Job Allocation in Large-Scale Service Systems with Affinity Relations
Ellen Cardinaels, Sem C. Borst, Johan S.H. van Leeuwaarden

TL;DR
This paper studies load balancing in large-scale service systems with affinity relations, proposing schemes that allocate jobs to primary or secondary servers, and analyzing stability and performance through coupling and fluid limit techniques.
Contribution
It introduces load balancing schemes considering affinity relations and develops novel coupling methods for stability analysis and performance bounds.
Findings
Stability conditions depend on affinity and load parameters.
Fluid limit analysis reveals the impact of model parameters on performance.
Coupling construction provides bounds for system stability.
Abstract
We consider load balancing in service systems with affinity relations between jobs and servers. Specifically, an arriving job can be allocated to a fast, primary server from a particular selection associated with this job or to a secondary server to be processed at a slower rate. Such job-server affinity relations can model network topologies based on geographical proximity, or data locality in cloud scenarios. We introduce load balancing schemes that allocate jobs to primary servers if available, and otherwise to secondary servers. A novel coupling construction is developed to obtain stability conditions and performance bounds using a coupling technique. We also conduct a fluid limit analysis for symmetric model instances, which reveals a delicate interplay between the model parameters and load balancing performance.
Click any figure to enlarge with its caption.
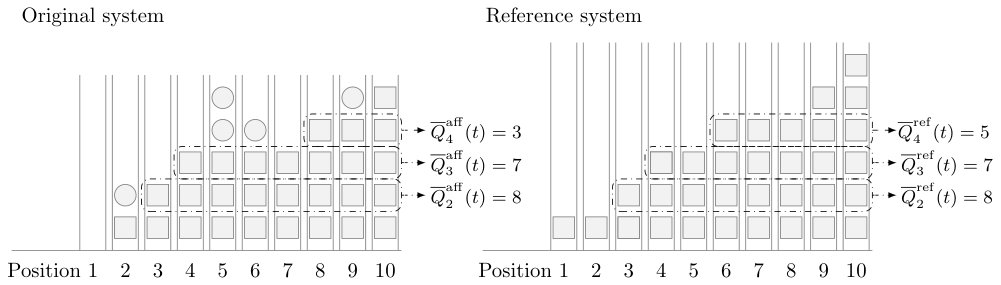 Figure 1
Figure 1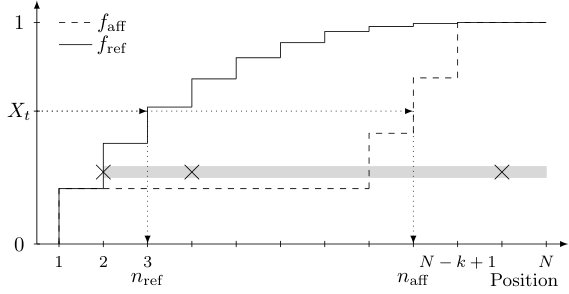 Figure 2
Figure 2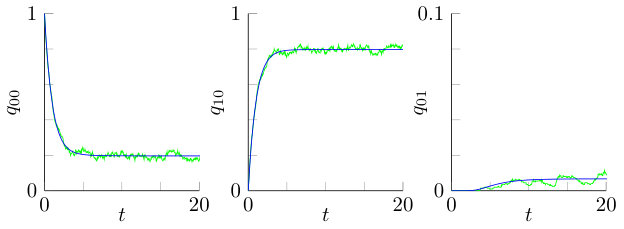 Figure 3
Figure 3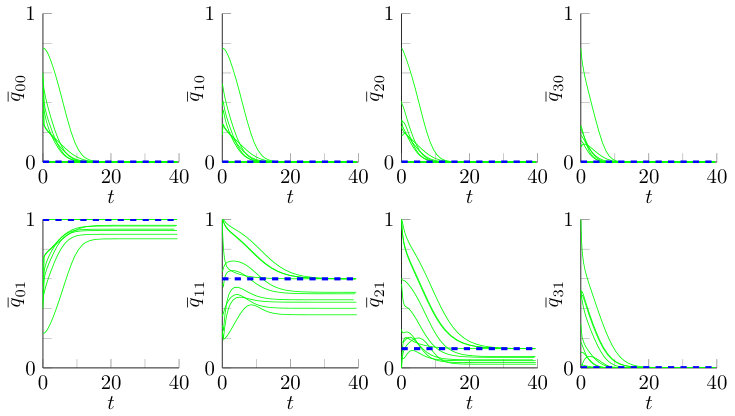 Figure 4
Figure 4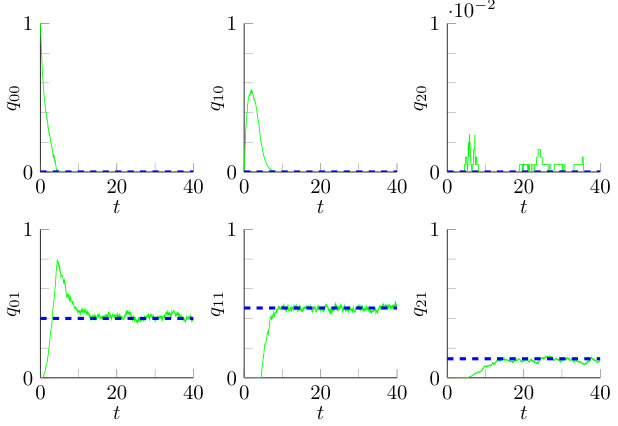 Figure 5
Figure 5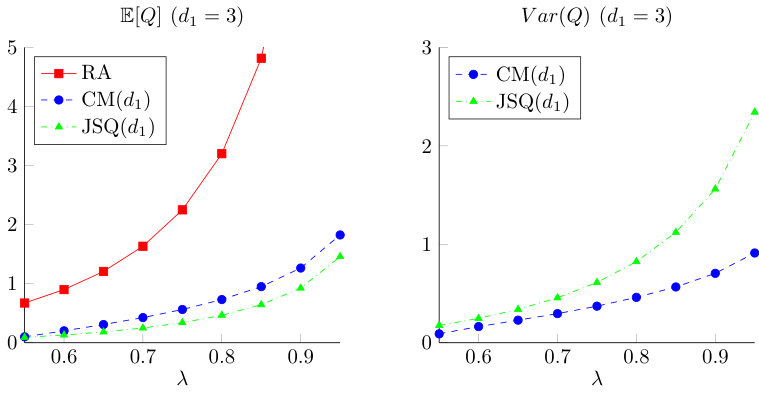 Figure 6
Figure 6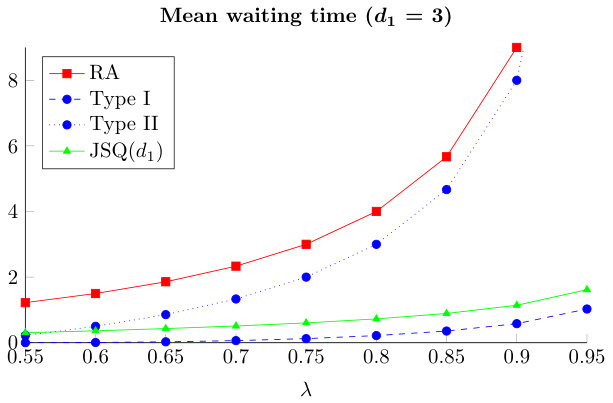 Figure 7
Figure 7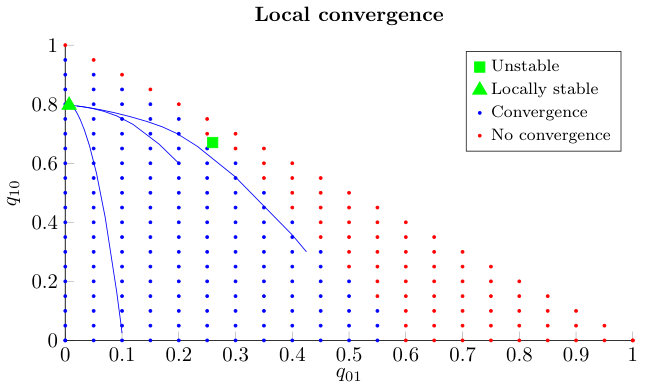 Figure 8
Figure 8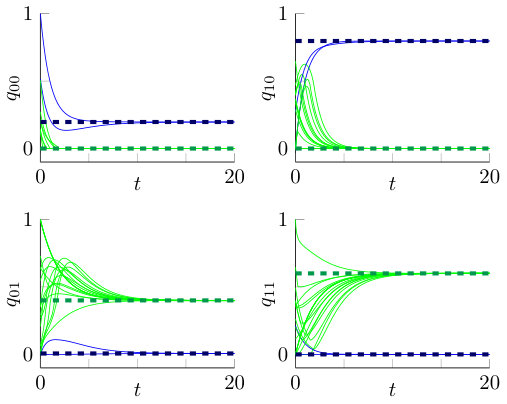 Figure 9
Figure 9| 2 | 3 | 4 | 5 | 10 | 15 | 25 | |
| 31 | 34 | 36 | 38 | 42 | 44 | 46 |
| 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|---|---|
| 5 | 9 | 18 | 46 | |||
| 3 | 5 | 7 | 12 | 22 | 54 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Queuing Theory Analysis · Simulation Techniques and Applications · Cloud Computing and Resource Management
Job Allocation in Large-Scale Service Systems with Affinity Relations
Ellen Cardinaels Corresponding author: Ellen Cardinaels ([email protected]) Eindhoven University of Technology, The Netherlands
Sem C. Borst
Eindhoven University of Technology, The Netherlands
Nokia Bell Labs, Murray Hill, USA
Johan S.H. van Leeuwaarden
Eindhoven University of Technology, The Netherlands
Abstract
We consider load balancing in service systems with affinity relations between jobs and servers. Specifically, an arriving job can be allocated to a fast, primary server from a particular selection associated with this job or to a secondary server to be processed at a slower rate. Such job-server affinity relations can model network topologies based on geographical proximity, or data locality in cloud scenarios. We introduce load balancing schemes that allocate jobs to primary servers if available, and otherwise to secondary servers. A novel coupling construction is developed to obtain stability conditions and performance bounds using a coupling technique. We also conduct a fluid limit analysis for symmetric model instances, which reveals a delicate interplay between the model parameters and load balancing performance.
