The role of grammar in transition-probabilities of subsequent words in English text
Rudolf Hanel, Stefan Thurner

TL;DR
This paper shows that incorporating grammatical constraints as local re-orderings into a sample-space reducing process effectively explains word transition probabilities and frequencies in English text, outperforming other models.
Contribution
It introduces a novel model combining SSR processes with grammatical re-ordering to better replicate linguistic structures in text generation.
Findings
The combined model reproduces word frequency distributions accurately.
It captures transition probabilities more effectively than baseline models.
The approach explains the structural properties of English text.
Abstract
Sentence formation is a highly structured, history-dependent, and sample-space reducing (SSR) process. While the first word in a sentence can be chosen from the entire vocabulary, typically, the freedom of choosing subsequent words gets more and more constrained by grammar and context, as the sentence progresses. This sample-space reducing property offers a natural explanation of Zipf's law in word frequencies, however, it fails to capture the structure of the word-to-word transition probability matrices of English text. Here we adopt the view that grammatical constraints (such as subject--predicate--object) locally re-order the word order in sentences that are sampled with a SSR word generation process. We demonstrate that superimposing grammatical structure -- as a local word re-ordering (permutation) process -- on a sample-space reducing process is sufficient to explain both, word…
Click any figure to enlarge with its caption.
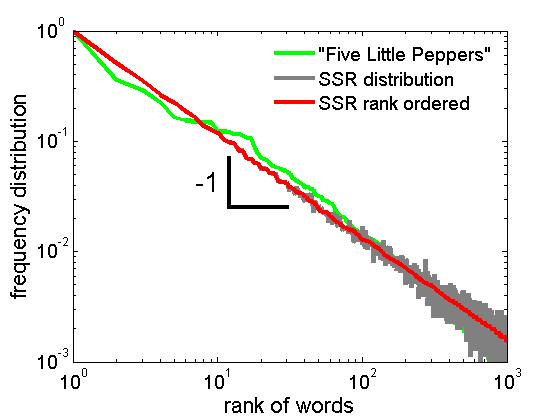 Figure 1
Figure 1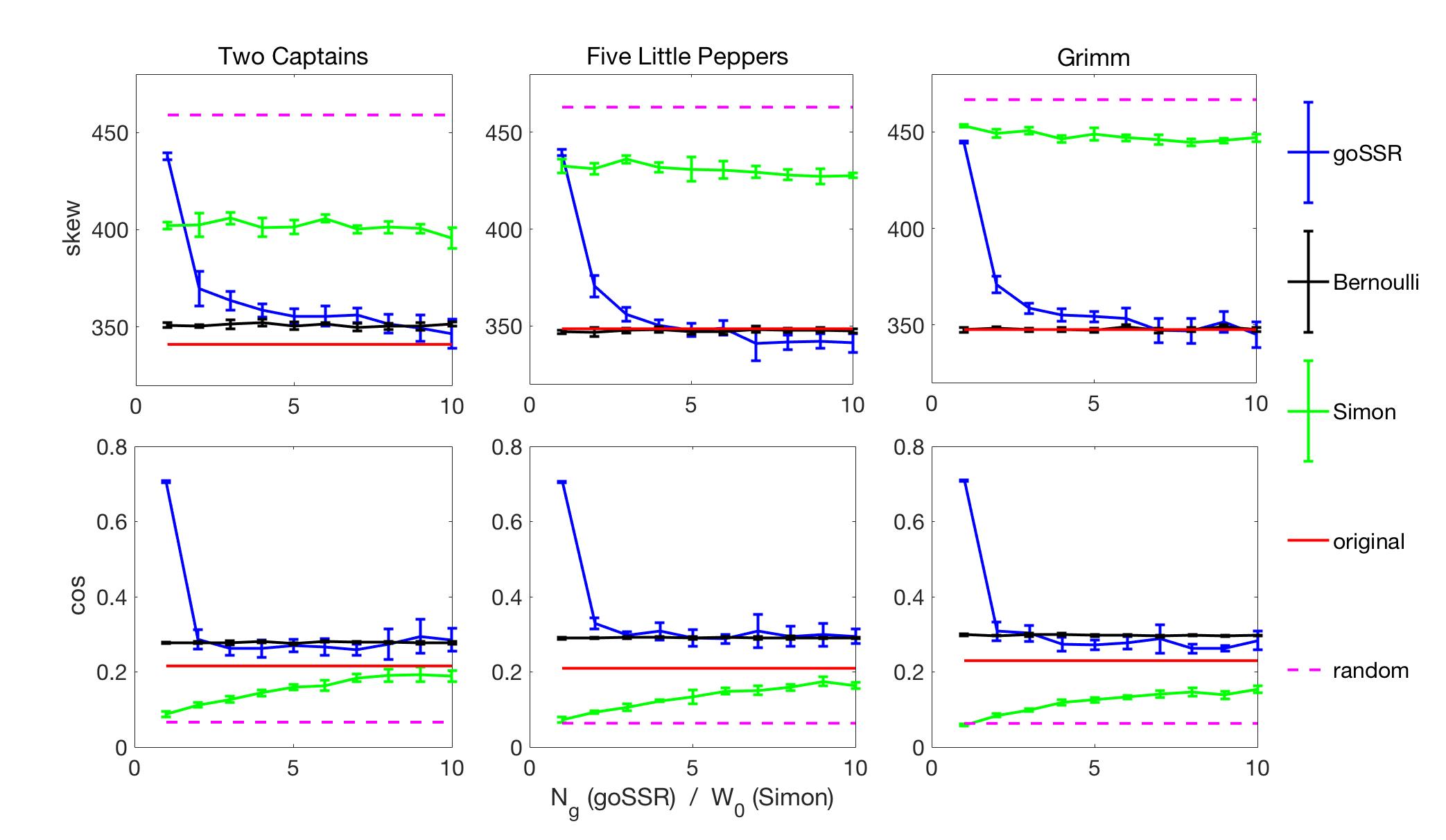 Figure 2
Figure 2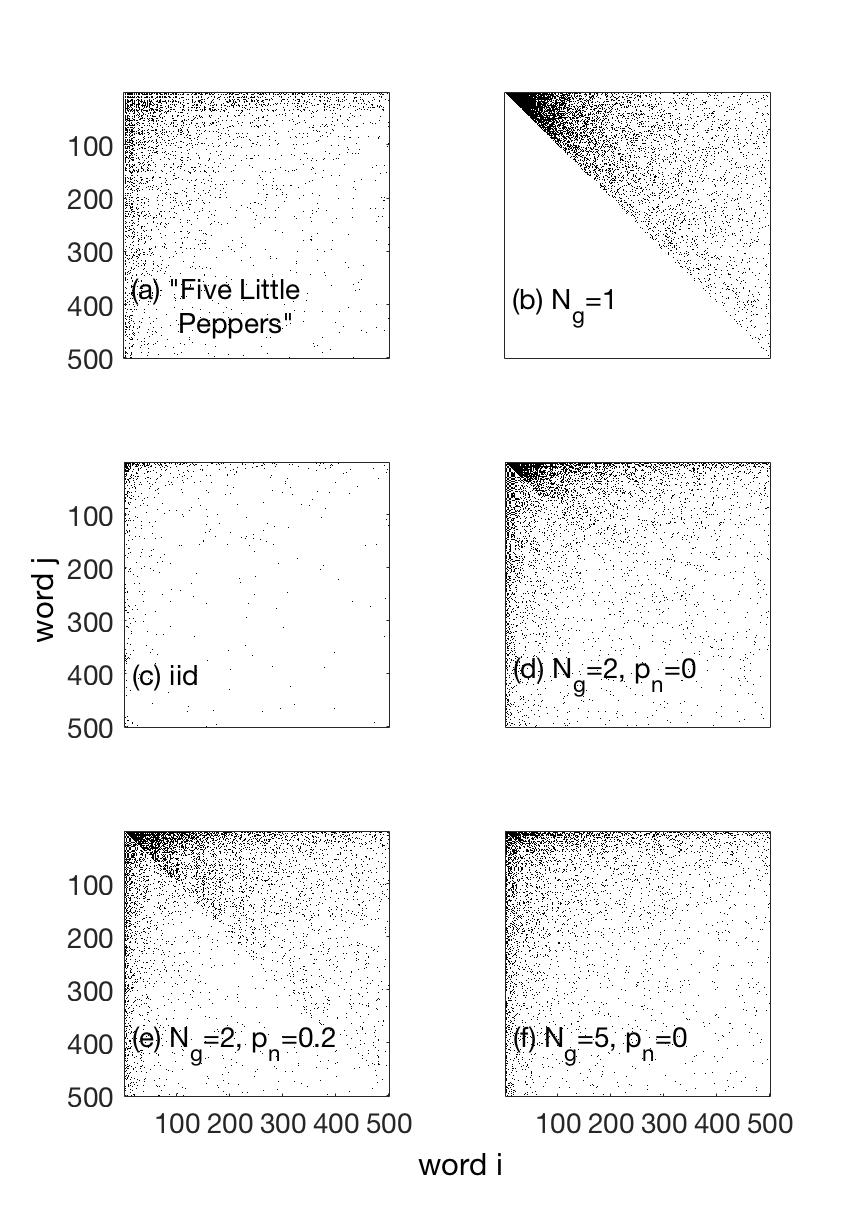 Figure 3
Figure 3| 2cpns | 5lpep | grimm | ||||
|---|---|---|---|---|---|---|
| skew | skew | skew | ||||
| original | ||||||
| Bernoulli | ||||||
| Simon | ||||||
| random |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
The role of grammar in transition-probabilities of subsequent words in English text
Rudolf Hanel; Stefan Thurner1,2,3,4∗
