Improving the performance of Twin-Field Quantum Key Distribution
Feng-Yu Lu, Zhen-Qiang Yin, Chao-Han Cui, Guan-Jie Fan-Yuan, Rong, Wang, Shuang Wang, Wei Chen, De-Yong He, Guang-Can Guo, Zheng-Fu Han

TL;DR
This paper enhances twin-field quantum key distribution by introducing an additional decoy mode, which tightens information leakage estimates and significantly improves key rate and distance without complicating experimental implementation.
Contribution
It proposes a novel method using an extra decoy mode to improve TF-QKD performance, addressing distance limitations and practical implementation issues.
Findings
Key rate and distance are significantly improved.
The method works with finite decoy states, suitable for practical use.
The additional decoy mode does not complicate experimental setup.
Abstract
Among the various versions of the twin-field quantum key distribution (TF-QKD) protocol [M.Lucamarini, Z. Yuan, J. Dynes, and A. Shields, Nature (London) 557, 400 (2018)] that can overcome the rate-distance limit, the TF-QKD without phase postselection proposed by Cui et al. [Phys. Rev. Appl. 11, 034053 (2019)] is an elegant TF-QKD that can provide high key rates since the postselection of global phases has been removed. However, the achievable distance of this variant is shorter than that of the original phase-matching QKD [X. Ma, P. Zeng, and H. Zhou, Phys. Rev. X 8, 031043 (2018)]. In this paper, we propose a method for improving its performance by introducing an additional decoy mode. The upper bound of the information leakage can be more tightly estimated; hence, both the key rate and the achievable distance are significantly improved. Interestingly, the operation of the proposed…
Click any figure to enlarge with its caption.
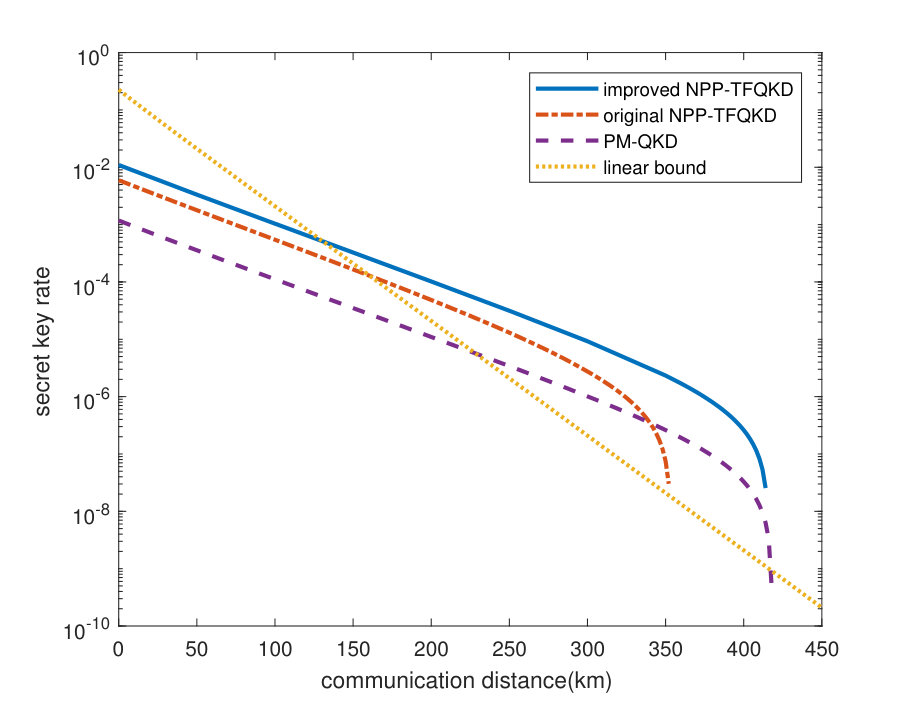 Figure 1
Figure 1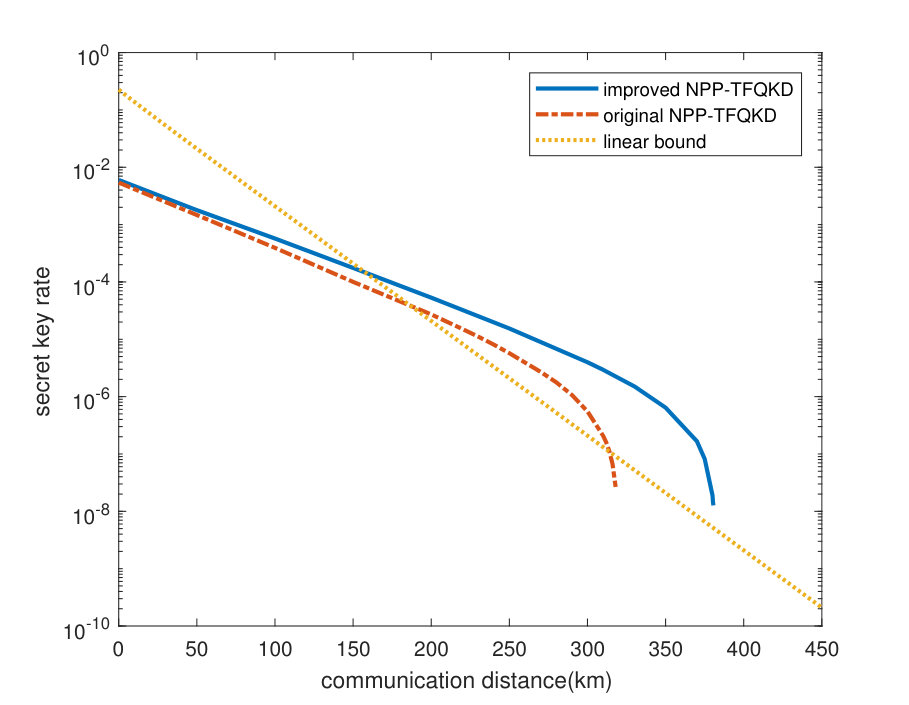 Figure 2
Figure 2| 111 denotes the dark count rate | 222 denotes the detection efficiency | 333 denotes the correction efficiency | fiber loss | M444 denotes phase post selection slice number in PM-QKD |
| 16 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Improving the performance of Twin-Field Quantum Key Distribution
Feng-Yu Lu
Zhen-Qiang Yin
Chao-Han Cui
Guan-Jie Fan-Yuan
Rong Wang
Shuang Wang
Wei Chen
