Structure Selection of Polynomial NARX Models using Two Dimensional (2D) Particle Swarms
Faizal Hafiz, Akshya Swain, Eduardo MAM Mendes, Nitish Patel

TL;DR
This paper introduces a novel two-dimensional particle swarm optimization method for selecting the structure of polynomial NARX models, demonstrating superior accuracy and robustness compared to traditional genetic algorithms, especially under noisy conditions.
Contribution
The study presents a new 2D-UPSO framework that explicitly considers the number of model terms, improving structure selection for polynomial NARX models over existing methods.
Findings
2D-UPSO outperforms genetic algorithms in structure selection.
The approach is effective with different information criteria.
Robust against measurement noise in nonlinear system modeling.
Abstract
The present study applies a novel two-dimensional learning framework (2D-UPSO) based on particle swarms for structure selection of polynomial nonlinear auto-regressive with exogenous inputs (NARX) models. This learning approach explicitly incorporates the information about the cardinality (i.e., the number of terms) into the structure selection process. Initially, the effectiveness of the proposed approach was compared against the classical genetic algorithm (GA) based approach and it was demonstrated that the 2D-UPSO is superior. Further, since the performance of any meta-heuristic search algorithm is critically dependent on the choice of the fitness function, the efficacy of the proposed approach was investigated using two distinct information theoretic criteria such as Akaike and Bayesian information criterion. The robustness of this approach against various levels of measurement…
Click any figure to enlarge with its caption.
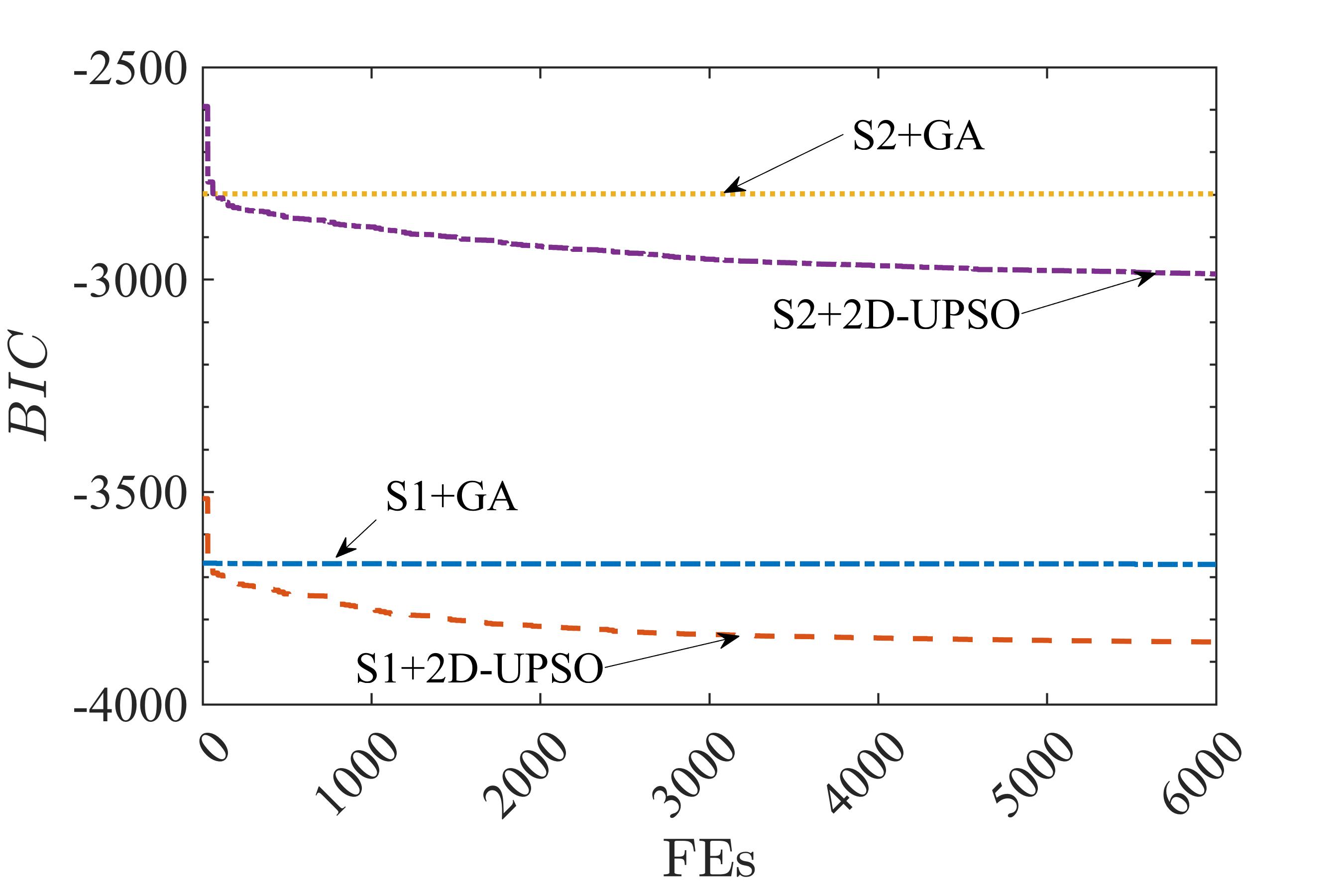 Figure 1
Figure 1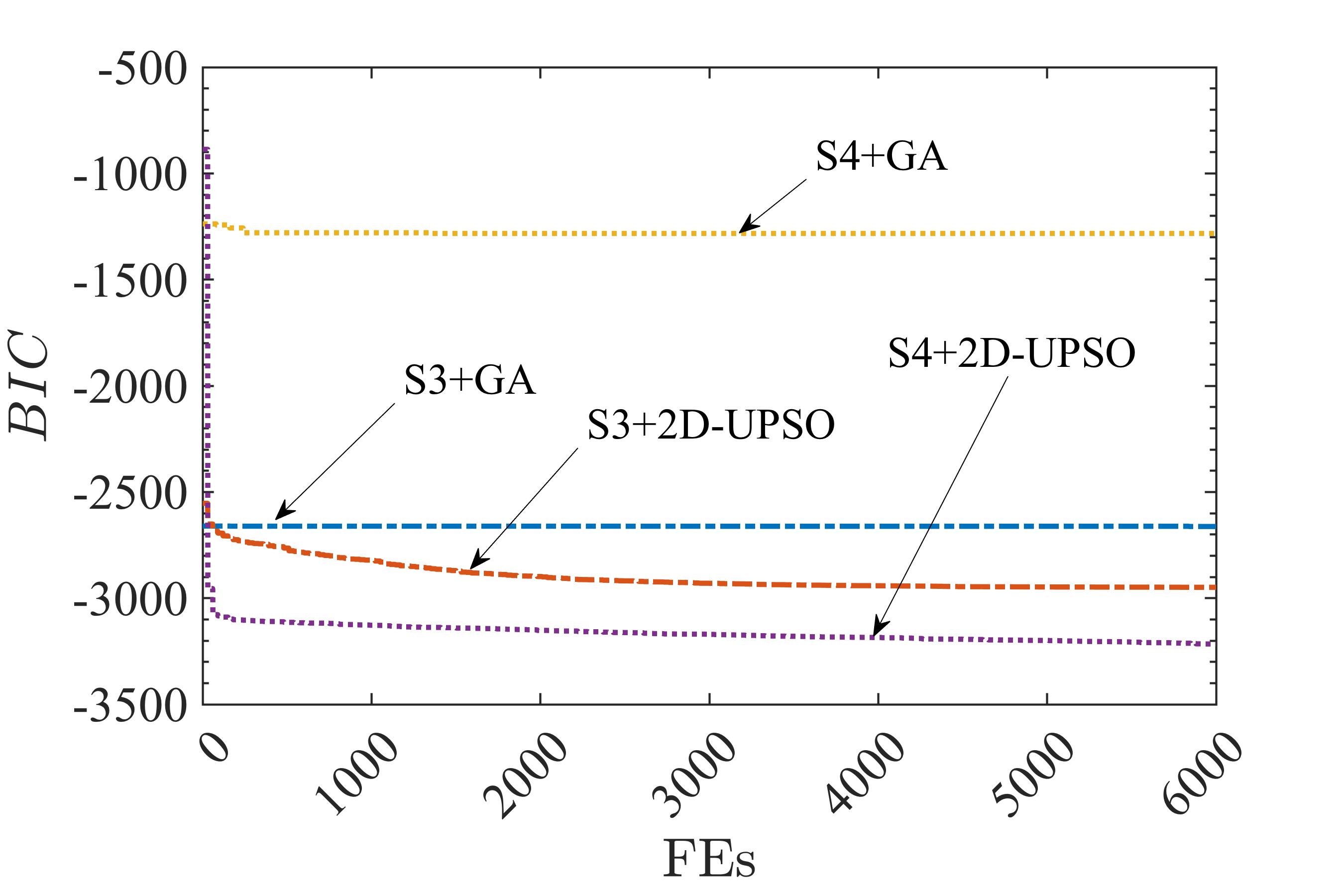 Figure 2
Figure 2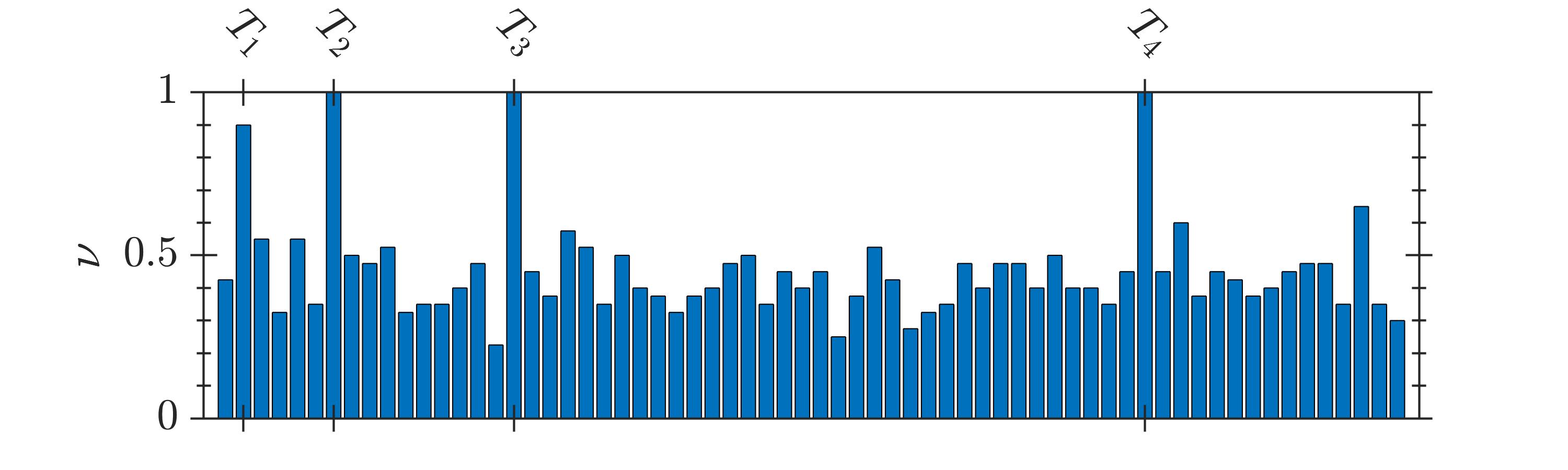 Figure 3
Figure 3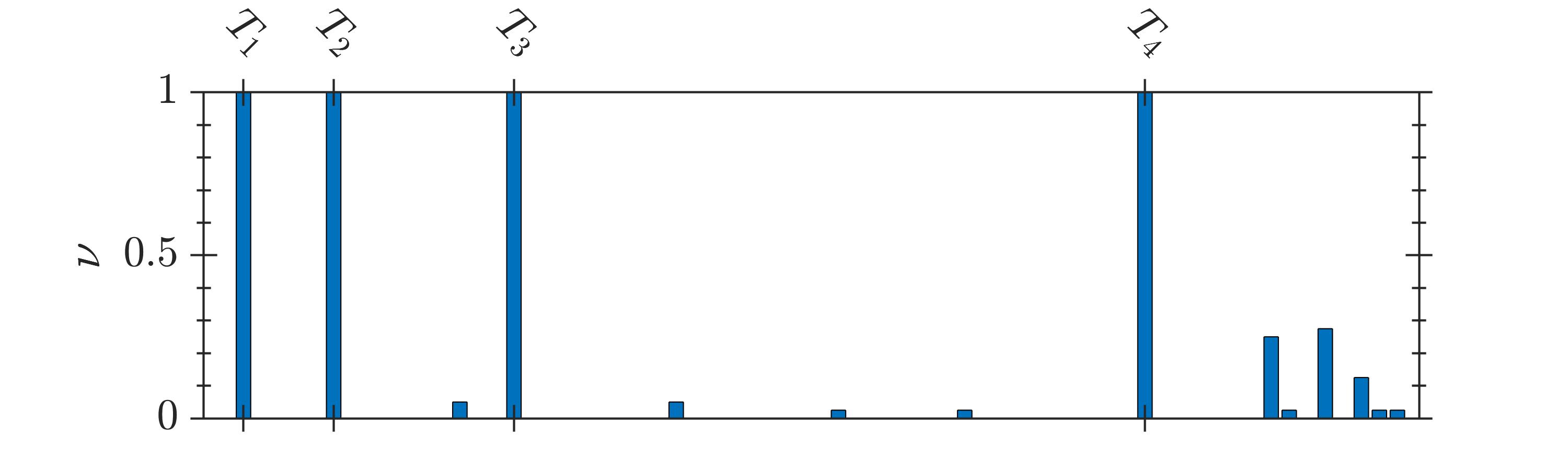 Figure 4
Figure 4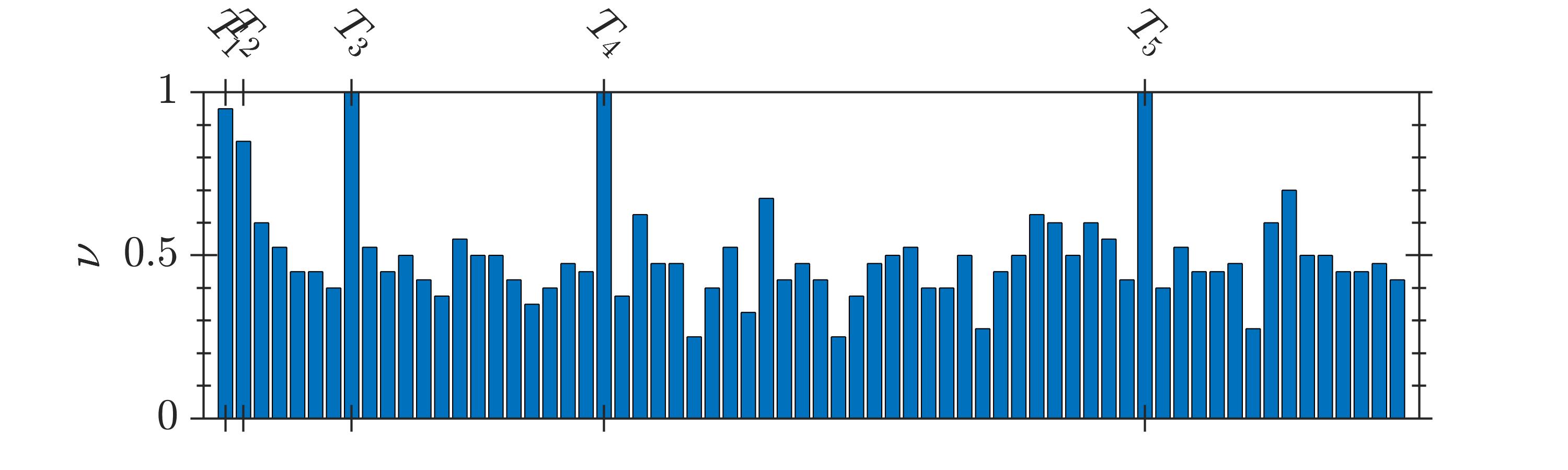 Figure 5
Figure 5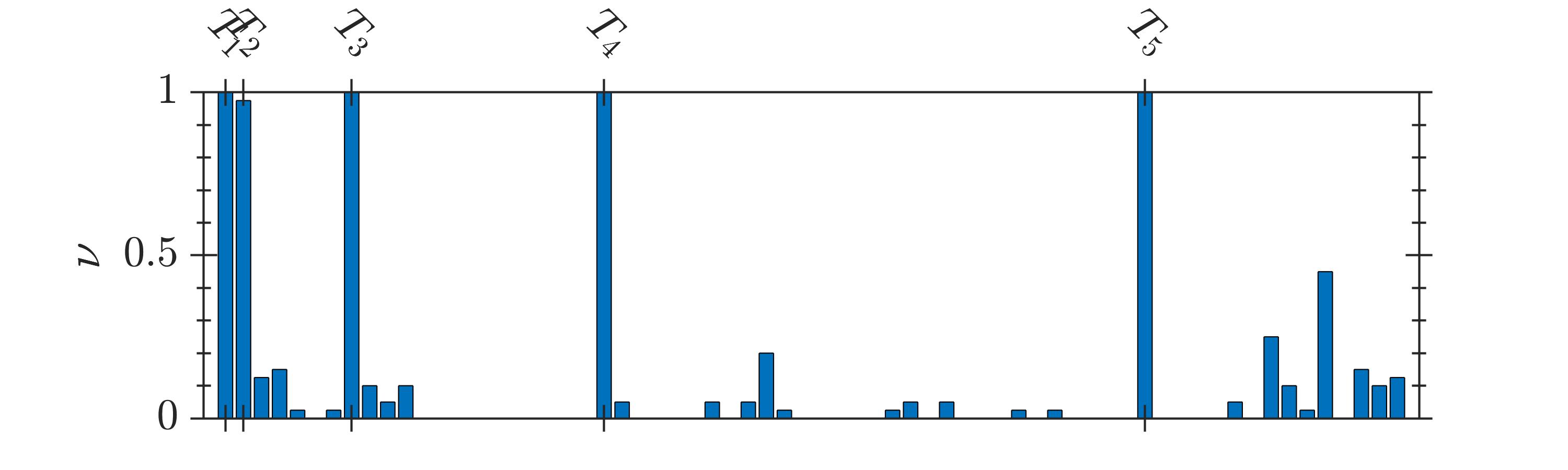 Figure 6
Figure 6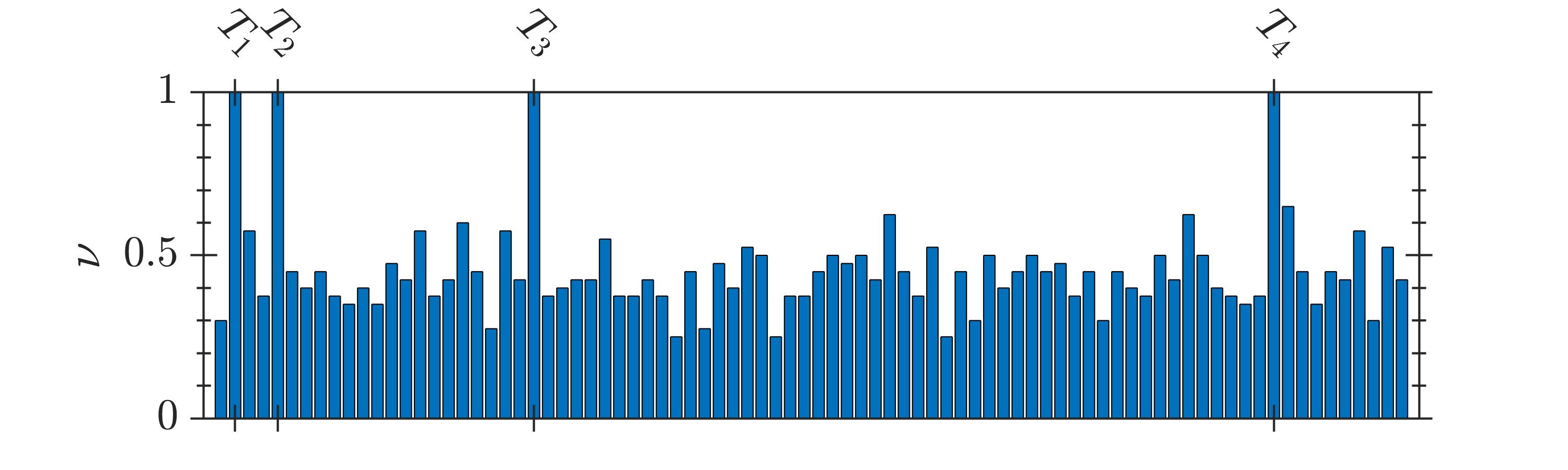 Figure 7
Figure 7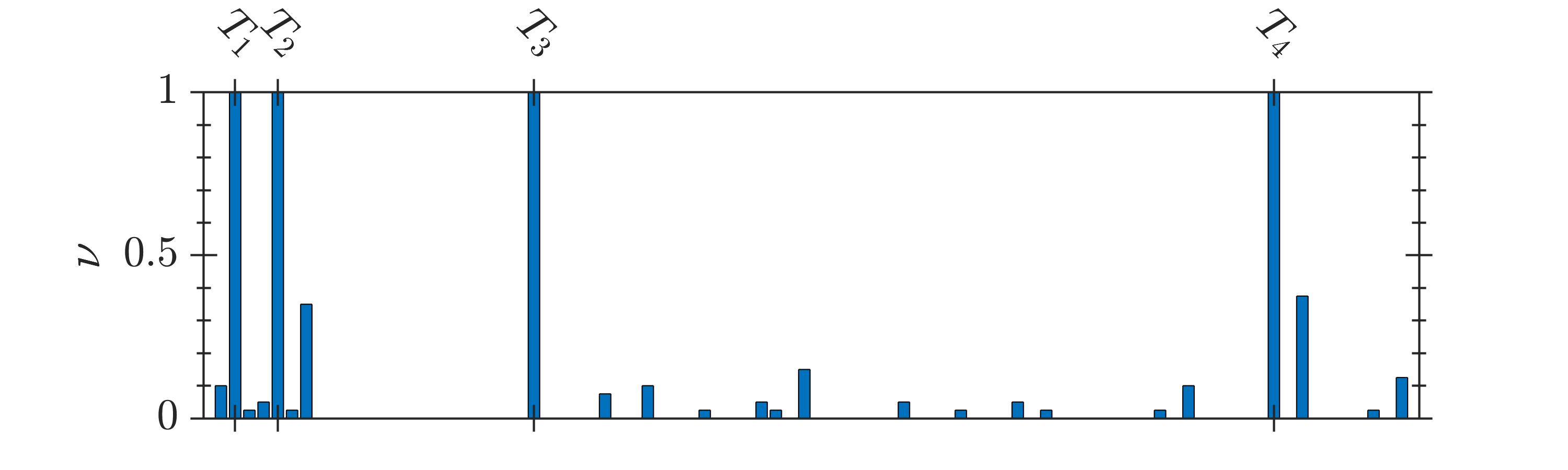 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Structure Selection of Polynomial NARX Models using Two Dimensional (2D) Particle Swarms
Faizal Hafiz1, Akshya Swain1, Eduardo MAM Mendes2 and Nitish Patel1
1Department of Electrical & Computer Engineering, The University of Auckland, Auckland, New Zealand.
Email: [email protected], [email protected]
2Department of Electronics Engineering, Federal University of Minas Gerais, Belo Horizonte, Brazil.
Abstract
