DAC: Data-free Automatic Acceleration of Convolutional Networks
Xin Li, Shuai Zhang, Bolan Jiang, Yingyong Qi, Mooi Choo Chuah and, Ning Bi

TL;DR
DAC is a data-free method that decomposes convolutional layers to reduce computational cost while preserving accuracy, enabling efficient deployment of deep models on resource-limited devices.
Contribution
This paper introduces DAC, a novel data-free decomposition technique that factorizes convolutional layers without training or data, outperforming existing methods in efficiency and accuracy preservation.
Findings
Reduces FLOPs by up to 53% with 2% accuracy loss on VGG16.
Achieves 29% FLOPs reduction on SSD300 object detection.
Maintains high accuracy while significantly decreasing computational cost.
Abstract
Deploying a deep learning model on mobile/IoT devices is a challenging task. The difficulty lies in the trade-off between computation speed and accuracy. A complex deep learning model with high accuracy runs slowly on resource-limited devices, while a light-weight model that runs much faster loses accuracy. In this paper, we propose a novel decomposition method, namely DAC, that is capable of factorizing an ordinary convolutional layer into two layers with much fewer parameters. DAC computes the corresponding weights for the newly generated layers directly from the weights of the original convolutional layer. Thus, no training (or fine-tuning) or any data is needed. The experimental results show that DAC reduces a large number of floating-point operations (FLOPs) while maintaining high accuracy of a pre-trained model. If 2% accuracy drop is acceptable, DAC saves 53% FLOPs of VGG16 image…
Click any figure to enlarge with its caption.
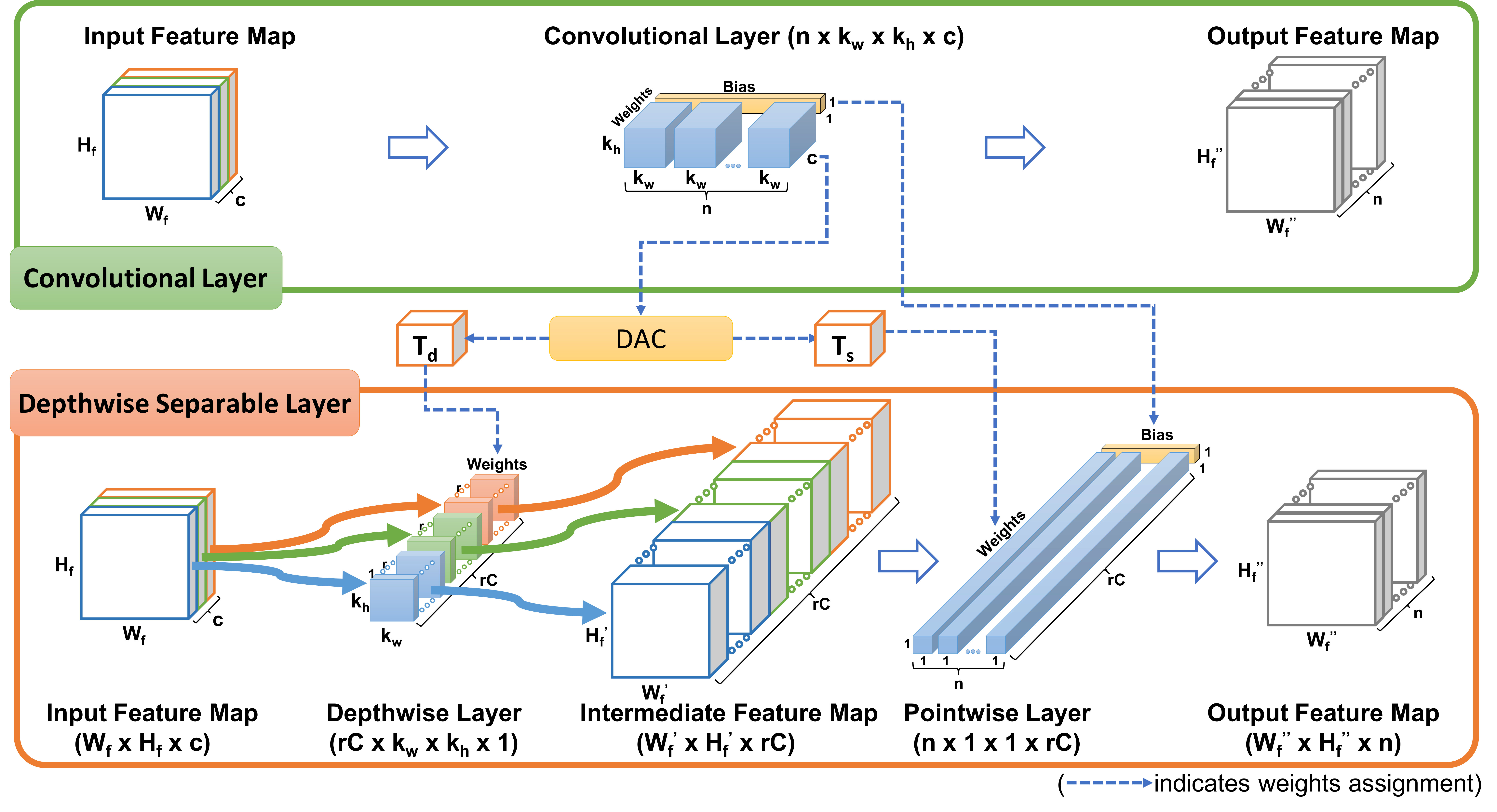 Figure 1
Figure 1 Figure 2
Figure 2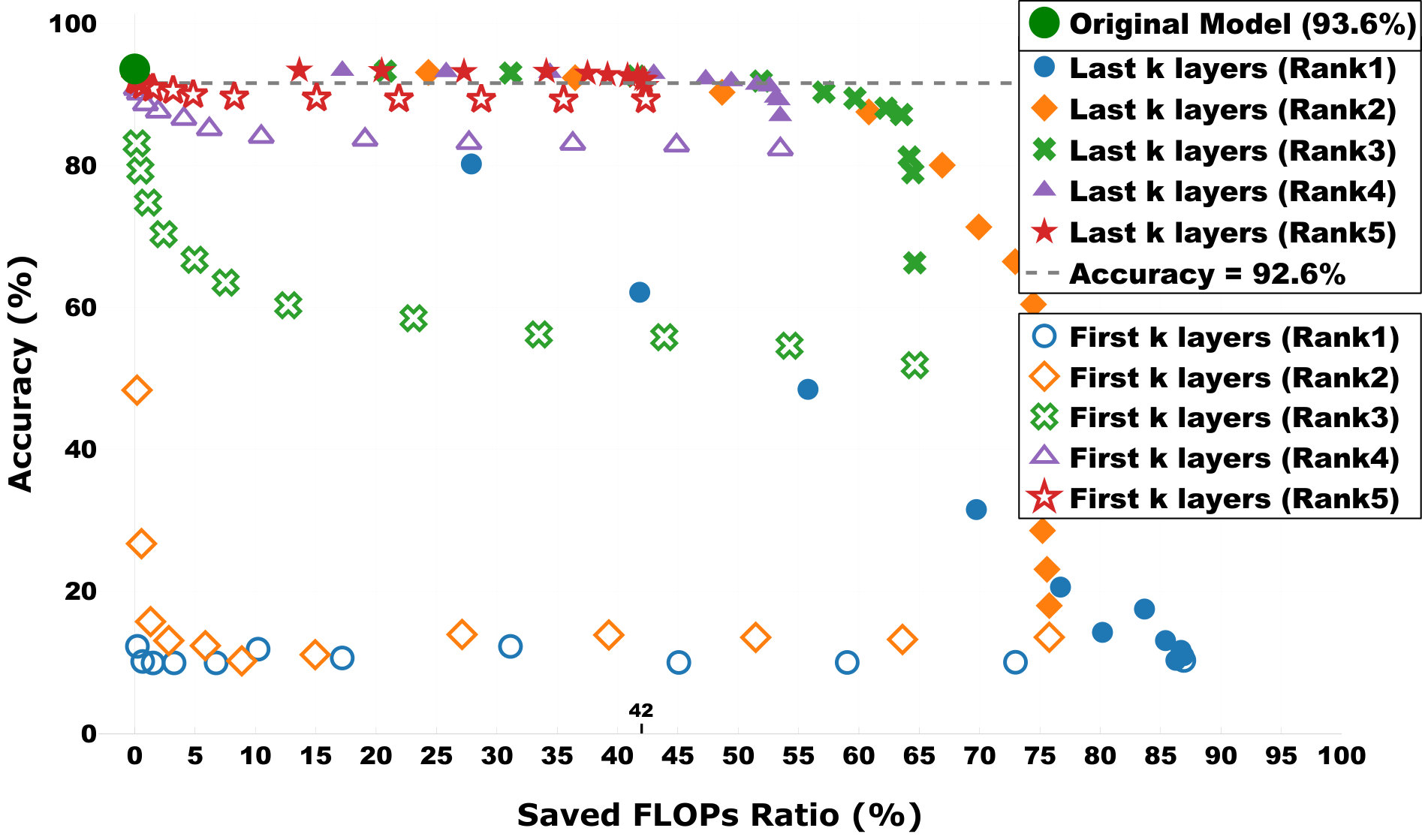 Figure 3
Figure 3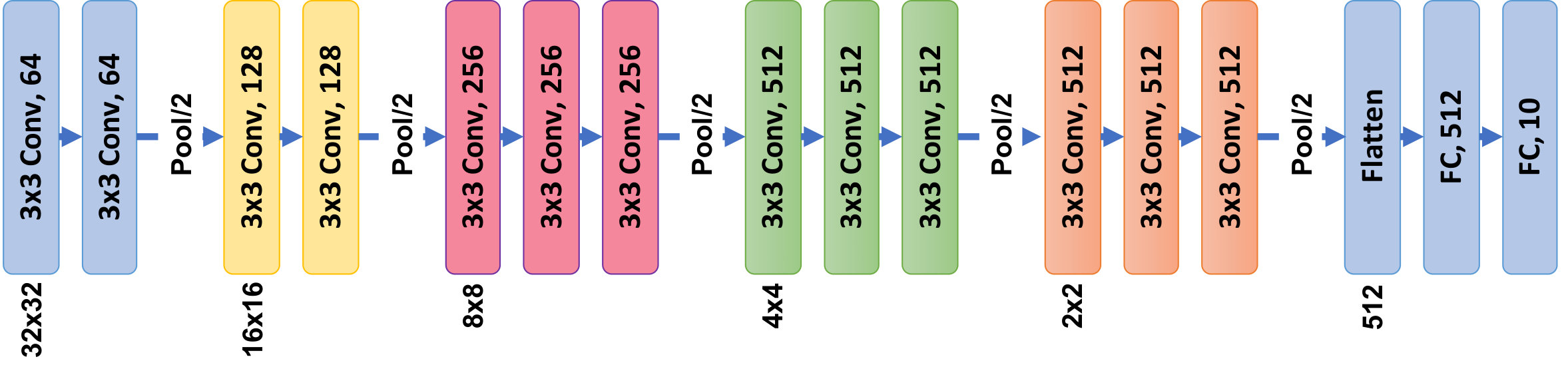 Figure 4
