TROVE Feature Detection for Online Pose Recovery by Binocular Cameras
Yuance Liu, Michael Z. Q. Chen

TL;DR
This paper introduces a real-time method for estimating 6-DoF ego-states using TROVE features, which are common in man-made environments, enabling accurate indoor localization without traditional corner detection or PnP methods.
Contribution
The paper presents a novel TROVE-based feature detection approach that enables fast and accurate pose estimation without relying on conventional corner features or PnP algorithms.
Findings
Achieves real-time pose estimation up to 60 Hz.
Attitude accuracy reaches 0.3 degrees.
Position accuracy reaches 2 cm indoors.
Abstract
This paper proposes a new and efficient method to estimate 6-DoF ego-states: attitudes and positions in real time. The proposed method extract information of ego-states by observing a feature called "TROVE" (Three Rays and One VErtex). TROVE features are projected from structures that are ubiquitous on man-made constructions and objects. The proposed method does not search for conventional corner-type features nor use Perspective-n-Point (PnP) methods, and it achieves a real-time estimation of attitudes and positions up to 60 Hz. The accuracy of attitude estimates can reach 0.3 degrees and that of position estimates can reach 2 cm in an indoor environment. The result shows a promising approach for unmanned robots to localize in an environment that is rich in man-made structures.
Click any figure to enlarge with its caption.
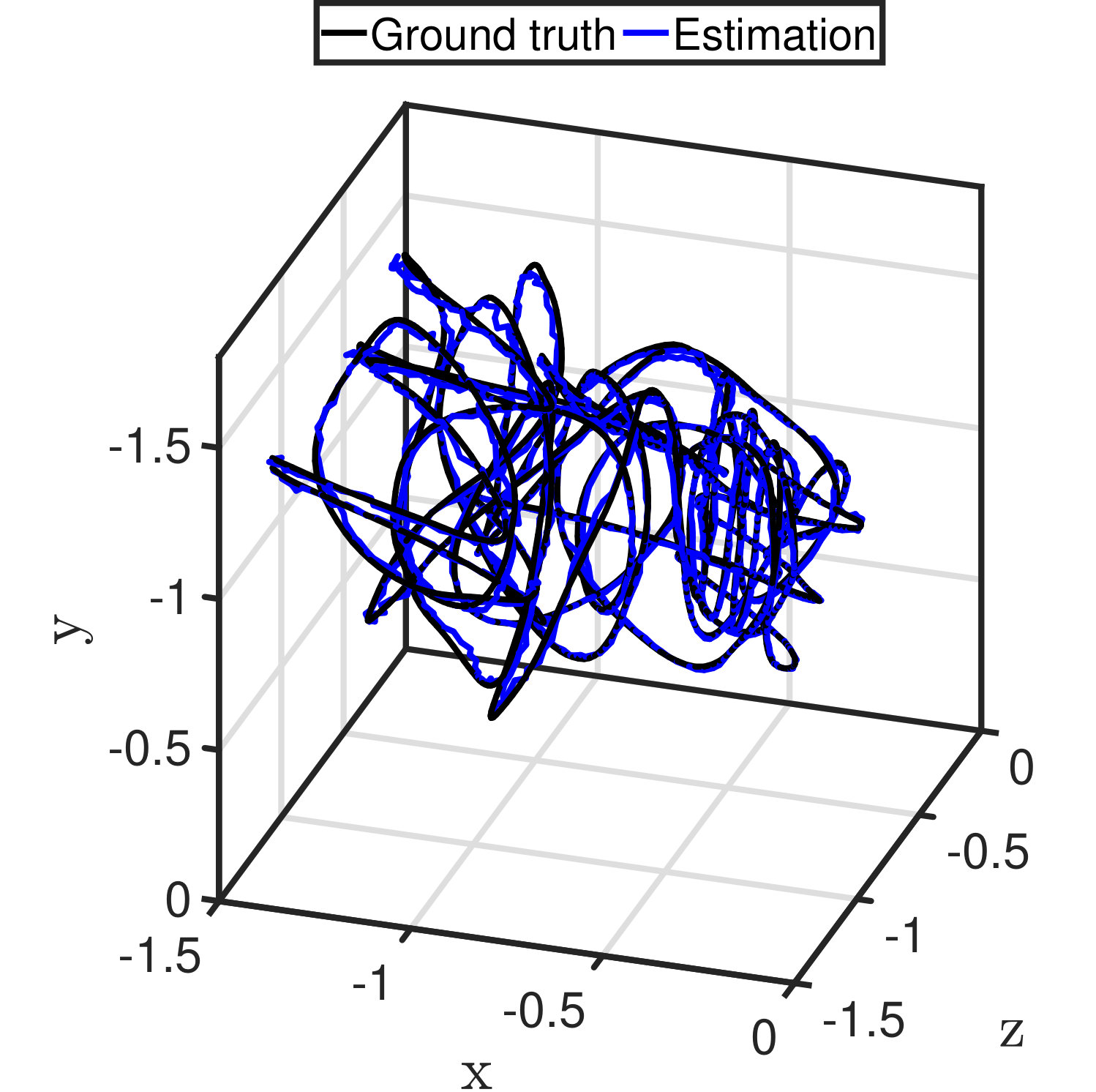 Figure 1
