Approximate State Space Modelling of Unobserved Fractional Components
Tobias Hartl, Roland Weigand

TL;DR
This paper introduces efficient inferential methods for nonstationary multivariate unobserved components models with fractional integration, utilizing ARMA approximations in state space to improve estimation accuracy and computational efficiency.
Contribution
It presents a novel ARMA-based approximation approach for fractional components models, enhancing estimation accuracy and computational efficiency over traditional truncation methods.
Findings
ARMA approximation outperforms autoregressive/moving average truncation
Proposed methods show good estimation properties in simulations
Methods are effective for high-dimensional, complex processes
Abstract
We propose convenient inferential methods for potentially nonstationary multivariate unobserved components models with fractional integration and cointegration. Based on finite-order ARMA approximations in the state space representation, maximum likelihood estimation can make use of the EM algorithm and related techniques. The approximation outperforms the frequently used autoregressive or moving average truncation, both in terms of computational costs and with respect to approximation quality. Monte Carlo simulations reveal good estimation properties of the proposed methods for processes of different complexity and dimension.
Click any figure to enlarge with its caption.
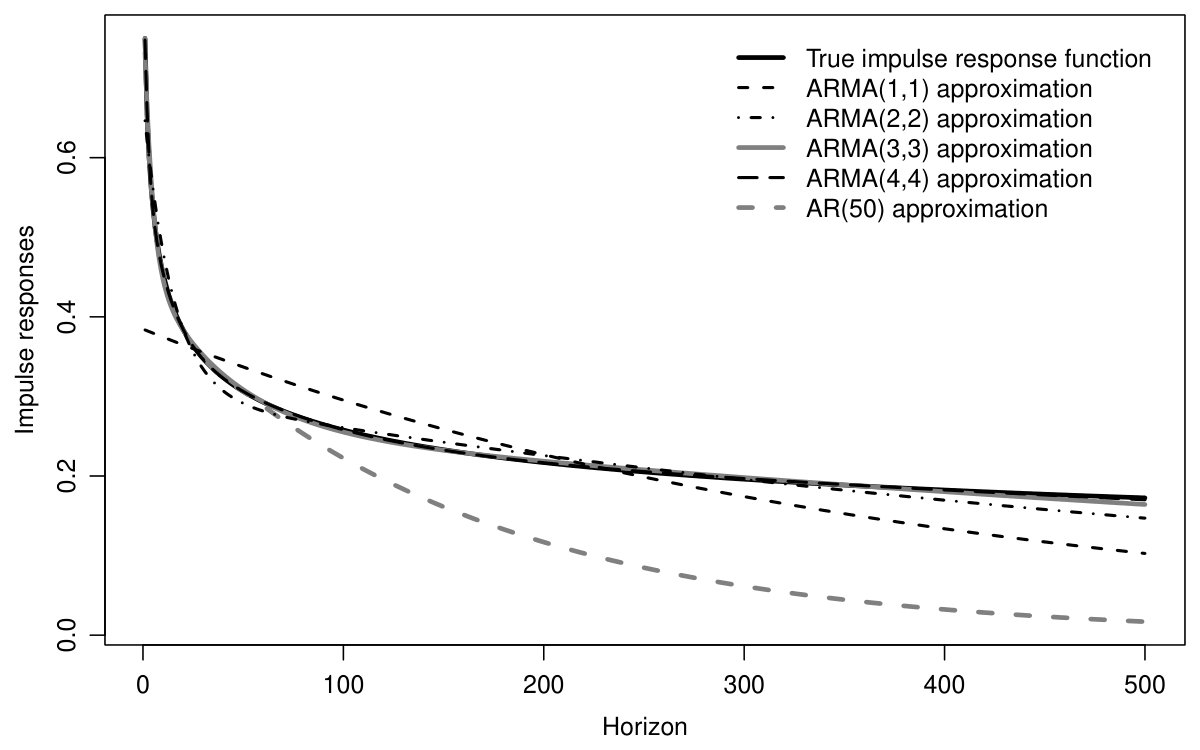 Figure 1
Figure 1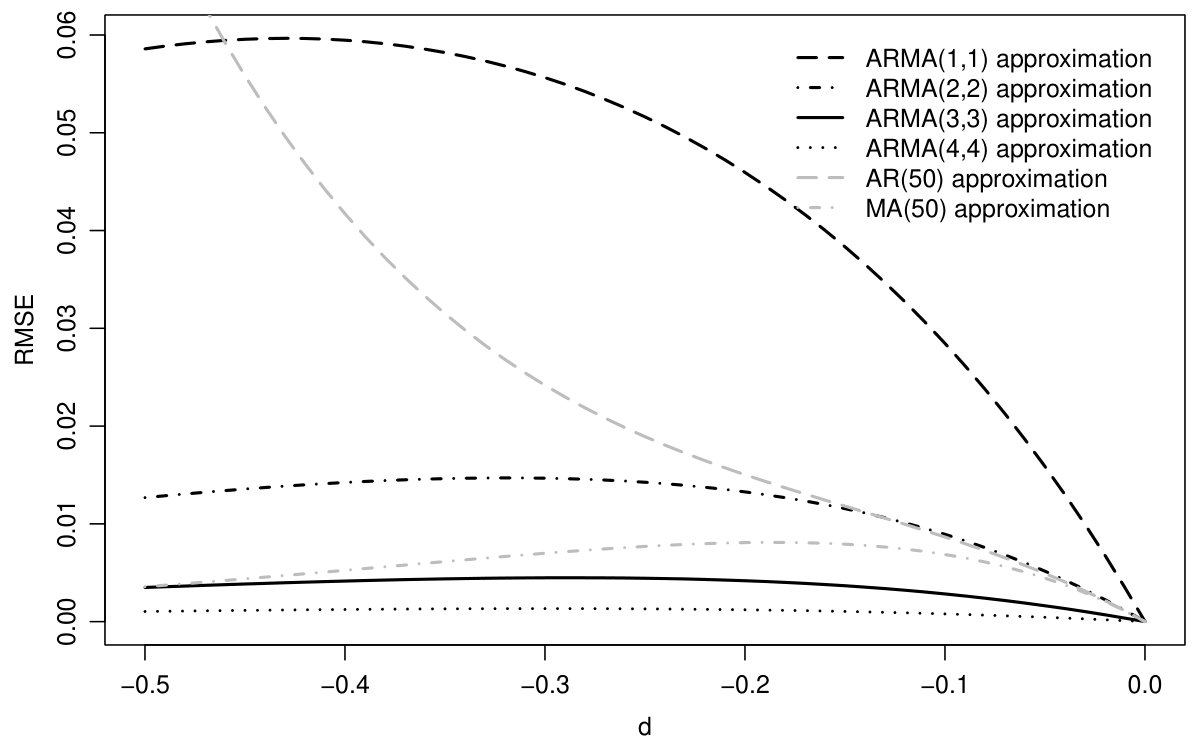 Figure 2
Figure 2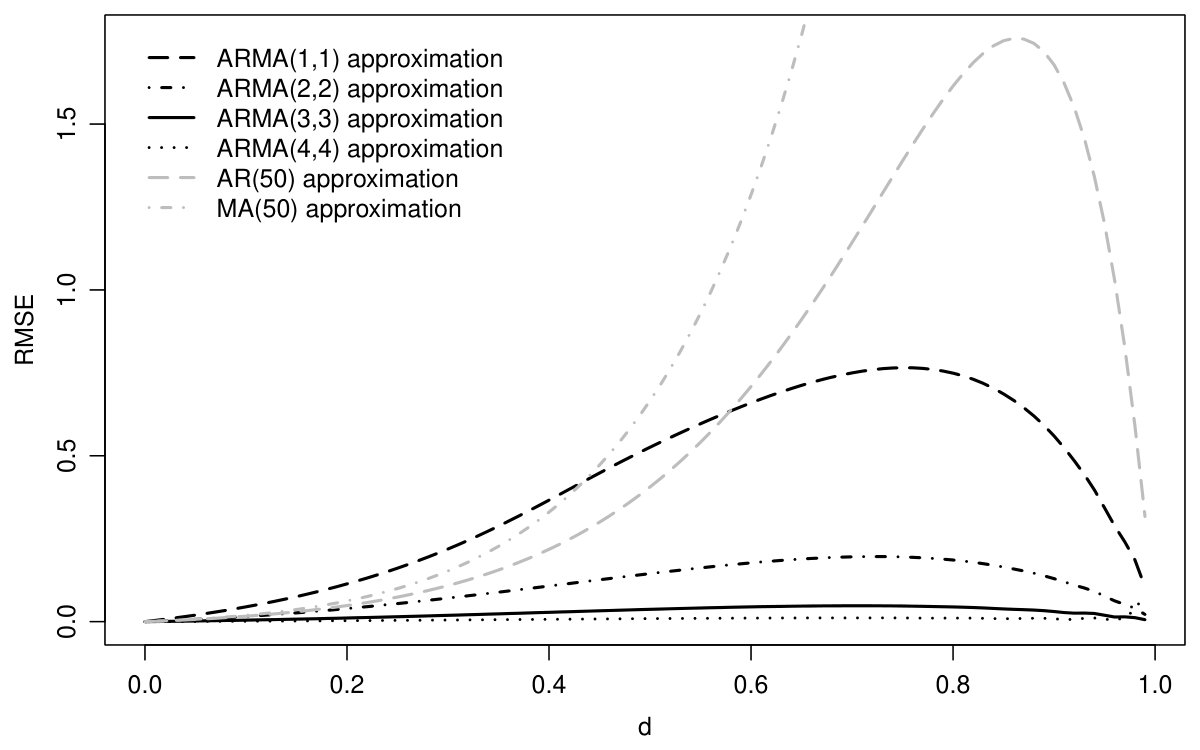 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9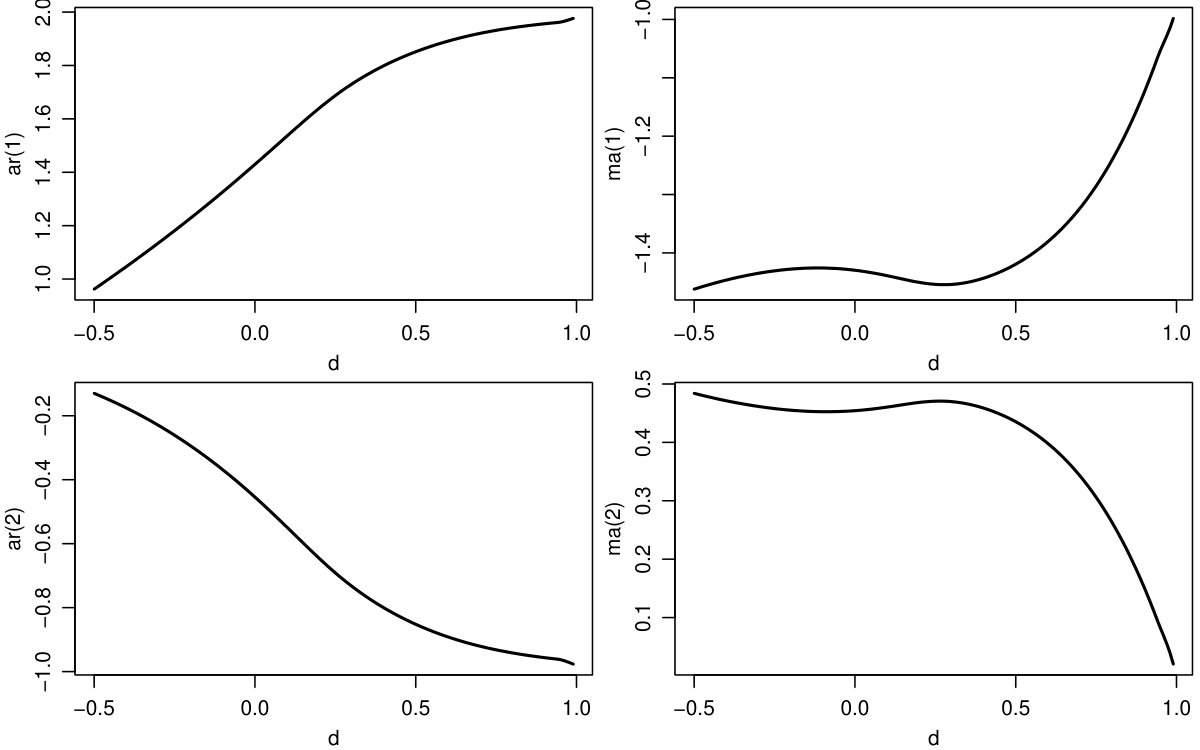 Figure 10
Figure 10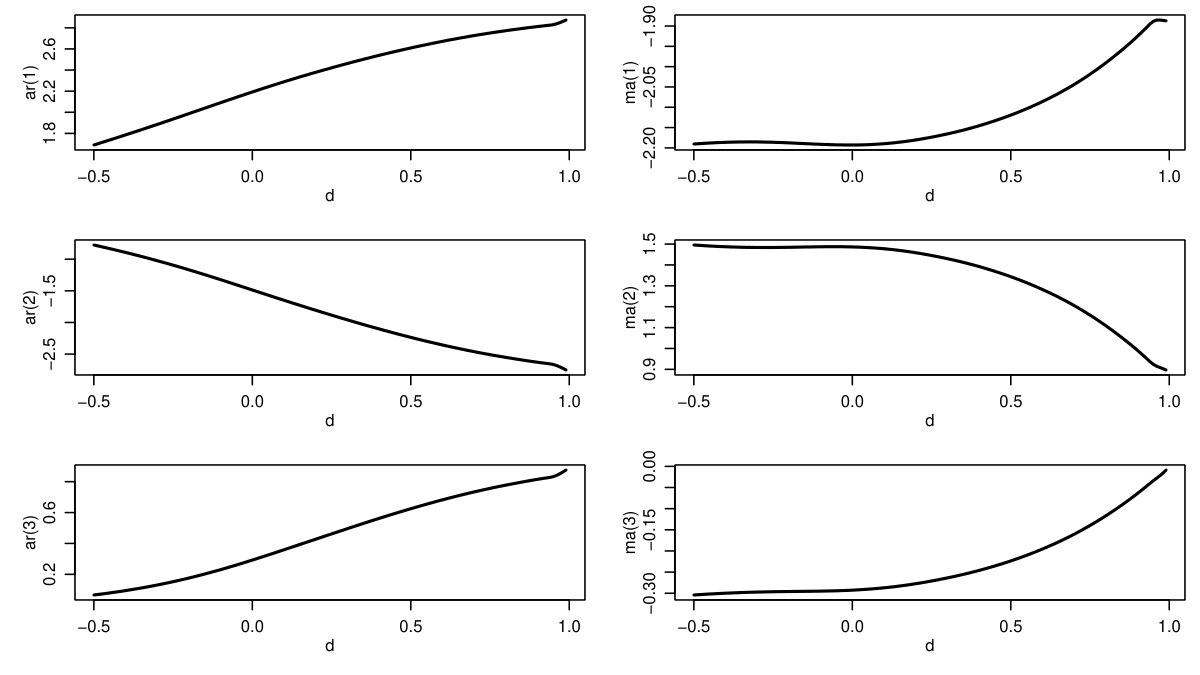 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16| q | d | n | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .25 | 250 | .130 | .132 | .132 | .131 | .130 | .123 | .122 | .161 | .414 | .102 |
| 500 | .077 | .075 | .075 | .075 | .075 | .075 | .074 | .138 | .324 | .069 | ||
| 1000 | .052 | .050 | .050 | .051 | .050 | .051 | .050 | .119 | .260 | .048 | ||
| .50 | 250 | .110 | .109 | .106 | .122 | .114 | .106 | .109 | .191 | .305 | .089 | |
| 500 | .068 | .068 | .068 | .078 | .071 | .071 | .070 | .157 | .212 | .060 | ||
| 1000 | .045 | .045 | .044 | .052 | .047 | .052 | .048 | .125 | .140 | .039 | ||
| .75 | 250 | .098 | .101 | .100 | .113 | .100 | .150 | .125 | .192 | .223 | .091 | |
| 500 | .069 | .066 | .066 | .096 | .079 | .108 | .096 | .148 | .157 | .066 | ||
| 1000 | .048 | .044 | .044 | .086 | .058 | .084 | .072 | .108 | .107 | .046 | ||
| 1.0 | .25 | 250 | .086 | .086 | .086 | .085 | .085 | .084 | .083 | .132 | .413 | .078 |
| 500 | .058 | .057 | .057 | .057 | .057 | .057 | .056 | .111 | .315 | .053 | ||
| 1000 | .040 | .038 | .038 | .039 | .039 | .039 | .038 | .090 | .230 | .037 | ||
| .50 | 250 | .077 | .078 | .078 | .086 | .081 | .082 | .078 | .145 | .279 | .072 | |
| 500 | .056 | .054 | .054 | .058 | .057 | .059 | .057 | .118 | .188 | .049 | ||
| 1000 | .038 | .036 | .036 | .042 | .038 | .042 | .040 | .089 | .125 | .033 | ||
| .75 | 250 | .076 | .075 | .075 | .081 | .075 | .114 | .096 | .143 | .200 | .074 | |
| 500 | .057 | .054 | .054 | .066 | .055 | .086 | .084 | .111 | .142 | .054 | ||
| 1000 | .044 | .037 | .036 | .068 | .044 | .059 | .069 | .079 | .098 | .038 | ||
| 2.0 | .25 | 250 | .072 | .072 | .072 | .071 | .072 | .068 | .068 | .114 | .402 | .065 |
| 500 | .049 | .048 | .048 | .048 | .048 | .047 | .047 | .094 | .308 | .044 | ||
| 1000 | .033 | .032 | .032 | .033 | .032 | .033 | .032 | .072 | .197 | .031 | ||
| .50 | 250 | .067 | .066 | .066 | .075 | .069 | .071 | .067 | .118 | .257 | .062 | |
| 500 | .049 | .046 | .046 | .051 | .049 | .052 | .050 | .096 | .178 | .043 | ||
| 1000 | .034 | .031 | .031 | .037 | .034 | .037 | .035 | .071 | .117 | .029 | ||
| .75 | 250 | .067 | .064 | .064 | .069 | .065 | .114 | .088 | .116 | .187 | .064 | |
| 500 | .052 | .046 | .046 | .057 | .047 | .108 | .080 | .093 | .133 | .046 | ||
| 1000 | .055 | .032 | .032 | .060 | .038 | .098 | .067 | .066 | .093 | .033 |
| q | d | n | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .25 | 250 | -.019 | -.019 | -.019 | -.027 | -.025 | -.032 | -.032 | -.125 | .167 | -.014 |
| 500 | -.012 | -.010 | -.010 | -.012 | -.015 | -.015 | -.018 | -.112 | .119 | -.004 | ||
| 1000 | -.007 | -.005 | -.005 | -.002 | -.008 | -.005 | -.010 | -.103 | .094 | .005 | ||
| .50 | 250 | -.006 | -.003 | -.003 | -.008 | -.006 | -.036 | -.034 | -.162 | .095 | -.010 | |
| 500 | -.011 | -.006 | -.005 | -.005 | -.010 | -.020 | -.030 | -.134 | .040 | -.008 | ||
| 1000 | -.012 | -.003 | -.003 | .011 | -.005 | .002 | -.017 | -.110 | .016 | -.007 | ||
| .75 | 250 | -.013 | -.005 | -.005 | .012 | -.003 | -.052 | -.066 | -.163 | .035 | -.010 | |
| 500 | -.016 | -.007 | -.006 | .024 | .002 | -.036 | -.067 | -.123 | .010 | -.010 | ||
