Motion Blur removal via Coupled Autoencoder
Kavya Gupta, Brojeshwar Bhowmick, Angshul Majumdar

TL;DR
This paper introduces a coupled autoencoder approach for motion blur removal, framing deblurring as a transfer learning problem, which enables faster, on-the-fly image restoration with improved quality over existing methods.
Contribution
It presents a novel formulation that recasts deblurring as transfer learning and employs a coupled autoencoder for simultaneous learning of weights and coupling maps.
Findings
Outperforms state-of-the-art techniques in image quality
Operates faster without costly inverse problems
Effective for real-time motion blur removal
Abstract
In this paper a joint optimization technique has been proposed for coupled autoencoder which learns the autoencoder weights and coupling map (between source and target) simultaneously. The technique is applicable to any transfer learning problem. In this work, we propose a new formulation that recasts deblurring as a transfer learning problem, it is solved using the proposed coupled autoencoder. The proposed technique can operate on-the-fly, since it does not require solving any costly inverse problem. Experiments have been carried out on state-of-the-art techniques, our method yields better quality images in shorter operating times.
Click any figure to enlarge with its caption.
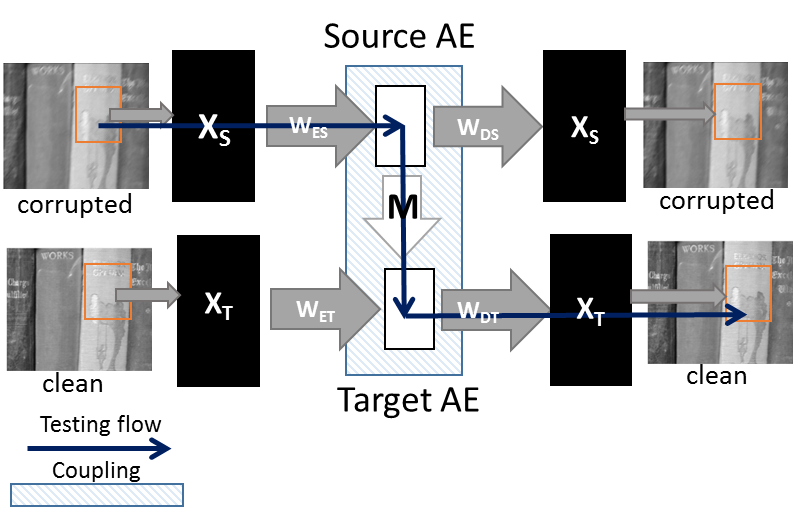 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5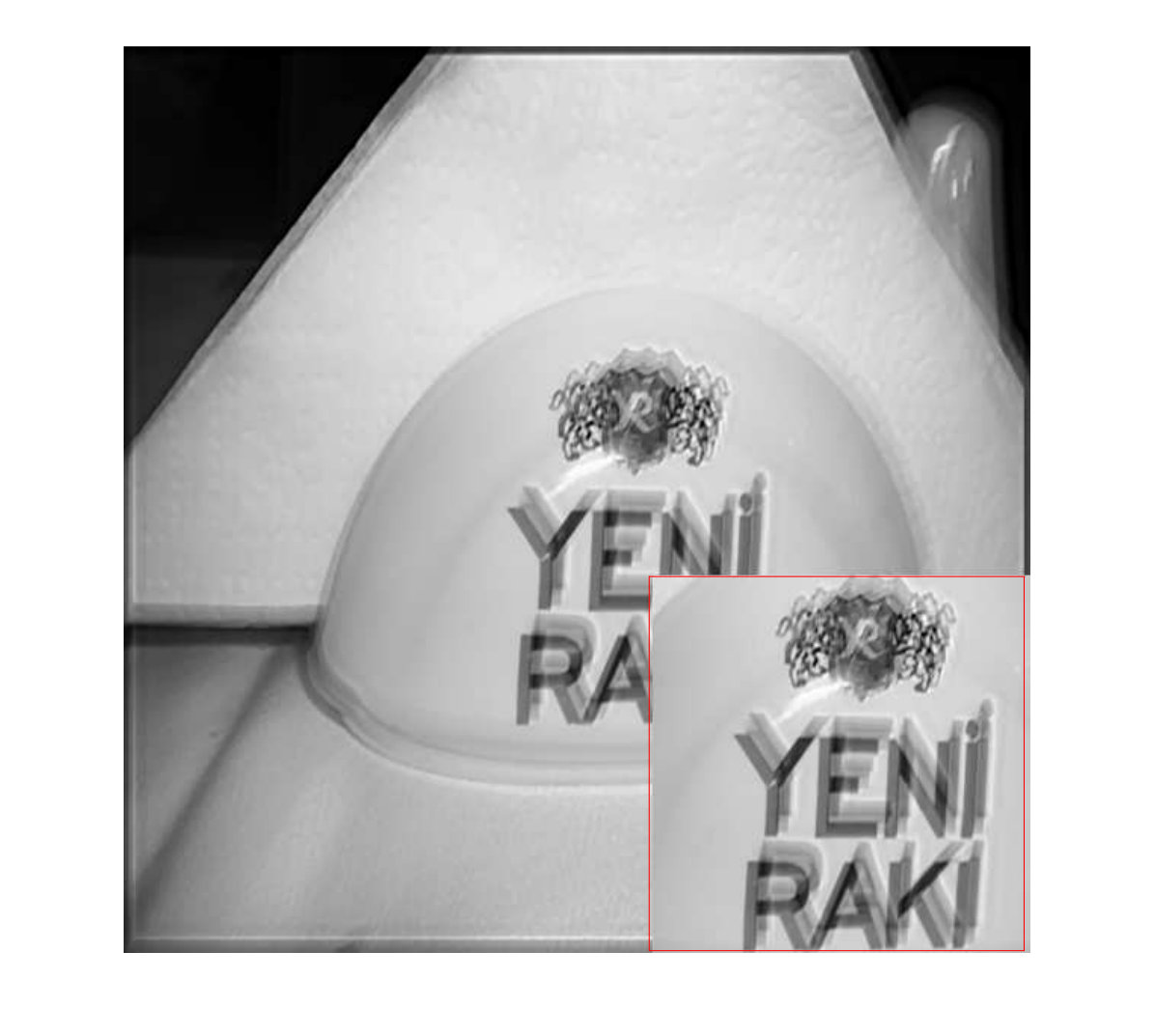 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22| Blur type | Krishnan et al.[8] | Whyte et al.[11] | Pan et al.[9] | Xu et al.[10] | Xu et al.[19] | Ren et al.[1] | Proposed | |
|---|---|---|---|---|---|---|---|---|
| Uniform blur | (PSNR) | 23.7679 | 23.5257 | 23.6927 | 22.9265 | 25.6540 | 20.9342 | 30.8893 |
| (SSIM) | 0.6929 | 0.6899 | 0.7015 | 0.6620 | 0.7708 | 0.7312 | 0.8787 | |
| Non Uniform blur | (PSNR) | 20.3013 | 20.4161 | 19.6594 | 20.5548 | 19.9718 | 20.8226 | 29.6364 |
