Off-the-grid model based deep learning (O-MODL)
Aniket Pramanik, Hemant Kumar Aggarwal, Mathews Jacob

TL;DR
This paper presents an off-the-grid deep learning approach for image reconstruction that learns non-linear Fourier space relations, offering reduced computational complexity and promising preliminary results compared to existing methods.
Contribution
It introduces a novel off-the-grid deep learning model that learns non-linear annihilation relations in Fourier space, differing from current approaches.
Findings
Preliminary comparisons show potential advantages over image domain MoDL.
Significant reduction in computational complexity.
Effective learning of non-linear Fourier space relations.
Abstract
We introduce a model based off-the-grid image reconstruction algorithm using deep learned priors. The main difference of the proposed scheme with current deep learning strategies is the learning of non-linear annihilation relations in Fourier space. We rely on a model based framework, which allows us to use a significantly smaller deep network, compared to direct approaches that also learn how to invert the forward model. Preliminary comparisons against image domain MoDL approach demonstrates the potential of the off-the-grid formulation. The main benefit of the proposed scheme compared to structured low-rank methods is the quite significant reduction in computational complexity.
Click any figure to enlarge with its caption.
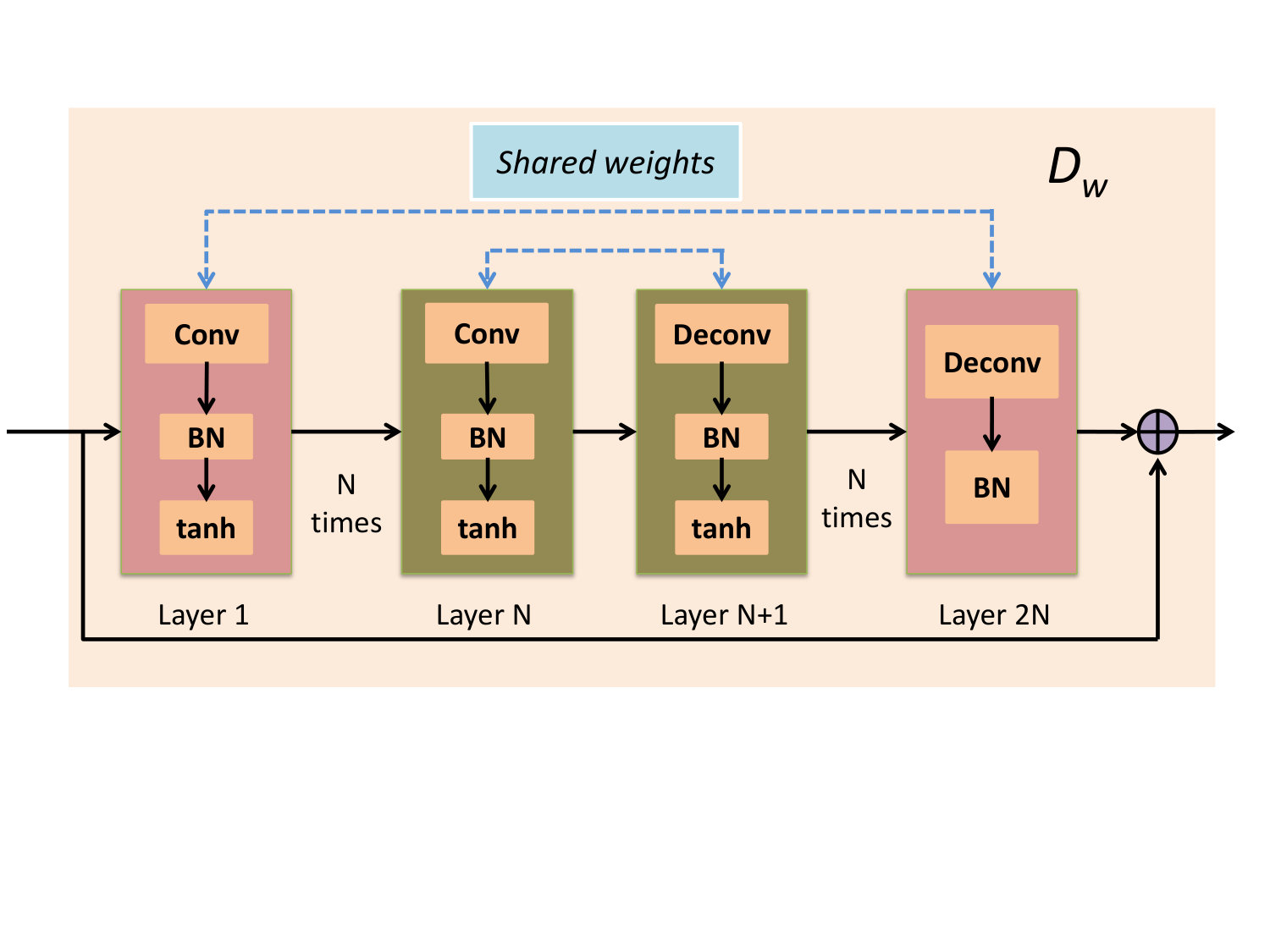 Figure 1
Figure 1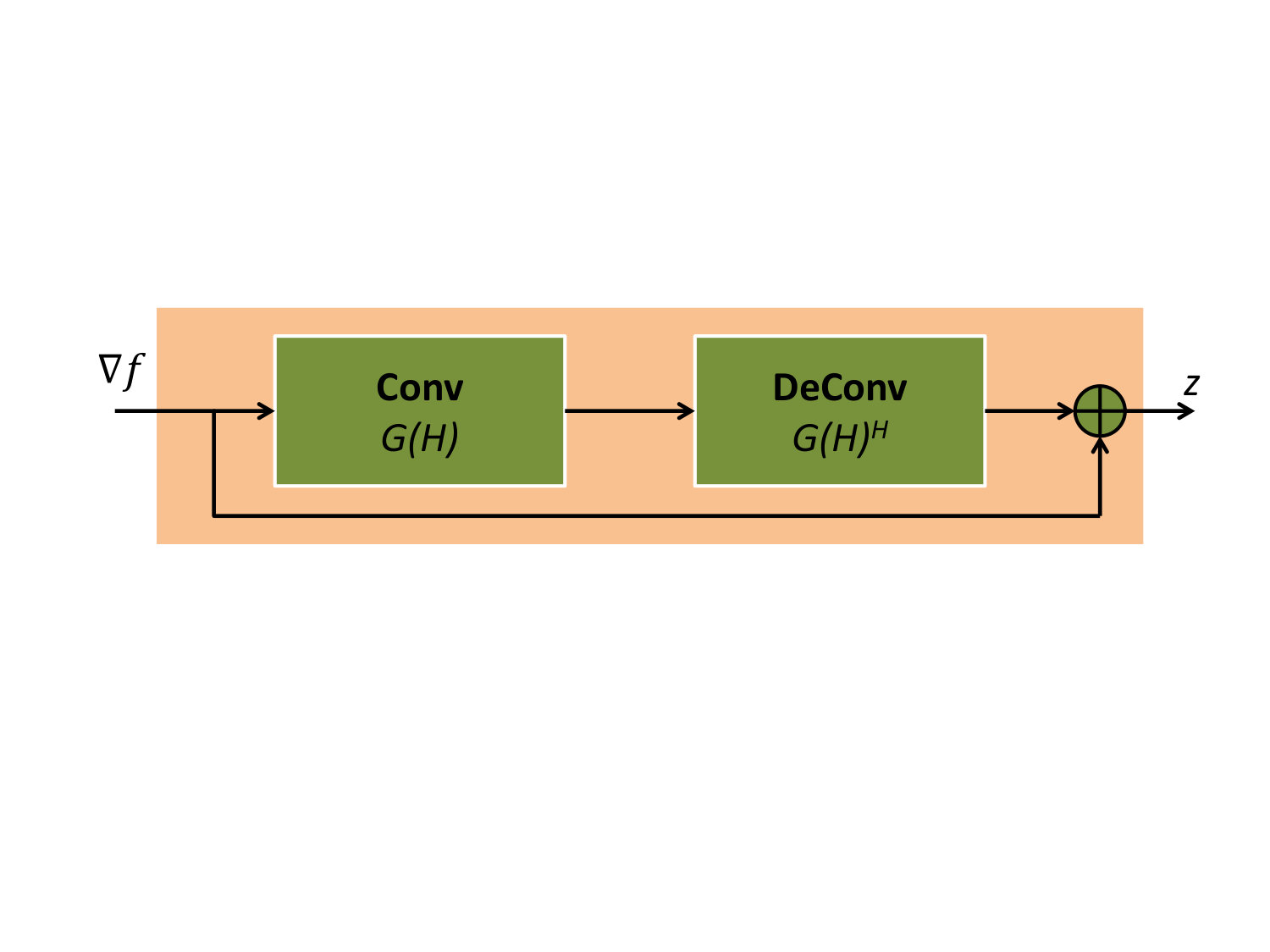 Figure 2
Figure 2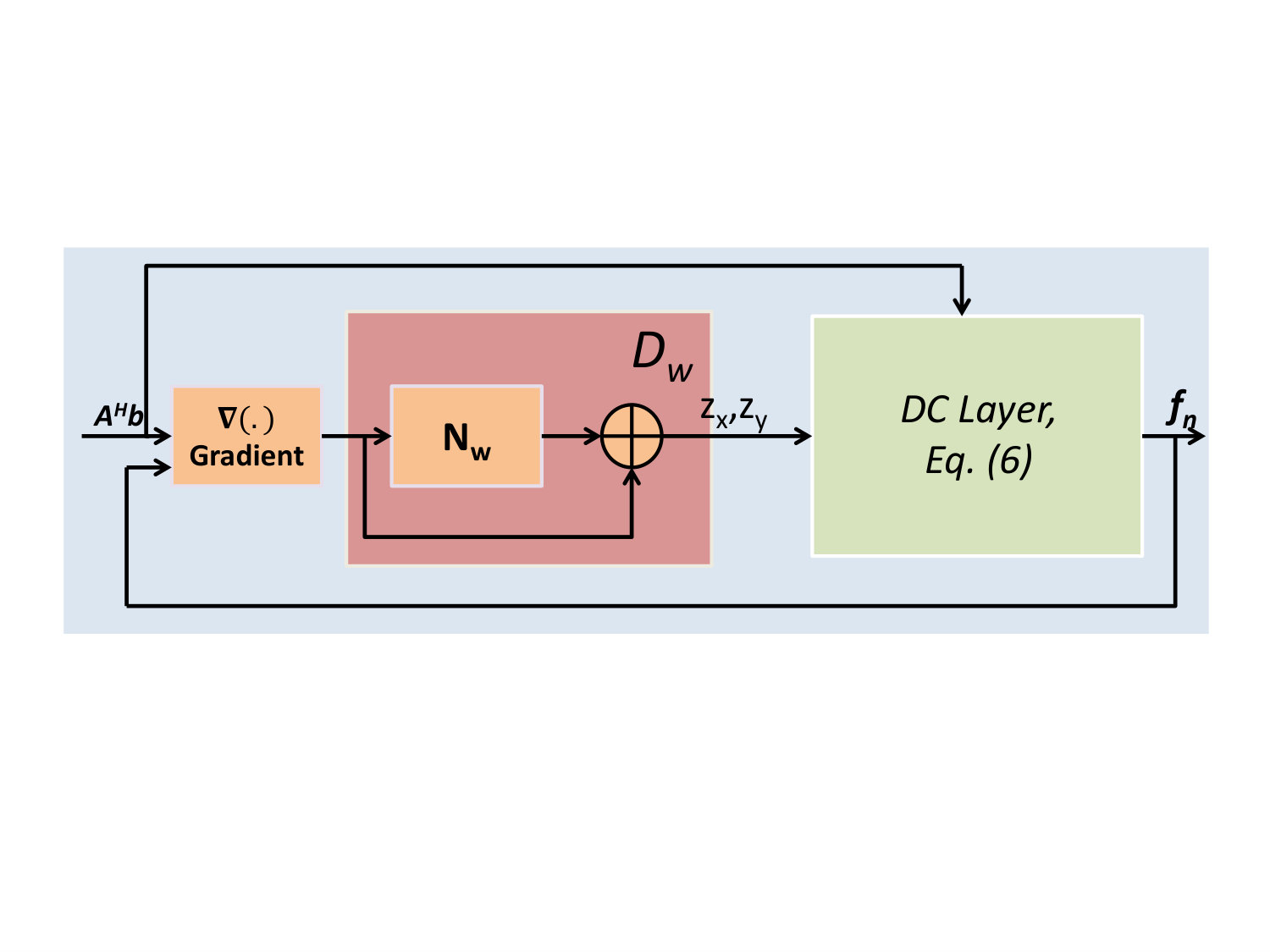 Figure 3
Figure 3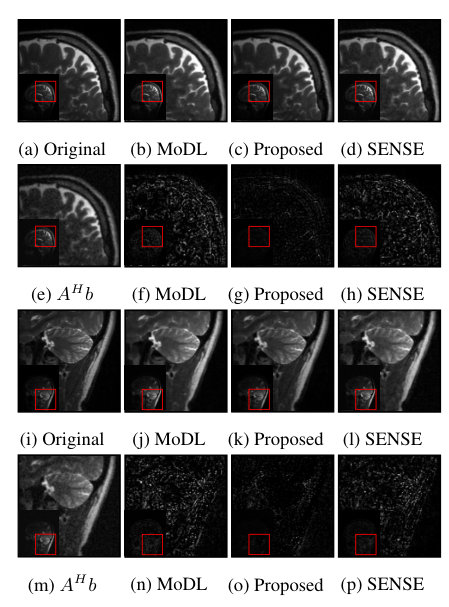 Figure 1
Figure 1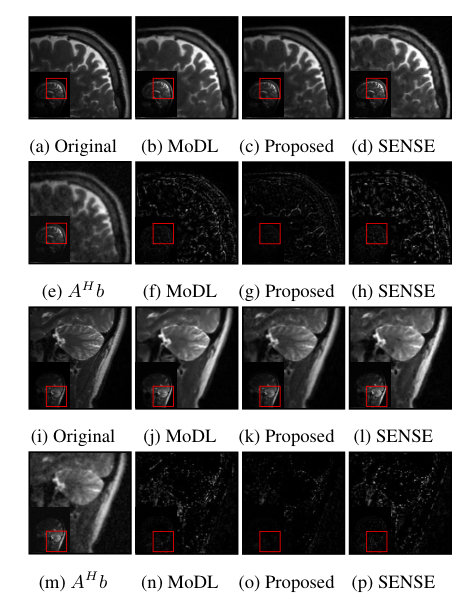 Figure 2
Figure 2| 2-fold/4-fold accelerated data | |||
|---|---|---|---|
| Noise () | MoDL | Proposed | SENSE |
| 10 | 16.42/12.46 | 18.30/13.71 | 11.7/11.44 |
| 11 | 16.35/12.22 | 18.29/13.68 | 11.06/10.54 |
| 12 | 15.92/11.91 | 18.27/13.68 | 10.66/9.89 |
| 13 | 15.77/11.51 | 18.25/13.66 | 10.48/9.76 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Off-the-grid model based deep learning (O-MoDL)
Abstract
We introduce a model based off-the grid image reconstruction algorithm using deep learned priors. The main difference of the proposed scheme with current deep learning strategies