Wasserstein Distributionally Robust Stochastic Control: A Data-Driven Approach
Insoon Yang

TL;DR
This paper develops a data-driven approach for designing control policies that are robust against distribution errors, using Wasserstein metrics and dynamic programming, with theoretical guarantees and explicit solutions for linear-quadratic cases.
Contribution
It introduces computational algorithms for Wasserstein distributionally robust control, extending performance guarantees from single-stage to multi-stage problems without loss of confidence.
Findings
Proposes tractable value and policy iteration algorithms.
Provides explicit forms for optimal policies in linear-quadratic problems.
Establishes out-of-sample performance guarantees using measure concentration.
Abstract
Standard stochastic control methods assume that the probability distribution of uncertain variables is available. Unfortunately, in practice, obtaining accurate distribution information is a challenging task. To resolve this issue, we investigate the problem of designing a control policy that is robust against errors in the empirical distribution obtained from data. This problem can be formulated as a two-player zero-sum dynamic game problem, where the action space of the adversarial player is a Wasserstein ball centered at the empirical distribution. We propose computationally tractable value and policy iteration algorithms with explicit estimates of the number of iterations required for constructing an -optimal policy. We show that the contraction property of associated Bellman operators extends a single-stage out-of-sample performance guarantee, obtained using a measure…
Click any figure to enlarge with its caption.
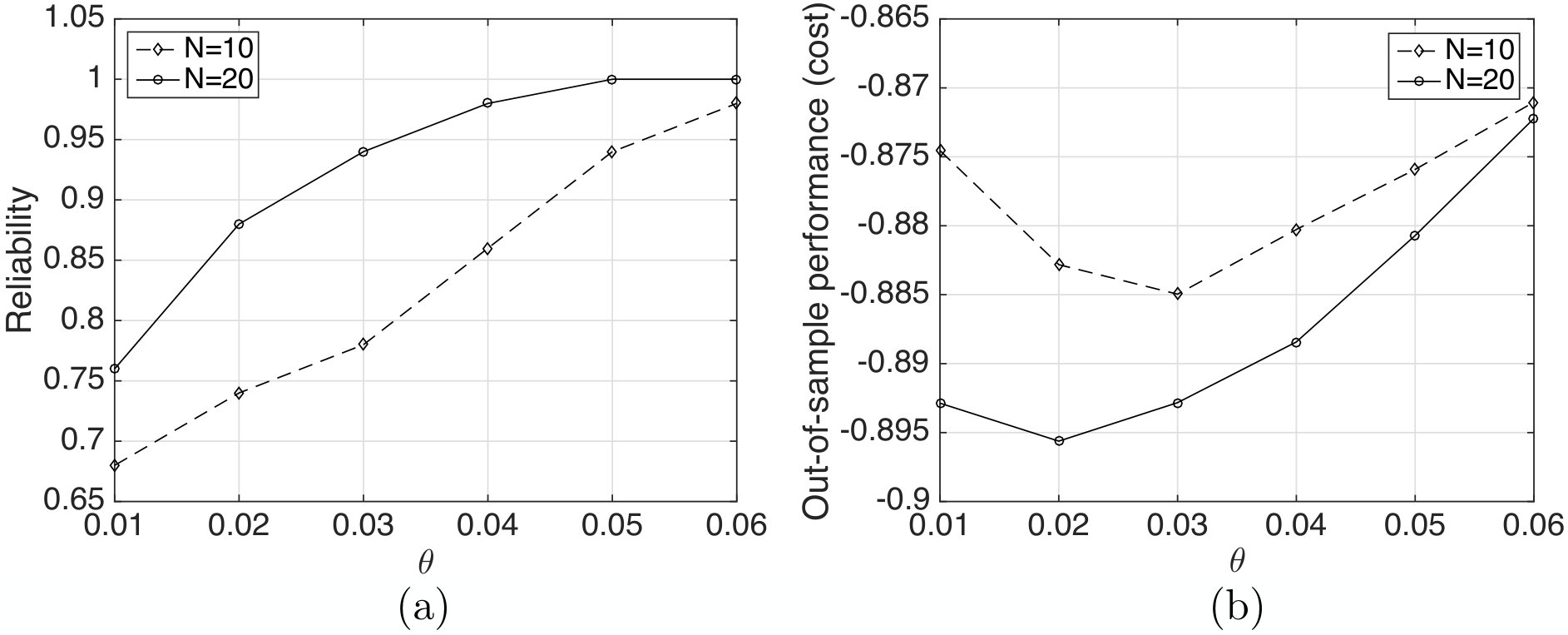 Figure 1
Figure 1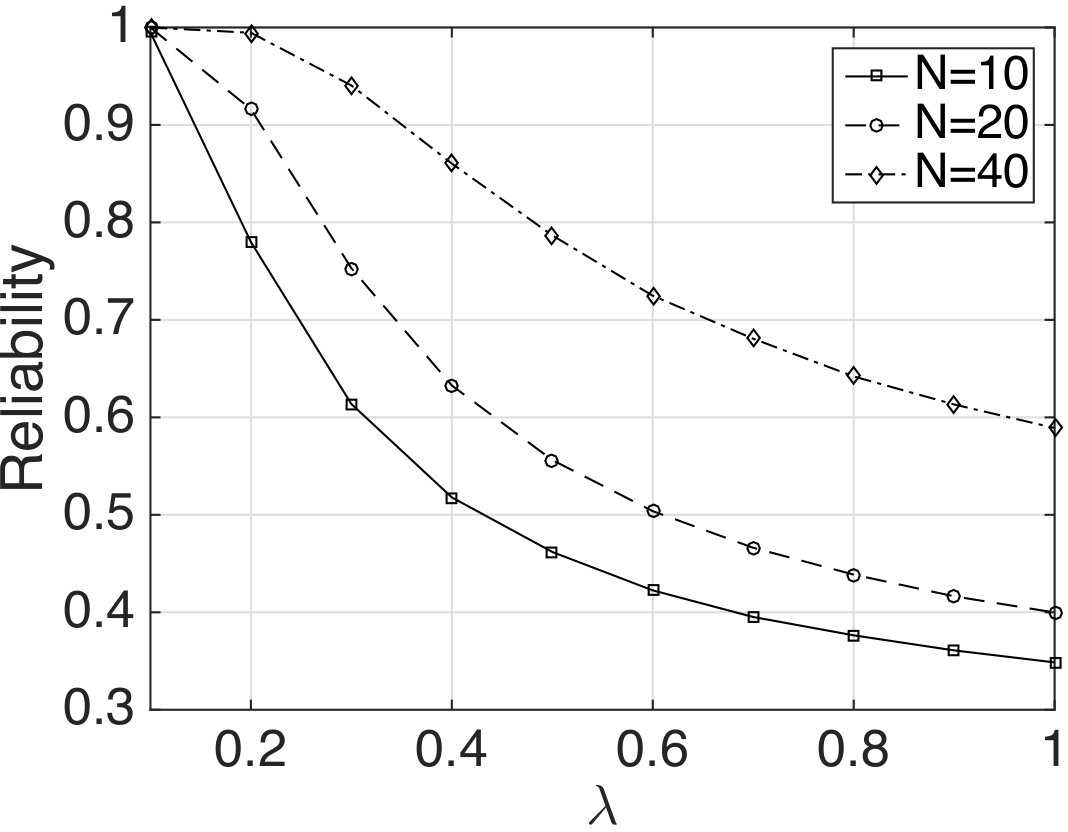 Figure 2
Figure 2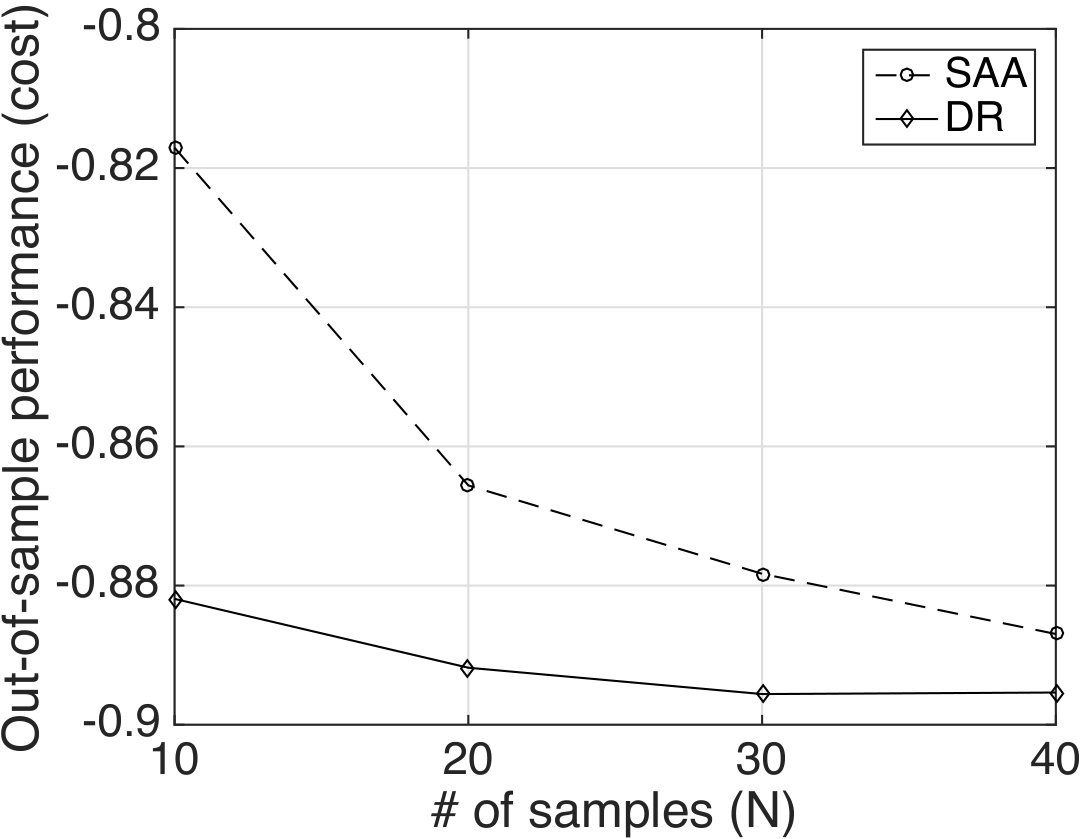 Figure 3
Figure 3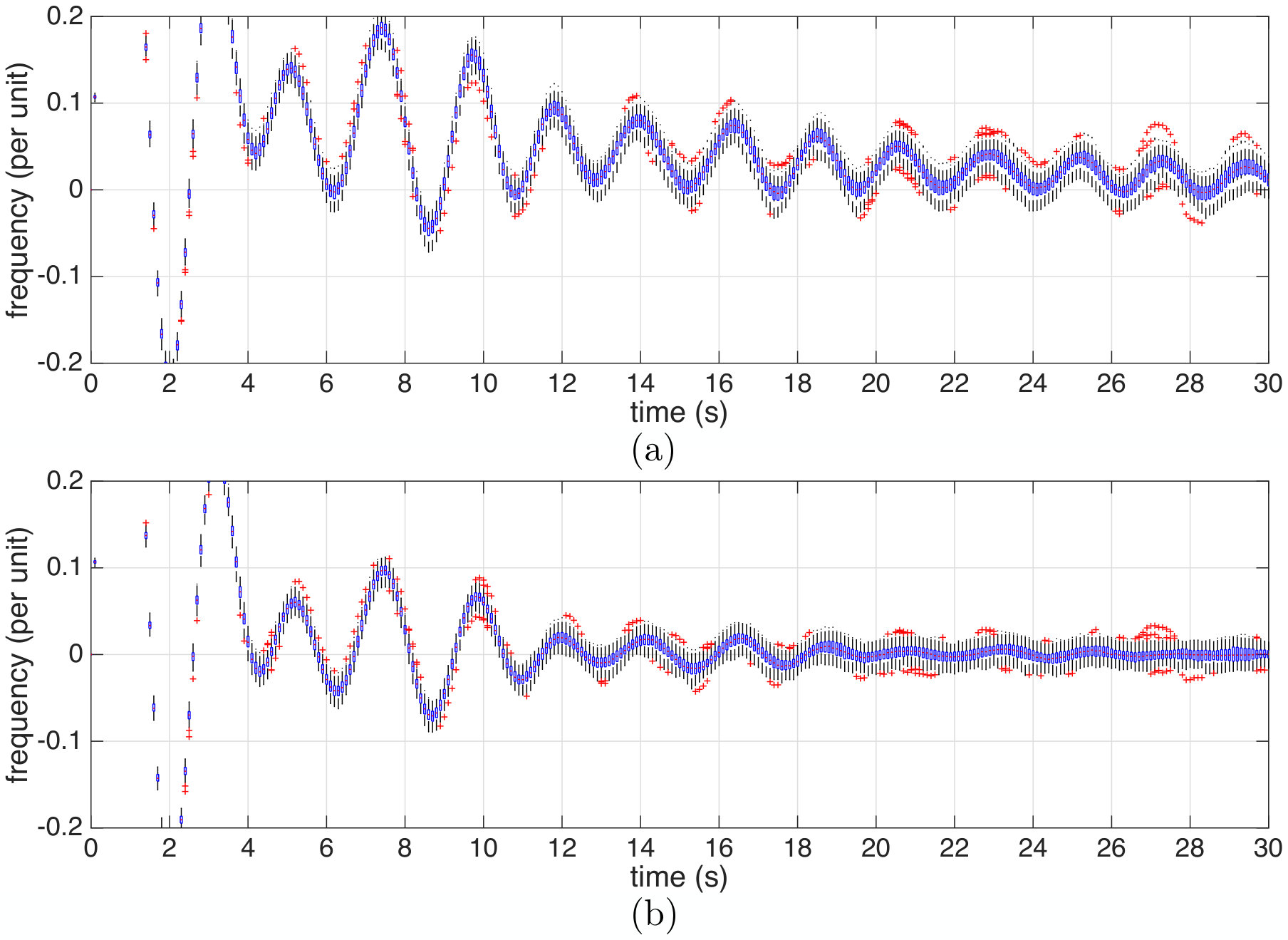 Figure 4
Figure 4| # of states | 36 | 71 | 141 | 281 |
|---|---|---|---|---|
| Time (sec) | 288. 69 | 854.61 | 2086.15 | 9350.04 |
| Bus | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 73.5 | 70.3 | 59.3 | 21.5 | 21.5 | 24.2 | 21.3 | 62.5 | 36.5 | 27.7 | |
| 25.0 | 24.2 | 19.8 | 12.4 | 12.3 | 11.6 | 12.2 | 20.8 | 14.3 | 14.3 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Wasserstein Distributionally Robust Stochastic Control:
A Data-Driven Approach
Insoon Yang Department of Electrical and Computer Engineering, Automation and Systems Research Institute, Seoul National University ([email protected]). Supported in part by NSF under ECCS-1708906 and CNS-1657100, Research Resettlement Fund for the new faculty of Seoul National University (SNU), the Creative-Pioneering Researchers Program through SNU, the Basic Research Lab Program through the National Research Foundation of Korea funded by the MSIT(2018R1A4A1059976), and Samsung Electronics.
