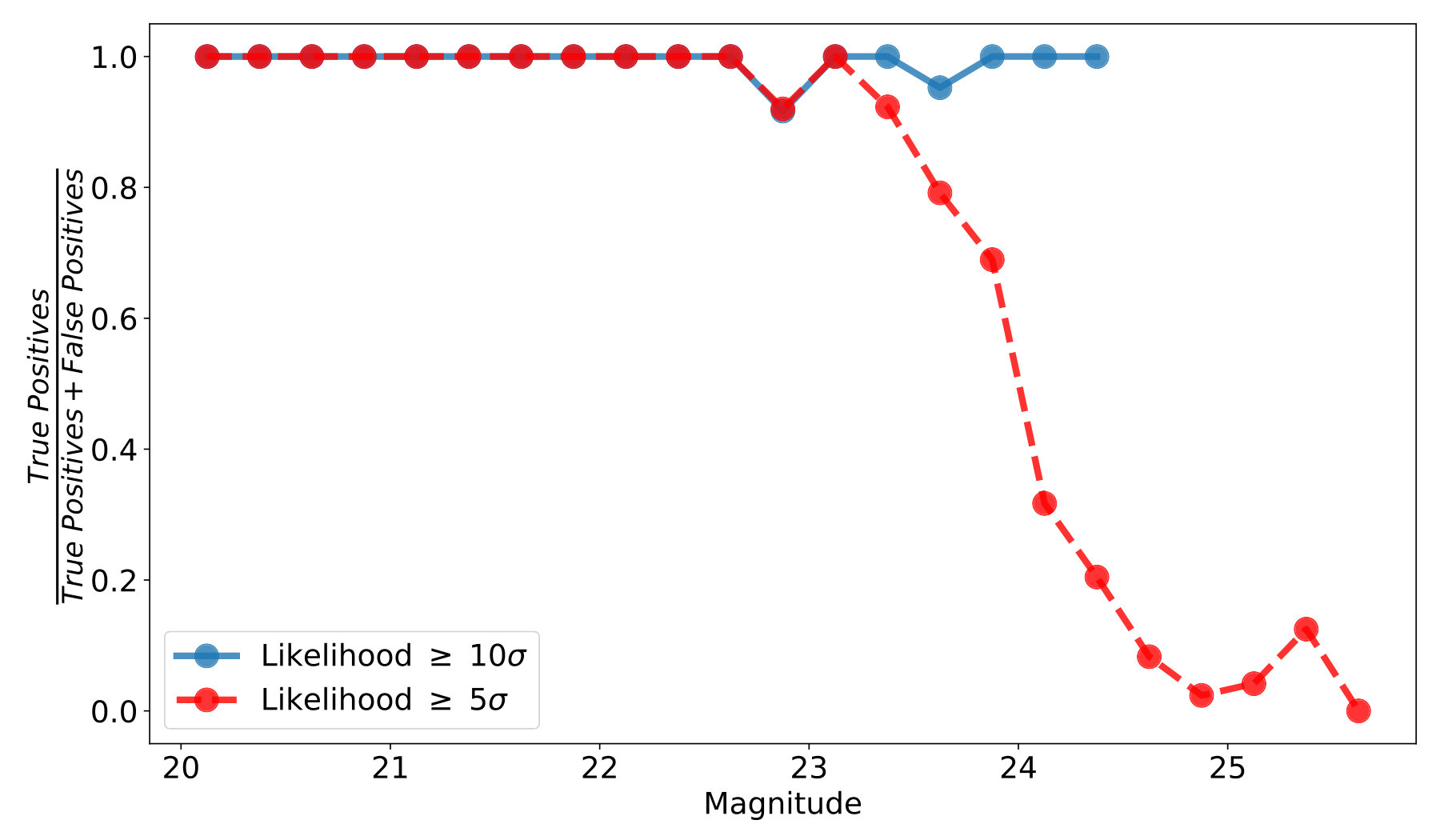 Figure 10
Figure 10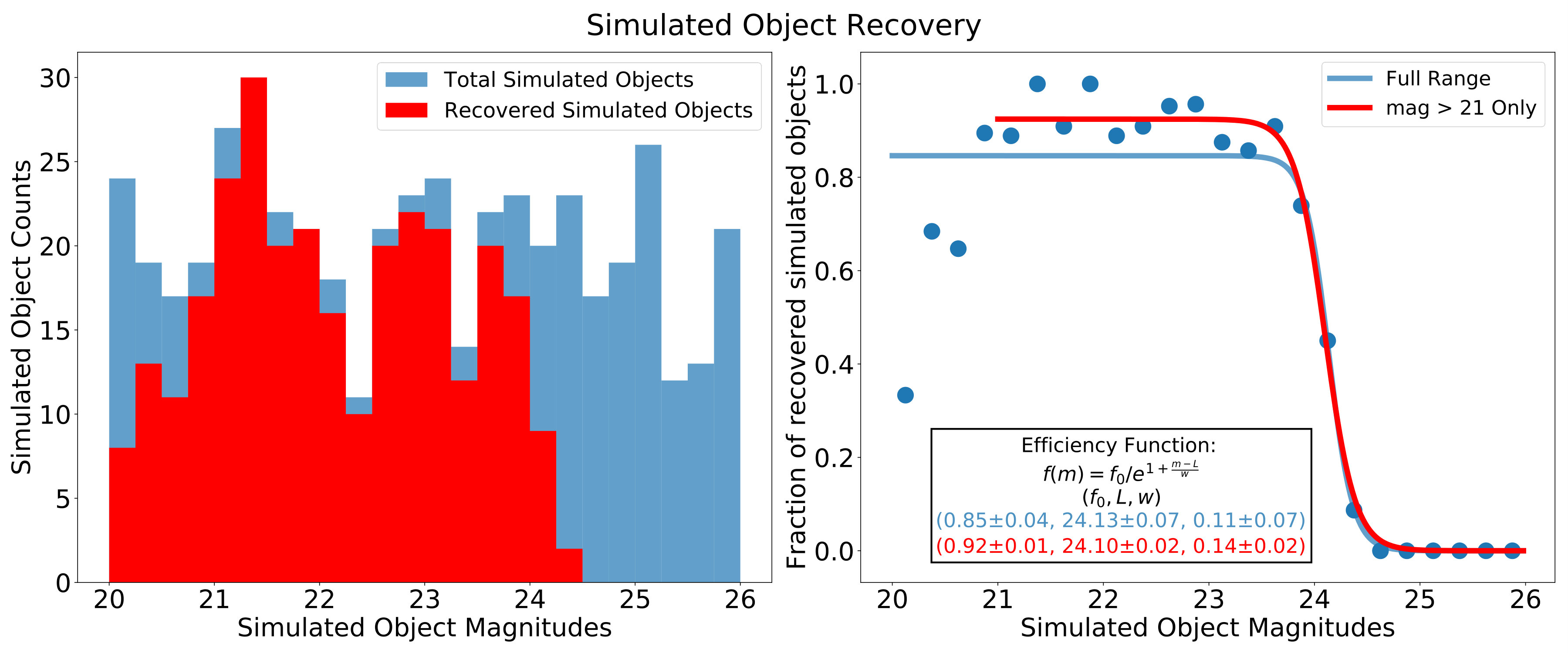 Figure 11
Figure 11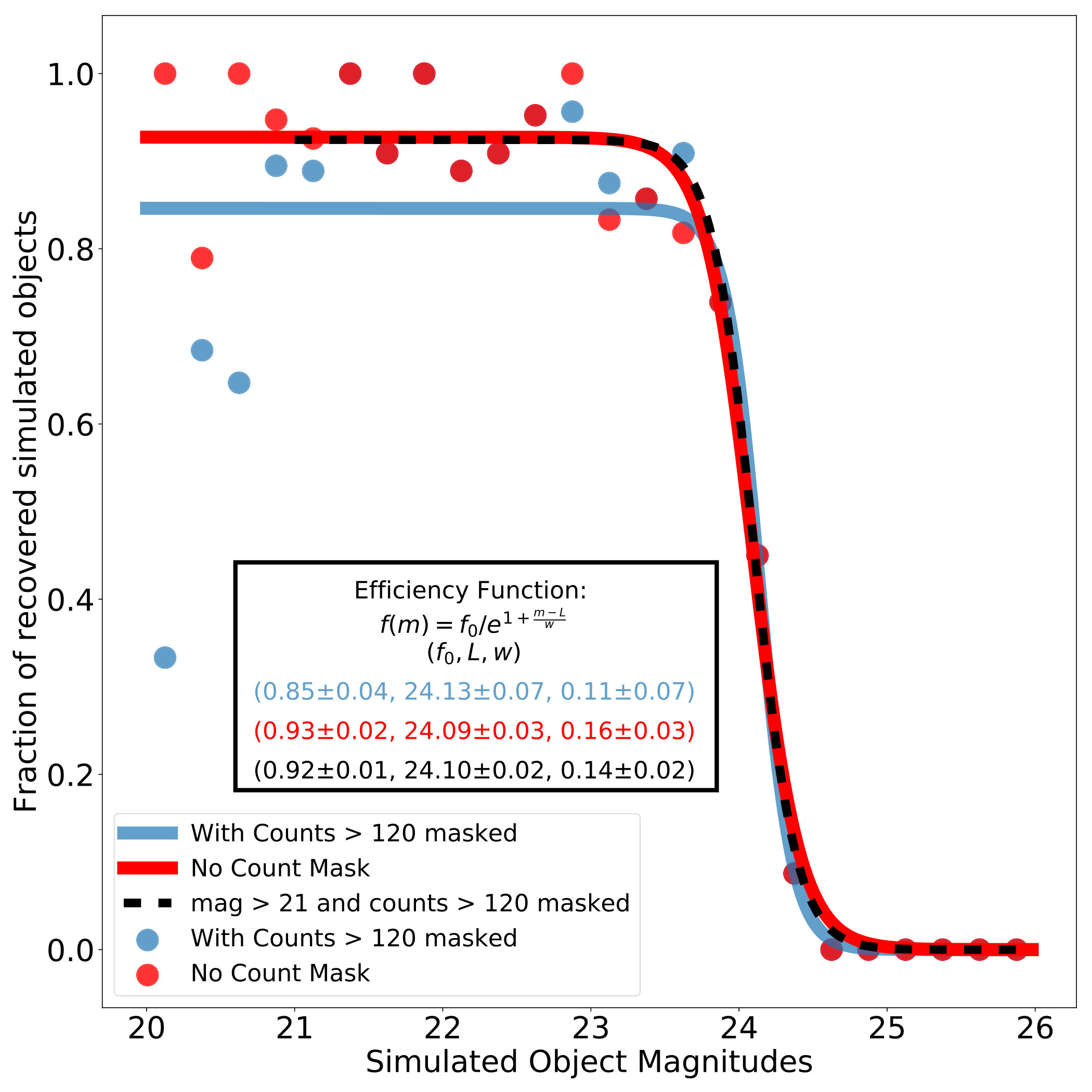 Figure 12
Figure 12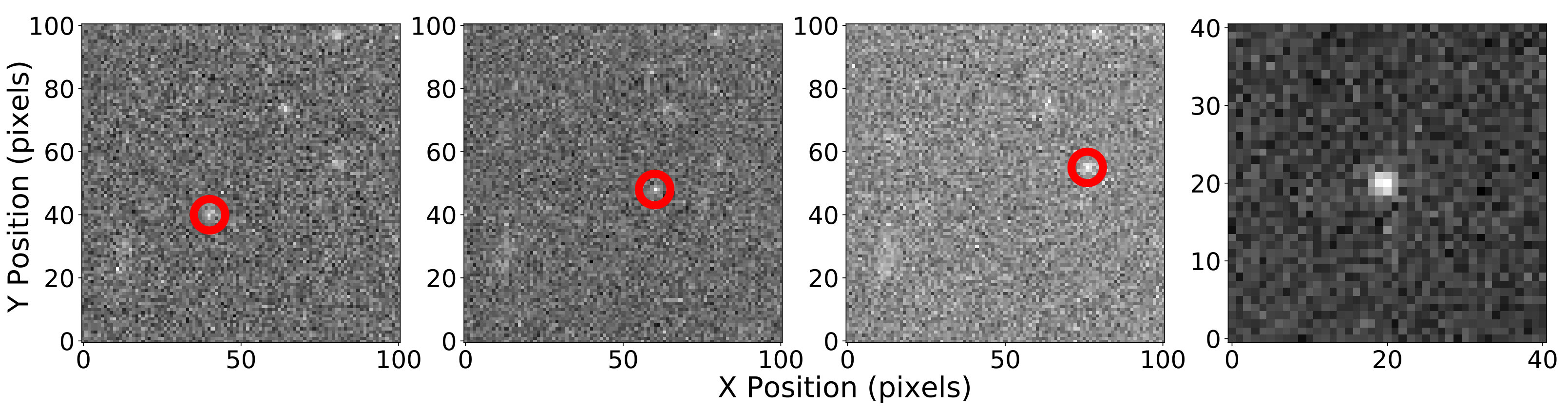 Figure 13
Figure 13| MPC designation | Semi-Major Axis (AU) | Eccentricity | Inclination | g_mag | New Discovery? |
| 2015 DZ248 | 67.33 | 0.42 | 17.60 | 23.68 | Yes |
| 2015 DT248 | 21.38 | 0.36 | 22.21 | 24.14 | Yes |
| 2015 DT249 | 43.67 | 0.20 | 25.76 | 23.74 | Yes |
| 2015 DY248 | 48.02 | 0.28 | 14.72 | 24.19 | Yes |
| 2015 DX248 | 37.61 | 0.02 | 24.67 | 24.24 | Yes |
| 2015 DV248 | 42.32 | 0.67 | 27.67 | 23.94 | Yes |
| 2015 DW248 | 48.52 | 0.62 | 31.42 | 23.02 | Yes |
| 2015 DU248 | 44.24 | 0.02 | 14.44 | 23.99 | Yes |
| 2015 DQ248 | 63.15 | 0.45 | 33.13 | 24.05 | Yes |
| 2015 DR248 | 41.61 | 0.31 | 15.81 | 23.95 | Yes |
| 2015 DS248 | 42.67 | 0.78 | 23.02 | 24.00 | Yes |
| 2015 DO248 | 46.90 | 0.27 | 22.65 | 24.08 | Yes |
| 2015 DP248 | 48.97 | 0.70 | 21.73 | 24.15 | Yes |
| 2015 DO249 | 48.99 | 0.29 | 19.88 | 24.35 | Yes |
| 2015 DP249 | 49.49 | 0.43 | 17.06 | 24.28 | Yes |
| 2015 DZ249 | 45.05 | 0.25 | 14.27 | 24.30 | Yes |
| 2015 DY249 | 38.14 | 0.03 | 25.72 | 24.41 | Yes |
| 2015 DN249 | 38.30 | 0.03 | 17.08 | 24.34 | Yes |
| 2015 DM249 | 44.39 | 0.14 | 12.05 | 23.74 | Yes |
| 2015 DX249 | 47.08 | 0.24 | 30.04 | 23.22 | Yes |
| 2015 DL249 | 44.18 | 0.27 | 13.83 | 24.23 | Yes |
| 2015 DK249 | 44.29 | 0.02 | 7.03 | 24.05 | Yes |
| 2015 DH249 | 46.85 | 0.02 | 20.71 | 24.63 | Yes |
| 2015 DJ249 | 42.81 | 0.19 | 12.99 | 23.44 | Yes |
| 2015 DW249 | 38.83 | 0.19 | 15.11 | 23.68 | Yes |
| 2015 DC249 | 41.67 | 0.16 | 20.77 | 23.62 | Yes |
| 2015 DD249 | 65.74 | 0.32 | 19.25 | 23.65 | Yes |
| 2015 DB249 | 40.31 | 0.27 | 24.58 | 23.56 | Yes |
| 2015 DU249 | 59.50 | 0.21 | 18.87 | 24.72 | Yes |
| 2015 DA249 | 38.40 | 0.15 | 19.97 | 23.61 | Yes |
| 2015 DF249 | 45.35 | 0.44 | 12.99 | 24.08 | Yes |
| 2014 BV64 | 50.20 | 0.31 | 15.43 | 22.10 | No |
| 2015 DE249 | 41.66 | 0.35 | 20.29 | 23.35 | Yes |
