Testing for the Rank of a Covariance Operator
Anirvan Chakraborty, Victor M. Panaretos

TL;DR
This paper introduces a novel bootstrap-based testing procedure to determine the rank of a covariance operator in functional data, effectively handling measurement errors and discretization without smoothing.
Contribution
It develops a matrix-completion inspired test statistic and a stepwise testing procedure with proven consistency and validity, advancing rank determination methods for functional data.
Findings
The procedure performs well across diverse simulation settings.
It effectively controls the family-wise error rate.
The method is demonstrated on real data analyses.
Abstract
How can we discern whether the covariance operator of a stochastic process is of reduced rank, and if so, what its precise rank is? And how can we do so at a given level of confidence? This question is central to a great deal of methods for functional data, which require low-dimensional representations whether by functional PCA or other methods. The difficulty is that the determination is to be made on the basis of i.i.d. replications of the process observed discretely and with measurement error contamination. This adds a ridge to the empirical covariance, obfuscating the underlying dimension. We build a matrix-completion inspired test statistic that circumvents this issue by measuring the best possible least square fit of the empirical covariance's off-diagonal elements, optimised over covariances of given finite rank. For a fixed grid of sufficiently large size, we determine the…
Click any figure to enlarge with its caption.
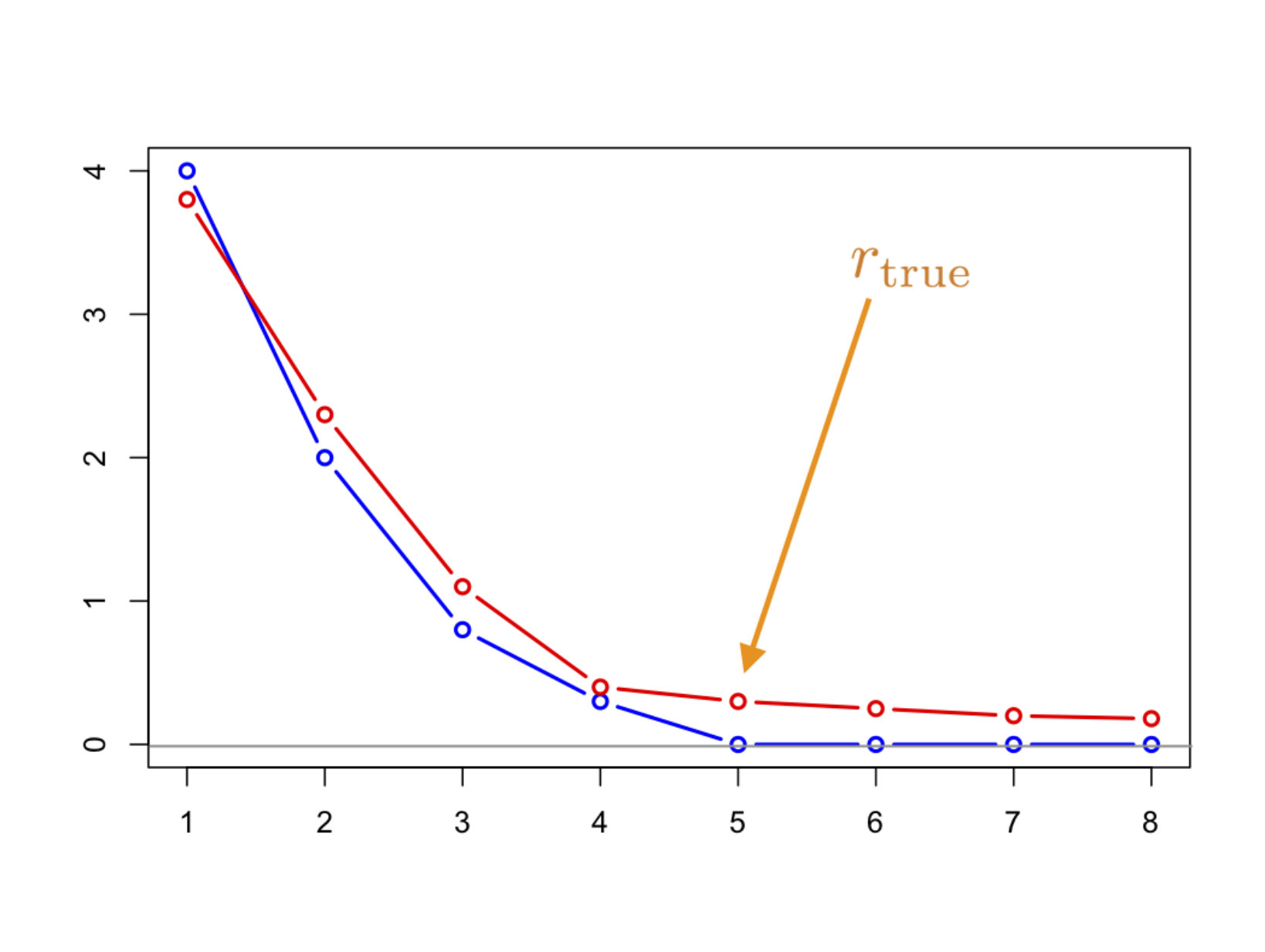 Figure 1
Figure 1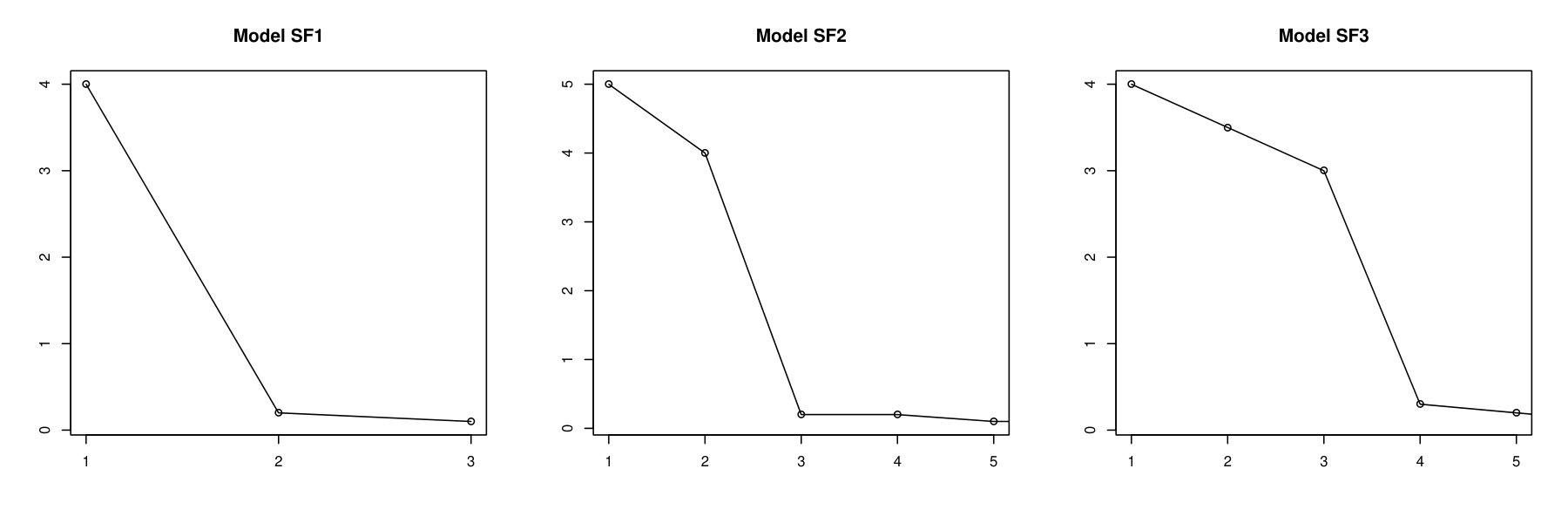 Figure 2
Figure 2 Figure 3
Figure 3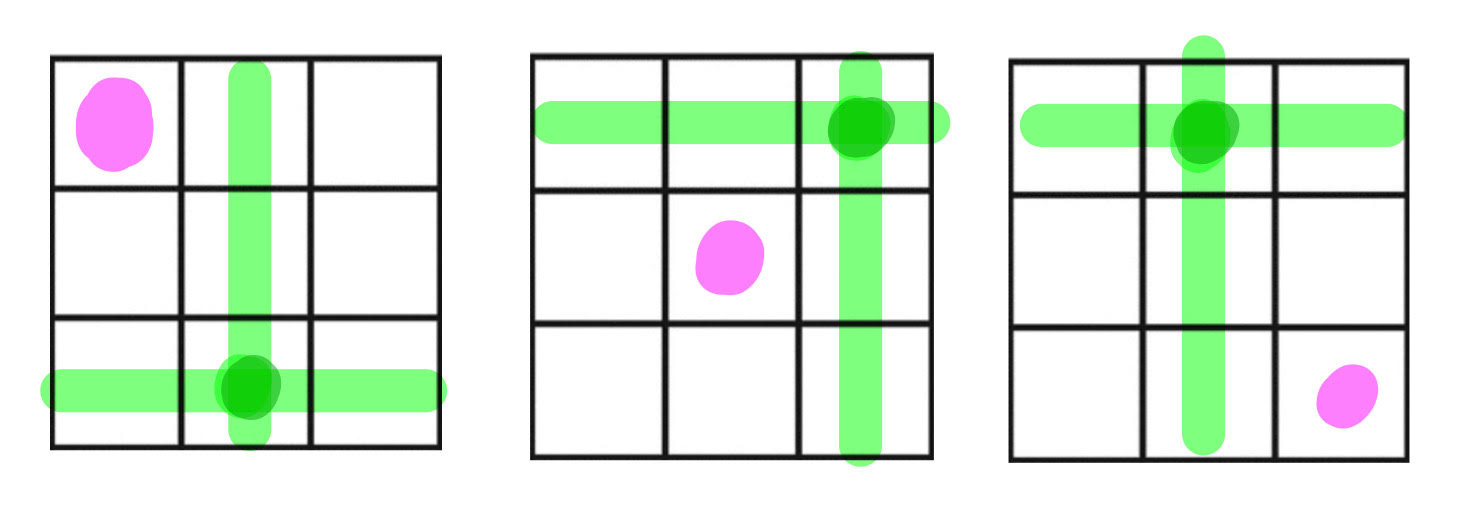 Figure 4
Figure 4| Model A1 | Model A2 | Model A3 | |||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |||||
| Proposed test | 0 | 2 | 97 | 0 | 1 | 0 | 1 | 98 | 1 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 13 | 59 | 26 | 0 | 0 | 16 | 64 | 20 | 0 | 0 | 74 | 25 | 1 | |||
| 34 | 54 | 12 | 0 | 0 | 41 | 53 | 6 | 0 | 0 | 80 | 20 | 0 | 0 | 0 | |||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 67 | 33 | 0 | 0 | 0 | 70 | 30 | 0 | 0 | 0 | 99 | 1 | 0 | 0 | 0 | |||
| 53 | 44 | 3 | 0 | 0 | 55 | 45 | 0 | 0 | 0 | 92 | 8 | 0 | 0 | 0 | |||
| Model A4 | Model A5 | ||||||||||||||||
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||||
| Proposed test | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 97 | 2 | 1 | ||||
| 0 | 0 | 68 | 32 | 1 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||||
| 77 | 23 | 0 | 0 | 0 | 77 | 19 | 4 | 0 | 0 | 0 | 0 | 0 | |||||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 33 | 67 | 0 | 0 | |||||
| 92 | 8 | 0 | 0 | 0 | 89 | 9 | 2 | 0 | 0 | 0 | 0 | 0 | |||||
| 90 | 10 | 0 | 0 | 0 | 90 | 8 | 2 | 0 | 0 | 0 | 0 | 0 | |||||
| Model A1 | Model A2 | Model A3 | |||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |||||
| Proposed test | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 1 | 99 | 0 | 0 | 0 | 2 | 98 | |||
| 9 | 38 | 52 | 1 | 0 | 8 | 37 | 55 | 0 | 0 | 47 | 46 | 7 | 0 | 0 | |||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 41 | 51 | 8 | 0 | 0 | 37 | 54 | 9 | 0 | 0 | 76 | 24 | 0 | 0 | 0 | |||
| 21 | 49 | 30 | 0 | 0 | 12 | 51 | 37 | 0 | 0 | 60 | 39 | 1 | 0 | 0 | |||
| Model A4 | Model A5 | ||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||
| Proposed test | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 0 | 0 | 0 | 1 | 99 | 0 | 0 | 0 | 0 | 0 | 92 | 8 | 0 | |||||
| 37 | 49 | 14 | 0 | 0 | 24 | 28 | 40 | 6 | 2 | 0 | 0 | 0 | |||||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||||
| 78 | 22 | 0 | 0 | 0 | 40 | 40 | 19 | 1 | 0 | 0 | 0 | 0 | |||||
| 62 | 36 | 2 | 0 | 0 | 46 | 37 | 16 | 1 | 0 | 0 | 0 | 0 | |||||
| Model S1 | Model S2 | ||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed test | 0 | 0 | 0 | 0 | 0 | 99 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 95 | 4 | 1 | |||
| 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 31 | 31 | 38 | 0 | 0 | 0 | 0 | 0 | 33 | 35 | 32 | 0 | 0 | 0 | 0 | 0 | ||||
| 0 | 0 | 0 | 0 | 77 | 23 | 0 | 0 | 0 | 0 | 0 | 2 | 77 | 21 | 0 | 0 | ||||
| 33 | 36 | 31 | 0 | 0 | 0 | 0 | 0 | 34 | 37 | 29 | 0 | 0 | 0 | 0 | 0 | ||||
| 65 | 31 | 4 | 0 | 0 | 0 | 0 | 0 | 63 | 32 | 5 | 0 | 0 | 0 | 0 | 0 | ||||
| Model S3 | Model S4 | Model S5 | |||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | |||||
| Proposed test | 0 | 0 | 0 | 93 | 5 | 2 | 0 | 0 | 0 | 94 | 4 | 2 | 0 | 0 | 94 | 4 | 2 | ||
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 77 | 22 | 1 | |||
| 1 | 8 | 56 | 35 | 0 | 0 | 1 | 8 | 53 | 38 | 0 | 0 | 1 | 20 | 79 | 0 | 0 | |||
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 1 | 10 | 60 | 29 | 0 | 0 | 2 | 11 | 55 | 32 | 0 | 0 | 1 | 20 | 79 | 0 | 0 | |||
| 7 | 14 | 64 | 15 | 0 | 0 | 16 | 17 | 55 | 12 | 0 | 0 | 3 | 23 | 74 | 0 | 0 | |||
| Model S1 | Model S2 | ||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 83 | 17 | 0 | 0 | 0 | 0 | 0 | 0 | 80 | 20 | 0 | ||||
| 0 | 2 | 3 | 13 | 57 | 25 | 0 | 0 | 0 | 0 | 7 | 14 | 51 | 28 | 0 | 0 | ||||
| 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 0 | 3 | 8 | 17 | 54 | 18 | 0 | 0 | 0 | 0 | 12 | 21 | 49 | 18 | 0 | 0 | ||||
| 1 | 11 | 27 | 36 | 25 | 0 | 0 | 0 | 1 | 10 | 27 | 37 | 25 | 0 | 0 | 0 | ||||
| Model S3 | Model S4 | Model S5 | |||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | |||||
| Proposed | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 0 | 3 | 42 | 55 | 0 | 0 | 0 | 3 | 43 | 54 | 0 | 0 | 0 | 1 | 99 | |||
| 0 | 1 | 16 | 83 | 0 | 0 | 0 | 0 | 9 | 91 | 0 | 0 | 0 | 8 | 92 | 0 | 0 | |||
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 0 | 2 | 17 | 81 | 0 | 0 | 0 | 0 | 9 | 91 | 0 | 0 | 0 | 7 | 93 | 0 | 0 | |||
| 0 | 2 | 15 | 83 | 0 | 0 | 0 | 0 | 18 | 82 | 0 | 0 | 0 | 9 | 91 | 0 | 0 | |||
| Model A1 | Model A2 | Model A3 | |||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |||||
| Proposed | 0 | 0 | 95 | 4 | 1 | 0 | 0 | 94 | 5 | 1 | 0 | 0 | 93 | 6 | 1 | ||
| 0 | 0 | 25 | 57 | 18 | 0 | 0 | 39 | 56 | 5 | 0 | 0 | 22 | 62 | 16 | |||
| 21 | 45 | 34 | 0 | 0 | 27 | 51 | 22 | 0 | 0 | 93 | 7 | 0 | 0 | 0 | |||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 60 | 38 | 2 | 0 | 0 | 63 | 37 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | |||
| 33 | 47 | 20 | 0 | 0 | 38 | 52 | 10 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | |||
| Model A4 | Model A5 | ||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||
| Proposed | 0 | 0 | 94 | 5 | 1 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 0 | 0 | 25 | 55 | 20 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||||
| 95 | 5 | 0 | 0 | 0 | 86 | 13 | 1 | 0 | 0 | 0 | 0 | 0 | |||||
| 0 | 1 | 99 | 0 | 0 | 0 | 0 | 0 | 0 | 45 | 55 | 0 | 0 | |||||
| 99 | 1 | 0 | 0 | 0 | 99 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| 98 | 2 | 0 | 0 | 0 | 97 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| Model A1 | Model A2 | Model A3 | |||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |||||
| Proposed | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 4 | 96 | 0 | 0 | 0 | 1 | 99 | |||
| 4 | 30 | 65 | 1 | 0 | 6 | 24 | 70 | 0 | 0 | 62 | 37 | 1 | 0 | 0 | |||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 35 | 53 | 12 | 0 | 0 | 27 | 51 | 22 | 0 | 0 | 84 | 16 | 0 | 0 | 0 | |||
| 10 | 41 | 49 | 0 | 0 | 7 | 44 | 49 | 0 | 0 | 79 | 21 | 0 | 0 | 0 | |||
| Model A4 | Model A5 | ||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||
| Proposed | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 0 | 0 | 0 | 1 | 99 | 0 | 0 | 0 | 0 | 0 | 65 | 35 | 0 | |||||
| 63 | 34 | 3 | 0 | 0 | 22 | 29 | 40 | 7 | 2 | 0 | 0 | 0 | |||||
| 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||||
