Passive-Aggressive Learning and Control
Dimitar Ho, Nikolai Matni, John C. Doyle

TL;DR
This paper introduces a passive-aggressive control method for scalar systems that adaptively learns system parameters while ensuring stability under adversarial disturbances, balancing exploration and exploitation.
Contribution
It presents a novel controller that simultaneously stabilizes the system and learns unknown parameters, especially under adversarial conditions, with a natural optimization-based design.
Findings
Controller guarantees global stability and improves bounds on state deviation.
Effective in stabilizing unstable, adversarial system dynamics.
Demonstrated efficiency through numerical simulations.
Abstract
In this work, we investigate the problem of simultaneously learning and controlling a system subject to adversarial choices of disturbances and system parameters. We study the problem for a scalar system with -norm bounded disturbances and system parameters constrained to lie in a known bounded convex polytope. We present a controller that is globally stabilizing and gives continuously improving bounds on the worst-case state deviation. The proposed controller simultaneously learns the system parameters and controls the system. The controller emerges naturally from an optimization problem and balances exploration and exploitation in such a way that it is able to efficiently stabilize unstable and adversarial system dynamics. Specifically, if the controller is faced with large uncertainty, the initial focus is on exploration, retrieving information about the system by applying…
Click any figure to enlarge with its caption.
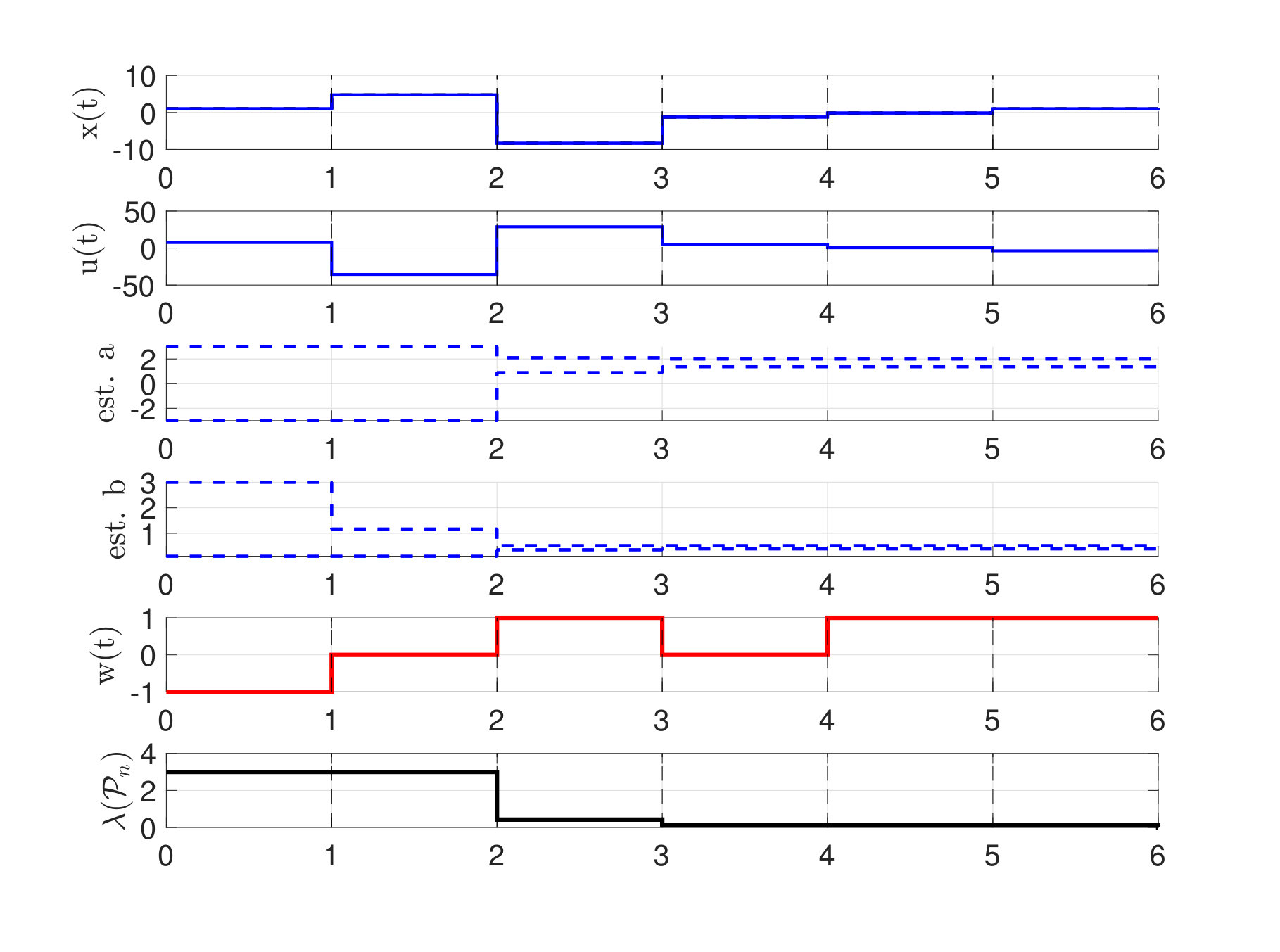 Figure 1
Figure 1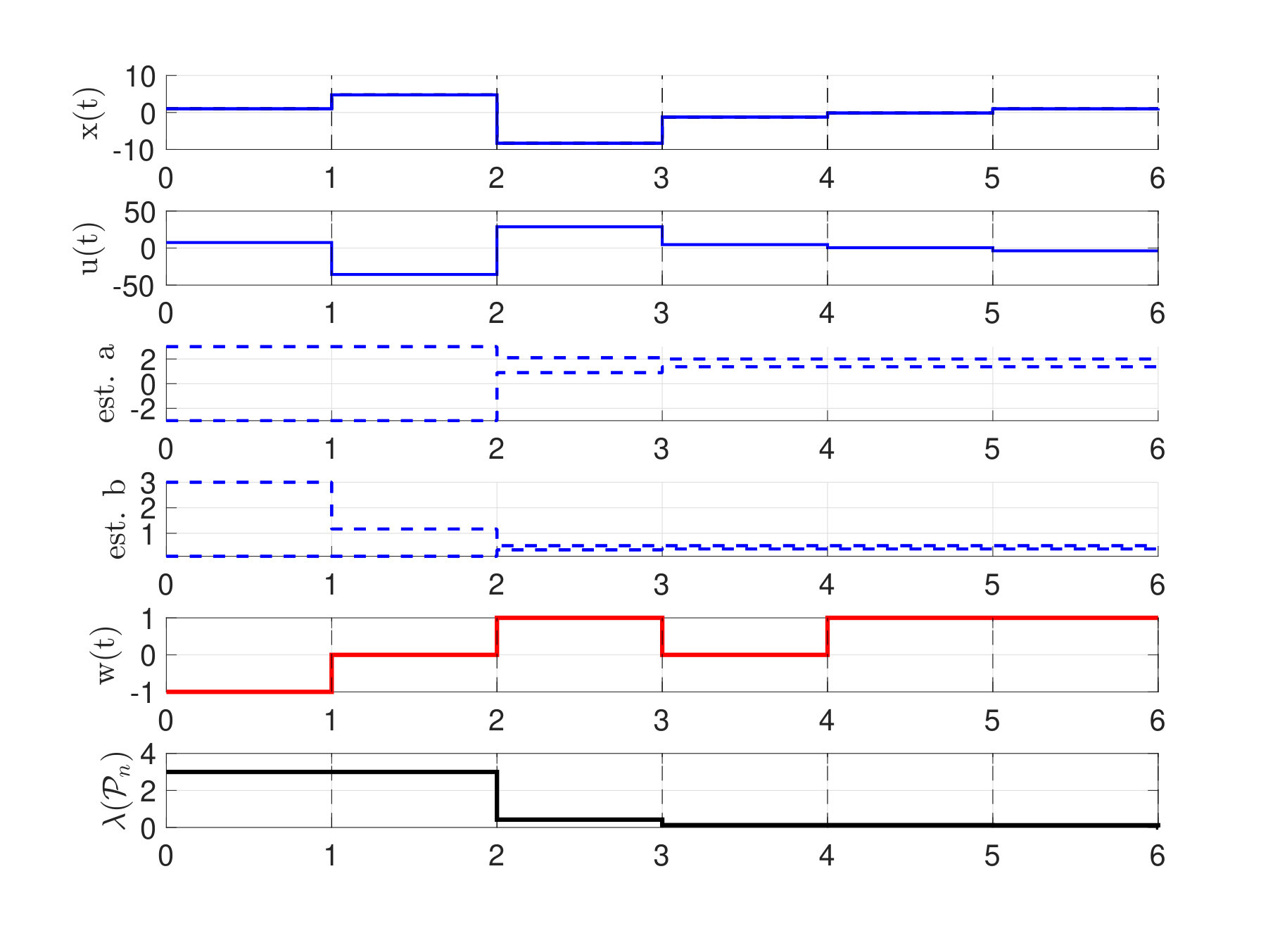 Figure 2
Figure 2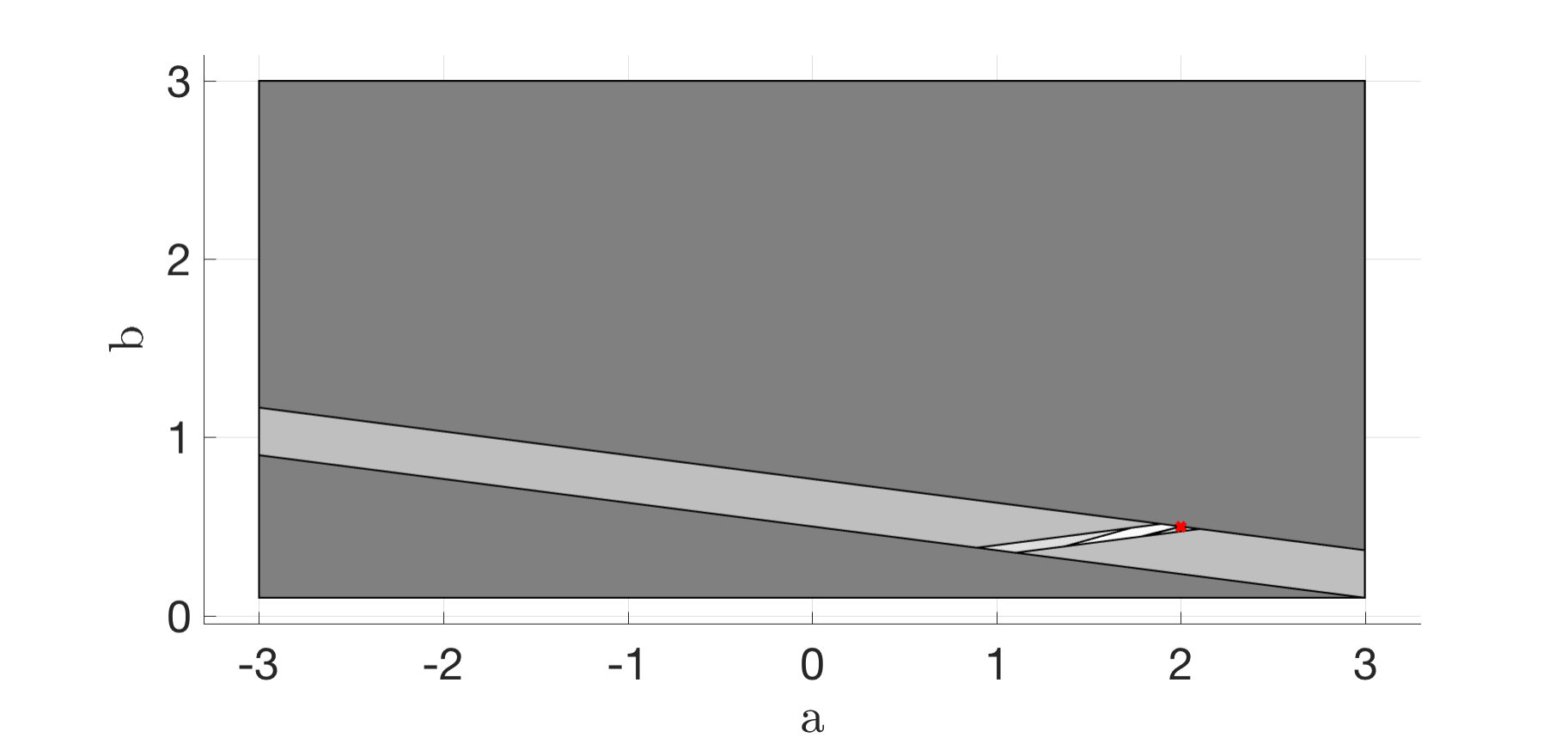 Figure 3
