TL;DR
This paper presents a deep learning-based method for super-resolving depth maps by optimizing visual appearance in 3D renderings, leading to improved 3D shape quality for applications like virtual reality.
Contribution
It introduces a novel perceptual loss based on 3D surface renderings for depth super-resolution, enhancing shape quality over existing methods.
Findings
Significant improvement in 3D shape quality using the proposed perceptual loss.
Effective use of deep prior and CNN-based models for depth upsampling.
Outperforms existing optimization and learning-based techniques in perceptual metrics.
Abstract
RGBD images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth maps by taking advantage of color information; deep learning methods make combining color and depth information particularly easy. However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important. The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We…
Click any figure to enlarge with its caption.
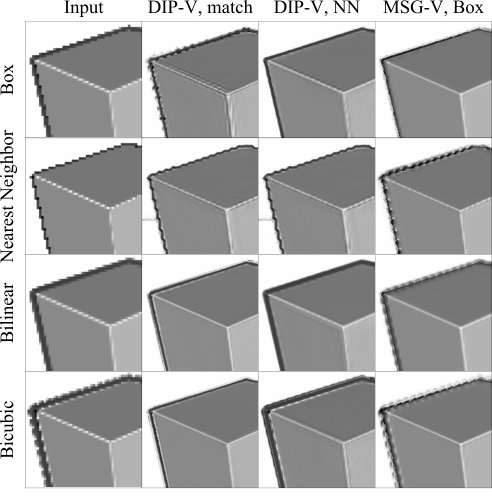 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6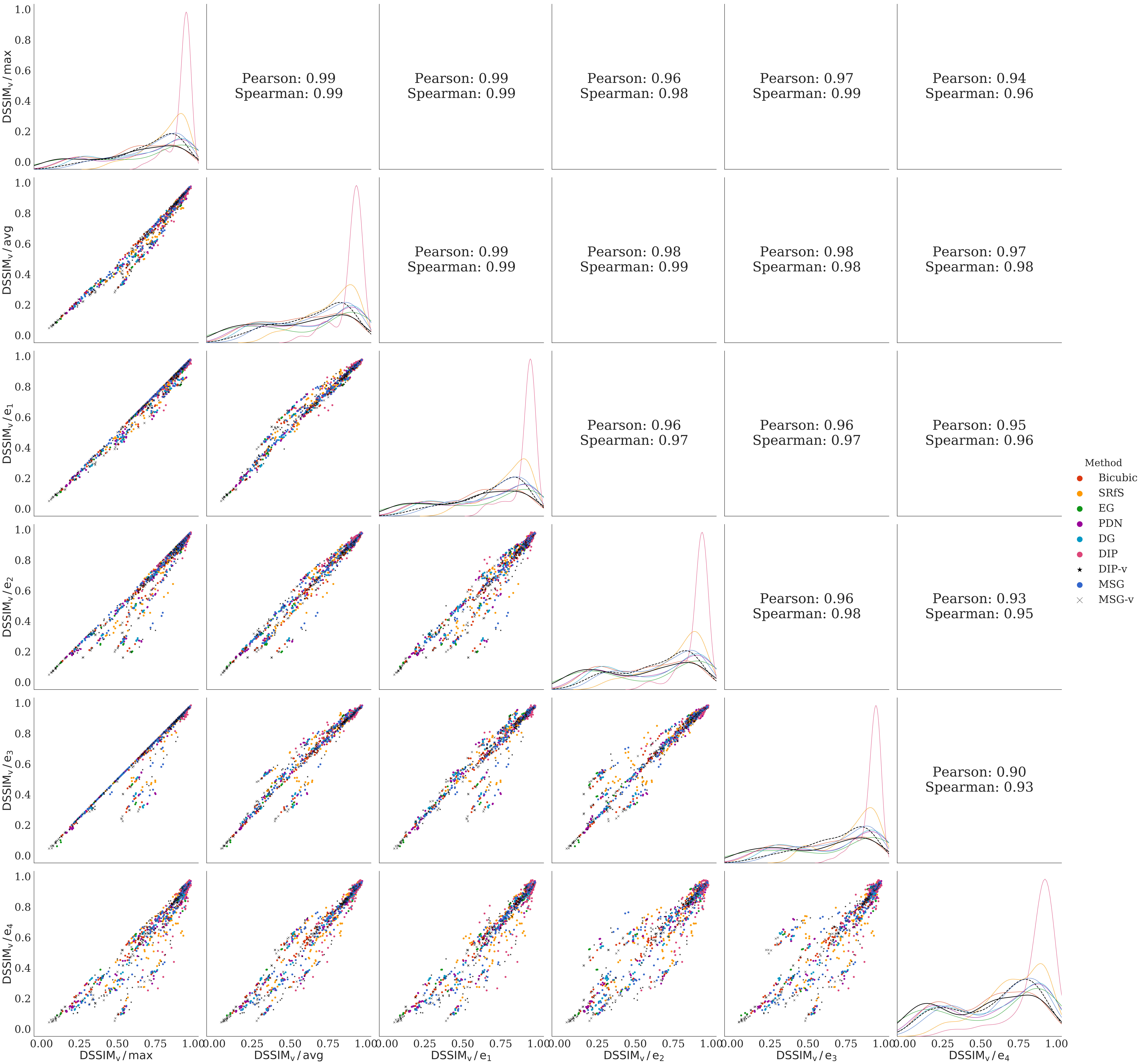 Figure 7
Figure 7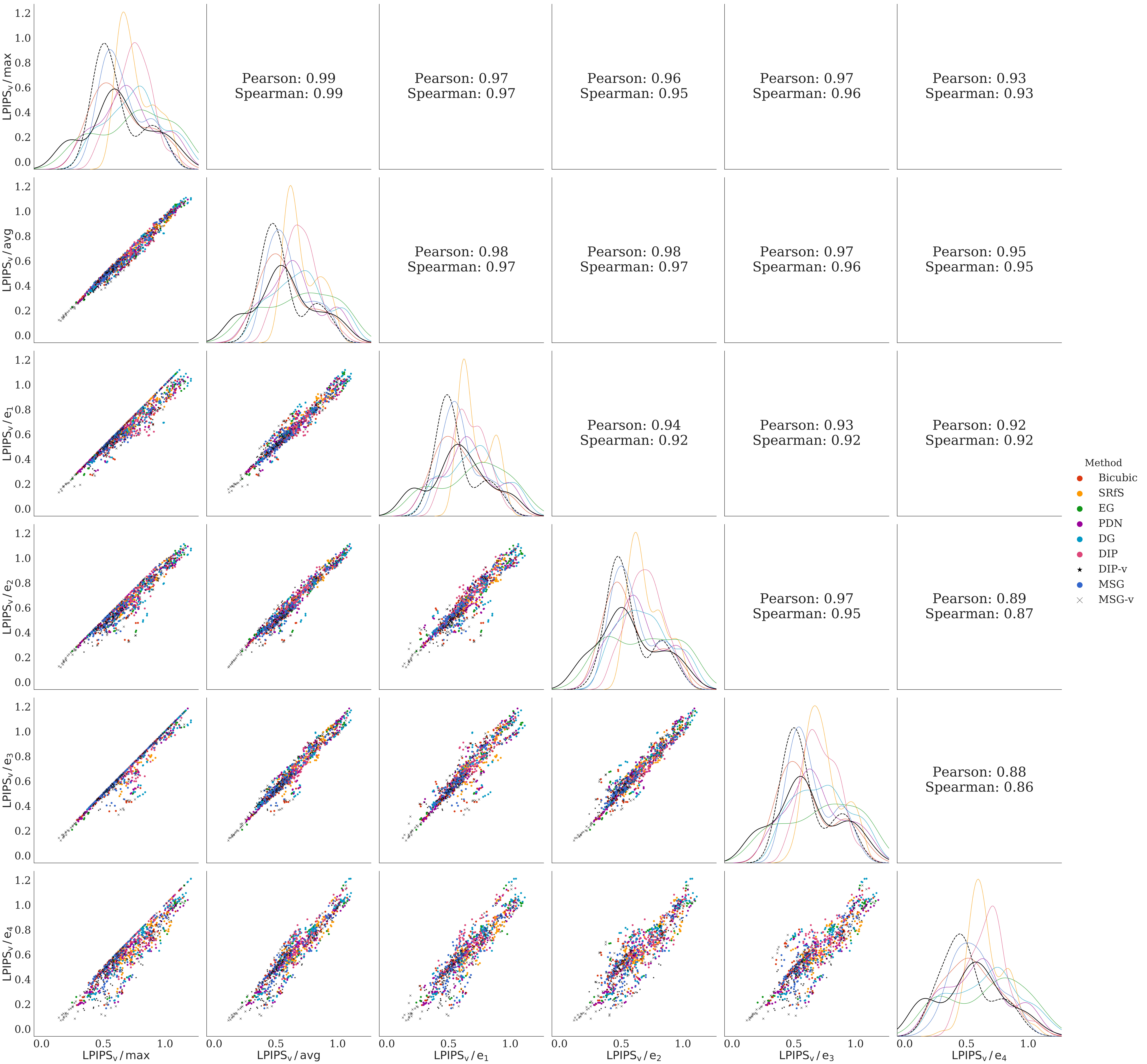 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10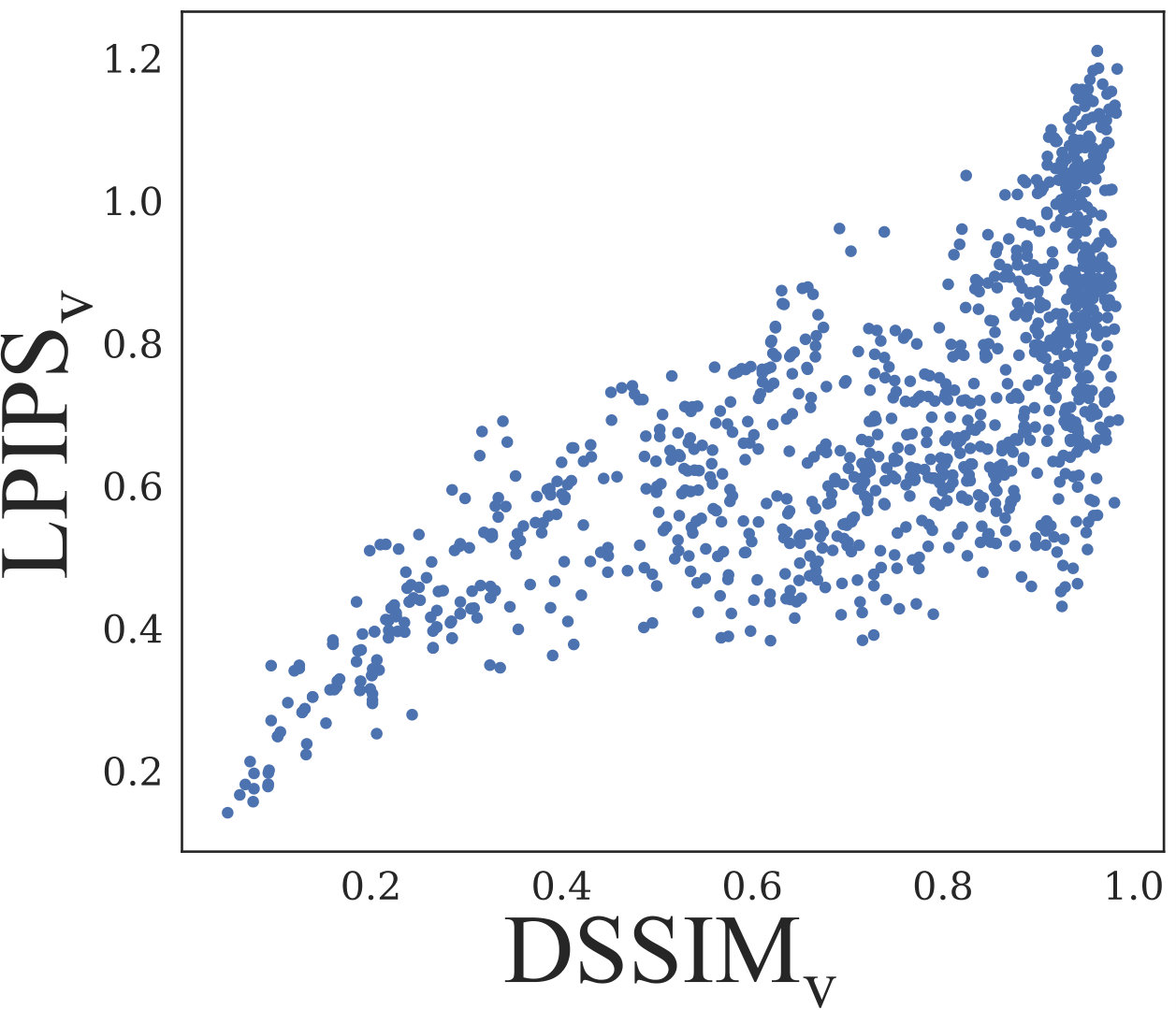 Figure 11
Figure 11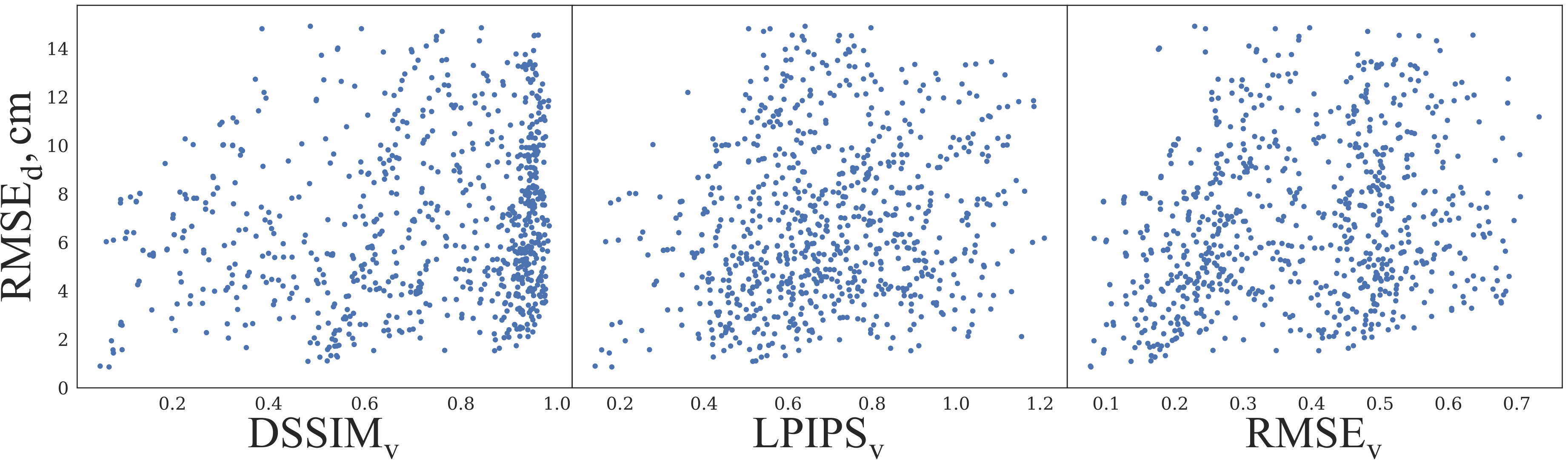 Figure 12
Figure 12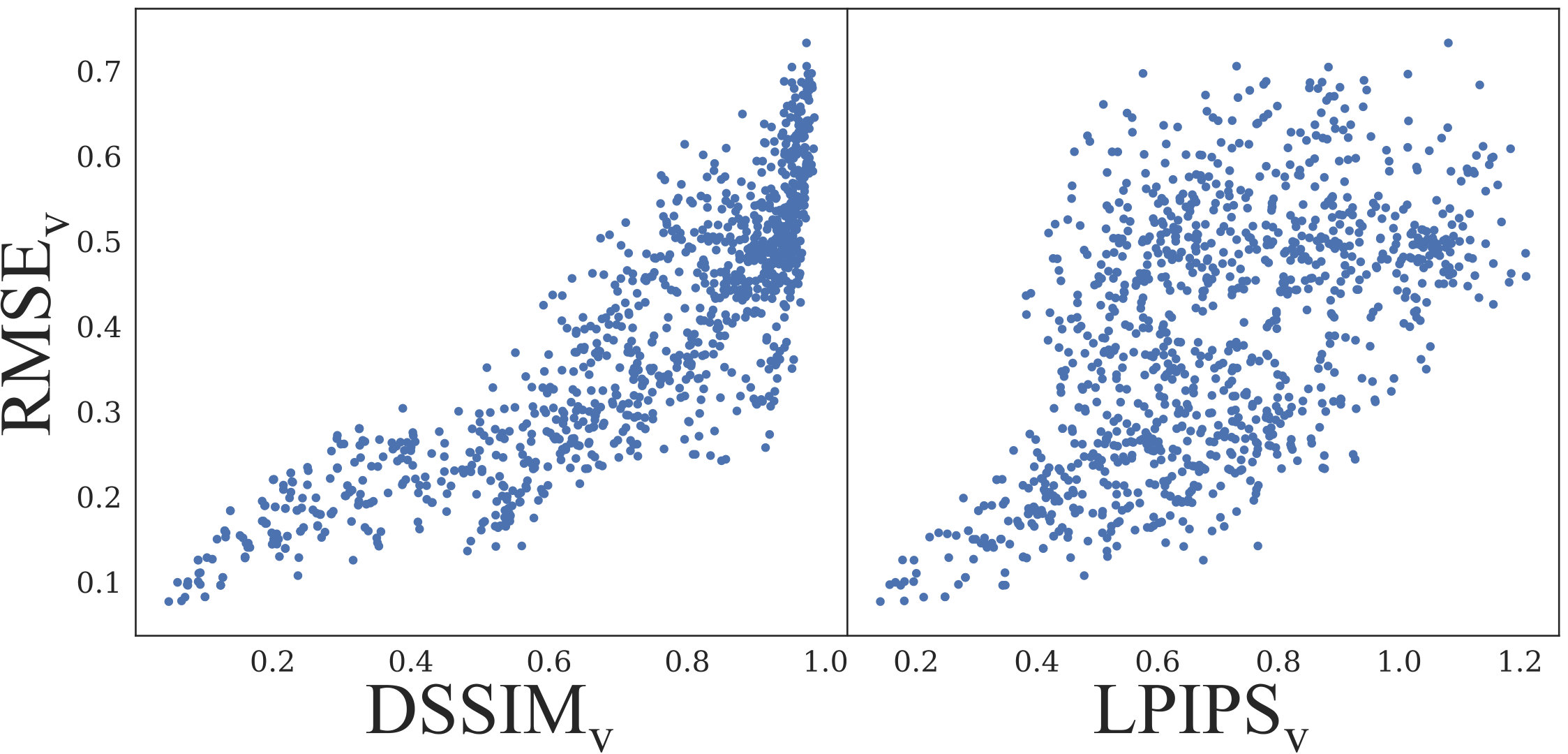 Figure 13
Figure 13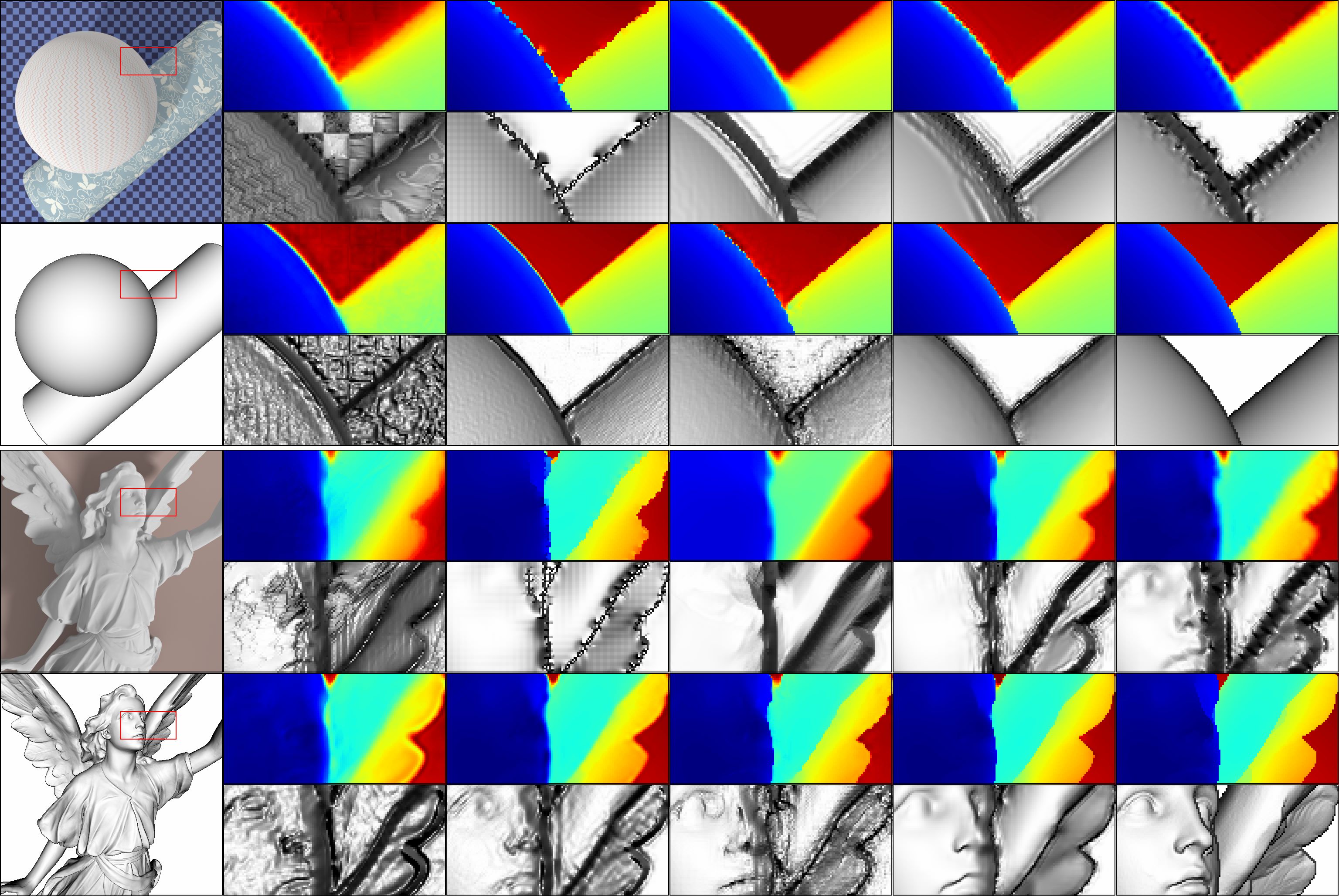 Figure 16
Figure 16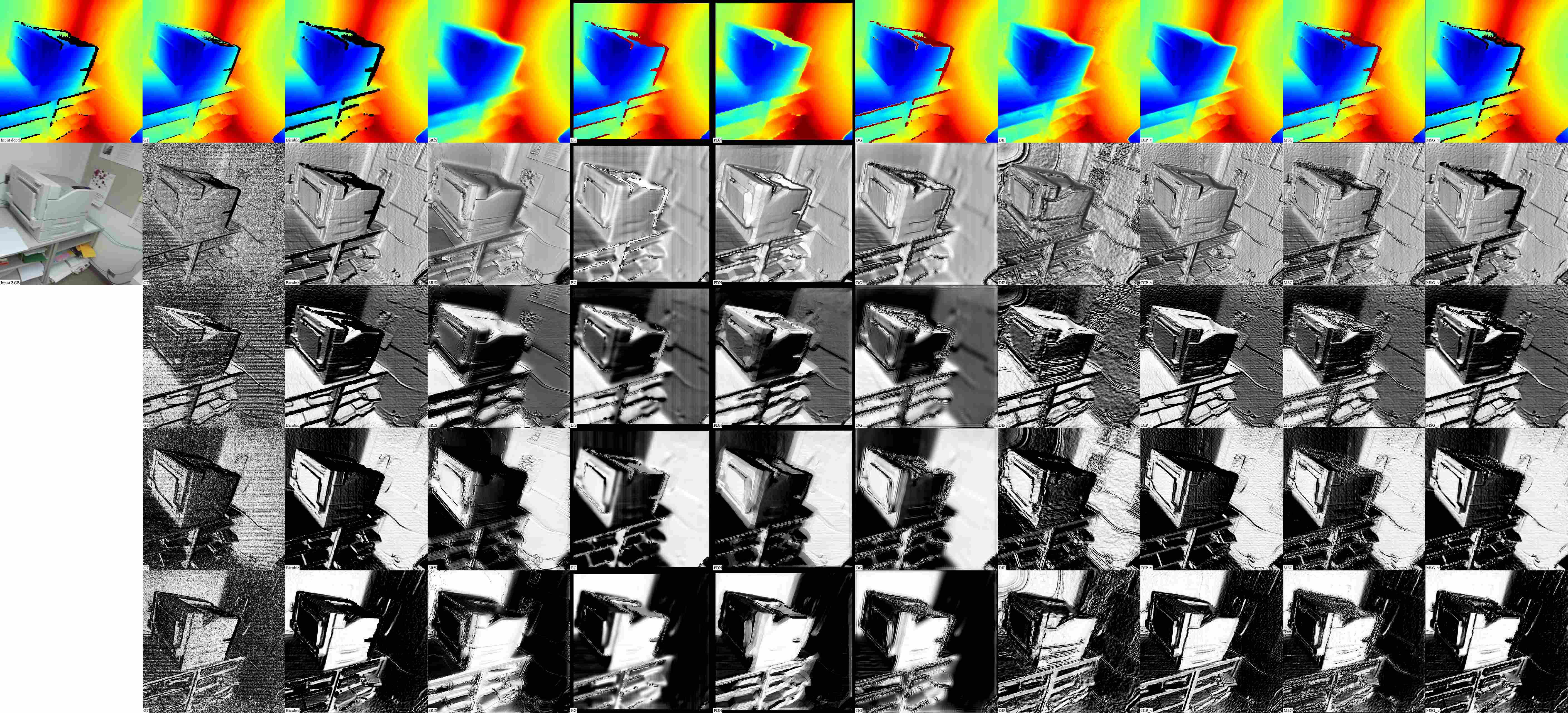 Figure 17
Figure 17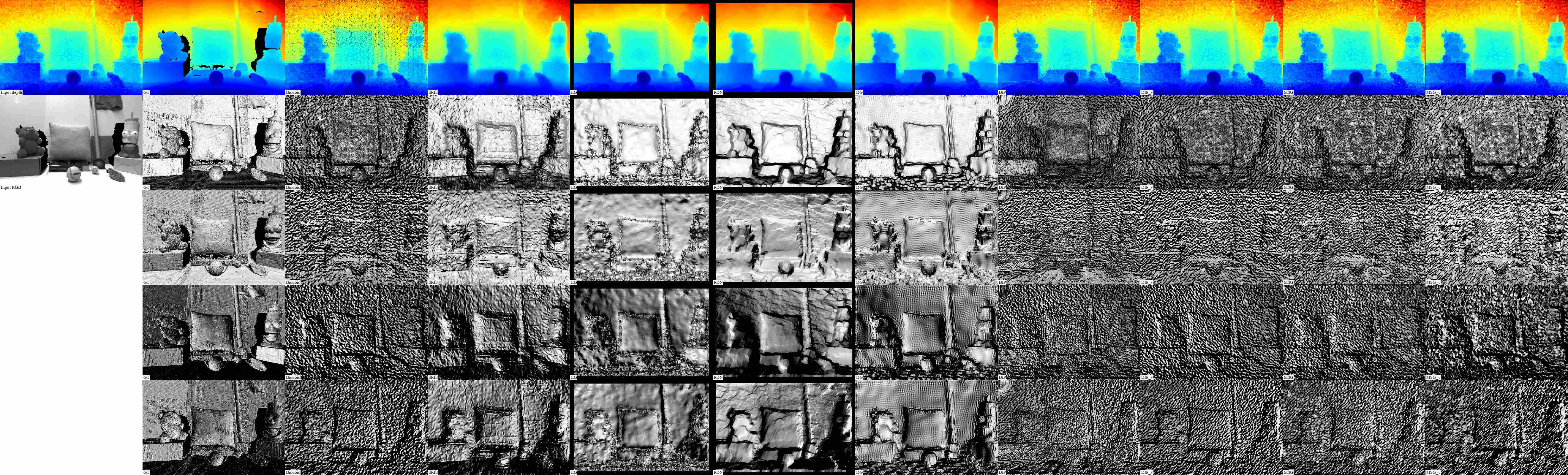 Figure 18
Figure 18| Sphere and cylinder, x4 | Lucy, x4 | Cube, x4 | SimGeo average, x4 | |||||||||||||
| SRfS [14] | 70 | 887 | 1025 | 417 | 82 | 811 | 781 | 367 | 52 | 934 | 1036 | 361 | 61 | 711 | 869 | 311 |
| EG [54] | 55 | 143 | 326 | 130 | 69 | 357 | 426 | 220 | 43 | 113 | 214 | 105 | 53 | 168 | 306 | 136 |
| PDN [39] | 157 | 198 | 295 | 150 | 173 | 456 | 368 | 251 | 164 | 156 | 250 | 145 | 162 | 224 | 278 | 165 |
| DG [13] | 56 | 265 | 372 | 166 | 69 | 523 | 558 | 249 | 44 | 218 | 411 | 139 | 54 | 293 | 420 | 171 |
| Bicubic | 57 | 189 | 313 | 189 | 72 | 355 | 398 | 267 | 44 | 131 | 287 | 160 | 55 | 197 | 320 | 193 |
| DIP [47] | 46 | 965 | 1062 | 548 | 53 | 827 | 615 | 344 | 45 | 963 | 906 | 530 | 52 | 887 | 893 | 395 |
| MSG [22] | 41 | 626 | 859 | 229 | 54 | 444 | 480 | 259 | 29 | 445 | 687 | 176 | 39 | 374 | 569 | 194 |
| DIP-V | 28 | 560 | 766 | 142 | 44 | 421 | 446 | 223 | 26 | 352 | 613 | 146 | 33 | 313 | 524 | 147 |
| MSG-V | 99 | 94 | 267 | 96 | 74 | 205 | 251 | 156 | 102 | 70 | 179 | 77 | 96 | 95 | 194 | 99 |
| Plant | Vintage | Recycle | Umbrella | |||||||||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | |
| SRfS [14] | 658 | 692 | 632 | 649 | 280 | 309 | 721 | 749 | 631 | 634 | 346 | 382 | 715 | 772 | 610 | 623 | 376 | 410 | 843 | 853 | 797 | 831 | 397 | 443 |
| EG [54] | 568 | 677 | 255 | |||||||||||||||||||||
| PDN [39] | 574 | 612 | 659 | 699 | 269 | 305 | 663 | 714 | 706 | 700 | 319 | 350 | 635 | 701 | 523 | 589 | 364 | 457 | 799 | 828 | 847 | 882 | 367 | 452 |
| DG [13] | 611 | 622 | 745 | 785 | 268 | 291 | 666 | 669 | 796 | 840 | 290 | 300 | 696 | 719 | 602 | 617 | 328 | 383 | 846 | 878 | 781 | 856 | 399 | 457 |
| Bicubic | 562 | 610 | 688 | 763 | 249 | 290 | 558 | 649 | 602 | 729 | 258 | 302 | 575 | 721 | 474 | 576 | 329 | 398 | 749 | 837 | 747 | 886 | 323 | 380 |
| DIP [47] | 919 | 880 | 764 | 723 | 490 | 437 | 953 | 965 | 910 | 872 | 656 | 687 | 871 | 923 | 576 | 605 | 434 | 500 | 915 | 953 | 737 | 722 | 467 | 528 |
| MSG [22] | 571 | 645 | 582 | 495 | 234 | 285 | 708 | 785 | 510 | 610 | 292 | 364 | 741 | 869 | 624 | 661 | 485 | 550 | 834 | 896 | 678 | 787 | 442 | 496 |
| DIP-V | 694 | 707 | 463 | 555 | 262 | 276 | 804 | 884 | 579 | 674 | 343 | 435 | 575 | 735 | 388 | 485 | 273 | 332 | 796 | 854 | 604 | 598 | 318 | 352 |
| MSG-V | 524 | 575 | 639 | 720 | 194 | 236 | 536 | 643 | 670 | 702 | 211 | 268 | 603 | 737 | 520 | 564 | 368 | 473 | 778 | 842 | 800 | 890 | 348 | 427 |
| Average performance on SimGeo dataset | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 55 | 79 | 4.1 | 7.9 | 23.2 | 38.3 | 197 | 301 | 320 | 427 | 0.70 | 0.98 | 193 | 234 | 0.5 | 7.8 | 8.3 |
| SRfS [14] | 61 | 88 | 7.5 | 14.3 | 74.2 | 77.1 | 711 | 729 | 869 | 865 | 1.48 | 1.69 | 311 | 328 | 0.0 | 0.0 | 0.0 |
| EG [54] | 53 | 2.2 | 33.1 | 168 | 306 | 0.54 | 136 | 0.2 | 3.9 | 4.2 | |||||||
| PDN [39] | 162 | 211 | 99.4 | 99.1 | 39.2 | 45.1 | 224 | 264 | 278 | 407 | 0.63 | 0.79 | 165 | 201 | 1.6 | 12.3 | 13.8 |
| DG [13] | 54 | 84 | 3.0 | 6.4 | 35.2 | 39.1 | 293 | 316 | 420 | 437 | 0.69 | 0.82 | 171 | 190 | 0.2 | 2.9 | 3.2 |
| DIP [47] | 52 | 59 | 8.5 | 12.5 | 90.5 | 92.0 | 887 | 880 | 893 | 915 | 2.21 | 2.77 | 395 | 475 | 0.6 | 0.9 | 1.5 |
| MSG [22] | 39 | 39 | 1.5 | 3.3 | 51.9 | 69.3 | 374 | 544 | 569 | 713 | 0.79 | 0.97 | 194 | 242 | 0.4 | 3.7 | 4.0 |
| DIP-v | 33 | 41 | 1.7 | 2.3 | 49.7 | 67.1 | 313 | 491 | 524 | 598 | 0.60 | 0.88 | 147 | 174 | 8.3 | 59.4 | 67.8 |
| MSG-v | 96 | 29 | 0.7 | 1.5 | 14.2 | 34.6 | 95 | 206 | 194 | 367 | 0.34 | 0.46 | 99 | 129 | 88.1 | 9.1 | 97.2 |
| Average performance on ICL-NUIM dataset | |||||||||||||||||
| Bicubic | 34 | 54 | 2.8 | 5.5 | 59.3 | 64.2 | 431 | 490 | 558 | 668 | 1.15 | 1.32 | 210 | 252 | 5.0 | 28.3 | 33.3 |
| SRfS [14] | 42 | 62 | 5.5 | 11.0 | 73.5 | 76.1 | 641 | 664 | 636 | 660 | 1.72 | 1.83 | 287 | 314 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 135 | 165 | 93.8 | 82.9 | 66.2 | 70.2 | 480 | 509 | 623 | 650 | 1.14 | 1.24 | 237 | 264 | 2.6 | 10.5 | 13.1 |