| (SSIM) | 0.5402 | 0.5361 | 0.5345 | 0.5812 | 0.5692 | 0.7328 | 0.8711 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSolana Customer Service Number +1-833-534-1729
MOTION BLUR REMOVAL VIA COUPLED AUTOENCODER
Abstract
In this paper a joint optimization technique has been proposed for coupled autoencoder which learns the autoencoder weights and coupling map (between source and target) simultaneously. The technique is applicable to any transfer learning problem. In this work, we propose a new formulation that recasts deblurring as a transfer learning problem; it is solved using the proposed coupled autoencoder. The proposed technique can operate on-the-fly; since it does not require solving any costly inverse problem. Experiments have been carried out on state-of-the-art techniques; our method yields better quality images in shorter operating times.
**Index Terms— ** autoencoder,coupling,deblurring,motion blur,split bregman
1 Introduction
Motion blurring is one of the common source of image corruption. It can be caused due to multiple reasons such as lens aberrations, camera shaking, long exposure time etc. The process of recovering sharp images from blurred images is termed as deblurring. This work proposes deblurring as a transfer learning problem, where the source domain is the blurred image and the target domain is the clean image. We solve it via coupled autoencoder. Our technique is generic and applicable for solving any inverse problem in imaging, e.g. denoising, inpainting, super-resolution etc. However, in this work we focus on deblurring. Despite significant progress in image deblurring, which is a well studied topic in computer vision, the existing deblurring algorithms often fail due to non-generalized kernel based approaches and also due to computational complexity. In this paper we recover the sharp image for a given blurred image with the help of a learning framework and hence can be generalized to broad class of blur. We focus on removal of the motion blur - uniform and non-uniform (space variant).