Figure 1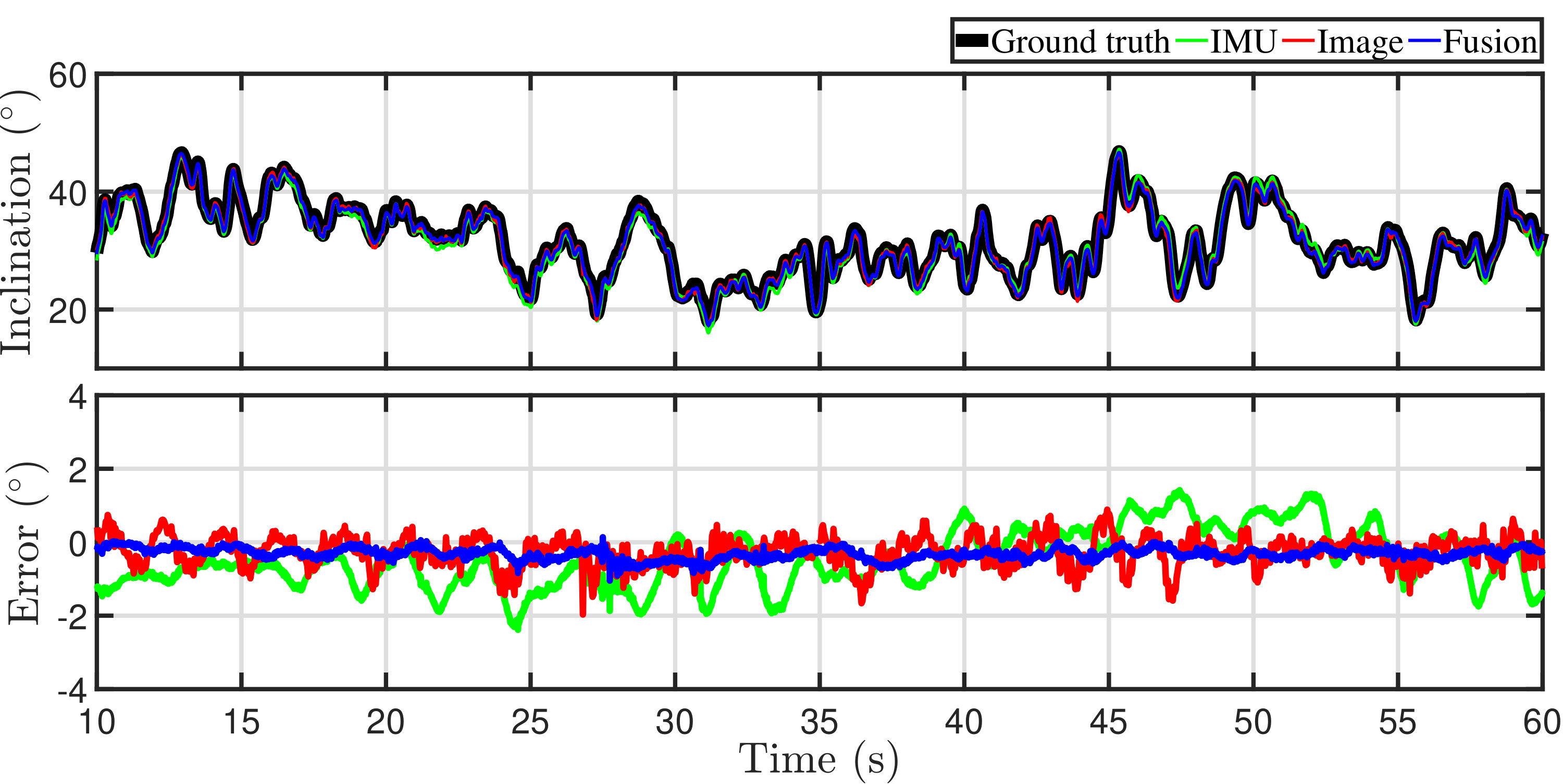 Figure 2
Figure 2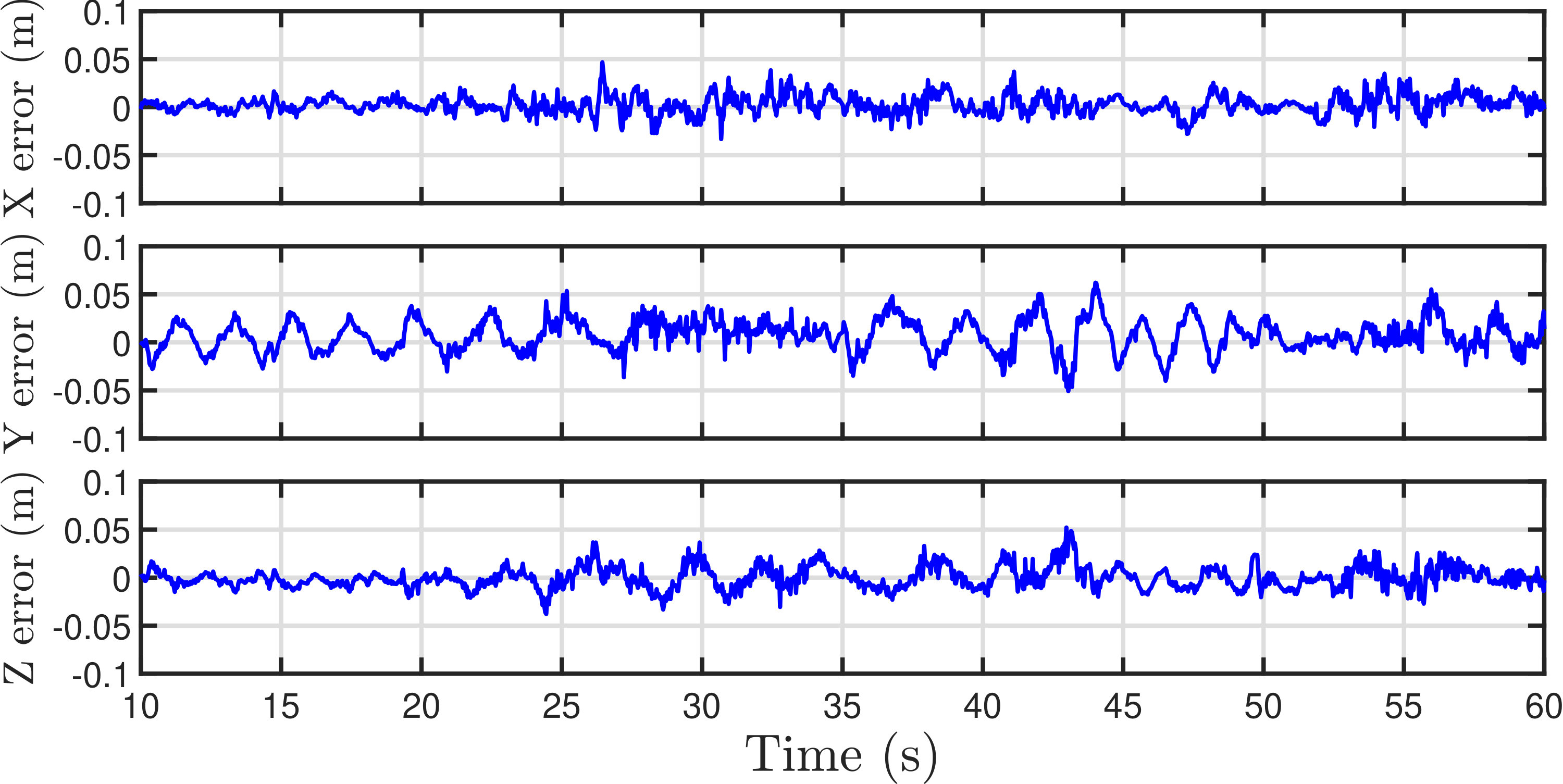 Figure 3
Figure 3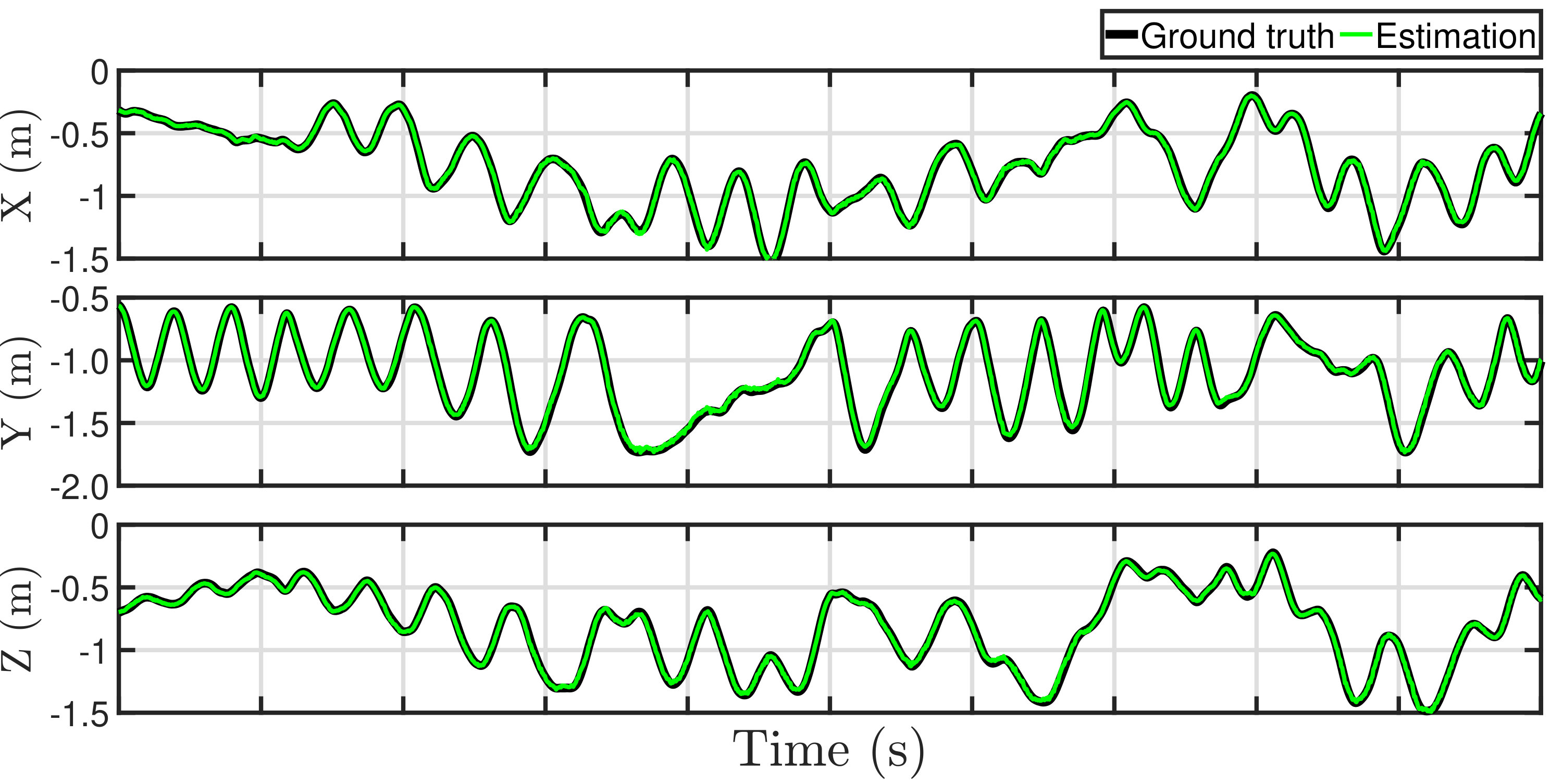 Figure 4
Figure 4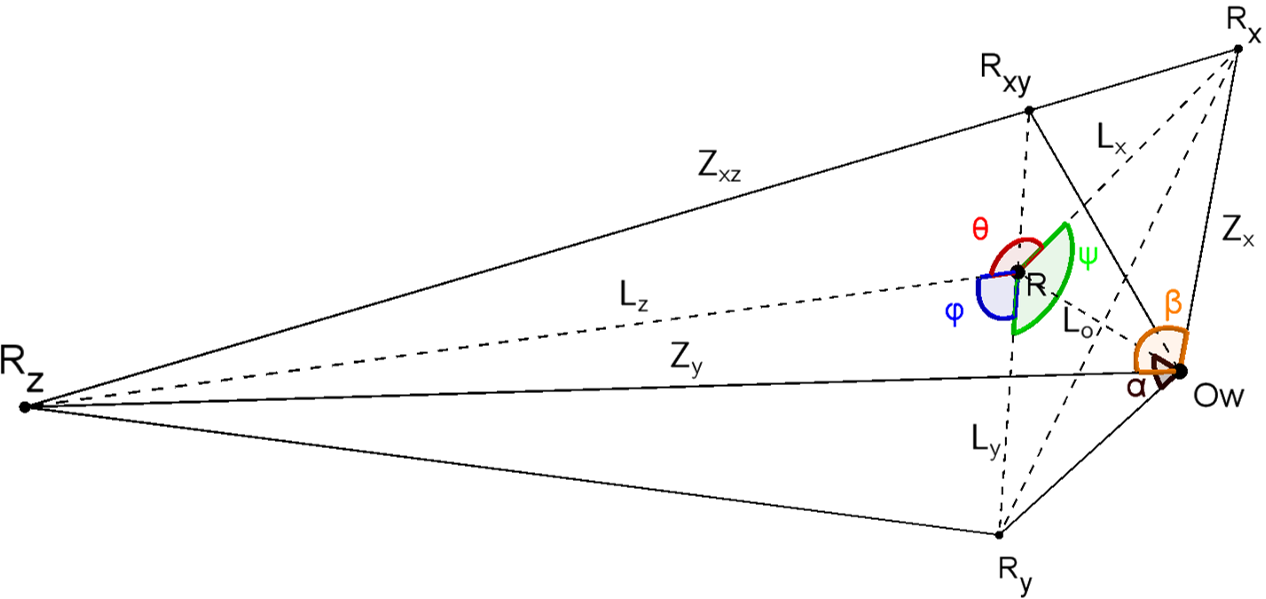 Figure 5
Figure 5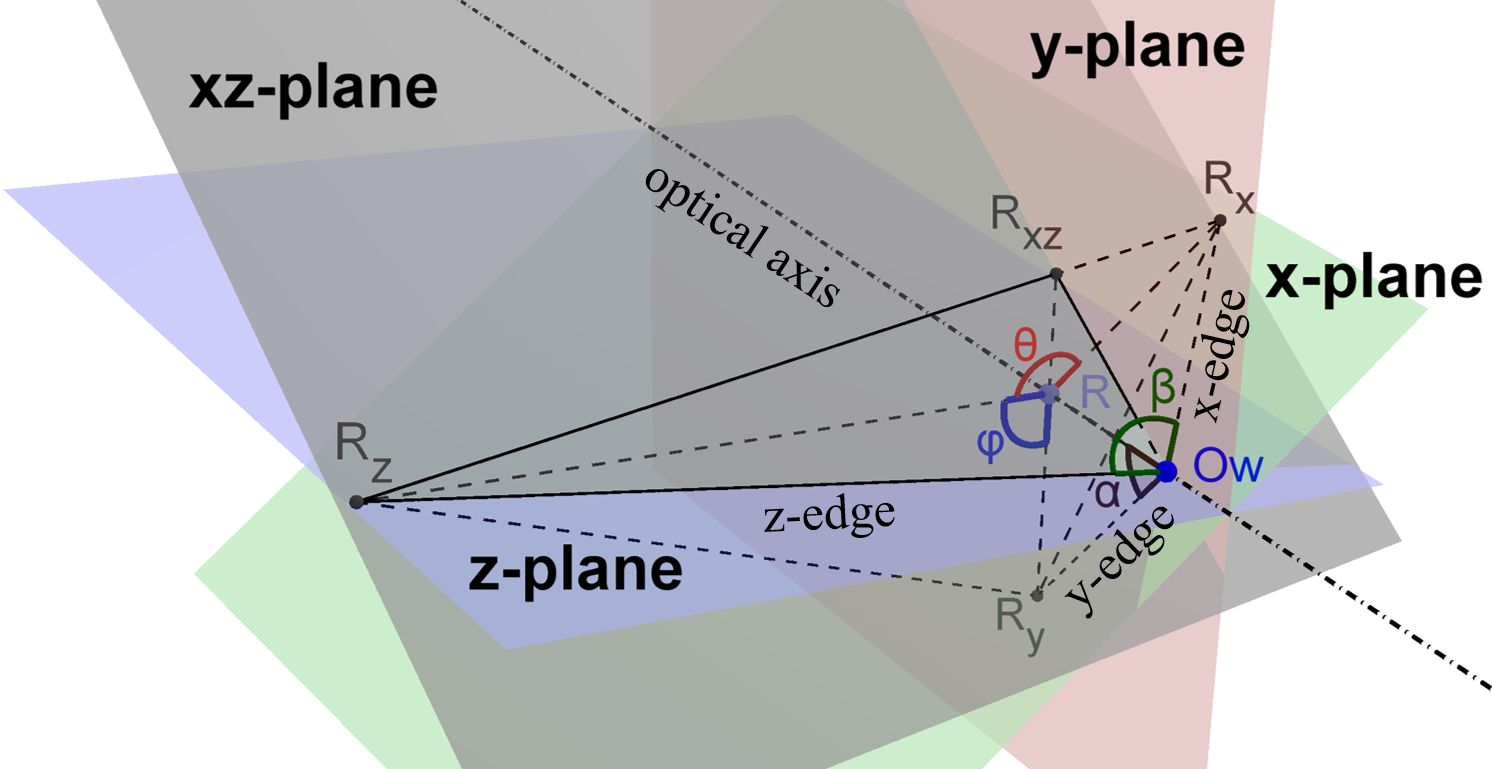 Figure 6
Figure 6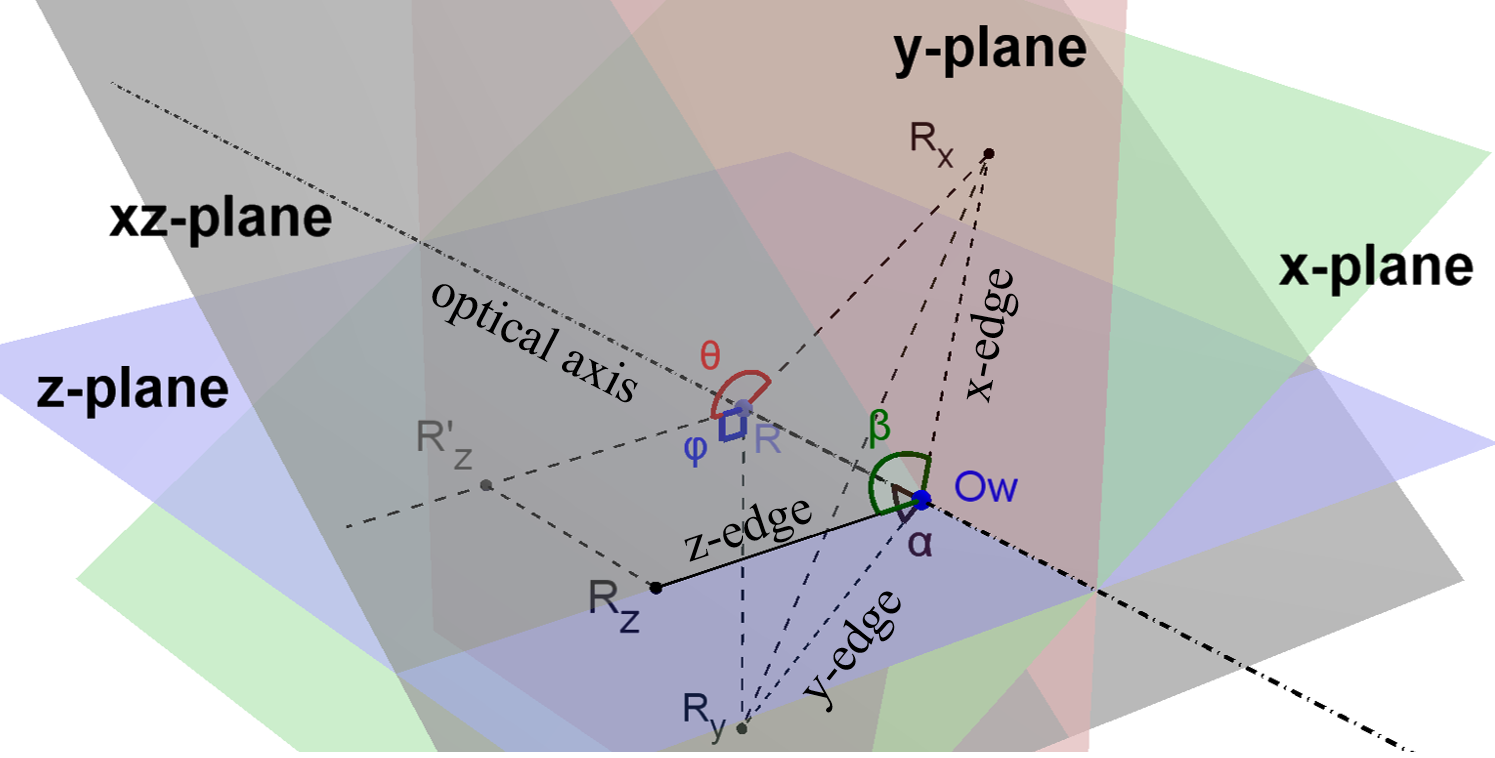 Figure 7
Figure 7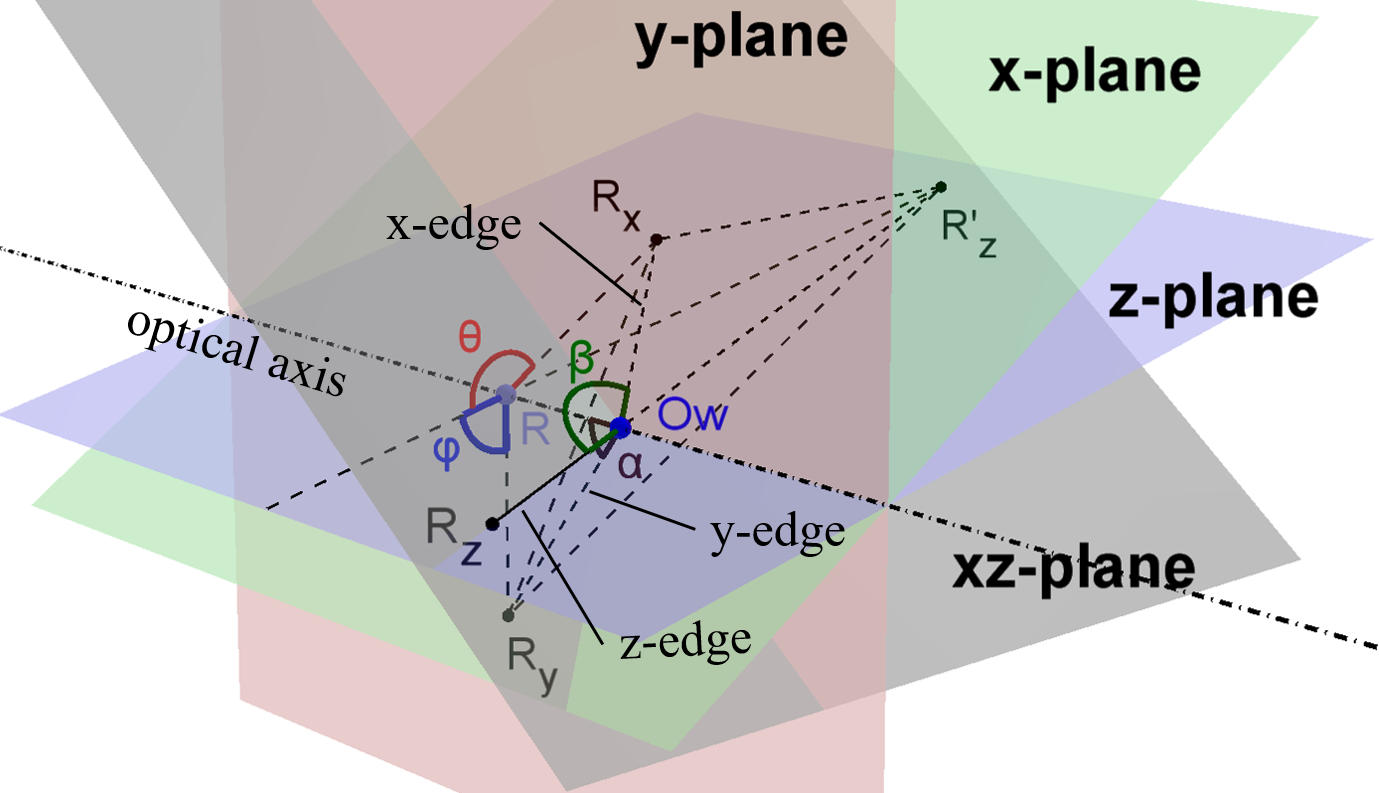 Figure 8
Figure 8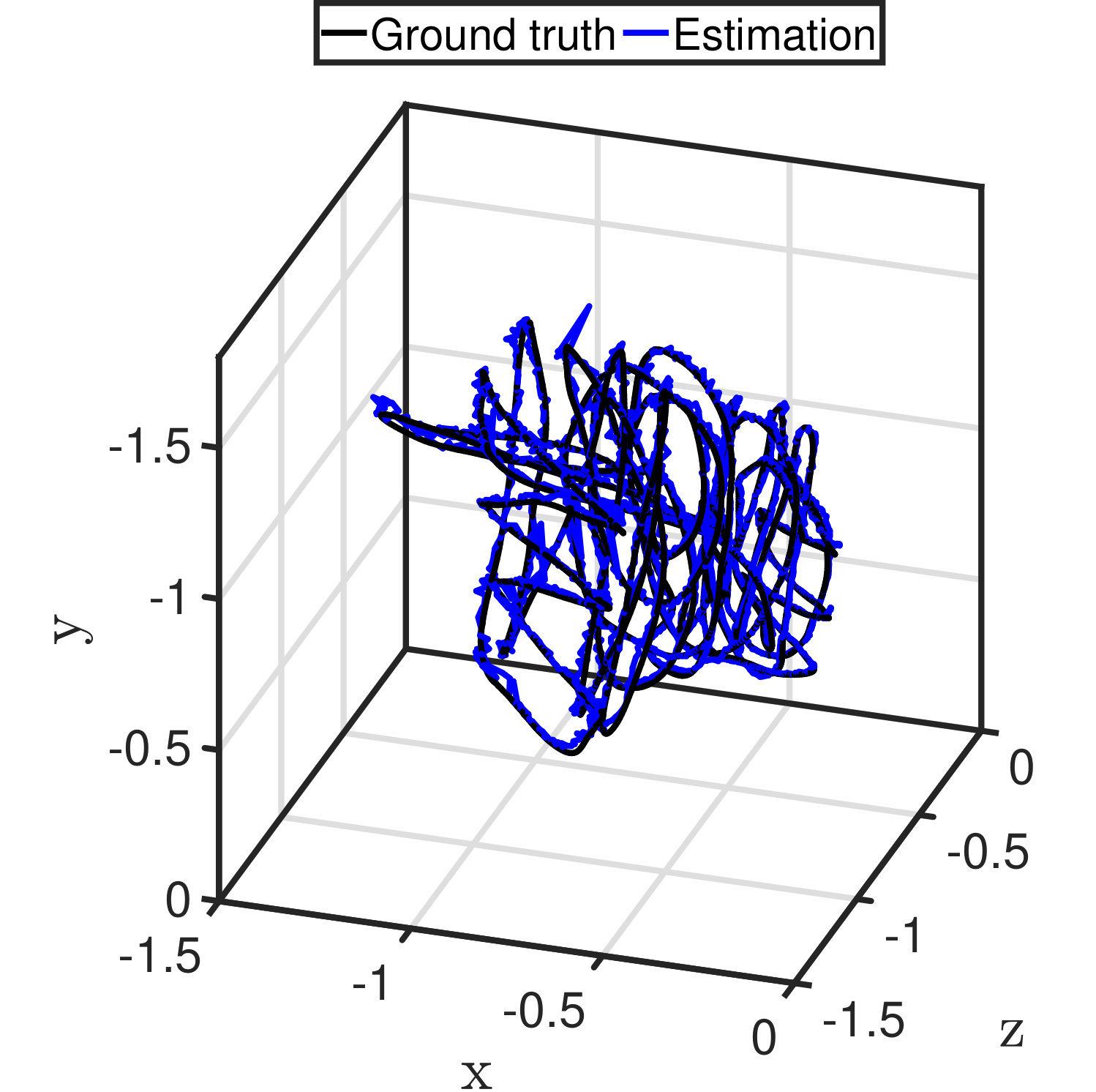 Figure 9
Figure 9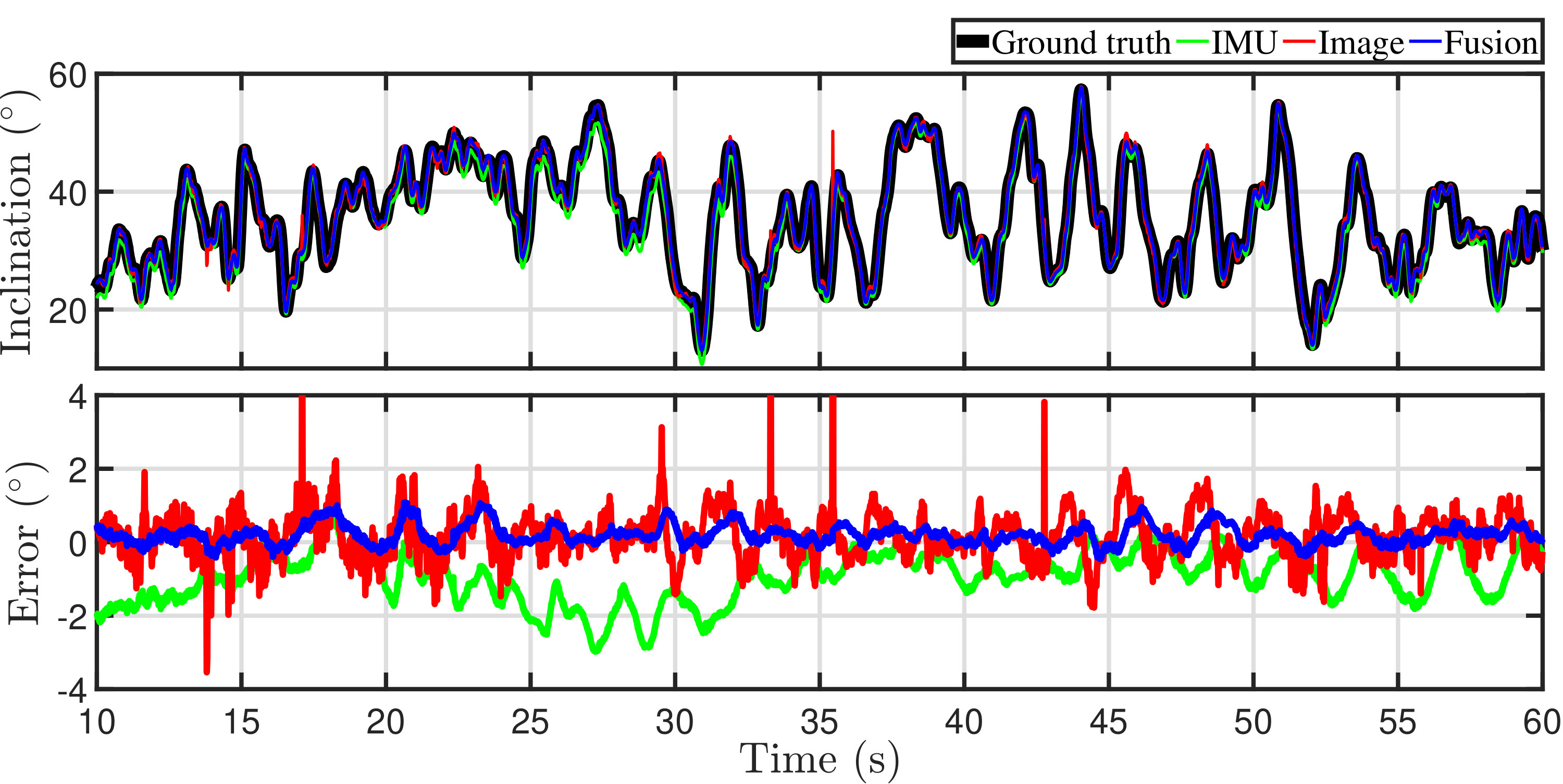 Figure 10
Figure 10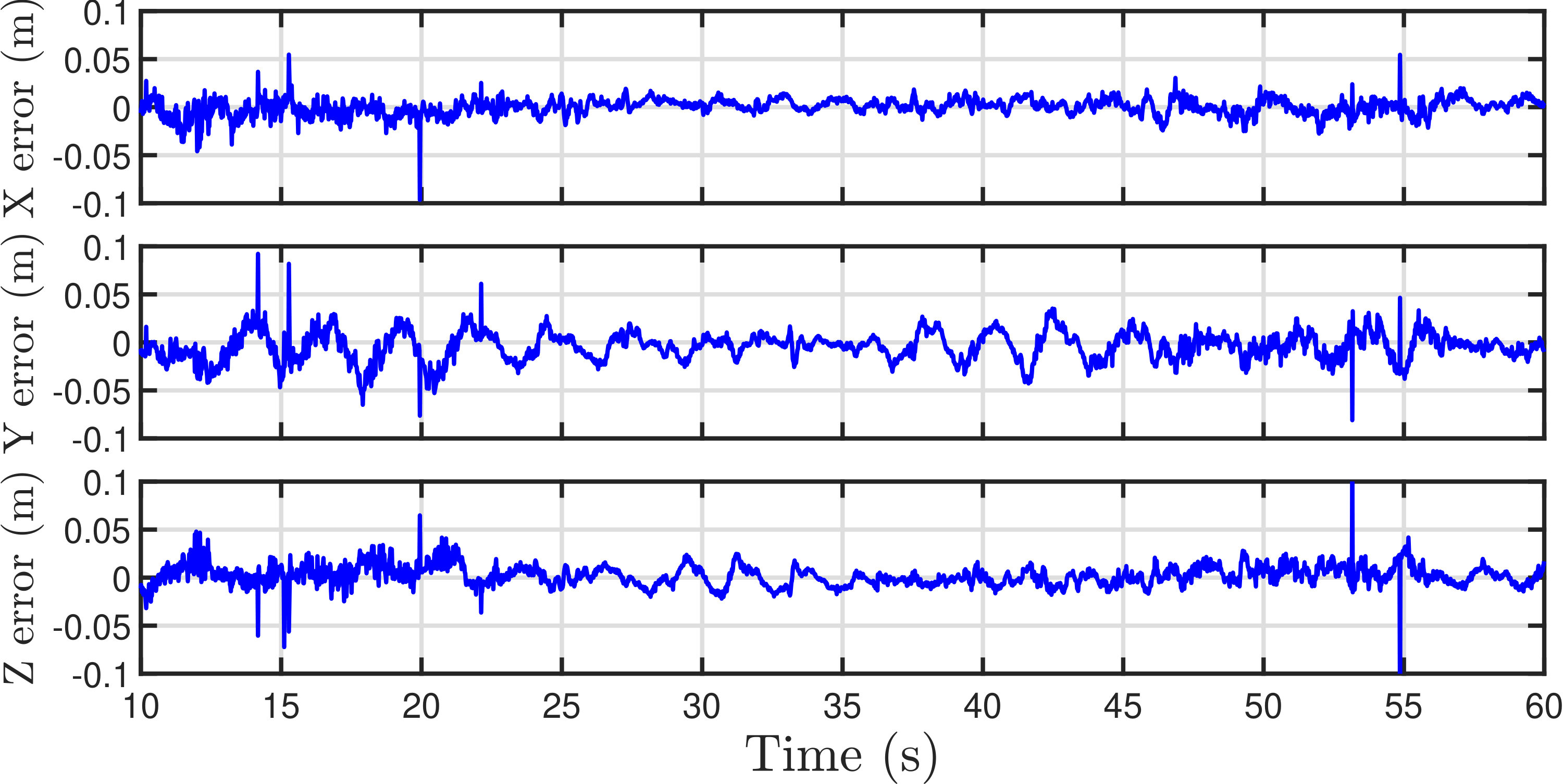 Figure 11
Figure 11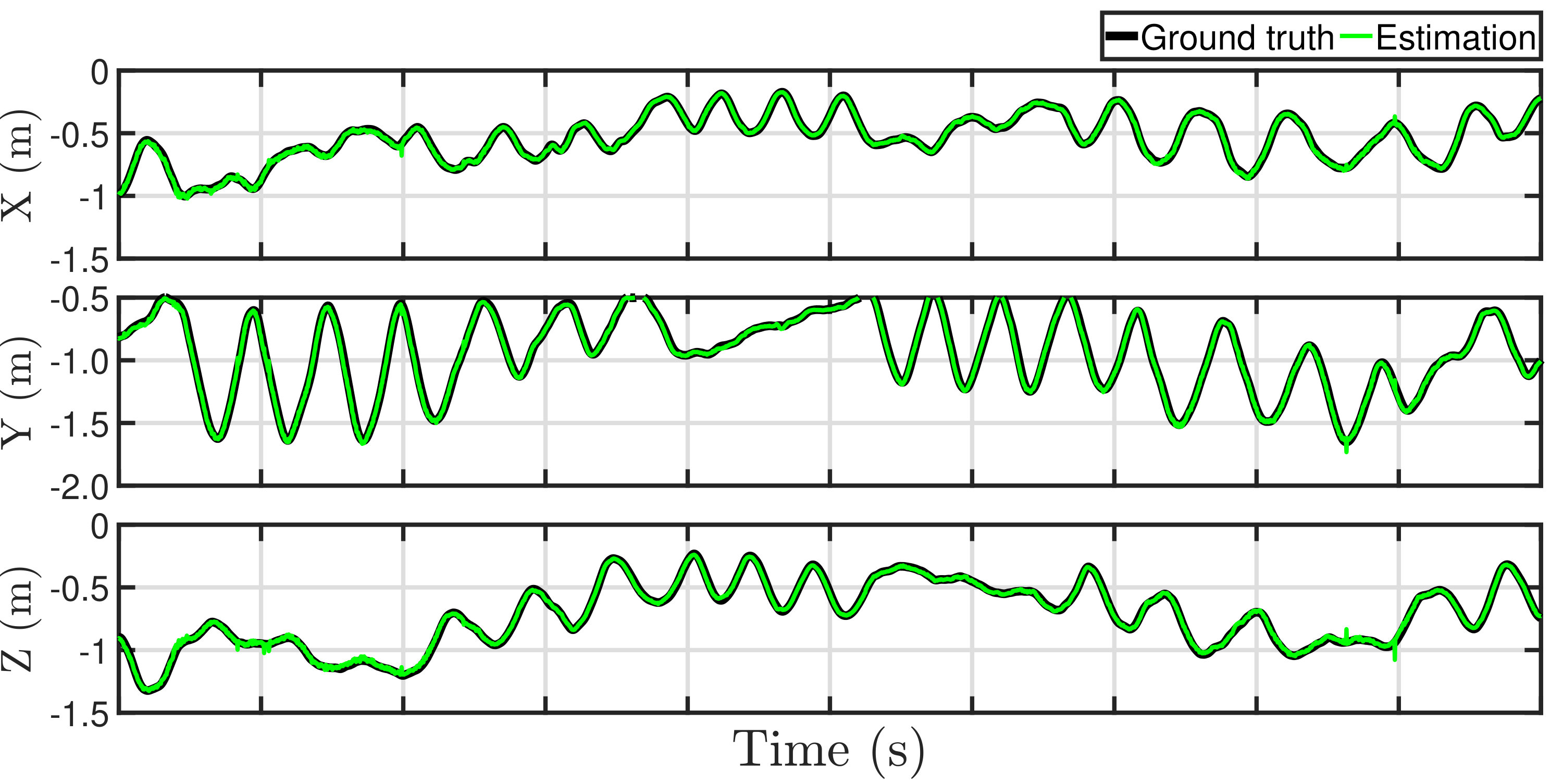 Figure 12
Figure 12 Figure 13
Figure 13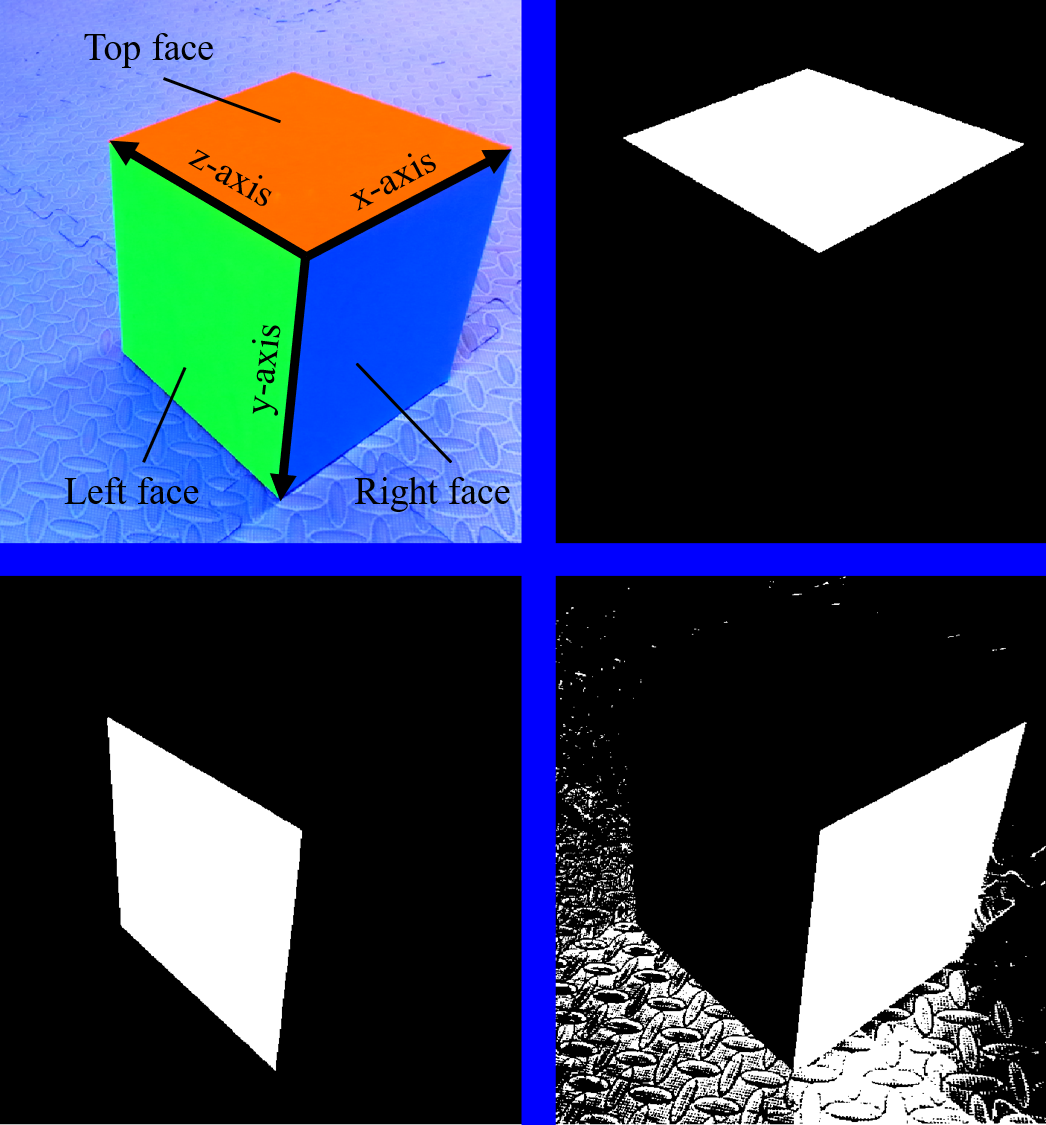 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17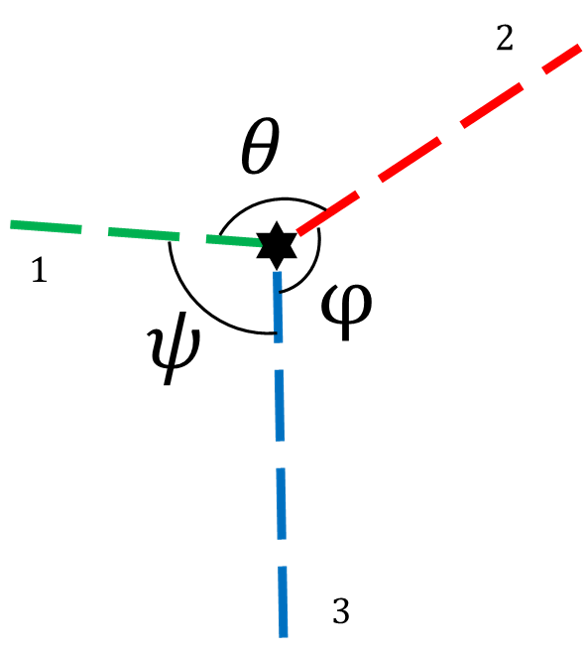 Figure 18
Figure 18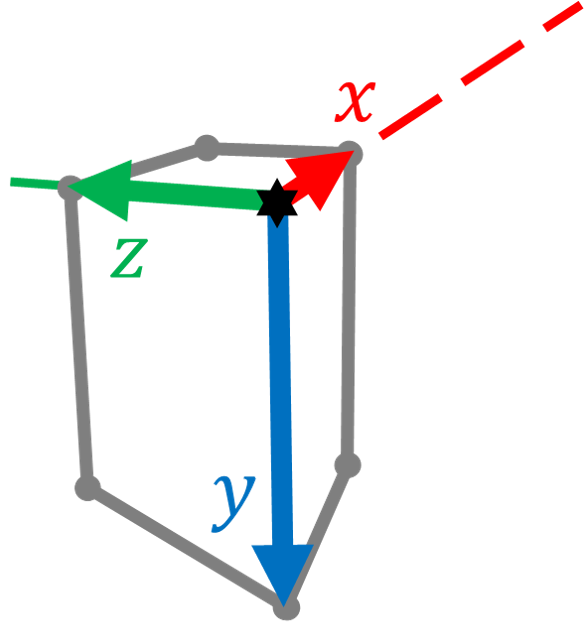 Figure 19
Figure 19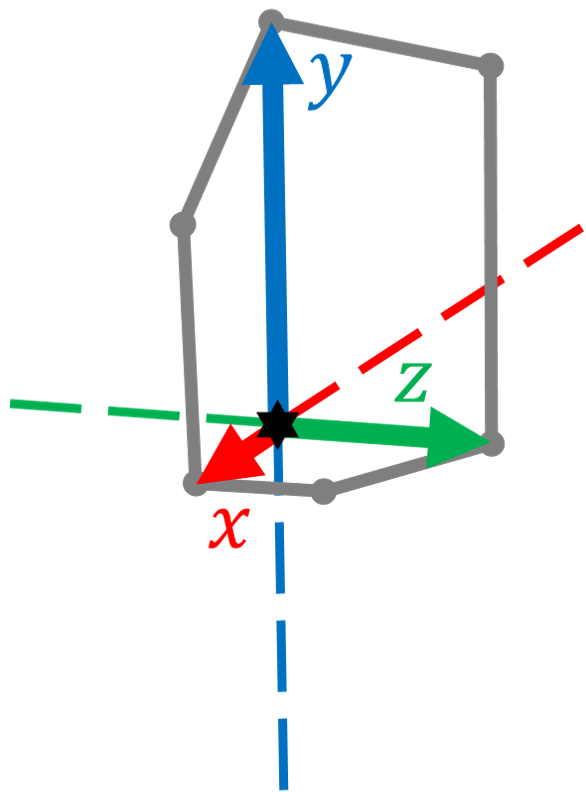 Figure 20
Figure 20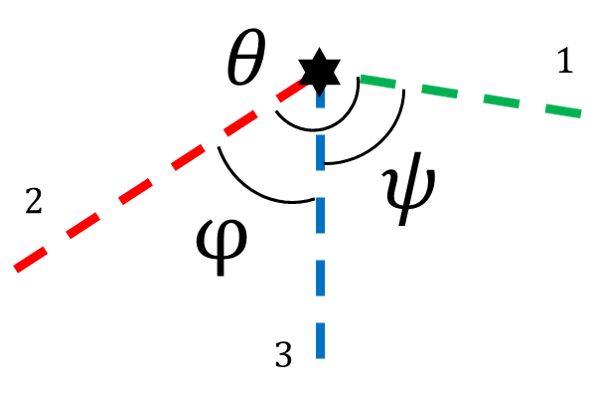 Figure 21
Figure 21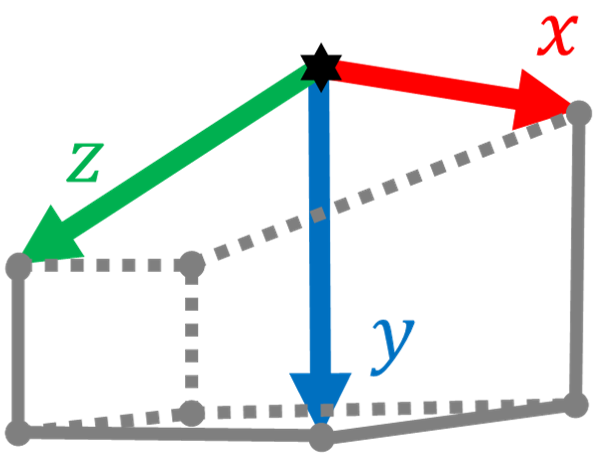 Figure 22
Figure 22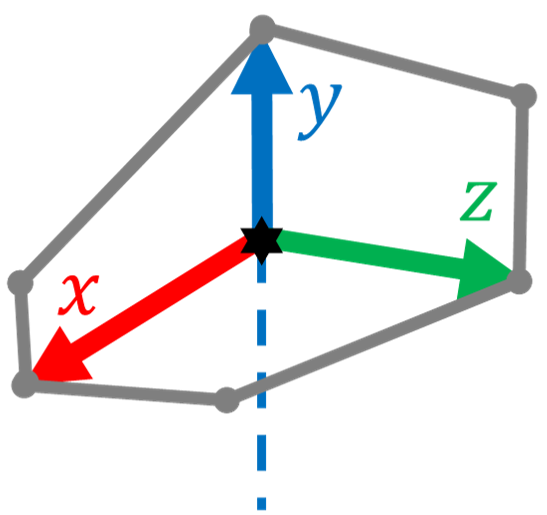 Figure 23
Figure 23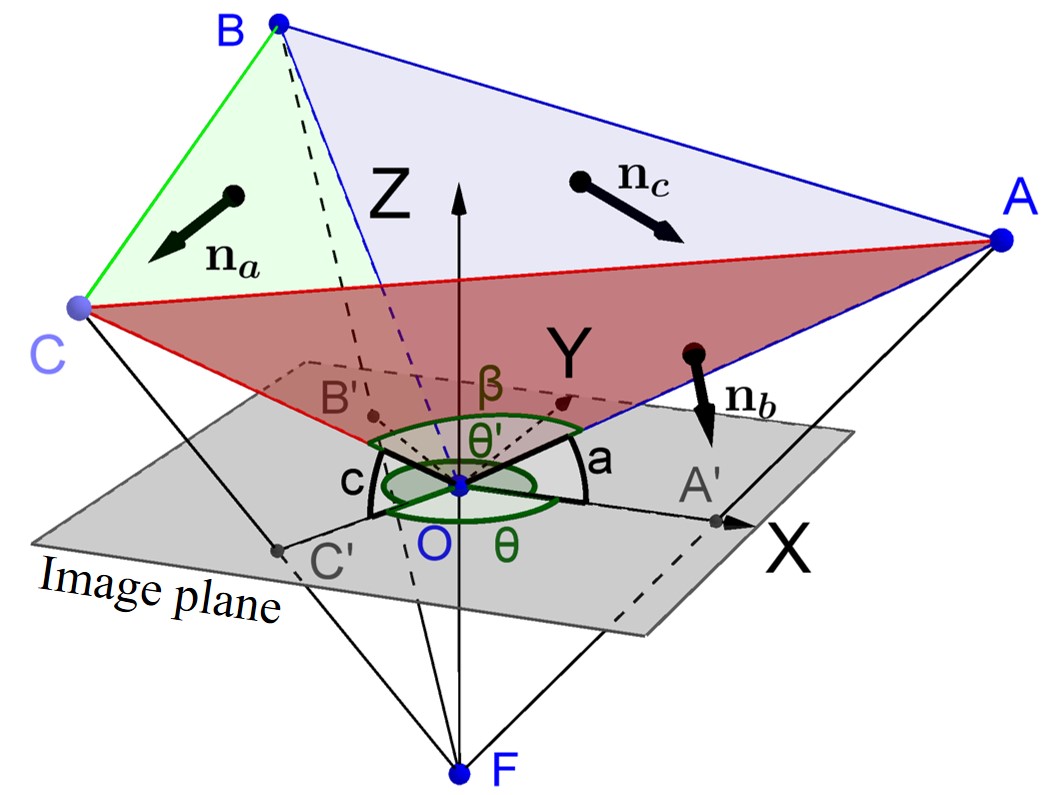 Figure 24
Figure 24 Figure 25
Figure 25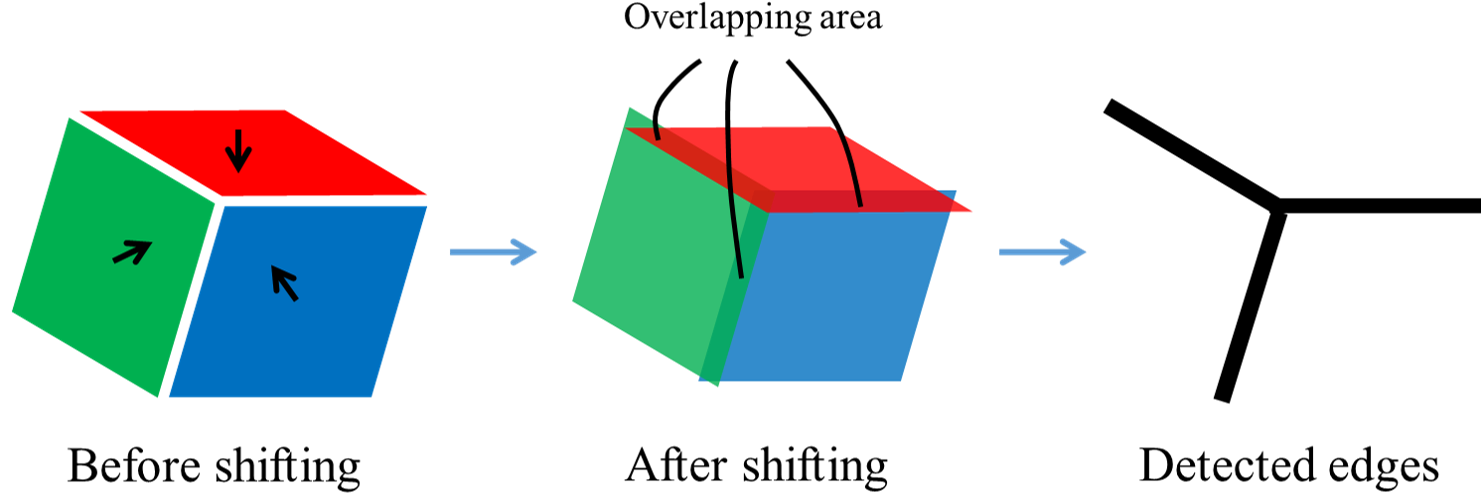 Figure 26
Figure 26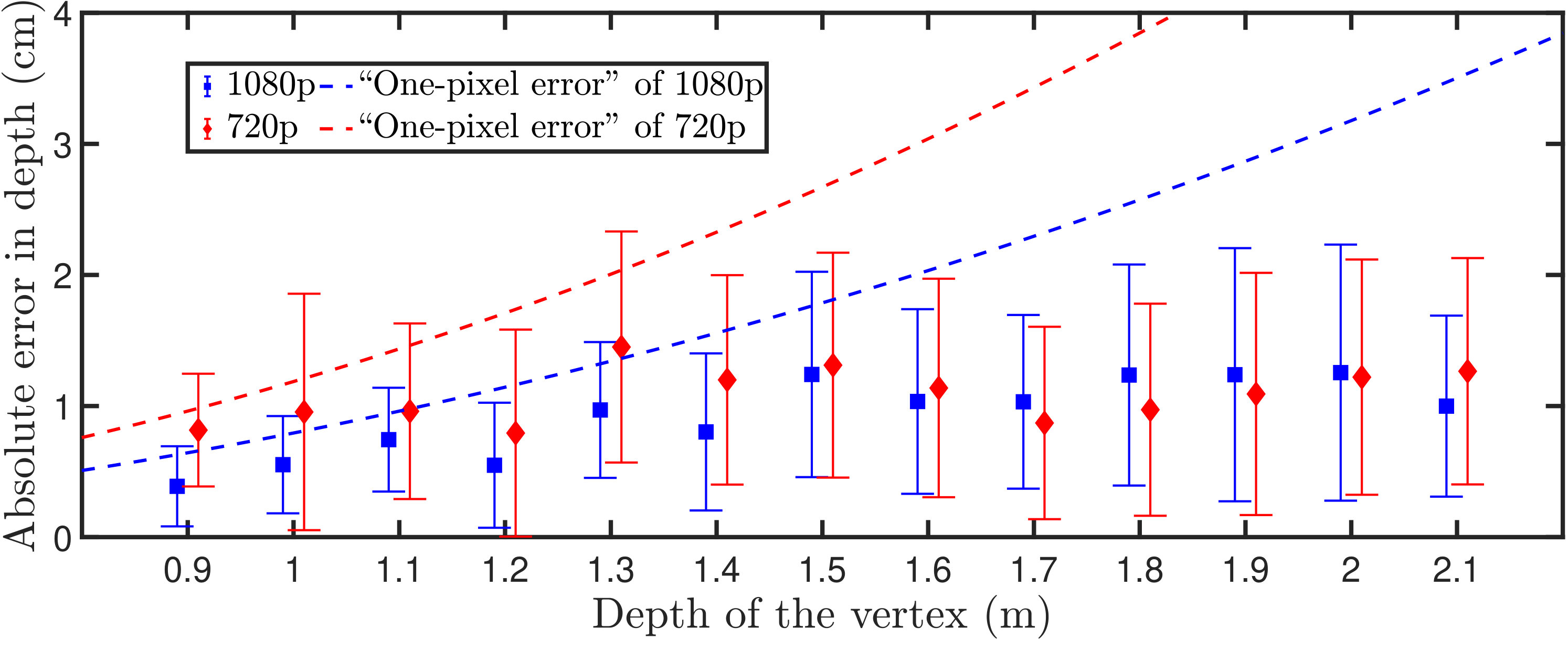 Figure 27
Figure 27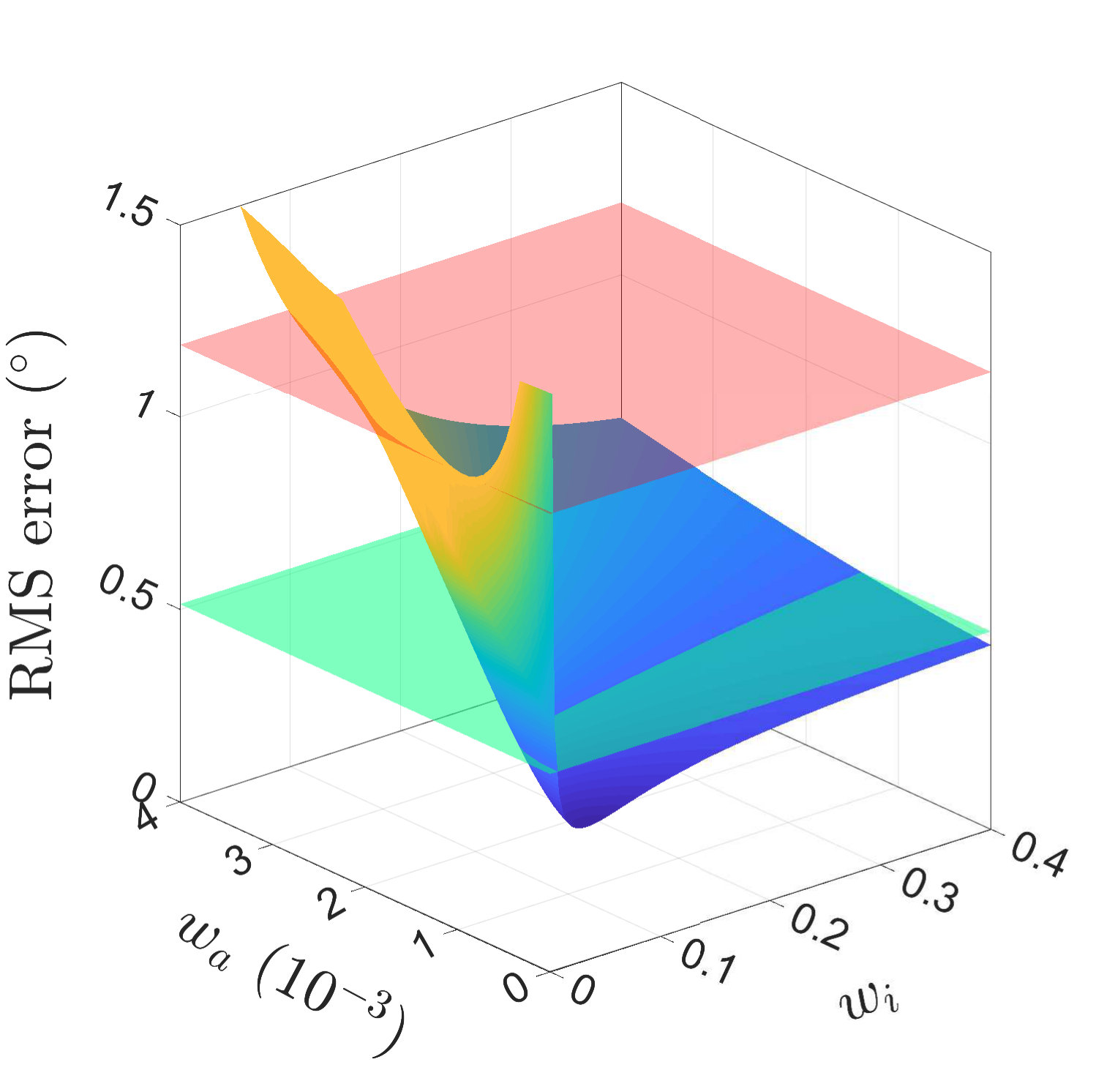 Figure 28
Figure 28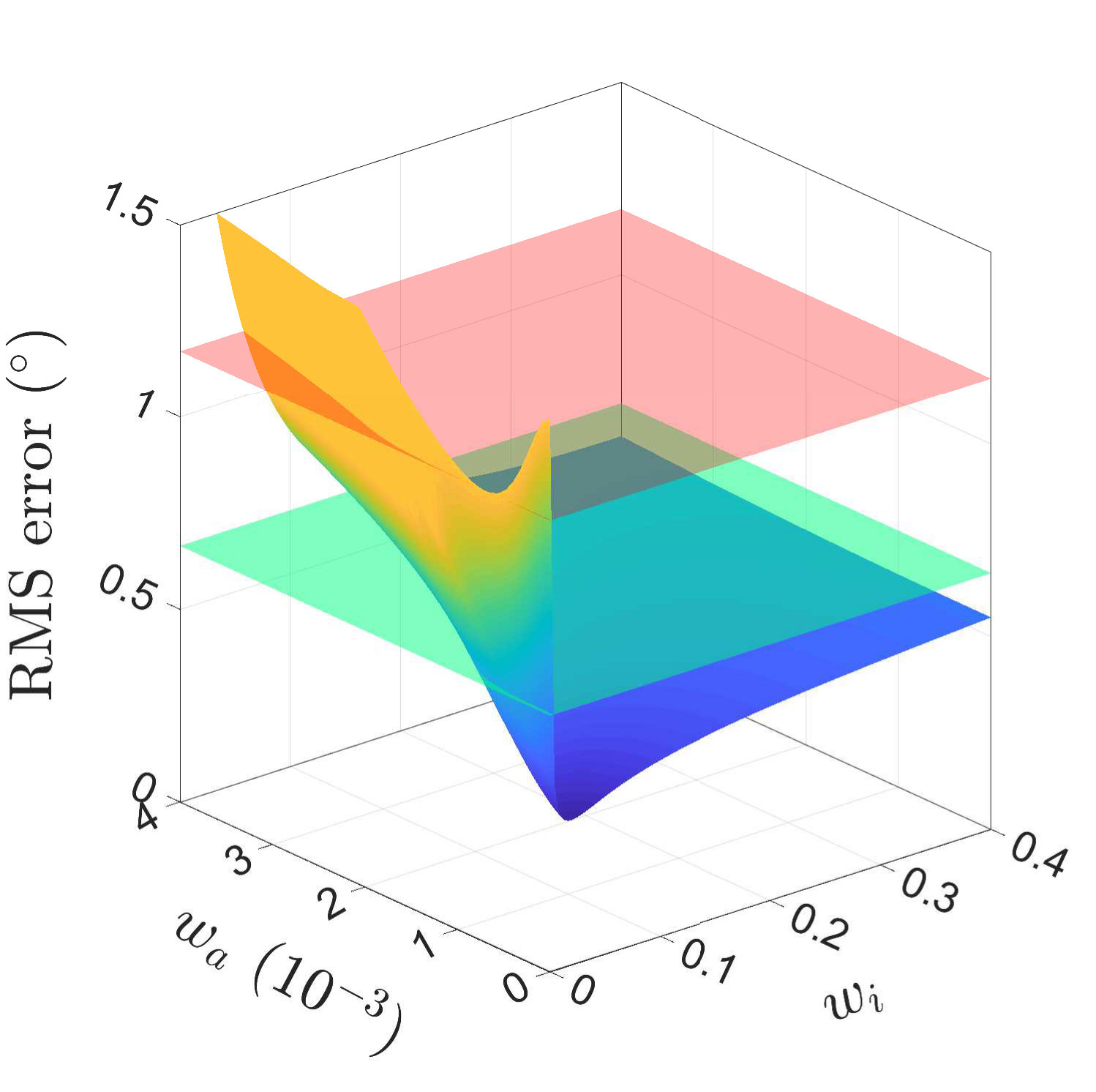 Figure 29
Figure 29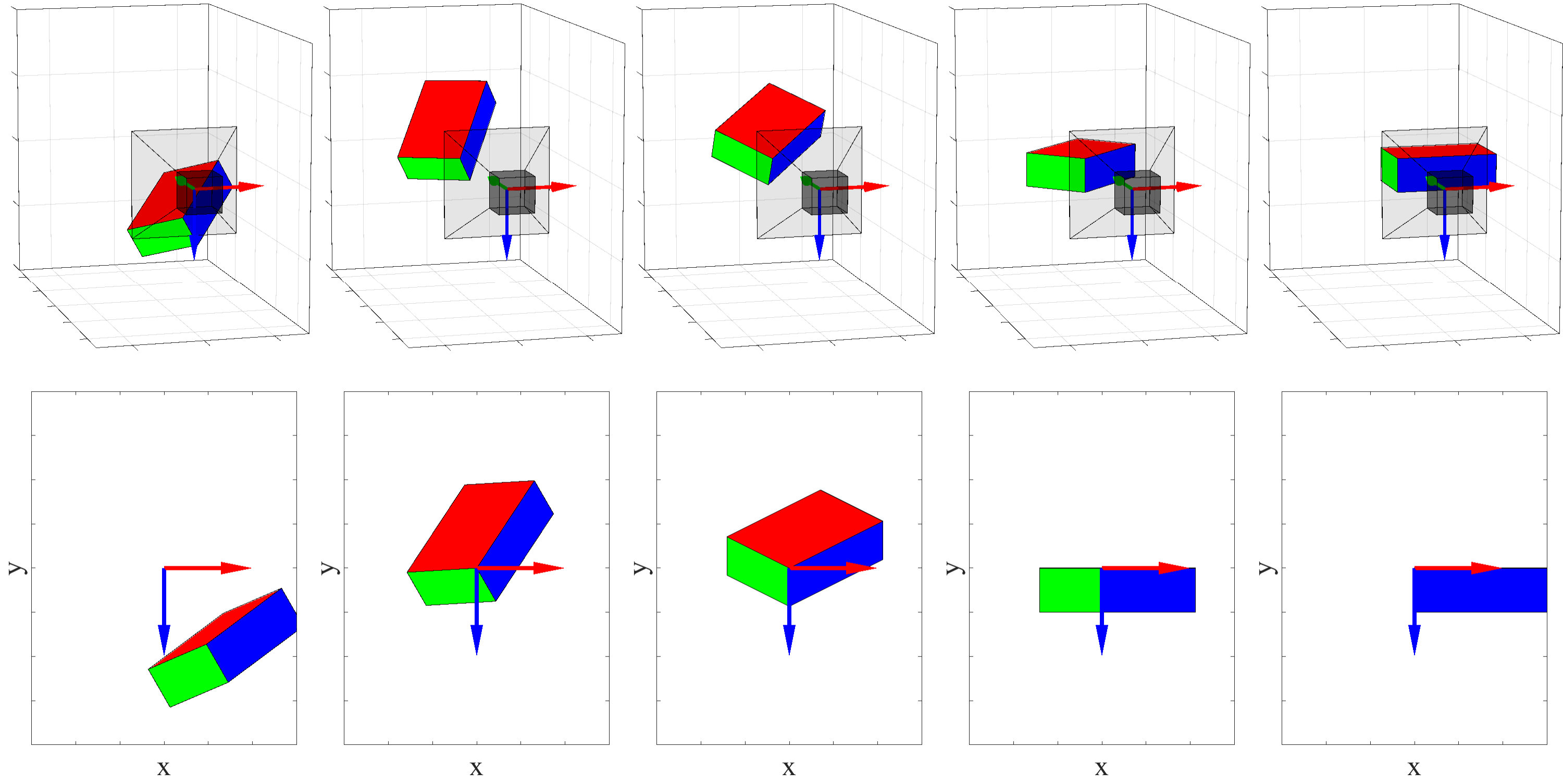 Figure 30
Figure 30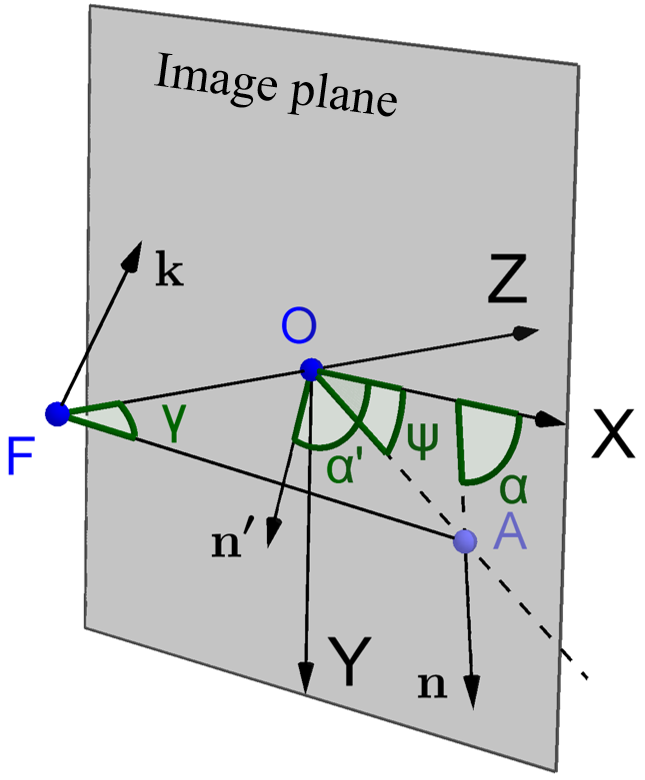 Figure 31
