The Online Event-Detection Problem
Michael A. Bender, Jonathan W. Berry, Martin Farach-Colton, Rob, Johnson, Thomas M. Kroeger, Prashant Pandey, Cynthia A. Phillips, Shikha, Singh

TL;DR
This paper introduces the online event-detection problem (OEDP), focusing on real-time identification of specific frequency-based events in data streams with strict accuracy and timeliness requirements, and proposes cache-efficient algorithms for it.
Contribution
The paper formulates the OEDP, proves its space complexity, and develops near-optimal cache-efficient algorithms with tunable parameters for false positives and reporting delay.
Findings
Algorithms are within a log factor of optimal in external memory.
The algorithms can be tuned for bounded false positives and delays.
Improved performance when input follows a power-law distribution.
Abstract
Given a stream , a -heavy hitter is an item that occurs at least times in . The problem of finding heavy-hitters has been extensively studied in the database literature. In this paper, we study a related problem. We say that there is a -event at time if occurs exactly times in . Thus, for each -heavy hitter there is a single -event which occurs when its count reaches the reporting threshold . We define the online event-detection problem (OEDP) as: given and a stream , report all -events as soon as they occur. Many real-world monitoring systems demand event detection where all events must be reported (no false negatives), in a timely manner, with no non-events reported (no false positives), and a low reporting threshold. As a result, the OEDP requires a…
Click any figure to enlarge with its caption.
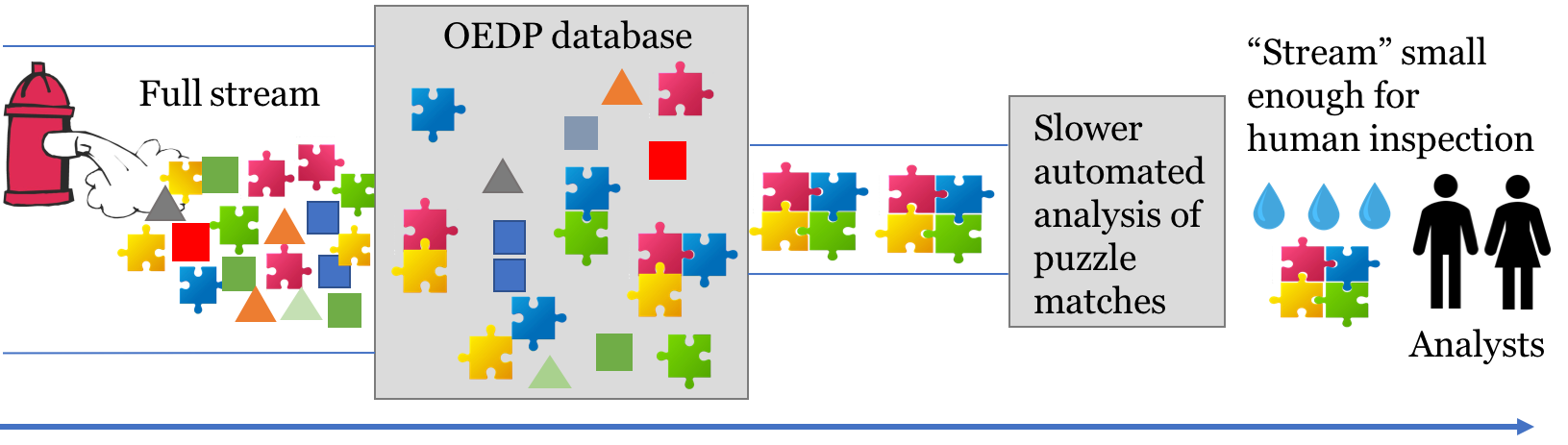 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsData Management and Algorithms · Advanced Database Systems and Queries · Data Stream Mining Techniques
The Online Event-Detection Problem
Michael A. Bender Department of Computer Science, Stony Brook University, Stony Brook, NY, 11794-2424 USA. Email: [email protected].
Jonathan W. Berry MS 1326, PO Box 5800, Albuquerque, NM, 87185 USA. Email: {jberry, caphill}@sandia.gov.
Martín Farach-Colton Department of Computer Science, Rutgers University, Piscataway, NJ 08854 USA. Email: [email protected].
Rob Johnson VMware Research, Creekside F 3425 Hillview Ave, Palo Alto, CA 94304 USA. Email: [email protected].
Thomas M. Kroeger MS 9011, PO Box 969, Livermore, CA 94551 USA. Email: [email protected].
Prashant Pandey Department of Computer Science, Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh, PA 15213. Email: [email protected].
Cynthia A. Phillips22footnotemark: 2
Shikha Singh Department of Computer Science, Wellesley College, Wellesley, MA 02481-8203 USA. Email: [email protected].
Abstract
Given a stream , a -heavy hitter is an item that occurs at least times in . The problem of finding heavy-hitters has been extensively studied in the database literature. In this paper, we study a related problem. We say that there is a -event at time if occurs exactly times in . Thus, for each -heavy hitter there is a single -event, which occurs when its count reaches the reporting threshold . We define the online event-detection problem (oedp) as: given and a stream , report all -events as soon as they occur.
Many real-world monitoring systems demand event detection where all events must be reported (no false negatives), in a timely manner, with no non-events reported (no false positives), and a low reporting threshold. As a result, the oedp requires a large amount of space ( words) and is not solvable in the streaming model or via standard sampling-based approaches.