The present study applies a novel two-dimensional learning framework (2D-UPSO) based on particle swarms for structure selection of polynomial nonlinear auto-regressive with exogenous inputs (NARX) models. This learning approach explicitly incorporates the information about the cardinality (i.e., the number of terms) into the structure selection process. Initially, the effectiveness of the proposed approach was compared against the classical genetic algorithm (GA) based approach and it was demonstrated that the 2D-UPSO is superior. Further, since the performance of any meta-heuristic search algorithm is critically dependent on the choice of the fitness function, the efficacy of the proposed approach was investigated using two distinct information theoretic criteria such as Akaike and Bayesian information criterion. The robustness of this approach against various levels of measurement noise is also studied. Simulation results on various nonlinear systems demonstrate that the proposed algorithm could accurately determine the structure of the polynomial NARX model even under the influence of measurement noise.
Index Terms:
Nonlinear system identification, structure selection, NARX model, particle swarm
I Introduction
System identification addresses the issue of constructing mathematical models from the observed input-output data and has been a major research concern from diverse fields such as statistics, control theory, information theory, economics, ecology, agriculture and others [1, 2]. Although, methods for linear systems identification are now well established, the development of nonlinear system identification methods, which can be valid for a broad class of nonlinear systems, is a research issue. This is partly due to the well-recognized highly individualistic nature of nonlinear systems which restricts the unifying dynamical features that are amenable to system identification.
The first step in the nonlinear system identification is the choice of the model amongst various models which are used to represent the system such as Volterra, Wiener, neural networks, polynomial models, rational models and others. The focus of this study is the identification of nonlinear systems represented by polynomial nonlinear auto-regressive with exogenous inputs (NARX) models [1]. Although this model could represent a wide class of nonlinear systems, the number of possible terms increases exponentially with the increase in the order of non-linearity and maximum lags of inputs and outputs. Inclusion of all the terms is not desirable as the parameter estimation problem may become ill-conditioned for the consequent complex model [1]. Therefore, determination of the model structure or which terms to include in the model is essential if a parsimonious model is to be determined from the large number of candidate terms.
During the past three decades, researchers have proposed several algorithms based on orthogonal least squares, evolutionary algorithms such as genetic algorithm, genetic programming to address this issue both in time and frequency domain identification. The related literature can be found in [1, 2, 3, 4, 5, 6, 7, 8] and the references there in.
In this study, a novel 2-D particle swarm algorithm [9] has been applied for selecting the correct structure of the NARX model of the nonlinear systems. The proposed algorithm explicitly include the cardinality (i.e., the number of terms) information in to the search process by extending the dimension of classical single dimensional particle swarm algorithm. This is different from the least squares based orthogonal search algorithms developed by Billings and co-workers where the structure selection is carried out using an error-reduction-ratio (ERR) test which is computed either from the one-step ahead prediction or simulated prediction of the output [1, 8].
The rest of the article is organized as follows: NARX model of the non-linear systems and the 2D learning approach are briefly described in Section II and III. The framework of this study is described in Section IV. The results are discussed at length in Section V, followed by the conclusions in Section VI.
