On Increasing Self-Confidence in Non-Bayesian Social Learning over Time-Varying Directed Graphs
C\'esar A. Uribe, Ali Jadbabaie

TL;DR
This paper analyzes how agents in a network can reliably learn a parameter over time despite changing connections and decaying influence, by establishing conditions for convergence.
Contribution
It introduces a necessary and sufficient condition for the decay rate of influence weights that guarantees successful social learning in dynamic, directed networks.
Findings
Convergence is achievable under specific decay rate conditions.
Decaying influence weights do not prevent social learning if conditions are met.
The network's connectivity over finite intervals is sufficient for learning.
Abstract
We study the convergence of the log-linear non-Bayesian social learning update rule, for a group of agents that collectively seek to identify a parameter that best describes a joint sequence of observations. Contrary to recent literature, we focus on the case where agents assign decaying weights to its neighbors, and the network is not connected at every time instant but over some finite time intervals. We provide a necessary and sufficient condition for the rate at which agents decrease the weights and still guarantees social learning.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6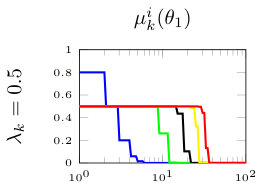 Figure 0
Figure 0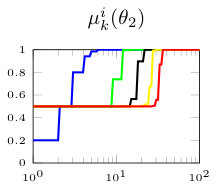 Figure 1
Figure 1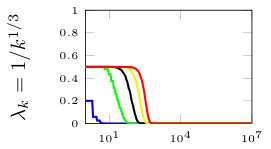 Figure 2
Figure 2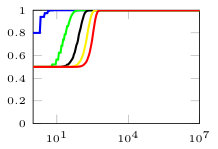 Figure 3
Figure 3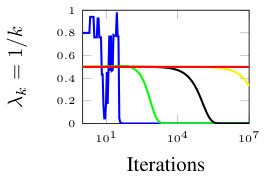 Figure 4
Figure 4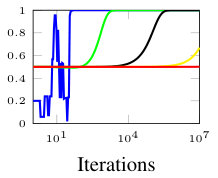 Figure 5
Figure 5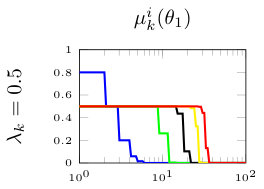 Figure 0
Figure 0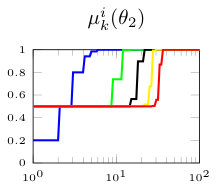 Figure 1
Figure 1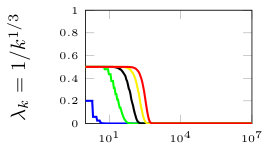 Figure 2
Figure 2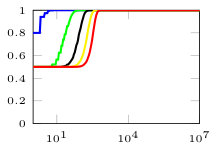 Figure 3
Figure 3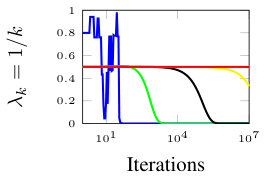 Figure 4
Figure 4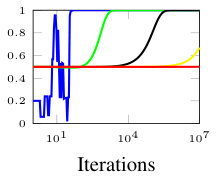 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On Increasing Self-Confidence in Non-Bayesian Social Learning
over Time-Varying Directed Graphs
César A. Uribe and Ali Jadbabaie This research was supported in part by DARPA Lagrange and a Vannevar Bush Fellowship.The authors are with the Laboratory for Information and Decision Systems (LIDS), and the Institute for Data, Systems, and Society (IDSS), Massachusetts Institute of Technology, 77 Massachusetts Ave, Cambridge, MA 02139 {cauribe,jadbabai}@mit.edu
Abstract
We study the convergence of the log-linear non-Bayesian social learning update rule, for a group of agents that collectively seek to identify a parameter that best describes a joint sequence of observations. Contrary to recent literature, we focus on the case where agents assign decaying weights to its neighbors, and the network is not connected at every time instant but over some finite time intervals. We provide a necessary and sufficient condition for the rate at which agents decrease the weights and still guarantees social learning.