Keywords load balancing, stochastic coupling, fluid limit, job scheduling, network topology
MSC2010 60K25, 68M20, 90B15, 90B22, 90B35
1 Introduction
In this paper we analyze a load balancing scheme in a service system where particular servers are better equipped to process certain jobs because of affinity or compatibility relations. Load balancing algorithms play a crucial role in distributing jobs among multiple servers and have attracted strong renewed interest due to proliferation of large data centers and cloud computing. Well-known load balancing algorithms include for instance the Join-the-Shortest-Queue (JSQ), Join-the-Shortest-Queue- (JSQ()) and Join-the-Idle-Queue (JIQ) policies. These policies have been extensively analyzed in an overarching framework called the supermarket model, consisting of a single dispatcher where jobs arrive that must be distributed among identical parallel servers. The JSQ policy assigns each arriving job to the server with the smallest queue length and has strong stochastic optimality properties among the class of policies without advance knowledge about the service requirements [5, 23]. The JSQ policy involves a significant communication burden however, which may be prohibitive in large systems.
This scalability issue has spurred an interest in the JSQ() policy which assigns a job to the server with the smallest queue length among randomly selected servers. Mitzenmacher [14] and Vvedenskaya et al. [22] analyzed the JSQ() policy in an asymptotic regime where the total arrival rate and the number of servers grow large in proportion. Substantial performance gains were established compared to purely random assignment, even for . Mukherjee et al. [15] show that the waiting time in fact vanishes when tends to infinity as the number of servers grows large. A vanishing waiting time is also achieved by the JIQ policy which directs arriving jobs to an idle server or a randomly selected server if all servers are occupied [12]. The JIQ policy only has a constant communication overhead per job, but requires memory at the dispatcher. We refer to Van der Boor et al. [21] and Gamarnik et al. [6] for further details.
A key feature of the supermarket framework is the exchangeability of the servers in the sense that any job can be handled equally well by any server, which is often not the case in practice. In the present paper we will focus on a scenario where jobs or servers are not intrinsically different, but where particular servers might be better equipped to process certain jobs because of affinity or compatibility relations. Such affinity relations may for example arise due to geographical proximity in spatial settings, or data locality in content distribution or transaction processing applications. The scenario will be modeled as follows: let denote the power set of all servers. Then for a selection of servers, , jobs arrive at rate . These jobs can be processed at rate at any of the servers in or at rate at any of the servers in , with . The arriving job is then labeled as a type I or type II job, depending on whether it can be served at rate or , respectively. Our affinity-scheduling policy allocates the new job to a server in with the shortest queue length unless it might be beneficial to redirect the job to a server outside . The precise allocation and scheduling strategies will be described in Section 2.
When contains all neighborhood sets of a graph on vertices, we refer to our model as the graph model. The graph model extends the models constructed by Gast [7], Turner [20] and Mukherjee et al. [15]. In these settings it is assumed that all nodes have equal arrival rates and jobs can only be forwarded to direct neighbors; it is not possible to redirect an arriving job to any other nodes. The model constructed by Yekkehkhany et al. [24] does allow for jobs to be redirected to higher-degree neighbors to be served at lower rates. When consists of all subsets of servers of fixed size , we refer to our model as the combinatorial model. In addition, the arrival rates will be equal among the server selections which strengthens the symmetric nature of the combinatorial model.
The lack of exchangeability among the servers makes the affinity-scheduling model complicated to analyze in general. The analytical techniques that are most commonly used in the context of the supermarket model, such as mean-field limits and even standard coupling arguments, fundamentally rely on this feature. These techniques can only be applied for the combinatorial model. For the general model, and in particular the graph model, the investigation of load balancing issues is challenging, and enters largely uncharted methodological territory.
We will establish a stochastic dominance result for the occupancy process of the general affinity-scheduling model, which will yield a sufficient stability constraint as an immediate by-product. Exploiting the coupling of this dominance result, we can derive two stronger dominance results for the graph model, which will in particular hold if the underlying graph structure is rather dense. To the best of our knowledge, these are the first results that explicitly capture the impact of network structure on load balancing performance.
For the combinatorial model we will conduct a fluid-limit analysis. A trajectory of the fluid limit will converge to one of the possibly multiple fixed points, depending on the mutual relationships of the model parameters and the initial configuration of the system. When the fixed point is unique, we demonstrate that this provides a good approximation for the intractable stationary distribution in a finite server setting. When multiple fixed points occur, we observe the phenomenon of ‘tunneling’ described by [8]. The stochastic process will switch between multiple modes corresponding to the locally stable fixed points of the fluid limit.
The remainder of this paper is organized as follows. A detailed model description will be provided in Section 2. Next, the main stochastic dominance result is presented in Section 3 together with the coupling that establishes this result. This section is completed with two stronger stochastic dominance properties for graph models. In Section 4 we present a fluid-limit analysis of the affinity-scheduling policy for combinatorial models. The proofs of all results are deferred to Section 5. Finally, Section 6 provides concluding remarks and some directions for further research.
2 Model description
We now describe the affinity-scheduling model with servers. For a selection jobs arrive as a Poisson process of rate . For these jobs, the servers in and are called the primary and secondary servers, respectively. An arriving job can be allocated as a type I job to a primary server or as a type II job to a secondary server. Type I jobs have independent and exponentially distributed service times with parameter . Type II jobs have on average longer service times which are independent and exponentially distributed with parameter . It is important to note that the job type is not predetermined on arrival, but established by the allocation strategy. The main idea behind our allocation strategy is: ‘Allocate a job to a server in the primary selection unless it might be beneficial to allocate a job to a secondary server even though the service time might be longer’. The rationale for this is to reduce the waiting time of a job. More precisely, the allocation strategy goes through the following three steps:
Is there at least one completely idle server in the primary selection ? If so, allocate the arriving job as a type I job to one of these servers. 2. 2.
Is there at least one completely idle server in the secondary selection ? If so, allocate the arriving job as a type II job to one of these servers. 3. 3.
If there are no idle servers present, then allocate the job as a type I job to the primary server with the smallest number of type I jobs. Ties are broken according to the number of type II jobs, in favor of a lower number.
