Biochemical Szilard engines for memory-limited inference
Rory A. Brittain, Nick S. Jones, Thomas E. Ouldridge

TL;DR
This paper explores how minimal molecular Szilard engines with limited memory can extract work from complex, correlated environments, revealing the trade-offs between inference complexity, energy extraction, and robustness.
Contribution
It introduces a molecular Szilard engine model for minimal inference, analyzing how environment complexity influences energy extraction and robustness considerations.
Findings
More complex environments enable more effective energy extraction.
Limited memory constrains the inference strategies and energy gains.
Robustness against fluctuations requires additional energy reserves.
Abstract
By developing and leveraging an explicit molecular realisation of a measurement-and-feedback-powered Szilard engine, we investigate the extraction of work from complex environments by minimal machines with finite capacity for memory and decision-making. Living systems perform inference to exploit complex structure, or correlations, in their environment, but the physical limits and underlying cost/benefit trade-offs involved in doing so remain unclear. To probe these questions, we consider a minimal model for a structured environment - a correlated sequence of molecules - and explore mechanisms based on extended Szilard engines for extracting the work stored in these non-equilibrium correlations. We consider systems limited to a single bit of memory making binary 'choices' at each step. We demonstrate that increasingly complex environments allow increasingly sophisticated inference…
Click any figure to enlarge with its caption.
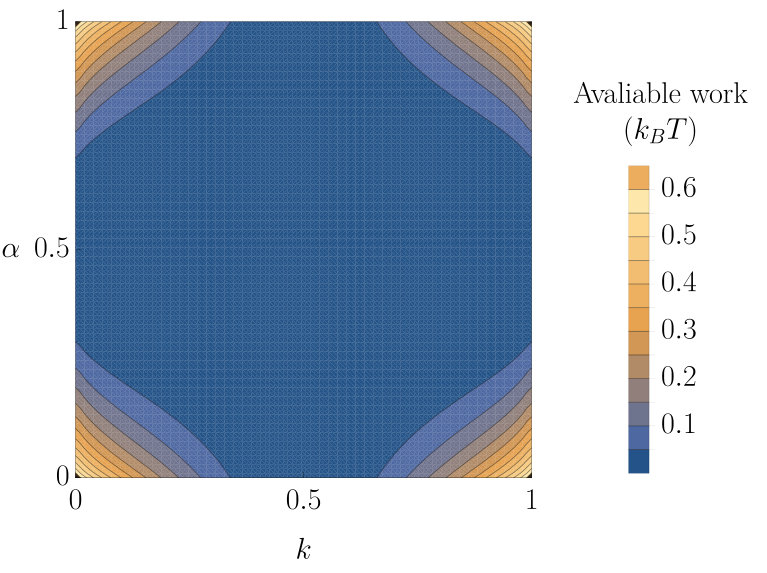 Figure 1
Figure 1 Figure 2
Figure 2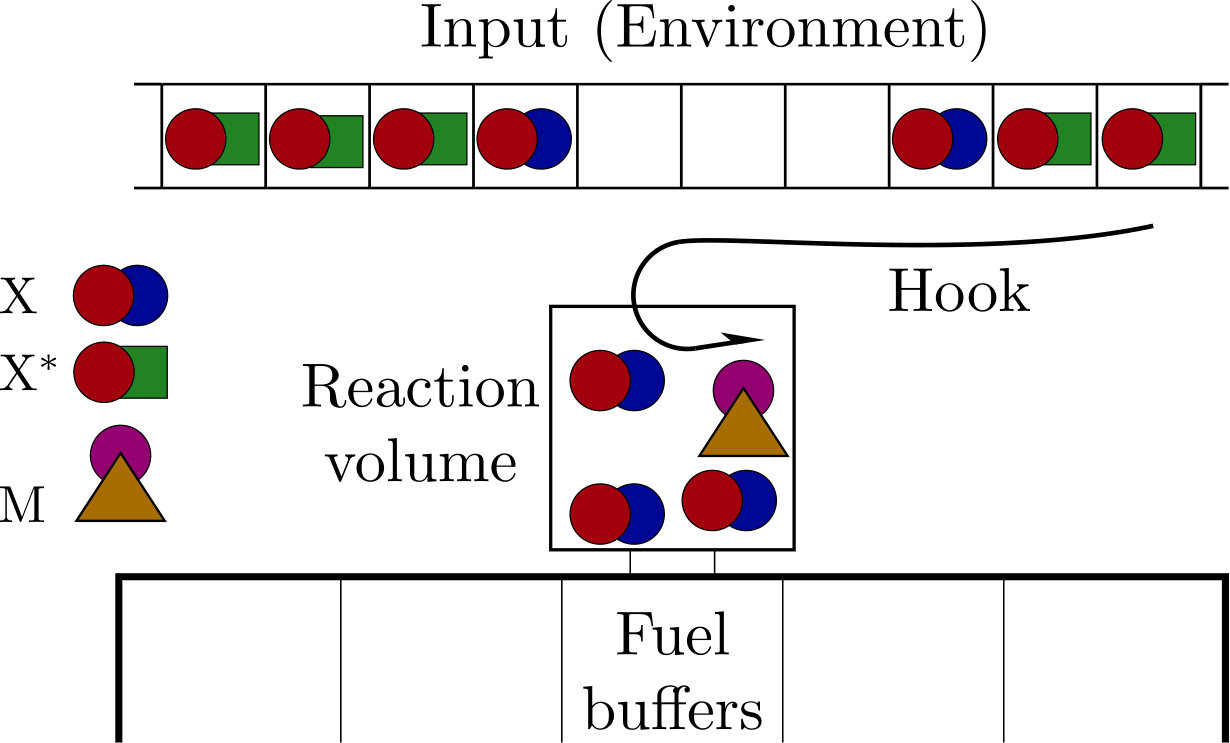 Figure 3
Figure 3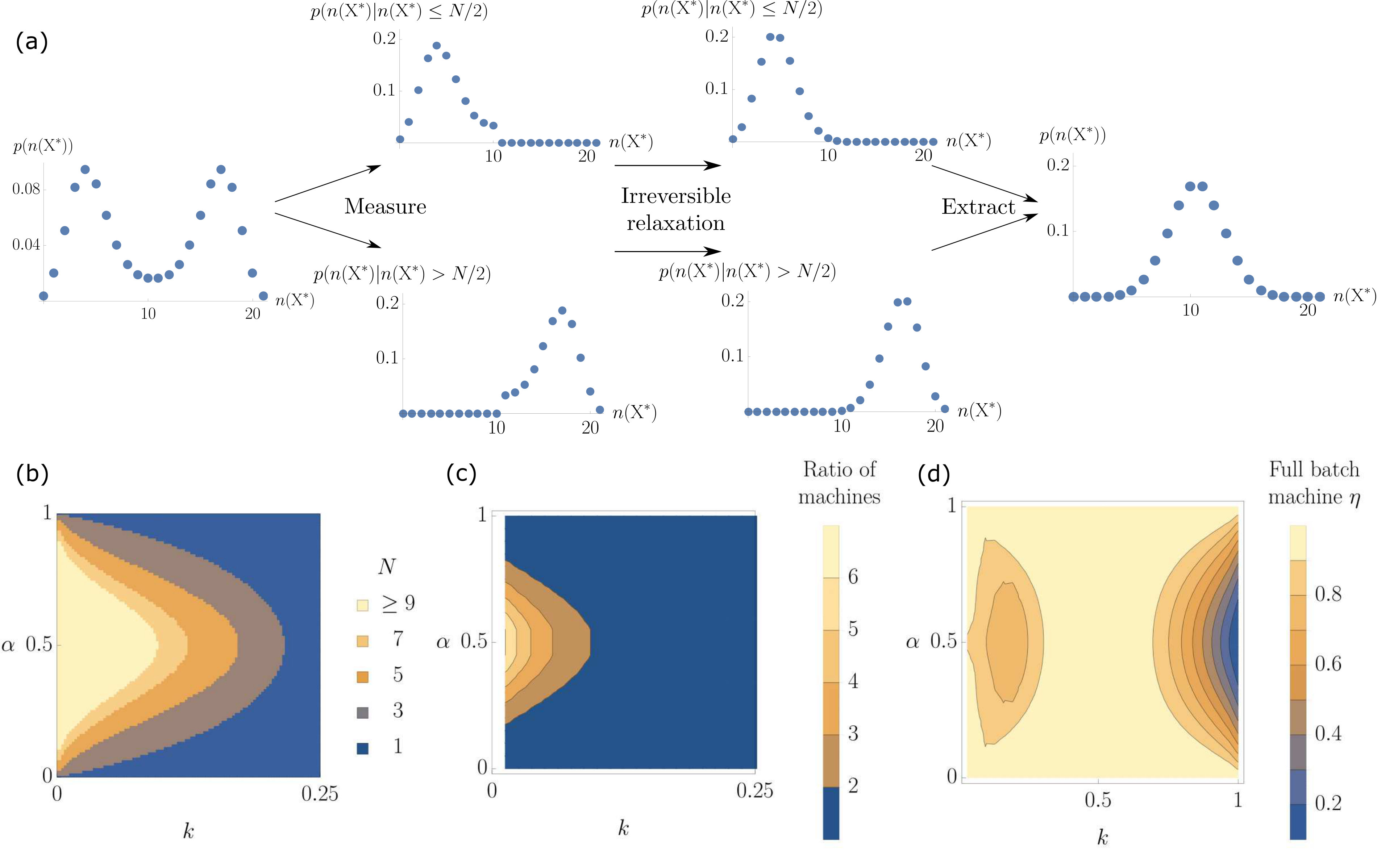 Figure 3
Figure 3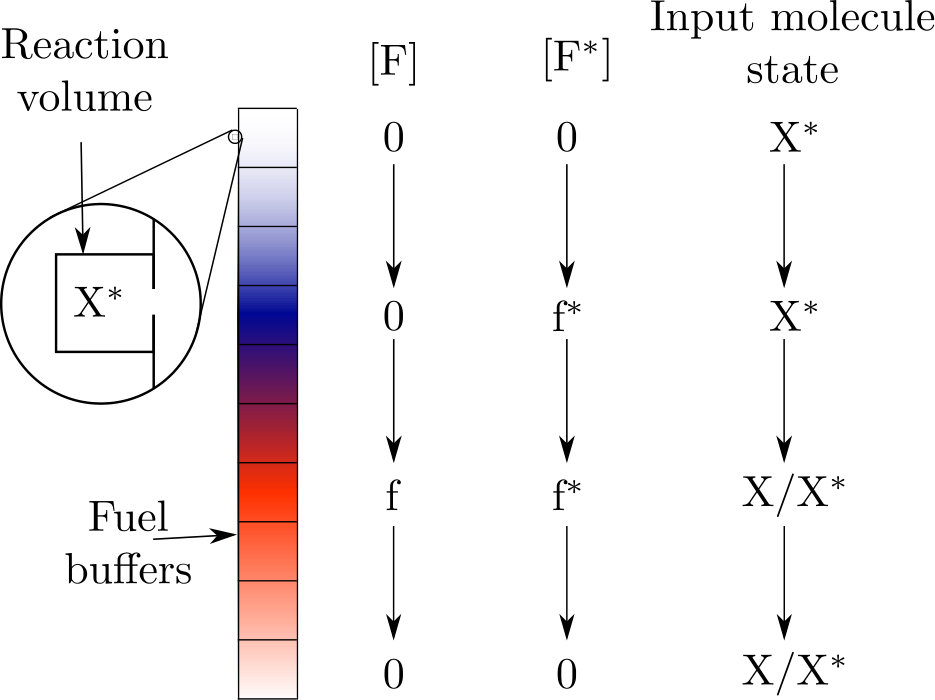 Figure 5
Figure 5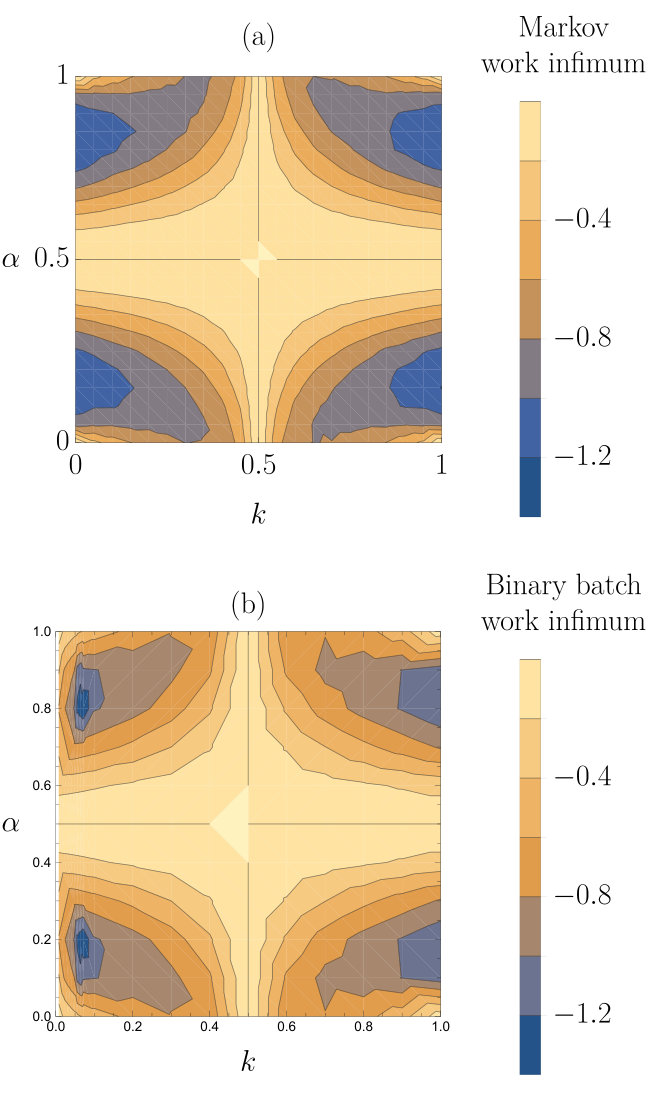 Figure 6
Figure 6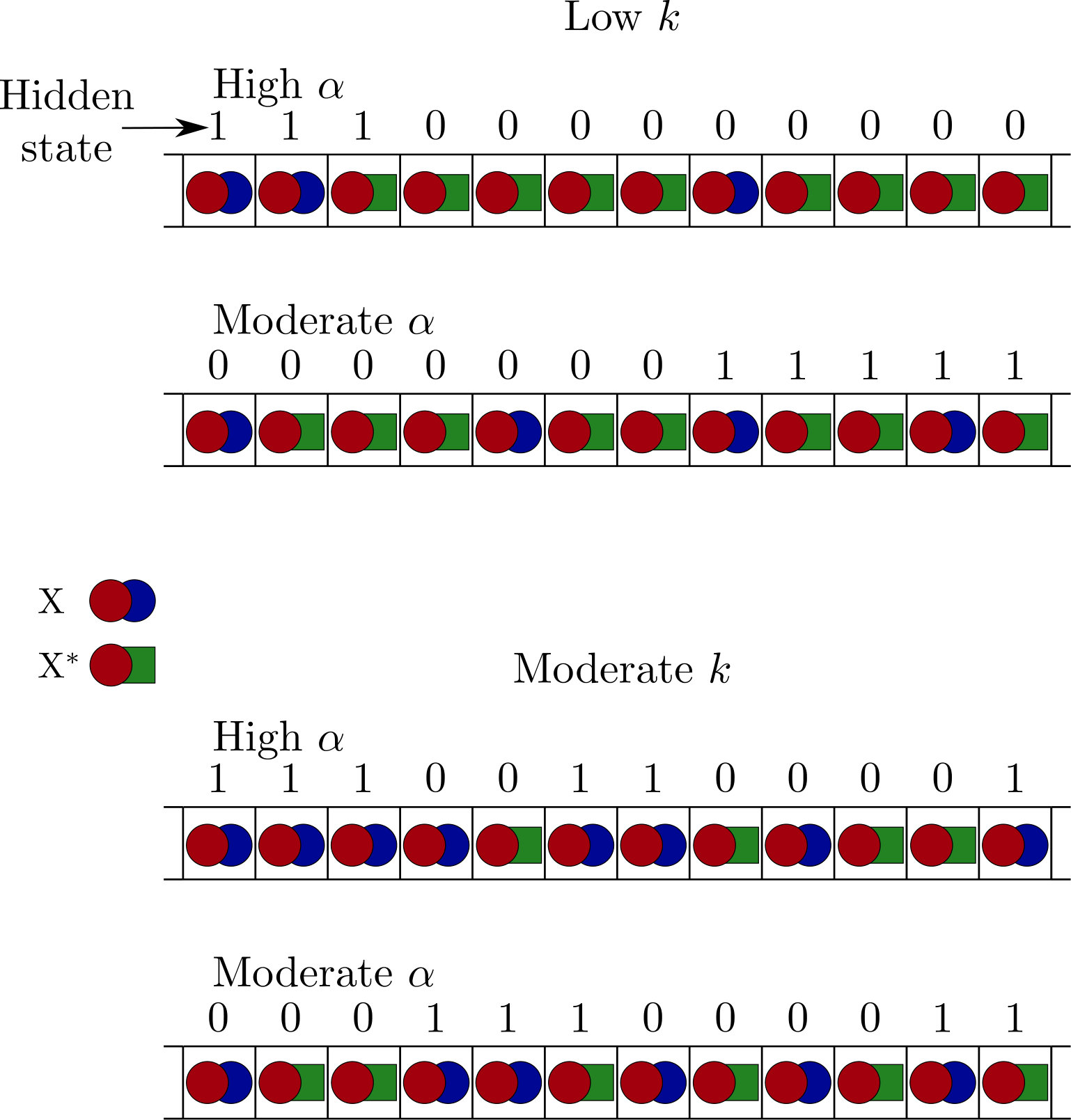 Figure 7
Figure 7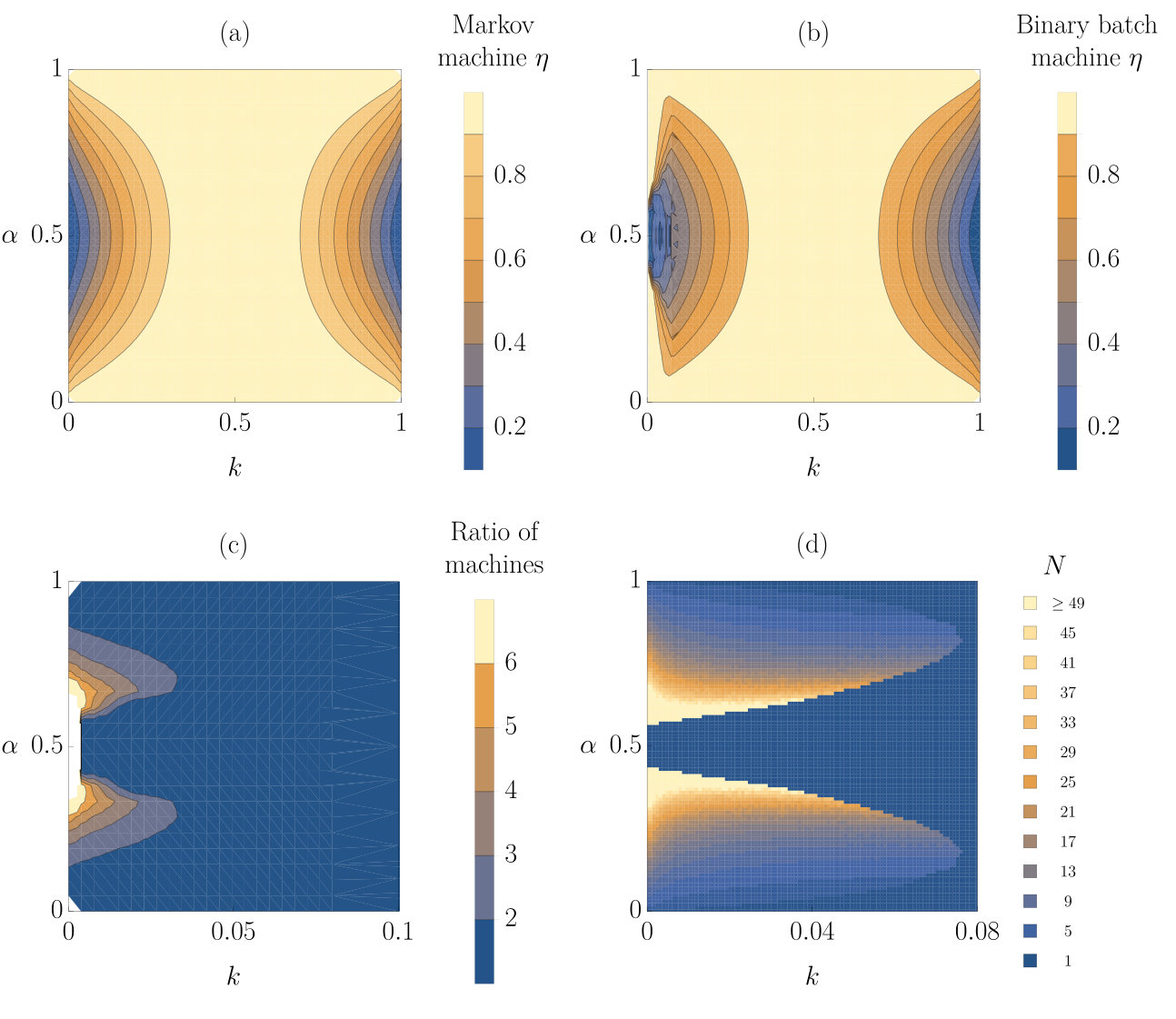 Figure 8
Figure 8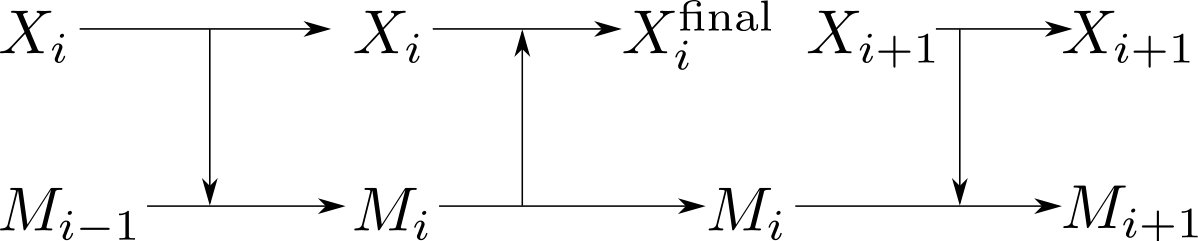 Figure 9
Figure 9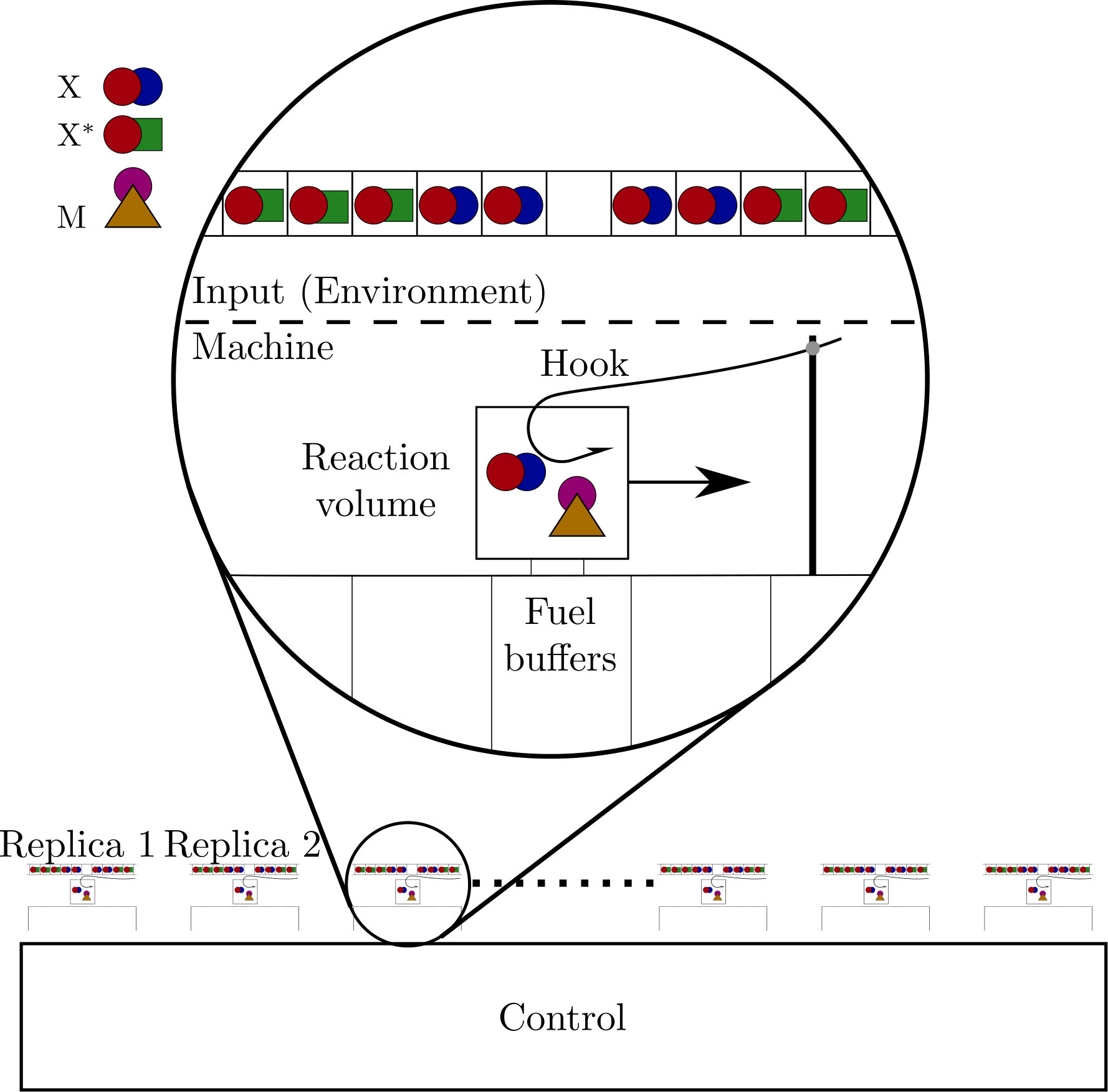 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12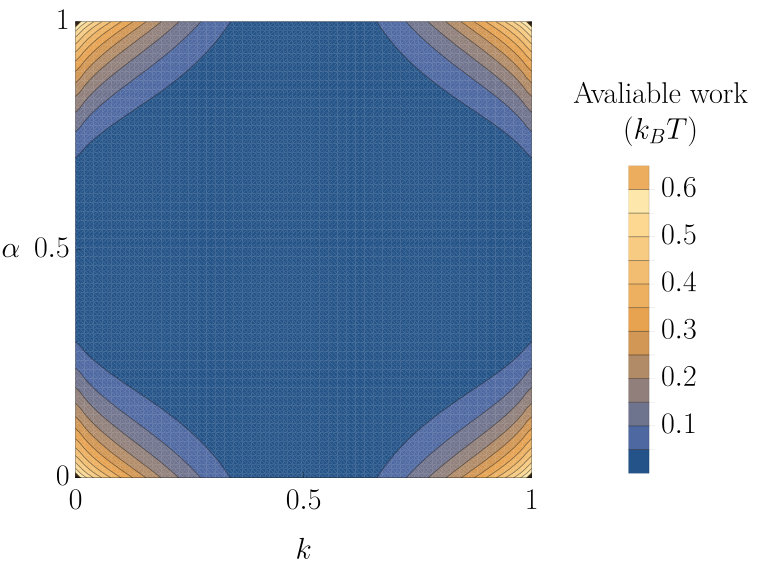 Figure 13
Figure 13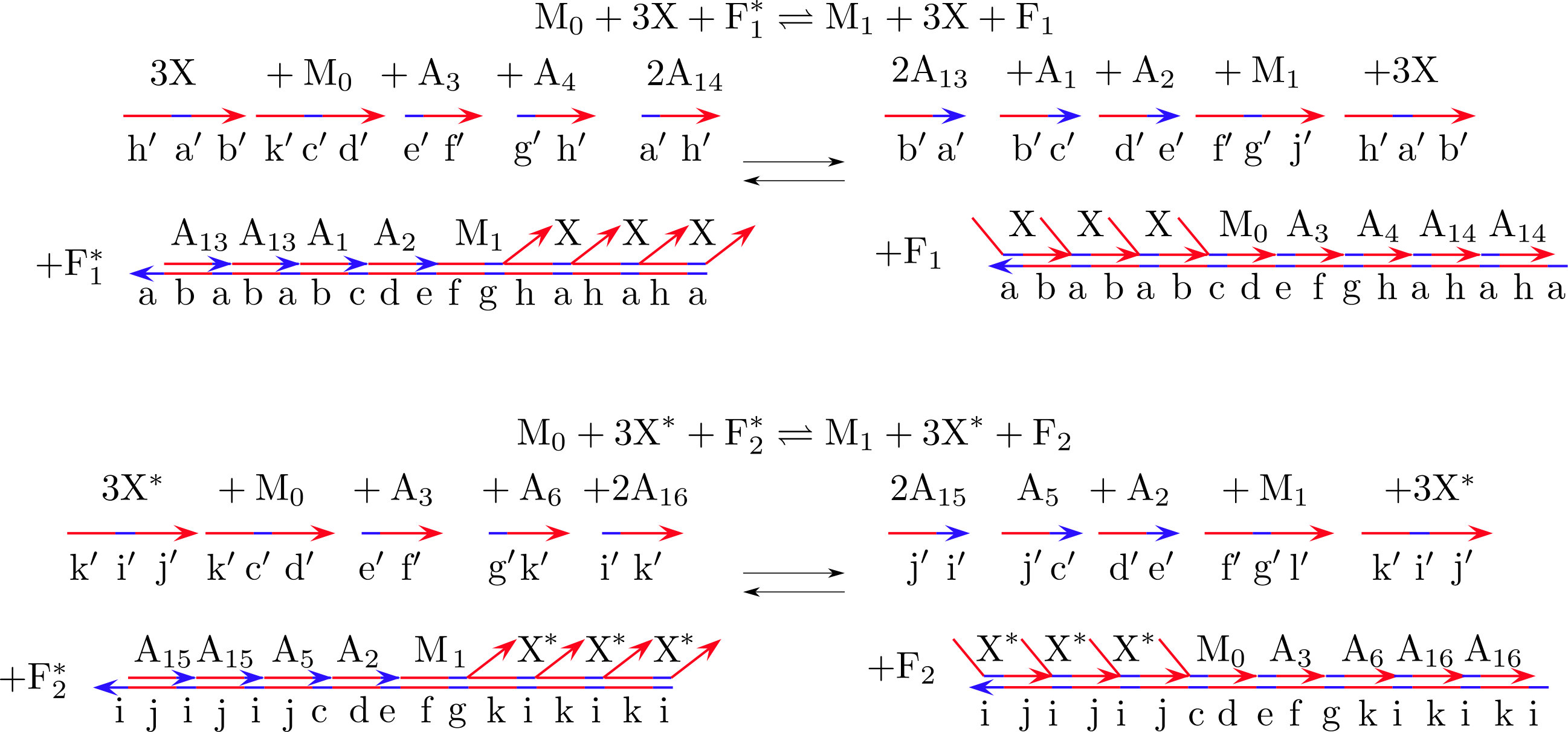 Figure 14
Figure 14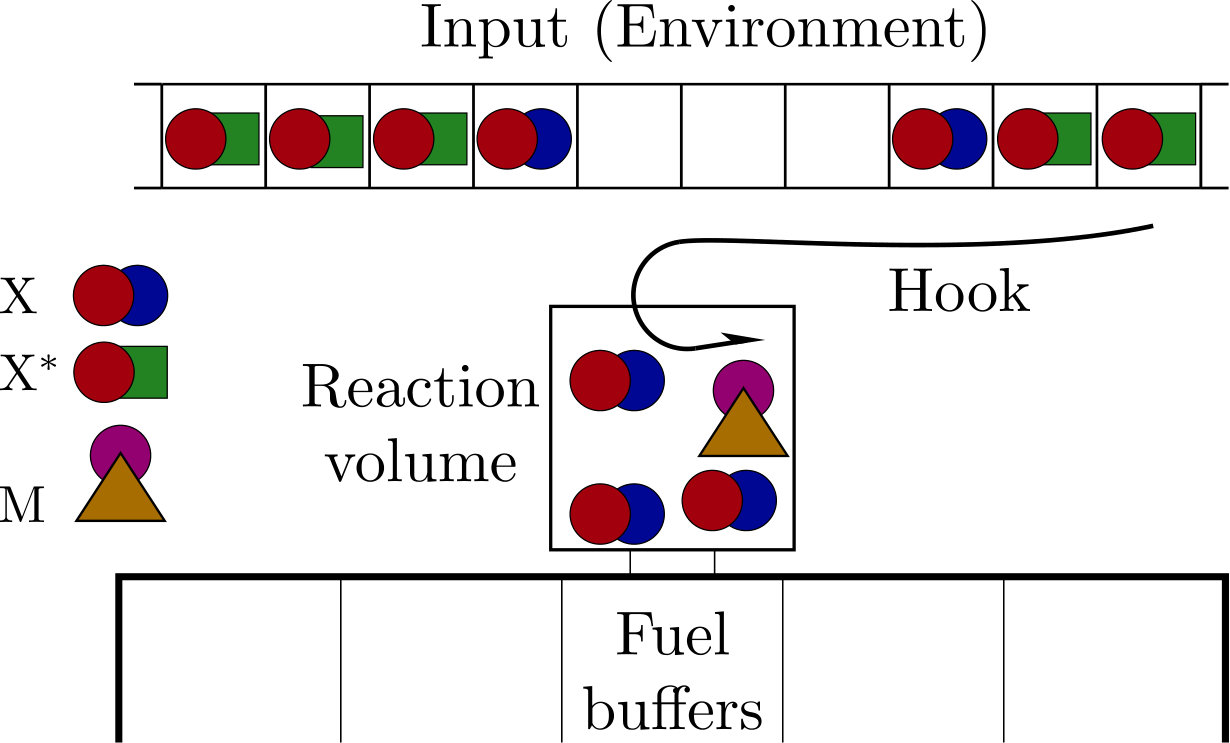 Figure 15
Figure 15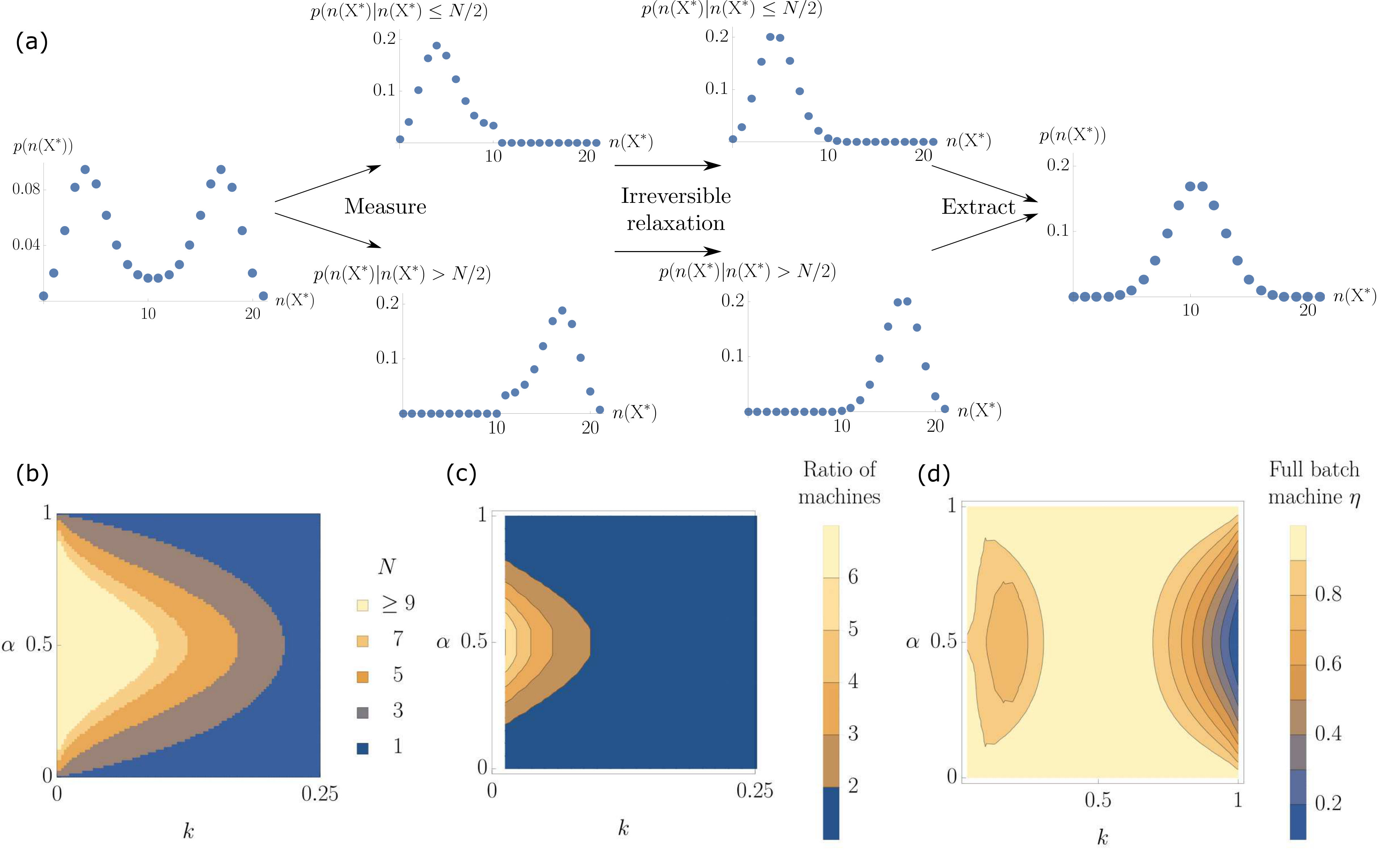 Figure 3
Figure 3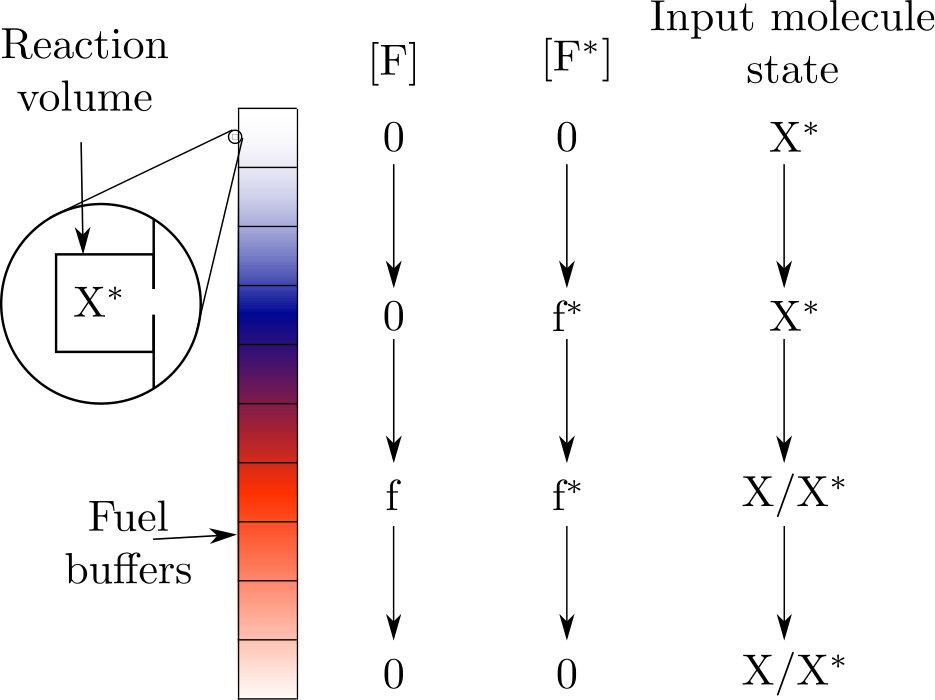 Figure 17
Figure 17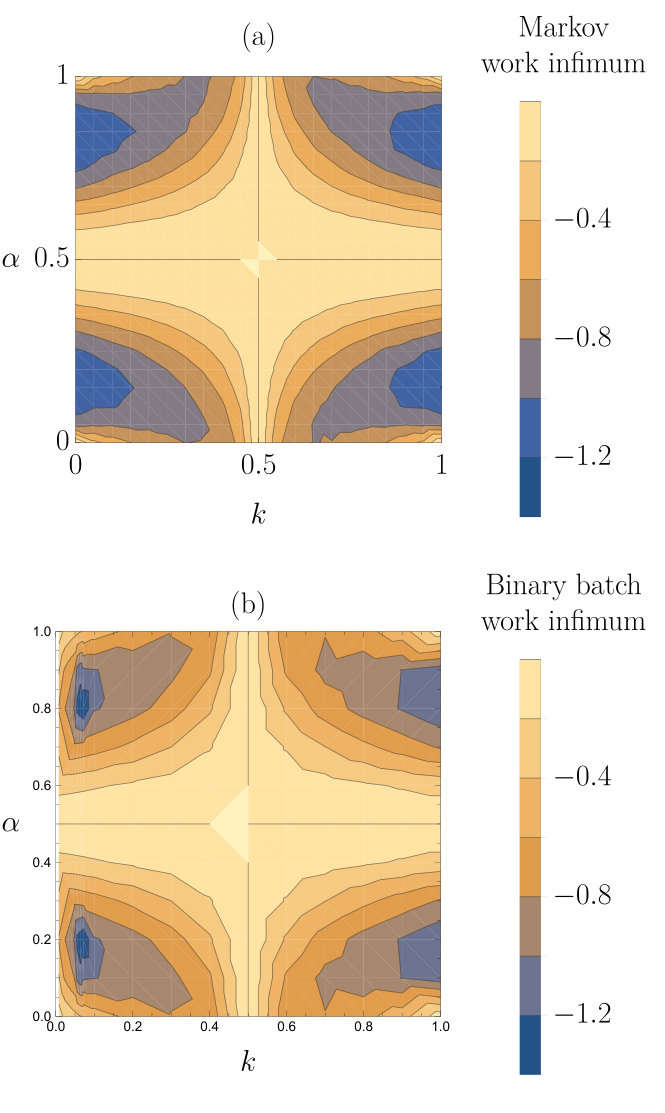 Figure 18
Figure 18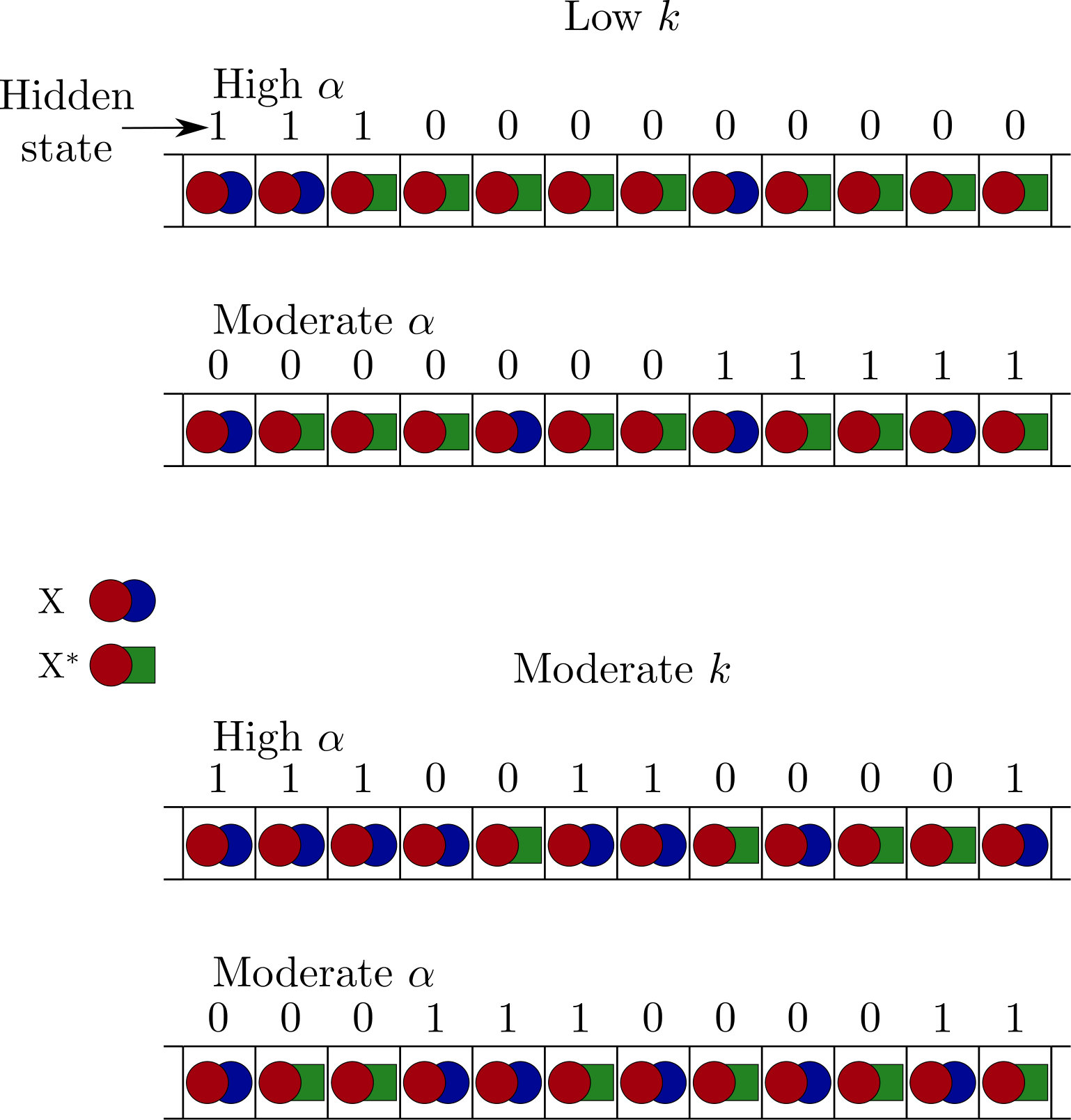 Figure 19
Figure 19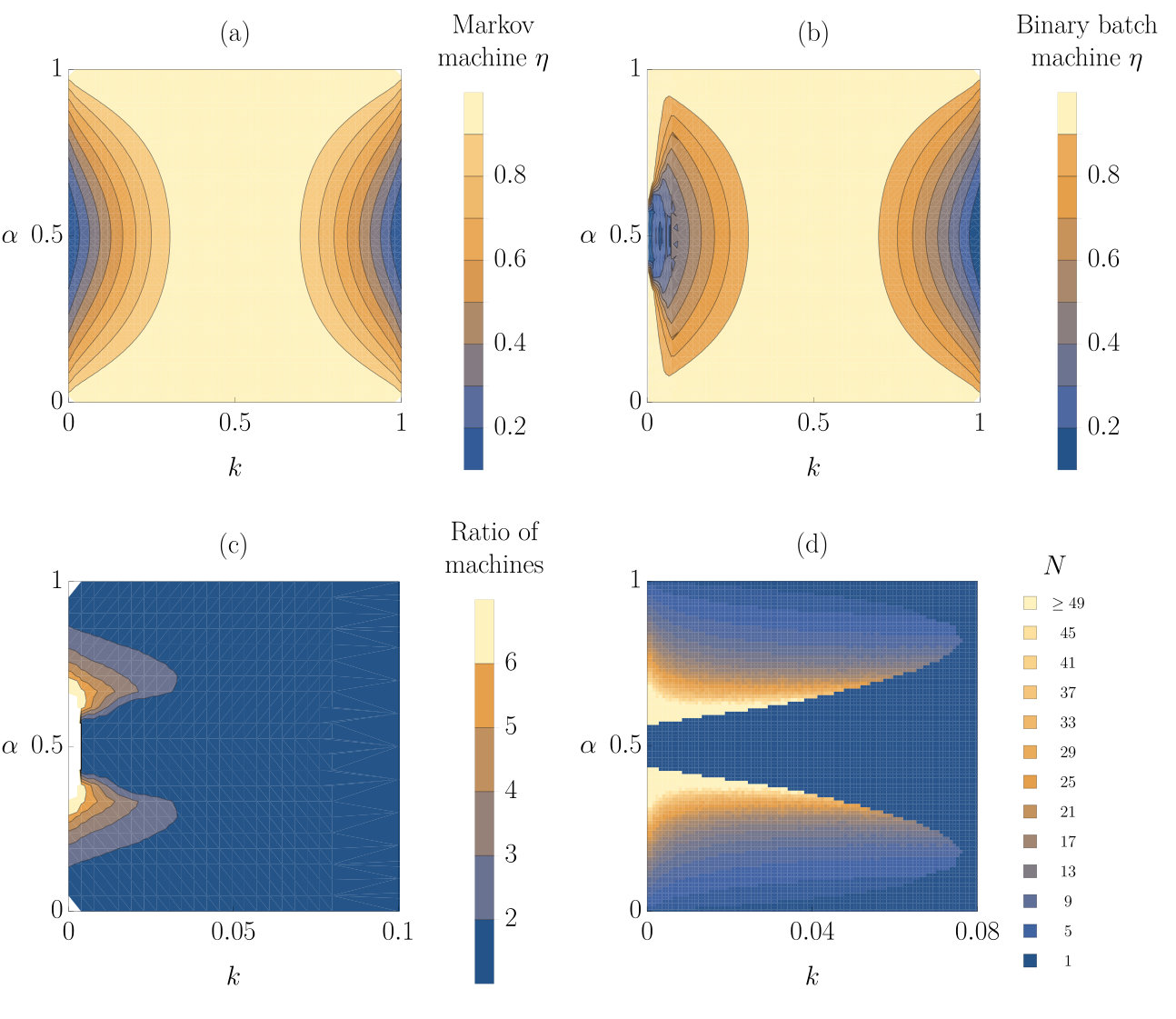 Figure 20
Figure 20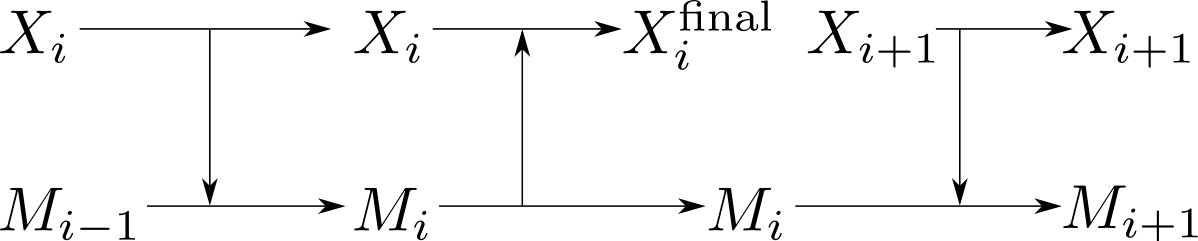 Figure 21
Figure 21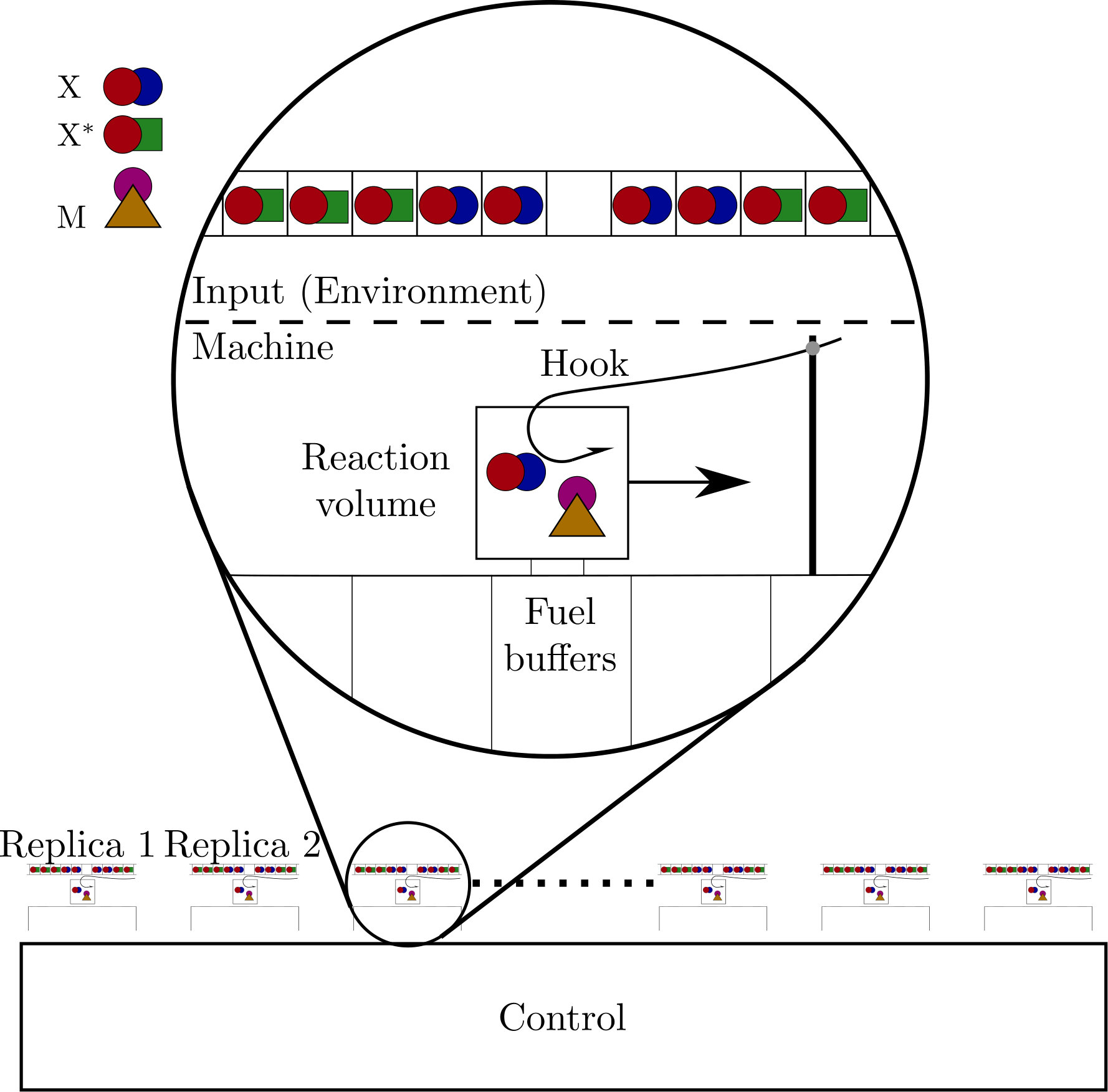 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Biochemical Szilard engines for memory-limited inference
Rory A. Brittain
Nick S. Jones
Department of Mathematics, Imperial College London, London, SW7 2AZ, UK
Thomas E. Ouldridge
Imperial College Centre for Synthetic Biology and Department of Bioengineering, Imperial College London, London, SW7 2AZ, UK
Abstract