Figure 31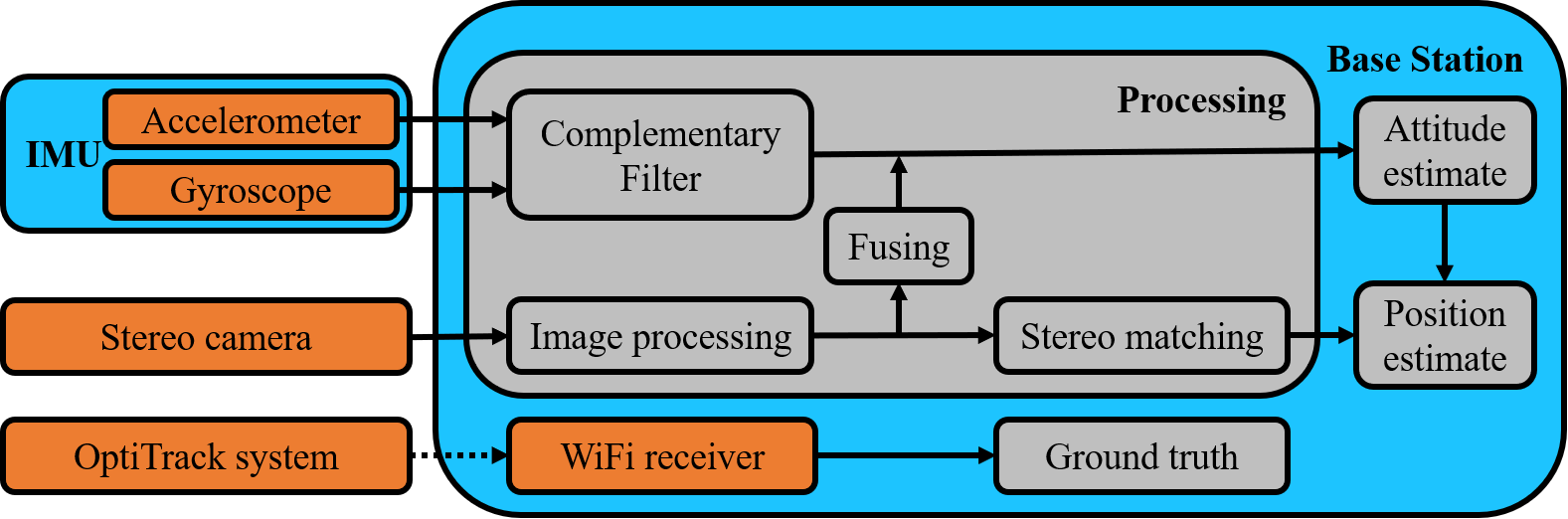 Figure 32
Figure 32| Process | Time () | |
|---|---|---|
| Color Segmentation | 1.360 | 0.638 |
| Edge Detection | 1.826 | 0.679 |
| RANSAC Line Detection | 0.032 | 0.044 |
| Attitude Estimation | 0.050 | 0.050 |
| Total | 3.267 | 1.411 |
| Resolution | Each image | Each pair | ||||
|---|---|---|---|---|---|---|
| RMS | RMS | |||||
| 0.182 | 0.240 | 0.265 | 0.161 | 0.193 | 0.222 | |
| 0.227 | 0.275 | 0.275 | 0.223 | 0.264 | 0.262 | |
| Resolution | Inclination error (∘) | |||
|---|---|---|---|---|
| IMU | Image | Fusion | ||
| 0.850 | 0.376 | 0.301 | ||
| 0.967 | 0.403 | 0.155 | ||
| RMS | 1.036 | 0.484 | 0.338 | |
| 240 | 30 | 270 | ||
| 1.010 | 0.525 | 0.267 | ||
| 0.949 | 0.710 | 0.284 | ||
| RMS | 1.274 | 0.733 | 0.351 | |
| 240 | 60 | 300 | ||
| Position error () | ||||||
| Depth range (m) | RMS | RMS | ||||
| 1.22 | 0.67 | 1.39 | 2.01 | 1.03 | 2.26 | |
| 1.69 | 0.85 | 1.89 | 2.27 | 1.17 | 2.55 | |
| 1.99 | 1.17 | 2.31 | 2.23 | 1.57 | 2.73 | |
| 2.17 | 0.86 | 2.33 | 2.49 | 1.27 | 2.79 | |
| 2.45 | 1.14 | 2.71 | 3.05 | 1.68 | 3.48 | |
| 2.69 | 1.00 | 2.87 | 2.93 | 1.84 | 3.46 | |
| 2.27 | 1.05 | 2.50 | 2.99 | 1.41 | 3.31 | |
| Average | 2.07 | 0.96 | 2.28 | 2.57 | 1.42 | 2.94 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Image and Video Retrieval Techniques · Advanced Vision and Imaging
TROVE Feature Detection for Online Pose Recovery by Binocular Cameras