When the second step is omitted, our policy resembles a JSQ() policy with the cardinality of the primary selection. However, the cardinality of the server selection is allowed to differ among arriving jobs in our model and the server selection itself is not sampled uniformly at random as is the case in a JSQ() policy. Moreover, the second step can be related to a JIQ policy on the set of secondary servers. Our affinity-scheduling policy thus shares similarities with both policies. We assume the time it takes for the dispatcher to make a decision for an arriving job, just as the possible time it takes a job to reach its selected server, to be negligible. Notice that due to this strategy, an arriving job will never be assigned as a type II job to a server that already has a job in its queue. Denote the configuration of a server, i.e. the number of type I and type II jobs in its queue, by , . As an illustrative example of the allocation strategy, the primary and secondary servers have and as their configurations, respectively. Due to the allocation strategy, the third step will be applied and the primary server with configuration will receive an additional type I job. In general, type I jobs are the preferred type of jobs, which also manifests itself in the scheduling strategy. Each server operates under a preemptive priority scheduling discipline in favor of the type I jobs. Moreover, type I jobs are served in order of arrival.
Let denote the number of type jobs at server at time . The configuration of server is then given by with state space . The vector evolves as an irreducible, time-homogeneous Markov process. We also introduce different variables that are more server-centric and will be more convenient in proving stochastic dominance and analyzing the fluid limit. Define as the number of servers with type I jobs and type II jobs at time , with . Then
[TABLE]
denotes the number of servers with at least type I jobs and exactly type II jobs. We note that by definition. It is important to note that these variables will no longer lead to a Markov process representation in the general settings mentioned in the introduction. This immediately limits the number of available techniques to analyze the performance.
Let denote the subset of with strictly positive arrival rates. Besides the general setting where can be any subset of we will also investigate some more restricted cases. In the graph model on graph topology , each node represents a server and the edges represent underlying relations between them. Then each set in consists of a server and its neighbors determined by . In total contains sets and jobs arrive to each of these sets independently at a uniform rate . This setting mimics a situation where a job’s physical arrival location plays a role in its service time at the various servers.
Let consist of all possible server selections of size . The cardinality of is and henceforth we refer to this model as the combinatorial model. We assume a uniform arrival rate per selection. We let per selection such that the total rate is given by . Observe that the combinatorial model captures the situation where a selection of servers is drawn uniformly at random as the primary selection for each job and arrivals occur at rate in total.
Remark 2.1
There are also instances of the affinity-scheduling model that are not captured by either the graph model or the combinatorial model. As an example, suppose a job arrives to a primary selection that consists of the servers or an arbitrary selection of size two of the remaining servers. Then consists of and all pairs of servers of . For some , the arrival rates per selection are given by and , respectively.
3 Stochastic dominance and coupling
In this section we establish several stochastic dominance results for our affinity-scheduling strategy. We will construct a stochastic coupling that allows a comparison with various reference systems in terms of the ordered server states, and refer to this coupling as the affinity coupling. In contrast to the original system with affinity relations, the various reference systems all involve exchangeable servers, and are therefore far more amenable to (asymptotic) analysis, yielding tractable performance bounds. We will not explicitly consider the type II jobs since our allocation strategy will never add such a job at any server where there are already type II jobs present and we assume that the initial configuration of the system will only have a finite number of type II jobs. Thus we focus on the type I jobs that enjoy higher affinity at each of the servers, hence the name of the coupling.
While each of the servers in the reference system processes jobs in a FCFS manner at rate , the various specific incarnations differ in the value of the normalized arrival rate per server and the policy for assigning jobs. The choice of the specific reference system is aligned with the properties of the original system in terms of the server selections and the associated arrival rates , . Loosely speaking, we obtain increasingly strong dominance results under increasingly restrictive symmetry and structural conditions on the server selections and the associated arrival rates. The three specific variants for the reference system that we consider operate under either (i) a purely random assignment (RA) policy, (ii) a MJSQ() policy (as specified later), or (iii) a JSQ() policy (as described in the introduction). While the RA system provides exact upper bounds in terms of independent M/M/1 queues, the MJSQ() and JSQ() systems yield asymptotic upper bounds based on fluid limits.
The dominance results revolve around stochastic majorization properties in terms of the ordered server states. Specifically, define
[TABLE]
with and denoting the number of servers with at least type I jobs in their queue at time in the original system and the reference system, respectively. We will establish results of the form
[TABLE]
This majorization result indicates that the number of type I jobs residing in the -th or higher queue position in the original system is stochastically bounded from above by the number of jobs residing in the -th or higher queue position in the reference system. In particular, taking , this implies that the total number of type I jobs in the original system is stochastically bounded from above by the total number of jobs in the reference system. As noted earlier, we know the exact distribution of the latter quantity in the RA system and have an asymptotic result for the MJSQ() and JSQ() systems.
In order to prove the stochastic majorization properties, we introduce the affinity coupling to construct sample paths for the original and reference systems on a joint probability space for which the stated inequalities hold in a deterministic way [11, 18, 19]. For all three specific reference systems, the common proof concept is to ensure that under the coupling two key properties always hold with respect to the ordered server states as illustrated in Figure 1: (a) addition of a type I job at an arrival epoch in the original system must be accompanied by insertion of a job at a higher-ordered server in the reference system; (b) removal of a job at a service completion epoch in the reference system must force disposal of a type I job at the same ordered server in the original system (unless there is no type I job at that server). We can prove the following general lemma.
Lemma 3.1
(Affinity coupling).* If a stochastic coupling between the original system and the reference system can be constructed such that and are satisfied, then is majorized by for . In the sense that*
[TABLE]
for all , provided that the initial configurations of both systems satisfy this inequality.
The proof of Lemma 3.1 can be found in Subsection 5.1. In the remainder of this section, we will precisely describe the affinity coupling for each of the reference systems under consideration and verify that the properties (a) and (b) are satisfied. The coupling at service completion epochs to ensure property (b) as further detailed below is fairly standard and common across all three reference systems.
Coupling at arrival epochs. In contrast to the service completions, the coupling at arrival epochs to guarantee property (a) is novel and highly specific to the reference system under consideration. Due to the lack of exchangeability among servers, the coupling at arrival epochs involves a further subtle complication that does not arise in constructing sample path comparisons in the context of the ordinary supermarket model. Even though we compare the evolution of the two systems in terms of the variables as usual, these generally do not provide a Markovian state description for the original system as noted earlier in Section 2. In particular, the transitions at arrival epochs intricately depend on the server selections , and cannot be suitably represented in terms of the variables.
Coupling at service completion epochs. The coupling generates potential service completions at rate , but the aggregate service rate in either the original or the reference system might be lower than because of servers being idle or only working at rate on type II jobs. Let and be the sets of ordered positions of servers in the original and reference system, respectively, that are working on (type I) jobs just before some time at which a potential service completion occurs. Define as the intersection which equals or due to the ordering and the preemptive strategy of the affinity-scheduling policy. A random variable , drawn from a uniform distribution on , decides which of the following actions is selected.
- (i)
: Sample uniformly at random a position from ; a departure will take place at time in both the original and the reference system at the server located at position .
- (ii)
where is ‘’ or ‘’: Sample uniformly at random a server position from ; one job will be removed from the corresponding server in system at time .
- (iii)
: No real departure will occur among the type I jobs in the original system or the jobs in the reference system.
We note that the total departure rate of type I jobs from the original system is indeed given by , likewise for the reference system with a total departure rate of . The idea to work with intersections of the active server sets comes from [16, Section 4].
3.1 Affinity coupling with the general model
We now consider a general structure for the server selections and the corresponding arrival rates per server selection. The reference system will operate under the RA policy with arrival rate per server. Thus is a sufficient stability condition for the reference system. So the purpose of this subsection is twofold: the affinity coupling is illustrated in a general setting of our affinity-scheduling policy in order to obtain a stochastic dominance result and a stability condition is obtained as an immediate by-product.