By designing and leveraging an explicit molecular realisation of a measurement-and-feedback-powered Szilard engine, we investigate the extraction of work from complex environments by minimal machines with finite capacity for memory and decision-making. Living systems perform inference to exploit complex structure, or correlations, in their environment, but the physical limits and underlying cost/benefit trade-offs involved in doing so remain unclear. To probe these questions, we consider a minimal model for a structured environment—a correlated sequence of molecules—and explore mechanisms based on extended Szilard engines for extracting the work stored in these non-equilibrium correlations. We consider systems limited to a single bit of memory making binary ‘choices’ at each step. We demonstrate that increasingly complex environments allow increasingly sophisticated inference strategies to extract more free energy than simpler alternatives, and argue that optimal design of such machines should also consider the free energy reserves required to ensure robustness against fluctuations due to mistakes.
I Introduction
Living and human-made systems exploit out-of-equilibrium fuel supplies to do useful work. For example, if glucose is present in the environment in higher than equilibrium concentrations relative to carbon dioxide and water, bacteria can power themselves through respiration. Similarly, internal combustion engines use an out of equilibrium concentration of their fuel, i.e. petrol, and are powered by the conversion of fuel and oxygen to carbon dioxide and water.
The amount of work that can be done using the fuel is bounded by the non-equilibrium free energy of the fuel parrondo2015thermodynamics . This free energy contains both energetic and entropic terms. As one would expect, if the fuel contains more energy, then, in general, the amount of work that can be done is higher. However, fuels are also more useful if they are in well-defined initial states, with limited microscopic uncertainty. This uncertainty is quantified by the entropy, which is why the entropy contributes to the free energy.
The idea of using high energy fuel is intuitive. If the fuel initially has greater energy than at equilibrium, then that extra energy can be transferred to somewhere else to do useful work as the fuel equilibrates. It is less obvious how to exploit low entropy fuel—nonetheless, entropy is an important component of the free energy stored in biochemical fuel molecules and cellular membrane potentials. For example, the free energy released by converting an ATP molecule to an ADP molecule in a cell is approximately 1.5 times the standard free energy difference between an ATP and an ADP molecule alberty1992standard .
Spurred by a desire to understand the fundamental physics of computation and information processing, there has been significant recent interest in the exploitation of purely entropic resources mandal2012work ; barato2013autonomous ; boyd2016identifying ; boyd2017correlation ; boyd2017leveraging ; mcgrath2017biochemical ; Stopnitzky2018Physical . Data arrays are physical systems, and the Shannon entropy of the data contributes to the overall physical entropy of the system. The data itself is therefore a potential resource, and manipulating data has thermodynamic consequences due to changes in the entropy of the data array landauer1961irreversibility . A data array can have a simple statistical bias towards 1 or 0, and several authors have discussed how such a bias, which implies a low entropy register, might be exploited to perform work mandal2012work ; barato2013autonomous . A more subtle and equally fundamental possibility is exploiting structure across multiple bits in the array—its entropy can be low due to correlations within the data, rather than an overall bias at the level of individual bits boyd2016identifying ; boyd2017correlation ; boyd2017leveraging ; mcgrath2017biochemical ; Stopnitzky2018Physical . However, the principles of designing devices to optimally exploit correlations in general settings remain unclear Stopnitzky2018Physical .
