Auto-weighted Mutli-view Sparse Reconstructive Embedding
Huibing Wang, Haohao Li, Xianping Fu

TL;DR
This paper introduces AMSRE, a novel multi-view dimensionality reduction method that leverages sparse reconstructive correlations and auto-weighted view contributions to improve low-dimensional representations of high-dimensional multi-view data.
Contribution
The paper proposes AMSRE, a new algorithm that exploits sparse reconstructive correlations and auto-weights multiple views for enhanced multi-view data embedding.
Findings
AMSRE outperforms existing methods in experiments.
It effectively captures complementary information from multiple views.
The auto-weighted mechanism improves discriminative power.
Abstract
With the development of multimedia era, multi-view data is generated in various fields. Contrast with those single-view data, multi-view data brings more useful information and should be carefully excavated. Therefore, it is essential to fully exploit the complementary information embedded in multiple views to enhance the performances of many tasks. Especially for those high-dimensional data, how to develop a multi-view dimension reduction algorithm to obtain the low-dimensional representations is of vital importance but chanllenging. In this paper, we propose a novel multi-view dimensional reduction algorithm named Auto-weighted Mutli-view Sparse Reconstructive Embedding (AMSRE) to deal with this problem. AMSRE fully exploits the sparse reconstructive correlations between features from multiple views. Furthermore, it is equipped with an auto-weighted technique to treat multiple views…
Click any figure to enlarge with its caption.
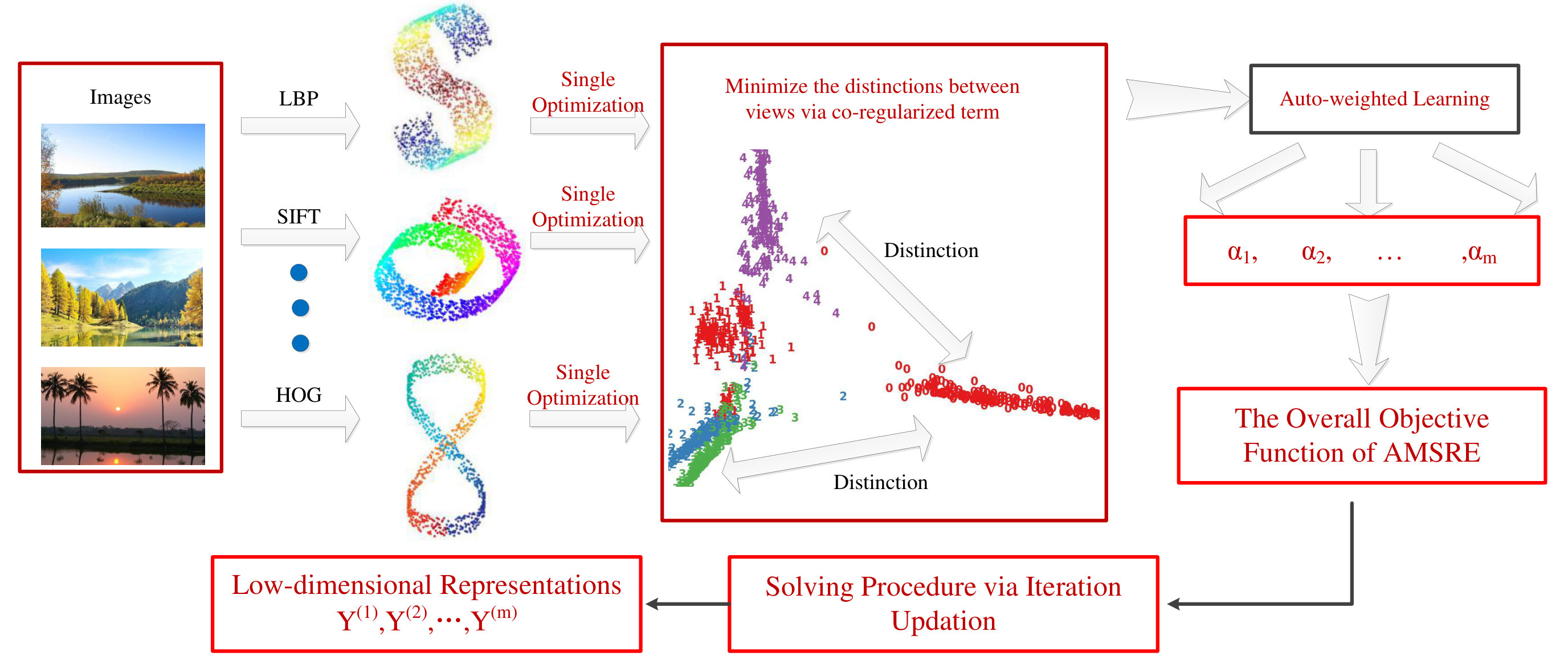 Figure 1
Figure 1 Figure 2
