Recommendation System based on Semantic Scholar Mining and Topic modeling: A behavioral analysis of researchers from six conferences
Hamed Jelodar, Yongli Wang, Mahdi Rabbani, Ru-xin Zhao, Seyedvalyallah, Ayobi, Peng Hu, Isma Masood

TL;DR
This paper presents a semantic mining approach using LDA topic modeling on conference publications to analyze research trends and improve conference organization and future research coverage.
Contribution
It introduces a novel application of LDA-based semantic mining to analyze research trends from conference data, linking topics with Scholar-Context-documents.
Findings
Effective identification of research trends
Relationship between LDA topics and Scholar-Context-documents
Potential to improve conference organization
Abstract
Recommendation systems have an important place to help online users in the internet society. Recommendation Systems in computer science are of very practical use these days in various aspects of the Internet portals, such as social networks, and library websites. There are several approaches to implement recommendation systems, Latent Dirichlet Allocation (LDA) is one the popular techniques in Topic Modeling. Recently, researchers have proposed many approaches based on Recommendation Systems and LDA. According to importance of the subject, in this paper we discover the trends of the topics and find relationship between LDA topics and Scholar-Context-documents. In fact, We apply probabilistic topic modeling based on Gibbs sampling algorithms for a semantic mining from six conference publications in computer science from DBLP dataset. According to our experimental results, our semantic…
Click any figure to enlarge with its caption.
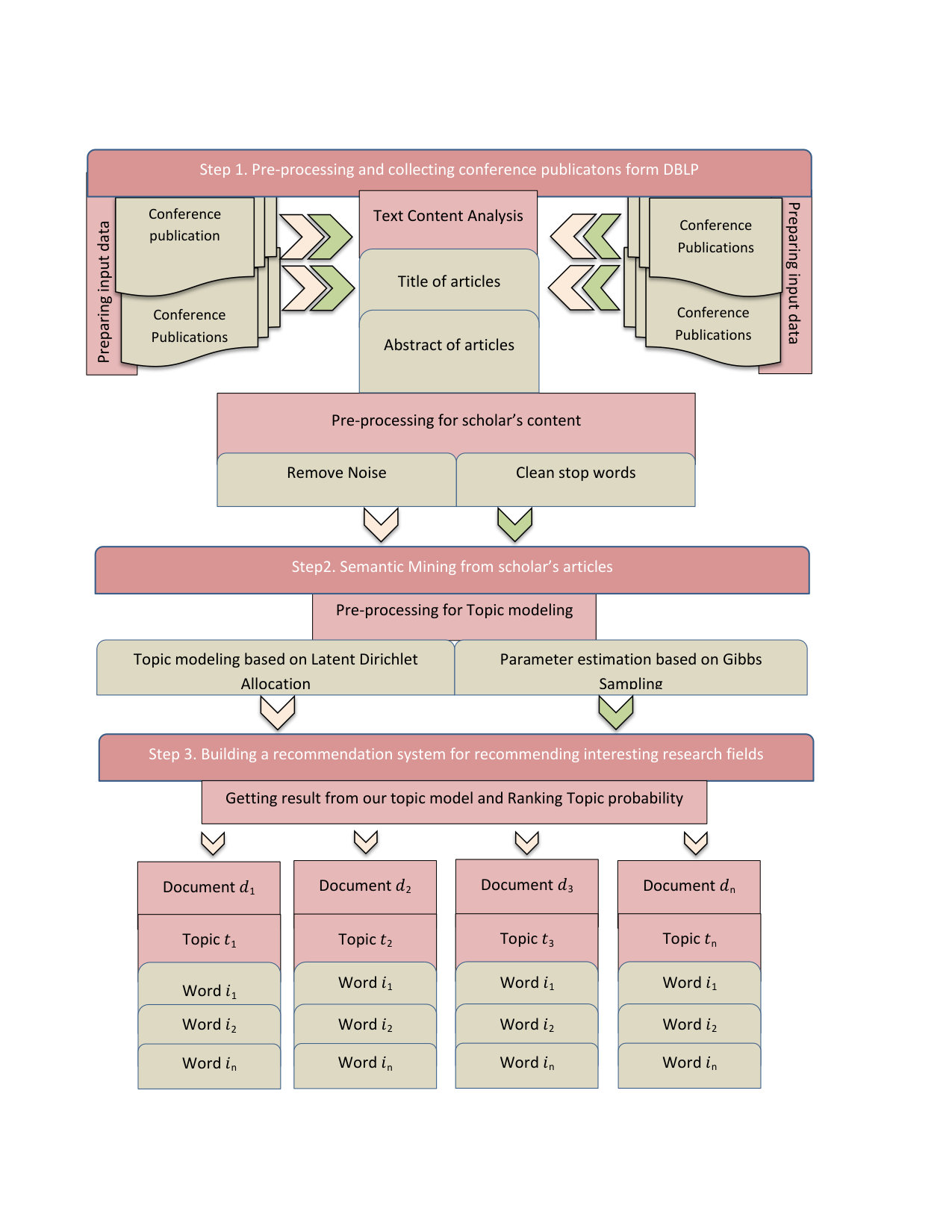 Figure 1
Figure 1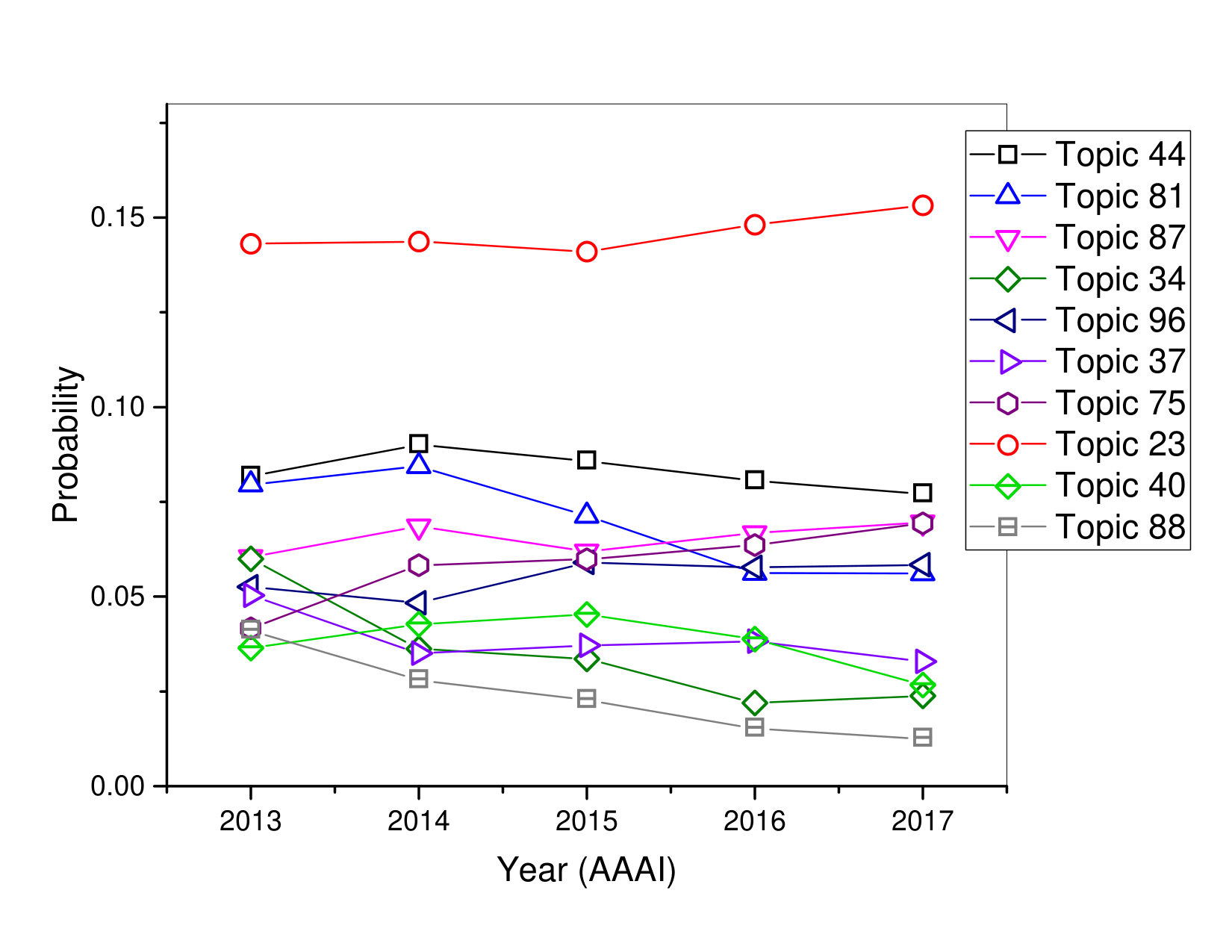 Figure 2
Figure 2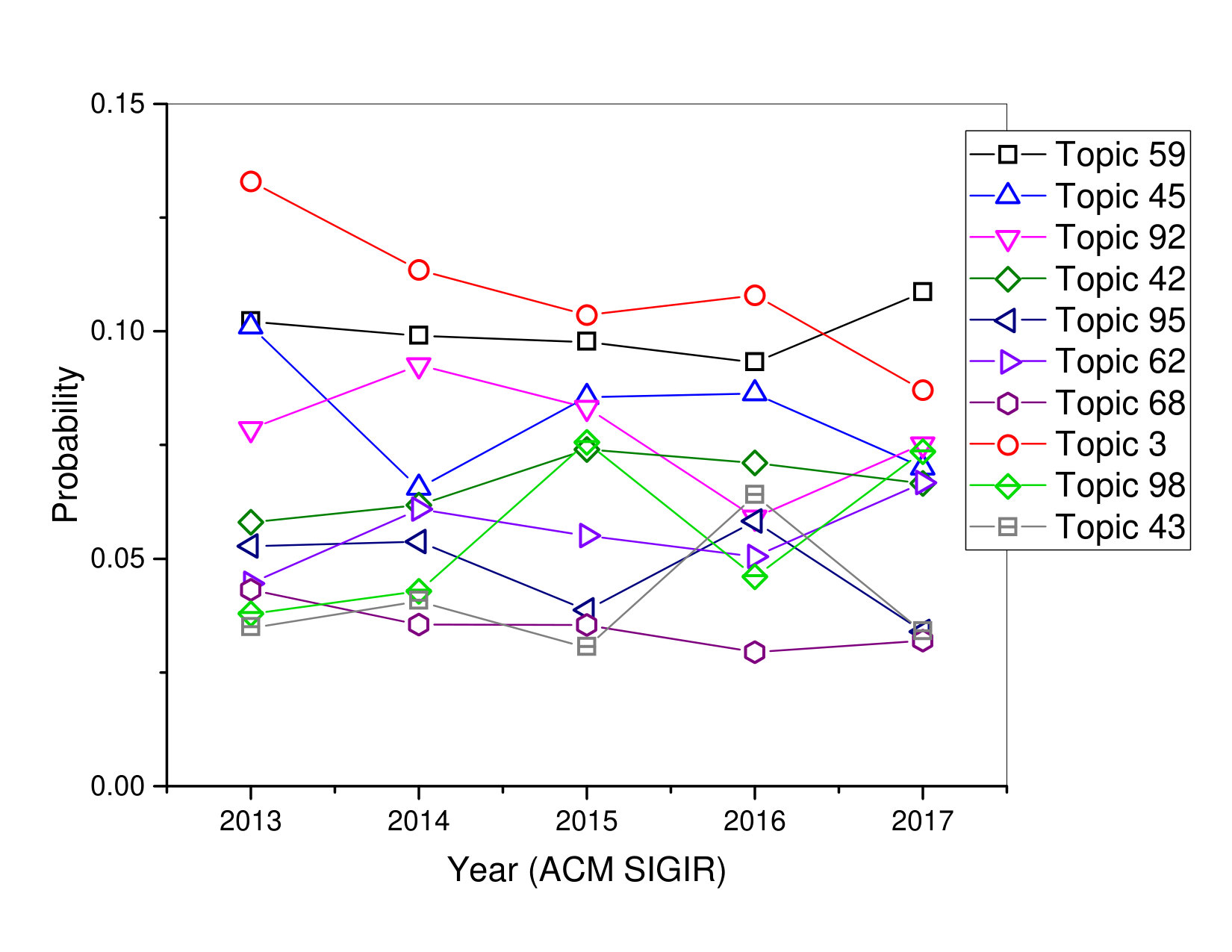 Figure 3
Figure 3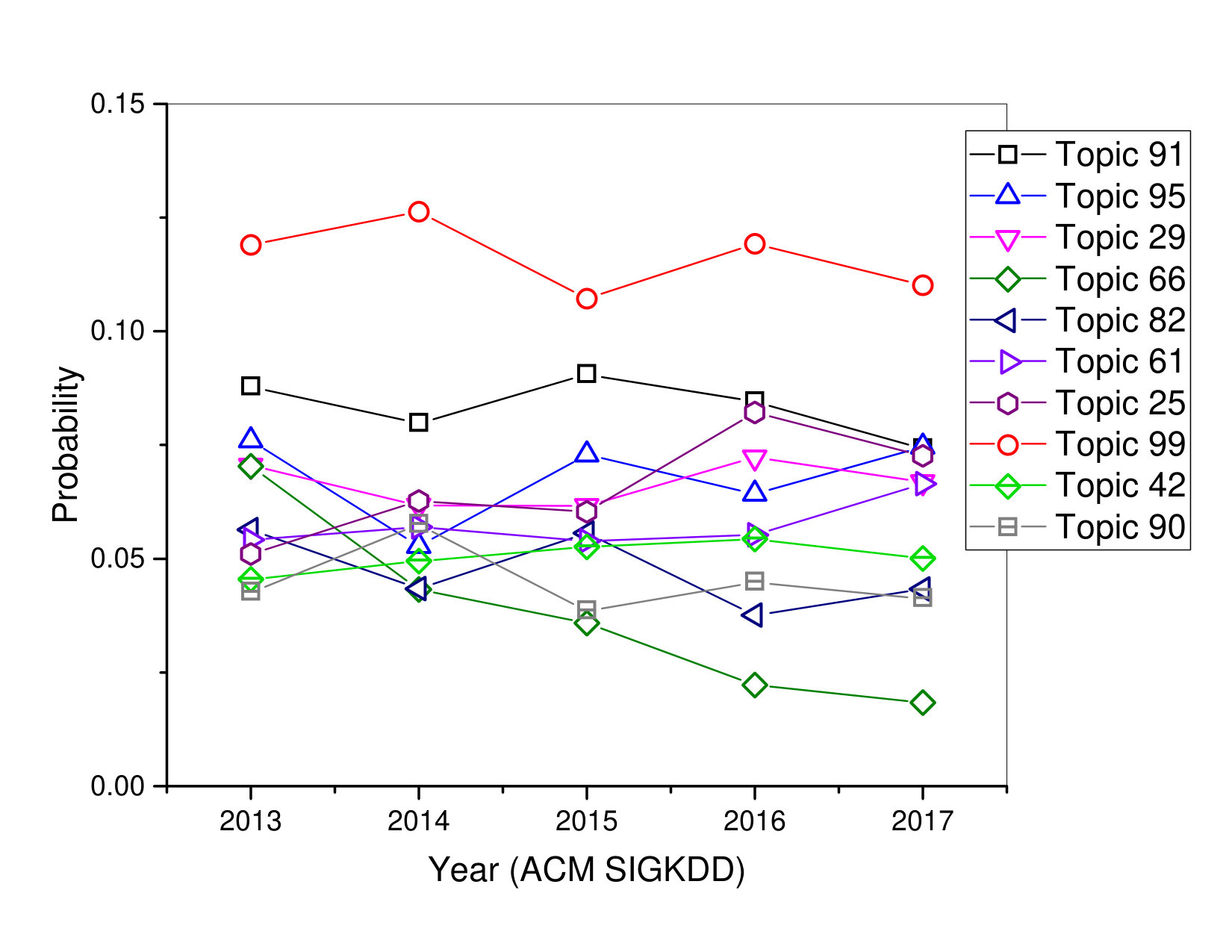 Figure 4
Figure 4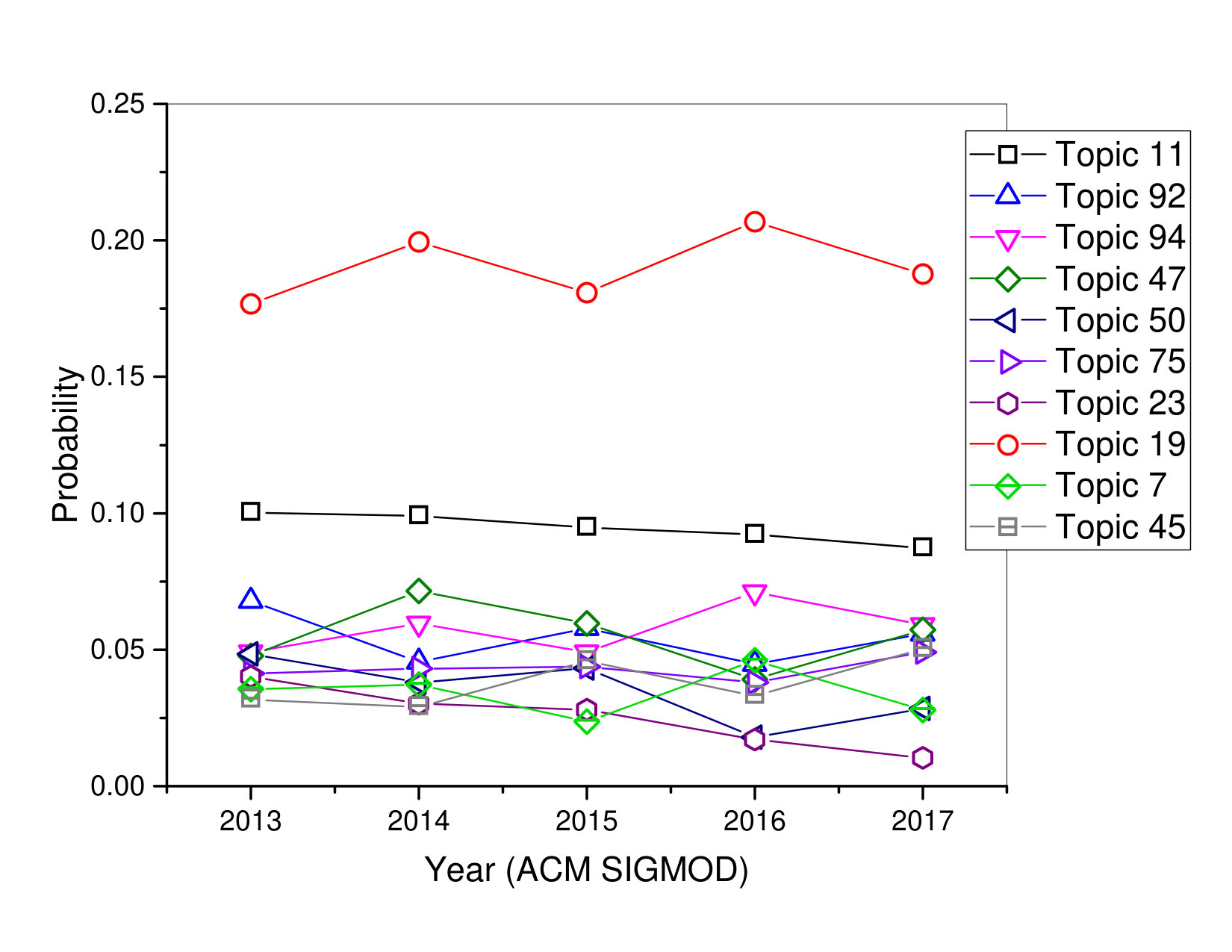 Figure 5
Figure 5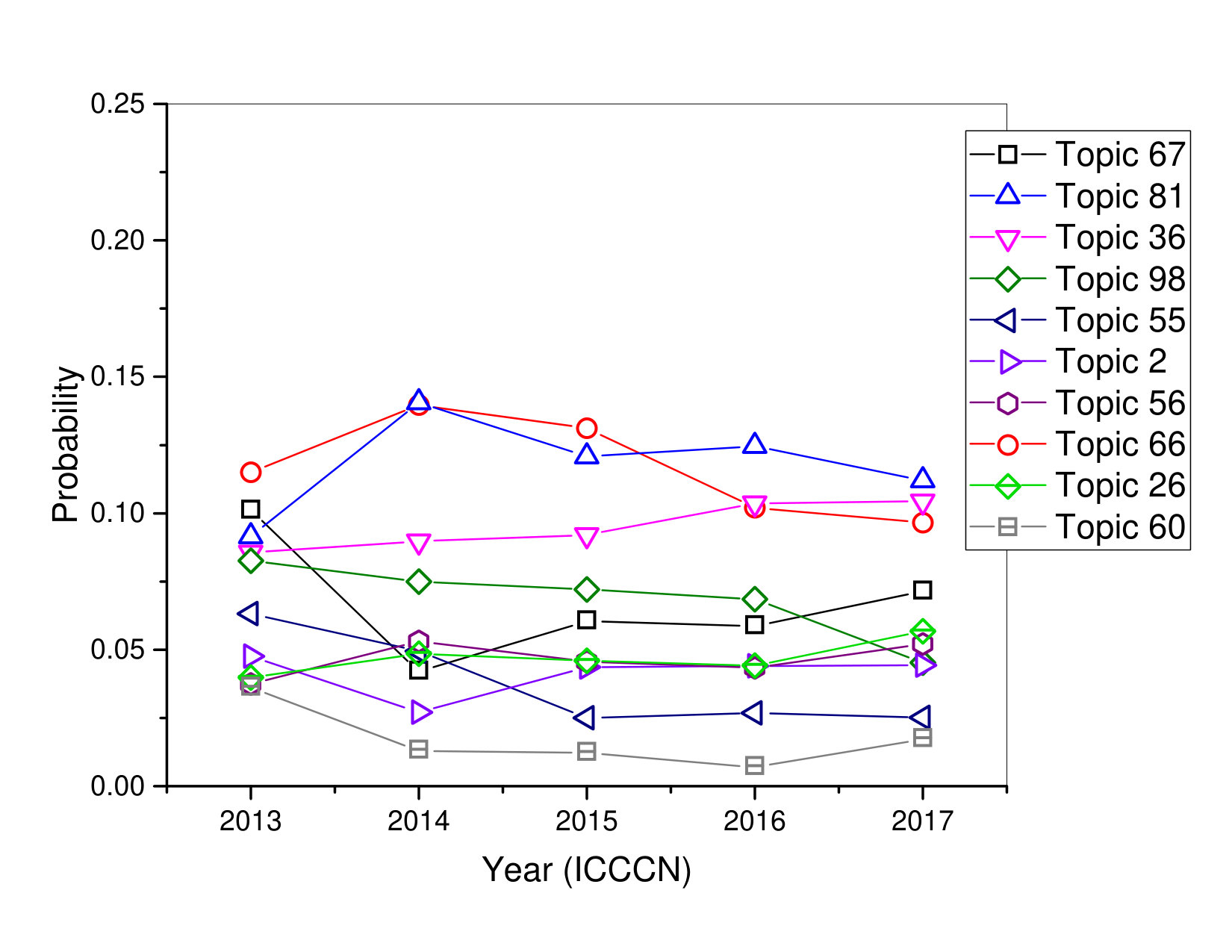 Figure 6
Figure 6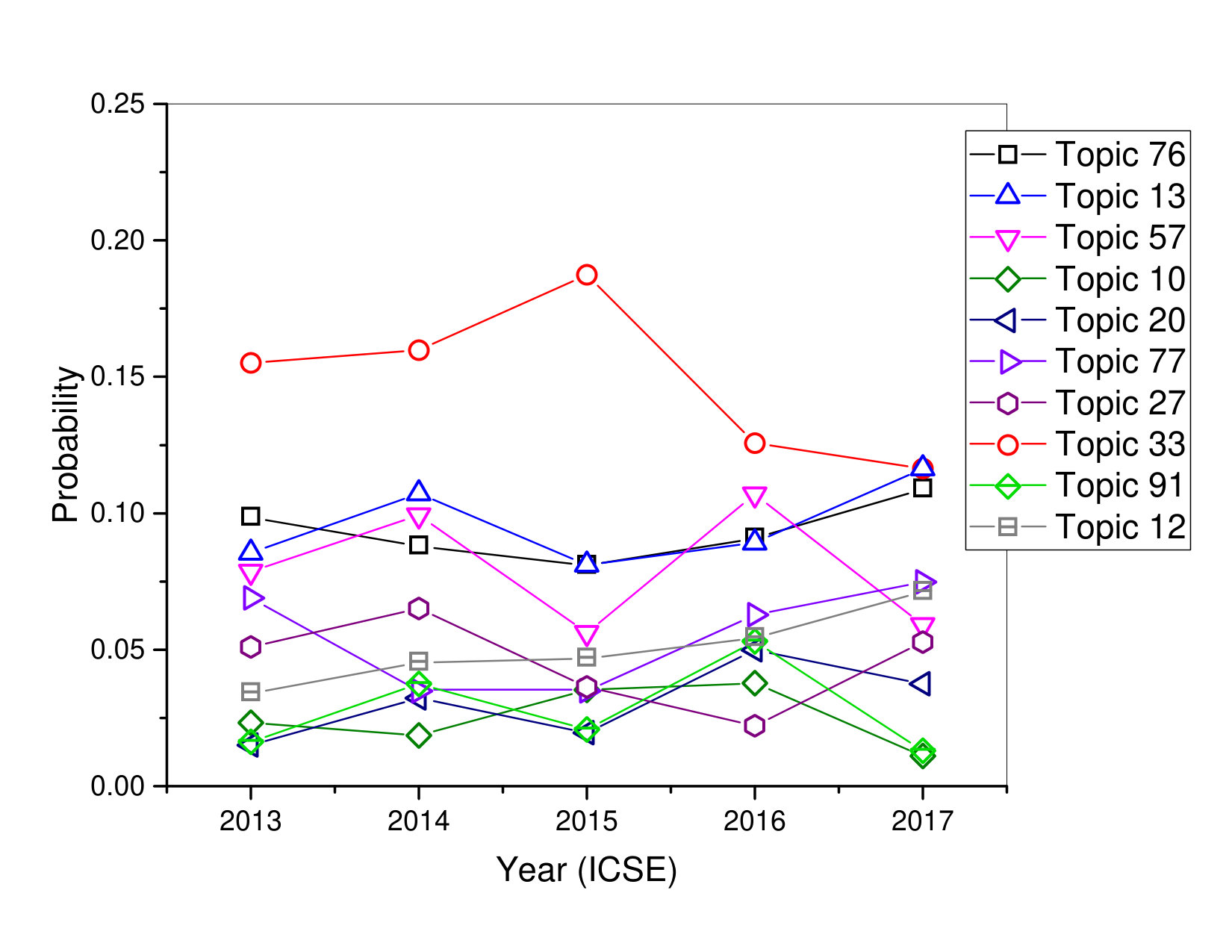 Figure 7
Figure 7 Figure 8
Figure 8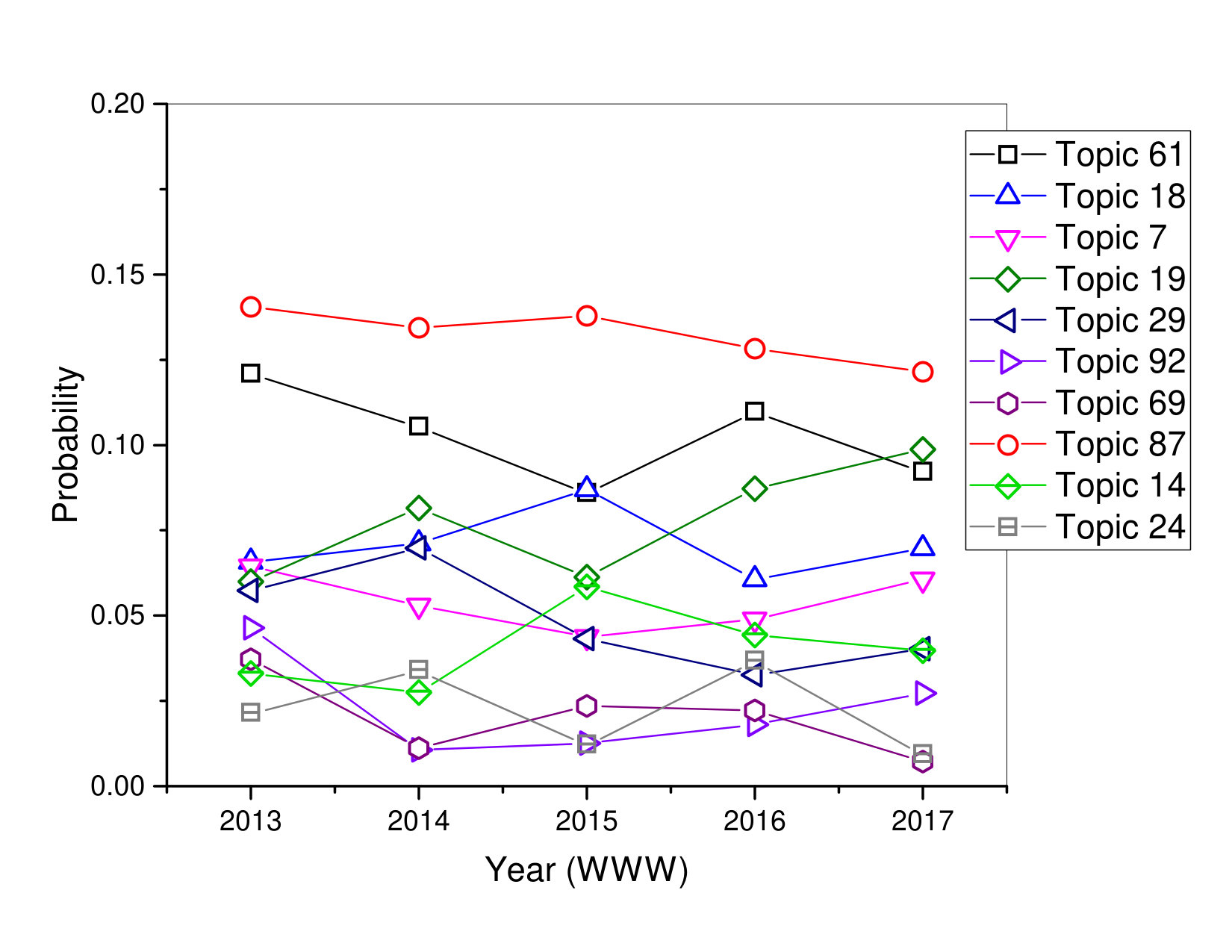 Figure 9
Figure 9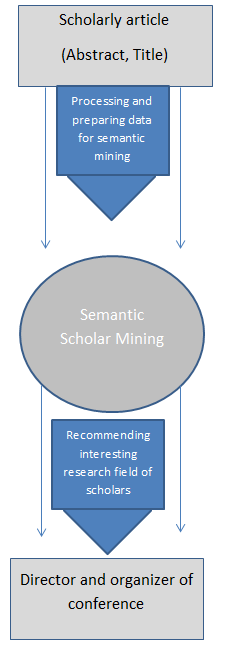 Figure 10
Figure 10 Figure 11
Figure 11| Study | Year | Purpose | Method | Dataset |
|---|---|---|---|---|
| [5] | 2014 | Present an approach to utilize this | LDA, Twitter-LDA | DBLP dataset |
| valuable information source to suggest | ||||
| scientific articles | ||||
| [2] | 2017 | A scientific paper recommendation approach | LDA, Gibbs sampling | ArnetMiner Dataset |
| DBLP dataset | ||||