Figure 3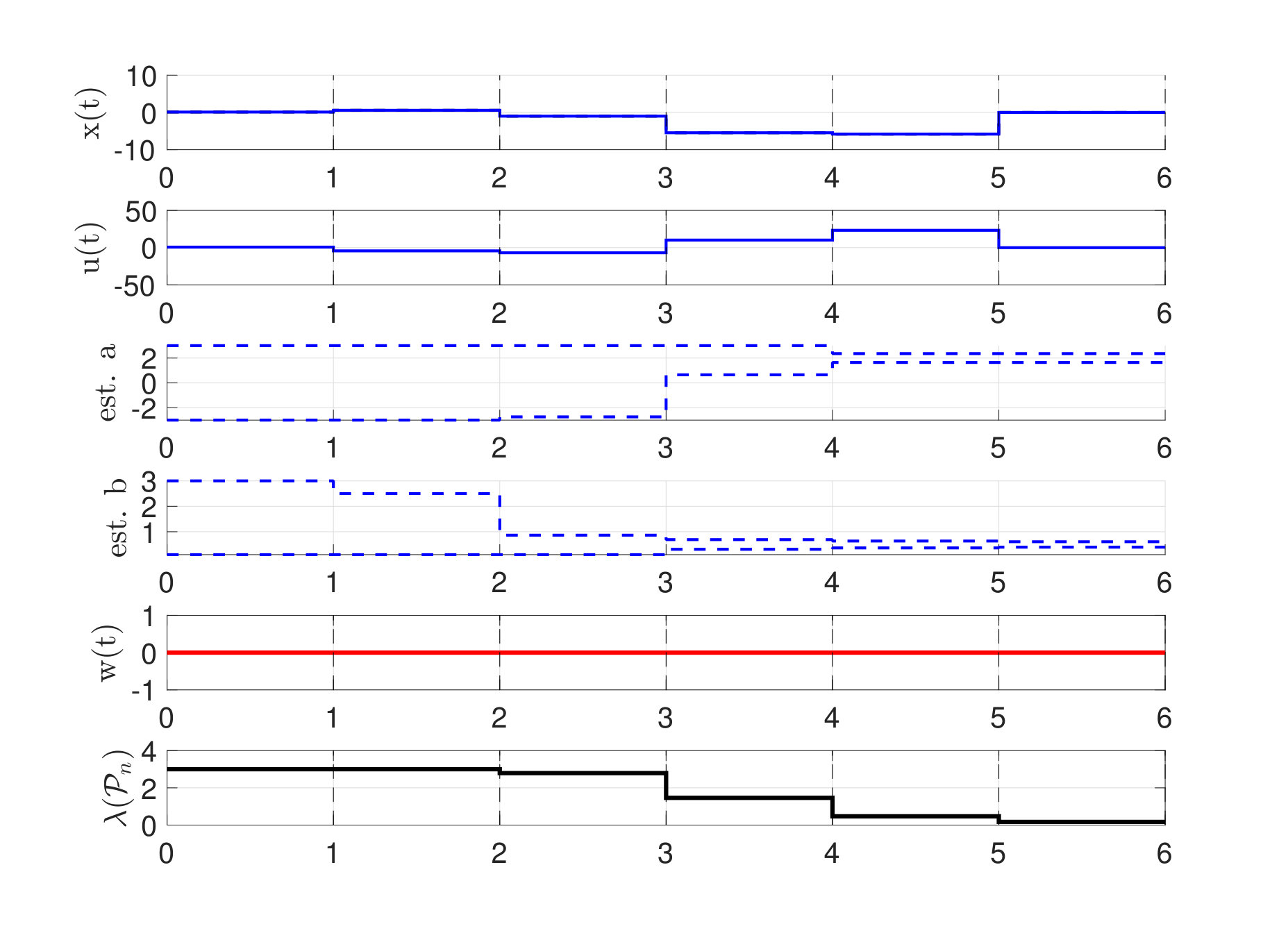 Figure 4
Figure 4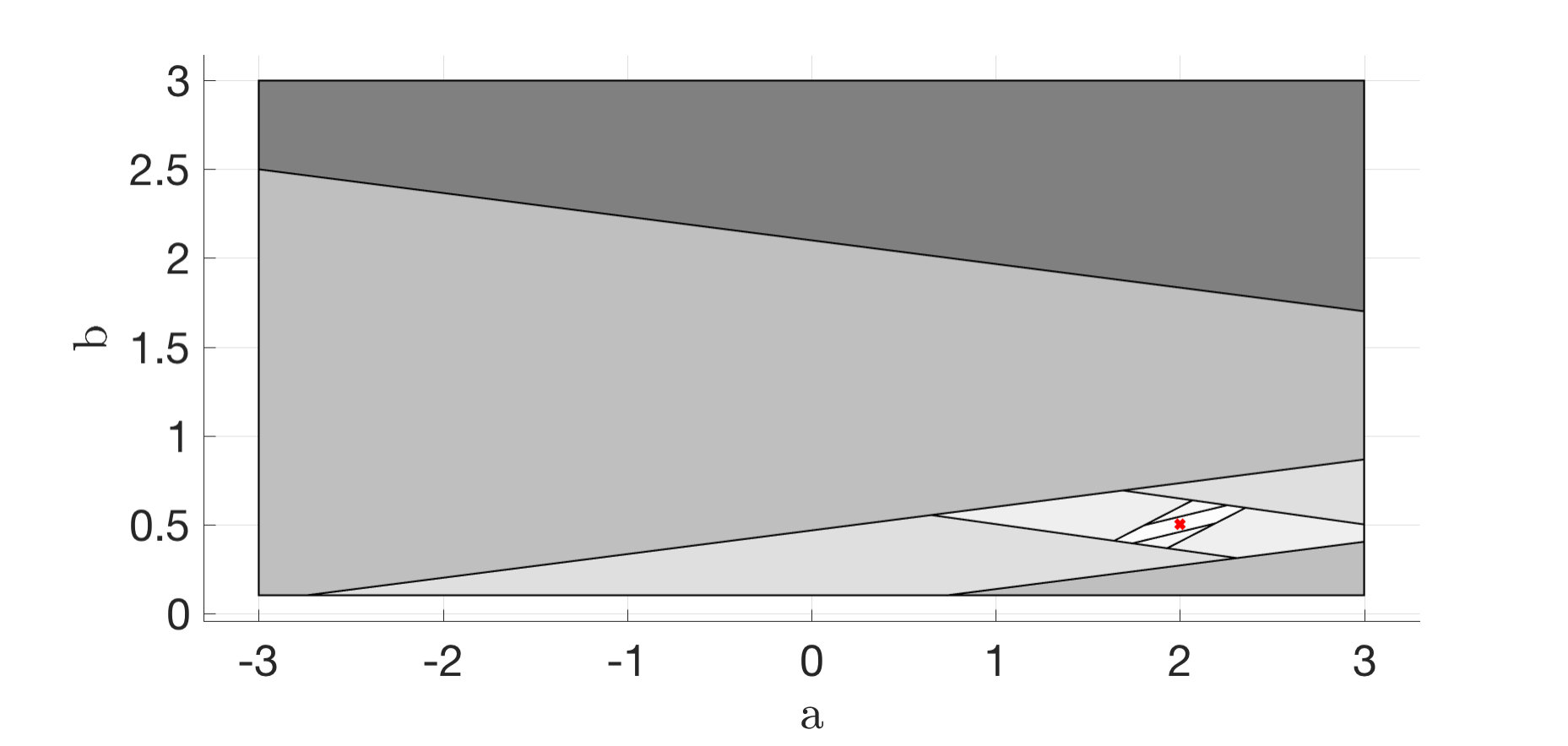 Figure 5
Figure 5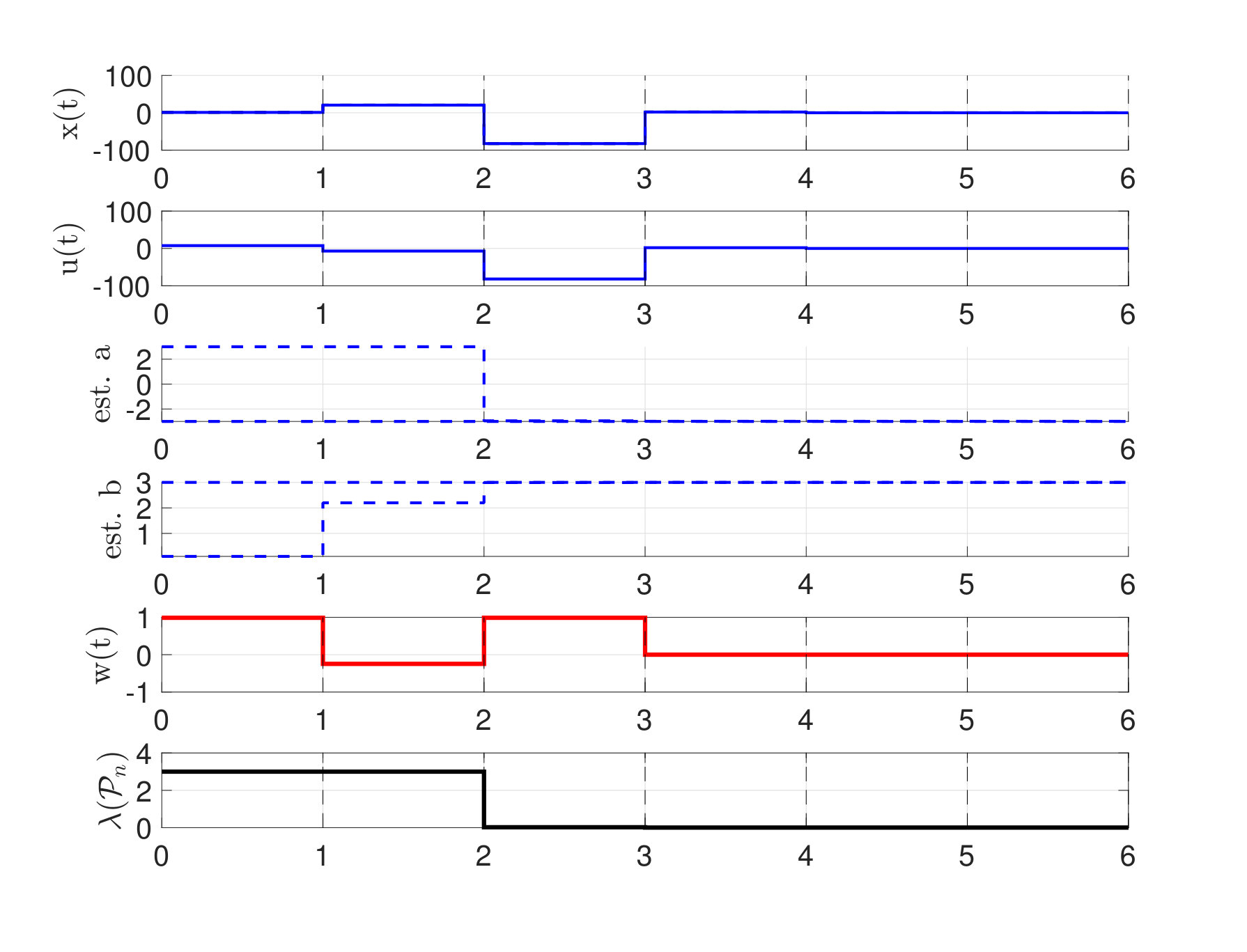 Figure 6
Figure 6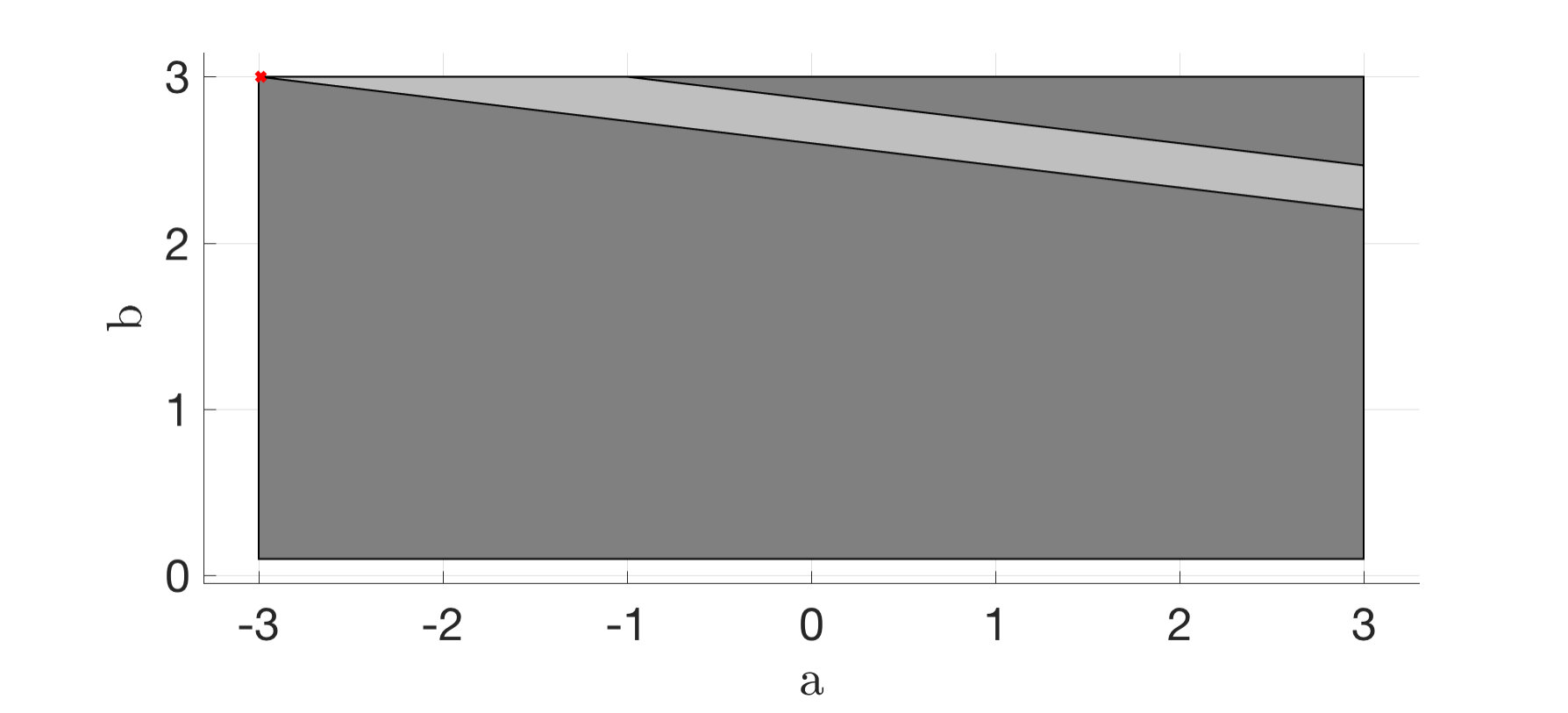 Figure 7
Figure 7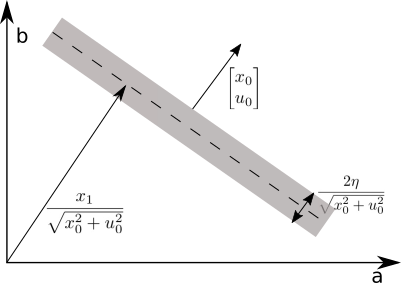 Figure 8
Figure 8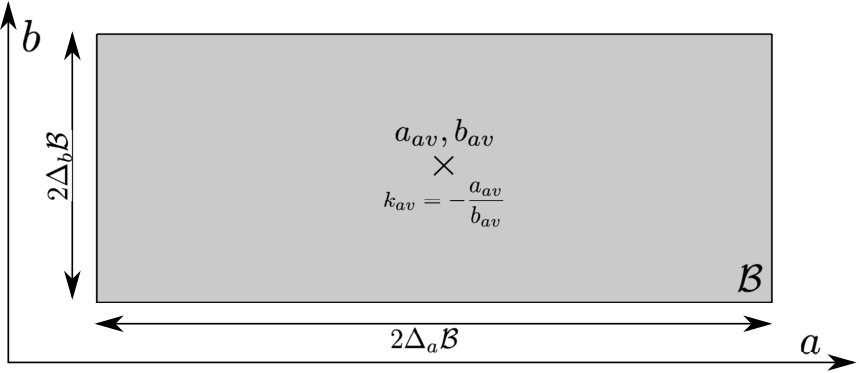 Figure 9
Figure 9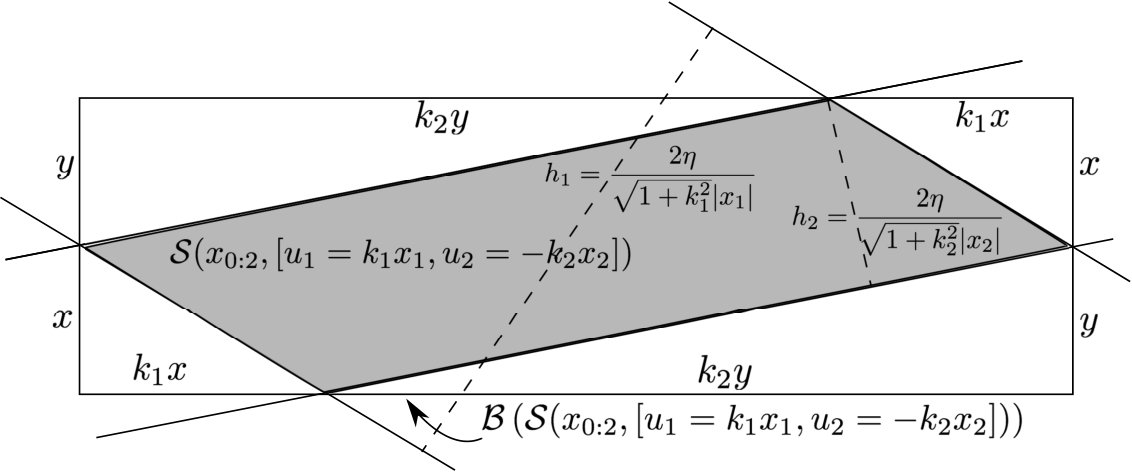 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Passive-Aggressive Learning and Control
Dimitar Ho, Nikolai Matni and John C. Doyle The authors are with the department of Control and Dynamical Systems, California Institute of Technology, Pasadena, CA 91125, USA ({dho,nmatni,doyle}@caltech.edu).Thanks to funding from AFOSR and NSF and gifts from Huawei and Google.
Abstract