De-Yong He
Key Laboratory of Quantum Information, CAS Center For Excellence in Quantum Information and Quantum Physics, University of Science and Technology of China, Hefei 230026, China
State Key Laboratory of Cryptology, P. O. Box 5159, Beijing 100878, P. R. China
Wei Huang
Bing-Jie Xu
Science and Technology on Communication Security Laboratory, Institute of Southwestern Communication, Chengdu, Sichuan 610041, China
Guang-Can Guo
Zheng-Fu Han
Key Laboratory of Quantum Information, CAS Center For Excellence in Quantum Information and Quantum Physics, University of Science and Technology of China, Hefei 230026, China
State Key Laboratory of Cryptology, P. O. Box 5159, Beijing 100878, P. R. China
Abstract
Among the various versions of the twin-field quantum key distribution (TF-QKD) protocol [M.Lucamarini, Z. Yuan, J. Dynes, and A. Shields, Nature (London) 557, 400 (2018)] that can overcome the rate-distance limit, the TF-QKD without phase postselection proposed by Cui et al. [Phys. Rev. Appl. 11, 034053 (2019)] is an elegant TF-QKD that can provide high key rates since the postselection of global phases has been removed. However, the achievable distance of this variant is shorter than that of the original phase-matching QKD [X. Ma, P. Zeng, and H. Zhou, Phys. Rev. X 8, 031043 (2018)]. In this paper, we propose a method for improving its performance by introducing an additional decoy mode. The upper bound of the information leakage can be more tightly estimated; hence, both the key rate and the achievable distance are significantly improved. Interestingly, the operation of the proposed additional decoy mode is the same as that of the code mode; hence, it does not introduce difficulties into the experimental system. In addition, the improvement is substantial with finite decoy states, which is meaningful in practice.
pacs:
Valid PACS appear here
††preprint: APS/123-QED
I introduction
Quantum key distribution (QKD) Bennett and Brassard (1984) enables two remote users, who we call Alice and Bob, to share secret random keys with information-theoretic security Lo and Chau (1999); Shor and Preskill (2000); Scarani et al. (2009); Renner (2008) that is guaranteed by principles of quantum physics, even if there is an eavesdropper, who we call Eve.