There are plethora of studies such as [1],[2],[3],[4] which use neural networks and CNNs frameworks for solving computer vision tasks. But there are only a few studies [5],[6],[7] which solve inverse problems via autoencoders. In [5], the authors used Sparse Stacked Autoencoders (SSAE) for denoising the images which can also be put in deblurring framework. The motivation for having fast deblurring techniques comes from the requirement of sharp and undistorted images for the purpose of SLAM (Simultaneous Localization and Mapping), visual odometry , optical flow etc. There is a constant problem of motion blur while acquiring images and videos with the cameras fitted to the high speed motion drones. Distorted images will intervene with the mapping of the visual points, hence the pose estimation and tracking will be corrupted. Usual deblurring techniques solve an iterative inverse problem. This yields good quality images, but precludes itself from real-time applications. Our proposed method is light weighted, learning source and target autoencoders with mapping between source and target simultaneously.
2 Literature Review
2.1 Deblurring Techniqes
Image deblurring techniques can be categorized into two types - blind and non-blind techniques. Non-blind techniques require priors about the blur kernel and it’s parameters whereas for blind deblurring techniques we assume that the kernel is unknown. Estimation of accurate kernels is detrimental for good deblurring especially in case of space variant blurs. Single image deblurring techniques jointly estimate the motion kernels and sharp image. [8],[9],[10] use sparsity priors to retreive latent sharp image for better kernel estimations. In [11], blur kernel is estimated in the camera motion space itself.
Recent development has been on devising learning based techniques for learning the degradation models. In [2] authors proposed an image deconvolution neural network for non-blind deconvolution which focuses on removal of uniform blur. In [1] a vectorization based CNN method was proposed which showed improvement on various high and low level vision tasks. [4] proposes a deep learning approach of predicting the motion kernel at patch level using a CNN.
2.2 Coupled Representation Learning
Coupled dictionary learning has a rich literature [12],[13],[14]. It has been applied to a wide range of problems in image synthesis, e.g., single image super-resolution, photo-sketch synthesis, cross spectral (RGB-NIR) face recognition, RGB-depth classification etc. It has also been used for trans-lingual information retrieval [15]. The main idea in coupled dictionary is learning of dictionaries (and corresponding coefficients) for the two domains - source and target, such that the coefficients from one domain can be linearly mapped to the other.
The concept of coupled autoencoder is new; it follows from dictionary learning. The main idea here is to learn an autoencoder for the source and another for the target along with a mapping from the source to the target (semi-coupled) and vice versa (fully coupled). There are only a handful of studies on this. In [7], it learns two deep stacked autoencoders for two domains - source (low resolution image) and target (high resolution image). These are learnt separately. Once the autoencoders are learnt a mapping from the deepest layer of the source autoencoder is learnt to the target autoencoder. The approach is piecemeal and hence sub-optimal. The autoencoders are learnt independently for the different domains and hence there is no feedback from one to the other during the learning stage. The mapping from the source to target is a stand-alone process which has no influence on the source and target autoencoder learning.
In another study [16], it learns coupled shallow autoencoders and stacks them up to form a deep architecture greedily. As in the prior work, their coupled autoencoder learning process is sub-optimal as well. The autoencoders (for source and target) are learnt separately; finally a mapping between the two is learnt, consequently the coupling has no bearing on the autoencoder training.
The only prior work that optimally learns the mapping during the autoencoder training process is [17]. However they use a marginalized denoising autoencoder, which is much simpler to solve compared to the full autoencoder having separate encoding and decoding layers.
3 Proposed Formulation
This is the first work that introduces an optimal formulation for coupled autoencoder. Unlike prior studies, the autoencoders for source and target will be learnt along with the linear mapping between the two. This is optimal in the sense that all the variables influence each other in the learning process - this has been missing in prior works.
Figure 1 shows the schematic diagram. The source autoencoder uses the blurred samples and the target autoencoder uses the corresponding clean samples. The coupling learns to map the representation from the source (blurred) to the target (clean). Mathematically this is expressed as,
[TABLE]
The first term is the standard autoencoder formulation for the source. Here corresponds to the decoder and is the encoder. The second term is the autoencoder for the target; and are the decoder and the encoder respectively. is the coupling term. The linear map M couples the representation from the source to that of the target.
We solve it using the variable splitting technique. The first step is to introduce proxies for the representations, i.e. and and forming the Lagrangian. A better approach to handle this is to use the Split Bregman technique [18]. A Bregman relaxation variable is introduced such that the value of the hyper-parameter need not be changed; the relaxation variable is updated in every iteration automatically so that it enforces equality at convergence. The Split Bregman formulation is,
[TABLE]
Here and are Bregman relaxation variables. We invoke the alternating minimization method of multipliers [20] to segregate (2) into the following (simpler) sub-problems.