| 1000 | -.011 | -.006 | -.003 | .046 | .013 | -.001 | -.052 | -.090 | .004 | -.010 | ||
| 1.0 | .25 | 250 | -.011 | -.009 | -.009 | -.017 | -.015 | -.022 | -.020 | -.085 | .207 | -.009 |
| 500 | -.009 | -.007 | -.007 | -.010 | -.012 | -.014 | -.014 | -.075 | .139 | -.004 | ||
| 1000 | -.006 | -.004 | -.003 | -.002 | -.006 | -.005 | -.008 | -.067 | .088 | .003 | ||
| .50 | 250 | -.006 | -.002 | -.002 | -.005 | -.004 | -.036 | -.028 | -.104 | .103 | -.008 | |
| 500 | -.009 | -.005 | -.004 | -.005 | -.007 | -.024 | -.027 | -.084 | .052 | -.007 | ||
| 1000 | -.009 | -.003 | -.002 | .008 | -.003 | -.005 | -.016 | -.067 | .026 | -.006 | ||
| .75 | 250 | -.009 | -.006 | -.005 | .009 | -.003 | -.068 | -.068 | -.101 | .048 | -.008 | |
| 500 | -.005 | -.008 | -.006 | .018 | -.000 | -.054 | -.066 | -.074 | .023 | -.009 | ||
| 1000 | .013 | -.006 | -.003 | .039 | .010 | -.026 | -.054 | -.053 | .015 | -.008 | ||
| 2.0 | .25 | 250 | -.004 | -.002 | -.002 | -.011 | -.007 | -.017 | -.013 | -.053 | .224 | -.006 |
| 500 | -.007 | -.005 | -.005 | -.008 | -.009 | -.012 | -.012 | -.047 | .148 | -.004 | ||
| 1000 | -.004 | -.002 | -.002 | -.001 | -.004 | -.005 | -.006 | -.041 | .086 | .002 | ||
| .50 | 250 | -.001 | .001 | .001 | .003 | .001 | -.033 | -.020 | -.061 | .108 | -.006 | |
| 500 | -.004 | -.003 | -.003 | -.001 | -.003 | -.026 | -.023 | -.049 | .061 | -.006 | ||
| 1000 | -.003 | -.001 | -.001 | .008 | -.000 | -.010 | -.015 | -.038 | .034 | -.005 | ||
| .75 | 250 | -.000 | -.004 | -.004 | .009 | -.002 | -.068 | -.067 | -.059 | .059 | -.006 | |
| 500 | .011 | -.006 | -.005 | .017 | -.000 | -.055 | -.066 | -.043 | .033 | -.008 | ||
| 1000 | .041 | -.003 | -.003 | .035 | .009 | -.030 | -.055 | -.030 | .022 | -.005 |
| d | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE of estimated fractional component | |||||||||
| 0.25 | 250 | 0.710 | 0.710 | 0.710 | 0.711 | 0.710 | 0.711 | 0.710 | 0.710 |
| 500 | 0.708 | 0.708 | 0.708 | 0.708 | 0.708 | 0.708 | 0.708 | 0.707 | |
| 1000 | 0.707 | 0.707 | 0.707 | 0.707 | 0.707 | 0.707 | 0.707 | 0.707 | |
| 0.50 | 250 | 0.700 | 0.700 | 0.700 | 0.701 | 0.700 | 0.704 | 0.701 | 0.699 |
| 500 | 0.699 | 0.698 | 0.698 | 0.699 | 0.698 | 0.702 | 0.700 | 0.698 | |
| 1000 | 0.699 | 0.697 | 0.697 | 0.698 | 0.697 | 0.701 | 0.699 | 0.697 | |
| 0.75 | 250 | 0.687 | 0.686 | 0.686 | 0.686 | 0.686 | 0.708 | 0.696 | 0.686 |
| 500 | 0.687 | 0.685 | 0.685 | 0.685 | 0.685 | 0.709 | 0.697 | 0.685 | |
| 1000 | 0.687 | 0.684 | 0.684 | 0.685 | 0.684 | 0.713 | 0.699 | 0.684 | |
| RMSE of out-of-sample forecasts | |||||||||
| 0.25 | 250 | 1.465 | 1.465 | 1.465 | 1.465 | 1.465 | 1.467 | 1.465 | 1.464 |
| 500 | 1.463 | 1.463 | 1.463 | 1.464 | 1.463 | 1.465 | 1.464 | 1.463 | |
| 1000 | 1.438 | 1.438 | 1.437 | 1.439 | 1.437 | 1.440 | 1.438 | 1.438 | |
| 0.50 | 250 | 1.680 | 1.678 | 1.678 | 1.688 | 1.681 | 1.733 | 1.697 | 1.677 |
| 500 | 1.688 | 1.685 | 1.684 | 1.699 | 1.691 | 1.753 | 1.712 | 1.684 | |
| 1000 | 1.645 | 1.641 | 1.640 | 1.657 | 1.643 | 1.724 | 1.669 | 1.641 | |
| 0.75 | 250 | 2.262 | 2.261 | 2.261 | 2.282 | 2.260 | 3.004 | 2.524 | 2.260 |
| 500 | 2.290 | 2.287 | 2.285 | 2.353 | 2.309 | 3.227 | 2.707 | 2.286 | |
| 1000 | 2.201 | 2.191 | 2.191 | 2.264 | 2.212 | 3.394 | 2.677 | 2.191 | |
| c | d | n | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .25 | 250 | .204 | .101 | .212 | .206 | .255 | .106 | .216 | .161 | .277 | .111 | .219 | .156 |
| 500 | .154 | .087 | .143 | .161 | .171 | .091 | .132 | .122 | .207 | .095 | .128 | .120 | ||
| 1000 | .086 | .075 | .097 | .125 | .113 | .079 | .088 | .097 | .125 | .086 | .091 | .098 | ||
| .50 | 250 | .207 | .122 | .094 | .082 | .222 | .126 | .083 | .066 | .238 | .134 | .084 | .063 | |
| 500 | .126 | .102 | .052 | .049 | .143 | .106 | .045 | .040 | .151 | .114 | .042 | .039 | ||
| 1000 | .086 | .080 | .025 | .031 | .094 | .084 | .021 | .026 | .097 | .093 | .022 | .026 | ||
| .75 | 250 | .188 | .108 | .042 | .031 | .192 | .112 | .030 | .025 | .203 | .120 | .022 | .023 | |
| 500 | .122 | .089 | .024 | .017 | .130 | .092 | .014 | .014 | .135 | .099 | .015 | .013 | ||
| 1000 | .090 | .067 | .015 | .009 | .091 | .069 | .008 | .008 | .093 | .075 | .006 | .008 | ||
| 1.0 | .25 | 250 | .266 | .119 | .358 | .429 | .309 | .124 | .365 | .314 | .344 | .128 | .374 | .280 |
| 500 | .186 | .124 | .294 | .367 | .251 | .128 | .291 | .262 | .281 | .133 | .291 | .238 | ||
| 1000 | .137 | .126 | .219 | .315 | .174 | .130 | .223 | .231 | .205 | .137 | .224 | .216 | ||
| .50 | 250 | .272 | .195 | .184 | .195 | .296 | .202 | .185 | .153 | .327 | .216 | .184 | .148 | |
| 500 | .169 | .182 | .098 | .124 | .192 | .189 | .092 | .095 | .217 | .204 | .098 | .093 | ||
| 1000 | .102 | .161 | .060 | .075 | .114 | .169 | .051 | .060 | .124 | .185 | .051 | .062 | ||
| .75 | 250 | .210 | .193 | .056 | .071 | .231 | .201 | .052 | .057 | .238 | .220 | .050 | .054 | |