In this work, we investigate the problem of simultaneously learning and controlling a system subject to adversarial choices of disturbances and system parameters. We study the problem for a scalar system with -norm bounded disturbances and system parameters constrained to lie in a known bounded convex polytope. We present a controller that is globally stabilizing and gives continuously improving bounds on the worst case state deviation. The proposed controller simultaneously learns the system parameters and controls the system. The controller emerges naturally from an optimization problem, and balances exploration and exploitation in such a way that it is able to efficiently stabilize unstable and adversarial system dynamics. Specifically if the controller is faced with large uncertainty, the initial focus is on exploration, retrieving information about the system by applying state-feedback controllers with varying gains and signs. In a pre-specified bounded region around the origin, our control strategy can be seen as passive in the sense that it learns very little information. Only once the noise and/or system parameters act in an adversarial way, leading to the the state exiting the aforementioned region for more than one time-step, our proposed controller behaves aggressively in that it is guaranteed to learn enough about the system to subsequently robustly stabilize it. We end by demonstrating the efficiency of our methods via numerical simulations.
I Introduction
With the proliferation of big-data, and the success of machine-learning algorithms being applied to planning and control problems, there has been a renewed interest in combining and applying learning and control to continuous systems. Modern results build on the foundational ideas of adaptive control [1, 2], which we cannot hope to adequately survey here, but place an emphasis on finite-time, rather than asymptotic, guarantees of performance and stability.
