TL;DR
This paper introduces a new theoretical framework for understanding DNN generalization by considering the entire margin distribution, and validates it through experiments optimizing the margin ratio.
Contribution
It presents a novel generalization bound based on the margin distribution and proposes a margin distribution loss function to improve DNN generalization.
Findings
Margin distribution statistics influence generalization performance.
Optimizing margin ratio reduces generalization gap.
Experimental results confirm the theoretical predictions.
Abstract
Recent research has used margin theory to analyze the generalization performance for deep neural networks (DNNs). The existed results are almost based on the spectrally-normalized minimum margin. However, optimizing the minimum margin ignores a mass of information about the entire margin distribution, which is crucial to generalization performance. In this paper, we prove a generalization upper bound dominated by the statistics of the entire margin distribution. Compared with the minimum margin bounds, our bound highlights an important measure for controlling the complexity, which is the ratio of the margin standard deviation to the expected margin. We utilize a convex margin distribution loss function on the deep neural networks to validate our theoretical results by optimizing the margin ratio. Experiments and visualizations confirm the effectiveness of our approach and the…
Click any figure to enlarge with its caption.
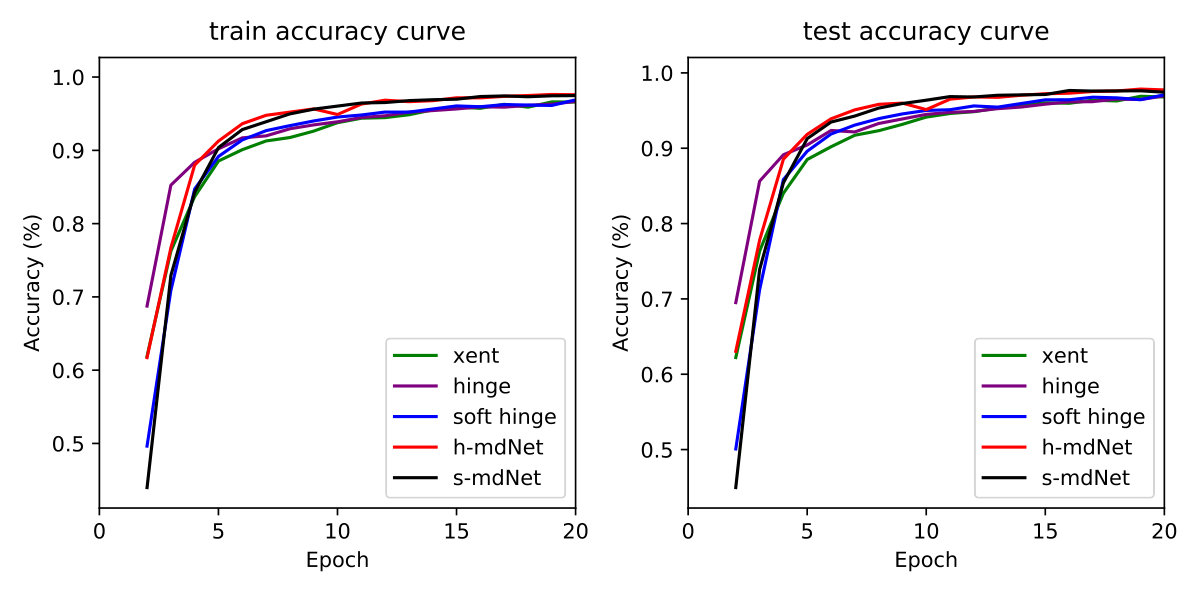 Figure 1
Figure 1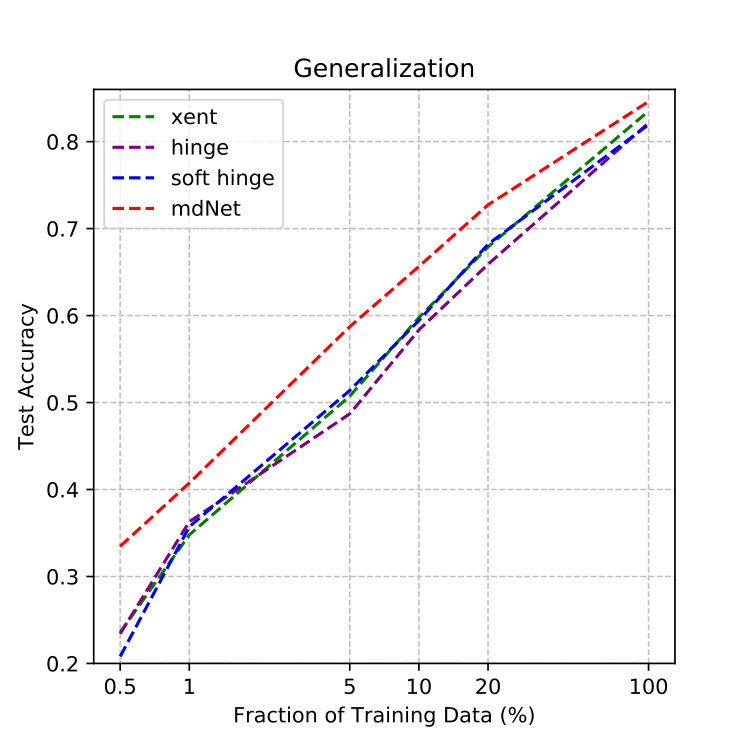 Figure 2
Figure 2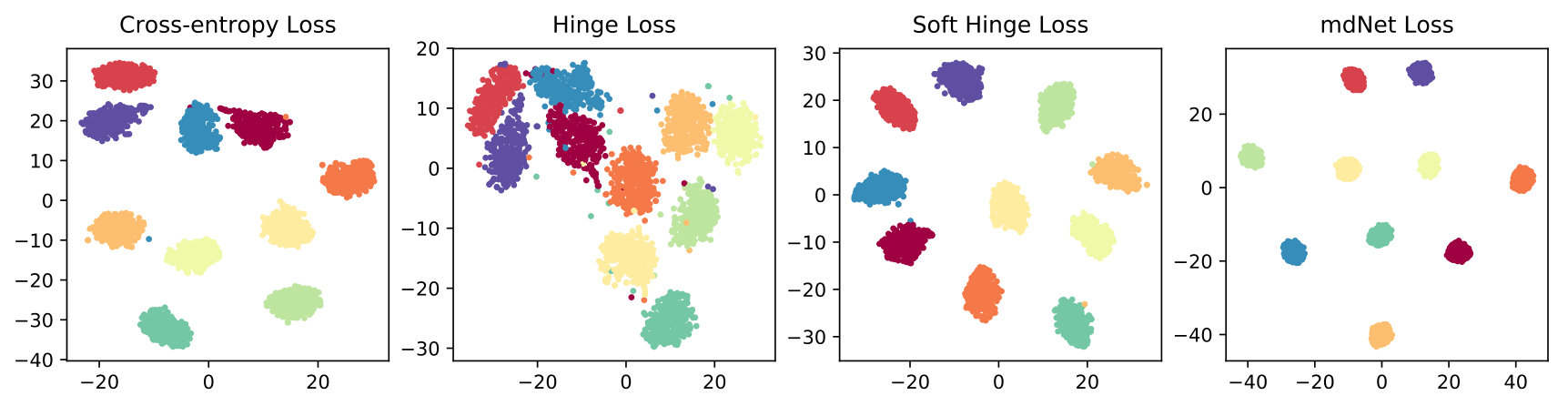 Figure 3
Figure 3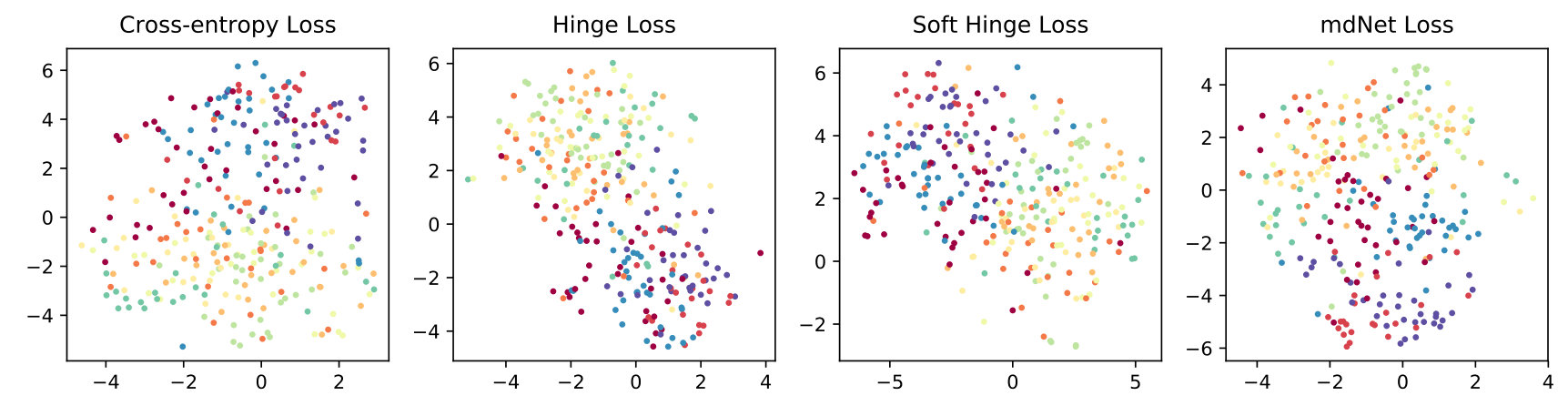 Figure 4
Figure 4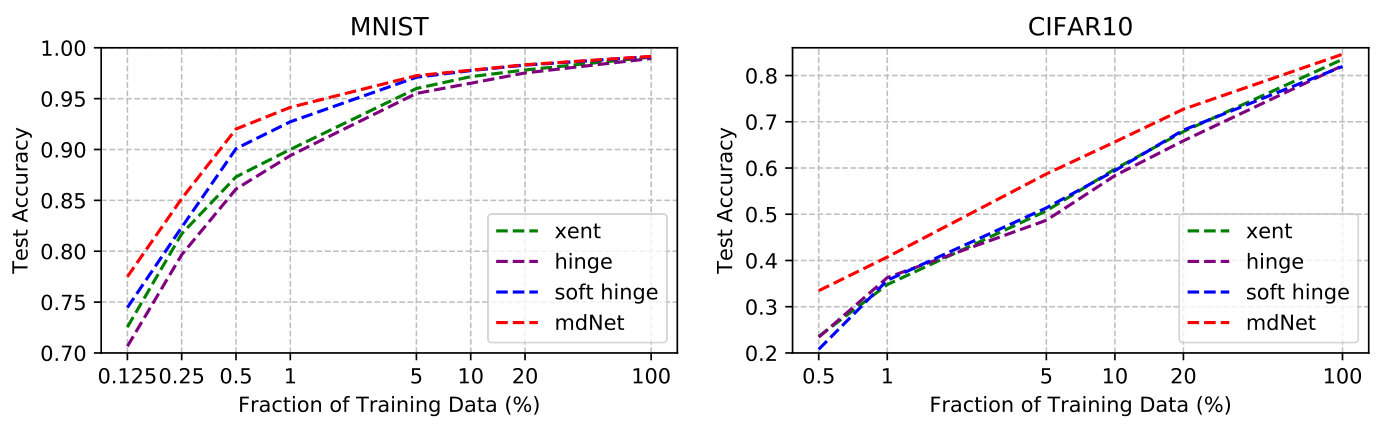 Figure 5
Figure 5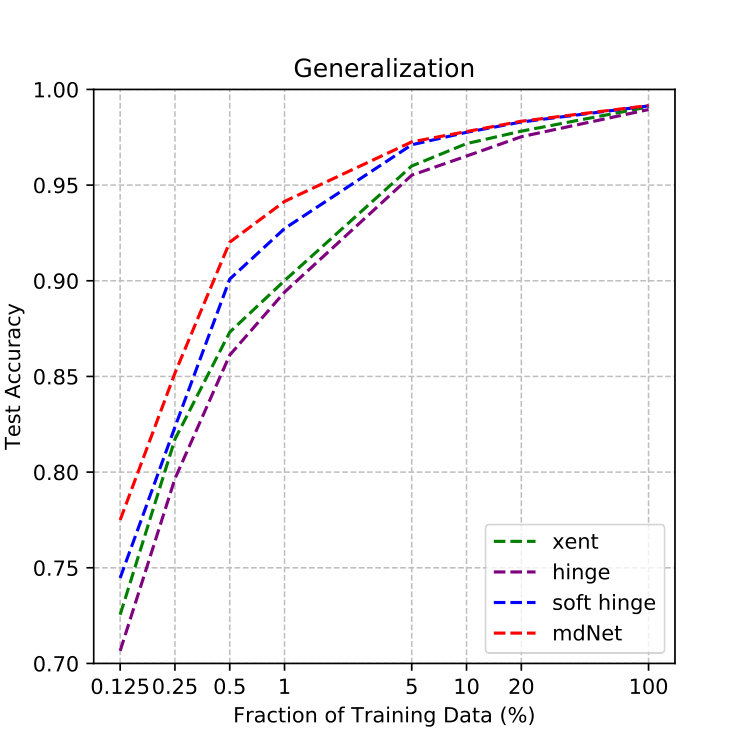 Figure 6
Figure 6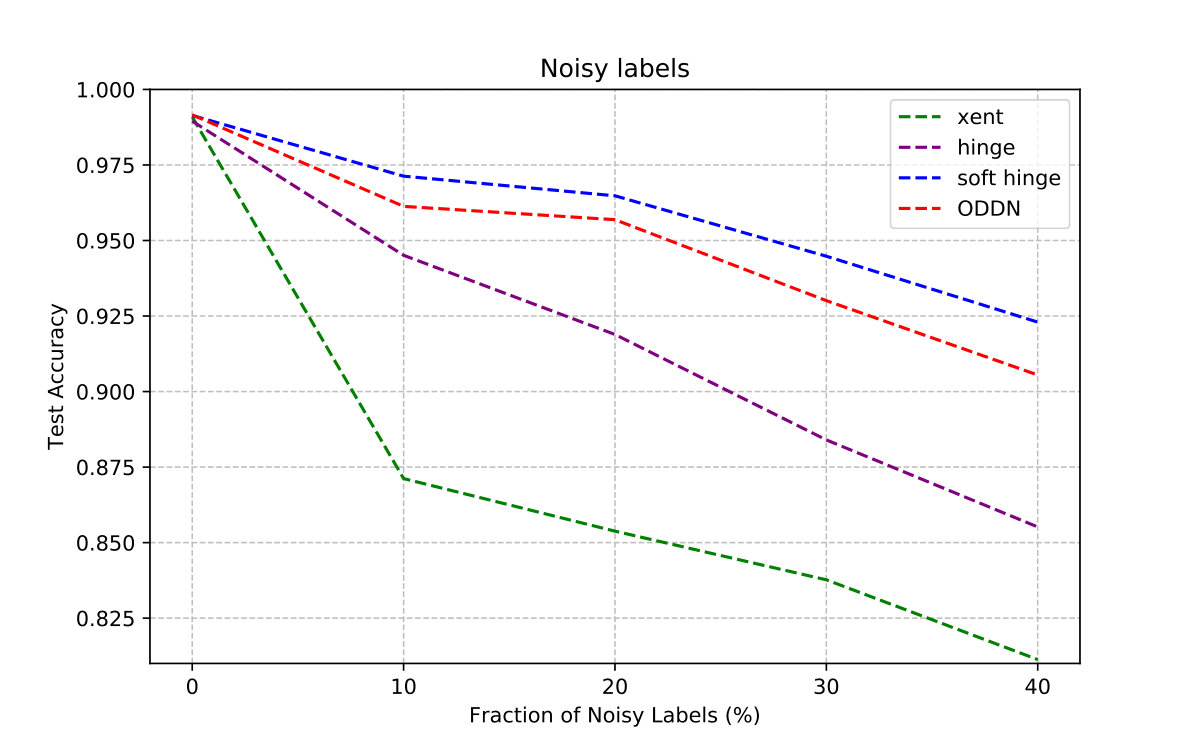 Figure 7
Figure 7 Figure 8
Figure 8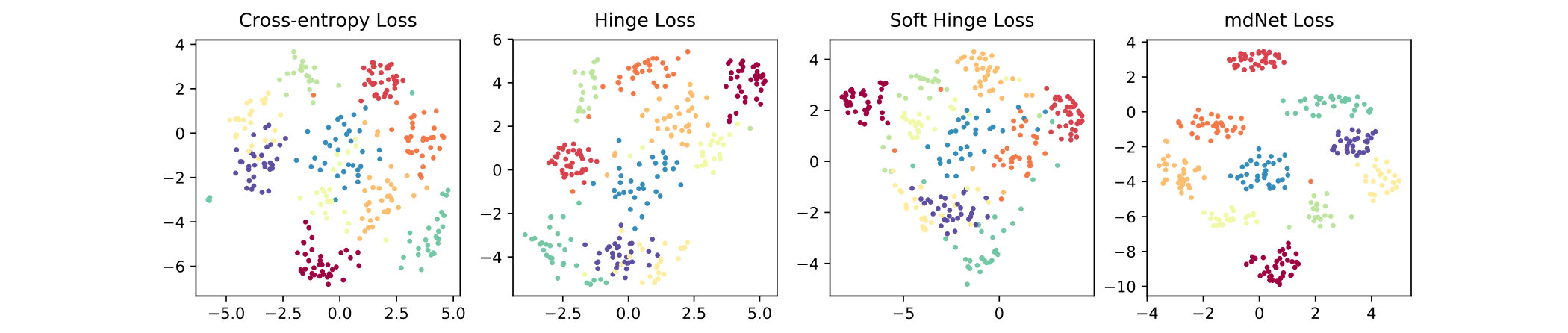 Figure 9
Figure 9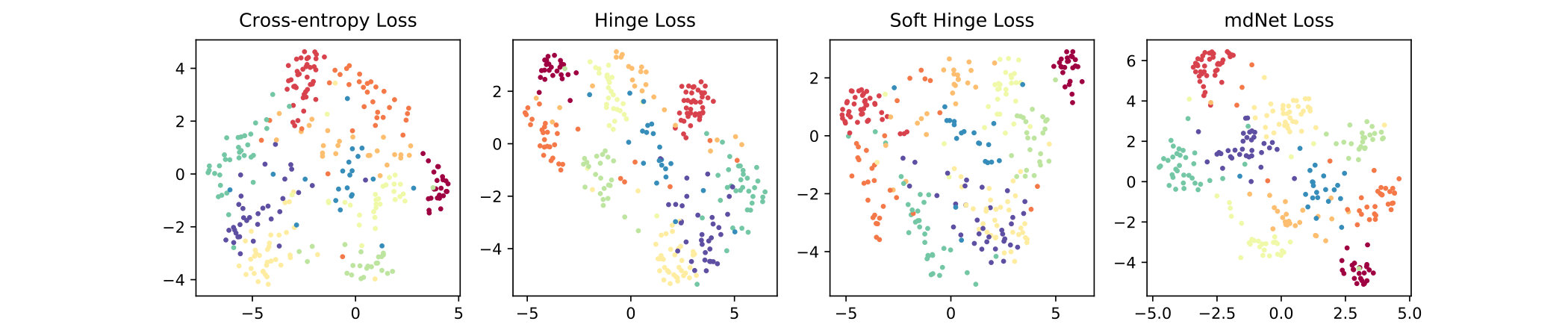 Figure 10
Figure 10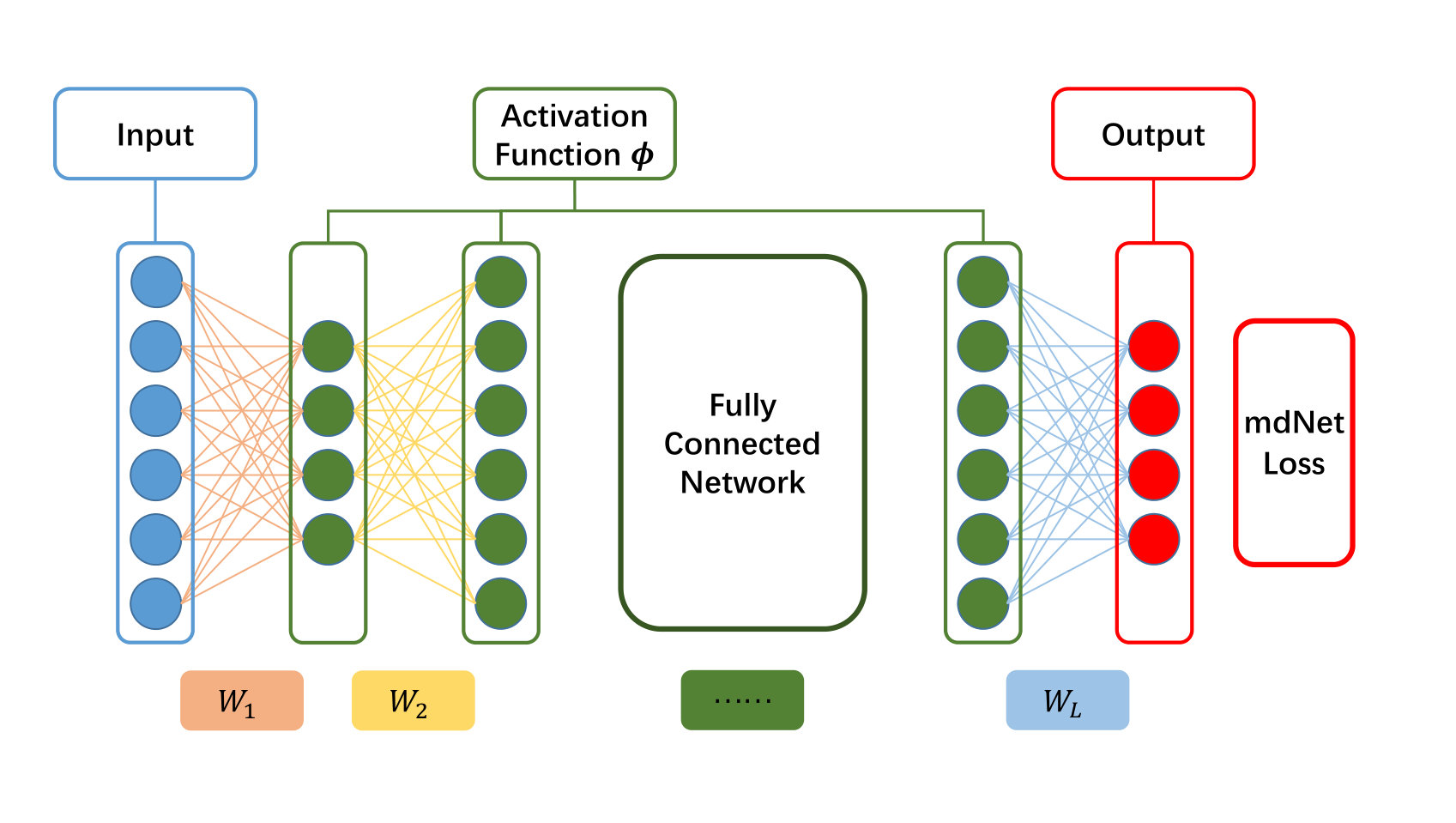 Figure 11
Figure 11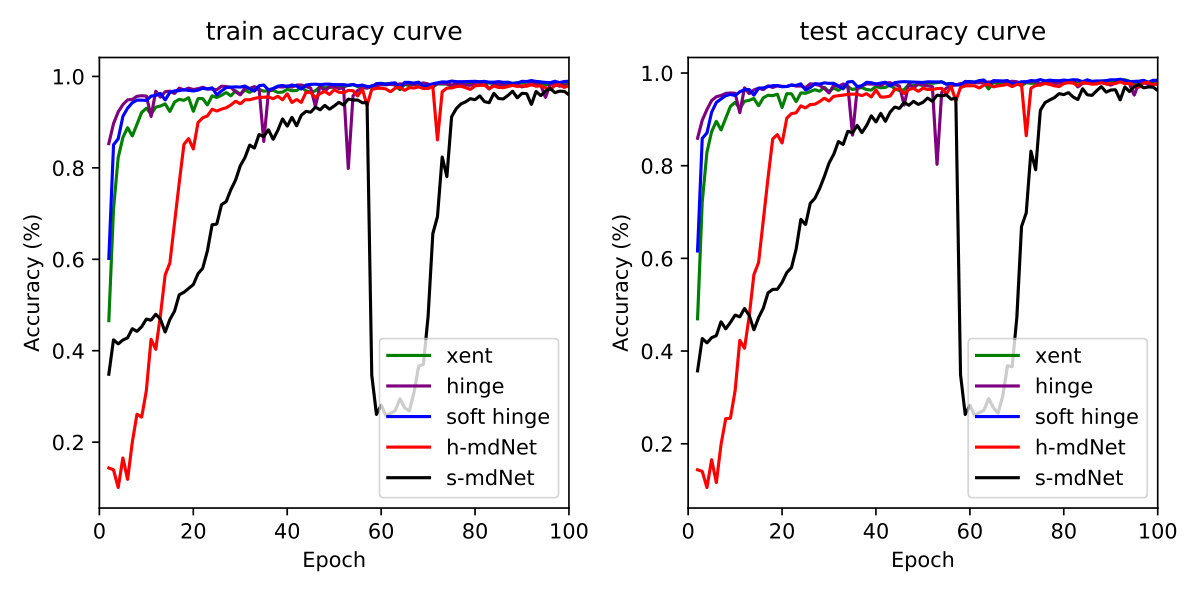 Figure 12
Figure 12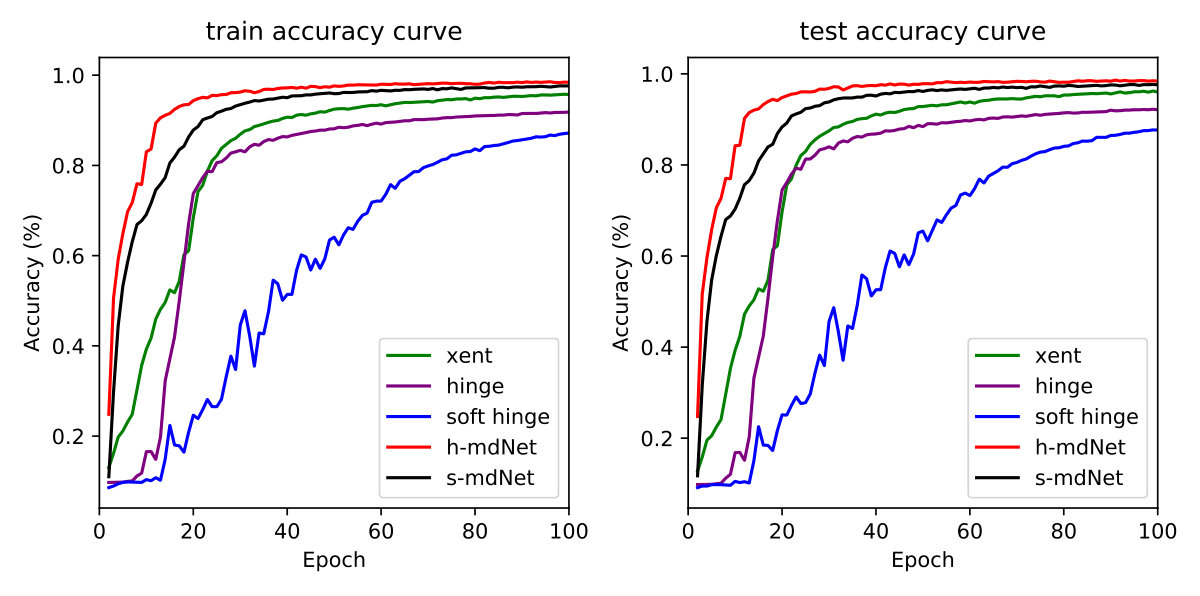 Figure 13
Figure 13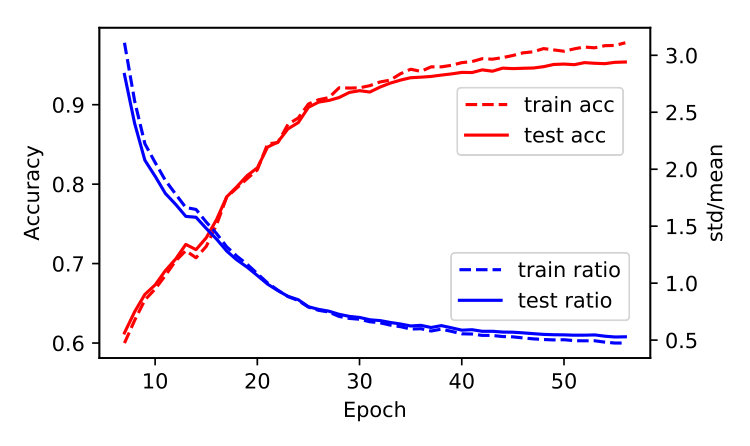 Figure 14
Figure 14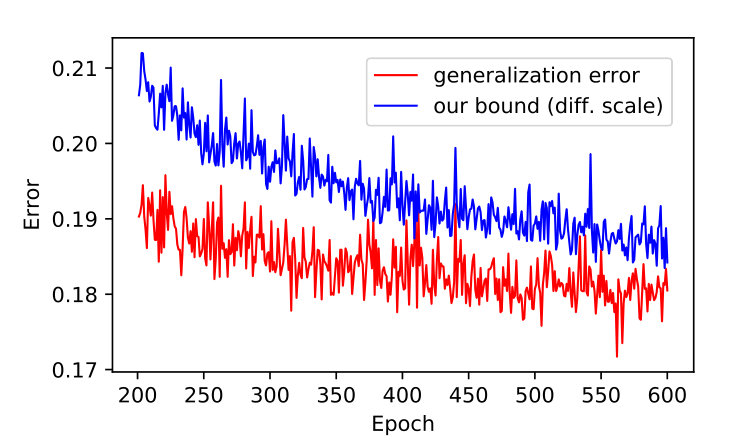 Figure 15
Figure 15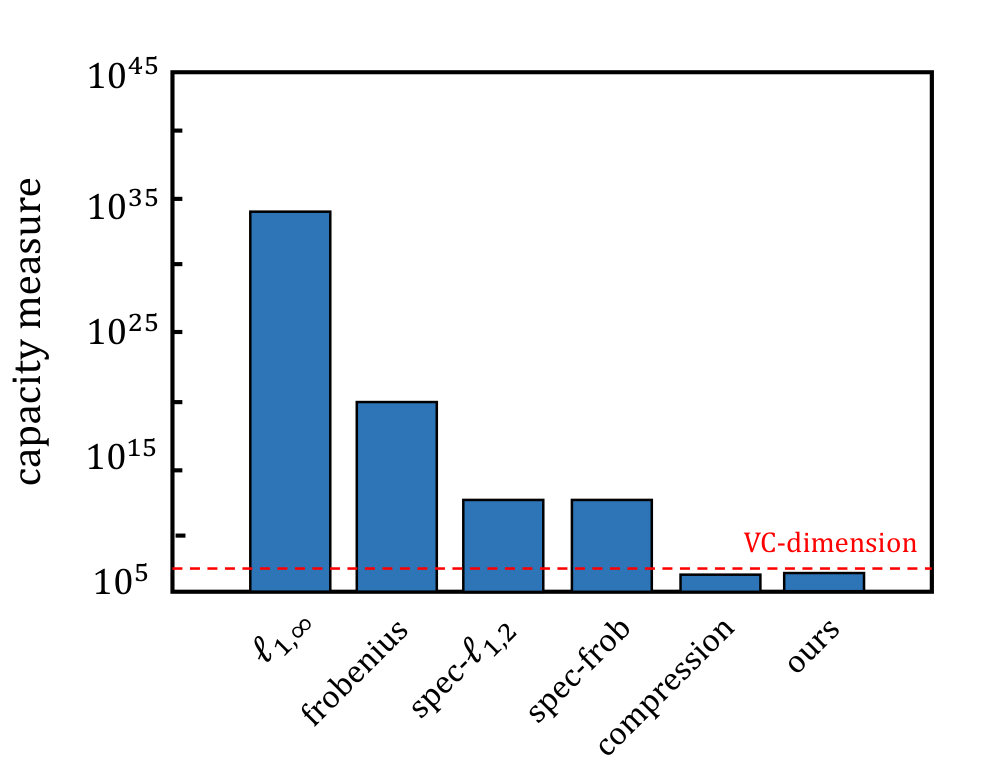 Figure 16