Since oedp requires large space, we focus on cache-efficient algorithms in the external-memory model.
We provide algorithms for the oedp that are within a log factor of optimal. Our algorithms are tunable: their parameters can be set to allow for bounded false-positives and a bounded delay in reporting. None of our relaxations allow false negatives since reporting all events is a strict requirement for our applications. Finally, we show improved results when the count of items in the input stream follows a power-law distribution.
1 Introduction
Real-time monitoring of high-rate data streams, with the goal of detecting and preventing malicious events, is a critical component of defense systems for cybersecurity [47, 39, 50] and physical systems, such as water or power distribution [15, 36, 40]. In such a monitoring system, changes of state are inferred from the stream elements. Each detected/reported event triggers an intervention. Analysts use more specialized tools to gauge the actual threat level. Newer systems are even beginning to take defensive actions, such as blocking a remote host, automatically based on detected events [43, 34]. When used in an automated system, accuracy (i.e., few false-positives and no false-negatives) and timeliness of event detection are essential.
Motivated by these applications, we define and study the online event-detection problem (oedp). Roughly speaking, the oedp seeks to report all anomalous events (events that cross a predetermined safety threshold) as soon as they occur in the input stream. The related problem of finding the most frequent elements or heavy hitters in streams has been extensively studied in the database literature [29, 30, 4, 24, 19, 18, 38, 16, 32, 42, 17, 31, 17, 14]. More formally, given a stream , a -heavy hitter is an element that occurs at least times in . Here we focus on the problem of finding -events, where we say that there is a -event at time step if occurs exactly times in . Thus for each -heavy hitter there is a single -event which occurs when its count reaches the reporting threshold .
Formally, we define the online event-detection problem (oedp) as: given stream , for each , report if there is a -event at time before seeing . A solution to the online event-detection problem must report
- (a)
all events111We drop the when it is understood. (no False Negatives) 2. (b)
with no non-events and no duplicates (no False Positives) 3. (c)
as soon as an element crosses the threshold (Online).
Furthermore, an online event detector must scale to
- (d)
small reporting thresholds and large , i.e., very small (Scalable).
In this paper, we present algorithms for the oedp. We also give solutions which relax conditions (b) and (c). However, our solutions are motivated by cybersecurity applications where (a) and (d) are strict requirements. Next, we discuss how each of these conditions relate to our approach and results. See Section 6 for more details about the application that motivates the oedp and its constraints.
No false negatives. We are motivated by monitoring systems for national security [1, 5]. The events in this context have especially high consequences so it is worth investing extra resources to detect them. We therefore do not allow false negatives (i.e., condition (a) is strict); see Section 6 for more details. This rules out sampling-based approaches for the oedp, which necessarily incur false negatives.
Scalability. Scalability (condition (d)) is essential in the broader context of detecting anomalies in network streams, since anomalies are often small-sized events that develop slowly, appearing normal in the midst of large amounts of legitimate traffic [41, 49]. As an example of the demands placed on event detection systems, the US Department of Defense (DoD) and Sandia National Laboratories developed the Firehose streaming benchmark suite [1, 5] to measure the performance of oedp algorithms. In the FireHose benchmark, the reporting threshold is preset to the representative value of , which translates to and thus a DoD benchmark enforces condition (d).
Scalable solutions to the oedp require a large amount of space, ruling out the streaming model [6, 51], where the available memory is small—usually just . In particular, streaming algorithms for the heavy-hitters problem assume (all candidates must fit in memory). Even if some false positives are allowed, as in the -heavy hitters problem222Given a stream of size and , report every item that occurs times and no item that occurs times. It is optional whether to report items with counts between and ., Bhattacharyya et al. [16] proved a lower bound of bits. Thus the space requirement is large when is small, as is the case for Scalable solutions where is small, since .
Bounded false positives. Our algorithms for the oedp are tunable: parameters can be set to allow bounded false positives (relaxing condition (b)). We show that allowing some false positives results in fewer I/Os per element.
Allowing False Positives does not lead to substantial space savings. If we allow false positives in a stream with true positives, for any constant , a bound of bits follows via a standard communication-complexity reduction from the probabilistic indexing problem [48, 37]. Besides, as argued above, Scalable solutions to the heavy-hitter problem require large space even when False Positives are allowed.
Bounded reporting delay. The national-security monitoring systems we are interested in (see Section 6) can tolerate a slight delay in reporting when the high-risk event gives sufficient warning for intervention. We show that allowing a bounded delay in reporting (relaxing condition (c)) allows us to circumvent the lower bounds on imposed by our online solution. Thus, bounded delay is especially desirable when we want our oedp algorithm to scale to arbitrarily small reporting thresholds.
Finally, we note that in a security setting like ours, all events need to be detected in real-time to mitigate the associated risk. Thus streaming algorithms for the heavy-hitter problem that require multiple passes over the data are not applicable.
Online Event Detection in External Memory
In this paper, we make the large space requirement ( words) of the oedp more palatable by shifting most of the storage from expensive RAM to lower-cost external storage, such as SSDs or hard drives. In particular, we give cache-efficient algorithms for the oedp in the external-memory model. In the external-memory model, RAM has size , storage has unbounded size, and any I/O access to external memory transfers blocks of size . Typically, blocks are large, i.e., [33, 3].