1Section of Science of Complex Systems; Medical University of Vienna; Spitalgasse 23; A-1090; Austria;
2Complexity Science Hub Vienna, Josefstädterstrasse 39, 1080 Vienna, Austria;
3Santa Fe Institute; 1399 Hyde Park Road; Santa Fe; NM 87501; USA;
4IIASA, Schlossplatz 1, 2361 Laxenburg, Austria;
Abstract
Sentence formation is a highly structured, history-dependent, and sample-space reducing (SSR) process. While the first word in a sentence can be chosen from the entire vocabulary, typically, the freedom of choosing subsequent words gets more and more constrained by grammar and context, as the sentence progresses. This sample-space reducing property offers a natural explanation of Zipf’s law in word frequencies, however, it fails to capture the structure of the word-to-word transition probability matrices of English text. Here we adopt the view that grammatical constraints (such as subject–predicate–object) locally re-order the word order in sentences that are sampled with a SSR word generation process. We demonstrate that superimposing grammatical structure–as a local word re-ordering (permutation) process–on a sample-space reducing process is sufficient to explain both, word frequencies and word-to-word transition probabilities. We compare the quality of the grammatically ordered SSR model in reproducing several test statistics of real texts with other text generation models, such as the Bernoulli model, the Simon model, and the Monkey typewriting model.
statistics in language, scaling law, stochastic processes, Zipf’s law, sentence formation, word-transition matrices
I Introduction
After almost a century of work, understanding statistical regularities in language is still work in progress. Maybe the most striking statistical feature is that rank ordered distributions of word frequencies follow an approximate power law,
[TABLE]
where is the rank assigned to every word in a given text; the most frequent word has rank one, the second most frequent has rank two, etc. For most word-based texts, one finds , independent of language, genre, and time of writing. This “universal” feature is called Zipf’s law zipf72 . Figure 1 shows the rank distribution of words in the novel “The Two Captains” by H.K.F. de la Motte Fouqué (green).