is the learning of non-linear annihilation relations in Fourier space. We rely on a model based framework, which allows us to use a significantly smaller deep network, compared to direct approaches that also learn how to invert the forward model. Preliminary comparisons against image domain MoDL approach demonstrates the potential of the off-the-grid formulation. The main benefit of the proposed scheme compared to structured low-rank methods is the quite significant reduction in computational complexity.
**Index Terms— ** off-the-grid, CNN, MRI
1 Introduction
The recovery of images from undersampled Fourier measurements is a classic problem in MRI and several other modalities. The popular approach is to constrain the reconstructions using compactness priors including sparsity. Several researchers have recently introduced off-the-grid continuous domain priors that are robust to discretization errors [1, 2], which provide significantly improved image quality in a range of applications. However, the main challenge is the significant increase in computational complexity.
Recently, several researchers have introduced deep learning methods as fast and efficient alternatives to compressed sensing algorithms. Current approaches can be categorized into direct and model based strategies. The direct approaches directly estimate the images from the undersampled measurements or their transforms/features [3, 4]. These methods learn to invert the forward operator over the space/manifold of images. While this approach is more popular, a challenge with these schemes is the need to learn the inverse, which often requires large models (e.g. UNET); this often translates to the need for extensive training data. Model based strategies instead formulate the recovery as a penalized optimization problem using a forward model that mimics the acquisition scheme [5]; the penalty is designed to encourage the reconstructed image to be close to the space/manifold of images. Since they rely on an explicit forward model, they often only require a much smaller network than direct methods, which significantly reduces the training data demand. Recent studies also show the benefit in sharing the network parameters across iterations, end-to-end training, as well as using optimization blocks within the network [5].