At first, it may appear trivial to detect heavy hitters using external memory: we can store the entire stream, so what is there to solve? And this would be true in an offline setting. We could find all events by logging the stream to disk and then sorting it.
The technical challenge to online event detection in external memory is that searches are slow. A straw-man solution is to maintain an external-memory dictionary to keep track of the count of every item, and to query the dictionary after each stream item arrives. But this approach is bottlenecked on dictionary searches. In a comparison-based dictionary, queries take I/Os, and there are many data structures that match this bound [26, 7, 22, 9]. This yields an I/O complexity of . Even if we use external-memory hashing, queries still take I/Os, which still gives a complexity of I/Os [35, 27]. Both these solutions are bottlenecked on the latency of storage, which is far too slow for stream processing.
Data ingestion is not the bottleneck in external memory. Optimal external-memory dictionaries (including write-optimized dictionaries such as -trees [22, 11], COLAs [10], xDicts [21], buffered repository trees [23], write-optimized skip lists [13], log structured merge trees [46], and optimal external-memory hash tables [35, 27]) can perform inserts and deletes extremely quickly. The fastest can index using I/Os per stream element, which is far less than one I/O per item. In practice, this means that even a system with just a single disk can ingest hundreds of thousands of items per second. For example, at SuperComputing 2017, a single computer was easily able to maintain a -tree [22] index of all connections on a 600 gigabit/sec network [8]. The system could also efficiently answer offline queries. What the system could not do, however, was detect events online.
In this paper, we show how to achieve online (or nearly online) event detection for essentially the same cost as simply inserting the data into a -tree or other optimal external-memory dictionary.
Results
As our main result, we present an external-memory algorithm that solves the oedp, for that is sufficiently large, at an amortized I/O cost that is substantially cheaper than performing one query for each item in the stream.
Result 1**.**
Given a stream of size and , the online event-detection problem can be solved at an amortized cost of I/Os per stream item.
To put this in context, suppose that . Then the I/O cost of solving the oedp is , which is only a logarithmic factor larger than the naïve scanning lower bound. In this case, we eliminate the query bottleneck and match the data ingestion rate of -trees.
Our algorithm builds on the classic Misra-Gries algorithm [28, 44], and thus supports its generalizations. In particular, similar to the -heavy hitters problem, our algorithm can also be relaxed so that items with frequency between and may be reported. Allowing false positives lowers the amortized I/O cost to ; see Theorem 1. For the oedp (i.e., no False Positives), we set .
Next, we show that, by allowing a bounded delay in reporting, we can extend this result to arbitrarily small . Intuitively, we allow the reporting delay for an event to be proportional to the time it took for the element to go from 1 to occurrences. More formally, for a -event , define the flow time of to be , where is the time step of ’s first occurrence. We say that an event-detection algorithm has time stretch if it reports each event at or before time .
Result 2**.**
Given a stream of size and , the oedp can be solved for any with time stretch at an amortized cost of I/Os per stream item.
For constant , this is asymptotically as fast as simply ingesting and indexing the data [22, 10, 23]. This algorithm can also be relaxed to allow false positives and achieve an improved I/O complexity. Thus, this result yields an almost-online solution to the -heavy hitters problem for arbitrarily small and ; see Theorem 2.
Finally, we consider input distributions where the count of items is drawn from a power-law distribution. Berinde et al. [14] show that the Misra-Gries algorithm gives improved guarantees for the heavy-hitter problem when the input follows a Zipfian distribution with exponent . If the item counts in the stream follow a Zipfian distribution with exponent if and only if they follow a power-law distribution with exponent [2].333Zipf and power-law are often used interchangeably in the literature, however, they are different ways to model the same phenomenon; see [2] and Section 5 for details. As our algorithms are based on Misra-Gries, we automatically get the same improvements when the power-law exponent (i.e., ).
We design a data structure for the oedp problem that supports a smaller threshold than in Result 1 and achieves a better I/O complexity when the count of items in the stream follow a power-law distribution with exponent . For a representative specification of 1TB hard drive and 32GB RAM, our algorithm is performant for Zipfian distributions with , a range that is frequently observed in practical data [25, 14, 45, 20, 2]. For instance, the number of connections to the internet backbone at the autonomous-system level follow a Zipfian distribution with exponent [2].
Result 3**.**
Given a stream of size , where the count of items follows a power-law distribution with exponent , and , where , the oedp can be solved at an amortized I/O complexity per stream item.
In contrast to the worst-case solution (Result 1), Result 3 allows thresholds smaller than and an improved I/O complexity when the power-law exponent . (This is because in this case; see Section 5 for details.)
2 Preliminaries
This section reviews the Misra-Gries heavy-hitters algorithm [44], a building block of our algorithms in Section 3 and Section 4.
The Misra-Gries frequency estimator. The Misra-Gries (MG) algorithm estimates the frequency of items in a stream. Given an estimation error bound and a stream of items from a universe , the MG algorithm uses a single pass over to construct a table with at most entries. Each table entry is an item with a count, denoted . For each not in table , let . Let be the number of occurrences of item in stream . The MG algorithm guarantees that for all .
MG initializes to an empty table and then processes the items in the stream one after another as described below. For each in ,
- •
If , increment counter .
- •
If and , insert into and set .
- •
If and , then for each decrement and delete its entry if becomes 0.