There are several ways to understand Zipf’s law through entirely different mechanisms. Zipf’s first qualitative explanation of the phenomenon was based on communication “efforts” of sender and receiver zipf72 , an idea that was later expressed in an information-theoretic framework mandelbrot1953 ; Harremoes:2001 ; sole2003 ; Corominas-Murtra:2011 . The first quantitative linguistic model by H. Simon features the idea of preferential attachment, i.e., words are added to the text with a probability that is proportional to their previous appearance in the text. New words are added at a low, constant rate simon:1955 . Zipf’s law follows immediately from those two assumptions. Preferential attachment models were later refined zanette2005 , relating Zipf’s law to Heap’s law Heaps1978 . The conceptually simplest way to understand Zipf’s law are random typewriting models, where words and texts are created by randomly typing on a typewriter li1992 ; miller1957 ; miller1963 . Yet another route to Zipf’s law was introduced on the basis of sample-space reducing (SSR) processes Language1-MHT , which successively reduce their sample-space (range of potential outcomes) as they unfold Zipf1C-MHT . SSR processes generically produce power laws, and Zipf’s law in particular driving . Think of how sentences are formed: one can pick any word to start a sentence. Once the first word is chosen, grammar and context constrain the possibilities for choosing the second word. The choice of the second word further constrains the possibilities for the third word, and so on; The sample space of possible words generally reduces as the sentence forms. In this view of sentence formation, grammar and context constrain the choice of words later in the sentence; therefore text generation is a SSR process, and Zipf’s law must follow. The existence of grammatical and contextual constraints allow us–at the receiving part of a communication–to complete sentences in advance, and to anticipate words that will appear later. This (at least partially) ordered hierarchical structure guides sentence formation and allows a receiver to robustly decode messages Partee:1976 .