Figure 16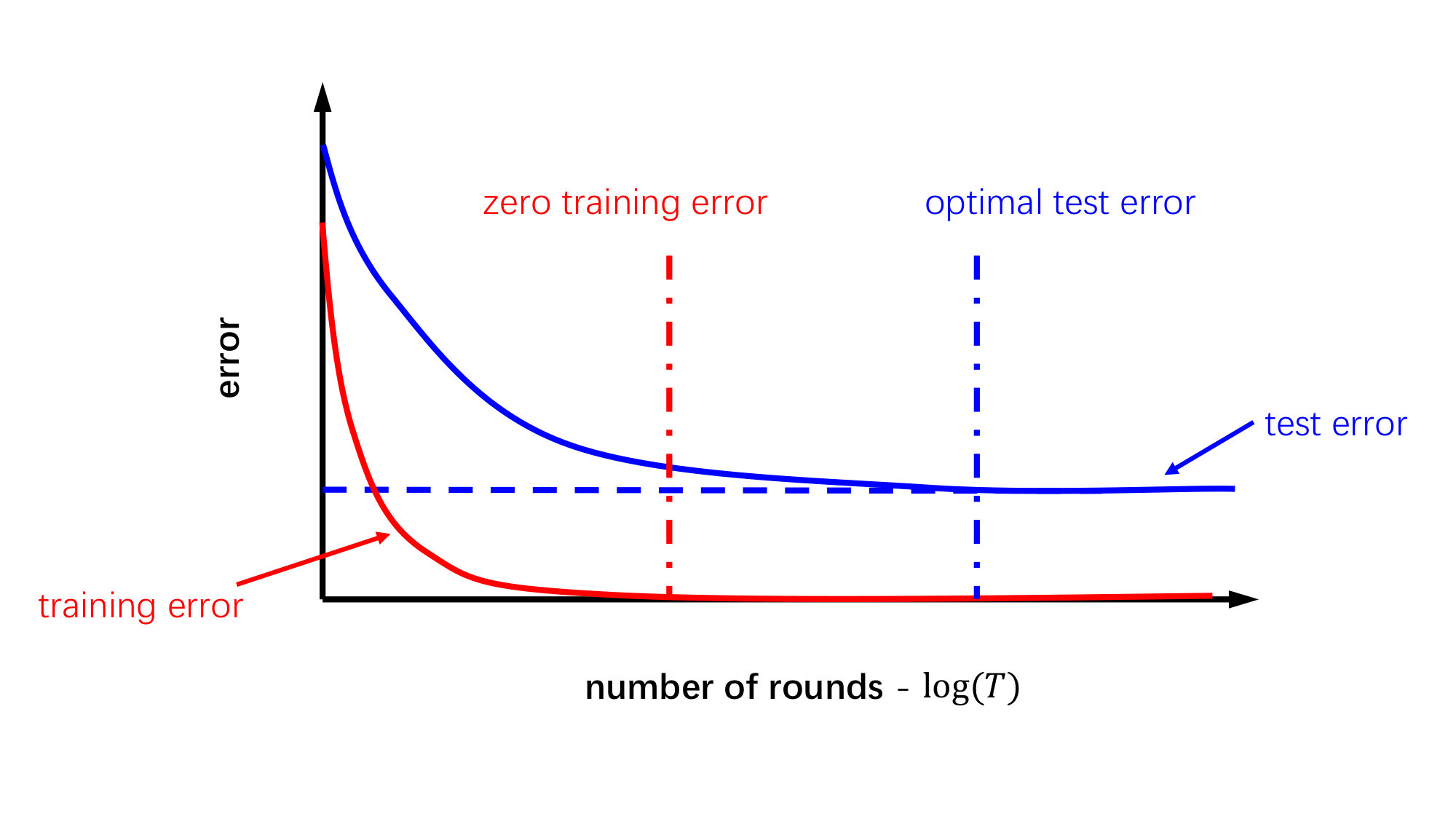 Figure 17
Figure 17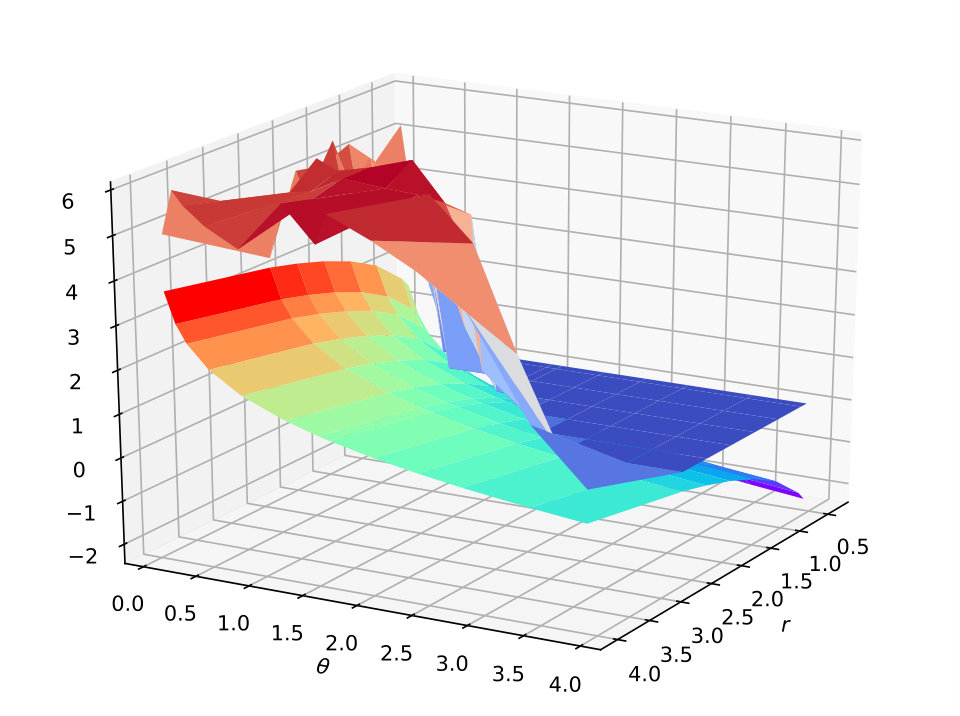 Figure 18
Figure 18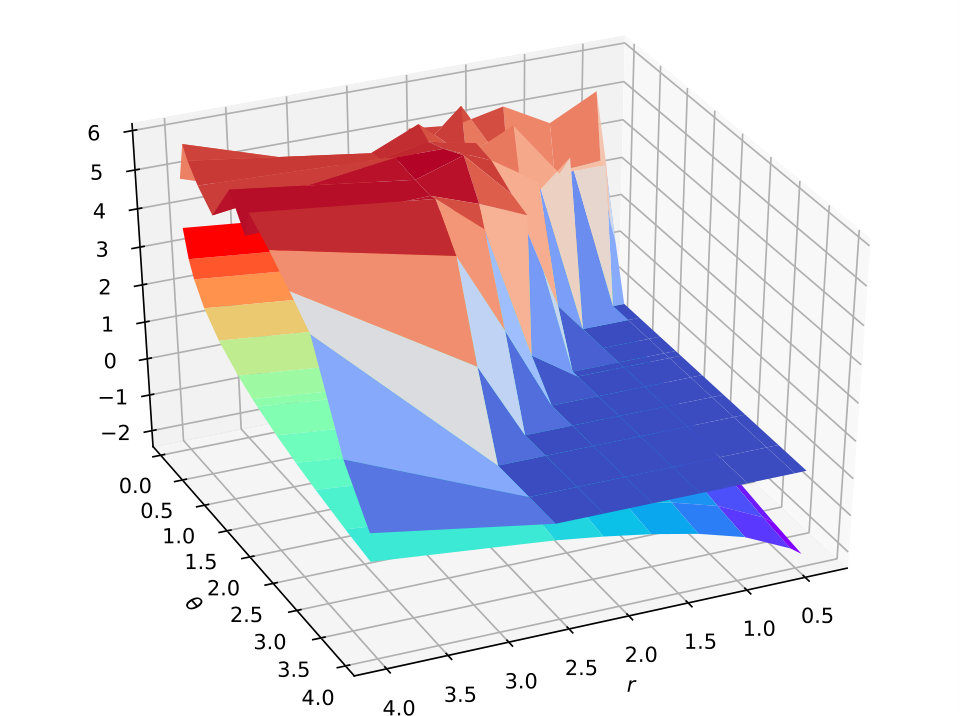 Figure 19
Figure 19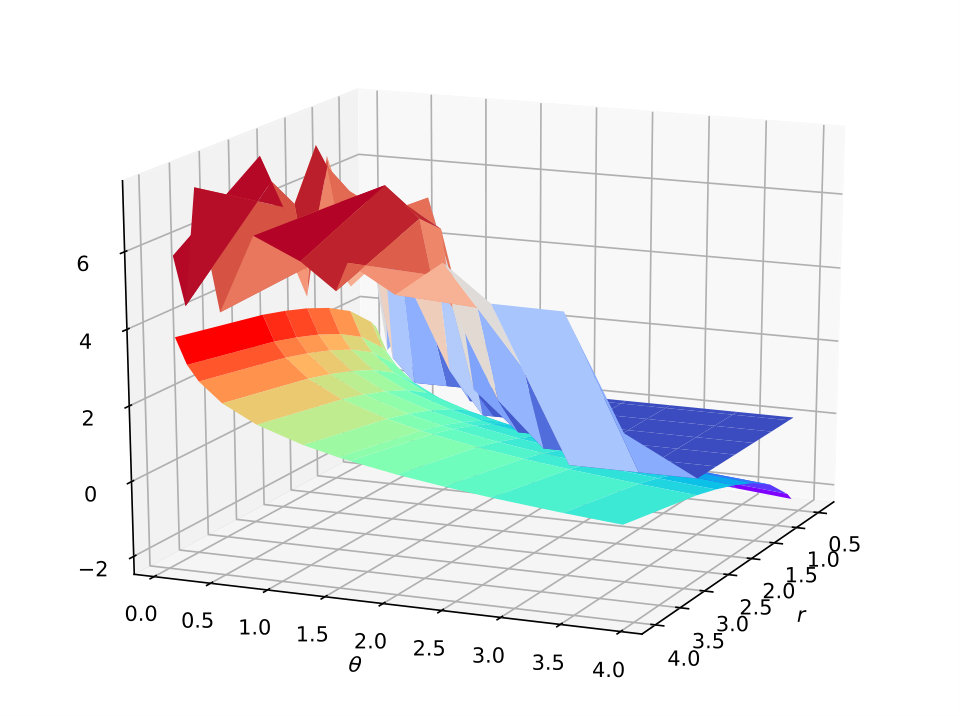 Figure 20
Figure 20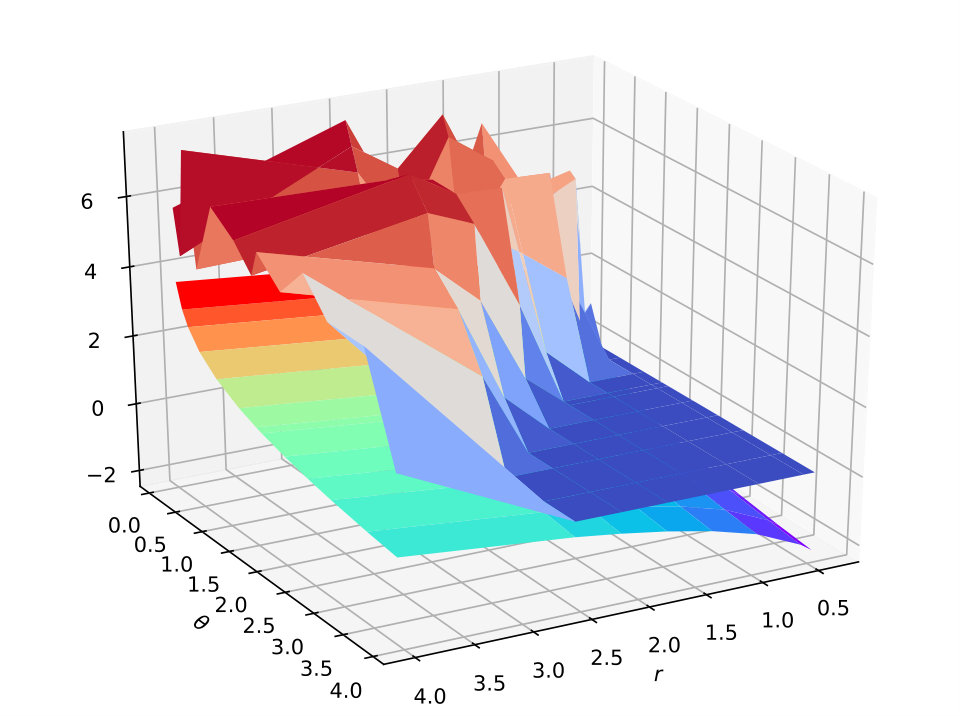 Figure 21
Figure 21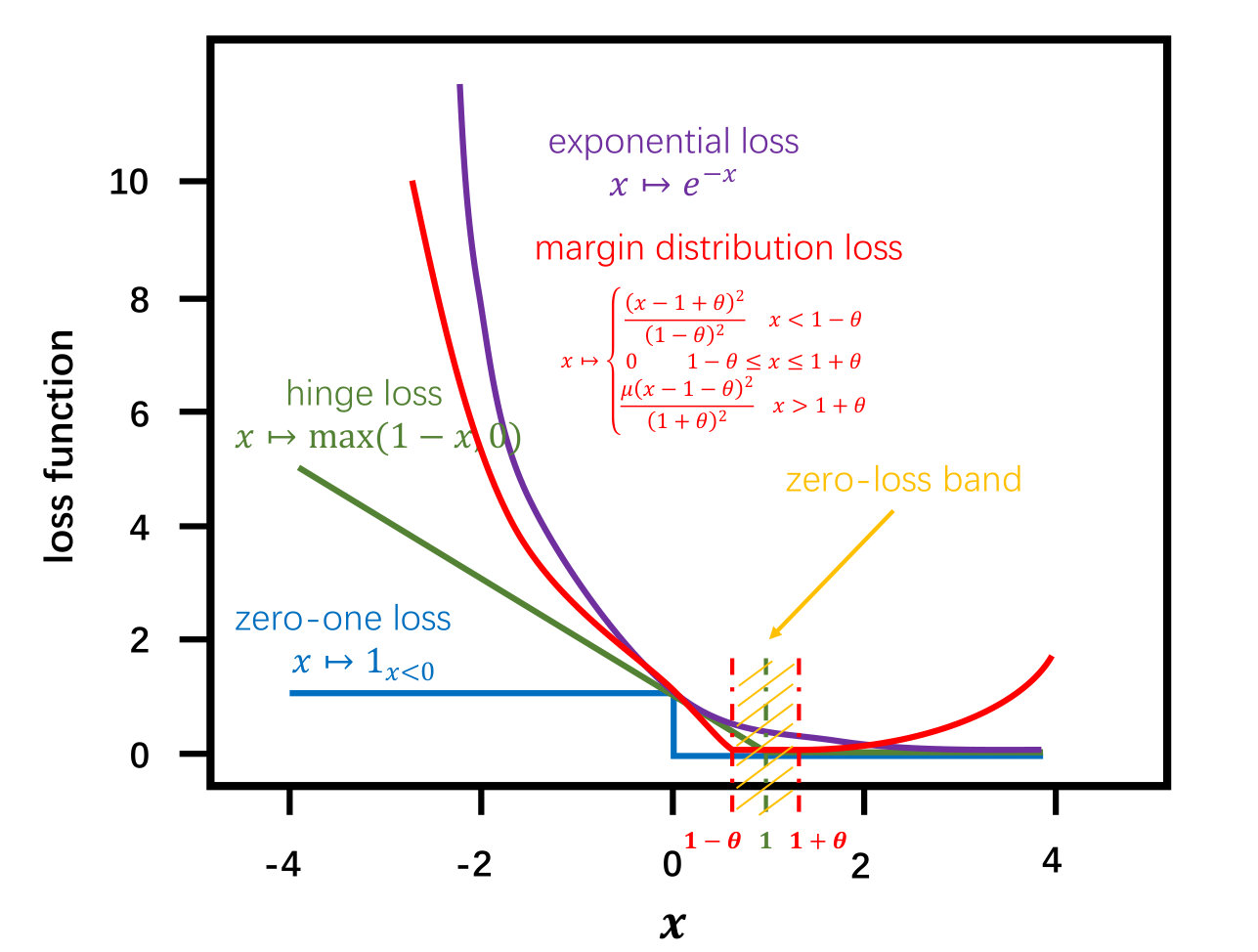 Figure 22
Figure 22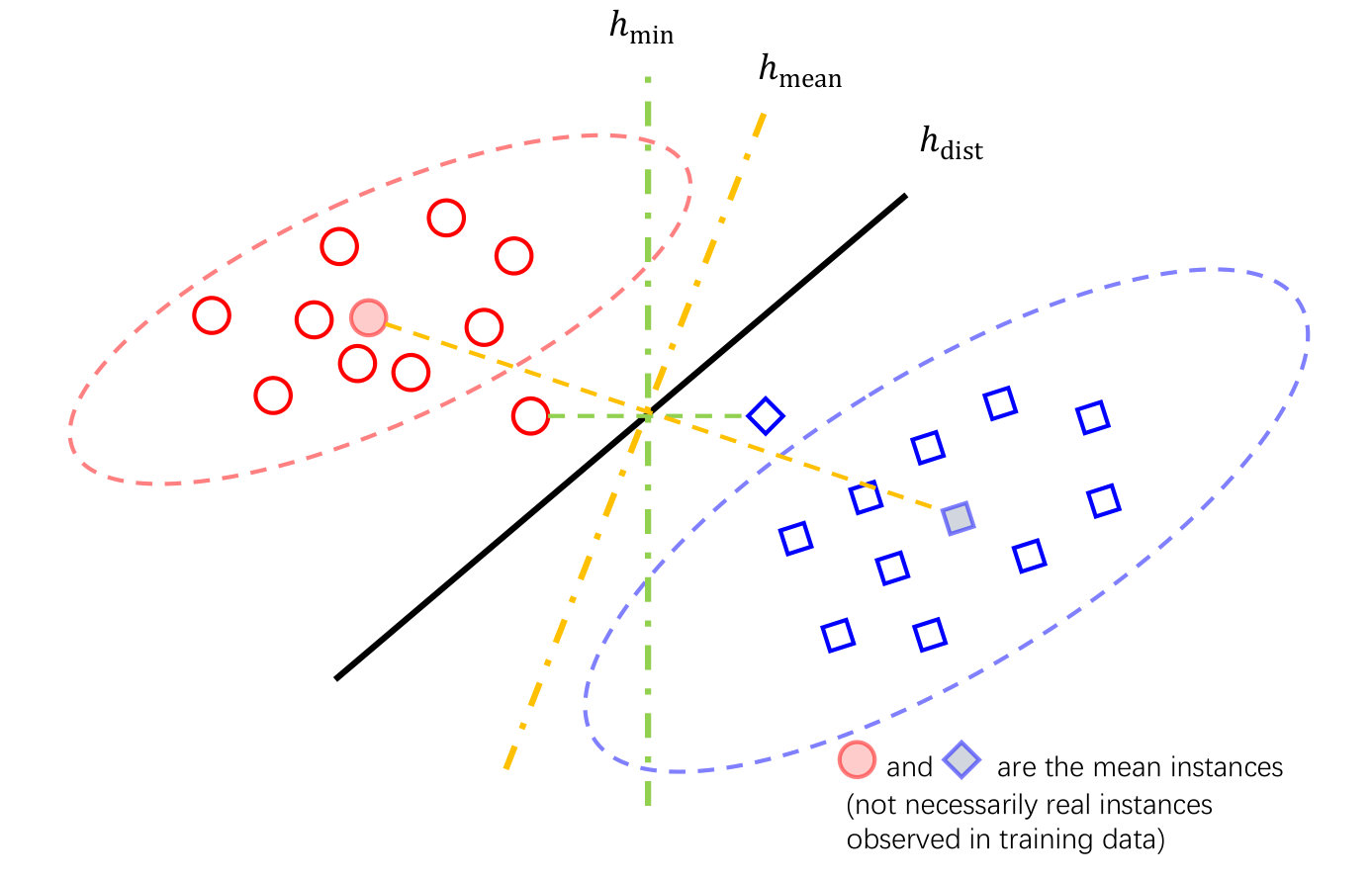 Figure 23
Figure 23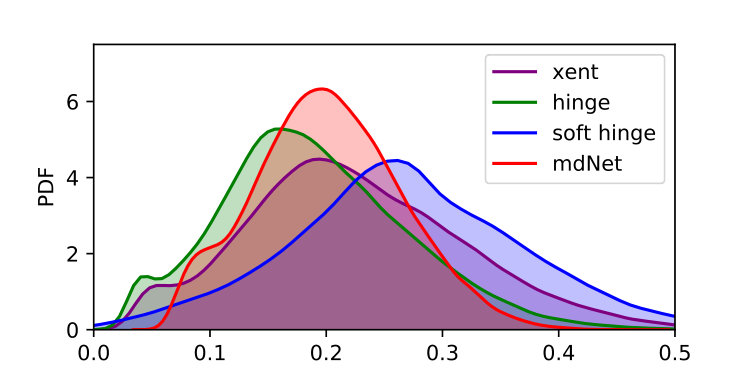 Figure 24
Figure 24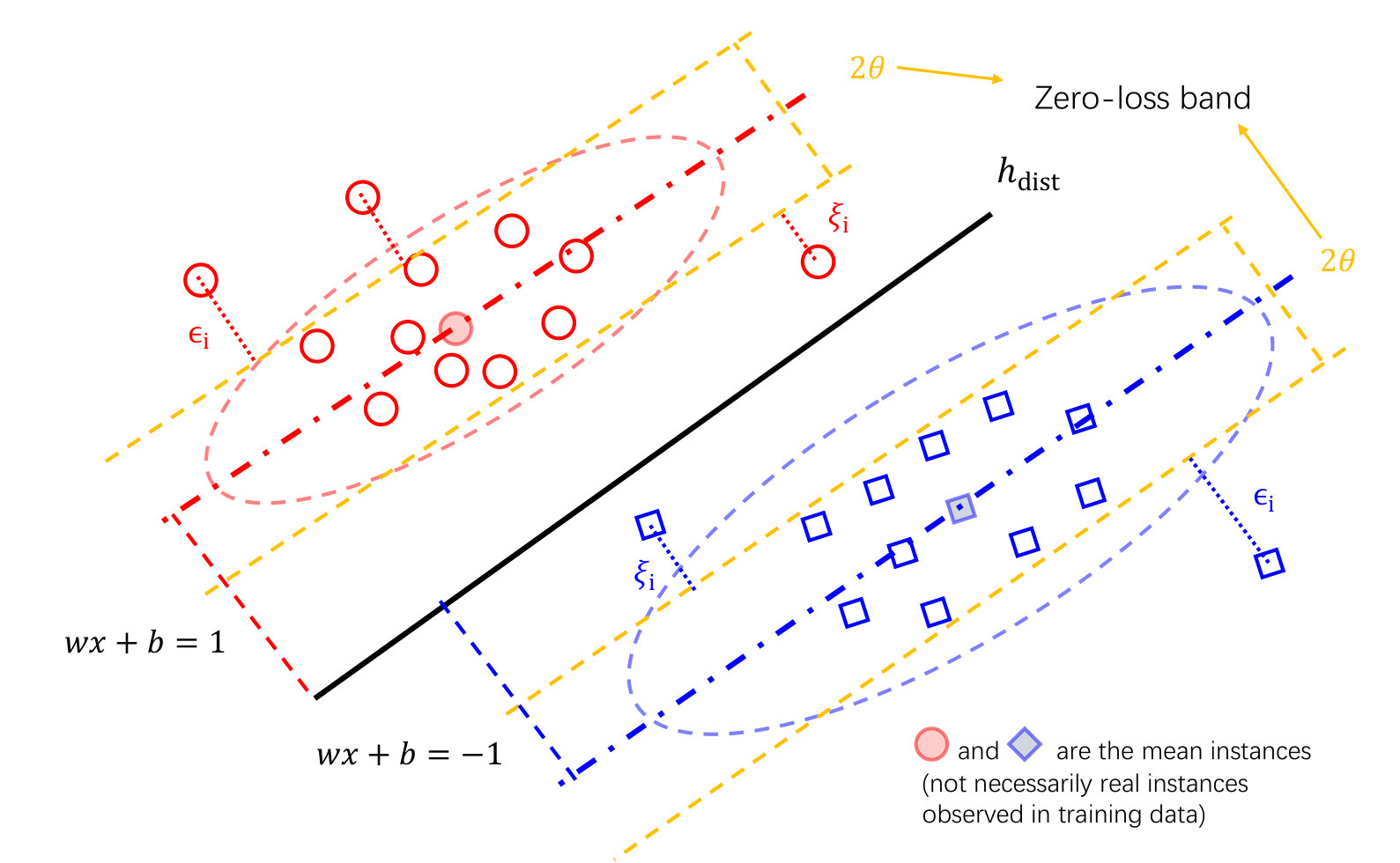 Figure 25
Figure 25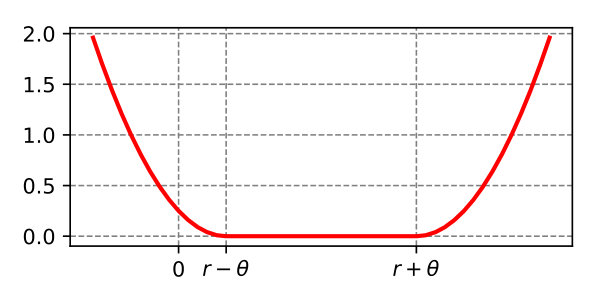 Figure 26
Figure 26| MNSIT | ||||
| Accuracy(%) | xent | hinge | soft hinge | mdNet |
| Batch Normalization | ||||
| 100%_Dropout | 99.095 ± 0.083 | 98.593 ± 0.164 | 99.148 ± 0.039 | 99.161 ± 0.073 |
| 100%_Non_Dropout | 98.384 ± 0.072 | 97.571 ± 0.178 | 98.475 ± 0.064 | 98.837 ± 0.091 |
| 5%_Dropout | 97.001 ± 0.131 | 96.527 ± 0.219 | 97.112 ± 0.092 | 97.268 ± 0.113 |
| 5%_Non_Dropout | 83.364 ± 0.452 | 83.292 ± 0.721 | 83.749 ± 0.273 | 84.483 ± 0.348 |
| Non Batch Normalization | ||||
| 100%_Dropout | 98.228 ± 0.079 | 98.029 ± 0.184 | 98.271 ± 0.055 | 98.342 ± 0.069 |
| 100%_Non_Dropout | 91.728 ± 0.117 | 90.237 ± 0.318 | 91.029 ± 0.098 | 92.274 ± 0.121 |
