A general centrality framework based on node navigability
Pasquale De Meo, Mark Levene, Fabrizio Messina, Alessandro Provetti

TL;DR
This paper introduces the Potential Gain as a unified centrality measure based on node navigability, linking it to existing centralities like Katz and Communicability, with scalable algorithms for large graphs.
Contribution
It proposes a new centrality measure called Potential Gain that unifies existing walk-based metrics and provides scalable computation methods for large networks.
Findings
Potential Gain unifies multiple walk-based centralities.
Geometric and Exponential Potential Gain relate to Katz and Communicability.
Formal proofs connect new measures to established centralities.
Abstract
Centrality metrics are a popular tool in Network Science to identify important nodes within a graph. We introduce the Potential Gain as a centrality measure that unifies many walk-based centrality metrics in graphs and captures the notion of node navigability, interpreted as the property of being reachable from anywhere else (in the graph) through short walks. Two instances of the Potential Gain (called the Geometric and the Exponential Potential Gain) are presented and we describe scalable algorithms for computing them on large graphs. We also give a proof of the relationship between the new measures and established centralities. The geometric potential gain of a node can thus be characterized as the product of its Degree centrality by its Katz centrality scores. At the same time, the exponential potential gain of a node is proved to be the product of Degree centrality by its…
Click any figure to enlarge with its caption.
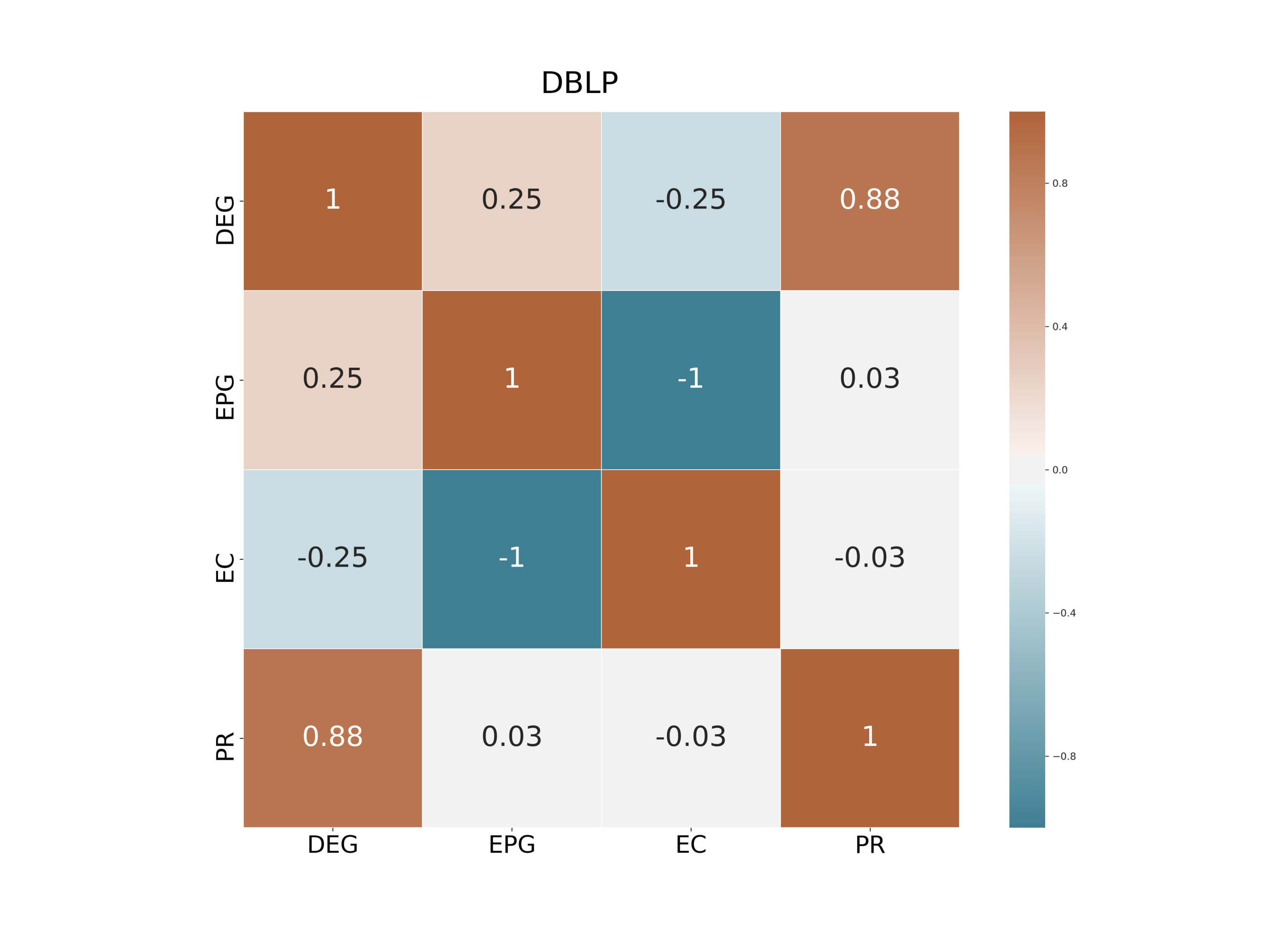 Figure 1
Figure 1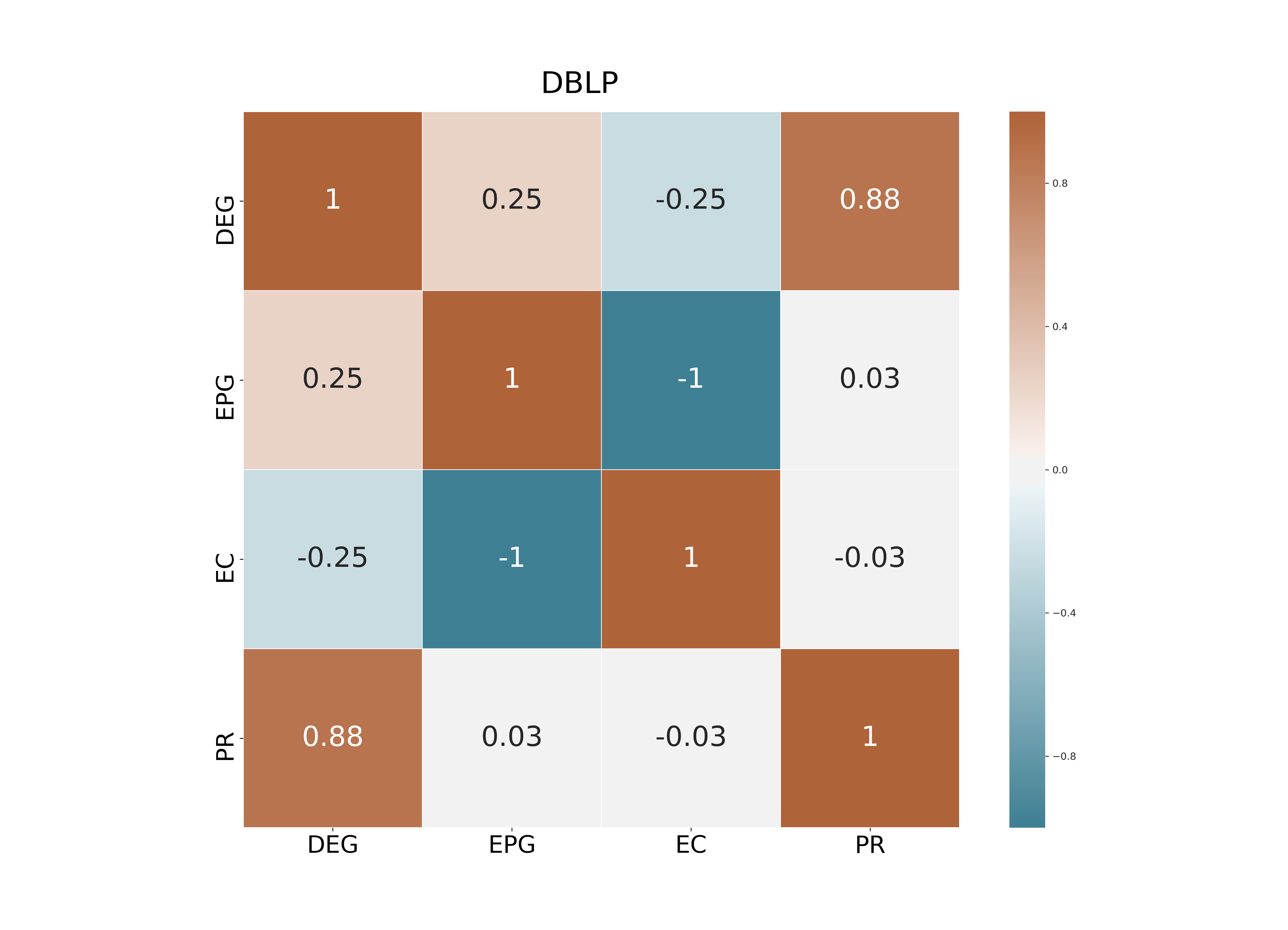 Figure 2
Figure 2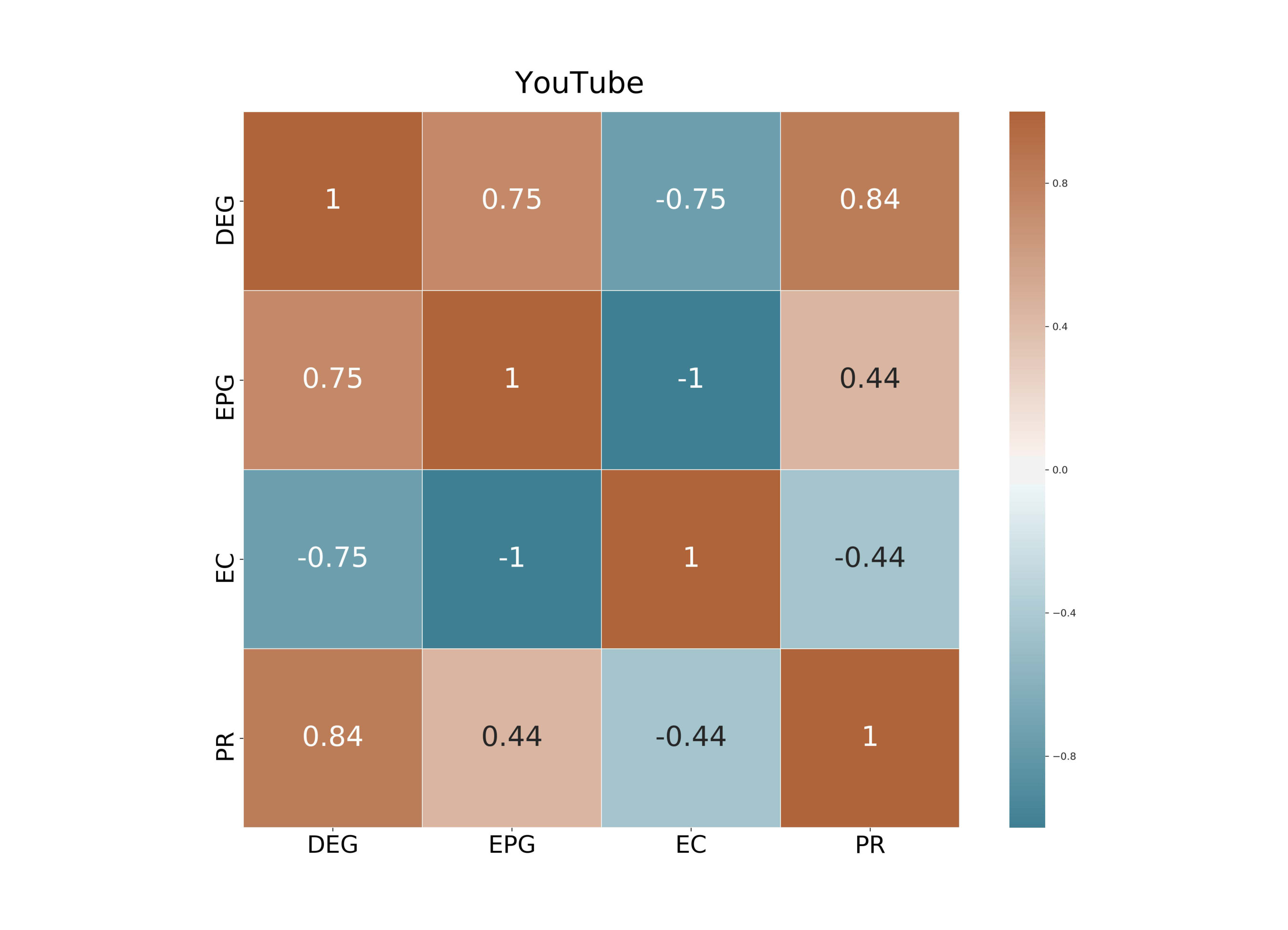 Figure 3
Figure 3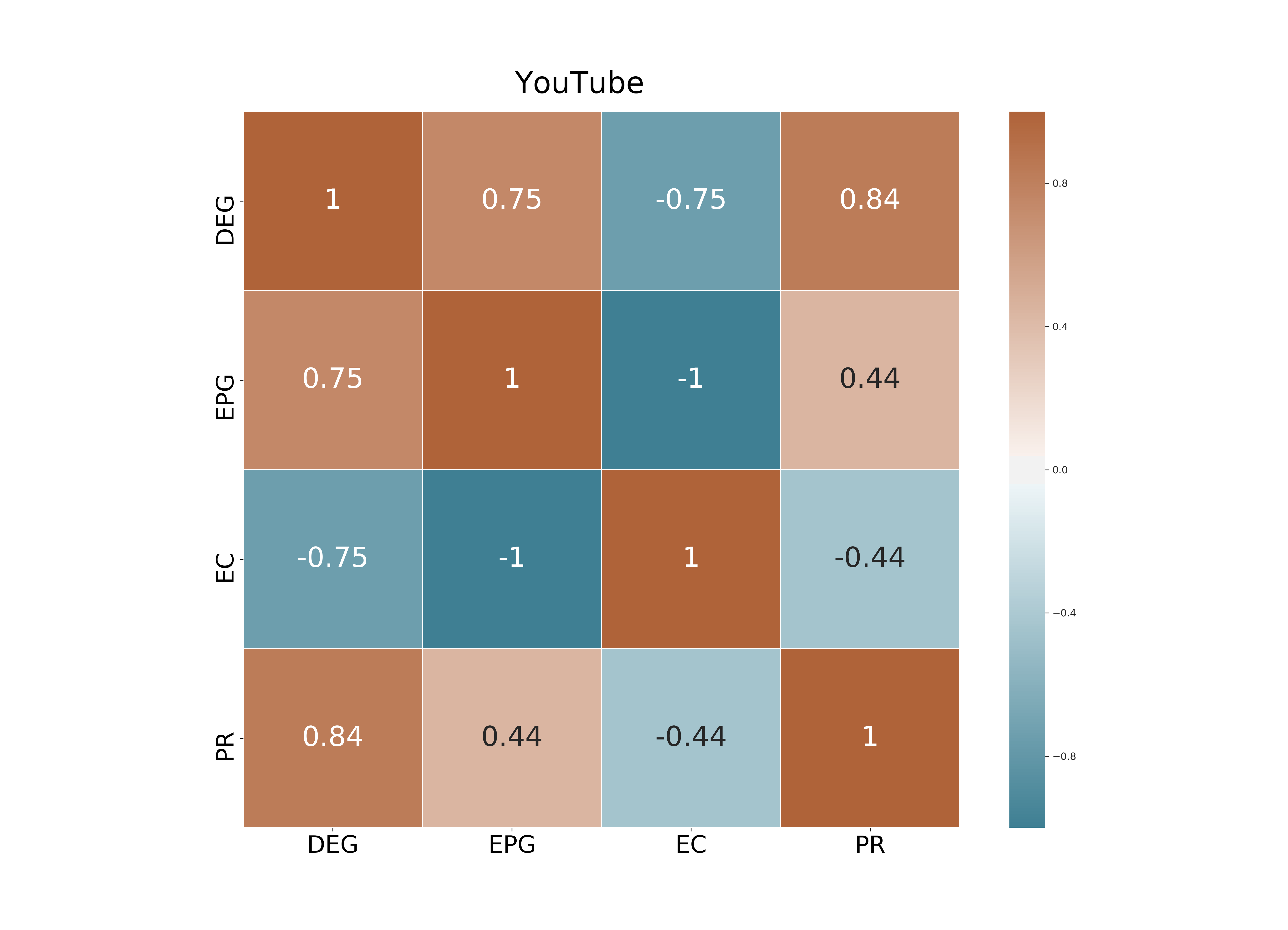 Figure 4