Yuance Liu and Michael Z. Q. Chen Yuance Liu is with the Department of Mechanical Engineering, The University of Hong Kong, Hong Kong, China (e-mail: [email protected]).Michael Z. Q. Chen (*, Corresponding Author) is with the School of Automation, Nanjing University of Science and Technology, Nanjing 210094, China (e-mail: [email protected]).
Abstract
This paper proposes a new and efficient method to estimate 6-DoF ego-states: attitudes and positions in real time. The proposed method extract information of ego-states by observing a feature called “TROVE” (Three Rays and One VErtex). TROVE features are projected from structures that are ubiquitous on man-made constructions and objects. The proposed method does not search for conventional corner-type features nor use Perspective-n-Point (PnP) methods, and it achieves a real-time estimation of attitudes and positions up to 60 Hz. The accuracy of attitude estimates can reach 0.3 degrees and that of position estimates can reach 2 cm in an indoor environment. The result shows a promising approach for unmanned robots to localize in an environment that is rich in man-made structures.
Index Terms:
Ego-State Estimation, Localization, Computer Vision, Unmanned Aerial Vehicles
I Introduction
Localization has always been pivotal for robots to autonomously navigate. Position in the Earth frame can be acquired by GPS sensors. Further fusing GPS information with measurements from other sensors, for instance: LiDAR, RGB-D cameras, ultrasonic sensors and etc., autonomous ground vehicles have already achieved robust and high-accuracy localization. However, for the limited payload and power supply some robots such as unmanned aerial vehicles (UAVs) can