Figure 2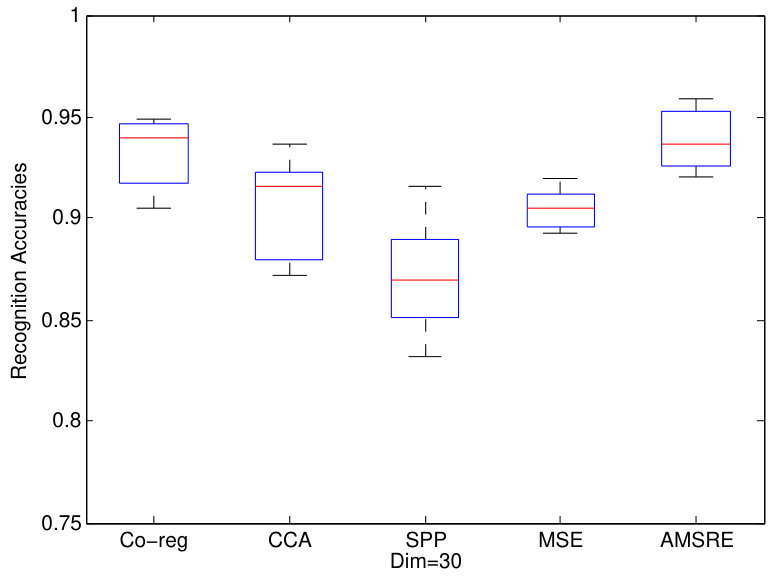 Figure 3
Figure 3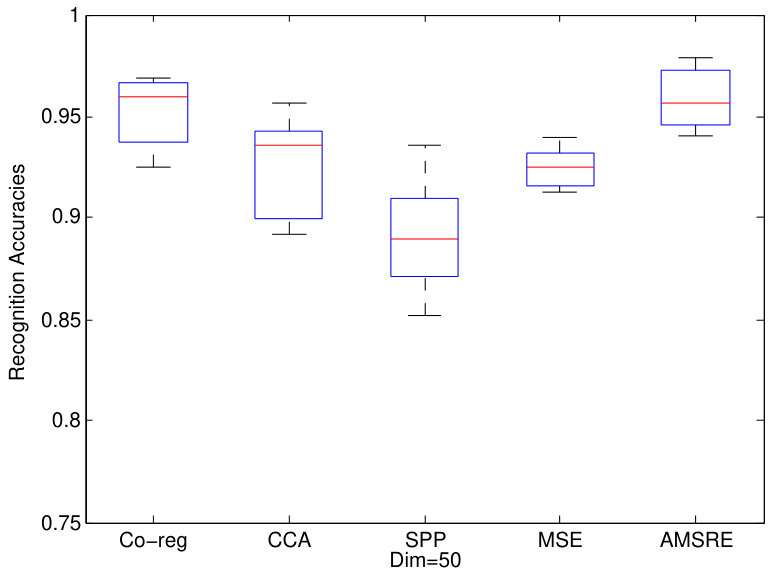 Figure 3
Figure 3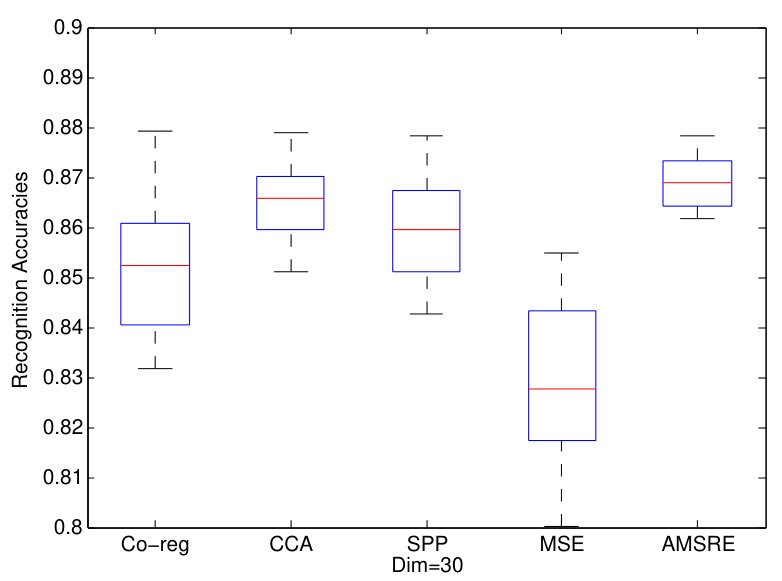 Figure 4
Figure 4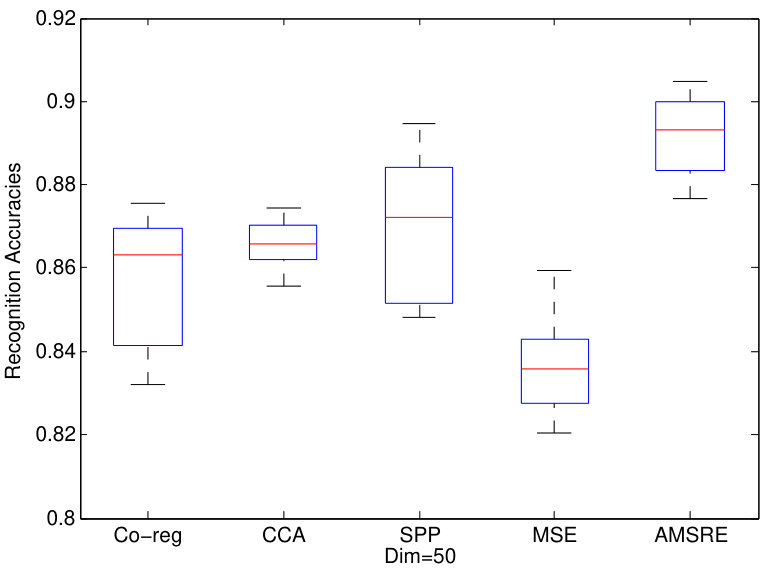 Figure 4
Figure 4 Figure 7
Figure 7| Input: |
| A set of multi-view features with training samples having views . |
| Initialization: |
| Initialize using single view optimization as Eq.4 |
| The optimization procedure of AMSRE: |
| 1. Do |
| 2. Using sparse representation to construct the sparse reconstructive weights |
| matrix for all views . |
| 3. Calculate for all views. |
| 5. For |
| 6. Update for the th view according to Eq.(11) |
| 7. End |
| 8. Update according to Eq.(14) |
| 9. Until converges |
| Output: |
| The low-dimensional representation for all views |
| 3Sources | Co-reg kumar2011co | CCA | SPP | MSE | AMSRE | |
|---|---|---|---|---|---|---|
| Dim=10 | Mean | 72.36% | 70.98% | 69.93% | 74.56% | 75.42% |
| Max | 82.73% | 82.64% | 80.33% | 85.70% | 86.73% | |
| Dim=30 | Mean | 75.49% | 74.98% | 73.14% | 76.49% | 78.47% |
| Max | 86.19% | 85.51% | 83.87% | 88.03% | 90.23% | |
| Dim=50 | Mean | 81.30% | 80.02% | 78.93% | 83.06% | 85.73% |
| Max | 88.14% | 86.96% | 85.34% | 88.34% | 91.44% |
| Cora | Co-reg kumar2011co | CCA | SPP | MSE | AMSRE | |
|---|---|---|---|---|---|---|
| Dim=10 | Mean | 44.37% | 42.11% | 39.51% | 48.72% | 51.80% |
| Max | 56.37% | 53.49% | 46.17% | 57.11% | 60.22% | |
| Dim=30 | Mean | 48.33% | 46.58% | 41.20% | 50.33% | 53.86% |
| Max | 56.37% | 53.49% | 46.17% | 57.11% | 60.22% | |
| Dim=50 | Mean | 52.10% | 49.74% | 42.78% | 54.37% | 56.49% |
| Max | 61.11% | 58.78% | 45.77% | 63.54% | 66.03% |