| 86 | 14 | 0 | 0 | 0 | 37 | 40 | 22 | 1 | 0 | 0 | 0 | 0 | |||||
| 85 | 15 | 0 | 0 | 0 | 44 | 38 | 17 | 1 | 0 | 0 | 0 | 0 | |||||
| Model S1 | Model S2 | ||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed | 0 | 0 | 0 | 0 | 3 | 97 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 96 | 3 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 60 | 34 | 6 | 0 | 0 | 0 | 0 | 0 | 65 | 31 | 4 | 0 | 0 | 0 | 0 | 0 | ||||
| 1 | 0 | 0 | 4 | 69 | 23 | 0 | 0 | 20 | 0 | 0 | 5 | 51 | 24 | 0 | 0 | ||||
| 64 | 31 | 5 | 0 | 0 | 0 | 0 | 0 | 77 | 21 | 2 | 0 | 0 | 0 | 0 | 0 | ||||
| 82 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 89 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | ||||
| Model S3 | Model S4 | Model S5 | |||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | |||||
| Proposed | 0 | 0 | 0 | 93 | 5 | 2 | 0 | 0 | 0 | 94 | 6 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 0 | 66 | 34 | 0 | 0 | 0 | 0 | 71 | 29 | 0 | 0 | 0 | 65 | 34 | 1 | |||
| 41 | 37 | 22 | 0 | 0 | 0 | 43 | 34 | 23 | 0 | 0 | 0 | 2 | 23 | 75 | 0 | 0 | |||
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 38 | 38 | 23 | 1 | 0 | 0 | 38 | 34 | 27 | 1 | 0 | 0 | 4 | 23 | 73 | 0 | 0 | |||
| 64 | 31 | 5 | 0 | 0 | 0 | 66 | 31 | 3 | 0 | 0 | 0 | 8 | 30 | 62 | 0 | 0 | |||
| Model S1 | Model S2 | ||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | 14 | 57 | 29 | 0 | 0 | 0 | 0 | 0 | 12 | 62 | 26 | ||||
| 0 | 8 | 20 | 35 | 35 | 2 | 0 | 0 | 1 | 7 | 22 | 37 | 33 | 0 | 0 | 0 | ||||
| 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||||
| 0 | 9 | 27 | 38 | 23 | 3 | 0 | 0 | 1 | 9 | 25 | 38 | 27 | 0 | 0 | 0 | ||||
| 13 | 26 | 39 | 20 | 2 | 0 | 0 | 0 | 16 | 21 | 43 | 19 | 1 | 0 | 0 | 0 | ||||
| Model S3 | Model S4 | Model S5 | |||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | |||||
| Proposed | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 4 | 96 | 0 | 0 | 0 | 0 | 5 | 95 | 0 | 0 | 1 | 6 | 93 | |||
| 0 | 1 | 18 | 81 | 0 | 0 | 0 | 0 | 13 | 87 | 0 | 0 | 0 | 4 | 96 | 0 | 0 | |||
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | |||
| 0 | 2 | 18 | 80 | 0 | 0 | 0 | 0 | 16 | 84 | 0 | 0 | 0 | 5 | 95 | 0 | 0 | |||
| 0 | 4 | 34 | 62 | 0 | 0 | 0 | 2 | 28 | 70 | 0 | 0 | 0 | 8 | 92 | 0 | 0 | |||
| Model SF1 | Model SF2 | Model SF3 | |||||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed | 0 | 2 | 98 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 44 | 49 | 7 | 0 | ||
| 0 | 0 | 13 | 49 | 38 | 0 | 0 | 0 | 0 | 6 | 94 | 0 | 0 | 0 | 0 | 0 | 0 | 66 | 34 | 7 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 54 | 46 | 0 | 0 | 0 | 0 | 0 | 0 | 59 | 27 | 14 | 0 | 0 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 0 | 98 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 80 | 20 | 0 | 0 | 0 | 0 | 0 | 0 | 75 | 21 | 4 | 0 | 0 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 64 | 36 | 0 | 0 | 0 | 0 | 0 | 0 | 74 | 22 | 4 | 0 | 0 | 0 | 0 | 0 | |||
| Model SF1 | Model SF2 | Model SF3 | |||||||||||||||||||||
| Selected rank | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| Proposed | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | ||
| 0 | 0 | 1 | 0 | 99 | 0 | 0 | 0 | 0 | 0 | 41 | 55 | 4 | 0 | 0 | 0 | 0 | 0 | 13 | 40 | 47 | |||
| 82 | 17 | 1 | 0 | 0 | 22 | 78 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 28 | 62 | 0 | 0 | 0 | 0 | 0 | |||
| 67 | 6 | 27 | 0 | 0 | 0 | 25 | 1 | 20 | 12 | 42 | 0 | 0 | 0 | 0 | 1 | 9 | 87 | 3 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 45 | 55 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 32 | 44 | 0 | 0 | 0 | 0 | 0 | |||
| 98 | 2 | 0 | 0 | 0 | 31 | 69 | 0 | 0 | 0 | 0 | 0 | 0 | 23 | 32 | 45 | 0 | 0 | 0 | 0 | 0 | |||
| Model I1 | Model I2 | |||||||||
| Selected rank | 1-3 | 4-6 | 7-9 | 10 | 1-3 | 4-6 | 7-9 | 10 | ||
| Proposed | 2 | 9 | 33 | 56 | 0 | 7 | 31 | 62 | ||
| Proposed (hom.) | 0 | 0 | 5 | 95 | 0 | 0 | 4 | 96 | ||
| 2 | 97 | 1 | 0 | 28 | 71 | 1 | 0 | |||
| 96 | 4 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 88 | 12 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| Model I3 | Model I4 | |||||||||
| Selected rank | 1-3 | 4-6 | 7-9 | 10 | 1-3 | 4-6 | 7-9 | 10 | ||
| Proposed | 0 | 1 | 24 | 75 | 1 | 4 | 11 | 84 | ||
| 5 | 93 | 2 | 0 | 49 | 51 | 0 | 0 | |||
| 64 | 36 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 42 | 58 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| 87 | 13 | 0 | 0 | 100 | 0 | 0 | 0 | |||
| Model I1 | Model I2 | |||||||||||||
| Selected rank | 1-3 | 4-6 | 7-9 | 10-12 | 13-15 | 15 | 1-3 | 4-6 | 7-9 | 10-12 | 13-15 | 15 | ||
| Proposed | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | ||
| 0 | 6 | 92 | 1 | 0 | 0 | 1 | 50 | 49 | 0 | 0 | 0 | |||
| 54 | 46 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 100 | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 30 | 70 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 87 | 13 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| Model I3 | Model I4 | |||||||||||||
| Selected rank | 1-3 | 4-6 | 7-9 | 10-12 | 13-15 | 15 | 1-3 | 4-6 | 7-9 | 10-12 | 13-15 | 15 | ||
| Proposed | 0 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 100 | ||
| 0 | 30 | 60 | 10 | 0 | 0 | 3 | 73 | 24 | 0 | 0 | 0 | |||
| 15 | 76 | 9 | 0 | 0 | 0 | 99 | 1 | 0 | 0 | 0 | 0 | |||
| 93 | 7 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 2 | 64 | 34 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| 41 | 59 | 0 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | |||
| Error variance | 1 | 0.5 | 0.1 | 0.05 | 0.01 | 0.005 | 0.001 | 0.0005 | 0.0001 |
| Proposed method | 2 | 2 | 2 | 2 | 3 | 3 | 4 | 4 | 6 |
| 7 | 8 | 11 | 12 | 12 | 12 | 9 | 1 | 1 | |
| 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | |
| 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · Neural Networks and Applications · Statistical Methods and Bayesian Inference
Testing for the Rank of a Covariance Operator
Anirvan Chakrabortylabel=e1][email protected] [
Victor M. Panaretoslabel=e2][email protected] [ Ecole Polytechnique Fédérale de Lausanne
Indian Institute of Science Education and Research Kolkata & Ecole Polytechnique Fédérale de Lausanne
, e2
Abstract
How can we discern whether the covariance operator of a stochastic process is of reduced rank, and if so, what its precise rank is? And how can we do so at a given level of confidence? This question is central to a great deal of methods for functional data, which require low-dimensional representations whether by functional PCA or other methods. The difficulty is that the determination is to be made on the basis of i.i.d. replications of the process observed discretely and with measurement error contamination. This adds a ridge to the empirical covariance, obfuscating the underlying dimension. We build a matrix-completion inspired test statistic that circumvents this issue by measuring the best possible least square fit of the empirical covariance’s off-diagonal elements, optimised over covariances of given finite rank. For a fixed grid of sufficiently large size, we determine the statistic’s asymptotic null distribution as the number of replications grows. We then use it to construct a bootstrap implementation of a stepwise testing procedure controlling the family-wise error rate corresponding to the collection of hypotheses formalising the question at hand. Under minimal regularity assumptions we prove that the procedure is consistent and that its bootstrap implementation is valid. The procedure circumvents smoothing and associated smoothing parameters, is indifferent to measurement error heteroskedasticity, and does not assume a low-noise regime. An extensive simulation study reveals an excellent practical performance, stably across a wide range of settings, and the procedure is further illustrated by means of two data analyses.