Although inspired by the physics of computation, the question of how to exploit correlations is also of fundamental biological relevance. If organisms existed in a homogeneous non-equilibrium environment, there would be no need to develop sophisticated information-processing machinery to survive. However, from the chemotaxis system of E. coli to the brains of humans, complex molecular and cellular networks have been evolved to exploit the fact that the environment exhibits correlated fluctuations. These systems rely on the fact that what is sensed at a certain point in space and time contains information about nearby points mcgrath2017biochemical . They have evolved even though they are costly to maintain, and despite the fact that the information obtained is limited by features such as the memory and processing power available govern2014optimal . However, the fundamental trade-offs that determine the sophistication of these systems are not fully explored.
In this paper we take steps towards unifying these two perspectives on the exploitation of correlations. We first present a molecular design for a measurement-and-feedback device (a Szilard engine szilard1929entropieverminderung ) in which the mechanics of the feedback is explicit within the molecular system. We then leverage this construct to propose biomolecular machines that make repeated binary choices about how to act based on measurements of their environment (an array of ‘molecular bits’). These machines use their single bit of memory to extract chemical work from correlated arrays, demonstrating that it is possible to design minimal biophysical systems that exploit minimal structured environments.
No memory at all is needed to extract all of the available work from an input consisting of an array of uncorrelated subsystems, and simple schemes with one-bit memories can extract all of the stored free energy from Markovian environments. If we increase the complexity of the environment further, by making it a hidden Markov process, 100% efficiency becomes impossible with a single-bit memory and some implicit inference of the hidden state is required. In this setting, schemes that perform batch averaging to obtain a better estimate of the hidden Markov state can become more efficient than the most direct approaches, at the expense of increased biochemical complexity. We are thus able to construct a minimal thermodynamic setting in which increasingly complex information-processing machinery becomes advantageous in increasingly complex environments.
We first, in section II.1, give the relevant assumptions and underlying statistical mechanics. Then, in section II.2, we discuss the previous work on information-exploiting systems and introduce our own model. Numerical methods are briefly discussed in section II.3. In section II.4 we demonstrate how work can be extracted from a single molecule in a non-equilibrium state by our setup. Next, in section III.1, we discuss how to make a biochemical version of the Szilard engine, which forms the basis of our machines to extract work from correlations. Subsequently we find the maximum amount of work that a device with a persistent memory can extract from a series of correlated bits (section III.2.1). We discuss a device based on the biomolecular Szilard engine that reaches this limit and can extract all of the work available from a Markovian input in section III.2.2. In sections III.2.3 and III.2.4, we discuss the limitations of this machine when acting on an input produced by a hidden Markov model. We propose a different machine, in section III.2.5, that averages over a batch of multiple input molecules that can extract more work in some cases. Finally, in section III.2.6, we discuss the robustness of such devices to fluctuations in the input.