| WebKB | WebKB-1 | WebKB-2 | WebKB-3 | WebKB-4 | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | Max | Mean | Max | Mean | Max | Mean | Max | |
| Co-reg kumar2011co | 83.46% | 87.33% | 67.95% | 76.54% | 87.18% | 90.10% | 75.43% | 80.24% |
| CCA | 83.34% | 89.44% | 78.23% | 81.62% | 87.02% | 92.47% | 68.18% | 76.23% |
| SPP | 82.54% | 87.30% | 67.19% | 72.33% | 88.81% | 92.79% | 77.53% | 79.80% |
| MSE | 85.33% | 89.23% | 75.26% | 80.99% | 90.33% | 91.93% | 79.68% | 83.22% |
| AMSRE | 87.25% | 90.96% | 77.18% | 82.99% | 92.17% | 94.36% | 81.63% | 85.92% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Image Enhancement Techniques · Advanced Vision and Imaging
∎
11institutetext: H. Wang 22institutetext: College of Information and Science Technology, Dalian Maritime University, Dalian, China, 116021
22email: [email protected] 33institutetext: H. Li 44institutetext: School of Mathematical Sciences, Dalian University of Technology, Dalian, China, 116024
44email: [email protected] 55institutetext: X. Fu 66institutetext: College of Information and Science Technology, Dalian Maritime University, Dalian, China, 116021
66email: [email protected]
Auto-weighted Mutli-view Sparse Reconstructive Embedding
Huibing Wang
Haohao Li
Xianping Fu 111Corresponding Author
(Received: date / Accepted: date)
Abstract
With the development of multimedia era, multi-view data is generated in various fields. Contrast with those single-view data, multi-view data brings more useful information and should be carefully excavated. Therefore, it is essential to fully exploit the complementary information embedded in multiple views to enhance the performances of many tasks. Especially for those high-dimensional data, how to develop a multi-view dimension reduction