Abstract
Standard stochastic control methods assume that the probability distribution of uncertain variables is available. Unfortunately, in practice, obtaining accurate distribution information is a challenging task. To resolve this issue, we investigate the problem of designing a control policy that is robust against errors in the empirical distribution obtained from data. This problem can be formulated as a two-player zero-sum dynamic game problem, where the action space of the adversarial player is a Wasserstein ball centered at the empirical distribution. We propose computationally tractable value and policy iteration algorithms with explicit estimates of the number of iterations required for constructing an -optimal policy. We show that the contraction property of associated Bellman operators extends a single-stage out-of-sample performance guarantee, obtained using a measure concentration inequality, to the corresponding multi-stage guarantee without any degradation in the confidence level. In addition, we characterize an explicit form of the optimal distributionally robust control policy and the worst-case distribution policy for linear-quadratic problems with Wasserstein penalty. Our study indicates that dynamic programming and Kantorovich duality play a critical role in solving and analyzing the Wasserstein distributionally robust stochastic control problems.
1 Introduction
The theory of stochastic optimal control is based on the assumption that the probability distribution of uncertain variables (e.g., disturbances) is fully known. However, this assumption is often restrictive in practice, because estimating an accurate distribution requires large-scale high-resolution sensor measurements over a long training period or multiple periods. Situations in which uncertain variables are not directly observed are much more challenging; computational methods, such as filtering or statistical learning techniques, are often used to obtain the (posterior) distribution of the uncertain variables given limited observations. The accuracy of the obtained distribution is often unsatisfactory, as it is subject to the quality of the collected data, computational methods, and prior knowledge regarding the variables. If poor distributional information is employed in constructing a stochastic optimal controller, it does not guarantee optimality and can even cause catastrophic system behaviors (e.g., [1, 2]).
To overcome this issue of limited distribution information in stochastic control, we investigate a distributionally robust control approach. This emerging minimax stochastic control method minimizes a cost function of interest, assuming that the distribution of uncertain variables is not completely known, but is contained in a pre-specified ambiguity set of probability distributions. In this paper, we model the ambiguity set as a statistical ball centered at an empirical distribution with a radius measured by the Wasserstein metric. This modeling approach provides a straightforward means to incorporate data samples into distributionally robust control problems. Our focus is to show that the resulting stochastic control problems have several salient features in terms of computational tractability and out-of-sample performance guarantee.
Due to its superior statistical properties, the Wasserstein ambiguity set has recently received a great deal of attention in distributionally robust optimization (e.g., [3, 4, 5, 6]), learning (e.g., [7, 8]) and filtering [9]. Specifically, the Wasserstein ball contains both continuous and discrete distributions while statistical balls with the -divergence such as the Kullback-Leibler divergence centered at a discrete empirical distribution is not sufficiently rich to contain relevant continuous distributions. Furthermore, the Wasserstein metric addresses the closeness between two points in the support, unlike the -divergence. Due to the incapability of the -divergence in terms of taking into account the distance between two support elements, the associated ambiguity set may contain irrelevant distributions [5]. For these reasons, we chose the Wasserstein metric to handle distribution ambiguity, although several other types of ambiguity sets have been proposed in the context of single-stage optimization by using moment constraints (e.g., [10, 11, 12]), confidence sets (e.g., [13]), and the -divergences (e.g., [14, 15]).
1.1 Related Work
Distributionally robust sequential decision-making problems have been studied in the context of finite Markov decision processes (MDPs) and continuous-state stochastic control. In the finite MDP setting, dynamic programming (DP) approaches have been proposed [16, 17, 18]. In [16], moment-based ambiguity sets are used to impose constraints on the moments of distributions, such as mean and covariance. This approach is further extended to handle more types of constraints, such as confidence sets and mean absolute deviation [17], by using the lifting technique given in [13]. Distributionally robust MDPs with Wasserstein balls are studied in [18], which provides computationally tractable reformulations and useful analytical properties.
Continuous-state distributionally robust control problems can be considered as a class of minimax stochastic control on Borel spaces [19]. In the case of linear dynamics and quadratic cost functions, [20] focuses on linear policies and proposes tractable semidefinite program formulation when moment constraints are imposed. A DP method is also proposed for moment-based ambiguity sets and applied to probabilistic safety specification problems [21]. On the other hand, [22] uses a total variation ball to model distribution ambiguity and proposes a modified version of the classical policy iteration algorithm. Furthermore, a Riccati equation-based approach is also developed in the linear-quadratic regulator setting with the total variation ambiguity set [23] and the relative entropy constraint [24].
1.2 Contributions
Departing from the aforementioned control approaches that indirectly use data samples, we consider continuous-state distributionally robust control problems with Wasserstein ambiguity sets and develop a dynamic programming method to solve and analyze problems by directly using the data. The following is a summary of the main contributions of this work. First, we propose computationally tractable value and policy iteration algorithms with explicit estimates of the number of iterations necessary for obtaining an -optimal policy. The original Bellman equation involves an infinite-dimensional minimax optimization problem, where the inner maximization problem is over probability measures in the Wasserstein ball. To alleviate the computational issue without sacrificing optimality, we reformulate Bellman operators by using modern DRO based on Kantorovich duality [3, 5]. Second, we show that the resulting distributionally robust policy has a probabilistic out-of-sample performance guarantee by using the contraction property of associated Bellman operators and a measure concentration inequality. In other words, when is used, a probabilistic bound holds on the closed-loop performance evaluated under a new set of samples that are selected independently of the training data. We observe that the contraction property of the Bellman operator seamlessly connects a single-stage performance guarantee to its multi-stage counterpart in a manner that is independent of the number of stages. Third, we consider a Wasserstein penalty problem and derive an explicit expression of the optimal control policy and the worst-case distribution policy, along with a Riccati-type equation in the linear-quadratic setting. We also show that the resulting control policy converges to the optimal policy of the corresponding linear-quadratic-Gaussian (LQG) problem as the penalty parameter tends to . The performance and utility of the proposed method are demonstrated through an investment-consumption problem and a power system frequency control problem.
This paper is significantly extended from its preliminary version [25], which models distribution ambiguity by using confidence sets. Specifically, we consider Wasserstein ambiguity sets and investigate new salient features of the corresponding distributionally robust control framework such as a characterization of the worst-case distribution policy, an out-of-sample performance guarantee, and an explicit expression of the solution to linear-quadratic problems.
1.3 Organization
In Section 2, we define optimal distributionally robust policies under ambiguous uncertainty and formulate the corresponding distributionally robust stochastic control problem as a dynamic game. In Section 3, we develop a tractable semi-infinite program formulation of the Bellman equation and characterize one of the worst-case distribution policies by using Kantorovich duality. In Section 4, we examine a probabilistic out-of-sample performance guarantee of the distributionally robust policy. In Section 5, we present the Wasserstein penalty problem and its explicit solution obtained from a Riccati-type solution. Finally, in Section 6, we provide the results of our numerical experiments.
