Comparing Sample-wise Learnability Across Deep Neural Network Models
Seung-Geon Lee, Jaedeok Kim, Hyun-Joo Jung, Yoonsuck Choe

TL;DR
This paper introduces a measure of sample-wise learnability in deep neural networks, showing it correlates across models and can inform curriculum learning and data understanding.
Contribution
It proposes a novel method to quantify individual sample learnability in deep learning, revealing model-independent properties of data.
Findings
Sample-wise learnability correlates across different DNN architectures.
The measure provides insights into data properties and training strategies.
Potential to improve curriculum learning and data analysis.
Abstract
Estimating the relative importance of each sample in a training set has important practical and theoretical value, such as in importance sampling or curriculum learning. This kind of focus on individual samples invokes the concept of sample-wise learnability: How easy is it to correctly learn each sample (cf. PAC learnability)? In this paper, we approach the sample-wise learnability problem within a deep learning context. We propose a measure of the learnability of a sample with a given deep neural network (DNN) model. The basic idea is to train the given model on the training set, and for each sample, aggregate the hits and misses over the entire training epochs. Our experiments show that the sample-wise learnability measure collected this way is highly linearly correlated across different DNN models (ResNet-20, VGG-16, and MobileNet), suggesting that such a measure can provide deep…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3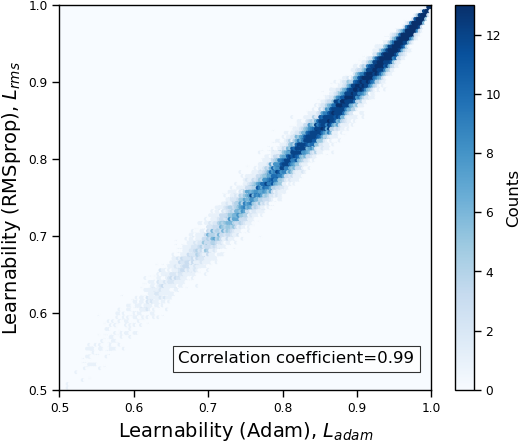 Figure 4
Figure 4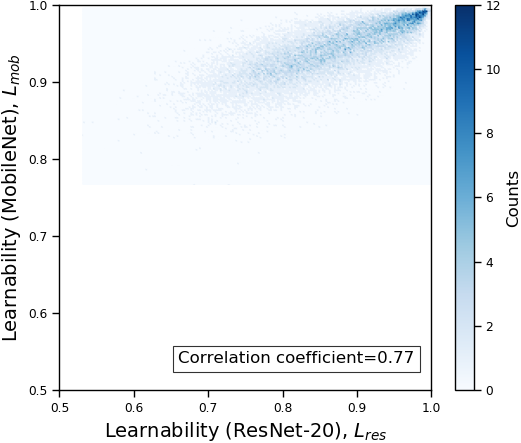 Figure 5
