Neuromemrisitive Architecture of HTM with On-Device Learning and Neurogenesis
Abdullah M. Zyarah, Dhireesha Kudithipudi

TL;DR
This paper introduces a neuromemristive architecture for Hierarchical Temporal Memory (HTM) that enables on-device learning, neurogenesis, and robust image recognition, optimized for mobile platforms.
Contribution
It presents a novel memristor-based crossbar architecture for HTM's spatial pooler, incorporating neurogenesis and plasticity mechanisms for improved robustness and efficiency.
Findings
Supports rapid on-chip training within 2 clock cycles
Achieves robustness in image recognition tasks with MNIST and Yale datasets
Demonstrates low power consumption suitable for mobile devices
Abstract
Hierarchical temporal memory (HTM) is a biomimetic sequence memory algorithm that holds promise for invariant representations of spatial and spatiotemporal inputs. This paper presents a comprehensive neuromemristive crossbar architecture for the spatial pooler (SP) and the sparse distributed representation classifier, which are fundamental to the algorithm. There are several unique features in the proposed architecture that tightly link with the HTM algorithm. A memristor that is suitable for emulating the HTM synapses is identified and a new Z-window function is proposed. The architecture exploits the concept of synthetic synapses to enable potential synapses in the HTM. The crossbar for the SP avoids dark spots caused by unutilized crossbar regions and supports rapid on-chip training within 2 clock cycles. This research also leverages plasticity mechanisms such as neurogenesis and…