| 500 | .139 | .161 | .025 | .037 | .157 | .169 | .032 | .030 | .155 | .188 | .025 | .028 | ||
| 1000 | .093 | .127 | .013 | .019 | .101 | .134 | .016 | .017 | .102 | .151 | .011 | .016 | ||
| 2.0 | .25 | 250 | .306 | .140 | .519 | .607 | .343 | .142 | .509 | .430 | .396 | .142 | .516 | .356 |
| 500 | .304 | .161 | .471 | .572 | .352 | .163 | .477 | .396 | .355 | .164 | .498 | .330 | ||
| 1000 | .241 | .174 | .410 | .539 | .292 | .176 | .430 | .380 | .301 | .179 | .464 | .325 | ||
| .50 | 250 | .355 | .297 | .322 | .413 | .378 | .302 | .327 | .302 | .402 | .309 | .347 | .271 | |
| 500 | .277 | .297 | .207 | .301 | .306 | .303 | .213 | .218 | .338 | .314 | .234 | .202 | ||
| 1000 | .175 | .283 | .117 | .201 | .191 | .290 | .120 | .151 | .219 | .305 | .125 | .149 | ||
| .75 | 250 | .261 | .354 | .106 | .169 | .294 | .364 | .102 | .132 | .317 | .384 | .112 | .128 | |
| 500 | .180 | .317 | .052 | .088 | .211 | .328 | .048 | .069 | .223 | .350 | .052 | .066 | ||
| 1000 | .123 | .270 | .028 | .043 | .143 | .281 | .031 | .036 | .146 | .305 | .026 | .036 | ||
| c | d | n | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .25 | 250 | -.017 | -.046 | -.023 | -.239 | .006 | -.047 | -.038 | -.179 | .019 | -.049 | .000 | -.198 |
| 500 | -.006 | -.053 | -.008 | -.188 | .012 | -.057 | -.012 | -.146 | .023 | -.063 | -.003 | -.168 | ||
| 1000 | -.004 | -.055 | -.006 | -.156 | .010 | -.058 | -.011 | -.123 | .021 | -.066 | -.001 | -.143 | ||
| .50 | 250 | .027 | -.069 | .002 | -.071 | .035 | -.073 | .000 | -.054 | .032 | -.083 | .002 | -.065 | |
| 500 | .018 | -.065 | .004 | -.041 | .030 | -.067 | .002 | -.031 | .036 | -.079 | .001 | -.037 | ||
| 1000 | .029 | -.057 | -.001 | -.023 | .043 | -.060 | .000 | -.019 | .042 | -.071 | .001 | -.022 | ||
| .75 | 250 | .046 | -.061 | .001 | -.015 | .046 | -.066 | .001 | -.011 | .043 | -.076 | .000 | -.014 | |
| 500 | .035 | -.057 | .002 | -.006 | .037 | -.061 | .001 | -.006 | .037 | -.068 | -.000 | -.005 | ||
| 1000 | .059 | -.045 | .001 | -.003 | .057 | -.047 | .000 | -.002 | .053 | -.055 | .000 | -.003 | ||
| 1.0 | .25 | 250 | -.035 | -.092 | -.102 | -.556 | -.016 | -.091 | -.052 | -.383 | -.006 | -.089 | -.041 | -.377 |
| 500 | -.017 | -.110 | -.023 | -.473 | -.002 | -.111 | .012 | -.344 | -.002 | -.116 | .004 | -.342 | ||
| 1000 | -.008 | -.117 | -.017 | -.422 | .002 | -.121 | -.007 | -.308 | .002 | -.130 | -.016 | -.319 | ||
| .50 | 250 | .014 | -.173 | -.006 | -.213 | .014 | -.178 | .002 | -.166 | .027 | -.191 | .000 | -.185 | |
| 500 | .007 | -.166 | .007 | -.136 | .007 | -.172 | .009 | -.106 | .012 | -.187 | .006 | -.121 | ||
| 1000 | .013 | -.151 | -.002 | -.083 | .026 | -.158 | .000 | -.067 | .023 | -.175 | .001 | -.078 | ||
| .75 | 250 | .029 | -.152 | .000 | -.051 | .026 | -.159 | .002 | -.039 | .023 | -.183 | .001 | -.047 | |
| 500 | .022 | -.135 | .003 | -.022 | .024 | -.140 | .003 | -.019 | .017 | -.160 | -.000 | -.022 | ||
| 1000 | .037 | -.113 | .000 | -.010 | .041 | -.117 | .000 | -.008 | .037 | -.133 | .000 | -.010 | ||
| 2.0 | .25 | 250 | -.054 | -.119 | -.367 | -.829 | -.023 | -.117 | -.275 | -.555 | -.046 | -.111 | -.241 | -.487 |
| 500 | -.037 | -.148 | -.156 | -.766 | -.014 | -.148 | -.144 | -.536 | -.059 | -.148 | -.278 | -.470 | ||
| 1000 | -.020 | -.167 | -.077 | -.731 | -.005 | -.169 | -.084 | -.517 | -.037 | -.172 | -.253 | -.470 | ||
| .50 | 250 | -.043 | -.286 | -.053 | -.525 | -.048 | -.285 | -.028 | -.369 | -.047 | -.290 | -.008 | -.358 | |
| 500 | -.034 | -.291 | -.009 | -.375 | -.036 | -.294 | .004 | -.276 | -.023 | -.307 | .003 | -.284 | ||
| 1000 | -.013 | -.278 | -.008 | -.261 | -.001 | -.285 | .005 | -.205 | .001 | -.300 | .004 | -.215 | ||
| .75 | 250 | -.033 | -.347 | -.007 | -.168 | -.041 | -.354 | -.001 | -.127 | -.020 | -.372 | .004 | -.148 | |
| 500 | -.035 | -.310 | .002 | -.078 | -.033 | -.320 | .002 | -.062 | -.021 | -.339 | .000 | -.071 | ||
| 1000 | -.000 | -.265 | -.002 | -.032 | -.005 | -.277 | -.001 | -.027 | .001 | -.299 | .001 | -.033 | ||
| a | d2 | d1 | n | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .2 | .6 | 250 | .154 | .142 | .306 | .172 | .260 | .070 | .121 |
| 500 | .176 | .112 | .310 | .143 | .326 | .051 | .090 | |||
| 1000 | .107 | .081 | .207 | .126 | .211 | .038 | .059 | |||
| .8 | 250 | .148 | .133 | .268 | .172 | .177 | .035 | .059 | ||
| 500 | .165 | .106 | .264 | .140 | .215 | .023 | .034 | |||
| 1000 | .121 | .079 | .166 | .123 | .156 | .014 | .014 | |||
| .4 | .6 | 250 | .156 | .137 | .249 | .214 | .400 | .122 | .177 | |
| 500 | .136 | .108 | .201 | .178 | .458 | .102 | .162 | |||
| 1000 | .109 | .079 | .167 | .150 | .461 | .085 | .145 | |||
| .8 | 250 | .199 | .131 | .302 | .214 | .363 | .064 | .122 | ||
| 500 | .235 | .105 | .290 | .176 | .470 | .048 | .104 | |||
| 1000 | .279 | .079 | .306 | .147 | .581 | .036 | .075 | |||
| 2.0 | .2 | .6 | 250 | .120 | .247 | .068 | .119 | .215 | .361 | .135 |