62G05, 62M40,
15A99,
bootstrap,
functional data analysis,
functional PCA,
Karhunen-Loève expansion,
matrix completion,
measurement error,
scree-plot,
keywords:
[class=AMS]
keywords:
\startlocaldefs\endlocaldefs
and
Contents
1 Introduction
Principal component analysis (PCA) plays a fundamental role in statistics due to its ability to focus on a parsimonious data subspace that is most relevant for many practical purposes. In the case of functional data, it assumes an even more prominent role because a reduction in the data dimension maps the statistical problem back to a more familiar multivariate setting. Furthermore, regularization techniques that are necessary for functional regression, testing, prediction, and classification typically hinge on the identification of the most prominent sources of variation in the data.
One of the main drawbacks of principal component analysis for any kind of data is that the procedure of estimation/selection of the number of components to retain is often exploratory in nature. Indeed, one has to either inspect the scree plot or select the first few components that explain, say of the total variation (see, e.g., Jolliffe, (2002)). There are but a few confirmatory procedures to this end (see, e.g., Horn, (1965), Velicer, (1976) and Peres-Neto et al., (2005)). However, each of these procedures rely on its own assessment of what is an appropriate definition of the dimension of the data corresponding to how many components to retain. In this paper, we view the problem from the perspective of hypothesis testing. Indeed, the high level or global problem that is being considered is that of versus , where is the covariance matrix of the -dimensional distribution that generates the data. Thus, we want to test whether the data gives us enough evidence to conclude that its intrinsic variation is lower dimensional. If this null hypothesis is rejected based on the observed data, one can also consider a more detailed analysis and test the local hypotheses versus for each .
When dealing with functional data, the object of interest is a covariance kernel (rather than a covariance matrix), which a priori is an infinite dimensional object. One would then wish to test versus at a global level, for some finite integer where the rank of is at most if and only if its Mercer expansion has no more than terms.
In practice, we can observe each of a sample of curves on a finite number, say , of grid nodes, so will certainly have to be at most for the testing problem to not be vacuous. The local hypotheses will then be versus for . Based on the sample curves, and assuming that the are observed on the same grid, the simplest procedure would be to look at the rank of the empirical covariance matrix.
At first sight, this problem seems simple: if the number of observations exceeds , then perfect inference will be feasible. However, functional data are most often additively corrupted by unobservable measurement errors that are usually modelled as independent random variables indexed by the grid points for each sample function. This additional noise adds a “ridge” to the true covariance. More specifically, the covariance matrix of the observed erroneous data is of full rank. Clearly, this gives rise to a problem of the true rank being confounded by the additive noise. One way of removing the effect of the errors is to use some smoothing procedure on the data (see e.g., Ramsay and Silverman, (2005)). But this smoothing step obfuscates the problem since the relationship between the rank of and the rank of the smoothed data is unknown, and further depends on the choice of tuning parameter(s) used for smoothing. At this stage, it would seem that the problem is “almost insolubly difficult” as pointed out by Hall and Vial, (2006), who further concluded that “conventional approaches based on formal hypothesis testing will not be effective”. As a workaround, Hall and Vial, (2006) considered a “low noise” setting (assuming the noise variance vanishes as the number of observations increases) and used an unconventional rank selection procedure based on the amount of unconfounded noise variance. A weakness of the procedure was that it required the analyst to provide acceptable values of the noise variance for the procedure to be implemented in practice, and these bounds are to be selected in an ad hoc manner.
An alternative approach altogether is to view the problem not as one of testing, but rather as one of model selection. For instance, as part of their PACE method, and assuming Gaussian data, Yao et al., (2005) offer a solution based on a pseudo-AIC criterion applied to a smoothed covariance whose diagonal has been removed. Later work by Li et al., (2013) provides estimates of the effective dimension based on a BIC criterion employing and the estimate of the error variance obtained using the PACE approach with the difference being that they used a adaptive penalty term in place of that used in the classical BIC technique. For densely observed functional data, Li et al., (2013) also studied a modification of the AIC technique in Yao et al., (2005) by assuming a Gaussian likelihood for the data. Li et al., (2013) finally considered versions of information theoretic criteria studied earlier by Bai and Ng, (2002) in the context of factor models in econometrics, where the latter method is used to choose the number of factors. For all of the procedures studied by Yao et al., (2005) and Li et al., (2013), the main drawback is the involvement of smoothing parameters which enter due to use of smoothing prior to dimension estimation. The asymptotic consistency of these procedures also depends on specific decay rates for the smoothing parameters, as well as on assumptions on the regularity of the true mean and covariance functions. In early work, not explicitly framed in the context of FDA, Kneip, (1994) used several smooth versions of the data constructed using a progression of smoothing parameters, to select a dimension based on a sum of residual estimated eigenvalues. Here too, the method’s performance and asymptotics depend on regularity assumptions and decay rates for smoothing parameters.
In this paper, we steer back to a formal hypothesis testing perspective for the dimension problem. We demonstrate that it is possible to construct a valid test that circumvents the smoothing step entirely, by means of matrix completion. The proposed test statistic measures the best possible least square fit of the empirical covariance’s off-diagonal elements by nonnegative matrices of a given finite rank, exploiting the fact that the corruption affects only the diagonal.
Compared to smoothing based alternatives, our approach presents the following advantages:
- •
It provides a genuine testing procedure, inferring the rank with confidence guarantees.
- •
It does not rely on pre-smoothing and consequently on the choice of smoothing parameters.
- •
It rests on minimal regularity, in particular continuity of the covariance and sample paths.
- •
It can handle heteroskedastic measurement errors, which are detrimental to smoothing.
- •
It does not require a “low noise” regime, indeed the noise variances can be aribtrary.
- •
It exhibits excellent finite sample performance, stably across a wide range of scenarios.
The paper is organized as follows. In subsection 2.1, we discuss the problem statement and setup in detail. We then develop a key identifiability result in subsection 2.2, which elucidates how the rank can be identified. Exploiting this result, Section 2.3 describes the testing procedure. The asymptotic distribution of the test statistic, and a valid bootstrap-based calibration approach are introduced in 2.4 and 2.5. Practical and computational aspects of its implementation are discussed in Section 2.6. An extensive simulation study is presented in section 3, where we benchmark the performance of our procedure relative to those studied by Yao et al., (2005) and Li et al., (2013). Two illustrative data analyses are presented in 4. Proofs of formal statements are collected in Section 5.1, and further technical details are given in sections 5.2 and 5.3.
2 Methodology
2.1 Problem Statement and Background
Let be the stochastic process in question, assumed zero mean and with continuous covariance kernel on ,
[TABLE]
Continuity of implies that it admits the Mercer expansion,
[TABLE]
with the series on the right hand side converging uniformly and absolutely. Consequently, is mean square continuous and admits a Karhunen-Loève expansion
[TABLE]
where is a sequence of uncorrelated zero-mean random variables with variances , respectively. Convergence of the series is in the mean square sense, uniformly in . Given i.i.d. replications of , we observe the noise-corrupted discrete measurements
[TABLE]
for a grid of points
[TABLE]
We will assume that the grid nodes are regularly spaced, i.e. , for the sake of simplifying our statements, but this can be considerably relaxed. We assume that the random variables ’s are continuous random variables, independent of the ’s and themselves independent across both indices, with moments up to second order given by
[TABLE]
Note, in particular that the are allowed to be heteroskedastic in , i.e. the measurement precision may vary over the grid points. The measured vectors are now i.i.d. random vectors in with covariance matrix
[TABLE]
where:
- –
is the matrix obtained by pointwise evaluation of on the pairs , and
- –
is the covariance matrix of the -vector .
In this setup, we wish to use the observations in order to infer whether the stochastic process is, in fact, low dimensional, and if so what its dimension might be. We use the term infer in its formal sense, i.e. we wish to be able to make statements in the form of hypothesis tests with a given level of significance. Concretely, the question posed pertains to whether the covariance is of reduced rank, in the sense of a finite Mercer expansion (2.1), and if so of what rank.
Formally, for some dimension , we wish to test the hypothesis pair
[TABLE]
Notice that we can never actually choose , since we have finite data, which is why we have to settle with a . Typically so that . This global hypothesis pair is related to the sequence of local hypotheses
[TABLE]
In particular, if we can sequentially test all local hypotheses with a controlled family-wise error rate, then we will have a test for the global hypothesis, and a means to infer what the rank is, when is valid (more details in the next section). In any case, can be replaced by in the null hypotheses , provided is sufficiently large relative to :
Proposition 1**.**
Let be a continuous covariance kernel and . If there exists such that whenever .
As noted in the introduction, while this question is of clear intrinsic theoretical interest, it also arises very prominently when carrying out a functional PCA as a first step for further analysis, in particular when evaluating a scree plot to choose a truncation level: the choice of a truncation dimension can be translated into testing whether the rank of is equal to .
The frustrating tradeoff faced by the statistician in the context of this problem is that:
Without any smoothing, the noise covariance confounds the the problem by the addition of a ridge to the empirical covariance, leading to an inflation of the underlying dimensionality. Specifically, the rank of is at most , with probability 1. 2. 2.
Attempts to denoise and approximate by means of smoothing will obfuscate the the problem, since the choice of smoothing/tuning parameters will interfere with the problem of rank selection.
It is this tradeoff that Hall and Vial, (2006) presumably had in mind when referring to this problem of rank inference as “almost insolubly difficult”. Despite the apparent difficulty, we wish to challenge their statement that “conventional approaches based on formal hypothesis testing will not be effective”, demonstrating that this can be achieved via matrix completion. The crucial obervation is that the corrupted diagonal can be entirely disregarded, while still being able to identify the rank, owing to the continuity of the problem. How precisely is described in the next section.
2.2 Identifiability
The main idea we wish to put forward here is that it is feasible make inferences about the rank of without resorting to smoothing or low noise assumptions, simply by focussing on the off-diagonal elements of the matrix for any sufficiently large but finite grid size . The point is that we have no information whatsoever on the diagonal matrix , and cannot attempt to annhilate it by means of smoothing without biasing inference on the rank. Still, we have
[TABLE]
i.e. the matrices are equal off the diagonal, even if their relationship on the diagonal is completely unknown. So the rank of may still be identifiable from its off-diagonal entries. The first of our main results shows that this is indeed the case, owing to the continuity of .
Theorem 1** (Identifiability).**
Assume that the kernel is continuous on , let , and let . Then, there exists a critical such that, for all , the functional
\Theta\mapsto\sum_{i\neq j}\Big{(}K_{W,L}(i,j)-\Theta(i,j)\Big{)}^{2}
restricted on the set of matrices of rank at most ,
Vanishes uniquely at when . 2. 2.
Is bounded below by a positive constant when .
Remark 1** (Notation).**
The sum-of-squares term is simply the squared Frobenius distance between and when disregarding their diagonal entries. We can re-write it more compactly as , where , is the Frobenius matrix norm, and ‘’ denotes the Hadamard (element-wise) product.
Remark 2** (Critical Grid Size).**
The precise critical value in Theorem 1 will generally depend on the on the boundary value in the global hypothesis pair (2.4), and the spectrum of . For most scenarios encountered in functional data analysis, the value
[TABLE]
suffices. This includes polynomial or trigonometric eigensystems and warped versions thereof, systems comprised of splines or other piecewise (non-vanishing) analytic basis elements, and more generally systems with eigenfunctions that are linearly independent over sets of positive Lebesgue measure. Note that it is not the regularity of the eigenfunctions that is elemental here – for instance, the last class described can include eigenfunctions that are nowhere differentiable. See Section 5.2 for a detailed discussion.
The theorem affirms that sequentially checking whether the rank of is equal to or exceeds , for , is feasible by means of the off-diagonal entries of alone, and indeed for any finite grid . That is, the collection of local hypothesis pairs is identifiable non-asymptotically in the grid size, even when observation is discrete and noisy. Consequently, we will henceforth be working in a framework where is assumed fixed but sufficiently large relative to (i.e. , where is as in Theorem 1).
Indeed, the identifiability is constructive, in that if we had access to the true matrix , starting with and proceeding sequentially, we could discern all hypothesis pairs as follows:
For any candidate rank , we check whether
[TABLE] 2. 2.
If the minimum is positive we are certain that rank.
2.3 The Testing Procedure
This constructive identifiability can be leveraged to construct a testing procedure. Of course, in practice the matrix is unobservable and we must rely on , the empirical covariance of the observed vector ,
[TABLE]
This motivates testing the local hypothesis pair by means of the test statistic
[TABLE]
rejecting in favour of for large values of . Note the interpretation of the test statistic: to test whether the rank is , we measure the best possible fit of the off-diagonal elements of the empirical covariance by a matrix of rank . We reject when this fit is poor, and the calibration of is considered in the next two sections, via an asymptotic analysis based on -estimation, and hinging on Theorem 1.
For the moment, though, assume that we can obtain a -value for (or some appropriately re-scaled version, e.g. ) under the hypothesis . In order to be able to test the global pair (2.4), and infer the rank when the global null is valid, we consider a stepwise procedure, for a given significance level :
- Step 1:
Test vs by means of .
Stop if the corresponding -value, exceeds ; otherwise continue to Step 2.
- Step 2:
Test vs by means of .
Stop if the corresponding -value, , exceeds ; otherwise continue similarly.
