Iterated Belief Revision Under Resource Constraints: Logic as Geometry
Dan P. Guralnik, Daniel E. Koditschek

TL;DR
This paper introduces the universal memory architecture (UMA), a geometry-based belief revision method for resource-constrained settings like mobile robots, offering computational efficiency and model comparison capabilities.
Contribution
It develops the formalism of UMA, linking inference to geometry via duality, and analyzes its complexity, learning guarantees, and practical viability through simulations.
Findings
UMA reduces computational costs in belief revision.
The duality framework enables model space comparisons.
Simulation results demonstrate UMA's practical effectiveness.
Abstract
We propose a variant of iterated belief revision designed for settings with limited computational resources, such as mobile autonomous robots. The proposed memory architecture---called the {\em universal memory architecture} (UMA)---maintains an epistemic state in the form of a system of default rules similar to those studied by Pearl and by Goldszmidt and Pearl (systems and ). A duality between the category of UMA representations and the category of the corresponding model spaces, extending the Sageev-Roller duality between discrete poc sets and discrete median algebras provides a two-way dictionary from inference to geometry, leading to immense savings in computation, at a cost in the quality of representation that can be quantified in terms of topological invariants. Moreover, the same framework naturally enables comparisons between different model spaces, making it possible…
Click any figure to enlarge with its caption.
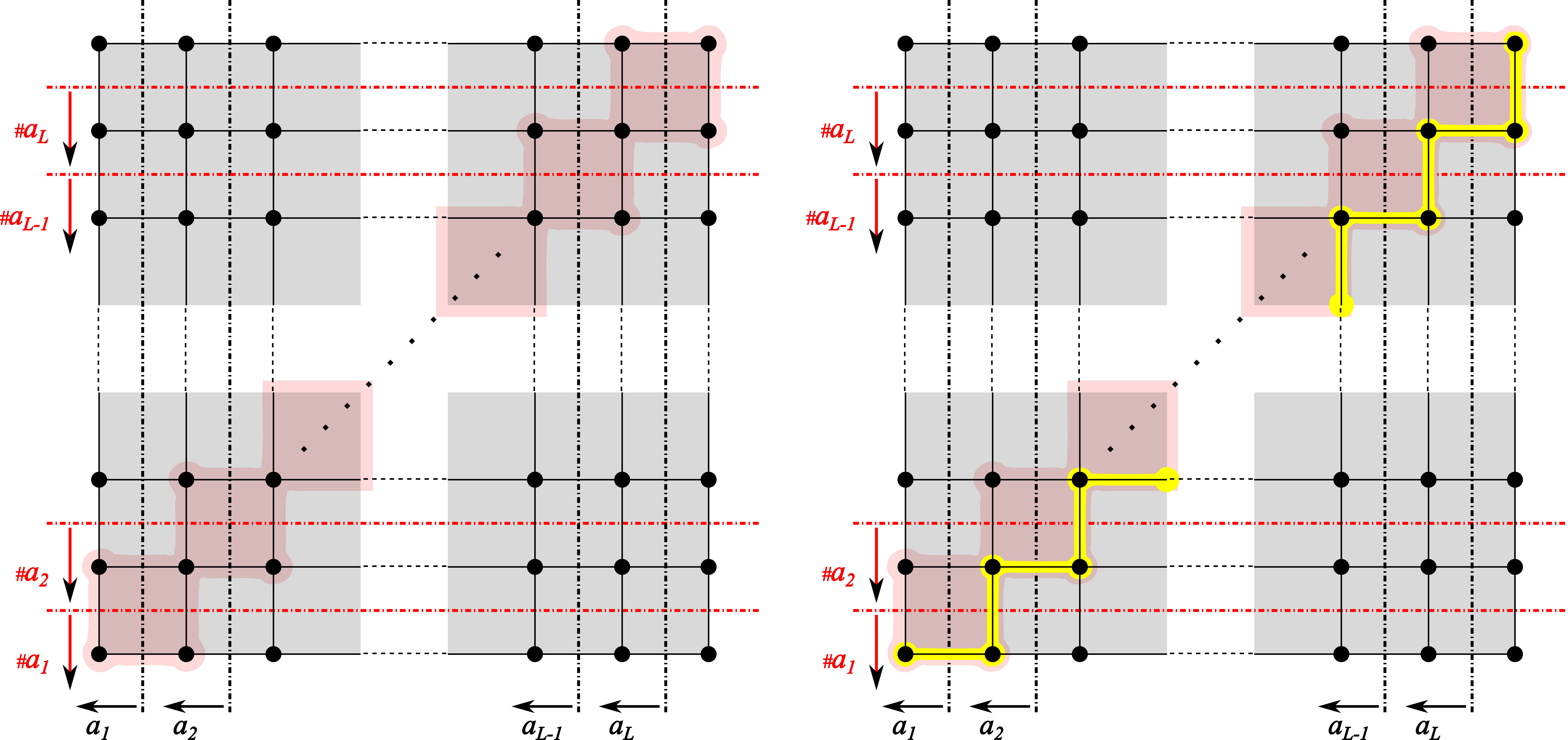 Figure 1
Figure 1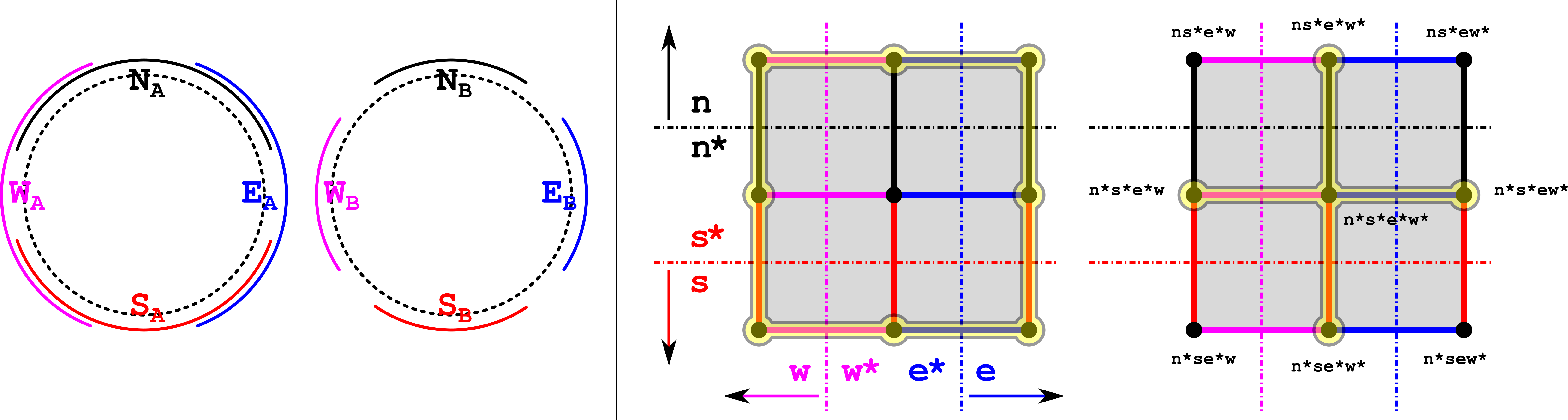 Figure 2
Figure 2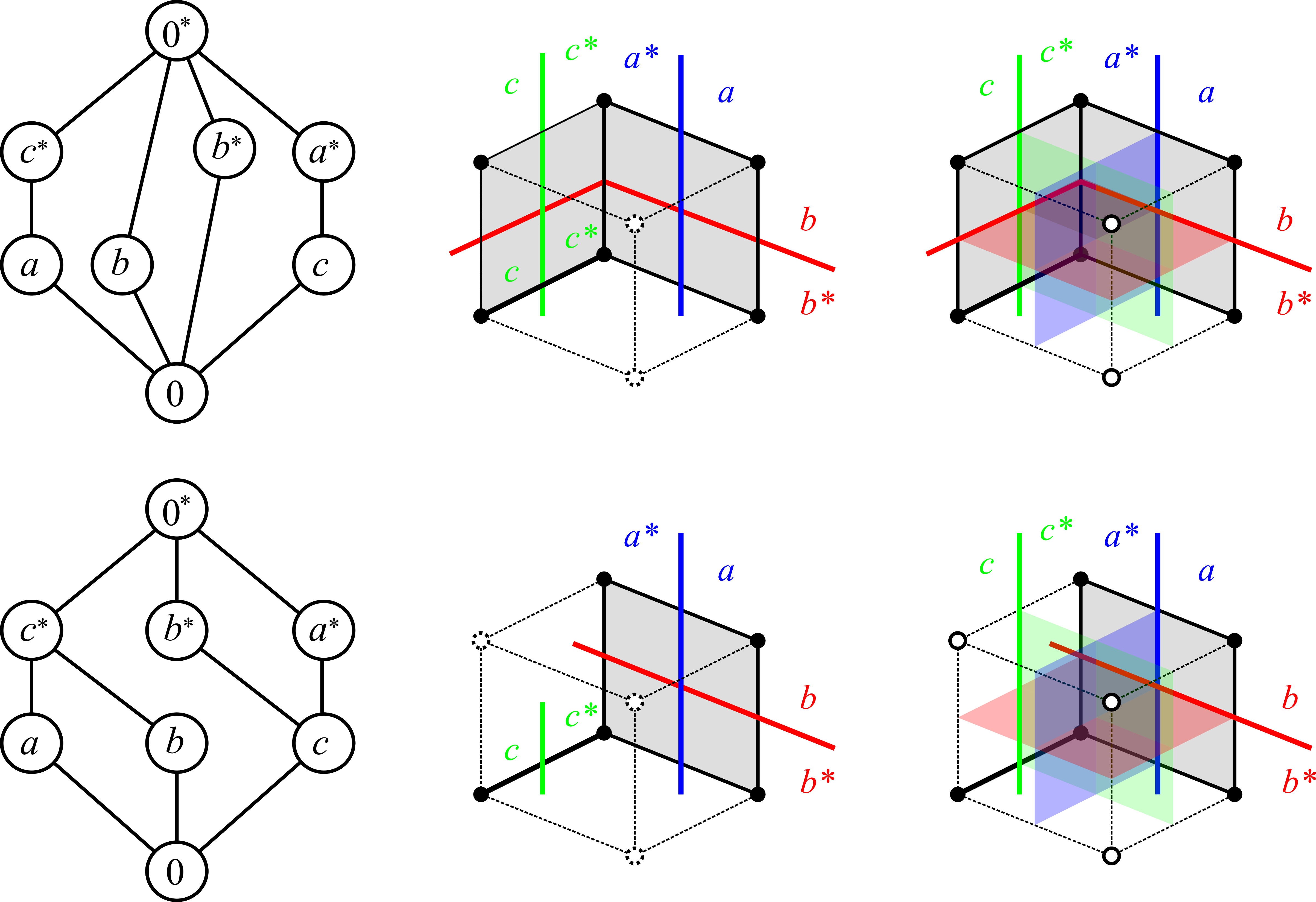 Figure 3
Figure 3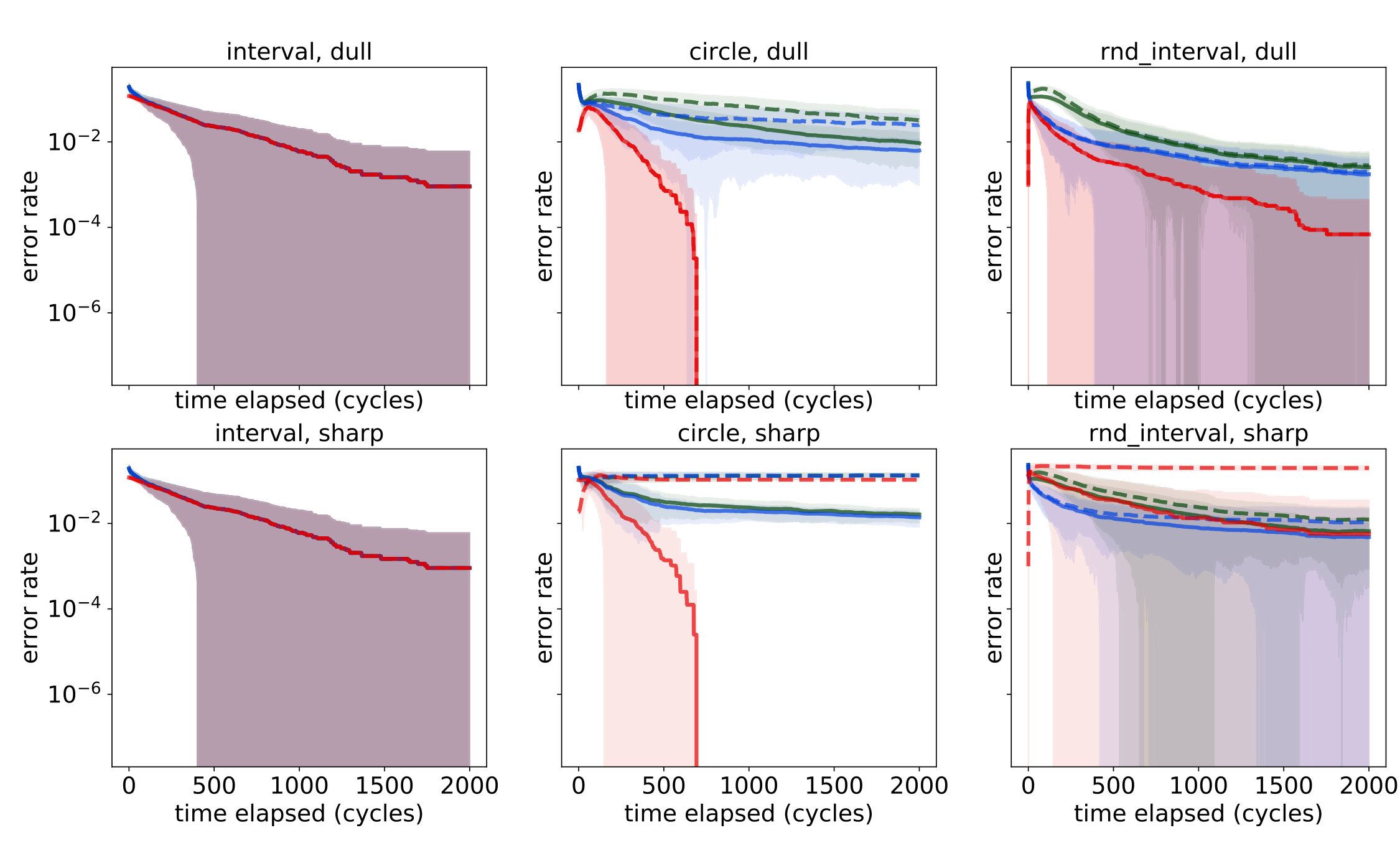 Figure 4
Figure 4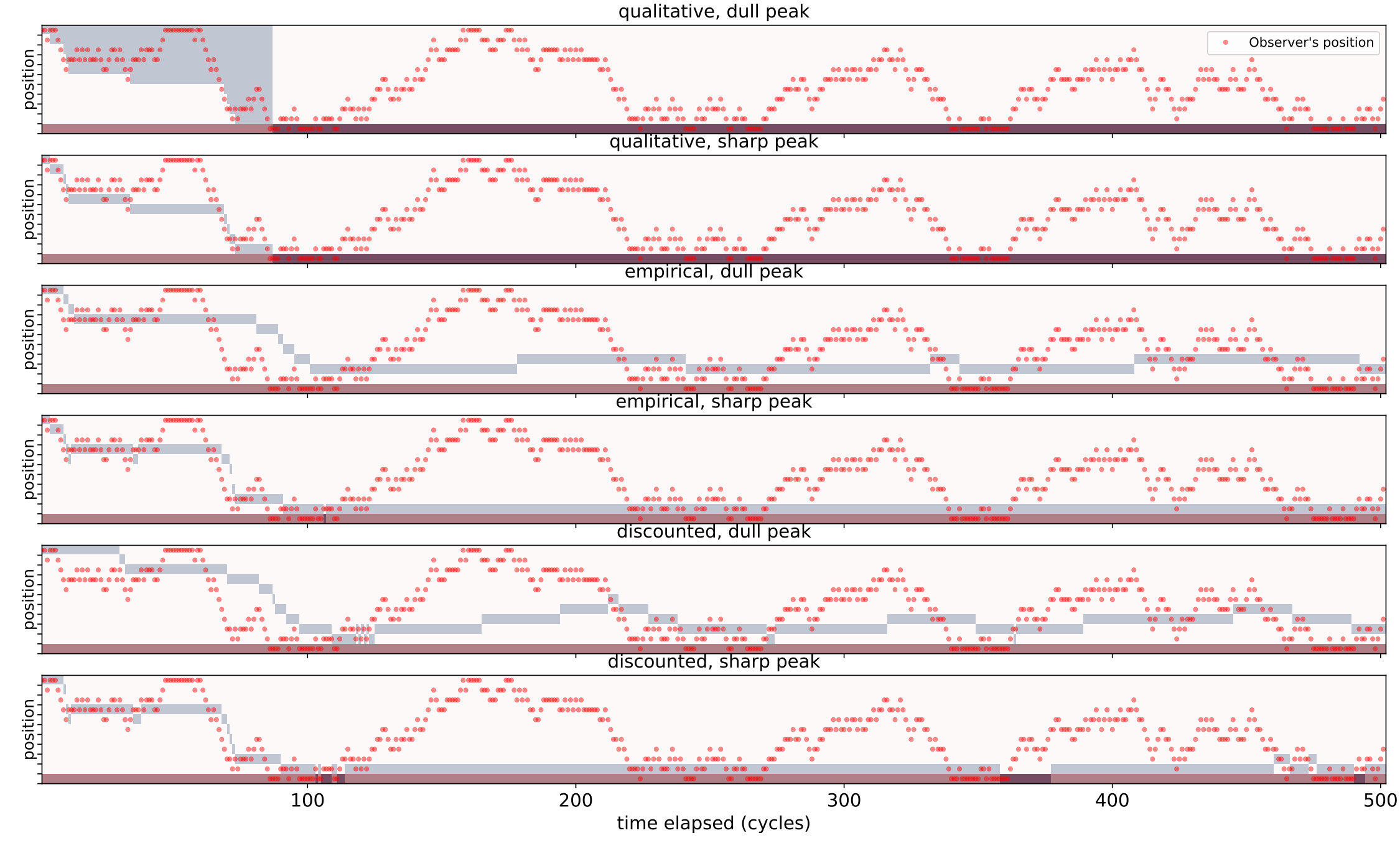 Figure 5
Figure 5 Figure 6
Figure 6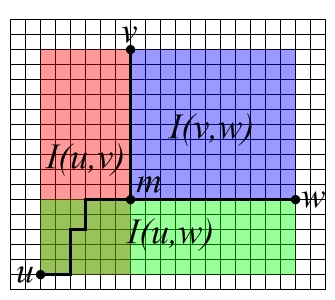 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9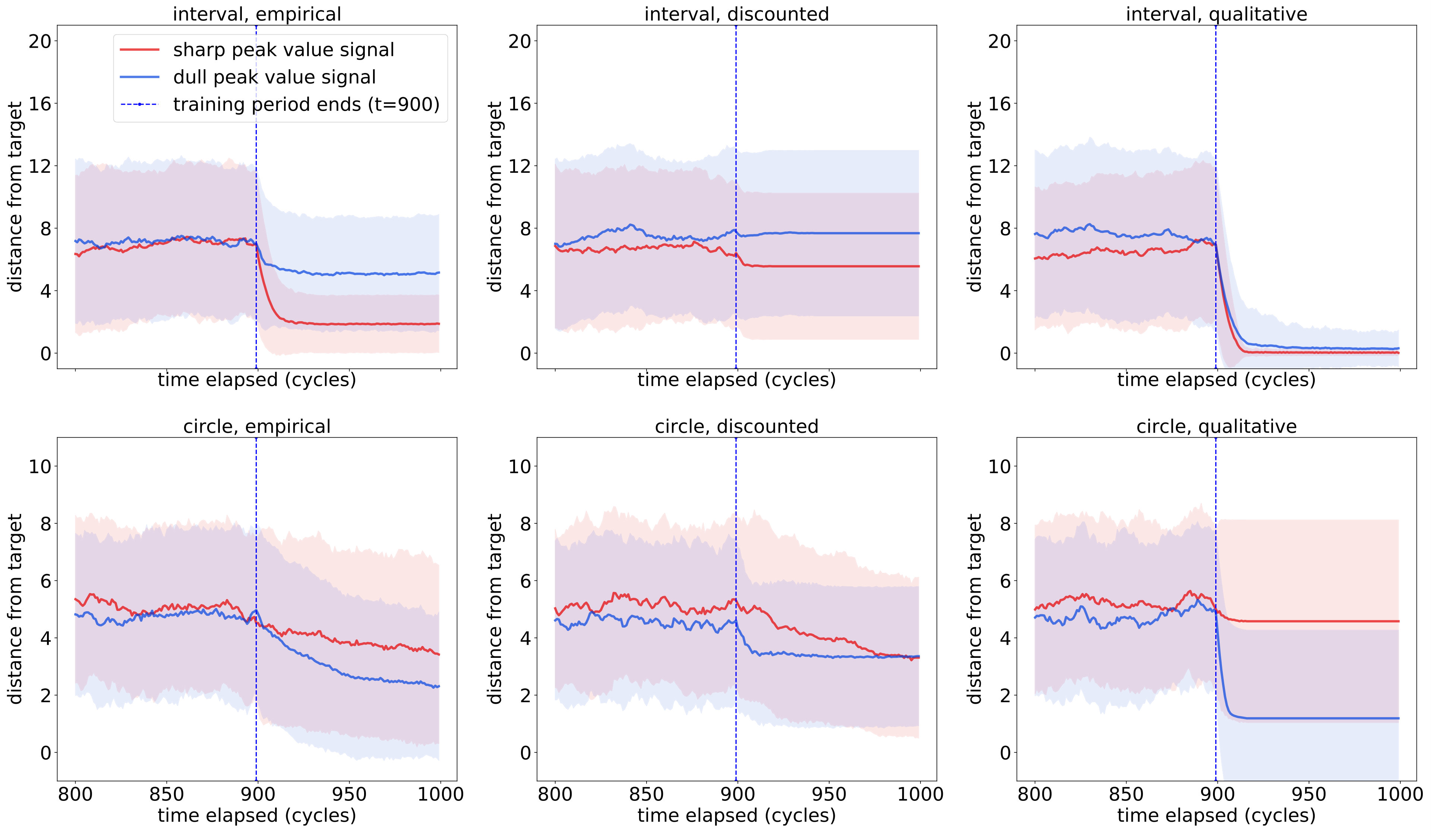 Figure 10
Figure 10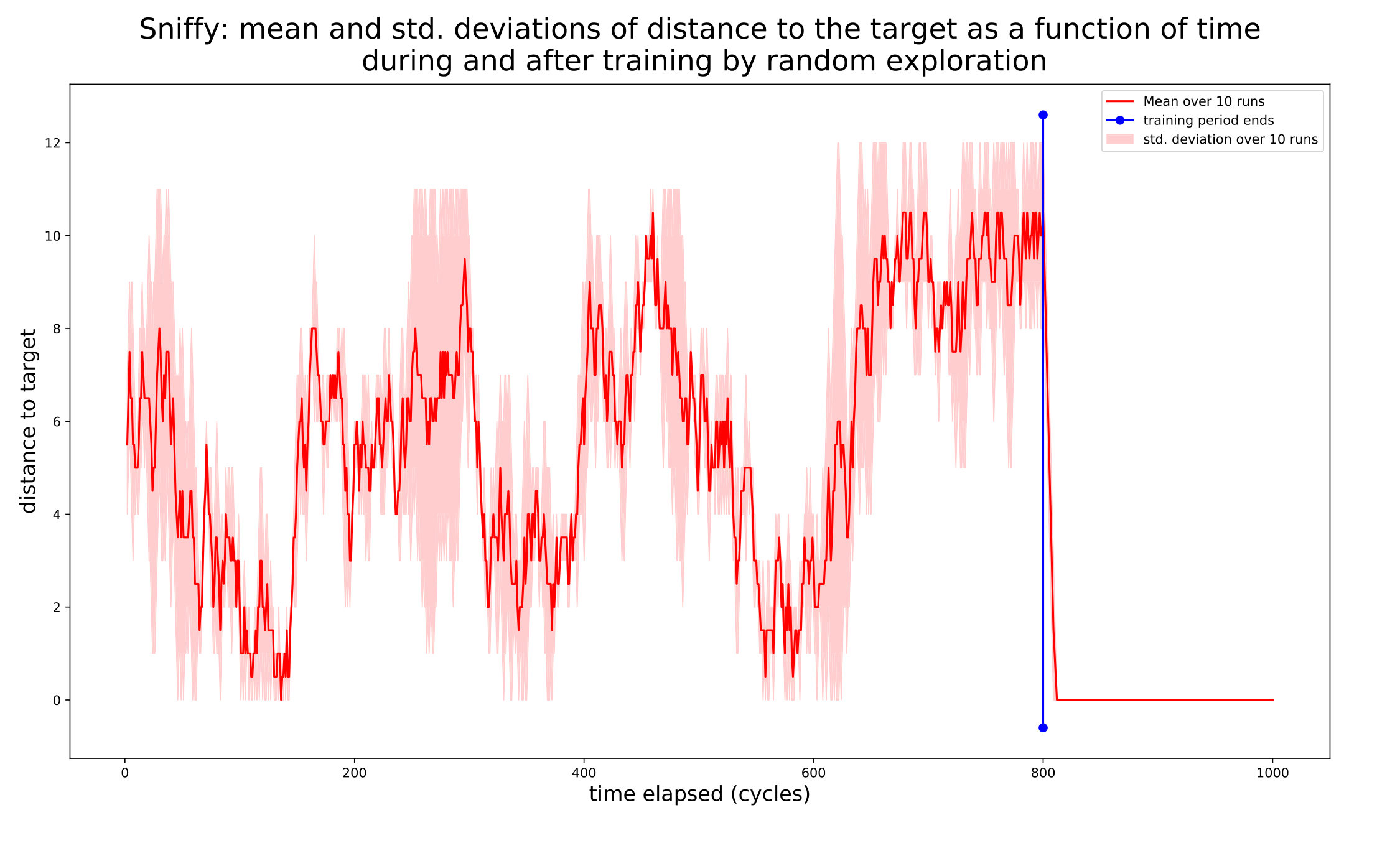 Figure 11
Figure 11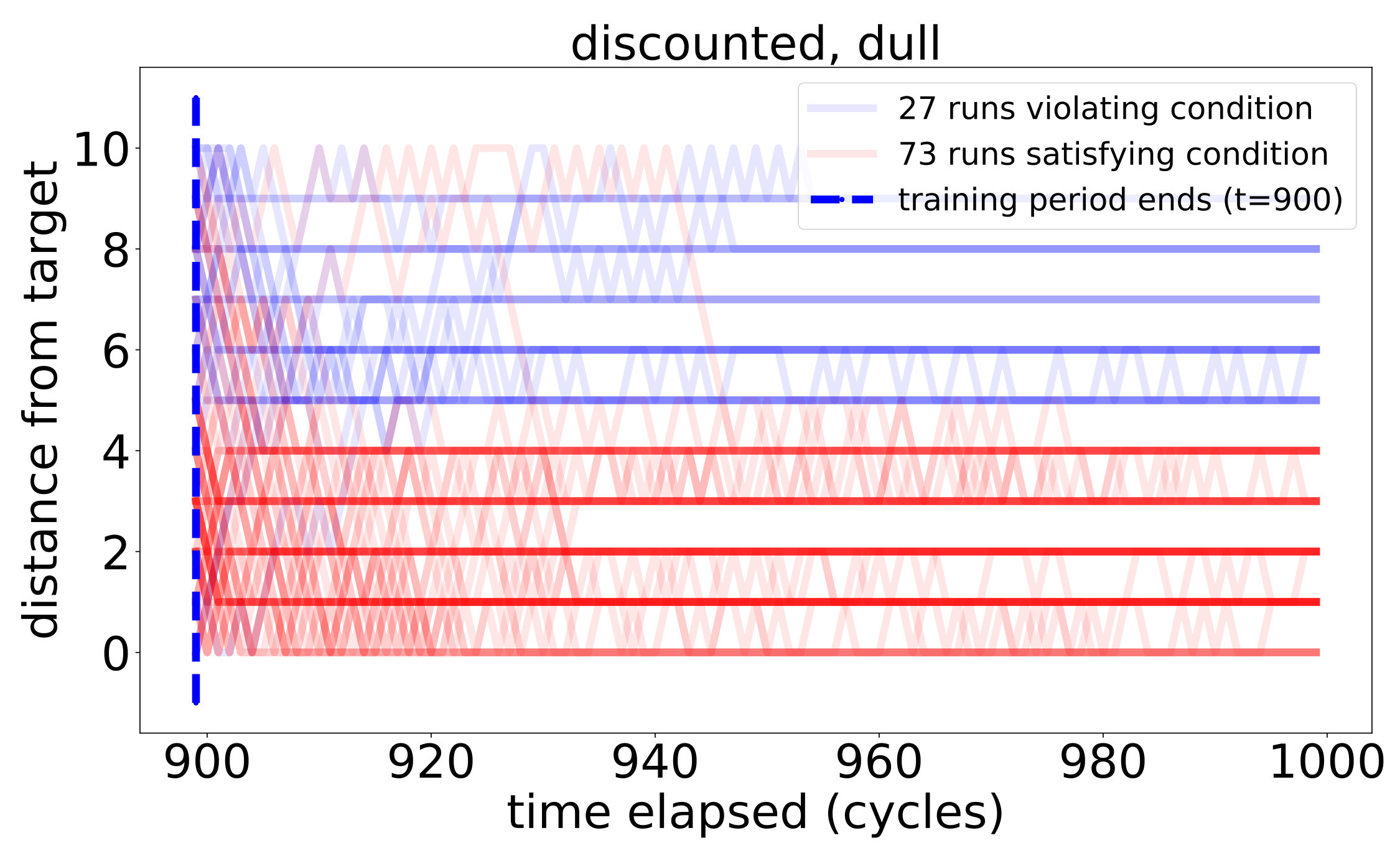 Figure 12
Figure 12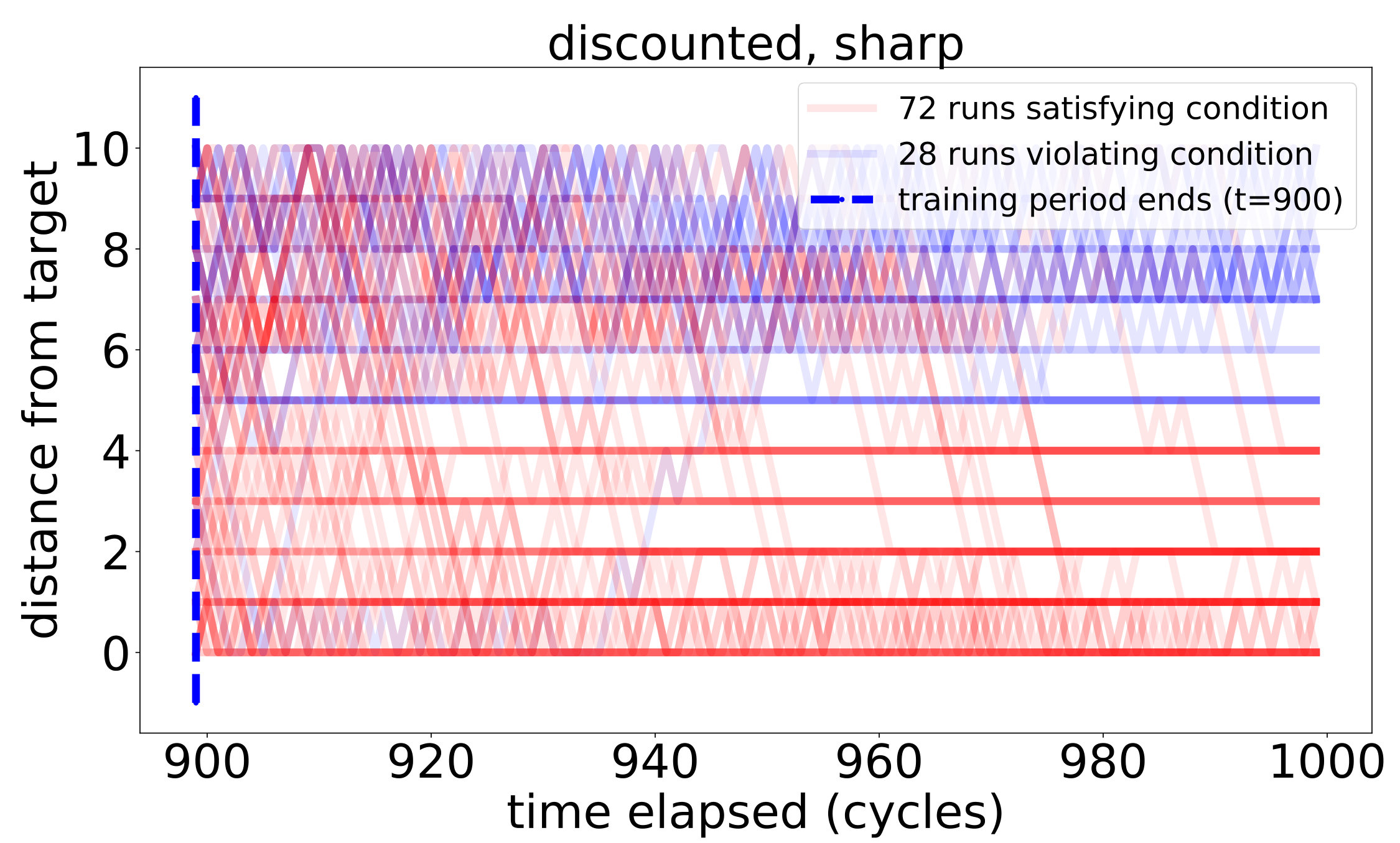 Figure 13
Figure 13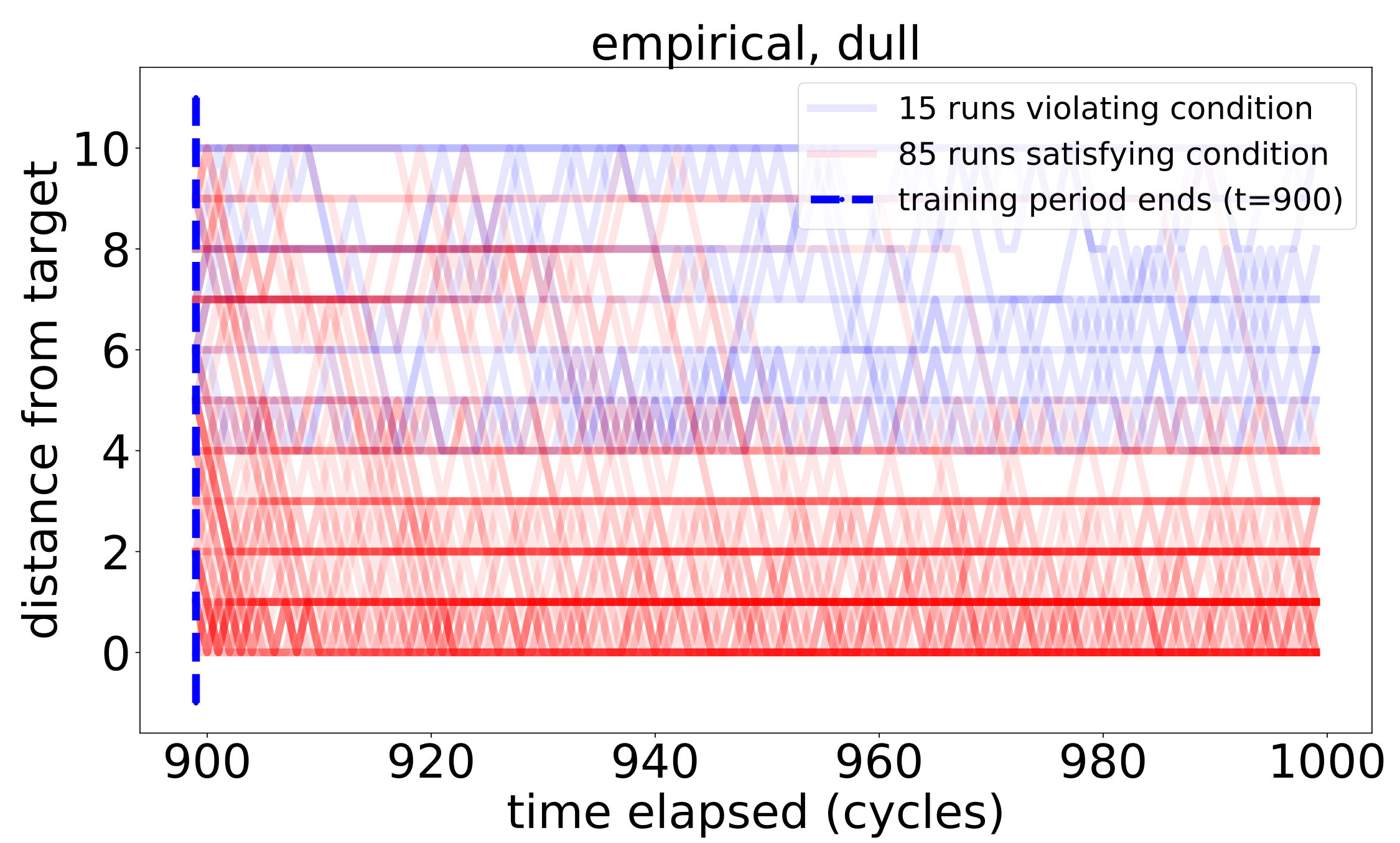 Figure 14
Figure 14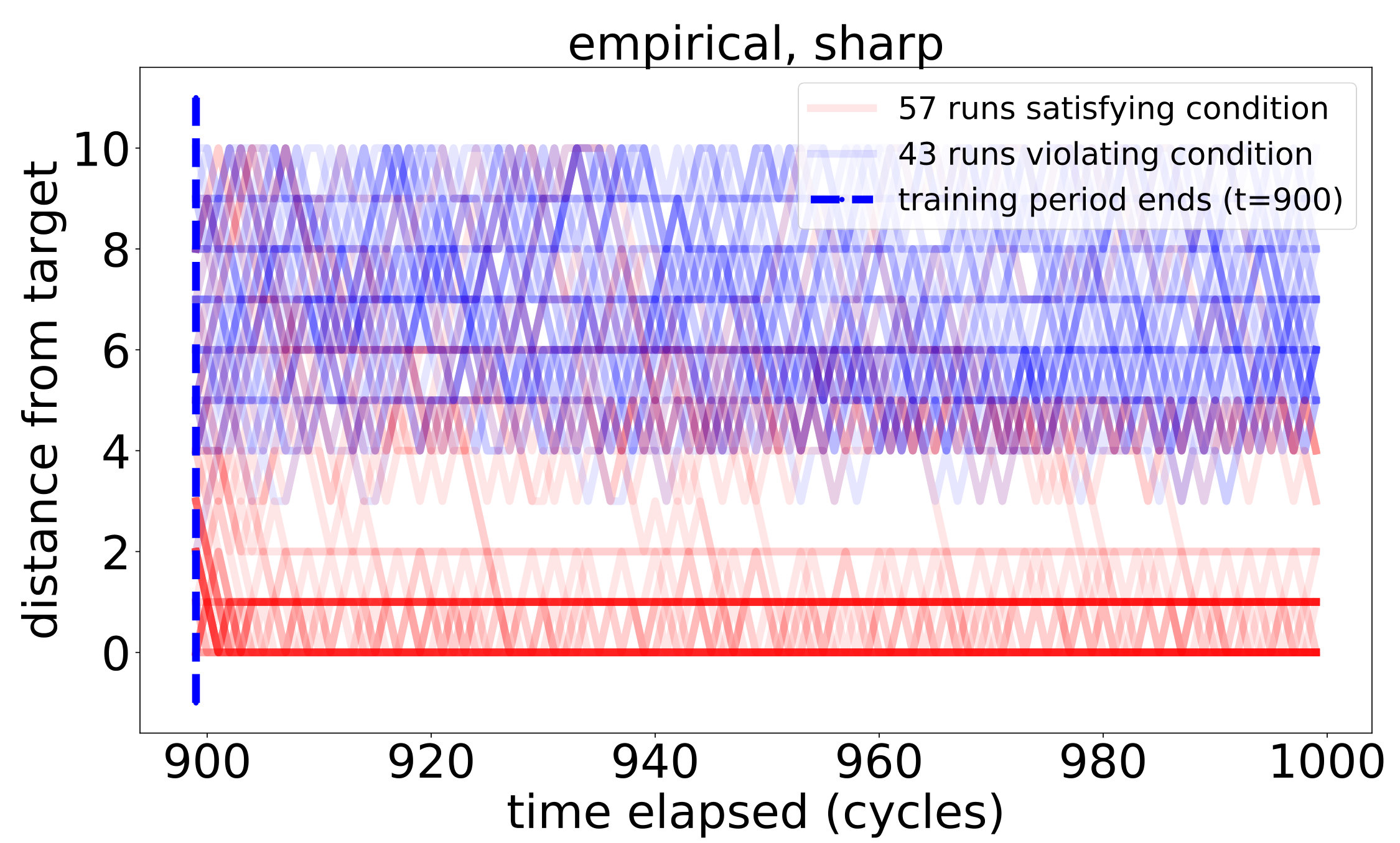 Figure 15
Figure 15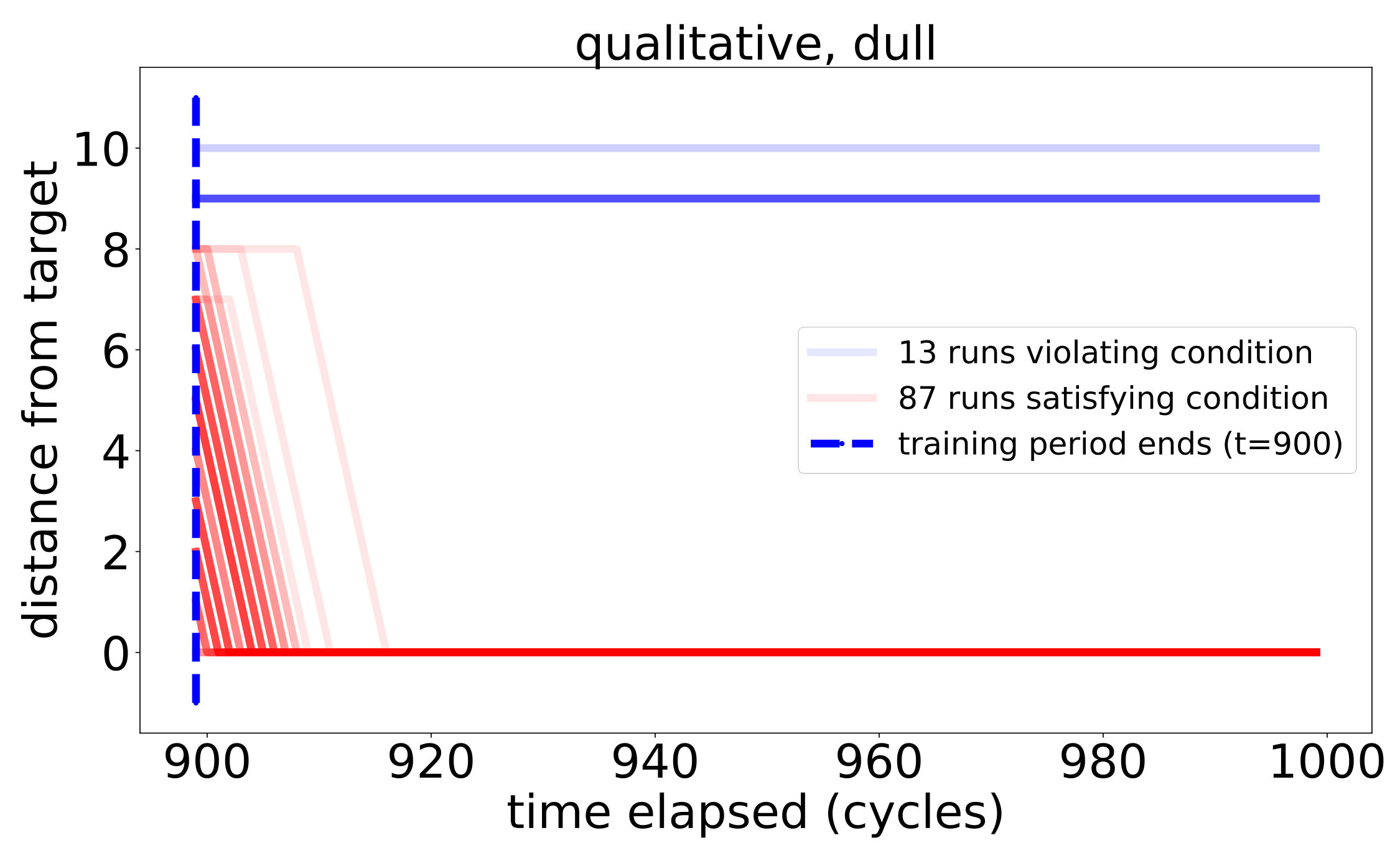 Figure 16
Figure 16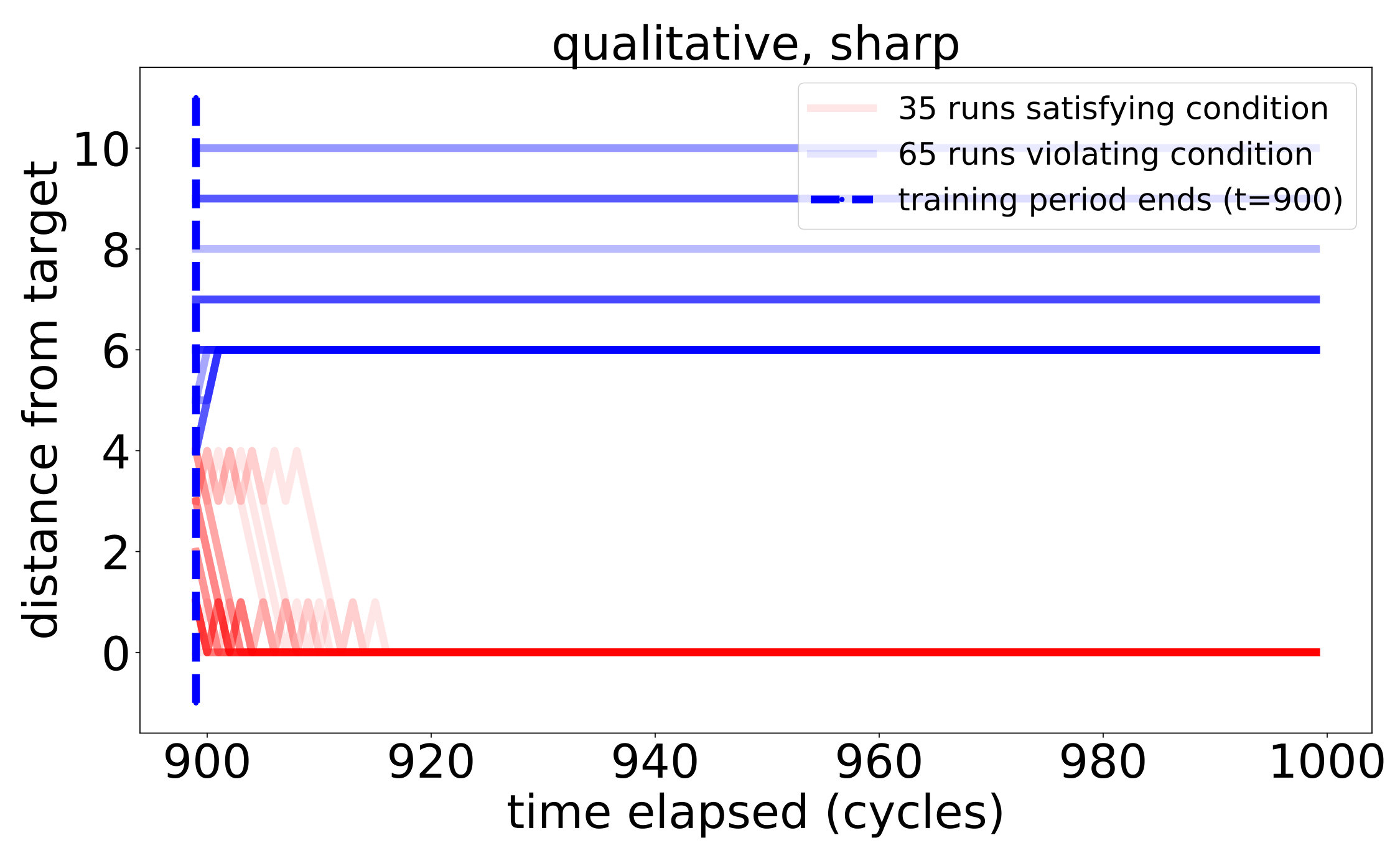 Figure 17
Figure 17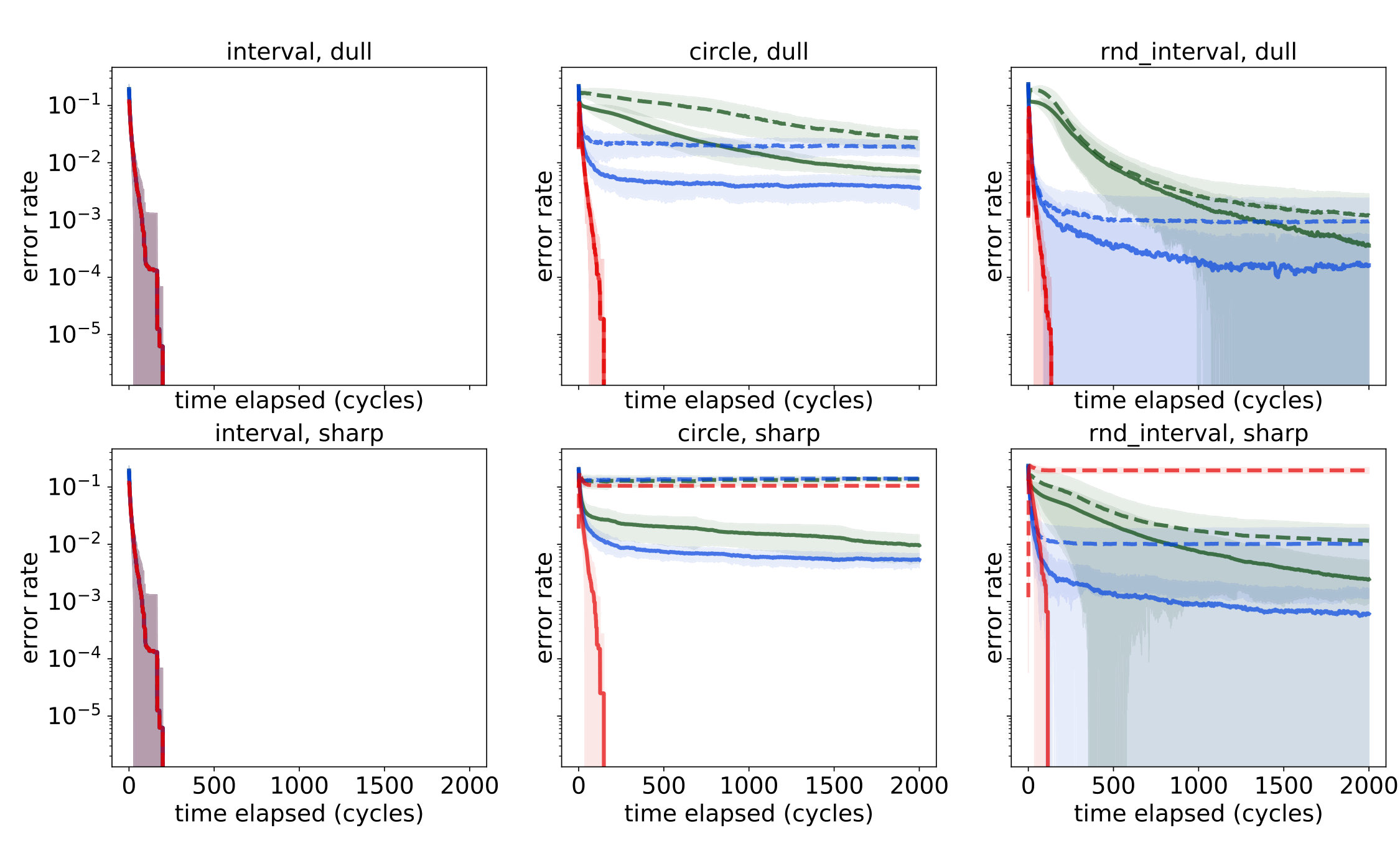 Figure 18
Figure 18Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLogic, Reasoning, and Knowledge · Bayesian Modeling and Causal Inference · AI-based Problem Solving and Planning
Iterated Belief Revision Under Resource Constraints: Logic as Geometry
Dan P. Guralnik
Electrical & Systems Engineering, School of Engineering & Applied Sciences, University of Pennsylvania, Penn Engineering Research & Collaboration Hub (PERCH), 3401 Grays Ferry Ave., Pennovation Center, Building 6176, 3rd Floor, Philadelphia, PA 19146
and
Daniel E. Koditschek
Electrical & Systems Engineering, School of Engineering & Applied Sciences, University of Pennsylvania, Penn Engineering Research & Collaboration Hub (PERCH), 3401 Grays Ferry Ave., Pennovation Center, Building 6176, 3rd Floor, Philadelphia, PA 19146
Abstract.
We propose a variant of iterated belief revision designed for settings with limited computational resources, such as mobile autonomous robots. The proposed memory architecture—called the universal memory architecture (UMA)—maintains an epistemic state in the form of a system of default rules similar to those studied by Pearl and by Goldszmidt and Pearl (systems and ).
A duality between the category of UMA representations and the category of the corresponding model spaces, extending the Sageev-Roller duality between discrete poc sets and discrete median algebras provides a two-way dictionary from inference to geometry, leading to immense savings in computation, at a cost in the quality of representation that can be quantified in terms of topological invariants. Moreover, the same framework naturally enables comparisons between different model spaces, making it possible to analyze the deficiencies of one model space in comparison to others.
This paper develops the formalism underlying UMA, analyzes the complexity of maintenance and inference operations in UMA, and presents some learning guarantees for different UMA-based learners. Finally, we present simulation results to illustrate the viability of the approach, and close with a discussion of the strengths, weaknesses, and potential development of UMA-based learners.
1. Introduction
1.1. Motivation.