| 500 | .082 | .216 | .045 | .089 | .151 | .222 | .117 | |||
| 1000 | .058 | .182 | .030 | .066 | .093 | .124 | .062 | |||
| .8 | 250 | .103 | .248 | .064 | .113 | .095 | .137 | .062 | ||
| 500 | .071 | .200 | .041 | .086 | .059 | .074 | .032 | |||
| 1000 | .052 | .160 | .028 | .066 | .033 | .045 | .011 | |||
| .4 | .6 | 250 | .122 | .180 | .068 | .127 | .435 | .756 | .224 | |
| 500 | .084 | .164 | .048 | .107 | .369 | .675 | .213 | |||
| 1000 | .061 | .147 | .034 | .085 | .288 | .551 | .192 | |||
| .8 | 250 | .110 | .226 | .067 | .124 | .214 | .331 | .172 | ||
| 500 | .076 | .193 | .045 | .092 | .153 | .205 | .149 | |||
| 1000 | .055 | .164 | .031 | .069 | .096 | .129 | .126 |
| a | d2 | d1 | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| .5 | .2 | .6 | 250 | .149 | .160 | .170 | .158 | .095 | .096 | .093 | .096 |
| 500 | .132 | .139 | .151 | .085 | .080 | .054 | .057 | .054 | |||
| 1000 | .091 | .082 | .051 | .042 | .065 | .029 | .034 | .029 | |||
| .8 | 250 | .145 | .134 | .075 | .047 | .039 | .033 | .038 | .033 | ||
| 500 | .099 | .089 | .048 | .018 | .028 | .012 | .018 | .012 | |||
| 1000 | .067 | .059 | .032 | .008 | .019 | .005 | .009 | .005 | |||
| .4 | .6 | 250 | .179 | .259 | .319 | .324 | .209 | .148 | .133 | .148 | |
| 500 | .157 | .176 | .329 | .239 | .196 | .104 | .099 | .104 | |||
| 1000 | .176 | .197 | .573 | .135 | .180 | .070 | .072 | .070 | |||
| .8 | 250 | .184 | .202 | .251 | .101 | .092 | .064 | .049 | .064 | ||
| 500 | .185 | .202 | .340 | .050 | .074 | .034 | .025 | .034 | |||
| 1000 | .120 | .121 | .216 | .023 | .059 | .016 | .015 | .016 | |||
| 2.0 | .2 | .6 | 250 | .126 | .079 | .211 | .205 | .203 | .064 | .120 | .064 |
| 500 | .090 | .052 | .126 | .121 | .206 | .033 | .073 | .033 | |||
| 1000 | .062 | .033 | .064 | .061 | .196 | .014 | .029 | .014 | |||
| .8 | 250 | .095 | .060 | .056 | .054 | .094 | .012 | .040 | .012 | ||
| 500 | .061 | .042 | .022 | .020 | .077 | .003 | .014 | .003 | |||
| 1000 | .042 | .030 | .010 | .010 | .060 | .002 | .005 | .002 | |||
| .4 | .6 | 250 | .128 | .082 | .379 | .373 | .820 | .092 | .276 | .092 | |
| 500 | .091 | .057 | .312 | .290 | .542 | .068 | .247 | .068 | |||
| 1000 | .075 | .040 | .231 | .213 | .362 | .044 | .189 | .044 | |||
| .8 | 250 | .120 | .067 | .165 | .161 | .210 | .050 | .094 | .050 | ||
| 500 | .077 | .047 | .080 | .074 | .204 | .018 | .040 | .018 | |||
| 1000 | .049 | .034 | .031 | .029 | .183 | .005 | .014 | .005 |
| d2 | d1 | p | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| .2 | .6 | 3 | 250 | .125 | .263 | .108 | .158 | .074 | .107 | .037 | .057 |
| 500 | .087 | .224 | .078 | .131 | .046 | .075 | .020 | .035 | |||
| 1000 | .064 | .187 | .055 | .115 | .032 | .048 | .013 | .023 | |||
| 10 | 250 | .063 | .268 | .069 | .157 | .013 | .029 | .013 | .036 | ||
| 500 | .044 | .226 | .046 | .129 | .008 | .019 | .009 | .033 | |||
| 1000 | .029 | .191 | .030 | .115 | .006 | .013 | .006 | .027 | |||
| 50 | 250 | .054 | .271 | .059 | .150 | .002 | .006 | .002 | .007 | ||
| 500 | .037 | .228 | .039 | .128 | .001 | .004 | .001 | .006 | |||
| 1000 | .028 | .189 | .026 | .113 | .001 | .002 | .001 | .005 | |||
| .8 | 3 | 250 | .104 | .274 | .108 | .167 | .033 | .047 | .018 | .028 | |
| 500 | .077 | .219 | .076 | .138 | .020 | .028 | .009 | .016 | |||
| 1000 | .059 | .171 | .053 | .119 | .013 | .017 | .005 | .009 | |||
| 10 | 250 | .064 | .281 | .070 | .164 | .007 | .013 | .012 | .036 | ||
| 500 | .045 | .222 | .047 | .135 | .004 | .007 | .009 | .033 | |||
| 1000 | .030 | .175 | .030 | .120 | .002 | .004 | .006 | .027 | |||
| 50 | 250 | .055 | .285 | .059 | .158 | .001 | .002 | .002 | .007 | ||
| 500 | .037 | .224 | .039 | .136 | .001 | .001 | .001 | .006 | |||
| 1000 | .029 | .173 | .027 | .118 | .000 | .001 | .001 | .005 | |||
| .4 | .6 | 3 | 250 | .121 | .237 | .121 | .190 | .163 | .192 | .034 | .059 |
| 500 | .078 | .204 | .081 | .150 | .124 | .159 | .020 | .035 | |||
| 1000 | .055 | .173 | .054 | .125 | .091 | .129 | .014 | .024 | |||
| 10 | 250 | .062 | .241 | .065 | .188 | .028 | .051 | .011 | .024 | ||
| 500 | .044 | .204 | .045 | .149 | .017 | .043 | .008 | .017 | |||
| 1000 | .029 | .175 | .030 | .124 | .013 | .035 | .005 | .011 | |||
| 50 | 250 | .054 | .243 | .059 | .184 | .004 | .010 | .002 | .004 | ||
| 500 | .036 | .207 | .038 | .148 | .003 | .008 | .001 | .003 | |||
| 1000 | .028 | .174 | .027 | .123 | .002 | .006 | .001 | .002 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsControl Systems and Identification · Fault Detection and Control Systems · Advanced Control Systems Design
MethodsARMA GNN
Approximate State Space Modelling of Unobserved Fractional Components
Tobias Hartl
University of Regensburg, 93053 Regensburg, Germany
Institute for Employment Research (IAB), 90478 Nuremberg, Germany
Roland Weigand111Corresponding author. E-Mail: [email protected]
AOK Bayern, 93055 Regensburg, Germany
(March 2020)
Abstract.