| 2015 DV249 | 54.12 | 0.15 | 11.79 | 24.00 | Yes |
| 2015 BF519 | 45.12 | 0.39 | 18.42 | 23.00 | No |
| 2015 DG249 | 64.80 | 0.33 | 15.44 | 24.19 | Yes |
| 2011 CX119 | 47.70 | 0.46 | 29.47 | 23.19 | No |
| 2015 DA250 | 45.12 | 0.29 | 34.11 | 23.89 | Yes |
| 2015 DB250 | 44.13 | 0.27 | 10.99 | 23.80 | Yes |
| 2014 XW40 | 58.03 | 0.32 | 16.43 | 23.39 | No |
| 2015 DQ249 | 28.07 | 0.44 | 43.91 | 23.93 | Yes |
| 2015 DR249 | 41.10 | 0.02 | 35.13 | 23.81 | Yes |
| 2014 XP40 | 78.02 | 0.62 | 11.53 | 22.33 | No |
| 2013 FZ27 | 57.12 | 0.25 | 13.54 | 22.73 | No |
| 2015 DS249 | 31.08 | 0.29 | 11.38 | 24.37 | Yes |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Fast algorithms for slow moving asteroids: constraints on the distribution of Kuiper Belt Objects
Peter J. Whidden
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
J. Bryce Kalmbach
Department of Physics, University of Washington, Seattle, WA, 98195, USA
Andrew J. Connolly
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
R. Lynne Jones
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Hayden Smotherman
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Dino Bektesevic
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Colin Slater
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Andrew C. Becker
Amazon Web Services, Seattle, WA, 98121, USA
Željko Ivezić
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Mario Jurić
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Bryce Bolin
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Joachim Moeyens
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
Francisco Förster
Center for Mathematical Modeling, Beaucheff 851, 7th floor, Santiago, Chile
Millennium Institute of Astrophysics, Chile
V. Zach Golkhou
Department of Astronomy, University of Washington, Seattle, WA, 98195, USA
The eScience Institute, University of Washington, Seattle, WA 98195, USA
Abstract