II Materials and Methods
II.1 Non-equilibrium generalised free energies and information as a resource
In this paper, all physical systems are assumed to be well-described by discrete macrostates of molecules in dilute solution. Each of these states has an associated chemical free energy, and all systems are in contact with a single heat bath at temperature ouldridge2018importance . We are concerned with small, fluctuating systems, so the state is characterised by a random variable . For any probability distribution over the states of the system , there is an expected chemical free energy
[TABLE]
Here, is the chemical free energy of the macrostate , incorporating both the typical energy of , and any entropic contribution from microscopic variability within ouldridge2018importance ; ouldridge2018power . We use because the chemical free energy plays the same role for macrostates as the energy for fully-resolved microstates. The distribution implies an uncertainty in the macrostate , quantified by the Shannon entropy macrostate (in nats):
[TABLE]
The generalised non-equilibrium free energy of the system is esposito2011second
[TABLE]
The generalised free energy is minimised by the equilibrium distribution to which the system eventually converges.
Now consider a system consisting of two subsystems; the overall state of the system is the joint random variable where and are the random variables that describe the individual subsystems. If we assume that the subsystems are not energetically coupled, so that it is possible to write the energy of any joint state as the sum of the energy of the states of the subsystems, then the free energy can be written parrondo2015thermodynamics
[TABLE]
where is non-negative the mutual information between the two random variables:
[TABLE]
The mutual information is a measure of how much knowledge of the state of one random variable reduces uncertainty about the state of the other random variable Elements_of_Information_Theory .
Eq. 4 shows that there is a real contribution of information to the free energy of a physical system. Fundamentally, correlation between two non-interacting subsystems means that the uncertainty in the state of the joint system is low without a compensating reduction in the energy—work is therefore available.
In terms of the non-equilibrium free energy, the second law of thermodynamics states that the free energy of an isolated system can never increase esposito2011second :
[TABLE]
Let consist of two non-interacting subsystems and , as in equation 4, and assume the mutual information between subsystems is zero at the time . Then for any process between time and that leaves and non-interacting in the final state,
[TABLE]
The reduction in the free energy of can be used to increase the free energy of by an amount up to the magnitude of the change in free energy of . In this paper we will refer to this increase of free energy of as ‘work’ being performed on the physical system, with work being a shorthand for the more formal term ‘chemical work’ van2015ensemble ; ouldridge2018power . Therefore, in a process that reduces the free energy of a subsystem by a work of can be done on another subsystem.