| 5%_Dropout | 77.842 ± 0.489 | 76.938 ± 0.827 | 77.727 ± 0.411 | 78.173 ± 0.619 |
| 5%_Non_Dropout | 58.023 ± 0.951 | 57.822 ± 1.280 | 59.384 ± 0.827 | 61.379 ± 0.588 |
| CIFAR-10 | ||||
| Accuracy(%) | xent | hinge | soft hinge | mdNet |
| Batch Normalization | ||||
| 100%_Dropout | 85.782 ± 0.198 | 84.234 ± 0.748 | 86.744 ± 0.294 | 87.644 ± 0.151 |
| 100%_Non_Dropout | 81.491 ± 0.143 | 80.938 ± 0.812 | 86.032 ± 0.298 | 86.233 ± 0.244 |
| 5%_Dropout | 61.955 ± 1.945 | 58.363 ± 2.450 | 59.441 ± 1.316 | 67.636 ± 1.633 |
| 5%_Non_Dropout | 57.753 ± 2.228 | 54.289 ± 3.482 | 56.839 ± 2.318 | 64.173 ± 1.982 |
| Non Batch Normalization | ||||
| 100%_Dropout | 83.517 ± 0.322 | 82.153 ± 1.236 | 81.961 ± 0.293 | 84.643 ± 0.255 |
| 100%_Non_Dropout | 72.223 ± 1.284 | 69.379 ± 2.907 | 75.267 ± 1.027 | 76.793 ± 1.279 |
| 5%_Dropout | 50.747 ± 3.735 | 42.739 ± 6.763 | 52.847 ± 1.823 | 58.739 ± 1.348 |
| 5%_Non_Dropout | 36.293 ± 4.872 | 30.984 ± 7.736 | 43.265 ± 4.263 | 47.056 ± 3.927 |
| ImageNet | ||||
| xent | hinge | soft hinge | mdNet | |
| Accuracy(%) | Batch Normalization | |||
| 100%_Dropout | 70.238 ± 1.221 | 69.782 ± 1.933 | 70.284 ± 1.022 | 70.758 ± 1.014 |