We introduce a new computational technique for searching for faint moving sources in astronomical images. Starting from a maximum likelihood estimate for the probability of the detection of a source within a series of images, we develop a massively parallel algorithm for searching through candidate asteroid trajectories that utilizes Graphics Processing Units (GPU). This technique can search over possible asteroid trajectories in stacks of the order 10-15 4K x 4K images in under a minute using a single consumer grade GPU. We apply this algorithm to data from the 2015 campaign of the High Cadence Transient Survey (HiTS) obtained with the Dark Energy Camera (DECam). We find 39 previously unknown Kuiper Belt Objects in the 150 square degrees of the survey. Comparing these asteroids to an existing model for the inclination distribution of the Kuiper Belt we demonstrate that we recover a KBO population above our detection limit consistent with previous studies. Software used in this analysis is made available as an open source package.
methods: data analysis, techniques: image processing, minor planets, asteroids: general, Kuiper belt: general
††software: KBMOD (Whidden et al., 2018), LSST DM Stack (Jurić et al., 2015), astropy (Astropy Collaboration et al., 2013), scikit-image (van der Walt et al., 2014), numpy (Oliphant, 2006), CUDA (Nickolls et al., 2008), scikit-learn (Pedregosa et al., 2012), pandas (McKinney, 2010), matplotlib (Hunter, 2007)
1 Introduction
Traditional approaches for detecting Trans Neptunian Objects (TNOs) rely on the identification of sources within individual images and then linking these sources to generate orbits (Kubica et al., 2007; Denneau et al., 2013). More recently digital tracking or “shift-and-stack” techniques have been developed to search for moving sources below the detection limit of any individual image (Gladman & Kavelaars, 1997; Allen et al., 2001; Bernstein et al., 2004; Heinze et al., 2015). These approaches are fundamentally different from the traditional techniques in that they assume a trajectory for an asteroid and align a set of individual images along that trajectory in order to look for evidence for a source.