II.2 Model systems
II.2.1 Prior models
In this work we consider machines designed to extract work from a non-equilibrium series of bits with both the machines and the bits rendered as biomolecules. These devices exploit pre-existing information within the input via a series of measurement and feedback operations implemented through a 1-bit memory. We now summarise prior work on theoretical constructs for the exploitation of information to put this study into context.
Underpinning our device is an exact and explicit biochemical formulation of the Szilard engine szilard1929entropieverminderung . Szilard used this thought experiment to argue against the possibility of an observer violating the second law by measuring a system’s equilibrium fluctuations and subsequently using feedback to exploit them – a problem originally considered by James Clerk Maxwell dougal2016kelvin in the context of his infamous ‘Demon’. Szilard explained that any exploitation required an ‘ominous coupling’ between the measured system and the system that performs the feedback—a correlation that persists beyond the physical decoupling of the two degrees of freedom. He argued that such a ‘measurement’ cannot be performed without a ‘compensation’ that preserves the second law. Eq. 4 is a more modern formulation of this argument: correlations between decoupled degrees of freedom store free energy, and therefore producing them has a thermodynamic cost. In his original work, Szilard analysed explicit mechanisms for both the measurement and exploitation separately, but he did not analyse a full cycle of measurement and feedback in a single system. Furthermore, he did not consider the challenge of extracting work from a series of correlated inputs.
Recent advances in nonequilibrium thermodynamics have prompted a resurgence of interest in Maxwell Demons, Szilard Engines and related systems. One significant avenue of investigation has focused on bipartite systems, in which two subsystems are physically coupled but undergo individual transitions. It has been shown that the full second law of bipartite systems can be decomposed into individual second laws for each subsystem horowitz2014thermodynamics ; barato2014efficiency ; allahverdyan2009thermodynamic . These individual second laws contain an additional term describing how transitions within the subsystems influence the information shared between them. If this term has the right sign, it can allow the other contributions to the entropy production in one of the subsystems to be negative—an apparent violation of the second law for an observer that is aware of only one subsystem. Esposito and collaborators have shown, through experiment and theory, that this effect can be observed even when the net energy transfer between the two subsystems is zero strasberg2013thermodynamics ; koski2015on-chip , describing such systems as ‘true Maxwell Demons’. However, these devices don’t demonstrate the kind of behaviour seen in Szilard’s Engine or Maxwell’s Demon in the sense of storing, then subsequently exploiting, free energy within correlations between non-interacting systems.
Simultaneously, a second major class of systems has arisen as a testbed for ideas about the thermodynamics of information: machines designed to extract work from a non-equilibrium series of bits. The first detailed analysis of such a machine was performed by Mandal and Jarzynski mandal2012work . The authors considered a three state device that couples to each bit in an input sequence for a period of time before being moved to the next bit. The machine changes state stochastically and couples the changing of the state of the input bit to the raising and lowering of a mass in a gravitational field. Although the authors pointed out that correlations within the tape could store free energy, their actual design could only exploit the overall bias of the input bits towards either 0 or 1. The device is powered by an increase in the entropy of its input, rather than a change in its energy, but the fundamental principle is not dissimilar to a device that exploits the difference in pressure between two volumes of ideal gasses, which is also entropic in nature. The analogy is particularly vivid if one assigns a ‘0’ to gas particles arriving from the left of a piston, and ‘1’ to particles arriving from the right.
This model was extended to allow the device to step stochastically along its tape, and furnished with a chemical realisation, by Barato and Seifert barato2013autonomous . In neither case is information in the environment—in the sense of structure induced by correlations—exploited, and there is no feedback from the state of the tape to the operation of the device.
Horowitz et al. discussed a device that interacts with a series of two-state systems via a process of measurement and feedback horowitz2013imitating . The input was an equilibrium system, however, without correlations between successive subsystems. Hence the mechanism of measurement and feedback, which was not explicitly described as an inherent part of the system under study, must necessarily consume at least as much work as could be extracted in the exploitation step. Diana et al. considered the converse problem: using measurement and feedback to reduce the work required to set an array of bits to 0 diana2013finite-time . Again, however, correlations within the tape were not considered, and the feedback mechanism was implicit.
Boyd et al. have sought to develop machines that extract work from ‘temporal’ correlations between successive bits boyd2016identifying ; boyd2017correlation ; boyd2017leveraging . The authors consider, in a similar fashion to the previous models, a machine with a number of discrete states coupled to successive bits in a long string of inputs. These machines are intended to extract work from tapes that have no overall bias towards one state or the other but contain correlations between the state of bits. As has been highlighted by Stopnitzky et al., however, the machines in these works were designed without ‘reversibly embeddable’ dynamics—a necessity if the machines are to operate without external control, as was assumed Stopnitzky2018Physical . Stopnitzky et al. did present systems with reversibly embeddable dynamics that extract positive work from a perfect sequence of alternating 1s and 0s, but the efficiency was very low. The extraction of work from perfectly correlated systems has also been analysed in a quantum mechanical setting chapman2015autonomous .
A biochemical machine for exploiting correlated pairs of molecules was presented by McGrath et al. mcgrath2017biochemical . Although information between non-interacting molecules is indeed exploited in this work, the nature of the correlations—which are much more simple than those in a string of bits encountered one after the other—allow a particularly straightforward, memory-free approach. In effect, the pairs of molecules could be described as a single 4-state non-equilibrium system, and processed in isolation from other pairs.
The lack of concrete physical rendering in some of these models mandal2012work ; diana2013finite-time ; boyd2016identifying ; boyd2017correlation ; boyd2017leveraging ; Stopnitzky2018Physical ; chapman2015autonomous makes the machines mysterious and increases the scope for error, as discussed in Stopnitzky2018Physical . If the inputs are simply described as an abstract string of bits without any explanation of their physical instantiation, the low entropy of the data is thereby made to seem like a new, and almost non-physical source of work. Measurement-and-feedback-driven devices in which the feedback mechanism is implicit can also ignore some of the costs of the process; down-play the challenges of inducing feedback-driven behaviour in which one component first influences the evolution of the other, and then vice versa. For those unfamiliar with the field, such an approach can provide misleading intuition as to how the measurement must be stored, as we will discuss.
II.2.2 Molecular implementation of a measurement-and-feedback machine
We now present a general description of the devices considered in this work. Although our devices would be challenging to engineer, operate in ideal limits, and are not direct models of living systems, we nonetheless render the machines, and the input bits, as biomolecules. All operations, including the measurement and feedback, are driven by a concrete molecular mechanisms that are explicitly part of the devices themselves. By considering a concrete realisation, even in an idealised limit, we can explore the limits of what is thermodynamically possible in a positive sense, rather than simply exploring the space of systems that are not forbidden by a particular aspect of the second law ouldridge2018power . Furthermore, we demonstrate the true complexity of systems required to instantiate efficient measurement-and-feedback systems like Szilard engines.
The schematic set-up of our devices is shown in figure 1. The model consists of an input, a reaction volume, a series of chemical buffers, and a molecular ‘hook’ that can bind to the input molecules independently of their state ouldridge2017thermodynamics ; ouldridge2017fundamental . The input is a series of small boxes each containing a single input molecule. This molecule can be in one of two strongly metastable states, and so these input molecules represent a string of bits. This input is a minimal analogue of a fluctuating chemical environment, as experienced by single-celled organisms micali2016bacterial ; becker2015optimal ; parkinson2015signaling ; mitchell2009adaptive .
The rest of the system is our machine, a minimal analogue of an organism exploiting its environment. The machine functions by transferring molecules to and from its reaction volume via the molecular hook. Once in the reaction volume, input molecules undergo reactions with molecules that are internal to the system—for example, a molecule M encoding the memory. These reactions are coupled to large fuel buffers that collectively allow the machine to store the work extracted from the environment, similar to Refs. barato2013autonomous ; mcgrath2017biochemical . The buffers are the molecular analogue of a weight in a gravitational field that can be lifted by the system mandal2012work ; boyd2016identifying ; boyd2017correlation ; boyd2017leveraging . To perform this role, the buffers should be sufficiently large that any reactions have a negligible effect on the probability distribution of bath macrostates ouldridge2018power ; in this limit, the buffer state is purely a deterministic concentration, whereas the input and other molecules within the reaction volume are represented through stochastic variables describing the fluctuating chemical macrostate. Recent experimental work from Joesaar et al. has demonstrated how molecules encapsulated within ‘proteinosome’ reaction volumes can be coupled to time-varying external buffer conditions, with the buffer molecules able to diffuse in and out of the reaction volumes and participate in reactions with the encapsulated species, as we require joesaar2019dna-based .
Details of how a molecular hook might operate are given in appendix A. Such a mechanism can transfer molecules to and from the reaction volume with no net expenditure of work, provided that the hook is controlled by a particular quasistatic protocol. The hook thus represents a work-free mechanism of ingesting and excreting molecules in a controlled manner. An alternative model without ingestion would have input molecules attached to consecutive sites on a polymer tape mcgrath2017biochemical ; the machine would then interact with one or more of these molecules at any one time, based on proximity.
In this work we shall assume that buffer concentrations are manipulated by a well-defined protocol ouldridge2017thermodynamics ; ouldridge2018importance ; rao2016nonequilibrium ; schmiedl2007stochastic , as illustrated in figure 2. These protocols will not follow directly from the dynamics of degrees of freedom explicitly modelled—they are essentially externally imposed. Our system is then non-autonomous. We use externally applied protocols for two reasons. Firstly, because it allows us to design mechanisms in which first measurement of by , and then feedback to exploit using , are performed sequentially, as in Szilard’s engine (see Section III A); and secondly, because driving forces can be increased in a quasistatic manner (see Section II D). Both features are essential if we are to maximise both the efficiency of the reactions, and the reliability of the implemented information-processing strategy: quasistatic manipulation allows us to push reactions implementing each step of the process to 100% completion, efficiently. We can then focus purely on the constraints on work extraction that arise from the fact that the implementable information-processing strategies are limited by the finite size of the device’s memory.
Crucially, however, although our systems require external protocols, the protocols themselves require no decision-making intelligence; the same series of manipulations will be applied repeatedly, without feedback from the state of the system. All ‘decisions’ and feedback strategies must be made by the molecules that are explicitly represented. By avoiding protocols that require external decision-making dependent on the state of the system, we avoid implicit costs that have caused much of the confusion in the thermodynamics of computation, since the original thought experiment of Maxwell maxwell1891theory . In principle, the protocols we invoke could be applied in parallel to an arbitrarily large number of replicas (as shown in figure 1), rendering the marginal cost per machine of the external protocol negligible. Indeed, this is the assumption usually made with macroscopic thermodynamics. By contrast, if separate decisions had to be made for each replica, the economy of scale would not exist. Although the use of external control makes the individual devices a weaker analogy for single, autonomous organisms, the combined set-up of many devices and their controller is then an analogy for a single, albeit more complex, organism. We note in passing that the need for a quasistatic protocol to control the hook is equivalent to the need for a quasistatic protocol to deterministically advance the tape with which a machine interacts, as has previously been assumed in many bit-driven machines mandal2012work ; boyd2016identifying ; boyd2017correlation ; boyd2017leveraging ; Stopnitzky2018Physical —our physical instantiation makes this need clearer.
II.3 Numerics
All devices studied in this work produce a deterministic output of extracted work given a specific input sequence. Numerical results presented in this work are therefore obtained either by exhaustive summation of short input strings, or by sampling of long input strings by simulating the underlying generative model. The code and data to produce the figures in this paper can be found at https://doi.org/10.5281/zenodo.1976932.
II.4 Example system and calculation: Extracting work from a biased environment
We illustrate the operation and analysis of the set-up outlined in section II.2.2 by demonstrating it in the simplest possible context. We consider the reversible extraction of work from a low entropy input by increasing the free energy of a chemical buffer. In this setting, the input array consists of input molecules each initially in the state with 100% probability. The and states of the input molecules have equal intrinsic free energy so in equilibrium a single input molecule is equally likely to be in either state. Therefore, it is possible to extract a work of per input molecule from the environment.
Each input molecule is transferred to and from the reaction volume by a hook with no net work expenditure, as outlined in appendix A. When the input is in the reaction volume, we extract work by increasing the free energy of a bath of fuel molecules and with chemical potentials and . To do this we need a chemical reaction
[TABLE]
which couples the interconversion of and to the interconversion of and . The interconversion of and , or and , is assumed to be infinitely slow except via this reaction. No other molecules, such as those representing a memory, are necessary in this simple context. The central idea is that an excess of can be used to pump into against a chemical potential difference, storing work in the buffers just as traditional heat engines store work by lifting a weight. We now consider the details of how this work might be done.
It is possible to extract some work by connecting the molecule to a single bath of and molecules with a high concentration of , so that . Both the input and the bath are individually out of equilibrium, and tend to drive the reaction in Eq. 8 in opposite directions. In this case, the drive from the input is stronger and the reaction in Eq. 8 proceeds from right to left, with the input doing work on the bath. Over time, the bias of the input will decrease until the driving force of both contributions cancel; although the bath and the input are individually still out of equilibrium and store free energy, the input has reach a bias which is in equilibrium with driving force of the bath. At this point, the input will be in state with probability and in state with probability where , . During this relaxation to equilibrium, molecules of are converted to on average. Therefore, the free energy of the bath is changed by —this is the work extracted per input molecule.
Different choices of lead to different values of the work; however, has a maximum of , which is less than . This protocol has not extracted all of the work available; indeed the input molecule has not even reached its equilibrium distribution, so it is still a store of free energy. Thus the input molecule could be put in contact with a second bath with a lower concentration of molecules but still with an excess of above the equilibrium concentration and some more work could be extracted.
If the input molecule is connected to two successive baths with a non-infinitesimal difference in fuel concentrations, then the input molecule undergoes a thermodynamically irreversible relaxation, with some fraction of the free energy being wasted. However, if we take this idea of connecting the input molecule to successive baths with lower to the limit of a continuous change in we get a quasistatic process with no irreversible relaxations to equilibrium: the system is at equilibrium with the bath(s) at all points in time. This protocol is achieved by connecting the reaction volume to a large number of baths in succession for enough time to reach equilibrium with each bath as shown in figure 2. There is only a small change in concentration of fuel molecules between successive baths. Therefore, in the limit of infinite baths and infinitesimal changes in concentration the reaction volume experiences a quasistatic change in the concentrations of the fuel molecules.
The specific protocol of fuel molecule concentrations, illustrated in figure 2, is as follows. Initially so reaction 8 cannot occur. Then is slowly increased up to an appreciable value we name . The reason the concentration must be increased slowly is so that fuel molecules are not irreversibly transferred between different buffers via the reaction volume. The reaction in equation 8 still cannot occur, since only and are present. Then, is slowly increased. Now reaction 8 can occur; although, initially, the rate of converting to is much slower than the reverse so the input molecule is still in state with high probability. is increased to , which is the concentration at which the free energy change in reaction 8 is , so the and states are equally likely.
To calculate the average work extracted in this quasistatic process we consider the increase in free energy of the baths. Let the probability of the input molecule occupying state , when equilibrated with a buffer with a chemical potential difference of , be . A change in chemical potential difference of to is then associated with a probability change of . This change is also equal to the number of molecules that are on average converted to molecules when the reaction volume is exposed to a new buffer. Therefore, the free energy of the bath increases by on average.
Taking the limit of infinitely many baths, we integrate the total work done
[TABLE]
where we integrate by parts and recall that . The quasistatic protocol is therefore able to recover all free energy stored in the initial low entropy state, , as work. In performing this calculation, we have ignored external costs associated with generating the quasistatic protocol, for reasons outlined in II.2.2. The transfer of molecules between adjacent buffers, mediated by the reaction volume, has a cost that tends to zero as the concentration difference between buffers tends to zero. With the basic approach to set-up and analyse of our machines explained, we can discuss specific measurement and feedback processes.