I INTRODUCTION
The theory of non-Bayesian social learning [1] has gained increasing attention in recent years for its ability to provide simple and practical models for inference in complex environments where a large number of decision makers repeatedly interact over some network structure. In contrast to a fully rational approach, where agents incorporate new information in a Bayesian manner, the non-Bayesian social learning model assumes agents use some other functional form to aggregate its information and construct new beliefs [2]. Some examples of these aggregation schemes build upon classical results on linear [3] and log-linear models [4].
The basic non-Bayesian social learning model assumes a group of agents tries to identify the state of the world via sequentially receiving information about an unknown state, and communicating with other agents in their social clique. Moreover, agents incorporate the received information using some social learning rule [1, 2]. A group is said to achieve social learning if all agents can identify the state of the world even if their local private signals do not provide sufficient information. For a summary of some of the recent results in non-Bayesian social learning see [5].
One of the enabling tools for the study of non-Bayesian social learning is the analysis of distributed averaging algorithms [6, 7, 8]. Therefore, most of the existing results about the convergence of beliefs in social learning inherit some requirements about the connectivity of the network and the persistence of weights an agent assigns to its neighbors. In terms of graph connectivity, a group of agents following log-linear update rules has been shown to be able to learn the unknown state parameter for fixed undirected graphs [2, 9], fixed directed graphs, time-varying undirected graphs [10], time-varying directed graphs [11]. In terms of graph connectivity, uniform connectivity has been shown sufficient for social learning [11]. However, the central assumption in most of the previous results is that the weight an agent assigns to a neighbor at any time instant is lower bounded by some positive constant. This implies that, although the graph might change with time, the links are persistent and its effects do not decay with time.
The assumption of the existence of lower bounds on the weights for time-varying graphs poses some structural constraints that ease the convergence analysis of the aggregating schemes. However, recent approaches pose the question of increasing self-confidence, where an agent gradually increases its self-weights and at the same time assigns a decaying weight to its neighbors [12]. Such behavior is justified by the intuition that an agent might become more and more confident in its own opinion as aggregates more information [12]. Also, one might consider agents that assume only they are becoming more informed over time, while others are not [13]. An increasing self-confidence implies that an agent will assign a zero weight to the opinion of its neighbors eventually.
In [13], the authors provided a condition for the rate at which the weights decay such that social learning is guaranteed for fixed graphs. In [1] this result was extended to time-varying graphs that are connected at each time instant. In [12], the authors considered a fixed rate of decay of and showed learning is achieved for both fixed and time-varying graphs that are always connected. Other authors have considered the phenomena of asymptotic isolation of agents in a network assuming the intervals of intercommunication between them increase with time [14, 15].
In this paper, we generalize existing results and provide the conditions for which social learning happens, even if agents have an increasing self-confidence or decaying weights for a uniform strongly connected sequences of graphs, that is, sequences of graphs that might not be connected at each time instant but over finite periods of time. Also, we show that this result is tight by providing a necessary condition for social learning, on the rate at which the weights decay. If such condition does not hold, one cannot guarantee learning occurs for general sequences of uniformly connected graphs. This result is of independent interests for the literature of average consensus and distributed optimization, as it provides a condition to guarantee that consensus is achieved even if the weight matrices do not have lower bounded non-zero entries.
This paper is organized as follows. Section II presents the problem of non-Bayesian social learning. Also, we recall some basic definitions and assumptions, and state our main result. Section III shows the proof our main results, and introduce some auxiliary technical lemmas. Section V extends the main result to the case of agents with conflicting hypotheses. Section IV presents a converse result, where we show a necessary condition to guarantee social learning. Section VI presents a numerical example that validates our theoretical results. Finally, Section VII presents some conclusions and future work.
Notation: Random variables are represented as upper case letters, i.e. , whereas their realizations as its corresponding lower case, i.e. . Subscripts will denote time indices and make use of the letter . Agent indices are represented as superscripts and use the letters or . The -th row and -th column entry of a matrix is denoted as . Moreover, for a sequence of matrices we denote for . We use to refer to almost sure convergence.