Figure 4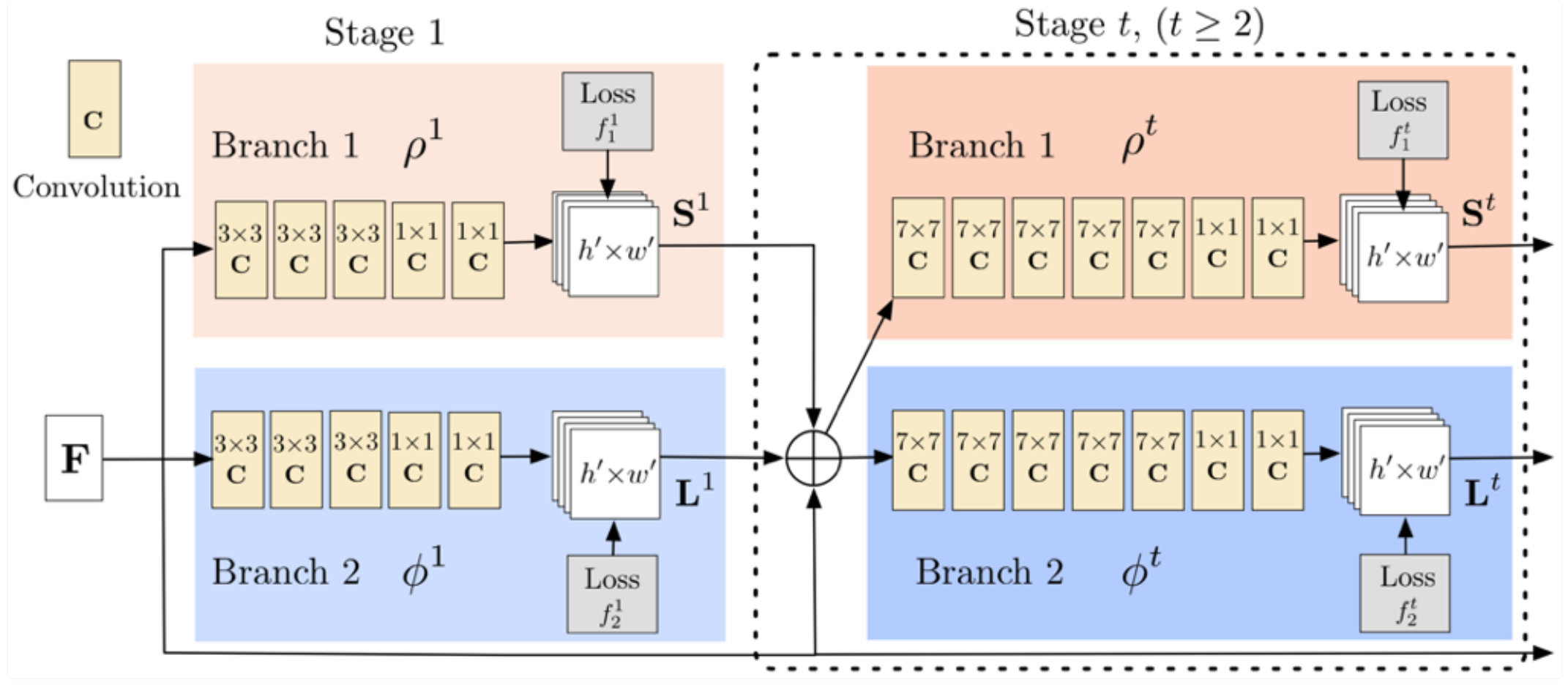 Figure 5
Figure 5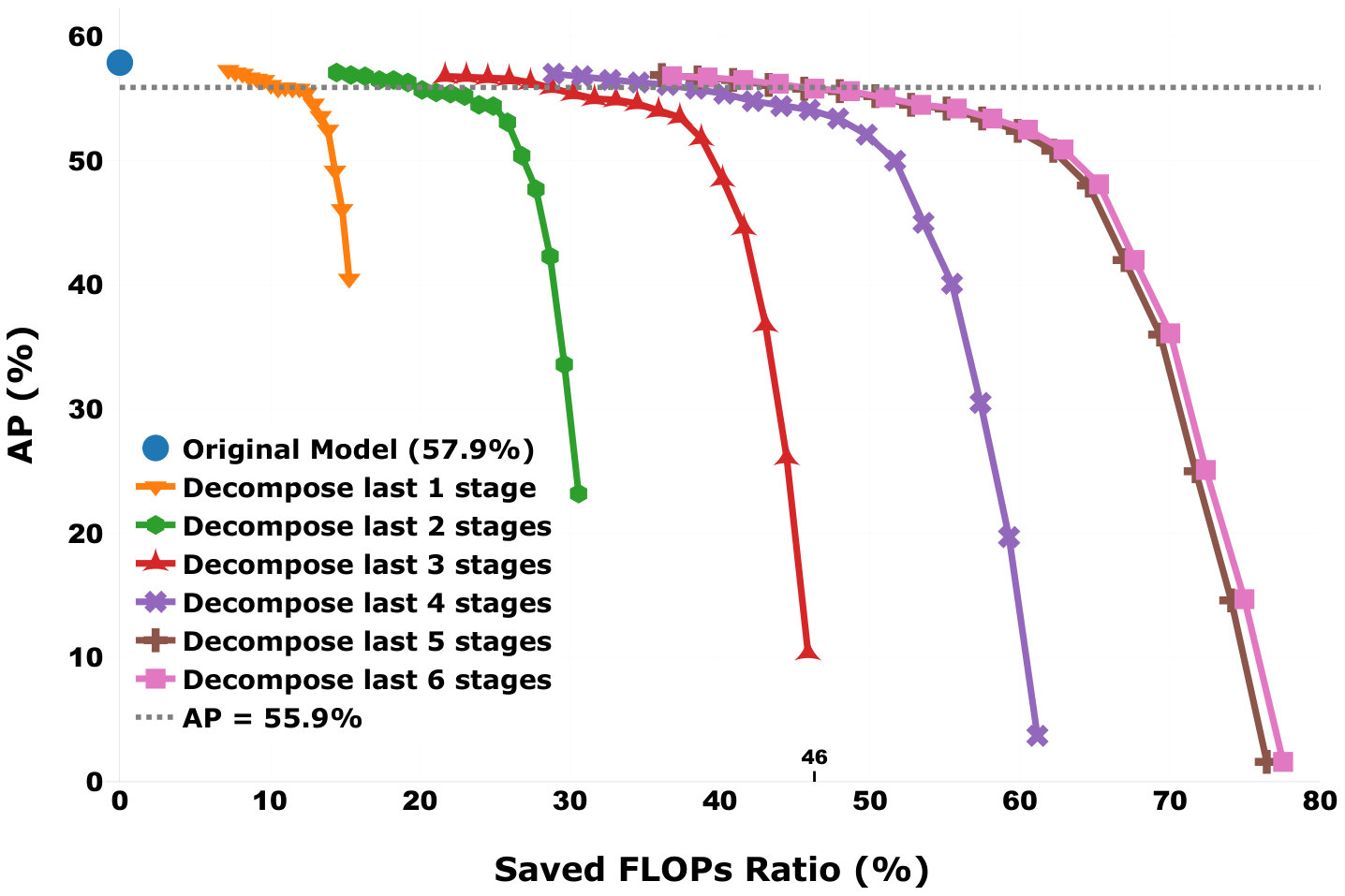 Figure 6
Figure 6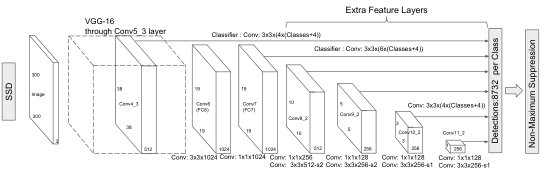 Figure 7
Figure 7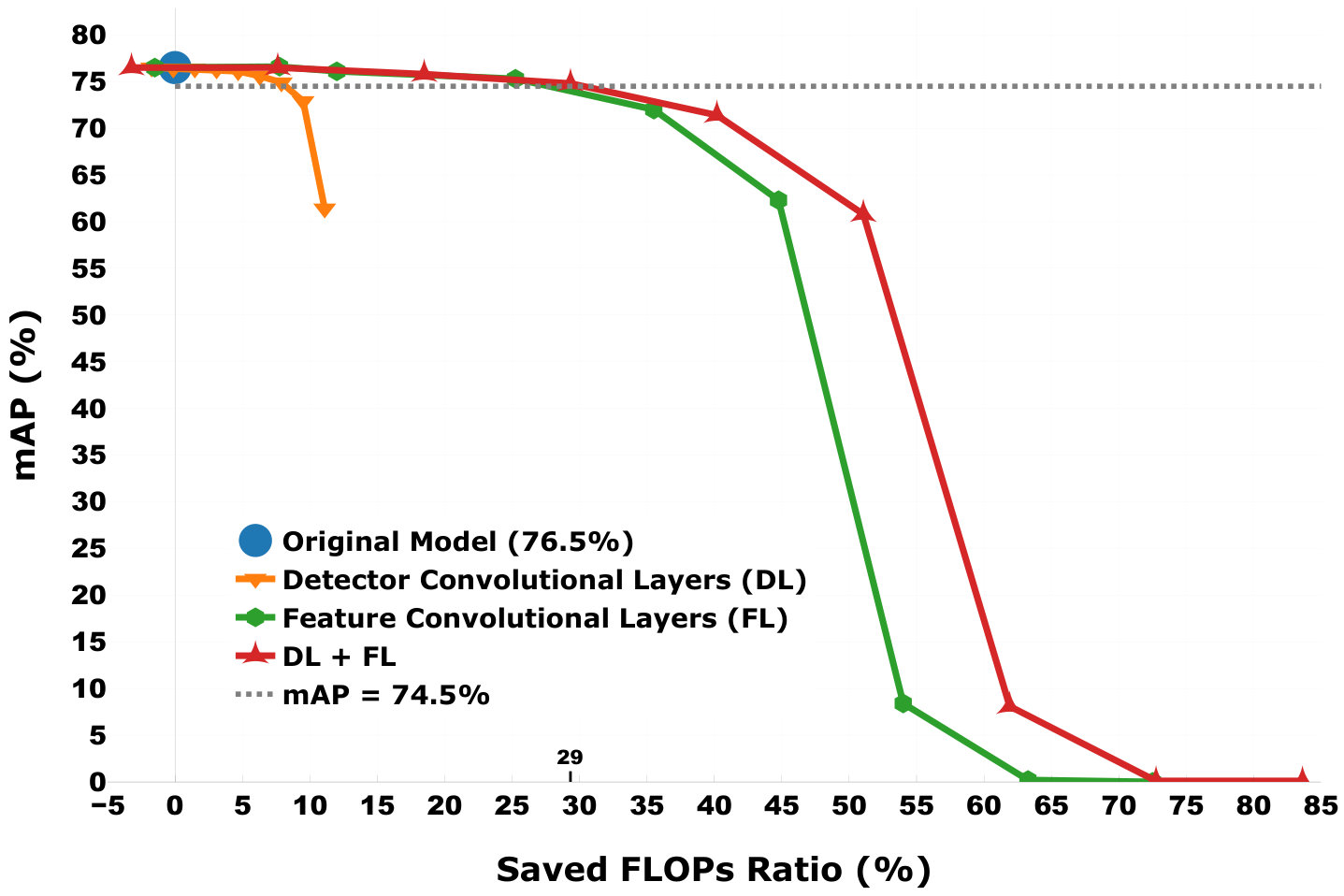 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10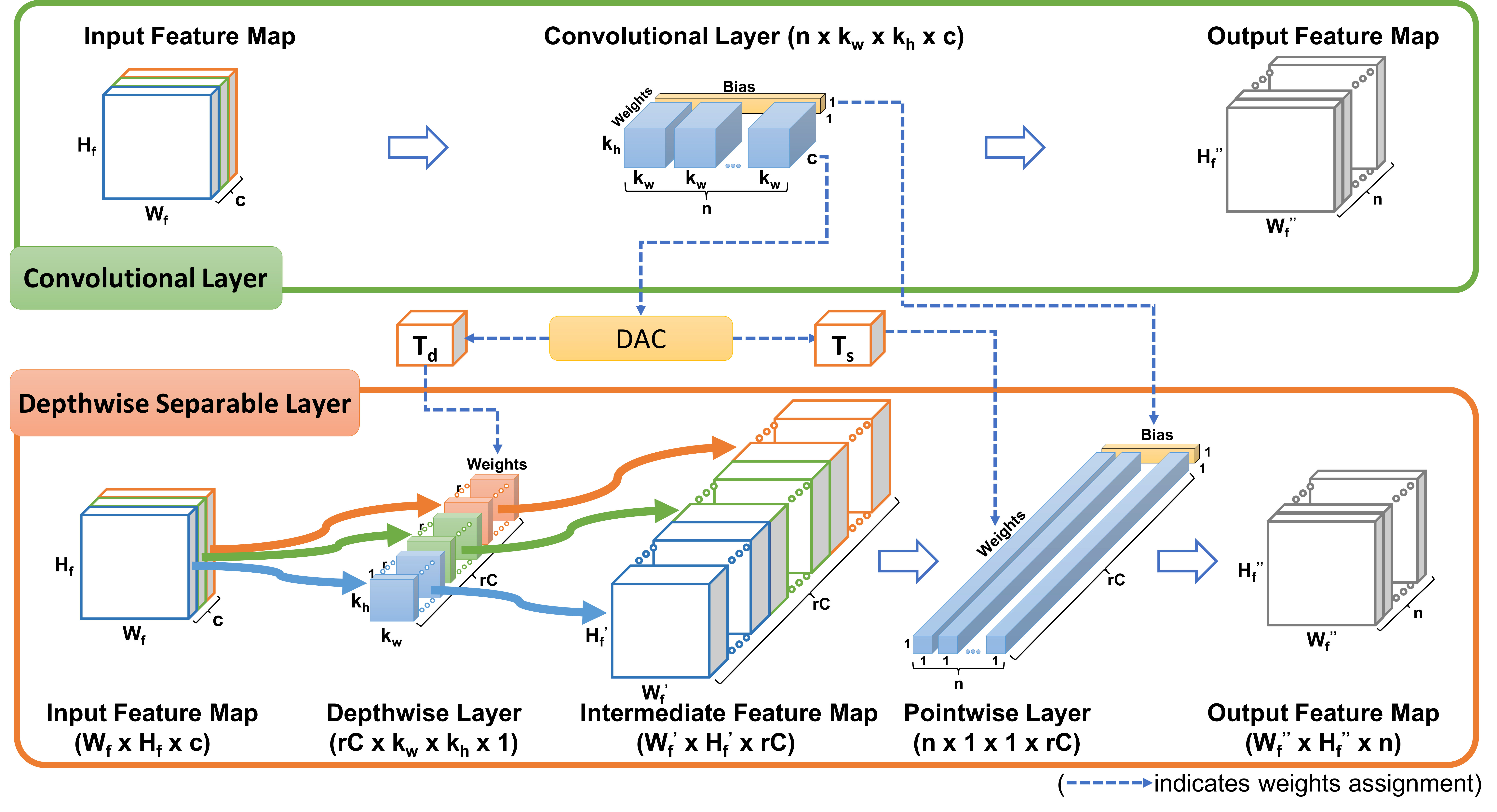 Figure 11
Figure 11 Figure 12
Figure 12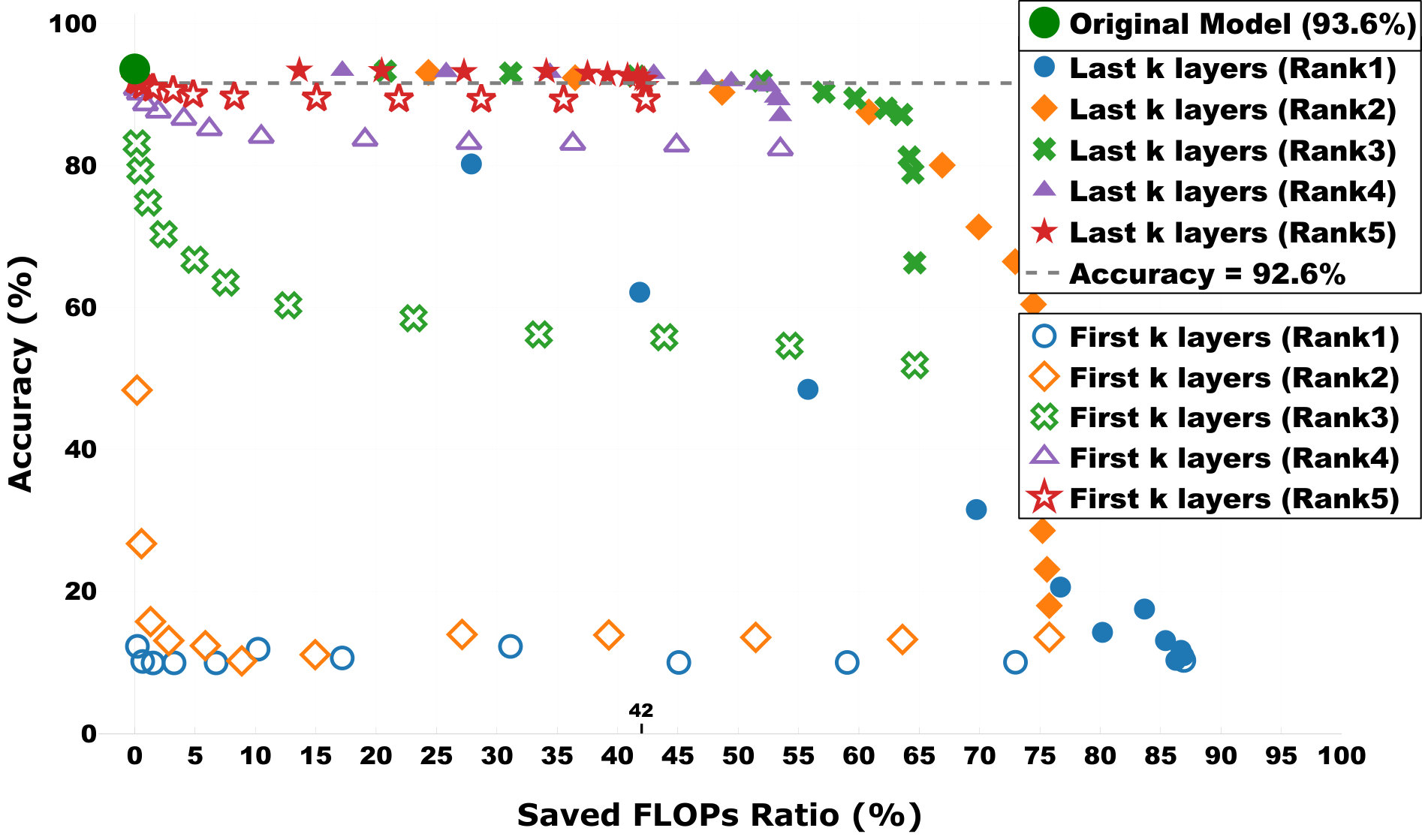 Figure 13
Figure 13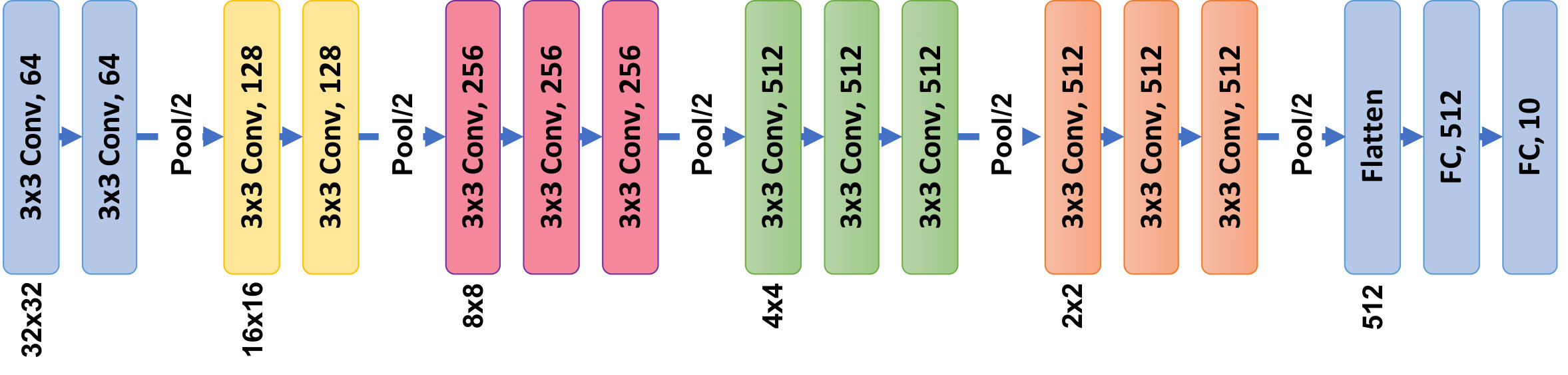 Figure 14
Figure 14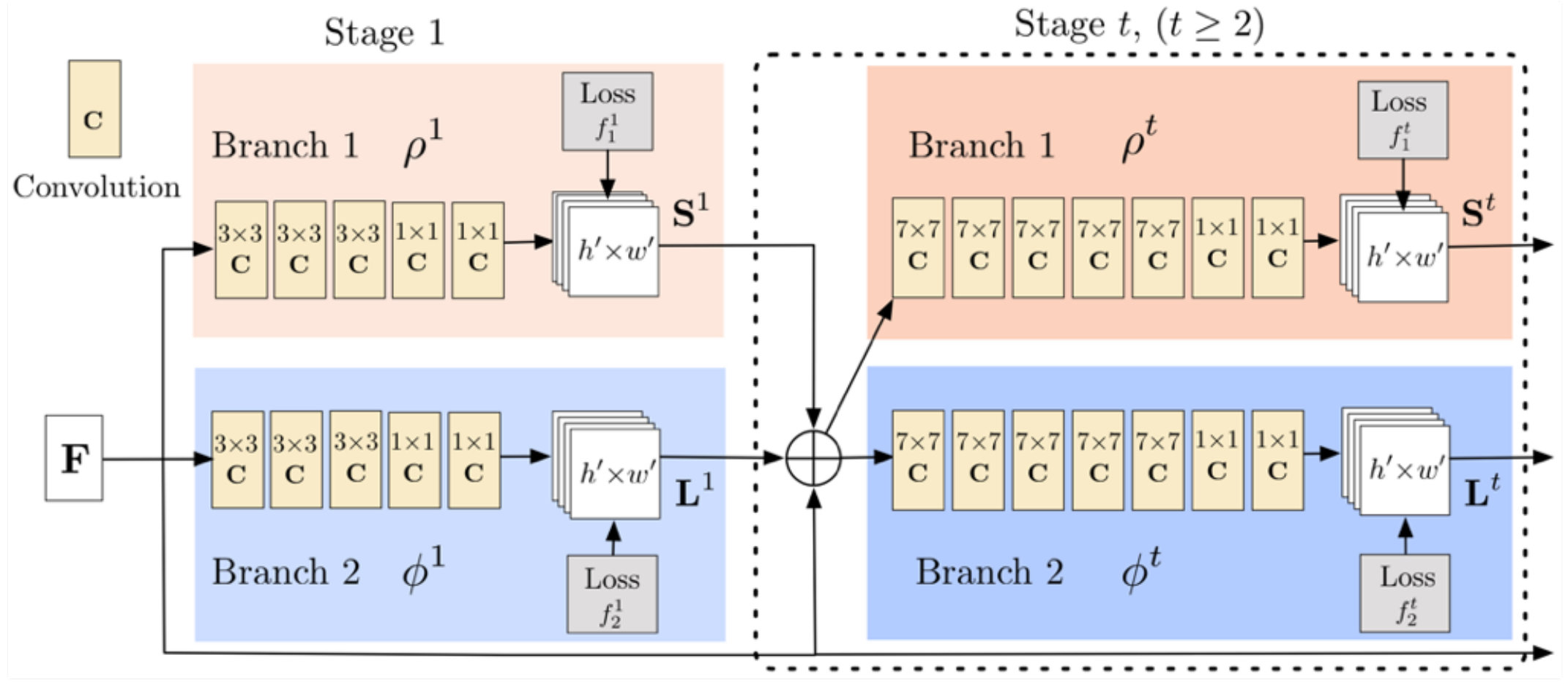 Figure 15
Figure 15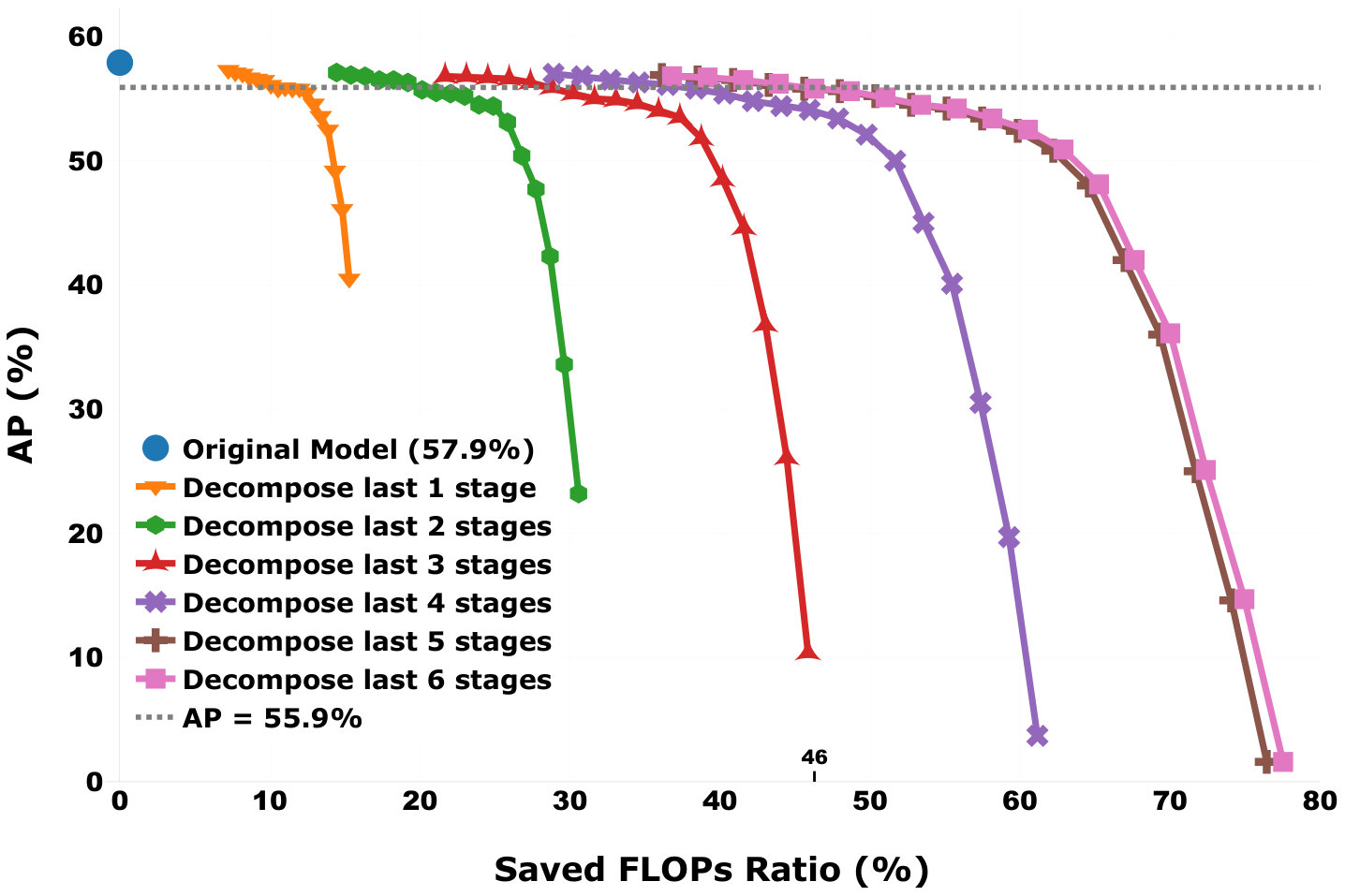 Figure 16
Figure 16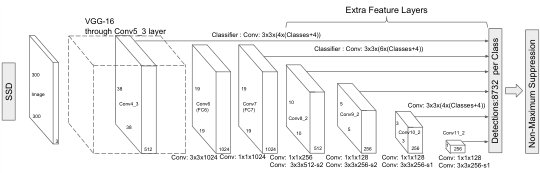 Figure 17
Figure 17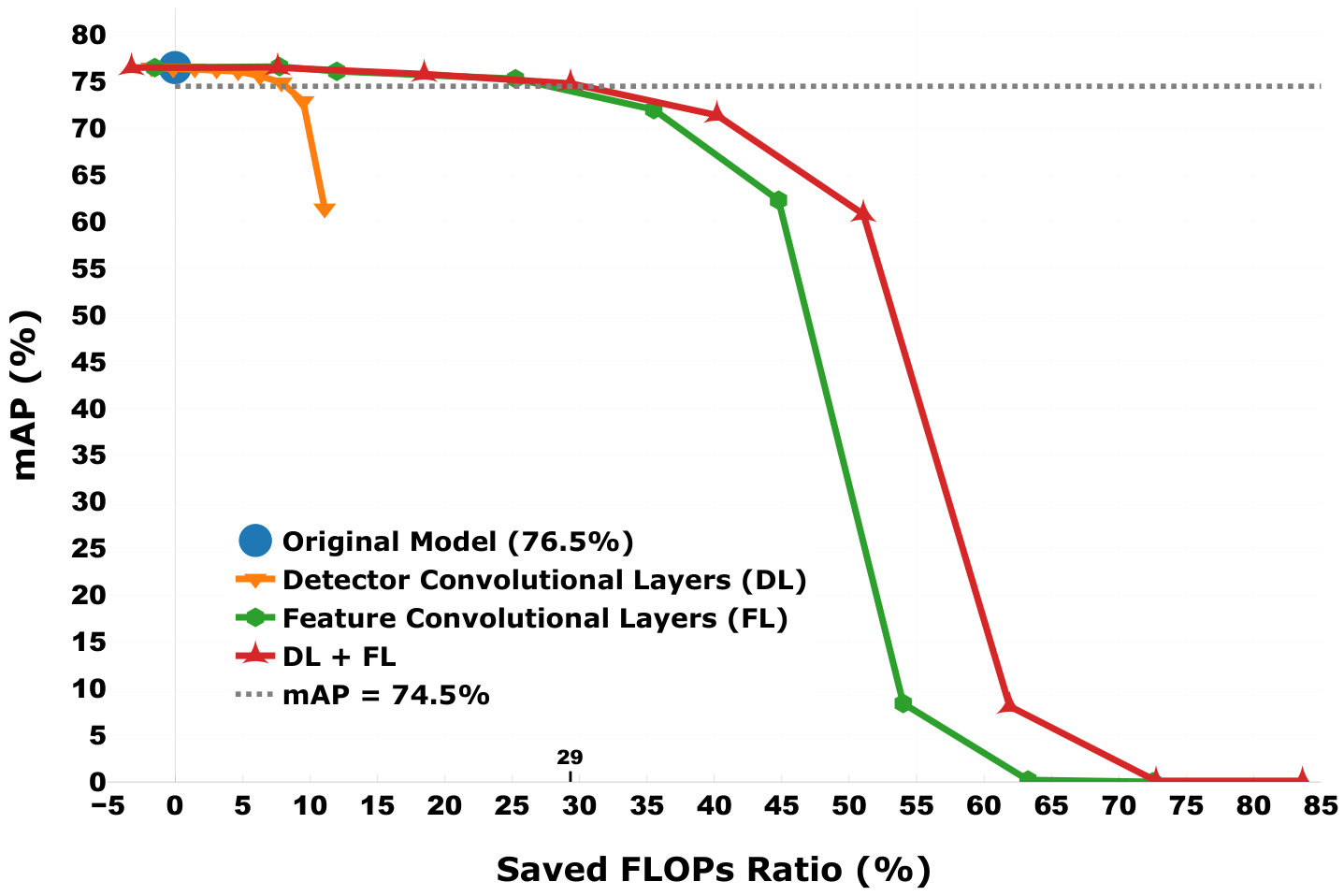 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Human Pose and Action Recognition · Domain Adaptation and Few-Shot Learning
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
DAC: Data-free Automatic Acceleration of Convolutional Networks
Xin Li
22footnotemark: 2 33footnotemark: 3 , Shuai Zhang11footnotemark: 1 22footnotemark: 2 , Bolan Jiang22footnotemark: 2 , Yingyong Qi22footnotemark: 2, Mooi Choo Chuah33footnotemark: 3, and Ning Bi22footnotemark: 2
iii1 Qualcomm AI Research
iiiiii2 Department of Computer Science and Engineering, Lehigh University
[email protected], [email protected], [email protected]
[email protected], [email protected], [email protected] Xin Li and Shuai Zhang are equally contributed authors. This work is done while Xin Li is interning at Qualcomm.
Abstract
Deploying a deep learning model on mobile/IoT devices is a challenging task. The difficulty lies in the trade-off between computation speed and accuracy. A complex deep learning model with high accuracy runs slowly on resource-limited devices, while a light-weight model that runs much faster loses accuracy. In this paper, we propose a novel decomposition method, namely DAC, that is capable of factorizing an ordinary