To the best of our knowledge, recent results of this nature have focused on the stochastic setting wherein system parameters are unknown, and must be identified despite stochastic excitations to the system. By combining concentration results from high-dimensional statistics with techniques from robust and optimal control, regret and performance bounds can be obtained as a function of the number of data points seen by the controller. Notable examples include [3, 4, 5, 6, 7], which provide varying degrees of guarantees and practically applicable algorithms. However, as far as we are aware, no comparable results exist for the setting of bounded but adversarial process noise and parametric uncertainty.
Recently it has been shown that in the bounded adversarial setting, solutions to the state-estimation problem [8, 9] and the robust control problem subject to quantization and delay in the control loop [10] admit particularly intuitive and appealing forms. This work shows that the same holds true for a joint learning and control problem.
Our main contribution is what we call a passive-aggressive learning and control algorithm that trades off between identifying the true system parameters and stabilizing the system. The defining feature of this controller is that unless the system parameters and noise act in an adversarial way, pushing the state sufficiently far away from the origin, it is content with passively observing the state evolution and updating its uncertainty set. However, when the system conspires to push the state sufficiently far from the origin, it aggressively learns the system parameters and applies control actions aimed at stabilizing the system.
The rest of the paper is organized as follows: in Section II we define the problem and the necessary notions of consistent parameter sets given a sequence of observations. In Section III we then show that in the case of “strongly stabilizable” initial parameter uncertainty sets, a simple static state-feedback policy is sufficient to guarantee robust stability for all possible choices of system realization. We then build on this result in Section IV to show that if the controller updates the set of feasible system parameters with each observation, the controller performance can be strictly improved. Finally, in Section V we consider the case of general initial uncertainty sets, and show that if a two-stage controller is applied, then the uncertainty set can eventually be reduced to one that is strongly stabilizable, allowing us to switch to the aforementioned control policies. We demonstrate the efficacy of our approach in Section VI, and end with conclusions and future work in Section VII.
II System and Problem Definition
II-A System Dynamics
We consider the scalar linear discrete-time system
[TABLE]
with the state , the disturbance and the causal controllers where we use the notation to refer to the stacked vector . We assume that the disturbance is bounded by , and that the state-space parameters and are unknown constants, but that are constrained to lie in a known bounded convex polytope .
We furthermore assume that
[TABLE]
i.e., that the system is controllable for all possible realizations of the unknown state-space parameters . To simplify notation, we will refer to the controllers as , where the subscript reminds that is a function of .
II-B Consistent Sets
We denote by and the stacked vector of state values and control inputs , respectively, for . It follows from the dynamics (1) that at time , the following entry-wise inequality must hold for the true parameters .
[TABLE]
where is the all ones vector of compatible dimension. This inequality therefore allows us to characterize the subset of the initial uncertainty set that is consistent with the observed state and control input histories given the known bound on the magnitude of the disturbance process .
This motivates the following definition of the consistent set at time :
[TABLE]
It then follows that given state and control histories , and the initial uncertainty set , we have that lies in the bounded convex polytope .
For , the set reduces to a slice of thickness with normal vectors in parameter space (see Fig.1). This motivates the following recursive definition of the consistent set at time as the intersection of such slices:
[TABLE]
II-C Problem Statement
Our objective is to find the best causal control strategy that minimizes the worst-case state deviation despite adversarial noise and system parameter choices .
Formally, we seek a solution to the following infinite-horizon min-max problem
[TABLE]
where we define as
[TABLE]
where (11) is an equivalent reformulation using the following definition.
Definition II.1**.**
Define the N-step reachable set as the set of possible trajectories , given the initial condition , the initial uncertainty set , the controllers and the disturbance bound , i.e.
[TABLE]
Our approach is to begin with what we term strongly stabilizable initial uncertainty sets , that is to say initial uncertainty sets for which an appropriately chosen static state-feedback gain is guaranteed to be stabilizing for all realizations of the system parameters . We show that such a policy is optimal for optimization problem (7) restricted to static memoryless control policies. We then show that by adding an adaptive element to such a control policy, the performance can be further improved, and that an exploration/exploitation strategy naturally emerges. Finally, we tackle the case of general initial uncertainty sets and show that after an initial “passive” learning phase, the uncertainty set is eventually “aggressively” reduced to one that is strongly stabilizable, allowing for our previously derived adaptive strategy to be applied.
III Robust Static State-Feedback for Strongly Stabilizable Uncertainty Sets
In this section, we consider a restriction of optimization problem (7) to static state-feedback control policies, i.e., we restrict for all . The resulting optimization problem then reads as
[TABLE]
As we are restricting ourselves to static state-feedback polices, it follows that is an upper bound for , i.e.:
[TABLE]
We consider this simpler problem as it has several appealing properties. First, and the corresponding minimizing can be solved for in closed form. Further it motivates the definition of strongly stabilizable initial uncertainty sets , which naturally captures how difficult an uncertain system can be to stabilize. To that end, we introduce the following measure of stabilizability for an uncertainty set .
Definition III.1**.**
We use to denote the stability margin of the parameter set , and define it as
[TABLE]
Furthermore, we call the corresponding minimizer
[TABLE]
the gain of the parameter set .
The stability margin of a set is a functional mapping sets to and describes the smallest system eigenvalue achievable by a constant state-feedback, assuming worst case parameter choice of . As presented in the following Lemma, it follows that if the initial uncertainty set satisfies , then we can use as a state-feedback control law to stabilize the system for all parameters in . We will refer to such initial uncertainty sets as strongly stabilizable.
In the following we let to help simplify notation.
Lemma III.1** (Comparison-Lemma).**
Let be a non-negative sequence in that satisfies with non-decreasing functions , then is bounded above by the sequence , where and .
Proof.
The result follows by induction from and . ∎
Lemma III.2**.**
If the initial uncertainty set is strongly stabilizable (i.e., if ), then the problem (18) attains its optimum with the controller and
[TABLE]
Conversely, if the initial uncertainty set is not strongly stabilizable (i.e., if ), then for any choice of , it holds that .
Proof.
Fix for some and consider the case . By definition (III.1), such that and it is easy to see that we can find to make grow unbounded. Therefore, we conclude if .
