Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Ladislav Mo\v{s}ner, Minhua Wu, Anirudh Raju, Sree Hari Krishnan, Parthasarathi, Kenichi Kumatani, Shiva Sundaram, Roland Maas, Bj\"orn, Hoffmeister

TL;DR
This paper enhances automatic speech recognition robustness to noise by using parallel data, teacher-student learning, and a logits selection method, achieving significant WER reductions on various noisy and clean datasets.
Contribution
It introduces a novel combination of teacher-student learning with logits selection and large-scale untranscribed data for noise-robust ASR.
Findings
Up to 10.1% relative WER reduction on clean data
Up to 28.7% relative WER reduction on noisy data
Effective use of 8000 hours of untranscribed data
Abstract
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
Click any figure to enlarge with its caption.
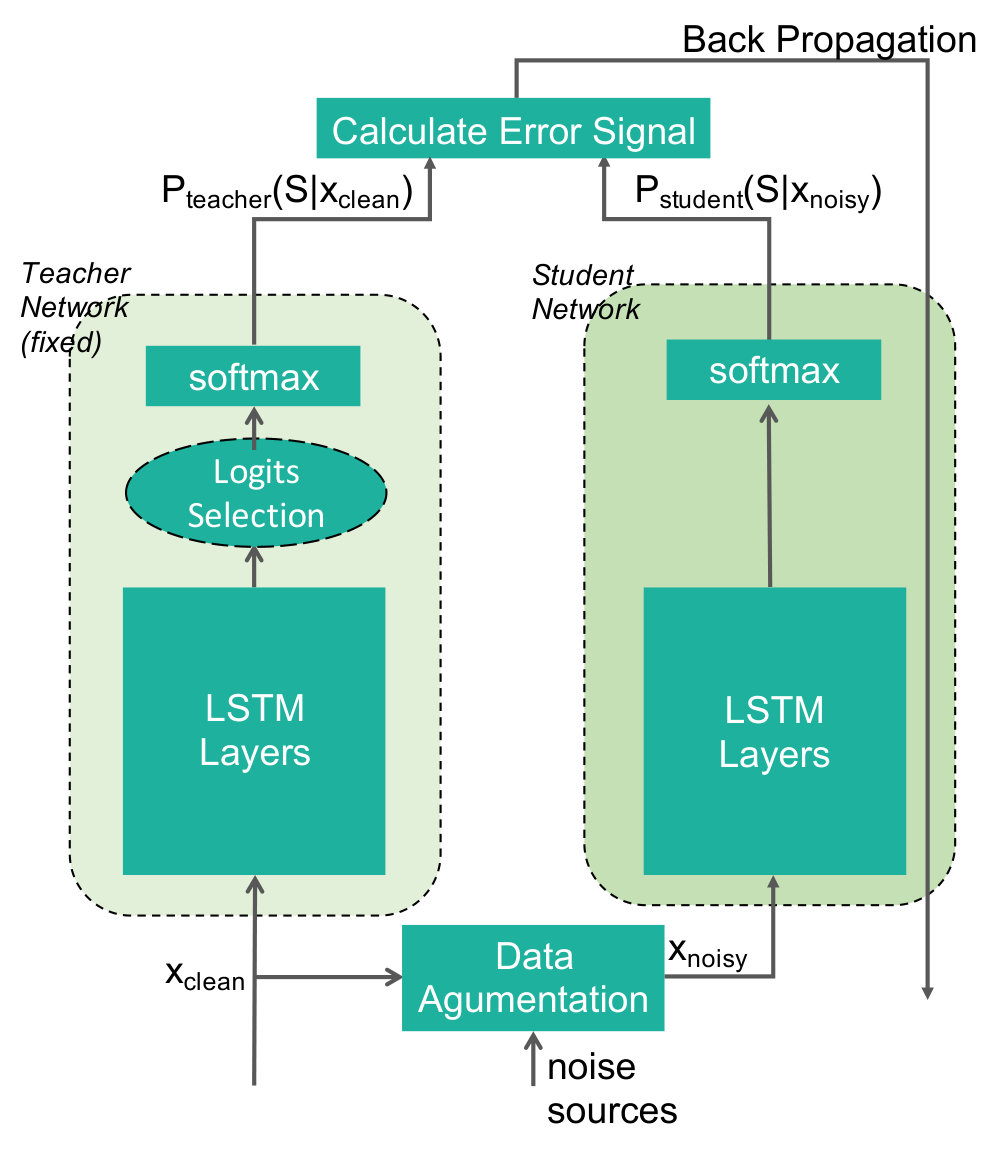 Figure 1
Figure 1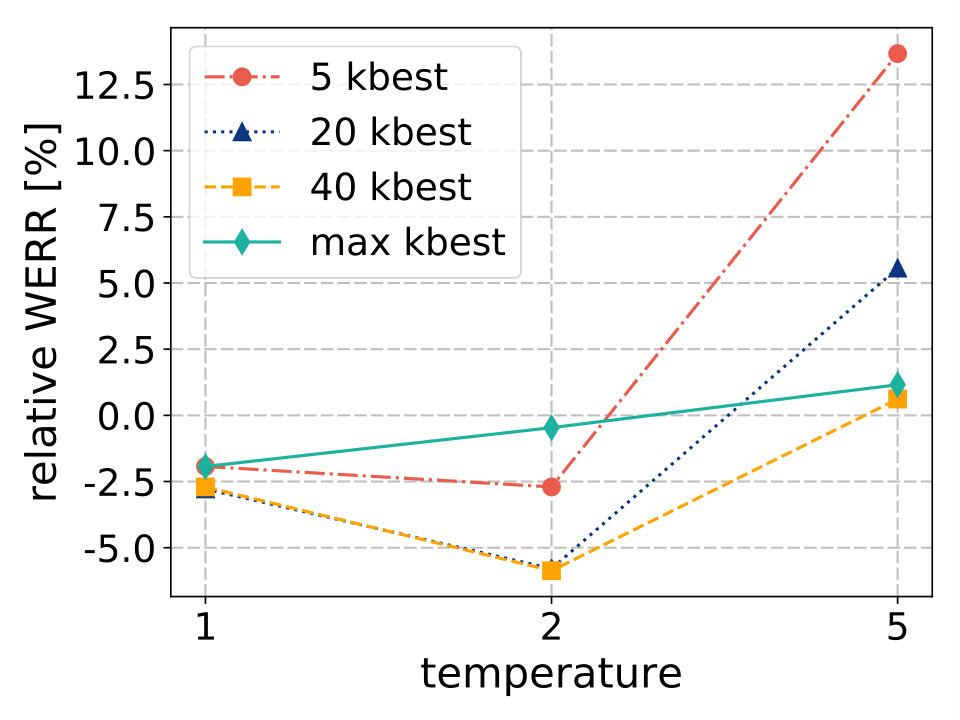 Figure 2
Figure 2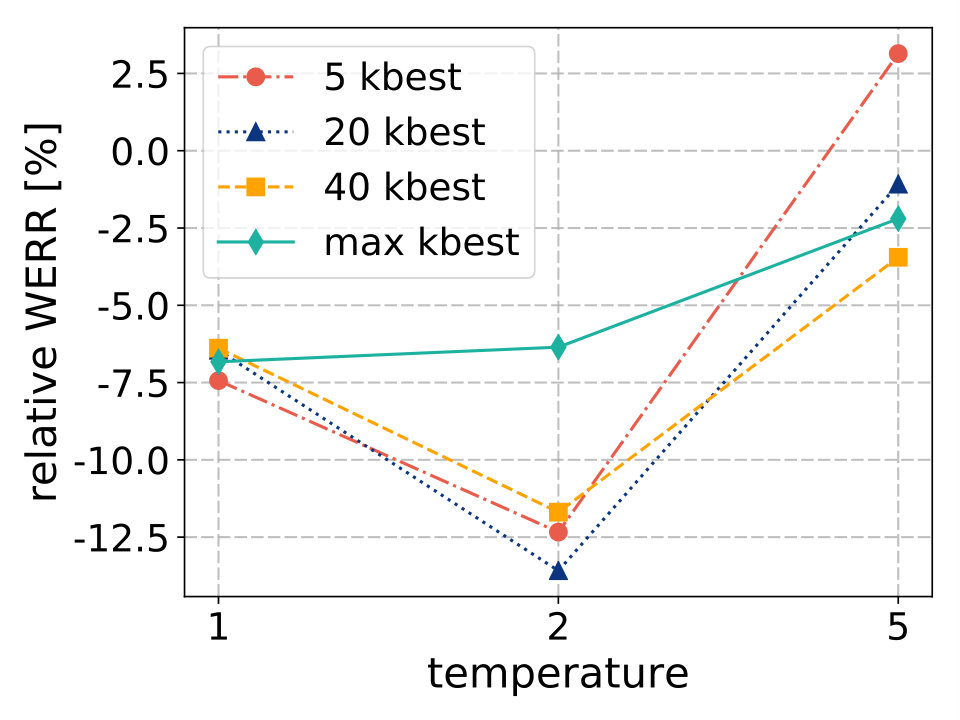 Figure 3
Figure 3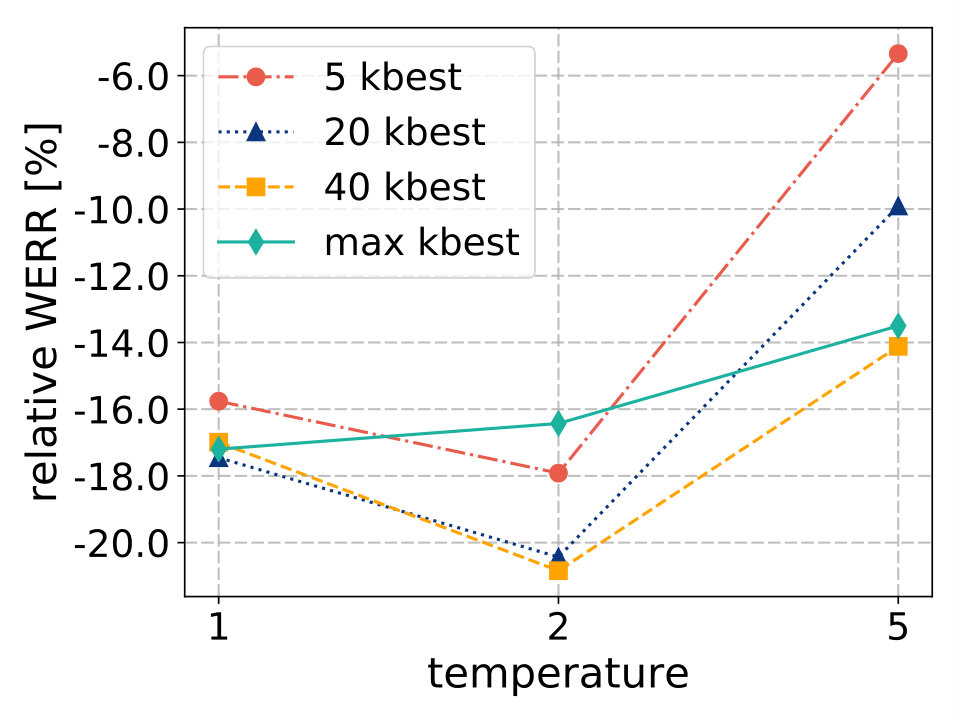 Figure 4
Figure 4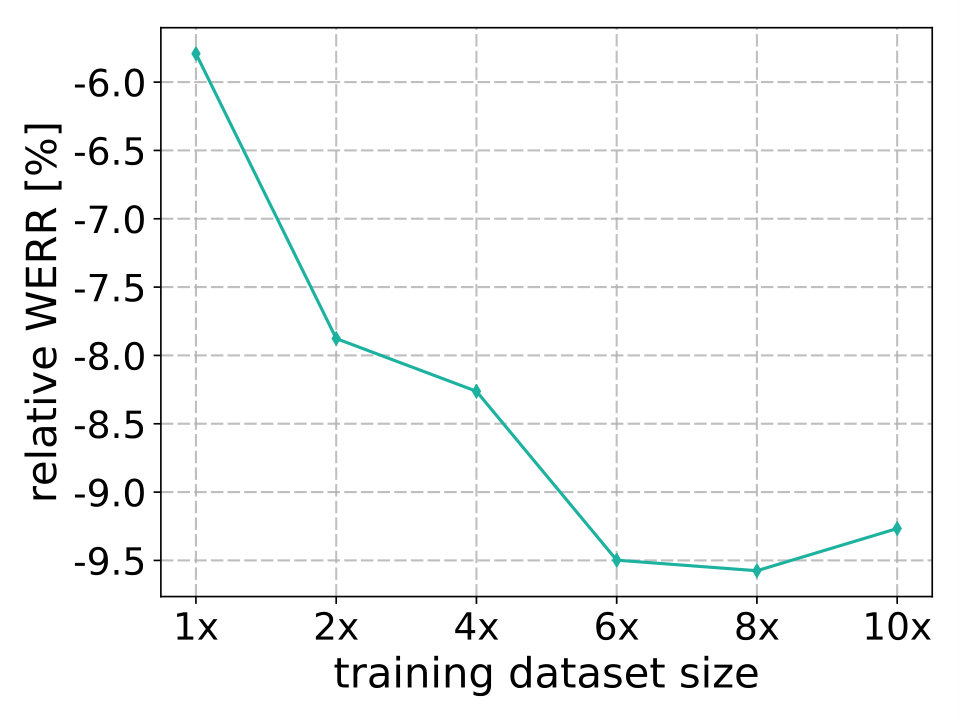 Figure 5
Figure 5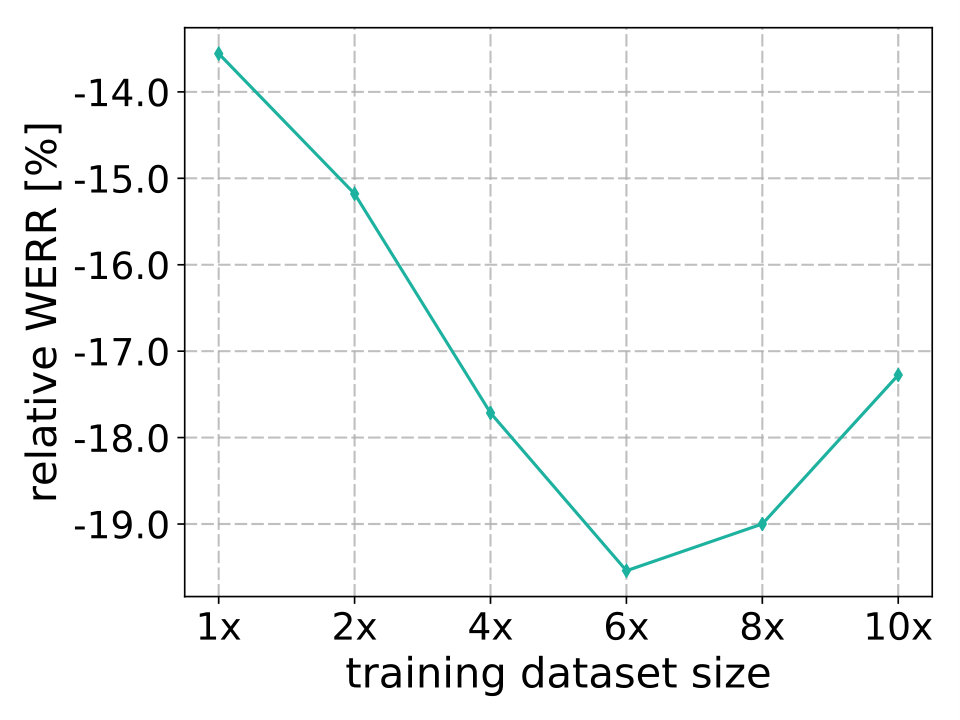 Figure 6
Figure 6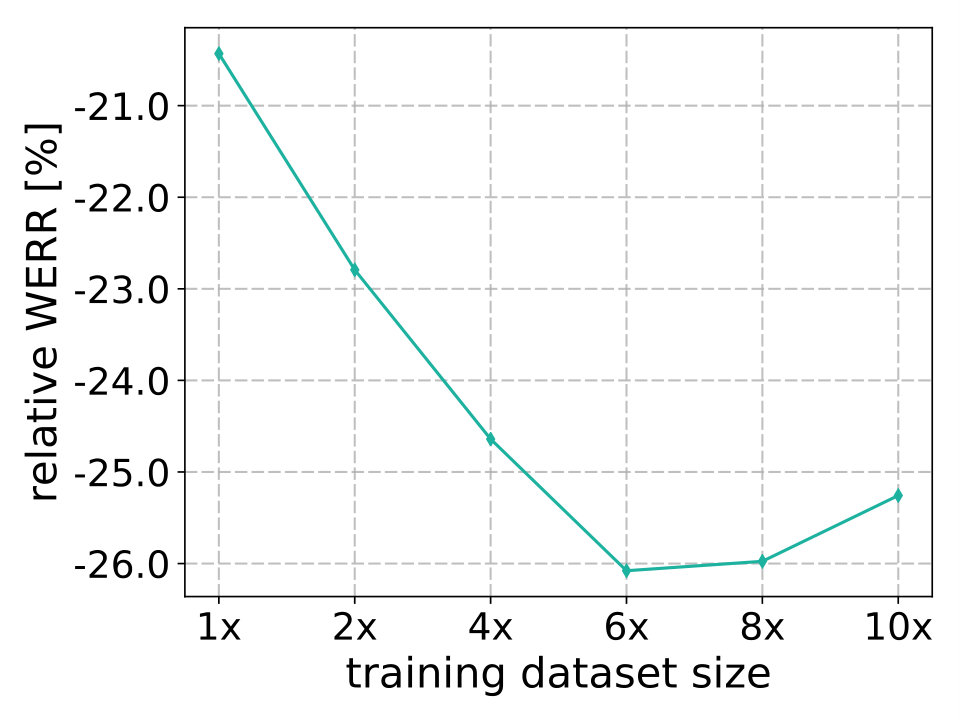 Figure 7
Figure 7| Acoustic model |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| Baseline/teacher (clean 800h) | 0.00 | 0.00 | 0.00 | ||||||
| Multi-condition (noisy 800h) | 0.69 | -15.20 | -4.26 | ||||||
| Student, (parallel 800h) | -1.93 | -17.20 | -6.82 | ||||||
| Student, (parallel 800h) | -0.46 | -16.43 | -6.35 | ||||||
| Student, (parallel 800h) | 1.16 | -13.50 | -2.20 |