To understand Zipf’s law of word frequencies, however, is not the end of the story. The word frequency distribution can be seen as the marginal distribution of the word transition probabilities, , the probability to produce word , given that the previous word was . Figure 2a shows the transition matrix for “Five Little Peppers”. Pure SSR processes show a triangular structure in the transition probabilities, see Fig. 2b, which obviously does not match the empirically observed transition matrices of real texts. Empirical transition probabilities look similar to transition matrices that correspond to independently sampled word sequences (Bernoulli model) with the correct marginal empirical word distribution functions, Fig. 2c. Empirical transition probabilities look as if they were random (in this sense), even though text generation is obviously a highly structured generative processes.
In this paper we assume that the formation of word sequences (sentences) is a combination of two processes: The word selection process, selects the words that are needed to encode a narrative or to convey a coherent message or meaning. The other process is grammar, which brings the selected words into a specific order. We assume that the word selection process is of SSR type: the context created by the generated words restricts the usage of other words as the sentence progresses. The SSR structure of word selection becomes plausible by realizing that any story line needs to connect the “protagonists” with their context. If we think of context as a network of words, then the process of connecting any chosen word to a given protagonist is comparable to a targeted diffusion process on the word network, where protagonists (and other central words) are the targets in this process. Targeted diffusion is an example of SSR processes, and leads to generic power laws in visiting frequencies targdiff . Grammatical ordering can be thought of as a post-processing of the word stream generated by the word selection process. It establishes a local word order, which differs from the order the words were generated, but is in line with grammatical expectations, such as the subject–predicate–object (SPO) order that is typically used in English sentences. In other words, grammar locally scrambles (permutes) the order of the word selection stream.
We will show here that if the word selection process is a pure SSR process, and if generic grammatical rules locally re-shuffle the word order of the word selection stream, the resulting word transition probabilities have statistical properties that closely resemble the empirically observed ones. We will see that grammar strongly masks the triangular structure introduced by the word selection process. This implies that empirical word transition probabilities provide us with limited information about the underlying word selection process that generates an information-carrying narrative. In particular, with a simple SSR model of word generation we demonstrate how imposing grammatical rules of variable strength changes the transition probabilities from structured (triangular, Fig. 2b) to seemingly unstructured, Fig. 2c.
We first discuss SSR processes and their frequency distributions and then introduce a modification, where the local word order of SSR sequences is permuted to conform with a grammatical word order, such as SPO. To implement a “grammatically ordered” SSR (goSSR) process we assign grammatical labels to all words contained in the lexicon of used words. The labels determine the local order in which words appear in a sentence. We compute statistical properties of natural language in English text corpora gutenberg and compare them with those obtained from goSSR processes. We find that three to five grammatical labels are sufficient to produce realistic results. We finally compare the Simon-, the random typewriting-, and the goSSR-models for specific English texts with respect to various statistical measures that can be used as a test-statistic for hypotheses testing. As a null-hypothesis we assume that sequences have been generated by a Bernoulli process. This provides us with a first quantitative understanding of how informative these models are with respect to actual text generation.
I.1 Grammatically ordered SSR model
We first discuss the sample-space reducing process for sentence formation and then augment it with a toy grammar. SSR processes are characterized by linearly ordered states. For example think of a staircase. The lowest stair is state 1, the next step is state 2, and so on; at the top of the staircase we have state . Imagine a ball bouncing downward this staircase with random jump sizes. We begin at state . The ball can jump to any of the lower states; say it jumps to state (subscript indicates the first jump). Obviously, . Again, the next state, , can only be a lower state, . After a sequence of visits to states , the ball reaches the bottom of the staircase, . At this state the process needs to be restarted, which means lifting the ball to any randomly chosen state, . If the process gets restarted multiple times, the visiting distribution of the process to states appears to be exactly Zipf’s law,
[TABLE]
where is a normalization constant Zipf1C-MHT .