For the second part of the proof, notice that and by the comparison lemma (III.1), we obtain the bound
[TABLE]
Now notice that is monotonic and if we have that is bounded and it takes either the value or . Therefore
[TABLE]
Furthermore, notice that for each and fix and , we can construct a sequence such that . Hence, we can rewrite the optimization problem (18) equivalently as
[TABLE]
We can now conclude the desired statement (22), by noticing that expression (24) is monotonic in and therefore we obtain the optimum value at . ∎
Following the arguments of the proof of Lemma (III.2), we also obtain the following performance bound of the robust state-feedback (RSF) controller :
Corollary III.1** (RSF bound).**
Assume the dynamics (1) with and , then , where
[TABLE]
Although the RSF controller is guaranteed to stabilize systems with strongly stabilizable uncertainty sets and (22) provides a finite upper bound to , it does so in an inefficient way. In particular, it does not update its control policy to reflect the fact that with each observation, more information about the underlying true parameters is revealed. As previously discussed, the observations allow us to reduce the space of consistent parameters to be . In what follows we improve upon the static state-feedback policy results of this section, and ultimately show that learning is necessary to compute stabilizing controllers for general initial uncertainty sets .
IV Robust Adaptive State-Feedback for Strongly Stabilizable Uncertainty Sets
Keeping our focus on strongly stabilizable initial uncertainty sets, we propose two controllers that strictly outperform the static state-feedback policy defined in the previous section. The following adaptive schemes, which we call weakly adaptive RSF (WRSF) and strongly adaptive RSF (SRSF), simultaneously learn the system dynamics while controlling the system. The latter algorithm decides at every time-step between a control action that reduces and an exploratory control action that leads to more information about the system parameters. Our key result is a decomposition theorem that exploits the fact that the control policy at time is allowed to be a function of all past state-measurements .
IV-A Decomposition and Properties of
Using the definition (11) and Lemma (IV.1), it is easy to derive the following properties of :
Lemma IV.1**.**
* holds*
[TABLE]
Proof.
This follows by change of variables and using definition (II.1). ∎
Corollary IV.1**.**
* holds *
We then have that the following decomposition theorem holds:
Theorem IV.1**.**
For the cost-to-go function as defined in optimization problem (7), it holds that
[TABLE]
Proof.
First notice that we can write
[TABLE]
where the last equality follows from the fact that the state is known to the sequence of control actions , and that . This last line can further be rewritten as
[TABLE]
where the first equality follows from the fact that , and the second from the definition of the cost-to-go function , as defined in (7), and from the identity . ∎
Theorem IV.1 sheds light on the structure of the optimal control policy. Specifically, let ; then the optimal control action at time is given by111This follows from Theorem IV.1 by a simple induction argument which is omitted in the interest of space.
[TABLE]
In particular, we see that the control action is a function of both the state history and the updated uncertainty set , and naturally results in a trade-off between exploration and exploitation. If the first term dominates the cost function, this indicates that the controller is in an exploitation mode, using its gathered information on the uncertainty set to minimize state deviation. In contrast, if the second term dominates, this can be interpreted as an exploration action aimed at reducing the effects of parametric uncertainty on future state deviations.
IV-B Weakly and Strongly Adaptive Robust State-Feedback Controller
Unfortunately, Eq. (27) does not provide a practical means of computing an optimal controller. Nevertheless, we can approximate (27) by using as an upper bound for the cost-to-go function in (27). In particular, we will define the weakly adaptive robust state-feedback (WRSF) controller as the solution to the optimization problems
[TABLE]
and the strongly adaptive robust state-feedback (SRSF) controller as the solution to the optimization problems
[TABLE]
Accordingly we will define and as
[TABLE]
After some standard manipulation, we can formulate the resulting controllers as
[TABLE]
turns out to present a simple yet significantly better strategy than the RSF controller, as it is basically using the information of recent observations to recompute an RSF controller. Therefore it is not surprising that we have
To apply on the other hand, requires the solution of a scalar min-max problem at every time-step. Notice from (36), how the objective of SRSF policy can be seen as a exploration vs. exploitation trade-off, as it incorporates the reduced uncertainty of the next time step. As we will show in the following theorem, if the initial uncertainty set is strongly stabilizable, then this SRSF policy is stabilizing and performs at least as well as the WRSF and RSF policy.
Theorem IV.2** (SRSF vs. WRSF vs. RSF).**
Let , , be sequences generated from running , and in closed loop with the same initial condition and assume a strongly stabilizable with the usual dynamics (1). Furthermore, assume that all sequences obtain the same uncertainty sets , then , and are upper bounded by
[TABLE]
where
[TABLE]
with . Furthermore, we have
Proof.
While we have proven the first part already for the RSF controller, we can obtain the performance bounds for WRSF and SRSF, by observing from their definition that they are upperbounds on the worst-case adversarial dynamics. Therefore, at every-time step holds
[TABLE]
Then using the comparison lemma (III.1), we can establish and . The inequality follows, by observing that
[TABLE]
and noticing that and are monotonic increasing in and by using comparison Lemma (III.1). ∎
V Passive Aggressive Feedback Controller
In this section we introduce a control policy that is applicable to initial uncertainty sets that are not strongly stabilizable. The controller evolves according to two stages: at first, a “passive-aggressive” feedback controller is deployed that is used as long as the consistent set is not strongly stabilizable. We show that this control policy is guaranteed to shrink the initial uncertainty set to one that is strongly stabilizable once the state becomes sufficiently large. Once the uncertainty set has been reduced to a strongly stabilizable one, the controller switches to the ARSF strategy described in the previous section and drives the state to the origin.
Definition V.1**.**
Let be the remaining uncertainty in the system parameters after observing and . Specifically
[TABLE]
where we set to be the initial uncertainty set.
Definition V.2**.**
Define as the maximum deadbeat controller gain among the parameters in :
[TABLE]
We begin with an intermediate result that shows if the system state is sufficiently large, then the stability margin of the uncertainty set can be reduced by an amount governed by the noise bound and the size of the state itself. In this way, there is a notion of signal-to-noise that comes into play in the ability to learn an uncertainty set.
Theorem V.3** (Passive-Aggressive Learning).**
Let be the initial (not necessarily strongly stabilizable) uncertainty set and fix positive constants satisfying . Consider the system (1) with the following time-varying state-feedback controller:
[TABLE]
where
[TABLE]
Then that satisfy holds .
Proof.
Assume to be such that and , to be and respectively. Then,
[TABLE]
where represents the smallest outer-bounding box set of the . Furthermore, and are the maximum uncertainty of parameters and in the set as discussed in the appendix (A). Finally we note that the last inequality follows from the discussion on stability margins of boxed uncertainties in (A). Now, as and have opposite sign by construction, we obtain from app.(A):
[TABLE]
Now, since by assumption we have that , we can upper bound equations (49), (50) by
[TABLE]
Furthermore, notice that so we have
[TABLE]
which lets us further upper-bound (51) by
[TABLE]
Finally, plugging the bounds (55) and (52) into equation (48) gives us the desired result:
[TABLE]
∎
With this ability to learn the uncertainty set, we now show how a two-stage controller can lead to a stabilizing (in the BIBO sense) adaptive controller.