| 100%_Non_Dropout | 68.484 ± 1.265 | 67.918 ± 2.166 | 68.83 ± 1.151 | 69.447 ± 1.124 |
| 5‰_Dropout | 60.176 ± 2.045 | 57.475 ± 2.023 | 61.379 ± 1.053 | 65.080 ± 2.373 |
| 5‰_Non_Dropout | 59.574 ± 2.747 | 56.621 ± 2.253 | 60.068 ± 1.773 | 63.529 ± 2.012 |
| Non Batch Normalization | ||||
| 100%_Dropout | 66.924 ± 1.552 | 67.387 ± 1.764 | 67.462 ± 1.017 | 68.655 ± 1.732 |
| 100%_Non_Dropout | 64.481 ± 2.183 | 61.820 ± 2.947 | 64.334 ± 2.367 | 65.838 ± 2.481 |
| 5‰_Dropout | 54.961 ± 3.382 | 52.543 ± 3.722 | 55.757 ± 2.357 | 58.774 ± 3.841 |
| 5‰_Non_Dropout | 47.374 ± 3.265 | 45.741 ± 5.349 | 48.798 ± 3.392 | 53.727 ± 4.235 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Improving Generalization of Deep Neural Networks by Leveraging Margin Distribution
Author:
Shen-Huan Lyu, Lu Wang, and Zhi-Hua Zhou (Corresponding author)
**A pre-printed manuscript
which is accepted by Neural Networks
**
Department of Computer Science and Technology
National Key Laboratory for Novel Software Technology
Nanjing, China
Citation: Shen-Huan Lyu, Lu Wang, and Zhi-Hua Zhou. Improving generalization of deep neural networks by leveraging margin distribution. Neural Networks, 2022. doi: https://doi.org/10.1016/j.neunet.2022.03.019.