| DG [13] | 36 | 58 | 4.3 | 6.4 | 64.4 | 65.5 | 497 | 505 | 663 | 689 | 1.28 | 1.32 | 234 | 259 | 0.6 | 5.5 | 6.1 |
| DIP [47] | 43 | 56 | 10.6 | 14.2 | 83.6 | 83.4 | 812 | 806 | 690 | 690 | 2.73 | 2.58 | 394 | 389 | 1.1 | 0.9 | 2.0 |
| MSG [22] | 25 | 36 | 1.6 | 3.5 | 64.1 | 69.0 | 489 | 557 | 510 | 534 | 1.27 | 1.46 | 210 | 255 | 1.1 | 7.2 | 8.3 |
| DIP-v | 28 | 40 | 2.6 | 3.9 | 67.8 | 69.6 | 516 | 548 | 407 | 503 | 1.45 | 1.56 | 209 | 236 | 9.6 | 31.9 | 41.4 |
| MSG-v | 24 | 41 | 1.3 | 3.1 | 56.3 | 61.1 | 387 | 437 | 527 | 602 | 0.94 | 1.06 | 157 | 192 | 79.9 | 11.8 | 91.7 |
| Average performance on Middlebury dataset | |||||||||||||||||
| Bicubic | 843 | 1139 | 10.8 | 13.9 | 71.5 | 76.7 | 648 | 748 | 575 | 720 | 0.87 | 0.76 | 344 | 386 | 4.1 | 25.3 | 29.4 |
| SRfS [14] | 100 | 145 | 21.4 | 33.6 | 86.4 | 89.5 | 780 | 810 | 669 | 704 | 1.32 | 1.28 | 428 | 461 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 173 | 225 | 85.3 | 76.5 | 83.4 | 86.4 | 744 | 790 | 653 | 711 | 1.38 | 1.67 | 405 | 467 | 9.9 | 28.1 | 37.9 |
| DG [13] | 266 | 330 | 15.0 | 24.5 | 81.8 | 84.1 | 765 | 784 | 728 | 740 | 1.54 | 1.73 | 421 | 442 | 0.7 | 10.6 | 11.3 |
| DIP [47] | 72 | 104 | 19.6 | 24.4 | 92.4 | 93.4 | 927 | 947 | 737 | 717 | 2.82 | 2.90 | 565 | 592 | 1.2 | 5.6 | 6.8 |
| MSG [22] | 228 | 426 | 10.8 | 13.1 | 81.8 | 87.2 | 774 | 858 | 649 | 696 | 1.96 | 2.19 | 477 | 525 | 0.2 | 1.6 | 1.8 |
| DIP-v | 56 | 87 | 6.4 | 10.6 | 83.1 | 87.4 | 728 | 821 | 506 | 568 | 1.34 | 1.56 | 353 | 409 | 72.3 | 18.2 | 90.5 |
| MSG-v | 96 | 133 | 7.3 | 9.2 | 73.3 | 79.0 | 667 | 757 | 639 | 690 | 1.20 | 1.35 | 376 | 431 | 10.8 | 9.9 | 20.7 |
| Average performance on the scenes without missing measurements (SimGeo, ICL-NUIM, Vintage) | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 46 | 69 | 3.5 | 6.9 | 43.7 | 53.3 | 333 | 415 | 452 | 561 | 0.97 | 1.19 | 206 | 248 | 3.0 | 18.9 | 21.9 |
| SRfS [14] | 55 | 81 | 7.3 | 14.1 | 74.6 | 77.4 | 680 | 701 | 743 | 753 | 1.60 | 1.75 | 303 | 326 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 148 | 187 | 94.4 | 90.1 | 55.0 | 59.8 | 378 | 412 | 482 | 542 | 0.93 | 1.06 | 210 | 241 | 1.9 | 10.5 | 12.4 |
| DG [13] | 47 | 73 | 3.9 | 6.7 | 52.1 | 54.4 | 416 | 430 | 561 | 584 | 1.02 | 1.10 | 209 | 230 | 0.4 | 4.0 | 4.4 |
| DIP [47] | 50 | 62 | 10.7 | 15.9 | 87.6 | 88.2 | 857 | 853 | 801 | 808 | 2.59 | 2.79 | 414 | 452 | 0.8 | 0.8 | 1.7 |
| MSG [22] | 33 | 39 | 1.7 | 3.6 | 59.8 | 70.3 | 454 | 569 | 547 | 622 | 1.08 | 1.26 | 210 | 258 | 0.7 | 5.8 | 6.4 |
| DIP-v | 31 | 43 | 2.2 | 3.3 | 60.8 | 69.9 | 444 | 548 | 474 | 560 | 1.09 | 1.32 | 191 | 223 | 10.2 | 45.5 | 55.8 |
| MSG-v | 38 | 38 | 1.1 | 2.6 | 38.0 | 50.1 | 264 | 346 | 385 | 501 | 0.69 | 0.81 | 135 | 169 | 82.7 | 10.9 | 93.6 |
| Average performance on the scenes with missing measurements (Middlebury excluding Vintage) | |||||||||||||||||
| Bicubic | 972 | 1313 | 11.8 | 14.7 | 71.3 | 76.6 | 663 | 765 | 570 | 718 | 0.77 | 0.61 | 358 | 400 | 3.8 | 24.7 | 28.5 |
| SRfS [14] | 100 | 145 | 22.2 | 33.8 | 86.9 | 89.8 | 790 | 820 | 676 | 716 | 1.26 | 1.21 | 441 | 474 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 178 | 234 | 88.3 | 76.1 | 83.5 | 86.6 | 757 | 803 | 644 | 713 | 1.36 | 1.69 | 419 | 487 | 11.5 | 32.8 | 44.3 |
| DG [13] | 298 | 367 | 16.3 | 26.9 | 82.2 | 84.7 | 781 | 803 | 716 | 724 | 1.55 | 1.76 | 442 | 465 | 0.9 | 12.2 | 13.1 |
| DIP [47] | 72 | 102 | 18.8 | 20.7 | 92.2 | 93.3 | 923 | 943 | 708 | 691 | 2.62 | 2.68 | 549 | 577 | 1.2 | 6.4 | 7.7 |
| MSG [22] | 259 | 488 | 12.1 | 14.1 | 82.0 | 87.7 | 785 | 870 | 673 | 711 | 2.02 | 2.24 | 507 | 552 | 0.2 | 0.2 | 0.5 |
| DIP-v | 58 | 91 | 7.1 | 11.4 | 82.7 | 87.2 | 716 | 811 | 494 | 550 | 1.23 | 1.41 | 354 | 405 | 80.1 | 13.8 | 93.9 |
| MSG-v | 107 | 145 | 8.1 | 9.8 | 73.6 | 79.2 | 688 | 776 | 634 | 688 | 1.19 | 1.34 | 404 | 458 | 1.3 | 8.8 | 10.1 |
| Average performance on SimGeo, ICL-NUIM, Middlebury | |||||||||||||||||
| Bicubic | 339 | 462 | 6.1 | 9.3 | 52.4 | 60.6 | 437 | 525 | 489 | 611 | 0.91 | 1.00 | 254 | 296 | 3.3 | 20.7 | 24.0 |
| SRfS [14] | 69 | 101 | 12.0 | 20.3 | 78.5 | 81.3 | 715 | 738 | 722 | 741 | 1.50 | 1.58 | 347 | 372 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 157 | 202 | 92.4 | 85.7 | 64.0 | 68.2 | 498 | 536 | 533 | 596 | 1.07 | 1.26 | 276 | 319 | 5.0 | 17.5 | 22.5 |
| DG [13] | 126 | 166 | 7.8 | 13.1 | 61.6 | 64.0 | 531 | 548 | 610 | 628 | 1.19 | 1.31 | 283 | 305 | 0.5 | 6.6 | 7.1 |
| DIP [47] | 57 | 75 | 13.3 | 17.4 | 89.1 | 89.8 | 878 | 881 | 771 | 771 | 2.60 | 2.76 | 457 | 491 | 1.0 | 2.6 | 3.6 |
| MSG [22] | 104 | 181 | 5.0 | 6.9 | 66.8 | 75.8 | 559 | 664 | 587 | 650 | 1.37 | 1.57 | 304 | 350 | 0.5 | 4.0 | 4.6 |
| DIP-v | 40 | 58 | 3.8 | 5.9 | 67.7 | 75.4 | 530 | 631 | 481 | 557 | 1.14 | 1.34 | 242 | 280 | 32.3 | 35.5 | 67.8 |
| MSG-v | 60 | 72 | 3.3 | 4.8 | 49.2 | 59.3 | 398 | 482 | 464 | 560 | 0.85 | 0.98 | 220 | 260 | 57.0 | 10.2 | 67.3 |
| Cube, high-frequency texture | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 44 | 63 | 2.7 | 5.2 | 15.0 | 27.3 | 131 | 204 | 287 | 395 | 0.43 | 0.61 | 160 | 188 | 0.7 | 13.2 | 14.0 |
| SRfS [14] | 52 | 75 | 6.2 | 12.1 | 89.2 | 80.3 | 934 | 818 | 1036 | 938 | 1.73 | 1.67 | 361 | 339 | 0.0 | 0.0 | 0.0 |
| EG [54] | 43 | 1.2 | 25.4 | 113 | 214 | 0.35 | 105 | 0.7 | 9.6 | 10.3 | |||||||
| PDN [39] | 164 | 219 | 99.6 | 99.4 | 27.5 | 29.5 | 156 | 186 | 250 | 368 | 0.39 | 0.49 | 145 | 171 | 0.7 | 4.4 | 5.1 |
| DG [13] | 44 | 67 | 1.9 | 4.2 | 26.4 | 30.1 | 218 | 240 | 411 | 437 | 0.44 | 0.55 | 139 | 159 | 0.7 | 7.4 | 8.1 |