Shift-and-stack methods share many commonalities with the “track before detect” (TBD) method used for the tracking of satellites and missiles (e.g. Reed et al., 1988; Johnston & Krishnamurthy, 2002). This field is mature in literature and implementation, and has been generalized to enable the detection of not just linear motion, but also the tracking of “acutely maneuvering non–cooperative targets” (Rozovskii & Petrov, 1999). We will adopt several of the features of TBD, in particular those described in Johnston & Krishnamurthy (2002), who outline the core principles of accumulating the track detection probability, and in quantifying the false alarm probability.
A related approach to faint moving object detection is presented in Lang et al. (2009), who describe a search for high proper motion stars. These objects move by a distance comparable to the PSF FWHM over the course of an entire survey (i.e. years). Thus a direct image stack is sufficient to detect objects. However, Lang et al. (2009) return to the individual science images to perform a joint fit for the proper motion and parallax of the objects, even though they appear at low signal–to–noise in any individual image. The scaling of detection depth in these techniques goes formally as = 1.26 log() magnitudes, or 1 magnitude deeper after the linking of 6 faint detections, and 2 magnitudes after 40 detections.
The advantage of digital tracking is that we increase the detection limit for a series of images as (assuming a constant point spread function (PSF) and background across all images). For objects having power–law distributions in apparent magnitude – e.g. the double power–law TNO model of Bernstein et al. (2004) – linking 6 epochs of data would yield an increase of 4–7 times as many objects from the same data. The cost of digital tracking comes from the combinatorial and computational complexity of having to search a large number of candidate trajectories for each pixel within an image. Digital tracking must combine the individual images along a proposed motion vector that will depend on the assumed distance of the asteroid. Even for slow moving asteroids searches will scale as where is the number of pixels in an image.
These computational costs have limited the application of digital tracking to searches for slowly moving objects or to narrow “pencil-beam” surveys. In this paper we introduce a new approach that utilizes a probabilistic formalism for the detection of sources in images (removing the need to stack or coadd images) and Graphics Processing Units (GPUs) to massively parallelize the number of searches that can be undertaken concurrently. In §2 we introduce a maximum-likelihood formalism for the detection of sources and extend this for the case of moving objects. In §3 we apply this approach to the High Cadence Transient Survey (HiTS) and describe some of the filtering techniques that were applied to exclude false positives in the candidate asteroids. In §4 we discuss the asteroids detected by this approach and compare their properties to current models and observations.
2 Fast tracking and stacking of images
Digital tracking assumes a set of images have been observed over a period of time (from minutes to days) with the individual images covering approximately the same part of the sky. The individual images are astrometrically shifted along a proposed motion vector, coadded, and then searched for point sources in the resulting coadds (Gladman & Kavelaars, 1997; Allen et al., 2001; Bernstein et al., 2004). This approach is illustrated in Figure 1 where the image on the far right is the sum of the previous three images added along the motion of the highlighted object. Creating a stack optimized for faint, moving objects must include astrometric offsets between the images that correspond to the distance that an object has moved between observations. Unfortunately, this angular velocity is not known a priori, and in fact differs for each moving object in the field. Thus a stacked search for Solar System objects in time–series data requires a sequence of coadds, each optimized for a particular motion vector. Due to the combinatorial complexity of the problem, these efforts have traditionally been optimized for TNO recovery, where apparent angular motions are small.
During an observation of a Solar System object, there are apparent motion contributions from the object’s own space velocity, as well as from the reflex motion of the Earth, which is primarily due to the Earth’s motion around the Sun but also includes the Earth’s rotation around its axis. These contribute to an apparent angular motion of the Solar System object, which will trail during an exposure. If the object trails by more than the PSF full-width half-maximum (FWHM) during observation, its signal is spread over additional background pixels, which lessens the overall signal-to-noise (Shao et al., 2014).
These “trailing losses” also apply to a stacked image: the image stack velocity must be close enough to the true velocity of the object to not spread the signal over more than the PSF FWHM. This requirement, together with the range of expected apparent motions of the desired objects, sets the number or sampling of the velocities (or orbits) that must be searched and stacks that must be examined. Typical apparent motions (at opposition) range from /hr for main belt asteroids at 3 AU to /hr for TNOs.
2.1 A likelihood-based approach for source detection
2.1.1 Form of single pixel likelihood function
Our goal is to derive the likelihood functions for a given source being present in the coaddition of a series of images. First we start by finding the form of the likelihood for a single pixel in a single image. The following derivation is based upon work in Kaiser (2004) and interpreted in Bosch (2015) and Bosch et al. (2017). Photons landing on a pixel in a detector follow Poisson statistics. For a given pixel the probability of counting photons with an expected value of is defined as
[TABLE]
This probability can also be interpreted as the likelihood that a model of the sources within an image (hereafter the true image) generates a predicted count given we observe counts on a pixel. The log-likelihood of our prediction model is, therefore,
[TABLE]
Differentiating with respect to , the log-likelihood has its peak when . Furthermore, if we Taylor expand around this maximum value then we get
[TABLE]
[TABLE]
where the constant contains all of the terms that depend only on and so are independent of our model. Finally, if is large we can ignore higher order terms and approximate our likelihood function as that of a Gaussian with likelihood proportional to .
