An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Devesh Walawalkar, Yihui He, Rohit Pillai

TL;DR
This paper empirically evaluates deep audio-visual speech recognition models, focusing on CNN-based architectures, attention mechanisms, and robustness to noise, to understand their performance and improvements over existing methods.
Contribution
It re-implements and extends state-of-the-art models, providing comprehensive experiments on attention, backbone networks, and noise sensitivity in audio-visual speech recognition.
Findings
Attention mechanisms improve model focus on relevant features.
Pre-trained residual networks enhance recognition accuracy.
Models show robustness to audio noise with visual cues.
Abstract
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio. Empowered by convolutional neural networks, the recent speech recognition and lip reading models are comparable to human level performance. We re-implemented and made derivations of the state-of-the-art model. Then, we conducted rich experiments including the effectiveness of attention mechanism, more accurate residual network as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
Click any figure to enlarge with its caption.
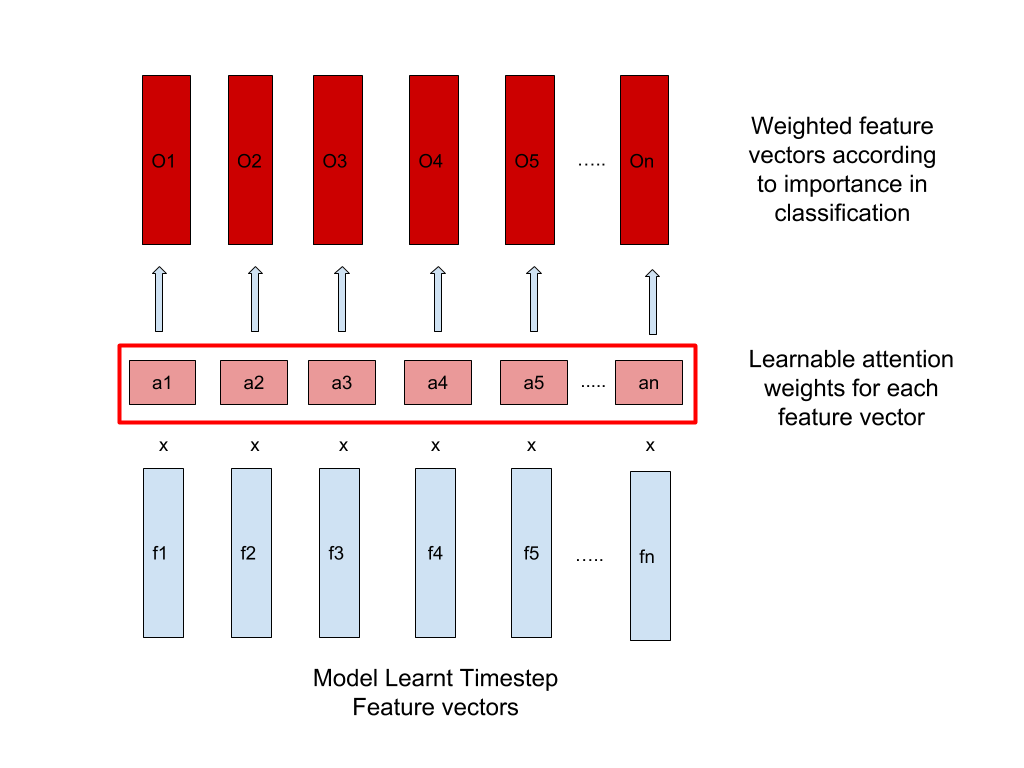 Figure 1
Figure 1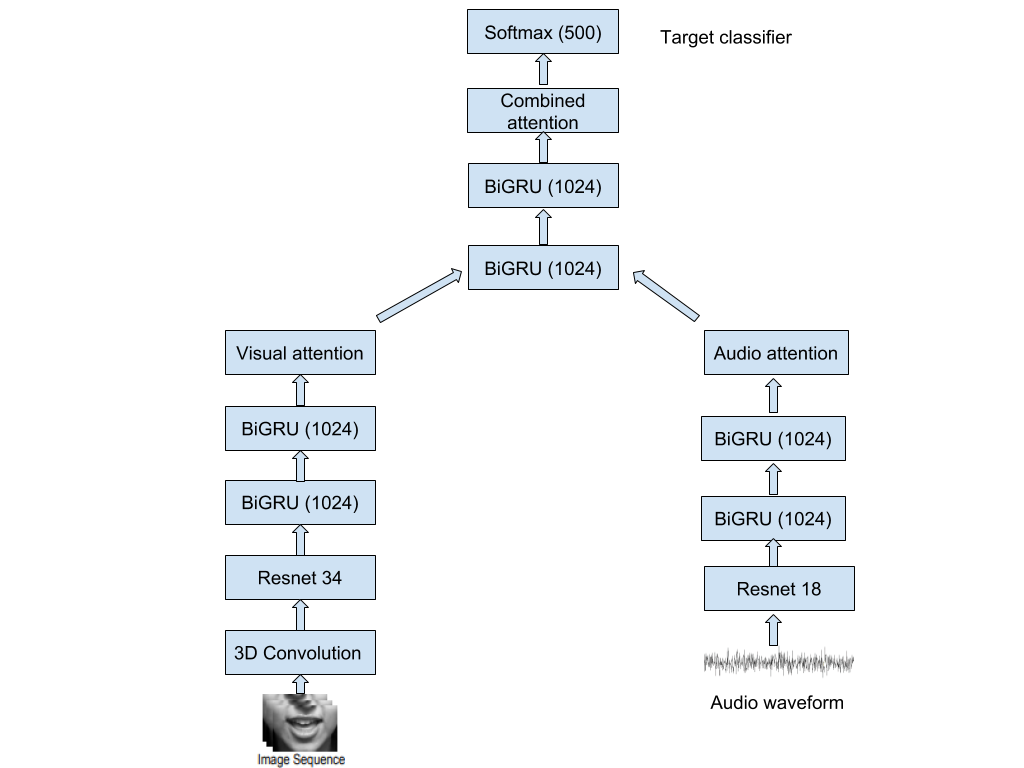 Figure 2
Figure 2| Without attention | With attention | |
|---|---|---|
| Audio | 0.9594 | 0.9702 |
| Visual | 0.8290 | 0.8617 |
| AudioVisual | 0.9743 | 0.9823 |
| Without noise | With noise | |
|---|---|---|
| Audio | 0.9702 | 0.9792 |
| Visual | 0.8617 | 0.8642 |
| AudioVisual | 0.9823 | 0.9864 |
| With ResNet 18 | With ResNet 34 | |
|---|---|---|
| Audio | 0.9702 | 0.9720 |
| Visual | 0.8617 | 0.8624 |
| Audio-Visual | 0.9823 | 0.9842 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech and Audio Processing · Music and Audio Processing · Face recognition and analysis
An Empirical Analysis of Deep Audio-Visual Models for Speech Recognition
Devesh Walawalkar, Yihui He, Rohit Pillai
Carnegie Mellon University
Pittsburgh, PA 15213
{dwalawal, he2, rrpillai}@andrew.cmu.edu
Abstract