algorithm to obtain the low-dimensional representations is of vital importance but chanllenging. In this paper, we propose a novel multi-view dimensional reduction algorithm named Auto-weighted Mutli-view Sparse Reconstructive Embedding (AMSRE) to deal with this problem. AMSRE fully exploits the sparse reconstructive correlations between features from multiple views. Furthermore, it is equipped with an auto-weighted technique to treat multiple views discriminatively according to their contributions. Various experiments have verified the excellent performances of the proposed AMSRE.
Keywords:
Multi-view Sparse Representation Auto-weighted Mutli-view Sparse Reconstructive Embedding Dimension Reduction
1 Introduction
Nowdays, we have witnessed the rapid development of information technology hu2017deep ; feng2018learning ; wang2018beyond . It is common that one sample can be described from multiple perspectives, which leads to the large-scale multi-view data produced in various fields shen2015supervised . Multi-view data not only contains more compatible and complementary information, but also improves the performances of those decision making systems wu2018and . For example, one image can be represented by features extracted from multiple descriptors, such as, Local Binary Patterns (LBP) ahonen2004face , Scale-Invariant Feature Transform (SIFT) ng2003sift and Locality-constrained Linear Coding (LLC) wang2010locality , etc feng2017spectral . All these features should be carefully exploited by multi-view learning algorithms. Therefore, researchers all over the world pay more attentions in the field of multi-view learning and develop various algorithms to meet the requirement of some applications wu2019cycle .