| DIP [47] | 45 | 48 | 6.4 | 8.5 | 93.5 | 92.5 | 963 | 947 | 906 | 918 | 2.98 | 2.50 | 530 | 494 | 0.0 | 0.7 | 0.7 |
| MSG [22] | 29 | 38 | 1.0 | 2.6 | 60.1 | 77.9 | 445 | 653 | 687 | 877 | 0.79 | 0.98 | 176 | 233 | 0.0 | 0.0 | 0.0 |
| DIP-v | 26 | 36 | 0.8 | 1.6 | 56.2 | 60.8 | 352 | 413 | 613 | 653 | 0.64 | 0.89 | 146 | 162 | 5.9 | 58.1 | 64.0 |
| MSG-v | 102 | 20 | 0.3 | 0.7 | 9.3 | 51.0 | 70 | 316 | 179 | 676 | 0.20 | 0.39 | 77 | 125 | 91.2 | 6.6 | 97.8 |
| Cube, no texture | |||||||||||||||||
| Bicubic | 44 | 63 | 2.7 | 5.2 | 15.0 | 27.3 | 131 | 204 | 287 | 395 | 0.43 | 0.61 | 160 | 188 | 0.0 | 5.9 | 5.9 |
| SRfS [14] | 43 | 63 | 2.1 | 4.5 | 53.4 | 51.7 | 516 | 476 | 754 | 728 | 0.67 | 0.89 | 219 | 228 | 0.0 | 0.0 | 0.0 |
| EG [54] | 43 | 1.2 | 25.4 | 128 | 282 | 0.35 | 105 | 0.0 | 2.9 | 2.9 | |||||||
| PDN [39] | 164 | 219 | 99.6 | 99.4 | 26.3 | 29.3 | 162 | 185 | 314 | 353 | 0.38 | 0.49 | 145 | 171 | 0.7 | 4.4 | 5.1 |
| DG [13] | 44 | 67 | 1.9 | 4.2 | 26.4 | 30.1 | 218 | 240 | 411 | 437 | 0.44 | 0.55 | 139 | 159 | 0.0 | 2.2 | 2.2 |
| DIP [47] | 72 | 56 | 23.2 | 17.3 | 94.3 | 99.1 | 912 | 980 | 1026 | 1133 | 2.05 | 4.22 | 434 | 683 | 0.0 | 0.7 | 0.7 |
| MSG [22] | 29 | 26 | 1.0 | 1.7 | 30.7 | 49.8 | 199 | 314 | 509 | 642 | 0.42 | 0.47 | 157 | 171 | 0.0 | 6.6 | 6.6 |
| DIP-v | 26 | 35 | 0.8 | 1.4 | 15.1 | 45.4 | 95 | 237 | 347 | 478 | 0.28 | 0.35 | 111 | 107 | 1.5 | 76.5 | 77.9 |
| MSG-v | 9 | 19 | 0.3 | 0.4 | 6.0 | 13.0 | 50 | 73 | 141 | 213 | 0.17 | 0.21 | 77 | 82 | 97.8 | 0.7 | 98.5 |
| Sphere and cylinder, high-frequency texture | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 57 | 82 | 4.1 | 8.1 | 20.1 | 36.7 | 189 | 294 | 313 | 420 | 0.67 | 0.98 | 189 | 234 | 0.0 | 0.7 | 0.7 |
| SRfS [14] | 70 | 102 | 12.1 | 24.6 | 91.9 | 91.8 | 887 | 865 | 1025 | 1008 | 2.43 | 2.41 | 417 | 403 | 0.0 | 0.0 | 0.0 |
| EG [54] | 55 | 2.4 | 30.4 | 143 | 326 | 0.50 | 130 | 0.0 | 1.5 | 1.5 | |||||||
| PDN [39] | 157 | 197 | 99.3 | 98.9 | 40.7 | 54.1 | 198 | 242 | 295 | 461 | 0.60 | 0.77 | 150 | 187 | 1.5 | 9.6 | 11.0 |
| DG [13] | 56 | 87 | 3.2 | 6.3 | 30.9 | 35.2 | 265 | 285 | 372 | 386 | 0.66 | 0.77 | 166 | 180 | 0.0 | 1.5 | 1.5 |
| DIP [47] | 46 | 69 | 3.9 | 27.2 | 97.0 | 99.2 | 965 | 975 | 1062 | 1014 | 4.01 | 4.80 | 548 | 696 | 1.5 | 2.9 | 4.4 |
| MSG [22] | 41 | 41 | 1.4 | 3.6 | 72.6 | 85.6 | 626 | 820 | 859 | 960 | 0.98 | 1.43 | 229 | 314 | 0.0 | 0.0 | 0.0 |
| DIP-v | 28 | 43 | 1.2 | 2.4 | 69.2 | 86.0 | 560 | 850 | 766 | 832 | 0.56 | 1.45 | 142 | 242 | 32.4 | 52.9 | 85.3 |
| MSG-v | 99 | 37 | 0.6 | 2.0 | 14.3 | 53.0 | 94 | 334 | 267 | 583 | 0.29 | 0.55 | 96 | 164 | 64.7 | 30.9 | 95.6 |
| Sphere and cylinder, no texture | |||||||||||||||||
| Bicubic | 57 | 82 | 4.1 | 8.1 | 20.2 | 36.8 | 189 | 294 | 325 | 437 | 0.67 | 0.98 | 190 | 233 | 0.0 | 0.7 | 0.7 |
| SRfS [14] | 59 | 85 | 4.6 | 8.6 | 51.4 | 70.8 | 430 | 619 | 657 | 766 | 0.77 | 1.25 | 193 | 256 | 0.0 | 0.0 | 0.0 |
| EG [54] | 56 | 2.4 | 30.9 | 160 | 383 | 0.50 | 128 | 0.0 | 1.5 | 1.5 | |||||||
| PDN [39] | 157 | 197 | 99.3 | 98.9 | 38.0 | 44.1 | 202 | 218 | 294 | 386 | 0.58 | 0.76 | 150 | 186 | 5.9 | 17.6 | 23.5 |
| DG [13] | 57 | 87 | 3.2 | 6.4 | 31.0 | 35.3 | 265 | 284 | 396 | 409 | 0.66 | 0.78 | 165 | 180 | 0.7 | 2.2 | 2.9 |
| DIP [47] | 49 | 56 | 5.0 | 5.5 | 85.6 | 81.6 | 856 | 662 | 927 | 723 | 1.01 | 0.96 | 244 | 249 | 1.5 | 0.0 | 1.5 |
| MSG [22] | 40 | 37 | 1.4 | 3.1 | 45.6 | 64.5 | 288 | 444 | 509 | 610 | 0.65 | 0.76 | 183 | 218 | 0.7 | 0.7 | 1.5 |
| DIP-v | 35 | 39 | 1.4 | 1.8 | 41.0 | 72.6 | 210 | 523 | 517 | 643 | 0.47 | 0.70 | 130 | 141 | 9.6 | 64.7 | 74.3 |
| MSG-v | 14 | 27 | 0.7 | 1.3 | 8.5 | 18.0 | 77 | 93 | 174 | 200 | 0.27 | 0.32 | 96 | 110 | 81.6 | 12.5 | 94.1 |
| Sphere and cylinder, low-frequency texture | |||||||||||||||||
| Bicubic | 57 | 82 | 4.1 | 8.1 | 20.1 | 36.7 | 189 | 294 | 313 | 420 | 0.67 | 0.98 | 189 | 234 | 0.0 | 2.2 | 2.2 |
| SRfS [14] | 62 | 91 | 6.8 | 14.9 | 74.9 | 81.0 | 691 | 738 | 961 | 956 | 1.38 | 1.65 | 311 | 335 | 0.0 | 0.0 | 0.0 |
| EG [54] | 54 | 2.4 | 30.4 | 160 | 377 | 0.50 | 129 | 0.7 | 7.4 | 8.1 | |||||||
| PDN [39] | 157 | 197 | 99.3 | 98.9 | 37.9 | 44.5 | 202 | 219 | 299 | 397 | 0.58 | 0.76 | 150 | 186 | 0.7 | 36.0 | 36.8 |
| DG [13] | 56 | 87 | 3.2 | 6.3 | 30.9 | 35.2 | 265 | 285 | 372 | 386 | 0.66 | 0.77 | 166 | 180 | 0.0 | 3.7 | 3.7 |
| DIP [47] | 49 | 52 | 8.0 | 4.9 | 85.5 | 84.7 | 796 | 812 | 821 | 924 | 1.19 | 1.18 | 267 | 250 | 0.0 | 0.0 | 0.0 |
| MSG [22] | 41 | 41 | 1.3 | 3.0 | 39.6 | 66.2 | 264 | 458 | 493 | 612 | 0.64 | 0.74 | 181 | 213 | 0.0 | 1.5 | 1.5 |
| DIP-v | 38 | 42 | 1.7 | 2.2 | 48.0 | 60.4 | 238 | 351 | 456 | 516 | 0.50 | 0.61 | 128 | 152 | 0.7 | 47.8 | 48.5 |
| MSG-v | 16 | 26 | 0.7 | 1.2 | 8.5 | 17.5 | 76 | 92 | 156 | 181 | 0.27 | 0.31 | 97 | 100 | 97.8 | 1.5 | 99.3 |
| Lucy | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 72 | 103 | 6.8 | 13.0 | 48.8 | 65.0 | 355 | 519 | 398 | 497 | 1.37 | 1.74 | 267 | 328 | 2.2 | 24.3 | 26.5 |
| SRfS [14] | 82 | 113 | 13.2 | 20.8 | 84.6 | 87.1 | 811 | 857 | 781 | 792 | 1.90 | 2.28 | 367 | 407 | 0.0 | 0.0 | 0.0 |
| EG [54] | 69 | 3.5 | 56.2 | 357 | 426 | 1.05 | 220 | 0.0 | 0.7 | 0.7 | |||||||
| PDN [39] | 173 | 234 | 99.0 | 98.8 | 64.9 | 68.9 | 456 | 535 | 368 | 480 | 1.24 | 1.47 | 251 | 303 | 0.0 | 1.5 | 1.5 |
| DG [13] | 69 | 108 | 4.9 | 11.0 | 65.5 | 68.6 | 523 | 562 | 558 | 565 | 1.28 | 1.50 | 249 | 281 | 0.0 | 0.7 | 0.7 |
| DIP [47] | 53 | 75 | 4.7 | 11.4 | 87.4 | 95.2 | 827 | 908 | 615 | 778 | 2.02 | 2.93 | 344 | 478 | 0.7 | 0.7 | 1.5 |