We propose convenient inferential methods for potentially nonstationary multivariate unobserved components models with fractional integration and cointegration. Based on finite-order ARMA approximations in the state space representation, maximum likelihood estimation can make use of the EM algorithm and related techniques. The approximation outperforms the frequently used autoregressive or moving average truncation, both in terms of computational costs and with respect to approximation quality. Monte Carlo simulations reveal good estimation properties of the proposed methods for processes of different complexity and dimension.
Keywords.
Long memory, fractional cointegration, state space, unobserved components.
JEL-Classification.
C32, C51, C53, C58.
1 Introduction
Fractionally integrated time series models have gained significant interest in recent decades. In possibly nonstationary multivariate setups, which arguably bear most potential e.g. for assessing macroeconomic linkages, and which are essential for the joint modelling of financial processes, several parametric models have been explored. Among the most popular are the fractionally integrated VAR model (Nielsen, 2004), the triangular fractional cointegration model of Robinson and Hualde (2003) and the cointegrated VARd,b model of Johansen (2008).
Meanwhile, also models with unobserved fractional components have proven useful, as empirical and methodological work by Ray and Tsay (2000), Morana (2004), Chen and Hurvich (2006), Morana (2007) and Luciani and Veredas (2015) documents. The unobserved fractional components model allows for a generalization of the classic trend-cycle decomposition, where the long-run component is typically assumed to be I(1). As Hartl et al. (2020) show, the model can be used to test the I(1) assumption against a fractional alternative. Furthermore, unobserved fractional components allow the formulation of parsimonious models, like factor models, in an interpretable way.
These methods offer a variety of potential applications to empirical researchers. Long-run components of GDP, (un-)employment, and inflation are typically estimated via unobserved components models that restrict the integration order to unity (cf. e.g. Morley et al., 2003; Doménech and Gómez, 2006; Klinger and Weber, 2016). Since there is comprehensive evidence for long memory in these variables (see e.g. Hassler and Wolters, 1995; van Dijk et al., 2002; Tschernig et al., 2013) unobserved fractional components may provide new insights regarding the form and persistence of the long-run components. On the other hand, fractionally integrated factor models are constructed straightforwardly using fractional unobserved components. They can be used to assess fractional cointegration relations and for forecasting, as Hartl and Weigand (2019) demonstrate.
Inferential methods for such unobserved fractional components are the subject of this paper. So far, the bulk of empirical work in this field has been conducted in a semiparametric setting, which may be explained by the high computational and implementation cost of state-of-the-art parametric approaches such as simulated maximum likelihood (Mesters et al., 2016). Especially for models of relatively high dimensions or with a rich dynamic structure, there is a lack of feasible estimation methods. Furthermore, in most empirical applications, methods are required to smoothly handle nonstationary cases alongside stationary ones.
We consider a computationally straightforward parametric treatment of fractional unobserved components models in state space form. An approximation of potentially nonstationary fractionally integrated series using finite-order ARMA structures is suggested. This procedure outperforms the more commonly used truncation of fractional processes (cf. Chan and Palma, 1998) by providing a substantial reduction of the state dimension and hence of computational costs for a desired approximation quality. We derive both, the log likelihood and an analytical expression for the corresponding score. Hence, parameter estimation by means of the EM algorithm and gradient-based optimization make the approach feasible even for high dimensional datasets. In Monte Carlo simulations we study the performance of the proposed methods and quantify the accuracy of our state space approximation. For fractionally integrated and cointegrated processes of different dimensions, we find promising finite-sample estimation properties also in comparison to alternative techniques, namely the exact local Whittle estimator, narrow band least squares and exact state space methods. By using a parameter-driven state space approach, our setup inherits several additional favorable properties: Missing values are treated seamlessly, several types of structural time series components such as trends, seasons and noise can be added without effort, and a wide variety of possibly nonlinear or non-Gaussian observation schemes may be straightforwardly implemented; see Harvey (1991); Durbin and Koopman (2012).
In this paper we apply the proposed approximation scheme to a -dimensional observed time series , which is driven by a fractional components (FC) process as defined by Hartl and Weigand (2019),
[TABLE]
Here, is a coefficient matrix with full column rank, the latent process holds the purely fractional components which are driven by a noise process , and holds the short memory components.
More precisely, while the stationary series is only required to have a finite state space representation, the components of the -dimensional are fractionally integrated noise according to
[TABLE]
where for a generic scalar , the fractional difference operator is defined by
[TABLE]
and denotes the lag or backshift operator, . We adapt a nonstationary type II solution of these processes (Robinson, 2005) and hence treat alongside the asymptotically stationary case in a continuous setup.
The fractional unobserved components framework captures univariate and multivariate processes with both long-run and short-run dynamics, fractional cointegration and polynomial cointegration, as well as possibly high-dimensional processes with factor structure. It allows for an intuitive additive separation of long run and short run components, i.e. cyclical and trend components in business cycle analysis, while obtaining similar flexibility as (cointegrated) multivariate ARFIMA models. See Hartl and Weigand (2019) for the relation of the FC model to several other fractional integration setups.
The paper is organized as follows. Section 2 discusses the state space form, while section 3 outlines maximum likelihood estimation. In section 4, the estimation properties are investigated by means of Monte Carlo experiments before section 5 concludes.
2 The approximate state space form
2.1 Approximating nonstationary fractional integration
Unlike the stationary long-memory processes considered in the literature, e.g., by Chan and Palma (1998), Hsu et al. (1998), Hsu and Breidt (2003), Brockwell (2007), Mesters et al. (2016) as well as Grassi and de Magistris (2012), our nonstationary type II specification of fractional integration is straightforwardly represented in its exact state space form by setting starting values of the latent fractional process to zero, for . The solution for is based on the truncated operator (Johansen, 2008) and given by
[TABLE]
For a given sample size , has an autoregressive structure with coefficient matrices , . Thus, a Markovian state vector embodying has to include lags of and is initialized deterministically with . In principle, this exact state space form can be used to compute the Kalman filter, to evaluate the likelihood and to estimate the unknown model parameters by nonlinear optimization routines. Since the state vector is at least of dimension , this can become computationally very costly, particularly in large samples and for a large number of fractional components, which makes a treatment of the system in its exact state space representation practically infeasible for a wide range of relevant applications.
For non-negative integration orders, note that the can be generalized to have non-zero starting values . In that case, is initialized via a diffuse initial state vector. Details on the initialization of nonstationary components are given in Koopman (1997). Deterministic components in are handled straightforwardly by defining where . Depending on the integration order the contribution of on converges to a trend of degree as .
The literature on stationary long-memory processes has considered approximations based on a truncation of the autoregressive representation, considering only lags of for in the transition equation (i.e., setting all autoregressive coefficients to zero for ). Alternatively, the moving average representation has been truncated to arrive at a feasible state space model; see Palma (2007), sections 4.2 and 4.3.
Instead, we will apply ARMA approximations to the fractional state vectors, which provide a better approximation quality than the autoregressive or moving average truncation. An ARMA approximation of long-memory processes has been considered in the importance sampling frameworks of Hsu and Breidt (2003) and Mesters et al. (2016), but, arguably due to their computational burdens, did not find usage in applied research so far. In our setup, where fractional integration appears in the form of purely fractional components rather than ARFIMA processes, this approach is particularly convenient. In contrast to recent attempts to approximate ARFIMA processes by ARMA ones (discussed e.g. by Basak et al., 2001), we do not freely estimate all ARMA parameters but only , and thus retain the original parsimonious parameterization of the process.
As a (nonstationary) approximation of a generic univariate , we consider the process
[TABLE]
for finite and , where and all and are made functionally dependent on to approximate by . In order to determine the parameters , we minimize the distance between and , using the mean squared error (MSE) over as the distance measure. For given , and , we observe
[TABLE]
Hence, the MSE for period is given by
[TABLE]
while averaging over all periods for a given sample size and ignoring the constant variance term yields the objective function for a given ,
[TABLE]
The approximating ARMA coefficients are thus given by
[TABLE]
To obtain the approximating ARMA coefficients in practice, we conduct the optimization (7) over a reasonable range of , such as , for a given . Computational details of the optimization are given in Appendix A. Interestingly, for , stationary ARMA coefficients provide the minimum MSE, while for we impose an appropriate number of unit roots to enhance the approximation quality.