2.1.2 Pixels and PSF
At this point we need to take a step back and understand what exactly goes into calculating photon counts at each pixel. To do this we will follow the derivation laid out in Bosch (2015) but for a two-dimensional image. First, we start with the number of counts we get from the true sky intensity on a pixel centered at . The observation on our detector will be the true sky intensity convolved with the PSF, . In addition, there will be an extra integral to account for the binning into a pixel centered at with side length . That gives us
[TABLE]
which can be rewritten in terms of two convolutions where we rewrite the pixel binning integral as a convolution with a square top hat function with height 1 and side length
[TABLE]
and if we exploit the associative and commutative properties of convolutions we can rewrite this as
[TABLE]
and following the procedure in Bosch (2015) simplifying the term in parentheses to
[TABLE]
and finally ending up with
[TABLE]
so that when we refer to the PSF below as we are referring to the PSF including the pixel transfer function.
2.1.3 Full likelihood function for a single image
Now we understand how to represent the pixel data as a function of the sky and PSF as well as how to write out the likelihood function of a single pixel. We consider an image x, where the th pixel is and the real sky is modeled as . Then we use our assumption of a large photon count to justify a Gaussian likelihood function as described in 2.1.1 and get
[TABLE]
but if we are looking at the entire image plane we need to go from a single variable Gaussian to a multivariate Gaussian distribution. Thus, the likelihood for the full image is
[TABLE]
where is the number of pixels and is the pixel covariance matrix. If we take the log-likelihood function then we have
[TABLE]
for the full form of the log-likelihood of a given sky model .
2.1.4 Likelihood of detection of a point source
If we want to find a point source at a pixel y in the image with flux then the sky model we are proposing is , a delta function located at the pixel lcoation of the source multiplied by the flux. Now let represent the flux counts for each pixel we have in a background subtracted image and notice that the first two terms in equation 13 are independent of the model . Furthermore, in order to keep values positive, we change to the negative log-likelihood function which we are now trying to minimize in order to get the most likely parameters. Thus, we get
[TABLE]
where the constant holds terms that are model independent. Also, we have defined which is the convolution of the point source sky model with the PSF and is thus equivalent to the PSF centered at y. is the same for the pixels in the indexed sum. We have two sums here since we are summing across every combination of pixels from the covariance matrix. If we multiply out these terms it looks like the following:
[TABLE]
Furthermore we define the following terms
[TABLE]
and once again add into constant the terms that are not model dependent. Finally, this gives us the likelihood in a compact form
[TABLE]
where and are new types of images that can be created using the PSF.
2.1.5 Coaddition of likelihood images for point source detection
We make the assumption that the signal for the majority of candidate detections will be dominated by the background noise and that the background noise is independent in each pixel. While there may be sources of correlation between pixels such as electronic detector effects (e.g. crosstalk or the dependence of the PSF on intensity), for this treatment we will assume these effects are small enough to ignore and thus will continue as if we have a completely diagonal covariance matrix. This simplifies our calculations into images that can be precomputed with a simple kernel that approximates the PSF.
Thus, our equations for and images are reduced to
[TABLE]
where is the inverse-variance weighted cross-correlation of the PSF and the data, which is also the convolution of the PSF rotated by 180 degrees or just the PSF if it is symmetric. is the effective area of the PSF weighted by the inverse variance (Bosch et al., 2017).
Bright pixels in the image can be dealt with by a mask and we set the inverse variance to zero so that they will add nothing to the likelihood sum. Since trajectories will only cross over this pixel once when we run them over a series of images this serves to give noisy pixels zero weight in the full sum of a trajectory while keeping the information in the other images.
Solving for the maximum-likelihood solution we end up with
[TABLE]
and as a result we find that,
[TABLE]
and
[TABLE]
where is the most likely flux for a source at pixel and is the probability of that source given the observation . The kernel that maximizes the likelihood of our flux measurements is, therefore, the 180 degree rotation of the PSF or, in the case of a symmetric PSF, the PSF itself. Additionally, Equation 23 is the log form of a Gaussian—where by analogy and —so we can approximate a distribution. If we define and then make an image of , we can call points above some threshold value to be -sigma detections (Szalay et al., 1999).
In order to make a coadded likelihood image, we create our and images from sums across all pixels in all images. This amounts to making and likelihood images for each of our original images, , with the appropriate PSF for each respective image and summing them separately so that
[TABLE]
Here, is the signal-to-noise of the detection of a source at pixel within the coadded image. Therefore, the final value for the likelihood of a point object is just the sum of the values at a given set of points in the image divided by the sum of the values at the same points in the image. This means that if we wish to do a moving object detection, all that is needed is to sum the and values as shown, but we must use the appropriate pixel coordinates for a given trajectory as the values in each image—there is no need to shift and stack the likelihood images at any point. The and images can also be precalculated meaning we are able to store them in memory as many trajectories are searched.
2.2 Object detection as Optimization
Detecting moving point sources in a stack of images can now be approached as an optimization problem. For the linear trajectories we are considering, the core task can be reduced to finding the initial positions and velocities v so that is maximized. For a given potential object, the best candidate source is then
[TABLE]
We hope to find all unique and v such that is above a desired detection threshold. The most straightforward computational approach to this problem is to evaluate for all possible values of and v that describe realistic orbits. An illustration of this approach is shown in Figure 2 starting from a single value of . This method directly computes and for every relevant trajectory through all images by sampling pixels along each trajectory and storing the result if the integrated is above the threshold. The computational complexity of this algorithm is bounded by where is the number of images to be stacked, is the area on the sky to be searched, is the area of a single pixel, is the duration between the first and last image, and is the range of an object’s apparent velocity. The complexity scales with time and velocity range quadratically because all trajectories ending anywhere inside an area with radius must be considered.
2.3 GPU Implementation
Comprehensively searching a stack of images for moving objects directly requires computing the value of billions of times. Fortunately each evaluation of is entirely independent from the others, and this allows for natural parallel execution. Rectangular patches of adjacent trajectories are grouped into thread blocks with dimensions 32x16 which are distributed across the GPU’s multiprocessors. and pixels are interleaved in memory and within each thread block horizontally adjacent trajectories access them contiguously, enabling high throughput. To achieve good performance all images must be stored in the GPU’s memory at once, which limits the size and number of images that can be used to about 100 4K x 4K images. In general, the runtime of this algorithm can be estimated as where is the number of images in the stack, is the number of trajectories, and is a performance constant that is experimentally determined by the computer hardware and implementation. In our implementation we have a measured value of about seconds per image for each trajectory. Practically this means searching for a wide range of objects (240 billion trajectories) in a stack of 30 images (4K x 4K) takes about 180 seconds. Besides computing , we also use the GPU for convolving the images. The convolution is done in a single pass with a spatially invariant kernel. In this work we only used a Gaussian PSF approximation, and could have used a two-pass separable convolution but chose to use a slower single pass to support non-Gaussian PSF’s in the future.