| MSG [22] | 54 | 53 | 2.7 | 5.4 | 62.9 | 71.7 | 444 | 577 | 480 | 578 | 1.30 | 1.42 | 259 | 306 | 1.5 | 13.2 | 14.7 |
| DIP-v | 44 | 55 | 4.6 | 4.4 | 69.0 | 77.5 | 421 | 574 | 446 | 468 | 1.15 | 1.27 | 223 | 239 | 0.0 | 56.6 | 56.6 |
| MSG-v | 74 | 47 | 1.6 | 3.7 | 38.8 | 55.0 | 205 | 325 | 251 | 348 | 0.82 | 0.96 | 156 | 195 | 95.6 | 2.2 | 97.8 |
| Painting | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 28 | 47 | 2.5 | 5.6 | 57.1 | 64.1 | 423 | 514 | 544 | 649 | 0.95 | 1.15 | 213 | 265 | 4.4 | 47.8 | 52.2 |
| SRfS [14] | 39 | 60 | 6.5 | 15.9 | 78.4 | 81.2 | 707 | 722 | 612 | 661 | 1.47 | 1.55 | 308 | 337 | 0.0 | 0.0 | 0.0 |
| EG [54] | 36 | 3.1 | 61.9 | 481 | 720 | 0.94 | 231 | 0.0 | 3.7 | 3.7 | |||||||
| PDN [39] | 151 | 215 | 99.3 | 99.2 | 65.2 | 70.2 | 488 | 532 | 669 | 709 | 0.89 | 1.01 | 237 | 275 | 4.4 | 10.3 | 14.7 |
| DG [13] | 31 | 49 | 2.4 | 5.5 | 61.9 | 63.9 | 503 | 506 | 678 | 700 | 1.08 | 1.13 | 232 | 272 | 0.7 | 3.7 | 4.4 |
| DIP [47] | 30 | 37 | 4.0 | 4.7 | 80.4 | 79.5 | 802 | 766 | 630 | 612 | 2.18 | 1.82 | 362 | 341 | 0.0 | 0.0 | 0.0 |
| MSG [22] | 21 | 29 | 1.2 | 2.2 | 63.7 | 67.9 | 495 | 570 | 475 | 507 | 0.97 | 1.12 | 203 | 243 | 2.2 | 5.1 | 7.4 |
| DIP-v | 22 | 32 | 2.3 | 3.2 | 70.1 | 70.3 | 567 | 564 | 386 | 501 | 1.07 | 1.12 | 210 | 239 | 2.9 | 21.3 | 24.3 |
| MSG-v | 17 | 34 | 0.9 | 1.8 | 51.4 | 58.0 | 354 | 410 | 532 | 607 | 0.67 | 0.77 | 142 | 170 | 85.3 | 8.1 | 93.4 |
| Sofa | |||||||||||||||||
| Bicubic | 38 | 58 | 1.8 | 3.6 | 75.4 | 77.0 | 566 | 616 | 704 | 764 | 2.12 | 2.33 | 212 | 250 | 3.7 | 15.4 | 19.1 |
| SRfS [14] | 39 | 58 | 2.0 | 3.5 | 82.3 | 88.1 | 715 | 832 | 631 | 743 | 2.97 | 3.45 | 310 | 405 | 0.0 | 0.0 | 0.0 |
| EG [54] | 42 | 2.5 | 79.0 | 598 | 767 | 2.28 | 213 | 0.0 | 8.8 | 8.8 | |||||||
| PDN [39] | 86 | 91 | 71.0 | 70.8 | 83.3 | 83.0 | 641 | 658 | 784 | 763 | 2.40 | 2.50 | 260 | 264 | 0.7 | 3.7 | 4.4 |
| DG [13] | 41 | 63 | 3.2 | 4.4 | 77.7 | 77.9 | 624 | 632 | 823 | 855 | 2.30 | 2.33 | 255 | 263 | 0.0 | 5.1 | 5.1 |
| DIP [47] | 45 | 57 | 7.1 | 12.7 | 93.1 | 94.0 | 928 | 946 | 758 | 738 | 3.91 | 3.99 | 518 | 560 | 0.0 | 0.0 | 0.0 |
| MSG [22] | 27 | 36 | 1.2 | 2.3 | 80.6 | 85.7 | 718 | 791 | 606 | 610 | 2.71 | 3.22 | 254 | 316 | 0.0 | 0.7 | 0.7 |
| DIP-v | 27 | 43 | 0.9 | 2.0 | 79.1 | 82.5 | 645 | 718 | 414 | 585 | 2.67 | 3.07 | 215 | 266 | 19.1 | 47.8 | 66.9 |
| MSG-v | 35 | 44 | 0.7 | 1.6 | 74.0 | 75.7 | 537 | 585 | 710 | 759 | 1.96 | 2.10 | 165 | 196 | 76.5 | 18.4 | 94.9 |
| Plant | |||||||||||||||||
| Bicubic | 38 | 58 | 3.7 | 6.4 | 75.9 | 79.9 | 562 | 610 | 688 | 763 | 1.58 | 1.79 | 249 | 290 | 1.5 | 22.1 | 23.5 |
| SRfS [14] | 46 | 65 | 5.8 | 9.5 | 82.9 | 85.0 | 658 | 692 | 632 | 649 | 1.96 | 2.13 | 280 | 309 | 0.0 | 0.0 | 0.0 |
| EG [54] | 43 | 4.5 | 82.2 | 568 | 677 | 1.64 | 255 | 0.0 | 0.7 | 0.7 | |||||||
| PDN [39] | 88 | 89 | 94.5 | 37.8 | 79.5 | 82.5 | 574 | 612 | 659 | 699 | 1.46 | 1.60 | 269 | 305 | 4.4 | 7.4 | 11.8 |
| DG [13] | 40 | 63 | 3.9 | 6.7 | 79.5 | 81.1 | 611 | 622 | 745 | 785 | 1.67 | 1.70 | 268 | 291 | 2.2 | 11.0 | 13.2 |
| DIP [47] | 38 | 47 | 6.9 | 6.1 | 93.9 | 92.8 | 919 | 880 | 764 | 723 | 4.33 | 3.95 | 490 | 437 | 0.0 | 0.7 | 0.7 |
| MSG [22] | 31 | 44 | 2.3 | 3.7 | 78.0 | 81.8 | 571 | 645 | 582 | 495 | 1.62 | 1.84 | 234 | 285 | 0.0 | 11.8 | 11.8 |
| DIP-v | 31 | 40 | 4.7 | 4.8 | 83.5 | 84.1 | 694 | 707 | 463 | 555 | 2.25 | 2.21 | 262 | 276 | 11.0 | 33.1 | 44.1 |
| MSG-v | 27 | 44 | 1.8 | 3.9 | 74.3 | 77.8 | 524 | 575 | 639 | 720 | 1.31 | 1.47 | 194 | 236 | 80.9 | 13.2 | 94.1 |
| Office | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 47 | 80 | 4.0 | 7.8 | 24.4 | 34.1 | 216 | 285 | 412 | 594 | 0.81 | 0.95 | 208 | 254 | 19.9 | 44.1 | 64.0 |
| SRfS [14] | 49 | 89 | 5.8 | 14.4 | 53.4 | 54.4 | 595 | 593 | 690 | 636 | 1.71 | 1.66 | 298 | 302 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 185 | 185 | 99.3 | 90.5 | 36.5 | 50.2 | 250 | 294 | 457 | 518 | 0.76 | 0.92 | 234 | 272 | 0.7 | 3.7 | 4.4 |
| DG [13] | 49 | 85 | 9.0 | 11.9 | 36.5 | 37.6 | 319 | 330 | 534 | 571 | 1.03 | 1.05 | 240 | 266 | 0.0 | 0.7 | 0.7 |
| DIP [47] | 76 | 109 | 30.3 | 48.2 | 72.1 | 73.9 | 726 | 819 | 690 | 797 | 2.45 | 2.70 | 372 | 408 | 1.5 | 1.5 | 2.9 |
| MSG [22] | 35 | 48 | 2.4 | 6.8 | 35.4 | 44.5 | 263 | 360 | 415 | 543 | 0.83 | 0.95 | 199 | 247 | 2.2 | 3.7 | 5.9 |
| DIP-v | 40 | 65 | 3.8 | 7.4 | 45.4 | 47.9 | 311 | 352 | 414 | 504 | 1.08 | 1.18 | 205 | 235 | 17.6 | 25.0 | 42.6 |
| MSG-v | 32 | 65 | 1.9 | 5.3 | 19.3 | 29.6 | 157 | 224 | 313 | 432 | 0.59 | 0.72 | 151 | 198 | 58.1 | 21.3 | 79.4 |
| Coat rack | |||||||||||||||||
| Bicubic | 13 | 20 | 1.5 | 3.0 | 73.1 | 75.3 | 507 | 539 | 537 | 651 | 0.54 | 0.60 | 171 | 196 | 0.0 | 19.1 | 19.1 |
| SRfS [14] | 24 | 28 | 3.8 | 5.4 | 82.3 | 80.5 | 672 | 556 | 650 | 612 | 0.83 | 0.57 | 237 | 203 | 0.0 | 0.0 | 0.0 |
| EG [54] | 13 | 1.2 | 77.8 | 541 | 550 | 0.55 | 186 | 0.7 | 7.4 | 8.1 | |||||||
| PDN [39] | 140 | 191 | 99.6 | 99.9 | 77.1 | 78.0 | 544 | 557 | 621 | 631 | 0.48 | 0.50 | 178 | 193 | 5.1 | 28.7 | 33.8 |
| DG [13] | 13 | 20 | 1.4 | 3.2 | 74.4 | 75.6 | 530 | 532 | 593 | 621 | 0.54 | 0.58 | 166 | 201 | 0.0 | 9.6 | 9.6 |
| DIP [47] | 15 | 24 | 1.9 | 3.5 | 85.5 | 85.4 | 766 | 701 | 625 | 624 | 1.15 | 0.97 | 256 | 246 | 4.4 | 2.2 | 6.6 |
| MSG [22] | 11 | 17 | 0.9 | 1.6 | 73.3 | 76.1 | 522 | 546 | 523 | 554 | 0.51 | 0.55 | 165 | 189 | 2.2 | 16.2 | 18.4 |
| DIP-v | 13 | 17 | 1.8 | 2.0 | 75.2 | 75.5 | 543 | 542 | 422 | 463 | 0.62 | 0.60 | 171 | 181 | 0.7 | 12.5 | 13.2 |
| MSG-v | 11 | 18 | 0.8 | 2.2 | 71.4 | 74.2 | 482 | 502 | 516 | 563 | 0.42 | 0.48 | 136 | 161 | 86.8 | 4.4 | 91.2 |