Click any figure to enlarge with its caption.
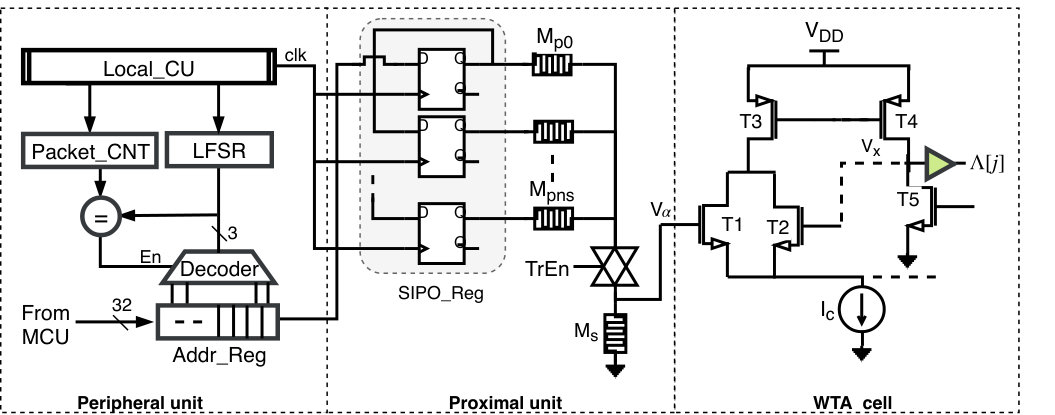 Figure 1
Figure 1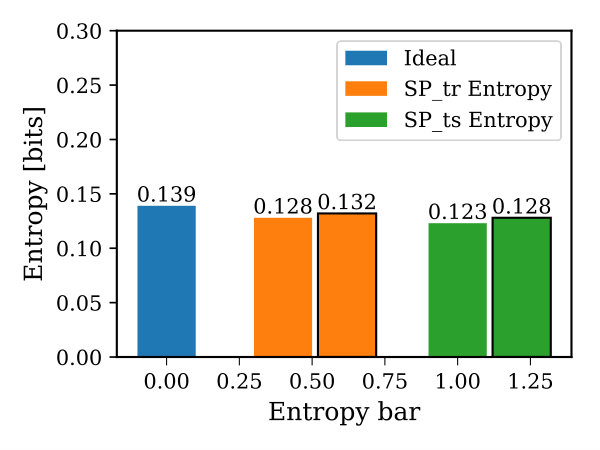 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4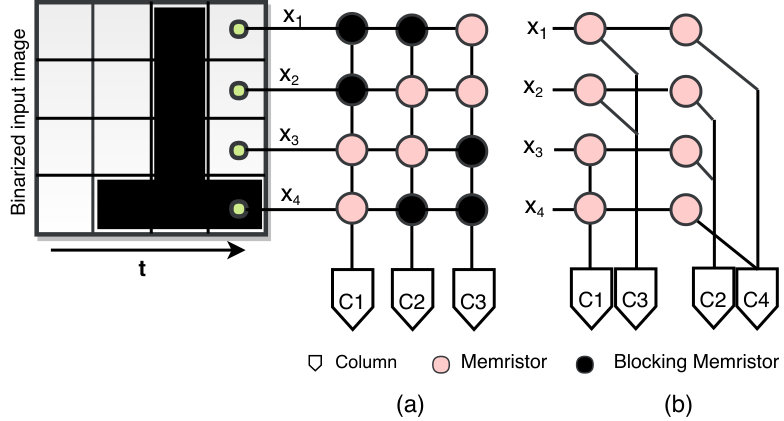 Figure 5
Figure 5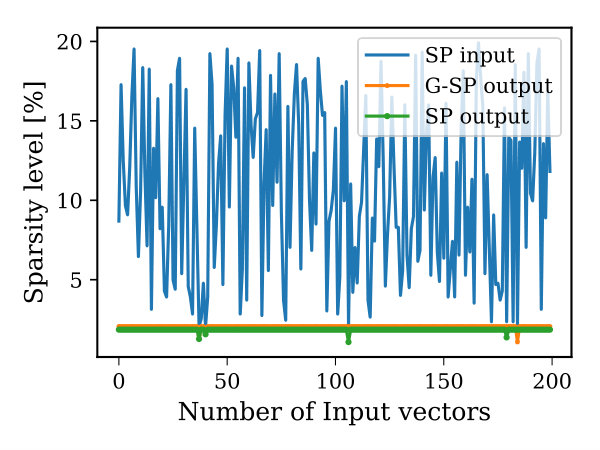 Figure 6
Figure 6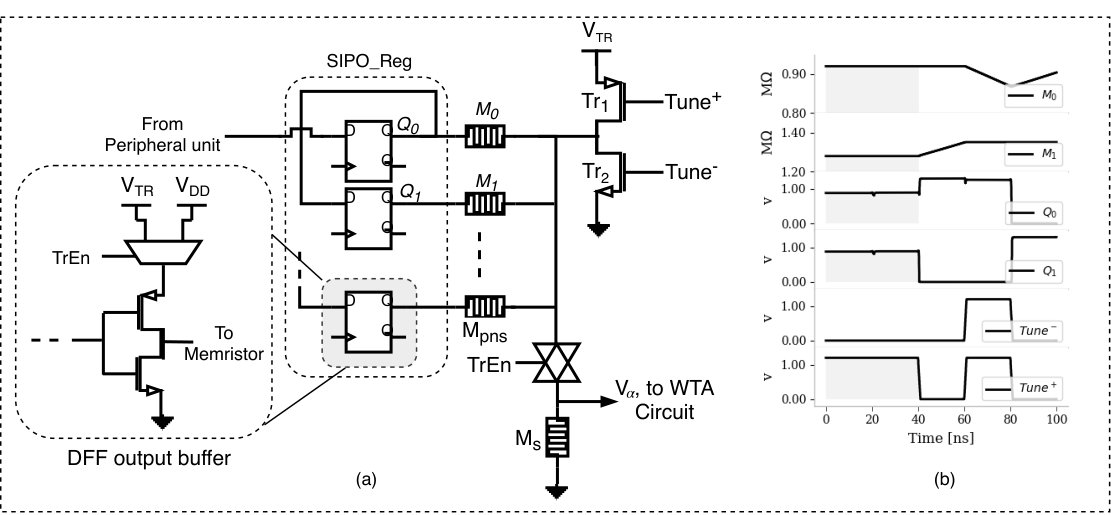 Figure 7
Figure 7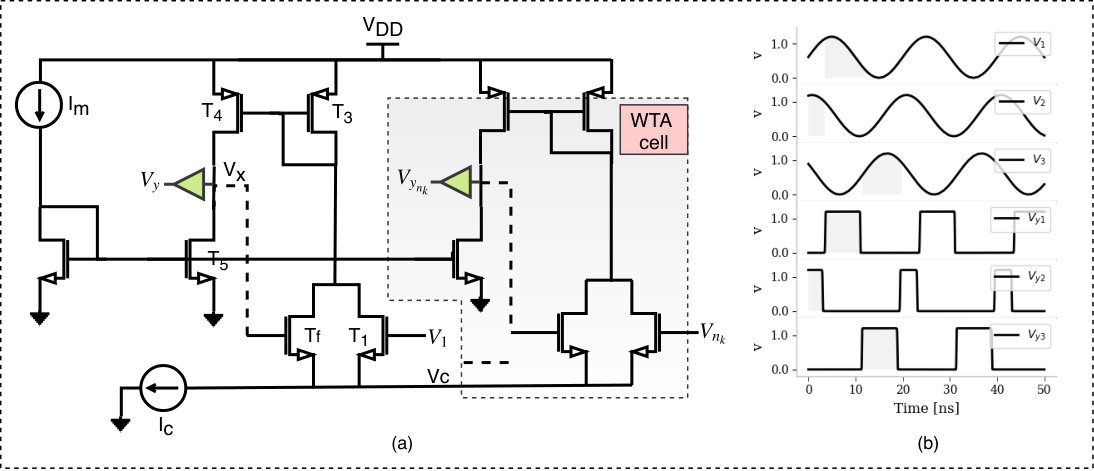 Figure 8
Figure 8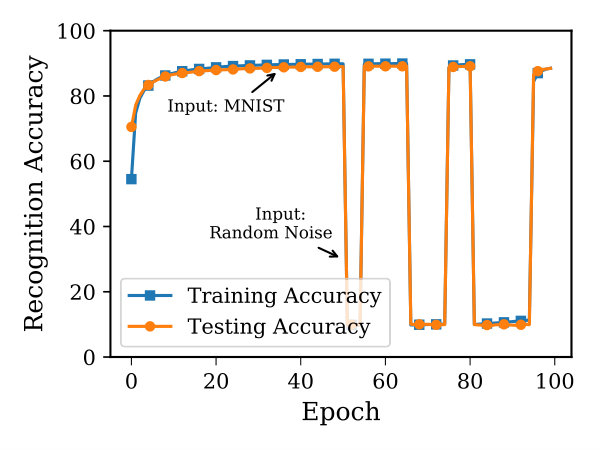 Figure 9
Figure 9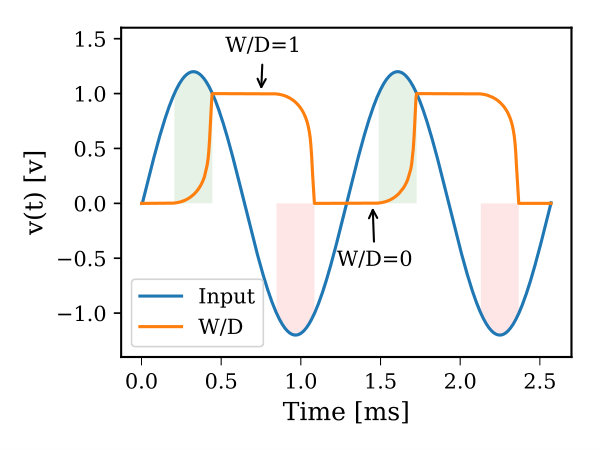 Figure 10
Figure 10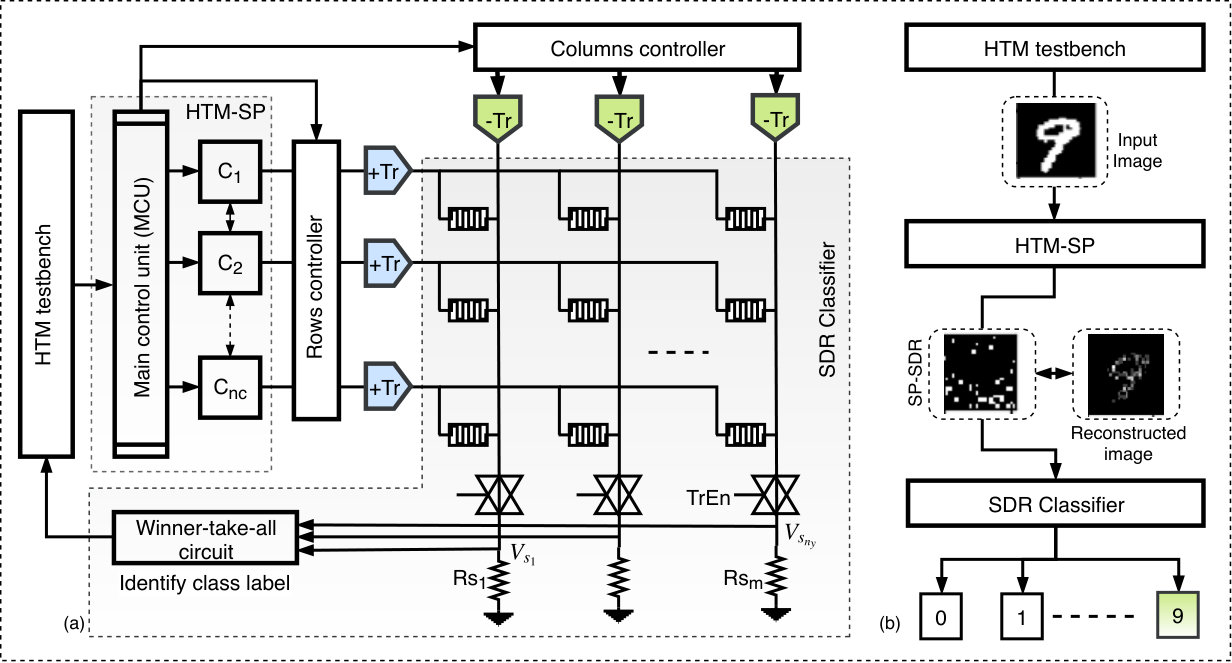 Figure 11
Figure 11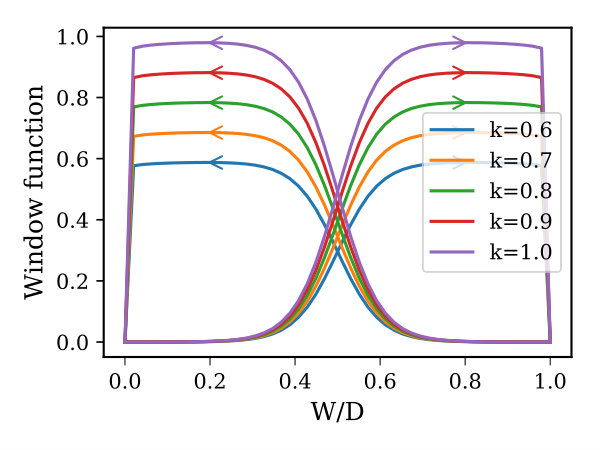 Figure 12
Figure 12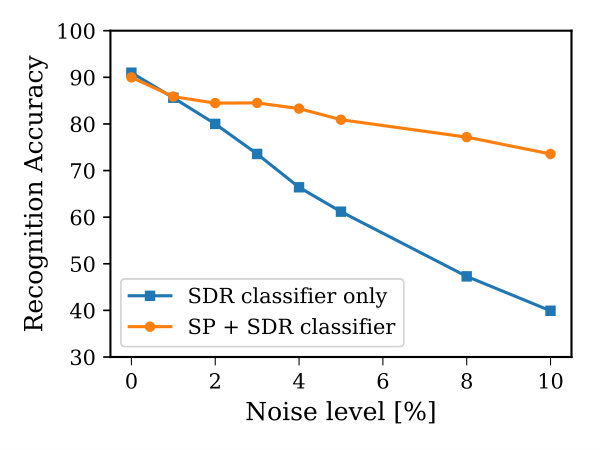 Figure 13
Figure 13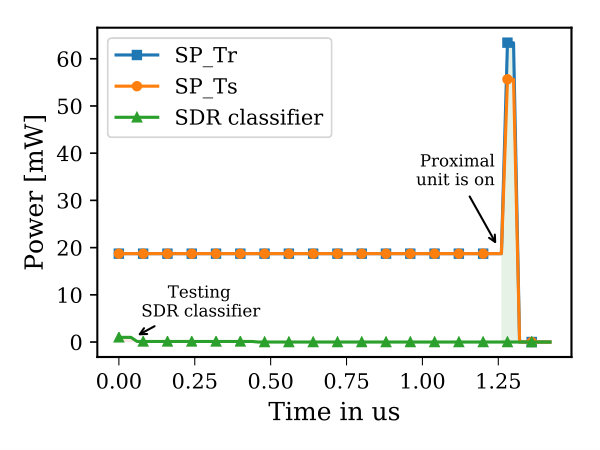 Figure 14
Figure 14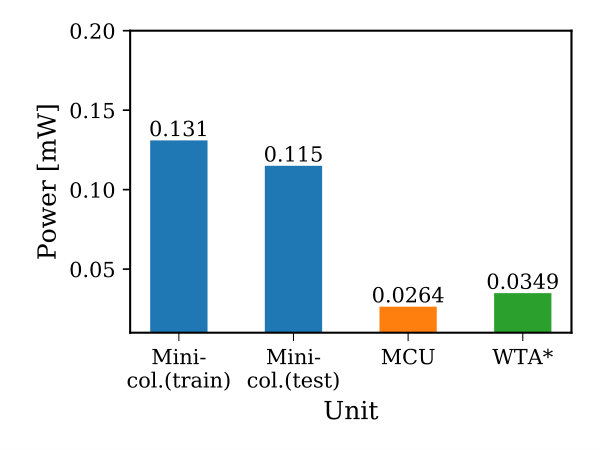 Figure 15
Figure 15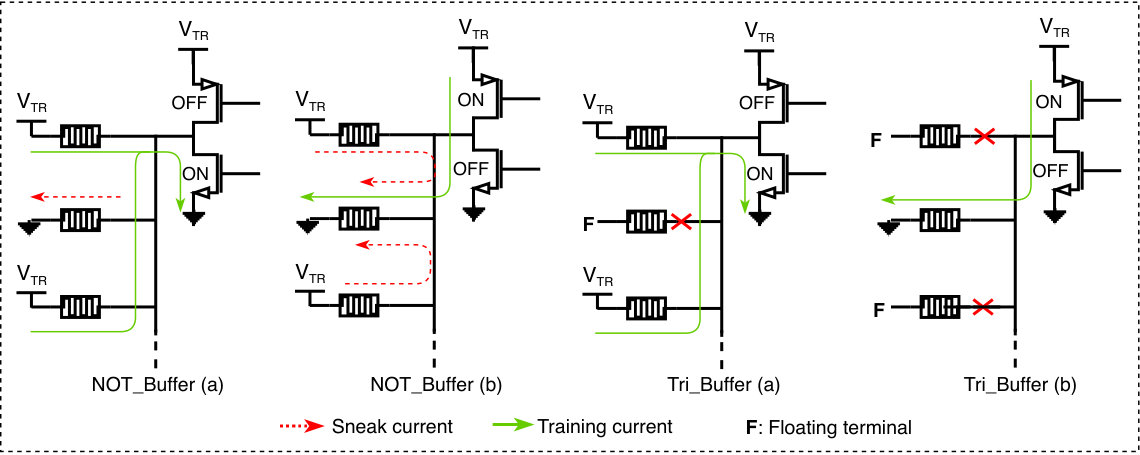 Figure 16
Figure 16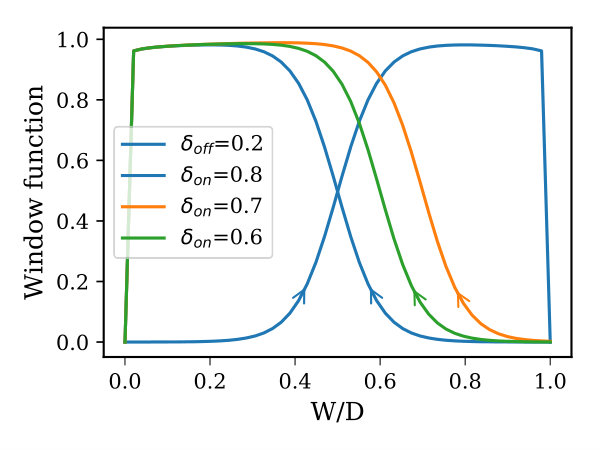 Figure 17
Figure 17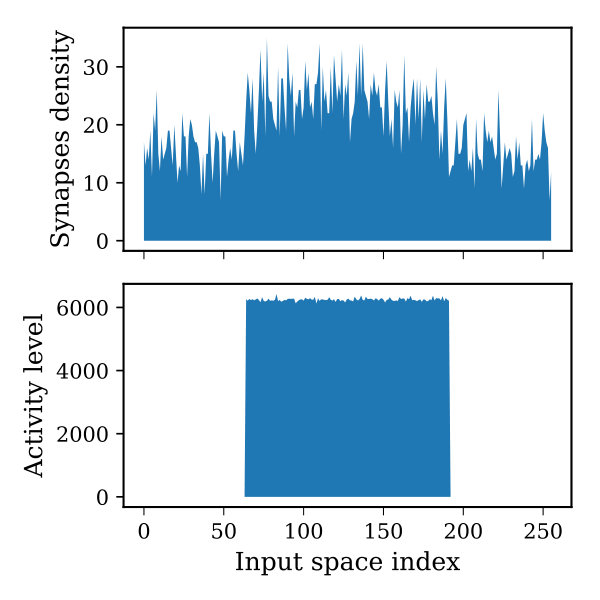 Figure 18
Figure 18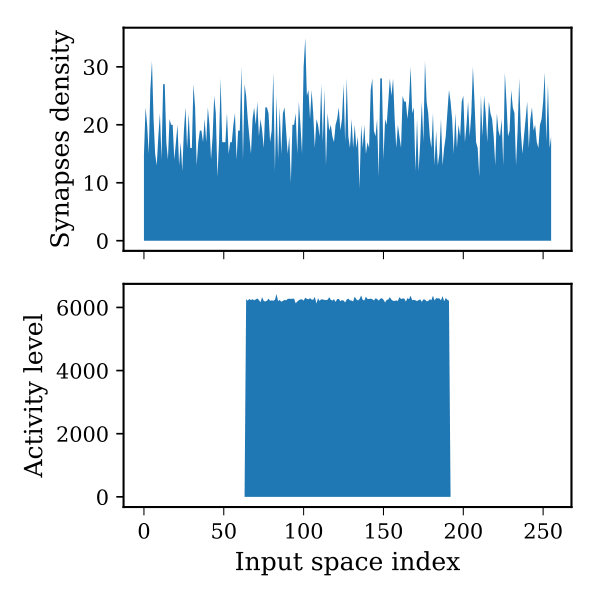 Figure 19
Figure 19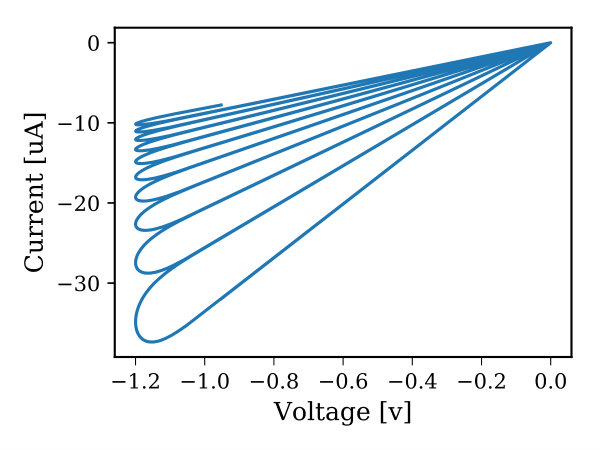 Figure 20
Figure 20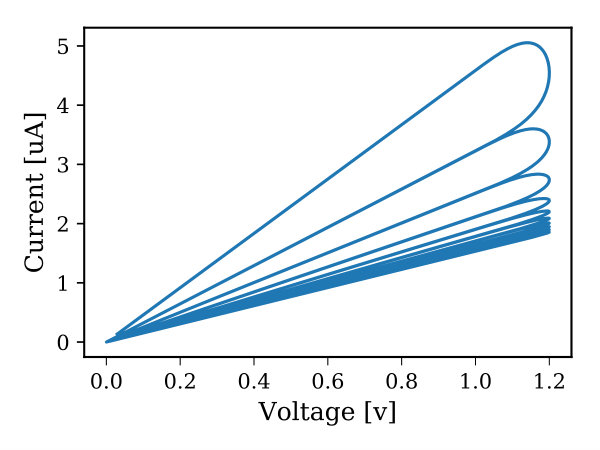 Figure 21
Figure 21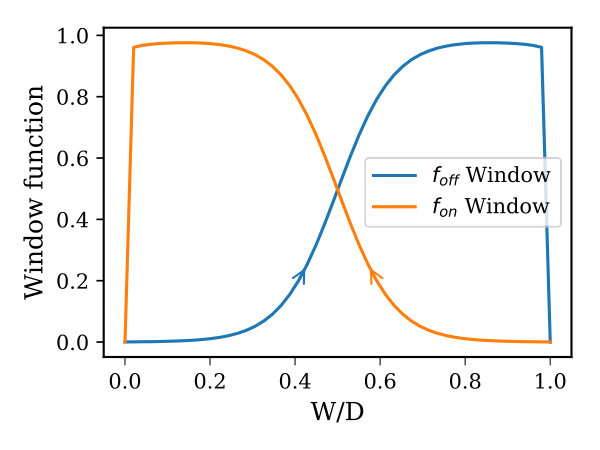 Figure 22
Figure 22| Parameter | Value |