Sentence formation can be seen as an SSR process Language1-MHT . Words are not randomly drawn from the sample space of all possible words (lexicon), but are used in context and grammatical order. The fact that words in a sentence restrict the usage of consecutive words, generates a SSR process. Imagine the first word in a sentence is randomly drawn from the entire lexicon with words (states), say “The wolf”. As soon as it is decided, the second word must be a verb (grammatical restriction), and it has to create a meaningful context (context dependent restriction) with the wolf, so we can not use “typewrite”. As the sentence progresses, typically more and more constraints occur and restrict word usage more and more. Once the final word (the target of a sentence, state 1) is reached the process gets restarted; (the next sentence or subordinate clause starts) Sample space reduction in text formation is necessary to robustly convey meaningful information, a fact that is for example exploited by text-completion apps.
While rank ordered word frequency distribution functions can be explained by the hypothesis that sentence and text formation follows SSR processes, word transition probabilities can not. Transition probabilities for pure SSR processes are triangular, see Fig. 2b, and do not resemble those of actual text, Fig. 2a.
We assume that the word selection process for a given narrative can be approximated by a SSR process that models the context-dependent restrictions only. Grammar enters as a process that enforces locally “correct” word order. Effectively, it locally re-assembles the word sequences generated by the SSR word selection process, and destroys local correlations of word occurrences as generated by the SSR sequence. We now augment SSR models with a “grammar” that determines the local ordering of words.
To implement a toy-grammar, assume that there exist grammatical labels that are associated to words. Every word, in the lexicon, carries one of the distinct labels, . For example, if , the three labels could represent , , and . For simplicity we assume that each label appears with approximately the same frequency in the lexicon. In addition there exists a grammatical label that we call the “neutral” label. Neutral elements are combined with the next non-neutral word (with label ) that follows in the text. This word complex is then treated as a single word with label . The probability of finding neutral words in the text is denoted by . We can now formulate the “grammar rules”:
- •
(i) Words must follow a strict repeating pattern of grammatical labels, . For example, if we will produce sentences with a sequence of labels: .
- •
(ii) Missing labels are skipped. If and if label is not present in a particular sentence, but labels , and are, we order words according to existing labels: .
- •
(iii) Neutral elements (label [math]) do not change their relative position to the next non-neutral element following in the sentence. Neutral elements together with their adjacent non-neutral element form a complex that in grammatical reordering is treated as a single word. This means that the local SSR sequence order of grammatically neutral fragments is untouched by the grammatical ordering process.
For example, an SSR sequence of words (states) is generated in a grammar with the corresponding grammatical label sequence: . The grammar-ordered label sequence is , and the grammar-ordered state sequence becomes .
The goSSR model of a given text is the following. Determine the number of distinct words in a text. Produce a random map that associates a label with each word . The neutral label gets sampled with probability , all other labels with probability . For each sentence in the text determine its length (in words) and generate a random SSR sequence of the same length. Then re-order this SSR sequence according to the grammar rules to get a grammatically ordered sentence. We call this sampled new text, the goSSR model of some original text. It contains as many words and sentences as the original text. Each sentence is a goSSR sequence.
For comparison, we consider three other models of text generation that yield power law distributed rank frequencies. The simplest is produced by independently sampling words from the word frequency distribution of the original text, which we refer to as the Bernoulli model of the original text. The others are the Simon model, and the random typewriting model of text, see Methods.
II Results
We consider three English novels. (i) The Two Captains (2cpns), by F. de La Motte-Fouque, with a length of roughly 18,000 words, 600 sentences, and a vocabulary of roughly 3,000 words. (ii) Five little peppers and how they grew (5lpep), by M. Sidney, with about 88,000 words, 5,200 sentences, and 4,800 distinct words. (iii) Collected tales by the Brothers Grimm (grimm), with 180,000 words, 4,500 sentences, and about 4,800 words. For these texts we sample the corresponding goSSR- , Bernoulli-, Simon-, and the random typewriting-model with the same sentence length distributions as the corresponding original text. Since the vocabulary of the texts is too large for computing the Simon-, and random typewriting-models, we restrict ourselves to the word transitions between the most frequent words in the texts. For notation, we use for the number of times we observe the word to follow word in a sentence of a text. estimates the conditional probability for to follow , where is the number of times word appears in the text.