hardly afford to mount those powerful sensors and computers to obtain and process data. The blocking and reflecting of GPS signals from high-rises also impede accurate localization, let alone the indoor environment where GPS signal is often completely denied. Were UAVs to accurately navigate amid high-rises, complementary sensors other than GPS should be adopted. In that scenario, RGB cameras are the common option for UAVs to localize themselves because visual sensors can provide rich information at a cheap cost. The state-of-the-art visual SLAM (simultaneously-localization-and-mapping) algorithm has made significant improvement over the last decade. Methods such as LSD-SLAM [1], ORB-SLAM2 [2] and S-PTAM [3] have recently drawn much attention and shown robust and accurate results. It is needless to mention that how pivotal real-time capability is to a system with fast dynamics like a quadrotor. Compared with other commonly used feature detectors: SIFT [4], SURF [5] and FAST [6], the aforementioned methods are much more efficient. The feature extraction and localization time for the SLAM algorithms can be roughly regarded as the tracking phase in a whole SLAM process. For LSD-SLAM, ORB-SLAM2 and S-PTAM, the tracking time using a rectified stereo image at a resolution of (can slightly vary by different rectification process) is 61.0, 49.5 and [4, 5, 6], respectively. The proposed method in this paper completes that phase in only for an unrectified stereo image at a resolution of . This allows the algorithm to run online at in the experiment.