The choice of is determined by the arrival rates per server selection in the original system, namely
[TABLE]
The variable may be interpreted as the fraction of jobs with server selection that are assigned to server . With this interpretation in mind, it is easily seen that at least one server must handle an arrival rate of or larger in case jobs are only allowed to be executed as type I jobs. Thus is clearly a necessary stability condition for any strategy in this case. The condition is sufficient as well, for instance for a simple static strategy that assigns a job with server selection to server with probability . However, the implementation of this strategy would require full knowledge of the arrival rates . We will establish that the condition is also sufficient for the stability of our affinity-scheduling strategy, which does not rely on any knowledge of the arrival rates at all.
We now specify the affinity coupling for the reference system with the RA policy.
Coupling at arrival epochs. The coupling generates potential arrival events at rate . If a potential arrival occurs at time , a position from the set is selected uniformly at random. For brevity we simply refer to the server at position as server . An addition of a new job in the reference system will take place at this server . Since this position was randomly selected, the coupling strategy will give rise to an addition according to the RA policy in a system with arrival rate per server.
In order to determine whether an arrival event of a type I job takes place in the original system and at which server this will happen, we follow the below-described strategy. Two random variables, and , are sampled from a uniform distribution on to take into account that the total arrival rate in the original system might be smaller than and to select a server selection for an arriving job. To make the decisions, we rely on the variables that attain the minimum in (4). First, establishes if an arrival occurs to a primary selection containing server , which happens with probability . If an arrival will take place, then a server selection containing is selected as the primary selection with probability for which is used. All remaining servers form the secondary selection. Note that the total arrival rate to a server selection
[TABLE]
will indeed be equal to in the original system as by definition such that this method to handle arriving jobs will coincide with the arrival process of general model described in Section 2. Once these selections are set for an arriving job, we apply the allocation policy as defined in Section 2. Due to the general structure of it is not possible to determine the exact server at which a job is allocated in terms of the variables . However, if the new job is allocated as a type I job in the original system to one of the servers in , it is known that the position of this server will be at most . Since the newly arrived job in the reference system is assigned to server , property (a) of the coupling is maintained.
With the notation as introduced above, we can prove the following theorem.
Theorem 3.1
(General affinity-scheduling model).* Let , as defined in , be the arrival rate per server in the reference system operating under the RA policy. Then, for suitable initial conditions,*
[TABLE]
holds for the general affinity-scheduling model with servers.
The above-described coupling between the original and the reference system operating under the RA policy satisfies the general framework of the affinity coupling, i.e. properties (a) and (b) hold. Then the result stated in Lemma 3.1 is applicable so that Theorem 3.1 follows from the majorization result established there. Theorem 3.1 provides a stochastic upper bound for the total number of type I jobs in the original system in terms of the number of jobs in a reference system with the RA policy by taking . Although this upper bound is sufficient to guarantee stochastic stability for , we will develop stronger majorization results for particular settings of the graph model in the next two subsections. The method to prove the two stronger results is captured in the general framework stated at the beginning of this section, but requires a different and more advanced coupling method between arrival events.
3.2 Graph model
We will further investigate our model on a graph topology as described in Section 2. It is challenging to get a grip on the performance of an allocation policy that is applied in a network structure, and establishing stochastic dominance relations can give an initial insight into the theoretical behavior of load balancing algorithms in structured environments. It was mentioned in Section 2 that the arrival rate over all server selections established by the graph structure is given by , and thus Theorem 3.1 is still valid if we set . However, we will make two different assumptions on the structure of the graph topology and for each of them a much stronger dominance result than Theorem 3.1 is obtained. The first scenario assumes that the minimum degree of is sufficiently high and the second scenario entails regular graph topologies.
3.2.1 Minimum degree
The reference system with exchangeable servers operates under an allocation policy related to JSQ, namely MJSQ() [15]. In this setting new jobs arrive at a total rate of and are processed at a server according to a FCFS policy at rate . An arriving job is allocated to the server with the -th smallest queue length. A clear analogy can be seen if the system is initially completely empty; then servers will constantly remain idle. The system operates as if only servers are present and applies a JSQ policy restricted to these servers. If is sufficiently large compared to , i.e. if
[TABLE]
then the MJSQ() policy is stochastically stable. It is intuitively clear that this policy can achieve much better performance than the RA policy.
Suppose that the minimum degree of the graph is at least , without any other structural assumptions. Let and satisfy the relation in (7), then we can describe a coupling between our graph model with underlying topology and the reference system with the MJSQ() policy. The coupling between both systems will fit the general framework of the affinity coupling but the coupling method for the arriving jobs will differ from the general setting in the previous subsection.
Coupling at arrival epochs. For each of the neighborhood sets in there is a uniform arrival rate such that the total arrival rate in the original system is also given by . Assuming that an event in the coupled sample path is an arrival, it is always directed to the server at position under the MJSQ() policy. For the graph model, the primary selection consists of a randomly selected server and its neighbors under the topology and the secondary selection contains all other servers. We do not know the exact ordered positions of the servers in the primary selection that is of size at least in terms of the variables. The worst-case scenario that could arise is a primary selection of size exactly where the servers are the highest ordered servers. Then a type I job is allocated to the server at position . All other scenarios where an arriving job is labeled as a type I job in the original system will lead to an allocation that is at most at the -th position. Hence property (a) of the affinity coupling is satisfied.
Together with the coupling between service completions as explained in the first part of this section, the coupling between our affinity-scheduling policy on a graph structure with minimum degree and the reference system with the MJSQ() policy satisfies the general framework of the affinity coupling stated in Lemma 3.1. Thus Theorem 3.2 follows from the majorization result in Lemma 3.1.
Theorem 3.2
(Graph model with minimum degree ).* Consider the graph model with an underlying graph topology with minimum degree and a reference system that operates under the MJSQ() policy. Then, for suitable initial conditions,*
[TABLE]
Once the reference system is stochastically stable, if condition (7) is fulfilled, we can give a meaningful upper bound on the total number of type I jobs in the graph model in terms of the total number of jobs under the MJSQ() policy. This upper bound will be stronger compared to the result in Theorem 3.1 since the MJSQ() policy outperforms the RA policy with arrival rate per server and service rate .
Remark 3.1
Theorem 3.2 can be generalized for scenarios where each server selection has a size of at least and a non-uniform arrival rate .
3.2.2 Regular graph
As mentioned in the introduction, JSQ() gives already substantial performance improvements for small values of compared to the RA policy. With this in mind, we show that the number of type I jobs under our affinity-scheduling policy on a -regular graph is stochastically dominated by the total number of jobs under a JSQ() policy, when and satisfy the following relation:
[TABLE]
The proof requires a coupling between the arrival events in both systems such that feature (a) of the affinity coupling is maintained. We will introduce a novel approach to represent or visualize all possible server selections in that an arriving job can choose from.
An arriving job in the reference system with JSQ() is allocated to the lowest positioned server among randomly selected servers. In total there are server selections and each server belongs to different server selections. Thus, the lowest positioned server of the system belongs to different server selections, the second lowest server is part of precisely different server selections without the lowest ordered server. One can continue this reasoning up to the -th lowest ordered server: this server belongs to only one more server selection that is not yet observed at any of the lower ordered servers. All higher ordered servers cannot be part of an unobserved server set. We will construct a step function from the positions to the interval in order to represent the server selections. Assume that the servers are ordered from 1 to and the lowest ordered position of selected servers is denoted by . We represent this selection as a block from position to with height . This procedure can be repeated for each of the possible selections. Stacking all these blocks according to their length will give rise to the following step function:
[TABLE]
An example of this visualization can be found in Figure 2.
We aim to construct a similar step function based on the possible primary server selections for the original system when the underlying graph topology is a -regular graph. Jobs arrive at a total rate and an arriving job selects uniformly at random a server selection from . By construction, contains different primary server selections, each of size . Then, the lowest ordered server in the system belongs to different server selections. However, it is not possible to count the number of additional server selections containing the second lowest ordered server without knowing the position of each of the servers, since we operate on a fixed graph structure. We construct a step function based on the worst-case scenario where the lowest positioned server of each of the server selections is still at the highest possible position. The first jump occurs at the lowest positioned server, while all remaining jumps will occur at the highest possible positioned servers. This induces stronger correlations between the servers that have more type I jobs. Notice that the worst-case ordering of the servers might not be a valid -regular structure, so that this approach might be too conservative. The step function of this worst-case scenario is given by
[TABLE]
An example of this step function can be found in Figure 2.