P1 :
P2 :
P3 :
P4 :
P5 :
P6 :
P7 :
Sub-problems P1, P2, P5, P6, P7 are simple least squares problems having an analytic solution in the form of pseudo-inverse. Sub-problems P3 and P4 are originally non-linear least squares problems; but since the activation function is trivial to invert (it is applied element-wise), we can convert P3 and P4 to simple linear least squares problems and solve them using pseudo-inverse. The final step in every iteration is to update the Bregman relaxation variables. This is achieved by simple gradient descent.
[TABLE]
[TABLE]
We have used two stopping criteria. Iterations stop when a specified maximum number of iterations is reached or when the objective function converges to a local minimum. By convergence we mean that the value of the objective function does not change much in successive iterations.
4 Results
For the experimental evaluation of our proposed method, we use images from standard image blur dataset [21]- CERTH dataset. It contains 630 undistorted, 220 naturally-blurred and 150 artificially-blurred images in the training set and 619 undistorted, 411 naturally blurred and 450 artificially blurred images in the evaluation set. For performance evaluation we take a small subset of the dataset. We take 50 images for training, 20 images for testing and corrupt them with the motion blur kernels. The algorithm is tested for two scenarios – uniform kernel and non-uniform kernel [22]. The images in the dataset have huge sizes so we did the deblurring patch wise, a protocol followed in [5]. For training and testing we divided the whole image into number of overlapping patches. Each individual patch acts as a sample. We do not do any preprocessing to the images or patches. We use the blurry patches to train the source autoencoder, the corresponding clean patches to train the target autoencoder and a mapping is learnt between the target and source representation. During testing, the blurred patch is given as the input of the source. The corresponding source representation is obtained from the source encoder from which the target representation is obtained by the coupling map. Once the target representation is obtained, the decoder of the target is used to generate the clean (deblurred) patch. Once all the individual patches of the testing image are deblurred we reconstruct the whole image by placing patches at their locations and averaging at the overlapping regions. We do not get blocking artefacts consequently we do not do any post processing to the recovered images.
We use patches of 40x40 with an overlapping of 20x20 for all the images. The input size for the autoencoders hence become 1600 and are learned with 1400 hidden nodes. There are just two parameters and while training which do not require much tuning. Whereas the testing is parameter free. The testing flow is shown in the Figure 1.
We compare the proposed method with several state-of-the-art techniques with [8],[9],[10],[11],[19] which estimates the kernel and retreive deblurred image by deconvolution and [1] which learns a Vectorized CNN for deblurring. The consolidated results are shown in Table 1. The PSNR and SSIM values are averaged over for all the 20 testing images. We see that we consistently perform better than all the methods on both PSNR and SSIM for both uniform and non-uniform blur. Our experimentation showed that the framework can learn characteristics for different kinds of motion blur and yields good performances on them as well.
For visualizing the results, we show two sets of testing images. Figure 2 and Figure 3 show the result comparison on uniform blur and non-uniform blur removal problem respectively.
5 Conclusion
In this paper, we proposed an optimal formulation of learning coupled autoencoders while simultaneously learning a mapping between source and target autoencoders. Our method is generalized and is applicable for any tranfer learning problem. Through experimental evaluation we showed success of our proposed method on motion blurred images. Our method is computationaly inexpensive and deblur images in seconds.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. S. Ren and L. Xu, “On vectorization of deep convolutional neural networks for vision tasks,” ar Xiv preprint ar Xiv:1501.07338 , 2015.
- 2[2] L. Xu, J. S. Ren, C. Liu, and J. Jia, “Deep convolutional neural network for image deconvolution,” in Advances in Neural Information Processing Systems , 2014, pp. 1790–1798.
- 3[3] C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE transactions on pattern analysis and machine intelligence , vol. 38, no. 2, pp. 295–307, 2016.
- 4[4] J. Sun, W. Cao, Z. Xu, and J. Ponce, “Learning a convolutional neural network for non-uniform motion blur removal,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2015, pp. 769–777.
- 5[5] K. Cho, “Simple sparsification improves sparse denoising autoencoders in denoising highly corrupted images,” in Proceedings of the 30th international conference on machine learning (ICML-13) , 2013, pp. 432–440.
- 6[6] X. J. Mao, C. Shen, and Y.B. Yang, “Image restoration using convolutional auto-encoders with symmetric skip connections,” ar Xiv preprint ar Xiv:1606.08921 , 2016.
- 7[7] K. Zeng, J. Yu, R. Wang, C. Li, and D. Tao, “Coupled deep autoencoder for single image super-resolution,” IEEE transactions on cybernetics , vol. 47, no. 1, pp. 27–37, 2017.
- 8[8] D. Krishnan, T. Tay, and R. Fergus, “Blind deconvolution using a normalized sparsity measure,” in Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on . IEEE, 2011, pp. 233–240.