| [3] | 2017 | A Citation recommendation | LDA | ACL Anthology |
| present a topic model | Maximum A Posteriori (MAP) | Network , | ||
| combing with author link | DBLP | |||
| community | ||||
| [4] | 2013 | A personalized recommendation | LDA, EM algorithm | Digg articles |
| system for Digg articles | (digg.com) | |||
| [7] | 2011 | A scientific articles recommendation | LDA, EM algorithm | CiteULike Dataset |
| to users based on both content and | ||||
| other users ratings |
| ACM SIGIR | ACM SIGKDD | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Information retrieval | Social media analysis | Graph, Behavior Analysis |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 59 | Topic 62 | Topic 91 | Topic 99 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Predicting information | Ad hoc information retrieval | Pattern mining | Multiple nodes and Query Analysis | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 68 | Topic 98 | Topic 29 | Topic 66 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ACM SIGMOD | AAAI | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Management of Data | Aggregation operators, Storage management | NLP and Knowledge Representation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 11 | Topic 45 | Topic 23 | Topic 37 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Semantic similarity | Cloud query processing | Heterogeneous Relations | Game Theory | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 19 | Topic 7 | Topic 40 | Topic 88 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ICCCN | ICSE | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wireless Networks, Security | Cloud Computing, mobility management | Programming and Code Analysis |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 66 | Topic 67 | Topic 13 | Topic 12 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| heterogeneous network | Communication networks | Program synthesis and repair | Mining software repositories | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Topic 2 | Topic 56 | Topic 10 | Topic 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRecommender Systems and Techniques · Topic Modeling · Advanced Text Analysis Techniques
MethodsLinear Discriminant Analysis
∎
11institutetext: H. Jelodar 22institutetext: School of Computer Science and Technology, Nanjing University of Science and Technology, Nanjing 210094, China
Tel.: +8615298394479
22email: [email protected] 33institutetext: Y. Wang 44institutetext: School of Computer Science and Technology, Nanjing University of Science and Technology, Nanjing 210094, China
44email: [email protected]
Recommendation System based on Semantic Scholar Mining and Topic modeling: A behavioral analysis of researchers from six conferences
Hamed Jelodar
Yongli Wang
Mahdi Rabbani
Ru-xin Zhao
Seyedvalyallah Ayobi
Peng Hu
Isma Masood
(Received: date / Accepted: date)
Abstract
Recommendation systems have an important place to help online users in the internet society. Recommendation Systems in computer science are of very practical use these days in various aspects of the Internet portals, such as social networks, and library websites. There are several approaches to implement recommendation systems, Latent Dirichlet Allocation (LDA) is one the popular techniques in Topic Modeling. Recently, researchers have proposed many approaches based on Recommendation Systems and LDA. According to importance of the subject, in this paper we discover the trends of the topics and find relationship between LDA topics and Scholar-Context-documents. In fact, We apply probabilistic topic modeling based on Gibbs sampling algorithms for a semantic mining from six conference publications in computer science from DBLP dataset. According to our experimental results, our semantic framework can be effective to help organizations to better organize these conferences and cover future research topics.