3 Searching for faint KBOS
3.1 The High Cadence Transient Survey (HiTS)
We tested our software using the first three nights (February 17-19, 2015) of the 2015 campaign of the High Cadence Transient Survey (HiTS) (Förster et al., 2016). The 2015 HiTS campaign involved repeatedly visiting 50 3-square-degree fields in the DECam g-band filter. There were typically 5 visits per night to each of the 50 fields, taken with a 1.6hr cadence. The remaining three nights of the 2015 HiTS campaign data, also taken with the DECam g-band, were used for follow up of the detected objects (Förster et al., 2016).
These data were taken using the Dark Energy Camera (DECam) at Cerro Tololo Interamerican Observatory (CTIO). The best quartile of seeing at CTIO is about 0.4” full width at half maximum (FWHM). DECam has 60 2K x 4K CCDs, each with a pixel scale of 0.26 arcsec/pixel. We processed all of the data using the LSST Data Management (DM) Software (Jurić et al., 2015) and ran our software using the warped science images that were laid out in 4K x 4K pixel patches. This means that the effective field of view of each warped image is about 0.34 square degrees (Flaugher et al., 2015). Because we currently do not search trajectories across CCDs, this is the effective field of view of any individual search. We also used the masks and variance planes from the LSST DM processing output.
3.2 Application of the KBO search
We created and images from the individual science images. To mask static objects we identify all sources that are detected at more than 5 above the background and mask the pixels associated with these sources. Masks for each static source are grown by an additional two pixels (in radius) to exclude lower surface brightness halos around these sources. To ensure that we do not mask bright moving sources we require that any masked pixel in a science image must be masked in at least one of the other science images (i.e. a source must be present at the same position in two of the images for it to be defined as static and masked). We apply the union of the mask for all individual images as a global mask to the final science images.
Our search started at every pixel in the earliest observation (in time) for each HITS field and covered a range of 32,000 trajectories across the stacks of 12-13 images corresponding to three nights of HITS data. The 32,000 trajectories came from a linearly-spaced grid of 128 angular steps within of the ecliptic and 250 steps in velocities ranging from 1”– 5.7”/hour. This grid was set up so that at the end of the search period, our maximum separation between the final pixels in a search pattern would be no more than approximately 2 PSF widths. This means that that we would be within 1 PSF width of any possible trajectory. For this search, we went down to a signal-to-noise ratio (SNR) threshold of 10, as measured by the parameter introduced in Section 2.1.5. For these data, this corresponds to a single image limiting magnitude in g of 23.1.
3.3 Filtering of candidate trajectories
After running the initial GPU search, we use a set of Python tools to filter out false detections. One such tool is an outlier filtering process that modifies estimates of the flux and variance of an object given a sequence of observations. This is done using the light curve of the candidate trajectory and a variation on the Kalman filter (Kalman, 1960) commonly used in signal processing. We filter out any observations that are more than five standard deviations away from the best fit Kalman flux at that observation and use the remaining observations to recalculate the likelihood of the candidate. As an example of this process, Figure 3 shows postage stamps of the candidate before and after the filtering. In this case a fast, bright, moving object moved across the trajectory in a single image. Excluding that image leads us to the correct decision to discard this candidate trajectory, as the likelihood of an object along this trajectory drops to near zero, once the interloping object is removed.
After the outlier detection we build coadded postage stamps for all remaining candidate trajectories. We then use scikit-image (van der Walt et al., 2014) to calculate the central moments of the images and filter based upon the similarity of the moments to a Gaussian centered at the middle of the stamp. This does a good job of eliminating elongated shapes and trajectories where a bright source appeared in a single image but was off center. For example, in Figure 4 the left column shows postage stamps of real objects that passed through the filtering. The right column of the figure shows postage stamps that made it through the outlier filtering but were ruled out after the image moment filter.
Our final step in the filtering process is clustering to remove duplicate results from the same object. We take the starting x and y pixels and the horizontal and vertical velocities of the candidate trajectories and use the DBSCAN clustering method (Ester et al., 1996) in the scikit-learn python package (Pedregosa et al., 2012) to group similar trajectories. We then take the highest likelihood trajectory for each group and save the results with postage stamps and light curves to file for final examination by eye.
3.4 Found Objects
3.4.1 KBO properties in the HiTS field
In total we found 45 KBOs in our search, of which only 6 were previously detected by the Pan-STARRS 1 (PS1) survey according to the Minor Planet Center (MPC). PS1 used the Pan-STARRS Moving Object Processing System (MOPS) which links detections from sources identified in individual difference images (Denneau et al., 2013).
The full information for all our object detections is shown in Table 1 in Appendix A. We used the orbit fitting code of Bernstein & Khushalani (2000) for initial orbit determination and used the remaining HITS data (see Section 3.1) to get additional observations where possible before submitting to the MPC. From this we estimated that, for the 45 KBOs, semi-major axes ranged from 21 AU to 67 AU and DECam g-band magnitudes ranged from 22.1 to 24.7 mags. Figure 5 compares semi-major axis to inclination for our discoveries and shows the overlap with KBO populations commonly discussed in the literature.
3.4.2 Comparison with known asteroids
The candidate objects were checked with the MPC database of known objects. Of the 45 objects that were detected, 6 were known. Four of these objects were detected in our search down to a SNR threshold of 10 and they are noted in Table 1. The 2 remaining objects were much fainter at V magnitudes of 24.1 and 24.3 while the faintest MPC object we recovered in our search was at V = 23.0. We attempted to recover the objects at a fainter SNR threshold by rerunning the search on the image stacks corresponding to the predicted locations. One of the objects was recovered when we reduced our SNR threshold to 5.96. The final object ran from the edge of one image stack to another between the first and second night. Our code cannot currently account for this situation in our search. However, we ran the search using only the second and third nights of data to find the object and our code was able to find it at a reduced SNR value of 5.31. This means that when going to a faint enough search threshold we were able to recover all of the known KBOs in the search area.
After submission to the MPC database two more results were matched to objects in the MPC catalogs. Previous observations had not predicted the orbits to fall within the observation fields, but were linked and recalculated by the MPC after submission of our results. These new matches are also noted as previously discovered in Table 1.
4 Results
4.1 Recovery Efficiency
To understand the efficiencies of our search method, we inserted simulated objects with g magnitudes between 20-26 into the images from one of the 2015 HITS fields and tested our ability to recover these objects. The objects all had a simple Gaussian PSF that matched our search PSF and the velocity angles and magnitudes were uniformly distributed within the ranges of our search parameters. Figure 6 shows the results in terms of counts on the left and the fraction of the total simulated set on the right. Both plots are a function of DECam g magnitude with bin widths of 0.25 magnitudes. For the right plot we fit an efficiency function of the form , where is the efficiency ceiling, is the 50% detection probability magnitude, and is the width in magnitudes of the drop-off in sensitivity.
