Quark-Gluon Tagging: Machine Learning vs Detector
Gregor Kasieczka, Nicholas Kiefer, Tilman Plehn, and Jennifer M., Thompson

TL;DR
This paper compares machine learning methods for quark-gluon discrimination at the LHC, demonstrating improved performance with a 4-vector-based LoLa tagger even after detector effects, and shows benefits in specific search scenarios.
Contribution
It introduces a 4-vector-based LoLa tagger for quark-gluon tagging and evaluates its performance with detector effects, highlighting advantages over standard analysis in LHC searches.
Findings
LoLa tagger outperforms traditional methods
Detector effects reduce but do not eliminate performance gains
Enhanced sensitivity in mono-jet and di-jet resonance searches
Abstract
Distinguishing quarks from gluons based on low-level detector output is one of the most challenging applications of multi-variate and machine learning techniques at the LHC. We first show the performance of our 4-vector-based LoLa tagger without and after considering detector effects. We then discuss two benchmark applications, mono-jet searches with a gluon-rich signal and di-jet resonances with a quark-rich signal. In both cases an immediate benefit compared to the standard event-level analysis exists.
Click any figure to enlarge with its caption.
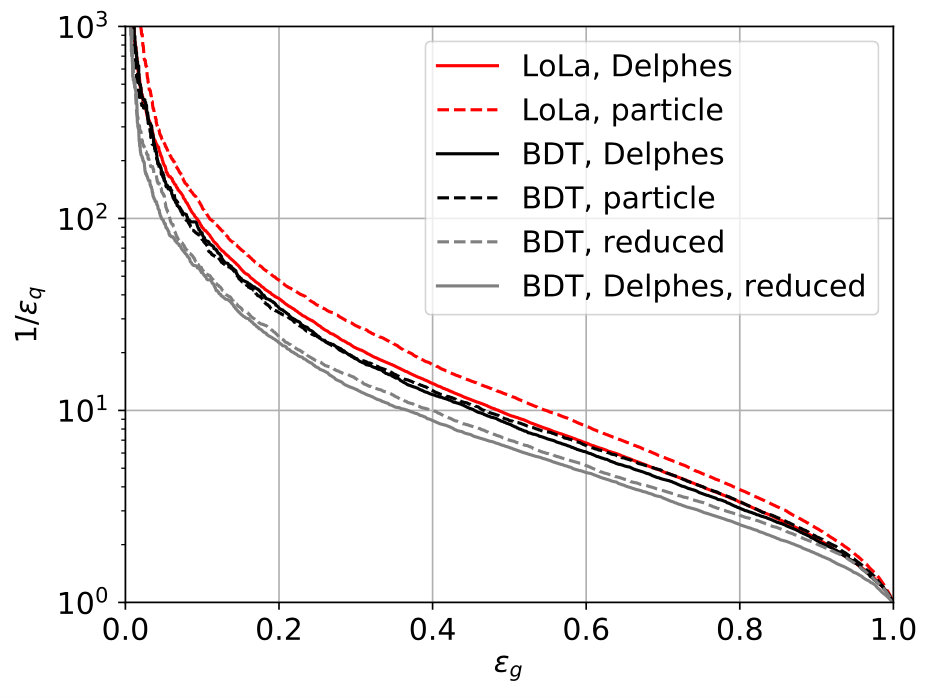 Figure 1
Figure 1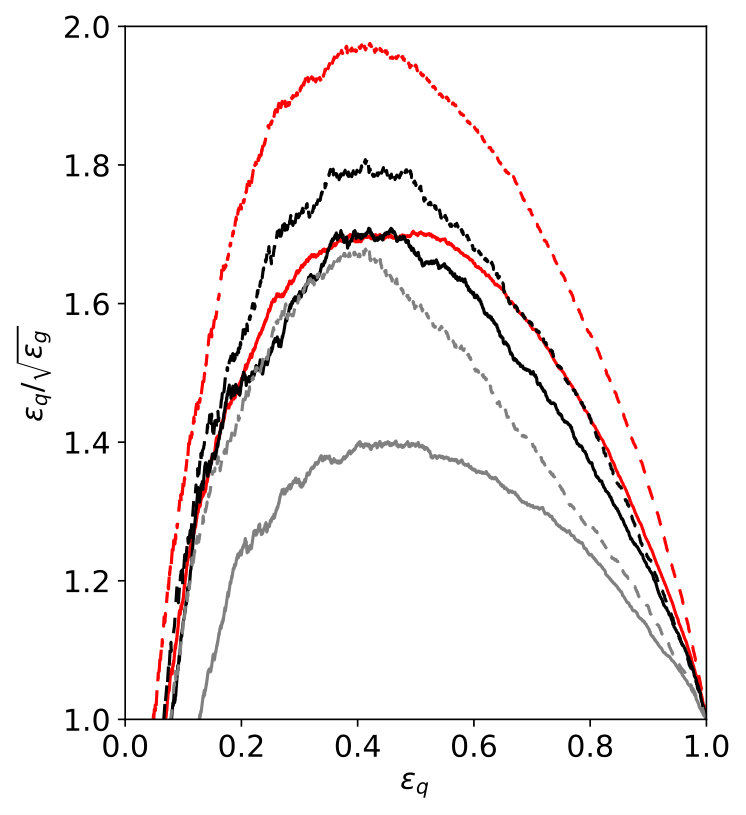 Figure 2
Figure 2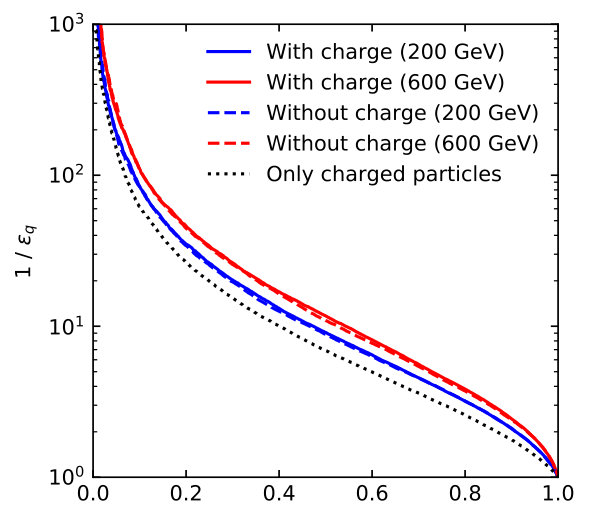 Figure 3
Figure 3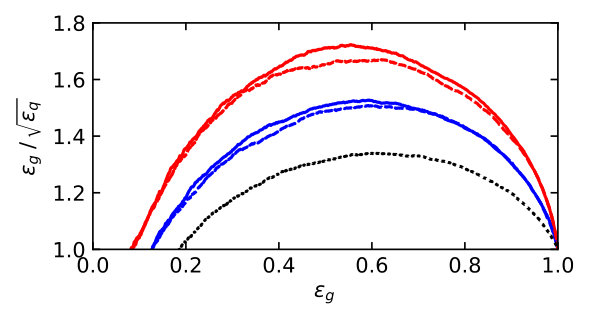 Figure 4
Figure 4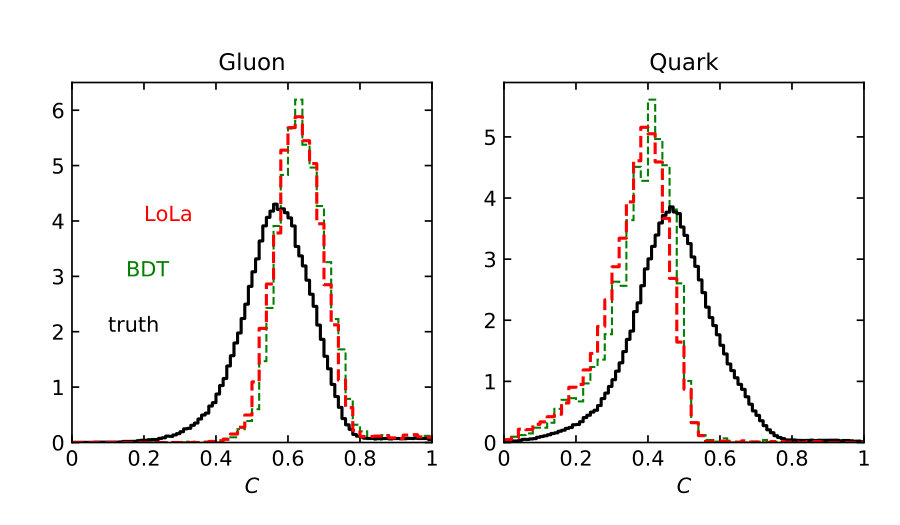 Figure 5
Figure 5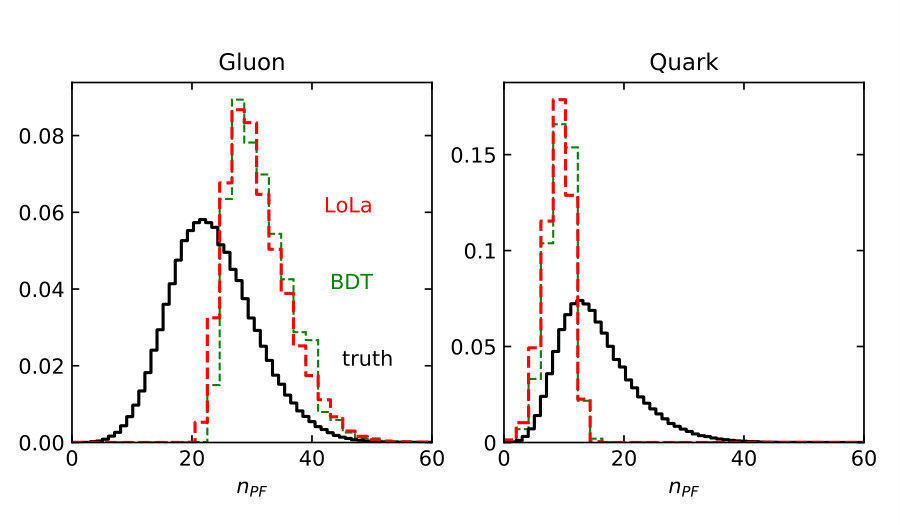 Figure 6
Figure 6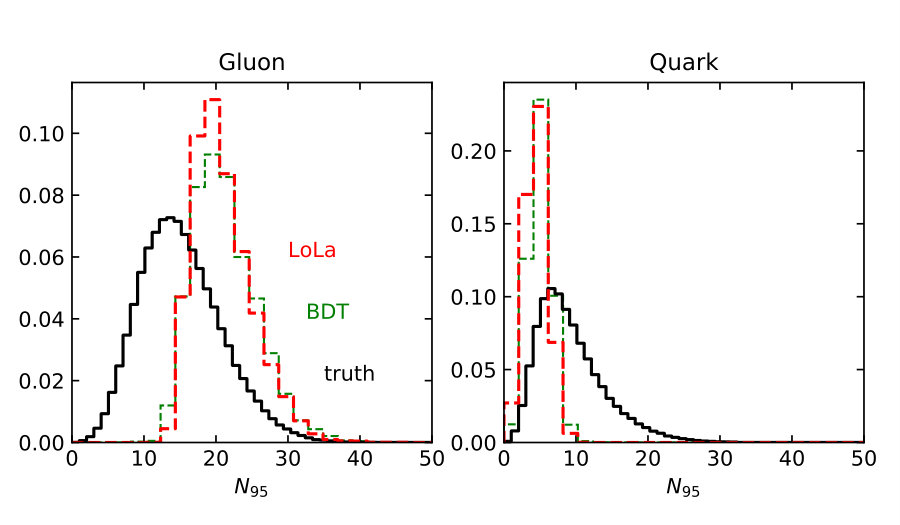 Figure 7
Figure 7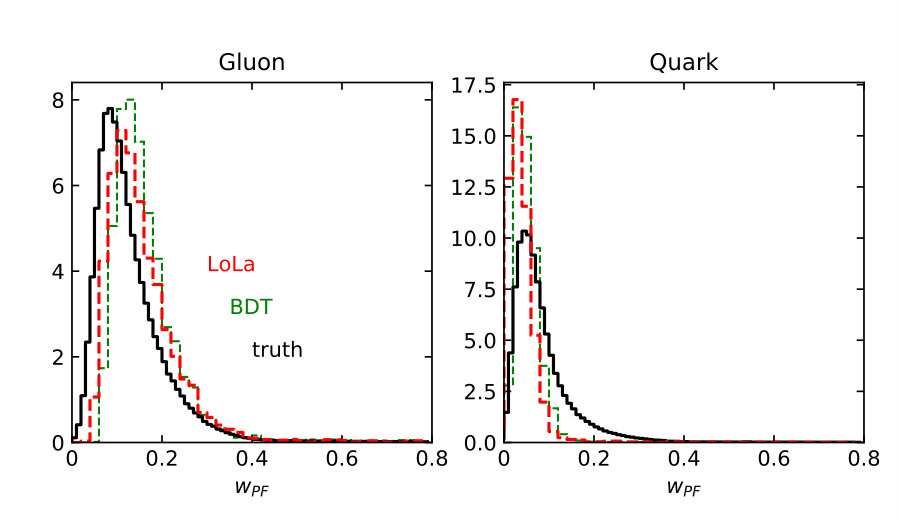 Figure 8
Figure 8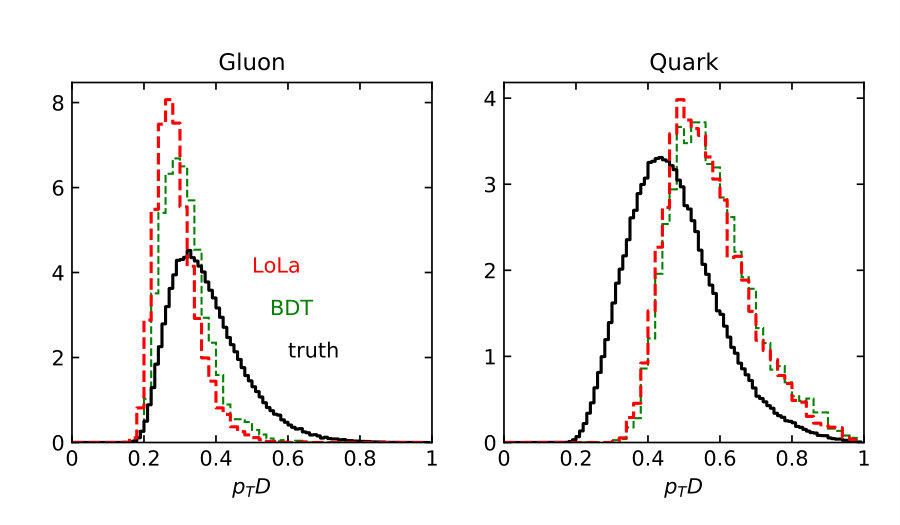 Figure 9
Figure 9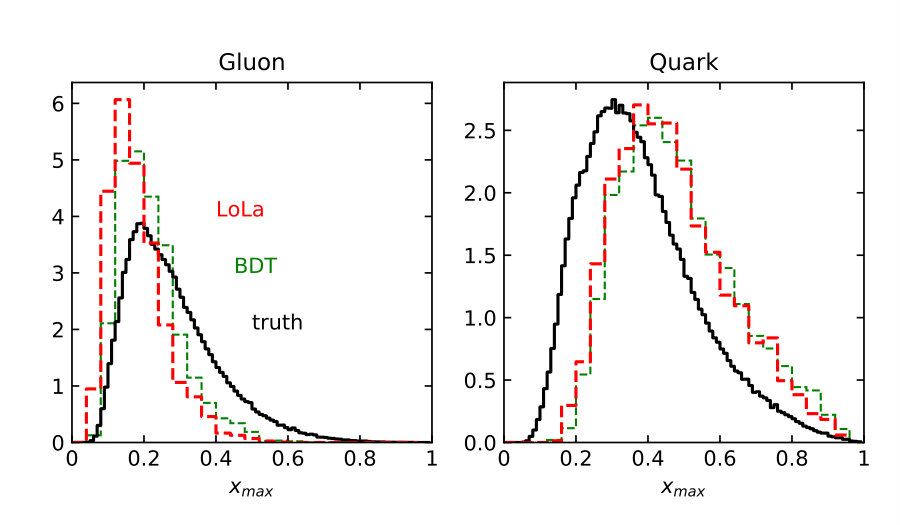 Figure 10
Figure 10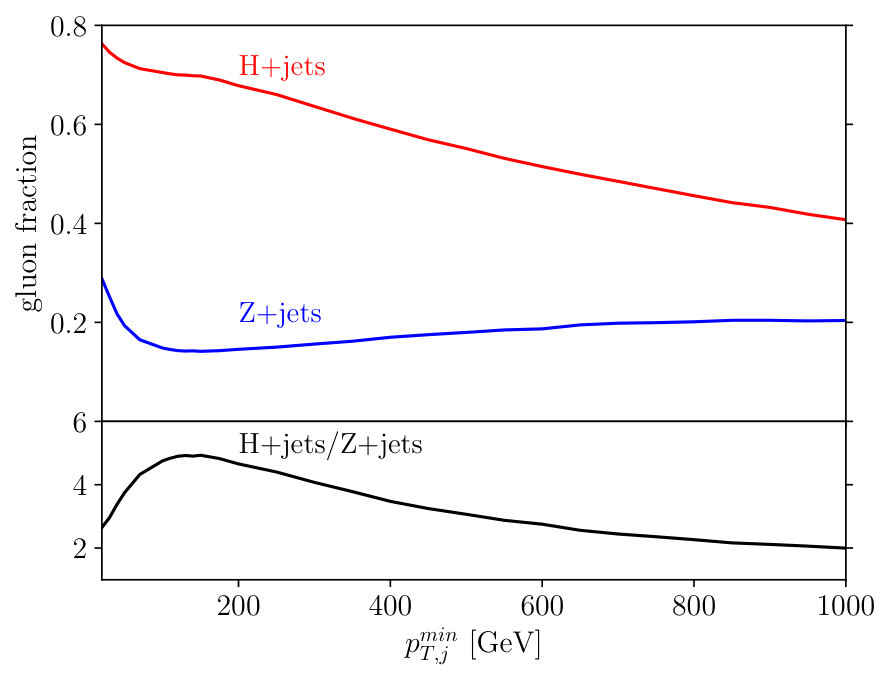 Figure 11
Figure 11 Figure 12
Figure 12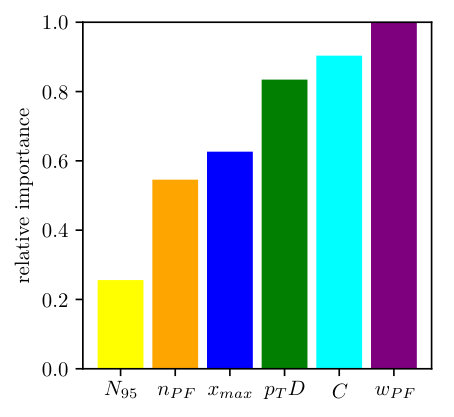 Figure 13
Figure 13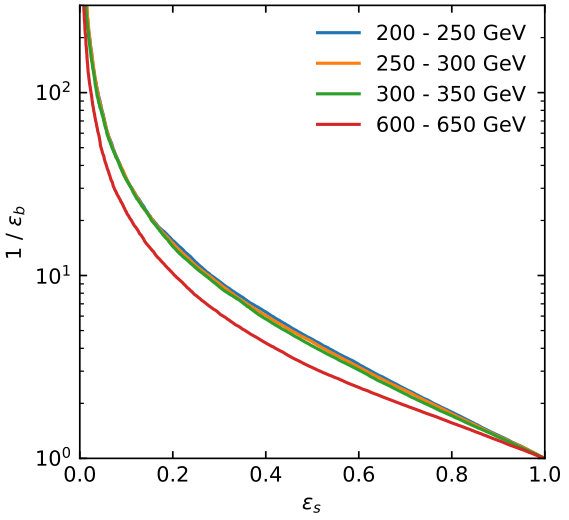 Figure 14
Figure 14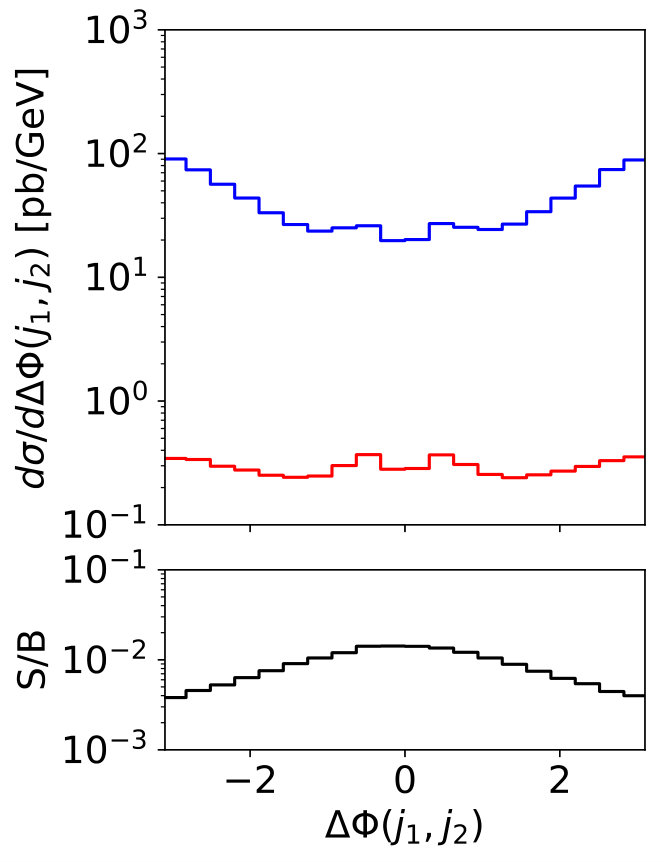 Figure 15
Figure 15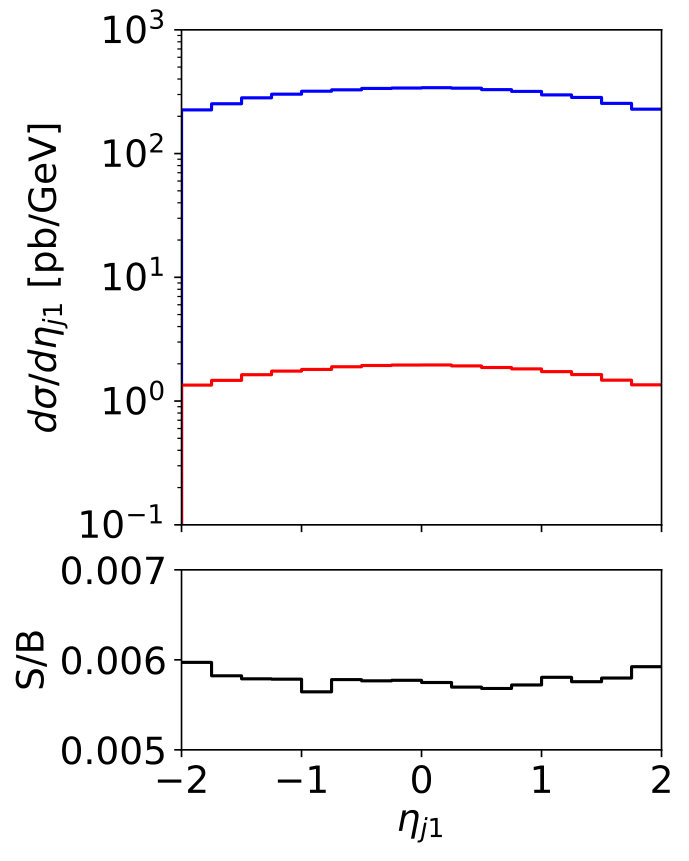 Figure 16