Figure 5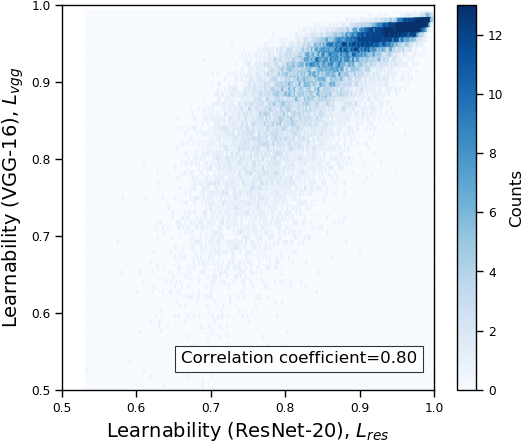 Figure 6
Figure 6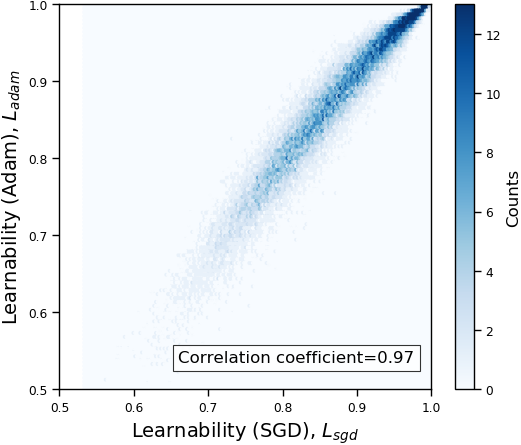 Figure 7
Figure 7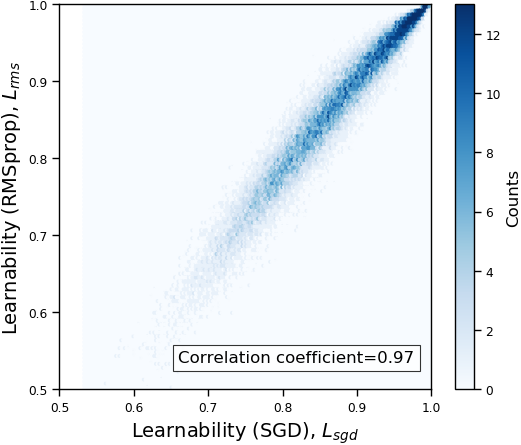 Figure 8
Figure 8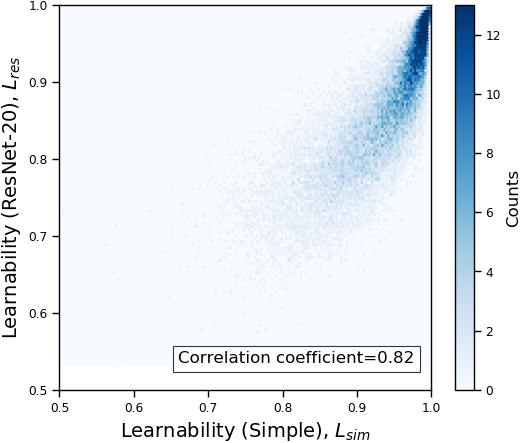 Figure 9
Figure 9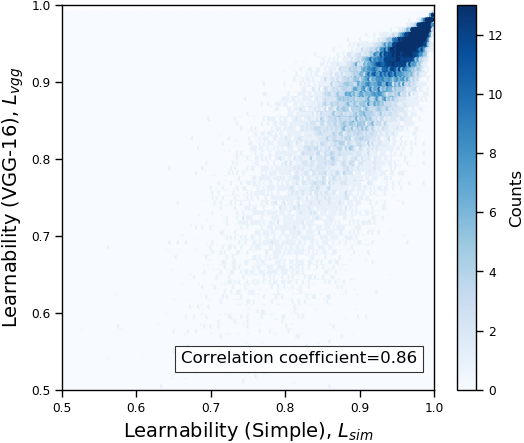 Figure 10
Figure 10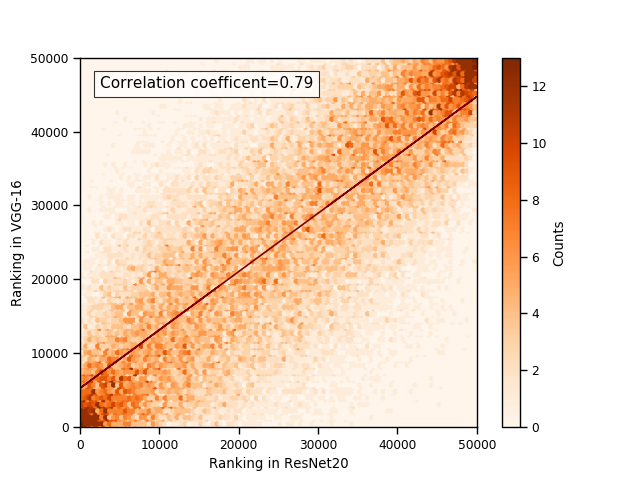 Figure 18
Figure 18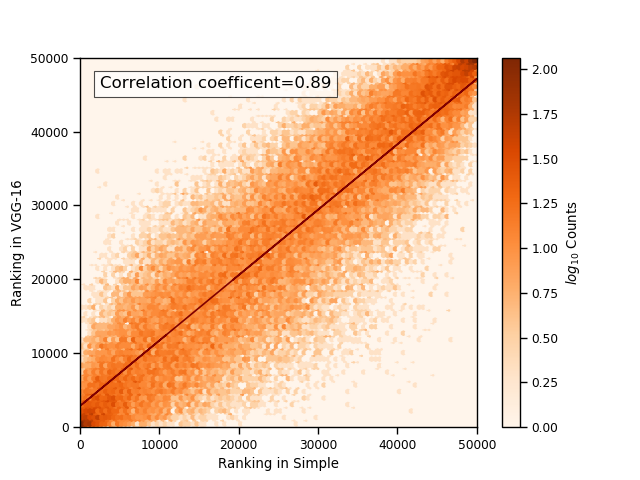 Figure 19
Figure 19| VGG-16 | ResNet-20 | MobileNet | |
|---|---|---|---|
| VGG-16 | - | 0.796 (0.867) | 0.713 (0.792) |
| ResNet-20 | - | - | 0.774 (0.782) |
| MobileNet | - | - | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Machine Learning and Data Classification · Adversarial Robustness in Machine Learning
Comparing Sample-wise Learnability Across Deep Neural Network Models
Seung-Geon Lee1 Jaedeok Kim2 Hyun-Joo Jung2 Yoonsuck Choe2,3
1 Department of Computer Science and Engineering, Seoul National University
1 Gwanak-ro, Gwanak-gu, Seoul, Korea, 08826
2Machine Learning Lab, Artificial Intelligence Center, Samsung Research, Samsung Electronics Co.
56 Seongchon-gil, Secho-gu, Seoul, Korea, 06765
3Department of Computer Science and Engineering, Texas A&M University
College Station, TX, 77843, USA
This work was performed when Seung-Geon Lee, an undergraduate student, worked as a summer intern at Samsung Research (2018).
Corresponding author ([email protected])
Abstract
Estimating the relative importance of each sample in a training set has important practical and theoretical value, such as in importance sampling or curriculum learning. This kind of focus on individual samples invokes the concept of sample-wise learnability: How easy is it to correctly learn each sample (cf. PAC learnability)?
In this paper, we approach the sample-wise learnability problem within a deep learning context. We propose a measure of the learnability of a sample with a given deep neural network (DNN) model. The basic idea is to train the given model on the training set, and for each sample, aggregate the hits and misses over the entire training epochs. Our experiments show that the sample-wise learnability measure collected this way is highly linearly correlated across different DNN models (ResNet-20, VGG-16, and MobileNet), suggesting that such a measure can provide deep general insights on the data’s properties. We expect our method to help develop better curricula for training, and help us better understand the data itself.
Introduction
The performance of DNN models depends heavily on the quantity and quality of data. Furthermore, the order in which the data points are sampled during training makes a big difference in the learning outcome, as shown in latest studies in curriculum learning and self-paced learning (?; ?). In this paper, we propose the concept of sample-wise learnability: How easy is it to learn each individual sample, in general, when multiple learning models are considered. Learnability is a well known concept in computational learning theory. However, in the PAC-learning framework for example, learnability is usually defined over a whole concept class, not over individual samples. We show that sample-wise learnability for a fixed data set, measured using different DNN models, are strongly linearly correlated.
This way, our approach helps us gain deeper insights into the data itself, and we expect our measure to help automatically generate better curricula for improved performance in DNN training.