We now argue that . We have because is incremented only for an occurrence of in the stream. MG underestimates counts only through the decrements in the third condition above. This step decrements counts at once: the item that caused the decrement, since it is never added to the table, and each item in the table. There can be at most executions of this decrement step in the algorithm. Thus, .
The -heavy hitters problem. The MG algorithm can be used to solve the -heavy hitters problem, which requires us to report all items with and not to report any item with . Items that occur strictly between and times in are neither required nor forbidden in the reported set.
To solve the problem, run the MG algorithm on the stream with error parameter . Then iterate over the set and report any item with . Correctness follows from 1) if , then will not be reported, since , and 2) if , then will be reported, since .
Approximate online-event detection. Analogous to the -heavy hitters problem, we define the approximate oedp as:
- •
Report all -events at time ,
- •
Do not report any item with count at most
- •
Items with count greater than and less than are neither required nor forbidden from being reported.
All the errors with respect to oedp in the -heavy hitters problem and the approximate oedp are false positives, that is, non-events (items with frequency between and that get reported as -events. No false negatives are allowed as all -heavy hitters and -events must be reported. In the rest of the paper, the term error only refers to false-positive errors.
Space usage of the MG algorithm. For a frequency estimation error of , Misra-Gries uses words of storage, assuming each stream item and each count occupy words.
Bhattacharyya et al. [16] showed that, by using hashing, sampling, and allowing a small probability of error, Misra-Gries can be extended to solve the -Heavy Hitters problem using slots that store counts and an additional bits, which they show is optimal.
For the exact -hitters problem, that is, for , the space requirement is large— slots. Even the optimal algorithm of Bhattacharyya uses bits of storage in this case, regardless of .
3 External-Memory Misra-Gries and Online Event Detection
In this section, we design an efficient external-memory version of the core Misra-Gries frequency estimator. This immediately gives an efficient external-memory algorithm for the -heavy hitters problem. We then extend our external-memory Misra-Gries algorithm to support I/O-efficient immediate event reporting, e.g., for online event detection.
When , then simply running the standard Misra-Gries algorithm can result in a cache miss for every stream element, incurring an amortized cost of I/Os per element. Our construction reduces this to , which is when B=\omega\big{(}\log\big{(}\frac{1}{\varepsilon M}\big{)}\big{)}.
3.1 External-memory Misra-Gries
Our external-memory Misra-Gries data structure is a sequence of Misra-Gries tables, , where and is a parameter we set later. The size of the table at level is , so the size of the last level is at least .
Each level acts as a Misra-Gries data structure. Level 0 receives the input stream. Level receives its input from level , the level above. Whenever the standard Misra-Gries algorithm running on the table at level would decrement a item count, the new data structure decrements that item’s count by one on level and sends one instance of that item to the level below ().
The external-memory MG algorithm processes the input stream by inserting each item in the stream into . To insert an item into level , do the following:
- •
If , then increment .
- •
If , and , then .
- •
If and , then, for each in , decrement ; remove it from if becomes 0. If , recursively insert into .
We call the process of decrementing the counts of all the items at level and incrementing all the corresponding item counts at level a flush.
Correctness. We first show that the external-memory MG algorithm still meets the guarantees of the Misra-Gries frequency estimation algorithm. In fact, we show that every prefix of levels is a Misra-Gries frequency estimator, with the accuracy of the frequency estimates increasing with .
Lemma 1**.**
Let (where if ). Then, the following holds:
- •
, and,
- •
.
Proof.
Decrementing the count for an element in level and inserting it on the next level does not change . This means that changes only when we insert an item from the input stream into or when we decrement the count of an element in level . Thus, as in the original Misra-Gries algorithm, is only incremented when occurs in the input stream, and is decremented only when the counts for other elements are also decremented. Following the same arguments as the MG algorithm, this is sufficient to establish the first inequality. The second inequality follows from the first, and the fact that . ∎
Heavy hitters. Since our external-memory Misra-Gries data structure matches the original Misra-Gries error bounds, it can be used to solve the -heavy hitters problem when the regular Misra-Gries algorithm requires more than space. First, insert each element of the stream into the data structure. Then, iterate over the sets and report any element with counter .
I/O complexity. We now analyze the I/O complexity of our external-memory Misra-Gries algorithm. For concreteness, we assume each level is implemented as a B-tree, although the same basic algorithm works with sorted arrays (included with fractional cascading from one level to the next, similar to cache-oblivious lookahead arrays [10]) or hash tables with linear probing and a consistent hash function across levels (similar to cascade filters [12]).
Lemma 2**.**
For a given , the amortized I/O cost of insertion in the external-memory Misra-Gries data structure is .
Proof.
Recall that the process of decrementing the counts of all the items at level and incrementing all the corresponding item counts at level is a flush. A flush can be implemented by rebuilding the B-trees at both levels, which can be done in I/Os.
Each flush from level to level moves stream elements down one level, so the amortized cost to move one stream element down one level is I/Os.
Each stream element can be moved down at most levels. Thus, the overall amortized I/O cost of an insert is , which is minimized at . ∎
When no false positives are allowed, that is, , the I/O complexity of the external-memory MG algorithm is .
3.2 Online event-detection
We now extend our external-memory Misra-Gries data structure to solve the online event-detection problem. In particular, we show that for a threshold that is sufficiently large, we can report -events as soon as they occur.