| Acoustic model | Training objective | Training data | Clean test set | Noisy test set | Realistic test set |
| Teacher | xent | 800h clean | 0.00 | 0.00 | 0.00 |
| Student | xent | h parallel | -9.50 | -26.08 | -19.57 |
| Teacher | xent, sMBR | 800h clean, 800h clean | -5.79 (0.00) | -0.98 (0.00) | -3.68 (0.00) |
| Student | xent | h parallel | -11.89 (-6.48) | -26.80 (-26.08) | -21.63 (-18.63) |
| Student | xent, sMBR | h parallel, 800h noisy | -15.29 (-10.08) | -29.36 (-28.67) | -22.54 (-19.58) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
Abstract
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the highest values to prevent wrong emphasis of knowledge from the teacher and to reduce bandwidth needed for transferring data. We incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained models apart from cross entropy trained ones. The best sequence trained student model yields relative word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively comparing to a sequence trained teacher.
**Index Terms— ** automatic speech recognition, noise robustness, teacher-student training, domain adaptation
1 Introduction
With the exponential growth of big data and computing power, automatic speech recognition (ASR) technology has been successfully used in many applications. People can do voice search using mobile devices. They can also interact with smart home devices such as Amazon Echo or Google Home through distant speech recognition [1][2] for entertainment, shopping or other personal assistance. For such real-world applications, noise robustness is important since the device needs to work well under various acoustic environments, and it still remains to be a challenging task [3, 4]. Although large-vocabulary speech recognition is of high accuracy by applying deep neural networks [5, 6, 7], it requires thousands of hours of transcribed data which is time-consuming and expensive to collect, and its performance under noisy environment may still suffer. Considerable efforts have been made to improve noise robustness by applying algorithms in the front-end feature domain [8, 9, 10, 11, 12, 13, 14] or in the back-end model [15, 16, 17, 18, 19, 20]. Another natural way to deal with noise in the acoustic environment is to use multi-style training [21], which trains the acoustic model with noisy speech data. All these approaches require supervision where the speech data is manually transcribed.