1.4 Notation
Given a Borel space , we denote by the set of Borel probability measures on . In addition, denotes the Banach space of measurable functions on with a finite weighted sup-norm, i.e., given a measurable weight function . Let be the set of lower semicontinuous functions in .
2 Distributionally Robust Control of Stochastic Systems
2.1 Ambiguity in Stochastic Systems
Consider a discrete-time stochastic system of the form
[TABLE]
where and denote the system state and control input, respectively. Here, is a random disturbance. The probability distribution of is denoted by . However, in practice, the probability distribution is not fully known and is difficult to estimate accurately. We assume that , and are Borel subsets of , and , respectively.
Suppose that ’s are i.i.d. and that we have access to the sample of . One of the most straightforward approaches is to use the sample average approximation (SAA) method and solve the corresponding optimal control problem with the empirical distribution. This SAA-control problem can be formulated as
[TABLE]
where denotes the empirical distribution constructed from the -samples:
[TABLE]
with the Dirac delta measure concentrated at . Here, is a discount factor, is a stage-wise cost function of interest, and denotes the expected value taken with respect to the probability measure induced by the control policy and the empirical distribution . As the number of samples, , tends to infinity, the empirical distribution well approximates the true distribution ; thus, an optimal policy of the SAA-control problem presents a near-optimal performance.
Unfortunately, it takes a long simulation period or multiple episodes to obtain a large number of samples. Furthermore, in practice, it is likely that the sample data do not reflect the true distribution due to inaccurate sensor measurements or data corruption by malicious attackers (e.g., hackers). To resolve these issues in data-driven stochastic control, we propose an optimization method to construct a policy that is robust against errors in the empirical distribution (2.3). More specifically, our policy minimizes the worst-case total cost that is calculated under a probability distribution contained in a given set , which is called the ambiguity set of probability distributions. The ambiguity set can be designed to adequately characterize errors in the empirical distribution.
2.2 Distributionally Robust Policy
To formulate a concrete distributionally robust control problem, we consider a Markov (or stochastic) game with complete information (e.g., [26, 19]), which is a class of two-player zero-sum dynamic games: Player I (controller) determines a policy to minimize the total cost while Player II (adversary) selects the disturbance distribution of from the ambiguity set to maximize the same cost value. Let be the set of histories up to stage , whose element is of the form .111All the results in this paper are valid with histories of the form that also contains Player II’s actions ; that is because under Assumption 1, without loss of optimality, it suffices to focus on stationary policies that depend only on current state information. We intentionally use the reduced version of histories, as the realized distributions may not be observable in practice. The set of admissible control strategies (for Player I) is given by , where is a stochastic kernel from to and is the set of admissible control actions (given that the system state is at stage ). Similarly, the set of Player II’s admissible strategies is defined by , where is the set of extended histories up to stage , whose element is of the form and is a stochastic kernel from to . Note that the ambiguity set is the action space of Player II. Here, we allow Player II can change the distribution of over time. Thus, the strategy space for Player II is larger than necessary, and this gives an advantage to the adversary. However, later we will show that an optimal policy of Player II is stationary under some assumption (see Proposition 5).
We consider the following infinite-horizon discounted cost function:
[TABLE]
where denotes expectation with respect to the probability measure induced by the strategy pair .
Before defining a concrete stochastic control problem, we impose the following standard assumption for measurable selection in semicontinuous models [19]:
Assumption 1**.**
Let .
The function is lower semicontinuous on , and
[TABLE]
for some constant and continuous function such that is continuous on for any . In addition, there exists a constant such that for all ; 2. 2.
For each continuous bounded function , the function is continuous on for any ; 3. 3.
The set is compact for every , and the set-valued mapping is upper semicontinuous.
The first condition trivially holds when is bounded. In fact, is a weight function introduced to relax the boundedness assumption. Assumption 1 ensures the existence of an optimal policy , which is deterministic and stationary, of a minimax control problem with the cost function (2.6) [19, Theorem 4.1]. Furthermore, the corresponding optimal value function lies in as discussed later.
We now define the optimal distributionally robust policies as follows:
Definition 1**.**
A control policy is said to be an optimal distributionally robust policy if it satisfies
[TABLE]
In words, an optimal distributionally robust policy achieves the minimal cost under the most adverse policies that select disturbance distributions in the ambiguity set . Such a desirable policy can be obtained by solving the following problem:
[TABLE]
which we call the distributionally robust control (DR-control) problem. The existence of an optimal policy under Assumption 1 will be formalized in Theorem 1 in Section 3.1.
The most important part of this formulation is the inner maximization problem over all disturbance distribution policies in , which encodes distributional uncertainty through . An optimal policy has a performance guarantee in the form of an upper-bound, , if the ambiguity set is sufficiently large to contain the true distribution. This performance guarantee may not be valid when a different control policy is used, as shown in (2.5).
2.3 Wasserstein Ambiguity Set
To complete the formulation of the DR-control problem, we consider a specific class of ambiguity sets using the Wasserstein metric. Let be a statistical ball centered at the empirical distribution defined by (2.3) with radius :
[TABLE]
Here, the distance between the two probability distributions is measured by the Wasserstein metric of order ,
[TABLE]
where is a metric on , and denotes the th marginal of for . The Wasserstein distance between two probability distributions represents the minimum cost of transporting or redistributing mass from one to another via non-uniform perturbation, and the optimization variable can be interpreted as a transport plan.
The minimization problem to identify an optimal transport plan in (2.8) is called the Monge-Kantorovich problem. The minimum of this problem can be found by solving the following dual problem:
[TABLE]
where . This equivalence is known as the Kantorovich duality principle. Then, the Wasserstein ball (2.8) can be expressed as follows:
Lemma 1**.**
The Wasserstein ambiguity set defined by (2.7) is equivalent to
[TABLE]
A proof for this lemma is contained in Appendix A. Note that the minimization problem in the reformulated Wasserstein ball is finite dimensional, unlike the original Monge-Kantorovich problem. In the following section, we propose computationally tractable value and policy iteration algorithms by using the reformulation results in DRO based on Kantorovich duality.
3 Dynamic Programming Solution and Analysis
Our first goal is to develop a computationally tractable dynamic programming (DP) solution for the DR-control problem (2.6). We begin by characterizing an optimality condition using the Bellman’s principle.
3.1 Bellman’s Principle of Optimality
For any , let be the Bellman operator of the DR-control problem (2.6), defined by
[TABLE]
for every . Assumption 1 enables us to conduct the contraction analysis with respect to the weighted sup-norm defined by
[TABLE]
The second and third conditions in Assumption 1 play a critical role in preserving the lower semicontinuity of the value function when applying the Bellman operator as well as in the existence and optimality of deterministic stationary policies. Let be the set of deterministic stationary policies, i.e., , measurable}. Then, the following lemmas hold:
Lemma 2** (Contraction and Monotonicity).**
Suppose that Assumption 1 holds. Then, for any . Furthermore, the Bellman operator is a -contraction mapping with respect to , where 222Here, the constant is defined in Assumption 1-1)., i.e.,
[TABLE]
Furthermore, is monotone, i.e.,
[TABLE]
Lemma 3** (Measurable selection).**
Suppose that Assumption 1 holds. There exist a measurable function and a deterministic stationary policy such that
* is the unique function in that satisfies the following Bellman equation:*
[TABLE] 2. 2.
given any fixed ,
[TABLE]
and for all .