Theorem V.4** (Passive-Aggressive Learning and Control).**
Let be an initial (not necessarily strongly stabilizable) uncertainty set, and fix positive constants , s.t. . Consider the system (1) with the following switched control strategy:
[TABLE]
where represents the Passive-Aggressive Learner from (V.3) and is one of the Adaptive Robust State-Feedback controller from section (IV). Then, it holds:
- (i)
The closed loop system response is bounded as:
[TABLE] 2. (ii)
If , then , satisfies the convergence bounds associated with from section (IV). In particular, it always satisfies the bound
[TABLE]
Proof.
(ii) follows directly from our analysis in Sec.(IV): Since , the parameter uncertainty set is strongly stabilizable and will stay so for all . Therefore, the convergence bounds from Sec.(IV) apply.
To establish (i), we have to consider different worst-case scenarios. First, assume holds, then we get the bound from part (ii). On the other hand, if , then the system is being controlled by . Recall that under that regime we have guaranteed that if , we obtain a strongly stabilizable uncertainty set for , i.e. . Therefore, for all times after we will apply and by our previous discussion in (ii), we obtain the bound . It is therefore, left to consider the worst case , where is the first time that grows outside the interval . It is easy to see that we can bound the worst case transient for , by considering the two time-step worst-case transient starting from an initial condition and no prior knowledge of the system. Stating that transient bound in terms of the definitions in Sec. (II-C), we get
[TABLE]
∎
The “passive-aggressive” nomenclature is chosen because the policy is such that if the system parameters and process noise are stabilizing (i.e., keep the state close to the origin), then we only focus on learning the uncertainty set via the learning control policy (47) – this is the passive phase of the control policy. In particular, if for the specific process noise and system parameter realizations no such exists, then by definition we are guaranteed to have for all , where is a constant depending only on , and – this follows by noting from (IV.1) that grows sublinear in . In contrast, when the noise is such that the state is pushed sufficiently far from the origin, we are able to aggressively decrease the stability margin of the uncertainty set and switch to an ARSF policy. The result is a stabilizing control scheme that is applicable to arbitrary initial uncertainty sets .
VI Simulation Results
In the following we show how the passive-aggressive controller performs under different scenarios. Recall, that our plant is modeled as
[TABLE]
We set the initial uncertainty set to be
[TABLE]
and we pick the true parameters of the system to be
[TABLE]
The controller is parametrized with and . Notice that this initial uncertainty set is not strongly stabilizable. In what follows, we apply the controller described in Theorem V.4 for different noise and system parameter realizations: fixed system parameters and adversarial/random noise, adversarial system parameters and noise, and fixed parameters with no noise.
Each of the figures (2)-(4) show sequences of the state and control action and the maximum and minimum feasible and of the current polytope . The right subfigures overlay the area of all polytopes and display how the uncertainty polytopes shrink with each iteration. The shade of the polytopes becomes lighter with increasing .
For the simulations with adversarial noise, we choose which is easily seen to be the solution to the inner maximization problem in equation (IV.1) with the surrogate function to determine the adversarial noise and system parameters.
Notice that decreases monotonically, and in presence of noise the controller learns to stabilize the system within two time-steps. It is also worth noticing that in presence of no noise, the controller still chooses to perturb the system on purpose to gather information, i.e. an exploration phase naturally emerges to better identify the system parameters before a robustly stabilizing control policy is applied.
VII Conclusions and Future Work
In this paper we defined and analyzed the passive-aggressive learning and control strategy for scalar systems with bounded but adversarial process noise and parametric uncertainty. We showed that for strongly stabilizable initial uncertainty sets, sharp bounds on the state-deviation can be obtained using an ARSF control policy. We then extended these results to the general setting by proposing a two-stage controller: the first stage seeks to passively learn the system so long as the state remains sufficiently close to the origin. However, if the process and system noise are such that the state is pushed sufficiently far from the origin, the controller is able to aggressively reduce the uncertainty set to one that is strongly stabilizable, thus allowing for either the weakly or strongly ARSF policies to be applied. Future work will look to actively inject noise into the passive stage of the aforementioned two-stage control policy to expedite the learning process, as well as characterize sharp regret bounds on the proposed policy. Of additional interest is the extension of the proposed methods to the vector valued setting.
Appendix A Stability Margin Bounds
A-A Box-shaped Uncertainty Sets
Lemma A.1**.**
Let be a controllable boxed uncertainty
[TABLE]
and define , , , , as
[TABLE]
where , is the average system of the box and the corresponding deadbeat feedback. Then the stability margin of can be computed as
[TABLE]
Proof.
The proof is omitted but follows by solving the following optimization problem
[TABLE]
∎
A-B Approximation for in Passive-Aggressive Learning
Consider applying and as a feedback controller with , . Then the resulting uncertainty set resembles a parallelogram as shown in Fig.(6). An approximation of the stability margin is the stability margin of its outer-bounding box, i.e. . Using the notation in Fig.(6) and Lem.(A.1), the approximation can be computed as
[TABLE]
From simple geometry, notice that the shaded area can be computed in three ways:
[TABLE]
We can use these equations to solve for and and finally obtain:
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Astolfi, D. Karagiannis, and R. Ortega, Nonlinear and adaptive control with applications . Springer Science & Business Media, 2007.
- 2[2] K. J. Åström and B. Wittenmark, Adaptive control . Courier Corporation, 2013.
- 3[3] A. Rantzer, “Concentration bounds for single parameter adaptive control,” IEEE 2018 American Control Conference, Submitted to. , 2017.
- 4[4] S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu, “On the sample complexity of linear quadratic regulator,” Working draft , 2017.
- 5[5] C.-N. Fiechter, “Pac adaptive control of linear systems,” in Proceedings of the tenth annual conference on Computational learning theory . ACM, 1997, pp. 72–80.
- 6[6] Y. Abbasi-Yadkori, D. Pál, and C. Szepesvári, “Online least squares estimation with self-normalized processes: An application to bandit problems,” ar Xiv preprint ar Xiv:1102.2670 , 2011.
- 7[7] Y. Abbasi-Yadkori and C. Szepesvári, “Regret bounds for the adaptive control of linear quadratic systems,” in Proceedings of the 24th Annual Conference on Learning Theory , 2011, pp. 1–26.
- 8[8] G. N. Nair, F. Fagnani, S. Zampieri, and R. J. Evans, “Feedback control under data rate constraints: An overview,” Proceedings of the IEEE , vol. 95, no. 1, pp. 108–137, 2007.