In this paper, a new method for attitude estimation and localization based on stereo vision is proposed. The method is dedicated to an environment where horizontal and vertical edges are common. Unlike classic PnP problems as described in [7, 8, 9], the proposed algorithm does not require any priori knowledge about the dimensions or positions of the observed object. It requires the included angle between two horizontal edges to be known and the existence of a vertex intersected by two horizontal edges and one vertical edge. This structure will be projected onto an image as three rays and one vertex. In this paper, such a feature is called a “TROVE” (Three Rays and One VErtex) feature and such a structure is called a “TROVE” structure. An environment with some priori knowledge is regarded as a semi-known environment. Some approaches have been attempted for pose estimates in such an environment, for instance [10, 11, 12, 13]. Those methods utilize preset markers or patterns, whereas the approach in this paper does not require any modifications on the environment. TROVE structures are ubiquitous in artificial constructions such as the outlines of buildings and corners of rooms and corridors. In the most common type of the structures, the horizontal edges are perpendicular to each other. The edges are usually formed by mutually orthogonal faces like ceilings, walls and facades of buildings. One of the earliest works utilizing those structures to extract ego-states can be found in [14], where it referred those edges as Manhattan Grid and the environment rich in those structures as Manhattan World. In [15, 16], the authors utilized Manhattan Grid for attitude estimation and environment mapping. Some scholars have explored the possibility of estimating ego-states from other reliable world reference, including methods of horizon detection [17] and vanishing points [18]. More variations of them can be found in a comprehensive survey in [19]. Nevertheless, localization has not been achieved in those methods.
The main contributions of this paper are:
A new feature has been proposed, which can associate its properties with the physical properties of the corresponding entity in the real world. Solution uniqueness of estimating ego-states from a feature is proved for the majority of cases, while easy-to-implement methods to discard incorrect solutions are also given. 2. 2.
The solution is given in a closed-form expression. Unlike common tools in projection geometry [20] that need to solve eigenvectors of matrices or zeros of polynomials [21] to estimate ego-states, the proposed method derives a direct closed-form expression of the estimates which greatly eases the computation burden. 3. 3.
It has been demonstrated in the experiment that the algorithm can run in real time at for stereo videos. The limiting factor for the efficiency is the camera’s capability of capturing and transmitting images. 4. 4.
The attitude estimates have high accuracy up to . When fused with measurement from inertial measurement units (IMUs) in a straightforward way, the image estimates noticeably improve the conventional method. 5. 5.
The method exhibits high accuracy in localization up to on average.
Edge detection in Manhattan-world scenario has been discussed by [15, 22]. Such a process is not the scope of this paper and is experimentally simplified by color segmentation.
The rest of this paper is organized as follows. Section II elaborates the definitions and the proof of the TROVE feature and its properties. Section III discusses the approach to detect edges and vertices of TROVE features, thus estimating 6-DoF ego-states. Section IV describes the experiments that evaluates the proposed method. All the findings and future work are summarized in Section V.
II TROVE Feature Detection
In this section, the process to extract TROVE features in an image is presented. Such a feature is projected from a common structure, referred to as a TROVE structure, on man-made buildings both indoors and outdoors. Subsection II-A elaborates on the definition and properties of a standard TROVE feature with a real-world example. How a general TROVE feature could be transformed into a standard one and the proof of its properties is given in the latter half of this subsection. The following Subsections II-B and II-C describe how a raw image is processed to extract the rays and the vertex of a TROVE feature in the experiment.
II-A TROVE Feature
A TROVE feature consists of three rays and one vertex which the rays all originate from. A TROVE feature is projected from a TROVE structure, which consists of three edges and one vertex. All three edges of a TROVE structure intersect at the same vertex with one being vertical and the other two being horizontal in the Earth frame. Horizontal and vertical edges are ubiquitous on man-made structures, or more generally in Manhattan World [14]. The vertices, usually corners of room, corridors or outlines of buildings, man-made objects are naturally reliable landmarks for unmanned robots to refer to in unknown 3D environment. When those robots navigate indoors, the relative position to the environment is often much more important than their absolute position in the Earth frame. Those features are usually distinctively away from each other in distance and have properties such as orientations, positions, included angles by horizontal edges and being formed by different number of internal and external surfaces. More interestingly, these properties are associated with their physical properties such as shapes, relative distances and heights to the observer. These properties potentially enable them to have unique descriptors to be identified.
A TROVE structure can be represented by a corner of an imaginary box. Fig. 1 shows an example of such a process in an image of a corridor. Fig. 1(a) is the raw image taken in a corridor. Fig. 1(b) shows the edges (solid lines) and vertices (white stars) of the TROVE features, where one vertical line and two horizontal lines intersect at a real physical vertex. If one imagines the walls, ceilings and floors of the corridor as the faces of boxes, each of the left two vertices is the intersection of three internal surfaces of a box, all visible to the camera. Each of the right two vertices is the intersection of three external surfaces of a box, two of which are visible and vertical and one of which is invisible and horizontal. In Fig. 1(c), four imaginary boxes are constructed with the edges being collinear with the rays of the corresponding TROVE features in the image.
II-A1 Definition
The definitions of the imaginary box are: 1) the box is a parallelepiped, i.e. a hexahedron with all faces as parallelograms; 2) of the three unparallel edges, one is vertical and the others are horizontal; 3) it has three faces visible to the camera and the intersections of them (three edges) are projected onto the image, collinear with the rays of the feature; 4) all edges are in equal unit length because dimensions are not concerned. Note that a necessary condition for a face crossing the principal point to be visible is that its outward normal vector points to the focal point.
The benefits of imagining a TROVE structure belonging an imaginary box are: 1) the positions/directions of vertices and edges remain the same; 2) the object frame can be uniquely defined by the box; 3) if more than one feature is found in an image, the model of such a hexahedron gives us a unique solution to attitude and position estimates when interpreted from a TROVE feature. Therefore, those boxes are reliable references for estimating ego-states of attitudes and positions.
II-A2 Standard Model
In a standard model the vertex is projected onto the principal point. If the vertex is not originally on the principal point in the raw image, one can always rotate the observed object around the fixed focal point so that the new vertex can be projected onto the principal point. After such a rotation, the projection of edges has to adjust accordingly. Unless specifically mentioned, a TROVE feature is always rotated so that the vertex is projected onto the principal point. The following are the details of the transformation. Denote the intrinsic matrix of a pin-hole model camera as:
[TABLE]
where is the focal length and is the width of a pixel assuming and is identical in the x- and y-direction. and are the coordinate of the principal point in the image frame. In this paper, the image frame is defined that and are both [math]. As shown in Fig. 2, the projection of a line is represented by a unit vector starting from . is the focal point and is the principal point. If one rotates the object so that is projected onto , the direct path is to rotate around the axis by , where is the normalized cross product of passing through and . Let the position of be , then one has:
[TABLE]
Let (not shown in the figure) be the rotated , be the projection of in the image plane, be the angle that makes with the x-axis , be the angle that makes with the x-axis, be the angle that makes with the x-axis. and are the inclination angles before and after rotation. It can easily be derived that .
The objective is to find . Rodrigues’ rotation formula yields:
[TABLE]
Denote the element of a vector as . Note that: . By (3) and difference formulas for tangent, one has:
[TABLE]
where . Thus, the re-projected line after rotation is found.
After the vertex is rotated onto the principal point, the configuration ambiguity has to be tackled. It can be observed from Fig. 1 that the imaginary boxes are not constructed following the same rule. Whenever a TROVE feature is detected, one obtains three rays and their intersections in the image. How the box can be constructed from the detected rays is not unique. Suppose a TROVE feature is detected as shown in Fig. 3(a) that the sum of the three included angles is . This type of feature is referred as the standard type. From a standard type of the feature in Fig. 3(a), the two and only two feasible imaginary boxes that can be interpreted are those in Fig. 3(b) and Fig. 3(c), so that 1) their edges are collinear with the rays; 2) their edges are either all on or all not on the rays; 3) the three faces formed by the three edges are visible. If as shown in Fig. 3(d), that TROVE feature belongs to a different type. In such a case, among the three faces that are formed by the three edges, one must be occluded as shown in Fig. 3(e). In this case, the ray that is not the side of the largest angle should be flipped so that the feature is transformed into a standard type. It is noteworthy that the two included angles of the new imaginary box with the flipped ray as their side will be the supplementary angles of the corresponding original ones. One feasible interpretation after the flipping is illustrated in Fig. 3(f). In the following discussion, all features are the standard type.
The objective frame is also uniquely defined for each imaginary box. The object frame is a right-hand Cartesian coordinate system with the origin at the box’s vertex which is the intersection of the three visible faces. As shown in Fig. 3, the y-axis is defined to be collinear with the vertical edge of the box. The x-axis is defined to be collinear with a horizontal edge of the box. The box is then in the positive y-direction and positive z-direction of the object frame. Note that the included angle by the two horizontal edges can be either acute, right or obtuse. Therefore, the z-axis is not necessarily aligned with any edge of the box. Furthermore, the box is imaginary that its edges do not necessarily overlap with any physical edges.
II-A3 Properties
The three rays of a TROVE feature have three included angles. Recall that the corresponding included angles in 3D space are either right between vertical and horizontal edges or a known angle between two horizontal edges, which is smaller than as a property of a hexahedron. Denote the angle between two horizontal edges as and the corresponding projected angle in the image as . Denote the projection of two angels in the image, each made by one vertical and one horizontal edge, as and respectively. In this paper, the direction of an edge means the direction that points from the vertex to the other end.
The properties can be summarized as: 1) in all cases; 2) if , and ; 3) if , ; 4) if , and with at most one belongs to . These properties are the premises of the uniqueness of the analytic solution in the following section. They can also be utilized to screen out incorrect detections, identify horizontal or vertical edges and estimate the orientation and relative height of the observed structure. The proof is given in the following paragraphs.
Definitions, notations and basic properties of the model are given before the proof of the properties. Since the projected vertex is at the principal point, the vertex of a TROVE structure can be translated onto the principal point for convenience without changing the projected angle. An illustration of a translated TROVE structure and its projection is shown in Fig. 4, where three unit segments , and belong to the three edges of the TROVE structure. They are projected as , and , respectively. In the earth frame, and are horizontal while is vertical. follows the positive x- and y-direction of the object frame and subsequently follows the cross product . Without loss of generality, the TROVE structure is rotated around the z-axis so that is on the positive x-axis. is the focal point at the origin of the camera frame, while is at . Denote as and as . Positive signs of mean that point to the positive direction of z-axis. Note that the projection of an edge has to be observable, therefore . Denote the angle between and the positive x-axis in a counterclockwise direction as , the angle between and as , the angle between and as . and are projected from the angles between the horizontal edges and the vertical edge of the TROVE structure. For clarity, and are not annotated in the figure.
The position of in the camera frame can be found as and in the camera frame as . The projected point and can be expressed in a homogeneous form in the image frame as and . The vectors in the camera frame pointing to the same direction as and are denoted as , and , respectively. The corresponding projected vectors in the image frame , and are denoted as , and , respectively. Since vector magnitude does not change the concerned included angles, these vectors can be chosen as unit vectors following the original direction as:
[TABLE]
By dot product, it can be calculated that:
[TABLE]
It is noteworthy that and . By cross product of , three vectors are obtained, which are denoted as respectively. These three vectors are normal to the three faces of the imaginary box and pointing away from the box as shown in the figure. Denote the element of a vector as . Note that all faces are visible and cross the principal point. Hence, their normal vectors’ z-components are negative:
[TABLE]
Since , the vertical edge can never point to the focal point. From (14), one can easily obtain .
As the premise for further derivations, the authors first prove that in all cases.
Study the case of . If , namely . By multiplying the two sides of (13) and (15) one has , which is a contradiction. Therefore, cannot both be negative, i.e. cannot both point towards the focal point. One must have . Assume , namely . Without loss of generality, suppose . By the assumption, one has:
[TABLE]
When , substituting into (16) and (13) yields a contradiction. Thus, . Substituting (15) into (16) gives:
[TABLE]
which contradicts in the range of . Therefore, the assumption must be false and when .
Study the case of . In this case one and only one angle can be negative. Without loss of generality, suppose . Substituting by (12), can be rewritten as:
[TABLE]
Since , (13) and (15) can be transformed into:
[TABLE]
Note . Substituting (20) into (19) yields:
[TABLE]
By (21), one knows that . Further note . (22) must be greater than 0. Thus, .
With the previous efforts, the properties of the feature with respect to the properties of the observed structure can also be derived. The properties are discussed regarding the range of in three cases.
Case 1:
First, is proved. Assume , namely . Note that from (12) when . gives:
[TABLE]
Note it is always true that . Obviously, the expression in (24) is less than 0, which contradicts the fact that . Therefore, the assumption must be false. Since it was previously pointed out that cannot both be negative angles, .
Second, for any two orthogonal vectors starting from the origin in 3D space, if their projected included angle must belong to (the proof is omitted for brevity). Since , it can be concluded that and .
Case 2:
Similar to Case 1, it can be proved that . All the projected angles included by the mutually orthogonal edges must .
Case 3:
Study the case where . For any two orthogonal vectors starting from the origin in 3D space, if their projected included angle must be (the proof is omitted for brevity). Hence, one of and will be a right angle. If , it is obvious that from (24) . If their projected included angle must belong to (the proof is omitted for brevity). Hence, one and only one of and will be an acute angle. In summary, one of the following statements will be true: 1) and with at most one of and equals to ; 2) and one of and belongs to with the other belonging to .
II-B Edge Detection
Three adjacent faces of a cuboid are colored in red, green and blue, respectively referred to as the top, left and right faces. Multi-thresholding is applied for color segmentation, concept of which was introduced in [23]. The standards of labeling a pixel are chromaticity, the proportion of each RGB value, and intensity, the absolute value of each primary color. The pixels at the edges are often labeled as none of the target colors, where one color transits to another. An example of recognized patches and the x-axis, y-axis, z-axis of the object frame are shown in Fig. 5.
The edges are found at the pixels that neighbor more than one type of color pixels. One can find the edge by examining every pixel whether it has neighbors of two types of color pixels. Direct implementation of this logic turns out to be computationally intensive since one needs to navigate through all the pixels and examine all their neighbors. Specifically with a search area of a window, to determine if a pixel belongs to one of the three edges all its 8 neighboring pixels have to be examined. For a image, it requires about 50 million operations, let alone a search window. Even for a image, it still requires about 22 million operations, which is demanding for a processing unit especially on payload-limited robots such as UAVs. The process can be optimized by shifting color patches [24]. As shown in Fig. 6, the patches are shifted towards the gap. Then the candidate points for the edge detection are found in the overlapping area.
However, there exists a contradiction that one needs to know the direction of a gap before the gap is even found. To solve this dilemma, one can make use of priori estimates of attitudes, either from itself or other sensors. If the camera frame’s upward direction also points upward in the Earth frame, the top face of the cuboid is on the upper side compared with the other two faces. To detect the projection of the y-axis edge, the top face is shifted downward and leftward. Overlapping area of those two shifted patches are the cluster of the candidate pixels. Similar methods apply to detect the other two edges and also the case where the camera is upside down.
Different from [24], this propose method is not realized by copying and writing pixel values into a new position but optimized by examining the pixel at the position where it is supposed to be shifted from. Pseudo code of this process, taking the case when the camera is not upside down, is illustrated in Alg. 1. It is noteworthy that the algorithm takes unrectified images and only rectifies the coordinates of the recognized edge pixels. Specifically for a pixel , if it belongs to none of the target faces or the top face the program skips to the next pixel. If belongs to the right face, one examines the pixel to the left of the current whose distance to is defined by a search width . If belongs to the left face, the middle pixel between and belongs to the y-axis. The coordinate of is rectified according to stereo parameters and then stored for line detection. Then the program continues to the next pixel. Similar methods apply to the other edges. Note that at most three operations are performed for each pixel and the overall number of operations for a image has been reduced from 50 million to less than 3 million on average. Having the candidate coordinates for each edge, the authors use the Random Sample Consensus (RANSAC) method [25] to find a line from a cluster of points. In image processing, the method of Hough Transform is also commonly adopted to detect lines through points. But this is an exhaustive method that calculates all possible lines through every point. In this scenario RANSAC is far more efficient, especially under the condition that there exist many outliers. In the experiment, RANSAC is more than 40 times faster than the Hough Transform method.