Figure 16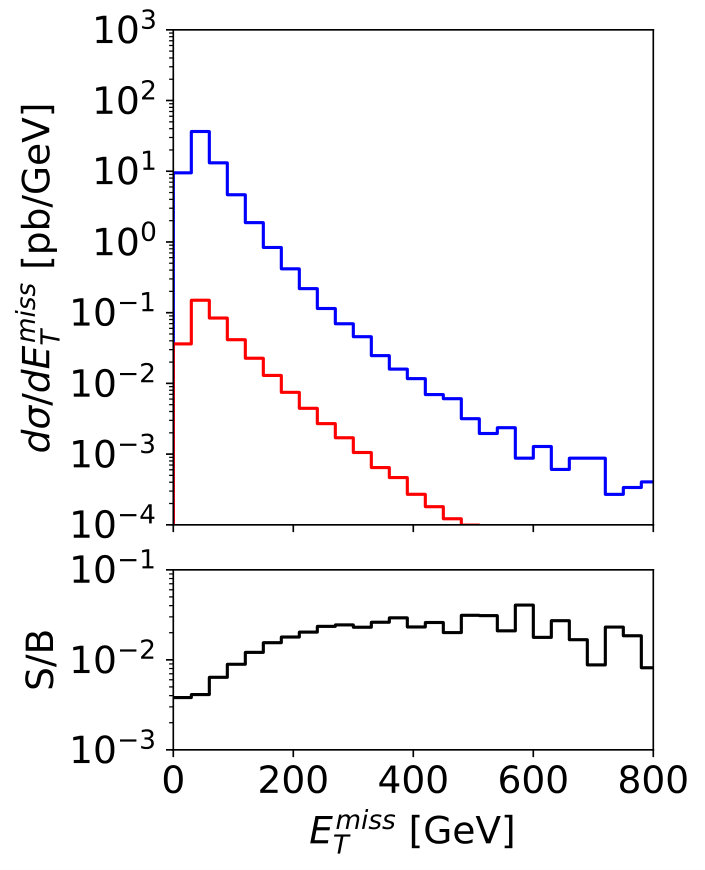 Figure 17
Figure 17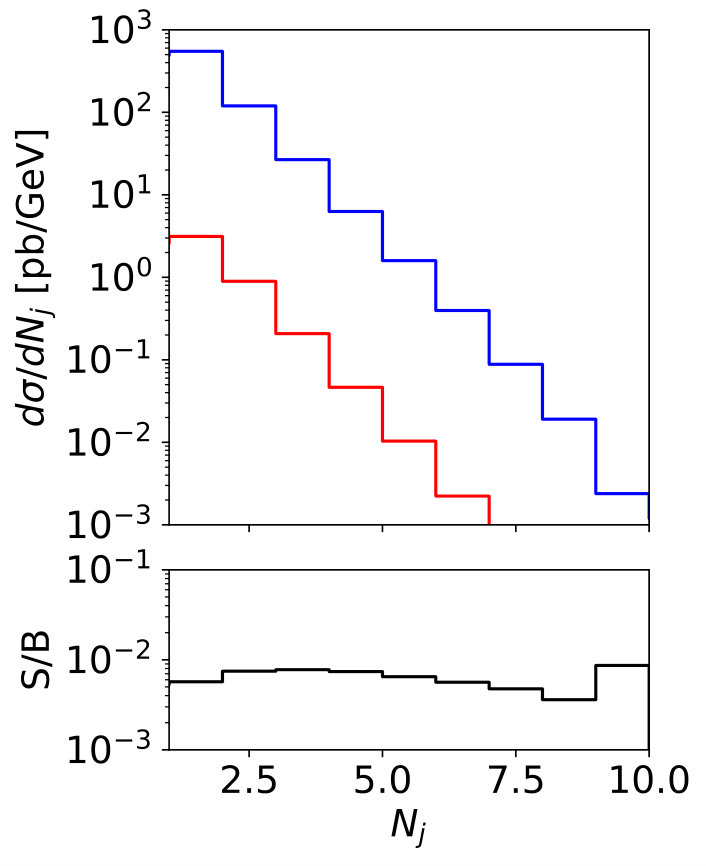 Figure 18
Figure 18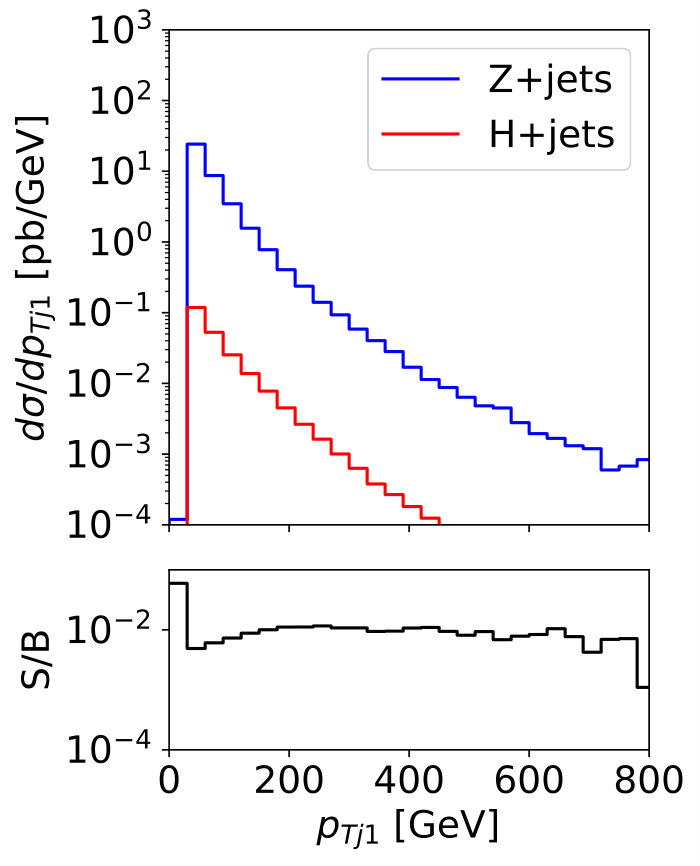 Figure 19
Figure 19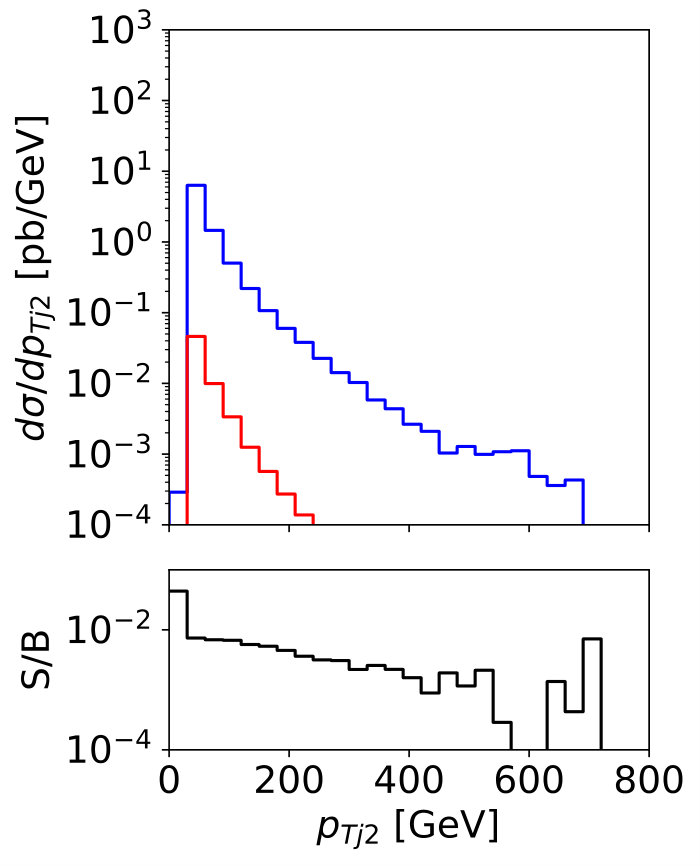 Figure 20
Figure 20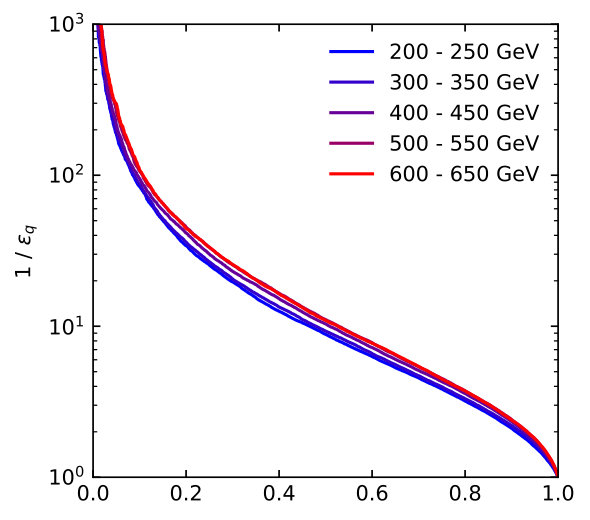 Figure 21
Figure 21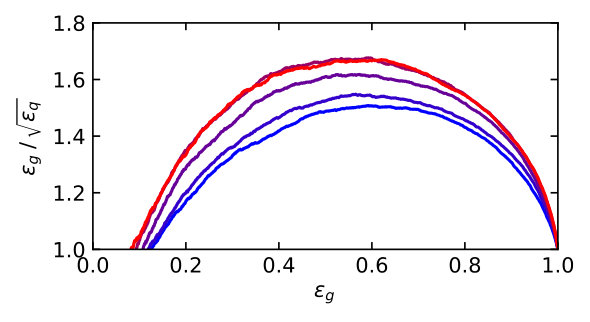 Figure 22
Figure 22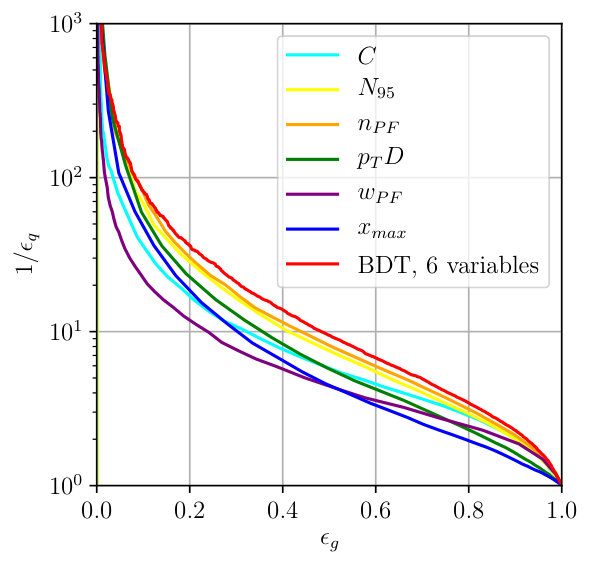 Figure 23
Figure 23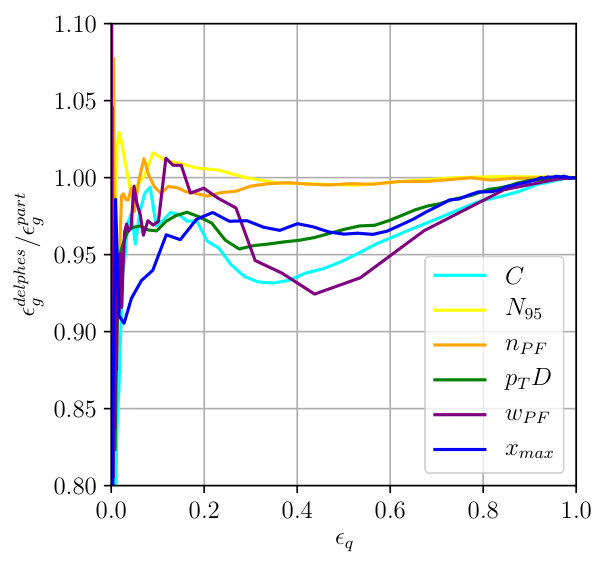 Figure 24
Figure 24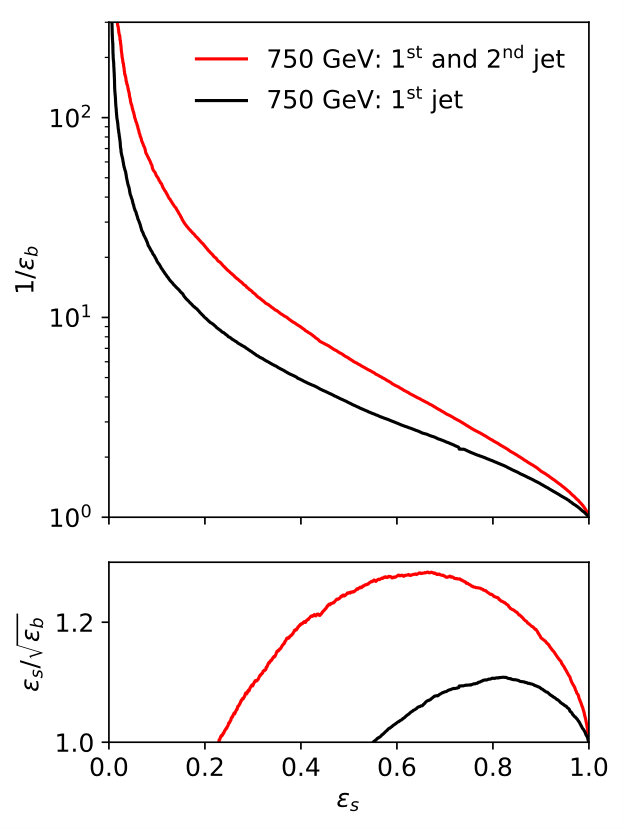 Figure 25
Figure 25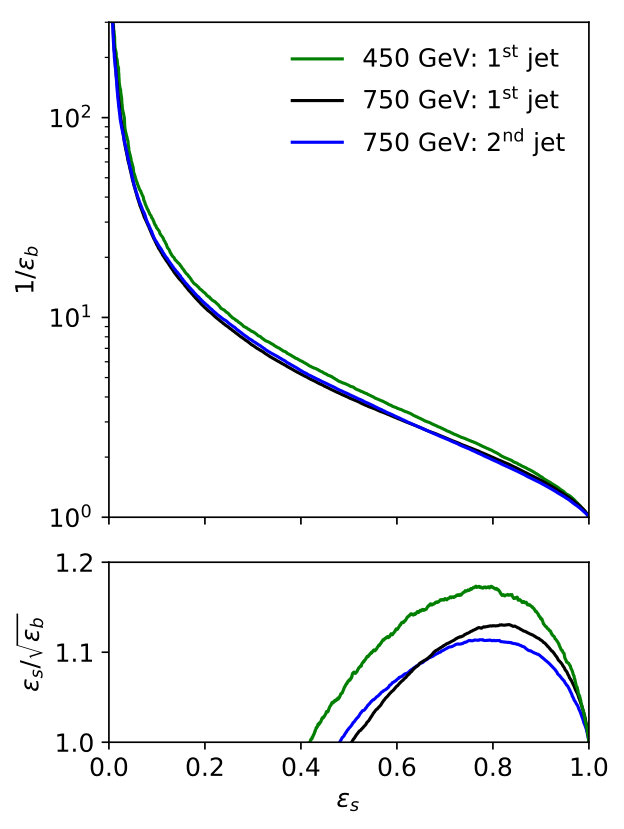 Figure 26
Figure 26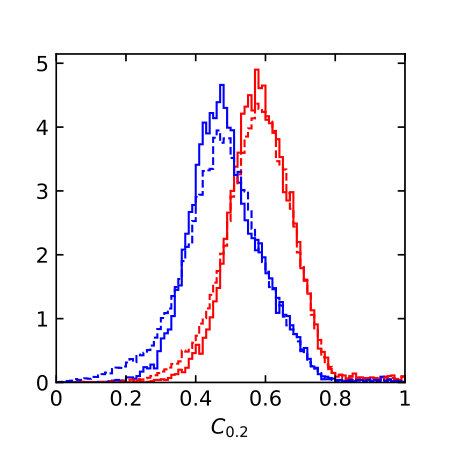 Figure 27
Figure 27 Figure 28
Figure 28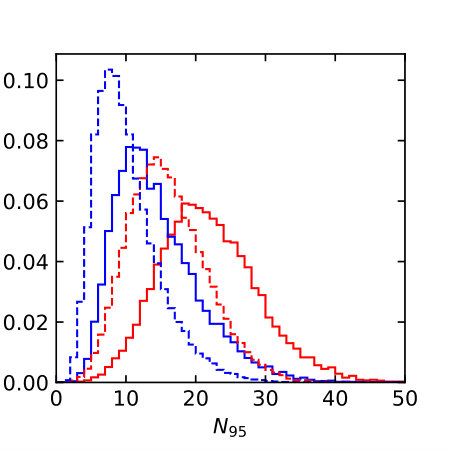 Figure 29
Figure 29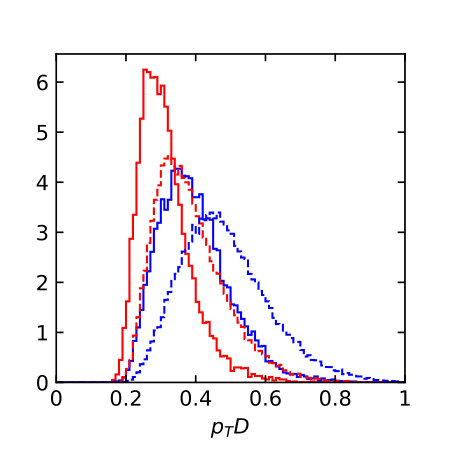 Figure 30
Figure 30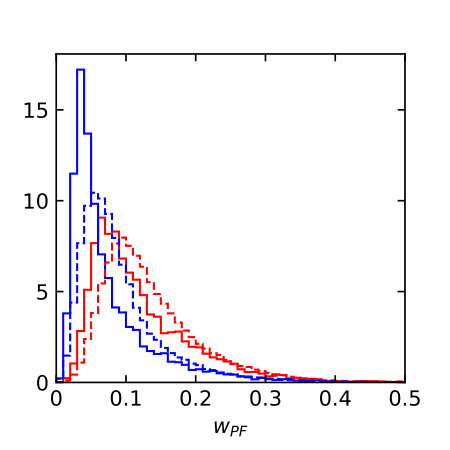 Figure 31
Figure 31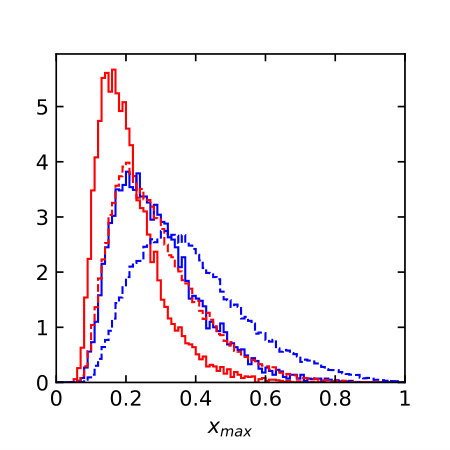 Figure 32
Figure 32 Figure 33
Figure 33| Train | Test | ||||
| 200-210 | 210-220 | 220-230 | 230-240 | 240-250 | |
| 200-210 | 0.812 | 0.812 | 0.812 | 0.818 | 0.816 |
| 210-220 | 0.812 | 0.813 | 0.812 | 0.819 | 0.817 |