To illustrate the results we plot the approximating ARMA(2,2) parameters as a function of for ; see figure 1. A closer look at the coefficients reveals that for typically both the autoregressive and the moving average polynomial have roots close to unity which nearly cancel out. For example, to approximate a process with we have , which can be factorized as . Despite their similarity, AR and MA roots do not cancel out for non-integer , since the approximation quality is improved by additional free parameters. For integer integration orders the optimization yields for and for . Consequently, our ARMA-approximation is consistent with the finite representation of inter-integrated processes.
To compare the ARMA(,) approximations with to a truncated AR() process, we contrast the approximating impulse response function to the true one, , for a given . The autoregressive truncation lag is used for our comparison, since this is among the largest values which we consider as feasible in a typical multivariate application. The result of this comparison is shown in figure 2 for and . The autoregressive truncation approach gives the exact impulse responses for horizons , but then tapers off too fast. The ARMA approximations improves significantly over the autoregressive truncation whenever . For orders 3 or 4, the approximation error is even hardly visible. For the moving average truncation, the impulse responses equal zero for horizons exceeding the truncation lag (not shown).
To perform the comparison for different , we plot the square root of the MSE (6) as a function of for different approximation methods. For negative integration orders, as shown in figure 3, the moving average approach clearly outperforms the autoregression, while the ARMA method with orders are better. The moving average approximation becomes inaccurate, however, for the case , and worse even than the autoregressive method as can be seen in figure 4. In contrast, the ARMA(3,3) and ARMA(4,4) approximations are well-suited to mimic fractional processes over the whole range of . Further evidence in favor of the ARMA approximation will be presented in the Monte Carlo simulation of section 4.1.
2.2 The state space representations
Based on these methods we introduce the state space form of the multivariate model (1), where each is approximated by the ARMA approach. In the following we drop the tilde for the approximation of for notational convenience. To cover the very general case, we allow for residual auto- and cross-correlation by modelling the latent -dimensional short memory process via a stationary state space model, which can capture vector autoregressive, vector ARMA or factor models, among others, and include an additional noise term . The model can be written in state space form as
[TABLE]
where the states may be partitioned into , the states related to the fractional and the stationary components, respectively.
Regarding the fractional part, we define and which contain the approximating AR and MA coefficients of the fractional noise introduced in section 2.1, while for and for . Then . For a minimal state space representation, define such that . For , the first part of the state vector is a -dimensional process . Thus, with , , and
[TABLE]
The observation equation for the fractional part is , which enters the observed process through . Thus, the observation matrix for the fractional part is
[TABLE]
For the nonfractional part, we allow a general specification with and , where the distribution of unknown parameters over and reflect the choice of the specific model. Without loss of generality, we set , so that scales and cross correlations of are determined by . The full state space model (8) is given by an obvious definition of the system matrices as , , and . The dynamics are complemented by the initial conditions for the states. From the definition of our type II fractional process we set fixed starting values such as , while is initialized by its stationary distribution.
The fractional components do not explicitly appear as states in this representation. However, filtered and smoothed states can be constructed using the relation . To obtain conditional covariance matrices for , it is more convenient to use an alternative state space form of the ARMA process, where the MA coefficients appear in rather than in ; see Durbin and Koopman (2012), section 3.4. The current setup, however, is appropriate for estimating the parameters via the EM algorithm which is discussed in the next section.
3 Maximum likelihood estimation
The EM algorithm was proposed for maximum likelihood estimation of state space models by Shumway and Stoffer (1982) and Watson and Engle (1983). Especially in the context of high-dimensional dynamic factor models with possibly more than hundred observable variables, i.e. , this method has been found very useful in finding maxima of high-dimensional likelihood functions; see, e.g., Quah and Sargent (1993), Doz et al. (2012) and Jungbacker and Koopman (2015). After rapidly locating an approximate optimum, the final steps until convergence are typically slow for the EM algorithm, and hence it has been suggested to switch to gradient-based methods with analytical expressions for the likelihood score at a certain step.
We will present these algorithms for our fractional model and thereby extend existing treatments in the literature. For the model represented by (8), the matrices and both nonlinearly depend on and other unknown parameters, so that there are nonlinear cross-equation restrictions linking the transition and the observation equation of the system.
The EM algorithm in general consists of two steps, which are repeated until convergence. In the E-step the expected complete data likelihood is computed, where the expectation is evaluated for a given set of parameters , while the M-step maximizes this function to arrive at the parameters used in the next E-step, . Thus, we define , where in this section all expectation operators are understood as conditional on the data . In the course of the EM algorithm, after choosing suitable starting values , the optimization is iterated for until convergence.
To state the algorithm for the model defined by (1) and specified further in section 2.2, we follow Wu et al. (1996) to obtain the expected complete data likelihood as
[TABLE]
where in our case , while , and are functions of the vector of unknown parameters and a possible dependence of the initial conditions for on has been discarded for simplicity. The conditional moment matrices , , …, are given in appendix B and can be computed by a single run of a state smoothing algorithm (Durbin and Koopman, 2012, section 4.4) based on the system determined by .
Rather than carrying out the full maximization of at each step, we obtain a computationally simpler modified algorithm. To this end, we partition the vector of unknown parameters as where , contains the unknown elements in , holds the unobserved parameters for in and , while the noise variance parameters in are collected in . First, the expectation / conditional maximization (ECM) algorithm described by Meng and Rubin (1993) in our setup amounts to a conditional optimization over for given variance parameters and optimization over for given . Second, as suggested by Watson and Engle (1983), the optimization over is not finalized for each , but rather a single Newton step is implemented for each iteration of the procedure. Neither of these departures from the basic EM algorithm hinders reasonable convergence properties.
A Newton step in the estimation of for given yields the estimate in the -th step
[TABLE]
The derivation of (10) and expressions for , , and can be found in appendix B. Finally, the free variance parameters of , collected in , are estimated using the derivative of with respect to ; see (24). The estimate is given by the corresponding elements of
[TABLE]
For using gradient-based methods in later steps of the maximization, the likelihood score can be obtained with only one run of a state smoothing algorithm. This has been shown by Koopman and Shephard (1992), who draw on the result
[TABLE]
where denotes the Gaussian log-likelihood of the model. Evaluation of the score for our model can therefore be based on (22) and (24).
An estimate of the covariance matrix can be computed using an analytical expression for the information matrix. Denoting by and the model residuals and forecast error variances obtained from the Kalman filter, the -th element of the gradient vector for observation is given by
[TABLE]
while the -th element of the information matrix is
[TABLE]
see Harvey (1991, section 3.4.5). To obtain a feasible estimator , either the expectation term in (12) is omitted, as suggested by Harvey (1991), or the techniques of Cavanaugh and Shumway (1996) may be used to compute the exact Fisher information. An estimate of the covariance matrix of the estimator is then given by
[TABLE]
or by the sandwich form
[TABLE]
which is robust to certain violations of the model assumptions; see White (1982).
The asymptotic theory for maximum likelihood estimation in the fractionally cointegrated state space setup with integration orders is derived in Hartl et al. (2020) for an exact representation of (2). As shown there, the approximation error of the Kalman filter that results from ARMA approximations can be calculated via (5) and is . Hence, it is measurable given the -field generated by , such that an approximation-corrected estimator can be constructed (Hartl et al., 2020, Corollary 2.3). For this estimator, consistency and asymptotic (mixed) normality is shown. While the approximation-corrected maximum likelihood estimator is computationally feasible for long time series (i.e. large), it is limited to low-dimensional . Thus, especially for models where typically holds a large number of observable variables, e.g. factor models, the proposed ARMA approximations provide a computationally feasible parametrization of state space models. We compare the performance of the maximum likelihood estimator for our approximate state space model with the approximation-corrected maximum likelihood estimator of Hartl et al. (2020) in a Monte Carlo study in section 4.1, where it will become clear that the mean squared error of the approximate estimator for converges to the mean squared error of the exact estimator as increases.
Our estimation approach can be straightforwardly generalized to additional situations of great practical relevance. To include a treatment of further components causing nonstationarity such as deterministic trends or exogenous regressors, one can use diffuse initialization of one or more of the states which may be based on Koopman (1997). While we have discussed maximum likelihood estimation under a setting where all data in are available, our algorithms can be generalized for arbitrary patterns of missing data using the approach of Banbura and Modugno (2012). For very high-dimensional datasets, the computational refinements of Jungbacker and Koopman (2015) may be used. For common trends of similar persistence, nonparametric averaging methods may turn out to be useful (cf. e.g. Ergemen and Rodríguez-Caballero, 2016).
4 A Monte Carlo study
We study the performance of the described methods for a number of stylized processes which are nested in the general setup (1). The simulation study is designed to answer several questions. Firstly, we assess whether the finite-order ARMA approximation of the state space system performs well as compared to other parametric or semiparametric approaches. Secondly, we assess the feasibility of joint estimation of memory parameters and cointegration vectors in bivariate fractional systems with and without polynomial cointegration, again considering popular semiparametric approaches as benchmarks. Thirdly, the precision of cointegration estimators is studied in case of several cointegration relations of different strengths and for higher dimensions of the observed time series.
For each specification, we simulate replications and estimate the models using semiparametric estimates for from the exact local Whittle estimator as starting values for maximum likelihood estimation. The coefficients of the unobserved components can be recovered via the variance of the fractionally differenced observables, since the disturbance terms are standardized. The precision of the estimators is assessed by the root mean squared error (RMSE) criterion or the bias or median errors of the parameter estimators, of state estimates or of out-of-sample forecasts. We vary over different sample sizes which cover relevant situations in macroeconomics and finance.
4.1 Finite state approximations in a univariate setup
As the simplest stylized setup of our model, we first assess the fractional integration plus noise case, which has been studied in a stationary setup, e.g., by Grassi and de Magistris (2012). For mutually independent and , the data generating process is given by
[TABLE]
The fractional integration plus noise model is a special case of (1) where , , , and , are independent. For the signal-to-noise ratio we consider , while the memory parameters cover cases of asymptotically stationary and nonstationary fractional integration. We estimate the free parameters , and the noise variance by maximum likelihood using the state space approach.