Coupling at arrival epochs. Let the total arrival rate be in both systems. For an arriving job at time we determine the servers of interest using the inverse transform sampling method [4, Chapter 2]. First, we note that the functions and are cumulative distribution functions by construction. Second, the only server of interest of the server selection in the original system or the server selection in the reference system is the lowest positioned server. So we sample a random variable from a uniform distribution on and determine the two servers positions, and , of interest of both systems. In the original system a server can be allocated as a type I job to the selected server or to any other server as a type II job. This procedure is visualized in Figure 2.
So in order to guarantee feature (a) of the affinity coupling, it needs to be ensured that . Feature (a) is guaranteed if the step function of the original system is above the step function of the reference system, i.e. for all positions . First we observe that the -regular graph must be rather dense in order to obtain a stronger upper bound than provided by the RA policy. This can be seen if we investigate the step function at position
[TABLE]
Once the degree is at least , it is straightforward to show that . This immediately implies that the step function only makes two jumps, at positions 1 and of sizes and , respectively. Since the step function is concave in its discrete points, we only need to ensure that holds so that the step function of the original system is above the step function of reference system. This results in condition (9) on the values of and . Due to the coupling construction, we can prove the following dominance result.
Theorem 3.3
(Graph model with -regular graph).* Consider the graph model with an underlying -regular graph topology and a reference system operating under a JSQ() policy. If the model parameters and satisfy condition , then, for suitable initial conditions,*
[TABLE]
Due to the coupling construction using the block interpretation of the server selections, the above-described coupling fits the general framework of the affinity coupling as stated in Lemma 3.1. Therefore, the result of Theorem 3.3 follows from the result in Lemma 3.1. If , the reference system is stochastically stable and provides a meaningful upper bound on the performance of the graph model on a -regular topology.
We list in Table 1 the minimum value of as a function of that guarantees the required dominance of the step functions for a system with servers. We observe that the graph structure is rather dense in order to stochastically dominate our process with a JSQ() policy even for small values of . One can argue that the primary selection of our affinity scheduling strategy must be much larger compared to the server selection under JSQ() in order to guarantee better performance. But we should keep in mind that the underlying graph structure is fixed and all possible server selections are predetermined while the JSQ() strategy can be seen as a strategy on a complete graph where an arbitrary set of size of the servers can be selected. This will affect the performance compared to a system with exchangeable servers, which is intuitively clear.
Moreover, it is important to note that the obtained value of might be too conservative. Our coupling method using the step functions requires a degree that is at least equal to in order to upper bound by the strategy JSQ(1), i.e. the RA policy. On the other hand, we showed in the general result that the number of type I jobs under any structural interpretation is stochastically dominated by the number of jobs under a random assignment strategy.
Remark 3.2
(Combinatorial model).* Applying our affinity-scheduling strategy to the combinatorial model with servers shows a lot of similarities with the JSQ() policy in a setting of exchangeable servers. Namely, an arriving job is allocated to the server with the shortest queue length among arbitrarily selected servers and sometimes the job can be directed to an idle server outside this selection. The coupling can be adjusted such that the number of type I jobs at the -th ordered position under our affinity-scheduling policy is less than or equal to the number of jobs at the -th ordered position under a JSQ() policy. The relation between the two policies will become more apparent in Section 4 when fluid-limit results are investigated.*
Moreover, it can be shown that the combinatorial model is stochastically stable under a preemptive and a non-preemptive scheduling strategy using a Foster-Lyapunov argument. This result is shown under the assumption that the number of type II jobs at each server never exceeds one. When the initial condition already satisfies this feature, the affinity-scheduling policy will never add a second type II job to a server. The fact that stability is preserved under a preemptive strategy in favor of the type I jobs is no surprise due to the structure of the server selections and the resemblance of the first step in the allocation strategy with the JSQ() policy. Under a non-preemptive strategy it is no longer intuitively clear, as any finite value of is allowed and one could imagine a situation where all servers are processing a type II job and type I jobs start to accumulate behind these type II jobs.
4 Fluid limit and fixed point analysis
As mentioned in the introduction, the affinity model in general lacks the exchangeability among the servers that underpins the use of mean field limits as the main analytical techniques in the supermarket model. Due to its inherent symmetry, the combinatorial model with uniform arrival rates for each of the server selections in as described in Section 2 is one of the exceptions. The variables will give rise to a Markov process representation in this case. The primary and secondary server selections for an arriving job are of sizes and , respectively; we refer to both selections as the -selection and -selection. In order to gain insight in the system performance, we introduce the fluid scaled variables, i.e.
[TABLE]
and analyze a sequence of systems where the number of servers tends to infinity. The (weak) limit that arises is referred to as the fluid limit and is denoted by . When it is helpful to stress the proportion of servers with exactly type I jobs, instead of at least type I job, we consider the variables . In this section we consider initial configurations of the system that give rise to a process with at most one type II job at each server through the complete process. as mentioned in Remark 3.2. Furthermore, we assume that to guarantee stochastic stability. Throughout this section we will consider a system with , , and in the numerical and simulation experiments, unless specified otherwise.
4.1 Fluid limit
We now provide a characterization of the (deterministic) fluid limit in terms of a set of discontinuous differential equations. The reference in the notation will be omitted, if the context allows this.
We introduce a reduced arrival rate . A job will always be directed to an idle server if available, either as a type I job or a type II job and idle servers are generated at rate . This implies that if is sufficiently high, i.e. , only a fraction of the arriving jobs will start to queue in front of a server as type I jobs on fluid level. This fraction is given by with
[TABLE]
Then,
[TABLE]
with .
Since the system operates under a preemptive priority discipline, the structure of the departure rate in each of the equations in (15) is clear. For instance, in order to change the proportion due to a job completion, this job completion must take place at a server with configuration . Exactly a fraction of the servers has this configuration and since these servers each work at rate the total rate of change is given by .
Let us illustrate the representation of the arrival term for the derivative of . Only an arrival of a type I job at a server with configuration can contribute to the arrival term and the probability that this configuration is the smallest among the servers in the -selection is given by . Ties are broken according to the presence of a type II job, in favor of having no type II jobs. Moreover, there should be no idle servers because otherwise an arriving job would be allocated here as a type II job. Since type I jobs arrive at a reduced rate , the total rate of change is given by .
The expressions for the arrival terms in the derivatives of (15) and the reduced arrival rate should be considered more carefully due to the discontinuity at . We will give a sketch of the derivation of this fluid limit in Subsection 5.2. This derivation relies on the martingale method for point processes and Markovian queueing settings outlined by Pang et al. [17] and Brémaud [3].
The fluid-limit expression can be validated with simulations of the fluid-scaled stochastic process. Consider for instance Figure 3 where the solution of the fluid limit (15) is presented together with a simulated trajectory of a reasonably large system. It can be observed that the simulated trajectory fluctuates closely around the numerical solution of the fluid limit, which supports the connection between the fluid limit and the behavior of the stochastic system in a many-server setting.
4.2 Fixed points
To investigate the long-run behavior of the fluid limit (15), we are interested in its fixed points. It turns out that the mutual relationships between the model parameters , , and play a crucial role. In the remainder of this section we investigate the setting where , in order to compare one of the fixed points with the fixed point of a JSQ() policy with reduced load.
Theorem 4.1
(Fixed points).* When and , the system of differential equations always has the following fixed point:*
[TABLE]
Furthermore, when precisely two more fixed points exist. These fixed points are such that and . With the minimum selection size that satisfies
[TABLE]
The proof of this theorem can be found in Subsection 5.2. It can be observed that there always exists a sufficiently large value that satisfies both inequalities of condition (17) for given values of , and . This is trivial to see for the first inequality. The second inequality can be rewritten as
[TABLE]
with . The left hand side is increasing as function of with limit . Table 2 gives the value of , so that the condition (17) is satisfied for given model parameters and all . It can be seen that the higher the load, the larger the size of the primary selections must be for multiple fixed points to persist. The additional fixed points have a strictly positive fraction of idle servers and it is intuitively clear that the number of servers where a job can be processed at rate must grow with the load in order for these fixed points with a strictly positive fraction of idle servers to persist.