These lemmas follow immediately from [19, Lemma 4.4 and Theorem 4.1]. In fact, for any , there exists such that for every under Assumption 1 (see [19, Lemma 3.3]).333Thus, the outer minimization problem in the definition of admits an optimal solution when , and “” can be replaced by “.” If we let for each , then is an optimal distributionally robust policy, which is deterministic and stationary. More specifically, the following principle of optimality holds:
Theorem 1** (Existence and optimality of deterministic stationary policy).**
Suppose that Assumption 1 holds. Then, defined in Lemma 3 satisfies
[TABLE]
In words, is the optimal value function of the DR-control problem (2.6), and is an optimal policy, which is deterministic and stationary.
The existence and optimality results are shown in a more general minimax control setting in [19, Theorem 4.1].
3.2 Value Iteration
To compute the optimal value function , we first consider a value iteration (VI) approach, , where denotes the value function evaluated at the th iteration and is initialized as an arbitrary function in . By the contraction property of (Lemma 2), the Banach fixed-point theorem implies that converges to pointwise as tends to under Assumption 1. However, this approach requires us to solve the infinite-dimensional minimax optimization problem in the Bellman operator for each in each iteration. To alleviate this issue, we reformulate the problem into a computationally tractable form by using modern Wasserstein DRO [3, 5].
Proposition 1**.**
Suppose that the function lies in for each . Then, the Bellman operator can be expressed as
[TABLE]
for each , where the first inequality constraint holds for all .
This reformulation can be obtained by using Kantorovich duality on the Wasserstein ambiguity set (Lemma 1). It is shown in [5, Theorem 1] that there is no duality gap.
Note that the reformulated optimization problem in Proposition 1 has finite-dimensional decision variables as , and . However, the first inequality constraint must hold for all in the support , which could be a dense set. Thus, in general, the reformulated problem is a semi-infinite program. This semi-infinite program can be solved by using several existing convergent algorithms, such as discretization, sampling-based methods (see [27, 28, 29, 30] and the references therein).
To interpret this reformulation, we consider the following equivalent integral form:
[TABLE]
The integrand above can be interpreted as a regularized cost-to-go function. The regularized value is then integrated using the empirical distribution . The first term , which is nonnegative, is added to compensate for this regularization effect and the optimism induced by the empirical distribution so that the reformulated optimization problem is consistent with the original one.
We define an -optimal policy of (2.6) as that satisfies
[TABLE]
for , where is the (worst-case) value function of a policy , i.e.,
[TABLE]
The following VI algorithm can be used to find an -optimal policy:
Initialize as an arbitrary function in , and set ; 2. 2.
For each , compute
[TABLE]
by solving the semi-infinite program (3.2) with ; 3. 3.
If the stopping criterion is met, then go to Step 4); Otherwise, set and go to Step 2); 4. 4.
For each , set
[TABLE]
where is an optimal of the semi-infinite program (3.2) that computes , and stop.
Note that the existence of an optimal in Step 4) is guaranteed under Assumption 1 by [19, Lemma 3.3]. A typical stopping criterion in VI is for some threshold . However, we can even compute the number of iterations required to achieve the desired precision . Given any and , let
[TABLE]
for all . The Bellman operator has the following properties:
Lemma 4**.**
Suppose that Assumption 1 holds. Then, given any , we have for any . Furthermore, the operator is a -contraction mapping with respect to , i.e.,
[TABLE]
where . Furthermore, is monotone, i.e.,
[TABLE]
Proof.
By Assumption 1, it is clear that if . Fix arbitrary , and an arbitrary . For any , there exists such that
[TABLE]
Thus, we have
[TABLE]
where the last inequality holds due to Assumption 1-1). By switching the role of and , we also have . Since the two inequalities hold for any and , and , we conclude that . It is straightforward to check that is monotone. ∎
This lemma implies that the value function is the unique fixed point of in . By using the contraction property of and , we can estimate the number of iterations needed to obtain an -optimal policy as follows:
Proposition 2**.**
Suppose that Assumption 1 holds. We assume that given , the total number of iterations, , in the VI algorithm satisfies
[TABLE]
where and are the constants defined in Assumption 1 and Lemma 4, respectively. Then, obtained by the VI algorithm is an -optimal policy, i.e.,
[TABLE]
Proof.
By Lemma 4 and Theorem 1, we have . We observe that
[TABLE]
where the last inequality holds because of Lemma 4, and . By Lemma 2, we have
[TABLE]
On the other hand, by [19, Theorem 4.2 (a)],
[TABLE]
where the second inequality holds due to the proposed choice of . Combining (3.4) and (3.5), we conclude that . ∎
A practical implementation of the VI algorithm requires a finite-state approximation such as a discretization of the state space. A review on such approximation methods can be found in a recent monograph [31].
3.3 Policy Iteration
Policy iteration (PI) is an alternative way to construct an -optimal policy. The PI algorithm can be described as follows:
Initialize as an arbitrary policy in , and set ; 2. 2.
(Policy evaluation) Find the fixed point of ; 3. 3.
(Policy improvement) For each , set
[TABLE]
where is an optimal of the semi-infinite program (3.2) that computes ; 4. 4.
If the stopping criterion is met, then stop and set . Otherwise, set and go to Step 2);
Here, the stopping criterion can be chosen as for a positive constant . To perform the policy evaluation step (Step 2) in a computationally tractable manner, we reformulate the infinite-dimensional maximization problem in the definition of as finite dimensional by using Wasserstein DRO [3, 5].
Proposition 3**.**
Suppose that Assumption 1 holds and that . Then, the operator satisfies
[TABLE]
*where {B}:=\big{\{}(\underline{w}^{(1)},\ldots,\underline{w}^{(N)},\overline{w}^{(1)},\ldots,\overline{w}^{(N)})\in\mathcal{W}^{2N},q\in\Delta\mid\frac{1}{N}\sum_{i=1}^{N}[q_{1}d(\underline{w}^{(i)},\hat{w}^{(i)})^{p}+q_{2}d(\overline{w}^{(i)},\hat{w}^{(i)})^{p}]\leq\theta^{p}\big{\}}. *
This proposition follows immediately from [5, Corollary 2]. The optimization variables , can be interpreted as the probability atoms that characterize one of the worst-case distributions. By the contraction property of (Lemma 4), we can find the fixed point of by value iteration. In other words, we perform , , until convergence. When computing , we solve the finite-dimensional optimization problem in Proposition 3 with to completely remove the infinite-dimensionality issue inherent in the definition of . In the policy improvement step, we use the semi-infinite program formulation of in Proposition 1 instead of directly solving the infinite-dimensional minimax optimization problem in the definition of . It is well known that under Assumption 1 by the monotonicity and contraction properties of and (Lemmas 2 and 4) [32, Proposition 2.5.4].
However, it is usually difficult to find the exact fixed point of in the policy evaluation step. Thus, we propose a modified PI algorithm, which is also called optimistic policy iteration [33, 32]:
Initialize as an arbitrary function in and as a sequence of positive integers, and set ; 2. 2.
(Policy improvement) For each , set
[TABLE]
where is an optimal of the semi-infinite program (3.2) that computes ; 3. 3.
(Policy evaluation) Compute
[TABLE]
by solving the finite-dimensional optimization problems in Proposition 3; 4. 4.
If the stopping criterion is met, then stop and set . Otherwise, set and go to Step 2);
Note that the modified PI algorithm approximately evaluates the performance of a policy as instead of finding the exact fixed point of . Concrete choices of the order sequence are discussed in [34]. However, for any choice of , the modified PI algorithm converges under Assumption 1 [32]:
[TABLE]
As in the case of VI, we can estimate the number of iterations required for obtaining an -optimal policy.