Figure 4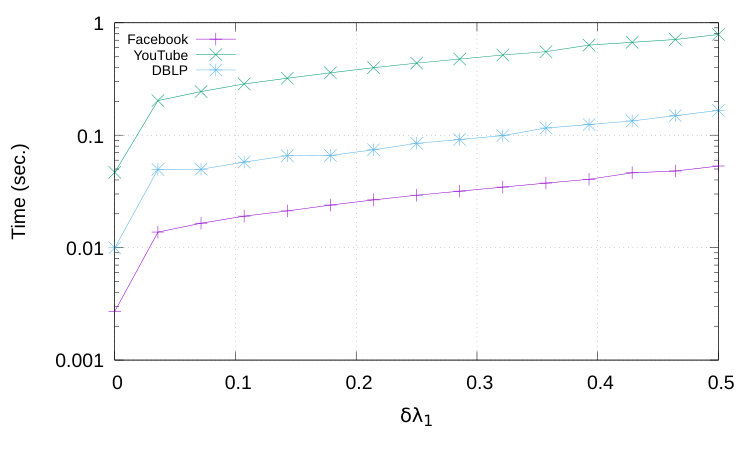 Figure 5
Figure 5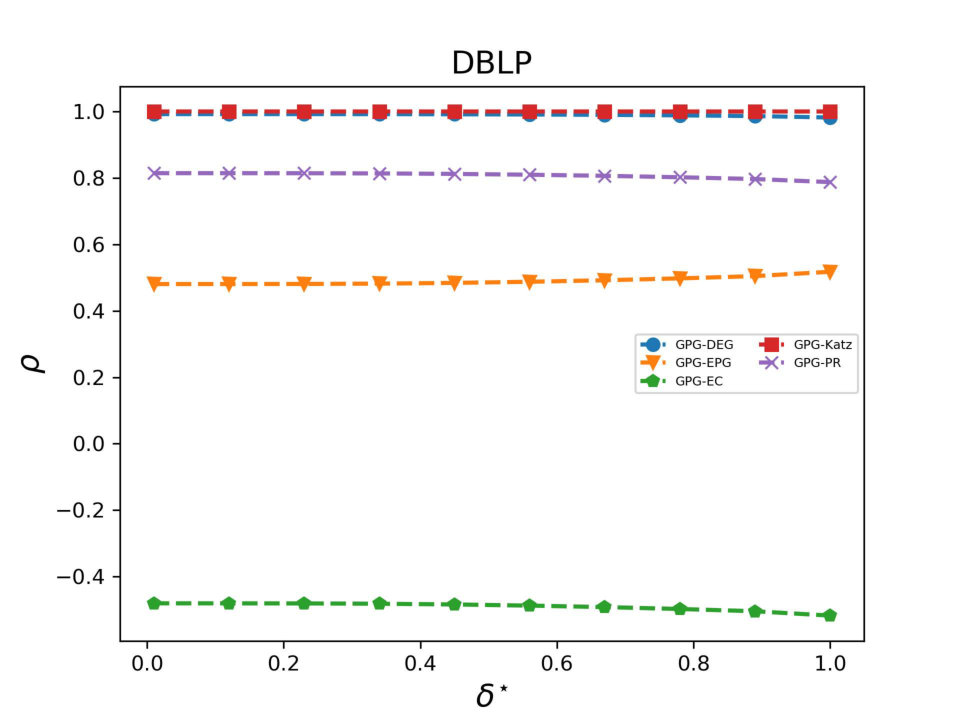 Figure 6
Figure 6 Figure 7
Figure 7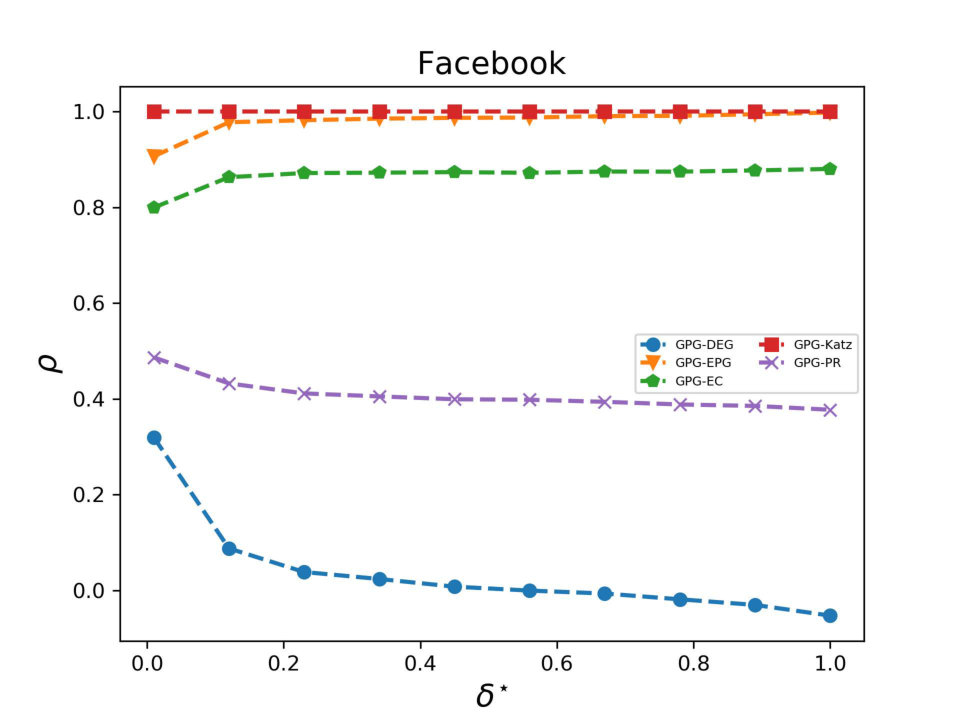 Figure 8
Figure 8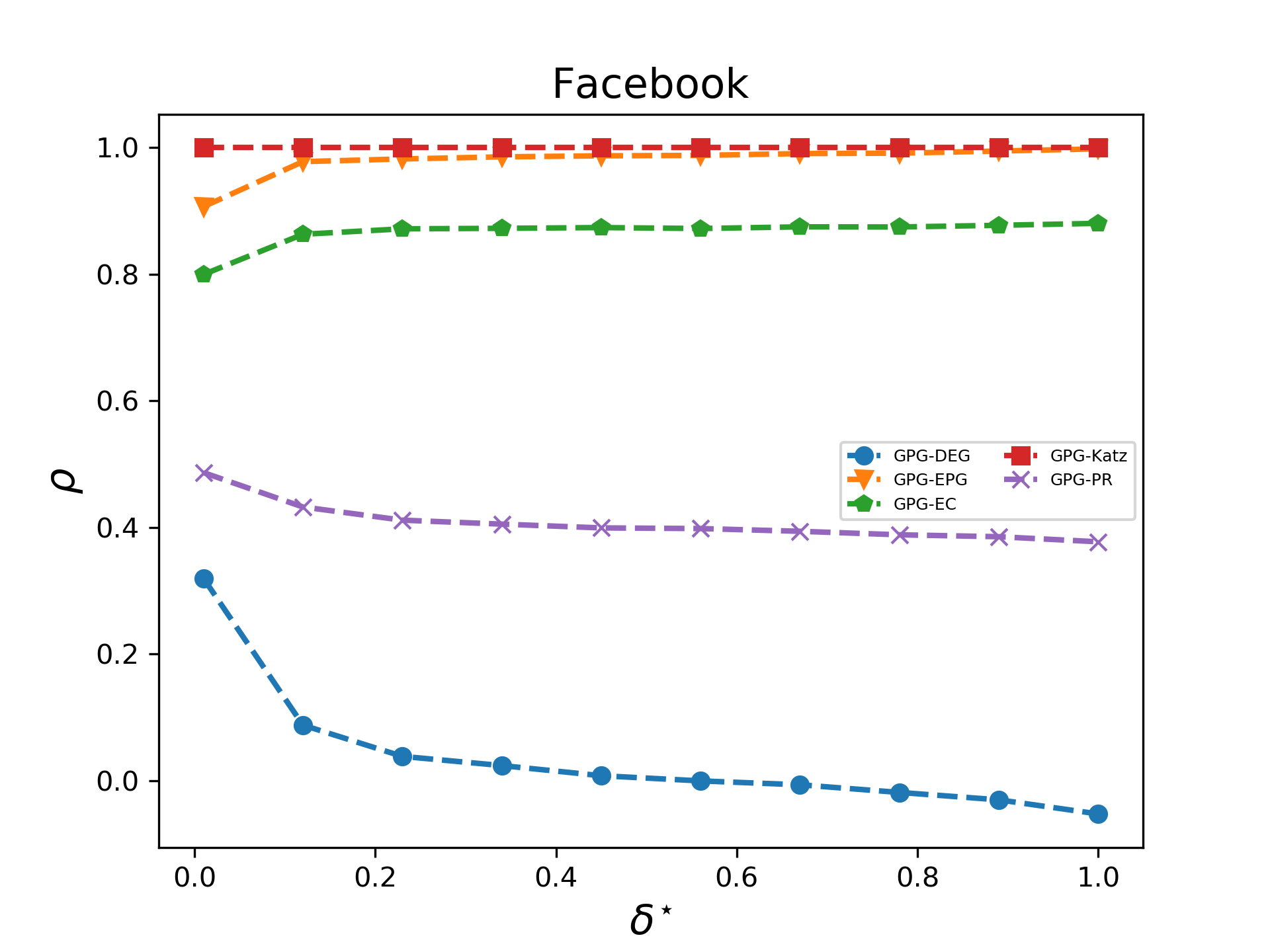 Figure 9
Figure 9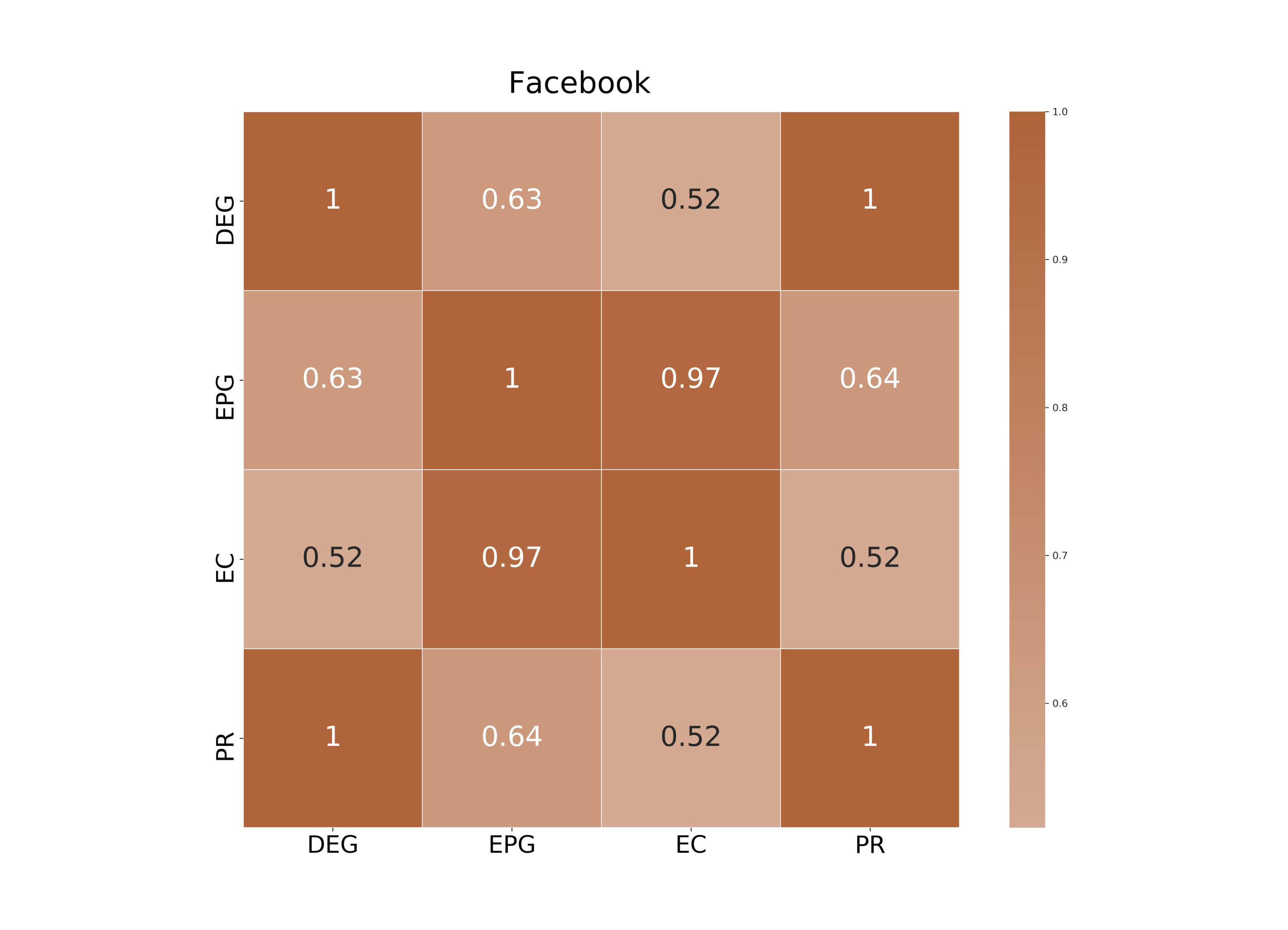 Figure 10
Figure 10 Figure 11
Figure 11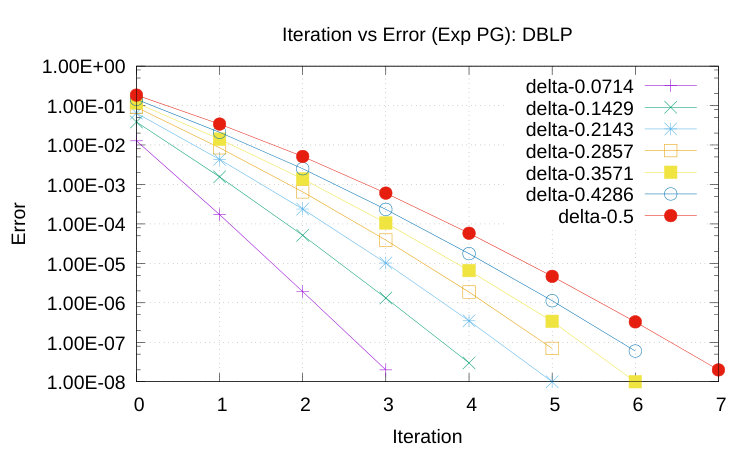 Figure 12
Figure 12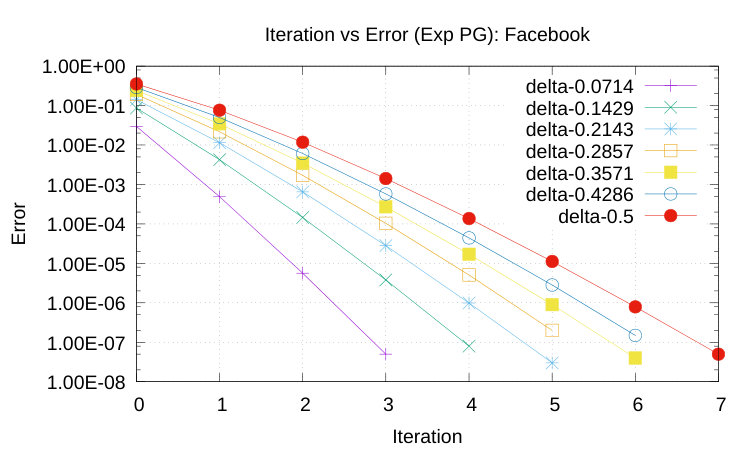 Figure 13
Figure 13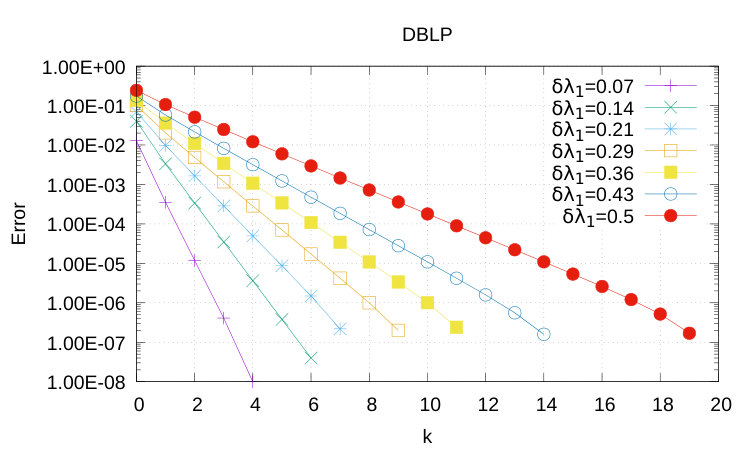 Figure 14
Figure 14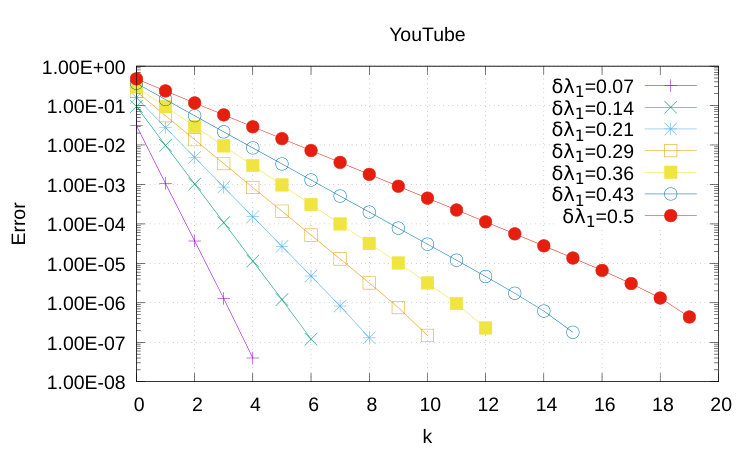 Figure 15
Figure 15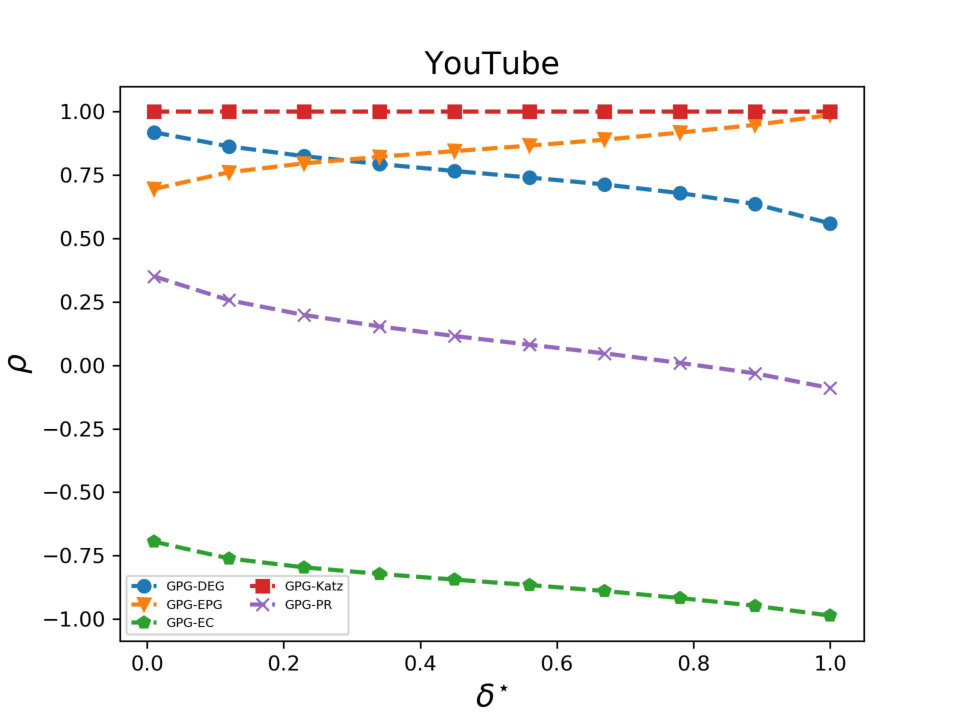 Figure 16
Figure 16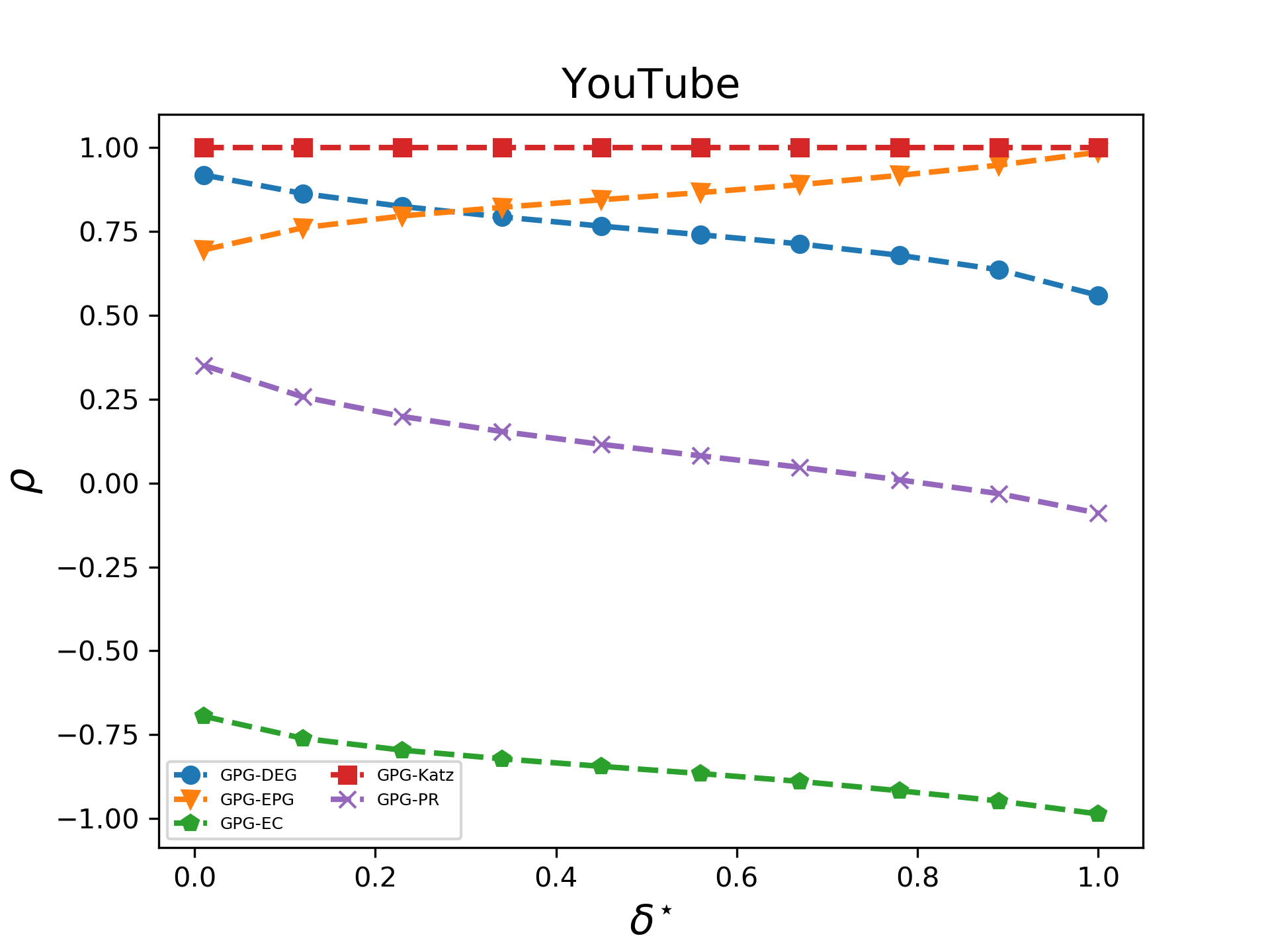 Figure 17
Figure 17| Dataset | Nodes | Edges | Year | ||
|---|---|---|---|---|---|
| 1 | Facebook Friendship | 2009 | |||
| 2 | DBLP co-authorship | 2012 | |||
| 3 | Youtube friendship | 2012 |
| Dataset | Time (sec.) |
|---|---|
| DBLP | |