We then compute two statistical measures that allow us to quantify properties of the transition matrices. The skew is a measure of the asymmetry of , and the -measure is a proxy for the largest eigenvalue of .
We compute the transition matrices , , , , and , and present the corresponding measures in Fig. 3. The top line in Fig. 3 shows the skew for 2cpns, 5lpep, and grimm. The bottom line shows the -measure. The values corresponding to the original texts are shown as red lines. The values for the Bernoulli models (black) are averages over 5 realizations of the model. For the original text and the Bernoulli model the -axis of the plot has no meaning since neither the original text nor the Bernoulli model depend on model parameters. For the random typewriting model (magenta) we fix the number of letters on the typewriter to , see Methods. For the goSSR and the Simon model the -axis has a different meaning. For the goSSR model (blue) the -axis is the number of grammatical labels , for the Simon model (green) it corresponds to the number of words, used for the initialization, see Methods. For all models we created realizations and present the mean and standard deviations. For the Bernoulli model the error bars are only slightly larger than the line-width. The goSSR model is computed with a neutral element probability of . The value for the pure SSR models (no grammar, ) is marked with a black square.
For the three novels we observe in Fig. 3 that for the two measures we find that the goSSR model outperforms both, the Simon-, and the random-typewriting models. For increasing the goSSR model approaches both, the skew and the -measure of the real text. For levels of convergence is reached. For the skew, both, the random typewriting and Simon model can not explain the real text value. For the -measure the typewriting clearly fails. The Simon model approaches the real text value for large values of . The -measure for the goSSR model is similar to the Bernoulli case, more so than the original text. There is almost no dependence on , practically all values for are similar. Since typically the skew of written text is close or identical to that of the Bernoulli model (see, 5lpep and grimm), one may be inclined to interpret the skew measure as something like the “grammatical depth” of a text. However, keep in mind that the Bernoulli model can per se not explain the Zipf law in word frequencies; that is a massive exogenous input.
In Table 1 we show the corresponding p-values. To compute those, consider the randomly generated texts (corresponding to a particular novel) by the different models as data. We would like to test whether we can reject the null hypothesis that this data has been generated by the Bernoulli model at a confidence level of . To this end we sample the Bernoulli model of the particular novel for times, compute the respective measure for each realization of the model, rank the values, and compute the respective p-values for the realizations of models of the novel. If a value is smaller than the the smallest of the 5000 samples drawn for the test statistics we interpret of the associated p-value as a number less than . We present the average of the 5 p-values for the three novels. We find that both measures for the original texts and their Bernoulli models are numerically similar, which confirms the similarity (on rough visual inspection) of transition matrices of original text and corresponding Bernoulli models, compare Fig.2(a) and (b). The cases where we can not reject the null hypothesis are for the Bernoulli model itself, which for all test statistics is accepted with , and for the goSSR model for grammars with , see Tab. 1.
Similarly, for the skew-measure of “Two Captains”, for p-values also exceed the confidence level. That is, the transition probabilities of the goSSR process cannot be distinguished from the Bernoulli model with respect to the skew if the grammar becomes sufficiently complex.
Both measures indicate that original text in fact has transition matrices that resemble those of the corresponding Bernoulli model to a high degree, and that for reasonable choices of and , the goSSR model also matches these. The used measures indicate that the word transition matrices of goSSR models are located somewhere between real text and Bernoulli models in a statistical sense.
We considered additional measures to derive test-statistics that allow us to compare the rank-increment distributions of the real texts and the models. These included the -norm, the Kolmogorov-Smirnov distance, and the Kullback-Leibler divergence. They are not shown here since they add little additional aspects. However, a note of caution for the naive interpretation of p-values is necessary. The skew and -measure are among the most simple ones and are easy to interpret. There are many more, and it is conceivable that not all corresponding test-statistics necessarily confirm that the goSSR model outperforms the other models. In fact, we found that one test-statistic, based on the Kolmogorov-Smirnov of rank-increment statistics, the Simon model performed slightly better than the corresponding goSSR model. What is true for all considered test-statistics, however, is that goSSR models show values of test-statistics that are generally between real text and the Bernoulli model. Using different test-statistics for comparing models of complex phenomena may lead to distinct notions of similarity, which need not coincide. Different models may be adequate for some features (test-statistics) of the modeled phenomenon, while they may be quite inadequate with respect to others.