Proposition 4**.**
Suppose that Assumption 1 holds. Let be a positive constant such that
[TABLE]
We assume that given , the total number of iterations, , in the modified PI algorithm satisfies
[TABLE]
where is the constant defined in Lemma 4. Then, obtained by the modified PI algorithm is an -optimal policy, i.e.,
[TABLE]
Proof.
According to Lemma 4 and Theorem 1, we have . By [32, Lemma 2.5.4], we obtain that
[TABLE]
which implies that
[TABLE]
On the other hand, is a greedy policy when the value function is chosen as . As in the proof of Proposition 2, we have . Thus, by (3.6),
[TABLE]
where the second inequality holds due to the proposed choice of . ∎
3.4 The Worst-Case Distribution Policy
Given a policy (for Player I), the worst-case distribution policy (for Player II) can be found by solving
[TABLE]
which is an optimal control problem. By the dynamic programming principle, the worst-case value function , defined by (3.3), is the unique solution to the following Bellman equation:
[TABLE]
under Assumption 1. The worst-case value function can be computed, for example, via value iteration. Given , how can we characterize the worst-case distribution policy? The following proposition indicates that, if the optimization problem involved in admits an optimal solution for all , then there exists an optimal policy for Player II, which is deterministic and stationary, and it generates a finitely-supported worst-case distribution.
Proposition 5** (Worst-case distribution policy).**
Suppose that Assumption 1 holds, and that given
[TABLE]
admits an optimal solution for any . Then, the deterministic stationary policy defined by
[TABLE]
is an optimal policy (for Player II) that generates a worst-case distribution for each state , where is an optimal solution of the maximization problem in Proposition 3 with .
The existence of an optimal policy, which is deterministic and stationary, follows from the dynamic programming principle when the assumptions in the proposition hold. Thus, it is sufficient for Player II to use the same worst-case distribution for all stages. The structure of is obtained by applying [5, Corollary 1] to the maximization problem in the proposition. Note that the worst-case distribution of this form is consistent with the discussion below Proposition 3. By using [5, Corollary 2], we have the following sharper result of characterizing the worst-case distribution with atoms: if the assumptions in Proposition 5 hold, one of the worst-case distribution policies has the form
[TABLE]
where , , , and for all . Here, is a dual minimizer, which must exist when the worst-case distribution exists [5, Corollary 1].
It is worth mentioning that Kantorovich duality and DP play a critical role in obtaining all the results in this section. Based on the reformulation results and analytical properties of DR-control problems, we demonstrate their utility in the following sections.
4 Out-of-Sample Performance Guarantee
A potential defect of the SAA-control formulation (2.2) is that its optimal policy may not perform well if a testing dataset of is different from the training dataset . This issue occurs even when the testing and training datasets are sampled from the same distribution. Such a degradation of the optimal decisions in out-of-sample tests is often called the optimizer’s curse in the literature of decision analysis [35]. We show that an optimal distributionally robust policy can alleviate this issue and provide a guaranteed out-of-sample performance if the radius of Wasserstein ambiguity set is carefully determined.
Let denote an optimal distributionally robust policy obtained by using the training dataset of samples. The out-of-sample performance of is measured as
[TABLE]
which represents the expected total cost under a new sample that is generated (according to ) independent of the training dataset. Unfortunately, the out-of-sample performance cannot be precisely computed because the true distribution is unknown. Thus, instead, we aim at establishing a probabilistic out-of-sample performance guarantee of the form:
[TABLE]
where denotes the optimal value function of the DR-control problem with the training dataset , and .444Here, , and are viewed as random objects. The inequality represents a bound on the probability that the expected cost incurred by is no greater than the optimal value function. Note that the probability and the expected cost are evaluated with respect to the true distribution . Thus, this inequality provides a probabilistic bound on the performance of evaluated with unseen test samples drawn from . Here, , which depends on , plays the role of a certificate for the out-of-sample performance.
Our goal is to identify conditions on the radius under which an optimal distributionally robust policy provides the probabilistic performance guarantee. We begin by imposing the following assumption on the true distribution :
Assumption 2** (Light tail).**
There exists a positive constant such that
[TABLE]
This assumption implies that the tail of decays exponentially. Under this condition, the following measure concentration inequality holds:
Theorem 2** (Measure concentration, Theorem 2 in [36]).**
Suppose that Assumption 2 holds. Let
[TABLE]
Then,
[TABLE]
where
[TABLE]
and
[TABLE]
Here, are positive constants depending only on , and .
This theorem provides an upper-bound of the probability that the true distribution lies outside of the Wasserstein ambiguity set . The measure concentration inequality provides a systematic means to determine the radius for to contain the true distribution with probability no less than . As shown in the following theorem, the contraction property of Bellman operators enables us to extend the single-stage out-of-performance guarantee to its multi-stage counterpart with no additional requirement on .
Theorem 3** (Out-of-sample performance guarantee).**
Suppose that Assumptions 1 and 2 hold. Let and denote an optimal policy and the optimal value function of the DR-control problem (2.6) with the training dataset and the following Wasserstein ball radius:555This choice includes the radius proposed in [3] in the single-stage setting as a special case (when and ).
[TABLE]
where satisfies , and are the positive constants in Theorem 2.666The constants and in Theorem 2 can be calculated using the proof of Theorem 2 in [36]. However, this calculation is often conservative and thus results in a smaller radius than necessary. Bootstrapping and cross-validation methods can be used to reduce the conservativeness in the a priori bound , as advocated and demonstrated in [3]. Then, the probabilistic out-of-sample performance guarantee (4.2) holds.
Proof.
Using Theorem 2, we can confirm that our choice of provides the following probabilistic guarantee:
[TABLE]
Define an operator as for all . It follows from (4.3) that the following single-stage guarantee holds:
[TABLE]
given any fixed . It is straightforward to check under Assumption 1 that is a monotone contraction mapping.
We now show that if , then for any using mathematical induction. For , we have by the minimax definition of . Suppose now that the induction hypothesis holds for some . By the monotonicity of and the definition of , we have
[TABLE]
and thus the induction hypothesis is valid for .
We now notice that
[TABLE]
since is a contraction mapping under Assumption 1. Therefore, if , then
[TABLE]
By (4.3), the probabilistic performance guarantee holds as desired. ∎
Remark 1**.**
Note that the contraction property of and plays a critical role in connecting the single-stage performance guarantee (4.4) to the multi-stage guarantee (4.2) in a way that is independent of the number of stages. This is a quite powerful result, because if we have a radius that provides a desirable confidence level in the single-stage guarantee, we can use the same radius to achieve the same level of confidence in the multi-stage guarantee with no additional requirement.
5 Wasserstein Penalty Problem
We now consider a slightly different version of the DR-control problem, which can be considered as a relaxation of (2.6) with a fixed penalty parameter :
[TABLE]
where the strategy space of Player II no longer depends on a Wasserstein ambiguity set. Instead of using an explicit ambiguity set , Player II is penalized by , which can be interpreted as the cost of perturbing the empirical distribution .
5.1 Dynamic Programming
Under Assumption 1, the Bellman operator of the Wasserstein penalty problem is defined by
[TABLE]
for all . By using the strong duality result [5, Theorem 1], we have the following equivalent form of :
Proposition 6**.**
Suppose that the function lies in for each . Then, the Bellman operator can be expressed as
[TABLE]
for all . Furthermore, we have
[TABLE]
By the results of [19] in the general minimax control setting, the optimal value function is the unique fixed point (in ) of under Assumption 1 because is a contraction. We can use value iteration to evaluate due to the Banach fixed point theorem. Analogous to Theorem 1, there exists a deterministic stationary policy , which is optimal, where for all , under Assumption 1.