| Displays | |||||||||||||||||
| Bicubic | 41 | 63 | 3.2 | 6.4 | 49.9 | 54.9 | 315 | 374 | 460 | 585 | 0.92 | 1.08 | 208 | 256 | 0.7 | 21.3 | 22.1 |
| SRfS [14] | 53 | 75 | 9.0 | 17.3 | 61.9 | 67.3 | 500 | 591 | 599 | 659 | 1.35 | 1.60 | 288 | 328 | 0.0 | 0.0 | 0.0 |
| EG [54] | 46 | 5.9 | 66.7 | 388 | 587 | 0.94 | 216 | 0.0 | 2.9 | 2.9 | |||||||
| PDN [39] | 159 | 220 | 99.2 | 99.0 | 55.4 | 57.2 | 381 | 403 | 547 | 580 | 0.85 | 0.95 | 242 | 275 | 0.0 | 9.6 | 9.6 |
| DG [13] | 43 | 66 | 5.8 | 6.7 | 56.5 | 56.7 | 395 | 406 | 606 | 601 | 1.06 | 1.10 | 243 | 265 | 0.7 | 2.9 | 3.7 |
| DIP [47] | 52 | 60 | 13.4 | 9.7 | 76.9 | 74.6 | 732 | 724 | 672 | 645 | 2.36 | 2.06 | 365 | 344 | 0.7 | 0.7 | 1.5 |
| MSG [22] | 26 | 42 | 1.7 | 4.4 | 53.9 | 58.0 | 367 | 430 | 461 | 493 | 0.97 | 1.08 | 204 | 251 | 0.0 | 5.9 | 5.9 |
| DIP-v | 32 | 45 | 2.4 | 4.0 | 53.7 | 57.6 | 336 | 407 | 344 | 409 | 1.00 | 1.18 | 191 | 221 | 5.9 | 51.5 | 57.4 |
| MSG-v | 23 | 43 | 1.4 | 3.5 | 47.2 | 51.0 | 271 | 324 | 451 | 531 | 0.69 | 0.80 | 152 | 190 | 91.9 | 5.1 | 97.1 |
| Vintage | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 67 | 98 | 4.6 | 9.0 | 72.8 | 77.3 | 558 | 649 | 602 | 729 | 1.51 | 1.64 | 258 | 302 | 5.9 | 28.7 | 34.6 |
| SRfS [14] | 101 | 145 | 16.8 | 32.3 | 83.7 | 87.2 | 721 | 749 | 631 | 634 | 1.64 | 1.68 | 346 | 382 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 140 | 174 | 67.6 | 79.0 | 82.3 | 85.7 | 663 | 714 | 706 | 700 | 1.51 | 1.57 | 319 | 350 | 0.0 | 0.0 | 0.0 |
| DG [13] | 72 | 107 | 7.1 | 10.4 | 79.4 | 80.1 | 666 | 669 | 796 | 840 | 1.50 | 1.52 | 290 | 300 | 0.0 | 0.7 | 0.7 |
| DIP [47] | 74 | 117 | 24.8 | 46.9 | 93.6 | 94.2 | 953 | 965 | 910 | 872 | 4.01 | 4.16 | 656 | 687 | 0.7 | 0.7 | 1.5 |
| MSG [22] | 41 | 59 | 3.2 | 6.8 | 80.6 | 84.6 | 708 | 785 | 510 | 610 | 1.62 | 1.85 | 292 | 364 | 0.0 | 9.6 | 9.6 |
| DIP-v | 42 | 67 | 2.7 | 5.9 | 85.2 | 88.8 | 804 | 884 | 579 | 674 | 1.94 | 2.48 | 343 | 435 | 25.7 | 44.1 | 69.9 |
| MSG-v | 33 | 65 | 2.5 | 5.9 | 71.4 | 77.6 | 536 | 643 | 670 | 702 | 1.29 | 1.43 | 211 | 268 | 67.6 | 16.2 | 83.8 |
| Recycle | |||||||||||||||||
| Bicubic | 587 | 880 | 9.2 | 16.6 | 70.6 | 78.6 | 575 | 721 | 474 | 576 | 1.23 | 1.17 | 329 | 398 | 0.0 | 11.0 | 11.0 |
| SRfS [14] | 47 | 72 | 10.2 | 22.1 | 86.1 | 88.8 | 715 | 772 | 610 | 623 | 1.68 | 1.81 | 376 | 410 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 95 | 128 | 90.5 | 79.8 | 84.0 | 85.7 | 635 | 701 | 523 | 589 | 1.66 | 2.18 | 364 | 457 | 0.0 | 6.6 | 6.6 |
| DG [13] | 39 | 82 | 3.4 | 11.7 | 81.6 | 83.6 | 696 | 719 | 602 | 617 | 1.75 | 1.99 | 328 | 383 | 2.9 | 65.4 | 68.4 |
| DIP [47] | 29 | 45 | 3.9 | 9.3 | 91.0 | 91.8 | 871 | 923 | 576 | 605 | 2.95 | 3.31 | 434 | 500 | 1.5 | 5.9 | 7.4 |
| MSG [22] | 106 | 1182 | 5.8 | 11.9 | 82.8 | 89.6 | 741 | 869 | 624 | 661 | 2.60 | 3.01 | 485 | 550 | 0.7 | 0.0 | 0.7 |
| DIP-v | 20 | 34 | 1.5 | 4.2 | 78.9 | 85.0 | 575 | 735 | 388 | 485 | 1.56 | 1.86 | 273 | 332 | 94.9 | 3.7 | 98.5 |
| MSG-v | 51 | 76 | 3.9 | 7.9 | 73.9 | 82.1 | 603 | 737 | 520 | 564 | 1.66 | 2.02 | 368 | 473 | 0.0 | 7.4 | 7.4 |
| Umbrella | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 1013 | 1507 | 6.9 | 12.1 | 77.7 | 80.9 | 749 | 837 | 747 | 886 | 0.60 | 0.60 | 323 | 380 | 5.9 | 35.3 | 41.2 |
| SRfS [14] | 148 | 217 | 19.4 | 35.5 | 87.5 | 90.8 | 843 | 853 | 797 | 831 | 0.71 | 0.78 | 397 | 443 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 220 | 287 | 94.9 | 89.1 | 86.6 | 88.1 | 799 | 828 | 847 | 882 | 0.79 | 1.13 | 367 | 452 | 3.7 | 22.8 | 26.5 |
| DG [13] | 365 | 507 | 9.1 | 20.3 | 84.6 | 87.3 | 846 | 878 | 781 | 856 | 0.92 | 1.36 | 399 | 457 | 0.0 | 0.7 | 0.7 |
| DIP [47] | 138 | 145 | 48.5 | 21.6 | 90.5 | 93.2 | 915 | 953 | 737 | 722 | 1.19 | 1.65 | 467 | 528 | 2.9 | 16.2 | 19.1 |
| MSG [22] | 292 | 555 | 7.4 | 12.4 | 84.3 | 88.1 | 834 | 896 | 678 | 787 | 1.27 | 1.47 | 442 | 496 | 0.0 | 0.7 | 0.7 |
| DIP-v | 91 | 129 | 3.4 | 5.7 | 83.4 | 85.3 | 796 | 854 | 604 | 598 | 0.67 | 0.79 | 318 | 352 | 82.4 | 8.1 | 90.4 |
| MSG-v | 129 | 218 | 5.2 | 9.7 | 79.1 | 82.3 | 778 | 842 | 800 | 890 | 0.72 | 0.89 | 348 | 427 | 5.1 | 16.2 | 21.3 |
| Classroom1 | |||||||||||||||||
| Bicubic | 966 | 1371 | 6.7 | 9.0 | 75.8 | 78.3 | 636 | 728 | 581 | 784 | 0.41 | 0.30 | 268 | 295 | 12.5 | 37.5 | 50.0 |
| SRfS [14] | 135 | 202 | 18.5 | 28.5 | 82.6 | 85.7 | 761 | 781 | 718 | 756 | 0.62 | 0.62 | 332 | 363 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 239 | 324 | 96.0 | 91.0 | 81.5 | 82.9 | 739 | 759 | 751 | 807 | 0.62 | 0.76 | 279 | 342 | 16.9 | 26.5 | 43.4 |
| DG [13] | 307 | 503 | 8.8 | 16.8 | 82.0 | 82.7 | 743 | 762 | 766 | 812 | 0.74 | 0.87 | 313 | 337 | 0.0 | 1.5 | 1.5 |
| DIP [47] | 96 | 145 | 17.0 | 22.4 | 94.4 | 94.6 | 956 | 952 | 789 | 751 | 1.94 | 2.12 | 540 | 557 | 0.0 | 1.5 | 1.5 |
| MSG [22] | 297 | 408 | 7.3 | 10.0 | 81.2 | 83.8 | 723 | 810 | 626 | 604 | 0.90 | 1.01 | 351 | 391 | 0.0 | 0.7 | 0.7 |
| DIP-v | 69 | 117 | 4.1 | 9.3 | 81.0 | 86.0 | 700 | 789 | 516 | 537 | 0.64 | 0.86 | 266 | 327 | 64.0 | 18.4 | 82.4 |
| MSG-v | 127 | 203 | 5.4 | 8.4 | 76.9 | 79.4 | 678 | 735 | 739 | 803 | 0.60 | 0.64 | 283 | 330 | 2.2 | 11.8 | 14.0 |
| Playroom | |||||||||||||||||
| User, 1st | User, 2nd | Top 2 | |||||||||||||||
| x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x8 | x4 | x4 | x4 | |
| Bicubic | 1263 | 1744 | 14.4 | 20.4 | 72.0 | 76.9 | 684 | 783 | 509 | 675 | 0.80 | 0.52 | 386 | 441 | 0.0 | 2.2 | 2.2 |