III Results
III.1 A Biochemical Szilard engine
Before analysing structured environments, we first present a measurement-and-feedback device that acts on a single binary input. This simpler setting allows us to illustrate the explicit measurement-and-feedback cycle that will underlie all the devices in this work. In particular, we demonstrate a mechanism by which the input is first able to influence the state of a memory, and subsequently the influence is reversed so that the state of the memory affects how work is extracted from the input.
The biochemical Szilard engine consists of an input molecule, a memory molecule, and chemical fuel buffers that are used to supply or recover chemical work; to implement a single cycle, we do not require a series of inputs, or a molecular hook. The input molecule is in one of two states: or . For simplicity, we assume the states have equivalent intrinsic free energy, and that the system is in equilibrium: the molecule is then found in each state with probability . The memory molecule also has two states with equivalent intrinsic free energy, and is initially in state with probability and in state with probability .
To ‘measure’ the state of the input means to set the state of the memory to if the input is or to if the input is : we correlate the states. This step follows the optimal copy protocol in ouldridge2017thermodynamics and can be done using the chemical reactions
[TABLE]
where , , and are a fuel molecules that are present in excess, and and act as catalysts for the transformation of between its states. Interconversions other than via the catalytic reactions in equation 10 are assumed to be so slow as to be negligible. The central idea is to drive the catalytic reactions in opposite directions through fuel imbalances, so that M can be set to in the presence of , and to in the presence of .
The selective catalysis in equation 10 is an approximation of the behaviour demonstrated by bi-functional kinases in cell signalling networks stock2000two , and can also be engineered from nucleic acid networks (see appendix E for details). The free energy changes of the reactions and the reaction rates can be controlled by the concentrations of the fuel molecules, as in the simple example in section II.4.
It would be possible to set the memory molecule to the correct state by directly coupling to a buffer with and . As in section II.4, however, the associated process would be thermodynamically irreversible, wasting the ability of the fuel buffer to do useful work. We therefore change the fuel concentrations quasistatically, as illustrated in figure 3, gradually forcing the memory to the state when in the presence of , and to the state in the presence of .
Initially, , , and are all set to zero. The reactions in equation 10 therefore cannot occur. Then, the concentrations are simultaneously increased at a fixed ratio of and that maintain an overall free energy change of zero for the reactions in equation 10. One of these interconversions (determined by whether there is an or and present) now occurs at an appreciable rate, but forwards reactions exactly balance reverse reactions so there is no overall change in the probability of observation of and .
Next, and are increased while and are kept constant. As a result, the first reaction in equation 10 is pushed to the left and the second to the right. Consequently, if the input is then the memory molecule is more likely to be and if the input is the memory molecule is more likely to be . Eventually, when and have been increased so that and , the memory molecule will be perfectly correlated with the input . Next, , , and are decreased while maintaining and until . Finally and are decreased to zero. Now the reactions in equation 10, again, cannot occur so the memory molecule is fixed to be if the input is and if the input is .
In this correlated state the entropy of the combined system is because there are two equally likely states: or . Prior to measurement the entropy was because the four combinations of and are equally likely. Thus the entropy of the system has decreased by and so the free energy of the system has increased by .
The increase in free energy of is compensated by a decrease in the free energy of the buffers. This decrease can be calculated as in section II.4, except with the limits on the integral reversed and considering two equally likely possibilities: either the input molecule was and the concentrations of and are changed due to the first reaction in equation 10, or the input molecule was and the concentrations of and are changed due to the section reaction in equation 10. The result is that the free energy change of the buffers is , which exactly cancels the free energy increase of , as it should because the process is thermodynamically reversible (see appendix B.1 for more details on this calculation). This reduction in free energy of the buffers is the ‘cost’ to measurement that was recognised by Szilard as the resolution to the Maxwell’s demon paradox szilard1929entropieverminderung .
We now consider the feedback step. The device extracts chemical work from the correlated state by allowing the input molecule to evolve in a manner that reflects the outcome of the measurement. The machine uses the reactions
[TABLE]
in which the , , and are further fuel molecules. Now, and act as catalysts for the transformation of between its states; non-catalysed reactions are again assumed to be impossible. and must therefore be mutual bifunctional catalysts, which can be effectively switched on and off by modulating fuel concentrations. This explicit rendering demonstrates the complexity necessary in a minimal measurement-and-feedback device such as Szilard’s engine, in which the memory and input must reverse their roles as the determinants of the dynamics. A design based on DNA strand displacement soloveichik2010dna ; cardelli2013two ; chen2013programmable is presented in appendix E.
As in the measurement step, the reaction rates are slowly manipulated by coupling to buffers with different concentrations of fuel molecules. Initially , along with the fuels used in the measurement process, and no reactions occur. Subsequently, and are increased. At this point the reactions in equation 11 do not occur since the right combination of fuels and substrates are not present.
Next, and are increased until the free-energy change of reactions in equation 11 is zero. As a result, the input molecule is slowly decorrelated from the memory, but the memory state determines which fuel buffer the input couples to during this process. Finally, , , and are decreased to zero while maintaining a free-energy change of zero for the reactions in equation 11.
As with the measurement, we can calculate the change in free energy of the input molecule and measurement molecule system and the chemical work done by the chemical fuel buffers. This extraction step is essentially the reverse of the measurement step, so the free energy of the input molecule and measurement molecule system decreases by while simultaneously the free energy of the buffers increases by (see appendix B.2 for more details on this calculation).
At the end of the cycle, both the memory molecule and the input have been returned to unbiased and statistically uncorrelated states. Chemical free energy has been transferred from the buffers 1 and 2, to buffers 3 and 4. The net chemical work extracted is then zero since the cost of measurement balances the work extracted. This is, of course, expected—extracting work from the initially equilibrated input should be impossible. However, this basic design will underpin that of devices intended to exploit structured environments, and recover net positive work.
We note, in passing, three instructive features of our explicitly-described biochemical Szilard engine. Firstly, the measurement and feedback reactions can be implemented sequentially by coupling to buffers of first one, then another, type of fuel molecule. This ability to switch from having the input set the memory, to having the memory modulate the evolution of the input, is the key feature of our setup that allows us to represent the full cycle. Secondly, there is no need for an ‘erase’ step to reset the memory to a specific state bennett1982thermodynamics . Whilst it would be possible to include such a reset, it is not necessary, either for efficient operation or to preserve the second law of thermodynamics. The second law is preserved simply by the ‘ominous’ nature of the non-equilibrium correlations originally identified by Szilard. Thirdly, the measurement is simply the act of setting the engine into the correct state to exploit the input (setting the memory to or ). There is no need for any other system, intelligent or otherwise, to record or be aware of the outcome of the measurement. In the context of the typical one-particle-gas description of Szilard’s engine szilard1929entropieverminderung , the measurement is simply the correlation of the pulley and particle positions. Any additional recording of the particle position (for example in the brain of an intelligent being) corresponds to a useless extra correlation or measurement, with associated costs that must be carefully recovered at a later time to reach 100% efficiency.
III.2 Exploiting a series of correlated bits
Although the Szilard engine cannot extract useful work from its equilibrium input, it forms the basis of a device for exploiting a series of identical biochemical bits labelled with the index , whose correlated states, described by the random variables , are generated by a stationary stochastic process. The random variable has the possible outcomes of or . We consider the series to be infinite in both directions. As with the Szilard engine in section III.1, both states of the input bits are assumed to be equally intrinsically stable, and separate bits do not interact (they are in different boxes in the language of figure 1). The equilibrium distribution of the inputs is, then, for each molecule to be independently distributed uniformly between its two states.
Free energy is stored in the input array if either an initial bias towards or is present, and/or correlations exist between and for . Since designing a system to exploit an intrinsic bias is simple, and requires no measurement or inference (see section II.4), we focus exclusively on the case in which the marginalised probability of each bit occupying either state is .
III.2.1 Bounds on work extraction
The free energy per bit stored in such an array, and hence the available work per bit, is determined by the difference between the equilibrium Shannon entropy per bit of and the entropy rate boyd2016identifying
[TABLE]
where
[TABLE]
An array of bits has a state space of size . For an array with arbitrary correlations, an operation must be ‘globally integrated’ across all bits to fully extract boyd2018thermodynamics . Even if a system were able to achieve this integration by coupling to all bits in an array simultaneously, extracting the full available work would be highly non-trivial. In practice, the protocol would need to be tuned to the expected initial occupancy of each of the states to avoid losses.
The opposite limit to a device that is able to interact with the entire input at once is a device that interacts with each bit separately and in an independent manner. However, such a device can only extract the free energy stored in the state , , having marginalised over all other . In our setting, and thus no work can be extracted. The correlations are wasted and a ‘modularity cost’ is incurred due to the fact that before the work extraction there is mutual information between and later input states, but after the work extraction that mutual information is zero boyd2018thermodynamics .
Let us consider a simple extension to the independent-bit device that is interpretable and offers the potential of extracting at least some of the stored work whilst retaining limited complexity. We still manipulate input bits individually, but allow for a memory that maintains its state when the device moves to the next subsystem. This memory permits some of the free energy stored in correlations between successive inputs to be exploited. We now derive a bound on work extraction by this method.
Consider two adjacent input bits labelled and , and the memory system. The initial state of the th bit is the random variable . can take two values: or . During the interaction of the memory system with the th bit, is both measured and recorded in the memory as the state , and work is extracted from the th bit as it relaxes to a state . We are now concerned with the work that can subsequently be extracted from the th bit following the same procedure, given the correlations between and induced by the measurement.
Let be the free energy of the joint system consisting of the th bit and the memory system when in states and respectively. Before and after the coupling of the th bit and the memory system, there is no direct interaction between the two subsystems, and hence the free energy can be written as the sum of individual contributions calculated using marginalised probabilities and an informational term arising from the correlation between and as in equation 4 parrondo2015thermodynamics . Prior to measurement, we have
[TABLE]
After the interaction window, we have
[TABLE]
The work extracted by any process operating between these start and end points is bounded by
[TABLE]
If the process that produces the inputs is stationary and the measurement protocol is the same each time, then . Moreover, by design, is minimal since the marginalised distribution of is the equilibrium one. Invoking the positivity of the mutual information Elements_of_Information_Theory , we see that the available work is maximal when also follows an equilibrium distribution, and the extraction process fully decorrelates the input from the memory (). Thus the work extracted per input bit is bounded by
[TABLE]
A system that does not make use of a memory, such as the setup for directly exploiting biased inputs discussed in section II.4, would therefore extract no work.
The value of the mutual information in equation 17 depends on the details of the measurement process. The state of the memory system, , only depends on the state of the next input, , through the previous input state, , so by the data processing inequality the maximum work that can be extracted is
[TABLE]
This work is, of course, not greater than the available work in the input. The input is stationary so it is possible to write the entropy rate as Elements_of_Information_Theory
[TABLE]
and if we use the fact that the conditional entropy is not increased when conditioning on additional variables then
[TABLE]
These results are a special case of the ‘modularity cost’ outlined in boyd2018thermodynamics .
Single bit memory devices are therefore constrained by the amount of information they carry forward to the next bit in the chain. Note that carrying this information forward is not sufficient—it must also be used effectively during the interaction window. One might assume that there is an inherent trade-off between updating the memory to be the best possible predictor of the next bit, and using the memory to make the extraction of work from the current bit as efficient as possible. We will now explore this potential trade-off, and these bounds on work extraction more generally, in the context of two distinct devices in two different types of environment.
III.2.2 Exploiting a Markovian input
We first consider the case in which the binary input is Markovian. That is, the probability distribution of the state of each input molecule only depends on the state of the previous molecule. Since we consider processes which have no bias to either state 0 or 1, this process is a one parameter model given by the probability of transitioning state from one input to the next. The entropy of a series of Markovian random variables is
[TABLE]
in which we have first used the chain rule for conditional entropies Elements_of_Information_Theory and second the Markov property. Therefore, from Equation 12, the available work if the Markov chain is stationary is
[TABLE]
Comparing Equations 18 and 22, we see that the maximum work for a single bit memory is equal to the full available work in a Markovian environment: . We now outline a device that extracts all of this work, both achieving the required measurement accuracy and using this measurement to extract all of for each bit.
We first note that any update of the memory from to must occur before the th bit is allowed to evolve. Thermodynamically efficient manipulation of the th bit requires that any protocol is quasistatic, with the reactions reaching equilibrium with respect to the control faster than the control is updated. Thus, as soon as transitions are allowed by the control, all memory of the previous state is necessarily forgotten, and subsequent updates of the memory using the initial value of are impossible.
At first glance it might then seem impossible to extract all the work stored in this setting. We must apparently pay to update the memory from to using input to carry information forward, before we are able to use the memory to exploit . The recent result of owen2017number does not preclude the possibility of extracting all the stored work, but leaves open the possibility that a single additional ‘hidden’ state might be required to circumvent this apparent problem (see appendix C).
In fact, no additional states are required. The solution is to use the information carried forward from the measurement of the previous input, , to make a low work-cost but faithful measurement of , () and then to use that measurement to extract of work from the relaxation of the th bit exactly as in Szilard’s engine, see Section III.1. Here, the low work cost is measured relative to the cost of a naïve measurement performed without information carried forward from the previous bit.
An overview of this process is shown in figure 4. First the new input is copied to the memory. This copy is done using the same chemical reactions as in the measurement step of the biochemical Szilard engine in section III.1, repeated here for convenience
[TABLE]
The only difference from section III.1 is that now the initial state of input and memory is different. It is still the case that the input molecule and memory molecules are each, when treated in isolation, equally likely to be in both of their states. Now, however, the states of the two molecules are correlated since the memory molecule has been set using the state of the previous input molecule, . A different measurement protocol is therefore needed to make an optimal (reversible) measurement. Instead of starting from a chemical potential difference for the fuels, we must start with either and in excess so that the equilibrium distribution dictated by this buffer matches the actual biased probability distribution of the memory molecule given that the input molecule is . Similarly, either and must be in excess so that the equilibrium distribution dictated by this buffer matches the biased probability distribution of the memory molecule given that the input molecule is .
The ideal protocol therefore proceeds as follows. Initially, as in the biochemical Szilard engine in section III.1, , , and are all set to zero so the reactions in equation 23 cannot occur. Then, the concentrations are simultaneously increased at a fixed ratio of and that maintains constant free-energy changes for the reactions of equation 23, and , such that
[TABLE]
The reactions catalysed by whichever of or is present now occur at an appreciable rate, but forwards reactions exactly balance reverse reactions so there is no overall change in the probability of observing of and . If there is no overall bias towards or then by symmetry. We have used the term ‘’ because the chemical potential difference has been ‘offset’ from zero, which is what it would be if the successive input molecules were uncorrelated.
The rest of the protocol is the same as for the measurement step of the biochemical Szilard engine in section III.1. Next, and are increased while and are kept constant until and . Then, , , and are decreased while maintaining and until . Finally and are decreased to zero. Now the reactions in equation 23, again, cannot occur so the memory molecule is fixed to be if the input is and if the input is .
The work done by the chemical fuel baths to make this measurement is once more calculated as in section II.4 but with different limits on the integral due to the different . As shown in appendix D.1, the work done is exactly , as expected from the change in entropy of the input molecule and memory molecule joint system.
Now that the state of the memory molecule has been updated so that perfectly reflects , work is extracted in exactly the same way as in the biochemical Szilard engine. Thus the net work extracted per input molecule is
[TABLE]
which is all the available work in a stationary Markovian input as in equation 22. This machine has 100% efficiency and there is no irreversible dissipation.