Iterated belief revision (BR) deals with the problem of maintaining syntactic propositional knowledge representations that are sufficiently flexible to accommodate reasoning about a stream of incoming observations in the form of propositional formulae (over a finite alphabet of atomic propositions), while taking into account the possibility of any such observation being inconsistent with the current state of the knowledge representation. It is not unreasonable then to argue that BR operators should be used for maintaining well-reasoned internal representations for autonomous learning agents (see, e.g. [47]). However, one needs merely to observe the high computational costs associated with revision operators [31, 30] to conclude that such representations are too expensive to implement them in a mobile autonomous agent. Attempts at making the representations more palatable using prime forms [6, 33] have been made, but the fundamental complexity barriers remain [26].
We introduce a computationally cheap form of iterated propositional belief revision—the universal memory architecture (UMA)—which harnesses the geometry of model spaces in place of the model-theoretic techniques characteristic of this field. The computational advantages come at the price of modifying the notion of an observation and restricting the syntactic form of the epistemic state maintained by the agent (understood in the broad sense of Darwiche and Pearl [11]) to a special type of default system in the sense of [39]. Most notably, observations are no longer allowed to take the form of arbitrary propositional formulae; rather, we restrict them to conjunctive monomials in the underlying propositional variables. Equivalently, an observation is a partial truth-value assignment to the agent’s inputs. In addition, each observation is accompanied by a value signal—a quantity indicating a notion of the value of the experience to the agent at that time. 111The value signal should not be confused with the notion of reward, as used in Reinforcement Learning. One of our learning schemes (see Section 4.2) leads to a (partial) syntactic representation of the distribution from which observations are being drawn, and does not encode any preference of one state over another.
These alterations to the classical setting of iterated BR are motivated by the prospect of implementing iterated BR on mobile robotic platforms in real time. While the Boolean component of the observation corresponds to the robot’s raw sensory inputs, the value signal may correspond to an encoding of a task, or to feedback from a teacher. The limited form of the epistemic state maintained by an UMA instance reduces the space and time complexity costs of maintenance (applying the revision operator) and exploitation (e.g. inference) down to an absolute minimum, as we review next.
1.2. Contributions: Introduction and Analysis of UMAs.
Motivated by the problem of realizing iterated belief revision and update in a bounded resources setting, we seek a class of lightweight general-purpose representations. From a learning perspective, ours is a problem of learning from positive examples: an observer of an unknown, unmodeled system experiences some process—a sequence of transitions—in that system through an array of Boolean sensors, and is required to reason about regularities in the observed sequence of experiences, constructing a formal theory of what is possible for that system.
We assume that observations occur in discrete time steps. An observation at time will consist of (1) a complete truth-value assignment222Henceforth, the symbol (\big{|}_{\scriptscriptstyle{t}}) appended to anything else should be read as “at time ”. \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}}—the observation at time —to a fixed set —the sensorium—of Boolean queries of the agent’s interactions with its environment; and of (2) a sample \varphi\big{|}_{\scriptscriptstyle{t}} of a fixed value signal, .
Little needs to be assumed about the sensorium: for the purpose of this paper, we allow any query expressible as a Boolean function of the state history (finite or infinite) of the system (an appropriate formalism is developed in Section 2.1.1); it is also assumed that truth-value assignments \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}} are consistent in the sense that each agrees with the values of the available queries on the history that manifested at the corresponding time; finally, observations are assumed to be time shift-invariant in the sense that observing the same histories at different times must yield the same Boolean observation vector. The value signal, for now, is assumed to be static, in the sense that it factors through a function of the observation (more detail in Section 3.1). The architecture itself does not rely on any of these assumptions, but the learning guarantees we provide in this paper do.