In this project, we worked on speech recognition, specifically predicting individual words based on both the video frames and audio [7, 8, 6]. Empowered by convolutional neural networks [20, 33], the recent speech recognition and lip reading models are comparable to human level performance [3, 38]. We re-implemented and made derivations of the state-of-the-art model presented in [28]. Then, we conducted rich experiments including the effectiveness of attention mechanism [4], more accurate residual network [12] as the backbone with pre-trained weights and the sensitivity of our model with respect to audio input with/without noise.
1 Introduction
In recent years, very deep convolutional neural networks (CNNs) [40, 5, 37, 14] have led to a series of breakthroughs in many audio and image understanding problems [21, 24, 41, 19, 22], such as image recognition [12, 36, 16, 13], object detection [10, 31, 15], video surveillance [25, 39] and speech recognition [27]. In particular, the recent speech recognition and lip reading models empowered by CNNs are comparable to human level performance [3, 38, 34, 17, 2, 1, 35, 32].
Audio-visual speech recognition systems usually consist of three parts [29, 9]: visual, audio and fusion. First, the visual part detects and tracks a speaker’s lip movements and extracts relevant speech features. Second, noise-robust features are extracted from the audio signals with the acoustic part. Third, the fusion module is responsible for joint training of the audio-visual streams using models such as hidden Markov Models (HMM), deep networks with the gated recurrent unit (GRU).
In this project, we first re-implemented a deep end-to-end model for audio-visual recognition [28]. To the best of our knowledge, it is the state-of-the-art approach to tackling this problem. Specifically, we used a multi-modal deep learning model to learn the words pronounced in a particular time frame. We trained a CNN based model infused with temporal learning to extract temporal features from the video frames. We used a combination of 3D convolution and GRU techniques to learn the same.