Keywords:
Recommendation systems, Semantic mining, Scholar article analysis, Topic modeling, LDA
††journal:
1 Introduction
Recommendation Systems in computer science are of very practical use these days in various aspects of the Internet Society. Generally, a recommendation system offers a new item to a user after specifying which of the users item is most similar to the new item. Recommendation systems have been widely used in many fields, the most typical one is E-commerce, which has a good development and application prospect. A successful recommendation system can significantly improve the revenue and sales of e-commerce companies, so as to promote their rapid development. For instance, Amazon shopping that Amazon recommends items to a user based on items the user previously visited, or YouTube Website that YouTube recommends movies to a user based on the users prior ratings and watching habits. There are several methods based one recommendation systems, such as content-based filtering, collaborative filtering, and hybridizations. Recently, researchers proposed various methods based on probabilistic topic modeling methods. Latent Dirichlet Allocation (LDA) is becoming a standard tool in topic modeling [1]. LDA is a generative probabilistic model broadly used in the information retrieval field. Recently, researchers have used topic modeling approaches based on LDA to build recommendation systems in various subjects, such as scientific paper recommendation [2-9], music and video Recommendation [10-19], location recommendation[20-26], hashtag recommendation [27-39], travel and tour recommedation[40-43], app recommendation [44-48], event recommendation[49-54], social networks and media [55-59].Forc example, from an applied perspective in the field of music and video recommendation, Yan and et al focused on the efficiency of user’s information content on the online social network and provided a solution as a personalized video recommendation with considering users cross-network social and content data. They applied a topic model based on LDA for each user, that user as document and user’s hashtags as word, with considering user information from Twitter. In this paper, we evaluate scholar publications from six conferences to discover hidden behavioral aspects and discover the trends of the topics and find relationship between LDA topics and paper features. In summary, this paper makes three main contributions:
- •
This study shows the application of the topic models for building a recommendation systems based on semantic scholar mining for predicting interesting research field from scholarly articles.
- •
We consider six conference publications from DBLP Library.
- •
We discover relationship between Scholar-Context-documents and topics, and also analyses the trends of the topics in various years
2 Research related concepts
Recommendation systems play increasingly significant role in online web services. Many recommendation systems rely on data mining; that is, attempting to discover useful patterns in large data sets. While such recommendation systems are helpful, it is not always practical to create, maintain, and use the large data sets they require. Recommendation systems are increasingly being used in various applications such as movie recommendation, mobile recommendation, article recommendation and etc. For instance, Amazon shopping that Amazon recommends items to a user based on items the user previously visited, or YouTube Website that YouTube recommend movies to a user based on the users previous ratings and watching habits. The aim of a recommendation system is to use historical data about the users behavior (e.g., their purchases as well as ratings on purchased items) and provide a list of items to each user such that they are likely to be purchased by the user in near future. The Content-Based (CB)[60] and Collaborative Filtering (CF) [61] are most important techniques in recommendation system.
2.1 Semantic analysis and topic modeling in recommendation systems
LDA developed has become a widely used topic modeling algorithm [1]. LDA assumes that each word in a document is produced in two steps. First, assuming that each document has it’s own topic distribution, a topic is randomly drawn based on the document’s topic distribution. Next, assuming that each topic has its own word distribution, a word is randomly drawn from the word distribution of the topic selected in the previous step. Repeating these two steps word by word generates a document. In recent years a considerable amount of research has addressed the task of defining models and systems for scientific papers recommendation; this trend has emerged as a natural consequence of the increasing growth of the number of scientific publications. For example, Youn and et al, proposed an approach to scientific articles’recommendation of user’s interests based on a topic modeling framework. The authors, used a LDA model in order to extract the topics of the followees’tweets (followed Twitterers) and the paper titles [5]. They apply the Twitter-LDA algorithm simultaneously on the followees’tweets and the paper titles with the number of topics set to 200, they utilized the intersection of topics found in both paper titles and followees’s tweets. Each followee of a user is ranked as follows:
[TABLE]
where denotes all tweets by a followee,
{Topics}_{p},\denotes the set of topics defining the titles of scientific articles,
{Topics}_{f},\denotes the set of topics defining the tweets of a followee and** n\left(t,T_{f}\right)\**the number of times a particular topic ‘t’ from within occurs among the tweets of a followee. Based on the ranking scores of all followees of a particular user,and obtained top-k researchers followed by a target user. For evaluation approach, considered DBLP database as a large academic bibliographic network.
Also, some researchers, introduced a combined model based on traditional collaborative filtering and topic modeling and designed a novel algorithm to scientific articles recommendation for users from an online community, called CTR model. They considered LDA to initialize the CTR model, Infact they combined the matrix factorization and the LDA model, and is shown their approach better than the recommendations based on matrix factorization. For evaluation and test, Used a large dataset from a bibliography sharing service (CiteULike) [7]. Table 1, shown some impressive work based on LDA for paper recommendation.
3 Research framework and Semantic mining
In this section, we present a semantic mining framework based on topic modeling to build a recommendation system for discovering interesting research field of scholars from six conferences publication, showed this semantic framework in figure 1. And also, we discover temporal topic trends of conferences in various years by advanced content mining. Figure 2 shows the applicability of our topic modelling for recommending interesting research field of scholars to director conferences and also showed a example of word distribution in scholar’s articles in figure 3. The framework presented for this semantic scholar mining is performed in three steps:
Step 1. We extracted six conference publications from DBLP website by only considering conferences for which data was available for years 2013-2017. DBLP is bibliographic information in computer science. After collecting scholar’s articles, the novel text information will be more concentrated. Then a stop list is used for removing stop-words from the set of terms in all documents. Stop-words are common words (such as “which”, “the”, “a” ,”as”), which do not effect on on our semantic analysis . These words do not support any beneficial data and eliminating them can decrease noise. Therefore, we need to find and remove them for avoiding interference with our framework. In this research, we use the stop list given by MALLET Topic Model to eliminate stop words by the step of word segmentation.