A first attempt to add immediate reporting to our external-memory Misra-Gries algorithm is to compute for each stream event and report as soon as . However, this requires querying for for every stream item and can cost up to I/Os per stream item.
We avoid these expensive queries by using the properties of the in-memory Misra-Gries frequency estimator . If , then we know that and we therefore do not have to report , regardless of the count for in the lower levels on disk of the external-memory data structure.
Online event-detection in external memory. We modify our external-memory Misra-Gries algorithm to support online event detection as follows. Whenever we increment from a value that is at most to a value that is greater than , we compute and report if . For each entry , we store a bit indicating whether we have performed a query for . As in our basic external-memory Misra-Gries data structure, if the count for an entry becomes 0, we delete that entry. This means we might query for the same item more than once if its in-memory count crosses the threshold, it gets removed from , and then its count crosses the threshold again. As we will see below, this has no affect on the overall I/O cost of the algorithm.444It is possible to prevent repeated queries for an item but we allow it as it does not hurt the asymptotic performance.
In order to avoid reporting the same item more than once, we can store, with each entry in , a bit indicating whether that item has already been reported. Whenever we report a item , we set the bit in . Whenever we flush a item from level to level , we set the bit for that item on level if it is set on level . When we delete the entry for a item that has the bit set on level , we add an entry for that item on a new level . This new level contains only items that have already been reported. When we are checking whether to report a item during a query, we stop checking further and omit reporting as soon as we reach a level where the bit is set. None of these changes affect the I/O complexity of the algorithm.
I/O complexity. We assume that computing requires I/Os. This is true if the levels of the data structure are implemented as sorted arrays with fractional cascading.
We first state the result for the approximate version of the online event-detection problem that allows elements with frequency between and to be reported as false positives.
Then, we set to get the result for the oedp.
Theorem 1**.**
Given a stream of size and parameters and , where and , the approximate oedp can be solved at an amortized I/O complexity per stream item.
Proof.
Correctness follows from the arguments above. We need only analyze the I/O costs. We analyze the I/O costs of the insertions and the queries separately.
The amortized cost of performing insertions is .
To analyze the query costs, let , i.e., the frequency-approximation error of the in-memory level of our data structure.
Since we perform at most one query each time an item’s count in goes from 0 to , the total number of queries is at most . Since each query costs I/Os, the overall amortized I/O complexity of the queries is . ∎
Exact reporting. If no false positives are allowed, we set in Theorem 1. For error-free reporting, we must store all the items, which increases the number of levels and thus the I/O cost. In particular, we have the following result on oedp.
Corollary 1**.**
Given a stream of size and the oedp can be solved at amortized I/O complexity per stream item.
Summary. The external-memory MG algorithm supports a throughput at least as fast as optimal write-optimized dictionaries [22, 11, 10, 21, 23, 13], while estimating the counts as well as an enormous RAM. It maintains count estimates at different granularities across the levels. Not all estimates are actually needed for each structure, but given a small number of levels, we can refine the count estimates by looking in only a few additional locations.
The external-memory MG algorithm helps us solve the oedp. The smallest MG sketch (which fits in memory) is the most important estimator here, because it serves to sparsify queries to the rest of the structure. When such a query gets triggered, we need the total counts from the remaining levels for the (exact) online event-detection problem but only levels when approximate thresholds are permitted. In the next two sections, we exploit other advantages of this cascading technique to support much lower without sacrificing I/O efficiency.
4 Event Detection With Time-Stretch
The external-memory Misra-Gries algorithm described in Section 3.2 reports events immediately, albeit at a higher amortized I/O cost for each stream item. In this section, we show that, by allowing a bounded delay in the reporting of events, we can perform event detection asymptotically as cheaply as if we reported all events only at the end of the stream.
Time-stretch filter. We design a new data structure to guarantee time-stretch called the time-stretch filter. Recall that, in order to guarantee a time-stretch of , we must report an item no later than time , where is the time of the first occurrence of , and is the flow time of .
Similar to the external-memory MG structure, the time-stretch filter consists of levels . The th level has size . Items are flushed from lower levels to higher levels.
Unlike the data structure in Section 3.2 for the oedp, all events are detected during the flush operations. Thus, we never need to perform point queries. This means that (1) we can use simple sorted arrays to represent each level and, (2) we don’t need to maintain the invariant that level 0 is a Misra-Gries data structure on its own.
Layout and flushing schedule. We split the table at each level into equal-sized bins , each of size . The capacity of a bin is defined by the sum of the counts of the items in that bin, i.e., a bin at level can become full because it contains items, each with count 1, or 1 item with count , or any other such combination.
We maintain a strict flushing schedule to obtain the time-stretch guarantee. The flushes are performed at the granularity of bins (rather than entire levels). Each stream item is inserted into . Whenever a bin becomes full (i.e., the sum of the counts of the items in the bin is equal to its size), we shift all the bins on level over by one (i.e., bin 1 becomes bin 2, bin 2 becomes bin 3, etc), and we move all the items in into bin . Since the bins in level are times larger than the bins in level , bin becomes full after exactly flushes from . When this happens, we perform a flush on level and so on. Starting from the beginning, every elements from the stream causes a flush that involves level .
Finally, during a flush involving levels , where , we scan these levels and for each item in the input levels, we sum the counts of each instance of . If the total count is greater than , and (we have not reported it before) then we report555For each reported item, we set a flag that indicates it has been reported, to avoid duplicate reporting of events. .