We also trained a separate model for extracting the features from the audio present in the video. Pronunciation of the words is an essential factor which distinguishes words having the same lip movement, thus making classification of words based on only the visual cues very difficult. We used similar GRU techniques as for the video to extract the audio features.
We then combined both these models using Bidirectional GRU to learn features from the combination of the frames and audio. This is then given to a soft-max layer to predict the respective classes. The detailed model architecture is shown in Figure 2. To show the generality of our method, we tested on Lip Reading in the Wild (LRW) BBC dataset [7] that has up to 1000 utterances of the same word for more than 500 different words.
We summarize our contributions as follow:
We re-implemented and made derivations of the state-of-the-art model presented in [28]. 2. 2.
We introduced attention mechanism [4] to our model, which improves the performance by around 4% for the video only model, by around 2% for the audio-only model and by around 1% for the combined model. 3. 3.
We replaced the ResNet model [12] with a more accurate CNN model with pre-trained weights, which interestingly improves the performance. 4. 4.
We further studied the sensitivity of our model with respect to audio input with/without noise.
2 Related works
Earlier solutions to speech recognition mostly used either classical signal processing techniques or deep learning on only the video data or audio data to do the actual recognition. In the video space, LipNet [3] is one example where a CNN is used with bi-directional GRU’s to predict the word being said in the current frame using the sequence of words said before. It then uses these frame wise predictions to determine the optimal sequence of predicted words. Similarly, Chung et al. [7] built multiple CNNs based on the architecture of VGG-M that would use 25 fps to detect words from a sequence of lip movements. [34] also uses spatiotemporal convolutions to generate a prediction for the word being said in the current frame after landmarking and using standard 3D convolutions to augment the input video data.
From [30], we see that speech recognition has evolved from the classical techniques of phoneme matching, which assumed that all sounds could be produced from a fixed number of sounds to pattern matching that is based on a solid mathematical background. Pattern matching involved learning the structure of audio waveforms during training using an HMM, a template or some other construct and then comparing these learned structures with the test input to match the best one. These techniques gave way to the state of the art knowledge-based approaches that use machine learning. One of the earliest knowledge-based approaches was the SVM, that was severely limited in the fact that it could not be used to translate variable length sentences into text. Every test input had to convert to a fixed size sentence before the SVM could classify it. However, the concept of feature extraction led to the development of several techniques to accurately extract the essential features to a sound (using PCA, LDA, ICA, kernel-based feature extraction, etc.) that would then be fed into a classifier to produce an output. Nowadays, neural networks have replaced all these techniques since they are able to learn and extract much more complex features than any of the previously mentioned techniques were. In terms of state of the art techniques, [11] published by DeepMind describes a network architecture that transcribes speech to text without intermediary representations of this data. The architecture involves bidirectional LSTM’s as the hidden layers in a bidirectional deep RNN. In addition to this, the objective function used to train the network is the Connectionist Temporal Classification function.
Deep architectures that use both audio and video data also tend to use LSTM or GRU units for their predictions. This is seen in the encoder-decoder architecture employed in [6] which uses unidirectional LSTMs to encode both the image and audio data and generates attention vectors to predict the word being said. While [34] used only video frames as input, it can be easily extended to incorporate both audio and visual information as seen in [28]. This uses two separate ResNets and BGRUs to extract features and model temporal dependencies from the visual and audio inputs and two additional BGRU’s to combine the extracted audio and visual features. [18] uses another approach which uses temporal multimodal networks to learn a joint distribution over a mouth and lip movements along with the audio at every frame. These joint distributions are then combined to get a time-dependent sequence of frames and audio.
3 Dataset
The dataset used for this project was the LRW BBC dataset [7] that has up to 1000 utterances of the same word for more than 500 different words. Each utterance is taken from different BBC presenters and guests on the air and is presented in the form of a video that is 29 frames (1.16 seconds) long. Every video also has metadata associated with it that indicates the duration of the word, which allows us to determine the start and end frames of the word being uttered. This dataset is challenging since there may be multiple words being said in a video, and as a result, the lip movements may be influenced by both past and future words in addition to the word we are trying to learn. Some of the classes are also very similar to one another (different tenses of the same word, singular vs. plural) which makes this dataset even more challenging. In total, there are 538786 different videos out of which 488786 are training examples, 25000 were for validation, and 25000 were used to test.