| YouTube |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A general centrality framework based on node navigability
Pasquale De Meo, Mark Levene, Fabrizio Messina, and Alessandro Provetti P. De Meo is with the Department of Ancient and Modern Civilizations, University of Messina. Messina, Italy, 98166.
E-mail: [email protected] M. Levene and A. Provetti are with the Department of Computer Science and Information Systems, Birkbeck, University of London. London WC1E 7HX, UK.
E-mail: {mark,ale}@dcs.bbk.ac.uk F. Messina is with the Department of Computer Science, University of Catania, Catania, Italy.
E-mail: [email protected]
Abstract
Centrality metrics are a popular tool in Network Science to identify important nodes within a graph. We introduce the Potential Gain as a centrality measure that unifies many walk-based centrality metrics in graphs and captures the notion of node navigability, interpreted as the property of being reachable from anywhere else (in the graph) through short walks. Two instances of the Potential Gain (called the Geometric and the Exponential Potential Gain) are presented and we describe scalable algorithms for computing them on large graphs. We also give a proof of the relationship between the new measures and established centralities. The geometric potential gain of a node can thus be characterized as the product of its Degree centrality by its Katz centrality scores. At the same time, the exponential potential gain of a node is proved to be the product of Degree centrality by its Communicability index. These formal results connect potential gain to both the “popularity” and “similarity” properties that are captured by the above centralities.
1 Introduction
Centrality metrics [1] provide a ubiquitous Network Science tool for the identification of the “important” nodes in a graph. They have been widely applied