Correctness. We first prove correctness of the time-stretch filter.
Lemma 3**.**
The time-stretch filter reports each -event occurring at time at or before , where is the flow-time of .
Proof.
In the time-stretch filter, each item inserted at level waits in bins until it reaches the last bin, that is, it waits at least flushes (from main memory) before it is moved down to level . This ensures that items that are placed on a deeper level have aged sufficiently that we can afford to not see them again for a while.
Consider an item with flow time , where is a -event and is the time step of the first occurrence of .
Let be the largest level containing an instance of at time , when has its th occurrence. The flushing schedule guarantees that the item must have survived at least flushes since it was first inserted in the data structure. Thus, .
Furthermore, level is involved in a flush again after time steps. At time during the flush all counts of the item will be consolidated to a total count estimate of . Note that and the count-estimate error of can be at most , where is the number of the stream items seen up till . Thus, we have that . That is, , which means that gets reported during the flush at time , which is at most time steps away from . ∎
I/O complexity. Next, we analyze the I/O complexity of the time-stretch filter. We treat each level of the filter as a sorted array.
Theorem 2**.**
Given a stream of size and parameters and , where , the approximate oedp can be solved with time-stretch at an amortized I/O complexity per stream item.
Proof.
A flush from level to costs I/Os, and moves stream items down one level, so the amortized cost to move one stream item down one level is I/Os.
Each stream item can be moved down at most levels, thus the overall amortized I/O cost of an insert is , which is minimized at . ∎
Exact reporting with time-stretch. Similar to Section 3.2, if we do not want any false positives among the reported events, we set . The cost of error-free reporting is that we have to store all the items, which increases the number of levels and thus the I/O cost. In particular, we have the following result on oedp.
Corollary 2**.**
Given and a stream of size , the oedp can be solved with time stretch at an amortized cost of I/Os per stream item.
Summary. By allowing a little delay, we can solve the timely event-detection problem at the same asymptotic cost as simply indexing our data [22, 11, 10, 21, 23, 13].
Recall that in the online solution the increments and decrements of the MG algorithm determined the flushes from one level to the other. In contrast, these flushing decisions in the time-stretch solution were based entirely on the age of the items. The MG style count estimates came essentially for free from the size and cascading nature of the levels. Thus, we get different reporting guarantees depending on whether we flush based on age or count.
Finally, our results on oedp and oedp with time stretch show that there is a spectrum between completely online and completely offline, and it is tunable with little I/O cost.
5 Power-Law Distributions
In this section, we present a data structure that solves the oedp on streams where the count of items follow a power-law distribution. There is no assumption on the order of arrivals, which can be adversarial. In contrast to worst-case count distributions, our data structure for power-law inputs can support smaller reporting thresholds and achieve better I/O performance.
We note that previous work has analyzed the performance of Misra-Gries style algorithms on similar input distributions. In particular, Berinde et al. [14] consider streams where the item counts follow a Zipfian distribution, the assumptions of which are similar but distinct from power-law.
Next, we briefly review the distinction and relationship between Zipfian and power-law distributions. This will allow us to compare Berinde et al.’s result to our work. For detailed review of these distributions, see [45, 25, 20, 2].
Zipfian vs. power-law distributions. Let be the ranked-frequency vector, that is, of distinct items in a stream of size , where . The item counts in the stream follow a Zipfian distribution with exponent if frequency , where is the normalization constant. In contrast, the item counts in the stream follow a power-law distribution with exponent if the probability that an item has count is equal to , where is the normalization constant.
An stream follows a Zipfian distribution with exponent if and only if it follows a power-law distribution with exponent ; see [2] for details on this conversion.
Berinde et al. [14] show that if the item counts in the stream follow a Zipfian distribution with , then the MG algorithm can solve the -approximate heavy hitter problem using only words. Alternatively, on such Zipfian distributions, the MG algorithm achieves an improved error bound using words. Since all our algorithm so far use the MG algorithm as a building block, we automatically achieve these improved bounds for Zipf exponents (that is, power-law exponents ).
However, many common power-law distributions found in nature have [45].
In this section, we design a new external-memory data structure for the oedp with improved guarantees when the power-law exponent .
Preliminaries. We use the continuous power-law definition[45]: the count of an item with a power-law distribution has a probability of taking a value in the interval from to , where , where and is the normalization constant.
In general, the power-law distribution on may hold above some minimum value of . For simplicity, we let . The normalization constant is calculated as follows.
[TABLE]
Thus, .666In principle, one could have power-law distributions with , but these distributions cannot be normalized and are not common [45]. We will use the cumulative distribution of a power law, that is,
[TABLE]
5.1 Power-law filter
First, we present the layout of our data structure, the power-law filter and then we present its main algorithm, the shuffle merge, and finally we analyze its performance.
Layout. The power-law filter consists of a cascade of Misra-Gries tables, where is the size of the table in RAM and there are levels on disk, where the size of level is .
Each level on disk has an explicit upper bound on the number of instances of an item that can be stored on that level. This is different from the MG algorithm, where this upper bound is implicit: based on the level’s size. In particular, each level in the power-law filter has a level threshold for , (), indicating that the maximum count on level can be .