We reject the global null in (2.4) if and only if the sequential procedure terminates with the rejection of all local hypotheses up to and including the -th one. If the procedure terminates earlier, the global null is not rejected, and we subsequently declare the rank of the functional data to be the value
[TABLE]
i.e. the smallest for which we fail to reject . This stepwise procedure strongly controls the Family Wise Error Rate (FWER) at level (see Maurer et al., (1995) and Lynch et al., (2017)). Indeed, observe that at most one of the hypotheses can be true, and suppose it corresponds to . Then, if denotes the number of false discoveries among the number of rejections, one has
[TABLE]
So, FWER = , where the probabilities are calculated under the given configuration of true and false null hypotheses, equivalently, under the assumption that is true (which automatically ensures that the other hypotheses are false). Since is arbitrary, the FWER is controlled at level .
Finally, if , we have
[TABLE]
Thus, the control over the FWER translates into a control over the probability of over-estimating the true rank.
To implement the procedure, we will require the -values corresponding to (an appropriately re-scaled version of) the test statistic under . To this aim, the next two sections determine the large- sampling distribution of under and describe a valid bootstrap procedure for approximating -values under in practice. En route, they also establish the consistency of the resulting test (and bootstrap procedure) as under , for all sufficiently large.
2.4 Asymptotic Theory
To justify the use of the test statistic for testing (for some given ), we will derive its asymptotic distribution under the null and the alternative as for any and , after appropriate re-scaling (by , in particular). To this aim, we introduce the functional,
[TABLE]
Furthermore, we collect the following assumptions:
Assumption (C):
The covariance kernel is continuous on , the grid nodes are regularly spaced, and .
Assumption (H):
Under , there exists a factor of , i.e. , such that the Hessian is non-singular.
Remark 3** (On The Hessian Condition).**
A sufficient condition for (H) to hold true is
Assumption (E):
The leading eigenvectors of have non-zero entries.
In particular, if (E) is valid, then can be taken to be equal to where is the eigendecomposition of , and the Hessian is provably non-singular. Condition (E), and hence Assumption (H), is automatically satisfied in all the settings listed in Remark 2. See Section 5.3 for more details.
We can now state our second main result:
Theorem 2** (Asymptotic Distribution of the Test Statistic).**
Suppose that Assumptions (C) and (H) hold and let be as in Theorem 1. Denote the weak (centered Gaussian) limit of by the random matrix . Then, for any ,
- •
When is valid, we have as
[TABLE]
- •
When is valid, diverges to infinity as .
The theorem justifies the use of as a test statistic: though will not be precisely zero even when the true rank is , the test statistic will converge to zero under , with an asymptotic variance of the order of . The diffuse limiting law of under in principle allows for calibration (though it does depend on unknown quantities, see the next Section). That diverges under establishes the consistency of a test based on .
2.5 Bootstrap Calibration
Since the limiting null distribution of established in Theorem 2 depends on unknown quantities, we consider a bootstrap strategy in order to generate approximate -values of for testing the pair . If is truly valid, then a naïve bootstrap would suffice. But if is actually valid instead, a naïve bootstrap will fail to correctly approximate the sought -values under . In effect, we need a re-centering (or rather, re-ranking) scheme in order to generate bootstrap replications “conforming” to , even when holds true in reality. The purpose of this section is to present such a scheme and establish its validity.
The proposed bootstrap scheme is:
(1)
Find a minimizer of over nonnegative definite matrices satisfying .
(2)
For each , define
where . Under the null hypothesis , this is an estimator of the best linear predictor of the discretely sampled curve given the noise-corrupted version , i.e.
(3)
Estimate by , defined as the diagonal matrix with th diagonal element defined as
where is a minimiser of over nonnegative definite matrices satisfying , and
with
and an arbitrary constant.
(4a)
Draw bootstrap observations from .
(4b)
Draw i.i.d. observations from an -dimensional centered Gaussian distribution with covariance matrix , where .
(5)
Define the -vectors for .
(6)
Let be the law of
(7)
To test the pair use the bootstrap -value
Of course, in practice we use random samples to approximate the -value in Step (7) by
[TABLE]
where
[TABLE]
If one is willing to assume that the measurement errors are heteroskedastic, one can replace in Step 3 by its diagonally averaged version,
[TABLE]
The next remark explains the heuristic behind the bootstrap procedure, and the theorem succeeding it establishes the bootstrap procedure’s validity. The procedure’s finite sample performance is investigated thoroughly in the next Section.
Remark 4** (Bootstrap Heuristic).**
Assume that the errors in (2.3) are Gaussian. Let be the -truncated Karhunen-Loève expansion of the curve and its discrete version when evaluated at the . If we had access to the -vectors and , then we would generate a bootstrap sample conforming to by means of constructing random -vectors
[TABLE]
These bootstrapped vectors would have covariance matrix , where
[TABLE]
If instead of observing and , we only had access to their covariance and , then we would do the “next best thing”, i.e. replace by its best linear predictor given the actual observations,
[TABLE]
and replace by
[TABLE]
The reason this is the “next best thing” is that the resulting has zero mean and covariance matrix
[TABLE]
In other words, is a
“rank proxy version of + Gaussian measurement error”.
whose first and second moments match those of the ideal (but unobservable) bootstrap samples (and thus when and are Gaussian, their laws match, too).
The idea of the bootstrap procedure is to materialise this heuristic, replacing the unknown matrices by their “hat counterparts” . In particular, as part of the next theorem, the informal statement that the bootstrap scheme generates samples conforming to even when is true will be made rigorous, by means of establishing validity of the bootstrap.
Theorem 3** (Bootstrap Validity).**
Let be as in Theorem 1 and assume that (C) and (H) hold true. Let be the bootstrapped -value as defined in Step (7) of the bootstrap procedure above. Then, for all ,
- •
When holds true, one has
[TABLE]
provided the underlying processes and errors are Gaussian.
- •
When holds true, one has
[TABLE]
Remark 5**.**
Regardless of whether or not the are Gaussian, as part of the proof of the theorem we establish that under the (random) bootstrap law converges pointwise almost surely to the distribution function of the random variable
[TABLE]
where is as in Assumption (H), and the random vector is the (centred Gaussian) weak limit of under . When the are Gaussian, the covariance of coincides with that of the centred Gaussian encountered in Theorem 2, and so the the bootstrap distribution asymptotically coincides with the limiting law of under as given by Theorem 2.
When the are not Gaussian, it is not guaranteed the centred Gaussians and will share the same covariance. Hence the large limit of (given by ) may not behave as a uniform random variable under , leading to a significance level different than the nominal one. We investigate the potential effect of non-Gaussianity on calibration of the bootstrap in our simulation study (Section 3), and find that this effect is negligible (in fact undetectable). We expect that Gaussianity can be weakened to higher-order moment conditions, at the expense of an even lengthier proof.
2.6 Practical Implementation
We now discuss practical aspects related to the implementation of our procedure.
2.6.1 Hypothesis Boundary, Grid Size, Bootstrap Parameters
Recall that the global hypothesis pair (2.4) to be tested is given by versus for some prescribed . Notice, furthermore, that the bottom-up nature of our iterative testing procedure (Section 2.3) translates to the FWER remaining invariant to the choice of boundary value in the global hypothesis pair . This means that as far as FWER control is concerned, we may choose as we wish. Indeed, we are even free to “data snoop” when choosing to set up the global hypothesis pair, i.e. formulate our hypothesis boundary by looking at the data.
The only constraint on the choice of is the need to ensure that the grid size is sufficiently large relative to for our identifiability result (Theorem 1) to hold true. As per Remark 2, it suffices to have grid size for virtually any type of covariance operator encountered in FDA practice, so it is prudent to always respect the constraint . Of course, one can always choose to be smaller if an inspection of the data suggests so: for instance we can set to be a value near an elbow of the off-diagonal scree plot111use of the off-diagonal rather than the classical scree plot is recommended, since the former is immune to the presence of measurement errors when is large
[TABLE]
provided this choice not exceed .
The value in Step (3) of the bootstrap procedure can similarly be chosen by inspection of the off-diagonal scree plot, as its formal definition suggests: it should represent an elbow of the graph, but can be taken no larger than our choice of .
These observations motivate the following practical recommendations:
- (I)
The boundary should be no larger than .
- (II)
In particular, can be chosen empirically, for instance as a value near an elbow of the off-diagonal scree-plot .
- (III)
If the empirical choice is equivocal or exceeds , we simply recommend fixing .
- (IV)
Either way, we recommend setting in Step (3) of the bootstrap procedure as the minimum of or a value slightly above an elbow of the off-diagonal scree-plot .
In our simulations, we set throughout for reasons of automation. As for , we inspected the off-diagonal scree plots from a sample simulation run in each scenario, and fixed the value of as a value distinctly above an apparent elbow in that run’s plot, to accommodate potential variation in other realisations of the plot (unless this exceeded , in which case we took ). This yielded excellent results irrespectively of the simulation setting.
2.6.2 Computation
Recall that evaluation of the test statistic requires the solution of the optimisation problem
[TABLE]
This being a non-convex optimization problem, we cannot ensure that standard techniques like gradient descent will converge to a global minimum (note that there are infinitely many minima when using the parametrisaion due to the fact that if is a minimum, so is for any orthogonal matrix .
However, recent work by Chen and Wainwright, (2015) shows that projected gradient descent methods with a suitable starting point have a high probability of returning a “good” local optimum in factorised matrix completion problems. For our simulation study, we used the in-built solver optim in the R software with starting point , where is the spectral decomposition of , is the matrix obtained by retaining the first columns of , and is the matrix obtained by keeping the first rows and columns of . Although we do not exactly use the approach by Chen and Wainwright, (2015), it is seen in the simulations that our chosen method of optimisation converges reasonably quickly and yields stable results.
Although our procedure bootstraping a statistic whose value is the solution of a non-convex problem, its implementation was feasible in quite reasonable computational time in all the simulations that we carried out. A single implementation of our bootstrap test procedure, when run on a 64-bit Intel(R) Core(TM) i7-8550U CPU @ 1.80 GHz machine with 16 GB RAM, typically took about 10 seconds when the sample size was and the grid size was .
3 Simulation study
We will now investigate the finite sample performance of our procedure. Recall that in our notation
[TABLE]
where are the eigenfunction/eigenvalue pairs of and the principal component scores satisfy and for all . We observe for and , where are equispaced grid points. For the purposes of the simulation, the errors are taken to be independent and normally distributed, potentially heteroskedastic in the grid index, for each . We will initially define our simulation scenarios with homoskedastic errors, and in a later section switch to heteroskedastic regimes.
3.1 Homoskedastic errors
In the case of homoskedastic measurement errors, we consider the following models (and we comment on their features as we define them):
Model A1
, , , , , , , and for all .
Model A2
Same as Model A1 except that we now set , and now has a mixture distribution that is with probability and with probability . Thus, the -paths are somewhat “curvier” and the principal component scores follow skewed Gaussian mixture models. The latter is chosen to investigate the behaviour of the bootstrap procedure for non-Gaussian processes (see Remark 5).
Model A3
, , , , , , , and for all .
Model A4
Same Model A3 but with principal component scores having a skewed Gaussian mixture law as in Model A2.
Model A5
, , , , , for , for , and for all .
Models (A1)-(A3) are similar to those considered in Li et al., (2013). To go beyond globally defined eigenfunctions, the next set of models feature piecewise polynomial eigenfunctions.
Model S1
, , , , the eigenfunctions are orthonormalised functions obtained from the basis of cubic splines with knots at , and for all .
Model S2
The model parameters are the same as in Model S1, with the only difference that being that the principal component scores are now distributed according to the skewed Gaussian mixture form in Model A2.
Model S3
, , , , the ’s are orthonormalized functions obtained from the basis of quadratic splines with knots at , and for all .
Model S4
The model parameters are the same as in Model S3 except that now the principal component scores now have a skewed Gaussian mixture distribution as in Model A2.
Model S5
, , , the ’s are orthonormalized functions obtained from the basis of linear splines with knots at , and for all . The principal component scores now have the same skewed Gaussian mixture form as in Model A2.
For each of these models, we have considered two combinations of sample size and grid size , namely equal to and , to emulate more sparsely/densely observed settings. The parameter described in the bootstrap algorithm in the previous section is set to for all the simulations in this and the next sub-section. As discussed in the previous section, we can choose by visual inspection of the off-diagonal scree plot . When using this approach in a trial runs from each scenario, the plot was suggestive of for models A5, S1 and S2, and for the other models. The fixed value of was thus chosen for use across the simulation scenarios.
To probe the performance of the bootstrap procedure, we set the number of bootstrap samples to and set the significance level to . For each model, we carried out independent replications to report the empirical distribution of the estimated rank. We benchmark the performance of our procedure with two well-known techniques for selecting the rank of a functional data, namely: the AIC based criterion () in Sec. 2.5 of Yao et al., (2005); the modified AIC () and modified BIC () criteria proposed in equations (16) and (6), respectively, in Li et al., (2013); and the modified information theoretic criteria and given in equation (20) in Li et al., (2013). The information theoretic criteria are inspired by similar techniques in Bai and Ng, (2002) who used them to estimate the number of factors in an approximate factor model. We underline that these procedures are used purely for the purpose of benchmarking, since these are procedures whose purpose is model selection and thus are geared toward inducing parsimony, though some come with theoretical guarantees of consistently selecting the true rank asymptotically, if the rank is truly finite. The results are tabulated in Tables 1–4.
It is observed from Tables 1–4 that the proposed method selects the true rank in at least of the iterations for all of the chosen models, irrespective of whether the true rank is large/small, the observation grid is sparse/dense, the distribution is Gaussian or not, the signal is smooth/rough, and the noise is large/small compared to the signal. In fact, the when , the bootstrap procedure chooses the true rank in all the iterations under all of the above simulation models. Moreover, the evidence (as seen from the magnitude of the -values) is quite strong. In cases where the detection of the true rank is not perfect, we found that on making the test procedure more conservative (by choosing a smaller , e.g., or ), the rate of correct identification of the rank surged to .