| 220-230 | 0.804 | 0.805 | 0.810 | 0.811 | 0.808 |
| 230-240 | 0.803 | 0.804 | 0.801 | 0.814 | 0.809 |
| 240-250 | 0.810 | 0.811 | 0.811 | 0.820 | 0.818 |
| Train | Test | ||||
| 200-210 | 210-220 | 220-230 | 230-240 | 240-250 | |
| 200-210 | 0.692 | 0.692 | 0.691 | 0.692 | 0.687 |
| 210-220 | 0.692 | 0.692 | 0.692 | 0.692 | 0.687 |
| 220-230 | 0.692 | 0.692 | 0.692 | 0.692 | 0.688 |
| 230-240 | 0.692 | 0.692 | 0.692 | 0.692 | 0.688 |
| 240-250 | 0.692 | 0.692 | 0.692 | 0.692 | 0.688 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Quark-Gluon Tagging: Machine Learning vs Detector
Gregor Kasieczka2, Nicholas Kiefer1, Tilman Plehn1, and Jennifer M. Thompson1
1 Institut für Theoretische Physik, Universität Heidelberg, Germany
2 Institut für Experimentalphysik, Universität Hamburg, Germany [email protected]
Abstract
Distinguishing quarks from gluons based on low-level detector output is one of the most challenging applications of multi-variate and machine learning techniques at the LHC. We first show the performance of our 4-vector-based LoLa tagger without and after considering detector effects. We then discuss two benchmark applications, mono-jet searches with a gluon-rich signal and di-jet resonances with a quark-rich signal. In both cases an immediate benefit compared to the standard event-level analysis exists.
Content
1 Introduction
Since the start of the LHC our view of jets as analysis objects has fundamentally changed. While jets with reconstructed 4-momenta matching hard partons still serve as the key objects of essentially all analyses, their internal structure can now be exploited systematically. In that sense, jets merely define the boundary between event-level observables and subjet observables. The subjet aspect is currently undergoing a paradigm change: rather than defining high-level kinematic observables for the jet constituents and analyzing them using multivariate methods, we can use modern machine learning approaches to analyze low-level detector outputs like the measured 4-vectors entries directly [1]. For this low-level input we employ modern machine learning techniques, usually advertized with the term deep learning.