The main focus of this work is to extend deep learning to the off-the-grid setting, similar to the structured low-rank setting in [1, 2]. Specifically, we consider an iterative reweighted least-squares (IRLS) formulation of our off-the-grid algorithm, termed as GIRAF. We show that the structure of GIRAF, which alternates between data consistency enforcement and denoising of the Fourier coefficients of the partial derivatives by projecting it to the constraint set, has extensive similarities to the MoDL framework. The main difference with MoDL is that the learning is performed in the Fourier domain, and the denoising network is linear; GIRAF relies on a residual convolution and deconvolution (flipped convolution) denoising filter-bank with shared filters, which is learned from the available k-space measurements in an iterative fashion. The residual filterbank projects the Fourier coefficients to the signal subspace, thus denoising them. To significantly reduce the computational complexity of these off-the-grid methods, we propose to use a deep non-linear convolutional neural network as the denoiser for the Fourier coefficients of the partial derivatives. Similar to GIRAF, we propose to use convolutional and deconvolutional blocks with shared parameters. The parameters of the deep network are learned in an end-to-end fashion as in MoDL. This work has connections with k-space deep learning approach [6], which follows a direct approach of estimating images from measurements, bypassing a forward model. By contrast, we follow a model based strategy, which has the benefits discussed above.
We determine the utility of the proposed scheme in the single coil image recovery setting. Thanks to the MoDL formulation, few training datasets were sufficient to reliably learn the parameters of the model. The comparisons of the proposed scheme against MoDL shows the potential of the proposed scheme. Our future work will focus on the extension of the framework to the multi-coil setting and more elaborate comparisons with state of the art algorithms.
2 Problem Setting and Background
We consider the recovery of the Fourier coefficients of a function from its noisy undersampled Fourier measurements , where denotes the Fourier transform of , and is an undersampling matrix, while is additive noise.
2.1 Piecewise smooth images & annihilation relations
Recent work off-the-grid methods [1, 2] model the signal to be piecewise smooth, when the partial derivatives of vanish everywhere except on an edge set. Similar to [1], we model the edge set as the zero-set of a bandlimited function . With these assumptions, the first order partial derivatives of the signal satisfies , which translates to , where is the bandlimited Fourier transform of . The theory in [1] shows that if the assumed size of the filter is greater than the true bandwidth, there exist several linearly independent finite impulse response (FIR) filters that satisfy . The above relation can be expressed in a matrix form as
[TABLE]
Here, is a block Toeplitz matrix that corresponds to 2-D convolution. i.e, . Using commutativity of convolutions, the above relation can also be expressed as
[TABLE]
where is the block Toeplitz matrix constructed from .
2.2 GIRAF algorithm for off-the-grid image recovery
In practice, the filters are unknown. Two step methods [1, 2] estimate the filters or equivalently from fully sampled regions of Fourier space, which is also called as calibration regions, using (2). When the Fourier samples are non-uniformly sampled, the above two step approach is not feasible. Note that (2) implies that the matrix is low-rank. The unconstrained version of GIRAF algorithm poses the recovery as
[TABLE]
where is the nuclear norm that encourages the matrix to be low-rank. GIRAF relies on an iterative least squares optimization problem, which majorizes the nuclear norm as . This algorithm alternates between the estimation of as \mathbf{H}=\big{[}\mathbf{T}^{*}(\mathbf{T}(\widehat{\nabla f}))+\epsilon\mathbf{I}\big{]}^{-1/4} and updating by
[TABLE]
A challenge with the alternating minimization strategy is the high computational complexity of the algorithm. Motivated by the fast computation offered by our MoDL framework [5], we introduce a deep learning solution.
3 Off-the-grid model based deep learning (O-MoDL)
We first show that the GIRAF algorithm can be viewed as a recursive network, which has alternating blocks imposing data consistency and denoising of the data.
3.1 Network structure of GIRAF
We consider a penalized version of (4), using an auxiliary variable :
[TABLE]
Note that the above formulation is equivalent to (4) when . We use an alternating algorithm to solve for and :
[TABLE]
Problem (6) is analytically solved, when is a sampling operator. Solving (7), we get . Using matrix inversion lemma and assuming , we approximate the solution as:
[TABLE]
Note from (2) that filters are surrogates for the null space of . Hence, can be viewed as the projection of onto the null-space of ; (8) can be viewed as a residual block, which removes the null-space components of . The alternating algorithm specified by (8) and (6) can be unrolled to a deep architecture as in [5].