It is observed from the results shown in Tables 1–4 that estimates the true rank accurately if the rank is large (equal to as in Models (A5), (S1) and (S2)). When the rank is small, the performance of varies depending on the model. Investigating a bit more, it may be observed that it overestimates the rank under Models A1 and A2 (rank = 3), where the error dominates the leading eigenvalue of the signal. On the other hand, for Models (S3) and (S4) (rank = 4), accurately selects the true rank. When the rank is small (equal to or ) but the grid is dense (), it is seen that grossly over-estimates the true rank in almost all models. This over-estimation is exacerbated when the eigenfunctions are trigonometric, which is surprising since one would expect this to be an easier setting than in (S3), (S4) and (S5). The over-estimation of the rank by was also observed by Li et al., (2013).
The , and criteria do not perform well in general and mostly under-estimate the rank irrespective of the sample size and the sparse/dense regime. The procedure, on the other hand, yields the same perfect estimation results as our procedure when the grid is dense (). It does so also when the grid is sparse provided that the true rank is small (equal to or ). However, for Models (S1) and (S2) with , where the rank is large (equal to ) and the grid is sparse (), the criterion mostly selects a smaller rank. This is different from its performance under Model (A5) with (which is also of rank ), where it selects the true rank in of iterations. The difference in this behaviour of may be attributed to the fact that for Model (A5), the eigenfunctions are smooth, while they are only twice continuously differentiable for Models (S1) and (S2) due to the presence of knots.
Summarising the observations from Tables 1–4, it may be concluded that the and the criteria are most appropriate among the competing information-based procedures. Some tentative conclusions on the two methods are as follows. While the latter works well when the rank is large (irrespective of the sparsity/denseness of the grid), the former is suited when the grid is dense (irrespective of the magnitude of the rank). The procedure also works very well when the grid is sparse, provided that the rank is small. However, both procedures appear to be quite sensitive to departures from the above situations – grossly over-estimates, while mildly under-estimates. Note that the difference in performance is observed between and . This change in number of observations is not so stark so as to be classified immediately as sparse versus dense, and the fact that the performance of these two procedures vary in such a moderate change of grid size is concerning. We also mention in passing that the performance of the and the procedures crucially depend on the choice of the smoothing parameters. Indeed, Li et al., (2013) considered models similar to Models (A1)-(A5) but worked with an undersmoothing choice of the bandwidth parameter, and the relative performance of the above two procedures differs from that observed in our simulation results.
On the other hand, Table 1–4 shows that our proposed procedure always selects the true rank in at least of the iterations (the percentage being much higher in most cases), irrespective of the magnitude of the rank and the sparsity/denseness of the grid. Thus, the proposed method seems to provide an effective and stable alternative. Beyond this advantage, our method also comes with a probabilistic guarantee on overestimation, and hence provides an automatic quantification of uncertainty about the true rank, while not relying on smoothing.
3.2 Heteroskedastic errors
Our theory suggests that our testing procedure automatically adapts to a heteroskedastic variance structure for the measurement errors. We therefore the same model scenarios as before, but this time with heteroskedastic errors in order to gauge how this translates into practical performance. All else being the same, the measurement error variances are now given by
[TABLE]
where , and . This specific error structure may be viewed from the perspective of a local averaging of the signal along with a downscaling by a factor of . For these simulation models, the results obtained are provided in Tables 5 to 8. It is observed that the performance of the proposed procedure remains invariant to the presence of homoskedasticity, as our theory predicts.
3.3 Spiked functional data
One may also consider a spiked covariance model, in analogy to high-dimensional statistics (see, e.g., Johnstone, (2001), Paul, (2007)) where some of the eigenvalues are considerably larger than the rest (Amini and Wainwright,, 2012). One instance of the latter setting is the Tecator data set considered in Section 4. This is a particularly challenging setting: heuristically, a prominent bend is expected to appear in the scree plot, well before the index value of the true rank (see Figure 2 which shows the scree plots for the spiked models considered immediately below). To probe the performance of our method in this setting, we also consider the following spiked scenarios:
Model SF1
Model (A1) is modified to now have and for all . Here the first eigenvalue explains about of the total variation in the signal. Note that the error variance is five and ten times the size of the penultimate and last eigenvalue, respectively.
Model SF2
Model (A5) is modified to have and . Here the top two eigenvalues explain of the total variation in the signal, and there are three more trailing eigenvalues are of order between 1/5 and 1/10 the size of the noise variance.
Model SF3
Model (A5) is modified to have and . Here the top three eigenvalues explain about of the total variation in the signal, and the last three are between 1/10 and 1/300 the size of the of the noise variance. This is a very challenging setup which features several trailing eigenvalues the last of which has size negligible relative to the noise variance.
Table 9 gives the empirical distribution of the selected rank for each of the above three models when and – sparse and dense grids, contrasting our proposed methods with the benchmark methods. The vale of was used again in these settings. Intriguingly, it is observed that the proposed method yields near perfect estimation of the rank under all of the above models. The only exception is the most challenging model (SF3), and this only when the grid is sparse, where our method returns the true rank or the true rank minus in approximately a 50-50 split. Note that this is the scenario where the smallest eigenvalue is 1/300 the size of the error variance and the grid is sparse. The results suggests a certain degree of robustness of the proposed procedure against extreme forms of the spectrum.
By comparison, the benchmark procedures markedly underperform relative to our procedure. The , and procedures yield poor results as in the previous two subsections. The performance of performs similarly as in earlier simulations, namely, it does well when the rank is large and the grid is sparse and the error variance is small. Its performance degrades significantly if the grid is dense or the rank is small, which results in either overestimation. When the error variance is not small, underestimates the true rank. The most striking difference in performance is observed for the procedure, which now heavily underestimates the true rank in the spiked regime. The situation does not improve much even if we take dense grids (here ). While this can be explained by the fact that is a model selection procedure targeting parsimonious models, it does also show that the consistency of may be slow to manifest in unbalanced spectra.
3.4 Infinite dimensional models
We now proble the finite sample performance of the procedure when the data are truly infinite dimensional, even prior to noise contamination; and we compare this with the output of model selection-based alternative procedures in such situations. To this aim, we consider infinite dimensional models with , for all . The measurement error again satisfies for each . We consider four settings:
Model I1
is a standard Brownian motion, which features polynomial decay of eigenvalues and non-differentiable sample paths. Also, for .
Model I2
is a Gausian process with – which features exponential decay of eigenvalues and infinitely smooth paths. Also, for .
Model I3
is as in Model (I1). However, for , where is the observation grid.
Model I4
is as in Model (I2). However, for , where is the observation grid.
Inspection of the off-diagonal scree plot in a trial run from each scenario suggested no evident elbow below , and so as per the recommendations of Section 2.6.1, we chose in each case. Tables 10 and 11 give the estimated ranks in iterations under Models (I1)-(I4) for and .
It is observed that the model selection procedures like , and target some level of parsimonious representation of the data, the degree of parsimony depending on the method used. Unsurprisingly, they fail to inform us on whether the model is truly infinite dimensional or not (similar to having low power error in the testing paradigm). In the majority of cases, regardless of scenario, the chosen rank is between 1 and 3, in fact. By contrast, the proposed method exhibits very good performance in terms of power, typically rejecting low-dimensional representations across all scenarios. In the case of dense grids (), the procedure never chose a rank below 15. In the case of a sparser grid (), the results varied somewhat between homoskedastic and heteroskedastic noise settings. In the two heteroskedastic scenarios, the procedure chose a rank of at least ten in 75% and 85% of runs. In the two homoskedastic scenarios, these percentages were modestly lower at about 56% and 62%. When we incorporated the assumption of homoskedasticity in the procedure (as per the comment in Section 2.5, at the top of p. 2.5), the performance surged in the two homoskedastic scenarios, with a rank of at least ten being chosen in 95% and 96% of runs. This suggests that, when operating with sparse grids, it can be beneficial in terms of power to make use of homoskedasticity if this can indeed be assumed.
4 Data Analysis
We will apply the bootstrap technique for estimating the rank to some benchmark data sets. The first of these is the well-known Tecator dataset which contains spectrometric curves for samples of finely chopped meat (see Ferraty and Vieu, (2006)). Each curve corresponds to the absorbances measured over wavelengths. A standard functional PCA followed by a scree plot of the eigenvalues reveal an essentially finite dimensional structure since the eigenvalues decay to zero very fast. A scree-plot approach would suggest the underlying rank to be three/four. In fact, the top four eigenvalues are , , and . The percentage of total variation explained by these principal components are , , and , respectively. So the first four eigenvalues explain of the total variation. Since these data are recorded to high precision, and the curves are very smooth, it may be safely assumed that the measurements are essentially error-free. We will artificially add i.i.d. noise to the data and then apply our method and the alternative procedures considered in the previous section to evaluate their performance. Also, we will vary the error variance to investigate the effect of the magnitude of the signal-to-noise ratio on the rank selection algorithms.
The errors are taken to be i.i.d. centered Gaussian with variances and . These values range from “noise dominating signal completely” to “noise smaller than fourth largest eigenvalue”. For our procedure and each value of the noise variance, we choose as suggested by the off-diagonal scree plot.
Table 12 shows the estimated ranks obtained from the different procedures under the chosen levels of the error variance. It is seen that unless the error variance is very small (comparable to the fourth largest eigenvalue), generally chooses unrealistically high values of the rank. In the other situations, the rank is chosen to be one. On the other hand, all of , and select the rank to be one unless the error variance completely overwhelms the signal. The procedure always selects the rank as one. These observations can be explained by noting that the Tecator data is an example of a spiked functional dataset and the behaviour of these model selection procedures for such data was found to exhibit such behaviour in Section 3.3. The procedure proposed in the paper estimates the rank to be three or four in all cases where the error variance is interlaced and comparable with the second/third/fourth eigenvalues. Only when the error variance is very small (1/3 of the the fourth largest eigenvalue), is the rank overestimated (as being six), which is arguably modest a deviation.
Thus, when the error variance is moderate (neither too small nor overwhelming the signal), only the proposed method seems to provide a proper estimate of the rank of the Tecator data.
The next data set that we consider concerns the number of eggs laid by each of female Mediterranean fruit flies (medflies), Ceratitis capitata, in a fertility study described in Carey et al., (1998). The data222Accessible at http://anson.ucdavis.edu/$\sim$mueller/data/medfly1000.txt contain the total number of eggs laid by each medfly as well as the daily breakup of the number of eggs laid. It is discussed in Carey et al., (1998) that there is a change in the pattern of egg production at day post birth for those medflies which lived past that age. Also, the variation in the number of eggs laid from day onwards is in general much larger than that before day . Taking these observations into account, it seems more pertinent to look at the egg-laying data till the age days for those medflies that live past that age. This results in a sample of medflies. Since the number of eggs laid in days to for these medflies equal zero, we only keep the number of eggs laid from day onwards for our analysis.
Among the competing procedures, estimates the rank of the data to be equal to while selects the rank to be . All of , and select the rank to be one, which appears way off based on a visual inspection of the data. The bootstrap procedure proposed in this paper is carried out by selecting . In fact, the off-diagonal scree plot as well as the results obtained from the competing methods indicate that the rank is likely smaller than . Our procedure selects the rank to be at significance level . Further, our bootstrap test rejects the hypotheses for with -values that are numerically zero.
Our procedure thus yields the same result as the approach, in this case, in addition to providing a confidence level. We compared the , the and the approaches by computing the average relative squared error
[TABLE]
where is the prediction of using the PACE estimates of , and ’s (see Yao et al., (2005)). For computing the for each approach, we use the estimated value of the rank obtained from the corresponding approach. It is found that the for the approach (with ) equals and the for the approach (with ) is . Note that since our approach yields the same estimate of the rank as the approach, the for our approach is also equal to . Thus, there is no significant improvement in the by considering principal components (obtained using ) instead of (obtained using our approach or ). The of the approach (as well as that of the and the approaches) equals . It would seem that these three approaches perform poorly in determining the true rank of the process in this example.
5 Appendix
5.1 Proofs of Formal Statements
We will first state and prove some auxiliary results that will simplify the proofs of our main results.
Lemma 1**.**
If the covariance kernel is continuous and , then we can find such that the matrix is of full rank .
Proof.
Using Mercer’s theorem we may write
[TABLE]
for any collection of points . Note that both and are non-negative definite matrices, so it suffices to prove that we can find such that the matrix is of full rank . We may write
[TABLE]
where
[TABLE]
and of course . We claim that there exists -tuple such that . For suppose that for all . Using the Leibniz formula for the determinant this translates to
[TABLE]
where is permutation group on elements and is the signature of a permutation . Keeping fixed, multiply both sides of the equation by and integrate with respect to to get:
[TABLE]
Repeating the same process, multiplying both sides of the equation by for while keeping the remaining variables fixed, and then integrating with respect to eventually yields
[TABLE]
This last equality contradicts the fact that . Thus for at least one -tuple, say . The elements of this -tuple will necessarily be distinct, because would otherwise have two coincident lines, contradicting , and hence we may re-order them to get the sought . ∎
Corollary 1**.**
If the covariance kernel is continuous and , then we can find and such:
The balls are pairwise disjoint; 2. 2.
The matrix is of full rank for all such that .
Proof.