in a range of domains such as early detection of epidemic outbreaks [2], viral marketing [3], trust assessment in virtual communities [4], preventing catastrophic outage in power grids [5] and analysing heterogeneous networks [6].
Some centrality metrics define the importance of a node in a graph as function of the distance of to other nodes in : for instance, in Degree Centrality, the importance of is defined as the number of the nodes which are adjacent to , i.e. which are at distance one from . Analogously, Closeness Centrality [7, 8] classifies as important those nodes which are few hops away from any other node in
Another class of centrality metrics looks at walk/path structures in : for instance, the Betweenness Centrality [7] of a node depends on the number of shortest paths crossing it and, thus, nodes with largest betweenness centrality scores are those which intercept most of the shortest paths in . A further popular metric is the Katz’s Centrality Score [9], which is understood as the weighted number of walks terminating in the node. In Katz’s centrality metric the weighting factor is inversely related to walk length and, thus, long (resp., short) walks have a small (resp., large) weight. For a suitable choice of the weighting factor, the Katz centrality score converges to the Eigenvector Centrality [10, 8] and to the PageRank [11, 8].
To the best of our knowledge, however, there is no previous work in which the centrality of a node is closely related to the notion of navigability, defined as the ease at which it is possible to reach a target node regardless of the node chosen as source node. Navigability is one of the most important features for a broad range of natural and artificial systems which have the transportation of information (e.g. a computer network) or the trade of goods (e.g. a road network) as their primary purpose.