II PROBLEM FORMULATION AND RESULTS
Consider a set of agents, denoted by , who seek to learn a fixed underlying and unknown state of the world by sequentially observing realizations from a set of random variables. Particularly, at each time step , each agent receives an independent (in time and among the agents) private realization of a finite random variable , where we assume has full support over the realizations of . Moreover, each agent has a private parametrized family of distributions for , where is a finite set. We will generally refer to as the set of hypotheses. The group objective is to find a parameter that solves the following optimization problem
[TABLE]
where is the Kullback-Leibler (KL) divergence between the distribution and . In words, the group of agents tries to identify a member of their joint parameter space such that it generates a probability distribution that minimizes the KL divergence with the true distribution of the observations . The fact that is finite guarantees that a solution of always exists. We will denote as the subset of that minimizes (1). Moreover, in order to avoid trivial solutions we assume .
Clearly, if for each individual agent is non-empty and has only one element that is common to all agents, each agent can solve (1) separately. However, we study the general case where there are identifiability limitations, e.g., the set has more than one element for some , yet is non-empty, and . Moreover, we also study the case where is empty, that is, there might be conflicting hypothesis [16] in the sense that the minimizer of the local functions might not be the same for all agents.
Under these identifiability issues, the agents collaborate with each other to jointly solve problem (1). This collaboration comes in the form of exchange of information among them. We will assume that in addition to their private signals, each agent receives at each time step the beliefs of a subset of the other agents that we will call the neighbors. We define the beliefs of an agent as a probability distribution over the simplex generated by . We denote by the belief that agent has at time about the hypothesis . The communication among the agents is modeled as a sequence of graphs , where , and is a set of edges such that if agent can send information to agent at time .
In this paper, we study the group dynamics where each agent updates its beliefs following the log-linear social learning rule:
[TABLE]
where denotes the probability of observing the realization at time conditioned on the true hypothesis being . Moreover is a non-negative matrix of weights compliant with the underlying structure of the graph .
In contrast with other works, our objective is to establish necessary conditions for the convergence of the beliefs of all the agents in the network to the solution of (1) for a weaker connectivity assumption. Mainly, we are interested in whether social learning is achieved with the log-linear update rule (2) for agents with increasing self-confidence, i.e., the weights an agent assigns to its neighbors decay to zero, or equivalently, the self-weight converges to , for all , as increases. In general, one should expect that the rate at which an agent increases its self-confidence should not be too fast, as not enough information from its neighbors might arrive.
Next, we recall some basic assumptions and definitions.
Definition 1
A sequence of graphs is uniformly strongly connected or -strongly connected, if there exists an integer such that the graph with edge set
[TABLE]
is strongly connected for every .
Definition 2** (Definition in [17])**
Let be a sequence of row stochastic matrices. We say that is ergodic if for any , where is a stochastic vector.
Assumption 1
Given a sequence of graphs that is -strongly connected, then
- (a)
For each , there exists a weight matrix that is row-stochastic and compliant with the underlying graph topology, i.e., if . 2. (b)
There exists a sequence , with , and constants and , such that
[TABLE]
for all and all pairs of agents such that and .
Assumption 1(a) ensures that the sequence of weights used in the update rule (2) is consistent with the structure of the communication network among the agents. Particularly, if agent can send information to agent at a time instant , then the edge , and therefore the agent assigns a positive weight to the information coming from agent , i.e., . Assumption 1(b) limits the rate of decay of the weights an agent assigns to its neighbors. Particularly, even if an edge does not exist at every time step, its corresponding strength do not decay faster than the sequence . This in turn limits the rate at which the self-confidence of an agent increases. Our main result will characterize the conditions on to guarantee the network of agents will learn the state.
Assumption 2
The set , where for each , is non-empty. Moreover, .
Assumption 2 guarantees that even if some agents cannot correctly identify , the optimal set that solves (1) lies inside the optimal set of the solution of their local problem. Later in Section V, we will remove this assumption by allowing conflicting hypotheses, i.e., being empty.
Next, we state our main result regarding the consistency of the learning rule (2). That is, all the agents in the network concentrate their beliefs on the set that solves (1).
Theorem 1
Let Assumptions 1 and 2 hold. If
[TABLE]
Then, the update rule (2) has the following property:
[TABLE]
Condition (3), on the rate of decrease on , states that sequential products of the form should not decrease too fast. Particularly, for a connectivity parameter it is sufficient to guarantee that . That is, the total decreases in the time period of size should not be faster than . Moreover, if we recover the same condition as in [1, 13]. Additionally, (3) implies that .