By Lemma 1 we know that there exist such that is of full rank. Define the function as
[TABLE]
Since is uniformly continuous on it follows that so is on . Now
[TABLE]
It follows that there exists a depending on the modulus of continuity of , such that whenever , i.e. whenever , the ball of radius centred at . Since the are pairwise distinct, we can take sufficiently small so that the balls are also pairwise disjoint. ∎
Proof of Proposition 1.
If , we can choose nodes and corresponding balls as in the statement of Corollary 1. Since are regularly spaced nodes for any , there is a finite such that for each of the balls contains at least grid point. Since the balls are disjoint, one can thus choose a subcollection of distinct grid points such that the matrix has full rank , as ensured by Corollary 1. It follows that has a non-vanishing minor of order , and hence . ∎
The next lemma will be used in the proof of Theorem 1. Informally, it states that a diagonal entry of an matrix of rank can be imputed from the off-diagonal entries of provided there is a non-vanishing -minor of that does not depend on .
Lemma 2**.**
Let be an matrix of rank and let be a submatrix of that is also of rank . If and for all , it follows the diagonal element is uniquely determined as a continuous function of and the entries .
Proof.
Since the statement is invariant to conjugations of by permutation matrices , we may assume without loss of generality that and . Thus we may extract a submatrix of , of the form
[TABLE]
where , . Now because , so we may write
[TABLE]
showing that is uniquely determined as a rational function of the entries of , , and . ∎
Proof of Theorem 1.
Without loss of generality, we will prove the theorem for the largest possible value of , i.e. for . When , as is considered in the conclusions (1) and (2) of the Theorem’s statement, we can choose and as in the statement of Corollary 1. Since are regularly spaced for any , there is a finite such that for all each of the balls contain at least grid points. It follows that for any the matrix contains a submatrix , which can be organised into an matrix of blocks, with the property that: any submatrix of extracted by retaining one row from each of the consecutive triples of rows, and one column from each of the consecutive triples of columns, has rank (Figure 3 provides a visualisation).
Moreover, it is possible to extract such rank- submatrices of that contain no diagonal cells of among their entries (simply by making sure that we do not choose the same order of row and column from corresponding consecutive triples of rows/columns, e.g. always picking the first row from each consecutive row triple and the second column from each consecutive column triple).
Finally, given any specific diagonal element of , we can extract a submatrix of of rank- that: (a) contains no diagonal cells of , and (b) has row/column indices distinct from the index of the diagonal entry . To see this, notice that any submatrix constructed as in the preceding paragraph satisfies both (a) and (b) whenever the index is not among the row/column indices forming . Otherwise, the diagonal element in question is contained on the diagonal of one of the blocks of size along the diagonal of , say the bottom right block without loss of generality. In this case choose the first row from every row triple and the second column for column triple, except for the last row/column triples. From the last row/column triples: choose the third row and second column of this block, if is the top-left element in that block; choose the first row and third column of this block, if is the central element in that block; choose the first row and third column of this block, if is the bottom-right element in that block. See Figure 4 for an illustration.
Collecting all these facts, we can now see that for ,
When , the matrix uniquely solves the equation among matrices of rank ,. To see this, let be an element on the diagonal of , for some . Then, based on the discussion in the previous paragraph, we can find a submatrix of of rank that contains no diagonal elements of and no elements from the th column or row of . As a result, Lemma 2 implies that we can determine uniquely as a continuous function of the elements of . Repeating this process for all effectively shows that any rank matrix that coincides with off the diagonal must also coincide with on the diagonal (equivalently that there exists a continuous function , such that ). 2. 2.
When , there is no matrix of rank less than such that . This is because there exists a submatrix of of full rank that contains no diagonal elements of . So would imply that . Indeed, when , we have the stronger statement that . This is because
[TABLE]
where is the rank submatrix of as in point 1 above and is the corresponding submatrix of . Since is of rank at most , so is . Hence
[TABLE]
where is the -th singular value of . The set of rank matrices being closed now shows that .
Taken together, statements 1 and 2 above yield the theorem as stated, and thus complete the proof.
∎
In order to prove Theorm 2, we introduce some additional short hand notation, in the form of the following spaces and functionals:
[TABLE]
Proof of Theorem 2.
Assumption C guarantees the validity of Theorem 1. We will throughout assume that is finite and fixed, and satisfies , where is the critical grid size whose existence is guaranteed by Theorem 1. We will divide the proof into several parts. As defined earlier, . Also, . Then, the test statistic can be written as
[TABLE]
The proof will be broken down into the following sequence of steps:
First we will determine the gradients and Hessians of the functionals and . 2. 2.
Then we will show the strong consistency any empirical minimiser of the functional for the minimiser of . 3. 3.
We will translate this into consistency of an appropriately chosen factor of (i.e. ) to the factor of defined in Assumption (H). 4. 4.
Finally, we will use the penultimate step combined with a Taylor expansion of and in order to determine the sought weak convergence.
Step 1: We begin by determining the gradient and Hessian of , denoted by and , respectively. Since is a real valued function of a matrix, is a matrix and is a tensor (Kronecker product). Note that for any , we have
[TABLE]
The last equality is obtained by using the fact that for a symmetric matrix , we have and . Thus,
[TABLE]
where , and the form of follows from the same calculations as above.
To determine the Hessian, we note that for any , we have
[TABLE]
Now observe that for any matrix , we have , where is the matrix whose th entry is one and all other entries are zero. So,
[TABLE]
Next, recall that for compatible matrices and , we have , where denotes the standard vectorization operator. Hence,
[TABLE]
where is the commutation matrix of order , i.e. the permutation matrix satisfying for . Further, , which implies that . So,
[TABLE]
Observe that equals . Thus, using equations (5.4), (5.5) and (5.6), we have
[TABLE]
Now note that . Also, is the projection matrix onto the rows for each . Thus, for a matrix of order , we have . Hence,
[TABLE]
Let us also note that for a matrix of order ,
[TABLE]
and sets the diagonal entries of this matrix equal to zero, equivalently, the diagonal entries of each on the diagonal equal to zero. Thus, . Next, for a matrix , we have
[TABLE]
These two observations yield the form of the Hessian as
[TABLE]
Step 2: Strong Consistency of Empirical Minimizers. We will now show that any minimizer of the functional over the space of matrices with is consistent for as when is valid.
To show this, let be the (unobservable) random matrix
[TABLE]
Under , . Thus, if is a local minimiser of , it must be that
[TABLE]
[TABLE]
The right hand side, however, converges to zero almost surely by the strong law of large numbers and the continuous mapping theorem (note that since is continuous, the covariance operator of the process is trace-class, and so is any discretization thereof). Since converges to almost surely as , we therefore have
[TABLE]
as , which implies that
[TABLE]
This being the case, the event
[TABLE]
satisfies . This is because matrices of rank bounded by an integer form a closed set, and thus no sequence can converge almost surely to unless eventually , almost surely.
Consequently, with probability 1, eventually in , a minor of is non-vanishing if and only if the corresponding minor of is non-vanishing. But is always at most rank , by definition. Thus, under , we follow the exact same steps as in the proof of Theorem 1, by forming the submatrix of and corresponding submatrix of , in order to obtain that
- •
for a continuous map (i.e. the diagonal of , and hence the entire matrix can be determined as a continuous function of the off-diagonal entries).
- •
with probability 1, eventually in , (i.e. the diagonal of , and hence the entire matrix , can be determined as a continuous function of the off-diagonal entries; indeed the function is the same function we use for ).
Thus, with probability 1, for all sufficiently large, is well defined, equals , and thus we
[TABLE]
In summary, we have established strong consistency of any minimising sequence of .
Step 3: Consistency of an Appropriately Chosen Factor Since , we can write , where . Thus, . Of course, will also yield the same minimum value for any orthogonal matrix . Since we are not interested in the law of the argument itself, but with the law of the optimised objective , we can will work with any choice of , even an “oracle choice”. Define, in particular,
[TABLE]
and subsequently, define . Thus, is the version of that is “aligned” with in the above sense. The solution above minimization problem, known as the orthogonal Procrustes problem, is given by , where is the singular value decomposition of the matrix . Furthermore, as earlier remarked,
[TABLE]
so the asymptotic distributions of and will agree.
We will now show that (to be explicit about the dependence on ) converges to almost surely as under . Note that since converges almost surely to , we have that converges almost surely to . Thus, the set has probability measure one. Fix any . Since lies in the compact set (closed ball of radius ) for all large , so in order to show that converges to , we will show that all subsequences of converge to . Suppose that there exists a subsequence of such that as , where . But then . Thus, for some orthogonal matrix . Suppose that , equivalently, . Define for each . Then,
[TABLE]
On the other hand, Recall that as per our construction. So, there exists such that
[TABLE]
This leads to a contradiction unless . Hence, so that the limit does not depend on . A standard subsequence argument (using the fact that lies in a compact set for all sufficiently large almost surely) now shows that the entire sequence must converge to as on .
Step 4: Determination of the Asymptotic Distribution We will now proceed to derive the asymptotic distribution of under . First, observe that equals
[TABLE]
and is thus not dependent on . Furthermore, it is as .
Observe that by Taylor’s theorem,
[TABLE]
where for some . Since converges weakly to a centered Gaussian random matrix , and we have shown above that in probability, it follows that
[TABLE]
as . Now is non-singular by Assumption (H), so the inverse function theorem applied to the function implies that:
- (i)
the function is invertible in a neighbourhood of .
- (ii)
the function is continuously differentiable in that same neighbourhood.
- (iii)
in that same neighbourhood.
Since in probability, we have . Also, from the fact that is continuously differentiable in that neighbourhood, it follows that . Further,
[TABLE]
in probability as by the continuity of and the continuous differentiability of . It now follows from (5.9) and (5.10) that
[TABLE]
as .
Next note that for some with , we have
[TABLE]
It now follows from equations (5.10), (5.11) and (5.12) that
[TABLE]
as . Thus, as argued earlier, we have
[TABLE]
as .
The proof of the last statement will follow by establishing that
[TABLE]
as , the latter term being strictly positive under by statement (2) of Theorem 1. To establish this limit, apply the reverse triangle inequality to obtain
[TABLE]
Thus
[TABLE]
and notice that the right hand side converges almost surely to . It follows that diverges almost surely as , and the proof is complete. ∎
Proof of Theorem 3.
The proof will be broken down into the following series of steps:
We will first show that the quantities , , , , and either converge -almost surely as , or are -strongly tight as (meaning they eventually lie in a compact set with -probability 1). This will be broken down into three sub-cases: when is true; when and are both true; and, finally, when is true. 2. 2.
We will then prove statement (a) in the present theorem under the assumption that is true. This proof will be further broken down into the following five sub-steps:
- 2a.
We will first show that the minimizer, say , of the bootstrap functional over converges to -almost surely, -almost surely.
- 2b.
Then we will show that an appropriately chosen rank factorization of converges to the rank factorization of defined in Assumption (H).
- 2c.
We will next derive the -weak convergence of to an appropriate limit, -almost surely.
- 2d.
Step (2c) will be used along with Taylor’s formula on the bootstrap functional in Step (2a) to derive the -weak limit of the bootstrapped test statistic .
- 2e.
We will conclude step (2) by showing that the weak limit obtained in Step (2d) is the same as the weak limit of , thus establishing (a) in the theorem’s statement. 3. 3.
We will then prove statement (b) in the present theorem under the assumption that is true.
Step 1: Empirical estimators are either strongly convergent or strongly tight. Consider first the case when is true. We will show that, in this case, we have strong consistency of the required quantities. Suppose that we can show that under , converges almost surely to as . Since is integer-valued, this wold imply that eventually, -almost surely. Consequently, eventually, -almost surely. So, following the same steps as in the proof of Theorem 2, we would obtain that converges -almost surely to , which in turn would imply that converges -almost surely to .
To prove that converges almost surely to , we claim that
[TABLE]
To see this, we first note that converges to zero -almost surely as by the continuous mapping theorem (applied to the strong convergence of to ). Next, we observe that is eventually bounded -almost surely, by means of the law of the iterated logarithm333Recall that under , it -almost surely holds that for all sufficiently large. This, combined with (5.8), yields (for all sufficiently large)
Now each entry of is an average of iid random variavbles of mean zero and finite variance. So if we pick , the LIL will imply that is in a bounded set, almost surely. picking will then yield convergence of to zero, -almost surely. So
[TABLE]
for any . The term converges -almost surely to the positive constant . Therefore , and consequently , converges -almost surely to under .
Now consider the setting where both and the global null are true. In this case, one of is true. Say it’s for . By arguments similar to above, we can show that converges -almost surely to . Thus, eventually, equals . Since is true, converges -almost surely to , yielding strong consistency of for . As for , this may not converge almost surely, since , but we will show that it is strongly tight. Define so that . Since is a minimizer of the function over matrices of rank at most ,
[TABLE]
The right hand side converges almost surely to a constant, therefore eventually lies in a closed ball of finite radius centred at . To see that the diagonal elements of must also eventually lie in some compact set almost surely, consider an arbitrary diagonal such element of . Since , where is as in Theorem 1, there exists a submatrix of that contains but contains no other diagonal elements of (see, e.g., the first part of the proof of Theorem1). The matrix is clearly of rank at most , thus the column that contains is in the span of the remaining columns of , . In other words, there exist coefficients such that
[TABLE]
Now all entries of other than are elements of , and the latter eventually lies in a compact set almost surely. It follows that
- (i)
Any coefficients such that also eventually lie in a compact set almost surely. This because for all and the are all eventually bounded almost surely.
- (ii)
Thus, lies in a compact set eventually almost surely, since .
Since was arbitrarily chosen, we establish that almost surely.