Sample-wise Learnability
Let be a domain of inputs and be the set of all possible labels. A DNN model is a prediction function over , , such that for . During training, the weights of the DNN model is updated by an optimizer. So we denote by the DNN model after training step .
We take a sample , a pair of input and label, from as our reference. Then is the prediction of by the DNN model after training steps and can be considered a stochastic process of predictions (by the DNN Model) of the tagged sample during training. If the tagged sample is easily learnable, in most training steps a model should correctly predict the true label of the tagged input .
Based on such an intuition, we define the learnability of an individual sample with respect to a model as
[TABLE]
where denotes the total number of training steps. Although is the probability that the model predicts the label of as , it is still a random variable since the model is evolved randomly due to the randomness in the initialization and optimization. Eq. 1 is the expected value over such a quantity .
So, if is easily learnable, the value of increases rapidly to 1 as the training step increases. Accordingly, the value of also increases. Otherwise, the value of the probability remains small and so does the value of . We therefore can say that Eq. 1 faithfully represents the learnability of the sample .
Training of a DNN model is considerably affected by the order in which the samples are drawn and presented to the model, e.g. as shown in curriculum learning (?). So it is also worthy to consider the relative order among training samples in terms of the learnability.
Denoted by a training dataset of size over . Let be the learnability rank of the th training sample in with respect to the model . Formally, we can write
[TABLE]
Then if , which implies learning the th sample is easier than learning the th sample in terms of the learnability.
Experimental Results
We applied the proposed learnability measure to the CIFAR-10 data set, using ResNet-20 (?), VGG-16 (?), and MobileNet (?). To compare the learnability of each sample with respect to different models, we used the same training options for all models. In our experiment we considered a single training epoch as a training step and used .
We plot the learnability of samples with respect to the VGG-16 and ResNet-20 in Figure 1(a). As we can see in the figure, the learnability of both models are positively correlated, and the correlation coefficient is 0.80. Figure 1(b) shows the relation of learnability rank induced by VGG-16 and that induced by ResNet-20. Similar with the case of learnability, the learnability rank of samples are also positively correlated (correlation coefficient = 0.87).
Figure 1(c) shows actual examples from the CIFAR-10 training set (the set includes a total of 50,000 images). The images in the top row have high rank (small learnability rank value) which means that they are easy to learn. As we can see in the figure, the images in the top row have well defined features and we can easily classify them. In contrast, the images in the bottom row have low rank (large learnability rank value) and hard to classify even for humans. For example, scale is too small (Figure 1(c) (vi) and (vii)) or viewpoint is atypical (Figure 1(c) (ix) and (x)).
The full comparison across all tested models in summarized in Table 1. The correlation coefficients in all cases are higher than 0.71. The results suggest that our proposed learnability and rank are consistent across models.
From the above results, we can argue that the proposed sample-wise learnability is an effective measure to estimate the importance of individual samples in a given training set.
Conclusion
In this paper, we introduced the concept of sample-wise learnability (and it’s rank-based variant) based on the prediction performance during training. We experimentally showed that the sample-wise learnability (and its rank) for a given data set is linearly correlated across different models. We expect our measure to help develop better curricula for training, and help us better understand the data itself.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Bengio et al . 2009] Bengio, Y.; Louradour, J.; Collobert, R.; and Weston, J. 2009. Curriculum learning. In ICML , 41–48. ACM.
- 2[He et al . 2016] He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In CVPR , 770–778.
- 3[Howard et al . 2017] Howard, A. G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; and Adam, H. 2017. Mobilenets: Efficient convolutional neural networks for mobile vision applications. ar Xiv preprint ar Xiv:1704.04861 .
- 4[Jiang et al . 2015] Jiang, L.; Meng, D.; Zhao, Q.; Shan, S.; and Hauptmann, A. G. 2015. Self-paced curriculum learning. In AAAI , volume 2, 6.
- 5[Simonyan and Zisserman 2014] Simonyan, K., and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. ar Xiv preprint ar Xiv:1409.1556 .