An UMA representation integrates its accumulated experiences by repeatedly revising two structural components, based on the incoming observations: (a) a relation G\big{|}_{\scriptscriptstyle{t}}, called a pointed complemented relation (PCR), representing a system of implications, or defaults, which the agent believes to hold true among the queries in ; and (b) a set \mathtt{Curr}\big{|}_{\scriptscriptstyle{t}}\subset\mathbf{\Sigma}, representing the agent’s belief regarding the current state of the system. The machinery for maintaining these data structures will be referred to as a snapshot. Briefly, our results about UMA representations are as follows.
Universality of Representation.
In our intended setting, the learner’s sensors realize the formal sensorium as a family of subsets of the space of histories, closed under complementation. The possible worlds actually witnessed by points of this space correspond to the learner’s perceptual equivalence classes (in the sense of, e.g. [13, 42]). Intuitively, an element of the PCR G\big{|}_{\scriptscriptstyle{t}} should be seen as correct if no history falsifies the formula , and, more generally, if histories falsifying are improbable, or insignificant according to the user’s formal model of these notions.
It turns out that a PCR supports a natural dual space, a set of possible worlds canonically associated with the PCR. Recall that a possible world over is a complete truth value assignment . We prove that, given a PCR over a set of literals , its dual space has the following universality property (Proposition 2.22): is the smallest set of possible worlds over which, for any realization of as a set of Boolean queries over a space not falsifying a relation listed in , contains every model for .
Returning to UMA learners, this means that the model space \mathbf{M}\big{|}_{\scriptscriptstyle{t}} encoded by the PCR G\big{|}_{\scriptscriptstyle{t}} is a minimal envelope for the true space of possible worlds, provided just the information that all the relations recorded in G\big{|}_{\scriptscriptstyle{t}} are correct.
Computational Complexity.
From a computational perspective, the maintenance costs of an UMA representation are roughly the same as those of maintaining a neural representation (=the cost of maintaining and using a matrix of weights), but with the added benefit of affording a formal understanding of the model space, its geometry, and its deficiencies. Here are some results, all of which are corollaries of the geometric properties of the class of model spaces defined by PCRs. Let denote the cardinality of the sensorium . Then:
- •
Maintaining an UMA snapshot structure requires space;
- •
Update operations for learning the PCR structure require time;
- •
Inference requires time, reducible to on fully parallel hardware. 333We will remark that our current implementation is, in fact, an implementation utilizing matrix multiplication on a GPU. This kind of implementation makes it possible to multiply fairly big matrices very quickly, improving on the performance of the naïve quadratic algorithm we provide later in this paper.
Multiple Learning Paradigms.
The mathematical foundations for UMA provide sufficient flexibility to admit a variety of learning mechanisms and settings, spanning the range from probabilistic filtering, as proposed in [19], to a variation on [iterated] revision and update introduced in [11], while keeping maintenance costs down to the bare minimum (see preceding paragraph). Depending on the snapshot type, different learning scenarios and guarantees may be provided, while maintaining a uniform revision and update scheme at the symbolic level.
Flexibility of Representation.
A central feature of the UMA architecture is that the duality theory of PCRs allows one to interpret maps between PCRs as maps between the associated model spaces and vice versa. This makes it possible to formally introduce—as well as operate with—notions of approximate equivalence, of redundancy and negligibility of queries. This also enables the study of the impact on model space geometry of operations augmenting a sensorium with new queries (see, for example, Section A.2.4) or removing existing ones. In particular, this opens a way to formal (and, possibly, automated) cost/benfit analysis of such extension and pruning operations—a topic of ongoing research at the moment, which we will touch upon briefly in our final discussion of the results presented in this paper.
1.3. Related Work.
Given the focus of this work on the representation of knowledge using defaults, we believe it is most tightly related to work in the field of propositional iterated belief revision. Early work in BR resulted in wide acceptance of the AGM framework [4, 3, 2] for maintaining a belief set—a deductively closed set of formulae representing the state of the observed system. Convenient, intuitive axioms for belief revision in the propositional setting, the KM axioms, were developed by Katsuno and Mendelzon in [25].