II The Polynomial NARX Model
A wide class of nonlinear system can be represented by a polynomial nonlinear auto-regressive moving average with exogenous (NARMAX) model given by,
[TABLE]
where , and represent the output, input and noise respectively at time intervals , , and are corresponding lags and is some nonlinear function of degree . The polynomial NARX model is a subclass of NARMAX model where the noise terms are absent and is given by,
[TABLE]
The total number of possible terms or model size () of the NARMAX model is given by
[TABLE]
This model is essentially linear-in-parameters and can be expressed as
[TABLE]
where ,
[TABLE]
where, ; ; ; ;; ; and is the degree of polynomial expansion. For the polynomial NARX model, which does not contain any noise terms, and this indicates that contains no terms.
III Two-Dimensional (2D) Particle Swarms
The Two-Dimensional (2D) learning framework was developed for the particle swarms to effectively address the feature selection problem [9]. The core idea of this approach is to integrate the information about the cardinality (i.e., the number of features) into the search process. This learning approach has been applied to address the power quality problems [10] and has been shown to perform better than some of the existing approaches [11, 12, 13]. In this study, it has been shown that this learning approach can easily be applied to address the model structure selection problem, as in essence, the main objective of both the feature selection and the structure detection are similar, i.e., detect a parsimonious model or remove redundant features/terms.
The following subsections briefly describe the 2D learning approach. More details about this approach can be found in [9].
III-A Learning Philosophy
The selection of a parsimonious model in the problems such as feature selection or structure selection involves mainly two issues : 1) How many attributes (e.g., features or terms) are required? 2) Which attributes shall be selected? The main philosophy of the 2D learning approach is to explicitly use the information about the cardinality (i.e. the number of attributes/features/terms) as an additional learning dimension in order to facilitate informed decision on both issues.
To understand the 2D learning approach, consider a structure selection problem with a total of ‘’ possible terms. For this problem, a particle position (model), ‘’, is usually represented as a -dimensional binary string wherein selected terms are represented by bit ‘’.
Further, in the conventional Binary PSO and its variants, the velocity of a particle is given by,
[TABLE]
where, represents the selection likelihood of the corresponding attributes. In other words, in each iteration, a new position (model) is derived only on the basis of selection likelihoods of the attributes.
In contrast, in 2D learning, the selection likelihood of both cardinality and attributes are considered to derive a new position. This is achieved by extending the learning dimension and separately storing selection likelihood of cardinality and attributes in a two-dimensional matrix of size as follows:
[TABLE]
The elements in the first row of store the selection likelihoods of cardinality. For example, ‘’ gives the probability of selecting attributes in a new model. Similarly, the elements in the second row give the selection likelihood of the corresponding attributes, e.g., the selection probability of the ‘’ attribute is given by ‘’.
III-B Velocity Update
The 2D learning approach was developed as a generalized learning framework to adapt any continuous PSO variant (i.e., ) for the model selection task (i.e., ). However, the results of comparative analysis of various PSO variants [14] indicate that Unified Particle Swarm Optimization (UPSO) [15] is more suitable for the problem in the discrete domain (i.e., ) and therefore it is selected in this study.
In essence, UPSO combines the ‘global’ and ‘local’ variants of the conventional PSO through the unification factor, ‘’. Following the 2D learning approach, UPSO is adapted for the structure selection task as follows:
[TABLE]
where, ‘’ is inertia weight and denotes acceleration constants.
Further, in the 2D learning, a learning set, ‘’, is derived from each learning exemplar, e.g., personal best (), global best (), neighborhood best (). For example, , , and are the learning sets derived from , , and the particle position , respectively. Note that the ring topology is being used to define the neighborhood.
The learning set is a two-dimensional binary matrix of size (). Similar to the velocity matrix, learning sets store the learning about cardinality and attribute in separate rows. More details about the learning process and the derivation of the learning sets can be found in [9].
Note that, in addition to the learning exemplars, the particle position () is used to extract a learning set, referred as a self learning set. The influence of the self learning set is controlled by the ‘’ which is given by,
[TABLE]
where, ‘’ and ‘’ are respectively the fitness of the particle and the vector containing the fitness of the entire swarm at iteration . The objective here is to adjust the selection likelihood of the terms included in the particle position as per : 1) the relative improvement over other particles and 2) the relative improvement in the self-fitness over the previous iteration.
III-C Position Update
To understand the position update process, consider the velocity of an particle for a structure selection problem with as follows:
[TABLE]
To integrate the information about both the cardinality and the attributes/terms, the position update is carried out in two stages. In the first stage, the cardinality of the new position is determined. Consequently, the beneficial terms are selected as per the selected cardinality. This procedure is explained in the following example.
For the sake of clarity, the velocity of the particle in (7) is segregated into two vectors and as follows:
[TABLE]
The cardinality of the new position is selected following the roulette wheel approach as outlined in Lines 1-1, Algorithm 1. For the particle considered in (7) the cardinality of the new position, is derived as follows:
Accumulative likelihoods,
2. 2.
Let random number be , which gives as .
The next step is to select most beneficial terms (as ). For this purpose, the steps outlined in Line 1-1, Algorithm 1 are followed.
Ranking of the terms,
which gives, 2. 2.
Selection of terms as per ,
and
which gives,
IV Investigation Framework
The main objective of this study is to evaluate the search performance of 2D particle swarms on the structure selection problem. For this purpose, the performance of the 2D-UPSO has been compared with Binary Genetic Algorithm (GA) over several known non-linear systems, as shown in Table I.