II-C Vertex Detection
The location of the vertex where three edges intersect should also be estimated. The necessity of vertex location information will be discussed in the following section. In practice, the three detected edges never intersect at exact one point, and thus an estimate is necessary. A line in 2D space passing through can be represented by , where is the signed normal distance from the origin to the line; is the angle between the normal of the line and the positive -axis in a range of .
In this paper, the vertex is found at the position where the sum of its squared distance to the three edges is minimized. Denote the position of a vertex as . Let a line in the Hough Space be . The signed distance from this line to the vertex can be represented by:
[TABLE]
Let denote the projection of the three edges of a TROVE structure, respectively. Denote:
[TABLE]
Their distance to the vertex can be represented in a simple matrix form: . The estimated position is found by:
[TABLE]
Subsequently the sum of squared errors can also be obtained, which is utilized to screen out invalid vertices.
III Pose Estimation
The previous section has discussed the properties of a TROVE feature associated with their counterpart: a TROVE structure in 3D space and the detection methods for the projected edges and the vertex. Knowing the edges and vertex, one can estimate the attitudes and positions of the camera in the object frame. The initial orientation is defined that the x-axis and y-axis of the camera frame are aligned with those of the object frame. The attitude is defined as the rotation from the initial orientation to the current one in the object frame. By comparing the vertex in two stereo images and integrating the attitude estimate, the position of the camera can be recovered.
When a line is projected onto an image, the line must be on the plane that passes through the focal point and the projected line. Once a TROVE feature is detected, three planes that the corresponding three rays lie on are also determined. For simplicity, the three edges of the imaginary box are denoted as x-, y- and z-edge. The x- and y-edge align with the x- and y-axis of the object frame, respectively while the z-edge is not necessarily aligned with the z-axis. Denote the plane where the x-edge lies as the x-plane, that where the y-edge lies as the y-plane and that where the z-edge lies as the z-plane.
Three possible cases exist: all edges of the imaginary box point away from the focal point; only one edge of the imaginary box is perpendicular to optical axis; only one edge of the imaginary box points towards the focal point. One of such configurations is depicted in Fig. 7. The vertical edge of the imaginary box intersects the optical axis with an angle . The orientation of the imaginary box can be recovered by finding the angle . The following contents discuss the approaches to find in the three configurations.
III-A All Edges Point Away from Focal Point
When all edges point away from the focal point, . An illustration of this case is shown in Fig. 7. Let the green plane be the x-plane, the red plane be the y-plane and the blue plane be the z-plane. The long dashed line is the optical axis of the camera. Those three planes are determined by the focal point and the projections of the respective edges. Since the projection of the vertex is on the principal point, the x-, y- and z-plane have a mutual intersection which is the optical axis. The vertex of the object must also be on the optical axis. Denote the vertex of the imaginary parallelepiped in the object frame as . Suppose is on the y-edge of the imaginary parallelepiped, where is on the y-plane. Construct xz-plane that passes through and are perpendicular to . has an angle of with the optical axis.
As being pointed out in the previous section that the vertical edge must point away from the focal point, is constrained in the range of . Construct a perpendicular line to the optical axis from intersecting the optical axis at . The xz-plane would intersect the x- and y-plane respectively at two lines: and . and are chosen so that and are perpendicular to the optical axis, hence and are coplanar. Denote the angle as and as .
Since the x- and z-edge are perpendicular to the y-edge, they must be on the xz-plane. Further, the x-edge must be on the intersection line of x-plane and xz-plane. Therefore, must be collinear with the x-edge. Similarly, must be collinear with the z-edge. In such a case, should equal to the known angle between the two horizontal edges of the object. Now the problem becomes straightforward that to find an given .
A closer inspection of the space near is illustrated in Fig. 8. Note that , and are perpendicular to . The angles of is the included angles between y-plane and z-plane, and the angle of is the included angles between x-plane and z-plane. Since x-, y- and z-plane all intersect at the optical axis, is actually the included angle between projected y-edge and z-edge in the image while is the included angle between projected x-edge and z-edge. Since the slope of edge projections has been obtained from edge detection, and are known.
As denoted in Fig. 8, let be , be , be , be , be , be and be . Since plane is perpendicular to , one has:
[TABLE]
Note that plane is perpendicular to , one has:
[TABLE]
Applying the law of cosines for triangles to , , and gives:
[TABLE]
By substituting (28), (29), and (30) into (31) and (32), it can be obtained that:
[TABLE]
Combining (33), (34), (35) and (36), one can derive:
[TABLE]
By denoting as , as , as , as and as , (37) can be rewritten as:
[TABLE]
the solution of which must satisfy:
[TABLE]
Denote as . Solving (38) gives:
[TABLE]
Note that . The solution uniqueness of indicates that of .
It is obvious that the existence of a solution is guaranteed in that the image is from the projection of an existing instance. As having been proved in Section II-A3, in this case. Since is always greater than 0, only one feasible solution is available when (so that only one solution is greater than zero). When , both solutions are positive and . Criteria (39) is then used to examine the feasibility of the solution. Denote the two solutions as and . Study the product:
[TABLE]
When , and only one solution is available. When and , must be negative. Thus, product (41) must be smaller than zero and only one solution satisfies (39). Therefore, only one feasible solution is available in the case where .
is known as priori knowledge and are found by edge detection. In summary, is uniquely determined in a closed form as:
[TABLE]
III-B One Edge Perpendicular to Optical Axis
Without loss of generality, suppose z-edge is perpendicular to the optical axis. An illustration of this case is shown in Fig. 9. As having been mentioned in the earlier Section II-A3, the only possible range for in this case is and must be . The problem becomes much simpler with a straightforward unique solution:
[TABLE]
which is true for either the x-edge or z-edge is perpendicular to the optical axis. Because is always negative in this case, (43) gives the same result as (42).
III-C One Edge Points to Focal Point
As having been mentioned in the earlier Section II-A3, the only possible range for in this case is . It has properties that and . Without loss of generality, suppose the z-edge points towards the focal point. An illustration of this configuration is shown in Fig. 10. is extended in the opposite direction to so that . All the other notations share the same definition as Section III-A. Following a similar method, one can obtain:
[TABLE]
the solution of which must satisfy:
[TABLE]
This inequality is easily satisfied since . Note that the only difference from (44) to (37) is a minus sign. In solving , the equation is exactly the same as (40). Since is always smaller than when , will have two feasible solutions in a closed form as:
[TABLE]
Two roots will be different when:
[TABLE]
In summary, can be uniquely determined in a closed form in all cases except the case where and (47) all hold. This exceptional case will be discussed at the end of the following subsection.
III-D Recover Attitude from
A rotation matrix is defined in the camera frame that aligns the object frame with the camera frame. Note that is identical to the attitude of the camera in the object frame. Fig. 11 illustrates a sequence that rotates an object into alignment with the camera frame. The object is represented by a cuboid and the camera is represented by a horizontal pyramid. The top row displays the camera and the object in 3D space. The bottom row displays the projected object in the image. The origin of the camera frame is at the focal point of the camera. The red, blue and green arrows represent the x-, y- and z-axis of the camera frame, respectively. Each column represents a phase during rotation in a sequence from left to right. First column: the original positions of the object and the camera are depicted; second column: rotation, denoted as a matrix , is applied around the focal point so that the vertex is projected onto the principal point; third column: rotation, denoted as a matrix , is applied so that y-edge is projected vertical in the image; third column: rotation, denoted as a matrix , is applied so that y-edge is aligned with the y-axis; forth column: rotation, denoted as a matrix , is applied so that x-edge is aligned with the x-axis. Thus far, the object frame is in alignment with the camera frame. The following paragraph elaborates on finding and subsequently the attitude of the camera.
As having been previously derived in Section II-A2, the rotation axis and angle of can be determined by (2). Rotation is applied so that the y-edge is projected vertical in the image. The rotation axis is the z-axis of the camera frame while the rotation angle is the included angle by the projected y-edge and the y-axis of the image frame. The rotation axis of is the x-axis and the angle is . By using the notations in Fig. 7, rotation is to align the x-edge with the x-axis of the camera frame after the xz-plane is rotated horizontal. Denote the rotation angle as . Obviously, . It can easily be calculated that for all aforementioned three cases in Section III-A, III-B and III-C . Thus, can be expressed as:
[TABLE]
There is still one more process before the actual attitude of a camera is recovered. Whenever a TROVE feature is detected, two interpretations are possible as illustrated in Fig. 3(b) and 3(c). If the attitude in Fig. 3(b) is expressed as (48), the attitude in Fig. 3(c) can be expressed as , where is the rotation around the z-axis by . Two methods can be applied to discard the incorrect interpretation.
Method 1: if an image captures more than one TROVE feature that has parallel frames to each other or the same feature is captured by two parallel cameras simultaneously (the case of a stereo camera), the result from the correct interpretation will always be consistent but the result from the incorrect one will vary. One simply accepts the consistent result as the estimation. Proof is give as follows. If two features have parallel frames, the attitude estimate should be the same. Let features 1 and 2 yield the same correct attitude estimate:
[TABLE]
where the subscripts 1 and 2 represents the two features. Then the incorrect estimate can be expressed as:
[TABLE]
Suppose the incorrect estimates are equal. Equating (51) (52) yields:
[TABLE]
It can be proved that the only possible instances are or is a rotation around the z-axis as . Recall that is determined by the position of the vertex in the image. Different features cannot share the same vertex in one image and the vertex of a structure will be projected differently in the images by different parallel cameras. Therefore . is a rotation around the axis . It can also be proved that cannot be a rotation around the z-axis unless . Hence, the assumption must be false and the incorrect estimates will always be different across different features in an image or across the same features in different images captured by parallel cameras.
Method 2: the interpretation of Fig. 3(b) is correct only if the camera has a negative pitch angle, namely the z-axis of the camera frame points downward. Similarly, the interpretation of Fig. 3(c) is correct only if the camera has a positive pitch angle. If the inclination of the camera to the horizontal surface is known, one can directly discard the incorrect interpretation. Method 2 appears to have a paradox where one needs to know the attitude to estimate the attitude. By the help of priori estimates or other sensors such as accelerometers, one can distinguish whether the camera points upward to downward. Even a rough estimate can help discard the incorrect interpretation for the interpretations have obvious discrepancies on the sign of the pitch angle.
Another rare but possible case where the solution is not unique is that and (47) all hold as described in Section III-C. That means the angle formed by the two horizontal edges are obtuse and one of the horizontal edge points towards the observer. When one edge points towards the observer, one face will usually be occluded. But it is still possible that the three concerning faces are visible. In this case, has two solutions unless (47) does not hold. One characteristic of this case is that one and only one of and is an acute angle. One only needs to take measures when this characteristic has been observed. The two methods to discard the incorrect solutions are almost the same as the previous ones to discard incorrect interpretations. The only difference is in Method 2 that the pitch angle could be of the same sign in this case, therefore a relatively more accurate priori estimate is needed.
III-E Recover from Attitude
If one knows the relative attitude to the imaginary box, recovering is straightforward as it is uniquely determined by . Suppose that the relative attitude is obtained. Since can be directly estimated from the image, one can easily obtain from (48) that:
[TABLE]
Expanding the rotation matrices yields:
[TABLE]
With the value of available, can be directly obtained.
The angles of and are obtained from image processing. When , can be computed by (37). When one of and is , can be computed by (43) as . When one of is less than , can be computed by (44).
III-F Recover Position
The vertex of a TROVE structure is often a stationary point of the environment, such as the corner of a room and the apex of a building. For a robot to autonomously navigate through a certain environment, the relative position to the environment is often much more important than the absolute position in the Earth frame.
The camera is a binocular camera. By the disparity of the same vertex in two images, the relative position of the camera to a stationary point in space is obtained. The position of a vertex in each image is not detected by investigating the pixel itself or neighbouring groups like other stereo matching methods. The vertex is determined as the intersection of three detected lines, each of which is estimated by hundreds of pixels. Therefore, the accuracy can easily reach a sub-pixel level. Despite errors of installation and calibration, the result still remains in high accuracy, detail of which is given in Section IV.
IV Experiment and Result
In this section, the experiments that evaluate the accuracy and effectiveness of the proposed method are presented. Attitude estimation is verified by comparison with the ground truth and the conventional method of the Complementary Filter. Position estimation is verified by direct comparison with the ground truth. The camera and IMUs are mounted on a board. The board is manually moved around to simulate a robot navigating in an unknown environment. Infra-red sensitive markers are also mounted on the board for the motion tracking system (OptiTrack) to capture poses which are then used the ground truth. A colored cuboid is placed horizontally on the ground as the object the robot refers to for ego-states estimation. All the data are recorded and processed online. The details of the system architecture and experiment setup are enclosed in the following subsections. Since attitudes are measured as rotation from an initial pose, having a consistent initial pose in all sensors’ frames is pivotal to evaluate the accuracy of estimates. The description of calibration process is also enclosed in the following subsection. It has been observed that without calibration the errors would be more than threefold.
IV-A Experiment Setup
The saturation, white balance and sharpness of the camera have all been fixed so that the color in RGB values is consistent. The resolution of the camera is set as and , respectively. As shown in Fig. 12, the camera together with IMUs and infrared sensitive markers are rigidly mounted onto a flat board. The top face of the board is referred as the horizontal plane of the board. The camera is a ZED Camera manufactured by Stereolab. The baseline of the stereo camera is . The focal length of the lens is 1049 and 702 in pixels at a resolution of and , respectively. The IMU sensor is MPU6050, which includes an accelerometer of a range of g and a gyroscope of a range of 2000\text{,}\mathrm{\SIUnitSymbolDegree}\text{,}{\mathrm{s}}^{-1}$$. The IMU sensor has also been calibrated to offset the misalignment of the horizontal plane between the IMU frame and the Earth frame. The infrared sensitive markers form a rigid body which is registered in the optical tracking software. The optical tracking software together with the infrared cameras are the OptiTrack system developed by NaturalPoint Inc. OptiTrack cameras can capture the markers and offers the 6-DoF states of the rigid body in real-time. The infrared cameras are mounted on the walls of the laboratory. The accuracy is within millimeters and the latency is at most . The measurement from the OptiTrack system is used as the ground truth in this paper. In the experiment, the Earth frame actually refers to the frame that is defined in the OptiTrack system.
A cuboid is placed on the ground of the laboratory, as shown in Fig. 13. Three adjacent faces of the cuboid are colored in red, green and blue, respectively. In the experiment, captured pixels of the red, green and blue face are around , and in RGB values, respectively. As previously discussed, color segmentation is based on the thresholds of chromaticity and intensity. Those colors share similar characteristics so that the standards are the same for each color as out of in intensity and in chromaticity. Additional lighting is applied to the side of the cuboid to compensate the insufficient luminosity in the laboratory. It is apparent that all the edges of the cuboid passing through the concerning vertex are perpendicular to each other. As having been proved in Section II-A3, the edges of the imaginary box must all point away from the focal point. With , (42) yields:
[TABLE]
The data from the camera and IMUs are transmitted through a wire to a desktop computer as the base station. Then the data are processed and stored by the computer. The measurement from OptiTrack system is received through local wireless network by the same computer. Fig. 14 illustrates the system architecture. Using the USB 3.0 interface of the stereo camera, images can be captured and transmitted at at a resolution of and at a resolution of . Both data from IMUs and OptiTrack system are received at . Whenever data are received, time stamps are recorded for synchronization. When IMU data are available, readings from the accelerometer and gyroscope are fused by the Complementary Filter for an attitude estimate. Whenever an attitude estimate from an image is available, the priori estimate is incremented by rotational rates and then fused with the image estimate. In the mean time, the disparity of the vertex on stereo images is found for position estimation. Attitude estimates are also used to obtain the position in the object frame.
The computer is of a moderate configuration with an Intel i7-7700 quad-core CPU running at . No graphics card is used for the processing. The program is in C++ language utilizing multithreading and OpenCV library. Processing time (from Steps 2 to 23 in Alg. 1 and attitude estimation) is recorded for each image. For images at a resolution of , 90 pairs of stereo images are processed 20 times to take the average. For each pair of stereo images, namely two images, it takes in total or for each image. For the resolution of , 1000 pairs of stereo images are processed 20 times to take the average. For each pair, namely two images, it takes in total or for each image. Table I shows the detailed time spent in the processing for each image. Compared with image processing, the other processing time is trivial. However, the image transmission time turns out to be much longer than the processing time. The update frequency is largely determined by a camera’s capability of capturing and transmitting images. The latency of each image is about for both resolutions.
IV-B Camera Calibration
As discussed in [26], camera distortion includes radial distortion, centering distortion, thin prism distortion and total distortion. In this paper only the edge pixels are of the concern, therefore the rectification is only applied to the found edge pixels just before line detection. Many tools can be utilized to calibrate distortion, one of which is the calibration tool provided by MATLAB as discussed in [27]. The images (actually the coordinates of pixels) used by the proposed algorithm in this paper have all been rectified. Another calibration to be conducted is the attitude difference between the two lenses of the stereo camera, because the two lenses are not installed perfectly facing the same direction.