In order to improve noise robustness of the distant speech recognition system in an unsupervised mode, it is desirable to scale multi-style training with an even larger training dataset. However, acquiring manually transcribed data for noisy speech can be slow and expensive. In this work, we explore the technique of teacher-student (T/S) learning using a parallel corpus of clean and noisy data. We focus on improving the ASR performance under multimedia noise which is commonly present at home.
T/S learning was at first explored in speech community [22] [23] to distill the knowledge from bigger models to a smaller one, and was successfully applied in the areas of ASR [24, 25] and keyword spotting [26] afterwards. Instead of knowledge distillation, we adopt the T/S learning for domain adaptation which was proposed in [27] to build an ASR system performing more robustly under multimedia noise. On top of this system, we apply logits selection keeping only the highest values and experiment it with multiple settings of temperature . This method was proposed in [28] to optimize storage and to parallelize the target generation for teacher-student training, and we find that it even helps improve performance of the adapted student model since it prevents over-emphasizing wrong senones by the teacher. Because the T/S learning technique applied in this work does not require transcribed data, we also explore how much the system performance can be further improved by gradually incorporating more training recordings. Finally, we study the effects of doing sequence training on top of the T/S learning for domain adaptation, which was not reported in [27].
2 Method
2.1 Teacher-student training for domain adaptation
In order to apply T/S training for domain adaptation (to adapt from clean teacher to noisy student domain in our use case), parallel clean and noisy corpus is needed and it could be generated by artificially adding noise on top of the clean data, which will be described in detail in section 3.2. As shown in Figure 1, a teacher network outputs discrete probability distribution over senones given a clean feature vector , and a student network estimates probabilities of senones given a noisy feature vector . The objective is to minimize the Kullback-Leibler (KL) divergence between these two distributions in order to make behavior of the student network in the target domain approach that of the teacher network in the source domain.
Since the teacher parameters are fixed when training the student model, minimizing the KL divergence is equivalent to minimizing the cross entropy between output distributions from the teacher and the student, where the teacher’s output distribution (“soft targets”) are considered as the ground truth. Therefore, student training relies completely on teacher outputs and no transcriptions are required.
2.2 Logits selection
The discrete probability distribution over senones at each time frame from the teacher will guide the learning of the student model. Since there are usually thousands of senones for a typical ASR system, a large number of values need to be loaded when processing just one frame. Moreover, the majority of the output probability mass is usually covered by just a few outputs, while the rest of output values are very small and noisy, which might confuse the student model instead. In this case, we adopt the logits selection method [28] with which only highest logit values are preserved so that only the most reliable information from the teacher is preserved to train the student. At the same time, this method also reduces the bandwidth of transferring frames of soft targets for training. Let be an activation before the softmax (logit), be number of classified senones. Without any selection, the output probability of senone is computed as follows:
[TABLE]
where T is the temperature controlling softness of the distribution[23].
When considering only highest logit values whose indices lie in the set , the highest probabilities of senones are preserved with an emphasizing factor while the rest are suppressed to be zero.
[TABLE]
[TABLE]
With this selection method, we are able to dramatically reduce storage space needed for soft targets and also I/O operations during training since is significantly small compared with . In fact, we notice that this method even helps to improve performance of the student model since it is boosting confidence of the teacher model and suppressing the confusing part as indicated in Equations (2) and (3).
3 Experimental setup
3.1 Model architecture
Both teacher and student have the same architecture for all the experiments. The neural network consists of three LSTM [29] layers each of which comprises 512 units. The last LSTM layer is followed by a fully connected layer outputting probability distribution over 3,010 senones. 64-dimensional feature vectors of Log Mel-Filter-Bank Energies (LFBE) are used as inputs to the network. There is no frame stacking, and the output HMM state label is delayed by 3 frames. We run decoding in a single-pass framework using a smoothed 4-gram language model (LM) trained on both internal and external data sources. The total text used to train the LM is over billion words.111Our experimental ASR system does not reflect the performance of the production Alexa system.