Threshold invariant. We maintain the invariant that at most instances of an item can be stored on level . Later, we show how to set ’s based on the item-count distribution.
Shuffle merge. The external-memory MG data structure and time-stretch filter use two different flushing strategies, and here we present a third for the power-law filter.
The level in RAM receives inputs from the stream one at a time. When attempting to insert to a level that is at capacity, instead of flushing items to the next level, we find the smallest level , which has enough empty space to hold all items from levels . We aggregate the count of each item on levels , resulting in a consolidated count . If , we report . Otherwise, we pack instances of in a bottom-up fashion on levels , while maintaining the threshold invariants. In particular, we place instances of on level , and instances of on level for .
Thus, the threshold invariant prevents us from flushing too many counts of an item downstream. As a result, items get pinned, that is, they cannot be flushed out of a level. Specifically, we say an item is pinned at level if its count exceeds .
Too many pinned items at a level can clog the data structure. In Lemma 4, we show that if the item counts in the stream follow a power-law distribution with exponent , we can set the thresholds based on in a way that no level has too many pinned items.
Online event detection. As soon as the count of an item in RAM (level [math]) reaches a threshold of , the data structure triggers a sweep of all the levels, consolidating the count estimates of at all levels. If the consolidated count reaches , we report ; otherwise we update the ’s consolidated count in RAM and “pin” in RAM, that is, mark a bit to ensure does not participate in future shuffle merges. Reported items are remembered, so that each event gets reported exactly once.
Setting thresholds. We now show how to set the level thresholds based on the power-law exponent so that the data structure does not get “clogged” even though the high-frequency items are being sent to higher levels of the data structure.
Lemma 4**.**
Let the item counts in an stream of size be drawn from a power-law distribution with exponent . Let for and . Then the number of keys pinned at any level is at most half its size, i.e., .
Proof.
We prove by induction on the number of levels. We start at level . An item is placed at level if its count is greater than . By Equation (1), there can be at most such items which proves the base case.
Now suppose the lemma holds for level . We show that it holds for level . An item gets pinned at level if its count is greater than .
Using Equation (1) again, the expected number of such items is
[TABLE]
By the induction hypothesis, this is at most half the size of level , that is,
[TABLE]
Using this, we prove that the expected number of items pinned at level is at most .
The expected number of pinned items at level is
[TABLE]
∎
5.2 Analysis
Next, we prove correctness of the power-law filter and analyze its I/O complexity.
We first establish notation. Let be the stream of size where the count of items follow a power-law distribution with exponent . For simplification we use in the analysis.
Correctness. Next, we prove that the power-law filter reports all -events as soon as they occur. In the approximate oedp, it may report false positives, that is, items with frequency between and . As before, for error-free reporting we set .
Lemma 5**.**
The power-law filter solves the approximate oedp on .
Proof.
Let denote the count estimate of an item in RAM in the power-law filter. Let be the frequency of in the stream. Since at most instances of a key can be stored on disk, we have that: .
Suppose item reaches the threshold at time , then its count estimate in RAM must be at least . This is exactly when we trigger a sweep of the data structure consolidating the count of across all levels; if the consolidated count reaches , we report it. This proves correctness as the consolidated count can have an error of at most . ∎
I/O complexity. We now analyze the I/O complexity of the power-law filter. Similar to Section 3.2, we assume each level is implemented as a B-tree, although the same basic algorithm works with sorted arrays (included with fractional cascading from one level to the next, similar to cache-oblivious lookahead arrays [10]).
Theorem 3**.**
Let be a stream of size where the count of items follow a power-law distribution with exponent . Let \gamma=2\bigl{(}\frac{N}{M}\bigr{)}^{\frac{1}{\theta-1}}. Given , and , such that and , the approximate oedp can be solved at an amortized I/O complexity per stream item.
Proof.
The insertions cost as we are always able to flush out a constant fraction of a level during a shuffle merge using Lemma 4. This cost is minimized at .
Since we perform at most one query each time an item’s count in RAM reaches . The total number of items in the stream with count at least is at most . Since each query costs I/Os, the overall amortized I/O complexity of the queries is . ∎
Exact reporting. To forbid false positives, we set and get the following corollary.
Corollary 3**.**
Let be a stream of size where the count of items follow a power-law distribution with exponent . Let \gamma=2\bigl{(}\frac{N}{M}\bigr{)}^{\frac{1}{\theta-1}}. Given , the oedp can be solved at an amortized I/O complexity per stream item.
Remark on scalability. Notice that the power-filter on an stream with a power-law distribution allows for strictly smaller thresholds compared to Theorem 1 and Corollary 1 on worst-case-distributions, when . Recall that we need for solving oedp on worst-case streams. In contrast, in Theorem 3 and Corollary 3, we need . When we have a power-law distribution with , we have for .
Remark on dynamic thresholds. Finally, we argue that level thresholds of the power-law filter can be set dynamically when the power-law exponent is not known ahead of time.
Initially, each level on disk has a threshold [math] (i.e., ). During the first shuffle-merge involving RAM and the first level on disk, we determine the minimum threshold for level () required in-order to move at least half of the items from RAM to the first level on disk. When multiple levels, , are involved in a shuffle-merge, we use a bottom-up strategy to assign thresholds. We determine the minimum threshold required for the bottom most level involved in the shuffle-merge () to flush at least half the items from the level just above it (). We then apply the same strategy to increment thresholds for levels .