Pointing out some inadequacies of the KM axioms in the context of repeated application of revisions, Darwiche and Pearl (DP) argue in their seminal paper [11] that, to achieve the overarching goal of iterated revision, one must maintain a set of conditional statements—an epistemic state—which, upon revision by an incoming observation, always produces a belief set accommodating that observation (axiom of the DP system of axioms for iterated revision). Building on Spohn’s framework of ordinal conditional functions [46] and its implications for ranked default systems [39, 17] and revision of the associated belief sets [18], they propose to view ranking functions as epistemic states (interchangeable with the associated system of ranked defaults), as they construct appropriate revision operators. Consequent work by many authors [24, 12, 27, 22, 34, 28]—much of it very new—considers different weaknesses and benefits of the DP axioms, relating to the effect of the order in which observations are made and the manner of mutual dependence they present, and resulting in a variety of iterated revision methods, as well as in some proposals to apply belief revision methods to the control of general agents [47] based on varying computational approaches to belief revision operators (e.g. [6, 33] on the use of prime forms for this purpose).
Clearly, the problems tackled by this field generalize the representation problem we posed at the beginning of Section 1.2, but one needs merely to observe the high computational costs associated with revision operators [31, 30] (or with computing normal forms and prime forms [26]) to reach the conclusion that the existing computational approaches cannot be considered viable candidates for a solution of the representation problem in any setting where computational resources are limited.
Aiming to reduce the computational burden on the learner, we shift attention from precise syntactic computation with arbitrary propositional formulae to imposing radical simplifying assumptions on the allowed model spaces. The postulated mode of interaction between the agent and its environment—specifically the fact that the agent is constrained to processing sequences of samples from the space of realizable models (rather than arbitrary propositional formulae)—suggests constructing successive upper approximations \mathbf{M}\big{|}_{\scriptscriptstyle{t}}\supset\mathbf{M} of , belonging to a restricted class which satisfying the following intuitive properties:
- (1)
Syntactic characterization of an element in is computationally inexpensive; 2. (2)
Each approximation is, in some sense, optimal/minimal among members of , given its predecessor and the last observation; 3. (3)
Reasoning (e.g., forming a belief set) over a member of is cheap.
We present results on what is, in essence, the simplest possible class of model spaces satisfying these three requirements: the class of finite median algebras. This class of spaces is well studied, in several different guises, and in very disparate fields. These include: event structures in parallel computation [40]; median graphs in metric graph theory [8]; simply connected non-positively curved cubical complexes in formalizations of reconfiguration in robotic systems [16]; and the spectacular recent achievements in the topology of 3-dimensional manifolds by Agol [1] are much due to the notion of a cubulated group from Geometric Group Theory [50].
1.4. Structure of this Paper.
In Section 2, we extend Sageev-Roller duality444See [43] for a detailed development of that theory; chapters 6-7 of [50] for a brief intuitive review; and here, Appendix A for background material and examples developed specifically to support this paper., to obtain all finite median algebras as duals (model spaces) of PCRs, viewed as systems of defaults. Further, we explain how to reason over model spaces in this class by leveraging their geometry to avoid satisfiability checks, or any kind of explicit search in model space, for that matter. We then explain in Section 3 how, using UMA snapshot structures to perform a variant of iterated revision, where the model-theoretic outlook on the problem is replaced by its geometric counterpart arising by Sageev-Roller duality. We discuss the necessity of relaxing the DP axiom , and show there is a natural operator for computing a belief set, the coherent projection.
Section 4 presents two different classes of snapshot structures—mechanisms for learning PCR representations—one motivated by Goldszmidt and Pearl’s interpretation of default reasoning as qualitative probabilistic reasoning [18], and the other based on statistical integration of the observed value signal. Finally, Section 5 presents two kinds of simulation studies:
- (1)
First, in a range of settings with a-priori known (or readily computable) implications in the sensorium, we consider the deviation of the learned PCR from the ground truth as a function of the number of samples. This is done for both snapshot types, and under different exploration paradigms: sampling and diffusion. 2. (2)
Next, we consider settings closer to the heart of a roboticist. We implement agents with a reactive control paradigm based entirely on their internal UMA representations and conduct comparative simulation studies of their performance given different domains for exploration, and snapshot types.
We close with a discussion of our results and of avenues for additional research in Section 6.
2. Model Spaces for Systems of Approximate Implications.
In this section we construct a representation for finite median algebras (see above) that is sufficiently flexible to be maintained dynamically, and we explain how to reason over these representations. We review and apply existing results about the geometry of model spaces of this class of representations, leading to complexity bounds on maintenance and exploitation.
Section 2.1 formally introduces the basic formal notions required for discussing our representations. Section 2.2 constructs the model spaces as dual spaces of pointed complemented relations (PCRs) and discusses their universal properties. Section 2.3 relates PCRs and their duals (the associated model spaces) to the earlier duality theory of poc sets that motivated our approach, showing that PCR duals are, in fact, poc set duals. Section 2.4 reviews known results about the geometry and topology of poc set duals. Finally, in Section 2.5 we discuss the connection between the geometry of PCR duals and algorithms enabling reasoning over PCRs.
2.1. Pointed Complemented Relations (PCR).
The nature of our application requires a generalization of the formal theory we are about to use, the Sageev-Roller duality theory of poc sets [43], prompting some changes in the language. We start with:
Definition 2.1** (pointed complemented set, PCS).**
A pointed complemented set is a set endowed with a self-map satisfying and for all , and containing a distinguished element, denoted . The element will be denoted . Whenever possible and safe, we will abuse notation and use the symbols in different PCSs. For any we will denote by the set of all , .∎
Definition 2.2** (PCS morphism).**
By a PCS morphism we mean a function between PCSs satisfying and for all . The set of all PCS morphisms from to will be denoted by .∎
Example 2.3** (set families, power sets).**
Any collection of subsets of a fixed non-empty set satisfying (1) , and (2) . Then is a PCS with respect to the choices and .
The power set of a singleton is, up to isomorphism, the smallest PCS, which we denote by , and identify with the set . Also, the power set will be routinely identified with the set of all functions .
Example 2.4** (PCS over an alphabet).**
Suppose is a finite collection of symbols, and think of them as atoms of the propositional calculus over . The extended collection of literals over ,
[TABLE]
may be thought of as a PCS when one declares , , and , for all . Hereafter, and stand for the truth values True and False, respectively.
The reason for considering PCSs is that -selections “live on them”:
Definition 2.5** (-selection, the Hamming cube).**
Let be a PCS. By a -selection on we mean a subset such that . In addition, a -selection on is complete, if . The set of all -selections with will be denoted by , and referred to as the [combinatorial] Hamming cube on . Its set of vertices, the complete -selections in , will be denoted by . ∎
We now consider these notions in the context of our intended application.
2.1.1. Binary Sensing, Possible Worlds and Perceptual Classes.
Suppose is an observer of some system as it undergoes the transitions along a state trajectory , and suppose is a finite set of unique labels for the Boolean queries available to —this observer’s sensorium. We assume observations of by begin at . It will not matter for our discussion whether the trajectory of in any particular instance does indeed extend indefinitely into the past or future: if needed, one may set the value of to be eventually constant (in either direction).
By a history of we mean a sequence of the form , where is a state of for all , and represents the current state of the history ; represents the preceding state, and so on. Given a trajectory of observed by , at each time , the history that manifests at time is given by .
Henceforth, we let denote the space of histories possible for the system given the initial history manifested at time (as is the case in all physical systems, may have its own dynamics, disqualifying some histories from manifesting at any time , or making such events highly improbable). To say that ’s queries/sensors are time-shift invariant is to say that each query is represented by a fixed Boolean function of the manifested history. In other words, the sensorium is defined by a PCS morphism , , with a sensor reporting on history if and only if .
The mapping induces a partition on —its partition into perceptual classes—as follows. Construct a map by setting if and only if ; each point is mapped to the set of queries (including complements) which evaluate to on that point. Two points are sensory-equivalent if . The image are the possible perceptual states of in the system , given and the system’s initial history. We will also refer to a world/-selection as consistent, if, and only if , or, in other words, if and only if is witnessed (through ) by a point of .
2.1.2. Concept Presentation of Perceptual States.
Digging deeper into the formalism presented just now, observe that -selections are in one-to-one correspondence with vectors, as defined in concept learning [48]. Recall that a vector is an assignment of values standing for , , and “undetermined”, respectively, to the alphabet . A vector is total if it has no values. The map is then a correspondence between vectors over and -selections on the PCS , mapping the set of total vectors onto the set of complete -selections. In more geometric terms, a complete -selection—which corresponds to a complete conjunctive monomial (aka complete term) over —defines a vertex of the cube , while a -selection with corresponds to a -dimensional face. We will refer to as the Hamming cube. The advantage of PCS terminology here is that -selections on enumerate the faces of the Hamming cube without us having to pick an origin for the cube.
Pushing the geometric viewpoint a bit further, we consider the notion of concepts. In [48], Valiant defines concepts as mappings of the space of vectors to , satisfying the requirement that on a vector if and only if for all total vectors which agree with on those where . In other words, concepts correspond to collections of faces of the Hamming cube, possibly of varying dimensions, satisfying the condition that a face belongs to if and only if every vertex of lay in . Such are precisely the sub-complexes of the Hamming cube obtainable from it by vertex deletions.555Similarly to case of graphs, the operation of deleting a vertex from a cubical complex requires the removal of all the adjoining faces.
Now we return to the observer and the system whose evolution it observes through the queries realized by , as discussed in the preceding section. Thinking of the space of perceptual classes as a concept gives rise to a cubical sub-complex, say , of the Hamming cube, whose faces correspond to those -selections on the PCS that are witnessed (via ) by a point in . Thus, precise reasoning and planning over depends on one’s ability to efficiently capture/encode: (1) the notion of consistency produced by the map ; (2) the topological properties (e.g. connectivity, contractibility) of ; and (3) the geometric properties (e.g. shortest paths, curvature, isoperimetric inequalities) of . The class of approximating model spaces we propose to use as proxies for is a result of weakening this notion of consistency to the extreme, all the way to the notion of coherence discussed in the next section.
2.1.3. PCRs, Implications and Coherence.
Definition 2.6** (pointed complemented relation, PCR).**
Let be a PCS. By a pointed complemented relation over we mean a set satisfying666To avoid a proliferation of parentheses, we write to denote the pair . and for all .∎
In the context of the representation problem, one should think of a PCR over as a record of Boolean implications believed to be valid over , conditioned on the particular space of histories being observed. In this respect, a PCR is a restricted form of the notion of a system of defaults, as discussed, e.g. in [18]. Some of these implications are specified directly ( to be read as “it is believed that follows from ”), while others are derived as their consequences, by transitive closure. Hence the following language:
Definition 2.7**.**
Given a PCR over a PCS , for any , , one defines the following:
- •
Write if lies in the reflexive and transitive closure of ;
- •
The -equivalence class of , denoted , is the equivalence class of under the relation on ;
- •
The forward (backward) closure, (resp. ), of with respect to is the set of all for which (respectively ) holds for some ;
- •
Note that . One says that is forward-closed if ;
- •
Finally, we observe that for all .
We will often drop the subscripts when no ambiguity can arise.∎
Definition 2.8** (PCR morphism).**
Let be PCRs over , respectively. A morphism of PCRS from to is a PCS morphism , additionally satisfying in whenever . The set of all morphisms from to will be denoted by .∎
The primary example of a PCR for this work derives from the view of a power set as a PCS (Example 2.3):
Example 2.9** (Set Families as PCRs).**
Let be a set. Then any collection of subsets of that is closed under complementation and satisfies gives rise to the PCR of all pairs with , and . In what follows, will always be regarded as a PCR in this way, for any .∎
Another ‘canonical’ example of a PCR to keep in mind is:
Example 2.10** (Less classical PCRs).**
Let be any set. Then may be endowed with the structure of a PCR by setting , , and, for any , setting , and if and only if , .∎
Our notion of model for a PCR rests on the following weak form of consistency:
Definition 2.11**.**
Let be a PCR over . A subset is said to be -coherent, if no pair satisfies .∎
Note that a -coherent set is always a -selection on . Furthermore:
[TABLE]
so coherence is preserved by forward closure. Coherent, forward-closed sets may be thought of as the natural counterparts of the notion of a belief state in this setting. We now turn to studying the appropriate notion of model.
2.2. Model Spaces as Dual Spaces
Definition 2.12** (duals).**
Let be a PCR over . The set of maximal -coherent subsets of is the dual of . The set of all forward-closed -coherent subsets will be denoted .∎
A standard application of Zorn’s lemma shows that any -coherent subset of is contained in an element of . Note also that .
Example 2.13** (the orthogonal PCR and the Hamming cube).**
The simplest example of a dual space is one where the PCR in question is as small as possible. Let be a PCS. The smallest PCR over contains only pairs of the forms and . We will denote this PCR by and refer to it as the orthogonal PCR over . It is clear that , the “Hamming cube” from Definition 2.5.∎
Example 2.14** (‘bad’ queries).**
The definitions given above do not preclude one from considering, for example, the PCR . It is easy to see that . At the same time, the smaller has . More generally, for any , having precludes from belonging in any -coherent set. In particular, if both and hold, then no -coherent set is a complete selection on .∎
Following the last example, two definitions are in order:
Definition 2.15**.**
The trivial PCR, henceforth also denoted by , is the PCR over containing only .∎
Definition 2.16** (negligible query, degenerate graph).**
Let be a PCR over . An element is -negligible, if . Denote the set of negligible elements by . We say that is degenerate if contains a negligible element whose complement is also negligible. Note that .∎
Proposition 2.17**.**
For a PCR over , the following are equivalent:
- (1)
* is non-degenerate;* 2. (2)
Every element of is a complete selection on ; 3. (3)
Some element of is a complete selection on .
Proof.
See Section B.1.∎∎
The impact of this result on our representation problem is twofold. First, it provides a clear and easily verifiable criterion for when the dual space of a PCR consists (only!) of possible worlds. Second, it introduces a new and consistent notion of a query of low import, not involving arbitrary choices such as thresholding.
Proposition 2.18**.**
Let be a non-degenerate PCR over the PCS . Then the mapping defined by is a bijection.
Proof.
See Section B.2.∎∎
Remark 2.19**.**
Note that the mapping is independent of the choice of .
The last proposition explains the sense in which may be thought of as a dual space of . As with other instances of duality, this is useful because it enables dual mappings:
Definition 2.20**.**
Let be a PCR morphism. The dual mapping is defined by . Alternatively, upon applying the identification in Proposition 2.18, for any , one has to obtain an element of . ∎
We remark that, since morphisms are composable (meaning that the composition of two morphisms is a morphism as well), so are their dual mappings, producing the identity .
Example 2.21**.**
Let be a non-degenerate PCR over a PCS . Then it is clear that the identity mapping — that is: for all — is a morphism of PCRs. The dual mapping is then, clearly, an injection. This reflects the intuitive notion that the dual of any (non-degenerate) PCR may be “excavated” out of a standard Hamming cube by going over all -incoherent pairs, one by one, and successively deleting any vertices of which contain the given pair.
We further specialize the example to our representation problem, considering the effect of fixing a PCR structure on a given PCS:
Proposition 2.22** (Universality of Representation).**
Let be a non-degenerate PCR over . Then, for any non-empty set and every PCS morphism , the set of all complete -selections witnessed (via ) by a point in (in the sense of Section 2.1.1) is contained in whenever is a PCR morphism. Moreover, is the smallest subset of having this property.
Proof.
See Section B.3.∎∎
Thus, the dual of a non-degenerate serves as a minimal model of the state space of the system , and remains valid under any change to this system for as long as remains order-preserving. This is a form of robustness of the representation to changes in the coupling between the agent’s sensory equipment and the environment: changes leaving the implication record invariant provide no reason for the agent to alter its reasoning.
2.3. Reducing PCR Representations.
The universality of PCR duals motivates a deeper study of their properties, seeking a better understanding of the degree of redundancy in the description of by a PCR . This is not a mere technical issue: while non-degeneracy guarantees the adequacy of our notion of an associated “possible world”, it is not obvious that it also provides for sufficient control over the quality of inference. The intended application—inferring approximate implications from partial observations—is well known to be problematic in the absence of simplifying assumptions (e.g. the ubiquitous restriction to directed acyclic graphs in the context of Bayesian networks). It is therefore crucial to clarify the precise formal sense in which a PCR may be viewed as encoding a “record of implications”, which is the purpose of this section. A crucial notion in any such discussion is that of what it means for a query, as well as for the difference of two queries, to be negligible, because negligible but non-zero differences tend to accumulate in the transitive closure into material ones.
Looking more closely at the setting of the last proposition, notice that, for a fixed , the assumption that is a morphism translates into the following. The property for all implies for any (because is the only negligible element of ); furthermore, must hold whenever and are -equivalent (recall Definition 2.7). These identifications lead us to recall Roller’s definition of a poc set from [43]:
Definition 2.23** (poc set).**
A poc set is a tuple where is a partially ordered set with a minimum element , endowed with an order-reversing involution777That is, and for all . satisfying and for all .∎
In other words, a poc set is a transitive and anti-symmetric PCR over whose only negligible element is .
Proposition 2.24** (canonical quotient).**
For any non-degenerate PCR there exists a surjective PCR morphism of onto a poc set such that any PCR morphism gives rise to one and only one PCR morphism satisfying .
Proof.
We defer the proof to Section B.4, but define the canonical quotient mapping here. We set:
[TABLE]
and let , and setting to hold in if and only if . It remains to verify that (1) is a well-defined PCS; (2) is a well-defined poc set structure over ; and (3) the assertions of the proposition hold.∎∎
One should view this result as stating the precise conditions necessary for presenting a poc set in terms of a set of generators and a set of relations. However, the emphasis on what happens to morphisms leads to powerful realizations about dual spaces:
Corollary 2.25** (all duals are poc set duals).**
If is a non-degenerate PCR then is a bijection.
Proof.
See Section B.5.∎∎
Corollary 2.26** (naturality of canonical quotients).**
Let be non-degenerate PCRs. Then, for every morphism there exists one and only one morphism satisfying .
Proof.
See Section B.6.∎∎
A particular consequence of the last corollary is that one also has . This means the dual maps of and coincide up to the identifications between the pre- and post-projection duals. Thus, any results about poc set duals apply to duals of PCRs. In the next two sections we review these results, and then harness them in our construction of the universal memory architecture (UMA).
2.4. Convexity theory of PCR duals.
To discuss the geometry of PCR duals, we need to endow PCRs with more structure. From this point on, all PCRS we consider will be finite, with the sole possible exception of power sets.
Definition 2.27** (Hamming metric).**
Let be a PCR over . The Hamming metric on is defined by , where is the canonical quotient map. We define to be the simple888That is: loopless, unoriented, with no multiple edges. graph with vertex set , and edges of the form for all with .∎
In the case when is already a poc set, two vertices form an edge if and only if is a singleton, that is: the perceptual classes represented by and differ by the truth value of a single query. The common edge they span in the Hamming cube corresponds to the -selection in the concept presentation. In the general case ( not necessarily a poc set), since both and are coherent, each is the union of with a number of -equivalence classes , (recall Definition 2.7 and Proposition 2.24). Thus and span an edge in if and only if for some . Intuitively, we think of the different as counting for a single Boolean query.
We briefly recall the graph-theoretic notion of convexity:
Definition 2.28** (convexity in graphs).**
Let be a graph and let . The hop distance is defined to be the minimum length of an edge-path in joining with . The interval is defined to be the set of all vertices satisfying the equality . A set is said to be convex in , if holds for all . A set is a half-space of , if both and are convex sets in . Finally, we denote by the poc set whose elements are the half-spaces of (note that is a half-space of ), ordered by inclusion, and with .∎
We refer the reader to [38], section 4, for the (very elegant and much more general) proofs of the following two lemmas (stated there for poc sets, but valid for finite non-degenerate PCRs as well, due to Proposition 2.24 and its two corollaries):
Lemma 2.29**.**
Let be a finite non-degenerate PCR. Then the hop metric on coincides with the metric .∎
Lemma 2.30**.**
Let be a finite non-degenerate PCR. Then the half-spaces of are precisely the subsets of of the form999Note that for all , by Proposition 2.17.
[TABLE]
In particular, subsets of of the form
[TABLE]
are convex in , for any .∎
Definition 2.31**.**
To simplify notation, we will abuse it in the following ways:
- •
Writing , without specifying will henceforth refer to the subsets of , those are and , respectively.
- •
When is explicitly known, , we will write instead of when convenient.
As a side note, observe that , where coincides with the vertex set of a face of the hamming cube . In particular, presenting any subset of as a concept is equivalent to decomposing it as a union of convex subsets of .
Median Graphs.
The two preceding lemmas are results of being a median graph [8, 49]:
Definition 2.32**.**
A connected simple graph is said to be a median graph, if the set contains exactly one vertex for each . This vertex is the median of the triple and denoted by – see Figure 1. For median graphs , , a median morphism of to is a map which preserves medians: . ∎
Median graphs are a special subfamily of median algebras, [44, 45, 23, 5]. Some modern generalizations and applications may be found in [7].