During the past decade, there are many multi-view learning algorithms wang2017unsupervised ; Wang2017Effective proposed using various techniques. Most multi-view learning algorithms focus on the task of clustering. Kumar et al. kumar2011co proposed a co-regularized framework which can minimize the distinctions between multiple views. And it has achieved good performance to deal with multi-view clustering. Xia et al. xia2010multiview has developed a auto learning trick to learn the factors corresponding to all views and combined graphs from multiple views. The proposed MSE has also attracted attentions from researchers in this field. Wang et al. wang2018multiview finished the task of subspace clustering via structured low-rank matrix factorization and also achieved good performance. Moreover, there are some algorithms proposed to construct low-dimensional subspace wang2016multi for multi-view data. Kan et al. kan2016multi extended Linear Discriminant Analysis (LDA) mika1999fisher into multi-view mode and proposed a method called Multi-view Discriminant Analysis (MvDA). Luo et al. luo2015tensor extended canonical correlation analysis to the tensor mode, which can deal with multi-view data in tensor form and finish the task of dimension reduction. All these methods are proposed from different perspectives to deal with multi-view data wang2015lbmch .
Meanwhile, high-dimensional data wu2018deep has caused many problems to many applications, such as metric learning shen2011scalable ; wang2016semantic , face alignment liu2018face , et al deng2018learning ; wu20183d . Therefore, how to obtain low-dimensional representations for high-dimensional features is also a hot topic in the last decades. Principle Component Analysis (PCA) Agarwal2009Face and LDA mika1999fisher are two most traditional ones in this fields. PCA is an unsupervised method which maximizes the global variance of data to obtain the low-dimensional subspace. Even though it is simple and convenient, it lacks discriminative ability since it can not fully utilized enough information. LDA is a supervised method and fully utilizes label information. It has been utilized in many classification tasks because of it’s ability. Locality Preserving Projections (LPP) he2004locality is a local DR method which considers the relationships between each two neighbours and maintained them in the low-dimensional subspace. Neighborhood Preserving Embedding (NPE) he2005neighborhood is another local DR method which maintained the linear reconstructive relationships between samples. Sparsity Preserving Projection qiao2010sparsity is a DR method which exploits the sparse relationships between samples. All these methods are proposed to construct low-dimensional subspace for high-dimensional data, which has attracted wide attentions wu2018whatand from authors all over the world.
In this paper, we focused on constructing the low-dimensional representations for multi-view data and proposed a novel method named Auto-weighted Mutli-view Sparse Reconstructive Embedding. Because multiple views have different impacts on the algorithm, AMSRE can automatically assign differnet factors to multiple views according their contributions. Furthermore, AMSRE fully exploited the sparse reconstructive relationships between features within their perspective views. Then, AMSRE maintained the relationships and forced all views to help each other to improve its discriminative ability. The overall framework of AMSRE has been shown as Fig.1. And we summarized the contributions of AMSRE as follows:
1.1 Constructing Procedure
- •
AMSRE is successfully equipped with a auto-weighted method to assign multiple views with different factors. This procedure can help AMSRE better understands the contributions of different views.
- •
AMSRE can better maintain the spares reconstructive relationships between features within their perspective views, which can improve the discriminative ability of the low-dimensional representations.
- •
We carefully construct an alternating optimization method to obtain the solution of AMSRE, which can be refered by some related studies.
The following paper is organized as follows: in section 2, we introduced the basic knowledge of multi-view learning and summarized some related works in this field. In section 3, we illustrated the construction process of AMSRE and described the solving procedure in detail. Section 4 shown various experiments to verify the performance of our proposed AMSRE. And we made a conclusion of this paper in section 5.
2 Related Works
In this section, we introduced some basic knowledge of multi-view learning Wang2016Iterative . Furthermore, we have shown 2 typical multi-view learning methods.
Assume we are given a multi-view dataset which contains samples from views. consists of features in the th view. All features in the th view locate in a -dimensional space. Multi-view learning is an essential research field to fully utilize information from multiple views to obtain a better decision. Therefore, the goal of our proposed AMSRE is to construct a common subspace for features from all views and obtain the low-dimensional representations for the original multi-view data, where .