We apply different approximations to avoid an otherwise -dimensional state process. Firstly, the ARMA(,) approximation given by (4) and (7) is considered, setting . The corresponding estimators are denoted as in the result tables. Secondly, we assess truncations of the autoregressive representation of the fractional process at and lags as suggested in Palma (2007, section 4.2), and label these estimators and , respectively. Thirdly, moving average representations as proposed in Chan and Palma (1998) are used, also with a truncation at and lags ( and ). Furthermore, we employ the exact local Whittle () estimator of Shimotsu and Phillips (2005) as well as the univariate exact local Whittle approach () as defined by Sun and Phillips (2004), which accounts for additive perturbations. For both semiparametric estimators of the fractional integration order, we use Fourier frequencies as a common pragmatic choice. Using other typical values such as , would not change the results qualitatively, but is the best choice in most settings considered here. Finally, to grasp the performance of the exact maximum likelihood estimator and to compare our approximate approach with it, we also include the approximation-corrected maximum likelihood estimator of Hartl et al. (2020), which corrects for the approximation error induced by ARMA(3,3) approximations.
The root mean squared errors of estimates of for this setup are shown in table 1. Not surprisingly, for this stylized process with only three free parameters, the parametric approaches clearly outperform the semiparametric Whittle estimators. For the EW approach, the performance gets worse for more volatile noise processes (lower ), which is not the case for the UEW estimator. The bias of the EW estimator is negative due to the additive noise; see table 2 and also Sun and Phillips (2004). In contrast, the UEW estimator is positively biased, independently of . Overall, it has inferior estimation properties, so that we do not show the UEW results for the other data generating processes.
Focusing on the state space approximations, we find that the ARMA approach for is always among the best approaches. Overall, the ARMA(3,3) and ARMA(4,4) approximations exert a very similar performance, and their relative performance does not seem to depend on the specification of and . The truncation methods, in contrast, show mixed results. The moving average approximation tends to dominate the autoregressive one for smaller , which mirrors the conclusion from Grassi and de Magistris (2012) in their stationary setting. However, we find that the autoregression is better whenever nonstationary or higher signal-to-noise ratios are considered.
As expected, the exact maximum likelihood estimator of Hartl et al. (2020) outperforms the approximation methods for most parameter settings. Considering the computational costs which are about 10 times higher than for the ARMA-approximations with , and about 250 times higher with , the improvements are moderate, however. The median improvement in RMSE over the ARMA(3,3) across parameter setups is 7.7%. As the most extreme scenario, the RMSE can be reduced from 0.132 in the ARMA(3,3) method to 0.102 by the exact estimator for , , . As the signal-to-noise ratio increases, benefits from the approximation-corrected estimator get smaller, and also an increase in the integration orders lowers the benefits from the approximation-corrected estimator. But most interestingly, the RMSE of the ARMA approximations converges to the RMSE of the approximation-corrected estimator as increases. This indicates that for long time series, where the approximation-correction is particularly costly, it may not even be required.
Directing attention to table 2 again, we find that the bias for the ARMA approach for does not contribute significantly to the estimation errors. Often, it does not appear until the third decimal place. The bias is generally small also for the truncation approaches, but there exist some situations where it is noticeable, mostly for larger . There, larger sample sizes even tend to increase the bias, while higher truncation lags do not always lessen the problem.
We investigate if the results carry over to estimation precision of the fractional components and to forecasting performance of the different approaches. This seems to be the case as table 3 shows. We restrict attention to the medium signal-to-noise case and apply only the state space approaches. In the upper panel, the fractional component is estimated by a Kalman smoother and the RMSE averages across all in-sample observations and iterations. We find rather small differences between the approaches, especially for small , while ARMA(4,4) and ARMA(3,3) dominate the approximation-based methods in each constellation. The exact method is only slightly superior. The same holds for the forecasting performance, where 1- to 20-step ahead forecasts are evaluated against realized trajectories, again by their RMSE averaging both across horizons and iterations. The differences between the approaches are only slightly more pronounced than above, and again, ARMA(3,3) and ARMA(4,4) are very close to the best-performing exact method. Interestingly, with the low signal-to-noise ratio (not shown in the table), each approach does a poorer job to recover the underlying fractional component, and neither is able to appropriately separate the fractional from the noise component in any case.
In sum, we find good performance of the ARMA approximations. The ARMA(3,3) approach appears sufficient in typical empirical applications. This finding is very appreciable in light of the great reduction in computational effort: A fractional component is represented by 4 states, rather than by 50 in a truncation setup with inferior performance, while an approximation-corrected approach has higher computational costs especially for even in this very simple setup. Both these alternatives can easily become impractical in more complex situations.
Overall, the differences between the approximations account for a small fraction of the overall estimation uncertainty, even in this stylized setting with high overall estimation precision. Also the benefits of the approximation-corrected approach are limited. Together with the finding of accurate ARMA approximations in section (2.1), this suggests that the need of approximations might not be a serious obstacle to the state space modelling of fractional unobserved components.
4.2 A basic fractional cointegration setup
The performance of the state space approach in estimating fractionally cointegrated systems is studied in a bivariate process with short-run dynamics,
[TABLE]
with , , , and . This implies that the true cointegration vector , , where the first entry was normalized to one. Again the innovations are mutually independent. Note that , , which allows for an interpretation of (16) as a fractionally cointegrated setup with cross- and autocorrelated short-run dynamics. We vary over values of the fractional integration order . The perturbation parameter controls the signal-to-noise ratio and short-memory correlation between the processes is introduced, which will be governed by different values of . Cases where could be considered straightforwardly.
Here and henceforth, we apply the ARMA(3,3) approximation for maximum likelihood estimation of the unknown model parameters. In the current setup, the latter consist of the eight entries in , where is the loading of on , while the variance parameters are normalized to achieve identification. Starting values for the AR parameters are obtained by fitting an autoregressive model for the difference . To contrast the properties to standard semiparametric approaches again, we apply the EW estimator componentwise to the univariate processes and investigate the mean of the univariate estimates. For the cointegration relation we apply the narrow-band least squares estimator which has been studied by Robinson and Marinucci (2001) in the nonstationary single equation case and by Hualde (2009) in a setup with cointegration subspaces (for details on cointegration subspaces, see Hualde and Robinson, 2010; Hartl and Weigand, 2019). We follow the literature which suggests to use a small number of frequencies and choose , amounting to 5, 6 and 7 frequencies for our sample sizes.
Since the cointegration vectors are not identified without further restrictions, we investigate the angle between true and estimated cointegration spaces. Nielsen (2010) provides an expression for the sine of this angle, which is given in our framework by
[TABLE]
where is an estimated cointegration matrix and is the Euclidean norm of . In the current bivariate setup with one cointegration relation, we have for the maximum likelihood estimator and for the narrow-band least squares estimator applied to . Values of closer to zero indicate preciser estimates and thus we compute the corresponding root mean squared error criterion as the square root of in what follows. To get some intuition for the bivariate case, estimating a true value by would result in a loss of .
In table 4 we show root mean squared errors for memory parameters ( and ) and evaluate estimated cointegration spaces (by and ) applying either the maximum likelihood or the semiparametric technique, respectively. Consider the case first. Regarding the memory estimators, we find relatively large errors for this data generating process, with root mean squared errors frequently around 0.2 or larger, most prominently when the variances of the short-memory processes are large (). The Whittle estimator often performs better than maximum likelihood, especially for smaller and and in smaller samples.
For estimating the cointegration space, however, the state space approach appears worthwhile and outperforms narrow band least squares in most constellations. Not surprisingly, strong cointegration relations () are precisely estimated, as is cointegration with small short-memory disturbances (). While the relative merits of maximum likelihood are unchanged for different cointegration strengths, we find that strong perturbations are better captured by the state space estimators. For , the RMSE of the semiparametric approach exceeds the parametric RMSE by about in some cases.
Short memory correlation as introduced through overall decreases the precision of the memory estimators. Interestingly, however, the performance of the cointegration estimators improves when is considered. This is the case for both the maximum likelihood and the narrow band approach. To gain some insights into this finding, we assess the typical signed errors of the cointegration estimates. To this end, we consider a normalization of the cointegration vectors as , and assess estimated for both approaches. Note that the narrow-band least squares estimator estimates directly, whereas is computed via . For small, the estimator becomes imprecise. Therefore, it is informative to compute an outlier-robust measure of the typical signed deviation. The median errors () for this data generating process are shown in table 5.
The typical deviations for the narrow band estimates exert a negative median bias of the estimates. A positive correlation between the short-memory components appears to work in the opposite direction so that the negative bias is reduced. In contrast, we find that the maximum likelihood estimators are essentially median-unbiased. Here, correlation between the short-memory components may improve the distinction between short and long-memory components and hence reduce variability.
4.3 Correlated fractional shocks and polynomial cointegration
A further simulation setup extends the model setup (1) by introducing contemporaneously correlated , and also allowing for polynomial cointegration through perfectly correlated . Polynomial cointegration refers to a situation where lagged observations nontrivially enter a cointegration relation; see Granger and Lee (1989) as well as Johansen (2008, section 4) for nonfractional and fractional treatments, respectively. To motivate polynomial cointegration in terms of our model, assume for simplicity . Let hold the first columns of , and let be its orthogonal complement. Then annihilates the first common unobserved components . If a vector exists, such that is integrated of a lower order than for any and any , , then polynomial cointegration occurs. Whenever , also and are perfectly correlated, and hence there exists a linear combination with a smaller integration order than .