III Consistency of Social Learning with Increasing Self-Confidence
In this section, we prove our main result in Theorem 1. Initially, we provide a fundamental assumption about the existence of a strictly positive lower bound on the weights a node assigns to the information coming from other nodes.
Assumption 3
For each , the matrix is stochastic, i.e., for , with positive diagonal entries. Additionally, there exists a constant such that if then .
With Assumption 3 at hand, we state a well-known result about the ergodicity of the backward product of row stochastic matrices.
Lemma 2** (Lemma in [18])**
Suppose that the graph sequence is uniformly strongly connected and let Assumption 3 hold. Then, for each integer , there is a stochastic vector such that for all and
[TABLE]
One immediate conclusion from Lemma 2 the sequence is ergodic.
The next auxiliary lemma states that the entries of the sequence of stochastic vectors are lower bounded by a strictly positive value that depends on the structure of .
Lemma 3** (Lemma and Corollary in [18])**
Given a graph sequence , define
[TABLE]
If the graph sequence is -strongly connected, then . Moreover, if is doubly stochastic for all or if is regular, then . Furthermore, as defined in Lemma 2 satisfies for all and .
Next, we state our first auxiliary result that will be fundamental to the construction of the proof of Theorem 1. Particularly, we provide a condition on the sequence such that the , for which Assumption 1 holds, is ergodic. The next lemma will limit the rate at which the self-confidence increases such that we can guarantee there is sufficient mixing among the nodes in the network.
Lemma 4
Suppose Assumption 1 holds for a -strongly connected sequence of graphs . If (3) holds. Then, is ergodic.
Proof:
Initially, it follows from Assumption 1, that each member of the sequence of weight matrices can be written as
[TABLE]
where is a sequence of stochastic matrices whose nonzero elements are uniformly lowered bounded by , i.e., for all .
Following the approach proposed in [13], we define as a sequence of independent Bernoulli random variables where , and . Therefore, we can write each of the elements of the sequence of matrices as
[TABLE]
where the expectation is taken with respect to the random variable . Moreover, define the random matrix by
[TABLE]
Thus,
[TABLE]
Now, define the sequence of random variables by
[TABLE]
The random variable serves as an indicator function for the event . Particularly, if , then the product . Moreover, if the event occurs infinitely many times, then from Lemma 2 it follows that
[TABLE]
Therefore, to complete the proof we need to show that if (3) holds, then the event occurs infinitely often. Initially, note that
[TABLE]
Thus, by the Borel-Cantelli lemma, if , then .
Moreover, if 3 holds then
[TABLE]
and the desired result holds. ∎
Lemma 4 shows that if (3) holds, then is ergodic. That is, even if the weights, an agent assigns to its neighbors, decays to zero, if the rate at which that happens is sufficiently slow, then the resulting infinite product is equivalent to an infinite product of row stochastic matrices with lower bounded entries.
The next lemma states the existence of an absolute probability sequence for the Markov chain generated by [17]. Later in the proof of our main theorem, we will make use of this absolute probability sequence.
Lemma 5
There exists an absolute probability sequence for the chain , i.e.,
[TABLE]
Proof:
This result follows immediately from Lemma 4 and Lemma in [17]. ∎
Now, we are ready to prove our main result regarding the conditions for a group of agents with increasing self-confidence to reach social learning.
Proof:
Initially, define the random variables
[TABLE]
Thus, it follows form the update rule (2) that
[TABLE]
or equivalently, by stacking all entries of and into single column vectors and , where and ,
[TABLE]
where we have assumed without loss of generality that for all and all , which is equivalent to all agents having uniform beliefs at time .
To complete the proof, we first show that . This will imply that the weighted sum of belief the beliefs of all neighbors on the wrong hypothesis will asymptotically converge to zero.
If we pre-multiply (6) by the absolute probability sequence from Lemma 4, we have that
[TABLE]
Moreover, by adding and subtracting , it follows that
[TABLE]
Furthermore, by dividing by on both sides and taking the limit supremum as , the first term on the right in (III) goes to zero almost surely by the strong law of large numbers, thus
[TABLE]
where we have used Lemma 3 and the fact that . Moreover, by Assumption 2 it holds that .