2.1 Multiview Spectral Embedding
MSE is a good performance for multi-view dimension reduction. It can encode different features from multiple views to achieve a physically meaningful embedding. Xia el al. xia2010multiview extends Laplacian Eigenmaps (LE) belkin2002laplacian into multi-view mode and develops an architecture to learn weights for different views according to their contributions. Furthermore, MSE integrates laplacian graphs from multiple views via global coordinate alignment. And the proposed objective function of MSE can be summarized as follows:
[TABLE]
where is the laplacian graph for features in the th view. It reflects the neighborhood relationship between features in the th view. is a set of coefficients which can reflect the importance of different views. And is the low-dimensional representation for the original multi-view data. And MSE develops an iterative optimization procedure to update and alternately.
2.2 Co-regularized Multi-view Spectral Clustering
Co-regularized Multi-view Spectral Clustering kumar2011co is a novel multi-view method to deal with the task of clustering wang2015robust . It first utilized a co-regularized term to minimize the distinctions between multiple views and calculated the low-dimensional representations for all samples in each view. Then, traditional spectral clustering strategy can be carried on to assign all samples into different clusters. And an iterative optimization procedure is adopted to solve the solution of this method. The objective function is shown as follows:
[TABLE]
where is the low-dimensional representation for features in the th view. is the laplacian graph for the the view. is a regularized parameter to balance the weights of each two views. The second term in Eq.2 can minimize the distinctions between each two views to help them to learn from each other to obtain the low-dimensional representations.
3 The Proposed Method
3.1 The Construction Process of AMSRE
In this section, we introduced the proposed Auto-weighted Mutli-view Sparse Reconstructive Embedding (AMSRE) in detail. AMSRE aims to integrate compatible and complementary information from multiple views and utilized the co-regularized term to minimize the distinctions between all views. Furthermore, AMSRE is equipped with a auto-weighted strategy to assign factors to each views according to their contributions. Therefore, the obtained low-dimensional representation can better maintain information from multi-view data. First, we aim to maintain the sparse reconstructive correlations in the th view as follows:
[TABLE]
where is the set of features in the th view, which has not contain . is the sparse reconstructive correlation vector which can be calculated by sparse representation qiao2010sparsity . Eq.3 aims to construct the low-dimensional representation for which can contain sparse reconstructive correlations in the original multi-view data. According to mathematical transformation, Eq.3 can be expressed as follows:
[TABLE]
where and . And is the low-dimensional representation for features in the th view. However, Eq.4 is the single view method which can only calculate for one single. In order to extend Eq.4, we first minimize the sum of Eq.4 for all views as follows:
[TABLE]
Even though Eq.5 take all views into considerations, it cannot help all views to learn from each other. Therefore, we introduced a co-regularized term to minimize the distinctions between all views. We propose the following cost function as a measure of disagreement between each two views:
[TABLE]
where is the similarity matrix for , and denotes the Frobenius norm of the matrix. Eq.6 can be utilized measure the disagreement between each two views. And minimizing Eq.6 can keep all views to be consensus. Because , Eq.6 can be further transformed as follows:
[TABLE]
The transform from Eq.6 to Eq.7 neglects constant additive and scaling terms. Therefore, combines with Eq.7, The objective function of AMSRE can be organized as
[TABLE]
It is clear that we can obtain the low-dimensional representations through Eq.8. However, because multiple views have different influences on the construction of low-dimensional representations. Therefore, we should further exploit information in different views and assign different weights to different views. Therefore, we equip an auto-weighted trick with Eq.8 and reformulate the objective function of AMSRE as follows:s
[TABLE]
where is the weight to reflect the importance of the th view. is the weight vector. And the low-representations in Eq.9 can be calculated by eigen-decomposition. And we provide the solving process of AMSRE in the following section.
3.2 Solving Procedure of AMSRE
We have shown how we construct the objective funciton of AMSRE before. In this section, we provide the solving process of it. Because AMSRE should optimize with at the same time, we adopts an iterative optimization strategy to obtain the solution. For each iteration, if we want to update , we should maintain all the other variables to be unchanged, including and . Therefore, the objective function of AMSRE can be organized as follows:
[TABLE]
Due to the additive operation of trace, Eq.10 can be further transformed as
[TABLE]
Therefore, we can get the low-dimensional representation by calculating the eigenvector of with the constraint . We can update all the low-dimensional representations by keep the other variable unchanged and just update one view.
