TL;DR
This paper investigates the feasibility of gradient-based deterministic inversion methods within the latent space of GANs for geophysical data, revealing significant limitations due to nonlinearity and emphasizing the robustness of probabilistic approaches.
Contribution
It demonstrates the challenges of applying gradient-based deterministic inversion in GAN latent spaces for geophysical problems, highlighting the importance of inversion approach and initial conditions.
Findings
Gradient-based methods often fail to find suitable solutions within limited iterations.
Gauss-Newton method was unable to recover solutions with correct data misfit.
Probabilistic global optimization reliably finds appropriate solutions.
Abstract
Global probabilistic inversion within the latent space learned by a Generative Adversarial Network (GAN) has been recently demonstrated. Compared to inversion on the original model space, using the latent space of a trained GAN can offer the following benefits: (1) the generated model proposals are geostatistically consistent with the prescribed prior training image (TI), and (2) the parameter space is reduced by orders of magnitude compared to the original model space. Nevertheless, exploring the learned latent space by state-of-the-art Markov chain Monte Carlo (MCMC) methods may still require a large computational effort. As an alternative, parameters in this latent space could possibly be optimized with much less computationally expensive gradient-based methods. We show that due to the typically highly nonlinear relationship between the latent space and the associated output space of…
Click any figure to enlarge with its caption.
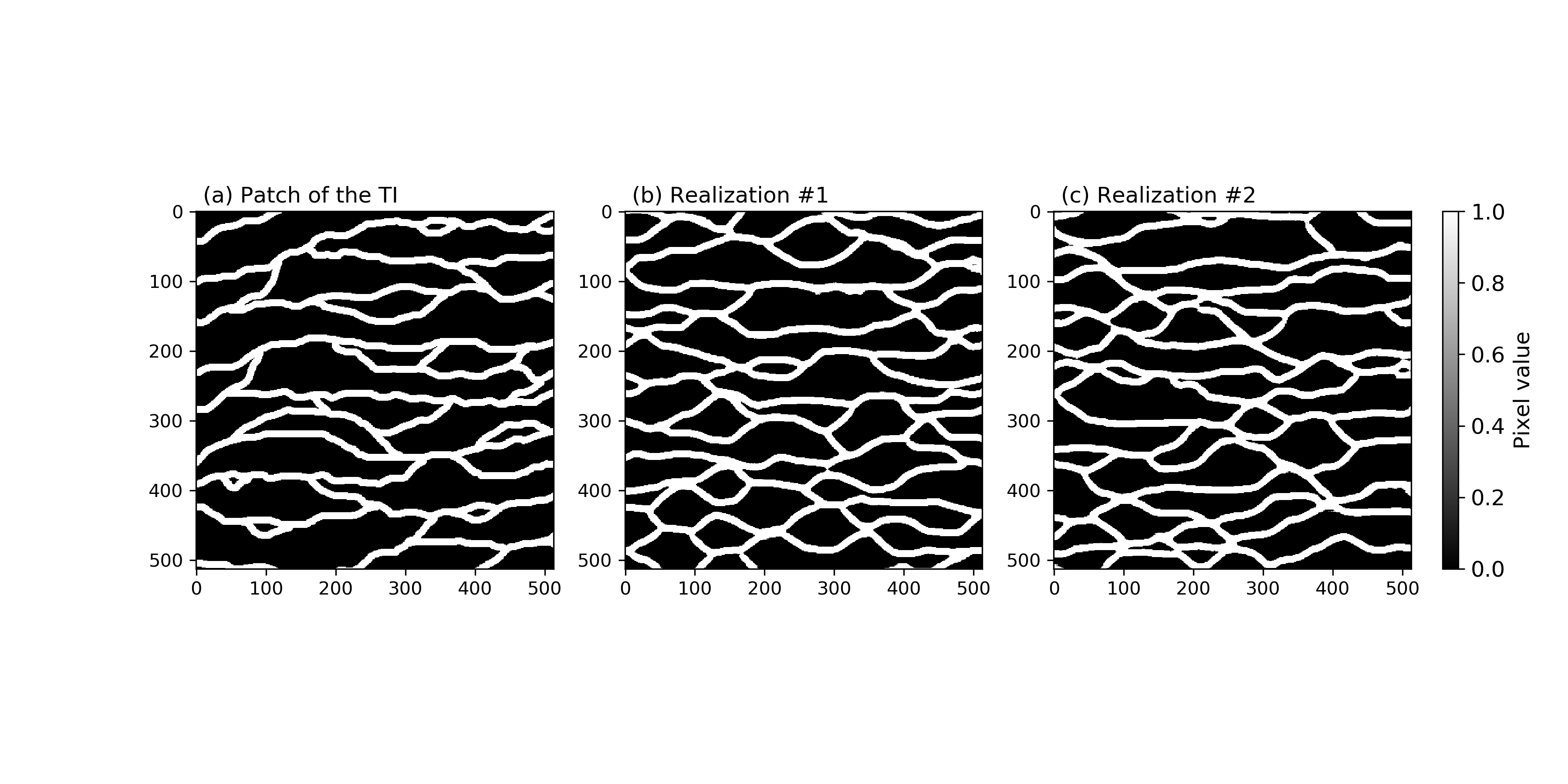 Figure 1
Figure 1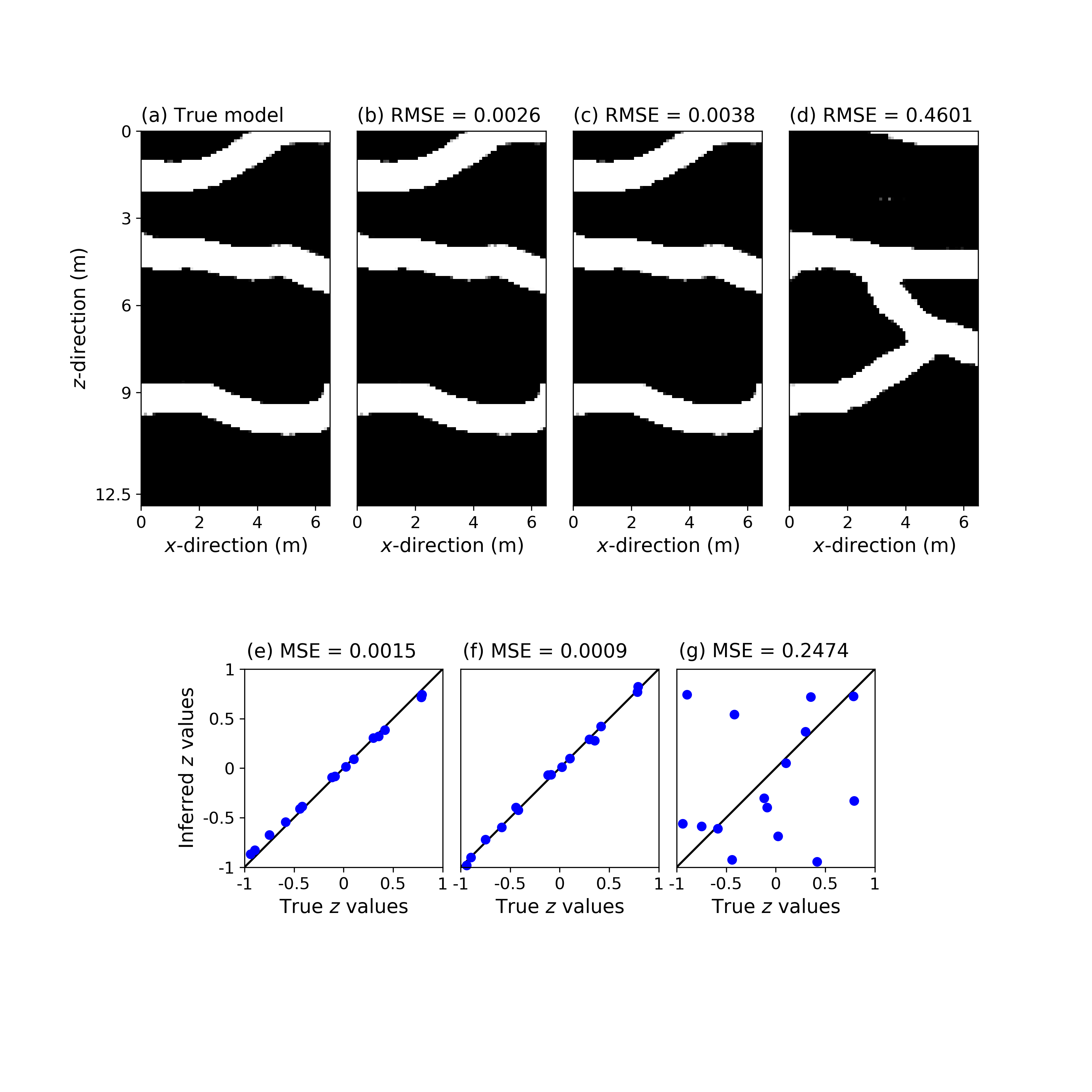 Figure 2
Figure 2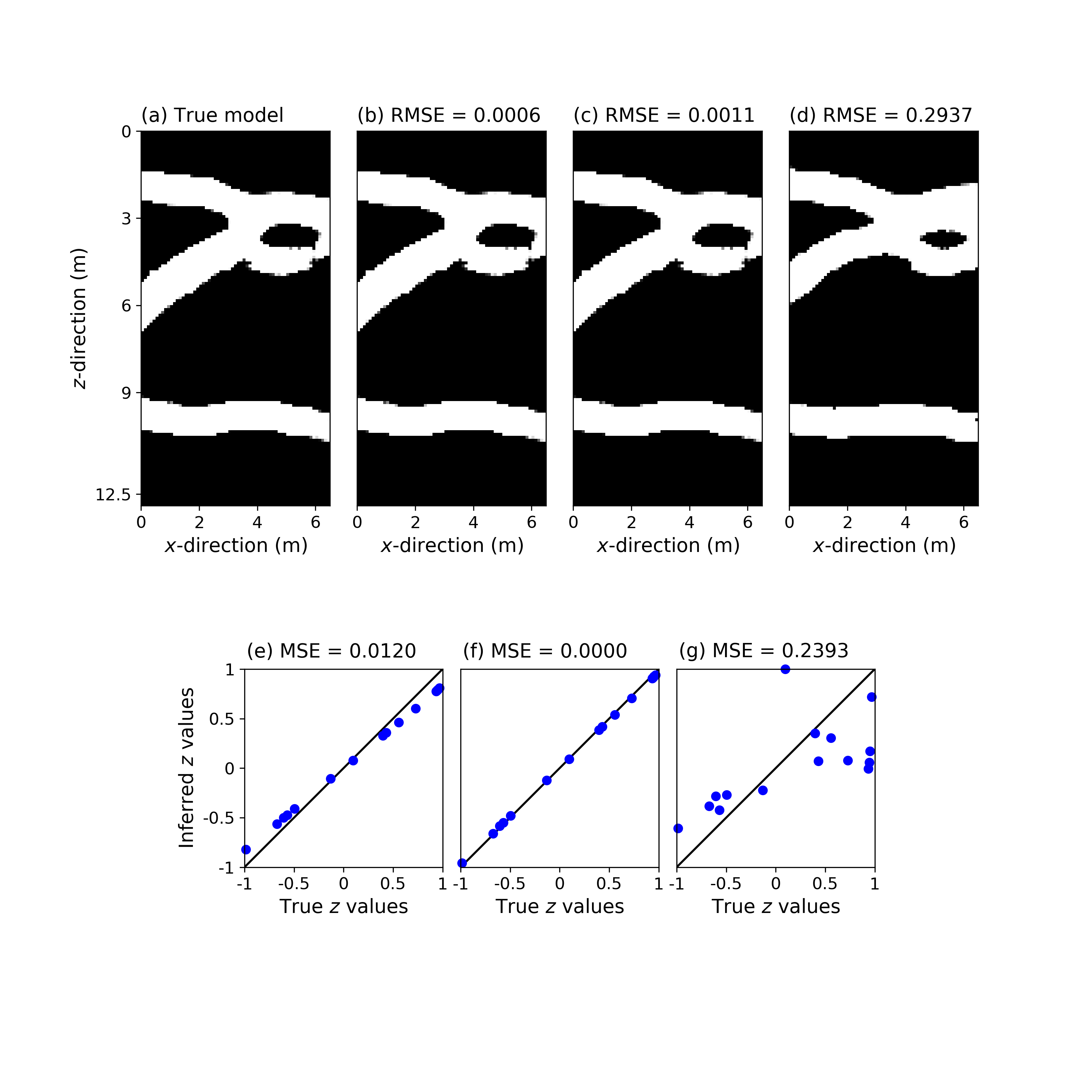 Figure 3
Figure 3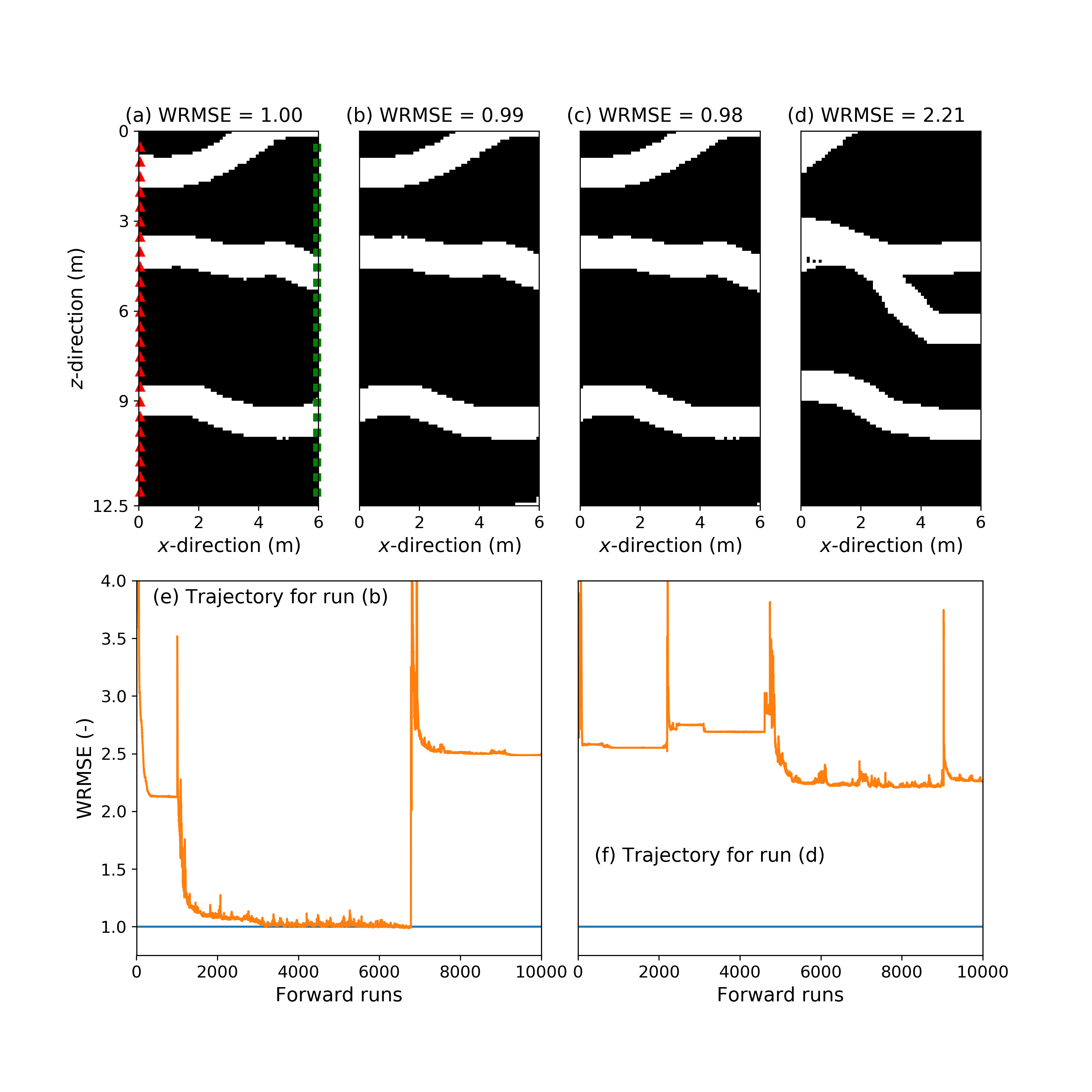 Figure 4
Figure 4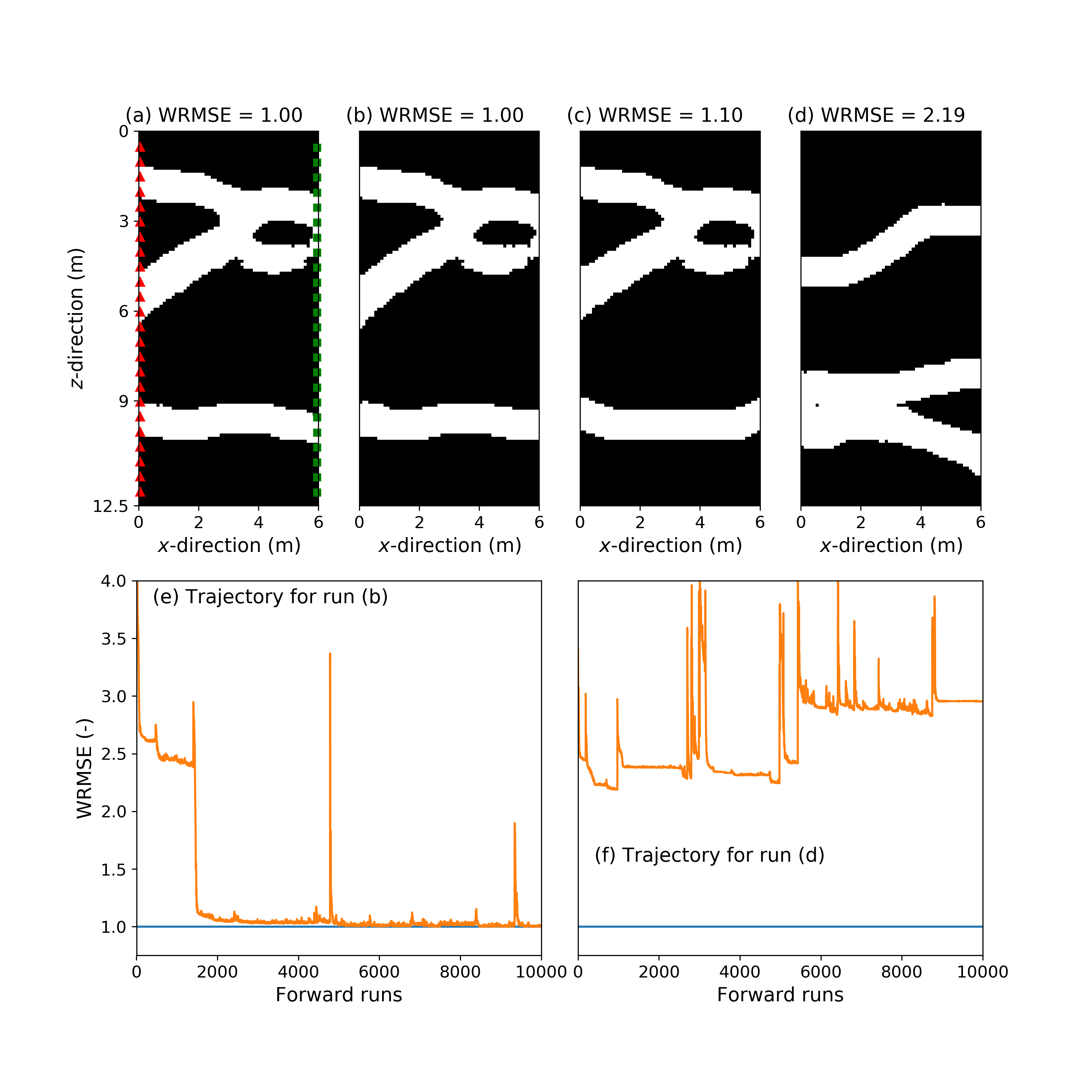 Figure 5
Figure 5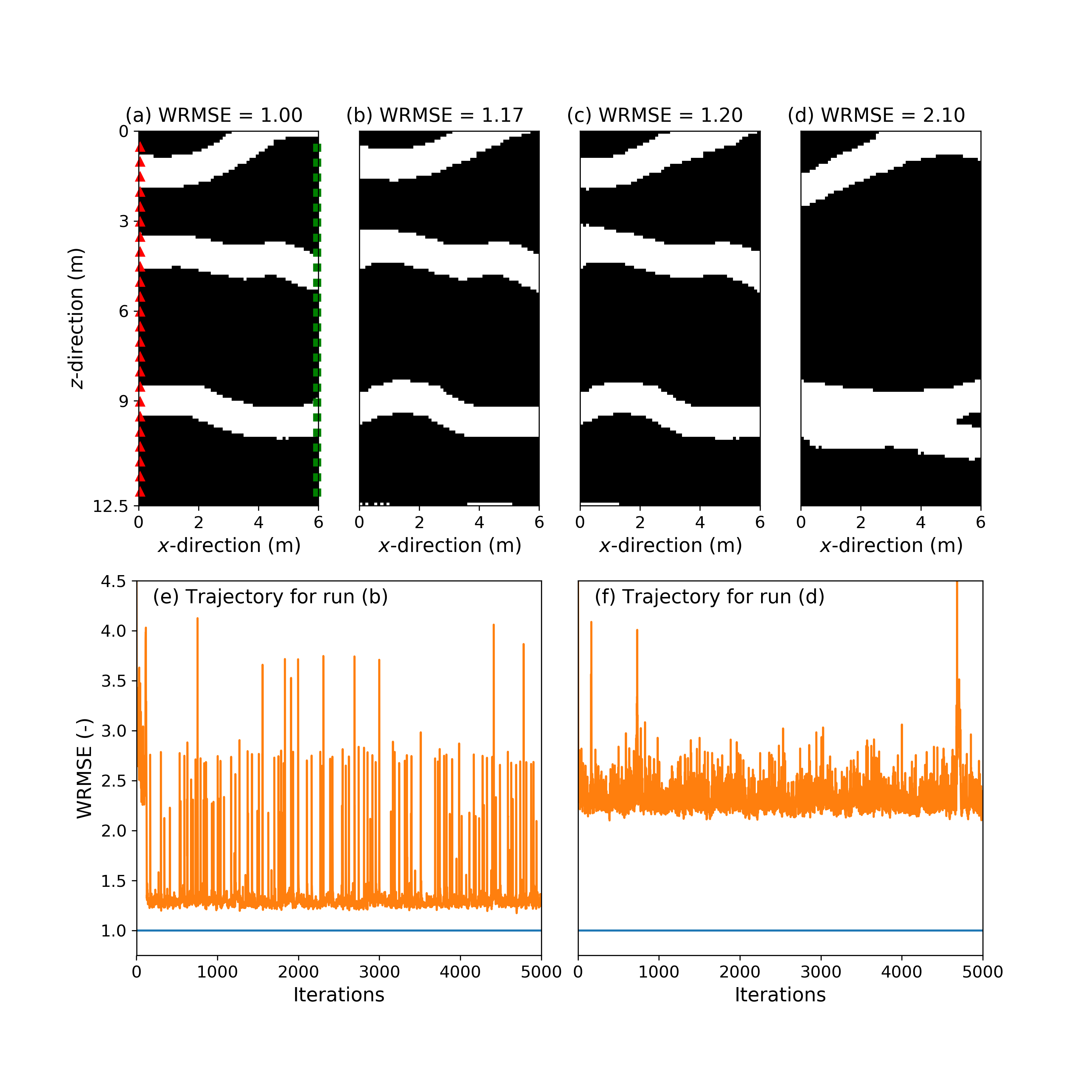 Figure 6
Figure 6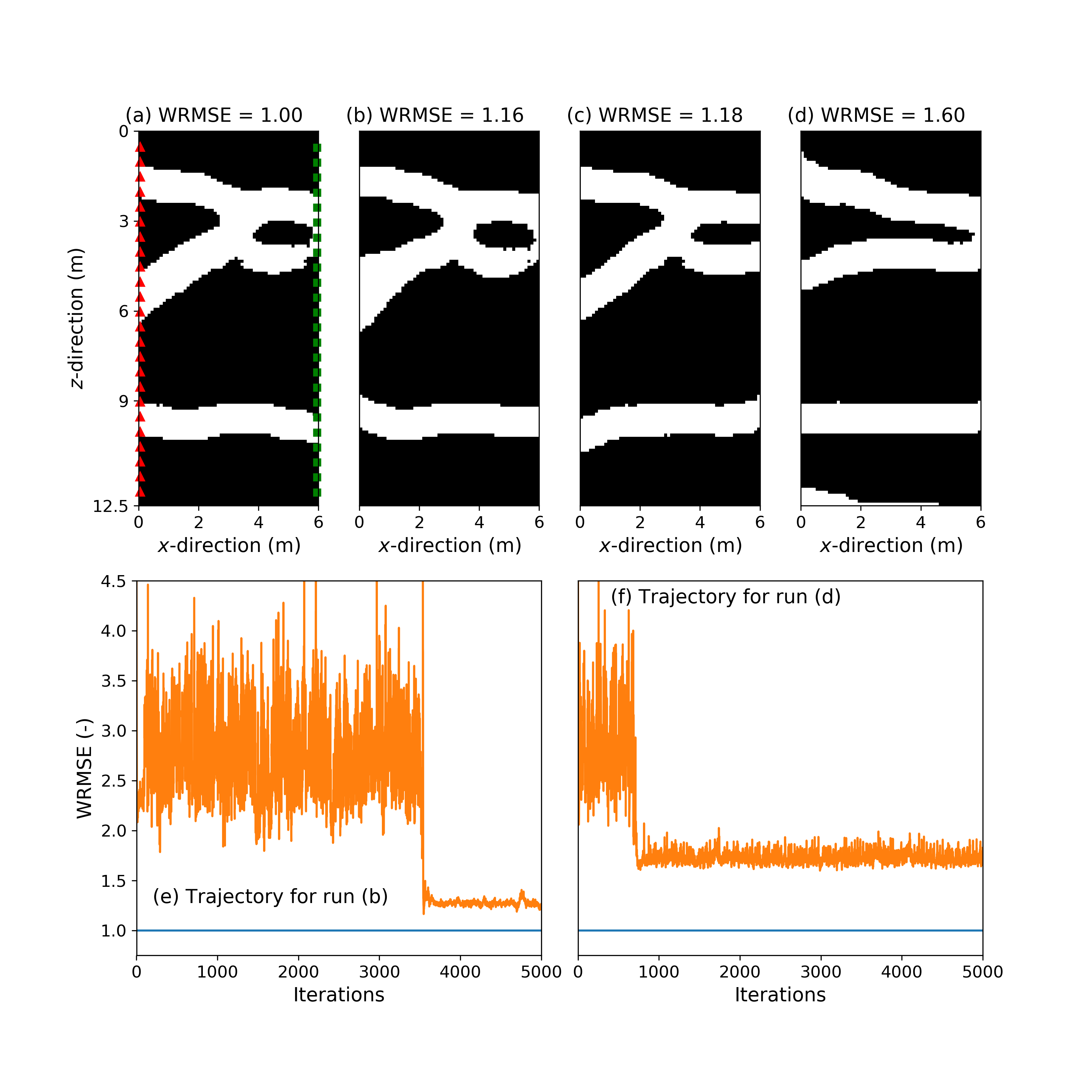 Figure 7
Figure 7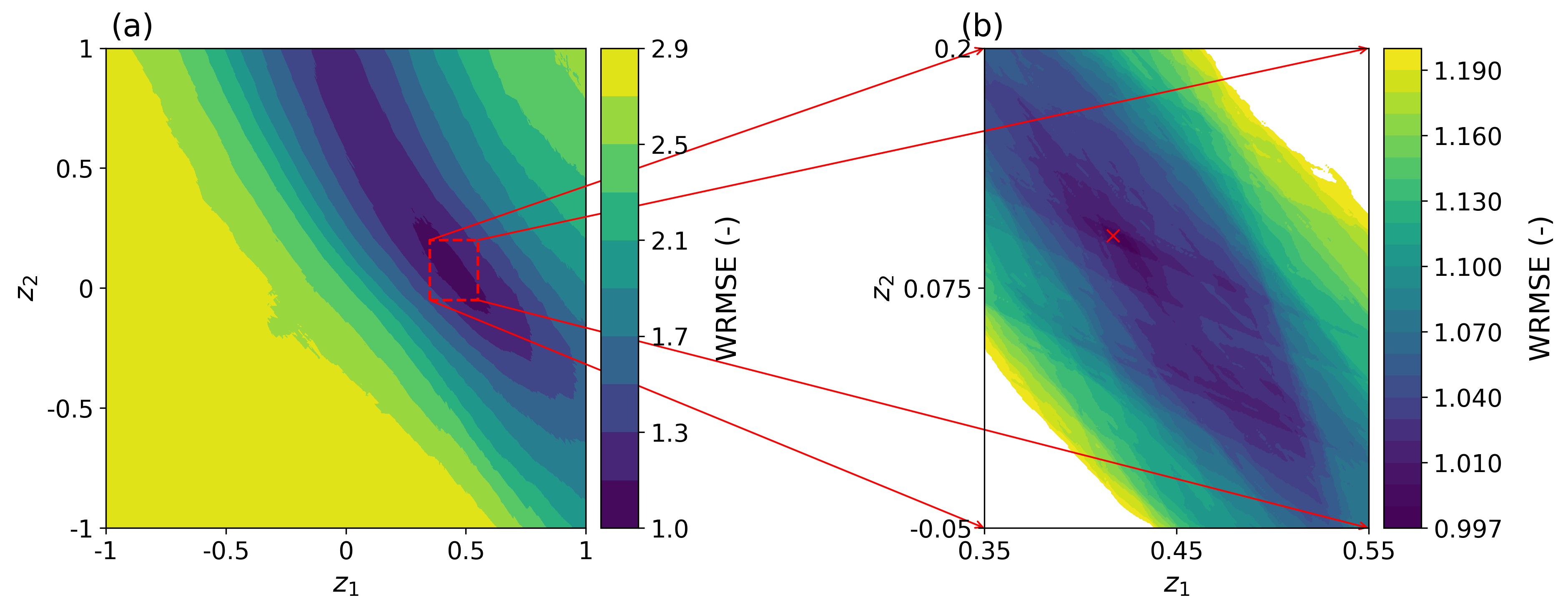 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Gradient-based deterministic inversion of geophysical data with Generative Adversarial Networks: is it feasible?
Eric Laloy, Niklas Linde, Cyprien Ruffino, Romain Hérault*‡, Gilles Gasso‡*,
and Diederik Jacques*∗* Belgian Nuclear Research Centre, Email: [email protected] of LausanneINSA-Rouen
Abstract
Global probabilistic inversion within the latent space learned by a Generative Adversarial Network (GAN) has been recently demonstrated. Compared to inversion on the original model space, using the latent space of a trained GAN can offer the following benefits: (1) the generated model proposals are geostatistically consistent with the prescribed prior training image (TI), and (2) the parameter space is reduced by orders of magnitude compared to the original model space. Nevertheless, exploring the learned latent space by state-of-the-art Markov chain Monte Carlo (MCMC) methods may still require a large computational effort. As an alternative, parameters