With the developments of QKDs in both theory and experiment, QKD implementations with longer achievable distance Boaron et al. (2018); Yin et al. (2016) and higher secret key rate(SKR) Wang et al. (2012); Gordon et al. (2005); Wang et al. (2018a) were realized. However, all these implementations must obey limits on the SKR as a function of the channel transmittance Takeoka et al. (2014); Pirandola et al. (2017), which are called repeaterless bounds. Surprisingly, a recently proposed protocol, namely, twin-field QKD (TF-QKD) Lucamarini et al. (2018) and its variants, e.g., phase-matching QKD(PM-QKD) Ma et al. (2018), sending-or-not QKD Wang et al. (2018b) and no phase post-selection TF-QKD(NPP-TFQKD) Cui et al. (2019); Curty et al. (2018); Lin and Lütkenhaus (2018), can overcome this bound; hence, the performance of QKDs can be significantly improved. In addition, these protocols have been proven to be immune to all potential side-channel attacks on the measurement device, like the measurement-device-independent protocol Lo et al. (2012); Ma and Razavi (2012); Liu et al. (2013); Wang et al. (2015, 2017).
In the original TF-QKD and PM-QKD, Alice (Bob) encodes a key bit as the phase of the weak coherent pulse, adds an additional random phase (), and sends it to an untrusted middle station, namely, Charlie, who interferes with the incoming pulses to measure the phase difference between them. Upon receiving the message from the middle station, Alice and Bob publicly announce the values of and and post-select the trials that satisfy to generate secret key bits. The post-selection of inevitably degrades the SKR and complicates the postprocessing. For overcoming this problem, Cui et al. proposed NPP-TFQKD Cui et al. (2019). Soon after, two other groups independently proposed similar schemes Curty et al. (2018); Lin and Lütkenhaus (2018). In Cui et al. (2019), Alice(Bob) randomly selects two different modes. The first mode runs without adding random phase () and can be used to generate a key bit. The latter is used to monitor the security. Removing the phase randomization and the post-selection from the code mode observably improves the secure key rate. However, its achievable distance is much shorter than that of PM-QKD.
In this work, we explain why the achievable distance is shorter compared with PM-QKD and propose a practical method for improving the performance of NPP-TFQKD substantially. Our work is mainly based Cui et al. (2019) and the core strategy of our method is to introduce an additional decoy mode into the NPP-TFQKD protocol that is run with the same phase as code mode and can estimate tightly the information leakage, which is denoted as . As a result, the achievable distance is increased.
The remainder of this paper is organized as follows: In Sec.II, we briefly review the procedure of NPP-TFQKD and its method for calculating the upper bound of from Cui et al. (2019). In Sec.III, we introduce our new method, which simultaneously maintains the superiority of the higher SKR, longer distance and practicability. In Sec.IV, the simulation results are presented, which demonstrate the superior performance of our method. The details of our method and derivations can be found in the appendix.
II TF-QKD without phase post selection
The process of NPP-TFQKD is described as follows:
Step 1. Preparation and measurement: Alice and Bob randomly select code mode or decoy mode. If code mode is selected, Alice (Bob) prepares a phase-locked weak coherent pulse (WCP) and randomly modulates the [math] or phase that corresponds to the raw key bit [math] or , respectively. If the decoy mode is selected, they prepare a phase-randomized WCP with an intensity that is selected from a pre-specified set at random. Then, they send the modulated quantum state to Charlie for interference. Since the randomized phase in the decoy mode is never publicly announced, we assume Alice and Bob prepare a mixed state in photon number space assume
[TABLE]
where and denote, respectively, the intensity chosen by Alice and Bob, and .
Step 2. Announcement: For each trial, Charlie must publicly announce the detector (L or R) that clicks or a non-click event.
Step 3. Sifting: Alice and Bob repeat the above steps many times to collect sufficiently many click events. Then, they publicly announce which trials are conducted in code mode and which are conducted in decoy mode. For the trials, they both choose code mode and Charlie announces a click event (L or R clicked); the raw key bits are generated. Bob must flip his bit if Charlie’s announcement is ’R’.
Step 4. Parameter estimation: Alice and Bob estimate the gain of code mode , namely, the probability of a click event for each trial in code mode, and the gains in decoy mode. For decoy mode, we denote the gains as , which corresponds to the probability of a click event conditioned on Alice and Bob preparing . In decoy mode, we also define the yield of Fock states as . The relation between them is expressed as
[TABLE]
where and can be experimentally observed.