Theoretically and experimentally well-controlled applications of machine learning in subjet physics include hadronic -jets [2, 3, 4, 5, 6, 7], Higgs jets [8, 9], top jets [10, 11, 12, 13, 14, 15, 16, 17], or model-independent searches for hard new physics in jets [18] quark–gluon discrimination has a long history [19, 20, 21, 22, 23] and is used at the LHC [24, 25]. However, distinguishing quark and gluon jets poses serious theoretical and simulational challenges, like, that they are not defined in QCD beyond tree level [26, 27, 28, 29, 30]. Nevertheless, efficient machine learning approaches have been devised to separate ‘quark jets’ from ‘gluon jets’ [31, 32, 34, 35, 36, 37, 38, 39, 40]. One way we can overcome the fundamental problems in defining quark and gluon jets is to instead ask for a well-defined hypotheses in terms of LHC signatures, involving mostly gluons vs gluons in the signal and background processes [41, 42, 43, 44].
Before we employ modern machine learning to separate processes with mostly hard quarks from those with mostly hard gluons we review the known high-level variables. Unlike for many other subjet analyses these observables rely on tracking information with its excellent resolution, and cannot be considered infrared-safe observables or easily interpretable in perturbative QCD [26, 27, 28]. When we switch to low-level inputs this means that we cannot hope for the calorimeter resolution to provide a generous binning and to render us insensitive to additional detector effects. Moreover, any promising network architecture needs to combine standard calorimeter images and tracking information with its vastly better angular resolution [31]. We will use our 4-vector-based LoLa framework developed for top tagging including calorimeter and tracking information [13] to extract the necessary information from measured particle-flow objects and to quantify the sensitivity to soft tracks in the detector. The latter is especially relevant when we benchmark the machine learning approach compared to a multi-variate analysis of the traditional quark–gluon variables. In Sec. 2 we analyze idealistic, pure quark and gluon samples to benchmark our tagger in the presence of detector effects [32], to compare its performance to the classic quark–gluon variables, and to study the correlation with the jet momentum.
Finally, we will establish realistic and relevant benchmark analysis for quark–gluon tagging at the LHC. Unfortunately, it is already known that quark–gluon tagging does not significantly improve weak-boson-fusion analyses at the LHC [43]. Two often-discussed candidate analyses for quark-gluon tagging in LHC searches are
mono-jet dark matter searches with a gluon-dominated signal, Sec. 3, and 2. 2.
di-jet resonance searches with a quark-dominated signal, Sec. 4.
For both cases we motivate the use of quark–gluon tagging, show how our LoLa tagger helps extract the signal, and discuss the limitations in a realistic analysis setup.
2 Ideal world
In spite of the fact that a parton-level definition of quark and gluons becomes ambiguous beyond leading-order QCD, we start with an analysis of jets coming from hard quarks and gluons at tree-level and based on Monte Carlo truth. The impact of this simplification should eventually be tested including higher-order effects. At this point it will allow us to identify the leading subjet properties of such jets and to compare our deep learning approach with established approaches.
We generate quark and gluon jet samples using di-jet events with Sherpa2.2.1 [45] at 14 TeV. We do not simulate any multiple interactions and any effects from pile up could be dealt with by using established techniques as well as recently proposed tools [46]. For quark jets we extract the subprocesses and , for the gluon jets we keep the subprocesses . We pass these events through Delphes3.3.2 [47], using the standard ATLAS card. Finally, we cluster the particle flow objects [48] into anti- [49] jets of radius using FastJet3.1.3 [50]. All jet constituents have to be central in the detector, with and GeV. Unless explicitly mentioned, our jets have
[TABLE]
This setup closely follows Ref. [31], with an additional fast detector simulation. We do, however, find that switching from Pythia to Sherpa makes quark–gluon discrimination generally a little harder [28].
2.1 Standard observables
Distinguishing quark jets from gluon jets exploits two features [51]: first, radiating a gluon off a hard gluon versus off a hard quark comes with a ratio of color factors . This leads to a higher particle multiplicity () and a broader radiation distribution or girth () [52] for hard gluons; second, the splitting functions and differ in the soft limits. The harder fragmentation for quarks makes quark jet constituents carry a larger average fraction of the jet energy, tracked by the variable [25]. In addition, the two-point energy correlator separates quarks and gluons with an optimized power of [53]. This allows us to define the four established observables
[TABLE]
In addition, we evaluate the highest fraction of contained in a single jet constituent [54], and the minimum number of constituents which contain 95% of [55],
[TABLE]
The latter is obviously correlated with the number of constituents . All jet constituents summed over are defined as Delphes E-flow objects, combining both the calorimeter and the tracking information.
Distributions of all these observables for pure quark and gluon samples are shown in Fig. 1, both in an ideal setup and at the level of particle flow object after fast detector simulation. The IR-sensitive and theoretically challenging observable shows large differences because LHC detectors rapidly lose sensitivity for soft constituents. The distribution is similarly sensitive. When we add a soft constituent we find that the numerator and denominator change differently,
[TABLE]
This way shifts towards smaller values, which do not survive a detector simulations, as seen in Fig. 1. The situation is more stable for the -weighted and for .
The individual performance of these six observables in tagging pure quark and gluon jets without detector effects is illustrated in the left panel of Fig. 2. Each of the observables indeed contributes to quark-gluon discrimination. The number of constituents is the most powerful single variable, with almost identical performance to . This confirms the findings of Ref. [31] in the absence of detector effects. To maximize their separation power we combine all six of them into a boosted decision tree (BDT), implemented in Scikit-Learn using a gradient boosting classifier with 50 estimators, a maximum tree depth of 4, a sub-sampling fraction of 0.9 and a learning rate of 1. The classifier is trained on a sample of 500k quark and gluon jets, 5% of which are set aside as a test sample. The corresponding ROC curves are also shown in Fig. 2, showing a small improvement over the most powerful, but poorly defined variable . In the right panel of Fig. 2 we compare the ROC curves with and without detector simulation. From Fig. 1 we know that for all variables the detector affects the quark and gluon distributions systematically, both shifting and broadening the features. We can quantify the detector effect for instance by comparing the gluon tagging efficiencies with and without Delphes as a function of the quark efficiency in the right panel of Fig. 2. The result suffers from numerical fluctuations for extremely small , but for the bulk of the ROC curves for each observable the detector effect are within 10% of the ideal curve. Interestingly, the simplest observables and turn out the most stable in distinguishing quarks from gluons. This suggest that they offer sizeable quark-gluon separation power already in phase space regions which are not affected by detector effects.
Given that our six jet observables are an ad-hoc collection and do not form any kind of basis in a space of correlators, it is neither guaranteed that they include all available information nor that they form a minimal set. The first question can be answered when we eventually compare their separation power to our deep-learning tagger. To tackle the second question we plot the feature importance of each input variable in Fig. 3. For a variable we want to look at individual nodes making up a tree and how often is used for a split . For each split we first compute the probability for a sample to reach the node and define the purity of each node by the Gini index
[TABLE]
where the last step holds for two classification hypotheses and gives twice the probability of choosing a data point of category at node , multiplied by the probability of mis-labeling it. It reaches its maximum for even probabilities and tends to zero if all the samples in a node are of the same category. In that sense it is a measure of the purity or impurity of the sample at node . Next, we compute the change in purity of the node when we define a split in terms of the variable , defining . This allows us to quantify the importance of a variable as
[TABLE]
modulo a normalization constant. A decision tree is essentially a series of nodes which splits the samples such that the decrease in impurity is maximized, hence more important features are more often used to split the samples. Because cutting on a one-dimensional distribution as shown in Fig. 2 masks correlations, the importance allows us to define the feature that best separates the data whilst being least correlated with other variables. We show the results in Fig. 3 and find a start constrast to the single-variable results of Fig. 2. The most powerful single observables and are strongly correlated with the leading variable and therefore contribute little to the multi-variate analysis. Instead, the two-point correlation , which carries extra information than the other (first-order moment) variables, is the most important additional feature. Amusingly, these two leading observables and are also IR-safe [53]. All other observables constribute to the quark-gluon separation, but with different impact.
We close with a word of caution. The subjet observables given in Eq.(2) are not theoretically well-defined observables which we can compute based on QCD. Instead, they are statistical descriptions of jet constituents, including two-object correlators, in some cases IR-modified by an appropriate energy scaling. Relying on not consistently IR-safe observables complicates quark-gluon separation at the LHC, but does not make it impossible [26, 27, 28, 30]. The main problem is that we cannot define quark or gluon jets in perturbative QCD or in Monte-Carlo simulations beyond leading order in QCD. Clearly, these observables as well as low-level observables cannot be directly used to study QCD properties of subjets. On the other hand. IR-safety does not have to be an issue for data-to-data analyses, like quark-gluon tagging trained on observed jets. All we need to do is define the quark and gluon labels in relation to a hard process which predicts mostly quarks or mostly gluons, rather than jet by jet [29]. This way we can use the potentially powerful soft and collinear subjet information as long as we do not attempt to interpret these measurements in terms of QCD.