The relation in (III) shows that for at least one of the agents, the beliefs on the non-optimal hypotheses will asymptotically go to zero. To complete the proof, we proceed to show that the difference between the beliefs among the agents decays to zero as well, which in turns implies that all agents eventually assign a zero belief to the non-optimal hypotheses.
Now, following the same approach as in [1], we proceed to bound the asymptotic difference between the logarithmic ratio of beliefs among the two agents with the most separate beliefs. Initially we have that,
[TABLE]
where the function is defined as
[TABLE]
and is convex and sub-multiplicative, see Lemma in [1].
Under the assumption that the variables are finite for all and , it follows that there exists a constant , independent of , such that
[TABLE]
Next, without loss of generality we assume the value is such that we can write it as for some . This will allow us to group the summation on the right side of (10) into some initial finite sum and sets of size as follows
[TABLE]
As next step, we use Lemma 2 to bound the entries of and count how many events occur. Particularly, we know that if occurs times, the smallest entry of will be lower bounded by . Thus
[TABLE]
where we have defined .
Using the fact that the random variables are independent, we have that
[TABLE]
Now, define , then
[TABLE]
Finally, divide both sides of (III) by and take as , then
[TABLE]
where the last line follows from (3) and the fact that the last term on the right of (III) is finite. Thus,
[TABLE]
The desired result will follow from (III) and (III) since they imply that almost surely for all agents. Therefore, , which subsequently imply that for all with probability . ∎
IV A CONVERSE RESULT FOR THEOREM 1
In this section, we state an additional result regarding the ergodicity of the backward product of the matrices from the sequence . Particularly, Lemma 4 shows that if (3) holds then is ergodic. This indicates that if the weight an agent assigns to its neighbors decays sufficiently slow, the infinite backward product of its weight matrices is equivalent to an infinite product of a sequence of matrices whose positive entries are lower bounded. Now, we explore the case when (3) does not hold.
Lemma 6
Suppose Assumption 1 holds for a -strongly connected sequence of graphs . If
[TABLE]
Then, .
Proof:
The desired result follows from the same argument as the proof of Lemma 4. By the Borel-Cantelli lemma, if
[TABLE]
Then, . Therefore, the infinite backward product of the sequence of stochastic matrices corresponds to the product of a finite number of matrices of the form , which is not sufficient for ergodicity. ∎
Lemma 6 shows that if the sequence decays to zero too fast, can be non-ergodic since it is only equivalent to a finite number of products of matrices with lower bounded positive entries, which might not result in a rank one matrix for general graphs.
The next corollary presents a consequence of Lemma 6 in the context of non-Bayesian social learning.
Corollary 7
Let Assumptions 1 and 2 hold. For a group of agents following the update rule (2). If (13) holds. Then, there exists a sufficiently large graph such that a subset of agents remains uncertain about the state of the world almost surely.
Proof:
If (13) holds we know that the infinite product corresponds to a finite product of matrices with lower bounded entries. Define the number of finite products as . Assume there are agents, and they are connected over a path graph. Moreover, only one of the agents at the end of the path has informative signals. Then, , will have zero entries for some points, i.e., not enough mixing happens. Furthermore, a subset of agents will not learn. ∎
V SOCIAL LEARNING WITH CONFLICTING HYPOTHESES
Assumption 2 is central for the results presented in Theorem 1. In this section we explore the consistency of the log-linear learning rule (2) when Assumption 2 does not hold. Particularly, the fact that the optimal set is contained in the optimal set of the individual local functions, guarantees that the distance between any hypothesis to the true distribution of the observations is larger than the distance (note that the KL divergence is only a premetric) between the hypotheses and , i.e.,
[TABLE]
which in turn makes (III) hold.
If Assumption 2 does not hold, one cannot guarantee (15) holds, because in general we only have , and some of the terms in the sum might be negative. Moreover, each term will be multiplied (weighted) by the corresponding entry of the vector and thus (III) will depend on the specific sequence of graphs used.
One way to avoid this issue is to assume that every matrix in the sequence is doubly stochastic, which guarantees, by Lemma 3, that , making (III) hold. However, in general, this approach has two main issues. First, if the graph is assumed directed, the agents might not be able to compute a set of doubly stochastic weights distributedly. Moreover, not every directed graph allows a doubly stochastic set of weights [19].
In [11], the authors proposed a modified log-linear update (16), and showed that it guarantees all nodes in the network will correctly learn the solution of (1) even in the present of conflicting hypotheses.