in this latent space could possibly be optimized with much less computationally expensive gradient-based methods. This study shows that due to the typically highly nonlinear relationship between the latent space and the associated output space of a GAN, gradient-based deterministic inversion may fail even when considering a linear forward physical model. We tested two deterministic inversion approaches: a quasi-Newton gradient descent using the Adam algorithm and a Gauss-Newton (GN) method that makes use of the Jacobian matrix calculated by finite-differencing. For a channelized binary TI and a synthetic linear crosshole ground penetrating radar (GPR) tomography problem involving 576 measurements with low noise, we observe that when allowing for a total of 10,000 iterations only 13% of the gradient descent trials locate a solution that has the required data misfit. The tested GN inversion was unable to recover a solution with the appropriate data misfit. Our results suggest that deterministic inversion performance strongly depends on the inversion approach, starting model, true reference model, number of iterations and noise realization. In contrast, computationally-expensive probabilistic global optimization based on differential evolution always finds an appropriate solution.
1 Introduction and Scope
Laloy et al. (2018) recently proposed to use generative adversarial networks (GANs), a game changer data generation algorithm (e.g., Goodfellow et al., 2014, 2016), to define a low-dimensional parameterization encoding complex geologic prior models, thereby allowing efficient and accurate geostatistical inversion with Markov chain Monte Carlo (MCMC) methods (Laloy et al., 2018). GANs have permitted impressive advancements for a wide range of applications such as image and texture synthesis, image-to-image translation and super-resolution (Creswell et al., 2017). In the near future, we expect to witness a dramatic increase in development and use of GAN-inspired algorithms for geostatistical simulation (e.g., Mosser et al., 2017; Laloy et al., 2018) and inversion (e.g., Laloy et al., 2018; Mosser et al., 2018; Richardson, 2018). A key element of the GAN approach is that the dimensions of the learned low-dimensional or “latent” space are independent from each other and have a known probability distribution, typically either a uniform or a standard Gaussian distribution. Laloy et al. (2018) have shown that inversions based on such parameterizations work well for global probabilistic inference of complex binary 2D and 3D prior subsurface models. However, exploring the GAN-derived latent space with state-of-the-art MCMC sampling (Vrugt et al., 2009; Laloy and Vrugt, 2012) still necessitates tens of thousands (or more) forward evaluations (Laloy et al., 2018). Such a computational expense can be prohibitive when using computationally-demanding forward solvers encountered in the geosciences. However, the latent space might also lend itself to a conventional deterministic gradient-based local search, which is often much more computationally frugal than global and probabilistic inversion.