The other objective is to evaluate the effects of the measurement noise and the choice of the fitness function on the search performance. For this purpose, the search performance is quantified using two performance metrics and compared over two distinct fitness functions at noise levels, SNR.
The following subsections provide the details about compared algorithms, fitness function and the performance metrics being used in this investigation.
IV-A Search Setup
To evaluate the efficacy of 2D particle swarms, the performance of 2D-UPSO has been compared with GA. Both algorithms were implemented in MATLAB. Due to stochastic nature of these algorithms, independent runs were carried out for each system. Each run was set to terminate after Function Evaluations (FEs). The parameter settings of the compared algorithms are shown in Table II.
IV-B Fitness Function
The fitness function is the only link between the search algorithm and the problem being solved. Hence, the choice of fitness function is likely to have a significant impact on the search performance. In this study, to evaluate the ‘fitness’ of a candidate model (particle position) ‘’, sum-squared-error (SSE) with respect to ‘model-predict output’ over validation data is evaluated,
[TABLE]
where, ‘’ denotes the total number of validation data samples and ‘’ denotes ‘model-predicted output’ corresponding to . For each system shown in Table I, 2000 pairs of input-output data, , were generated. Out of these data, data were used for the validation purposes (i.e., ).
Note that minimization of ‘’ does not guarantee a parsimonious model. It is therefore necessary to assign a penalty for a higher cardinality (number of terms) to ensure the removal of the redundant terms. Hence, the structure selection is essentially multi-objective problem. To balance both search objectives (i.e., minimizing and cardinality) several information theoretic criteria have been proposed over the years such as Akaike Information Criterion (AIC), Minimum Description Length (MDL), Bayesian Information Criterion (BIC) and others [1]. In this study, BIC (11) and AIC (12) are selected as the fitness function, ,
[TABLE]
Here, ‘’ denotes a model structure (particle position) under consideration, ‘’ gives number of terms included in (or cardinality of ). Further, in AIC (12) is a constant and requires a careful tuning. In this study, four distinct values of have been used, .
IV-C Performance Metrics
The stochastic nature of the compared algorithm requires a multiple independent runs ( in this study) for each system. Since, it is likely that each run provides a different model structure, a usual approach is to select the model structure with the best fitness out of all runs. In contrast, in this study a comprehensive approach is followed. For a given system, a model structure (selected terms) and its cardinality are stored at the end of each run of the algorithm. The objective is to evaluate the frequency of selection of each term (‘’) over runs. The final model structure is obtained by including terms with over certain fixed threshold. The details are discussed in the following.
Let us define the following sets to quantify the search performance,
- •
: set of all possible terms present in the search domain, i.e., it contains the complete possible model terms.
- •
: set of the terms which are present in the actual system,
- •
: set of terms selected by a search algorithm,
- •
: set of spurious terms which are selected by the search algorithm but which are not present in the actual system, i.e.,
In order to quantify the search performance, selection frequency, (13), of system () and spurious () terms is observed over 40 runs. It is desirable to have a higher selection frequency of the system terms and fewer spurious terms.
[TABLE]
To extract the final structure, a threshold can be fixed at any suitable value in , e.g. with threshold at , only the terms are included in the final structure.
Further, to account the spurious terms selected by the algorithm, the following two metrics are used:
[TABLE]
where, ‘’ denotes the number of spurious terms identified by the search algorithm; ‘’ denotes the model size which is given by (1). The metric gives the maximum selection frequency of the spurious terms. A lower value is desirable, as it ensures that of the spurious terms will be less than selection threshold. Similarly, a lower value of metric ‘’ is desirable, as it indicates that a small number of spurious terms are selected by the search algorithm.
V Results
The main objective of this study is to investigate the search performance of 2D particle swarms on the structure selection problem. Further, we are also interested in evaluating the effects of measurement noise and the choice of the fitness function on the search performance. For this purpose, two well-known information theoretic criteria such as AIC and BIC have been used as a fitness function. In the first stage of the investigation, we compare these criteria for structure selection problem in the presence of various levels of measurement noise. The results indicate that BIC is more suitable for this task (as discussed in Section V-A). Consequently, the search performance of 2D-UPSO and GA is compared with BIC as the fitness function during the second stage of the investigation.
V-A Stage-1 : Choice of the fitness function
Following the procedure described in Section-IV, the effects of fitness function on structure selection in the presence of various levels of noise was investigated as follows:
The search performance of 2D-UPSO was recorded for each combination of test system and fitness function in the presence of distinct noise levels in the input-output data. For a given system, 40 independent runs of 2D-UPSO were carried out for each combination of fitness function (i.e. AIC or BIC) and noise level. The objective here is to examine the change in the selection frequency of system and spurious terms with different fitness function. For this purpose, the performance metrics outlined in Section IV-C are determined. Note that, AIC requires the selection of constant (as seen in 12). To explore the effects of , four different value of have been used.
The results of this test are shown in Table IV-VI, which indicate that in most of the cases the system terms are identified with the frequency , irrespective of the fitness function. However, the fitness function has a significant impact on the spurious terms. For example, for system , (Table IV), the ratio and maximum frequency of the spurious terms are reduced significantly from to when in AIC is changed from to . Similar effects are observed for system (change in from with to with , Table IV) and , (change in from with to with , Table V). These observations further underline the role of the fitness function.