Abstract
Recent research has used margin theory to analyze the generalization performance for deep neural networks (DNNs). The existed results are almost based on the spectrally-normalized minimum margin. However, optimizing the minimum margin ignores a mass of information about the entire margin distribution, which is crucial to generalization performance. In this paper, we prove a generalization upper bound dominated by the statistics of the entire margin distribution. Compared with the minimum margin bounds, our bound highlights an important measure for controlling the complexity, which is the ratio of the margin standard deviation to the expected margin. We utilize a convex margin distribution loss function on the deep neural networks to validate our theoretical results by optimizing the margin ratio. Experiments and visualizations confirm the effectiveness of our approach and the correlation between generalization gap and margin ratio.
Contents
1 Introduction
Deep neural networks (DNNs) are making major advances in solving problems that have resisted the best attempts of the artificial intelligence community for many years [LBH15], especially in the field of computer vision [Gor22]. Recently, many research try to explain the practical success of DNNs via generalization, which is the ability of a classifier to perform well on unseen samples. However, some new empirical evidence has started to question this explanation. Adversarial training samples can cause the model to misclassify seriously by slight feature perturbation [GSS15, Pap+17]. On the other hand, [Zha+21] find that the deep neural networks have enough complexity to fit an arbitrarily corrupted data, and a small geometric transformation may cause networks deteriorating in performance [AW19]. This complex and fragile nature of DNNs leads to a key problem, how to use the data distribution and network parameters to estimate the generalization ability of DNNs. Although several regularization techniques, such as dropout [Sri+14], batch normalization [IS15], and weight decay [KH92], do improve the generalization performance of the over-parameterized deep models, [Zha+21] show that these regularizers cannot solve this problem either.
Consequently, several recent works [NTS15, BFT17, NBS18, Aro+18] have started to address this question, proving that we can control the capacity of DNNs via different upper bounds based on the minimum margin. However, the generalization bounds based on analyses of model complexity and noise stability only focus on the minimum margin, which is based on the closest distance of the training points to the decision boundary. This notion is brittle and sensitive to outliers due to a lack of the entire margin distribution information. [Jia+19] propose a measure by looking at the entire distribution of distances, and conduct empirical studies on how well it can predict the generalization gap. However, how the margin distribution information affects the generalization error of the model still needs more specific theoretical analysis, which will lead us to optimize the entire margin distribution appropriately.
The margin distribution has been shown to correspond to generalization properties in the literature on linear models and boosting algorithms, [Sch+97] first introduce it to explain the phenomenon that AdaBoost seems resistant to overfitting problem. Two years later, [Bre99] indicates that the minimum margin is crucial for margin theory. [RS06] conjecture that the margin distribution, rather than the minimum margin, plays a key role. The debate has been finally solved by [GZ13] who theoretically proved that the AdaBoost process attempts to maximize the margin mean and minimize margin variance simultaneously; highlighting for the first time that two factors rather than a single factor are crucial for margin theory. These two factors are the first and second-order statistics describing the margin distribution, while in most cases the higher-order one is less useful. Their result successfully explains why AdaBoost seems resistant to overfitting: even when the training error reaches zero, the margin mean can be increased and/or the margin variance can be decreased further, leading to the improvement of generalization performance; it also discloses that AdaBoost will finally overfit: when the margin mean cannot be increased and margin variance cannot be decreased further. The long march of the theoretical exploration of AdaBoost is summarized in [Zho14], and [GZ13]’s result has been theoretically confirmed by [Grø+19]. Inspired by [GZ13]’s finding, powerful learning machines can be built by maximizing the margin mean and minimizing margin variance simultaneously, rather than simply maximizing the minimum margin like in traditional large-margin machines. [ZZ19] propose the optimal margin distribution machine (ODM) for binary classification. In [ZZ17, ZZ18, ZZ18b, Tan+20, ZZJ20], ODM is extended to many forms.
In this paper, we study a -layer feed-forward network with ReLU activation functions. Our theoretical result states that the statistics of margin distribution play an important role in the generalization estimation rather than the traditional minimum margin. This result is consistent with the previous results on boosting and linear algorithms [Sch+97, GZ13, ZZ19]. It also inspires us to understand the similarities between deep learning and traditional machine learning from the perspective of margin distribution. Specially, we propose a new loss function to optimize the statistics-based measure in the theoretical results. A strong correlation between generalization and our measure is empirically shown by studying a wide range of network structures trained on the MNIST, CIFAR-10 and ImageNet datasets. The detailed contributions of this paper are as follows:
PAC guarantee
Our bound shows that we can restrict the capacity of deep nets by the ratio of second- to first-order statistic of margin distribution at the last layer. Compared with the existing results based on minimum margin [BFT17, NBS18, Aro+18], our bound contains more information on the entire margin distribution to estimate the generalization error. Moreover, the empirical evaluation shows that optimizing the margin ratio can control the model capacity to alleviate the overfitting risk.
Optimization
Inspired by our theoretical result, we encourage DNNs to optimize the margin ratio for better generalization performance. Therefore, we propose a new approach called margin distribution Networks (mdNet), which utilizes a convex margin distribution loss function to optimize the first- and second-order statistics of margin. Moreover, we empirically evaluate our loss function on deep neural networks across different image datasets and model structures. Specifically, empirical results demonstrate the effectiveness of the proposed method in learning tasks with limited training data.
The rest of paper is organized as follows. The related work is introduced in Section 2. Some notations are introduced in Section 3. In Section 4, we present a generalization bound leveraging margin distribution rather than minimum margin and demonstrate that the ratio of the margin standard deviation to the expected margin is the key to control the model capacity. Section 5 list the detailed proofs for our theorems and lemmas. In Section 6, we formulate the convex loss function to optimize the margin ratio. Section 7 reports our experimental studies and empirical observations. Finally, Section 8 concludes with future work.
2 Related work
Recently, margin-based deep learning algorithms have developed rapidly. [SKP15] use the triplet loss to encourage a distance constraint similar to the contrastive loss. Similarly, [Cha+15] enhance the supervision of the learned filters by incorporating the information of class labels in the training data and learn the filters based on the idea of multi-class linear discriminant analysis (LDA) for classification task. [Liu+16] propose a generalized large-margin softmax loss which explicitly encourages intra-class compactness and inter-class separability in the learned representation space. It would be interesting to theoretically study feature space transformation which might be a key to understanding mysteries behind the successes of deep neural networks [Zho21]. Since [BFT17] and [Aro+18] associate the generalization of deep neural networks with the minimum margin, a line of work establishes that first-order methods can automatically maximizing the minimum margin in the settings of logistic regression [Gun+18], deep linear networks [Sou+18, Gun+18a, JT19, LMZ18], and symmetric matrix factorization [LMZ18]. However, [Wei+18] point that how to extend these results to non-linear neural networks remains unclear. Recently, [Wu+21] propose to understand the model dynamics from the perspective of control theory. Another line of algorithm-dependent analysis of generalization [HRS16, Mou+18, CJY18] uses stability of specific optimization algorithms that satisfy certain generic properties like convexity, smoothness, etc. Specially, [Kes+17, Din+17, Zhu+19] make a connection between the sharpness of the solution obtained using the SGD algorithm and its ability to generalize well. The notion of sharpness corresponds to robustness to adversarial perturbations of parameters. Furthermore, [Ney+17, NBS18] draw a connection to the PAC-Bayesian theory for sharpness. The margin distribution measure presented in this paper is closely related to sharpness [Kes+17], because we use the statistics of the margin distribution to theoretically describe the value of the allowable perturbation. Compared with the sharpness measure which is difficult to optimize, the margin distribution measure proposed in this paper is easy to calculate, and can be directly optimized through the SGD algorithm by designing a convex loss function. Recently, [Jia+19] present abundant empirical evidence to validate that the generalization in deep learning can be estimated from the margin statistics. In addition, the relevant theories of domain adaptation [MMR09, ZZY12, MS14] are also used to improve the generalization capability of deep learning [Pan+09, BCF13, KTP17, RSF19]. Domain generalization cannot see existing training source domains during training. This makes domain generalization more challenging than domain adaptation but more realistic and favorable in practical applications [Ghi+15, Dub+21, Wan+21, Mat+22].
3 Notations
Consider the multi-class task with feature domain and label domain . Let be an unknown (underlying) distribution over . A training set and a validation set are drawn identically and independently according to . We denote a labeled sample as .
Let be the function represented by a -layer feed-forward network with parameters
[TABLE]
and output domain . The entire network can be formulated as
[TABLE]
where is the ReLU activation function and let be an upper bound on the number of output units in each layer.
We can define the fully connected networks (FNNs) recursively:
[TABLE]
where denotes the output of the -th layer.
The predicted label is denoted by
[TABLE]
where is a map from the feature domain to the label domain and is the -th element of the score vector.