A central result in Sageev-Roller duality, specialized here to the finite case, and reformulated for non-degenerate PCRs is:
Theorem 2.33**.**
The dual of a finite non-degenerate PCR is a finite median graph, with the median calculated according to the formula:
[TABLE]
and with intervals in calculated according to the formula:
[TABLE]
Conversely, if is a finite median graph then is naturally isomorphic to by sending every vertex to the -selection of all half-spaces of which contain .∎
This result is the consequence of a very strong convexity theory:
Theorem 2.34** (Properties of median graphs, [43], section 2).**
Let be a finite median graph. Then:
- (1)
Any family of pairwise intersecting convex sets has a common vertex; 2. (2)
Every convex set is an intersection of halfspaces; 3. (3)
For any convex subset , the subgraph of induced by is a median graph; 4. (4)
For any convex and any there is a unique vertex at minimum hop distance from ; 5. (5)
For any convex , the nearest point projection is a median preserving, distance non-increasing retraction of onto its subgraph induced by .
Property (1) is often referred to as the Helly property.∎
The Helly property is, perhaps, the most notable of the results stated above. In our setting of PCR duals, it may be interpreted as guaranteeing the satisfiability of any family of conjunctive monomials over in which every pair is separately satisfiable.
Convex hulls.
Given the central role of half-spaces in the convexity theory of median graphs, a notion of the set of half-spaces dual to a given set of vertices is useful:
Definition 2.35**.**
For , its dual set of halfspaces, , is defined to be the set of all with .∎
An immediate corollary of Theorem 2.34(2) is:
Corollary 2.36**.**
Suppose is a non-degenerate PCR, and . Then is -coherent and forward-closed, and the convex hull of in coincides with .∎
Thus, every convex subset of may be written as for some . This representation is unique, by last assertion of the following lemma:
Lemma 2.37**.**
Let be a non-degenerate PCR over . Then, for all :
- (1)
* if and only if is coherent;* 2. (2)
For all one has ; 3. (3)
If then ; 4. (4)
If is coherent then ; 5. (5)
If , then 6. (6)
For all one has .
Proof.
See Section C.1.∎∎
Another important result helps bound the distance from the points of one convex set to another:
Lemma 2.38**.**
Let for a poc set over . Then for all .
Proof.
See Section C.4.2.∎∎
This motivates the following definition for the general case:
Definition 2.39**.**
Let be a non-degenerate PCR over and let . The divergence of from is defined to be .∎
Note how seems independent of ; it is not, however, since it is only applied to upwards-closed coherent sets . We will use this notion of divergence in Section 5.3, to drive the decision-making mechanism of the binary UMA agents briefly introduced there.
More details about the convexity theory of a median graph will be discussed in the appendices, as we go about proving our algorithmic results.
2.5. Propagation: A Computational Workhorse.
We are now ready to present another central result of this paper: a low-complexity method for computing nearest point projections in , which we call propagation. This method obviates the need for maintaining an explicit representation of each vertex of in memory, reducing space requirements for this architecture from in the worst case to . The time complexity is, at worst, , coming down to sub-linear on a fully parallel architecture, as will become evident below.
Definition 2.40** (coherent projection).**
Let be a PCR over a finite PCS . For any , the set is said to be the -coherent projection of .∎
Coherent projection itself plays an important role in obtaining an observer’s belief state from its epistemic state (the learned PCR structure) and the latest observation (see Section 3.3).
The promised formula for computing projections works as follows.
Proposition 2.41**.**
Let be a PCR over a finite PCS . Let and suppose is -coherent. Let and . Then:
[TABLE]
where is the nearest-point projection to in defined in Theorem 2.34.
Proof.
See Section C.4.∎∎
This description of nearest point projection is easy to visualize as being computed by an algorithm propagating excitation among nodes of a directed graph:
Definition 2.42**.**
Let be a PCR over a finite PCS . Let . Denote by the graph with vertex set , edge set and with Boolean weights , attached to its vertices. We refer to it as * being loaded with *.∎
Definition 2.43**.**
A propagation algorithm over is any algorithm which, for any -coherent load and any accepts and as input and produces as its output the loaded graph , where
[TABLE]
Note that coherent closure is obtainable via .∎
Envisioning as describing a graph of ‘cells’ labeled by and ‘synapses’ labeled by pairs , the loaded graph represents a state of the network indicating that the cells of are in an excited state. A propagation algorithm should be seen as exciting, additionally, the cells of and spreading this excitation along the directed connections while inhibiting for each cell encountered along the way. Realized on a modern day computer, this may be achieved in quadratic time in . For example, propagation could be implemented using a variant of depth-first search (DFS) on \mathbf{\Gamma}\big{|}_{\scriptscriptstyle{t}}, while maintaining an expanding record of vertices visited [9]—see Algorithm 1. On a fully parallel machine allowing the ‘cells’ to compute their own excitation, the time complexity is clearly of the order of the longest directed vertex path in the network, which is sub-linear in .
We now turn to a high-level description of the UMA architecture and its use of the results of this section.
3. Universal Memory Architecture (UMA): a High-Level View.
In this section we provide a high-level description of the basic UMA functionalities: PCR update/revision and maintaining a belief state.
3.1. Observation Model.
Recall from Section 2.1.1 that an observer is given a set of initial Boolean queries over the space of histories of the observed system. The system of queries and their complements is modeled as a PCS morphism , which is unknown to the observer. The observer is presented with a sequence of observations \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}}\in\mathbb{H}(\mathbf{\Sigma}(\mathbb{A})), and values \varphi\big{|}_{\scriptscriptstyle{t}}\in\mathds{R}_{{}_{\geq 0}}, , one per update cycle. One must distinguish between two settings:
**Static signal.: **
The value signal \varphi\big{|}_{\scriptscriptstyle{t}} only depends on the raw observation \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}};
**Dynamic signal.: **
The value signal may produce \varphi\big{|}_{\scriptscriptstyle{t}}\neq\varphi\big{|}_{\scriptscriptstyle{s}} while \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}}=\mathtt{Obs}\big{|}_{\scriptscriptstyle{s}}.
While ultimately interested in covering the dynamic setting, we will only deal with the static setting in this paper. However, the setting being static by no means implies it is unchanging. We will see in Section 5 that instances of the static setting may, nevertheless, have rich and interesting dynamics. This will happen, in part, as a result of introducing delayed queries. By these we mean the following: if denotes the operation of truncating the last state from a given history, then, for any conjunction of already available queries it is possible to introduce a new query of the form101010Here and on we abuse notation, applying the symbol to denote both a delayed query and the history truncation/shift operator. Which is which is clear from the context. , where reports its value according to the rule , . Of course, implementing this operation requires that the UMA architecture retain the latest raw observation, but this seems like a small price to pay for increasing the range of application of the static setting.
The basic task of an UMA is to evolve a sequence G\big{|}_{\scriptscriptstyle{t}}, of non-degenerate PCRs over while aiming for the PCRs G\big{|}_{\scriptscriptstyle{t}} to eventually satisfy the following:
- •
**‘Completeness’: ** \rho:G\big{|}_{\scriptscriptstyle{t}}\to\mathbf{2}^{\mathbf{X}} is a PCR morphism, ensuring that every perceptual class is represented;
- •
**‘Precision’: ** \mathbf{M}\big{|}_{\scriptscriptstyle{t}}:=\mathtt{Dual}\!\left(G\big{|}_{\scriptscriptstyle{t}}\right) is as close as possible to the true model space .
These requirements should not be taken literally, however. For example, it stands to reason that in some contexts the observer could afford to misclassify a few perceptual classes of low import. We will see how—at least under some of the learning schemes we propose—these vague requirements become possible to state precisely in terms of PAC learning.
3.2. Maintaining a PCR presentation: Snapshot Structures.
A rather restrictive notion of a snapshot structure—a method for learning a poc set structure from positive observations—was introduced by the authors in [19]. Here we merely review the main ideas to provide intuition, while deferring the formal constructions to Section 4.
Snapshot weights.
Motivated loosely by Hebbian ideas about learning [21], we consider maintaining an evolving symmetric system of weights \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t}}=(\mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}})_{a,b\in\mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t}}}, with \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}} quantifying in some prescribed way a notion of cumulative degree of relevance of the event to the observer, at time .
In addition, rules to maintain \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t}} as time progresses, must be provided. First, a completion rule, to insert missing values into when it undergoes an extension. Second, an update rule, computing \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t+1}} from \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t}} and the incoming observation.
It is important for both rules to be as simple—and as local—as possible, so as not to sacrifice tractability. In our constructions, we constrain the update laws to ones where \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t+1}} depends only on \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}}, the value signal \varphi\big{|}_{\scriptscriptstyle{t+1}}, the truth value of the bit \mathtt{Obs}\big{|}_{\scriptscriptstyle{t+1}}\in\mathfrak{h}(ab) and possible global parameters (e.g. the system clock ).
PCRs from snapshot weights.
Inspired by the rough mechanism proposed in [19], we seek weight systems for which the loosely specified rule—
[TABLE]
ranging over all with is guaranteed to define a non-degenerate PCR over . The motivation for the rule is, of course, the fact that is equivalent to , where is the PCS morphism defining the semantics of the queries in .
Finally, note how the properties of a PCR are guaranteed (to the extent that the rule is well-defined, of course), and non-degeneracy is the only remaining question. Of course, the precise notion of ‘negligible’ defined for the purpose of comparing weights is crucial, and is expected to greatly affect the quality and limitations of the emerging representations.
3.3. Maintaining a Belief State.
Since, for each time , we only get to observe states from , we are facing the problem of having to learn negative statements—that is, the list of G\big{|}_{\scriptscriptstyle{t}}-incoherent pairs—from the stream of positive examples (\mathtt{Obs}\big{|}_{\scriptscriptstyle{t}},\varphi\big{|}_{\scriptscriptstyle{t}}). From what we have observed so far we must reason about what it is we might never encounter. Seeing that the implication record G\big{|}_{\scriptscriptstyle{t}} is inherently uncertain, providing no guarantee at any time that the completeness requirement from Section 3.1 will be met, it is quite possible for the observation \mathtt{Obs}\big{|}_{\scriptscriptstyle{t+1}} to land outside the model space \mathbf{M}{}\big{|}_{\scriptscriptstyle{t+1}}=\mathtt{Dual}\!\left(G\big{|}_{\scriptscriptstyle{t+1}}\right) despite its prior role in forming this model space, during the snapshot update. In fact, its value may be too low to trigger a revision of G\big{|}_{\scriptscriptstyle{t}} into a G\big{|}_{\scriptscriptstyle{t+1}} for which \mathtt{Obs}\big{|}_{\scriptscriptstyle{t+1}} becomes coherent.
Contrary to the approach adopted by modern iterated revision schemes based on Darwiche and Pearl’s [11], we do not insist on a revision forcing \mathtt{Obs}\big{|}_{\scriptscriptstyle{t+1}} into \mathbf{M}\big{|}_{\scriptscriptstyle{t+1}}. Instead, we apply G=G\big{|}_{\scriptscriptstyle{t+1}} to the raw observation with aim to relax it, replacing it with a -coherent and forward-closed set:
[TABLE]
in the role of the current state of record, or the belief state. This way, UMA naturally resolves possible contradictions at the price of introducing ambiguity into its record of the current state: instead of marking a single vertex of \mathbf{M}\big{|}_{\scriptscriptstyle{t+1}} as the current state, any vertex of the convex set may turn out to be the correct current state from the observer’s point of view.
The choice of the coherent projection for the purpose of forming the belief state is motivated by its geometric and categorical properties. In our class of model spaces it is a canonical method of producing coherent sets, as witnessed by the following two results:
Proposition 3.1** (Coherent Approximation).**
Let be a PCR over . Then, for any , if realizes the Hamming distance
[TABLE]
—that is, if —then we must have .
Proof.
See Section C.2.∎∎
Thus, the operation ) yields the “best approximation” of \mathtt{Obs}\big{|}_{\scriptscriptstyle{t+1}} by a convex subset of \mathbf{M}\big{|}_{\scriptscriptstyle{t+1}}, echoing the principle of minimal change as seen through Dalal’s way [10] of quantifying the distance between theories. Moreover:
Proposition 3.2** (Coherent Projection).**
Let be a PCR over . Then the following hold for all :
- •
(a) * is coherent and ;*
- •
(b) * ;*
- •
(c) * whenever is -coherent;*
- •
(d) * if and only if is -coherent and .*
In other words, as a self-map of , the operator is an idempotent whose image coincides with .
Proof.
See Section C.3.∎∎
Note how properties (a) and (c) turn into a closure operator on the subspace of -coherent sets with respect to inference (implication). At the same time, (b) and (d) characterize the set of all terms that are closed under inference.
Overall, Equation 11 provides an intriguingly natural way of maintaining an internal model and belief state with a built-in degree of resilience to observations that fail to make immediate sense to the agent given its epistemic state. Finally, the complexity of this computation is the complexity of propagation over G\big{|}_{\scriptscriptstyle{t+1}}, by Proposition 2.41 and the discussion following Definition 2.43.
4. Learning Algorithms for UMAs: Snapshot Structures.
4.1. Qualitative Snapshot Structures.
The goal of this section is to construct a snapshot structure suitable for a scenario in which the learner’s value signal is a ranking function in the sense of Pearl [39, 18] (which is a special form of Spohn’s OCFs [46]), its values providing a qualitative notion of the degree of irrelevance of the current experience. Thus, an observation with \varphi\big{|}_{\scriptscriptstyle{t}}=0 is considered desirable, while \varphi\big{|}_{\scriptscriptstyle{t}}=1,2,\ldots renders an observation increasingly more irrelevant.
4.1.1. Rankings and 2-rankings
Throughout this section we let be a PCS and let denote the Hamming cube . Also, let . We use the slight variation of the notion of a ranking from [39], which was introduced in [11]:
Definition 4.1**.**
A ranking on is a function , satisfying:
- •
for all ;
- •
for some ;
- •
.
Hereafter, we shall abuse notation, writing to mean whenever . Note that the minimum value of a ranking is . ∎
Remark 4.2**.**
Note that, since is assumed to be finite, the first requirement may be replaced with the requirement that for all .
The simplest examples of rankings seem to be:
Example 4.3** (point-mass ranking).**
Let and , . Then the following function is a ranking:
[TABLE]
Example 4.4** (pointwise minimum).**
If are rankings on , then the function is also a ranking.∎
Recall now the sets from Lemma 2.30. They will help us study the interaction between rankings and concepts:
Definition 4.5**.**
The concept representation of a ranking , is the function , where ranges over subsets of . To simplify notation, we will often write whenever is explicitly provided. ∎
Remark 4.6**.**
Note that if is not a -selection. Also, , the minimum value of .
Lemma 4.7** (triangle inequality).**
For any ranking on , the following holds for all .
Proof.
See Section D.1.∎∎
We are interested in studying the interactions between rankings on and non-degenerate poc-graph structures on . A weakened notion of ranking is required for this purpose.
Definition 4.8**.**
A 2-ranking on is a symmetric matrix with entries in , satisfying the following for all :
- (1)
; 2. (2)
; 3. (3)
; 4. (4)
.
We will say that a ranking agrees with , if for all . Also, we will abbreviate as follows: and , for all . Finally, note how must hold, too, for all , by virtue of requirements 1. and 3.∎
Of course, the idea is to have a 2-ranking play the role of a snapshot weight, from which one needs to derive a non-degenerate PCR. In our learning setting, the best one could do is to derive from the samples of the value signal the 2-ranking . The main question is, then, how much of the original could be recovered from this information. The following family of PCRs helps answer this question:
Proposition 4.9**.**
Suppose is a 2-ranking, and let . Consider the PCRs on defined by:
[TABLE]
for , and by:
[TABLE]
Then is a non-degenerate PCR for all .
Proof.
See Section D.2.∎∎
A surprising consequence of the non-degeneracy of these PCRs is the following corollary, leading to the conclusion that every 2-ranking has a ranking that agrees with it:
Corollary 4.10**.**
Let be a 2-ranking on , and let . Set . Then there exists a vertex such that the point mass ranking satisfies for all .
Proof.
See Section D.3.∎∎
Proposition 4.11**.**
Let be a symmetric -valued matrix. Then is a 2-ranking if and only if there exists a ranking with which it agrees. Moreover, if is a 2-ranking, then there exists one and only one ranking,
[TABLE]
that agrees with and satisfies for every ranking that agrees with .
Proof.
See Section D.4.∎∎
The upshot of the last proposition is that, henceforth, any 2-ranking may be treated as encoding a ranking. Formally:
Definition 4.12**.**
Suppose is a 2-ranking and is a ranking. The completion of is the ranking from the preceding proposition. The 2-restriction of is the 2-ranking, denoted , obtained from via the concept representation, that is: for all . The 2-closure of is the ranking, denoted , obtained from as the completion of its 2-restriction. In particular one has .∎
4.1.2. Derived PCRs and their duals.
We now introduce the PCR used in the qualitative snapshot structure. As systems of defaults, these PCRs are strengthened (more restrictive) versions of the (ranked) default systems constructed by Goldzmidt and Pearl in [18], and they satisfy an analogous characterization.
Proposition 4.13**.**
Suppose is a 2-ranking. For , let its derived PCR be defined by:
[TABLE]
and for let it be defined by:
[TABLE]
Then, is a non-degenerate PCR for all .
Proof.
Let and . Once again, the basic properties of a PCR are baked into the definition of . Furthermore, observe that implies (though not the other way around). In particular, we have and it follows that , as required. ∎∎
Definition 4.14**.**
Proposition 4.11 and Definition 4.12 make it possible for us to abuse notation and talk about the residual and derived PCRs of a ranking by setting , and , dropping all mention of when , as before. Of course, may be replaced with its 2-closure throughout .∎
We proceed to study properties of derived PCRs and their duals, to verify their utility to our representation problem. Specifically, we are interested in the geometry of level sets, as we try to answer the question: how well does the 2-restriction of a ranking capture the set of global minimum points of (the most meaningful states according to )?
Definition 4.15**.**
Given an integer and a 2-ranking , denote:
[TABLE]
The set will be referred to as the minset of . By virtue of Proposition 4.11, this notion extends to rankings as follows:
[TABLE]
with being the minset of .∎
It is clear that a global minimum point of a ranking must contain . Hence, contains all global minima of , but what does this have to do with the derived PCR and its dual? The main result is as follows:
Proposition 4.16**.**
Let be a ranking on and set and . Let and be the sets of global minima of and , respectively. Then and . Moreover, is the convex hull of in
Proof.
See Section D.5.∎∎
Upon inspection, the details of the proof generate the impression that is, for lack of a better word, a form of convex smoothing of , the last proposition showing how the collection of possibly disparate minimum points of coalesces into a convex plateau of minimum points of in the dual space of the derived PCR.
4.1.3. A Snapshot Structure to Learn a Ranking.
We return to our learning problem. Suppose is a fixed ranking on , and we are given a sequence of samples \varphi\big{|}_{\scriptscriptstyle{t}}=\varphi(\mathtt{Obs}\big{|}_{\scriptscriptstyle{t}}), where \mathtt{Obs}\big{|}_{\scriptscriptstyle{t}}\in\mathbb{H} are the observations made by our agent. We will assume \varphi\big{|}_{\scriptscriptstyle{t}}<\infty for all , reserving for the impossible observations.
We must define the weight update taking place in response to an incoming observation; and the weight extension in response to a query being added to the sensorium.
Weight update (static case).
For our snapshot structure, we propose the following update rule for the snapshot weights:
[TABLE]
By Example 4.4, \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t}} is a 2-weight for every , giving rise to a non-degenerate PCR in the form of
[TABLE]
Since the sequence of weights is pointwise non-increasing, its convergence is guaranteed. Moreover, exposure to (at most) observations covering all pairs with , sampling a minimum rank world in for each pair at least once, will result in coinciding with . This motivates the question “How much less exposure is required for delivering the same result on average, in, say, an appropriately formulated PAC setting?”, and emphasizes the good fit of ranking-based snapshot structures to settings featuring a teacher.
4.2. Statistical Integrators of a Real-Valued Signal.
The original suggestion of [19] for maintaining a system of weights in the role of a snapshot structure was based on the idea that \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}} should be the empirical estimate at time of the probability of the event , so that ab\in G\big{|}_{\scriptscriptstyle{t}} could be put on record if and only if \mathtt{w}_{ab{{}^{\scriptscriptstyle\ast}}}\big{|}_{\scriptscriptstyle{t}}<\min(\mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}},\mathtt{w}_{a{{}^{\scriptscriptstyle\ast}}b{{}^{\scriptscriptstyle\ast}}}\big{|}_{\scriptscriptstyle{t}},\mathtt{w}_{a{{}^{\scriptscriptstyle\ast}}b}\big{|}_{\scriptscriptstyle{t}},\tau_{ab}\big{|}_{\scriptscriptstyle{t}}), where \tau_{ab}\big{|}_{\scriptscriptstyle{t}} is a fixed threshold. That is, the implication is put on record whenever the event has sufficiently low empirical probability. We have since found out that the improved formalization provided by Propositions 2.17 and 2.24 enables the use of a far more general weight update scheme that is capable of incorporating a value signal into the learner’s reasoning while also taking into account the observed frequency of events.