convolutional layer into two layers with much fewer parameters. DAC computes the corresponding weights for the newly generated layers directly from the weights of the original convolutional layer. Thus, no training (or fine-tuning) or any data is needed. The experimental results show that DAC reduces a large number of floating-point operations (FLOPs) while maintaining high accuracy of a pre-trained model. If 2% accuracy drop is acceptable, DAC saves 53% FLOPs of VGG16 image classification model on ImageNet dataset, 29% FLOPS of SSD300 object detection model on PASCAL VOC2007 dataset, and 46% FLOPS of a multi-person pose estimation model on Microsoft COCO dataset. Compared to other existing decomposition methods, DAC achieves better performance.
1 Introduction
Deep learning techniques have been applied to many areas of artificial intelligence, which affects our daily lives. For example, smart surveillance video systems that can detect and identify suspects help law enforcement personnel to maintain a safer living environment. Self-driving cars liberate drivers from steering wheels so that they can do more meaningful things, e.g., read business news. As technology for high-performance mobile or edge computing devices continues to improve, more and more deep learning models are deployed on these devices, e.g., face recognition systems are used on cell phones to unlock screens, etc.
However, some of these AI tasks, e.g., voice recognition, requires internet access, which means the model is not entirely run on mobile/IoT devices. The major reason is that most of the deep learning models with high accuracy run too slowly on resource-limited devices. Many techniques to reduce the size of neural network models, e.g., model quantization of neural network models using fewer bits, have been proposed to facilitate their implementations on mobile chips [28, 26, 27, 25]. However, limited