| Proximal memristor range | 200k - 5M |
| Memristor threshold | 1v |
| High-Frequency clock | 50 MHz |
| Training voltage | 1.2 v |
| Sense memristor range | 20k-80k |
| Parameter | Range | MNIST | YaleFaces |
| Number of winning mini-columns | 5-40 | 40 | 16 |
| MinOverlap | 2-25 | 3 | 20 |
| Permanence threshold | 0-0.8 | 0.52 | 0.5 |
| Permanence increment () | 0-0.2 | 0.01 | 0.1 |
| Permanence decrement () | 0-0.2 | -0.01 | -0.15 |
| Proximal segment size | 10-500 | 32 | 250 |
| Work | No. of columns | Classifier | Accuracy (%) STD | |
| MNIST | F-HTM (Streat et al., 2016) | 784 | SP + SVM (Linear kernel) | 91.98 |
| Memristive-LCA (Woods et al., 2015) | 300 | LCA | 90.0 | |
| Digital-HTM (Zyarah and Kudithipudi, 2018) | 100 | SP + SVM (RBF kernel) | 91.16 | |
| Crossbar HTM (Truong et al., 2018)\tnotextnote:r3 | 1024 | SP+X | 90.5 | |
| This work | 484 | SP+SDR classifier | 90.33 0.17\tnotextnote:r4 | |
| YaleFaces | Memristor HTM (James et al., 2017)\tnotextnote:r2 | - | SP+XOR classifier | 86.67 |
| Smooth-MFA(Cai et al., 2007)\tnotextnote:r1 | - | S-MFA | 81.1 | |
| This work | 1024 | SP+SDR classifier | 86.86 3.82\tnotextnote:r4 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Neuromemrisitive Architecture of HTM with On-Device Learning and Neurogenesis
Abdullah M. Zyarah
and
Dhireesha Kudithipudi
Neuromorphic AI Lab, Rochester Institute of Technology1 Lomb Memorial DrRochesterNY14623USA
(2018)
Abstract.