Meanwhile, in order to obtain , we adopt Lagrange multiplier to update it. After we update all the , we keep them unchanged and update . . By using a Lagrange multiplier to take the constraint into consideration, we get the Lagrange function as
[TABLE]
By setting the derivative of with respect to and to zero, we have
[TABLE]
Therefore, can be update by the following rules.
[TABLE]
It can be calculated by Eq.14 to update . And we can obtain the optimal and by updating one of them and keeping the other variables unchanged. And we conclude the solving procedure in Table.1.
4 Experiment
In this section, we conduct several experiments on the benchmark multi-view datasets (including 3Sources, Cora, WebKB, Yale and ORL) to verify the performance of our proposed AMSRE. First, we introduced the utilized datasets in this section and listed some comparing methods. Then, we carry on experiments on these datasets and provide the results on them.
4.1 Datasets and Comparing Methods
In our experiments, 5 datasets are utilized to illustrate the effectiveness of AMSRE, including document datasets (3sources 222http://mlg.ucd.ie/datasets/3sources.html, Cora 333https://relational.fit.cvut.cz/dataset/CORA and WebKB 444http://www.webkb.org/) and face datasets (Yale 555http://cvc.cs.yale.edu/cvc/projects/yalefaces/yalefaces.html and ORL 666https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html). For those images datasets, we extract features using multiple descriptors as multi-view features for our experiments,which has been shown in the corresponding experiments. Some images from these datasets are shown as Fig.2.
We adopt the following methods as comparing ones: 1. Co-reg kumar2011co , 2 .Canonical correlation analysis (CCA) hardoon2004canonical , 3. Sparsity preserving projections (SPP) qiao2010sparsity , 4. Multiview spectral embedding (MSE) xia2010multiview . We project multi-view data into low-dimensional subspace and then using 1NN denoeux1995k to test all the performance of the comparing methods and AMSRE. We calculated all the experiment results on the low-dimensional representations from each single view. And the experiment results are the best ones from all views. All samples from each dataset are randomly separated as two parts (training set and testing set).
4.2 Document Classification
In this section, we conducted related experiments on 3 document datasets, including 3Sources, Cora and WebKB datasets. For 3 Sources, it is collected from three online new sources, BBC, Reuters and Guardian. Therefore, 3Sources consisits of features from 3 views and each source is viewed as one view of 3Sources. There are 169 samples which comes from 6 classes in total. The dimensions of features from these 3 views are 3068, 3631, 3560 respectively. In our experiment, we randomly select twenty percent samples as testing ones while the other samples are assigned as training ones. After dimension reduction by those methods, we conduct this experiment for 20 times and calculated the mean and max classification accuracies as table.2.
We have projected multi-view data into subspaces with different dimensions (such as 10, 30, 50). It can be found easily that AMSRE can achieve best performances in most situations. Only SPP is the single view DR method and it performs worst among all methods. Furthermore, MSE also performs well than the other methods. Therefore, AMSRE is a better multi-view DR methods and it can fully exploits sparse reconstructive correlations between features from multiple views.
Cora dataset is collected by 2708 scientific publications which come from 7 classes. Each document is represented by content and cites information. Therefore, Cora is a multi-view data which contains 2 views. In our experiment, we randomly select twenty percent samples as testing ones while the other samples are assigned as training ones. After dimension reduction by those methods, we conduct this experiment for 20 times and calculated the mean and max classification accuracies as table.3.
WebKB contains 4 subsets of documents over 6 labels. A web pages consists of the following information: the text on it, the anchor text on the hyperlink pointing to it and the text in its title. Therefore, WebKB is a multi-view data which has 3 views. In our experiment, we randomly select twenty percent samples as testing ones while the other samples are assigned as training ones. After we project multi-view data into a 30-dimensional subspace, we calculated the mean and max classification accuracies as table.4.