In the geosciences, gradient-based deterministic inversion methods can be roughly divided into (1) methods that make use of the so-called sensitivity or Jacobian matrix, J, that is, the matrix of derivatives of the forward model outputs, , with respect to the model parameters, m (e.g., physical properties of the model grid blocks): , and (2) methods that only require the gradient vector of the misfit (that is, objective or loss) function, , with respect to m, with , such as the steepest descent method. Although is often cheaper to calculate than J, it is generally understood that methods relying on J are more effective and robust than those based on because J can be used to (implicitely) approximate the Hessian matrix, H with , which contains information about the local curvature of the misfit function (Aster et al., 2012).
Complex spatial prior models are usually represented by a so-called training image (TI). A TI is a large gridded 2D or 3D unconditional representation of the expected target spatial field that can be either continuous or categorical (e.g., geologic facies image) and is typically used to guide geostatistical simulation by multiple-point statistics (MPS) algorithms (e.g, Strebelle, 2002; Mariethoz et al., 2010). When using a GAN (see, e.g., Goodfellow et al., 2016, for details about the GAN architecture and training) to encode the prescribed TI (or, alternatively, MPS realizations from it), a GAN-based model realization is produced by feeding the so-called generator, , with a latent vector, z: , and the inversion is performed within the latent space . For gradient-based inversion, the required Jacobian is then the matrix of derivatives of with respect to z: with . In principle, the derivatives of with respect to z, V with , can be directly computed by autodifferentiation (Al-Rfou et al., 2016; Abadi et al., 2016; Paszke et al., 2017). When J is available, for instance through the use of an adjoint model, can be obtained as . In our experience, calculating each element of V using the reverse-mode autodifferentiation engine that equips current deep learning (DL) libraries such as TensorFlow (Abadi et al., 2016) and PyTorch (Paszke et al., 2017) can be slow, especially for large m and when run on a CPU. For instance, for the PyTorch implementation of the spatial GAN (Jetchev et al., 2016) used herein it takes about 5 minutes to construct the V array on a last generation Intel® i7 CPU and about 1 minute using a NVIDIA Quadro M2000M GPU, when z is 15-dimensional and is of size 129 65. More importantly, generating high-quality categorical geologic structures with a GAN may require postprocessing of the realizations through filtering and/or thresholding (e.g., Mosser et al., 2017; Laloy et al., 2018). If not differentiable, this postprocessing, , decouples the V array computed by the DL code from the actual realization, .
Another solution that alleviates the need of having an adjoint model and is not perturbed by postprocessing operations consists of estimating directly using a finite-difference approximation. This incurs a relatively low computational cost since it requires forward runs to evaluate with a central difference scheme, with the length of the z vector, which by construction is low-dimensional (say two orders of magnitude less than m).
Lastly, when using the gradient vector, with respect to z, , instead of the Jacobian, , and the trained can be integrated within a single DL computational graph (Richardson, 2018; Mosser et al., 2018). This is possible because is fully differentiable end-to-end and DL libraries are equipped with advanced gradient descent algorithms such as Adam (Kingma and Ba, 2015). If is fully differentiable then the DL library can compute internally by autodifferentiation. This is for instance the case when is linear and the continuous realizations do not need postprocessing such as thresholding. As shown by Richardson (2018), when or is not differentiable can however be externally computed and integrated within the DL graph. In this work, we used an adjoint model giving and backpropagated where the product can be efficiently computed within a single backward pass without explicitely calculating the V array (see our companion code).
No matter whether or is used or regardless of how they are calculated, an important open question is to what extent the nonlinearity in the transform adversely affects the convergence of gradient-based deterministic inversion performed in the latent space . Working with rather the original model space conveniently ensures that (1) any generated model honors the prior TI and (2) the parameter dimensionality is reduced by orders of magnitude compared to traditional deterministic inversion (e.g., de Groot-Hedlin and Constable, 1990). Nevertheless, the non-linear relationship between and z adds significant nonlinearities to the inverse problem, in addition to those of the forward model, . In this work, we consider a best case scenario and use a linear tomography problem based on ground penetrating radar (GPR) data to show that even if is linear with respect to m, the nonlinearity in may frequently affect the performance of gradient-based deterministic inversions. In contrast, probabilistic global optimization using the DREAM*(ZS)* code (Vrugt et al., 2009; Laloy and Vrugt, 2012) is found to work well for the considered problem, although at a rather high computational cost. The overall motivation of this work is to raise awareness that although model parameterizations based on GAN algorithms can be very powerful in representing prior information and reducing model dimensionality, the resulting inverse problems may become too non-linear to enable adequate convergence of deterministic gradient-based inversions even when the forward solver itself is only weakly-nonlinear or even linear.
The remainder of this paper is organized as follows. Section 2 summarizes related work before section 3 briefly describes our used GAN and considered inversion algorithms, and details the considered inverse problem. This is followed by section 4 which presents our inversion results. In section 5, we discuss our main findings and outline possible future developments. Finally, section 6 provides a short conclusion.
2 Related work
To the best of our knowledge, Laloy et al. (2018) were the first to introduce and demonstrate the idea of using the latent space learned by a GAN to perform probabilistic inversion of hydrologic or geophysical data. Richardson (2018) recently proposed to embed and a generator, , trained beforehand within a single (fully differentiable) DL computational graph to deterministically solve a 2D seismic full-waveform inversion problem by making use of the stochastic gradient descent algorithms implemented in DL libraries. Mosser et al. (2018) recently used a trained generator for solving a 2D seismic inversion problem within a probabilistic framework. They combined the estimation of obtained from an adjoint model together with and the DL-based calculation of V within the same (fully differentiable) computational graph to perform Metropolis-adjusted Langevin MCMC sampling (e.g., Roberts and Rosenthal, 1998). Outside of the geosciences, Creswell and Bharath (2016) and Lipton and Tripathi (2017) inverted full images produced by a trained generator using usual benchmarks in computer vision and studied to what extent latent vectors can be recovered. In addition, Bora et al. (2017) showed that gradient descent within the latent space of a GAN works overall well to recover an image from a set of measurements obtained by applying a linear operator to the true image. Conceptually, the Bora et al. (2017) study has a lot in commons with ours. However, Bora and coworkers consider a totally different training set than us: the CelebA dataset which consists of face images of celebrities. In section 5, we compare our findings to those of Bora et al. (2017).
3 Methods
3.1 Generative Adversarial Networks
We use a PyTorch implementation of the spatial GAN (SGAN, Jetchev et al., 2016) used by Laloy et al. (2018) to generate realizations from the 2D channelized aquifer training image (TI) depicted in Figure 1a. Our method is not limited to such channel images, but this example is selected to be similar to benchmark images that are typically used to test MPS algorithms. For brevity, we refer the reader to Laloy et al. (2018) for a description of the basic network architecture and training procedure, and only provide below the main principles behind the used SGAN.
The building blocks of a GAN are the generator and discriminator. The generator, , is fed with a low-dimensional latent vector, z, and produces a model realization, , whose spatial statstics match those found in the TI provided that the GAN training performed beforehand (see below) was successful. The z vector is trained to obey either a standard normal distribution, , or a truncated uniform distribution, , and the variables are independent of each other. For image generation, the discriminator component only serves for training as detailed below.
Due to its purely convolutional nature (see, e.g., Goodfellow et al., 2016, for more details on convolutions and convolutional layers in deep neural networks), for an ergodic TI our SGAN can be trained at relatively low computational cost using a small realization domain, before being used to generate arbitrarily large realizations. The latent space of our SGAN has a spatial structure, with z being reshaped into an array Z for the 3D case. As detailed in Laloy et al. (2018), the , and dimensions are directly related to the three spatial dimensions while , which we set to 1 in this work, is an extra dimension that can encode additional information about the data representation (see geostatistical simulation case study 2 in Laloy et al., 2018). For a square () or cubic () generation domain, the relationship between and is given by
[TABLE]
where is the number of stacked convolutional layers in . This allows for a rather strong dimensionality reduction. For example, when and , we have . We refer to Jetchev et al. (2016) for more details on the (2D) SGAN architecture.