4.2.1. Real-valued 2-weights.
Once again, the learner is presented with a sequence of observations , accompanied by the signal \varphi\big{|}_{\scriptscriptstyle{t}}=\varphi(u_{t}). This time we require that the value signal \varphi\big{|}_{\scriptscriptstyle{t}} presented to the agent at time is a real number greater than or equal to , where a higher value of indicates a more meaningful state of the observed system.
Definition 4.17**.**
A real-valued 2-weight on a PCS is a symmetric, real-valued function on , satisfying the following requirements for all :
- (1)
, and ; 2. (2)
; 3. (3)
; 4. (4)
; 5. (5)
.
When for all , we say is trivial.∎
The following example provides motivation for the definition:
Example 4.18**.**
Suppose is a measure space and is a non-negative function in . Suppose is a PCS morphism, when is viewed as a sub-PCS of (recall Example 2.3). Then is a real-valued 2-weight. Indeed, since the integral of a non-negative function is non-negative, the requirements 1.-5. become corollaries of various set-theoretic identities applied to , and , respectively:
- (1)
, . 2. (2)
, 3. (3)
, 4. (4)
(see Figure 2), 5. (5)
,
where , for short.
Example 4.19** (point mass weight).**
Similarly to the qualitative setting, the simplest example of a weight of this form is given by a point-mass measure on :
[TABLE]
where (Compare with Example 4.3).∎
4.2.2. Derived PCRs and their duals.
The resulting notion of a derived PCR requires a system of threshold values, denoted \tau_{ab}\big{|}_{\scriptscriptstyle{t}}\in(0,1), , satisfying the identities
[TABLE]
for all and . This makes it possible to construct a non-degenerate PCR as follows:
Proposition 4.20**.**
For any choice of threshold values satisfying Equation 24, if is non-trivial, then
[TABLE]
defines a non-degenerate PCR.
Proof.
See Section E.1.∎∎
Let for a real-valued 2-weight . A notion analogous to that of a minset may be considered in the real-valued setting, taking into account the reversal of the value hierarchy (now, bigger values of are considered the most significant):
[TABLE]
The argument that is -coherent and forward-closed, for any choice of the thresholds , is the same as the one given for minsets in the qualitative setting (Lemma D.1 in Section D.5), upon reversing the relevant inequalities. This time around, however, the non-empty convex subset of does not directly relate to extreme points of the value signal in , but, rather, to a notion of center of mass of with respect to , seen as a representation of the distribution of the value signal over .
4.2.3. Snapshot update.
Similarly to the qualitative setting, in the real-valued setting we will also be assembling our estimate of the [integrals of the] observed value signal from point-masses, this time replacing minimization with linear combinations. The update rule for a discounted integrator snapshot takes the form:
[TABLE]
where the q\big{|}_{\scriptscriptstyle{t}}\in(0,1] are the discount coefficients, . The fact that \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t+1}} is a convex combination of real-valued 2-weights ensures that \mathtt{w}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t+1}} is a real-valued 2-weight as well.
Types of update.
We studied two variants of the discounted integrator snapshot:
- (1)
**Empirical Snapshot. ** In this case, one sets q\big{|}_{\scriptscriptstyle{t}}:=\tfrac{t+1}{t+2}, resulting in
[TABLE]
which is the empirical estimate for the integral of over . For this snapshot type, we used fixed thresholds . 2. (2)
Fixed Discount Snapshot. Here one sets q\big{|}_{\scriptscriptstyle{t}}:=q, a constant, playing the role of a rate at which information acquired about the signal ‘fades’ unless continually reinforced by incoming observations:
[TABLE]
The eventual purpose of using an update of this form is to accommodate settings where has multiple peaks, as well as, possibly, the dynamic setting, provided the value signal changes sufficiently slowly.
PAC learning guarantees.
The notion of probably approximately correct (PAC) learning introduced by Valiant [48] is one framework within which the quality of UMAs based on real-valued snapshots could be discussed. The assumptions of this setting are that the observations are i.i.d. samples of a fixed distribution on , in which case, for any fixed pair with , one could think of the sequence of input values \mathrm{X}_{ab}\big{|}_{\scriptscriptstyle{t}}:=\varphi\big{|}_{\scriptscriptstyle{t}}\cdot\delta_{u_{t}}(\mathfrak{h}(ab)) as a sequence of i.i.d. samples of a random variable , where is an upper bound on the value signal . Equation Equation 27 then lets us think of \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}} as random variables \mathrm{Y}_{ab}\big{|}_{\scriptscriptstyle{t}} constructed according to \mathrm{Y}_{ab}\big{|}_{\scriptscriptstyle{t+1}}=q\big{|}_{\scriptscriptstyle{t}}\mathrm{Y}_{ab}\big{|}_{\scriptscriptstyle{t}}+(1-q\big{|}_{\scriptscriptstyle{t}})\mathrm{X}_{ab}\big{|}_{\scriptscriptstyle{t+1}}. Applying induction one immediately verifies that \mathbb{E}\left[\mathrm{Y}_{ab}\big{|}_{\scriptscriptstyle{t}}\right]=\mathbb{E}\left[\mathrm{X}_{ab}\right] for all . It thus becomes reasonable to ask how many samples are required in order to bring the probability that \left|\mathrm{Y}_{ab}\big{|}_{\scriptscriptstyle{t}}-\mathbb{E}\left[\mathrm{X}_{ab}\right]\right|>\varepsilon below a specified threshold. Valiant [48] had long ago observed that Chernoff bounds are a powerful tool for answering such questions. Computing Chernoff bounds for our setting yields:
Proposition 4.21** (PAC learning in empirical snapshots).**
Given , the empirical snapshot learning mechanism attains a precision of on all weights, with probability from a number of i.i.d randomized samples that is at most linear in , at a rate depending only on the value signal.
Proof.
See Section E.2.∎∎
Our simulation results indicate that similar guarantees could be expected for the discounted setting, but the standard Chernoff-inspired approaches for leveraging the independence of the observations do not seem to work. Since discounted snapshot learning makes it easier for the representation to recover from false implications, it is important to ascertain whether or not a result of the form Proposition 4.21 could be proved, and if not—in what circumstances it might fail.
Other learning scenarios.
The PAC learning guarantees of the preceding paragraph are predicated on the assumption that the sequence of observations is statistically independent. This assumption becomes unreasonable for an observer of a system whose state evolves continuously over time, subject to some internal dynamics, in which case it is often unlikely that contiguous observations will be uncorrelated.
A fairly general model of such settings is provided by Markov chains [42], where the underlying Markov process models the (uncertain) dynamics of the observed system. In our setting, one regards —the set of observable possible worlds in (Section 2.1.1)—as the set of states of a fixed (albeit unknown) Markov process. Then, by the ergodic theorem for Markov chains [15], one has:
Proposition 4.22**.**
Suppose the sequence of observations is sampled from an a-periodic, irreducible, positive-recurrent Markov chain with limiting distribution . Then the empirical snapshot weights \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}} learned from the constant value signal \varphi\big{|}_{\scriptscriptstyle{t}}=1 converge to the marginals , for all .∎
In particular, any thresholded implications derived from the real-valued 2-weight will be recovered in this process.
Finally, it follows from the decomposition theorem for Markov chains [15] that the ergodicity assumption in the above proposition does not impose undue restrictions on our model, as we only expect an agent to learn implications from recurring observations anyway. We also note that the special case of lazy random walks guarantees an exponential rate of convergence to the limiting distribution in many interesting cases (see Theorem 5.1 of [32] and Theorem 9 of [42]).
5. Simulations.
We present two kinds of simulation studies. Section 5.2 illustrates the preceding results about learning with different snapshot types in a sample of ‘toy’ settings. Section 5.3 explains how to construct simple UMA-based binary agents, whose performance is considered in Section 5.4.
5.1. Simulation settings.
Each setting considered in Section 5.2 consists of an observer/agent situated in a discrete environment, . For simplicity, the queries assigned to are functions of the agent’s current position in the environment, which we denote by . Let . The environments and sensory endowments we consider are:
- •
**Discretized interval with GPS. ** Here , and has queries , with holding true at time iff ;
- •
**Discretized circle with beacons. ** Now set with () holding true iff is close enough to , modulo ;
- •
**Discretized interval with random position sensors. ** again, and , with true at time iff , where are chosen uniformly at random ahead of each simulation run.
We consider different value signals, all set to be functions of the position, depending on snapshot type:
- •
**Qualitative Snapshots. ** Two natural choices of the signal are considered,
[TABLE]
where should be regarded as a “target” position of high significance.
- •
**Real-valued Snapshots. ** To parallel the “sharp peak”/“dull peak” signal variants from the qualitative setting, we pick:
[TABLE]
respectively. For discounted snapshots, the discount coefficients were picked to be . Learning thresholds are constant, where relevant, and are chosen to equal to ensure correct learning of implications among the initial sensors by the real-valued snapshots.
5.2. Simulation results for observers.
To assess the speed and quality of PCR learning, we track the error-rate of the learned PCR representation—the fraction of correctly learned PCR implications—over time.
5.2.1. Repeated i.i.d. sampling (PAC-style setting).
Figure 3 compares logarithmic plots of two mean error rates over observation sequences generated by repeated i.i.d. uniform sampling of positions from the environment, for the settings described in Section 5.1 for :
- (1)
**Solid lines. ** The mean fraction of incorrect implications in the learned PCR relative to the expected PCR for the given learner in each setting, as a function of time; 2. (2)
**Dashed lines. ** The mean fraction of incorrect implications in the transitive closure of the learned PCR relative to the poc set of actual implications among the provided sensors, as a function of time; 3. (3)
**Shaded regions ** depict the meanstandard deviations for the corresponding quantities.
The first most notable feature of the figures—beyond confirming (and, in fact, exceeding) the theoretical results—is the complete agreement of the curves for all six learners on the interval (left column). Since the sensors in this case are nested, the poc set of true implications coincides with the derived PCR induced by the expected weights and is recovered quickly and completely.
Next, on the circle we begin to see the difference between the quality of the learned PCR and the quality of the inferred system of implications as compared to the real ones. This deterioration in quality was to be expected, as transitive closure enables the deduction of implications from chains of approximate implications recorded in the PCR. Observe that the discrepancy is bigger for the sharp peak settings, in which a very small degree of significance is assigned to positions farther away from the target. This difference is most notable in the qualitative learners: while completely absent in the dull peak setting, it is very visible in the sharp peak setting. We account for these differences, among other things, in the detailed analysis of the true PCR provided in Appendix F.
A similar discrepancy is visible, but less pronounced in the third column, though we must keep in mind that, in this column, each run was executed with a different random collection of sensors. The differences are less pronounced than on the circle because in the sensorium we have chosen for the circle there is very little nesting, while in a random sensorium, the probability of nesting is non-negligible. Nesting relations in the sensorium forces \mathtt{w}_{ab{{}^{\scriptscriptstyle\ast}}}\big{|}_{\scriptscriptstyle{t}}=0 in real-valued snapshots, and \mathtt{w}_{ab{{}^{\scriptscriptstyle\ast}}}\big{|}_{\scriptscriptstyle{t}}=\infty in qualitative snapshots at all times , guaranteeing that will be learned with sufficient exposure. The rotation-invariant sensorium we chose for the circle has very little nesting, and hence much more room for error if the provided value signal happens to discount too many positions as being insignificant. Deeper differences arise as a result of the circle’s non-trivial homotopy type, which we discuss in Section 5.4.2 and further in Section 6.
Finally, let us remark that we do not yet have a good explanation for the good behavior of the discounted learners. We were unable to prove any concentration inequalities for the discounted weight update to parallel the ones obtained for the empirical one. Moreover, the quality of learning appears to be very sensitive to the choice of discount parameter. In fact, it was this difficulty with appropriately selecting and controlling the discount parameter that motivated the construction of qualitative learners in the first place.
5.2.2. Lazy random walk (learning from “motor babble”).
For a robotic system, a more realistic mode of sampling from the environment is “motor babble”: a random walk on generated by repeated i.i.d. sampling from the space of available actions/decisions. In this mode, each instance of the agent is constrained to a small set of available actions, depending on :
- •
**Discretized interval. ** The allowed actions are a single step to the right (), a step to the left (), or to remain in place;
- •
**Discretized circle. ** Similarly, on the circle , or or to do nothing at all.
Figure 4 shows the evolution of the error rates we had considered earlier in Section 5.2.1, in the new sampling mode.
This set of plots provides a good illustration of the robustness of UMA learning—especially with qualitative snapshots—where the quality of learning improves over time (though now at a much slower pace, due to the change in the sampling process), as the observer gains more exposure to the observed system.
5.2.3. Learning the target set over time.
We compare how UMA learners of different snapshot types develop their notion of the target set, , over time. For this purpose, Figure 5 shows this evolution for a single run from a separate batch of lazy random walk observations in a smaller environment (), over a shorter period of time ( cycles). The features observed in this plot are, however, typical of the runs we generated for Figure 4. “Downgrading” the experiment to a smaller environment enabled faster learning, and hence plotting the run at a lower resolution, without requiring the reader to magnify the plot attempting to discern its significant features.
Observe the eventual precision and efficiency of the qualitative reasoners, compared to the drift (away from the target) clearly noticeable for the real-valued learners. Also note some initial delay in learning the target (in comparison with other types) in the discounted learners: the value of places a bound on how quickly an implication may be learned.
Both these observations are typical of all the batches we have observed. This suggests the qualitative UMA learners as the best bet for upgrading UMAs to perform learning in the dynamic setting. This also suggests that the real-valued learners could benefit from more careful shaping of the value signal, with significantly sharper peaks, as well as from lower values of the discount parameter (for discounted learners), if learning on shorter time scales is important.
5.3. Binary UMA agents.
Postponing a more general formal definition of a binary UMA agent to another paper, let us describe just the simple sub-class of these agents considered here.
Actions as agents.
Given the environment and the associated set of queries as described above in Section 5.1, we regard each of the actions available to as an individual agent , in charge of making the decision whether to act () or not to act (). Any conflicts between decisions made by different are, at this stage of development, arbitrated by hard-wiring (see example in Section 5.4.1 below).
Extended query set.
For to be capable of considering the consequences of its decisions, we have to extend so as to enable reasoning about the past. Specifically, each is assigned a value signal , and an initial set of queries , where is the delay operator: the query holds true at time if and only if held true at time .
UMA representation conditional on action.
The BUA maintains two snapshots, , . The -weight is updated precisely in those transitions in which acted according to . Thus, at any time , \mathtt{w}^{\beta}_{{\scriptscriptstyle\bullet}}\big{|}_{\scriptscriptstyle{t}} may be used to infer implications conditioned on taking place, by computing a derived graph, G^{\beta}\big{|}_{\scriptscriptstyle{t}}.
Prediction.
Given the current state \mathtt{Curr}^{\beta}\big{|}_{\scriptscriptstyle{t}} at time as represented by the snapshot, , the prediction for time given , \mathtt{Pred}^{\beta}\big{|}_{\scriptscriptstyle{t+1}}, is defined to be the coherent projection of \sharp\mathtt{Curr}^{\beta}\big{|}_{\scriptscriptstyle{t}} with respect to G^{\beta}\big{|}_{\scriptscriptstyle{t}}. This is the collection of sensations which can prove will occur if is chosen to take place, provided, of course, G^{\beta}\big{|}_{\scriptscriptstyle{t}} persists into the -st cycle.
Decision.
At the same time, each of the agent’s two snapshots has a notion of where it is that the agent should be: the subset \mathfrak{h}(\mathtt{M}(\mathtt{w}^{\beta}_{{\scriptscriptstyle\bullet}});G^{\beta}\big{|}_{\scriptscriptstyle{t}}). A simple way for to make a choice of is to pick the value of for which \mathtt{Div}(\mathtt{Pred}^{\beta}\big{|}_{\scriptscriptstyle{t+1}};\mathtt{M}(\mathtt{w}^{\beta}_{{\scriptscriptstyle\bullet}})\big{|}_{\scriptscriptstyle{t}}) is smaller, and to flip an even coin in the case of a tie (recall Definition 2.39).
5.4. Simulation results for agents.
5.4.1. Sniffy: locating a stationary target using “place field” sensors.
Consider an agent in one of the two fixed settings described above in Section 5.1, with two actions and , as defined in Section 5.2.2, implemented as BUAs according to Section 5.3 with the value signals given in Equations (30) and (31). To minimize interference between and , we impose a hard-wired arbitration mechanism: if and decide to act at the same time, a Bernoulli random trial decides which one of them to suppress.
At the beginning of each simulation run, Sniffy (our pet agent ) and its target are placed in random positions in , denoted and , respectively. The agent then experiences a training period during which every decision by every BUA is overridden by a random one, resulting in a lazy random walk. Once the training period is over, the BUAs are given control authority, with Sniffy acting according to their decisions.
Finally, following the indications of Section 5.2.3, we have chosen to replace the discount parameter of with , to enable a faster response by the discounted learners.
Figure 6 reports the results of our simulations. Each plot shows the mean, plus/minus standard deviation, over distinct runs, of the distance of the agent to its target as a function of time, in each setting.
Section A.2.4 discusses the representations expected to arise in the case of the interval in some detail, explaining Sniffy’s success in that environment, shown in the figure. However, we also notice a deterioration of the results as Sniffy is moved from the interval to the circle. This is due to subtle interactions between the propagation mechanism generating the BUAs’ predictions (which drives decision-making), and the non-trivial homotopy type of the circle, which forces inconsistent states into all the model spaces involved (the latter, we recall, are always contractible). This discrepancy between the topology of UMA model spaces and the spaces they come to model provides the main motivation for our future project of studying the control of situated agents by networks of BUAs, where the deliberation among agents is meant to generate an emergent joint representation of reactive behavior patterns with the competence to overcome topological constraints and obstacles (more in Section 6).
5.4.2. What did Sniffy learn on the circle?
All the graphs in Figure 6 indicate a significant change of behavior at the end of training. It therefore seems sensible to attempt splitting the set of runs in each setting into those finishing closer to the target than to its antipodal point on the circle, as shown in Figure 7.
What emerges is that all the learned representations experience difficulties dealing with the situation loosely characterized as “Sniffy approaches the point on the circle antipodal to the target”. Note that the “dull peak” qualitative learners emerge as the most apt, both in terms of efficiency and in terms of separation between the desirable and undesirable modes of behavior. In this setting, the target clearly emerges as an attracting point except for a small neighbourhood of its antipode, which seems to play the role of an unstable equilibrium. This is reminiscent of gradient descent over the function on the unit circle, viewed as a differentiable manifold: the target is a robust attractive equilibrium, complemented by an unstable equilibrium that is forced by the non-trivial homotopy type of the circle. Since qualitative snapshots enable direct computation of the eventual values of the snapshot weights, it becomes possible to obtain explicit insights into the behavior learned by Sniffy in this setting. We refer the reader to Appendix F for a detailed discussion proving the preceding claims.
6. Discussion.
Motivated by the goal of implementing well-reasoned general learning on mobile robots, this paper introduces algorithms implementing a simplified version of iterated belief revision and update that is consistent with budgetary constraints on storage space and computational complexity, collectively named “universal memory architectures” (UMAs). We establish and study the mathematical language necessary for the analysis of UMA instances, and show how the standard model-theoretic approach to belief revision gets naturally replaced by the study of the geometry of convex sets in the model spaces represented by UMAs.
By construction, UMA representations are systems of default rules that are closed under counter-positives. We show that such representations may be learned both by means of sampling and statistical integration of a real-valued signal (empirical and discounted snapshots, Section 4.2), as well as by means of aggregating samples of a ranking function on the space of possible worlds, in the sense of Spohn [46] and Pearl [39] (qualitative snapshots Section 4.1). In the latter case, we are able to guarantee the correct encoding of the convex hull, in the learned geometry, of the set of minimum rank worlds, provided sufficient exposure. Finally, we show the potential of UMA representations for the motivating application by considering its behavior in a pair of simple learning settings simulating a standard task formulation from Robotics: localize a target in the presence of (highly impoverished) sensing in a global frame (Section 5.4.1).
The need for expanding the set of queries (‘self-enrichment’).
It is important to state clearly the limitations of UMA learners in the form presented in this paper. From a practical perspective, attempting to learn a PCR structure for a fixed sensorium will yield no learning at all in the case of an arbitrary and/or ‘unstructured’ binary sensorium such as the pixel grid of a B/W video camera, where no two pixels are a-priori correlated. Consider an even simpler example: the situation of satisfying , and cannot be encoded by a PCR unless the query set explicitly contains an element whose realization is . Finally, it is clear that PCRs are not geared for studying temporal interactions unless explicitly outfitted with appropriate queries (as in the example of BUAs in Section 5.3).