We plotted two efficiency functions, one for the entire range of magnitudes of the simulated objects and then one at magnitudes . The drop-off at the brighter magnitudes is due to the extra masking we did at a specific count threshold. We will say more about this effect in the discussion in Section 5. On the fainter end we see the limit set by the SNR cutoff at SNR = 10. The detection efficiency ceiling for the full range is % with a 50% threshold at and drop-off width of mags. When we look at efficiencies at we get an efficiency ceiling of % and a 50% detection threshold at the very similar value and drop-off width of mags.
4.2 Comparison with Existing Models
While our original searches used only three nights of data, we had additional nights in the HITS data that we used for supplying additional observations when estimating the orbits of the discovered KBOs. This still limited our baseline for the discovered objects to a range from 3-10 days and made accurate estimates of semi-major axis and eccentricity difficult. We have confident measurements on the inclinations and all our inclination estimates for objects in the MPC catalog matched the published inclinations within 1 of the output values from the Bernstein & Khushalani (2000) orbit fitting code. Therefore, we present a comparison of our inclination distribution to the general KBO population such as that in Brown (2001).
4.2.1 Inclination Distribution
Our inclination values range from - where the lower limit comes from the fact that our closest field to the ecliptic is at . Even though our fields are all at moderate latitudes off the ecliptic (as far as ), Brown (2001) provides a method to compare our results to a predicted distribution by using the inclinations of the objects and the ecliptic latitude of discovery.
Brown (2001) estimates an inclination distribution for the full KBO population with a double Gaussian multiplied by :
[TABLE]
where , and . To compare our results to this distribution we follow the method outlined in Section 3 of Brown (2001). For a given inclination distribution, , the probability that an object, , with discovery latitude, , would have an inclination equal to or below the actual inclination, is given by Equation 29.
[TABLE]
The distribution of for the actual KBO population estimated by Brown (2001) varies uniformly between 0 and 1. Therefore, if we take as the null hypothesis for our observations that they are an unbiased sample down to our magnitude limits and representative of the distribution of KBO inclinations in the fields we searched we should compare the distributions of for our objects to the uniform distribution. To do this we start by calculating for each of our objects and plot their sorted distribution in Figure 7. We compare our observed distribution to the inclination distribution of Brown (2001) using the Kuiper variant of the Kolmogorov-Smirnov (K-S) test as done in Brown (2001) and according to Equation 30.
[TABLE]
The actual test statistic is where is the sample size which is in our data set. In order to find the confidence levels for the test, we create sets of N=45 random samples drawn from a uniform distribution and calculate comparing to a uniform distribution. The confidence value occurs when the probability of getting higher than a given value is 84.1%. We find this to be at .
Finally, we calculate the values using the Monte Carlo methods described in Brown (2001). We first draw inclinations from the Brown (2001) distribution and randomly place them along circular orbits. For each of our observed objects, , we then take all of the Monte Carlo objects within of the latitude of discovery, and construct an empirical inclination distribution. In order to derive for an object, we use this distribution to calculate the probability that an object with the given will have an inclination at or below . Using this set of values we then perform the K-S test compared to a uniform distribution between 0 and 1. We perform the Monte Carlo simulation 1000 times and use the mean value as our test statistic for comparison. The K-S test comparison for one of the Monte Carlo distributions is shown in Figure 7. Our mean value after 1000 runs was 1.37, corresponding to a confidence level of 75% and within the level. This means that we cannot reject the hypothesis that our observations come from the Brown (2001) distribution and are consistent with this prediction.
As a further comparison we did a basic survey simulation to determine the expected distribution of objects we would find in the HITS data. We used the Monte Carlo distribution of inclinations and locations of objects scattered around circular orbits from Figure 7 along with the locations of the HITS fields and approximated the DECam field of view as a circle with diameter. With this information, we recorded the objects in the Monte Carlo simulation visible through the survey pattern. We then scaled this distribution to the discovery of the same number of objects that we found in the data and plotted them on top of one another in Figure 8. A test on this data gives and a p-value of 0.69, meaning we cannot reject the hypothesis that our observed samples come from the Brown (2001) inclination distribution function for the general KBO population.
4.2.2 Magnitude Distribution
We next compare the magnitudes of our discoveries to the KBO magnitude distribution of Fraser et al. (2008). This distribution gives the number of observed objects per square degree as:
[TABLE]
where and for R magnitudes. Since Equation 31 is based upon the number of expected objects per square degree at the ecliptic we needed to scale our viewing area appropriately. Satisfied by the work in Section 4.2.1, where we showed our results are consistent with the Brown (2001) inclination distribution, we converted this to a latitudinal distribution. We then multiplied the 3 square degree DECam viewing area for each field by the fraction of expected objects at the field’s ecliptic latitude compared to the maximum value at the ecliptic. This gave us an effective viewing area of 91.05 square degrees. The next step was converting between the R magnitudes used for Equation 31 and the g magnitudes of our observations. Fraser et al. (2008) also had to do magnitude conversions for various datasets and used a KBO color of 0.95 which we use here as well. Putting together the scaling and magnitude offsets we compare our results to the Fraser et al. (2008) expected number of objects for our survey fields in Figure 9.
The drop-off expected from Section 4.1 around 24th magnitude is present and seems to occur after after which we fall below 50% completeness which is consistent with the magnitude where our search drops below 50% efficiency as shown in Section 4.1. Figure 9 also shows the 10-sigma threshold we used in our search of the HITS data. A test on the data for gives and a p-value of 0.25, meaning our results are consistent with the Fraser et al. (2008) luminosity distribution.
5 Discussion
5.1 Filtering Analysis
We used the field with simulated objects from Section 4.1 to study the effects of the various stages of our filtering process. The red line in Figure 10 shows the results for the searches over the full field in our processing which included an extra masking step that we discuss below. We start with the total number of searches based upon the number of grid steps multiplied by the number of pixels on the focal plane. We only keep those above our detection threshold which is the biggest single reduction in the number of possible results. After that, each step in our filtering process is able to reduce the number of false positives by 1-3 orders of magnitude in the number of total results. The most effective is the postage stamp filtering which uses the moments of the postage stamp image and their resemblance to those of a Gaussian source model.