Let be as defined in (14) for the fixed point (16). Then the long-term fraction of servers with at least jobs under a JSQ() policy where each server works at rate is given by
[TABLE]
for [14]. This shows a strong similarity with the fixed point (16) where two types of jobs are taken into account. Next we consider the case . When there still is a unique fixed point with , given by:
[TABLE]
This shows strong resemblance with the RA policy with load . Allowing a primary selection of at least two servers leads to a super-exponential improvement compared to a primary selection of size one. On the other hand, there is no fixed point with and . Only if we can show that there is a unique fixed point with , namely
[TABLE]
4.3 Further analysis
We will conduct a further analysis of the fluid limit (15) where we distinguish between sufficiently small and large compared to in the sense of conditions (17) in Theorem 4.1.
4.3.1 Sufficiently small primary selections
When is sufficiently small in terms of the model parameters , and , i.e. , the fixed point (16) of the fluid limit (15) is unique. Numerical experiments suggest that this fixed point is a global attractor, i.e. the trajectories of the fluid limit will converge to this fixed point for every initial state of the system. As an example, we present Figure 4 where the numerical solution of the fluid limit is visualized for ten randomly sampled initial configurations. We consider a system with the above-mentioned model parameters and a primary selection of size . As can be seen from the figure, all cumulative fractions tend to zero. Although some variability can be seen in the limiting behaviour of , the values are of the same order of magnitude as those of the theoretical fixed point. These deviations may be caused by numerical issues. There are two main reasons: (i) The fluid limit (15) is an infinite system of differential equations, so in order to solve the system numerically we need to truncate the system at some point. We choose to work with the variables up to . (ii) The fluid limit (15) contains the indicator function , while we use . This plays a role for initial conditions where a large fraction of the servers has an empty type II queue, since the system still needs to make the transition to a state where every server has a type II job.
In the previous section we used the affinity coupling to show stochastic stability and the existence of an (unknown) stationary distribution for . Assuming global stability of the unique fixed point, Theorem 1 by Benaïm and Le Boudec [2] ensures that the large- limit of the stationary distribution will converge to the fixed point. Moreover, from simulations it can be observed that the trajectories converge to the unique fixed point of the fluid limit (15). As an example consider a system with above-mentioned model parameters. Figure 5 shows a simulated trajectory of the fluid-scaled variables for a system with servers that is initially completely empty. It can be seen that the trajectory converges to the fixed point , rounded at four decimals.
The asymptotic approximation for the mean stationary queue length, excluding the job in service, suggested by the fixed point is given by
[TABLE]
Here CM() refers to the combinatorial model with a primary server selection of size . It is interesting to compare this with the asymptotic approximation for the mean queue length under a JSQ() policy in the ordinary supermarket model with arrival rate and service rate [14, 22],
[TABLE]
and the exact mean queue length under the RA policy,
[TABLE]
Figure 6 presents a comparison of the number of waiting jobs as a function of , with , and . It is known that the mean queue length for the RA policy tends to infinity when the offered traffic grows to one. We see that the mean queue length in the combinatorial model is slightly larger than for the JSQ() policy. On the other hand the variance of the queue length in the JSQ() model is almost twice as large compared to the combinatorial model. We conclude that the combinatorial model still performs well from a queue length perspective, even though each server has a type II job and possibly multiple type I jobs in its queue.
From the fixed point expression, it is not immediately visible that type II jobs finish their service since the fraction is zero. However, an idle server will be filled instantly with an arriving job. A total fraction
[TABLE]
of the arriving jobs undergo this ‘immediate switch’: they are allocated as a type II job to a server that just emptied its queue. This fraction decreases in and for example for the above-mentioned model parameters, this leads to a fraction of . Furthermore, the type II jobs will leave the system at the same rate as they enter the system, since we study the system in equilibrium. Moreover, due to Little’s law we know that the expected waiting time of an arbitrary job is finite. Let denote the waiting time, then \mathbb{E}\left[Q_{\textrm{CM(d_{1})}}\right]=\lambda\mathbb{E}[W]. Since the expected queue length under our affinity-scheduling policy is finite, this results in a finite expected waiting time for an arbitrary job, so also for the type II jobs.
Since each server operates under a preemptive scheduling policy, we can calculate the average waiting time of a type I job using Little’s law. Let denote the number of type I jobs at a server. Then
[TABLE]
Furthermore, the reduced arrival rate gives the arrival rate of type I jobs on fluid level. If represents the waiting time of a type I job, then due to Little’s law Let and have the same interpretation as above but for the type II jobs. We condition on the type of job to obtain
[TABLE]
Because of Little’s law this results in
[TABLE]
We can also immediately apply Little’s law to the type II jobs. We know that they arrive at rate and the mean waiting queue length is by definition given by
[TABLE]
In Figure 7 we compare the mean waiting time of a type I or type II job with the mean waiting time under the RA or the JSQ() policy. The mean waiting time of type II jobs is fairly high, but still lower than the waiting time under the RA policy. We also observe that the mean waiting time of type I jobs is significantly smaller than under a JSQ() policy. We conclude that our allocation strategy leads to a reduction in the mean waiting time for a large group of arriving jobs at the expense of some other jobs that encounter longer waiting times. The uniqueness of the fixed point allows us to analyze the asymptotic stationary distribution of the model, on the other hand we observe that the value of the size of the server selection is too small to achieve a zero waiting time for an arriving job.
4.3.2 Sufficiently large primary selections
Assume that the primary selection has a sufficiently large size for given model parameters in terms of the conditions (17), i.e. . From Theorem 4.1 we know that, next to the closed form fixed point (16), there are two additional fixed points with . We prove the following theorem using the indirect Lyapunov method.
Theorem 4.2
(Local (in)stability).* Of the two additional fixed points mentioned in Theorem 4.1 with when , one is locally stable and the other one is unstable.*
The proof of Theorem 4.2 is given in Subsection 5.2. In the remainder of this subsection, we will provide a numerical illustration, where we consider a system with , , and throughout. We observed similar qualitative behavior across many different scenarios, but only present results for those parameter values because of space constraints. To get a better notion of the local stability we present Figure 8. For several initial values such that , the system of differential equations (15) is solved numerically. All trajectories with initial states indicated in blue will converge to the locally stable fixed point from the previous theorem and a few of these trajectories are also visualized. All other initial states, indicated in red, will not converge to this locally stable fixed point. We see that these states have a large fraction of servers with a type II job present and a small fraction of idle servers, since there is a smaller probability to select an idle server in the -selection. So jobs will have a longer mean service time as a type II job and jobs will start to accumulate.
In total this gives rise to two locally stable fixed points: the closed-form fixed point (16) where each server has a type II job and possibly multiple type I jobs and the fixed point from Theorem 4.2 where at most one job is present at each server. In the remainder of this section we will refer to these fixed points as the queueing fixed point and no-queueing fixed point, respectively. We do not formally prove this statement but we will illustrate it with a representative example. For a system with the above-mentioned parameters, the two fixed points under consideration (non-cumulative fractions) are given by:
[TABLE]
Both fixed points are indicated with dashed lines in Figure 9, in dark blue and dark green, respectively. Furthermore, the graphs contain 20 trajectories starting from randomly sampled initial configurations with , all these trajectories converge to one of the two fixed points. This implies that the convergence area presented in Figure 8 to the single-user fixed point will in fact be larger. As can be seen, most of the trajectories will converge to the type-II fixed point. This phenomenon will be even more apparent if we allow initial states with more than two jobs.
The literature often describes systems with a unique global attractor as a fixed point of the fluid limit so that there is a direct connection between the stationary distribution in a many-server setting and this fixed point. However, the non-uniqueness of the fixed points does not imply that these two concepts are completely uncorrelated. For instance, Figure 3 presents a comparison between the numerical solution of the fluid limit and a simulation with servers with the above-mentioned model parameters. The system is initially empty and the simulated trajectory seems to converge to the no-queueing fixed point. We can presents a similar figure, where in the initial configuration each server has one type II job, in which case both the numerical solution and the simulation seem to tend to the queueing fixed point.