III Discussion
The main objective of this paper was to demonstrate that goSSR models can explain both, the shape of the marginal distribution function, i.e. Zipf’s law, and important structural/statistical features of the empirical word transition matrix, as shown in Fig. 2. Our results show that indeed, understanding the statistics of streams of English texts as a result of a grammatical ordering process (locally reshuffling), superimposed on a SSR word selection process, is consistent with the statistical evidence. While a pure SSR process offers a natural explanation for the observed (approximate) Zipf’s laws in written texts, based on the necessity of contextual coherence, it fails to produce realistic word transition probabilities. Pure SSR transition probabilities are triangular and very different from empirical transition probabilities. The natural assumption that grammar is a process that locally rearranges word order, allows us to show that very simple grammatical rules are sufficient to explain the empirical structure of word transition matrices, in a statistical sense. Grammatical ordering that locally reshuffles selected words to comply with grammatical structures, sufficiently destroys the triangular (SSR) transition structure of the word selection process. goSRR models are therefore adequate, in the sense that they explain both the empirical word frequency distribution functions and basic statistical properties of the word transition probabilities of texts.
Of course, we can not say that actual English language is a superposition of a SSR process and grammatical reordering. We have seen that the goSSR model, at the level of statistics of the transition probabilities, performs similarly well as the Bernoulli model, which we know is a truly bad model. However, the Bernoulli model can not explain the Zipf law in word frequencies. It can only explain features of the transition matrices, given that the that the Zipf law in word frequencies is provided as exogenous input.
Note that this particular superposition of processes exemplifies a more general phenomenon. If highly structured processes interact with each other, the resulting (still very complex) process may look much more random than the underlying processes themselves. This emphasizes the often neglected fact, that statistical data alone is often insufficient for inferring the generative structure of the process that produces the data. Only if a specific parametric process class can be identified as being adequate for describing a given phenomenon, then data can be used to estimate which process within that class is likely to have generated the data. In other words, in the context of entangled, possibly multi-causal generative processes, even “big data” becomes worthless, without what is sometimes called a thick description of the phenomenon, which in mathematical terms, is the requirement of having identified the process class that produces the observed phenomenon reasonably well. A minimal way to “thicken” a description consists of considering a spectrum of measures that provides clues to the underlying structure of a process instead of reducing a complex phenomenon to a singular notion of similarity.
IV Methods
Implementing grammatical word order. We first identify the full-stop, exclamation mark, and question mark in an original text as sentence ends, and obtain the sentence lengths in the text body. We produce a SSR sequence, , of words, using a vocabulary of words. The sequence is produced sentence by sentence, meaning that for every sentence in a text we generate a SSR sequence of the same length as the sentence , a sub-sequence of the text , that starts at some position in the text. If the SSR process reaches word in mid-sentence, the SSR process is continued by restarting the SSR process. Each takes integer values between and . For simplicity, assume here that there are no neutral words (grammatical label value [math]). To every of the distinct words , we randomly assign one of grammatical labels . We now work through sentence by sentence; the sentence length structure of the model is defined by the sentence lengths in the original text that we model. Let be such a sentence. Then we form sub-sequences of consisting only of words with a particular grammatical label, , where , and . Let be the index of the ’th word in the sentence that carries the grammatical label , then , where is the number of words with label in sentence . The sequences are typically not of the same length. To make all sequences equally long we define to be an “empty word”, whenever . In this way we can think of the sequences, , to be all of the same length and parse them in lexicographical order with respect to , where , if , or and .
The resulting sequence is the grammatically ordered sentence. Note that the grammatically ordered SSR sequence and the SSR sequence have identical word frequency distributions. If the SSR model explains Zipf’s law, then so does the goSSR model. However, unlike SSR models, goSSR models now exhibit word transition probabilities that for a low enough fraction of neutral words (sufficiently small ), and a complex grammar (sufficiently large ), statistical properties of the transition probabilities of the goSSR model start to resemble those of real texts.