5.2 Linear-Quadratic Problem
We now develop a solution approach, using a Riccati-type equation, to linear-quadratic (LQ) problems with the Wasserstein penalty when
[TABLE]
where denotes the Euclidean norm on . Consider a linear system of the form
[TABLE]
where , , and . We also choose the following quadratic stage-wise cost function:
[TABLE]
where is positive semidefinite, and is positive definite. For the sake of simplicity, we assume that . The case of non-zero mean is considered in Appendix B. Let . In the LQ setting, we also set , , and . Note that, unlike the standard LQG, the LQ problems with Wasserstein penalty do not assume that the probability distribution of random disturbances is Gaussian. In fact, the main motivation of this distributionally robust LQ formulation is to relax the assumption of Gaussian disturbance distributions in LQG, and to obtain a useful control policy when the true distribution deviates from a Gaussian distribution.
By using DP, we obtain the following explicit solution of the LQ problem:
Theorem 4**.**
Suppose that there exists a symmetric positive semidefinite matrix that solves the following equation:
[TABLE]
with
[TABLE]
for a sufficiently large . Then, solves the Bellman equation, where . If, in addition, is the optimal value function,777Sufficient conditions for to be the optimal value function are provided in [37]. Under the stabilizability and observability conditions, the algebraic Riccati equation has a unique positive semidefinite solution as well. then the unique optimal policy is given by
[TABLE]
where
[TABLE]
Furthermore, if we let
[TABLE]
the deterministic stationary policy , defined as
[TABLE]
is an optimal policy for Player II that generates a worst-case distribution for each .
Its proof is contained in Appendix B. We first note that an optimal distributionally robust policy is linear in the system state. Furthermore, the control gain matrix is independent of the covariance matrix as in standard LQG. The worst-case distribution’s support elements ’s are affine in the system state. More specifically, is obtained by scaling the th data sample by the factor of and shifting it by the vector , which is linear in the system state. Distributional robustness is controlled by the penalty parameter : As increases, the permissible deviation of from decreases. This is equivalent to decreasing the Wasserstein ball radius in the original DR-control setting. Thus, by letting tend to , the optimal distributionally robust policy for the LQ problem converges pointwise to the standard LQ optimal control policy.
Proposition 7**.**
Suppose that is stabilizable and is observable, where . Let be the unique symmetric positive definite solution of the following discrete algebraic Riccati equation:
[TABLE]
and let
[TABLE]
Then, for each
[TABLE]
as , where and are defined in Theorem 4.
Proof.
Let denote a symmetric positive semidefinite solution of (5.3) given any fixed . As tends to , the right-hand side of (5.3) tends to , which corresponds to the right-hand side of (5.4) with . Therefore, solves the algebraic Riccati equation (5.4) as . On the other hand, (5.4) admits a unique positive definite solution when is observable and is stabilizable (e.g., [38, Section 2.4]). Thus, converges to as . Likewise, we can show that the feedback gain matrix and the worst-case distribution’s support element (defined in Theorem 4) tend to and , respectively, as . Therefore, the result follows. ∎
6 Numerical Experiments
6.1 Investment-Consumption Problem
We first demonstrate the performance and utility of DR-control through an investment-consumption problem (e.g., [39, 40]). Let be the wealth of an investor at stage . The investor wishes to decide the amount to be invested in a risky asset (with an i.i.d. random rate of return, ) and the amount to be consumed at stage . The remaining amount is automatically re-invested into a riskless asset with a deterministic rate of return, . Then, the investor’s wealth evolves as
[TABLE]
We assume that the control actions and satisfy the following constraints:
[TABLE]
i.e., .
The cost function is given by the following negative expected utility from consumption:
[TABLE]
where the utility function is selected as . The following parameters are used in the numerical simulations: , , , and . The data samples of are generated according to the normal distribution . We numerically approximate the optimal value function and the corresponding optimal policy on a computational grid by using the convex optimization approach in [41]. This method approximates the Bellman operator by the optimal value of a convex program with a uniform convergence property. Furthermore, it does not require any explicit interpolation in evaluating the value function and control policies at some state other than the grid points, by using an auxiliary optimization variable to assign the contribution of each grid point to the next state.
The numerical experiments were conducted on a Mac with 4.2 GHz Intel Core i7 and 64GB RAM. The amount of time required for simulations with different grid sizes and are reported in TABLE 1. For the rest of the simulations, we used 71 states (with grid spacing 0.02).
6.1.1 Out-of-sample performance guarantee
To demonstrate the out-of-sample performance guarantee of an optimal distributionally robust policy, we compute the following reliability of :
[TABLE]
which represents the probability that the expected cost incurred by under the true distribution is no greater than . As shown in Fig. 1 (a), the reliability increases with the Wasserstein ball radius and the number of samples. This result is consistent with Theorem 3. Our numerical experiments also confirm that the same radius can be used to achieve the same level of reliability in both single-stage and multi-stage settings as indicated in the theorem.
Fig. 1 (b) illustrates the out-of-sample cost (4.1) of with respect to and . Interestingly, the out-of-sample cost does not monotonically decrease with .888This observation is consistent with the single-stage case in Section 7.2 of [3]. For a too-small radius, the resulting DR-policy is not sufficiently robust to obtain the best out-of-sample performance (i.e., the least out-of-sample cost). On the other hand, if a too-large Wasserstein ambiguity set is selected, the resulting DR-policy is overly conservative and thus sacrifices the closed-loop performance. Thus, there exists an optimal radius (e.g., in the case of ) that provides the best out-of-sample performance.
6.1.2 Comparison to SAA
To compare DR-control (2.6) with SAA-control (2.2), we first compute the out-of-sample performance of and that of the corresponding optimal SAA policy obtained by using the same training dataset . The radius is selected as the one that provides the best out-of-sample performance. As shown in Fig. 2, the proposed DR-policy achieves 8% lower out-of-sample cost than the SAA-policy when . As expected, the gap between the two decreases with the number of samples. Note that the proposed DR-policy designed even with a small number of samples () maintains its performance under the test dataset that is generated independent of the training dataset, unlike the corresponding SAA-policy.
6.2 Power System Frequency Control Problem
Consider an electric power transmission system with buses (and generator buses). This system may be subject to ambiguous uncertainty generated from variable renewable energy sources such as wind and solar. For the frequency regulation of this system, we use the proposed Wasserstein penalty method to control the mechanical power input of generator. Let and be the voltage angle (in radian) and the mechanical power input (in per unit), respectively, at generator bus . The swing equation of this system is then given by
[TABLE]
where and denote the inertia coefficient (in pusec2/rad) and the damping coefficient (in pusec/rad) of the generator at bus . Here, is the electrical active power injection (in per unit) at bus and is given by , where and are the conductance and susceptance of the transmission line connecting buses and , respectively, and is the voltage at bus . Assuming that all the voltage magnitudes are per unit, the angle differences ’s are small, and all the transmission lines are (almost) lossless, the AC power flow equation can be approximated by the following linearized DC power flow equation:
[TABLE]
where , , and is the Kron-reduced Laplacian matrix of this power network.999The Kron reduction is used to express the system in the reduced dimension by focusing on the interactions of the generator buses [42]. More precisely, we can obtain the Kron-reduced admittance matrix , by eliminating nongenerator bus , as for all such that . The Kron-reduced Laplacian can then be obtained by setting and for , where denotes the susceptance of the Kron-reduced admittance matrix [43].