Note that the structure selection is essentially a multi-objective problem and the aim of both information criteria, AIC and BIC, is to balance search objectives, i.e., reduction in and cardinality of the model. The selection of in (12) is equivalent to guiding a search towards a particular region of the Pareto front. Although this gives the freedom to decision maker to guide the search as per requirement, it is quite challenging to properly tune .
This is evident from the results shown in Table IV-VI. These results indicate that is suitable for systems , and , as this value of leads to significant reduction in the spurious terms (Table IV-V). In contrast, for system , even the system terms are not identified with whereas desirable results are obtained with , as seen in Table VI. This can be explained as follows: a higher value of assigns a high penalty to model structures with higher cardinality (as seen in (12)) and hence drives the search toward a smaller structures.
From these observations, it is apparent that a proper value of depends on the structure of the system, i.e., a higher is effective for the systems with smaller number of terms/cardinality while a lower is desirable for the system with higher cardinality structures. Given that in practice only the input-output measurement data pairs , , are available and the cardinality of the structure is not known, it is quite challenging to judiciously select .
Further, it is interesting to note that, with BIC, all the system terms are identified with irrespective of the structure cardinality of the corresponding systems, as seen in Table IV-VI. In addition the maximum selection frequency of the spurious terms, , is always less than minimum selection frequency of the system terms. Consequently, the spurious terms can easily be removed from the final model structure through a simple thresholding. For this reason, BIC is preferred as the fitness function for the structure selection problem.
V-B Stage-2 : Comparative Evaluation of Search Algorithms
To benchmark the search performance of 2D particle swarms, 2D-UPSO and GA were applied to the test non-linear systems shown in Table I. For this test, BIC (11) was used as the fitness function. For all the systems, independent runs of each algorithm were carried out and the results are shown in Fig. 1, 2 and Table VII.
The search performance of GA and 2D-UPSO is captured through run-length distribution graphs shown in Fig. 1. These results indicate that the search process in GA quickly stagnates for all the systems which could be explained by the premature convergence. On the contrary, for the same systems, 2D-UPSO could maintain continual improvement in the fitness function, , throughout the search.
The selection frequency of the terms, , identified by GA and 2D-UPSO is shown in Fig. 2. It is observed that even-though GA could identify the system terms, a higher number of spurious terms is present for the systems -. In contrast, 2D-UPSO could identify the correct structure of each system with comparatively fewer spurious terms.
The results of comparative evaluation on are shown in Table VII. For this system, 2D-UPSO could identify all system terms with , irrespective of the noise level. In contrast, GA could not identify the structure of as the selection frequency of many system terms is less than , i.e., it is not possible to remove spurious terms with thresholding as their selection frequency is higher than the system terms. For example, at SNR, is higher than the selection frequency of (out of ) system terms, as seen in Table VII.
VI Conclusion
A new two-dimensional learning framework (2D-UPSO) for particle swarms has been applied to address the structure selection problem for a class of non-linear systems which are represented by nonlinear auto-regressive with exogenous inputs (NARX) models. One of the important and advantageous feature of the proposed approach is that it explicitly incorporates the knowledge about the cardinality into the search process. The performance of this approach has been compared with the classical GA based structure selection. For the structure selection, two of the well-known information theoretic criteria such as AIC and BIC have been used as the fitness function. Several non-linear systems have been identified through the proposed approach under various levels of measurement noise using both criteria. First, it was established that BIC criteria is often consistent compared to AIC. Further, it has been established that 2D-UPSO could accurately determine the structure of the systems with significantly less number of spurious terms.
Appendix A System Terms
- •
System : , where, , , and
- •
System : , where, , , , and
- •
System : , where, , , and
- •
System : , where, , , , , , , , , , , , , , , , , , , , , , ,
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. A. Billings, Nonlinear system identification: NARMAX methods in the time, frequency, and spatio-temporal domains . John Wiley & Sons, 2013.
- 2[2] L. Ljung, Ed., System Identification : Theory for the User . Upper Saddle River, NJ, USA: Prentice Hall PTR, 1999.
- 3[3] C. M. Fonseca, E. Mendes, P. Fleming, and S. A. Billings, “Non-linear model term selection with genetic algorithms,” in Proceedings of IEE/IEEE Workshop on Natural Algorithms in Signal Processing , vol. 2, 1993, pp. 271–278.
- 4[4] A. Swain and S. Billings, “Weighted complex orthogonal estimator for identifying linear and non-linear continuous time models from generalised frequency response functions,” Mechanical Systems and Signal Processing , vol. 12, no. 2, pp. 269–292, 1998.
- 5[5] E. Mendes and S. A. Billings, “An alternative solution to the model structure selection problem,” IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans , vol. 31, no. 6, pp. 597–608, 2001.
- 6[6] K. Rodriguez-Vazquez, C. M. Fonseca, and P. J. Fleming, “Identifying the structure of nonlinear dynamic systems using multiobjective genetic programming,” IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans , vol. 34, no. 4, pp. 531–545, 2004.
- 7[7] K. Kar, A. K. Swain, and R. Raine, “Identification of time-varying time constants of thermocouple sensors and its application to temperature measurement,” Journal of Dynamic Systems, Measurement, and Control , vol. 131, no. 1, p. 011005, 2009.
- 8[8] T. Baldacchino, S. R. Anderson, and V. Kadirkamanathan, “Structure detection and parameter estimation for NARX models in a unified EM framework,” Automatica , vol. 48, no. 5, pp. 857–865, 2012.