Hierarchical temporal memory (HTM) is a biomimetic sequence memory algorithm that holds promise for invariant representations of spatial and spatiotemporal inputs. This paper presents a comprehensive neuromemristive crossbar architecture for the spatial pooler (SP) and the sparse distributed representation classifier, which are fundamental to the algorithm. There are several unique features in the proposed architecture that tightly link with the HTM algorithm. A memristor that is suitable for emulating the HTM synapses is identified and a new Z-window function is proposed. The architecture exploits the concept of synthetic synapses to enable potential synapses in the HTM. The crossbar for the SP avoids dark spots caused by unutilized crossbar regions and supports rapid on-chip training within 2 clock cycles. This research also leverages plasticity mechanisms such as neurogenesis and homeostatic intrinsic plasticity to strengthen the robustness and performance of the SP. The proposed design is benchmarked for image recognition tasks using MNIST and Yale faces datasets, and is evaluated using different metrics including entropy, sparseness, and noise robustness. Detailed power analysis at different stages of the SP operations is performed to demonstrate the suitability for mobile platforms.
Hierarchical temporal memory, Spatial pooler, Sparse distributed representation, Memristor, Neurogenesis
††journal: JETC††journalvolume: x††journalnumber: x††article: 1††journalyear: 2018††publicationmonth: 5††articleseq: 9††copyright: acmlicensed††doi: 0000000.0000000††copyright: acmcopyright††journal: JETC††journalyear: 2018††journalvolume: 1††journalnumber: 1††article: 1††publicationmonth: 1††price: 15.00††doi: 10.1145/3300971††ccs: Computing methodologies Neural networks††ccs: Hardware Emerging technologies
1. Introduction
Mammalian brains process massive amounts of multi-model data for learning, memory, perception, and cognition. All of this information is either spatial, spatio-temporal or spectro-temporal. Modeling such behavior in information processing algorithms can facilitate solutions to complex real-life tasks. Hierarchical temporal memory (HTM) (Hawkins et al., 2009; George and Hawkins, 2009) is a theoretical framework that processes spatial and temporal information by emulating the structural and algorithmic properties of the neocortex. HTM offers features such as online learning, multiple simultaneous predictions, sparse distributed representations, and noise robustness (Hawkins and Ahmad, 2016). These properties make the algorithm attractive for a wide range of applications such as regression and classification (Rice et al., 2008; Melis and Kameyama, 2009; Xing et al., 2012), prediction (Padilla et al., 2013), natural language processing and anomaly detection (Numenta, 2014; Lavin and Ahmad, 2015). At a high level, HTM is a sequence-memory algorithm that learns and recalls patterns of multi-variate time series data. At its core, this is achieved through three key components: encoder, spatial pooler (SP) and temporal memory. The input encoder constitutes the binary distributed representation of input data, whereas the SP and temporal memory continuously transform the input data into sparse distributed representations (SDR) and learn transitions between sequences, respectively.
Deploying the HTM algorithm on mobile and embedded devices can enable real-time prediction and anomaly detection tasks. Specifically, the SP of HTM has critical features including fast adaptation to changing input statistics and noise robustness that can be adopted in hardware. There are few research groups that study the digital and mixed-signal architectures for HTM. However, HTM has been continually evolving and most of the published architectures focus on the earlier deprecated versions of the algorithm. The first wave of architectures were published circa 2007, that focused on the first generation of the algorithm (Zeta). In 2007, Kenneth et al. realized Zeta-HTM on FPGA for image recognition (Rice et al., 2008). The model has 81 parallel computational nodes arranged hierarchically in 3 layers and offers 148x speedup over the software counterpart. A Verilog implementation of the single fundamental unit in HTM, a node, is proposed in 2013 (Vyas and Zaveri, 2013). The second generation of the architectures were investigated circa 2015. Zyarah et al. (Zyarah and Kudithipudi, 2015), designed a scalable design with 100 mini-columns and demonstrated for classification with SVM. The authors also proposed a temporal memory design for prediction (Zyarah, 2015). In 2016, nonvolatile memory based SP implementation is presented by Streat et al. (Streat et al., 2016), considering the physical constraints of the commodity NVRAM. Later, a memristor-based implementation of SP is proposed by James et al. (James et al., 2017). Although the proposed design is power efficient, it lacks reconfigurability which is important for learning and making predictions. Recently, Truong et al. presented a memristor-based crossbar to model the SP of HTM algorithm (Truong et al., 2018). However, due to the fact that HTM is dominated by dynamic sparse connections, using the traditional crossbar structure leads to dark spots (unused regions) in the crossbar. Additionally, most of these research studies do not include the hardware classifier design which is integrated with the SP. Therefore, designing an overarching HTM SP architecture and its associated SDR classifier for energy-constrained platforms with on-device learning supported by dynamic interconnects is still an open research area.
This paper presents a comprehensive memristor crossbar architecture of the HTM-SP and its associated SDR classifier. The proposed architecture incorporates several unique features that tightly link with the HTM algorithm. A memristor that is suitable for emulating the HTM synapses is identified and a new Z-window function is proposed. The architecture exploits the concept of synthetic synapses to enable potential synapses in the HTM. The crossbar for the SP avoids dark spots caused by unutilized crossbar regions and supports rapid on-chip training within 2 clock cycles. This research also leverages plasticity mechanisms such as neurogenesis and homeostatic intrinsic plasticity to strengthen the robustness and performance of the SP. The proposed design is benchmarked for image recognition tasks using MNIST and Yale faces datasets, and is evaluated using different metrics including entropy, sparseness, and noise robustness. Detailed power analysis at different stages of the SP operations is performed to demonstrate the suitability for mobile platforms.
The rest of the paper is organized as follows: an overview of HTM is presented in Section 2. Section 3 and 4 discuss the design methodology and the hardware implementation. The experimental setup and SP evaluation are described in Section 5 and 6. Section 7 demonstrates the experimental results. The paper is summarized in Section 8.
2. Overview of HTM
HTM is a sequence memory algorithm that aims at emulating the foundational principles of the neocortex. HTM is structured from ascending hierarchical regions of cellular layers that enable the network to capture spatial and temporal patterns. The cells in HTM are a simplified model of the common excitatory neuron in the neocortex, known as the pyramidal neuron. Similar to pyramidal neurons, HTM cells have hundreds of synaptic connections that enable them to recognize independent patterns of cellular activities. The cell synaptic connections are assigned to three integration zones, namely proximal, basal, and apical (Cui et al., 2016; Hawkins and Blakeslee, 2004). Each zone is composed of either one proximal segment or several dendritic segments. A segment, either proximal or dendritic, comprises multiple synapses to capture the cellular activities of the space to which it is linked. The proximal dendritic segment defines the cell’s receptive field in the input space (feed-forward input) and sufficient activities detected on the proximal dendrites lead to the generation of a somatic action potential. The basal and apical dendritic segments hold the synaptic connections with nearby cells and other cells in higher levels in the hierarchy. Therefore, the basal and apical segments are dedicated to observe contextual and feedback inputs. It is important to note that the activities detected on the basal and apical dendrites enable the cells to make prediction via depolarizing it slightly without causing the generation of an action potential (Hawkins and Ahmad, 2016).
The cells, in each HTM region, are arranged in a columnar organization called a mini-column. In a given mini-column, cells share the same proximal synaptic connections, i.e. they share the same feed-forward receptive field and stimulated by the same input. Basal segments, on the other hand, allow for the interaction among cells within the same region as such cells learn and recall sequences. The learning in HTM involves adjusting the synaptic connections strength which is defined by a positive scalar value called permanence. However, this process occurs in an online fashion which enables the algorithm to learn not only the spatial features of the input, but also the temporal correlation between them (Padilla-Baez, 2015). The HTM algorithm is composed of two core phases, namely spatial pooler (SP) and temporal memory, which are discussed in the following subsections:
2.1. Spatial Pooler Model
In HTM, learning the spatial patterns in sequential data is performed by the SP. When an input is presented to the network, it gets encoded into a set of sparsely distributed active mini-columns using a combination of competitive Hebbian learning rules and homeostasis (Cui et al., 2017). The sparse activation of mini-columns represents the core feature that grants HTM algorithm appealing properties, such as distinguishing the common features between inputs (Földiak, 1990), learning sequences, and making simultaneous predictions (Ahmad and Hawkins, 2015). Generally, each mini-column is connected to a unique subset of the input space using a set of proximal synaptic connections. When the synapses are active and connected to a reasonable number of active bits in the input space, the proximal dendritic segment becomes active. The activation of the proximal dendritic segment will nominate that mini-column to compete with its neighboring mini-columns to represent the input. By using the -winner-take-all computation principle, the mini-column with the most overlapped active synapses and active inputs inhibits its neighbors and becomes active (winner). The output of the SP is a binary vector, which represents the joint activity of all mini-columns in the HTM region in response to the current input. This binary vector is also known as an SDR vector. The operation of the SP can be divided into three distinct phases: initialization, overlap and inhibition, and learning, as described in Algorithm 1.