To conclude Step 1 of the proof, consider now the case where the global alternative is true (i.e. the true rank exceeds ). In this case, we will show that converges almost surely to . We will also show that is eventually almost surely in a compact set. To prove that , let us revisit the quantity
[TABLE]
Recalling the reverse triangle inequality (applied to the Frobenius norm)
[TABLE]
we may write
[TABLE]
Under , for any , we thus have
[TABLE]
and we notice that the right hand side converges to . This is a strictly positive quantity from part 2 of Theorem 1. It follows that diverges almost surely, and thus converges to almost surely. The proof of the strong tightness of is established in exactly in the same way as the proof of the strong tightness of in the case where is valid, considered in the previous paragraph.
Step 2: Asymptotic theory for bootstrap under (statement (a) of the Theorem). As announced earlier in the proof, this step is broken down into five substeps, and we now establish these in order.
Step 2a: Consistency of minimizer of bootstrap functional. We can, for simplicity, assume that , and drop the term in the definition of . We will fix a set of -measure one on which a.s. convergence and law of iterated logarithm results hold as will be required in the proof. Fix any and work with the resulting population . All statements will be conditional on this population. We will drop the dependence on for simplicity of notation.
Assume that is true, and recall that . Define
[TABLE]
Now, observe that
[TABLE]
where the last equality follows from the independence of and along with the fact that . It is standard that all of , and converge to zero -almost surely -almost surely (though, for completeness, we show this in Lemma 3, after this proof). Thus, combining these statements, it follows that converges to zero -almost surely.
Now define the function . Define to be a minimizer of the functional over . We will now prove that converges to -almost surely, -almost surely under . To show this, let be the (unobservable) random matrix satisfying
[TABLE]
where is the (unobservable) bootstrap sample from the (also unobservable) (i.e. with those indices sampled by the bootstrap). Under , . Also, define . Thus, it must hold that
[TABLE]
Under , it has been proved above that converges -almost surely to . Further, converges -almost surely to . So, converges -almost surely to . Also, . Thus, the right hand side converges to zero -almost surely, -almost surely by the classical as well as the bootstrap almost sure convergence results and the continuous mapping theorem (note that since is continuous, the covariance operator of the process is trace-class, and so is any discretization thereof). We therefore have
[TABLE]
-almost surely, -almost surely as , which implies that
[TABLE]
-almost surely, -almost surely as . Now, the same arguments as in the remainder of the proof of Step 2 (Consistency of Empirical Minimizers) in Theorem 2 show that converges -almost surely, -almost surely as to .
Step 2b: Consistency of appropriate rank factorization. Since , we can write , where . Thus, , where . We now make the observation that will also yield the same minimum value for any orthogonal matrix . So, we will work with the following modified estimator instead. Define
[TABLE]
and subsequently, define . Thus, is the version of that is “aligned” with in the above Procrustes distance minimization sense. It is well known that the solution of the above minimization problem is given by , where is the singular value decomposition of the matrix . Further,
[TABLE]
So, the bootstrap asymptotic distributions of and will agree -almost surely. Since it is these asymptotic distributions that we wish to determine, we can work with , even though it is an oracle quantity (similar to Step 3 of Theorem 2).
We will now show that (to be explicit about the dependence on ) converges to -almost surely as , -almost surely under . Note that since converges -almost surely to -almost surely (proven in Step (2b)), we have that converges -almost surely to -almost surely. Thus, the set has -probability measure one.
Fix any . Since lies in the closed ball of radius for all large , in order to show that converges to , we will show that all subsequences of converge to . Suppose that there exists a subsequence of such that as , where . But then . Thus, for some orthogonal matrix . Suppose that , equivalently, . Define for each . Then,
[TABLE]
On the other hand, Recall that as per our construction. So, there exists such that
[TABLE]
This leads to a contradiction unless . Hence, so that the limit does not depend on . A standard subsequence argument (using the fact that lies in a compact set for all sufficiently large almost surely) now shows that the entire sequence must converge to as on .
We will now derive the asymptotic distribution of under . Define .
Step 2c: Asymptotic distribution of bootstrap covariance matrix. We know determine the asymptotic distribution of the bootstrap covariance matrix First, use the form of the Hessian established in Step 1 of Theorem 2 to observe that is free of . We will now derive the asymptotic distribution of . This will then imply that as -almost surely. For simplicity of notation, denote by . In order to derive the -weak convergence of , it is enough to derive the -weak convergence of for each fixed . Observe that from the definition of , it follows that , where is a -tuple given by
[TABLE]
Clearly,
[TABLE]
We now proceed to find . Clearly,
[TABLE]
Using the fact that for compatible matrices and , we have , the above term equals
[TABLE]
Using the properties of Kronecker products, it follows that . So, the above term equals
[TABLE]
The matrix above converges -almost surely under to
[TABLE]
Assuming Gaussianity of the observations , we have that follows a central -dimensional Wishart distribution with parameter . Also, observe that for any vector , we have . It now follows from equations (3.131), (3.132) and (3.135) in Izenman, (2008, p. 64) that
[TABLE]
where is a -dimensional vector, and is the commutation matrix that satisfies for any matrix . So, converges -almost surely to
[TABLE]
Observe that converges -almost surely to . Also, note that for vectors and for matrices and , we have
[TABLE]
Thus, it follows that
[TABLE]
Next, let us consider . This can be simplified as follows by using the fact that the ’s are themselves centered Gaussians.
[TABLE]
where and .
Next, we use the independence of the ’s and the ’s to write
[TABLE]
Similarly,
[TABLE]
Now note that by independence of ’s and ’s, and using the fact that the ’s are centered, we have
[TABLE]
Further,
[TABLE]
since is bounded -almost surely and converges to zero -almost surely since by assumption. Similarly,
[TABLE]
Finally,
[TABLE]
So, collecting all the expressions together, we get that
[TABLE]
Observe that for an matrix and an -dimensional vector , we have
[TABLE]
by the definition of and noting that is a symmetric matrix. Thus,
[TABLE]
Now, observe that for any two vectors and any covariance matrix equalling for a centered -dimensional random variable , we have
[TABLE]
which follows by using the fact that for two -dimensional vectors and , we have . Thus, we have that
[TABLE]
Now, in order to derive the asymptotic distribution of we verify the Lyapunov condition. Recall that and . Also, converges -almost surely to a positive constant (derived previously). We will now show that
[TABLE]
So, it is enough to show that
[TABLE]
Now,
[TABLE]
Since the right hand side of the above expression converges -almost surely to a positive finite constant, it follows that as -almost surely.
Hence, by the Lindeberg CLT
[TABLE]
where the second statement follows upon using Slutsky’s theorem combined with the fact that converges to as -almost surely. This concludes Step (2c). As a side remark, observe that even if the Gaussian assumption is not true, we still have the above weak convergence (under ) albeit with a different expression for the asymptotic variance.
Step 2d: Asymptotic distribution of . Denote the Procrustes aligned rank factorization of by . Since converges -almost surely to under , it can be shown that converges -almost surely to by using arguments similar to those used to prove the almost sure convergence of .
Recall that we denoted by . First, use Taylor’s formula to observe that
[TABLE]
where for some . We have already proved that converges -weakly to a centered Gaussian random matrix as , -almost surely, in Step (2c) above. Further, we have that -almost surely, -almost surely (Step (2b)), and similarly that converges -almost surely to . This statement implies that -almost surely, -almost surely. As earlier, by the invertibility of , there is an open neighbourhood of where (i) the function is invertible,
(ii) the function is continuously differentiable, and
(iii) for any in that neighbourhood.
Since, in -probability -almost surely, we have
[TABLE]
as , -almost surely. Also, from the fact that is continuously differentiable in that neighbourhood, it follows that as , -almost surely. Moreover, in -probability as , -almost surely.
It now follows from the above equations that
[TABLE]
Since -almost surely, and -almost surely as , -almost surely, it follows that in -probability as , -almost surely. Hence, as , -almost surely. Also, the inverse converges to in -probability as , -almost surely. Combining these facts, we get that
[TABLE]
as , -almost surely.
Next note that for some with , we have
[TABLE]
By (5.15), the facts that as -almost surely, and -almost surely as -almost surely, the convergence -almost surely of to as -almost surely, and the continuity of , it follows that
[TABLE]
Thus,
[TABLE]
as -almost surely. Thus, the bootstrap version of the test statistic, namely, satisfies
[TABLE]
as -almost surely.
Step 2e: Bootstrap weak limit coincides with original weak limit in Theorem 2. We will now conclude Step 2 by showing that has the same distribution as , which was the weak limit of under in the statement of Theorem 2. For this, observe that it is enough to show that converges -weakly to . Note that . Now, under Gaussainity of the ’s and the assumption that , we have
[TABLE]
So, using the classical CLT, it follows that converges -weakly to . Hence, under Gaussianity of the observations and . Consequently, the asymptotic distribution of the bootstrap statistic is the same as that of the original statistic under Gaussianity and .
Wrapping up Step 2 of our proof, we are now ready to establish statement (a) of the present theorem. Denote by the empirical CDF of and that of by . Then, for each and each . Let denote the generalized inverse CDF of . From the usual properties of the generalized inverse of a cdf, it follows that the two events (equivalently, ) and are the same for any . Let us denote the -quantile of the asymptotic limit, say , of by . Since converges -weakly, -almost surely to , and has a continuous distribution (continuous map of the Gaussian random matrix ), it follows from Lemma 21.2 in van der Vaart, (1998) that converges to for all -almost surely. Now, converges -weakly to which has the same distribution as (since and have the same distributions). So, by Slutsky’s theorem, converges -weakly to for any . Hence,
[TABLE]
for any . Observe that . Thus,
[TABLE]
for any . This completes the proof of the first conclusion of the present theorem.
Step 3: Asymptotic theory for bootstrap under . For the second claim in the theorem, assume . We will first consider the case when the global null is also still true, i.e., is true for some . In this case, it has been proven in Step 1 that converges almost surely to so that converges almost surely to . Though might not converge, it has also been shown in Step 1 of the proof that is almost surely tight. So, . We will work with an that satisfies all the almost sure convergences and laws of iterated logarithm as needed earlier along with the previous tightness requirement (such ’s comprise an event of -measure one). So, by the compactness condition, there will exist a subsequence (possibly depending on ) such that converges to some as . Clearly, converges to along this subsequence. We will work by viewing this subsequence as our original sequence, and all convergence statements will be as .
Since converges to along , observe that we will be able to prove (following the same arguments as in Step 2d) that converges -weakly to along for each . Note that the limiting variance term will be different from the that is Step 2, which assumes to be true. We can denote the limiting random matrix of by .
Next observe that since (by construction), it follows from the definition of a minimum that
[TABLE]
for each . So, is -tight along since it is bounded above by a -weakly convergent sequence. Note that since almost surely, the entire sequence diverges to as -almost surely. So, for each in a -measure one set and along the corresponding sequence (depending possibly on as discussed thus far in the proof), we have
[TABLE]
as . In fact, a stronger statement is actually true – for each , there exists such that for all . This is because of the following: if there exists a infinite sequence (possibly depending on and ) such that along , one can find a further subsequence, say (obtained in a similar way as discussed previously in the case of the original subsequence ) such that along this subsequence of . This would lead to a contradiction. Hence,
[TABLE]
Observe that . So, replacing by in the previous displayed equation, it follows that
[TABLE]
Consequently, as for each . This completes the proof of the second statement of the present theorem in case is not true but the global null is true.
Finally, consider the situation when the global null is not true, i.e. is true. In this case, it follows that both and are strongly tight. A simple extension of the subsequence arguments provided in the previous situation (to accommodate for in addition to ) carries over and proves the second statement of the present theorem.
∎
Lemma 3**.**
In the setting and notation of Theorem 3 and its proof, all of , and converges to zero -almost surely, -almost surely, where , and .
Proof.
We will only give the proof of the convergence of . The proofs of the convergence of the other two terms are similar. Note that , where has zero mean. We will show that
[TABLE]
-almost surely for any choice of . We will then be able to conclude the first convergence by using the Borel-Cantelli lemma. Define (omitting the dependence on and for simplicity of notation). Observe that
[TABLE]
since the other terms vanish by using the fact that the ’s are i.i.d. and have zero mean. Now,
[TABLE]
We have already derived the expression of the above variance term while deriving the weak convergence of in the proof of Theorem 3 (see Step (2c) for details). Since the above variance term converges -almost surely to a constant (depending on and ), the first term in (5.19) is as -almost surely. Next, observe that
[TABLE]
We have already shown in the proof of Theorem 3 (see Step (2c) for details) that the first term in (5.20) is bounded above by a quantity which converges to a constant -almost surely. Further, converges to -almost surely. These facts show that the first term in (5.19) is as -almost surely. So, (5.18) is true -almost surely. This completes the proof of the almost sure convergence of . ∎
5.2 On the Critical Grid Size
As noted in Remark 2, the critical value in Theorem 1 depends on the choice of hypothesis boundary , and the spectrum of . The purpose of this section is to show that, for a very wide variety of continuous kernels, we have
[TABLE]
Namely, we will show the following for continuous :
- •
If is strictly positive definite, and hence certainly of infinite rank, then the bound holds true for any placement of the pairwise distinct grid nodes (not just for regular grids) without any additional assumptions on the form of the eigenfunctions.
- •
If is positive semidefinite (whether finite or infinite rank), and the Reproducing Kernel Hilbert Space (RKHS) of contains
- –
the collection of monomials , then the bound holds true for any placement of the distinct grid nodes (not necessarily equi-spaced); if the monomials are replaced by linearly independent polynomials of highest degree greater than , the bound still holds true for all but finitely many configurations of the grid nodes.