Step 2. After collecting articles and also preparing input data, a topic model based on Gibbs sampling applied for knowledge discovery and semantic mining in scholar’s articles. Topic modeling In our approach, the goal of topic modeling is to search the topic words related to a novel document so as to obtain the summary candidate sentences for building a recommendation system. LDA (Latent Dirichlet allocation) developed has become a widely used topic modeling [1]. LDA assumes that each word in a document is produced in two steps. First, assuming that each document has it’s own topic distribution, a topic is randomly drawn based on the document’s topic distribution. Next, assuming that each topic has its own word distribution, a word is randomly drawn from the word distribution of the topic selected in the previous step. Repeating these two steps word by word generates a document. Essentially, LDA reduces the extraordinary dimensionality of Scholar-Data from words to topics, based on word co-occurrences in the same document, similar to cluster analysis or principal component analysis. Therefore, we applied a LDA topic model with Gibbs sampling for semantic mining and discover relationship between Scholar-Context-documents and topics. According to LDA algorithm we define set of documents as Scholar-Context and words as topics. In mathematically, given the parameters and , the joint distribution of a topic mixture , a set of *N *topics z, anda set of *N *words w is given by:
[TABLE]
Finally, taking the generate of the marginal probability of every Scholar-articles in the corpus, the construction process probability of a corpus is determined as follows: (4)
[TABLE]
The parameters and are corpus level parameters, assumed to be sampled once in the process of generating a corpus. The variables * *are document-level variables, sampled once per document. Finally, the variables *zdn *and *wdn *are word-level variables and are sampled once for each word in each document. Gibbs sampling is applied to learn the LDA model and each instance is then expressed with topic distributions. Then, we use a Gibbs sampler to allocate a new label(topic) to the word, by sampling:
[TABLE]
where are the respective counts of topics with words or in documents hyperparameters as before. There are several methods to determine the model parameters that EM and Gibbs samplig are the most popular methods for parameter estimation. Gibbs sampling is a technique used to rapidly explore the space around a target distribution using repeated sampling.
Step 3. After semantic mining and extracting topics, in this paradigm, keywords generated based on ranking and high probability as a burst topic. In fact, Theses topic recommenced as research field of scholar data. These result will be helpful for direct of conference for understanding and scholar behavior analysis. And also we can discover trend topics in various years. Also, based on this framework and result obtained from this step, we answer two important question: Which research fields are very interesting for scholars in these conferences in computer science, between 2013-2017? What is relationship between LDA topics and articles features?
4 Researcher behavior analysis from conferences publication
We extracted six conference publications from DBLP website by only considering conferences for which data was available for years 2013-2017, including; AAAI, ACM SIGMOD, ACM SIGIR, ACM SIGKDD, ICCCN and ICSE Conferences. We pre-processed our data by a) removing stop-words, symbols, punctuations, and numbers b) down-casing the obtained words, and c)in the next step, prepared the dataset and then setting the parameters for topic modeling. It should be noted that in these experiments, we considered abstracts and titles from each article. In this paper, we used MALLET (http://mallet.cs.umass.edu/) to implement the inference and obtain the topic models. In addition, our full dataset is available at https://github.com/JeloH/Dataset_DBLP.
4.1 Parameter Settings
In this paper, all experiments were carried out on a machine running Windows 7 with CoreI3 and 4 GB memory. We learn a LDA model with 100 topics; , and using Gibbs sampling as a parameter estimation. Related words for a topic are quite intuitive and comprehensive in the sense of supplying a semantic short of a specific research field. The research topic associated with each topic for different years are quite representative. In addition, by doing analysis of our DBLP dataset, we found that all highly ranked research topic for various years have published papers in various conferences. For example, field of social media analysis (topic 62) for ACM SIGIR conference, we can see for Topic 62, published many papers in 2017 as a ranked first and in 2016 as a ranked second.
4.2 Statistical analysis and Topic probability
In this section, we provide the results and discovered topics of 100-topics for six conferences and we present temporal topic trends of conferences in various years.
According to Table 2 and Figure 4-6 , the following observations can be made:
In ACM SIGIR conference, Topic 59 has a trend of rising from 2016 to 2017. Topic 59 sounds considerably more generic and is consistent with ’Information Retrieval’ in general, and marked by search, retrieval, queries, relevance, documents, social. Topic 62 has a high degree possibility in 2017. Moreover, the result indicated that the topic also had many interested points for researchers that focused on ’Social Media Analyses’. The derivative curves show that Topics 59, 62 and 98 in ACM SIGIR are gaining popularity in recent years.
In ACM SIGKDD conference, Topic 99 has a trend of rising in 2016, but falling in 2017. It indicates that the publications of this topic increase in 2016 but decreases in 2017. Topic 99 sounds considerably more generic and is consistent with ’Decision Systems and Optimization Approaches’ in general, and marked by learning, systems, techniques, decision, specific, optimization. Topic 91, we can see that this topic probability curve is continuously decreasing from 2015 to 2017, although there is a high degree possibility in 2013 that there had a lot of interested points for researchers that focused on this topic. This topic is actually a mixture of two concepts. First is ’Graph-based Algorithms’, which is indicated by red words and some words are very related to each other such as model, algorithm, network, real, graph, scale. Second, it covers papers that proposed ’Approaches based on Behavior Analysis, which is indicated by blue words and some words are much related to each other such as classification, text, behavior, large, data, features. The derivative curves show that Topics 82, 61, 95 in ACM SIGKDD are gaining popularity in recent years.
In ACM SIGMOD, Topic 11, we can see that this topic probability curve is slowly decreasing from year 2013 to 2017. Topic 11 sounds considerably more generic and is consistent with ’Management of Data’ in general, and marked by store, key, operations, workloads, transaction, schema, cases. Topic 45, we can see that this topic has a trend of falling in 2016, but a trend of rising in 2017, and in another perspective, there is a high degree possibility in 2017 that there was a lot of interested points for researchers that focused on this topic. This topic is actually a mixture of two concepts. First is ’aggregation operators’, which is indicated by red words and some words are very related to each other such as algorithm, user, learning, operators, computing. Second, it covers papers that proposed ’Approaches based on Storage Management’, which is indicated by blue words and some words are very related to each other such as aggregation, cache, stored, questions, security. The derivative curves show that Topics 50, 45, 7, 75, 92 in ACM SIGMOD are gaining popularity in recent years.
In AAAI conference, Topic 23, we can see that this topic probability curve is continuously increasing from 2015 to 2017. This topic sounds considerably more generic and is consistent with ’NLP and Knowledge Representation’ in general, and marked by data, networks, semantic, stochastic, dimensional, and convex.
Topic 37, we can see that this topic probability curve is continuously decreasing from 2015 to 2017, although there is a high degree possibility in 2017 that there had a lot of interested points for researchers that focused on this topic. This topic is actually a mixture of two concepts. First is ’Large Scale Models’, which is indicated by blue words and some words are much related to each other such as models, large, scale, inference, target, and matrix. Second, it covers papers that proposed is based on ’Policy Search and Applications of Unsupervised Learning’, which is indicated by blue words and some words are very related to each other such as latent, address, standard, policy, unsupervised.