During the initialization phase (Algorithm 1, lines 2-5), which occurs only once, all the parameters of the regions are initialized including mini-columns’ connections to the input space, synapse permanences, and boosting factor. Let be an array which holds all the synaptic connections that link SP mini-columns with dimensional input space. Now, let be the maximum number of potential synapses associated with each mini-column and is defined by the non-zero elements in ( is a row vector in ) whose indexes are generated by a pseudo-random number generator. Similarly, let be a array that describes the permanence of the potential synapses in , where the permanence values are randomly initialized with a uniform distribution. After initializing the synaptic connections, the boosting factor for each mini-column is defined to be a scalar value of one. The initialization phase is followed by the overlap and inhibition phase (lines 7-11) in which the feed-forward input is collectively represented by a subset of active mini-columns, namely winning mini-columns. The selection of winning mini-columns occurs after determining the activation level of each mini-column, called overlap score (). The mini-columns’ overlap scores for a given region is computed by counting each mini-column’s active synapses that associate with active bits in the input space. Mathematically, it is achieved by performing a dot product operation between the feed-forward input vector () and the active synapses vector as in line 9, where the active synapses vector is the result of an element-wise multiplication (denoted as ) between and . , here, denotes the boosting factor that regulates mini-column activities. is a permanence binary vector to indicate the status of each potential synapse, where ‘1’ indicates a connected synapse and ‘0’ an unconnected synapse. Upon the completion of computing the overlap scores, each mini-column overlap score gets evaluated by comparing it to a threshold, known as () (line 10). The resulting vector () is an indicator vector representing the nominated mini-columns with high overlap scores. The nominated mini-columns compete against each other with a radius defined by to represent the feed-forward input. Based on the mini-column overlap scores and desired level of sparsity (), number of mini-columns will be selected to represent the input, as shown in line 11, where kmax is a function that implements -winner-take-all which returns the top elements within . After determining the winning mini-columns (), the learning phase (lines 12-15) starts to update the permanence values of the mini-columns’ synapses as necessary, i.e. only the synapses of the active mini-columns are updated. The approach followed in updating the permanence of the synapses is based on the Hebbian rule (Hebb, 1988). The rule implies that the connection of synapses to active bits must be strengthened, increase their permanence by , while the connection of synapses to inactive bits will be weakened, decrease their permanence by , as in line 14, where is the change in the permanence array for all mini-columns given an input , and denotes the sum of and . After adjusting the synapses permanence, the boosting factor is updated to regulated the activities of the mini-columns, as in line 15, where and <$$\bar{a}(t)$$> contain each mini-column time-averaged activity level and its activity level with respect to its neighbor, and is a positive constant controlling the adaptation pace (Cui et al., 2017).
2.2. Temporal Memory Model
The main role of the temporal memory is learning sequences and making predictions for future inputs. The cells of the winning mini-columns are involved in this process. The active cells of the winning mini-columns form lateral synaptic connections with the prior active cells, such that cells can anticipate their active state by just examining the distal segments. The number of distal segments that a cell may have depends on the number of distinct patterns that can be predicted. The more distal segments a cell has, the more connections it can have with other cells and thereby more patterns can be predicted. The operation of the temporal memory essentially involves activating the cells of the winning mini-columns to model the input patterns within the context, predicting the future cellular activities, and updating the distal synaptic permanences. As the scope of this paper focuses on hardware implementation of the SP and its SDR classifier, the aforementioned operation will not be discussed. However, a detailed description of the temporal memory and its implementation can be found in (Zyarah and Kudithipudi, 2018).
3. Design Methodology
In spite of the fact that the HTM network, in theory, has several hierarchical levels, this aspect has not yet been studied throughly. This work is therefore confined to study and implement only one level/region in HTM. Using one region is equivalent to implementing only the primary sensory region of the neocortex. In the following subsection, modeling of every aspect of the region will be discussed.
3.1. HTM Synapse Modeling
HTM cells have a large number of synaptic connections allowing them to detect the pattern of activities occurring in the input space and within the region. Each synaptic level of growth is defined by its permanence value. Typically, the permanence value ranges between 0-1, where 0 indicates the absence of the synaptic connection with a likelihood to form one and 1 indicates the full growth of the synaptic connection (Hawkins and Ahmad, 2016). When the permanence value exceeds the threshold, the synapse provides a low-impedance path to the input and vice-versa when the permanence value is below the threshold. However, HTM synapses are binary in nature in the sense that if two synapses permanence exceed the threshold, they exhibit the same properties regardless of their connection strength. While this is the case, the synapse with the highest permanence is harder to forget. In this research, memristor devices are chosen to emulate the synaptic connections in HTM. A memristor is a two-terminal synapse-like nanoscale resistive memory. Its term was coined by Leon Chua in 1971 (Chua, 1971) and the device received rekindled interest when it fabricated by HP labs in 2008 (Strukov et al., 2008). The device exhibits properties such as low-energy consumption (Prezioso et al., 2015), small footprint, high integration density (Jo et al., 2010), and non-volatility (Borghetti et al., 2010). These features make it an ideal candidate to model the synaptic connections in neuromorphic chips.
The VTEAM memristor model described in (Kvatinsky et al., 2015) is used for this research. The device, essentially, is described with two variables: and which define the state variable of the device and its thickness. Changing the state of the device, i.e. its resistance value (), is considered to have an analog nature. Thus, it is gradual and bounded between the memristor’s high resistance state (HRS ) and low resistance state (LRS ). The change in the memristor is a function of the voltage applied across the device or the current through it. This work mainly focuses on the voltage driven memristors whose resistance change can be described by Equation (1) (Strukov et al., 2008) and Equation (2) (Kvatinsky et al., 2015).
[TABLE]
[TABLE]
where , , , and are constants, and are the memristor threshold voltages, and and describe the device window function. In order to use the memristor device to emulate the HTM synaptic connections, we need to have a memristor that manifests a slight drift when it moves from the boundary toward the mid-point of the device, and as it approaches the mid-point, the drift should be accelerated. In 2016, Brivio et al. proposed a physical memristor that demonstrates properties, which to some extent, match HTM synapse requirements (Brivio et al., 2016). However, modeling this device for circuit simulation requires a special window function so that it exhibits the aforementioned properties. To the best of our knowledge, there is no memristor window function that captures this exponential attribute of HTM synapses. Thus, we developed a window function, called Z-window function, derived from the mathematical formulation of the sigmoid function. The Z-window function has built-in control parameters for adjusting its characteristics and it takes into account the memristor device boundary conditions. Furthermore, it possesses all the attributes of an effective window function such as circumventing the boundary lock problem, providing a linkage with linear dopant drift model, scaling the window function upward and downward (Prodromakis et al., 2011; Zha et al., 2016), and modeling the non-symmetrical behavior of some memristor devices. The proposed window function is given in Equation (3), where , , and 111Nominal parameters used to achieve most of the plots in Figure 2 are: =15, =0.5, =1, and =0.01. are constants that control the slope of the window function, sliding level (over the x-axis), scalability, and falling slope as it approaches either ends of device terminal, respectively. The subscript denotes the and subscript of the window function. is a sign function used to make the window function not only depends on the normalized state variable () but also on the voltage across the device and in this case the boundary lock problem is avoided. Figure 2 illustrates the window function characteristic curves and its hysteresis222A sine wave signal has an amplitude of 1.2v and frequency of 20kHz is used to achieve the hysteresis plots. as simulated in Cadence using Verilog-A memristor model.
[TABLE]
[TABLE]
3.2. Receptive Field
The receptive field (RF) defines a sub-region in the input space to which a mini-column’s proximal synaptic connections are tapped. This section discusses the various approaches of realizing the RFs of the SP mini-columns. It also highlights the advantages of each approach, its constraints and feasibility in realizing a large-scale neuromorphic chip for the HTM algorithm:
3.2.1. Memristive Crossbar
The memristive crossbar is mainly composed of perpendicular metal nanowires sandwiching memory elements modeled by memristors (Lu et al., 2011). The memristive crossbar offers several advantages such as enabling the integration of a large number of memory elements within a compact area and allowing highly-parallel vector-matrix computations. As most neural networks are dominated by vector-matrix multiplications, this makes the memristive crossbar a natural fit for such networks. However, the memristor crossbar structure is really beneficial for densely connected neural networks. When it comes to sparsely connected networks such as HTM, using the crossbar would only be possible by randomly disconnecting devices or setting them to a high impedance state 333There is another approach proposed in (Cui and Qiu, 2016) to map a sparse matrix to the crossbar. It is based on decomposing the sparse matrix into a small sub-blocks mapped separately to the crossbar. The sub-blocks with all-zero elements are excluded from the mapping process and therefore reduce the crossbar size. However, such a process requires continuous matrix manipulation and is infeasible for networks with on-chip training. Thus, this approach is not considered here.. Although both these approaches may result in a sparsely connected crossbar, it is still inefficient modeling. This is because disconnecting devices requires a special burning process, while setting them to a high impedance will not result in perfect current blocking. Having said that, there is a research group that has explored the high impedance method to fulfill a part of HTM’s requirements (Truong et al., 2018). The authors suggest using a crossbar in which each column models an HTM mini-column and the rows represent the mini-column’s synaptic connections which are connected to the input space. For a given crossbar, the adjacent columns have to maintain a certain level of overlap in the input space. Figure 3-(a) shows an example of adjacent columns with two proximal connections each, connected to 4x1 input space (a slice of the presented 4x4 image). Here, it can be noted that the mini-columns and share the input but not . In spite of the fact that this method results in partially sparse connections and it enables high-speed computation in the SP, it has several limitations. The first of which is the limited range in the overlap that can be achieved among the neighboring mini-columns because more overlap space implies more unused regions in the crossbar (called the ”dark-spot” in the rest of the paper). Second, it leads to current sneak path as the memristors cannot be programmed to zero conductance. Lastly, it lacks the reconfigurability and it makes online learning, which is the most important feature in HTM, more challenging as it requires a training circuit with feedback.
The other possible approach to achieve sparely connected crossbars is based on changing its structure. Instead of using the regular perpendicular cross connections, a regional space to each column is defined such that its connections can be tapped, as shown in Figure 3-(b). However, such an approach may have its own challenges during the fabrication process and the same current sneak path issue.
In general, the biggest challenge of adapting the crossbar approach in order to establish the receptive field of each mini-column is the integration between the HTM region and the input space. Using crossbar structure in the ways described above involves establishing hundreds of connections to the input space. This makes HTM architecture over-dominated by the interconnects which eventually lead to undesired noise, scaling limitations, and more power consumption. Furthermore, these connections are rigid in nature and lacks reconfigurability, which is an essential feature to develop an HTM network on chip.