It is therefore possible that a machine with a two-state memory that is well-calibrated for this Markovian environment—with the correct initial in chemical potentials to reflect the nearest-neighbour correlations in the Markov chain—can extract all of the work available. Such a machine faces no trade-offs between exploiting and measuring ; the exact measurement of both carries the maximal information forward, and enables its full exploitation. How a machine might obtain the optimal offset parameter, either via design or some form of evolution (to effectively infer the one parameter specifying the Markov process), is beyond the scope of this paper. We emphasise that calibration of to the environment is not equivalent to being tuned to the specific fluctuations of one realisation of the environment, but rather to the overall statistical properties of the fluctuations. A poorly-chosen parameter would result in the ‘mismatch costs’ identified by Kolchinsky and Wolpert kolchinsky2017dependence .
III.2.3 Exploiting a non-Markovian input
In a Markovian environment, if a machine measures the state of an input molecule it knows everything it could about the distribution of the next input. A more complex environment might have correlations that are not fully-described by those of adjacent inputs. In particular, we might imagine an environment with a hidden state that influences the probability of ; as the hidden state changes, the device moves between regions in which the apparent environmental bias is different. The machine’s challenge then becomes a more obvious inference task: to infer the overall state of the environment, and to accordingly exploit the inputs.
Specifically, we will consider a hidden state with . When moving from one input molecule to the next the hidden state has a probability of changing. Conditioned on the hidden state, each input molecule is an independent Bernoulli random variable. The probability of an molecule is if and if . Some example sequences produced by this process are shown in figure 5. Due to the overall symmetry of the process, and are both equally likely having marginalised over all inputs . Thus, as in section III.2.2, no free energy is stored in the state of single molecules—only in the correlations between different molecules. The available work that can be extracted per input molecule is plotted against the parameters and in figure 6. Hidden states that either reliably persist () or switch (), and which provide a predictable output () lead to the most free energy stored in the environment.
Given the history of the inputs , the optimal statistical prediction of the next input can be made via the forward algorithm stratonovich1960conditional . A machine capable of both iterating the forward algorithm at each step, and using the previous value to optimally exploit the current input, would be able to extract the full . However, implementing the forward algorithm is impossible for our machine with a single bit of memory that can make only a binary ‘decision’ during its feedback. For a hidden Markov process, the conditional probability distribution of the next input molecule given the entire history of the input is different for all possible states of the history. Equivalently, the process cannot be described by a finite state -machine shalizi2001computational , and thus the forward algorithm requires a memory that is a real number, and the exploitation step would need to have a continuous dependence on this real number.
It might be tempting to think that a simpler alternative to the forward algorithm, in which the two-bit memory variable is set based on both the current input variable and its previous value , would give better predictions by allowing the machine to take in more historical information at each step. Such an approach would represent a trade-off, with a maximal information carried forward being obtained only at the expense of an increased uncertainty in the state of the current input after the measurement. Whether or not the reduced measurement cost could compensate for the reduction in work obtained during the extraction step is moot, however, since such a strategy is impossible, at least in the quasistatic setting. One cannot update the memory from to quasistatically, in a way such that , without access to additional hidden memory states wolpert2017minimal ; owen2017number . All information on initial conditions is necessarily lost immediately when a degree of freedom evolves under a quasistatic process. Thus in the quasistatic setting at least, our single bit memory cannot trade off the accuracy of measurement of the current input and information carried forward.
III.2.4 Markov machines in non-Markovian environments
With the above limitations in mind, we first ask how well the Markov machines considered in Section III.2.2, that are limited to interact with one bit at a time, and carry only one bit of memory forward, function in the non-Markovian environment specified. For a perfect measurement of each bit, such that , the expected work extracted per molecule for a quasistatically-operated device still follows from Equation 18
[TABLE]
but now since there is additional information in long range correlations that is not taken into account by the information between nearest neighbours. Therefore, the machine has efficiency and irreversibly generates entropy.
This efficiency, , of Markov machines acting on a hidden Markov model input is plotted in figure 7(a). In making these plots, we first identify the optimal Markov machine offset parameter at each and , and then calculate the efficiency of that device—once again assuming that the machine’s parameters are optimised to the statistical properties of its environment (perhaps through evolution). It is notable that the Markov machines perform reasonably well in these environments, except when or 1, and or 1. In these environments, the hidden state behaves predictably and so correlations are long-ranged, but fluctuates considerably within the hidden state, effectively fooling the Markov machine that is only able to predict based on .
The behaviour of the Markov machine can be related to that of the Kalman filter kalman1960new , an algorithm for making real-time predictions of the state of a noisy dynamical system with noisy measurements of the system’s state. The relative weight put on previous measurements versus the most recent input is a parameter that can be adjusted, and it is well known that high intrinsic noise implies that the current measurement should be weighted strongly, whereas high measurement noise calls for greater emphasis on the previous measurements. The Markov machine is effectively constrained to put all of its emphasis on the most recent measurement; it therefore functions better when the ‘intrinsic’ noise of the hidden state is relatively high ( and ), and worse when the ‘measurement’ noise of the inputs is relatively large (, ).
III.2.5 Batch averaging machines in non-Markovian environments
We now ask whether a more sophisticated strategy, still involving only a single memory molecule and a single binary decision, can overcome this weakness of the Markov machine. If we consider the region where , then it is likely that a run of multiple input molecules will be produced by the same hidden state. Inspired by our analogy with the Kalman filter, we look for a mechanism of somehow considering multiple input molecules to provide more reliable information about the hidden state, allowing more efficient work extraction. Indeed, in the context of cellular sensing of the concentration of external ligands govern2014optimal ; berg1977physics , it has been observed that averaging approaches can be beneficial when correlation times in the environment are long Malaguti2018Theory .
We therefore introduce the batch machine, illustrated in figure 8, which is similar to the Markov machine except that it interacts with (i.e. measures and exploits) a batch of multiple molecules simultaneously, rather than just one. An -batch machine operates by: (a) transferring inputs to the reaction volume (with no work cost—see appendix A); (b) performing an operation to set a memory based on these inputs (for a low work cost because the state of the batch is correlated with the state of the memory, which is set based on the state of the previous batch); (c) exploiting the inputs simultaneously using the memory; and (d) transferring the inputs back to their array in a random order.
We will first consider a ‘binary’ machine that, like the Markov machine, has only two measurement reactions and two work extraction reactions. Let be the random variable representing whether the number of molecules in batch is greater than half the batch-size, ( if true, 0 otherwise). The machine performs measurement of batch by setting the memory molecule to if , and to if ; we note that other binary measurement choices are possible, but this simple one serves to illustrate the possibilities of a more complex inference strategy. The machine then exploits the imbalance of inputs in the same way that the Markov machine exploits a measured or , by allowing the inputs to relax to an unbiased distribution whilst transferring free energy to chemical buffers. For , the binary batch machine is identical to the Markov machine of section III.2.2; for the initial measurement essentially performs an average over inputs to set its memory. In the limit , the batch machine interacts with all molecules at once. However, with only two possible measurement states (and hence two possible work extraction strategies), this limit is generally inefficient.
The measurement can be done with the reactions
[TABLE]
when is odd and
[TABLE]
when is even. There is an in one of the reactions in equation 28 and an in the other because for even there is an arbitrary choice as whether to assign the state where there are molecules of in the batch to or . We have chosen to assign the state with molecules to . Clearly, if there are molecules of and in total, then only one of these reactions in equations 27 and 28 can occur at once. As a result, if the reactions are once more driven in opposite directions by fuel imbalances, an excess of molecules can be used set the memory to , and an excess of can be use to set the memory to . We immediately see the price for a more complicated strategy—our reactions now require molecules to act as combined catalysts, rather than just a single input molecule (see appendix G for a DNA strand displacement design for these reactions).
The protocol of changes to the fuel molecule concentrations required for measurement is very similar to that of the Markov machine. Initially, , , and are all set to zero so the reactions in equations 27 and 28 cannot occur. Then, the concentrations are simultaneously increased at a fixed ratio of and that maintain overall free energy changes for the reactions, and , such that
[TABLE]
In exactly the same way as in the biochemical Szilard engine and in the Markov machine, depending on whether there are more or molecules in the batch, one of the measurement reactions can now occur at an appreciable rate. The initial offsets and allow information between batches to be exploited, and are exactly analogous to the constant offsets introduced in section III.2.2. Like in the Markov machine, if is odd then by symmetry. If is even then because .
Then, as in the previous machines, and are increased while and are kept constant until and . Subsequently, , , and are decreased while maintaining and until . Finally and are decreased to zero. Now the reactions in equations 27 and 28, again, cannot occur and the memory molecule has been set to state if the batch contains more molecules that or equal number of and molecules, and to state if the batch contains more molecules than .
The cost of making the measurement is calculated in exactly the same way as for the Markov machine (see appendix F.1), and gives
[TABLE]
The negative sign represents negative work extraction.
Subsequently, work is extracted from the correlated state of the measurement molecule and the batch. The binary batch machine uses the same reactions as the biochemical Szilard engine and the Markov machine to extract work; they are repeated here for convenience:
[TABLE]
However, the protocol is modified, which is necessary because the state of the memory molecule does not report perfectly on the state of the inputs: any number of molecules in state greater than correspond to and hence , for example. Initially , along with the fuels used in the measurement process. Then, the concentrations are simultaneously increased at a fixed ratio of and that maintain an overall free energy changes for the reactions, and , such that
[TABLE]
where is the probability that an input molecule in the batch is in the state , conditioned on , and is the probability that an input molecule in the batch is in the state conditioned on . It is clear that (assuming that the and molecules have equal free energy) because and because . On average, no chemical work is done at this stage. Similar to the measurement, if is odd then by symmetry. If is even then because .
Work can then be extracted from the batch exactly as for independent molecules with a bias represented by and . Therefore, and are increased quasistatically until the free energy differences, and , are zero. Then , , and are decreased to zero while maintaining the same and ratios. When again the reactions in equation 31 cannot occur. So, finally, the batch reaches an unbiased equilibrium, and during this process the free energy of the buffers are increased. The work extracted in this step is simply times the work extracted from one input molecule with a bias of if or if the number of . It is therefore
[TABLE]
Therefore, the net work extracted by the binary batch machine from one batch is
[TABLE]
As with the Markov machine, we can ask the question of how the optimal batch machine (with and the free-energy offsets of the fuel baths optimally tuned to the environmental parameters and ), would perform. Note that since the binary batch machine with is a Markov machine, the optimal binary batch machine must perform at least as well as the optimal Markov machine.
The efficiency of the optimal binary batch machine is plotted for different values of and in figure 7(b), showing apparently higher efficiency than the optimal Markov machine for some values of and as . To make this comparison clearer, in figure 7(c) we have plotted the work extracted by the binary batch machine per molecule divided by the work extracted by the Markov machine per molecule. We see that there are two regions where the binary batch machine extracts more work. Also, in figure 7(d) we have plotted the optimal batch size for the binary batch machine for the different values of the parameters. For the optimum batch size is always so the Markov machine and the binary batch machine are the same, but for smaller values of larger batches are frequently favoured. It is always the case that the optimum batch size is odd, since the extraction reactions of the binary batch machine cannot extract work from a batch with equal numbers of and molecules.
The binary batch machine delivers, at least in part, on the prospect of improving work extraction from an environment with more complexity. It is unsurprising that a long hidden state life time, , is necessary for this advantage to be manifest: the averaging strategy will clearly fare poorly when the hidden state switches rapidly. When is close to 0 or 1 the state of the input molecule reflects the hidden state with a high probability so the string of input molecules is approximately Markovian, preventing the batch machine from finding a competitive advantage. The most subtle question, however, is why the binary batch machine does not extract more work than the Markov machine when and . Naïvely, this regime would seem to be ideal for the batch machine to extract work from weak, but long-lived biases towards either or . From the perspective of the analogy with Kalman filters, this regime should favour the approach that considers a wide range of inputs, rather than just the most recent. To understand why this intuition fails, we consider where the thermodynamic losses occur during the operation of the binary batch machine.
Several stages of the operation of the optimal binary batch machine are thermodynamically irreversible, resulting in efficiencies . They include the point at which the memory is updated without taking into account correlations between non-neighbour batches; the point at which the batch of input molecules are mixed within the reaction volume (figure 8); and the point at which the work extraction begins using the measurement molecule. In the first process, a modularity cost is incurred. In the second, mixing causes the positional order within a batch to be lost, reducing our ability to extract work from the sequence of molecules within the batch. All that remains is a non-equilibrium distribution of the number of molecules in each state. In the third process, this non-equilibrium distribution relaxes further to a binomial distribution for the number of with parameter if or if , with no work extracted on average during this relaxation, as shown in figure 9(a).
We can imagine a putative ‘full batch machine’ that could extract all of the work available from the unordered batch, after the initial mixing and measurement. Such a machine would require additional extraction processes to which the memory could couple in each state. The optimal batch size for this full batch machine is plotted in figure 9(b). We can see that for this machine it is not the case that the optimal batch size is 1 when . The contour plot for this machine is more similar to expectations: as optimal batch size increases for all values . We have also plotted the ratio between the work extracted by the full batch machine and the Markov machine in figure 9(c), and see that the full batch machine extracts more work than the Markov machine when is close to 0 and . Thus the reason that the binary batch machine fails to provide an improvement in the vicinity of is at least in part because the free energy wasted during the simple binary work extraction mechanism is too large compared to the relatively low amounts of work available (as seen in figure 6).
III.2.6 Robustness
On average, all the machines can extract a positive amount of work from each input molecule or batch of input molecules. However, in a single realisation of the input produced by the stochastic process it is possible for the machines to extract a negative amount of work; i.e. lose free energy, since the prediction of the upcoming state is only probabilistic even in the best case.
Thus, the total work extracted by any machine is a biased random walk. If the machine is unlucky it can receive a fluctuation in the input and get many negative steps with few positive steps. If we are imagining that the machine needs to harvest enough work to power its decision-making, like a biological organism, a fluctuation in its environment where it loses all of its stored free energy would be disastrous. We therefore also consider fluctuations in the work extracted by the machines. If one protocol has a higher expected work extraction but a larger variance it might not be truly better.
The expected worst-case energy-loss—the infimum of the work extracted—can be thought of as the starting larder-size/fuel-reserves that such a reasoning machine requires. It also gives a minimum timescale that any machine would need to run before it could create a replica that is also robust to environmental fluctuations. This infimum of the total work extracted by the machines in a trajectory averaged over many simulated trajectories is plotted against the parameters of the input process in figure 10. When or , the work that is extracted by the machines is small so the size of the negative fluctuations are also small for both machines. Comparing figures 10(a) and (b) shows that the binary batch machine exhibits reduced fluctuations in the regions where is close to 0 and is not close to 0, 0.5 or 1, where a batch size greater than 1 is favoured by the average work extracted. This fact is perhaps unsurprising, given that averaging over many inputs is inherently conservative.
IV Discussion
We have considered the question of how minimal molecular devices might be designed to exploit the free energy stored in simple non-equilibrium environments. Having outlined a concrete design for a biomolecular Szilard engine, we have shown how such a device can form the basis of machines for exploiting a correlated series of molecular bits, expanding on previous work that has only considered environments with a very particular structure mcgrath2017biochemical ; Stopnitzky2018Physical ; chapman2015autonomous .
Although our devices require externally-applied protocols to operate, all information-processing is performed by degrees of freedom that are explicitly represented as biomolecules undergoing reactions in dilute solution—there are no concealed degrees of freedom. As a result, the complexity of implementing minimal systems that exhibit efficient measurement and feedback is made clear, and ambiguities are eliminated. In particular, we have outlined a molecular mechanism for implementing sequential measurement and feedback in an explicit setting, providing clarity not only to the extended correlation-exploiting devices, but also to our representation of the canonical Szilard engine itself. The continuing debate surrounding such devices (see references in ouldridge2018importance ; parrondo2015thermodynamics ) shows the importance of a concrete physical representation.