From these gains, Alice and Bob can calculate the upper bound on the information leakage, which is denoted as .
Step 5. Key distillation: Alice and Bob generate their secure key by applying error correction and privacy amplification to the sifted key. The SKR is expressed as
[TABLE]
where is the Shannon entropy.
In Cui et al. (2019), depends on , which is defined as the state of Eve’s ancilla if Alice and Bob send Fock states and , respectively. Defining and as even and odd sets, respectively, the relation between and is as follows:
[TABLE]
where and
[TABLE]
The subscript () denotes that the photon-number or belongs to set ().
The main challenging is bounding \big{|}|\psi_{xy}\rangle\big{|}^{2}(x,y\in\{o,e\}). Since the values of inner product are unknown, what we can make sure are the constraints given by:
[TABLE]
The upper bound can be obtained by maximizing the objective equation
[TABLE]
without violating the constraints in Eq.(LABEL:cons).
A very interesting and meaningful question is whether the above bound on can be tightened.
III Method to improve the distance of NPP-TFQKD
According to the constraints in Eq.(LABEL:cons), we posit that is bounded loosely. Let’s consider the upper bound of \big{|}|\psi_{ee}\rangle\big{|}^{2} as an example. Defining , \big{|}|\psi_{ee}\rangle\big{|}^{2} can be regarded as two parts:
[TABLE]
where
[TABLE]
represents sum of the inner products whose subscripts of bra and ket are the same, and
[TABLE]
represents the remaining inner products, whose subscripts of bra and ket are different. We refer to and as the non-cross term and the cross term, respectively.
Since must be a real number in the range of , the original upper bound is estimated too loosely since Eq.(LABEL:cons) replaces all by , which is the worst case. However, if Charlie is honest, his interference measurement preserves the orthogonality between Fock states, from which follows directly. Thus, this replacement may severely degrade SKR if the channel loss is large, which is the main reason why the distance of NPP-TFQKD is shorter than that of PM-QKD. It is natural to consider whether there is any method for estimating more tightly while preserving the practicability of the protocol. Fortunately, the answer is yes.
By observing Eq.(2) and the fifth constraint condition in Eq.(LABEL:cons), we can find the gains of code mode and decoy mode are very different, since the phase randomization in decoy mode eliminates all cross terms. Concretely, we can see
[TABLE]
By defining
[TABLE]
we obtain a new linear equation in terms of :
[TABLE]
Similar to the principle of the infinite decoy state method Wang (2005); Lo et al. (2005); Hwang (2003), we can obtain infinite linear equations that are similar to Eq.(13) if infinite intensities in both code and decoy modes are applied. By solving these infinite linear equations, all can be obtained in principle. In the ideal scenario, in which Charlie is honest, should be satisfied for any intensities and . To satisfy these infinite equations, must hold, namely, the cross term in Eq.(8) must be zero. As a result, tighter estimation of and a higher SKR are expected.
To introduce the linear equations such as Eq.(13) into the NPP-TFQKD protocol, one must monitor the gains of various intensities with the same phase in code mode. For this and to avoid ambiguity, we modify Step 1 and Step 4 of NPP-TFQKD as follows:
To introduce the linear equations like Eq.(13) in NPP-TFQKD protocol, one must monitor the gain of various intensities with the same phase of code mode. For this and avoiding ambiguity, we modify the Step.1 and Step.4 of NPP-TFQKD as follows.
New Step 1. Preparation and measurement: Alice and Bob randomly choose decoy mode 1, decoy mode 2 or code mode. If code mode is selected, Alice (Bob) prepares a phase-locked WCP and randomly modulates the [math] or phase that corresponds to raw key bit [math] or , respectively. If decoy mode 1 is selected, they prepare a phase-randomized WCP and randomly choose an intensity from a pre-specified set . If decoy mode 2 is selected, Alice (Bob) prepares a phase-locked WCP , in which the intensity is chosen from a pre-specified set at random. The quantum state of decoy mode 2 shares the same phase as WCP in code mode and is a subset of .