This means that the s for levels increase monotonically. Moreover, during shuffle-merges, we increase thresholds of levels involved in the shuffle-merge from bottom-up and to the minimum value so as to not clog the data structure, which means that the s take their minimum possible values. Thus, if the have a feasible setting, then this adaptive strategy will find it.
Summary. With a power law distribution, we can support a much lower threshold for the online event-detection problem. In the external-member MG sketch from Section 3.1, the upper bounds on the counts at each level are implicit. In this section, we can get better estimates by making these bounds explicit. Moreover, the data structure can learn these bounds adaptively. Thus, the data structure can automatically tailor itself to the power law exponent without needing to be told the exponent explicitly.
6 Motivating National Security Application
In this section, we describe the more complex national-security setting that motivates our constraints. We describe Firehose [1, 5], a clean benchmark that captures the fundamental elements of this setting. The oedp in this paper in turn distills the most difficult part of the Firehose benchmark. Therefore our solutions have direct line of sight to important national-security applications.
We are motivated by monitoring systems for national security [1, 5], where experts associate special patterns in a cyberstream to rare, high-consequence real-life events. These patterns are formed by a small number of “puzzle pieces,” as shown in Figure 1. Each piece is associated with a key such as an IP address or a hostname. The pieces arrive over time. When an entire puzzle associated with a particular key is complete, this is an event, which should be reported as soon as the final puzzle piece falls into place. In Figure 1, the first stage is like our oedp algorithm, except that it must store puzzle pieces with each key rather than a count and the reporting trigger is a complete puzzle, not a count threshold.
There can still be a fair number of matches to this special pattern, most of which are still not the critically bad event. This might overwhelm a human analyst, who would then not use the system. However, automated tools, shown in the second stage of Figure 1, can pare these down to the few events worthy of analyst attention.
The first stage filter, like our oedp solution, must struggle to handle a massively large, fast stream. It is reasonable to allow a few false positives in the first stage to improve its speed. The second stage can screen out almost all of these false positives as long as the stream is significantly reduced. The second stage is a slower, more careful tool which cannot keep up with the initial stream. This second tool cannot, however, repair false negatives since anything the first filter misses is gone forever. So the first tool cannot drop any matches to the pattern. Experts have gone to great effort to find a pattern that is a good filter for the high-consequence events. We do not allow false negatives because the high-consequence events that match this carefully crafted pattern can and must be detected.
Each of these patterns are small with respect to the stream size, so the detection algorithm must be scalable, that is, must be able to support a small . The consequences of missing an event (false negative) are so severe that it is not reasonable to risk facing those consequences just to save a little space. Thus we must save all partial patterns, motivating our use of external memory.
The DoD Firehose benchmark captures the essence of this setting [1]. In Firehose, the input stream has (key,value) pairs. When a key is seen for the 24th time, the system must return a function of the associated 24 values. The most difficult part of this is determining when the 24th instance of a key arrives. Thus like Firehose, the oedp captures the essence of the motivating application.
7 Conclusion
Our results show that, by enlisting the power of external memory, we can solve online event detection problems at a level of precision that is not possible in the streaming model, and with little or no sacrifice in terms of the timeliness of reports.
Even though streaming algorithms, such as Misra-Gries, were developed for a space-constrained setting, they are nonetheless useful in external memory, where storage is plentiful but I/Os are expensive. Furthermore, using external memory for problems that have traditionally been analyzed in the streaming setting enables solutions that can scale beyond the provable limits of fast RAM
Acknowledgments
We would like to thank Tyler Mayer for many helpful discussions in earlier stages of this project. In Figure 1, the full-puzzle icon is from theme4press.com, the fire-hydrant icon is from https://hanslodge.com and the water-drop icon is from stockio.com.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Fire Hose streaming benchmarks. www.firehose.sandia.gov . Accessed: 2018-12-11.
- 2[2] L. Adamic. Zipf, power law, pareto: a ranking tutorial. HP Research. http://www.hpl.hp.com/research/idl/papers/ranking/ranking.html, 2008.
- 3[3] A. Aggarwal, J. Vitter, et al. The input/output complexity of sorting and related problems. Communications of the ACM , 31(9):1116–1127, 1988.
- 4[4] N. Alon, Y. Matias, and M. Szegedy. The space complexity of approximating the frequency moments. In Proc. 28th Annual ACM Symposium on Theory of Computing , pages 20–29, 1996.
- 5[5] K. Anderson and S. Plimpton. Firehose streaming benchmarks. Technical report, Sandia National Laboratory, 2015.
- 6[6] B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom. Models and issues in data stream systems. In Proc. 21st Symposium on Principles of Database Systems , pages 1–16, New York, NY, USA, 2002.
- 7[7] R. Bayer and E. M. Mc Creight. Organization and maintenance of large ordered indexes. Acta Informatica , 1:173–189, 1972.
- 8[8] M. A. Bender, J. W. Berry, M. Farach-Colton, J. Jacobs, R. Johnson, T. M. Kroeger, T. Mayer, S. Mc Cauley, P. Pandey, C. A. Phillips, A. Porter, S. Singh, J. Raizes, H. Xu, and D. Zage. Advanced data structures for improved cyber resilience and awareness in untrusted environments: LDRD report. Technical Report SAND 2018-5404, Sandia National Laboratories, May 2018.