It can be found that our proposed AMSRE can achieve best performances compared with the other methods. Meanwhile, multi-view algorithms are better than single-view ones to deal with multi-view dataset. Even though some methods can also achieve good performances in some situations, our proposed AMSRE is the best one. It can exploit sparse reconstructive correlations maintained in multi-view data and assign different weights to multiple views according to their contributions, which are the reasons why AMSRE is the best one.
4.3 Face Recognition
In this section, we construct some experiments on face recognition. We utilized 2 face datasets as experiments datasets and applies all DR methods on them. For Yale dataset, there are 165 faces corresponding to 11 people. We extract features by GSI fant1994grey , LBP ahonen2004face and EDH gao2008image as three views. The dimensions of features from these 3 views are 1024, 256, 72 respectively. Similar with the experiments before, twenty percent samples are assigned as testing ones while the other faces are assign as training ones. 1NN classifier is adopted to calculate the recognition results after the dimension reduction. And we show the experiments results in Fig.3.
For ORL dataset, there are 400 faces corresponding to 40 people in total. We also extract features by GSI fant1994grey , LBP ahonen2004face and EDH gao2008image as three views. The dimensions of features from these 3 views are 1024, 256, 72 respectively. twenty percent samples are assigned as testing ones while the other faces are assign as training ones. 1NN classifier is adopted to calculate the recognition results after the dimension reduction. And we show the experiments results in Fig.4.
We can also find that our proposed AMSRE can achieve best performances in Yale and ORL face datasets. Furthermore, the performances of multi-view DR methods are better. Because AMSRE fully exploits sparse reconstructive correlations between samples, it can better maintain information from multi-view data.
5 Conclusion
In this section, we proposed a novel multi-view DR method named AMSRE. It can fully exploit sparse reconstructive correlations between features from multiple views. Furthermore, it develops a technique to integrate multi-view information together and adopts a auto-weighted learning method which can assign multiple views with different weights according to their contributions. We have conducted several experiments to verify the performance of our proposed AMSRE. And it can achieve excellent performances in most situations.
Compliance with Ethical Standards
This study was funded by the National Natural Science Foundation of China Grant 61370142 and Grant 61272368, by the Fundamental Research Funds for the Central Universities Grant 3132016352, by the Fundamental Research of Ministry of Transport of P.R. China Grant 2015329225300. Huibing Wang, Haohao Li and Xianping Fu declare that they have no conflict of interest. This article does not contain any studies with human participants or animals performed by any of the authors.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Qichang Hu, Huibing Wang, Teng Li, and Chunhua Shen. Deep cnns with spatially weighted pooling for fine-grained car recognition. IEEE Transactions on Intelligent Transportation Systems , 18(11):3147–3156, 2017.
- 2[2] Lin Feng, Huibing Wang, Bo Jin, Haohao Li, Mingliang Xue, and Le Wang. Learning a distance metric by balancing kl-divergence for imbalanced datasets. IEEE Transactions on Systems, Man, and Cybernetics: Systems , 2018.
- 3[3] Yang Wang and Lin Wu. Beyond low-rank representations: Orthogonal clustering basis reconstruction with optimized graph structure for multi-view spectral clustering. Neural Networks , 103:1–8, 2018.
- 4[4] Fumin Shen, Chunhua Shen, Wei Liu, and Heng Tao Shen. Supervised discrete hashing. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 37–45, 2015.
- 5[5] Lin Wu, Yang Wang, Junbin Gao, and Xue Li. Where-and-when to look: Deep siamese attention networks for video-based person re-identification. IEEE Transactions on Multimedia , 2018.
- 6[6] Timo Ahonen, Abdenour Hadid, and Matti Pietikäinen. Face recognition with local binary patterns. In European conference on computer vision , pages 469–481. Springer, 2004.
- 7[7] Pauline C Ng and Steven Henikoff. Sift: Predicting amino acid changes that affect protein function. Nucleic acids research , 31(13):3812–3814, 2003.
- 8[8] Jinjun Wang, Jianchao Yang, Kai Yu, Fengjun Lv, Thomas Huang, and Yihong Gong. Locality-constrained linear coding for image classification. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on , pages 3360–3367. IEEE, 2010.