3.2 Deep learning in k-space
Motivated by the success of MoDL [5], we introduce a novel deep learning solution to reduce the computational complexity of GIRAF. Specifically, we replace the denoiser in GIRAF, specified by (8), by a CNN, whose parameters are learned from exemplar data. The structure of O-MoDL is similar to GIRAF, involving two alternating blocks, (denoiser) and DC (data consistency). We rely on an -layer O-MoDL block consists of ’’ convolution layers followed by ’’ deconvolution (convolution with flipped filters) layers, followed by batch normalization (BN) and non-linear activation function. We chose the non-linear activation function as a hyperbolic tangent (tanh) activation function. Each convolution layer only retains the valid convolutions to eliminate boundary effects. The use of deconvolution blocks ensures the smaller image obtained after convolution grows back to its original size. The DC block refers to (6). The main difference of this framework with GIRAF is the depth of the denoiser network (see Fig. 1(c)) and the presence of non-linearities and batch normalization steps within the network. The key difference of the proposed scheme with MoDL is that the learning is performed in k-space, unlike most deep learning image recovery strategies. The denoiser network uses convolution and deconvolution layers similar to GIRAF, which share weights. This is a another distinction with MoDL, which uses a series of convolutional blocks with no weight sharing. Similar to MoDL, we also share the same network across iterations.
4 Results
Multi-channel brain MRI data was collected from five subjects at University of Iowa Hospitals using 3D T2 CUBE sequence with Cartesian readouts using a 12-channel head coil. The data from four subjects was used for training, while the data from the fifth subject was used for testing. We retrospectively undersampled the phase encodes to train and test the framework; we note that this approach is completely consistent with a future prospective acquisition, where a subset of phase encodes can be pre-selected and acquired. All the experiments were performed with variable-density Cartesian random sampling mask with different undersampling factors. We chose 30 most informative slices from each coil, yielding 360 from each subject to form a training dataset of 1440 slices.
We trained a network with an block consisting of five convolution and five deconvolution layers as described in section 3.2. Each layer consisted of 64 complex 3 x 3 filters. The iterative model was unrolled with five iterations, which was trained to minimize the mean square error between the output and the non-undersampled images. The training took 7 hours on an NVIDIA Tesla p100 GPU on 1440 slices. By contrast, the run time for reconstucting a single image is only 50 milliseconds. We compare the performance of O-MoDL against our image domain deep learning method (MoDL) and SENSE reconstructions for two-fold and four-fold accelerated data. For fair comparisons, we train both the networks with same number of iterations and trainable parameters. The SNR improvement in each case can be observed in table 1. Fig. 2 and 3 show reconstructions of different coil images from two and four fold accelerated data respectively. Results show that the proposed scheme can provide improved reconstructions over the MoDL scheme [5], which was trained exactly in the same fashion.
5 Conclusion
We proposed an off-the-grid deep learning architecture for model based MR image reconstruction. Unlike many of the current CNN architectures, the algorithm works in the Fourier domain. The algorithm is a non-linear extension of recent structured low-rank off-the-grid methods, which rely on annihilation relations in the Fourier domain resulting from continuous domain image properties. Unlike the linear annihilation relations that are self learned in structured low-rank setting, the proposed framework learns non-linear annihilation relations in the Fourier domain from exemplar data; the non-linearities facilitate the the generalization of the annihilation properties to images unseen by the training algorithm, eliminating the need for self-learning the weights. The main benefit of the proposed scheme is the quite significant reduction in run time, compared to structured low-rank algorithms. The preliminary experimental comparisons demonstrate the improvements offered by the proposed scheme over image domain MoDL framework.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Greg Ongie and Mathews Jacob, “Off-the-Grid Recovery of Piecewise Constant Images from Few Fourier Samples,” SIAM on Imag. Sci. , vol. 9, no. 3, pp. 1004—-1041, 2016.
- 2[2] Justin P Haldar, “Low-rank modeling of local k 𝑘 k -space neighborhoods (loraks) for constrained mri,” IEEE transactions on medical imaging , vol. 33, no. 3, pp. 668–681, 2014.
- 3[3] Jong Chul Ye, Yoseob Han, and Eunju Cha, “Deep convolutional framelets: A general deep learning framework for inverse problems,” SIAM Journal on Imaging Sciences , vol. 11, no. 2, pp. 991–1048, 2018.
- 4[4] Kyong Hwan Jin, Michael T. Mc Cann, Emmanuel Froustey, and Michael Unser, “Deep Convolutional Neural Network for Inverse Problems in Imaging,” vol. 29, pp. 4509–4522, 2017.
- 5[5] Hemant Kumar Aggarwal, Merry P Mani, and Mathews Jacob, “Modl: Model based deep learning architecture for inverse problems,” ar Xiv preprint ar Xiv:1712.02862 , 2017.
- 6[6] Yoseob Han and Jong Chul Ye, “k-space deep learning for accelerated mri,” ar Xiv preprint ar Xiv:1805.03779 , 2018.