In a GAN, the generator and discriminator are trained (or “learned") simultaneously with opposing goals. The discriminator, , is fed with samples from the “real" training set, which from now on will be referred to as with distribution , and “fake" samples (i.e., realizations) created by the generator: . In our case, the real samples are a set of patches randomly cut from the TI. The discriminator tries to distinguish between and m by computing, for each received sample, the probability that it belongs to . Conversely, the generator, , aims at fooling into labeling m as a sample from (Goodfellow et al., 2014). This translates into the following minimization-maximization problem
[TABLE]
Compared to the SGAN code used by Laloy et al. (2018), we replaced batch normalization by instance normalization and added two transposed dilated convolutional layers to the generator, before its output (see section 8). Upon selection of the appropriate training epoch (see below), this removes the need to post-process the realizations by median filtering to eliminate small impurities, thereby leaving us with thresholding as the unique postprocessing operation. The realizations produced by our trained are continuous on the range and they are converted into binary images by thresholding at the 0.5 level.
Training was performed on a GPU Tesla K40 for 50 epochs with 64 mini-batches of 100 training samples per epoch. Epoch 36 was deemed to produce the best realizations. Figures 1b-c show two (randomly chosen) realizations generated by the trained SGAN before thresholding, . These 513 513 realization are obtained by sampling a 289-dimensional z vector from (see Laloy et al., 2018, for details and a performance comparison with a popular MPS algorithm). Even if these images are continuous, they appear almost categorical in this representation, which also suggests that the subsequent thresholding is a relatively mild operation.
3.2 Gradient-Based Deterministic Inversion
A common representation of the forward problem is
[TABLE]
where is the number of measurement data, denotes a deterministic forward model with parameters or model m and the noise term e lumps all sources of errors. If the probability distribution of e can be assumed to be zero-mean Gaussian with covariance matrix , and m is assigned a multiGaussian prior distribution, then the optimal model, , minimizes the following objective or loss function,
[TABLE]
[TABLE]
[TABLE]
where and signify the a priori model and its covariance matrix, respectively, and where weights the influence of honoring prior Gaussian information about m on . In case of a linear relationship between d and , reduces to the product F****m. In practice, it is common to replace by a regularization operator, L. This leads to the joint minimization of the misfit, , and
[TABLE]
The popular Gauss-Newton (GN) method for minimizing equation (7) iteratively updates m until either the target data misfit or a maximum number of iterations has been reached using the following update mechanism
[TABLE]
with
[TABLE]
where denotes the iteration number. In the context of our GAN-based dimensionality reduction, we learn a for the latent vector z. Limited testing with learning a standard normal distribution, , is found to provide good results but the generated realizations are nevertheless of slightly lower quality than when using . Fortunately, when the components of a random vector, x are independent, they can be converted into standard normal variables using the iso-probabilistic transform: labeling as () the cumulative density function (CDF) of (a standard normal variable ), the direct and inverse transform are given by
[TABLE]
To perform the inversion within the GAN latent space, we therefore place a standard normal uncorrelated prior (so-called damping regularization) on a vector of the same size as z and achieve GN updates of while converting each proposed into the corresponding with equation (10) before creating the resulting realization. Under the standard normal prior on , the GN update simplifies to
[TABLE]
where is the Jacobian matrix of , and I is the identity matrix. In this work, we simply set as adjusting dynamically did not show any advantages over fixing .
When only the gradient of the objective or loss function with respect to the model parameters, , is used, a steepest descent type of update can be performed
[TABLE]
where is a step length parameter that is generally adapted dynamically.
In this study, we used the Adam algorithm (Kingma and Ba, 2015) implemented in Pytorch to update using the prior directly. Adam is an advanced gradient-based algorithm that only makes use of the loss function gradient (see Kingma and Ba, 2015, for details). We used the following algorithmic parameters, a learning rate of 0.01 and the default values of 0.9 and 0.999 for the and momentum parameters. Since our considered forward operator, , is linear (see section 3.4), it implies that for continuous realizations it is straightforward to have the DL library internally computing (at least for common loss functions ). Yet this is no longer possible if the realizations require thresholding. To circumvent this issue, we implemented an adjoint model giving within the Pytorch computational graph (Richardson, 2018). Here is backpropagated through the generator network to update, using Adam, the latent vector, z, that produced the model, . As explained earlier, this is possible because the generator is fully differentiable end-to-end and (see also our companion code for more details).
A simple sum of squared errors (SSR, see equation 14) was chosen for the loss function, . Consequently, specific steps are needed to deal with the fact that the estimates in z can move outside the support of the prior. Three options to deal with this situation have been investigated by Lipton and Tripathi (2017) in the context of direct inversion of a full (face) image: (i) allow values to leave the interval, (ii) replace components that are too large with the maximum allowed value and components that are too small with the minimum allowed value (i.e., standard clipping), (iii) reassign the exceeding z components uniformly at random in the range (i.e., stochastic clipping). In agreement with the findings by Lipton and Tripathi (2017), limited testing revealed that stochastic clipping produces slightly better results for our considered case studies. Therefore, stochastic clipping is adopted throughout.
3.3 Global Optimization
For comparison purposes, we used the DREAM*(ZS)* algorithm (Laloy and Vrugt, 2012; Vrugt, 2016) as global optimizer. This is a MCMC sampler designed to sample the posterior density function of the parameters. Yet it is herein used to solely find an appropriate solution rather than sampling the full posterior distribution. The DREAM*(ZS)* scheme runs parallel interacting Markov chains and is thus population-based, and makes use of differential evolution principles to propose candidate points. It has been proven efficient in many hydrologic and geophysical applications (see, e.g., Vrugt, 2016, for references). Full algorithmic details can be found in Laloy and Vrugt (2012) and Vrugt (2016). Using a population-based search method requires finding the right trade-off between the size of the population (or “exploration") and the number of generations (or “exploitation") for a given number of forward model runs. After some testing, we selected 8 Markov chains, meaning a 8-member population, and performed as many MCMC iterations, that is, population generations, as necessary to fit the data to the assigned noise level.
3.4 Inverse Problem
We consider a synthetic 2D straight-ray cross-hole GPR tomography exemple. Given that the physics is assumed to be fully linear, any convergence problems arising in solving the inverse problem can be attributed to the nonlinear relationship between z and . We use two binary images with two facies of homogeneous GPR velocity (0.06 m ns*-1* and 0.08 m ns*-1*) as true models (see Figures 2a, 3a, 4a, and 5a). Both are produced using with z randomly sampled from . Cross-hole GPR imaging uses a transmitter antenna to emit a high-frequency electromagnetic wave at a location in one borehole and a receiver antenna to record the arriving energy at a location in another borehole (e.g., Annan, 2005). The considered measurement data are first-arrival traveltimes for several transmitter and receiver locations. These data contain information about the GPR velocity distribution between the boreholes. The GPR velocity primarily depends on dielectric permittivity, which is strongly influenced by volumetric water content and, consequently, porosity in saturated media. Our setup consists of two vertical boreholes that are located 6.0 m apart. Sources (left) and receivers (right) are located between 0.5 and 12.0 m depth with 0.5 m spacing (Figures 2a, 3a, 4a, and 5a), leading to a total dataset of = 576 traveltimes. Under the linear physics assumption, synthetic traveltime data, d, are simulated as
[TABLE]
where contains the path length in each model cell, e represents independent random draws from a zero-mean homoscedastic Gaussian distribution with a typical standard deviation = 1 ns. When a simple SSR loss function (without regularization) is used
[TABLE]
then the gradient vector of with respect to m becomes
[TABLE]
As explained above, this allows us to use Pytorch to backpropagate (equation (15)) through the GAN generator and optimize z such that equation (14) is minimized within a single computational graph using gradient descent. From now on, this will be referred to a strategy 1. In addition, estimating at each iteration by a centered 2-point finite difference scheme together with using a GN search as described by equations 7-11 will be called strategy 2. Here is derived using a perturbation factor of 0.1. This perturbation value was found to be the most appropriate after testing with several values in the range. A perturbation of 0.1 for a prior might seem large. Yet one must keep in mind that the necessary thresholding of the produced realizations, , can cause one or more sensitivies in to be zero or near-zero if the used perturbation is too small. Such excessively small values will induce instabilities in the GN search described by equation (11).