However, the stochastic process with a finite number of servers is an irreducible Markov process which implies that any state can be reached as long as the process is observed long enough and a unique equilibrium distribution must exist. Nevertheless, it can be observed that the process spends a long Nevertheless, it can be observed that the residence time near each of the locally stable fixed points, which increases with , is long before the process makes the transition to the other locally stable fixed point. Gibbens et al. [8] describe this concept of switching between multiple modes by ‘tunneling’. We can call these locally stable points the ‘quasi-stationary’ distributions of the stochastic process as in [25].
Examples of models with multiple local fixed points in loss and communication networks can be found in [1, 8, 25]. More recent work by Martirosyan and Robert [13] considers an allocation strategy closely related to the affinity-scheduling policy in a loss network setting, i.e. jobs can be redirected to distant servers with a penalty or can be omitted if none of the servers has enough spare capacity. Also in this setting, a fluid-limit analysis reveals multiple locally stable fixed points.
5 Proofs
5.1 Proof of Lemma 3.1: Affinity coupling
Since the system configurations between two consecutive events remain unchanged, we will condition on the discrete event times and use forward induction.
Assume that (3) holds up to the time of the -th event, we will argue that the majorization property still holds at time of the -th event by making a distinction between arrival and departure epochs. But first we need a formal way to express the effect of these events in terms of and . For instance, let be the server position selected for a departure. Due to the ordering we know that there are at least servers with the same number of jobs or more in their queues as the server at position . It might also be possible that the server at position has the same number of jobs as the server at position , there is notable difference in in terms of the variables whether a removal takes place at position or at position . Instead of removing from the server at position and reordering the servers before computing and , we can also immediately compute these quantities. The difference is subtle and valid because the proof does not rely on the present type II jobs or on the actual servers but only on their relative positions. Therefore we define two intermediate quantities:
[TABLE]
For instance in the original system in Figure 1, is given by 3. Furthermore, only one job will be added or removed at a discrete time event. A new event at time could only violate (3) if at time (3) holds with equality, i.e.
[TABLE]
with . Therefore we only focus on this setting in the induction step.
Arrival. At time an arrival occurs and first position is selected, the updated reference system looks as follows:
[TABLE]
If the newly arrived job is allocated as a type II job in the original system or no arrival takes place due to the coupling, (3) is trivially satisfied. We consider the setting where the job is allocated as a type I job to a server at position which is at most , such that
[TABLE]
Moreover, the left hand side of (3) remains unchanged if so that the order in (3) is preserved. Now, fix , if we now show that also , then (3) remains valid since both sides are raised by one. We use (32) and the induction hypothesis for at time to obtain
[TABLE]
Then it follows that implies which concludes the derivation if the event at time is an arrival.
Departure. If at time a departure will take place, one of the following four scenarios will occur.
There is a job completion of a type I job in the original system and of a job in the reference system. 2. 2.
There is only a departure at the jobs of the reference system. 3. 3.
There is only a departure of a type I job in the original system. 4. 4.
There is no departure at the type I jobs of the original system or the jobs of the reference system.
It is clear that we only need to investigate the first two scenarios.
Scenario 1. Let be the position of the servers in both the original and the reference system from which a job will be removed. The updated systems will look as follows,
[TABLE]
We will focus on , since for (3) remains trivially valid. A similar argument as above will be used to show that , so that both sides will be lowered by one compared to the event time . We use (32) and the induction hypothesis for at time to obtain . Then it follows that implies which concludes the proof of scenario 1.
Scenario 2. Let be the position where a job leaves the reference system, then for all
[TABLE]
Again we focus on . Fix , we will show by contradiction that (32) cannot occur so that (3) is preserved at time since the right hand side can be lowered by at most one. Assuming that (32) does hold and using the induction hypothesis on , we conclude that . Now,
[TABLE]
since . This implies that , however there are only servers working on a type I job in the original system. This leads to a contradiction and concludes the proof of Lemma 3.1.
5.2 Proofs: Fluid limit and fixed point analysis
5.2.1 Derivation fluid limit
First, consider the stochastic process with servers and its corresponding flow conservation equations. Next, the martingale methods as outlined by Pang et al. [17] and Brémaud [3] are applied and the limit of to infinity of the fluid scaled process is studied. Then (15) is obtained from the resulting system of integral equations.
Step 1: flow conservation equations. Let be the probability that an arriving job at time is allocated to a server with type I jobs and type II jobs as a type job, with . As before, we will omit the time dependence to ease the notation.
Only to an idle server we can allocate a job as a type I or type II job; allocations to servers with a higher configuration will always take place as a type I job. The corresponding transition probabilities are given by
[TABLE]
the probability that an idle server is present in the -selection, and
[TABLE]
the probability that the -selection does not contain an idle server while they are present. As mentioned in the model description, the -selection contains all servers that are not in the -selection. Hence the indicator function emerges in the probabilities.
An arriving job will be allocated as a type I job to a server with configuration , with , if the minimum configuration in the -selection is given by and when there are no completely idle servers that can be included in the -selection. The corresponding probability is given by the probability that the -selection contains only servers with at least type jobs minus the probability that all servers have a configuration strictly higher than . Thus, for ,
[TABLE]
In a similar way, we obtain , for :
[TABLE]
Once these probabilities are set, the flow conservation equations can be constructed. The randomness in the stochastic model is caused by Poisson arrivals and exponentially distributed service times, so that the number of arrivals and service completions can be counted using Poisson processes with appropriately chosen rates. Define a set of independent Poisson processes with rate 1. Let denote the Poisson counting process for the number of arriving type jobs at servers with configuration , and reflects the arriving jobs at servers with configuration . Similarly, define the counting process of the service completions . Furthermore if , the number of servers at time with at least type I jobs and exactly type II jobs depends on its initial state , the number of service completions of jobs at servers with configuration and the number of arrivals at servers in configuration within the time interval . We obtain the following flow conservation equations for the stochastic model with servers and total arrival rate . Let :
[TABLE]
Due to the Poisson split property we define as the sum of the two processes and .
Step 2: Fluid scaled process. Dividing both sides of the equations by results in a fluid scaled process. Further, because of the martingale results in [3] and [17] we can define noise terms that tend to 0 as with and . The fluid scaled system can be rewritten as follows, with ,
[TABLE]
Step 3: Towards fluid limits. While making the transition from integral equations to differential equations with tending to infinity, the representation of the departure terms in (15) is straightforward. The arrival terms in the differential equations, on the other hand, are not immediately obvious.
To illustrate the difficulty, assume there are among the servers only a small number of idle servers. As the allocation strategy describes, one of these servers will be selected by an arriving job. If the number of idle servers is small and the arrival rate is sufficiently high, rapid switches will occur in the indicator function . A server that becomes idle due to a service completion will immediately be selected again by the arriving job. However, the fraction of empty servers () will be more robust against these changes due to the fluid scaling.
In general, this phenomenon is called ‘separation of time scales’ as described by Hunt and Kurtz [10]. One observes the interaction of two processes. One process evolves very fast, namely the number of empty servers, while the second process evolves much slower, the occupancy fractions in this setting. In order to obtain the arrival terms of the fluid limit, we should be able to combine these processes. Focusing on the first arrival integral in (44), the question arises how to handle the expression
[TABLE]
A similar problem is analyzed in [10] where one needs to take the limit of a integral of an indicator function. The existence of a measure is deduced such that
[TABLE]
The existence of this function , which does not need to be continuous, can be justified by the following reasoning. In a small time interval, say , the number of idle servers is a heavily fluctuating process, though the process describing the occupancy proportions is approximately constant. During this small interval, the number of idle servers can be considered as a birth-and-death process with ‘death’ rate , since an arriving job causes a reduction in the number of idle servers. The ‘birth’ rate is determined by the occupancy proportions, i.e. the proportion of servers that are working on type I or type II jobs. Then it is argued in [10] that
[TABLE]
after application of the ergodic theorem, converges to an invariant measure if tends to infinity. This invariant measure will give rise to the function . One already senses that the presence or absence of idle servers should be handled as two different cases. Therefore we make a distinction between strictly positive or equal to zero in the intuitive explanation of the structure of the fluid limit.
The case . When the number of idle servers is sufficiently large, each arriving job will be allocated to an idle server for sure. A fraction
[TABLE]
of the arriving jobs will be allocated as type II jobs which causes the changes in (15) for , and .