In ICCCN conference, Topic 66, this topic is actually a mixture of two concepts. First is ”Approaches based on Wireless Networks”, which is indicated by red words and some words are very related to each other such as network, energy, wireless, algorithms, sensor, problem, link. Second, it covers papers that proposed ”Approaches based on Security in Network”, which is indicated by blue words and marked by analysis, real, existing, content, security, mechanism. For Topic 67, we found this research field has a slowly increasing in curve from year 2016 to 2017, although there is a high degree possibility in 2014 that there had a lot of interested points for researchers that focused on this Topic. This topic is actually a mixture of two concepts. First is ”Cloud Computing”, which is indicated by blue words and some words are very related to each other such as cloud, applications, services, technique, storage, infrastructure. Second, it covers papers that proposed ’Approaches based on Mobility Management’, which is indicated by red words and some words are very related to each other such as management, radio, evaluation, approaches, performance, level.
In ICSE conference, Topic 13, we can see that this topic probability curve is continuously increasing from 2015 to 2017. This topic sounds considerable more generic and is consistent with ’Programming and Code Analysis’ in general, and marked by analysis, project, security, android, develop. Topic 12, probability curve was very smooth from year 2014 to 2016 and there was a high degree possibility in 2017 that there will be many interested points for researchers that focused on this topic. This topic covers papers that proposed algorithms based on ’Programming’ and marked by error, build, program, JavaScript, patches, GitHub and Java.
5 Discussion, Open Issues and Future Directions
In this study, we analysis six conference publications from DBLP conference and used the Gibbs sampling algorithm as an evaluation parameter. We succeeded in discovering the relationship between LDA topics and paper features and also obtained the researchers’ interest in research field in various years. According to our studies, some issues require further research, which can be very effective and attractive for the future.
5.1 Behavioral and conceptual angles with two technical questions
Technical question 1: Are all topic-words are generated from each Topic, are related to each other in each conference? Is it possible to allocate more than one concept for each topic? According to our observation, most of topics contain some words which are common in the corpus. And other side, some words provide a simple way to find concepts, for example; word ’retrieval’ can be easily recognized as a common word in the corpus about ’methods based on information retrieval’, and we can find that all the topics contain this words, Topic 59 in ACM SIGIR conference (Table 2). Also some cases, Topic words may create more than one concept for each topic. For example; there are two concepts for Topic 66 in ICCCN conference. In another case, the LDA may generate irrelevant words and create just a few words for a concept. So some of the topics can be a gathering of unnecessary words, irrelevant words provide no useful information in any context and we need to be aware of and address this challenge.
Technical question 2: ’Ad for network’ or ’Ad for advertisement’, Is there an instance ambiguity or different senses for words? One of the prominent feature of topic models is that they need no supervision in terms of data annotation. However, in some situations, limited amounts of labeled data may be available. When human read natural language text and encounter an ambiguous entity, we may make use of the context to help our understanding and choose the correct meaning between all the possibilities. For example (Topic 98, ACM SIGIR, in Table 2), the word of ’ad’! Is for ’advertisement’ or ’ad hoc network’? As we can see, the word ’ad’ can be related to ’advertisement’ or also to ’ad hoc network’. To answer this question, it is very easy to see that topic 98 reveals ’network’, ’graph’, ’mobile’, ’ad’ and ’interactions’ . If only we consider the words ’network’, ’graph’, ’ad’ we can predict that this topic can be related to ’ad hoc network’ and this topic covers papers that propose models in ’ad hoc information retrieval’. Due to this problem, a recommendation system may lead to inappropriate results.
5.2 Towards development of systematic and practical recommendation systems
Recommendation systems is increasing day-by-day with the development of scientific research, it will be more known and essential in the Internet community. Below we list a few important aspects which can be a part of future research.
- •
Recommender systems for famous publishers, Journals and conferences are a rich source to use recommender system, and it needs more research about this field and we believe that there are many important content that we can consider as dataset, such as KDD, RecSys, IEEE fuzzy, WWW UbiComp, ACM SIGSPATIAL LBSN, AAA, ACM TIST, ACM TWEB and etc. For example, Yang and et al. proposed a novel collaborative filtering for recommendations of venues with considering extract stylometric features to obtain the similarity between papers from their writing styles and extracted 119,927 papers with considering abstract, venue information from CiteSeer Digital Library .
- •
Hybrid approaches with machine technique, machine learning algorithms are one of the most prominent methods for text mining in computer science. Utilizing the combination of machine learning and topic modeling approaches can be effective for professional recommendation systems. As a relatively related work, we can refer to .
- •
Group recommendation, Group activities are essential components for online users in social networks. Group recommendation is a challenging problem because different group members have different preferences, and how to make a trade-off among their preferences for recommendation is still an open challenge. There are a few impressive works with considering topic modeling techniques for group recommendation that can be considered for future work .
6 Conclusion
In this paper, we applied LDA algorithm and Gibbs sampling on six conference publications from the DBLP website and analyzed the behavior of researcher’s interest in research field in different years. Our results showed that can discover hidden aspects to better understand the behavior of the researchers. Definitely, topic-modeling and LDA approaches can play an important role to develop the smart recommendation systems in various applications in future. Generally, recommendation systems can be an impressive interface between online users and websites in the Internet community. Certainly, the results of the article can help to scientific committee of these conferences to focus more on specific research topics for future conferences.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Blei et al . (2017) 1. D. M. Blei, A. Y. Ng, M. I. Jordan, Latent dirichlet allocation, J Machine Learning Research Archive 3 (2003) 993-1022.
- 2Amami et al . (2017) 2. M. Amami, R. Faiz, F. Stella, 455 G. Pasi, A graph based approach to scientific paper recommendation, in: the International Conference, 2017, pp. 777-782.
- 3Dai et al . (2017) 3. T. Dai, L. Zhu, X. Cai, S. Pan, S. Yuan, Explore semantic topics and author communities for citation recommendation in bipartite bibliographic network, Journal of Ambient Intelligence and Humanized Computing (9) (2017) 1-19.
- 4Kim et al . (2013) 4. Y. Kim, Y. Park, K. Shim, Digtobi:a recommendation system for digg articles using probabilistic modeling (2013) 691- 460 702.
- 5Li et al . (2013) 5. Y. Li, M. Yang, Z. Zhang, Scientic articles recommendation, in: ACM International Conference on Conference on Information and Knowledge Management, 2013, pp. 1147-1156.
- 6Sugiyama et al . (2013) 6. K. Sugiyama, M. Y. Kan, Exploiting potential citation papers in scholarly paper recommendation, 2013, pp. 153-162.
- 7Wang et al . (2011) 7. C. Wang, D. M. Blei, Collaborative topic modeling for recommending scientific articles, in: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2011, pp. 448-456.
- 8Wang et al . (2013) 8. H. Wang, B. Chen, W. J. Li, Collaborative topic regression with social regularization for tag recommendation, in:International Joint Conference on Artificial Intelligence, 2013, pp. 2719-2725.