2.2 Charging LoLa
Given our result for the multi-variate analysis of high-level substructure variables, it is natural to ask what happens when we attempt to capture all available information from low-level observables using a deep neural network. To combine information from the calorimeter and the tracker with its different resolution, a promising approach is the LoLa architecture applied to particle flow objects, developed for the DeepTopLoLa tagger [13]. The input to the network are the jet constituent 4-vectors sorted by ,
[TABLE]
Since varies from jet to jet, we zero-pad jets with fewer than constituents, and increase until the tagging performance is saturated, for most physics scenarios giving . Above this the soft jet constituents carry too little information to compensate for the increasing computation time. Inspired by the structure of recombination jet algorithms, we multiply the original 4-vectors with a trainable matrix , defining a combination layer (CoLa)
[TABLE]
This increases the number of inputs from to , where is a tunable hyper-parameter of the network. The entry is new for the quark–gluon implementation and encodes the information if a particles is charged or not, [31]. For most of the phase space considered in this paper, we will find that the tagging performance for our specific applications hardly improves, but obviously this result should not be generalized. To make it easier for the network to learn the mathematical structure of Lorentz transformations we pass the CoLa output to a Lorentz layer (LoLa)
[TABLE]
with . To adapt this layer to quark–gluon separation we augment it with the third and the last entries. They follow the definition of the the subjet variables and in Eq.(2), with the sum over constituents stripped off so that they are defined per constituent. The first three map individual 4-momenta onto their invariant mass and transverse momentum. The fourth entry is a linear combination of all energies with trainable weights , while the fifth entry sums over the Minkowski distance between and all other 4-momenta , again weighted by which is updated after each training epoch. For the lower three entries we can either sum over or minimize over while keeping fixed. For we choose the sum over the internal index; for we include four copies with independently trainable weights, two summing and two minimizing over the internal index; for the last entry we use two copies, one with a sum and one with a minimum. However, it turns out that the new LoLa observables have limited impact on the quark–gluon separation, independent of the options applied to the last the last entry in Eq.(9).
After the LoLa stage, the inputs are passed through ReLU-activated dense layers with 100 and 50 units and dropout rate 0.2 and 0.1, respectively. Both dense layers have an additional L2 regularization of and are initialized with He-normal functions. A final dense layer converts the weights into a normalized score with SoftMax activation. All training is done using Keras [56] with the Theano [57] back-end on a GPU cluster. The hyper-parameters are optimized with Adam [58], using a learning rate of and a batch size of 128. We have checked that both, for the size of the training sample and for the number of constituents our performance reaches safe plateaus. Throughout this paper we use constituents, significantly above where we would expect the soft activity to be universal.
Turning to the performance, we plot the ROC curves for our best-performing LoLa architecture in the left panel of Fig. 4, compared to the 6-observable BDT,
[TABLE]
In the right panel we also show the increase in signal significance as a function of the signal efficiency, to help us optimize the impact of the tagger as an analysis tool for instance in terms of . With our LoLa network we reproduce the performance of the enhanced images setup of Ref. [31] without detector simulation and after accounting for the move from Pythia to Sherpa. Our agreement is at the level that different trainings of our LoLa tagger on the framework of Ref. [31] shower a stronger variation than the agreement between the LoLa and the CNN performance. Different architectures without detector effects are studied in detail in Ref. [30]. They are very close in performance, including convolutional networks like that of Ref. [31], and we have good reason to assume that this pattern will not change once we include detector effects.
We also note an overall improvement with respect to our 6-observable BDT. The fact that the deep network does not hugely outperform the multi-variate analysis on the subjet level is not unexpected. The difference between the LoLa network and the BDT becomes smaller once we include detector effects. This points to the deep network finding additional information which even the theoretically poorly defined observables do not capture. As a test of stability we also show BDT results with a reduced and less IR-sensitive set of observables,
[TABLE]
As we can see in Fig. 4 this reduces the over-all performance of the BDT, but does not improve the stability with respect to detector effects.
Finally, we need to test if the quark–gluon network correctly captures the information we know exists at the subjet level [59]. Because we have access to Monte Carlo truth we can, for instance, plot the distributions of our six observables for quark jets identified as quarks and for gluon jets identified as gluons. We can compare these distributions between the LoLa network, the BDT, and the truth information, all including detector effects. In Fig. 5 we plot all observables introduced in Sec. 2.1, at truth-level and after selecting the 30% best-identified jets. For gluon jets the classifier favors slightly lower values of and , and larger values of , and . A significant sculpting of these distributions relative to truth indicates a challenge in separating the two hypotheses. The observables where LoLa best matches the truth are and . These are also the two most important observables in the BDT in Fig. 2, indicating that the BDT and LoLa indeed rely on similar information.
2.3 Jet kinematics
One dangerous sources of systematic uncertainties in subjet physics and elsewhere is mis-measuring the momentum of the jet [60]. Because the structure of parton splittings is sensitive to the range of energies described by the splitting history, we do not want to remove this information for example through an adversarial network. Instead, we want to include in the information available to the tagger. Before we do so, we need to understand at what level the quark–gluon network is sensitive to the transverse momentum of the jet [31, 32].
To this end we train and test individual LoLa networks in different slices of , again with detector effects, and test them on over a range of transverse momenta. We show the AUC values for different combinations of training and testing samples in Tab. 1. The left table shows the performance of the network for a small step size GeV. On the diagonal we see that the performance of the network slightly increases towards higher momenta. This can be understood through the larger number of constituents radiated off initial partons with higher momentum. For the off-diagonal entries there is also a small generic trend that using a network on somewhat higher- jets than it was trained for does not reduce its efficiency. Because the differences between quarks and gluons are more subtle for softer jets, a network trained on these subtle differences may also be applied to harder jets. However, in the other direction the network trained on the more obvious hard jets will slightly deteriorate for softer jets. In the right table we test a wider range of transverse momenta. We observe the same trend, but for networks trained between 200 and 350 GeV the performance seriously suffers when we compare it to GeV.
We only show central values in both of these tables, but we have estimated uncertainties on the performance measures in two ways. The larger error bar comes from using a trained network on different test samples, it gives typical uncertainties of for most of the entries, increasing to for the larger separations in . The error we find from using different trainings on the same test sample is, in our case, about an order of magnitude smaller.
For the slices in Tab. 1 we can compute the ROC curves for the LoLa quark–gluon discrimination. In the left panel of Fig. 6 we see how the performance of the tagger is stable, with a slight increase in performance towards higher jet momenta.
In the right panel of Fig. 6 we repeat the same exercise, but including the charge information discussed in Eq.(8). Indeed, the performance is unchanged for this specific change in the LoLa setup, at least up to GeV and once we include detector effects.
3 Mono-jets
To see at what level quark–gluon discrimination really helps at the LHC we need benchmark applications. For WBF jets we have unfortunately seen that the substructure of the tagging jets can alleviate the pressure on global observables like a central jet veto, but that the signal vs background system is already over-constrained by event-level kinematic information and jet substructure [43]. We therefore turn to the simplest jet analyses with the fewest number of established handles to control the background.
Our first candidate is the mono-jet signature probing invisible decays of a SM-like Higgs boson. Here, the transverse momentum of the tagging jet is essentially the only kinematic variable used in standard analyses. Far from the expected performance of the leading WBF and channels for invisible SM-like Higgs decays, this mono-jet channel is extremely versatile when we search for dark matter or want to learn more about the nature of an invisible Higgs signal. For a Higgs-like mediator it provides us with a benchmark process for a tagger extracting a gluon-dominated signal from a quark-dominated background [monojet_qg]. Obviously, all our findings can be generalized to searches for (pseudo-)scalar mediators at the LHC. For those the relative importance of the electroweak WBF and channels compared to the gluon-induced mono-jet channel can obviously be completely altered.
The key feature of mono-jet searches with scalar mediators is that the signal jet is almost always gluon-initiated, while for the +jets background it is mostly quark-initiated, as illustrated in Fig. 7. Increasing pushes the events kinematics towards larger proton momentum fractions and enhances the quark contribution, slowly reducing the gluon purity of the Higgs signal. Observing such a signal in mono-jet events requires exquisite control of the large backgrounds from +jets production. While the largest background is +jets, there exists a sizeable irreducible contribution from +jets, where the lepton either fakes a jet or escapes undetected [62]. Due to the rather inclusive signature of a high- jet with large missing transverse energy, there is little to cut on other than either of . In practice, a cut of at least is typically required at the trigger level.
We generate the +jets signal events, including the finite top mass effects with Sherpa2.2.1 [45] and OpenLoops [63] at a collider energy of 14 TeV. For the +jets background we also use Sherpa2.2.1 [45] with the Comix for matrix element generation [64], and we employ Ckkw-L merging [65] with up to two jets in the matrix element for both +jets and +jets. As in the case of the pure samples, we use anti- jets with all visible final-state particles of as constituents [50]. As long as we stick to leading-order simulation we can extract the parton content for example of the hardest jet from Monte Carlo truth.