by current hardware structure and the tolerance for model accuracy drop, most of these quantization methods for real applications only focus on the 8-bit format. To further accelerate neural network models, it is more important to reduce computation complexity directly from the network architectures. Some research [8, 21, 32, 17, 13, 14] has been done to simplify these models before running them on mobile/IoT devices. Such research can be roughly categorized into two classes:
Designing new light-weight network architectures: MobileNet proposed by Howard et al. in [8, 21] is an excellent example. The model is based on a streamlined architecture that uses depthwise separable convolutions to build a light weight deep neural network. The model achieves good accuracy and runs fast on mobile devices. Similar with MobileNet, ShuffleNet [32, 18] is another type of light weight network architecture, based on depthwise separable layers for acceleration. However, these models require powerful servers and massive data to tune the weights. This is not a friendly solution to those who cannot access such resources.
Modifying an existing model to a slim version: Another solution is to produce a slimmer version of an existing model. Unfortunately, the training data in some cases is exclusively available to the original designer of a model, which prevents other researchers from re-training the model after modification. Besides, it is costly and time-consuming to train a model from scratch. Thus, compared to designing new models and training them from scratch, accelerating an existing model based on its pretrained weights is a better solution. Network pruning and parameter decomposition are two common methods for this purpose. Network pruning is a practical tool for speeding up existing deep neural networks [19]. He et al. propose a channel pruning method [7] that utilizes LASSO regression