We consider
[TABLE]
where , , , and where we drop the assumption of orthogonal long-run shocks and allow for . Correlation between the innovations to the fractional processes is introduced through the parameter . Besides the standard setting , we refrain from the assumption of independent components for , while amounts to which is the case of polynomial cointegration since there is a second nontrivial cointegration relation in . Combinations of and contrast relatively weak and strong cases of cointegration, while the importance of the component varies with . We treat as free parameters, but also investigate estimates imposing the singularity when it is appropriate. Starting values for the fractional integration orders are obtained via the exact local Whittle estimator as in the preceding sections, where we consider the sum and the difference of and to estimate and . Initial values for are obtained from the covariance of the fractionally differenced processes .
Consider the results for first. The root mean squared errors, shown in table 6, include estimators of cointegration spaces as above (evaluated by and in the table). Now, there are two memory parameters to be estimated either by maximum likelihood ( and ) or by the Whittle approach ( and ). Semiparametric estimates of are obtained from the narrow band least squares residuals. The table also contains the maximum likelihood estimate of the correlation parameter ().
For most parameter settings, we observe that the parametric memory estimators perform satisfactorily. They outperform the semiparametric approach whenever there is strong influence of the components (), most pronouncedly in larger samples. Also regarding cointegration estimators, higher values of favor the parametric method. The correlation parameter is estimated with increasing precision in larger samples, while also the strength of the cointegration relation is relevant for this estimator. For , the correlation parameter (and also certain elements of ) would not be identifiable, and hence setups with small difference are problematic.
For , we additionally consider the properties of estimators for the polynomial cointegration relation. To evaluate estimators of the polynomial cointegration spaces, note that the cointegration space leading to the highest memory reduction in is the orthogonal complement of the span of
[TABLE]
where refers to the -th column of . This cointegration subspace is estimated replacing all entries in (19) by their maximum likelihood estimates, where is imposed. For the narrow band least squares estimator, this space is determined by the span of , where the coefficients are narrow band least squares estimates from with and replaced by local Whittle estimates. Estimators for this second (polynomial) cointegration relation are evaluated analoguously to (17) where now (19) takes the role of and the resulting angle is denoted by .
In table 7, the corresponding root mean squared errors are given. The elementary cointegration space is estimated by the unrestricted estimator (see ) and the restricted estimator (see , imposing ) with a very similar precision. This is in accordance with the notably precise estimation of in this case. The parametric estimators of both cointegration spaces are again better than semiparametric approaches (1) in large samples and (2) when a strong second fractional component is present. Overall, the results suggest that polynomial fractional cointegration analysis is feasible in our setup, while the maximum likelihood approach has reasonable estimation properties at least for larger sample sizes.
4.4 Cointegration subspaces in higher dimensions
Until now, we have considered one- or two-dimensional processes in our simulations which limits the empirical relevance of the findings so far. We claim that modelling high-dimensional time series constitutes a strength of our approach, at least if suitably sparse parametrizations with factor structures are empirically reasonable. As a second generalisation compared to the previous setups, we consider situations where two or more cointegration relations exist and where these may be of different strength, i.e., where the reduction in memory through cointegration differs among relations. The latter situation has been studied under the label of cointegration subspaces, among others by Hualde and Robinson (2010) and Hartl and Weigand (2019).
To assess the performance in this situation, consider the process
[TABLE]
where , , and with mutually independent noise sequences. We now vary over the dimension , while again combinations of and are considered. The parameter gives the relative importance of the fractional components and hence plays the role of a signal-to-noise ratio. We estimate , , for and as free parameters. Starting values for and are obtained as in section 4.3.
Along with the memory estimates, we show results for estimating the cointegration relations reducing the memory from to (the first cointegration subspace) which is evaluated by the angle between and the cointegration matrix estimate . Additionally, the cointegration relations reducing the memory from to [math] (the second cointegration subspace) are evaluated by the angle between and . The cointegration matrices are straightforwardly obtained for the maximum likelihood approach by the orthogonal complements of and , respectively. The narrow-band least squares method estimates cointegration matrices under specific normalizations as above. Estimating the first subspace, we construct to have free entries , …, in the first row and a identity matrix below, such that is obtained from for . In the estimation of the second subspace, we have two free rows in which are given by , …, , and , …, , respectively, and can be estimated from for .
In table 8, results are shown for while the other specifications yield qualitatively similar outcomes. The process allows for a precise estimation of both and by maximum likelihood. An increasing dimension leads to a better estimation by maximum likelihood which is not the case for the Whittle technique. The semiparametric Whittle estimates are obtained by averaging univariate estimates for and using narrow band least squares residuals to estimate . Notably, the estimates of hardly improve with larger , which can be explained by a specific shortcoming of the single equation approach: The univariate regression errors may each have integration orders of or lower. In our case, lower orders prevail for with odd, due to the special structure of . Knowledge about this specific structure is not exploited by both methods, however, to keep the simulation scenario realistic.
Also regarding the estimation of the cointegration spaces, maximum likelihood is superior. Both parametric and semiparametric estimators have smaller errors for higher dimension, whereas this “blessing of dimensionality” is more pronounced for the state space approach. Generally, the ratio between the maximum likelihood RMSE and the semiparametric RMSE decreases for larger .
Not surprisingly, the case with strongest basic cointegration (large difference , which implies a great reduction of persistence when is projected out) is the one with highest precision in estimating the first cointegration subspace. For estimating the second subspace, a slightly different logic applies, with a larger supporting the estimation. E.g., in the case and a higher precision is achieved than for and . Overall, we find that our approach profits from imposing the factor structure which is not the case for the benchmark methods applied in this comparison.
5 Conclusion
We have proposed estimation methods for nonstationary unobserved components models which are computationally efficient and provide a good approximation performance. These may be relevant for a wide variety of applications in macroeconomics and finance, as Hartl and Weigand (2019) have illustrated. Further work is needed to assess the performance of the methods in different, possibly very high-dimensional, settings.
Acknowledgements
The research of this paper has partly been conducted while Roland Weigand was at the University of Regensburg and at the Institute for Employment Research (IAB) in Nuremberg. Very valuable comments by Rolf Tschernig, Enzo Weber, and two anonymous referees, are gratefully acknowledged. Tobias Hartl gratefully acknowledges support through the projects TS283/1-1 and WE4847/4-1 financed by the German Research Foundation (DFG).
Appendix A Computational details of the approximating ARMA coefficients
As shown in (7) the ARMA approximation of a fractionally integrated process for a given integration order is defined as the set of ARMA parameters that minimize (6). The minimization problem has a unique solution for . We conduct the optimization (7) to obtain ARMA approximations of a fractional process over an appropriate, possibly nonstationary, range of . For , we impose stability of the autoregressive polynomial, while imposing unit roots is found to enhance the numeric stability of the optimization for . In order to achieve numerically well-behaved optimizations, we work with transformed parameters and then re-transform them when the optimum is reached. First, the stable autoregressive and moving average parts are individually mapped to the space of partial autocorrelations so that they take values in ; see Barndorff-Nielsen and Schou (1973) and Veenstra (2012). Then, we apply Fishers z-transform to obtain an unconstrained optimization problem. For a given sample size , we carry out an optimization for each value on a grid for . We smooth the values using cubic regression splines before the result is re-transformed to the space of ARMA coefficients. In this way, we obtain a continuous and differentiable function . Whenever discontinuities occur in the space of transformed parameters (as for ), we enforce a smooth transition between segments of by the sine function. All computations in this paper are conducted using R (R Core Team, 2020).
Appendix B Details on the EM Algorithm
In this appendix, all necessary expressions for the computation of the EM algorithm will be given. The log-likelihood where the unobserved state process is assumed known is called the complete data log likelihood and given by
[TABLE]
The expectation of the complete data likelihood, with expectation evaluated at parameters , is denoted by and given by (9). The terms involving expectations of the (partially unobserved) data and its cross-moments are
[TABLE]
Here, and can be computed by state smoothing algorithms based on the state space representation for given (Durbin and Koopman, 2012, section 4.4).
We turn to the derivation of (10). For notational convenience we denote the objective function for optimization over by . To describe the Newton step in the optimization of in detail, we explicitly state the nonlinear dependence of on by and consider the linearization at ,
[TABLE]
, and the subscript indicates evaluation of a specific expression at . The optimization over jointly involves elements in and , since enters the expression of both system matrices and hence, is not diagonal.
A single iteration of the Newton optimization algorithm is carried out by expanding the gradient around . The gradient is given by
[TABLE]
where we drop the function argument of for notational convenience. For the derivatives with respect to the system matrices we have
[TABLE]
so that
[TABLE]
Hence, for and given by
[TABLE]
we obtain the linear expansion
[TABLE]
Equating to zero and solving for yields (10). For the estimation of , see (24), we define
[TABLE]
and use
[TABLE]
to derive the estimator of the variance parameters.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Banbura and Modugno (2012) Banbura, M. and Modugno, M. (2012). Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data, Journal of Applied Econometrics 29 (1): 133–160.
- 3Barndorff-Nielsen and Schou (1973) Barndorff-Nielsen, O. E. and Schou, G. (1973). On the parametrization of autoregressive models by partial autocorrelations, Journal of Multivariate Analysis 3 (4): 408–419.
- 4Basak et al. (2001) Basak, G. K., Chan, N. H. and Palma, W. (2001). The approximation of long-memory processes by an ARMA model, Journal of Forecasting 20 (6): 367–389.
- 5Brockwell (2007) Brockwell, A. E. (2007). Likelihood-based analysis of a class of generalized long-memory time series models, Journal of Time Series Analysis 28 (3): 386–407.
- 6Cavanaugh and Shumway (1996) Cavanaugh, J. E. and Shumway, R. H. (1996). On computing the expected Fisher information matrix for state-space model parameters, Statistics & Probability Letters 26 (4): 347–355.
- 7Chan and Palma (1998) Chan, N. H. and Palma, W. (1998). State space modeling of long-memory processes, The Annals of Statistics 26 (2): 719–740.
- 8Chen and Hurvich (2006) Chen, W. W. and Hurvich, C. M. (2006). Semiparametric estimation of fractional cointegrating subspaces, The Annals of Statistics 34 (6): 2939–2979.