4 Audio Visual Recognition
4.1 Attention Mechanism
Not all frames and their corresponding audio snippets are equally important in learning to classify the word. In order to take this into account, we introduce the concept of attention into our model. For our model, attention is just a 1-D vector that is the same size as the output of the previous layer’s time-step count, and each value in the vector is multiplied across all features of a particular time-step. These values, which range from 0 to 1, can be learned and help us extract the more relevant features from our inputs. For the final model output of size we multiply all features of a single time-step feature vector with a single element from the dimensional vector learned by the model. In our experiments, we found out the vector learns a type of Gaussian distribution across the length of the vector, i.e. the centre elements have values in the range of 0.8 to 0.95, while those at the end and the beginning have values in the range of 0.1 to 0.2. This follows intuitively that the frames/audio slices at the middle are more important for classification compared to the ones at the end and the beginning.
We incorporate three types of attention in our models. They are as follows:
Video attention: This attention is used to weigh the importance of time-step feature vectors outputted by the video sub model alone. 2. 2.
Audio attention: This attention is used to weigh the importance of time-step feature vectors outputted by the audio sub model alone. 3. 3.
Combined attention: This attention is used to weigh the importance of time-step feature vectors outputted by the combined sub model at the final stages of the overall model. The combined attention weighted output is directly fed to the classification layer.
4.2 Visual sub model
The visual model consists of a spatiotemporal convolution followed by a 34-layer ResNet and a 2-layer BGRU. A spatiotemporal convolutional layer is capable of capturing the short-term dynamics of the mouth region. It consists of a convolutional layer with 3D kernels of 5 by 7 by 7 size (time/width/height), followed by batch normalization and rectified linear units. Once this convolution is done, we then feed it through a Resnet 34 that reduces the dimensionality of the input such that it outputs a 1-D tensor. This tensor is then passed through a two-layer BGRU’s of 1024 units each. Finally, we multiply it with a visual attention vector where each frame has a single attention value associated with it.
4.3 Audio sub model
The audio model consists of an 18-layer ResNet followed by two BGRU layers. We use the standard architecture for the ResNet-18 with the main difference being that we use 1D instead of 2D kernels which are used for frame data. The output of the ResNet is divided into 29 frames/windows to ensure that there is a 1-1 correspondence between a video frame and an audio snippet (29 for each training example) The output of the ResNet-18 is fed to a 2-layer Bi-GRU which consists of 1024 cells in each layer. The output from the second Bi-GRU is also multiplied by an attention vector of length 29 with each element corresponding to one snippet of the audio.
4.4 Overall model
Shown in Figure 2, for the overall combined model, outputs of each sub-model are concatenated and fed to another 2-layer BGRU of 1024 units each in order to fuse the information from the audio and visual streams and jointly model their temporal dynamics [28]. The output of the 2-dimensional BGRU is then multiplied by another attention vector which is also of length 29. Finally, the output layer is a softmax layer which provides a label to each frame. The sequence is labeled based on the highest average probability.
5 Experimental setup
Our implementation is based on PyTorch [26].
We trained the audio model end-to-end using only the audio data. Similarly, we trained the visual model end to end using only the frames extracted. We then plan to combine both the trained models and train the entire system end to end using both the types of data available. During the last stage of training, we plan to keep the weights of the base learned layers fixed, while only fine-tuning on the front combining Bi-GRU network.
5.1 Dataset Pre-processing
For our model training, we are using the Lip Reading Words (LRW) dataset. This dataset consists of up to 1000 utterances of 500 different words spoken during a short video clip. For the purpose of our model, we have extracted the frames and audio from these clips separately. We extracted the frames from each video example at the frame rate of 29 FPS. We then extract a region of the fixed area around the mouth for every sample. All video samples in the dataset have the mouth located in a specific region, which made it easy for us to extract it. We extracted the audio from the videos at the rate of 16KHz. We converted the audio files into numpy arrays so as to make it possible to feed this extracted information to our audio sub-model.
5.2 Training
Training for our model is done in 2 stages. We first learn the weights for our individual streams by training them on the audio and video streams separately. Once we have the weights for these layers, we then train the entire combined model end to end. While training, we also add Gaussian noise to both our video and audio inputs so that our network is more robust to different inputs. We just add Gaussian noise to the audio signal while for the video, we flip a frame or randomly crop it with probability 0.5.
5.2.1 Training Individual Streams
Since training each individual stream end-to-end is sub-optimal, the stream is trained using a 3 step procedure. For the first step, the 2 layers Bi-GRU is replaced by a temporal convolutional back end. The entire system (the ResNet, the temporal convolutional back end, the attention layer, and a softmax) is then trained until there is no improvement in accuracy for more than five epochs. Once this is achieved, the 2 layers Bi-GRU back is inserted and trained for five epochs with all the other weights (ResNet and attention layers) kept constant.