to prune the number of the input channels in each convolutional layer. Even though such network pruning scheme simplifies models, it still has some weaknesses. Network pruning is based on the statistical results of a set of samples. Thus: (1) it still requires data to discover which channel to prune, and (2) the accuracy of the model drops after pruning because the statistical results are not suitable for all data during testing. Louizos et al. incorporate relaxation [17] into the training loss function to enforce compactness of network parameters. Thus, this pruning method should only be used during the training process. Parameter decomposition is another way to simplify an existing model. It is a layer-wise operation that decomposes a layer into one or multiple smaller layers, either having smaller kernel sizes or fewer channels. Although there will be more layers after being decomposed, the total number of weights and the computational complexity will be reduced. The decomposition methods only use the pre-trained weights of a layer, with the fact that most neural network models have much redundant parameters and can be largely simplified with low rank constraints. In this paper, we propose a new parameters decomposition method which does not require access to data or retraining.
The contributions of this paper are:
1. We propose a novel decomposition method that replaces standard convolutional layers in a pre-trained model with separable layers to significantly reduce the number of FLOPs.
2. The newly generated model maintains high accuracy without using any data and training process.
3. The experimental results on three computer vision application scenarios show that DAC maintains high accuracies even when a vast amount of FLOPs is trimmed.
The rest of this paper is organized as follows. Some related works are summarized in section 2. In section 3, we describe the architecture of DAC and our factorization method. The experimental results are reported in section 4, followed by the conclusion in Section 5.
2 Related Work
Much work has been done to do parameter decomposition. In this section, we will discuss some prior work that decomposes convolutional layers. To simplify the description, we assume the weight of the convolutional layer that we are going to decompose has a size of , where is the number of kernels, and are the spatial width and height of a kernel respectively, and is the number of channels of the input feature map.
First, Jaderberg et al. [9] propose a spatial decomposition method. The method decomposes a convolutional layer with kernel size into two layers. One has horizontal filters with kernel size and the other consists of vertical filters with kernel size. In theory, this method indeed reduces parameters. However, running the decomposed model on a mobile device that has limited resources does not result in a significant speed up. This is due to the caching behavior of data. A feature map is horizontally (or vertically) loaded into a continuous block of memory. When we compute convolution using horizontal (vertical) filters, we access the memory sequentially. There is no impact on running time. However, if we compute the convolution using vertical (horizontal) filters, we cannot access memory sequentially any more which results in more cache misses and hence longer computation time.
Then, Zhang et al. describe a channel decomposition method in [33]. It decomposes a convolutional layer with kernel size into a convolutional layer with fewer output channels and a pointwise convolutional layer. The newly generated convolutional layer has kernel size, and the pointwise convolutional layer has kernel size. Notice that the first layer is also an ordinary convolutional layer, so it does not improve the situation fundamentally.