New Step 4. Parameter estimation: Alice and Bob estimate the gain of code mode , namely, the probability of a click event for each trial in code mode, and the gains of decoy modes 1 and 2. For decoy mode 1, we denote the gain as , which corresponds to the probability of a click event conditioned on Alice and Bob preparing in decoy mode 1. For decoy mode 2, we denote the gain as , which corresponds to the probability of a click event conditioned on Alice and Bob preparing and , respectively, in decoy mode 2. From these gains, Alice and Bob can calculate the upper bound on the information leakage . The method of calculating will be detailed in the appendix.
With the new step 1 and step 4, we have proposed an improved NPP-TFQKD.
IV Simulation of the improved NPP-TFQKD
IV.1 Infinite decoy states
To evaluate the performance of our improved NPP-TFQKD, we simulate its SKR with infinite decoy states, namely, the sets and are both infinite; hence, is calculated precisely and . The simulation model can be found in the appendix of Ref. Cui et al. (2019) and the parameters that are used in the simulation are listed in Tab.(1). The results of the simulation are plotted in Fig.(1), according to which the proposed improved protocol realizes higher SKR and longer communication distance.
IV.2 finite decoy states
The infinite decoy state method is not useful in practice. In this subsection, we evaluate the performance of applying 5-intensity decoy mode 1 and 4-intensity decoy mode 2. The intensity of code mode is denoted by . The 4 intensities of decoy mode 2 are , , and . Decoy mode 1 has an additional intensity, which is denoted by . The parameters are listed in Tab.(1). Compared with the original NPP-TFQKD with four decoy state intensities (red solid line), both the SKR and the achievable distance are improved substantially. The details will be introduced in the appendix.
It is worth noting that, The estimation of cross terms relies on the accuracy of . To estimate the high-order () more tightly, we add an intensity that is larger than the code mode intensity into decoy mode 1.
V Discussion
During the submission of our work, we found that the test states in other work Primaatmaja et al. (2019) are very similar to decoy mode 2. To help readers understand the variants of TF-QKD, we will briefly discuss Ref. Primaatmaja et al. (2019); Cui et al. (2019); Curty et al. (2018); Lin and Lütkenhaus (2018) and compare our work with ref. Primaatmaja et al. (2019) with the same parameters and number of intensities.
The protocols in Ref. Cui et al. (2019); Curty et al. (2018) are highly similar; both of them have higher SKR but much shorter achievable distance compared with PM-QKD. In the similar scheme that was proposed by Ref. Lin and Lütkenhaus (2018), the achievable distance is increased by using infinite test states, which include infinite intensities and infinite phase modulation. The achievable distance is the same as that of PM-QKD but the infinite phase modulation for each intensity is not feasible in practice. Our method divides each of the intensities into only two modes: a phase-randomized mode, namely, decoy mode 1, and a phase-locked mode, namely, decoy mode 2; this approach is more feasible than infinite phase modulation. Our method also reaches the distance realized by PM-QKD.
In Ref. Primaatmaja et al. (2019), the finite test state method was proposed. The method renders the protocol in Lin and Lütkenhaus (2018) useful in practice. Their method requires several test states for estimating the parameters and two key states for generating key bits (the two key states are also used for parameter estimation). We consider their six-test-state method as an example. The method requires six test states and two key states, which include four intensities and eight phase modulations in total. According to Fig.6(ii) of Primaatmaja et al. (2019), the protocol reaches 75 dB total loss with dark-count rate, detection efficiency and misalignment. We simulate our protocol with the same parameters, 4-intensity decoy mode 1 and 4-intensity decoy mode 2. The results demonstrate that our protocol achieves a total loss of 94 dB.
Both this work and Ref. Primaatmaja et al. (2019) have advantages and disadvantages. For our protocol, the phase randomization in in the decoy mode renders the system more complicated and may limit the repetition rate. Nevertheless, the phase randomization in our protocol does not assume the precision of phase modulation if the phase is random. For the approach in Primaatmaja et al. (2019), one need only realize a small number of phase modulations; however, these phase modulations are assumed to be very precise. For instance, the six test states in Primaatmaja et al. (2019) must modulate eight phases accurately, which introduces difficulties into the phase modulation system and may also limit the repetition rate of experiments. Using 4 intensities, our achievable distance is longer under the same conditions; however, the semi-definite programming method that was proposed by Primaatmaja et al. (2019) is more novel and general.