3.2.2. Dynamic Memristive Crossbar
The principle concept of this approach is based on using a linear feedback shift register (LFSR) and a memristor crossbar as a single entity to enable crossbar end-terminal reconfigurability444This is similar to the concept of using synthetic synapses which we proposed in (Zyarah and Kudithipudi, 2015), but here we apply it to crossbar structure.. Due to the fact that the columns in the crossbar share the rows, a full reconfigurability can only be achieved when the columns are separated to be one-dimensional arrays, where each column models a mini-column in HTM. Each column is assigned its own dedicated LFSR which is initialized by the mini-column index in the HTM region. The RF that is generated by the LFSR can either be local or global. In the global RF, all the registers of the LFSR, shown in Figure 4-(a), are used to generate random numbers such that the entire input space can be seen by the mini-columns. Given a mini-column, number of potential synapses can be generated by its LFSR to link it with locations in the input space. In the case of the local RF, the LFSR registers are used in a partial manner. Some of them will be used to generate the random numbers whereas the rest are dedicated to provide address shifting. Figure 4-(b) illustrates the concept of the partially used LFSR. The registers with a colored base represent the registers that will generate the synapses address while the rest are used for shifting. For instance, if an 8-bit LFSR is loaded with a seed of 200, random integer numbers ranged between 192-207 can be achieved if only the 4 least significant bits (LSB) of the LFSR are used.
It turns out that this approach of generating the RF of HTM mini-columns is more expensive in terms of resource utilization and latency in comparison to the rigid memristive crossbar discussed previously in 3.2.1. It is, however, more realistic when it comes to scalability because there is no restriction related to the crossbar size, or the number of interconnects being used. Furthermore, on one hand, it satisfies an essential requirement for HTM-SP which involves providing a reconfigurable interconnect that enables implementing topologies of HTM RF, both local and global. On the other hand, it facilitates the communication of the HTM network with the environment and reduces the physical interconnects.
3.3. Homeostasis and Neurogenesis Plasticity Mechanisms
Homeostasis is an essential mechanism in biologically inspired networks. It prevents neurons from being hyperactive through regulating its threshold of generating a somatic action potential (Zhang and Linden, 2003), named in HTM theory. The concept of homeostasis in HTM does not involve regulating the directly. Rather, it implies exciting the action potential of relatively low active neurons through multiplying the action potential by a positive scalar value called a boosting factor. This results in an effect similar to that of regulating the value. The boosting in SP is used to ensure equal likelihood for mini-columns to represent the spatial inputs in SDR form. It is applied through stimulating the mini-columns that have not been active over a predefined time period, i.e not frequently active with respect to its neighboring mini-columns. Consequently, low active mini-columns can have better chance of representing the feed-forward input in future.
It turns out that using the boosting mechanism is impactful when there is a uniform statistical distribution of information in the input space. Unfortunately, this requirement is not guaranteed especially for visual applications unless a custom encoder is used to process all the inputs. An example of a non-uniform distribution of information in the input space would be the usage of MNIST images. Such non-uniformity in the input space make several mini-columns rarely active or completely inactive. Even the use of boosting here would not cut down the number of inactive mini-columns. Therefore, as a possible solution to overcome this issue, this paper suggests applying the neurogenesis mechanism to HTM. Neurogenesis is a structural plasticity mechanism that suggests ’dead’ neurons be replaced with ’new’ neurons to enhance network computational capabilities (Soures et al., [n. d.]). Just as in homeostasis, neurogenesis can be applied via tracking the recent mini-column activities over a predefined period of time and comparing it with respect to its neighbor. The mini-columns that were not active frequently are considered ’dead’ neurons and should be replaced with new ones. For a given ’dead’ neuron, this is achieved by replacing its connections with new randomly initialized connections that are connected to different locations in the input space. Hence, the mini-columns proximal connections will start shifting toward the most active regions in the input space while maintaining a low number of connections to rarely active regions. Figure 5 demonstrates the influence of using neurogenesis on the synaptic connections density in the input space. It can be seen that when the activity in the input space is mediated in the mid-region and neurogenesis is disabled, the connections on the sides are not involved in any computations leading to form non-robust sparse representations. In contrast, when neurogenesis is enabled, the synaptic connections start to move toward the most active spots in the input space and form better representations.
Implementing the neurogenesis mechanism in hardware presents several challenges due to the lack of reconfigurability in interconnects which models the synaptic connections. Thus, we adopted the concept of synthetic synapses (Zyarah and Kudithipudi, 2015) to enable the reconfigurability in the interconnects and neurogenesis in HTM neuromorphic system. The synthetic synapse concept involves generating the synaptic connections by using an LFSR rather than using rigid connections (just as in dynamical memristive crossbar). By using this, when a given mini-column is ’dead’ and replaced by ’new’ mini-column, all the connections of will be removed and replaced by new connections assigned to different locations in the input space and the strength of the new connections are again, randomly initialized.
4. System Design and Implementation
The high-level architecture of the memristive HTM-SP along with the SDR classifier is shown in Figure 6-(a). The SP architecture comprises a set of mini-columns to spatially process the feed-forward input and a main control unit (MCU) to enable the mini-columns to interact with the ambient environment. When the input is presented to the network, the MCU relays it to the mini-columns such that each mini-column’s active proximal connections will be identified and counted. The mini-columns with active proximal segments compete against each other and the top X% mini-columns that receive most of the input are activated. The selection of the top X% mini-columns is performed using a voltage-mode winner-take-all (WTA) circuit. After identifying the best mini-columns that represent the input, the learning process starts. The learning process occurs in an online fashion which grants the network the ability to adapt continuously to the input changes. Learning is governed by a Hebbian rule and involves modulating the connections for the active columns only. Upon the completion of the learning, the output of the SP is generated and then passed to an SDR classifier when the network is used for classification applications (see Figure 6-(b)). In the following subsections more details about the implementation of the SP and the SDR classifier will be provided:
4.1. HTM Spatial Pooler
The SP is essentially composed of an MCU and mini-columns. As aforementioned, the MCU bridges the mini-columns with either the sensory input or other regions in the hierarchy and the mini-columns are the units where the main SP computations occur. In the next subsection, the mini-column circuit, its training circuity, and the WTA unit are discussed in more details.
4.1.1. Mini-Column
Figure 7 depicts the architecture of the SP mini-column. The mini-column is modeled by three units named: peripheral unit, proximal unit, and WTA cell. The peripheral unit models the part of the mini-column in which the proximal connections are generated and connected to the input space. The proximal unit and WTA cell hold the proximal connection permanences and a contesting unit that enables each mini-column to compete with its neighbors for the input representation, respectively. The input to the mini-column is generated by the network encoder (modeled by the network testbench). The encoder task, in this work, is confined to binarizing the images and slicing them into small patches to minimize data movement and the required storage units. Sequentially, each patch is presented to the mini-column and stored into an . Meanwhile, the LFSR generates a random number indexing the observe patterns activities in the feed-forward inputs.
Given an input image of size 32x32, it is sequentially fetched to the network in the form of patches, where each patch is a 32-bit row vector. When the input patch is stored in the and the LFSR generates an address for a location in the received patch, a matching score is stored in a synapses register which is modeled by serial-in-parallel-out shift register. Once all inputs are received, the output of the synapses register is fetched to the word-line of memristive crossbar where the proximal synapse permanences are stored. The input voltages to the crossbar will be converted in form of current through the memristor and the output is collected at the crossbar bit-line. The output of the crossbar which modulates the mini-column overlap score to current is then boosted. Boosting is done via the usage of a sense memristor (). The boosting factor is inversely proportional to () conductance as such decreasing value leads to increase the boosting factor and vice versa. The output at this point, , is given by Equation (5):
[TABLE]
[TABLE]
where () indicates the conductance of memristor and is the input voltage. () denotes the mini-column overlap score. Upon the completion of computing the overlap score, its value, which is sampled by the sense memristor, is then presented to a WTA circuit. The WTA performs a 555The function is computed in the next winner-take-all, section (4.1.2). operation on followed by a thresholding, to generate the final mini-column output, (), as given in Equation (7).
[TABLE]
The minimum input to the WTA circuit should be no less than 0.2v so that a cell is activated. This requirement implicitly realizes the concept of in HTM which implies that mini-columns overlap score should be large enough to enable it for competing against other mini-columns to represent the input. The output of the WTA cell indicates the mini-columns status, where logic ’1’ refers to a winner. Selecting the winners is followed by the learning process in which each winning mini-column synapses are adjusted in response to the stimulated feed-forward input and according to Hebbian learning rules.
4.1.2. Winner-take-all Circuit
The WTA cells are utilized as apart of the mini-columns circuit to select the winners in each local (or global) cluster and in the SDR classifier to identify the winning class labels. Figure 8-(a) depicts the WTA circuit which models a simple local competitive algorithm which is naturally imposed through Kirchhoff current law (KCL). Each branch in the circuit has an NMOS transistor () to capture the input signal ( in the mini-column circuit and in the SDR classifier) of one competitor. The competitors interact with each other through the shared point . When inputs are presented to the circuit, the potential of follows the input with the highest voltage and turns off all the other transistors. The cell conveying most of the bias current, , is identified as a winner. Given that all the transistors operate in subthreshold regime, applying an input voltage at the gate of the transistor in the branch results in a current , which can be approximated by Equation (8) (Razavi, 2017):
[TABLE]
where is the zero-bias current for the given device, is the transistor channel width to length ratio, and indicate the thermal voltage and the subthreshold slope coefficient, respectively. For the given circuit with branches, according to KCL, the branches’ current should sum up to , as given by Equation (9). By using Equation (8) and Equation (9), we can solve for the current flowing in each branch as shown in Equation (10), which is identical to the softmax function.