Once the ResNet’s and two-layer Bi-GRU’s weights are computed, they are put together and trained end to end with a softmax layer as the output. The system was trained with the Adam optimizer algorithm with learning rate = 0.0001 for the whole system except the attention layer whose learning rate was 0.0002 and batch size = 32.
5.2.2 End-to-end model training
The weights from the trained single streams were used to initialize the corresponding components in the final architecture. The outputs of the two streams were fed into another 2 layers Bi-GRU followed by an attention layer. The additional layers were trained for five epochs with all the weights in the individual streams not changed. After this, the entire network is trained with the Adam optimizer with an initial learning rate of 0.0001 for everything except the attention layers which had 0.0002 as the initial learning rate. We incorporated stepwise learning rate decay after every ten epochs, with a batch size of 32.
6 Results
As mentioned before, we make three modifications for our deep learning model experiments. Following are the results obtained:
6.1 Using attention mechanism
We introduce the concept of attention into our model in section 4.1 since not all frames and their corresponding audio snippets are equally important in learning to classify the word. Surprisingly using the attention mechanism [4], the performance is improved by around 4% for the video only model, by around 2% for the audio only model and by around 1% for the combined model, shown in table 1. We observed that the improvement for the combined model is limited (1%), since the baseline accuracy is already quite high (97.43%).
6.2 The Effectiveness of Noise Input
During training, we observed that the training accuracy could easily reach 99%, even 100% since the dataset is not challenging enough for deep neural networks. This motivates us to analyze the effectiveness of noise input. Shown in Table 2, we studied the effectiveness of noise input. With noise input, the accuracy is consistently improved for audio, visual and audiovisual models (0.9%, 0.25%, 0.41% respectively).
6.3 Making DNN model deeper
Deep residual learning [12] found that the performance is usually better when the convolutional neural network is deeper for the image classification task. This motivates us to verify this conclusion on our speed recognition and lip reading task. Shown in Table 3, we studied the effectiveness of deeper DNN model, namely ResNet-34. With ResNet-34, the accuracy is consistently improved across all three models (0.18%, 0.07%, and 0.21% improvement for audio, visual and audiovisual models respectively). We observed that the improvement is marginal and the improvement for audio model is slightly larger.
6.4 Overall comparison
Finally, we combined our modifications and demonstrated the overall comparison shown in Table 4. Empirically, with attention mechanism and noise input, our audio-visual combined model achieves 98.64%.
7 Conclusion
We re-implemented and made derivations of the model presented in [28]. We proposed a novel attention mechanism for the model and obtained improved state-of-the-art results on it. We replaced the ResNet model with a more accurate CNN model with pre-trained weights. We also studied the sensitivity of our model with respect to audio input with/without noise and found considerable accuracy gain by incorporating it in our model.
8 Future Works
We plan on training the complete model end-to-end with focal loss [23] to obtain better results. Besides, on the data processing part, we intend to sample the frames and audio at much higher sampling rates to extract much richer features to train the model.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] T. Afouras, J. S. Chung, and A. Zisserman. The conversation: Deep audio-visual speech enhancement. ar Xiv preprint ar Xiv:1804.04121 , 2018.
- 2[2] T. Afouras, J. S. Chung, and A. Zisserman. Deep lip reading: a comparison of models and an online application. ar Xiv preprint ar Xiv:1806.06053 , 2018.
- 3[3] Y. M. Assael, B. Shillingford, S. Whiteson, and N. de Freitas. Lipnet: End-to-end sentence-level lipreading. ar Xiv preprint ar Xiv:1611.01599 , 2016.
- 4[4] W. Chan, N. Jaitly, Q. Le, and O. Vinyals. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on , pages 4960–4964. IEEE, 2016.
- 5[5] F. Chollet. Xception: Deep learning with depthwise separable convolutions. ar Xiv preprint , pages 1610–02357, 2017.
- 6[6] J. S. Chung, A. W. Senior, O. Vinyals, and A. Zisserman. Lip reading sentences in the wild. In CVPR , pages 3444–3453, 2017.
- 7[7] J. S. Chung and A. Zisserman. Lip reading in the wild. In Asian Conference on Computer Vision , pages 87–103. Springer, 2016.
- 8[8] J. S. Chung and A. Zisserman. Lip reading in profile. In British Machine Vision Conference , 2017.