Lastly, note that besides true models I and II we use two different realizations of e in equation (13) which leads to two different “true” datasets for each true model. Realization I induces a true root mean square error (RMSE) between “true” (corrupted) and uncorrupted measurements of 1.006 ns. For realization II, the corresponding RMSE is 1.001 ns. Repeating the inversions with different noise realizations is useful to check the robustness of the inversion results against the exact noise values. Overall, this leads to 4 inverse case studies: 2 true models 2 noise realizations. To ease the comparisons between the different inversion runs, we use the weighted root mean square error (WRMSE) which we define as the ratio of the achieved RMSE by the inversion to the true RMSE. A WRMSE ns thus basically means that the data are underfitted while WRMSE denotes an appropriate data misfit.
4 Results
4.1 Inverting the Full Image
Before considering application of the forward operator, we tested whether gradient descent within the latent space of our trained GAN is able to recover the true (non-thresholded) model and corresponding z vector from the inversion of . In other words, is it possible to recover the values in z given exhaustive knowledge of the true ? This task is similar to the one considered by Lipton and Tripathi (2017), but in a geophysical context rather than for face images. The considered two true models in (I and II) generated by our trained GAN are depicted in Figures 2a and 3a. No data corruption was used and 50 inversion trials using 10,000 Adam iterations were performed with randomly chosen starting points. Table 1 and Figures 2-3 summarize the results. In Table 1, a RMSE of 0.02 between the true and reconstructed images is selected to define a successfull reconstruction. This choice is based on the observation that, visually, the retrieved models are either very similar to the true images with a RMSE 0.02 or largely differ from the true images with a RMSE 0.2 - 0.3. Furthermore, similarly to Lipton and Tripathi (2017), we report the percentage of inversion results for which the mean squared error (MSE) between the true and inferred values is 0.01. Overall, 37% of the inversion runs recover the true models (Table 1). Furthermore, each of these successful runs corresponds to a successful recovery in the latent space for true model I (Table 1 and Figure 2) but less for model II (Table 1 and Figure 3). As illustrated by Figures 3b and 3e, this is because a slight linear bias in the values can nevertheless produce good image reconstructions. Our results somewhat differ from those obtained by Lipton and Tripathi (2017) who report 100% recovery in the z-space to arbitrary precision. There are two major differences between our work and that of Lipton and Tripathi (2017). First, they consider face images which are much more clustered compared to our channelized model: the eyes, nose, ears, etc. tend to occupy the same portion of the image and they are located at globally similar distances from each other. Second, Lipton and Tripathi (2017) performed 100,000 gradient descent iterations while we performed 10 times less iterations.
4.2 Geophysical Inversion
We now turn our attention to the actual geophysical inversion, in which a subset of linear averages are observed under noise. For each strategy (1 and 2) and each combination of true model (I or II) and noise realization (I and II), the inversion was repeated 100 times using 100 different (randomly chosen) starting models. For strategy 1, the maximum total number of iterations (i.e., proposal steps) was set to 10,000. Here each Adam iteration consumes one forward solve. Since the resulting computational expense may be overly large for realistic nonlinear geophysical inverse problems, inversion results are also looked at after a total of 100 and 1000 iterations. Due to the used centered 2-point finite-difference approximation of (see above), for strategy 2 one iteration incurs a cost of 31 forward solves. Therefore, the maximum number of iterations for strategy is set to 5000 which translates into 155,000 forward model runs. In addition, inversion performance is also considered after 100 (3100 forward solves) and 1000 (31,000 forward solves) iterations. Moreover, to verify the impact of thresholding on the quality of the inferred models, each case study is also run without thresholding.
Strategy 1 without tresholding relies on the direct computation of by autodifferentiation with no adjoint model involved and is therefore basically the same as the approach by Bora et al. (2017). For the continuous case, we consider the continuous versions of the true models shown in Figures 2a and 3a and the same noise realizations as for the binary case. To convert a generated continuous model in into a continuous velocity field (m ns*-1*) in , the following relationship is used:
The results of the 100 repetitions of the 8 different inversions are summarized in Table 2 for the continuous case and in Table 3 for the binary case. Furthermore, Figures 4-7 depict for each strategy applied to the binary case, true models I and II, and noise realization II, the true model (subplot (a)), two best-fitting models found among the 100 repetitions (subplots (b) and (c)), the best-fitting model across the allowed iterations of a randomly chosen trial for which the corresponding best WRMSE is ns (subplot (d)), the sampled WRMSE trajectory corresponding to the best-fitting model shown in subplot (b) (subplot (e)) and the sampled WRMSE trajectory associated with the model displayed in subplot (d) (subplot (f)).
It is observed for both strategies 1 and 2, that the quality of the best-fitting solution heavily depends on the starting model and the allowed number of iterations. Indeed for the smallest budget of 100 iterations, no satisfying solutions are found no matter the inversion approach. We find that strategy 1 (Figures 4-5 and Tables 2-3) shows a much higher success rate than strategy 2 (Figures 6-7 and Tables 2-3) for the largest number of iterations allowed to each method. Hence strategy 1 retrieves solutions with a WRMSE 1.01 in 4% to 22% of the trials for the continuous case and in 7% to 19% of the trials for the binary case. On the contrary, strategy 2 never does so (Tables 2-3).
Strikingly, there appears to be very little negative impact of thresholding (compare Table 2 to Table 3), except for strategy 2 and true model I (compare the bottom row of Table 2 with those of Table 3). This indicates that plugging the externally computed into the DL graph to permit gradient descent works well for the considered examples.
When the maximum number of iterations is reduced to 1000, the proportion of solutions associated with a WRMSE 1.1 becomes small but is overall two times larger for strategy 1 (2% on average over the 4 datasets) than for strategy 2 (1% on average over the 4 datasets). Since a model with a WRMSE as large as 1.2 may still visually ressemble the true model well (see Figure 6c), it is instructive to also consider a WRMSE 1.2 as threshold. Here strategy 2 becomes more attractive, but for true model I only (Tables 2-3). We have tried to improve strategy 2 by (i) damping the model update at the early iteration before increasingly adding more contrast to the proposed models and (ii) decreasingly smooth the proposed models after each iteration as the search progresses. Nevertheless, neither of those schemes proved successful.
There is a systematic difference in peformance between the cases with true models I and II, with true model I always inducing a larger success rate no matter the inversion strategy and computational effort (Tables 2 and 3). This is due to the fact that model I has higher prior probability or, to use deep learning terminology, is closer to the range of the generator (Bora et al., 2017) than model II. This can be informally seen by comparing models I (Figure 2a) and II (Figure 3a) with the original TI (Figure 1a): the patterns displayed by model I are occuring more frequently in the TI than the eye-type of channel branching contained in model II. It is seen that strategy 1 offers greater robustness than strategy 2 against variations in prior model probability, as shown by the smaller differences in success rates between the model I and II cases for strategy 1 (Tables 2 and 3).
With respect to sampling trajectories of the inversions, for strategy 1 most of the data misift reduction in a productive run (i.e., a run with a favorable starting model) is achieved within the first 3000-5000 iterations (Figures 4e and 5e). The main reduction in data misfit for strategy 2 can occur both rather quickly ( 500 iterations) or much later (Figures 6e and 7e), while this strategy hardly recovers models with WRMSE 1.1. In addition, the sampling behavior of both algorithms can be unstable (Figures 4e, 5e, 6e and 7e). In accordance with those findings, it is also noted for strategy 1 that if WRMSE values larger than 2-3 are still sampled after some 2000 forward simulations, then the considered run will be unable to obtain a high-quality solution (Figures 4f and 5f).
It is worth noting that using strategy 2 with a trained GAN for which the latent space obeys a standard normal distribution, , thereby removing the additional nonlinearity caused by the transform, leads to globally similar results as those presented in Tables 2 and 3 for strategy 2.