To illustrate the challenge in observing this signal, we plot some kinematic distributions for the signal and background in Fig. 8. Note that following the discussion in Sec. 2.1 we do not distinguish gluon jets from quark jets, but the Higgs plus jets signal from the plus jets background. First, the expected signal-to-background ratio even assuming an invisible Higgs branching ratio of formally 100% is at the per-mille level. Second, the leading jet kinematics for the signal and background is essentially identical, while the second jet is actually softer in the signal. A cut-and-count analysis above a stringent requirement is not an optimal analysis strategy, because the small difference between the Higgs and masses hardly affects the kinematics. Of course, if the mono-jet signal is due to a light mediator, the signal -spectrum will be harder.
A subjet feature, which is not exploited in the event-level analysis is that the hardest background jet is quark-initiated in of events, while the leading signal jet is usually gluon-initiated. From Fig. 7 we expect the quark–gluon tagger to be most useful at low to intermediate . To study this question quantitatively, we generate mono-jet samples in non-overlapping slices of and train and test LoLa on all combinations of the above samples. The performance of each combination, given by the area under the curve (AUC), is shown in Tab. 2. These numbers can be directly compared to their counterparts for pure samples in Tab. 1. We see that the diagonal entries, corresponding to networks trained and tested in the same range, show the best performance, and the performance gradually decreasing with , reflecting the drop in quark vs gluon purity shown in Fig. 7.
The ROC curves corresponding to the diagonal train and test combinations of Tab. 2, and their corresponding SI curves, are shown in Fig. 9. All curves show the same behavior, with the drop in performance for high- jets visible for the GeV slice. For the actual mono-jet analysis this implies that quark–gluon discrimination is least efficient when the analysis focuses on the kinematic regime with the largest missing energy. However, from Fig. 8 we know that for heavy mediators like a SM-like Higgs this kinematic range is not the most promising. Instead, we typically analyze the entire distribution and extract a signal significance from a shape analysis in the presence of large systematic uncertainties. This is the reason why we cannot quote a simple significance improvement for the mono-jet analysis from quark–gluon tagging. Also for lighter mediators, the bulk of the distribution is what allows us to control the backgrounds at the required level [62], and here a systematic application of quark–gluon tagging may improve our limited event-level understanding of signal vs background features. On the other hand, at this level it should be clear that for quark-gluon discrimination in the presence of detector effects the mono-jet channel does not provide a useful benchmark.
4 Di-jet resonances
As a second application, we study resonances decaying to two jets. These signal decay jets are usually quark-initiated, while for relatively light resonances the background will be multi-gluon production. An interesting aspect of this analysis is that we could, in principle, use this quark–gluon information already at the trigger level to enhance the LHC reach in di-jet resonance searches.
We consider an axial vector with a democratic coupling to all quarks, ignoring the obvious problems with a UV completion [66]. This resonance might or might not be a dark matter mediator — in this study we only consider its decay to quarks described by the Lagrangian [67]
[TABLE]
The decay to quarks has the benefit that the entire signal only depends on one kind of coupling, and exactly the coupling we eventually need to quantitatively analyze mono-jet signals when the new resonance is a dark matter mediator. We consider two benchmark point for the mass, namely GeV and GeV, combined with , and simulate the signal and the background with Sherpa2.2.1 [45] to leading order. The selection criteria for a standard LHC search are at least two jets with [68]
[TABLE]
combined with the resonance-inspired requirements
[TABLE]
In the left panel of Fig. 10 we first analyze the leading jet for the low-mass case and both jets for the heavy-mass case. In both cases we use the pre-trained networks from the pure samples. We find that the quark–gluon tagging works slightly better for lower-mass resonances or lower typical . This has nothing to do with the signal and is driven by the purity of the QCD background in this phase space region. The second jet from the light resonance is comparably soft, which makes it hard to separate it from QCD radiation without strongly shaping the background.
We also see that, for GeV the harder jet has more sensitivity for high signal efficiencies, whereas the second hardest jet has more sensitivity for lower signal efficiencies. Consequently, in the right panel of Fig. 10 we show the performance of a dedicated two-jet LoLa network, combining the network output from the two jets into an additional set of layers and then producing the standard di-jet tagging output. As expected, the signal and the background independently predict two quarks and two gluons, so the combined network efficiency receives a significant boost. On the other hand, it is well known that there exist a wealth of observables which are sensitive to the quark vs gluon nature of jets at the event level, like additional jet activity. This kind of information is fully correlated with the quark-gluon tagging of the di-jets, and it is unlikely that the jet tagging significantly improves the LHC reach once all event-level observables are considered [43]. On the other hand, these event-level observables are non-trivial to control, so adding quark-gluon tagging should help controlling the backgrounds. In that sense, just as for the mono-jet case, our simple significance estimate is not the whole story. Resonance searches are only partly limited by statistical significance. Enriching the signal samples with quarks at an early stage will generally suppress multi-jet backgrounds. Because trained neural networks are fast, they could be used already at the trigger level to provide an improved event sample and to allow for searches in tough phase space regions.
5 Summary
Quark–gluon separation is one of the hardest problems in contemporary LHC physics. Technically, is has received a huge boots from machine learning on low-level observables. Also on the theory side, the general move towards likelihood-free analyses just comparing fully simulated and observed events at the detector level circumvents some of the fundamental QCD problems. In combination, these developments call for a realistic study of these methods using benchmark signal processes.
We have extended our LoLa tagger, previously used for top tagging, to statistically separate quarks from gluons. For the ideal case of pure quark and gluon jets we find that detector effects lead to a degradation of the machine learning results, to a point where a classic BDT analysis becomes competitive. However, we also remind ourselves that the standard observables entering the BDT are neither theoretically nor experimentally preferable and also show non-trivial correlations. Including charge information in LoLa can be useful for hard jets. Finally, we have shown that training and testing the network on sliced of leads to surprisingly stable results.
Our first benchmark channel is mono-jet production with a gluon-rich signal. Subjet information can be added to an otherwise very limited number of event-level observables. It has the potential to improve the LHC reach, especially when we use it to understand and control the entire distribution. The impact of -dependent training on the systematic uncertainties should be easily controllable.
The second benchmark channel are di-jet resonances with their quark-rich signal. We find that applying a network trained on pure samples already improves the reach for relatively light bosons just using their couplings to quarks. Using our LoLa setup we find that for hadronically decaying bosons with masses below the TeV range the quark–gluon discrimination can be useful.
Altogether, we have shown that quark–gluon tagging is a theoretical and experimental challenge, that deep learning provides competitive taggers, and that their tagging performance is significantly affected by detector effects. At the LHC, there exists a range of applications, both with quark-rich and gluon-rich signals, for which it would be interesting to see how quark–gluon tagging affects triggering, background systematics, or the signal extraction in a properly described experimental setup. Unfortunately, just like weak boson fusion [43] neither mono-jet searches nor di-jet resonance searches are obvious benchmarks to estimate the impact of quark-gluon tagging on the LHC reach.
Acknowledgments
We are very grateful to Michael Russell for his contributions during an early phase of this project. We also would like thank Monica Dunford and Hanno Meyer zu Theenhausen for very useful discussions about the di-jet channel. Finally, we acknowledge support by the state of Baden-Württemberg through bwHPC and the German Research Foundation (DFG) through grant no INST 39/963-1 FUGG (bwForCluster NEMO).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] for a review see e.g. A. J. Larkoski, I. Moult and B. Nachman, ar Xiv:1709.04464 [hep-ph].
- 2[2] J. Cogan, M. Kagan, E. Strauss and A. Schwarztman, JHEP 1502 , 118 (2015) 10.1007/JHEP 02(2015)118 [ ar Xiv:1407.5675 [hep-ph]]; L. de Oliveira, M. Kagan, L. Mackey, B. Nachman and A. Schwartzman, JHEP 1607 , 069 (2016) 10.1007/JHEP 07(2016)069 [ ar Xiv:1511.05190 [hep-ph]]. · doi ↗
- 3[3] P. Baldi, K. Bauer, C. Eng, P. Sadowski and D. Whiteson, Phys. Rev. D 93 , no. 9, 094034 (2016) 10.1103/Phys Rev D.93.094034 [ ar Xiv:1603.09349 [hep-ex]]. · doi ↗
- 4[4] J. Barnard, E. N. Dawe, M. J. Dolan and N. Rajcic, Phys. Rev. D 95 , no. 1, 014018 (2017) 10.1103/Phys Rev D.95.014018 [ ar Xiv:1609.00607 [hep-ph]]. · doi ↗
- 5[5] L. de Oliveira, M. Paganini and B. Nachman, Comput. Softw. Big Sci. 1 , no. 1, 4 (2017) 10.1007/s 41781-017-0004-6 [ ar Xiv:1701.05927 [stat.ML]]. · doi ↗
- 6[6] G. Louppe, K. Cho, C. Becot and K. Cranmer, ar Xiv:1702.00748 [hep-ph].
- 7[7] K. Datta and A. Larkoski, JHEP 1706 , 073 (2017) 10.1007/JHEP 06(2017)073 [ ar Xiv:1704.08249 [hep-ph]]; T. Roxlo and M. Reece, ar Xiv:1804.09278 [hep-ph]; L. Moore, K. Nordström, S. Varma and M. Fairbairn, ar Xiv:1807.04769 [hep-ph]. · doi ↗
- 8[8] J. Lin, M. Freytsis, I. Moult and B. Nachman, ar Xiv:1807.10768 [hep-ph].