In the multi-class setting [MRT18, Chapter 9.2], the label associated to point is the one resulting in the largest score . This naturally leads to the following definition of the margin of the function at a labeled example :
[TABLE]
Thus, misclassifies iff .
4 Margin distribution rather than minimum margin
In Subsection 4.1, we list error-resilience assumptions that will be used. In Subsection 4.2, we introduce the existed results based on the minimum margin. In Subsection 4.3, we present our main results based on the entire margin distribution.
4.1 Error-resilience assumptions
Here we formalize the error-resilience properties for deep neural networks. [Aro+18] show that if we inject a scaled Gaussian noise to the input of deep nets, as it propagates up, the noise has rapidly decreasing effect on higher layers. This fact implies compressibility of deep nets, i.e., low rank of parameters’ matrix. The empirical version of noise-sensitivity parameters are first proposed by [Aro+18]. It inspires us to bound the perturbation caused by Gaussian noise with the validation-based version of noise-sensitivity parameters below.
Assumption 4.1**.**
(Layer Cushion). The layer cushion of layer is defined to be largest number such that for any validation data :
[TABLE]
Assumption 4.2**.**
(Interlayer Cushion). For any two layers , we define the interlayer cushion , as the largest number such that for any validation data :
[TABLE]
Furthermore, for any layer we define the minimal interlayer cushion as . For any two layer , denote by the operator for composition of these layers and be the Jacobian matrix (the partial derivative) of this operator at input . Therefore, we have . Furthermore, since the activation functions are ReLU (hence piece-wise linear), we have .
Assumption 4.3**.**
(Interlayer Smoothness). For any two layers , we define the interlayer smoothness as the smallest number such that with probability over noise for any validation data :
[TABLE]
For a single layer, captures the ratio of input/weight alignment to noise/weight alignment. [Aro+18] show that the interlayer smoothness is indeed good: is a small constant.
The next two conditions qualify a common appearance: if the input in the activation and margin calculations is well-distributed and the calculations do not correlate with the magnitude of the input, then one would expect that, the effect of applying activation at any layer and margin at last layer is to decrease the norm of the vector by at most some small constant factor, i.e., and .
Assumption 4.4**.**
(Activation Contraction). The activation contraction is defined as the smallest number such that for any layer and any validation data :
[TABLE]
Assumption 4.5**.**
(Margin Contraction). The margin contraction is defined as the smallest number such that for any validation data :
[TABLE]
In this paper, we only use the noise-sensitivity parameters in Assumptions 4.1 - 4.5 as descriptions of error-resilience properties, from which the margin distribution term of our bound is derived. Therefore, we just need estimate these parameters based on validation data to show the magnitude of our bound rather than optimizing these parameters in the training process like [Aro+18] did.
4.2 Existed results
In the deep learning theory community, great efforts have been made to explain why over-parameterized deep neural networks can success, which is contrary to the classical VC dimension analysis [BMM98, HLM17]. [BFT17] and [NBS18] made an important stride by showing minimum margin based bounds for multi-layer neural networks. These bounds do not depend directly on the number of parameters of the network but depends on the normalized minimum margin. Theorem 4.6 provides a unified description of these bound. The only difference between them lies in the value of constants and the type of norms.
Theorem 4.6**.**
[BFT17, NBS18]** For any and , let be a -layer feed-forward network with ReLU activation. Then, for any , with probability over a training set of size , for any , we have:
[TABLE]
where is the 0-1 loss, is the empirical estimation of -margin loss and describes the limiting behavior of a function.
Based on this margin theory view, [Aro+18] provide an improved bound by considering the compressibility of deep nets as follows:
Theorem 4.7**.**
[Aro+18]** For any , let be a -layer feed-forward network with ReLU activation. Then, for any , with probability over a training set of size m, for any , we have:
[TABLE]
where are layer cushion, interlayer cushion, activation contraction and interlayer smoothness defined in Assumptions 4.1, 4.2, 4.4 and 4.5 respectively
These existed results follow the traditional margin theory, so they only focus on the minimum margin . Because they lack the description of the entire margin distribution, they can only take the minimum margin as the optimization target to improve the generalization performance. These methods ignore the information of the entire margin distribution. In the next subsection, we expect to prove a bound related to the entire margin distribution, so as to inspire us to directly optimize margin distribution for improving the generalization performance for DNNs.
4.3 Main results
We begin with an intuitive comparison of the minimum margin based classifier and the margin distribution based classifier. Figure 1(a) shows that maximizing the minimum margin will make the classifier easy to be misled by a small number of samples, thus ignoring the distribution information of samples, while the margin distribution based classifier considers the mean and variance of samples and generalizes better.
In order to utilize the mean and variance information into the theoretical analysis, we design a new margin loss, which uses to adjust the mean of margin and to adjust the variance of margin. For any parameter , we can define a -margin distribution loss function (see Figure 1(b)), which penalizes with a cost of when it predicts with a margin smaller than , but also penalizes when it predicts with a margin larger than . The margin distribution bound is presented in terms of this loss function, which is formally defined as follows.
Definition 4.8**.**
(Expected margin distribution loss function). For any , the -margin loss is the function defined for all as:
[TABLE]
Intuitively, our -margin distribution loss function looks for a classifier which forces as many data points as possible into the zero-loss band (). Therefore, we let , which implies that the expected margin is larger than the standard deviation. Actually, just need to be a second-order statistic, so we can re-scale to satisfy . In this way, the ()-margin distribution loss is a surrogate loss function. In particular, for and , the zero-loss band is the positive area () and corresponds to the 0-1 loss . Let be the empirical estimate of the expected margin distribution loss. So we also denote the expected risk and the empirical risk as and , which are bounded between 0 and 1.
We begin with bounding the change of output caused by the noise on the classifier with the noise-sensitivity parameters and the statistics of margin distribution:
Lemma 4.9**.**
Let be a -layer network. For any , and is a vector of perturbation parameters with and is a vector of random vectors with , the change of the output of the network can be bounded with a fixed probability ():
[TABLE]
The result shows that the perturbation caused by increases with the variance is related to the outermost edge of margin distribution , that is, the right green dotted line in Figure 1(b). The next Lemma shows that we can bound the generalization gap through a Kullback-Leibler divergence term, if we can guarantee that the perturbation caused by is smaller than with a constant probability. Therefore, the allowable value of under the -margin distribution assumption is consistent with the intuitive understanding (see Figure 3), i.e., , where . When the margin distribution is more compact (smaller ), the larger noise can be allowed, that is, it is not easy to cause misclassification. When the margin distribution is more loose (larger ), even a small noise have misclassification risk.
Lemma 4.10**.**
Let be any predictor with parameters , and be any distribution on the parameters that is independent of the training data. Then, for any , with probability at least over the training set of size , for any , and any random perturbation s.t. , we have:
[TABLE]
The detailed proof is presented in Section 5.2. This Lemma improves the result of [NBS18, Lemma 1 ], especially using two parameters to describe the entire margin distribution instead of using one parameter to describe the minimum margin. Based on this result, we can derive the following generalization bound, with proof deferred to Section 5.3 showing that the Kullback-Leibler divergence term is inversely proportional to .
Theorem 4.11**.**
For any , let be a -layer feed-forward network with ReLU activation. Then, for any , with probability over a training set of size m, for any , we have:
[TABLE]
where the margin ratio is defined by
We prove an upper bound on generalization gap related to the margin ratio term, where is a parameter denoting the ratio of the margin standard deviation to the expected margin over the underlying distribution, and the error-resilience term relies on the noise sensitivity [Aro+18] quantified by (See Assumptions 4.1, 4.2, 4.4 and 4.5). Theorem 4.11 states that the entire margin distribution has much leverage in generalization performance rather than the minimum margin. Specifically, restricting a smaller (larger and smaller ) can effectively control the capacity of models, so as to reduce the risk of overfitting. It inspires us that optimizing margin distribution can get better generalization performance than the traditional minimum margin maximization algorithm.
Discussion.
The main difference between [Aro+18] and our paper: [Aro+18] proved that the generalization performance of deep neural network is related to the sparsity of its parameters, focusing on how to compress the parameters of the trained model. Our paper studies the relationship between DNN generalization performance and margin distribution under the condition that DNN parameters is sparsity, focusing on optimizing margin distribution during training. Figure 2 shows that the improvement of our bound relative to [Aro+18] (the shaded part in the figure) is because the margin ratio will gradually decrease during the training process. The main difference between [Jia+19] and our paper: [Jia+19] conjectured that the generalization performance of DNN may be related to the interval distribution. The correlation between generalization and [GS01] is calculated experimentally, and no theoretical proof is given. Our paper proves theoretically that the generalization performance of DNNs can be bound by the margin ratio and gives the improved algorithm.
5 Proofs
In this section, we provide the detailed proofs for the main theorem and lemmas. First, we present a useful lemma as follows:
Lemma 5.1**.**
Let be a probability distribution over the reals. For any random variable identically and independently (i.i.d.), we have
[TABLE]
Proof of Lemma 5.1: Let the Cumulative Distribution Function (CDF) and Probability Density Function (PDF) of random variable be and , and we denote the maximum of a set of random variables by . Then
[TABLE]
In other word, the CDF and PDF of the minimum are and . Then we can use the minimum value of the sample’s set to bound the random variable with a probability , which converges to with a rate :
[TABLE]
According to Eq. \tagform@21 and Eq. \tagform@22, we have
[TABLE]
∎
5.1 Proof of Lemma 4.9
We begin with a lemma as follows:
Lemma 5.2**.**
For any layer , the point-wise compressibility of the layer-wise parameters can holds with a probability over as follows:
[TABLE]
where is the size of the validation set.
Proof of Lemma 5.2: According the independence between and , we can regard the noise-sensitivity parameters , and as random variables over reals relying on the randomness of variable . Then, the cushion parameters defined in Assumptions 4.1, 4.2, 4.3, 4.4 and 4.5 can be interpreted as choosing the maximum of multiple independent samples. We first prove Lemma 5.1 on the tail of a random variable by choosing the maximum of multiple independent samples of the random variable. Specifically, using the following simple lemma based on the distribution of the maximum, we can guarantee the point-wise compressibility of the learned parameters over the underlying data distribution with a high probability by calculating the maximum of the empirical dataset, i.e., , and . ∎
Proof of Lemma 4.9: First, we need to bound the perturbation of linear operator caused by injecting a scaled Gaussian noise . For any fixed vectors , we have
[TABLE]
According the Markov inequality, we have
[TABLE]
Now, we will bound the perturbation of the -layer deep nets by induction. For any layer , let be the output at layer with original net and be the output at layer if the weights in the first layers are replaced with . The induction hypothesis is then following:
Consider any , the following is true with probability over for any :
[TABLE]
For the base case , since we are not perturbing the input, the inequality is trivial. Now assuming that the induction hypothesis is true for , we consider what happens at layer .
[TABLE]
The second term in Eq. \[email protected] can be bounded by by induction hypothesis. Therefore, it is enough to show that the first term in Eq. \[email protected] is bounded by . We decompose the error into two error terms one of which corresponds to the error propagation through the network if activation were fixed and the other one is the error caused by change in the activations:
[TABLE]
The first term in Eq. \[email protected] is bounded by:
[TABLE]
where Equation \tagform@38 is bounded by Eq. \[email protected], Equation \tagform@39 is bounded by Lipschitzness of the activation function, Equation \tagform@40 is bounded by inductive hypothesis, Equation \tagform@41 is bounded by activation contraction, Equation \tagform@42 is bounded by layer cushion, and Equation \tagform@44 is bounded by interlayer cushion.
The second term in Eq. \[email protected] can be bounded as:
[TABLE]
Both terms in Eq. \[email protected] can be bounded using Assumption 4.3. By notations we find . By induction hypothesis, we have that . Now by interlayer smoothness property, . Similar to this term, . Putting everything together completes the induction with probability at least (if ).