| SRfS [14] | 97 | 151 | 26.9 | 42.1 | 88.1 | 91.2 | 802 | 829 | 663 | 715 | 1.24 | 1.08 | 493 | 540 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 181 | 253 | 85.0 | 69.7 | 86.3 | 89.2 | 820 | 862 | 583 | 656 | 1.54 | 1.88 | 472 | 543 | 25.7 | 61.8 | 87.5 |
| DG [13] | 425 | 133 | 22.4 | 25.0 | 85.4 | 86.0 | 845 | 826 | 779 | 691 | 1.96 | 1.63 | 519 | 469 | 1.5 | 2.2 | 3.7 |
| DIP [47] | 58 | 91 | 18.4 | 20.0 | 93.0 | 93.2 | 941 | 937 | 647 | 612 | 3.09 | 2.86 | 602 | 592 | 1.5 | 2.9 | 4.4 |
| MSG [22] | 433 | 349 | 16.1 | 22.3 | 85.8 | 89.9 | 855 | 911 | 685 | 705 | 2.51 | 2.74 | 576 | 616 | 0.0 | 0.0 | 0.0 |
| DIP-v | 49 | 83 | 5.4 | 12.2 | 83.8 | 88.5 | 728 | 847 | 459 | 530 | 1.29 | 1.52 | 357 | 433 | 70.6 | 27.2 | 97.8 |
| MSG-v | 112 | 166 | 9.4 | 15.5 | 75.2 | 80.1 | 721 | 810 | 565 | 615 | 1.46 | 1.67 | 453 | 510 | 0.0 | 3.7 | 3.7 |
| Backpack | |||||||||||||||||
| Bicubic | 985 | 1078 | 14.3 | 11.5 | 62.7 | 69.4 | 639 | 730 | 564 | 692 | 0.60 | 0.45 | 392 | 424 | 2.2 | 34.6 | 36.8 |
| SRfS [14] | 69 | 83 | 18.9 | 25.5 | 89.9 | 89.9 | 831 | 847 | 630 | 651 | 1.37 | 1.26 | 500 | 505 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 173 | 207 | 81.6 | 65.2 | 80.4 | 85.4 | 770 | 820 | 609 | 719 | 1.59 | 1.96 | 519 | 553 | 3.7 | 37.5 | 41.2 |
| DG [13] | 325 | 465 | 26.5 | 39.9 | 77.0 | 82.0 | 765 | 808 | 650 | 696 | 1.62 | 2.07 | 529 | 545 | 0.7 | 2.9 | 3.7 |
| DIP [47] | 41 | 67 | 8.2 | 17.9 | 93.2 | 94.5 | 943 | 984 | 766 | 692 | 3.36 | 2.95 | 639 | 645 | 1.5 | 11.8 | 13.2 |
| MSG [22] | 211 | 170 | 15.1 | 10.4 | 76.5 | 86.9 | 762 | 856 | 671 | 723 | 2.11 | 2.31 | 577 | 609 | 0.7 | 0.0 | 0.7 |
| DIP-v | 38 | 62 | 6.2 | 12.9 | 82.5 | 88.7 | 677 | 768 | 457 | 496 | 1.31 | 1.43 | 409 | 448 | 90.4 | 5.1 | 95.6 |
| MSG-v | 113 | 89 | 10.8 | 5.9 | 65.3 | 72.5 | 663 | 752 | 577 | 635 | 1.07 | 1.15 | 462 | 480 | 0.0 | 5.9 | 5.9 |
| Jadeplant | |||||||||||||||||
| Bicubic | 1017 | 1297 | 19.3 | 18.4 | 68.8 | 75.7 | 695 | 788 | 545 | 696 | 0.97 | 0.62 | 449 | 464 | 2.3 | 27.7 | 30.0 |
| SRfS [14] | 105 | 143 | 39.5 | 48.9 | 87.2 | 92.7 | 787 | 839 | 637 | 719 | 1.96 | 1.70 | 551 | 583 | 0.0 | 0.0 | 0.0 |
| PDN [39] | 161 | 205 | 81.8 | 62.0 | 82.4 | 88.0 | 778 | 849 | 551 | 625 | 1.95 | 2.20 | 512 | 572 | 19.1 | 41.4 | 60.5 |
| DG [13] | 326 | 512 | 27.8 | 47.6 | 82.6 | 86.8 | 791 | 823 | 718 | 670 | 2.28 | 2.66 | 567 | 601 | 0.0 | 0.5 | 0.5 |
| DIP [47] | 70 | 121 | 16.7 | 32.8 | 91.2 | 92.3 | 913 | 911 | 735 | 764 | 3.19 | 3.21 | 615 | 638 | 0.0 | 0.5 | 0.5 |
| MSG [22] | 216 | 263 | 21.1 | 17.8 | 81.5 | 87.6 | 796 | 880 | 751 | 783 | 2.73 | 2.90 | 614 | 649 | 0.0 | 0.0 | 0.0 |
| DIP-v | 84 | 121 | 21.8 | 24.0 | 86.6 | 89.5 | 820 | 870 | 542 | 654 | 1.92 | 1.99 | 503 | 535 | 78.2 | 20.5 | 98.6 |
| MSG-v | 109 | 117 | 13.9 | 11.2 | 71.0 | 79.0 | 688 | 781 | 605 | 622 | 1.61 | 1.66 | 507 | 529 | 0.5 | 8.2 | 8.6 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Perceptual Deep Depth Super-Resolution
Oleg Voynov1, Alexey Artemov1, Vage Egiazarian1, Alexander Notchenko1,
Gleb Bobrovskikh1,2, Denis Zorin3,1, Evgeny Burnaev1
1Skolkovo Institute of Science and Technology, 2Higher School of Economics,
3New York University
{oleg.voinov, a.artemov, vage.egiazarian, alexandr.notchenko}@skoltech.ru,
[email protected], [email protected], [email protected]
Abstract
RGBD images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth maps by taking advantage of color information; deep learning methods make combining color and depth information particularly easy.
However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important.
The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We compare this approach with a number of existing optimization and learning-based techniques.
1 Introduction
RGBD images are increasingly common as sensor technology becomes more widely available and affordable. They can be used for reconstruction of the 3D shapes of objects and their surface appearance. The better the quality of the depth component, the more reliable the reconstruction.
Unfortunately, for most methods of depth acquisition the resolution and quality of the depth component is insufficient for accurate surface reconstruction. As the resolution of the RGB component is usually several times higher and there is a high correlation between structural features of the color image and the depth map (e.g., object edges) it is natural to use the color image for depth map super-resolution, i.e. upsampling of the depth map. Convolutional neural networks are a natural fit for this problem as they can easily fuse heterogeneous information.
A critical aspect of any upsampling method is the measure of quality it optimizes (i.e., the loss function), whether the technique is data-driven or not. In this paper we focus on applications that require reconstruction of 3D geometry visible to the user, like acquisition of realistic 3D scenes for virtual or augmented reality and computer graphics. In these applications the visual appearance of the resulting 3D shape, i.e., how the surface looks when observed under various lighting conditions, is of particular importance.
Most existing research on depth super-resolution is dominated by simple measures based on pointwise deviation of depth values. However, direct pointwise difference of the depth maps do not capture the visual difference between the corresponding 3D shapes: for example, low-amplitude high-frequency variations of depth may correspond to significant difference in appearance, while conversely, relatively large smooth changes in depth may be perceptually less relevant, as illustrated in Figure 1.