Let and . By combining (6.1) and (6.2), we obtain the following state-space model of the power system (e.g., [44]):
[TABLE]
where and . We discretize this system using zero-order hold on the input and a sampling time of seconds to obtain the matrices and of the following discrete-time system model (5.1):
[TABLE]
where is the random disturbance (in per unit) at bus at stage . It can model uncertain power injections generated by solar or wind energy sources.
The state-dependent portion of the quadratic cost function (5.2) is chosen as
[TABLE]
where denotes the -dimensional vector of all ones, the first term measures the deviation of rotor angles from their average , and the second term corresponds to the kinetic energy stored in the electro-mechanical generators [45]. The matrix is chosen to be the by identity matrix.
The IEEE 39-bus New England test case (with 10 generator buses, 29 load buses, and 40 transmission lines) is used to demonstrate the performance of the proposed LQ control with Wasserstein penalty. The initial values of voltage angles are determined by solving the (steady-state) power flow problem using MATPOWER [46]. The initial frequency is set to be zero for all buses except bus 1 at which per unit. We use in all simulations.
6.2.1 Worst-case distribution policy
We first compare the standard LQG control policy and the proposed DR-control policy with the Wasserstein penalty under the worst-case distribution policy obtained by using the proof of Theorem 4. We set and . The i.i.d. samples are generated according to the normal distribution . As depicted in Fig. 3,101010The central bar on each box indicates the median; the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively; and the ‘+’ symbol represents the outliers. is less sensitive than against the worst-case distribution policy.111111The frequency deviation at other buses displays a similar behavior. In the (seconds) interval, the frequency controlled by fluctuates around non-zero values while maintains the frequency fluctuation centered approximately around zero. This is because the proposed DR-method takes into account the possibility of nonzero-mean disturbances, while the standard LQG method assumes zero-mean disturbances. Furthermore, the proposed DR-method suppress the frequency fluctuation much faster than the standard LQG method: Under , the mean frequency deviation averaging across the buses is less than 1% for any time after 16.7 seconds. On the other hand, if the standard LQG control is used, it takes 41.8 seconds to take the mean frequency deviation (averaging across the buses) below 1%. The detailed results for each bus are reported in Table 2.
6.2.2 Out-of-sample performance guarantee
We now examine the out-of-sample performance of and how it depends on the penalty parameter and the number of samples. The i.i.d. samples are generated according to the normal distribution . Given and , we define the reliability of as
[TABLE]
As shown in Fig. 4, the reliability decreases with . This is because when using larger , the control policy becomes less robust against the deviation of the empirical distribution from the true distribution. Increasing has the effect of decreasing the radius in DR-control. In addition, the reliability tends to increase as the number of samples used to design increases. This result is consistent with the dependency of the DR-control reliability on the number of samples. By using this result, we can determine the penalty parameter to attain a desired out-of-sample performance guarantee (or reliability), given the number of samples.
7 Conclusions
In this paper, we considered distributionally robust stochastic control problems with Wasserstein ambiguity sets by directly using the data samples of uncertain variables. We showed that the proposed framework has several salient features, including computational tractability with error bounds, an out-of-sample performance guarantee, and an explicit solution in the LQ setting. It is worth emphasizing that the Kantorovich duality principle plays a critical role in our DP solution and analysis. Furthermore, with regard to the out-of-sample performance guarantee, our analysis provides the unique insight that the contraction property of the Bellman operators extends a single-stage guarantee—obtained using a measure concentration inequality—to the corresponding multi-stage guarantee without any degradation in the confidence level.
Appendix A Proof of Lemma 1
Proof.
Recall that using the Kantorovich duality principle, the Wasserstein distance between and can be written as
[TABLE]
where . Let
[TABLE]
We claim that . Choose an arbitrary from . Note that for any ,
[TABLE]
Thus, we have
[TABLE]
where the last inequality holds becase . Therefore, , which implies that .
We now select an arbitrary from . Fix and define a function by
[TABLE]
Then, and . Thus,
[TABLE]
which holds for any . By the definition of , this implies that . Therefore, . ∎
Appendix B Linear-Quadratic Problems
Proof of Theorem 4.
Let be defined as . To compute , we first calculate the inner maximization part in Proposition 6 as follows:
[TABLE]
There exists a constant (depending on ) such that for any , the objective function of the maximization problem above is strictly concave in (i.e., is positive definite), and thus the unique maximizer is given by
[TABLE]
With this maximizer, we can rewrite the term as
[TABLE]
Since and , we have
[TABLE]
Recall that
[TABLE]
We notice is positive definite for because is positive definite and is positive definite for . Thus, the objective function in (B.2) is strictly convex in and has the unique minimizer . Therefore, we obtain that
[TABLE]
We conclude that solves the Bellman equation since and satisfy and . Furthermore, when is the optimal value function, the value of an optimal policy at is uniquely given by , i.e., .
We now characterize the worst-case distribution policy. Plugging and into (B.1), we obtain that
[TABLE]
Let for all . Then,
[TABLE]
Therefore, we have
[TABLE]
where the last equality holds by the definition of ’s. On the other hand, it follows from Proposition 6 that
[TABLE]
Thus, we conclude that is one of the worst-case distributions. ∎
We now consider the case in which the data samples ’s have non-zero mean, i.e.,
[TABLE]
The linear system (5.1) can be rewritten as
[TABLE]
where . We now normalize the data samples for all so that
[TABLE]
Let assuming it is well-defined. Then,
[TABLE]
By letting , we can rewrite the system as
[TABLE]
Define a positive semidefinite matrix by
[TABLE]
We then have
[TABLE]
Thus, the nonzero mean case is converted to the zero mean case with the normalized data ’s, the expanded state and the new positive semidefinite matrix in the quadratic cost function. Therefore, we can use Theorem 4 to compute the DR-control gain matrix . The corresponding optimal policy is obtained as for all .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Nilim and L. El Ghaoui, “Robust control of Markov decision processes with uncertain transition matrices,” Oper. Res. , vol. 53, no. 5, pp. 780–798, 2005.
- 2[2] S. Samuelson and I. Yang, “Data-driven distributionally robust control of energy storage to manage wind power fluctuations,” in Proceedings of the 1st IEEE Conference on Control Technology and Applications , 2017.
- 3[3] P. Mohajerin Esfahani and D. Kuhn, “Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations,” Math. Program. , vol. 171, no. 1–2, pp. 115–166, 2018.
- 4[4] C. Zhao and Y. Guan, “Data-driven risk-averse stochastic optimization with Wasserstein metric,” Oper. Res. Lett. , vol. 46, no. 2, 2018.
- 5[5] R. Gao and A. J. Kleywegt, “Distributionally robust stochastic optimization with Wasserstein distance,” ar Xiv:1604.02199 , 2016.
- 6[6] J. Blanchet, K. Murthy, and F. Zhang, “Optimal transport based distributionally robust optimization: Structural properties and iterative schemes,” ar Xiv:1810.02403 , 2018.
- 7[7] A. Sinha, H. Namkoong, and J. Duchi, “Certifying some distributional robustness with principled adversarial training,” in International Conference on Learning Representations , 2018.
- 8[8] R. Chen and I. C. Paschalidis, “A robust learning approach for regression models based on distributionally robust optimization,” Journal of Machine Learning Research , pp. 1–48, 2018.