Direct tensor decomposition methods including CP decomposition [12] and Tucker decomposition [10] are also applied to accelerate networks. After these tensor decompositions, one convolution layer will be factorized into 3 or 4 small layers with a bottleneck structure, opposite with [21] architecture. One big disadvantage of these tensor decomposition methods is that the depth of network architecture is tripled (3x) compared to the original model, thus it increases the memory access cost (MAC) and largely offset the gains from the reduction of FLOPs, as claimed in [18].
There are also many network decomposition works using low rank constraints in training process or solving layer-wise regression problem with data samples [24, 2]. But all these methods require the access of sufficient data from training/test domain.
Our research focus is based on the real application scenario with limited access of data. In this paper, we propose a novel data-free convolutional layers decomposition method and compare its performance to two most related works [33, 9]. (After this paper was accepted, we found Guo et al. proposed a similar solution in [6]. These two works are independent and concurrent.)
3 Proposed Solution
The intuition of our proposed scheme is that the depthwise + pointwise combination runs efficiently on mobile devices has already been proven by MobileNet [8]. It will be useful if we can convert an ordinary convolutional layer into such a structure and compute their weights from the original layer directly. The feasibility of decomposing the weights of a convolutional layer has been mathematically proved by Zhang et al. [33].
3.1 Convolutional Layer Factorization
In this section, we propose a novel factorization method for convolutional layers. Figure 1 shows the details of our scheme. An ordinary convolutional layer with the shape of is decomposed into two layers. One is a depthwise layer with the shape of , and the other is a pointwise layer with the shape of , where and is a factor used to balance the trade-off between model compression ratio and accuracy drop. There is no bias in the depthwise layer, and the bias vector in the original layer is assigned to the pointwise layer.
Even though our scheme is inspired by MobileNet, it is worth highlighting the differences between MobileNet and DAC. DAC has no non-linear layers (batch normalization layers and activation layers) between the depthwise and the pointwise layers. The absence of non-linear layers makes DAC quantization friendly and hence suitable for further hardware acceleration, which Sheng et al. [22] have already experimentally verified.
3.2 Weights Decomposition
Once a convolutional layer is factorized, we want to compute weights for the newly generated layers (a depthwise and a pointwise layer) from the original weights directly. We assume is the trained weights of the original convolutional layer, and its shape is . We denote as the weights of the depthwise layer and as the weights of the pointwise layer. Then, the objective function of factorizing a convolutional layer is:
[TABLE]
where operator is the combination of convolution operations of the depthwise and the pointwise layer, and is the Frobenius norm for tensor/matrix. Thus
[TABLE]
Here matrices , and are transformed from tensors , and respectively.
According to the SVD theory, the solution of minimization problem is the singular matrices with rank , where the top singular values can be merged into either or . Also, Frobenius norm can be defined as induced by vector norm, so the above DAC minimization objective function can be considered as
[TABLE]
where is the input feature maps and is the vector norm. In this formula, it minimizes the output feature maps with approximation error measured in Euclidean space and the constraint of the decomposition ‘rank’ (the factor used to balance the trade-off between model compression ratio and accuracy drop). The process of weights decomposition is described in Algorithm 1.
3.3 Computation Reduction
We consider the original convolutional layer with kernel size takes a feature map as an input and produces a feature map , where and are the spatial width and height of the feature maps. Here, we assume the output feature map has the same spatial size as the input for simplification. Then, the computation cost of the convolutional layer is:
The computation cost depends on the number of input channels , the number of output channels , the kernel size and the input features map size . After decomposition, the newly generated depthwise and pointwise layer in total have the cost of where and the reduction in computation is
[TABLE]
4 Experimental Results
To prove the universality of our proposed scheme, we apply DAC to three major application scenarios in the field of Computer Vision: (1) Image Classification, (2) Object Detection, and (3) Multi-person Pose Estimation. We implement our scheme using Python and Keras Library [4] with Tensorflow backend [1].
4.1 Datasets
Four datasets are used in this paper:
CIFAR-10 dataset: The CIFAR-10 dataset [11] consists of 50,000 training images and 10,000 test images in 10 categories. It is a small dataset, from which we can quickly get results after tuning parameters. Thus, we use it for ablation study to get some insights about DAC, e.g., the impacts of using different ranks or decomposing different layers.
ImageNet dataset: The ImageNet dataset [20] has 50,000 ILSVRC validation images in 1,000 object categories. We use this ILSVRC validation subset to evaluate the performance of DAC in the task of image classification.
Pascal VOC2007 dataset: For object detection task, Pascal VOC2007 dataset [5] is used. It consists of 4,952 testing images for object detection. The bounding box and label of each object from twenty target classes have been annotated. Each image has one or multiple objects.
Microsoft COCO dataset: The Microsoft COCO dataset [15] is used to evaluate the performance of DAC in the task of multi-person pose estimation. We use the COCO 2017 keypoints subset which consists of 5,000 validation images and 40K testing images.
4.2 Ablation Study
Here, we use a pre-trained CIFAR-VGG model iiiiiiiiihttps://github.com/geifmany/cifar-vgg, a simple Convolutional Neural Network, on the CIFAR-10 dataset as our original model. Figure 2 shows the architecture of the CIFAR-VGG. In total, the CIFAR-VGG model has 13 convolutional layers. The original model (trained on CIFAR-10 training subset) achieves 93.6% on CIFAR-10 testing subset.
First, we decompose a single convolutional layer to explore the impact of decomposing different layers. Table 1 shows the details of testing accuracy when applying varying ranks (rank 1 to rank 5) decomposition on different layers of CIFAR-VGG model. Each time, we only modify one layer. All results are collected using decomposed weights directly (no access to data or any training process).
From Table 1, we gain two insights: (a) Decomposing first few layers of a model causes large drops in accuracy (75% drop when rank 1 decomposition is applied on layer conv2d_1), while decomposing last few layers has a smaller impact on the accuracy (less than 1% drop when rank 1 decomposition is applied on layer conv2d_13). (b) Decomposing a layer using a larger rank helps to maintain the accuracy. This can be observed by comparing different columns in the same row. These two insights are consistent with our intuition. (a) Decomposing a layer generates tiny errors. If such errors occur at the beginning of a model, the errors will accumulate to bigger errors at the final prediction. (b) Compared to smaller ranks, larger ranks generate more parameters in the depthwise layers. Thus, the newly generated layers have more possibility of replicating the performance of the original layer.
Next, we explore the performance of DAC when multiple convolutional layers are decomposed. We decompose the model with two opposite directions: (1) from the last layer to the first one, and (2) from the first layer to the last one. To simply the experiment, we use the same rank to decompose all chosen layers. The experimental results are reported in Figure 3. First, one can quickly notice that most decomposition cases (solid points) achieve high accuracies (higher than 91.6% or 2% drop). Second, after saving 42% FLOPs, DAC still achieves 92.7% accuracy (drops less than 1%). Both of these prove that our proposed DAC has the capability of maintaining accuracy when the number of FLOPs is substantially reduced.
Besides, in Figure 3, red-star points (Rank 5) achieve high accuracies. If we compare the solid (open) red-star marks to other solid (open) marks, we can notice that the above insights also hold in the case of decomposing multiple convolutional layers. Ten (eight) out of twelve Rank 5 decomposition cases (solid red-star spots) drop accuracy by less than 2% (1%). The worst solid red-star case that achieves 91.2% (accuracy drops 2.4%) is caused by the decomposition of the first layers of the model (first insight discussed above). It is worth highlighting that these decomposed models that maintain high accuracies are generated by DAC without accessing data or training process.
4.3 Image Classification
For the task of image classification, we use the VGG16 model proposed by Simonyan et al. in [23]. It includes 12 (3x3) convolutional layers. We downloaded a model ivivivhttps://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5 pre-trained on ImageNet dataset. All convolutional layers but the first one are decomposed considering the first insight we got in our ablation study.