Hence, we propose to compare the rendered images of the surface instead of the depth values directly. In this paper we explore depth map super-resolution using a simple loss function based on visual differences. Our loss function can be computed efficiently and is shown to be highly correlated with more elaborate perceptual metrics. We demonstrate that this simple idea used with two deep learning-based RGBD super-resolution algorithms results in a dramatic improvement of visual quality according to perceptual metrics and an informal perceptual study. We compare our results with six state-of-the-art methods of depth super-resolution that are based on distinct principles and use several types of loss functions.
In summary, our contributions are as follows: (1) we demonstrate that a simple and efficient visual difference-based metric for depth map comparison can be, on the one hand, easily combined with neural network-based whole-image upsampling techniques, and, on the other hand, is correlated with established proxies for human perception, validated with respect to experimental measurements; (2) we demonstrate with extensive comparisons that with the use of this metric two methods of depth map super-resolution, one based on a trainable CNN and the other based on the deep prior, yield high-quality results as measured by multiple perceptual metrics. To the best of our knowledge, our paper is the first to systematically study the performance of visual difference-based depth super-resolution across a variety of datasets, methods, and quality measures, including a basic human evaluation.
Throughout the paper we use the term depth map to refer to the depth component of an RGBD image, and the term normal map to refer to the map of the same resolution with the 3D surface normal direction computed from the depth map at each pixel. Finally, the rendering of a depth map refers to the grayscale image obtained by constructing a 3D triangulation of the height field represented by the depth map, via computing the normal map from this triangulation, and rendering it using fixed material properties and a choice of lighting. This is distinct from a commonly used depth map visualization with grayscale values obtained from the depth values by simple scaling. We describe this in more detail in Section 3.
2 Related work
2.1 Image quality measures
Quality measures play two important roles in image super-resolution: on the one hand, they are used to formulate an optimization functional or a loss function, on the other hand, they are used to evaluate the quality of the results. Ideally, the same function should serve both purposes, however, in some instances it may be optimal to choose different functions for evaluation and optimization. While in the former case the top priority is to capture the needs of the application, in the latter case the efficiency of evaluation and differentiability are significant considerations.
In most works on depth map reconstruction and upsampling a limited number of simple metrics are used, both for optimization and final evaluation. Typically these are scaled or norms of depth deviations (see e.g. [9]).
Another set of measures introduced in [19, 20] and primarily used for evaluation, not optimization or learning, consists of heuristic measures of various aspects of the depth map geometry: foreground flattening/thinning, fuzziness, bumpiness, etc. Most of them require a very specific segmentation of the image for detection of flat areas and depth discontinuities.
Visual similarity measures, well-established in the area of photo-processing, aim to be consistent with human judgment, in the sense of similarity ordering (which of the two images is more similar to the ground truth?). The examples include (1) the metrics based on simple vision models of structural similarity SSIM [52], FSIM [57], MSSIM [53], (2) based on a sophisticated model of low-level visual processing [35], or (3) on convolutional neural networks (see [58] for a detailed overview). The latter use a simple distance measure on deep features learned for an image understanding task, e.g. distance on the features learned for image classification, and have been demonstrated to outperform statistical measures such as SSIM.
2.2 Depth super-resolution
Depth super-resolution is closely related to a number of depth processing tasks, such as denoising, enhancement, inpainting, and densification (e.g., [5, 6, 8, 21, 33, 34, 45, 46, 55]). We directly focus on the problem of super-resolution, or more specifically, estimation of high-resolution depth map from a single low-resolution depth map and a high-resolution RGB image.
Convolutional neural networks
have achieved most impressive performance among learning-based methods in high-level computer vision tasks and recently have been applied to depth super-resolution [22, 30, 39, 43]. One approach [22] is to resolve ambiguity in the depth map upsampling by explicitly adding high-frequency features from high-resolution RGB data. Another, hybrid approach [39, 43] is to add a subsequent optimization stage to a CNN to produce sharper results. Different approaches to CNN-based photo-guided depth super-resolution include linear filtering with CNN-derived kernels [26], deep fusion of time-of-flight depth and stereo images [1], and generative adversarial networks [62].
These techniques use either or norm of the depth differences as the basis of their loss functions, often combined with regularizers of different types. The recent approach of [62] is the closest to ours: it uses the difference of gradients as one of the loss terms to capture some of the visual information. For evaluation, these works report root mean square error (RMSE), mean absolute error (MAE), peak signal-to-noise ratio (PSNR), all applied directly to depth maps, and, rarely [4, 43, 44, 62], perceptual SSIM also applied directly to depth maps. In contrast, we propose to measure the perceptual quality of depth map renderings.
Dictionary learning
has also been investigated for depth super-resolution [11, 13, 29], however, compared to CNNs, it is typically restricted to smaller dimensions and as a result to structurally simpler depth maps.
Variational approach
aims to combine RGB and depth information explicitly by carefully designing an optimization functional, without relying on learning. Most relevant examples employ shape-from-shading problem statement for single-image [14] or multiple-image [38] depth super-resolution. These works include visual difference-related terms in the optimized functional and report normal deviation, capturing visual similarity. While showing impressive results in many cases, they typically require prior segmentation of foreground objects and depend heavily on the quality of such segmentation.
Another strategy to tackle ambiguities in super-resolution is to design sophisticated regularizers to balance the data-fidelity terms against a structural image prior [15, 24, 56]. In contrast to this approach, which requires custom hand-crafted regularized objectives and optimization procedures, we focus on the standard training strategy (i.e., gradient-based optimization of a CNN) while using a loss function that captures visual similarity.
Yet another approach is to choose a carefully-designed model such as [63] featuring a sophisticated metric defined in a space of minimum spanning trees and including an explicit edge inconsistency model. In contrast to ours, such model requires manual tuning of multiple hyperparameters.
2.3 Perceptual photo super-resolution
Perceptual metrics have been considered more broadly in the context of photo processing. While convolutional neural networks for photo super-resolution trained with simple mean square or mean absolute color deviation keep demonstrating impressive results [16, 18, 59, 60], it has been widely recognized that pixelwise difference of color image data is not well correlated with perceptual image difference. For this reason, relying on a pixelwise color error may lead to suboptimal performance.
One solution is to instead use the loss function represented by the deviation of the features from a neural network trained for an image understanding task [25]. This idea can be further combined with an adversarial training procedure to push the super-resolution result to the natural image manifold [28]. Another extension to this idea is to train the neural network to generate images with natural distribution of statistical features [12, 36, 50, 51]. To balance between the perceptual quality and pixelwise color deviation, generative adversarial networks can be used [7, 31, 49].
Another solution is to learn a quality measure from perceptual scores, collected from a human subject study, and use this quality measure as the loss function. Such quality measure may capture similarity of two images [58] or an absolute naturalness of the image [32].
3 Metrics
In this section, we discuss visually-based metrics and how they can be used to evaluate the quality of depth map super-resolution and as loss functions. The general principle we follow is to apply comparison metrics to renderings of the depth maps to obtain a measure of their difference instead of considering depth maps directly. The difficulty with this approach is that there are infinitely many possible renderings depending on lighting conditions, material properties and camera position. However, we demonstrate that even a very simple rendering procedure already yields substantially improved results. We label visually-based metrics with subscript “v” and the metrics that compare the depth values directly with subscript “d”.
From depth map to visual representation.
To approximate the appearance of a 3D scene depicted with a certain depth map we use a simple rendering procedure. We illuminate the corresponding 3D surface with monochromatic directional light source and observe it with the same camera that the scene was originally acquired with. We use the diffuse reflection model and do not take visibility into account. For this model, the intensity of a pixel of the rendering is proportional to cosine of the angle between the normal at the point of the surface corresponding to the pixel and direction to the light source : . We calculate the normals from the depth maps using first-order finite-differences. Any number of vectors can be used to generate a collection of renderings representing the depth map, however, any rendering can be obtained as a linear combination of three basis ones corresponding to independent light directions. Renderings for different light directions are presented in Figure 2.
Perceptual metrics.
We briefly describe two representative metrics: a statistics-based DSSIM, and a neural network-based LPIPS. Either of these can be applied to three basis renderings (or a larger sample of renderings) and reduced to obtain the final value. While, in principle, they can also be used as loss functions, the choice of a loss function needs to take stability and efficiency into account, so we opt for a more conservative choice described below.
Structural similarity index measure (SSIM) [52] takes into account the changes in the local structure of an image, captured by statistical quantities computed on a small window around each pixel. For each pair of pixels of the compared images , the luminance term , the contrast term and the structural term , each normalized, are computed using the means , standard deviations and cross-covariance of the pixels in the corresponding local windows. The value of SSIM is then computed as pixelwise mean product of these terms
[TABLE]
where is the number of pixels. Dissimilarity measure can be computed as .
Neural net-based metrics rely on the idea of measuring the distance between features extracted from a neural network. Specifically, feature maps , with spatial dimensions are extracted from layers of the network for each of the compared images. In the simplest case, the metric value is then computed as pixelwise mean square difference of the feature maps, summed over the layers
[TABLE]
Learned perceptual image patch similarity (LPIPS) [58] adds a learned channel-wise weighting to the above formula and uses 5 layers from Alexnet [27] or VGG [41] or the first layer from Squezenet [23] as the CNN of choice.
Our visual difference-based metric.
While the metrics described above are good proxies for human evaluation of difference between depth map renderings, they are lacking as loss functions due to their complex landscapes. Optimization with DSSIM as the loss function may produce the results actually inferior with respect to DSSIM itself compared to a simpler loss function we define below, as illustrated in Figure 3. LPIPS has a complex energy profile typical for neural networks, and having a neural network as the loss function for another may behave unpredictably [61].
The simplest metric capturing the difference between all possible renderings of the depth maps can be computed as the average root mean square deviation of three basis renderings in an orthogonal basis
[TABLE]
similarly to RMS difference of the normal maps.
We found that this simple metric for depth map comparison is efficient and stable as the loss function and at the same time, as we demonstrate in Section 5, it is well correlated with DSSIM and LPIPS, i.e., situations when the value of one metric is high and the value of another is low are unlikely. Our experiments confirm that optimization of this metric also improves both perceptual metrics.
4 Methods
We selected eight representative state-of-the-art depth processing methods based on different principles: (1) a purely variational method [14], (2) a bilateral filtering method that uses a high-resolution edge map [54], (3) a dictionary learning method [13], (4) a hybrid CNN-variational method [39], (5) a pure CNN [22], (6) a zero-shot CNN [47], (7) a densification [34] and (8) an enhancement [55] CNNs. Our goals were (a) to modify the methods for using with the visual difference-based loss function, and (b) to compare the results of the modified methods with alternatives of different types. In our experiments the last two methods did not perform well compared to others, so we did not consider them further. We found that two neural network-based methods (5) and (6), that we refer to as MSG and DIP, can be easily modified for using with a visual difference-based loss function, as we explain now.
MSG
[22] is a deep learning method that uses different strategies to upsample different spectral components of low-resolution depth map. In the modified version of this method, that we denote by MSG-V, we replaced the original loss function with a combination of our visual difference-based metric and mean absolute deviation of Laplacian pyramid [2] as a regularizer
[TABLE]
DIP
[47] is a zero-shot deep learning approach, based on a remarkable observation that, even without any specialized training, the structure of CNN itself may be leveraged for solving inverse problems on images. We note that this approach naturally allows simultaneous super-resolution and inpainting. In this approach, the depth super-resolution problem would be formulated as
[TABLE]
where and are the low-resolution and super-resolved depth maps, is the output of the deep neural network parametrised by , is the downsampling operator, and is direct mean square difference of the depth maps. To perform photo-guided super-resolution, we added a second output channel for intensity to the network
[TABLE]
where is the high-resolution photo guidance, and for visually-based version DIP-V we further replaced the direct depth deviation with the function from Equation 4.
We used the remaining four methods (1)-(4) for comparison as-is, as modifying them for a different loss function would require substantial changes to the algorithms.
SRfS
[14] is a variational method relying on complimentarity of super-resolution and shape-from-shading problems. It already includes a visual-difference based term (the remaining methods use depth difference metrics).
EG
[54] approaches the problem via prediction of smooth high-resolution depth edges with Markov random field optimization. It does not use a loss directly, therefore cannot be easily adapted.
DG
[13] is a depth map enhancement method based on dictionary learning that uses depth difference-based fidelity term. It makes a number of modeling choices which may not be suitable for a different loss function, and typically does not perform as well as neural network-based methods.
PDN
[39] is a hybrid method featuring two stages: the first is composed of fully-convolutional layers and predicts a rough super-resolved depth map, and the second performs an unrolled variational optimization, aiming to produce a sharp and noise-free result.
5 Experiments
5.1 Data
For evaluation we selected a representative and diverse set of 34 RGBD images featuring synthetic, high-quality real and low-quality real data with different levels of geometric and textural complexity. We employed four datasets, most common in literature on depth super-resolution. ICL-NUIM [17] includes photo-realistic RGB images along with synthetic depth, free from any acquisition noise. Middlebury 2014 [40], captured with a structured light system, provides high-quality ground truth for complex real-world scenes. SUN RGBD [42] contains images captured with four different consumer-level RGBD cameras: Intel RealSense, Asus Xtion, Microsoft Kinect v1 and v2. ToFMark [10] provides challenging real-world time-of-flight and intensity camera acquisitions together with an accurate ground truth from a structured light sensor.
In addition, we constructed a synthetic SimGeo dataset, that consists of 6 geometrically simple scenes with low- and high-frequency texture, and without any, using Blender. The purpose of SimGeo were to reveal artifacts that are not related to the noise or high-frequency geometry in the input data, like false geometric detail caused by color variation on a smooth surface.