- –
the collection of the first Fourier basis elements, then the bound holds true for any placement of the grid nodes; if the first Fourier elements are replaced by arbitrary linearly independent trigonometric polynomials, the bound still holds true for all but finitely many configurations of the grid nodes.
- –
a collection , where is any strictly increasing function, then the bound holds true for any placement of the distinct grid nodes (not necessarily equi-spaced); if the exponents are replaced by arbitrary exponents, the bound still holds true for all but finitely many configurations of the grid nodes.
- –
a collection of functions that are linearly independent on any subset of positive Lebesgue measure, then the bound holds true for almost all configurations of the grid nodes. Collections of functions of this type are ubiquitous, and include collections of linearly independent splines, or more generally of linearly independent piecewise analytic functions; such collections need not be comprised of smooth functions alone. One can easily produce examples of collections that contain nowhere differentiable functions444To see a concrete case, take to be independent realisations of a standard Brownian motion on ..
Notice that that the eigenfunctions of are by default elements of the RKHS of . So if the eigensystem of includes (orthonormalised) functions as described in the cases above, then certainly so does .
To show why the statements listed above hold true, let be the true rank of . Since is continuous, it admits the Mercer expansion
[TABLE]
This yields
[TABLE]
on our grid points . It follows that the matrix is represented as
[TABLE]
where the -th row of is comprised of the sequence , for . Schematically,
[TABLE]
where the horizontal dots signify that there may be infinitely or finitely many columns depending on whether or .
If is the submatrix of obtained by retaining rows in the index set and columns in the index set , then
[TABLE]
where (resp. ) represents the submatrix of obtained by retaining rows in the index set (resp. ). Formally, we can view the matrices and as linear operators from into . Continuity of ensures that they are indeed finite rank Hilbert-Schmidt555To see this, note that
So for a pair of index sets of cardinality if and only and are both of full column rank . In summary, since and are arbitrary, we have the following implication:
of column rank for any of cardinality all -minors of are non-vanishing
We will show in Subsection 5.2.2 that is indeed of full column rank for any index set of cardinality for the scenarios described at the top of this Section. First, though we will show in Subsection 5.2.1 why when the -minors of are non-vanishing.
5.2.1 Showing that When the -Minors of Are Non-Vanishing
Said differently, let us show that whenever all order minors of can be guaranteed to be non-zero, the critical value satisfies . We will do this by showing that when , each diagonal entry of of is a (rational) function of some of the off-diagonal entries (and thus the diagonal entries are uniquely imputed by the off-diagonal entries).
Assume first that exactly. Let be the submatrix of obtained by retaining the last rows and first columns of . Partition into four blocks,
[TABLE]
where:
- •
is the submatrix of obtained by retaining the last rows and last columns of .
- •
is the row vector with the first entries of the first row of .
- •
is the column vector with the last entries of the last column of
- •
is the middle element on the diagonal of , or equivalently the top right entry of the matrix .
Note that (because ) whereas (because we are operating in the regime where -minors of are non-zero). It follows that
[TABLE]
showing that is a rational function of the entries of , , and . It follows that the middle element of is uniquely specified by the off-diagonal elements of .
Notice that any diagonal element of can be brought to the middle position of the diagonal by means of the conjugation , with a suitable permutation matrix. This operation maps diagonal elements onto diagonal elements, and preserves the property that -minors of are non-vanishing. It follows that the diagonal elements of are uniquely determined by its off diagonal elements when .
For any one can apply the exact same procedure working with the top-left submatrix of instead of the entire matrix , and using permutations to bring the remaining diagonal elements in-and-out of the said submatrix. It follows that .
5.2.2 Covariance Spectra Guaranteeing That The -Minors of Are Non-Vanishing
In any scenario, we need to show (in the notation introduced in the beginning of the main Section) that
is of full column rank for any index set of cardinality
We will do this by means of verifying an equivalent condition stated in the next lemma:
Lemma 4**.**
Let be continuous, a collection of nodes, and an index set of cardinality . The matrix is of full column rank if and only if there exist functions such that the matrix is non-singular.
Proof.
Assume first that there are functions such that is non-singular. The function being in the RKHS is equivalent the existence of a square summable sequence such that . Using the Cauchy-Schwarz inequality and Mercer’s theorem, the series can be seen to converge uniformly and absolutely, as its square is bounded by
[TABLE]
Hence, we may write , which shows that the range of contains linearly independent vectors – namely the columns of the non-singular matrix . It follows that .
To prove the converse, assume that . Then too. But . Define for . It follows that there exist functions such that is non-singular.
∎
Let us now revisit the scenarios enumerated earlier, in light of the Lemma:
Case where is strictly positive definite. In this case, define , and notice that each such function is an element of the RKHS of . Indeed, the matrix is simply the matrix which is strictly positive definite by strict positive definiteness of for any pairwise distinct nodes .
Cases where is positive semidefinite.
- •
If , we can define . This is a Vandermonde matrix, and hence non-singular for any pairwise distinct -tuple . Clearly, the same discussion applies if for any for strictly increasing, by defining , and noting that simply yields a different grid of distinct points, so that is again a Vandermonde matrix over distinct nodes.
- •
If contains linearly independent polynomials of highest degree greater than , the matrix is is a polynomial matrix of generalised Vandermonde type, with a determinant proportional to , where is a finite degree polynomial. Hence, provided the grid points are distinct, this determinant vanishes nowhere but at the finitely many satisfying polynomial restrictions dictated by the root structure of . Since there are finitely many index sets of cardinality , there are also finitely many corresponding polynomials , and hence only a finite number of grids for which , for some choice of , vanishes. The same discussion applies if contains linearly independent polynomials of highest degree greater than , each composed with a monotone map , by switching to the grid .
- •
If contains the collection of the first Fourier basis elements, or linearly independent trigonometric polynomials, the same discussion can be repeated as in the polynomial case, except with trigonometric polynomials (seen as polynomials of pairwise distinct unit modulus complex arguments).
- •
If contains a collection of functions that are linearly independent on any subset of positive Lebesgue measure, we claim that is non-vanishing for almost all -tuples . This will require a more lengthy argument, and to relax the indexing notation, we will write . For , write .To show that is non-vanishing for almost all -tuples , we will use induction:
We will first prove that almost everywhere on . 2. 2.
Then we will prove that if almost everywhere on , implies that almost everywhere on , for any .
Step 1: Case . We need to show that for almost all . Equivalently, that cannot vanish on a set of positive Lebesgue measure. Since the functions are linearly independent on any set of positive Lebesgue measure, cannot vanish uniformly on such a set.
Step 2: Induction step. Now take , and suppose that almost everywhere on , but that for all , for some of positive -Lebesgue measure. We will obtain a contradiction. Note that,
[TABLE]
where is the -section of . It follows that for all in a set of positive -Lebesgue measure, i.e. .
With this observation in mind, we use the Leibniz formula for the determinant to translate the statement that
[TABLE]
into the equivalent statement
[TABLE]
where denotes the group of permutations on , and is the signature of a permutation . Thus, for any -tuple , we may view the last expression as a function of the last coordinate , and write
[TABLE]
Regrouping the summations now yields
[TABLE]
where for , the mapping gives the rank (in the sense of sequentially increasing order) of any , thus providing a bijection between and .
But we have observed that has positive -measure for any , and the are linearly independent on any set of positive measure. Hence, it must be that
[TABLE]
for any -tuple , where . But now notice that
[TABLE]
because for any . We have thus arrived at a contradiction of our inductive induction assumption that on any set of positive -measure.
5.3 On the Invertibility of the Hessian
The purpose of this section is to further analyse Assumption (H), used to deduce the large sample distribution of under ,
Assumption (H):
Under , there exists a factorisation , where , such that .
In particular, we will show:
That Assumption (H), is satisfied if Assumption (E) below holds true:
Assumption (E):
The leading eigenvectors of have non-zero entries. 2. 2.
That Assumption (E) is satisfied in the scenarios mentioned in Remark 2 and listed in detail at the beginning of Section 5.2, for almost all grids .
To show the first point, choose to be
[TABLE]
i.e. exactly as in Equation (5.22), which reduces to an equation for an matrix under . Mercer’s theorem implies that, indeed, . Let
[TABLE]
be the singular value decomposition of , where is diagonal, and and are orthogonal. Define
[TABLE]
and note that
[TABLE]
In particular note that the first and second line imply that has the leading eigenvectors of as its columns. Our aim will be to show that choosing the factor of yields
[TABLE]
provided has non-zero entries – equivalently, provided has non-zero entries, i.e. Assumption (E) holds true. Note that the form of the Hessian at any has been shown to be
[TABLE]
where is the Hadamard product, is the matrix containing [math]’s on the diagonal and ’s everywhere else, and is the order commutation matrix, i.e. the unique permutation matrix satisfying
[TABLE]
for any . Plugging in , the Hessian reduces to
[TABLE]
because and is a diagonal matrix. Therefore, it suffices to show that
[TABLE]
To this aim, we will make use of two Lemmas, the first of which probes the structure of :
Lemma 5**.**
The matrix is a block matrix of rank 1 blocks , defined as
[TABLE]
i.e. is the th column of .
Proof.
Let and define to be the matrices such that and . Then, for the Frobenius inner product, and recalling that is the order commutation matrix, we may write
[TABLE]
Let be the stipulated block matrix. We will now show that
[TABLE]
thus establishing that , by arbitrary choice of . To this aim, partition and as
[TABLE]
where are the th columns of and , respectively. This partitions the coordinates of and into groups of ,
[TABLE]
We can now calculate
[TABLE]
and
[TABLE]
so that
[TABLE]
The th diagonal element of the last expression is seen to be equal to . Consequently,
[TABLE]
Now we turn our attention to which is seen to be
[TABLE]
Upon observing that the last line coincides with expression (5.29), the proof is complete.
∎
The second Lemma is a standard fact about Hadamard products, stated here without proof for completeness (see, e.g. Horn and Johnson, (2012)).
Lemma 6**.**
Let and . Then,
[TABLE]
for the diagonal matrix with the elements of on its diagonal.
Using the fact that the entries of are assumed non-zero, and armed with the last two Lemmas, we will now show that \mathrm{det}\Big{\{}P_{qL}\circ\{(H^{\top}\otimes H)M\}\Big{\}}\neq 0. Clearly, it suffices to show that \mathrm{det}\Big{\{}Q[P_{qL}\circ\{(H^{\top}\otimes H)M\}]Q^{\top}\Big{\}}\neq 0 for any non-singular matrix . Define as a block diagonal matrix comprised of blocks of dimension ,
[TABLE]
The matrix is well defined since the entries of are all non-zero, and is clearly of full rank. Moreover, by Lemma 5,
[TABLE]
[TABLE]
We claim that the last matrix is equal to . To show this, we will show that:
- •
Diagonal blocks equal . The typical diagonal block is of the form , where is the diagonal matrix whose diagonal contains the elements of the column vector , and we have made use of Lemma 6 to obtain the last equality. Now we calculate
[TABLE]
where is known as the exchange matrix of order . Noting that and , we conclude that the typical diagonal block equals .
- •
Off-diagonal blocks equal . The typical off-diagonal block is of the form , and the latter equals
[TABLE]
In summary, we have shown that
[TABLE]
provided has non-zero entries. Now we use the fact that (which can be readily checked by row reduction), to conclude that the determinant is non-zero provided has non-zero entries, or, equivalently provided that has non-zero entries. In summary, we have established:
Assumption (E) Assumption (H)
Now we move to the second point, i.e. showing that Assumption (E) is satisfied in the scenarios listed in the beginning of Section 5.2, for almost all grids . To see this, recall the definition of as
[TABLE]
where the function is a linear combination of the scaled eigenfunctions,
[TABLE]
Now suppose that the collection remains linearly independent when restricted to any -subset of positive Lebesgue measure (as is the case in all of the scenarios listed at the top of Section 5.2). Then have the same property. To see this, let be any subset of positive measure and assume that for all . By definition, this implies that on , which can only happen if , because are linearly independent on . Since is orthogonal, now implies that . In particular, this property implies that almost everywhere on . Therefore, has non-zero entries for almost all grids , or equivalently, Assumption (E) is satisfied for almost all grids.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Amini and Wainwright, (2012) Amini, A. A. and Wainwright, M. J. (2012). Sampled forms of functional PCA in reproducing kernel Hilbert spaces. Ann. Statist. , 40(5):2483–2510.
- 2Bai and Ng, (2002) Bai, J. and Ng, S. (2002). Determining the number of factors in approximate factor models. Econometrica , 70(1):191–221.
- 3Carey et al., (1998) Carey, J., Liedo, P., Müller, H., Wang, J., and Chiou, J. (1998). Relationship of age patterns of fecundity to mortality, longevity, and lifetime reproduction in a large cohort of mediterranean fruit fly females. J. of Gerontology - Biological Sciences , 53:245–251.
- 4Chen and Wainwright, (2015) Chen, Y. and Wainwright, M. J. (2015). Fast low-rank estimation by projected gradient descent: General statistical and algorithmic guarantees. Tech. Report ar Xiv:1509.03025.
- 5Ferraty and Vieu, (2006) Ferraty, F. and Vieu, P. (2006). Nonparametric functional data analysis . Springer Series in Statistics. Springer, New York. Theory and practice.
- 6Hall and Vial, (2006) Hall, P. and Vial, C. (2006). Assessing the finite dimensionality of functional data. J. R. Stat. Soc. Ser. B Stat. Methodol. , 68(4):689–705.
- 7Horn, (1965) Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis. Psychometrika , 30(2):179–185.
- 8Horn and Johnson, (2012) Horn, R. A. and Johnson, C. R. (2012). Matrix analysis . Cambridge university press.