3.2 Parallel training datasets
The original clean corpus consists of approximately 8,000 hours of beamformed speech recordings. However, only 800 hours are transcribed and thus are used to build the teacher model with supervised training. We perform data simulation [30] to obtain the parallel noisy training data. Since our primary aim is to deal with multimedia noise in room conditions, we collected a corpus consisting especially of music samples and acoustic video content. For every utterance, one to three additional noises are randomly selected. The notion of sound propagation in enclosures is obtained by means of room simulation. The image method is used to acquire artificial room impulse responses [31, 32]. Reverberation times are uniformly drawn from the interval of ms. The mixture of noises is combined with the clean signal at signal-to-noise ratio (SNR) ranging from 0 to 30 dB.
3.3 Test datasets
In order to evaluate the performance of our acoustic models, we used three test datasets.
“clean”:
It is of similar domain to that of the clean training data ( 41k utterances).
“noisy”:
It is derived from the “clean” dataset by the same simulation method described in section 3.2, but different multimedia noise sources are selected and reverberation times are drawn from the different interval of (520, 920) ms.
“realistic”:
It is collected in a real room ( 2k utterances). Clean speech and multimedia noises are played by loudspeakers and recorded by multiple microphones varying in their positions.
4 Results
4.1 Multi-condition versus teacher student training
A teacher acoustic model is trained using the transcribed 800-hour clean corpus and treated as the baseline. The conventional multi-condition [21] trained acoustic model is also built using the transcribed portion of the noisy training dataset. As displayed in Table 1, the multi-condition trained acoustic model outperforms the teacher by a significant margin on the noisy test set. At the same time, its performance on the clean test set is comparable to the performance of the baseline.
When training the student acoustic model, we at first initialize it using the baseline teacher model. During the training process, the cross entropy between and are being minimized.
When the temperature is set to (standard softmax), we observe improvements in performance over the multi-condition trained model on all the datasets. Matching the student output probability distribution with that of the teacher enhances generalization ability of the student and we see an average relative reduction of about 1.9% in WER even on the clean test dataset. The increased temperature does not seem to help achieve further improvements but leads to worse performance. A temperature of even results in higher WER in comparison with the multi-condition trained model, which indicates that a flatter output distribution from the teacher may result in confusions for the student to learn effectively.
4.2 Number of candidate logits and temperature
To prevent needless emphasis of wrong senones from the teacher and reduce the bandwidth needed for transferring soft targets, we explore the logits selection approach explained in section 2.2. In our experiments, we slightly changed the computation of output probabilities previously defined by Equations (2) and (3). This modification is performed for the convenience of training but does not break the general idea. Instead of assigning zero probability to the non--best senones, we assign a sufficiently high negative constant to the corresponding logits. The output probability now becomes
[TABLE]
[TABLE]
We explore the resulting recognition accuracy for multiple settings of temperature and candidate logits selection , which are summarized in Figure 2.
4.2.1 Temperature = 1
While using a temperature of 1, no significant differences in WER can be seen even for a very aggressive logits selection (5 senones out of 3010). Inspecting the average output distribution after application of softmax, we find out that the highest probability is close to one and the rest close to zero. Therefore, a sum of probabilities of senones that do not belong to the 5-best is still small. Redistribution of this mass among 5-best senones then does not affect the distribution much.
4.2.2 Temperature = 2
Interestingly, the combination of temperature 2 with logits selection bring accuracy improvements. We observe that taking 5-best values into consideration is not sufficient. However, the difference between results obtained using 20-best and 40-best logits is minimal.
4.2.3 Temperature = 5
When the output distribution gets flatter (temperature 5), the difference among highest probabilities diminishes. Then the effect of multiplication by constant is similar for all senones and it becomes more difficult to estimate the correct one. The fewer candidates are taken into account, the more severe degradation occurs.
Based on the analysis, the most promising hyperparameters for our student models are: temperature and for logits selection. These values are fixed for the following experiments.