Accepting the above as the price of the radical reduction in computational costs achieved by UMA-based learning (as compared to unrestricted iterated belief revision), a natural avenue for increasing the descriptive power of an UMA representation is to allow the set of queries to expand (by adding ‘meaningful’ queries) and contract (by coalescing related queries, or deleting uninformative ones) over time, in a controlled fashion, at a known and minimal cost in computational resources. The fixed sensorium should be replaced with a sequence \mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t}}, as the map is replaced with a sequence \rho\big{|}_{\scriptscriptstyle{t}}:\mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t}}\to\mathbf{2}^{X}. Still, the advantage of UMA representations over others is in their efficiency at encoding a model space and reasoning about it in terms of its convex subspaces. This motivates the search for an enrichment method that meets the lower complexity bound for representing the observed system.
Looking for such a method, one must be mindful that the expansion steps cannot be arbitrary, as it is necessary for each map \rho\big{|}_{\scriptscriptstyle{t+1}}:\mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t+1}}\to\mathbf{2}^{\mathbf{X}} to be uniquely determined by its predecessor \rho\big{|}_{\scriptscriptstyle{t}} and the limited information that was available to the UMA at time . This suggests two natural elementary expansion operations, which also happen to interact well with our detailed understanding of the geometry of duals:
**Append a conjunction.: **
Adding a query of the form for some a_{1},\ldots,a_{k}\in\mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t}}, to form \mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t+1}}=\mathbf{\Sigma}\big{|}_{\scriptscriptstyle{t}}\cup\{q,q{{}^{\scriptscriptstyle\ast}}\}, forces the extension of via .
**Append a delayed sensor.: **
Let denote the operation of truncating the last state from a given history; Then it is possible to introduce a query of the form for , where reports the value of preceding the current one, or, in other words: .
Observing for all , we conclude that any composition of the above extension operations determines a unique extension of the original . Hence, an UMA endowed with these enrichment operations is capable, in principle, of eventually representing very rich theories of the observed system, both in terms of Boolean relations among the original sensors and in terms of temporal properties—provided we are willing to accept the cost in resources. Clearly, the burden is on us to decide when an extension is in order; for what purpose; and how to prevent the population of added sensors from exploding to a prohibitive size.
In the presence of delayed queries, the situation lends itself to the formation of a prediction operator, extending the simplistic one constructed in Section 5.3. This makes it possible to formulate learning objectives concerning the quality of prediction. Our ongoing work exploring analogies with perceptron learning [37] is directed towards studying the problem of optimizing prediction through gradual extension of the sensorium using the operations just formulated.
Agents.
The stated motivation for this project was that of producing computationally efficient agents whose reasoning is grounded in a suitably relaxed—though still formally reasoned—form of iterated BR. At the same time, the model spaces encoded by UMAs are uniquely suited for reactive control: the selection of a control instruction in direct response to a localized (in time, as well as in space) perception of the task. At all times that the goal set is represented by a coherent selection on (that is, the goal set is non-empty and convex in the relevant model space), propagation may be used to produce the nearest point projection paths from the current state to the goal set, within the model space, helping determine the appropriate actions as those provably propelling the agent roughly along one of these paths, using the mechanism described in Section 5.3.
A pertinent question for our current research is whether or not it is possible to employ self-enrichment procedures (see preceding paragraph) to guarantee—at least for some classes of problems—the emergence of a representation with the property that an agent’s predictions from time never fall outside the perceived current state at time , for all large enough. If, and when, that becomes possible, one will have to conclude that any planning failure is due to an obstacle in the relevant UMA model space(s) originating from an attempt to navigate into an impossible perceptual class. This would open the door to methods for efficient representation of such classes, as well as the leveraging of such representations for correcting the simplistic control scheme of navigation along geodesics.
Improving representation using multiple agents.
The possible presence of obstacles focuses our attention on another important deficiency of UMA representations. While the concept representations they encode are always contractible when regarded as cubical complexes (see Section A.3 for more details), the concept representations corresponding to the ground truth will, more often than not, possess cavities/holes, serving the role of obstacles to navigation along geodesics in the UMA model space, and driving up the complexity of continuous planning [14]. An example of this phenomenon is already encountered in our simulations of target localization on the circle, in Section 5.4.2, and investigated in detail in Appendix F.
A possible solution to this problem might lie with the accumulation of a flexible collection of specialized agents, each with its own sensors and its own value signal; each correctly representing some aspects of the ‘physical’ agent’s tasks, while having to rely on others in regions of its model space where its predictions fails. Fairly detailed descriptions of communities of this form have been proposed as possible models of human cognition by Minsky [35, 36], and studying the dynamics of such communities, charged with governing a situated agent, poses many interesting challenges.
In this context it is important to note that very recent results [41], demonstrating smooth(!) reactive switching between different control alternatives (behaviors/actions) using value-based motivational dynamics, provide a basis for speculation that (1) such methods may be applicable to our setting, too; and (2) formal understanding of the dynamics of the putative Minskian “societies” of UMAs just mentioned may be well within our reach.
Developing this approach will require the study of multi-agent systems incorporating means for the formation of “BUA coalitions”, for lack of a better term, to be recruited for action under appropriate circumstances. This is also where we expect the mathematical theory behind UMAs to prove most useful. Its categorical underpinnings (the fact that model spaces arise as dual spaces; see Section 2.2) provide a rigorous framework for comparing different models of the same system, and for studying the interaction between different perceptual components of a single model (see Sections A.2.4 and F where we carry out such detailed analysis).
acknowledgements
This research was developed in part with funding from Air Force Research Lab (AFRL) grant FA865015D1845 (subcontract 669737-1), and in part with funding from the Defense Advanced Research Projects Agency (DARPA) and the Air Force Research Lab (AFRL) under agreement number FA8650-18-2-7840. The views, opinions and/or findings expressed are those of the authors and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government. The authors are grateful to Siqi Huang, a Penn CGGT Master’s graduate, for his relentless work developing a hardware-accelerated implementation of the UMA architecture, making the simulations in this study possible. We also thank Kostas Karydis for helping proof-read some of the initial material on ranking-based UMAs during his last months as a post-doctoral fellow at Penn’s GRASP lab.
Appendix A Appendix: The Duality Theory of Finite Poc Sets.
The purpose of this appendix is to review known results about the geometry of duals of finite poc sets, while illustrating them with simple examples which emphasize our application. An additional goal is to provide a sufficient technical background for proofs of new results in the appendices that follow.
The concept presentation of the dual of a poc set leads to more intuitive understanding of the geometry of poc set duals. Recall from Section 2.1.2 that the concept representation of a subset of vertices of the Hamming cube over a PCS encodes the set of (cubical) faces of the Hamming cube obtained by deleting all faces containing at least one vertex of . The resulting structure is a (rather special) cubical complex111111See [29], Chapter 2, for a very brief introduction to polyhedral (in particular, cubical) complexes.. One way in which such cubical complexes are special is that they are completely determined by their 1-dimensional skeleton—their collections of vertices and edges.
The resulting freedom to consider a higher dimensional “enveloping structure” for when is a poc set over turns out to be useful in many ways, some of which we intend to explore in this section.
Definition A.1** (Dual Cubing).**
Let be a poc set structure over a finite PCS . The dual cubing is the cubical complex obtained as the concept representation of the subset .∎
In the very least, the ability to refer to will make it easier to visualize the graph , exposing its higher dimensional structure and bringing order to what otherwise would have been a chaos of edges (e.g. Figure 11). The notion of a dual cubing also makes it easier to understand cartesian products of dual graphs (Section A.2.2 below). Finally, we will use the dual cubing to explain some fundamental properties and limitations of PCR presentations (Section A.2.3 below) relating to their universality (Proposition 2.22).
A.1. Nesting, Transversality and Cubes.
Fix a poc set over a finite PCS . The purpose of this section is to present the known characterizations of the cubes arising in . Some additional standard terminology will be needed. The following are from [43], Section 1.4:
Definition A.2** (proper elements, proper pairs).**
Let be a PCS. A proper element of is any element such that . A pair of proper elements in is said to be proper, if .∎
Definition A.3** (nesting, transversality).**
Let be a poc set. For any proper at most one of the following holds:
[TABLE]
If any one of the above relations holds, we will say that * and are nested*. Otherwise, we say that * and are transverse*. Furthermore, for any , we say that * is nested (transverse)*, if every two elements of are nested (resp. transverse).∎
Recalling that a poc set is, first and foremost, a partially ordered set, for any subset it makes sense to consider
[TABLE]
Since is finite, is non-empty whenever is. The following is Proposition 10.1 of [43], restricted to the finite case and parsed into more elementary language:
Lemma A.4** (when a vertex meets a cube).**
Let be a finite poc set and let . Let be a -dimensional cube of . Then if and only if contains a transverse subset of with the property that every vertex is of the form for some .∎
In particular:
- •
every edge (-cube) containing is spanned by and a vertex of the form for some ;
- •
every square (-cube) containing is spanned by , , and for some transverse pair .
These properties give rise to a new understanding of how the half-spaces in interact with the geometry of :one could think of the splitting of in the form as the result of cutting the cubing along the hyperplane arising as the union of perpendicular bisectors of edges of the form —see Figure 8.
In addition, the last lemma plays a crucial role in deducing some fundamental properties of (Proposition 10.2 of [43]):
Theorem A.5**.**
Let be a finite poc set. Then is contractible.121212Contractibility of a topological space is a fundamental notion in Topology, formalizing the idea of a “space with no holes”. See [20], Chapter 0 for a quick and very intuitive introduction.∎
Moreover, the lemma implies that is non-positively curved (see [50], Section 2.1). This produces a characterization of complexes of the form (Theorem 10.3 of [43]):
Theorem A.6** (characterization of cubings).**
A cubical complex arises as the dual of a finite poc set if and only if it is contractible and non-positively curved.∎
All the above apply in far more general settings than the finite one: the interested reader should consult [43].
A.2. Examples of Duals.
To improve the reader’s intuition regarding dual graphs of poc sets, as well as to illustrate one of the example simulations (Section 5.4.1), we consider a sequence of examples in light of the results of Section 2.4.
A.2.1. Example: a bead on a string.
Suppose the system being observed consists of a bead strung on a tight piece of string. The observed state of the system is modeled by the interval in the obvious way, so the space of histories is the set of sequences , where corresponds to the current position of the bead given , is the previous position of the bead, and so on. Let us set with two different poc set structures, and , defined by the relations , in and , in . These may be regarded as PCR representations of two different sensoria constructed as follows. Let in be points that are pairwise at least apart, . Then may be realized by setting (“threshold sensors”), while may be realized, for example, by (“beacon sensors”).
The vertices of have the form , , with an edge joining to for all (recall that edges in are edges of the Hamming cube ). The graph has a different collection of vertices, dictated by the fact that all pairs with are incoherent: there is a ‘special’ vertex and a collection of ‘generic’ ones, ; all the , , are adjacent to , and no other pair of vertices are adjacent. Figure 9 shows (left), which is an -path, and (right), which we will refer to in the future as a starfish. Note how, of the two model spaces, seems to provide the better discretization of . Note that both duals are trees. This is a manifestation of the well-known fact that is a tree if and only if is nested (that is, any two elements of are nested).
A.2.2. Example: Cartesian products of duals.
The easiest way to join two poc sets together is to form their direct sum:
Definition A.7**.**
Let and be discrete poc sets. Their direct sum is defined to be the quotient of their external disjoint union by the identification and , endowed with the following:
- •
;
- •
.
We abuse notation by identifying each element of with the equivalence class in of its natural representative in .∎
Consider the two inclusion maps, and , each of which is an injective poc morphism. The dual maps and give rise to the median morphism defined by , where and , by definition. Since every proper pair with and satisfies , it follows that is coherent for any and , and we conclude that is bijective.
Finally, recall that an edge in joining with occurs iff . Since the intersection of with in is trivial, in terms of we obtain:
[TABLE]
so that span an edge if and only if exactly one of the pairs or spans an edge. Thus, is a median isomorphism of the dual graphs and we have:
Corollary A.8**.**
Let be discrete poc sets. Then the mapping
[TABLE]
is a median-preserving graph isomorphism.∎
For an alternative argument, note that for any and , if and are transverse sets, then and is a transverse set in . Therefore, by Lemma A.4, every cube in corresponds to a unique cube in . Thus from the corollary is much more than an isomorphism of graphs: it extends to an isomorphism of cubical complexes from onto .
A.2.3. Example: representing a circle.
Similarly to the example of a bead on a straigh piece of string (Section A.2.1), one could consider a bead on a circular bracelet, replacing the interval with the unit circle in the complex plane. This time, let be a cyclically ordered collection of marker points, say, .
We will compare several different representations over the PCSs:
[TABLE]
We regard as a sensorium whose realization is defined by setting for a history if and only if the currect state lies in the open circular arc segment of centered at and having radius . Depending on the choice of and , different PCRs (and duals) may arise. Specifically, We consider the examples with and ; with and , to illustrate possible differences and shared qualities.
Jack Sparrow’s compass, .
Rather than keep track of the indices modulo 4 in this example, let us identify it with a day-to-day object: a compass. We denote
[TABLE]
Figure 10(left) depicts the subsets of which determine , , for the realizations in the cases (A) and (B). Thinking of as the space of all possible positions of a compass needle—the needle of this compass points in the direction of your heart’s greatest desire and that may not be a visit to the magnetic north pole—one should think of, e.g., , , as the set of positions of the needle with which observer associates an affirmative answer to the question “Is the needle pointing North?”. The difference between the two examples is that are pairwise disjoint, while realizes the major directions so that only opposites are disjoint.
Let denote the poc set structure on with relations of the form131313We regard the indices in this example and any arithmetic operations on them as being defined modulo .
[TABLE]
Then is a poc morphism for either choice of , and the right hand side of Figure 10 illustrates the perceptual classes of (yellow highlighting) together with the edges they induce in the ambient structure, . Note how case (A) produces an embedded cycle sub-graph in —a coarse but topologically faithful reconstruction of , which is homotopically non-trivial—while case (B) produces a tree, a space homotopically equivalent to a point.
While providing an illustration for Proposition Proposition 2.22, this example also highlights the necessity in discussing what properties of the realization map could guarantee a degree of fidelity of the observer’s reconstruction of the observed space (the space of histories ? the ‘environment’ ?) as, say, the sub-graph of induced by the perceptual classes.
Higher dimensions, .
Figure 11 compares the dual graphs/cubings of two poc set representations, each optimal for its corresponding choice of the value of . The case again has the property that non-consecutive are disjoint, implying that is a poc isomorphism of the poc set structure
[TABLE]
onto its image in . Denote this poc set structure on by .
The case has fewer nesting relations among the , because every three consecutive sets of this form have a point in common. Formally, is a poc isomorphism of the poc set structure described by:
[TABLE]
onto its image. Denote this poc set structure on by . Note that the identity map is a poc morphism, while its inverse is not: a poc morphism is allowed to map a transverse pair to a nested one, but not the other way around. The dual of this map embeds in . This embedding can be seen clearly in Figure 11(right).
A.2.4. Example: moving bead on an interval.
Returning to the ‘thresholds’ example of Section A.2.1, we would like to consider it from the point of view of the agents described in Section 5.4.1.
The interval from Section A.2.1 will now be replaced with , a positive integer, for convenience. Once again we are given position sensors —more sensors will be added to in a moment—with realizations , where we recall that , is our current notion of a history, and is the current position of the bead on .
This time we are interested in reasoning about the possible motion of the bead along the interval, so we introduce delayed sensors into alongside the original position sensors. Formally, the delay operator acts on histories via , and acts on sensors via , that is: at any time, the current value of coincides with value of in the previous cycle.
The bead is endowed with two actuators. One, named , whose action at time pushes the bead one unit to the right along the interval. The only exception is the position : if is applied there, its contribution to the motion of the bead will be nil. Similarly, an actuator named pushes the bead one unit toward the endpoint [math] of , with no effect when the bead is already there. Finally, turning on both actuators at the same time results in no motion of the bead in either direction.
Two agents, also named and , are each in charge of deciding, respectively, whether to act (turn on their assigned actuator for the duration of one time interval), or not. Each agent maintains two PCR representations: is updated conditioned on the agent having acted, and is updated conditioned on resting.
Here we will consider the poc set representations we would like each agent to learn, as we attempt to draw their dual cubings. For this purpose, we analyze nesting relations in the sensorium
[TABLE]
In the absence of any additional assumptions, the following relations are consistent with the selected realization (and are, therefore, desirable as part of any learned poc set structure on ): encodes the geometry of the interval, and further implies also ; not knowing anything about the actions taken by the actuators one may only be certain of the relations , for . Denote the resulting poc set structure on by .
Leveraging our understanding of cartesian products (Section A.2.2), we set to be the sub-poc set of restricted to just the position sensors , while will be the sub-poc set of over the delayed position sensors . Then the identity mapping is a poc morphism, whose dual map is a median-preserving embedding of cubical complexes, of in the square grid arising as . We conclude that is the cubical complex shown in Figure 12(left), by applying the relations to erase redundant squares from the grid.
Now suppose that all the correct relations have been (somehow) learned and represented in the collection of PCRs , , and . Because the synchronous application of and yields no motion, there is no way to discriminate between and , as well as between and . However, the former two poc set presentations will have obtained the relations in addition to those of , causing the dual cubing to grow even smaller, as highlighted on the right-hand side of Figure 12 (of course, a symmetric situation arises for the other pair of indistinguishable representations).
To end this section we note that, by hard-wiring the actuators to never execute both and at the same time, it is possible to disambiguate the representations. In this regime, the (optimally learned) representations and will remain the same, while the PCRs and will each experience a collapse to a non-trivial canonical quotient: the PCR witnesses if and only if it witnesses (the diagonal vertices in Figure 12 are inconsistent given is active). The situation is symmetric (but not identical) for , and we obtain four distinct “world views” for each of the observers.
A.3. Homotopy type of the observed space.
The phenomenon witnessed by the examples of Section A.2.3 is very general, and brings to bear on the capabilities and limitations of knowledge representation using PCRs.
For a fixed PCS , a fixed space and PCS morphism , recall (Section 2.1.1) the subset of the Hamming cube consisting of those models for which is non-empty—the set of possible worlds with respect to . Let denote the cubical complex corresponding to the concept presentation of —the set of cubical faces of all of whose vertices lie in .
The authors proved in [19] that, for sufficiently tame topological spaces and PCS morphisms , the following holds:
Theorem A.9** (Recovery of Homotopy Type).**
Suppose that, for every cube , the set
[TABLE]
is contractible. Then is homotopy equivalent to .∎
In other words, if the collection of queries available to the observer is sufficiently rich that obviously contractible subspaces of (cubes) are witnessed by contractible subspaces of , then has, in the formal sense provided by algebraic topology, the same shape as the observed space .
In particular, under the condition of the theorem, if is a poc set structure on and is a poc morphism, then the universality of representation by PCRs (Proposition 2.22) implies that , making into a minimal contractible model space for housing a homotopy model of the observed space, and the discrepancy between the two is precisely the set of unobservable perceptual classes.
To illustrate the theorem, let us return to the examples of the preceding paragraph to observe that none of the phenomena we have encountered there had happened by accident. For any , a choice of leads to being a tree (a ‘starfish’) containing the vertex . Since the set of points in witnessing this vertex is disconnected (see Figure 10), the hypothesis of the last theorem fails, making it possible for to be contractible, which is exactly what happened for , . At the same time, any choice of results in the hypothesis of the theorem being fulfilled, which is why, in the three other cases considered here, is homotopy-equivalent to the circle.
Finally, we would like to emphasize that—similarly to the examples considered above—neither the tameness assumptions on and nor the hypothesis of the last theorem are excessive in standard Robotics settings. First, since the sensor values are often functions of merely the last few visited states, the realization map will often factor, up to sufficient approximation, through where is the configuration space of the robotic system (similarly to the role played by the circle and the interval in all the preceding examples). Second, is often a manifold, possibly with corners, or a cellular complex; in the absence of chaotic behavior, and provided sufficient sensing, it becomes possible to construct a sufficiently fine mesh of sensor values for “chopping up” the reduced history space into small contractible regions as required by our theorem.
Appendix B Appendix: Basic Results about PCRs.
B.1. Proof of Proposition 2.17.
Suppose is non-degenerate. Take any and any . One of the following holds:
- •
is coherent, and hence (by the maximality property of ) and ;
- •
is coherent, in particular and ;
- •
Neither of the above.
In the third case there are two possibilities. Either is empty, in which case the statement is that neither nor are coherent, which means that both and hold, and putting inside — a contradiction; or there exist such that and . But then — a contradiction to being coherent. Thus we are left with or for each , as desired.