[TABLE]
[TABLE]
Recall that the output of the SP is a voltage and is represented in a binary sparse form. Thus, we designed the WTA to be a voltage mode circuit. In order to maintain the same normalized exponential relationship between the input and output (described in Equation (10)), the current in each branch is sent to a current comparator via a current mirror formed by and , as shown in Figure 8. The mirrored current is compared to a fixed reference current resulting in a voltage drop across the point , which can be calculated using Equation (11):
[TABLE]
where is the channel-length modulation, is the transconductance parameter, and denote the current mirror gain between and and transistor threshold voltage. By substituting Equation (10) in Equation (11), the output node, , is calculated in Equation (12):
[TABLE]
Due to the fact that is approximately constant and is given by , Equation (12) indicates that the output voltage for branch has a normalized exponential relationship with the input . Such relation has a unique benefit for WTA circuit because it maximizes the difference between the inputs. It generously rewards the input with the highest value and punishes the losing ones. Most of the power consumption is dominated by the winning cells which are low in number compared to losing cells.
It is important to notice here that unlike most other WTA circuits, in literature (Lazzaro et al., 1989; Ramakrishnan and Hasler, 2014; Kulej and Khateb, 2017), all outputs are buffered to provide enough driving capabilities when transmitting signals across long distances. Also, few of the previous WTA circuits are endowed with a hysteresis mechanism to increase network stability and prevents the selection of a potential winner unless they are strong. Due to the fact that the hysteresis is achieved via a local excitatory feedback, some of these circuits require a reset process to any competition as in (Fish et al., 2005). In the proposed WTA circuit, the hysteresis characteristic is introduced via the positive feedback formed by the transistor . Additionally, having a current comparator improves the stability further as it imposes a threshold current that needs to be crossed to switch cells status. The other advantage of using the current comparator is that it enables more than one winner, which is a desirable feature especially in HTM as it allows controlling the network output sparsity level.
4.1.3. Mini-column Learning Circuit
The learning in HTM is performed in an online fashion and it involves modulating the synaptic permanence of the winning mini-columns only. As aforementioned, the proximal synaptic connections of each mini-column are emulated by one-dimensional memristive array. Therefore, the training here can be performed simultaneously. By using a modified Ziksa unit (Zyarah et al., 2017), training each mini-column synaptic connections can be performed in two clock cycles. After computing the mini-column overlap scores, the synaptic connections that were connected to active bits in the input space has their D-Flip-Flop (DFF) set to high and vice-versa for the synapses connected to inactive bits. All the DFF outputs are buffered with a modified NOT gate that generates a logical level output during the normal operation and a training voltage during the learning phase. When the signal is generated (active-low), the positive terminals of the memristors will be connected to if the output of the DFF is high and otherwise. The other terminal of the memristor will be controlled by and . During the first cycle of training, is set to ON by . If DFF output is low, this causes a voltage drop across the memristors that needs to be adjusted to exceed the threshold leading to an increase in its resistance. During the second clock cycle, the same procedure will be applied but in the opposite manner666The training circuit is verified while considering memristor device variability for resistance range and threshold voltage. Variability with normal distribution has been considered with mean defined by device parameters and standard deviation (STD) equals to 10% of the mean for resistance and 5% of the mean for threshold voltage..
The downside of using the inverters of DFFs in conjunction with Ziksa unit is that the network will suffer from the sneak path issue especially during the learning phase. However, this issue can be overcome by buffering the output of DFF with a tri-state buffer rather than an inverter gate. Using a tri-state buffer allows the memristors that are not involved in the training process 777The memristors that are not involved in the training are those that need to be decremented during the first clock cycles or those that need to be incremented in the second clock cycles of training. to be floating such that it does not draw any current. Figure 10 covers the possible scenarios for the sneak paths when a NOT and tri-state buffers are used.
4.2. SDR classifier
The SDR classifier recognizes the SDR combinations as generated by the SP and generates the predicted class label. It is built using a softmax circuit ( WTA circuit shown in Figure 8) with number of units, where denotes the number of class labels that needs to be recognized. All the SDR classifier units are interconnected with the SP mini-columns in a dense manner through weighted connections, . Initially, the weighted connections of the classifier are randomly initialized and then tuned according to the delta rule, given in Equation (13), where is the weight of the connection between the classifier unit and SP mini-column, is the learning rate. denotes the mini-column output, and and are the predicated and expected class labels, respectively. It is important to mention here that the delta rule can be applied using Ziksa training circuitry as described in (Zyarah et al., 2017).
[TABLE]
[TABLE]
5. Experimental Setup
5.1. Device Parameters
The Verilog-A memristor model, VTEAM (Kvatinsky et al., 2015) is mapped to the physical memristor device by Brivio (Brivio et al., 2016). The device resistance range is opted to fulfill the design constraints and to ensure proper operation. The low resistance state (LRS ) is chosen to be 200k and the high resistance state (HRS ) is 5M such that, sufficient amount of input current causes a voltage drop of 0.85v888This is when a mini-column overlap score exceeds across the sense memristor. This range of memristor resistance also minimizes the power consumption of the crossbar array. Given the technology node and the supply rail, from the mini-column circuit (Figure 7), the sense memristor range can be estimated as in Equation (15)999Parameter to find : =2e-7, =32, =0.2v, . Parameters to find : =5e-6, =24, =0.9v, . Here, the minimum value of the sense memristor is chosen such that it does not bring to more than 0.3v even when the inputs are set to high. On the contrary, activating three-quarter of the proximal connections is enough to bring the voltage drop across the sense memristor to maximum (0.85v).
[TABLE]
Recall that the proposed HTM-SP network offers online learning. However, in order to test the system for generalization, the learning might be turned off. Since a threshold voltage memristor model is adapted, a threshold voltage of 1v is used to disable the device undesired adjustment when the learning is disabled. Upon the completion of setting the mini-columns’ parameters, the system parameters are defined such that system offers real-time data processing, online learning, and minimum power consumption. The system parameters are reported in Table 1.
5.2. SP Network Setup
In order to set the optimal network parameters for the utilized verification benchmarks, the particle swarm optimization (PSO) (Eberhart and Kennedy, 1995) algorithm is used. The algorithm is integrated with the software module of the SP and the search space is defined within a range that meets the hardware constraints. The search space of the optimal hyper-parameters is observed by using 50 particles randomly initialized within the predefined range, and the algorithm runs over 100 iterations. The optimization is applied only for the SP network and the evaluation of the SP for any given hyper-parameters is performed using the SDR classifier, the highest accuracy of which represents the optimal point. For three separated runs and different benchmarks, we run PSO to get the optimal hyper-parameters that result in the highest recognition accuracy. The hyper-parameters that are included in the search space are: the number of winning mini-columns which impacts the SP sparsity level, which influences the sparsity level and SP noise robustness, permanence parameters which determine the learning and forgetting rate, and the proximal segment size which controls each mini-column overlap level with the input space. Table 2 lists the hyper-parameters search space and the optimal values for each benchmark.
6. Spatial Pooler Evaluation Metrics
The performance of the SP is evaluated using the metrics defined in (Cui et al., 2017), the sparseness and entropy, which reflect the sparsity level of encoding and efficient use of the available resources (mini-columns) in the encoding process. The dataset used during the evaluation is suggested in (Cui et al., 2017) and consists of a set of random vectors with sparsity level varies between 2% to 20% (it is called random dataset in the rest of the paper). In the following subsections, each evaluation metric is discussed in detail.
6.1. Sparseness
Sparseness () defines the activity of the mini-columns overtime to ensure the fixed sparsity level in the SDR produced by the SP. Given a SP SDR output vector (), its sparsity level can be measured by dividing the Hamming weight of , , by the mini-columns count () in the HTM region, and as given in Equation (16)
[TABLE]
Figure 11-(a) illustrates the sparsity level for 200 input samples before and after being treated by the SP. It can be observed that the wide variability in the sparsity level in the input has been significantly reduced to almost 2%. However, due to the fact that during this experiment the is set to 4, having 2% of the sparsity level is not guaranteed as each mini-column should have at least 4 active proximal connections to get involved in the input representation. This issue can be noticed in the negative spikes of the green line which is an indicator of a degradation in the sparsity level of SP output (below 2%). After adding the neurogenesis mechanism, this issue is actually reduced as seen in orange line (G-SP). This is because the mini-columns that were inactive are replaced with new ones with a higher likelihood to be active.
6.2. Entropy
The entropy metric quantifies whether the SP uses all the mini-columns in the region or not. This metric can be computed by summing up the binary entropy function of each mini-column in the HTM region and as given by Equation (17) (Cui et al., 2017), where is the mean SP entropy and indicates the average activation frequency of the mini-column across inputs. Figure 11-(b) illustrates the average entropy101010The mean entropy increases when the mini-columns are equally activated due to the SP fixed sparsity constraints (Cui et al., 2017). of the SP for the random dataset when the learning is enabled and disabled. It can be noticed that enabling the training in the network leads to improve the entropy from 0.123 bits/mini-column to 0.128 bits/mini-column (the maximum possible entropy that can be achieved for the same network setup is 0.139 bits/mini-column). This means that the fraction of mini-columns that are not involved in representing the input before learning became much more active after training. Furthermore, when the neurogenesis mechanism is enabled, further improvement in the entropy has been achieved for both training and testing results (bars with black boxes). This attributes to the continuous mini-columns renewing as a function of their activities.