We resized and cropped each RGBD image to the resolution of and generated low-resolution input depth maps with the scaling factors of 4 and 8, that are most common among the works on depth super-resolution. We focused on two downsampling models: Box, i.e., each low-resolution pixel contains the mean value over the “box” neighbouring high-resolution pixels, and Nearest neighbour, i.e., each low-resolution pixel contains the value of the nearest high-resolution pixel. For additional details on our evaluation data and the results for different downsampling models please refer to supplementary material.
5.2 Evaluation details
To quantify the performance of the methods, we measured direct RMS deviation of the depth maps (denoted by ) and deviation of their renderings with the metrics described in Section 3. For visually-based metrics we calculated their values for three orthogonal light directions, corresponding to the three left-most images in Figure 2, and the value for an additional light direction, corresponding to the right-most image. We then took the worst of the four values. With similar outcomes, we also explored different reducing strategies and a set of different metrics: BadPix and Bumpiness, applied directly to depth values, and BadPix and RMSE applied to separate depth map renderings.
Additionally, we conducted an informal perceptual study using the results on SimGeo, ICL-NUIM and Middlebury datasets, in which subjects were asked to choose the renderings of the upsampled depth maps that look most similar to the ground truth.
5.3 Implementation details
We evaluated publicly available trained models for EG, DG, and MSG and trained PDN using publicly available code; we used the implementation of SRfS provided by the authors; we adapted publicly available implementation of DIP for depth maps, as described in Section 4; we reimplemented MSG-V in PyTorch [37] and trained it according to the original paper using the patches from Middlebury and MPI Sintel [3]. We selected the value of the weighting parameter in Equation (4) so that both terms of the loss contribute equally with respect to their magnitudes (see supplementary material for more details).
5.4 Comparison of quality measures
To quantify how well different metrics represent the visual quality of a super-resolved depth map, we compared pairwise correlations of these metrics and calculated the corresponding values of Pearson correlation coefficient. Since LPIPS as a neural network-based perceptual metric has been experimentally shown to represent human perception well, we used its value as the reference. We found that the metrics based on direct depth deviation demonstrate weak correlation with perceptual metrics, as illustrated in Figure 4 for , and hence are not suitable for measuring the depth map quality when the visual appearance plays an important role. On the other hand, we found that our correlates well with perceptual metrics, to the same extent they correlate with each other (see Figure 4).
5.5 Comparison of super-resolution methods
In Table 1 and Figure 5 we present the super-resolution results on our SimGeo dataset with the scaling factor of 4; in Table 2 and Figure 6 we present the results on ICL-NUIM and Middlebury datasets with the scaling factors of 4 and 8. We use Box downsampling model in both cases. Please find the additional results in supplementary material or online111mega.nz/#F!yvRXBABI!pucRoBvtnthzHI1oqsxEvA!y6JmCajS.
In general, we found that the methods EG, PDN and DG do not recover fine details of the surface, typically oversmoothing the result in comparison to, e.g., Bicubic upsampling, the methods SRfS and original DIP suffer from false geometry artifacts in case of a smooth textured surface, and original MSG introduces severe noise around the depth edges. As illustrated in Figure 6 and Table 2, all the methods from prior works perform relatively poorly on the images with regions of missing depth measurements (rendered in black), including the ones that inpaint these regions explicitly (SRfS, DG) or implicitly (DIP). The method EG failed to converge on some images.
In contrast, we observed that integration of our visual difference-based loss into DIP and MSG significantly improved the results of both methods qualitatively and quantitatively. The visual difference-based version DIP-V do not suffer from false geometry artifacts as much as the original version. On the challenging images from Middlebury dataset, where it performed simultaneous super-resolution and inpainting, DIP-V mostly outperformed other methods as measured by the perceptual metrics and was preferred by more than 80% of subjects in the perceptual study. The visual difference-based version MSG-V produces significantly less noisy results in comparison to the original version, in some cases almost without any noticeable artifacts. On the data without missing measurements, including hole-filled “Vintage” from Middlebury, MSG-V mostly outperformed other methods as measured by the perceptual metrics and was preferred by more than 80% of subjects. On SimGeo, ICL-NUIM and Middlebury combined, one of our modified versions, DIP-V or MSG-V, was preferred over the other methods by more than 85% of subjects.
For reference, in Figure 5 we include pseudo-color visualizations of the depth maps. Notice that while the upsampled depth maps obtained with different methods are almost indistinguishable in this form of visualization, commonly used in the literature on depth processing for qualitative evaluation, the corresponding renderings and, consequently, the underlying geometry varies dramatically.
6 Conclusion
We have explored depth map super-resolution with a simple visual difference-based metric as the loss function. Via comparison of this metric with a variety of perceptual quality measures, we have demonstrated that it can be considered a reasonable proxy for human perception in the problem of depth super-resolution with the focus on visual quality of the 3D surface. Via an extensive evaluation of several depth-processing methods on a range of synthetic and real data, we have demonstrated that using this metric as the loss function yields significantly improved results in comparison to the common direct pixel-wise deviation of depth values. We have combined our metric with relatively simple and non-specific deep learning architectures and expect that this approach will be beneficial for other related problems.
We have focused on the case of single regularly sampled RGBD images, but a lot of geometric data has less regular form. The future work would be to adapt the developed methodology to a more general sampling of the depth values for the cases of multiple RGBD images or point clouds annotated with a collection of RGB images.
Acknowledgements
The work was supported by The Ministry of Education and Science of Russian Federation, grant No. 14.615.21.0004, grant code: RFMEFI61518X0004.
The authors acknowledge the usage of the Skoltech CDISE HPC cluster Zhores for obtaining the results presented in this paper.
Supplementary material
Appendix A Additional evaluation details
In the literature on range image processing, the term depth is used to denote three different types of range data:
- •
disparity, presented in, e.g., Middlebury dataset, i.e., the difference in image location of a feature within two stereo images;
- •
orthogonal depth, presented in, e.g., SUN-RGBD dataset, i.e., the distance from a point in the 3D-space to the image plane;
- •
perspective depth, presented in, e.g., low-resolution scans in ToFMark dataset, i.e., the distance from a point in the 3D-space to the camera.
We use the term depth map to denote any data of this kind, however, in our experiments we evaluated each super-resolution method on the range type that it was designed for. For evaluation of the disparity processing methods on the datasets that do not provide disparity maps, we calculated virtual disparity images with the baseline of 20 cm.
Here we describe the quality measures that we considered in addition to the ones discussed in the main text. We recall that we label the metrics that compare the depth values directly with subscript “d”, and the visually-based metrics with subscript “v”.
BadPix is the fraction of measurements with absolute deviation larger than a certain threshold
[TABLE]
or the fraction of measurements with relative deviation larger than a threshold
[TABLE]
where and are the compared depth maps, represents individual pixels, and is the number of pixels. We considered BadPix for depth map comparison with absolute thresholds of 1, 5, and 10 cm and relative thresholds of 1, 5, and 10%. We also considered this metric for comparison of depth map renderings with the absolute thresholds of 1, 5, and 10 each divided by 255 (which correspond to deviations by the respective numbers of shades of gray in 8-bit grayscale images).
Bumpiness, introduced in [20] for piece-wise planar regions and generalized in [19] for arbitrary smooth surfaces, is a measure of surface smoothness with respect to a reference. It is calculated as
[TABLE]
where is Frobenius norm and is the Hessian matrix of the function , calculated at point . We used the original implementation of this metric. Since this metric includes some parameter values, presumably, specific for the original evaluation dataset, we converted the depth maps to disparity using the camera intrinsics of this dataset.
We used the implementation of from scikit-image [48] and the original implementation of from [58].
In addition to our we considered RMS difference of two rendered images without averaging over the basis renderings, i.e., calculated for a single lighting condition. We denote this metric as : for a light direction and a pair of normal maps it is calculated as
[TABLE]
Appendix B Comparison of quality measures
In Figures 11-16 we compare the relations between different subsets of quality measures. We present pair-wise correlations of the metrics in the form of scatter plots in the lower half of the figure and Pearson and Spearman correlation coefficients in the upper half of the figure. For reference, on the diagonal of the figure we also include kernel density estimates of metric value distributions for each super-resolution method. The distributions for the modified methods DIP-v and MSG-v are represented with the dashed black and solid black curves respectively.
On the depth maps with missing measurements, the methods that do not inpaint the regions with the missing measurements (including MSG-v) sometimes produced severe outliers around these regions. To minimize the influence of such outliers on the results of the metric comparison, we limited the value of to a maximum of 0.5 meters. Among the collected super-resolved images, 8% exceeded this threshold.
For each metric, applied to rendered images, we gathered the values of this metric for four different light directions, as described in Section 5.2 of the main text. We then calculated two additional values, the worst and the average of these four. We label the respective versions of the metric with suffixes , , , , and . For each metric, we found that these six versions are strongly correlated, as illustrated in Figures 11-13, so we further focused on the worst value of each metric.
We also found that different versions of produce very similar results to our , as illustrated in Figure 11. It is consistent with the observation that if is bounded by a constant , then for any choice of the light direction , is bounded by , which can be easily seen from the fact that does not depend on the choice of the basis, so we can choose one of the basis light directions to be equal to .
In Figure 14 we compare the metrics of different types: pixel-wise , and applied to depth directly; “worst” versions of pixel-wise and perceptual and , applied to rendered images; geometrical and our . We found that all three pixel-wise metrics applied to depth directly demonstrate weak correlation with visual and geometrical metrics. Pixel-wise applied to rendered images, although strongly correlated with perceptual metrics, is inappropriate for gradient-based optimization. Additional comparison of pixel-wise and with different thresholds to perceptual and (Figures 15 and 16) leads to the same conclusions. is also strongly correlated with perceptual metrics but only measures local curvature deviation, while the visual appearance of 3D surface is determined by its local orientation.
Appendix C Comparison of super-resolution methods
In Tables 4-11 we present the results of quantitative evaluation of super-resolution methods on the datasets SimGeo, ICL-NUIM and Middlebury for Box downsampling model and scaling factors of 4 and 8. In Table 3 we present the average values. is in millimeters, is in percents, , and are in thousandths. For all visual metrics except the presented value is of the “worst” version. For all metrics the lower value corresponds to the better result. The best results are highlighted in bold and the second best results are underlined.
In addition to metric values, the last three columns of the tables contain the results of the informal perceptual study collected over approximately 250 subjects. In this study, for each scene from SimGeo, ICL-NUIM and Middlebury datasets subjects were shown the renderings of super-resolved depth maps, shuffled randomly, and were asked to choose the renderings, the most and second most similar to ground truth. The renderings calculated with the fourth light direction were used. The values in the columns “User, 1st”, “User, 2nd”, and “Top 2” represent the percentages of the subjects who chose the rendering of the super-resolved depth map, produced by the method in the corresponding method, as the most similar, second most similar, or one of the two most similar to the ground truth respectively. We found that our is mostly consistent with human judgements.
Appendix D Training with
Since optimization of alone is an ill-posed problem, we used a regularization term that penalizes absolute depth deviation. We found that among different regularizers, including , produces the best results. In general, we found that optimization leads to the best results if the terms are weighted in such way that geometrically corresponding depth error and angular normal error result in the same magnitudes of terms. The corresponding value of the weighing parameter in Equation 4 of the main text is determined by the properties of the training data, such as depth map scaling or field of view of the camera.
Appendix E Noisy depth measurements in the input
SimGeo, ICL-NUIM and Middlebury datasets were our primary evaluation sets, yielding the most pronounced outcomes, however, these datasets contain only noise-free scenes. As we were interested in evaluation of our approach on a diverse set of RGBD images, we included twelve scenes from SUN RGBD dataset and three scenes from ToFMark dataset that feature real-world noise patterns in our evaluation data. We observed that increased levels of noise are extremely harmful to all non over-smoothing methods, including those modified with our loss, as they fail to produce reasonable super-resolution results, as illustrated in Figures 9-10. To demonstrate that this is not a limitation of our approach, in Figure 7 we present the super-resolution results produced by modified and unmodified versions of MSG, trained on the data with synthetic multiplicative gaussian noise.
Appendix F Different downsampling models
In Figure 8 we present the results for different downsampling models, used for calculation of low-resolution input. We found that the visual quality remains high when the downsampling model used during training and that of the input match; if this is not the case, the quality deteriorates, as expected.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Gianluca Agresti, Ludovico Minto, Giulio Marin, and Pietro Zanuttigh. Deep learning for confidence information in stereo and tof data fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 697–705, 2017.
- 2[2] Piotr Bojanowski, Armand Joulin, David Lopez-Pas, and Arthur Szlam. Optimizing the latent space of generative networks. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research , pages 600–609, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR.
- 3[3] Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for optical flow evaluation. In A. Fitzgibbon et al. (Eds.), editor, European Conf. on Computer Vision (ECCV) , Part IV, LNCS 7577, pages 611–625. Springer-Verlag, Oct. 2012.
- 4[4] Baoliang Chen and Cheolkon Jung. Single depth image super-resolution using convolutional neural networks. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 1473–1477. IEEE, 2018.
- 5[5] Zhao Chen, Vijay Badrinarayanan, Gilad Drozdov, and Andrew Rabinovich. Estimating depth from rgb and sparse sensing. Co RR , abs/1804.02771, 2018.
- 6[6] Xinjing Cheng, Peng Wang, and Ruigang Yang. Depth estimation via affinity learned with convolutional spatial propagation network. In European Conference on Computer Vision , pages 108–125. Springer, Cham, 2018.
- 7[7] Manri Cheon, Jun-Hyuk Kim, Jun-Ho Choi, and Jong-Seok Lee. Generative adversarial network-based image super-resolution using perceptual content losses. In Laura Leal-Taixé and Stefan Roth, editors, ECCV Workshops , pages 51–62, Cham, 2019. Springer International Publishing.
- 8[8] Nathaniel Chodosh, Chaoyang Wang, and Simon Lucey. Deep convolutional compressed sensing for lidar depth completion. ar Xiv preprint ar Xiv:1803.08949 , 2018.