The second assertion trivially implies the third, and the third implying the first follows from the remark preceding Definition 2.16.∎
B.2. Proof of Proposition 2.18.
It is clear that is injective. Any is a function of to , a two-point set, and is therefore characterized by the (possibly empty) set of points on which it obtains the value .
Now let us verify that is well-defined, that is: that the set is a maximal coherent subset of with respect to . Indeed, were such that , this would force — a contradiction.
Finally, we prove the surjectivity of . Given a maximal coherent set , Proposition 2.17 implies is a selection on . This means that the function defined by satisfies the identity . We claim that is a PCR morphism. Since , proving this claim will finish the proof of the current proposition.
Suppose is not a morphism. Then there is satisfying . In the current setting this is tantamount to and , or, equivalently, . In turn, this means . However, is forward-closed (as is any maximal coherent set), so and imply . With we obtain a contradiction. ∎
B.3. Proof of Proposition 2.22.
The proof extends a standard argument from Sageev-Roller duality theory. Given and , pick any point . By definition, belongs in if and only if no satisfy in . Since is order-preserving, having for would imply while at the same time—contradiction. Thus, for all choices of , proving the first assertion of the proposition. To verify the second one, consider the choice of with given by . It is easily verified that is a morphism and that is the identity map (and hence surjective), finishing the proof.∎
B.4. Proof of Proposition 2.24.
Let be a fixed non-degenerate PCR over . For every , recall , and recall the definition of :
[TABLE]
Here are a few natural observations:
- •
For any , , where for any set we remember that .
- •
Since is backwards-closed, is a union of strong components of : indeed, if then every satisfies , which implies ; hence .
- •
Analogously for , since it is forward-closed.
This allows for the construction of a new PCR over the PCS , by setting . We claim that induces on the structure of a poc set. For this it will suffice to show that is a non-degenerate PCR and a partial order.
First we show that is a PCS. The identity yields for all . Suppose some satisfied . Since is non-degenerate, this means and . But then , at the same time, and the equality implies both and —contradicting non-degeneracy. We conclude that for all , and, since is surjective, is a PCS.
It is clear now that is a PCR, by construction. Suppose now that lay in . Then , and writing , we obtain , showing that . Thus, is trivial, as desired.
is partially ordered by general considerations, so to conclude that is a poc set, it remains to verify that is its minimum. Now, and imply that the edge for all . Since is surjective, is the minimum element of with respect to the new partial order.
Finally, let be any poc set, and let be any PCR morphism. Then is constant on for all , which defines the injective set map via . This map is a PCR morphism of complemented graphs by construction, and is, therefore, a morphism of into . If is any poc morphism satisfying , then for any we have . Since is surjective, coincides with .∎
B.5. Proof of Corollary 2.25.
Let be a PCR over a PCS , and let be the canonical quotient map. We apply Proposition 2.24 with .
For any morphism there exists one and only one morphism satisfying . Now, thinking of as an element of , we may write, by Propositions 2.18 and 2.20, .
On the other hand, for any , we may write , the last inequality following from the uniqueness assertion of Proposition 2.24, applied to the morphism .
We conclude that the map defined by is an inverse of , as desired.∎
B.6. Proof of Corollary 2.26.
We apply Proposition 2.24 again, to the PCR , the poc set and the morphism , to conclude there exists one and only one morphism satisfying . Substituting we see that is the required morphism.∎
Appendix C Appendix: Convexity theory of PCR duals.
The purpose of this section is to provide a self-contained account of our results regarding coherent projection and the use of propagation for the computation of nearest-point projections in poc set duals. Throughout this section, will be a fixed non-degenerate PCR over a finite PCS . Moreover, without loss of generality (through replacing with its canonical poc quotient ), we may assume is a poc set. Since is fixed, we will simplify notation by writing instead of , ‘coherent’ instead of ‘-coherent’, and so on, throughout this section.
C.1. Proof of Lemma 2.37:
Property (1) is a restatement of the fact that, if is non-degenerate, then every coherent subset of is contained in a coherent complete -selection. Items (2,3) are straightforward from the definition.
For item (4), observe that, if and , then as well: indeed, if , then and means is incoherent. We conclude that implies , from which (4) readily follows.
To prove item (5), we observe that implies , and then we apply (4).
Finally, one direction of (6) amounts to (3). To prove the converse, suppose are such that , and suppose there exists . If there is a such that , then its neighbor in (recall Lemma A.4) contains but not , contradicting . We are left to prove that must contain such a .
Indeed, pick any such that the number of satisfying is smallest possible. Since , we have , by . If (otherwise we are done), then and we may find an with . Consider the vertex : since , we conclude that , so and , with . This contradicts the choice of , and we are done.∎
C.2. Proof of Proposition 3.1:
Suppose is such that for all . We must show that .
Suppose . Then and there is an element with . Note that is then also an element of , by Lemma A.4.
Now, if , then , contradicting . Therefore, (since is a complete -selection), but then satisfies:
[TABLE]
—a contradiction again. We conclude that , as desired.∎
C.3. Proof of Proposition 3.2:
Recall that , and for all . We check that is coherent for all . For suppose that satisfy . Then implies , and therefore . But then cannot lie in .
Next, we verify that is forward-closed. It suffices to verify . By definition we have , hence , and it remains to check that no belongs to ; were there such a , there would have been with and , implying — a contradiction to . This proves (a).
Now let us calculate: , the last equality due to being coherent. At the same time, if itself is coherent then . Moreover, this shows whenever . Finally, if then because always is.∎
C.4. Proof of Proposition 2.41:
The proof of the projection formula will require additional notions and results from [43], which we now recall.
C.4.1. Separators and Gates
Definition C.1**.**
For any , the set
[TABLE]
is called the separator of and in .∎
The inequality follows immediately for all and . This motivates:
Definition C.2**.**
Let . A gate for is a pair of points , such that .∎
The following result is well known in our setting:
Proposition C.3**.**
Let be non-empty convex subsets of a median graph and let and . Then form a gate for if and only if and . Moreover, the pair has a gate.∎
We will apply this proposition without proof. An important consequence for us is the following:
Lemma C.4**.**
Suppose is coherent, and . Then, for any , if then there exists such that .
Proof.
Let and form a gate. Since , there exists such that .
Suppose there existed a with , and consider . Then, implies , but the inequality
[TABLE]
implies , since . On the other hand, implies —hence , a contradiction.
We have shown that is contained in . Equivalently, , which is the same as .∎∎
Lemma C.5**.**
Suppose are non-empty convex subsets of . If , then .
Proof.
Clearly, if then , so . For the reverse inclusion, suppose and write , . Pick any point . Setting we note that (because ) and
[TABLE]
The uniqueness of projection forces to coincide with . However, since we also have , showing .∎∎
We are now ready for the proof of one more lemma.
C.4.2. Proof of Lemma 2.38.
Since and is a complete -selection, we have . Since , we have . Overall, this yields , as required.∎
C.4.3. Computing Nearest Point Projection Maps
We now offer an explicit construction of a geodesic path in emanating from a given vertex and terminating at its unique nearest point in a specified convex target set:
Proposition C.6**.**
Suppose is a vertex. Let be a coherent subset. Then the following algorithm constructs a shortest path in from to :
- (1)
Find an element ; if no such element, stop and output . 2. (2)
Find an element with ; 3. (3)
Replace by and return to the first step.
Proof.
We have if and only if , which provides the stopping condition for the algorithm. Now, if and then for all one has and . Since , we have , implying and . As a result:
[TABLE]
Having reduced by a unit for all , we have reduced by a unit as well.∎∎
Corollary C.7** (Projection of a Point).**
Let and be as above. Then the closest point projection to is given by the formula:
[TABLE]
Proof.
Note that the second equality follows from the DeMorgan rules and the fact that , since is coherent. We now prove the first equality.
Set and proceed by induction on . If , then and therefore . In addition, is coherent and we conclude , leaving us with
[TABLE]
as desired. Now suppose . By the preceding proposition, there is such that , , and . We thus have:
[TABLE]
the last equality being due to and .∎∎
C.4.4. Projecting a Convex Set to a Convex Set
Proposition C.8**.**
Let be non-empty convex subsets of with and . Then:
[TABLE]
Proof.
Since is coherent, and are disjoint. This allows us to write:
[TABLE]
and the second equality in Equation 50 follows from the identity . Denote and .
For every we have , implying contains , by Corollary C.7. Thus, , as required.
For the converse, observe that the case was already dealt with in Lemma C.5: if , then
[TABLE]
In particular, is coherent, and hence does not intersect , and the formula Equation 50 holds.
Thus we may henceforth assume . Equivalently, . In fact, by Lemma C.4 we have .
Starting with we must show . Set , , and . Then since . Since , we have and . Consider the point : we have and ; by the choice of , must equal and therefore . Thus, and . By Proposition C.3, the pair is a gate for and we have
[TABLE]
Consider an element . If , pick . Then will satisfy as well as
[TABLE]
Now, since and a contradiction to is obtained. Thus, must be empty, which means . Applying Lemma C.4 we obtain .
Overall, we have shown that . We will now verify that , finishing the proof. Indeed, were it not so, there would have been . On one hand, implies , and hence . On the other hand, means and therefore , which forces . Since (by choice of ), we have , contradicting our choice of .∎∎
We will need the following technical corollary for the purposes of propagation:
Corollary C.9**.**
Let be subsets and suppose is coherent. Let and . Then:
[TABLE]
Proof.
Recall that , and set , so that and . Then,
[TABLE]
Since , the last expression equals , by the preceding proposition. The proof of the second equality is similar.∎∎
Appendix D Appendix: Qualitative Snapshots (proofs)
D.1. Proof of Lemma 4.7.
For all one has . Thus, either the minimum of over is attained at a point of or it is attained at a point of (or both). Therefore one has or , as required. ∎
D.2. Proof of Proposition 4.9.
Denote for the rest of this proof. First, we need to show that implies . This is baked into the definition, as . Also, is satisfied because . Finally, applying Lemma 4.7 we conclude that, for all one has when , and when . In particular, were , then would have implied (or equals if ), while would have given (or , respectively)). But that would have meant — a contradiction. ∎
D.3. Proof of Corollary 4.10.
With , we consider the PCR , for which we have if and only if . By Proposition 4.9, is non-degenerate, hence there exists . We set . For any , since , we must have . At the same time, if , then again. Thus is the desired vertex of . ∎
D.4. Proof of Proposition 4.11.
Sufficiency follows from Lemma 4.7 and the observations following Definitions 4.1 and 4.5. Now, suppose is a 2-ranking, and consider the set of all rankings satisfying for all . By Example 4.4, the family is closed under taking pointwise minima. Since is finite, must have a minimum element.
Let be given by Equation 16. To prove that it coincides with the minimum of it suffices to verify that (a) for all , and that (b) agrees with .
Fix . Then, for any and we have because is a ranking, and by the particular choice of , proving (a). Finally, to prove (b), it suffices to verify that, for every , there exists a ranking with . Indeed, Corollary 4.10 provides just such a ranking , setting , which finishes the proof. ∎
D.5. Proof of Proposition 4.16.
The first immediate observation regarding minsets is the following observation: An immediate result is this:
Lemma D.1**.**
Let , and let be a 2-ranking. Let and . Then and .∎
Proof.
Let and for some . Clearly, is a -selection. Now suppose that satisfy . If , then and . But then implies , and hence also . Similarly, , and we have , proving , and we conclude that is a forward-closed -selection. In particular, it is -coherent.141414For, suppose and we had ; then we would have also had because is forward-closed, contradicting being a -selection.∎∎
To prove Proposition 4.16, we need to analyze the relationship between level sets of the rankings and . We have the following lemma:
Lemma D.2**.**
Let be a ranking in and fix a value , . For the sub-level sets and one has: (a) , (b) , and (c) .
Proof.
Since , we have , which, in turn, implies . Conversely, if , then implies for all ; equivalently, . Since this information carries over to the 2-restriction of , we conclude that as well, which means , verifying (b). Assertion (c) follows directly from (b) via . ∎∎
One can say more about the lowest level sets of :
Lemma D.3**.**
In the notation of Lemma D.2, let with . Then:
- (a)
If , then ; 2. (b)
If , then .
Proof.
To prove (a), consider an arbitrary . Since is a complete -selection it suffices to show that it is forward-closed with respect to . Take any and . If , then:
[TABLE]
However, if , then we have . Since , we must have , by Equation 16. This, however, contradicts our assumption regarding .
To verify (b), suppose , but . Applying Equation 16 again, we conclude there is a pair with . In particular, no element of is contained in , which leads to the following two complementary cases:
- •
**Both and contain elements of . ** Then we have , which means and contradicts .
- •
**Either or . ** In other words, either or . Since , we conclude that one of must lie in . This contradicts the fact that , since is a complete -selection.
Thus, either case yields a contradiction, finishing the proof. ∎∎
We are finally ready to prove Proposition 4.16.
Setting —the minimum value of —we apply Lemma D.3(a) to conclude that . From Lemma D.3(b) and Lemma D.2(c) we obtain that coincides with . Since by Lemma D.2(a) we conclude that and we may apply Corollary 2.36 to deduce that is the convex hull of in . Finally, consider the set . For any , at least one of , equals . Therefore, we have if and only if and , if and only if for our current choice of . This finishes the proof.∎
Appendix E Appendix: Real-Valued Snapshots (proofs).
E.1. Proof of Proposition 4.20.
We must show that the derived PCR of a real-valued 2-weight satisfying the requirements 1.-5. of Definition 4.17 is non-degenerate. Recall Equation 25, defining given an assignment of thresholds :
[TABLE]
Define functions via and . From properties 1. and 4. of the 2-weight , one has the identities , and . From properties 2. and 5. of the 2-weight one also obtains the identities , , , and .
We are ready to prove the proposition. Suppose for some , and find a sequence with , , and for . We then must have , with equality if and only if for all . By the definition of , this implies for all .
But then we also have , which is only possible when is trivial—a contradiction.∎
E.2. Proof of Proposition 4.21.
The proof of this proposition follows a standard scheme, widely attributed to Chernoff, and is only included here for the sake of completeness.
Recall that the Kullback-Leibler divergence of a random variable relative to a random variable is given by151515We will always mean the natural base, , of the logarithm when using the notation .:
[TABLE]
We require the following standard lemma:
Lemma E.1** (KL-divergence bound).**
Let , and consider the function over the interval . Then
[TABLE]
Proof.
Differentiating one obtains:
[TABLE]
The function has only one critical point:
[TABLE]
and the value of at is the claimed value, f\left(\zeta_{0}\right)=\mathtt{e}^{-\mathbf{D}_{{}_{KL}}\!\left(q\big{\|}p\right)}.
Finally, if and only if , which is tantamount to . ∎∎
The setting for learning snapshot weights described in Proposition 4.21 simplifies to the following. Suppose is a non-constant random variable, and let . We posit a sequence \mathrm{X}\big{|}_{\scriptscriptstyle{t}}, of i.i.d. random variables \mathrm{X}\big{|}_{\scriptscriptstyle{t}}\sim\mathrm{X}.
We have the following probability bounds:
Lemma E.2**.**
Let be a non-negative integer and let . Then, for \mathrm{Y}:=\tfrac{1}{t+1}\sum_{s=0}^{t}\mathrm{X}\big{|}_{\scriptscriptstyle{s}} one has:
[TABLE]
where and .∎
To prove Proposition 4.21, observe that the first bound—the standard Chernoff bound—guarantees exponentially fast convergence in probability of the empirical snapshot weights \mathtt{w}_{ab}\big{|}_{\scriptscriptstyle{t}} to the mean value of the signal over the domain when we take \mathrm{X}\big{|}_{\scriptscriptstyle{t}}:=\varphi\big{|}_{\scriptscriptstyle{t}}\cdot\delta_{u_{t}}(\mathfrak{h}(ab)).
We are left to verify the Chernoff bound.
Proof of Lemma E.2:
Recall , and observe that because is non-constant. We proceed in the standard way to obtain a bound for the empirical estimate of the sample mean. For every fixed value of , and recalling one has:
[TABLE]
using the inequality for , . Finally, this yields:
[TABLE]
Using Lemma E.1 to minimize the right hand side over , we obtain, for every fixed :
[TABLE]
as claimed. Now replace with , with , and recall . We obtain:
[TABLE]
finishing the proof.∎
Appendix F Appendix: Debugging Sniffy on the Circle.
The purpose of this appendix is to explain in some detail the reasons for Sniffy’s behavior on the circle in its qualitative BUA incarnation, as discussed in Section 5.4.2. We proceed in a manner similar to the discussion of an agent on the interval from Section A.2.4.
F.1. Sensors and Relations.
Let denote the sensor centered at , reporting at time if and only if , where is the position occupied by Sniffy at time . It will be convenient to think of as a copy of the additive group , keeping in mind its action on subsets given by .
It is then easy to verify that are the only relations among the . Consequently, the analogous relations must also hold for all (see Section A.2.3 for details). Motion is described by the conditional relations and , leading to the unconditional implications (compare with the case of the interval discussed in Section A.2.4).
Finally, observing that the entire setting is rotation-invariant, without loss of generality we may assume for the rest of this section that Sniffy’s target is located at position . Setting , the eventual target sets (minsets) determined by the individual snapshots are:
[TABLE]
where, due to the hard-wired arbitration enforcing at all times, the derived PCR of the snapshot identifies each with ; and, similarly, identifies each with .
Finally, note that given it is impossible to witness or (while is still possible in conjunction with , if is active). We conclude that the relations hold in for every , as do their analogous counterparts in .
F.2. The “dull peak” value signal.
The weights recorded on any snapshot in this case are , implying that (1) any implications appearing in Sniffy’s four snapshots at any time are a subset of the implications listed in the preceding section; and (2) any raw observation generated by Sniffy is coherent for any of its snapshots.
Let . Each snapshot forms its prediction for the next state by propagating , and giving rise to:
[TABLE]
In order to compute the divergences from the targets, we first note that, for :
[TABLE]
For the snapshot this results in:
[TABLE]
By symmetry, we conclude that the snapshot has:
[TABLE]
Now, for the snapshot we have:
[TABLE]
where for , for , for . By symmetry:
[TABLE]
Armed with these formulae, we go over the possibilities and conclude:
- •
The BUA is active if and only if ;
- •
The BUA is active if and only if .
In particular, is a basin of attraction for the target position, , while is a region where both and seek to be active, triggering the hard-wired arbitration mechanism.
F.3. The “sharp peak” value signal.
Despite the value signal being more informative than that of its -valued “dull-peak” counterpart, a “sharp peak” qualitative agent’s performance on the target-finding task is clearly worse (Figure 7).
In a nutshell, the reason for this deficiency is that the limiting PCR satisfies the additional relations , which we verified by hand. As a result, properties (1) and (2) stated in Section F.2 for the “dull peak” setting will not hold in this one. In fact, just these extra relations (there may be others) suffice for the current state representation of any point other than in any of Sniffy’s snapshots to degenerate (through coherent projection) into a less and less complete -selection as Sniffy’s physical distance from the target (in the environment) increases, while the quality of prediction deteriorating accordingly.
Specifically, any yields a raw observation containing and both of and . On one hand, and are directed paths in each of Sniffy’s PCRs. On the other hand, though, so are . Thus, (1) the coherent projection of the raw observation generated by is merely , showing that Sniffy is unable to distinguish among the points of ; and (2) if is moved closer to the target, fewer conflicts of the above form will affect coherent projection.
In total, the observations above suffice for explaining the most visible differences (see Figure 7) between the behaviors of the two variants of Sniffy in the qualitative learning regime.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Ian Agol, Daniel Groves, and Jason Manning. The virtual Haken conjecture . Doc. Math , 18:1045–1087, 2013.
- 2[2] Carlos E Alchourrón, Peter Gärdenfors, and David Makinson. On the logic of theory change: Partial meet contraction and revision functions. The journal of symbolic logic , 50(2):510–530, 1985.
- 3[3] Carlos E Alchourrón and David Makinson. On the logic of theory change: Contraction functions and their associated revision functions. Theoria , 48(1):14–37, 1982.
- 4[4] Carlos E Alchourrón and David Makinson. On the logic of theory change: Safe contraction. Studia logica , 44(4):405–422, 1985.
- 5[5] Hans-J. Bandelt and Jarmila Hedlíková. Median algebras . Discrete Math. , 45(1):1–30, 1983. · doi ↗
- 6[6] Craig Boutilier. A unified model of qualitative belief change: A dynamical systems perspective. Artificial Intelligence , 98(1):281–316, 1998.
- 7[7] Indira Chatterji, Cornelia Druţu, and Frédéric Haglund. Kazhdan and Haagerup properties from the median viewpoint . Adv. Math. , 225(2):882–921, 2010. · doi ↗
- 8[8] Victor Chepoi. Graphs of some CAT ( 0 ) CAT 0 {\rm CAT}(0) complexes . Adv. in Appl. Math. , 24(2):125–179, 2000. · doi ↗