For example, with classes, , , and , for each sentence we get three sub-sequences, , , and . is the sub-sequence of all words in carrying label . It contains all words of the sentence that carry the label . We write for . Similarly, and are the sub-sequences for labels and , respectively. After following the procedure described above, we obtain the sequence
[TABLE]
Finally, by deleting the “empty words” we obtain a sentence that consists of the same words and has the same length as the SSR generated sentence . This sentence is the grammatically ordered sentence.
If neutral words are present we proceed by combining neutral words with the next non-neutral word in a the sentence. For instance, if we find a sentence fragment of the form with grammatical labels then we consider as a single word with grammatical label . After this blocking we proceed as before.
Word transitions of texts and models. How similar are word transition properties of the goSSR model to those of actual texts? For computational reasons we restrict ourselves to relative word transition frequency matrices for the most frequent words in a text. Since matrices for actual text, , can not be directly compared to those of a model, such as , we consider two appropriate statistical measures.
The first is a proxy for the largest eigenvalue of , the cosine of the angle between the vector and the vector ,
[TABLE]
It measures how quickly the transition probabilities transform an equi-distributed set of words into the stationary empirical word frequency distribution.
The second is a measure for the asymmetry, the skew of ,
[TABLE]
Bernoulli model. To keep the same sentence structure as in the original text, the Bernoulli model is obtained by first locating the positions of sentence-ends in the text. Then remove the sentence-ends and randomly re-shuffle the words of the entire text. Finally, we reinsert sentence ends at the previous positions in the text. We reshuffle the words of the text while keeping the lengthy of the sentences fixed.
Preferential Simon model. To generate a Simon model to fit a text with a vocabulary of words, and length we propose the following version of the Simon model. We initialize the process with a vocabulary of words with initial weights , for , and , for all other . We use . The probability for sampling a new word at time step is computed from the size of the used vocabulary up to , , and the remaining number of time steps, ,
[TABLE]
The probability of sampling word at time is given by
[TABLE]
Every time a word is sampled at time , we increase . In this way the process follows a Simon type of update rules, while adapting its parameters to match length and vocabulary of a given text.
Random typewriting model. Assume we have a keyboard (alphabet) with letters and a space key. The probability to hit the space key is . We initialize the model with an empty lexicon. For each time step , we sample a random sequence of letters (words), where each letter is produced with probability . If a space is hit, sampling letters stops, and it is checked, if the random word already exists in the lexicon. If not, the word is added to the lexicon, and its word-count, , is set to one; otherwise, the word count is increased by one. Knowing the number of words sampled up to time , , and the number of time steps to go, one can adjust to control the total number of words sampled by random typewriting. Heuristic considerations suggest for example to choose , with . For the random typewriting process text length and vocabulary size are harder to be matched with real texts.
**Acknowledgements
**This work was supported by the Austrian Science Fund FWF under P29032 and P29252. We gladly acknowledge important and insightful discussions on the presented topic with our dear colleague Bernat Cormominas-Murtra.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Zipf G.K. (1949) Human Behavior and the Principle of Least Effort. Addison-Wesley, Cambridge, Mass. .
- 2(2) Mandelbrot B. (1953) An informational theory of the statistical structure of language. (In: Jackson W, editor. Communication theory. London: Butterworths: 486 p.)
- 3(3) Harremoës P. and F. Topsøe (2001) Maximum Entropy Fundamentals. Entropy 3 : 191-226.
- 4(4) Ferrer i Cancho R., Sole R.V. (2003) Least effort and the origins of scaling in human language. PNAS 100 : 788-791.
- 5(5) Corominas-Murtra B., Fortuny J., Solé R.V. (2011) Emergence of Zipf’s law in the evolution of communication. Phys Rev E 83 : 036115.
- 6(6) Simon H.A. (1955) On a class of skew distribution functions. Biometrika 42 : 425-440.
- 7(7) Heaps H.S. (1978), Information Retrieval: Computational and Theoretical Aspects. (Academic Press, 206-208).
- 8(8) Zanette D.H. and Montemurro M.A. (2005) Dynamics of text generation with realistic Zipf’s distribution. Journal of Quantitative Linguistics 12 : 29-40.