[TABLE]
[TABLE]
7. Experimental Results
7.1. Image Recognition
SP performance is evaluated on the image recognition task which is conducted using several benchmarks including MNIST111111MNIST is the standard benchmark for hand-written images. It has grayscale images of 28x28 pixels associated with 10 classes for numbers from 0 to 9. The images are split into 60,000 training examples and 10,000 testing examples. and Yale faces121212Yale faces dataset contains 165 grayscale images corresponding to 15 subjects, 11 images each. The images are taken under different conditions and variations including illumination effects, facial expression, etc. In this work, the set is randomly split into training and testing examples, where the training examples contain 8 samples from each subject and 3 samples are used for testing. datasets. For MNIST, all the images are resized from their original size, 28x28, to 32x32 pixels. Then, all images are binarized by thresholding prior to introduce them to SP. The same process is applied for Yale faces, but here the images are cropped using the face detection Open-CV python library prior to the resizing. The binarization, here, is performed using adaptive thresholding to preserve most image details during the conversion process.
In separate experiments, the data is introduced to the SP as training and testing sets. When the training set is introduced, the SP learns the feed-forward input (images) in an unsupervised fashion. Then, its output is relayed to an SDR classifier implemented by the winner-take-all circuit. The SDR classifier, here, is trained in a supervised fashion using the delta rule. Then, the learning is disabled in both SP and SDR classifier and the testing set is presented to the network. The results, shown in Table 3, demonstrate that the network is able to classify the SDR representation generated by the SP with a testing accuracy of 90.33% for MNIST. In case of Yale faces, due to the limited available training samples, the same training set is presented to the network several times and the resulting accuracy for testing, averaged over 10 runs, is 86.86%.
In an attempt to compare our results with previous implementations of the SP, for MNIST, it is found that although our network is smaller in size, it still offers a comparable accuracy to other implementations. In case of our previous work, in which 100 mini-columns are used, the high accuracy mainly attributes to the use of high-performance classifier, support vector machine (SVM). When it comes to other sparsity classifiers such as the locally competitive algorithm (LCA), SP+SDR classifier still outperform this classifier with 0.33%. For Yale faces, SP+SDR classifier outperforms the smooth-marginal fisher analysis (S-MFA) and offers higher average accuracy than the SP implementation in (James et al., 2017) which did not consider the entire dataset during the training and testing.
7.2. Noise Robustness
In order to quantify the noise robustness of the SP+SDR classifier for image recognition applications, two experiments are performed. The first of which involves classifying MNIST images in the presence of noise and the second one involves interrupting the training process by injecting random SDRs. For the first experiment, the SP+SDR classifier is trained on clean training MNIST images and tested with noisy test images. The noise here is added by flipping the image pixels randomly. The noise level is defined by the percentage of the flipped pixels in an image. For a noise level ranging between 0% to 10%, both the SDR classifier ( softmax classifier) and SP+SDR classifier are tested separately. Figure 12 demonstrates the drop in recognition accuracy as both classifiers are tested with corrupted MNIST images with various noise levels. It can be observed that the SP+SDR classifier was able to handle the noise with a graceful degradation in accuracy in comparison to the SDR classifier which its accuracy dropped to 37.7%, when 10% noise is added to the images.
In the second experiment, the SP is used to generate the SDR representations of MNIST training and testing sets. Then, the SDRs representations are presented to the SDR classifier during the training and testing processes, where one cycle of training and testing is considered as one epoch. MNIST SDRs are presented to the SDR classifier for 100 epochs mediated by noise injection. The noise here consists of a set of random SDR vectors with sparsity level similar to that in MNIST SDR vectors as generated by the SP. 10,000 noise vectors are generated and injected in parts after the SDR classifier settles to a reasonable accuracy level ( 90.38). Between epochs 50-55, random 1000 SDR vectors are presented to the SDR classifier, between epochs 65-75, 5000 random SDR vectors are used, and between epochs 80-95, 10,000 random vectors are used. Figure 12-(b) illustrates the drop in recognition accuracy when the data streams are replaced by a stream of noisy vectors and the fast recovery after the noisy vectors are removed. The fast recovery, here, attributes to training the SDR classifier on sparse inputs which makes the likelihood of adjusting the critical connections (i.e. weights) less likely. This, consequently, shows that the degradation in classifier performance, even after removing the noise vectors, is almost negligible.
7.3. Power Consumption and Area
Figure 13-(a) shows the total power consumption131313The power consumption of the proposed design is evaluated in Cadence (analog blocks) and Synopsys (digital blocks) for 65nm technology node. The digital units are integrated with a testbench to fetch the training images to the network and their loads are emulated by D-FFs. Initially, we run the circuit for 1ms to capture the circuit switching activity. Then, we use Synopsys tools to measure the power consumption of the digital units. In case of the analog blocks, a crossbar network and mini-column training circuitry with memristor proximal connections serve as a testbed. During the testing, we consider an input voltage of 0.9v, whereas 1.2v is used during the training. It is important to mention here that while measuring the power consumption, all the memristors are replaced by resistors and we consider the worst case scenario, (all crossbar memristors are set to low resistance state). Then, the power consumption is estimated using Cadence ADE tools by covering all the input combinations and averaging the results. For the area estimation, we used Synopsys tools to estimate the area of the digital units and the analog units area is estimated from the physical layout designed in Cadence. of the SP and the SDR classifier during the training and testing processes when the network is used to recognize MNIST digits, running at 50MHz. For a single iteration141414Iteration in this context refers to the time starting from fetching an image to the network until it gets recognized. It also includes the training time of the SP and the classifier., initially, the power consumption resides at 18.72mW until each mini-column activates its corresponding proximal unit. During the training, the proximal connections are driven by the training voltage (1.2v) rather than the testing voltage (0.9v) to adjust the strength of the connections leading to greater power consumption. However, since the use of a proximal unit takes 2 clock cycles, we do not see this abrupt increase in the power last long. It is important to mention here that the SP and SDR classifier are working simultaneously and in a pipelined fashion. Thus, when the SDR classifier is used for inference, there is around 0.994mW of power consumption which then degrades to 0.121mW during the training as only one crossbar column is trained in 2 clock cycles. Finally, when the SP communicates with the testbench according to the hand-shake protocol to receive a new patch, the network experiences a sudden drop in power (last few cycles) as most system units are disabled. In Figure 13-(b), the total average power consumption of each unit in the SP design is illustrated. From here, we can see that the power consumption of the mini-columns is dominating the network. It can be reduced further by lowering the operating frequency and if memristors with higher resistance are used. Finally, the network (SP+SDR classifier) setup used to classify the MNIST dataset consumes an average total power of 18.47mW with an area estimate of 0.513mm2.
8. Conclusions
This paper proposes a memristor-based architecture for the HTM spatial pooler and its SDR classifier for mobile devices and energy constrained platforms. The proposed design enables high-speed computations, low power consumption, and reconfigurability, all in a single entity that has the capability to recognize images even in the presence of noise. The proposed design is implemented using 65nm technology node and verified using various datasets including MNIST (accuracy 90.33%) and Yale faces (accuracy = 86.86%). It is found that the network exhibits a strong robustness to noise especially from the classifier side as it is trained with SDR representations. Furthermore, during the power consumption analysis, it is observed that the power consumption while using the proximal unit is approximately tripled. However, limiting the use of this unit to 2 clock cycles significantly reduces the overall network power consumption to 18.47mW.
Acknowledgements.
The authors would like to thank the members of the Neuromorphic AI research Lab at RIT for their support and critical feedback. The authors also would like to thank the reviewers for their time and extensive feedback to enhance the quality of the paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Ahmad and Hawkins (2015) Subutai Ahmad and Jeff Hawkins. 2015. Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory. ar Xiv preprint ar Xiv:1503.07469 (2015).
- 3Borghetti et al . (2010) Julien Borghetti, Gregory S Snider, Philip J Kuekes, J Joshua Yang, Duncan R Stewart, and R Stanley Williams. 2010. Memristive switches enable stateful logic operations via material implication. Nature 464, 7290 (2010), 873–876.
- 4Brivio et al . (2016) S Brivio, E Covi, A Serb, T Prodromakis, M Fanciulli, and S Spiga. 2016. Experimental study of gradual/abrupt dynamics of Hf O 2-based memristive devices. Applied Physics Letters 109, 13 (2016), 133504.
- 5Cai et al . (2007) Deng Cai, Xiaofei He, Yuxiao Hu, Jiawei Han, and Thomas Huang. 2007. Learning a spatially smooth subspace for face recognition. In Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on . IEEE, 1–7.
- 6Chua (1971) Leon Chua. 1971. Memristor-the missing circuit element. IEEE Transactions on circuit theory 18, 5 (1971), 507–519.
- 7Cui and Qiu (2016) Jianwei Cui and Qinru Qiu. 2016. Towards memristor based accelerator for sparse matrix vector multiplication. In Circuits and Systems (ISCAS), 2016 IEEE International Symposium on . IEEE, 121–124.
- 8Cui et al . (2017) Yuwei Cui, Subutai Ahmad, and Jeff Hawkins. 2017. The HTM Spatial Pooler − - A Neocortical Algorithm for Online Sparse Distributed Coding. Frontiers in Computational Neuroscience 11 (2017).