5.2 Masking and Threshold Effects
We made a series of decisions in our search based upon our target objects and the use of science images instead of less contaminated difference images. The first choice we made was to include an additional bright pixel mask when creating our and images. This mask was in addition to the masking described in Section 3. Any pixel in any image that exceeded 120 counts, corresponding to , was masked in our searches. This additional masking covers extended bright halos, that were not covered by our initial footprint masking, and bright fast moving objects which are likely much closer to Earth than our target population. The effects of additional masking on recovery were tested on the simulated object field (Section 4.1). Comparing the red line with this extra masking to the blue line without it in Figure 10 shows the major benefit of this masking was a significant decrease in the amount of false positives we had to filter out after our likelihood cut. The amount of positive results after the likelihood cut in Figure 10 shows about five times more objects to filter after the threshold cut without the masking. A decrease of false positives over a single field saves us hours of computation time during our analysis since we processed the results through the lightcurve filter at a rate of 70 seconds for 500,000 objects. Over 50 fields this adds up to days of processing time that we were able to avoid.
However, we also looked to see what was the price we paid for this extra computational efficiency. Figure 11 compares the efficiency curves of Section 4.1 and Figure 6 to the results without the additional bright pixel masking. The recovery efficiency is higher across all magnitudes at %, but when we compare to the recovery at only with the masking it is very similar to the % of that result. The 50% efficiency depth is nearly unchanged at without the masking meaning the bright pixel masking does not affect our overall depth but only the bright end of our recovery at . Using the Fraser et al. (2008) curve for the expected number of KBOs for magnitudes in our survey fields, we calculate that the number of expected objects in this magnitude range to be less than 0.3. We find this to be an acceptable trade off for the computational savings in this particular example. When going to difference imaging or with a different population of brighter expected objects we do not plan to include this extra masking step.
Another decision we made was to set our threshold for detection at a limit of 10 instead of a lower, typical catalog level threshold of . This decision was motivated by the use of science images and the extra noise that would be present as this threshold was lowered. We looked at the increase of false positives as we go from 10 to 5 by rerunning the same field as Section 4.1 without any simulated objects and the timestamps randomly scrambled so that any detections were false positives. We show histograms comparing the false positives to true detections at the two thresholds in Figure 12. We also calculated the precision of our final results where precision is defined as and show the results in Figure 13. While we do detect objects to over a magnitude fainter () with the lower likelihood threshold we are overwhelmed by false positives at the fainter magnitudes and even at magnitudes at which we achieve high precision with a higher threshold. At a threshold of 5 we are below 50% precision at while we are never below 90% precision when using a 10 threshold. This degradation at a brighter magnitude in the 5 results happens because bright false positives with fewer observations will appear at a higher likelihood than a dim object with more observations (e.g., a greater number of the observations were in a masked area or off the edge of the CCD). Due to this false positive performance when running on science images we used the 10 threshold in this work to show the effectiveness of the algorithm and code while also producing useful results. We discuss our future plans in the next section including what we will do to run the code at a lower detection threshold going forward.
5.3 Future Work
There is ongoing work to decrease the detection threshold for sources in order to extend the searches ov er longer timescales thus allowing us to find fainter and more distant objects. Work with longer baselines and larger stacks of images would also allow us to push this detection limit lower and confidently go beyond the limits of current population studies of KBOs. We plan to use the code with difference images in the future which we hope will reduce the time spent filtering and also remove many of the artifacts from science images that lead to false positives above 5 and also pushed us to add in additional masking procedures in this work. We also plan to move to a deep learning based postage stamp classifier that we hope will perform well at fainter magnitudes and plan to do a comparison versus our existing technique on the difference imaging search. We will also address working with non-linear trajectories and methods to find objects that move from one chip to another during the survey period. Finally, we are also working on enhancements to the GPU algorithm that will allow us to spend less time searching low likelihood trajectories thereby increasing search efficiency.
All of these improvements will help us explore deeper into the Kuiper Belt and enhance our ability to use stacks of images from long baseline surveys such as ZTF or LSST in the future.
6 Conclusion
In this paper we presented a new algorithm that uses the power of GPU processing to search for slow moving sources across a sequence of images. Our approach is capable of searching over candidate moving object trajectories in one minute. Applying these techniques to existing data we discovered 39 new KBOs and the recovered 6 KBOs already present in the Minor Planet Center catalogs. Finally, we used the results of our search to compare to the Brown (2001) Kuiper Belt inclination distribution and the Fraser et al. (2008) magnitude distribution. We found both of the models to be consistent with observed results indicating that the recovered sample matches overall published characteristics of the KBO population. Combined with the high rates of detection efficiency recovered in tests, this indicates that our software provides a nearly complete recovery of an unbiased sample of moving objects down to the detection limit.
Our software, Kernel Based Moving Object Detection (KBMOD) is available to the public at https://github.com/dirac-institute/kbmod. This includes the GPU searching code as well as python analysis code we have used to process the search results. Development is continuing and can be followed at the Github repository hosting the code.
We would like to thank the anonymous referee for very helpful feedback that improved this paper. We also wish to thank Jim Bosch for valuable insights when we were starting this project. AJC and JBK acknowledge partial support from NSF awards AST-1409547 and OAC-1739419. AJC, JBK, PW acknowledge support from the DIRAC Institute in the Department of Astronomy at the University of Washington. The DIRAC Institute is supported through generous gifts from the Charles and Lisa Simonyi Fund for Arts and Sciences, and the Washington Research Foundation.
Appendix A Table of Detected Objects
\startlongtable
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Allen et al. (2001) Allen, R. L., Bernstein, G. M., & Malhotra, R. 2001, Ap J, 549, L 241
- 2Astropy Collaboration et al. (2013) Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A 33
- 3Bernstein & Khushalani (2000) Bernstein, G., & Khushalani, B. 2000, AJ, 120, 3323
- 4Bernstein et al. (2004) Bernstein, G. M., Trilling, D. E., Allen, R. L., et al. 2004, AJ, 128, 1364
- 5Bosch (2015) Bosch, J. 2015, Algorithms for Detection and Coaddition. https://github.com/lsst-dm/algorithm-docs/blob/master/2015-07-det%2Bcoadd-slides/slides.ipynb
- 6Bosch et al. (2017) Bosch, J., Armstrong, R., Bickerton, S., et al. 2017, ar Xiv.org, 502
- 7Brown (2001) Brown, M. E. 2001, AJ, 121, 2804
- 8Denneau et al. (2013) Denneau, L., Jedicke, R., Grav, T., et al. 2013, PASP, 125, 357