Even for our best performing strategy 1 and considered maximum number of iterations of 10,000, the overall success (WRMSE 1.01) rate remains relatively low (Tables 2 and 3). As posited earlier in this paper, we argue that the reason for this is the high degree of nonlinearity associated with the relationship between z and . More insights into the effect of the nonlinear transform on the considered simple inverse problem are provided by Figure 8. The latter displays a 2D slice in the WRMSE landscape corresponding to the true reference solution obtained by the combination of the true model I (see Figure 2a, 4a or 6a) and noise realization II. To construct Figure 8, the to components of the true z vector that induces model I are kept fixed while the and dimensions are gradually varied between -1 and 1. While the WRMSE response surface appears smooth when considered at a coarse resolution (Figure 8a), a zoom into the basin of attraction (Figure 8b) reveals that the problem is in fact multimodal with many local minima. Also, this WRMSE landscape contains many small spikes and some large flat areas.
Lastly, we find that performing a global optimization with DREAM*(ZS)* parameterized as described in section 3.3 provides a solution with a WRMSE of 1.000 for all of the 4 scenarios (true models I and II combined with noise realizations I and II). Nevertheless, this is at the cost of a serial total of 200,000 to 800,000 forward runs. Among these amounts, some 50,000 serial forward calls are consumed to reach a WRMSE of about 1.1 while the rest is spent by moving from 1.1 to 1. This points out that traveling across the relatively rough misfit terrain caused by the nonlinearities in may require global optimization or search methods even in the best case of a linear forward problem. Although not done herein, note also that population-based methods such as DREAM*(ZS)* are straightforward to evolve in parallel using one CPU per population member, which can save a large amount of time (Laloy et al., 2018).
5 Discussion
This paper demonstrates that even if the forward model is linear, the high degree of nonlinearity in the relationship between latent vector, z, and the generator of a GAN, , can cause gradient-based deterministic inversion performed in the GAN latent space to fail. This is here illustrated for a classical binary channelized aquifer TI. Less structured and/or continuous TIs might be more amenable to gradient-based deterministic inversion within since the transform might then be less nonlinear. The poor convergence to the target misfit is in stark contrast to the results obtained when inverting the full image without noise (Table 2, Figures 2-3). This suggests that limited sampling of spatial averages under noise further complicates the recovery of the true values.
Our findings might appear to contradict those of Bora et al. (2017) who investigated whether gradient descent within the latent space of a trained GAN can recover an image from a set of measurements obtained by applying a linear operator to the true image. In cases where this true image is itself created by running the trained GAN for a given z vector (similarly as in our study), Bora et al. (2017) systematically find small reconstruction errors. Nonetheless, Bora and coworkers consider face images (from the Celeba dataset) which are thus very different than our channelized aquifer training image. Face images are comparatively more clustered as the same structures (nose, ears, eyes,…) are more or less always located in the same areas of the image. Yet the channels in our training set can be anywhere (see Laloy et al., 2018, for the full 2500 2500 training image from which the training set is sampled). This larger degree of freedom in our images (for this aspect) might make the inversion problem harder to solve. In addition, Bora et al. (2017) do not give much details about their exact experimental setup which makes an in-depth comparison with our results difficult.
It might seem surprising that, if a sufficient number of iterations is allowed, strategy 1, which is based on the objective function gradient, , outperforms a GN search that uses a finite-difference approximation of the full Jacobian matrix in the space, . In the training of deep neural networks, stochastic gradient descent has proven highly successful. Goodfellow et al. (2016) argue that such first-order methods may more easily escape saddle points, while second-order methods tend to get attracted and stuck in them. The situation might be similar here where we try to estimate z for an already trained network, namely that the less “stable" gradient-based methods can more easily move away from saddle-points and possibly local minima. Furthermore, strategy 1 relies on a rather powerful stochastic gradient descent algorithm (Adam, Kingma and Ba, 2015) and uses a perfectly accurate estimation of since in the considered case, is available analytically. On the contrary, when approximated by finite differencing is inevitably fraught with errors.
Note that for the gradient descent used with strategy 1, no optimization of the Adam’s hyperparameters, that is, the learning rate, and and momentum parameters (see Kingma and Ba, 2015), was done. Only the learning rates of 0.1 and 0.001 were found to lead to a worse performance than using our choice of 0.01. Other Adam’s hyperparameter settings or other descent algorithms such as SGD, RMSPROP (see, e.g., Goodfellow et al., 2016) or Adabound (Luo et al., 2019) might enabled improved inversion quality for the considered case studies.
Lastly, notice that some recent work suggests that projecting the learned latent space onto a so-called “Riemannian" manifold may lead to a reduced non-linearity of with respect to the projected z (Shao et al., 2017; Arvanitidis et al., 2018; Chen et al., 2018). In the future, it might be worthwhile to attempt inversion within such a manifold.
6 Concluding remarks
Performing inversion within the low-dimensional, latent space of a trained GAN, , rather than within the original model space, , offers important advantages in that (1) any generated model proposal honors the prior training image (TI) and (2) the parameter space is reduced by orders of magnitude compared to the original model space. Global probabilistic inversion within has been recently shown to work well (Laloy et al., 2018). However, such probabilistic inversion still incurs a large computational cost while the learned could also be possibly used within computationally less demanding gradient-based deterministic inversions. In this work, we show that owing to the highly nonlinear relationship between the GAN generator, , and latent vector, z, gradient-based deterministic inversion may fail even though the physics of the forward problem is linear. For a channelized aquifer binary TI and a synthetic linear GPR tomography problem involving 576 measurements with low noise, we find that when allowing for a total of 10,000 iterations, about 13% of the trials by the considered gradient descent algorithm locate a solution that has the required data misfit, in average over the considered test cases. When restricting the maximum allowed number of iterations to 1000, the percentage of success becomes 0%, though approximately 2 % of the inferred models still closely ressemble their associated true model and induce a nearly correct data misfit. Furthermore, the tested Gauss-Newton inversion approach that approximates the Jacobian matrix to create updates proved to be unable to recover a solution with the appropriate data misfit. Overall, deterministic inversion performance is found to depend on the inversion approach, starting model, true reference model, number of iterations and noise realization. In contrast, costly global optimization with DREAM*(ZS)* always finds an appropriate solution.
7 Computer Code Availability
The GAN and associated inversion codes used in this study are available at https://github.com/elaloy/gan_for_gradient_based_inv.
8 Used GAN architecture
Compared to the generator architecture detailed in Laloy et al. (2018), we have the following differences.
- •
Batch normalization was replaced by instance normalization
- •
The nonlinearity in the 5th layer of the generator is a ReLU instead of an hyperbolic tangent.
- •
A first transposed dilated convolutional layer takes the output of the 5th layer as input. This 6th layer is parameterized with 64 output channels, a kernel size of 5 pixels, a stride of 1 pixel, a padding of 6 pixels, an output padding of 0 pixels and dilation coefficient of 3. The activation function in this 6th layer is a ReLU and instance normalization is applied after the nonlinearity.
- •
A second transposed dilated convolutional layer takes the output of the 6th layer as input. This 7th layer is parameterized with 1 output channel, a kernel size of 5 pixels, a stride of 1 pixel, a padding of 10 pixels, an output padding of 0 pixels and dilation coefficient of 5. The nonlinearity in this 7th layer is a hyperbolic tangent.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abadi et al. (2016) Abadi, M., Agarwal, A., Barham, P., et al. Tensor Flow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Ar Xiv e-prints, March 2016, https://www.tensorflow.org .
- 2Al-Rfou et al. (2016) Al-Rfou, R., Alain, G., Almahairi, A., et al. Theano: A Python framework for fast computation of mathematical expressions. ar Xiv e-prints, May 2016, http://arxiv.org/abs/1605.02688
- 3Annan (2005) Annan, A. P. GPR methods for hydrogeological studies, in Hydrogeophysics, pp. 185–214, eds Rubin, Y. & Hubbard, S.S., Springer. 2005.
- 4Arvanitidis et al. (2018) Arvanitidis, G., Hansen, L.K, and S. Hauberg. Latent space oddity: on the curvature of deep generative models. ar Xiv e-prints, 2018.
- 5Aster et al. (2012) Aster, R., Borchers, B., and C. H. Thurber. Parameter estimation and inverse problems, 2nd edition. Elsevier. 2012.
- 6Bora et al. (2017) Bora, A., Jalal, A., Price, E., and A. G. Dimakis. Compressed sensing using generative models. Ar Xiv e-prints, 2017.
- 7Chen et al. (2018) Chen, N., Klushyn, A., Kurle, R., Jiang, X., Bayer, J., van der Smagt, P. Metrics for deep generative models. Ar Xiv e-prints, 2018.
- 8Creswell and Bharath (2016) Creswell, A., and A.A. Bharath. Inverting the generator of a generative adversarial network. Ar Xiv e-prints, 2016.