For an environment with no structure—without correlations between successively encountered molecular bits—there is no need to process information and all of the available free energy can be extracted as work without use of a memory or any decision making. For a Markovian array with non-zero correlations between consecutive bits, we show that a simple two-state memory that can select one of two work extraction protocols can extract all of the stored free energy in the environment. The two-state memory is sufficient to carry all of the available information about the future of the environment forward, and we have identified a protocol that is simultaneously optimal for updating the memory according to the current input, and exploiting said input. For a more complex environment, involving a hidden variable that can only be inferred by the machine through noisy measurements, we argue that a machine with a finite memory cannot extract all of the available free energy as work. We demonstrate that in such a setting, a more complex strategy involving effectively averaging over a batch of molecules can be advantageous if correlations are long-ranged, but noise is substantial. This is similar to the result in seoane2018information that a more complex predictive model is advantageous in a more complex environment, but, in this paper, we give an explicit physical model for how our machines measure and exploit the environment. In our design, the complexity of the mechanism involved the ability to couple to multiple inputs simultaneously; we predict that alternatives (such as systems with larger memories and more possible decision) would also show the potential for improved performance.
A real living system must not only extract enough resources from its environment on average, but also over short intervals. In any fluctuating environment, an unlucky sequence of events might lead to starvation and death. We probe this situation in our minimal setting by considering the typical infimum (lowest point) of the work extracted by our devices, which represents the typical scale of negative fluctuations. We find that the more sophisticated inference strategy considered here also has smaller negative fluctuations when it is favourable on average, suggesting that it truly can be advantageous. In a minimal living system, reduced negative fluctuations would correspond to the need for a smaller reserve of energy, and the ability to produce viable offspring more quickly, since each offspring would need to be provided with the reserves to deal with typical negative fluctuations for a large fraction to survive.
The minimal devices we consider are clearly unnatural, and constitute only a first step towards understanding the physics of living or life-like systems that make simple decisions. A key feature of our design is that only single copies of some molecular species are present; it is an open question how to design optimal systems in which the information-processing components, and indeed the inputs, fluctuate more widely. We do note, however, that much of the molecular decision making within cells occurs at the level of transcription factors binding to DNA—these transcription factor binding sites are present with a low and predictable copy number. Future work will focus on constructing minimal models in which the systems are autonomous, requiring no external control, and power their own information-processing tasks by the free energy harvested. A major challenge here would be to implement reliable and efficient measurement and feedback without an externally imposed clock that allows sequential operation, as in this work. More realistic environments of fluctuating chemical concentrations, rather than input molecules that arrive one-by-one, will need to be considered. In such descriptions, it will be necessary to construct a more detailed kinetic model of the underlying elementary reactions than we present here. A deeper question is whether we can design concrete systems that actually learn the statistics of their environment, evolving the parameters of their decision making process towards an optimal strategy, rather than having fixed, optimal parameters as in this work.
Despite the simplicity of our current approach, however, we believe that concrete lessons can be drawn for the physics of living or life-like systems making simple decisions. In our physical model, successively more complex, and potentially costly, information-processing architectures perform better in successively more complex environments. We would expect that the information-processing carried out by living organisms reflects a similar trade-off: more complex decision-making strategies are more worthwhile in environments that exhibit statistical structure over time scales that are long compared to the decision-making time, and large fluctuations that must not be misinterpreted. We also expect that true evolved strategies will not optimise exploitation of the environment on average in isolation; strategies should also be designed to hedge against the risk of negative short-term fluctuations, to a degree that depends upon the cost of storing resources that compensate for these fluctuations.
V Data availability
The code and data to produce the figures in this paper can be found at https://doi.org/10.5281/zenodo.1976932.
VI Acknowledgements
T. E. O. acknowledges support from a Royal Society University Research Fellowship and R. A. B. acknowledges support from an Imperial College London AMMP studentship.
Appendix A The molecular hook
The input molecules can be moved reversibly between their boxes and the reaction volume. Hooks to reversibly move molecules between different volumes has been previously discussed in the supplementary material of [28]. First the input molecule must be attached to the hook. This can be done, for example, using the chemical reactions
[TABLE]
where H is the hook with no molecule attached inside the input molecule box and H and H are the hook with an input molecule attached. The binding of the hook is insensitive to the state of the input molecule.
The / molecule can be transferred to the reaction volume in the following steps. Initially, . After the hook is introduced to the box is increased up to a value of . Then, is increased to a value . Now the / molecule is for certain attached to the hook. Next, the hook is transferred from the input box to the reaction volume. This transfer can be done either chemically using a conformational change in the hook molecule mediated by another pair of fuel molecules as in the equations:
[TABLE]
or, alternatively, by a purely mechanical quasistatic process.
Then, to release the input molecule from the hook inside the reaction volume the reverse of the protocol the attach the input molecule is used. Initially and with . Then, is decreased to zero and, subsequently, is decreased to zero. Now the input molecule is for certain released from the hook inside the reaction volume.
Subsequently, the measurement and extraction protocols can be carried out. Afterwards, the input molecule, which could have changed state, is moved back to its box. This is done by attaching the input molecule to the hook, moving the hook and detaching the input molecule from the hook in the exact reverse of the protocol to transfer the input molecule to the reaction volume.
The free energy of the input molecule is the same whether it is in the or state. In general it is not the case that the free energy of the input molecule when it is in its box, , is the same as the free energy of the input when it is in the reaction volume, . Therefore, if the input molecule is transferred reversibly from its box to the reaction volume then the control must have done a work of on the input molecule. If the molecule is moved back to the box reversibly then this work is recovered.
Clearly, this principle can be extended to moving multiple molecules into the reaction volume as required by the batch machines, and then back again to the reaction volumes. Again, the whole process requires no net work. The initial transfer is not reversible for a structured environment, however, since the order of molecules is randomised within the reaction volumes.
Appendix B Work calculation for Biochemical Szilard engine
B.1 Measurement
The measurement follows the optimal copy protocol in [27]. Initially, the memory molecule is in states and with equal probability and the input molecule is independently in states and with equal probability. The state of the input is measured using the equations
[TABLE]
The free energy difference , where depends on the intrinsic nature of the and molecules and the reaction volume but not their concentrations, is quasistatically changed from 0 to and is quasistatically changed from 0 to .
Firstly, let us assume that the input molecule is in state , which occurs with prob of . In this case, only the first reaction in equation 37 can occur. At any point in the process there is a probability that the memory molecule is in state . This probability only changes with a corresponding change in the number of and in the buffer. If changes by a small amount then are converted into so a work of is done on the buffer connected to the reaction volume. Therefore, in a process a work is done on the buffers of
[TABLE]
Because the change in concentration of the fuels is quasistatic, at all times in the process the memory molecule is in equilibrium with the fuel buffer the reaction volume is connected to. Therefore,
[TABLE]
where .
The fact that only dependence has on time is through means that equation 38 can be converted into an integral over instead. Because the change is quasistatic the particular function of time that is does not matter. Only the change in matters. Therefore,
[TABLE]
Now to get the work we simply have to use equation 39 and evaluate the integral. It is convenient to first integrate by parts to get
[TABLE]
and then exploit equation 39 to get
[TABLE]
using l’Hôpital’s rule for the limit in the first line. A negative work corresponds to a decrease in free energy of the buffers.
Alternatively, there is a probability of that the input molecule is so only the second reaction in equation 37 can occur. In this case
[TABLE]
where and the work done on the buffers is
[TABLE]
To evaluate the upper limit it is convenient to substitute in equation 43
[TABLE]
Each of these possibilities is equally likely so the expected work is
[TABLE]
B.2 Extraction
Now the system is either in state or . Work is extracted from this high free energy state using the reactions
[TABLE]
If the system is in state then only the first reaction in equation 47 can occur. In this case the probability of the input molecule being in the state is:
[TABLE]
where . As is changed from to 0, we obtain
[TABLE]
This is exactly the same calculation as equation 42. The sign is positive because the free energy of the fuel molecule buffers is now increased.
If the system is in state then only the second reaction in equation 47 can occur. In this case the probability of the input molecule being in the state is:
[TABLE]
where . As is changed from to 0, we obtain
[TABLE]
This is exactly the same calculation as equations 44 and 45.
Each of these possibilities is equally likely so the expected work is
[TABLE]
Therefore, in a measure and extract cycle the net work done by the fuel molecule buffers is zero.
Appendix C Quasistatic embeddability of Markov machine
Any transformation of a probability distribution over discrete states can be represented by a stochastic matrix. A quasistatic embedding is a non-homogeneous continuous time Markov chain that produces such a transformation with no entropy production [43]. It is not possible to find such an embedding for all stochastic matrices. For some stochastic matrices the state-space must be extended with additional ‘hidden’ states before a quasistatic embedding can be found. Owen et al. [43] have found bounds on the number of hidden state required.
We can apply the results of [43] to the Markov machine. The joint system of the input molecule and memory molecule has four states. We order them . The transformation that measures the state of the input molecule to the state of the memory molecule and takes the input molecule to its equilibrium distribution is then
[TABLE]
The determinant of is zero so according to [43] the lower bound on the number of additional hidden states required for a quasistatic embedding is zero.
The upper found on the number of hidden states required is where is the nonnegative rank of . For an stochastic matrix, , the nonnegative rank is the smallest such that can be written where is a stochastic matrix and is a stochastic matrix.
can be written as
[TABLE]
so the nonnegative rank of this matrix is two and the upper bound on the number of additional hidden states required is one.
In the main text we see that the actual number of hidden states required is zero because we construct the protocol explicitly.
Appendix D Work calculation for Markov machine
D.1 Measurement
The measurement follows the optimal copy protocol in [27]. Instead of the input and memory molecules initially being independent, as they were for the Szilard engine, the molecules now start off correlated.
The reactions
[TABLE]
are, again, used. If the input is then only the first reaction in equation 55 can occur. Now is not , it is set by the input process. To set the memory molecule to using the least work must be initially set to such that
[TABLE]
and then quasistatically changed to . Therefore, the work done is
[TABLE]
Similarly, if the input molecule is then must be initially set to such that
[TABLE]
and then quasistatically changed to . Therefore, the work done is
[TABLE]
The first case occurs with probability and the second occurs with probability so the expected work is
[TABLE]
The random variable is an exact copy of so
[TABLE]
The input process is stationary so so [16]
[TABLE]
so the fact that the memory molecule and input molecule are initially correlated means that the measurement requires less work to be done on the system by the fuel molecule buffers.
D.2 Extraction
The extraction process is exactly the same as for the biochemical Szilard engine. Therefore, the work done on the fuel molecule buffers is so the net work per input molecule is
[TABLE]
Appendix E DNA design of Biochemical Szilard engine and Markov machine
In this section we present a domain level DNA-based design to implement the measurement and work extraction reactions of the Biochemical Szilard engine and Markov machine using DNA strand displacement. The design is shown in figure 11. Our designs leverage the general construction of [38].
The nature of DNA strand displacement reactions means that additional auxiliary strands, labelled A1 to A12, are required. We assume that these strands are always present in the reaction volume in excess.
Appendix F Work calculation for Binary batch machine
F.1 Measurement
The measurement follows the optimal copy protocol in [27]. The measurement is done using the reactions
[TABLE]
when is odd and
[TABLE]
when is even.
Let be the random variable representing whether the number of molecules in batch is greater than ( if true, 0 otherwise). The measurement process is exactly the same as for the Markov machine except that the chemical potential differences, and , are initially set to and such that
[TABLE]
and
[TABLE]
Therefore, the work done is
[TABLE]
and, similar to the Markov machine, is an exact copy of and so
[TABLE]
F.2 Extraction
The extraction step uses the same reactions as the biochemical Szilard engine and the Markov machine:
[TABLE]
However, the protocol of the chemical potential differences must be different. In the biochemical Szilard engine and Markov machine, if the memory molecule was in the state then the input molecule would be for certain in the state . However, in the binary batch machine if the memory molecule is in the state then there is a nonzero probability that some of the input molecules in the batch are in state .
The chemical potential differences, and , are started at and where and are set so that
[TABLE]
and
[TABLE]
First, there is an irreversible relaxation in the batch from the initial input distribution, which depends on the input stochastic process, to a binomial distribution over the number of molecules with a mean of or . If the memory molecule is is , the work extracted in this relaxation is
[TABLE]
where is the expected number of in the batch initially. If the memory molecule is is , the work extracted in this relaxation is
[TABLE]
where is the expected number of in the batch initially. Then, and are quasistatically changed to zero. If the memory molecule is in state the work that is done in this quasistatic step is
[TABLE]
Similarly, if the memory molecule is in state the work that is done in this quasistatic step is
[TABLE]
Therefore, if the memory molecule is in state the total work that is done in the irreversible relaxation and quasistatic steps is
[TABLE]
This is maximised if . Similarly, if the memory molecule is in state the work is maximised by setting . i.e. is the probability that an input molecule in the batch is if and is the probability that an input molecule in the batch is if . This means that initially no work is done on the fuel molecule buffers during the irreversible relaxation because on average there is no net change of number of in the batch.
Therefore, the expected work done in the extraction step is
[TABLE]
and the net work for the measure and extract cycle is
[TABLE]
Appendix G DNA design of batch machine measurement
In this section we present a domain level DNA-based design to implement the measurement reactions of the batch machine using DNA strand displacement. The design is shown in figure 12 for the case when . Our designs leverage the general construction of [38]. This design is the same as the measurement reactions for the Biochemical Szilard engine and Markov machine except for that the gates are extended so that three or strands must bind for the reaction to occur. In principle, the mechanism could be generalised to an arbitrary number of inputs—although this may prove challenging in practice.
The nature of DNA strand displacement reactions means that additional auxiliary strands, labelled A1 to A16, are required. We assume that these strands are always present in the reaction volume in excess.
Appendix H Work calculation for full batch machine
H.1 Measurement
The measurement is exactly the same as for the binary batch machine so the work is
[TABLE]
H.2 Extraction
In this section we will not give an explicit chemical scheme to extract all of the work from an unordered batch of input molecules. We will simply calculate the available work. In equilibrium the number of molecules in the batch, , is described by a random variable , which is distributed as
[TABLE]
If we define the free energy of each state of the unordered batch as
[TABLE]
then the equilibrium free energy is zero. Initially the number of molecules in the batch is described by a random variable The free energy of the batch is initially
[TABLE]
where is the initial distribution over the number of in the batch and is the random variable that describes the initial state of the batch. Therefore, using equation 4, the free energy of the joint system of the batch and the memory molecule is
[TABLE]
where is the state of the memory molecule after the batch has been measured. After the work extraction the free energy of the joint system of the batch and the memory molecule is
[TABLE]
As previously mention, . It is also the case that . Therefore, the maximum work that can be extracted is
[TABLE]
where the last line follows because knowing the state of gives you exact knowledge of the state of so . Therefore, the net work extracted per batch is
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Juan MR Parrondo, Jordan M Horowitz, and Takahiro Sagawa. Thermodynamics of information. Nat. Phys. , 11(2):131, 2015.
- 2(2) Robert A Alberty and Robert N Goldberg. Standard thermodynamic formation properties for the adenosine 5’-triphosphate series. Biochemistry , 31(43):10610–10615, 1992.
- 3(3) Dibyendu Mandal and Christopher Jarzynski. Work and information processing in a solvable model of maxwell’s demon. Proc. Natl. Acad. Sci. U.S.A. , 109(29):11641–11645, 2012.
- 4(4) Andre C Barato and Udo Seifert. An autonomous and reversible maxwell’s demon. EPL , 101(6):60001, 2013.
- 5(5) Alexander B Boyd, Dibyendu Mandal, and James P Crutchfield. Identifying functional thermodynamics in autonomous maxwellian ratchets. New J. Phys. , 18(2):023049, 2016.
- 6(6) Alexander B Boyd, Dibyendu Mandal, and James P Crutchfield. Correlation-powered information engines and the thermodynamics of self-correction. Phys. Rev. E , 95(1):012152, 2017.
- 7(7) Alexander B Boyd, Dibyendu Mandal, and James P Crutchfield. Leveraging environmental correlations: The thermodynamics of requisite variety. J. Stat. Phys. , 167(6):1555–1585, 2017.
- 8(8) Thomas Mc Grath, Nick S Jones, Pieter Rein ten Wolde, and Thomas E Ouldridge. Biochemical machines for the interconversion of mutual information and work. Phys. Rev. Lett. , 118(2):028101, 2017.