The case . Idle servers are generated at rate . Since is finite, the probability that the -selection would contain an idle server is negligible, each idle server will be provided with a type II job when the arrival rate is high enough. If is strictly larger than zero, a fraction
[TABLE]
of the stream of incoming jobs will immediately be redirected to the idle servers as a type II job. The excess stream of incoming jobs (fraction ) will not observe any idle server and will start to form (type I) queues in front of the servers of the -selection according to a straightforward generalization of the transition probabilities mentioned in step 1.
This concludes the derivation of the fluid limit (15).
5.2.2 Proof of Theorem 4.1: fixed points
We will start with the proof of the closed-form fixed point and show that this is the only fixed point without idle servers on fluid level, i.e. . Next, we will consider fixed points with .
Fixed points with . The correctness of the expression in (16) can easily be confirmed by substitution into (15). The result can be established in two steps. First, we observe that the derivatives of in (15) remain zero once equals zero. Then, we substitute into the derivatives of . For we obtain:
[TABLE]
These equations can be solved and one obtains the fixed point as given in (16). Note the similarity between (50) and the fluid limit of a JSQ() policy with reduced arrival rate
[TABLE]
in a setting where each of the exchangeable servers works at rate [14].
Second, this fixed point is unique under the condition that equals zero. From Lemma 2 in [14] we know that the fixed point of the fluid limit in the JSQ() setting is unique when . This implies that under the condition that all servers have a type II job, i.e. for all , uniqueness is guaranteed. Assume by contradiction that another fixed point exists without idle servers but with possibly a positive cumulative fraction for some . We focus on the differential equations of under this fixed point. From
[TABLE]
we get that . Repeating this procedure for ,
[TABLE]
results in . By induction we could show that for , this leads to for . This proves the uniqueness of the fixed point when equals zero.
Fixed points with . Under this setting, the fluid-limit equations (15) simplify significantly.
[TABLE]
For any fixed point it should hold that
[TABLE]
for , then it follows that and . This implies that the only positive fractions are , and . Rewriting the fluid limit in a non-cumulative expression gives us:
[TABLE]
From the second and third equality it is clear that once is known, we know the entire fixed point:
[TABLE]
The system in (56) is linearly dependent. We use the fact that , and must sum up to one to determine . It must hold:
[TABLE]
Define . We are interested in the zero points of the polynomial within with
[TABLE]
We will evaluate the existence of the fixed points based on the behaviour of and its derivative,
[TABLE]
Furthermore,
[TABLE]
and is monotone increasing on with
[TABLE]
Since is positive in both its endpoints and the derivative is monotone increasing, we need at least a vanishing derivative in in order to have a fixed point. This is guaranteed when , this is the first condition from (17). We now know that attains a local minimum at
[TABLE]
and is strictly positive in its endpoints. If is exactly zero, we have one fixed point, namely . But only in very special cases the second condition of (17) is satisfied with equality for a random choice of , , and . On the other hand, if , i.e. if also
[TABLE]
holds, we have exactly two fixed points such that . There is one fixed point situated at each side of in the interval . This gives that for large enough we can find two solutions of the reduced system of differential equations. It can be shown by contradiction that both fixed points are larger than , so the corresponding fractions of idle servers is smaller than .
For completeness we mention that would imply that and so the proportion of empty servers is zero which violates the assumption that . Moreover, if , then the polynomial vanishes in the interval . The monotone increasing property of the derivative of leads to the fact that there exists a unique fixed point in . This results in a unique fixed point with .
This concludes the proof of Theorem 4.1.
5.2.3 Proof of Theorem 4.2: local (in)stability
We will prove local (in)stability using the indirect Lyapunov method based on the Hartman-Grobman Theorem [9]. This theorem states that a system of differential equations behaves near its fixed points as its linearized version. The eigenvalues of the linearized system will define the local behavior of the system unless one of the eigenvalues has a real part equal to zero, then the Hartman-Grobman theorem is inconclusive. When we would immediately apply this theorem to one of the two fixed points of (56) we obtain an eigenvalue exactly equal to zero, but one can resolve this issue since (56) is a redundant system. Since , it is sufficient to know the instantaneous change of two variables. Each elimination will lead to the same two eigenvalues so we can remove for instance the third equation from (56):
[TABLE]
Let denote a fixed point, then the matrix of the linearized system looks as follows near its fixed point:
[TABLE]
The corresponding eigenvalues are given by
[TABLE]
Since the quantity under the root is always positive, so the square root is real. This implies furthermore that . To determine the sign of we need to make a distinction between the two fixed points. From the proof of Theorem 4.1, we know that the two fixed points are on both sides of , with as in (62). For
[TABLE]
we have that
[TABLE]
This shows that the fixed point with the smallest proportion of idle servers is unstable.
When , it follows in a similar way that This shows that the fixed point with the largest proportion of idle servers is locally stable. This concludes the proof of Theorem 4.2.
6 Conclusion and outlook
We investigated load balancing issues in a service system where particular servers are better equipped to process certain jobs due to affinity or compatibility relations. The general model in particular covers the setting with an underlying network topology , referred to as the graph model. The analysis of the graph model is severely complicated by the lack of exchangeability among the servers, a feature linked to the supermarket modeling framework that allows mean-field techniques. We constructed the a novel affinity coupling to obtain a stochastic performance bounds for the general model and more specific settings, for instance model instances where the underlying graph topology has a specific minimum degree or is a -regular graph.
Another instance of the general model, the combinatorial model, has enough inherent symmetry to conduct a fluid-limit analysis. The fluid limit was stated in terms of a set of discontinuous differential equations and its fixed point sensitively depends on the size of the primary selection. When is sufficiently small, a unique fixed point exist but the associated waiting time does not vanish. When the primary selection is sufficiently large, a fixed point arises that does provide a zero waiting time. On the other hand, the above-mentioned fixed point still persists, giving rise to bistability issues.
As mentioned above, the stochastic upper bounds for the graph model in terms of a supermarket model with a JSQ() policy require the degrees in the underlying graph to be relatively high compared to . To some extent, this reflects that the performance may be poor in certain pathological cases even when the node degrees are fairly high. An interesting topic for further research would be to extend the affinity coupling and possibly identify relevant structural conditions on the graph topology in order to sharpen these bounds.
Recall that a supermarket model with a JSQ() policy is equivalent to the combinatorial model with server selections of size and identical arrival rates when jobs could not be allocated as a type II job. A natural conjecture is that the latter combinatorial model is the best-case scenario given a maximum cardinality of the server selections. This would imply that the supermarket model with a JSQ() policy provides stochastic lower bounds in some appropriate sense for any affinity model with server selections of size at most .
The bistability of the fluid limit of the combinatorial model for large values of not only precludes any convergence statements for the stationary distribution, but also suggests that the allocation strategy could possibly be refined. In future work we intend to examine such refinements and establish that these eliminate the queueing fixed point and render the no-queueing fixed point globally stable.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] N. Bean, R. Gibbens, and S. Zachary. Dynamic and equilibrium behavior of controlled loss networks. The Annals of Applied Probability , pages 873–885, 1997.
- 2[2] M. Benaïm and J.-Y. Le Boudec. On mean field convergence and stationary regime. ar Xiv preprint ar Xiv:1111.5710 , 2011.
- 3[3] P. Brémaud. Point Processes and Queues, Martingale Dynamics . Springer-Verlag, New York, 1981.
- 4[4] L. Devroye. Non-Uniform Random Variate Generation . Springer-Verlag, 1986.
- 5[5] A. Ephremides, P. Varaiya, and J. Walrand. A simple dynamic routing problem. IEEE Transactions on Automatic Control , 25(4):690–693, 1980.
- 6[6] D. Gamarnik, J. N. Tsitsiklis, and M. Zubeldia. Delay, memory, and messaging tradeoffs in distributed service systems. ACM SIGMETRICS Performance Evaluation Review , 44(1):1–12, 2016.
- 7[7] N. Gast. The power of two choices on graphs: the pair-approximation is accurate? ACM SIGMETRICS Performance Evaluation Review , 43(2):69–71, 2015.
- 8[8] R. Gibbens, P. Hunt, and F. Kelly. Bistability in communication networks. Disorder in physical systems , pages 113–128, 1990.