[TABLE]
where is the out degree of node at time , and is the corresponding normalization factor.
The fundamental result in Lemma 4 extends to the update rule (16), which directly allow us to state the following result.
Theorem 8
Let Assumption 1(b) hold, and for each , assume there exists a weight matrix that is column-stochastic and compliant with the underlying graph topology, i.e., if . If
[TABLE]
Then, the update rule (16), with , has the following property:
[TABLE]
The proof of Theorem 8 follows similar arguments as in the proof of Theorem 1, see also [11]. We omit the proof due to space constraints.
VI NUMERICAL ANALYSIS
In this section, we present simulation results for the non-Bayesian social learning model under different variations of graph connectivity. We assume there is a group of agents, from which only one of them, agent , receives informative signals from a random variable . All agents have a parametrized family of distributions , where and , thus, . For the network model we assume that is a path graph if , and is the completely disconnected graph otherwise, see Figure 1. Therefore, every time steps, the graph is a path graph and otherwise, the nodes remain disconnected. We will simulate three different scenarios , , and .
Figure 2 shows the effect of the rate at which decays to zero. For a subset of agents, we show their beliefs on both hypotheses and . Agent , which is the only one with informative signals is plotted with blue color. Agent is plotted with red color. If , there is no decay and the existing results in non-Bayesian learning guarantee that the learning rate will be geometric. This can be seen since all nodes in the network concentrate their beliefs on , the optimal point, at around iterations. When , our results still guarantee convergence. Even though the convergence rate is slower, all nodes learn the correct state in around iterations. Finally, when , the sequence is not ergodic. Particularly, one can see that even after iterations, the red node still has not learned the state of the world.
VII CONCLUSIONS AND FUTURE WORK
We studied the problem of non-Bayesian learning for agents with increasing self-confidence. In our main result, we explicitly characterize the fastest rate at which an agent increases it self-confidence, or decreases the weights of its neighbors, and still guarantees that social learning occurs. Moreover, we do so for the learning problem where agents can have conflicting hypotheses. Finally, we show a converse of our main result, that states that if the rate at which the weight decreases is faster than our rate bound, there exist graphs for which no social learning occurs.
Two main questions remain open and require further work. First, what is the non-asymptotic convergence rate of beliefs generated by the log-linear update rule (2) when social learning occurs? How does this convergence rate depend on the convergence rate of the sequence ? Second, if social learning does not occur, is it possible to estimate the distance between the infinite product of the matrices and a rank one matrix?
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Molavi, A. Tahbaz-Salehi, and A. Jadbabaie, “A theory of non-bayesian social learning,” Econometrica , vol. 86, no. 2, pp. 445–490, 2018.
- 2[2] A. Jadbabaie, P. Molavi, A. Sandroni, and A. Tahbaz-Salehi, “Non-Bayesian social learning,” Games and Economic Behavior , vol. 76, no. 1, pp. 210–225, 2012.
- 3[3] M. H. De Groot, “Reaching a consensus,” Journal of the American Statistical Association , vol. 69, no. 345, pp. 118–121, 1974.
- 4[4] G. L. Gilardoni and M. K. Clayton, “On reaching a consensus using Degroot’s iterative pooling,” The Annals of Statistics , vol. 21, no. 1, pp. 391–401, 1993.
- 5[5] A. Nedić, A. Olshevsky, and C. A. Uribe, “A tutorial on distributed (non-bayesian) learning: Problem, algorithms and results,” in 55th IEEE Conference on Decision and Control (CDC) , pp. 6795–6801, Dec 2016.
- 6[6] A. Nedić, A. Olshevsky, A. Ozdaglar, and J. N. Tsitsiklis, “On distributed averaging algorithms and quantization effects,” IEEE Transactions on Automatic Control , vol. 54, no. 11, pp. 2506–2517, 2009.
- 7[7] J. N. Tsitsiklis and M. Athans, “Convergence and asymptotic agreement in distributed decision problems,” IEEE Transactions on Automatic Control , vol. 29, no. 1, pp. 42–50, 1984.
- 8[8] B. Touri and A. Nedić, “Product of random stochastic matrices,” IEEE Transactions on Automatic Control , vol. 59, no. 2, pp. 437–448, 2014.