4.3 Size of the training dataset
Building both the baseline and the multi-condition system require transcribed data. Compared to those methods, the major advantage of the teacher-student training approach is that it does not require transcripts once the teacher model is trained. Therefore, we could explore how much the WER can be further reduced by incorporating even larger number of utterances in the training set to build the student model. The student training dataset is gradually increased up to ten times more audio compared with the original amount. The relative word error rate reduction (WERR) is displayed in Figure 3 as a function of training data size. Similar trends are observed for all the test datasets. As expected, the accuracy improves with the increasing amount of data. However, the minimum WER is achieved when using approximately 4800 hours (). It could be possible that we only have about 4800 hours of unique noise resources and the model overfits after adding repeated noise examples. This hypothesis, however, requires further investigation. Alternatively, the fact that the teacher itself is erroneous could also affect dependence of accuracy on training data size.
4.4 Sequence training
Sequence training has been shown to be effective in improving ASR performance in general [33]. Wong and Gales also investigated the usefulness of the combination of sequence and teacher-student training [34]. In our experiment, we at first fine-tune the original cross-entropy trained teacher using state-level minimum Bayes risk (sMBR) criterion [35]. As displayed in Table 2, the new teacher outperforms the original one on all our test datasets. We then train a new student network on top of the new sequence-trained teacher using the parallel corpus. We used size of the parallel datasets to train the student as it was shown to be the best option in the previous experiment. The new cross-entropy trained student network is able to make use of the improved teacher, since its performance is better than that of the student taught by the weaker teacher. Finally, the new student is further optimized by means of sMBR training using only the transcribed portion of noisy data ().
5 Conclusion
In this paper, we explore the teacher-student learning approach using parallel clean and noisy corpus to improve speech recognition performance under multimedia noise. We gradually optimize this system by applying logits selection and incorporating larger amount of untranscribed training data. With a temperature of and logits selection of highest values, we obtain the best student model using a parallel clean and noisy corpus which is about 6 times more of the original clean training data. By applying standard sequence training on both the teacher and student model, the final student brings relative WER reductions of about 10.1%, 28.7% and 19.6% on the clean, simulated noisy and real test sets, respectively.
In the future, a larger corpus of noise sources will be collected to prevent the multimedia samples from being repeated. We will attempt to scale up architecture and training datasets. Soft targets selection based on teacher’s certainty could be explored as well.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Kenichi Kumatani, John Mc Donough, and Bhiksha Raj, “Microphone array processing for distant speech recognition: From close-talking microphones to far-field sensors,” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 127–140, 2012.
- 2[2] Minhua Wu, Kenichi Kumatani, Shiva Sundaram, Nikko Ström, and Björn Hoffmeister, “Frequency domain multi-channel acoustic modeling for distant speech recognition,” in 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . 2019, IEEE.
- 3[3] Jinyu Li, Li Deng, Yifan Gong, and Reinhold Haeb-Umbach, “An overview of noise-robust automatic speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 22, no. 4, pp. 745–777, 2014.
- 4[4] Brian King, I-Fan Chen, Yonatan Vaizman, Yuzong Liu, Roland Maas, Sree Hari Krishnan Parthasarathi, and Björn Hoffmeister, “Robust speech recognition via anchor word representations,” INTERSPEECH-2017 , pp. 2471–2475, 2017.
- 5[5] Tara N Sainath, Brian Kingsbury, Bhuvana Ramabhadran, Petr Fousek, Petr Novak, and Abdel-rahman Mohamed, “Making deep belief networks effective for large vocabulary continuous speech recognition,” in Automatic Speech Recognition and Understanding (ASRU), 2011 IEEE Workshop on . IEEE, 2011, pp. 30–35.
- 6[6] George E Dahl, Dong Yu, Li Deng, and Alex Acero, “Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition,” IEEE Transactions on audio, speech, and language processing , vol. 20, no. 1, pp. 30–42, 2012.
- 7[7] Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal processing magazine , vol. 29, no. 6, pp. 82–97, 2012.
- 8[8] Steven Boll, “Suppression of acoustic noise in speech using spectral subtraction,” IEEE Transactions on acoustics, speech, and signal processing , vol. 27, no. 2, pp. 113–120, 1979.