Here we compare our approach with two schemes, namely, the Filter Reconstruction Optimization proposed by Jaderberg et al. in [9] (Spatial Decomp. in Table 2) and the Channel Decomposition method proposed by Zhang et al. in [33] (Channel Decomp. in Table 2). Spatial Decomposition is the one that does not need data and training like DAC as we discussed in Section 2. Although the Channel Decomposition requires some data, we can still use the method as a filter reconstruction without accessing any data and training process. We implemented these two algorithms ourselves. For fair comparison, we choose appropriate parameters for Channel Decomposition and Spatial Decomposition, so that all schemes save roughly same FLOPs. Given a rank of DAC, the number of filters in the first newly generated layer in Channel Decomposition can be computed using:
[TABLE]
and for Spatial Decomposition, the number of filters in the first newly generated layer is
[TABLE]
where is the number of kernels in original convolutional layer, and are the spatial width and height of a kernel respectively, and is the number of channels of the input feature map.
Table 2 shows the accuracy of the model (after saving 40%, 50%, and 60% FLOPs respectively) on ImageNet validation set. First, DAC maintains high accuracy on both Top-1 and Top-5 accuracy even when a significant amount of FLOPs are reduced. Second, compared to the Channel Decomposition and Spatial Decomposition, DAC performs much better. Especially when we saved 60% FLOPs, DAC achieves 41.4% higher accuracy than Channel Decomposition and 6.7% higher accuracy than Spatial Decomposition.
4.4 Multi-person Pose Estimation
For the task of multi-person pose estimation, we use the scheme proposed by Cao et al. [3]. Figure 4 is the architecture extracted from their paper. After generating the feature map by a convolutional network (initialized by the first 10 layers of VGG-19 [23] and fine-tuned), the model is split into two branches: the top branch predicts the confidence maps, and the bottom branch predicts the affinity fields.
We download an implementation of Cao’s model vvvhttps://github.com/anatolix/keras_Realtime_Multi-Person_Pose_Estimation that was pre-trained on Microsoft COCO dataset as our original model. It achieves 57.9% average precision (AP) on the validation subset of 2017 COCO keypoints challenge. This model consists of six stages, which means in Figure 4. Thus, the first stage (Stage 1) has 6 convolutional layers (3x3 kernel size), and each of the following stage (Stage 2 to Stage 6) includes 10 convolutional layers (7x7 kernel size). Based on the above two insights, we decompose the model from the bottom to the top with variant ranks (from Rank20 to Rank3). Because the full rank of a (3x3) convolutional kernel (in Stage 1) is 9, so we set the maximum rank used to decompose these (3x3) convolutional layers equals to 5 for a large compression ratio.
Figure 5 shows the experimental results. First, it is obvious that in the task of person pose estimation, the DAC also maintains high accuracy without any retraining when large amounts of FLOPs are saved. Our proposed DAC saves up to 46% FLOPs when 2% AP drop is allowed. Second, for each curve, the AP decreases with decreasing decomposition rank. This observation is consistent with the above second insight. Then, we notice that “Decompose last 6 stages” achieves similar results (similar saved ratios and APs) as “Decompose last 5 stages” does. This can be explained as follows: the “Decompose last 6 stages” includes Stage 1 in which all decomposed convolutional layers (6 layers) have (3x3) kernel size. Comparing to a convolutional layer with (7x7) kernel size, these layers have much fewer parameters, so decomposing them does not contribute much.
Table 3 shows the accuracy of the model (after saving 40%, 50%, and 60% FLOPs respectively) on COCO 2017 keypoint challenge. The parameters of Channel Decomposition and Spatial Decomposition are computed using Equation 2 and 3 correspondingly. Compared to Channel and Spatial Decomposition, DAC achieves higher accuracy even when a significant amount of FLOPs is reduced. After saving 60% FLOPs, Channel Decomposition cannot correctly detect any person’s pose, while DAC can still achieve 7.1% higher accuracy than Spatial Decomposition.
Figure 6 shows the visualized multi-person pose estimation results on COCO dataset. It shows that after being decomposed using DAC, the model still works pretty well. There are only small changes observed. For example, the decomposed model misses a leg of a person in the first example (the second person on the right side) and the third sample ( the second person on the left side). Please refer to our Appendix for more visualized results.
4.5 Object Detection
Next, we evaluate the performance of DAC in the task of object detection using the Single Shot MultiBox Detector (SSD) model proposed by Liu et al. [16]. Figure 7 shows the framework of the SSD.
We use a model vivivihttps://github.com/pierluigiferrari/ssd_keras pre-trained on Pascal VOC2007 and VOC2012 trainval subset. The model uses VGG-16 [23] as its base net that has (300x300) input size. Ten extra convolutional layers are added to the VGG-16 model to provide extra information. In total, 18 (3x3) convolutional layers and 5 (1x1) convolutional layers are used to generate multi-scale feature maps for detection, and 12 (3x3) convolutional layers are used to produce a fixed set of detection predictions. This model achieves 76.5% on VOC2007 testing set.
There is no benefit in decomposing a convolutional layer with (1x1) kernel size, so we only decompose those layers with (3x3) kernel size. Furthermore, considering that decomposing first layers causes large drops of accuracy, we do not decompose the first convolutional layer of the model. To simplify the description, we denote 18 layers (the first layer, conv1_1, is not decomposed) that generate multi-scale feature maps by “Feature Convolutional Layers (FL)” and 12 layers that produce detection predictions by “Detector Convolutional Layers (DL)”.
We demonstrate the experimental results in Figure 8. First, one can see that if 2% mAP drop is acceptable, DAC saves up to 29% FLOPs. Second, decreasing the decomposition rank results in a drop of mAP, which is also observed in the previous experiment. Third, compared to “DL”, “FL” achieves a bigger FLOPs saved ratio. This is because that there are fewer layers in “DL” and each layer in “DL” has fewer channels than layers in “FL”. In addition, for this model, the maximum decomposition rank is 9 so when the decomposition rank is set to 9, the number of parameters increases after decomposition. This is because that all layers we decompose in this model have (3x3) kernel size whose full rank is 9. The newly generated depthwise layer with Rank9 has the same number of parameters as the decomposed layer, while an extra pointwise layer that has parameters is added.
Table 5 shows the comparison of the detection accuracy on PASCAL VOC2007 Dataset. One can see that DAC achieves higher accuracy than other schemes. In Table 4, we list the details of the detection results on PASCAL VOC2007 testing set. Comparing the results of DAC to the original model, one can see that decomposing the model using DAC does not impact the performance of the model too much, for all categories. The change of the accuracy happens on each category within a small range.
Figure 9 shows the visualized object detection results on PASCAL VOC2007 testing set. From the first two samples, one can see that after being decomposed, the model can still correctly detect objects. The locations and sizes of the detected bounding boxes have small changes. The third sample is an example that the original model does not detect an object (the bottle) that is successfully detected by our decomposed model. The fourth sample shows an extra false positive example (an unexpected potted-plant is detected), the fifth sample is a missing example (miss the car on the right), and the last sample is an example that the detected label changed (from bird to dog). Please refer to our Appendix for more visualized results.
5 Conclusion
In this paper, we propose a novel decomposition method, namely DAC. Given a pre-trained model, DAC is able to factorize an ordinary convolutional layer into two layers with much fewer parameters and computes their weights by decomposing the original weights directly. Thus, no training (or fine-tuning) or any data is needed. The experimental results on three computer vision tasks show that DAC reduces a large number of FLOPs while maintaining high accuracy of a pre-trained model.
We plan to evaluate the performance of DAC for deep learning models in other fields, e.g., voice recognition, language translation, etc. We also want to explore the possibility of adapting DAC on other types of layers, e.g. 3D convolutional layer, compared with other tensor decomposition formats [10, 12]. Another research direction is to combine low rank constraints with weight decomposition. These constraints could be convex regularizations like nuclear norm and Frobenius norm, or non-convex quasi-norms like Schatten and TS1 [30, 29, 31].
6 Acknowledgements
We would love to express our appreciation to Jacob Nelson for his useful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. ar Xiv preprint ar Xiv:1603.04467 , 2016.
- 2[2] J. M. Alvarez and M. Salzmann. Compression-aware training of deep networks. In Advances in Neural Information Processing Systems , pages 856–867, 2017.
- 3[3] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017.
- 4[4] F. Chollet et al. Keras. https://github.com/fchollet/keras , 2015.
- 5[5] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2007 (VOC 2007) Results. http://www.pascal-network.org/challenges/VOC/voc 2007/workshop/index.html.
- 6[6] J. Guo, Y. Li, W. Lin, Y. Chen, and J. Li. Network decoupling: From regular to depthwise separable convolutions. In BMVC , 2018.
- 7[7] Y. He, X. Zhang, and J. Sun. Channel pruning for accelerating very deep neural networks. 2(6), 2017.
- 8[8] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. ar Xiv preprint ar Xiv:1704.04861 , 2017.