In summary, we proposed a practically useful method that overcomes the disadvantages of NPP-TFQKD. By adding decoy mode 2, we obtain additional constraints that enable us to estimate tighter. The main strategy behind our method is that the inner products of the quantum states of Eve’s system can be well estimated via the proposed protocol, whereas the previous protocol assumes that these inner products attain the worst possible value. This work improves the communication distance substantially. According to the result of the simulation, our method of 5 intensities in decoy mode 1 and 4 intensities in decoy mode 2 is close to the infinite decoy state of PM-QKD in terms of the communication distance, while the advantage of phase post-selection not being required is retained.
Experimentally, the manipulation of decoy mode 2 is similar to that of code mode and the random intensities are a subset of decoy mode 1. Thus, our modification does not introduce any additional difficulties into the experimental system.
Our method analyzes why the upper bound on the information leakage in Cui et al. (2019) is too loose and provides a tighter bound such that the achievable distance reaches those of PM-QKD and Lin and Lütkenhaus (2018). We also propose the finite decoy state method, which renders the protocol useful in practice.
Some problems remain to be solved, such as the finite size key effect and the protocol with imperfect devices.
VI acknowledgment
This work has been supported by the National Key Research and Development Program of China (Grant No. 2016YFA0302600), the National Natural Science Foundation of China (Grant Nos. 61822115, 61775207, 61702469, 61771439, 61622506, 61627820, 61575183), National Cryptography Development Fund (Grant No. MMJJ20170120) and Anhui Initiative in Quantum Information Technologies.
Appendix A improved NPP-TFQKD with finite decoy-state
In this section, we will describe how to estimate a tight bound of with a finite decoy state in detail. The overline and underline denote upper and lower bounds, respectively. According to Ref. Cui et al. (2019), the key step of Eq.(7) is the estimation of constraints on , , and . In the original protocol, the constraints are specified as Eq.(LABEL:cons), which are too loose. By introducing decoy mode 2, tighter constraints can be obtained. Let’s consider as an example:
[TABLE]
where
[TABLE]
and
[TABLE]
where in Eq.(15)( in Eq.(16) ) can be estimated via linear programming, as shown in the appendix of Ref. Cui et al. (2019).
The bounds of are estimated via linear programming. The upper bound is as follows:
[TABLE]
where is the variable of the objective function. By adjusting without violating the constraint functions, we obtain the maximum value of the objective function, which is the upper bound of .
Similarly, by modifying the objective function to
[TABLE]
the lower bound of can be estimated.
Since , there are 16 constraints in the linear programming equation in total. By solving Eq.(LABEL:App_linear_prog), the upper bound of is obtained. , and can be obtained similarly.
After all and have been estimated, the constraints of Eq.(7) is reexpressed as
[TABLE]
By applying the new constraints Eq.(LABEL:App_cons) in Eq.(7), a tighter bound is obtained and improved performance of NPP-TFQKD can be expected.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bennett and Brassard (1984) C. H. Bennett and G. Brassard, in Proceedings of IEEE International Conference on Computers, Systems and Signal Processing (IEEE, 1984) pp. 175–179.
- 2Lo and Chau (1999) H.-K. Lo and H. F. Chau, science 283 , 2050 (1999).
- 3Shor and Preskill (2000) P. W. Shor and J. Preskill, Physical review letters 85 , 441 (2000).
- 4Scarani et al. (2009) V. Scarani, H. Bechmann-Pasquinucci, N. J. Cerf, M. Dušek, N. Lütkenhaus, and M. Peev, Rev. Mod. Phys. 81 , 1301 (2009) . · doi ↗
- 5Renner (2008) R. Renner, Int. J. Quantum Inf. 6 , 1 (2008).
- 6Boaron et al. (2018) A. Boaron, G. Boso, D. Rusca, C. Vulliez, C. Autebert, M. Caloz, M. Perrenoud, G. Gras, F. Bussières, M.-J. Li, et al. , Physical review letters 121 , 190502 (2018).
- 7Yin et al. (2016) H.-L. Yin, T.-Y. Chen, Z.-W. Yu, H. Liu, L.-X. You, Y.-H. Zhou, S.-J. Chen, Y. Mao, M.-Q. Huang, W.-J. Zhang, et al. , Physical review letters 117 , 190501 (2016).
- 8Wang et al. (2012) S. Wang, W. Chen, J.-F. Guo, Z.-Q. Yin, H.-W. Li, Z. Zhou, G.-C. Guo, and Z.-F. Han, Optics letters 37 , 1008 (2012).