The last calibration is to ensure that the OptiTrack system frame, experiment board, the IMU and the camera share the same horizontal plane. To evaluate attitude estimate, inclinations to the horizontal plane are used. The reasons for referring to inclinations are: 1) the horizontal plane of all the concerning frames is verified while aligning the other axes of all frames can be challenging. Direct comparison of attitudes (such as comparison in Euler angles) will inevitably contain those systematic errors; 2) the attitude obtained from the conventional Complementary Filter cannot recover the yaw angle in the Earth frame. Thus comparing the attitude is not convincing; 3) that such information is pivotal to stably and accurately control a UAV. The attitude of an object is defined as the rotation from an initial orientation to the current one. In the experiment, the initial orientation of the camera is defined when the board’s top face is placed horizontally, verified by a spirit level. Since the top face of the cuboid is placed horizontally which is also verified by a spirit level, the initial orientation of the board in the OptiTrack frame and the camera in the camera frame share the same horizontal plane. However, the top face of the board and the lenses are not horizontally parallel due to installation errors. Such a difference should be estimated and offset. In the experiment, cameras are placed at various positions and attitudes to capture images of the cuboid. Estimates from images are compared with the ground truth. The result shows that when in a resolution of the attitude of lens with respect to the board is -2.44\text{,}\mathrm{\SIUnitSymbolDegree}1.19\text{,}\mathrm{\SIUnitSymbolDegree}-0.01\text{,}\mathrm{\SIUnitSymbolDegree} in Euler angles in a rotation sequence of x-, y- and z-axis. When in a resolution of the difference is -2.39\text{,}\mathrm{\SIUnitSymbolDegree}1.17\text{,}\mathrm{\SIUnitSymbolDegree}0.03\text{,}\mathrm{\SIUnitSymbolDegree}. Without calibration the difference will introduce a bias of more than in inclination estimation.
IV-C Fusing Method
An IMU is one of the common devices to obtain attitudes for various types of robots. In the experiment, the attitude estimates from cameras are fused with those from IMUs to improve accuracy. Attitude estimates from IMUs are obtained by the Complementary Filter as discussed in [28]. A weighting is assigned to the measurements from the accelerometer in the Complementary Filter. In theory, the yaw angle, i.e. the rotation of an object around the vertical axis, cannot be determined solely by IMUs. But it can be estimated by the proposed method in the object frame.
Having estimates from cameras, one can fuse them for more accurate results. Even the estimates from cameras are already more accurate than IMUs. By such fusion the estimates from cameras are not only further improved in accuracy but also increased to . IMUs can run up to a thousand hertz while cameras can often only run at a few dozens of hertz. The fusion happens only when an image estimate is available. Suppose an image estimate, denoted as in a quaternion form, is available at time . The previous estimate is . By integrating the last rotational rates from the gyroscope during the period from to , an increment in attitude can be obtained as . An estimate based on rotational rates integration can be obtained as . The fusion is achieved by a Slerp interpolation [29] with a weighting assigned to image estimates:
[TABLE]
where represents the conjugate of .
IV-D Optimal Weighting
To find the optimal weighting, pairs of and are applied to the fusion. Two sets of data are recorded in a period of , during which the board is constantly moved around. The data of images are recorded at , consisting of 1801 frames of stereo images. The data of images are recorded at , consisting of 3601 frames of stereo images. IMU data are recorded at . The optical tracking data is referred to as the ground truth, and are recorded at .
Fig. 15(a) and Fig. 15(b) present the (Root-Mean-Square) RMS errors for various pairs of and by fusing images of resolutions of and , respectively. The z-axis is cut off at . The red plane represents the error of the Complementary Filter with the optimal while the green plane represents the error of sole image analysis. It can be obviously observed from the figure that the results from the fusion adopting the optimal weighting is better than both the optimal Complementary Filter and the image analysis with regard to RMS errors. It is noteworthy that when the fusion method degrades to the Complementary Filter. The pair that results with the smallest error is selected for the latter experiment. For the Complementary Filter, the optimal weighting is . For images of a resolution of , the optimal pair is and . For images of a resolution of , the optimal pair is and
The result suggests that with image estimates the estimation will be most accurate without any contribution from the accelerometer. Not only more accurate estimates are obtained by the fusion, but also estimates’ frequency increases up to . The fusion happens whenever an image is available. Therefore, the update interval is not constant after fusion. All the attitude estimation in the following experiments has adopted the optimal weighting.
IV-E Attitude Estimation Result
First, the camera is held by a tripod to keep a stationary pose when taking each image of the object. In this static scenario, image estimates are compared with the ground truth to verify the accuracy. Second, the board hovers and maneuvers simulating a navigating UAV to capture images dynamically. In this dynamic scenario, the image estimates suffer from motion blurs and latencies. Videos at and are recorded. By comparing the estimates from the Complementary Filter, images, the fusion with the ground truth, the accuracy is evaluated. The rest of this section discusses the results in the two scenarios.
IV-E1 Static Scenario
Other than the data collected for calibration, another 145 pairs of stereo images at are captured at various poses and distance to the observed object. Out of the total 290 images 278 have recognized the feature. For each image, the average of error magnitude , the standard deviation and the RMS error are all listed in Table II. If one averages the estimates from the two images of each pair, obvious improvement can be achieved as shown in the table. Similarly, 89 pairs of stereo images at are captured and analyzed. Out of the total 178 images 173 have recognized the feature. As expected, the estimates are less accurate than images at but the RMS errors are close between the two resolutions. After averaging two estimates for each pair, trivial improvement has been observed. The experiment indicates that the proposed method is of high accuracy, given that only a stereo camera is used. Images at are more accurate than those at . Averaging two estimates for each pair yields obvious improvement for images at , but trivial improvement for images at . In the experiment it has been observed that below the accuracy level of the estimation is more susceptible to calibration and systematic errors.
IV-E2 Dynamic Scenario
In a more practical case, a navigating robot constantly changes its attitudes and positions. The moving of the camera and inconsistent latency of sensors all affect the result. The effectiveness and accuracy needs to be evaluated in such a dynamic scenario. The experiment also compares the accuracy between the conventional method and the proposed method.
For both the Complimentary Filter and the image fusion method, the initial attitude estimate takes the measurement from the OptiTrack system. By such means, the estimation spends much less time to converge at the beginning and it mitigates the influence of variations of initial conditions. Because of such an adjustment, the first ten seconds of data are excluded in analysis. It has been observed a latency around for the camera. The image estimates have been shifted by the latency to be compared with the ground truth. For each pair of stereo images, the attitude is found by averaging the estimates from the two images. All the data are recorded and processed online.
For 1080p videos, the estimates of inclination angles are shown in Fig. 16. The figure includes the ground truth from OptiTrack system, IMU estimates (the Complementary Filter), image estimates and estimates from the fusion. It is obvious from the figure that all estimates roughly overlap with the ground truth all along. Only IMU estimates occasionally have notable deviation from the ground truth. The bottom plot of Fig. 16 shows the errors of each method. The numeric results of errors are listed in Table III. It is clear that the image estimates and fusion estimates are notably more accurate than those from IMUs. It is noteworthy that the fusion has a significantly smaller standard deviation than other methods and an update frequency of (with inconstant intervals) while images only update at . Another phenomenon in the figure is that the error of the Complimentary Filter usually reaches a local extremum when rotation changes abruptly. This is caused by the inherent drawback of the Complimentary Filter that it assumes the concerning object experiences no acceleration other than gravity. It is at the point when the pose changes fast, that assumption leads to the greatest errors. The proposed algorithm does not suffer from any of such assumptions and gives more stable result.
For 720p videos, the estimates of inclination angles are presented in Fig. 17. It has also been observed that all estimates roughly overlap with the ground truth all along. Only IMU estimates occasionally have notable deviation from the ground truth. The bottom plot in Fig. 17 shows the errors of each method. Compared with 1080p videos, the errors from image estimates have more sharp peaks. Further inspection into these peaks reveals that these errors are caused by noises in line detection. When a resolution reduces from 1080p to 720p, the number of edge pixels drops significantly. Thus, the line detection is more susceptible to outliers. The numerical results of errors are also listed in Table III. Similar to the 1080p videos, the image estimates and fusion estimates are notably more accurate than those from IMUs. The fusion has a significantly smaller standard deviation and an update frequency of (with inconstant intervals) while images only update at .
It is surprising that 720p videos yield estimates in the similar accuracy levels of 1080p videos after fusion, given that sole image estimates from 720p videos are relatively less accurate. The gyroscope in an IMU is generally very precise in a short term. The attitude estimates are deteriorated by noisy accelerometer measurements in the Complementary Filter. In fusion, image estimates completely replace the role of an accelerometer that to suppress drift in gyroscope estimates while maintaining high accuracy. Higher frequency of image estimates provides more opportunities to suppress the drift. This is likely one of the reasons why 720p videos give similarly accurate estimates after fusion. Nevertheless, the standard deviation of images estimates from the 720p video are still significantly larger.
In the two experiments, the errors from the conventional method drops significantly by more than in RMS errors after fusion. With regard to the standard deviation, the estimates become notably more stable after fusing image results. Even the estimates from solely images are evidently more accurate than the conventional method. The fusion combines the advantage of both methods that it has higher frequency and more accurate estimates. Considering that a 720p video can output 60 FPS in contrast to 30 FPS from a 1080p video and is much less computationally intensive, a resolution of is preferred for attitude estimation.
In practice, visual sensors have been hardly utilized for attitude estimation for robots. IMUs are much cheaper and easier to implement, and the accuracy of conventional method is sufficient in many scenarios. Vision sensors usually demand costly computation, thus suffering from low update frequency and long latency. However, the proposed method has processing time of only and an update frequency up to for a 720p video or even much higher after fusion. The accuracy is also notably higher than the conventional method. Imagine a scenario when a UAV, such as a quadrotor, performs an aggressive maneuver to navigate through chokes or obstacles. An accurate and timely attitude estimate is the key to a precise control. Moreover, the conventional method suffers the most from the abrupt acceleration and deceleration where image estimates can play as a preferable complement.
IV-F Position Estimation Result
The same sets of data as previous attitude estimation are analyzed online for position estimation. As having been previously explained, the proposed method can locate the position of vertices across a pair of stereo images. Thus, the position of the vertex in the camera frame can be found by triangulation. Since one already has the relative attitude in the object frame, the position of the camera in the object frame can be directly found by .
The the ground truth and estimates of trajectories of the observer are displayed in Fig. 18. It is noteworthy that the vertex of the object is at the origin and the x-, y- and z-component of the camera position is negative in the object frame. The trajectory estimated from a 1080p video smoothly follows the ground truth as shown in Fig. 18(a). The trajectory estimated from a 720p video also follows the ground truth but with slightly more spikes, as shown in Fig. 18(b). Similar to the errors in attitude estimation, the spikes are caused by noise in line detection. An incorrect edge line leads to deviation of the vertex and an incorrect attitude estimate, which both deteriorate position estimation.
The trajectories and corresponding errors in x-, y- and z-direction of videos at resolutions of and are displayed in Figs. 19 and 20, respectively. Both estimates follow close to the ground truth. The estimates from the 1080p video are more smooth, whereas occasional sharp errors present in estimates from the 720p video. For binocular stereo vision, the depth of an object is determined by where is the stereo baseline, is the disparity and is the focal length. The depth of an object is the z-component of the object position in the camera frame. By derivation and transformation, one has . Similarly, one can determine that and , where is the position of the vertex in the image. The equation indicates that the depth error and a part of and error are approximately proportional to the square of disparity. Therefore, the errors in Euler distance are listed against depth as shown in Table IV. The results in the table suggest that estimates from the 1080p video are better in all the average error magnitude, standard deviation and RMS. Considering the fact that a 720p video can update at compared with of a 1080p video without compromising too much on accuracy, 720p videos are more preferable. It is also the common practice in SLAM implementation that frequency weighs more than accuracy.
The average and standard deviation of absolute depth errors is investigated and presented in Fig. 21. A number on the x-axis represents the range to itself, for example represents the range of . The figure indicates that the accuracy of depth is not strongly affected by resolutions. 1080p videos have obviously better accuracy over 720p videos only near the object. By assuming an error in disparity of one pixel, one can approximate corresponding depth errors by the equation of . The approximated depth errors for 1080p and 720p videos are also displayed in the figure, labeled as “one-pixel error”. As shown in the figure, all the average error magnitude is notably below the “one-pixel error” and the actual error of depth does not grow quadratically. The sudden rise for 720p videos near the depth of is caused by some incidental noise in line detection. In terms of disparity errors by , the further the camera the better the accuracy generally becomes. For example, the average disparity error for 720p videos is estimated to be 0.85 pixels at the depth of and 0.36 pixels at the depth of .
V Conclusion and Future Work
This paper proposed a novel feature, named as “TROVE feature”. By observing the feature using a color stereo camera in an environment that is rich in man-made structures, 6-DoF ego-states can be efficiently obtained in high accuracy. A TROVE feature consists of three rays and one vertex in an image. The feature is projected from a common structure, named as “TROVE structure”, on man-made buildings and objects. A TROVE structure consists of three edges, one vertical and two horizontal, intersecting at one vertex. These edges are usually the dominating edges in an indoor environment, with the vertex being the corner of a building, man-made objects and etc. Such a structure favors navigation as a stationary reference. Many characteristics of a TROVE feature are associated with the physical properties of the corresponding TROVE structure. Compared with many commonly used features as SIFT, SURF, FAST, LSD, ORB/ORB2 and etc., the TROVE feature is more rich in physical information. This can possibly give more clues when conducting tasks on data registration. The angle between the two horizontal edges is known as priori knowledge and can be any angle between [math] to . By imagining a parallelepiped out of a TROVE structure, attitudes and positions can be obtained regarding the frame uniquely defined by the parallelepiped. Definition and how such an imaginary parallelepiped can be constructed is given in detail. It is proved in this paper that only two possible configurations of the imaginary parallelepiped can be constructed from an image of the TROVE feature. In most cases, the solution is proved as unique. Easy-to-implement solutions are given to discard incorrect interpretations and solutions. The algorithm is very efficient that for an image at the processing time is merely and for an image at the processing time is only .
Experiments have been conducted to evaluate the effectiveness and errors in pose estimation. Compared with the conventional method utilizing IMUs, the proposed method has significant improvement in accuracy without any drift. By fusing image estimates, the update frequency has reached while RMS error drops by more than compared with the conventional method. It has also been discovered that different resolution can result in similar accuracy after the fusion. Although giving less accurate estimates, lower-resolution images can update much more frequently. More importantly, localization can also be achieved by the proposed algorithm. The RMS error in position is relatively small as and respectively for a 1080p video and a 720p video. In the context of indoor environment, the accuracy is sufficient for most unmanned robots to navigate. Note that a 720p video offers estimates at and consumes much less computation without compromising too much on accuracy. Thus, it is more desirable and efficient for implementations especially for robots that have limited payload capability such as UAVs.
As a preliminary work to evaluate the feasibility and accuracy of the proposed method, the structure to be observed is represented by a colored object in the experiment. Future work will extend the approach to more general cases, where actual indoor scenes would be captured for analysis. In the actual implementation, losing sight of any TROVE structures is a common challenge the method will encounter. An active gimbal will be mounted to lock the camera facing to the structure.
Acknowledgment
The authors would like to thank Carlos Ma, Ka Wah Lee and Wenyutian Xu for their kind help in setting up and conducting the experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Engel, J. Stückler, and D. Cremers, “Large-scale direct SLAM with stereo cameras,” in 2015 IEEE/RSJ IEEE/RSJ International Conference on Intelligent Robots and Systems , 2015, pp. 1935–1942.
- 2[2] R. Mur-Artal and J. D. Tardós, “ORB-SLAM 2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,” IEEE Transactions on Robotics , vol. 33, no. 5, pp. 1255–1262, 2017.
- 3[3] T. Pire, T. Fischer, G. Castro, P. De Cristóforis, J. Civera, and J. J. Berlles, “S-PTAM: Stereo parallel tracking and mapping,” Robotics and Autonomous Systems , vol. 93, pp. 27–42, 2017.
- 4[4] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International Journal of Computer Vision , vol. 60, no. 2, pp. 91–110, 2004.
- 5[5] H. Bay, T. Tuytelaars, and L. Van Gool, “SURF: Speeded up robust features,” in European Conference on Computer Vision , 2006, pp. 404–417.
- 6[6] E. Rosten and T. Drummond, “Machine learning for high-speed corner detection,” in European Conference on Computer Vision , 2006, pp. 430–443.
- 7[7] B. K. Horn, H. M. Hilden, and S. Negahdaripour, “Closed-form solution of absolute orientation using orthonormal matrices,” Journal of the Optical Society of America A , vol. 5, no. 7, pp. 1127–1135, 1988.
- 8[8] R. M. Haralick, D. Lee, K. Ottenburg, and M. Nolle, “Analysis and solutions of the three point perspective pose estimation problem,” in Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition , 1991, pp. 592–598.