Instead of assuming that the input domain is bounded by a constant , we assume that the input boundary is relative to the expected value which implies the data-distribution information: . According to the margin contraction property, we can use the first- and second-statistics of the margin in the last layer to bound the perturbation instead of the worst situation:
[TABLE]
Connecting these two inequalities we prove that the equality holds with a probability at least :
[TABLE]
∎
5.2 Proof of Lemma 4.10
Proof of Lemma 4.10: Let , Let be the set of perturbations with the following property:
[TABLE]
then we will have .
Let be the probability density function over the parameters . We construct a new distribution over predictors where is restricted to with the probability density function:
[TABLE]
According to the lemma assumption, we have . Therefore, we can bound the change of the margins for any instance:
[TABLE]
Here we define a perturbed loss function as:
[TABLE]
We can get the following:
[TABLE]
Finally, using the proof of [NBS18, Lemma 1 ], with probability over the training set we have:
[TABLE]
∎
5.3 Proof of Theorem 4.11
Proof of Theorem 4.11: Since Lemma 4.9 proves that the perturbation caused by random vector is bounded by a term relative to the variance , we can preset the value of to make the random perturbation satisfy the condition for Lemma 4.10. Bounding the Kullback-Leibler divergence term by in PAC-Bayesian theorem, we can attain the generalization bound based on a specific margin distribution.
The proof involves chiefly two steps. In the first step we bound the maximum value of perturbation of parameters to satisfy the condition that the change of output restricted by hyper-parameters of margin and , using Lemma 4.9. In the second step we prove the final margin generalization bound through Lemma 4.10 with the value of Kullback-Leibler divergence term calculated based on the bound in the first step.
[TABLE]
We can derive from the above inequality. Naturally, we can calculate the Kullback-Leibler divergence in Lemma 4.9 with the chosen distributions for .
[TABLE]
Put it in Lemma 4.10 and let , with probability at least and for all such that, we have:
[TABLE]
∎
6 Optimizing margin distribution measure
The generalization theory shows the importance of optimizing the margin distribution ratio . The result inspires us to find a margin distribution band () containing as many training samples as possible to minimize the empirical estimate loss , but also a ratio as small as possible to minimize the generalization gap . This type of loss function was first proposed by [ZZ19] to optimize the first- and second-order statistics of margin distribution. We formulate a convex margin distribution loss function for DNNs:
Definition 6.1**.**
(Convex margin distribution loss function). For a labeled sample , we denote its margin by which is defined as Eq. \tagform@1. We define the margin distribution loss for networks (mdNet loss) as:
[TABLE]
where is the margin mean parameter, is the margin variance parameter and is a parameter to trade off two different kinds of deviation (keeping the balance on both sides of the margin mean). Figure 1(c) shows the shape of this convex loss function.
Equation \tagform@64 will produce a square loss when the margin satisfies or . Therefore, our margin loss function will force the zero-loss band to contain as many sample points as possible. The ratio of hyper-parameters can control the capacity measure, which implies our measure is dependent to our specific learning algorithm (loss function with specific hyper-parameters). Since our loss function aims at finding a decision boundary which is determined by the entire margin distribution, instead of the minority samples that have minimum margins, we name our method as margin distribution Networks (mdNet).
7 Experiments
In Subsection 7.1, we introduce the configuration of datasets and models. In Subsection 7.2, We design an ablation experiment to verify the superiority of our method. In Subsection 7.3, we show the correlation between separability of representations and margin ratio via visualization. In Subsection 7.4, we design experiments to confirm that our method can control the capacity of deep nets. In Subsection 7.5, we discuss the influence of the different hyper-parameters on the test accuracy.
7.1 Configuration
Since our method only works on the loss function part of deep models and does not change the architecture of deep neural networks, we can verify the effectiveness of mdNet on the classic CNNs (convolutional neural networks) and image classification benchmark datasets. We consider the following architectures and datasets: a LeNet architecture for MNIST dataset [LeC+98], an AlexNet architecture [KSH12] for CIFAR-10 dataset [Kri09] and a ResNet-18 architecture [He+16] for ImageNet dataset [Rus+15]. From the literature, these datasets come pre-divided into training and testing sets, therefore in our experiments, we use them in their original format. The loss functions used for comparison in the experiments are as follows: cross-entropy loss (abbr., xent), hinge loss and soft hinge loss. Hinge loss [CV95] and soft hinge loss [Liu+16] are loss functions specially proposed to optimize the minimum margin, both of them are inspired the traditional margin theory.
As for details about the architecture, we remove the weight decay [KH92], dropout [Sri+14] and batch normalization (BN) [IS15] from all the models, because the batch normalization operation and weight decay will shift the data distribution. The notable dropout technique, in which some neurons are dropped from the DNNs in each iteration, can also be viewed as an ensemble method composed of different neural networks, with different dropped neurons [BS13]. It is hard to analyze the influence of the ensemble structure on the margin distribution, so we remove this technique in these architectures in the experiments except to understand the contribution of the components to the whole models in the ablation study.
For special hyper-parameters, including the expected margin parameter and margin variance parameter for mdNet loss model, and margin parameter for hinge loss model, we perform hyper-parameter search. We hold out 5000 samples of the training set as a validation set, and use the remaining samples to train models with different special hyper-parameters values on all datasets. As for the common hyper-parameters, such as learning rate and momentum, we set them as the default commonly used values in PyTorch [Pas+19] for all the models. We chose batch stochastic gradient descent as the optimizer. We run all the experiments on four K80 GPU machines. As for the influence of the different hyper-parameters on the test accuracy, we discuss it empirically in Subsection 7.5.
7.2 Ablation study
Since the optimization algorithm proposed in this paper only focuses on the improvement of loss function, we design an ablation experiment to study the performance of our proposed mdnet method and the traditional benchmark loss functions under different regularizations in Table 1. The mdNet loss outperforms the others consistently across different situations, no matter whether dropout, batch normalization or the entire dataset are used or not. The experiments are evaluated on three MNIST (LeNet), CIFAR-10 (AlexNet) and ImageNet (ResNet-18) datasets. Specifically, when the amount of training samples is small, the advantage of mdNet loss is significant. Moreover, the mdNet loss function can cooperate with both batch normalization and dropout, achieving the best performance in Table 1, which is highlighted in bold red text. Unlike dropout and batch normalization which lack solid theoretical grounds, the mdNet loss function is inspired by the margin distribution bound in Theorem 4.11, which guides us to find a suitable margin ratio to restrict the model capacity and alleviate the overfitting problem efficiently.
7.3 Feature visualization
In this experiment, we use t-SNE method to visualize the learned representations on the last hidden layer. Figure 4(a), 4(b) and 4(c) plot the 2D t-SNE [MH08] embedding image on limited datasets, including MNIST (LeNet), CIFAR-10 (AlexNet) and 10-class ImageNet (ResNet-18). Consistently, we can find that the result of mdNet loss model is better than all the others, the distribution of samples which have the same label are more compact. To quantify the degree of separability of data distribution, we perform a variance decomposition on the data in the embedding space. By comparing the ratio of inter-class variance to intra-class variance in Figure 4(d), 4(e) and 4(f), we see that the mdNet loss always attain the most separable distribution among these four loss functions. Moreover, the visualization result is consistent with the margin distribution ratio of these four models, which means that optimizing the margin distribution (searching an appropriate margin ratio ) is helpful to attain a good learned representation space. This representation features space can further alleviate the overfitting problem of deep learning, we verify empirically that a network trained with mdNet loss shows stronger clustering. Specially, Figure 4(d), 4(e) and 4(f) show the relationship between the margin ratio and test error. Moreover, Figure 5 plots the test error of mdNet and the margin ratio across the different epochs. We can see that more compact margin distribution gets better prediction performance across different models and epochs. This exhibits that optimizing margin distribution can indeed improve the learning ability of deep nets.
7.4 Controlling capacity
The first two experiments have demonstrated that our mdNet can outperform other classical loss functions and our method can learn a more separable feature representation, as the corresponding margin ratio is also smaller. However, it leads to the last question:
*Can smaller margin ratio reduce the capacity of models and accelerate the convergence of generalization gap?
Let’s go back to the theoretical result obtained by Theorem 4.11. The generalization gap of the model is bounded by , where the margin distribution measure determines the worse case of generalization gap when the number of samples are equal:
[TABLE]
Therefore, we design experiments to compare the empirical value of generalization gap with the increase of training samples under different loss functions. In Figure 6, it shows that the red dotted line representing the convergence curve of our method always convergences faster than the other lines under different datasets and models. It also demonstrates that our method can effectively control the capacity of the model by optimizing the margin distribution ratio, so that the trained model has better generalization performance.
Given a fixed number of samples , we find that the worst case of generalization gap is proportional to the model capacity. When is large enough, the scale factor will be close to 0, and the difference of sample complexity is not significant. The advantage of optimizing margin distribution is relatively significant when is relatively small. Therefore, in the right of Figure 6 (the ImageNet experiment), we specially truncate the most significant result of convergence rate (form 0.1‰ to 5‰ of training set), which shows that optimizing margin distribution can control the capacity of the model even on such a complex dataset.
7.5 Influence of the hyper-parameters
Figure 7 plots the 3D surface figure for the test accuracy on the MNIST, CIFAR-10 and ImageNet datasets varying with two hyper-parameter and . It shows that the ratio (the lower surface with rainbow colors) increases with increasing and decreasing. As for the test accuracy (the upper surface with warm-cool colors), we find that its trend is consistent with the ratio . Therefore, the influence of the hyper-parameters demonstrates that our theoretical result. Within a certain range, getting a smaller ratio through specific optimization (the margin distribution loss function) will effectively reduce the size of the hypothesis set for deep nets (returned by the specific algorithm), so as to improve the generalization ability of the learned model. In other words, the test accuracy changes consistently with the ratio of hyper-parameters (an estimation of the ratio of margin distribution). The parameter to trade off two different kinds of deviation (keep the balance on both sides of the margin mean) is always fixed to in practice.
8 Conclusion
This paper proves generalization bound for deep neural networks by considering the margin distribution at the last layer instead of the minimum margin. The theoretical result inspires us to utilize a margin distribution loss function to improve the generalization performance of neural networks. Experimental results show that our method can effectively control the model capacity by optimizing the margin distribution measure, so that the trained model learns more separable representations and has better generalization performance. In future work, we will explore the effectiveness of regularization methods from a margin theory perspective.
Acknowledgement
This research was supported by the National Science Foundation of China (61921006) and the Collaborative Innovation Center of Novel Software Technology and Industrialization. The authors would like to thank the anonymous reviewers for constructive suggestions, as well as Yi-Xiao He and Yi-He Chen for helpful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[Aro+18] Sanjeev Arora, Rong Ge, Behnam Neyshabur and Yi Zhang “Stronger Generalization Bounds for Deep Nets via a Compression Approach” In Proceedings of the 35th International Conference on Machine Learning , 2018, pp. 254–263
- 2[AW 19] Aharon Azulay and Yair Weiss “Why do deep convolutional networks generalize so poorly to small image transformations?” In Journal of Machine Learning Research 20.184 , 2019, pp. 1–25
- 3[BS 13] Pierre Baldi and Peter J Sadowski “Understanding dropout” In Advances in Neural Information Processing Systems 27 , 2013, pp. 2814–2822
- 4[BMM 98] Peter L Bartlett, Vitaly Maiorov and Ron Meir “Almost linear VC-dimension bounds for piecewise polynomial networks” In Neural Computation 10.8 , 1998, pp. 2159–2173
- 5[BM 02] Peter L Bartlett and Shahar Mendelson “Rademacher and Gaussian complexities: Risk bounds and structural results” In Journal of Machine Learning Research 3 , 2002, pp. 463–482
- 6[BFT 17] Peter L. Bartlett, Dylan J. Foster and Matus J. Telgarsky “Spectrally-normalized margin bounds for neural networks” In Advances in Neural Information Processing Systems 31 , 2017, pp. 6241–6250
- 7[BCF 13] Carlos J. Becker, C. Christoudias and Pascal Fua “Non-Linear Domain Adaptation with Boosting” In Advances in Neural Information Processing Systems 26 , 2013, pp. 485–493
- 8[BE 02] Olivier Bousquet and André Elisseeff “Stability and generalization” In Journal of Machine Learning Research 2.Mar , 2002, pp. 499–526