Early studies on graph navigability were inspired by the seminal work of Travers and Milgram [12] on the “small world” property for social networks: in a celebrated experiment, randomly-chosen Nebraska residents were asked to send a booklet to a complete stranger in Boston. Selected individuals were required to forward the booklet to any of their acquaintances whom they deemed likely to know the recipient or at least might know people who did. In some cases, the booklet actually reached the target recipient by means, on average, of 5.2 intermediate contacts, thus suggesting an intriguing feature of human societies: in large, even planetary-scale, social networks, pairs of individuals are connected through shorts chains of intermediaries and ordinary people are able to uncover these chains [13, 14, 15]. Several empirical studies have revealed the small-world effect in diverse domains such as metabolic and biological networks [16], the Web graph [17], collaboration networks among scientists [18] as well as social networks [19, 20].
So far, centrality metrics and navigability have been investigated in parallel, yet their research tracks are disconnected. Thus, an important (and still unanswered) direction of inquiry is the introduction of centrality metrics that are related to the navigability of a node.
Our main contribution is to tackle the questions above by extending previous work by Fenner et al. [21] who studied navigability in the context of web surfing. The main output of our research is a general framework in which the Potential Gain unifies several walk-based centrality metrics and captures the notion of navigability.
The potential gain of a node depends on the number of walks of length that connect with any other node The underlying idea is that, for a fixed the larger the higher the chance that will reach regardless of the specific navigation strategy. In our model, the contribution of each walk to the potential gain shall decrease with its length This intuition is formalized by the introduction of a weighting factor which monotonically decreases with to penalize long walks.
We have developed two variants of the potential gain of [21], namely:
- •
the Geometric Potential Gain, in which decays as , where is a parameter ranging between [math] and the inverse of the spectral radius of 111Recall that the spectral radius of is defined as the largest eigenvalue of the adjacency matrix of ., and
- •
the Exponential Potential Gain, in which decays in exponential fashion.
Both the geometric and exponential gain of can be thought as the product of one index (Degree Centrality) related to the popularity of and another (Katz Centrality score, for the geometric potential gain, and the Communicability Index [22, 23] for the exponential potential gain) which reflects the degree of similarity of with all other nodes in the network. The combination of popularity and similarity has proven to closely resemble the way humans navigate large social networks [24] or attempt to locate information in large information networks such as Wikipedia [25, 26, 27].
Our formalisation applies the Neumann series expansion [28] to efficiently, yet accurately approximate both the geometric and exponential gain. Both theoretical and experimental analysis show that our approach is appropriate for accurately computing the geometric and exponential potential gain in large real-life graphs consisting of millions of nodes and edges, even with modest hardware resources.
We validated our approach on three large datasets: Facebook (a graph of friendships among Facebook users), DBLP (a graph describing scientific collaboration among researchers in Computer Science) and YouTube (a graph mapping friendship relationships among YouTube users).
The main findings of our study can be summarized as follows:
The amount of time needed to compute the geometric or the exponential potential gain does not depend on the number of nodes/edges of a graph; instead, it depends on the spectral radius : the larger , the better connected the graph and, thus, the larger the number of walks needed to get a good approximation of the geometric/exponential potential gain. 2. 2.
For small values of , the geometric potential gain is highly correlated with Degree Centrality, while for large values of it displays a strong and positive correlation with Eigenvector Centrality. 3. 3.
In the case of the geometric potential gain, walks of small length (i.e., up to ten) are sufficient to obtain a good approximation. In contrast, to compute the exponential potential gain our algorithm needed to construct longer random walks, in some cases up to ten times longer than those required for the computation of the geometric potential gain. 4. 4.
As a consequence of the above point, the geometric potential gain seems to be the most efficient solution for large graphs.
This article is organized as follows: in Section 2 we provide basic definitions that will be used throughout the paper. In Section 3 we review related work. Section 4 introduces the geometric and exponential potential gain and illustrates their main properties. In Section 5 we discuss how to efficiently calculate the geometric and exponential potential gain, while Section 6 details the experiments we have performed. Finally, in Section 7 we draw our conclusions.
2 Background
In this section we introduce some basic terminology for graphs that will be largely used throughout this article.
Let a graph be an ordered pair where N is a set of nodes, here also called vertices, and is the set of edges. As usual, is undirected if edges are unordered pairs of nodes and directed otherwise. In this article we will consider only undirected graphs.
Also, let be the number of nodes, the number of edges of . For any given node i its neighborhood is the set of nodes directly connected to it; its degree is the number of edges incident onto it, i.e., .
A walk of length (with a non-negative integer) is a sequence of nodes such that consecutive nodes are directly connected: for Also, we use the term path for walks that do not have repeated vertices. A walk will be closed if it starts and ends at the same node.
We will represent graphs by their associated adjacency matrix, defined as if and 0 otherwise. Sometimes we may slightly simplify notation with The adjacency matrix provides a compact formalism to describe many graph properties: for instance, the matrix where , gives the number of walks of length two going from to . Inductively, for any positive integer , the matrix will give the number of closed (resp., distinct) walks of length between any two nodes and if (resp., if ) [29].
It is a well-know fact that the adjacency matrix of any undirected graph is symmetric and, hence, all its eigenvalues are real. The largest eigenvalue of is also called its principal eigenvalue or spectral radius of Moreover, the corresponding eigenvectors will form an orthonormal basis in [30]. Eigenpairs are formed by the eigenvalue and the corresponding eigenvector .
3 Related Work
The task of searching for and navigating in large networks has been extensively studied in the past for a broad range of domains such as routing in small world networks [12], locating pages in the World Wide Web [31, 17], finding the most knowledgeable individual in an enterprise/academic social network, discovering resources in a P2P network and building recommender systems [32]. Inspired by the classification scheme introduced by Helic et al., [27], we divide search and navigation into two main classes: (a) Endogenous Search. In this class, there are multiple agents embedded in the network and the navigation task is depicted as a decentralized decision process in which agents collaborate to discover a path in the network. Agents are assumed to have only a local knowledge of the network topology and, in addition, querying a neighboring node (e.g., to route a message) may have a non-negligible cost. (b) Exogenous Search. This class occurs whenever a user aims at navigating the Web [21, 33] or an information network such as Wikipedia [26, 34]. In exogenous search, there is only one agent involved in navigation task and it does not belong to the network. As in endogenous search, the agent (either human and artificial) only posses local knowledge about the network topology. Unlike the endogenous search, however, the cost for visiting a node is generally low.
In the following two sections we review methods in endogenous and exogenous search (see Sections 3.1 and 3.2 below).
3.1 Endogenous search approaches
Many mathematical models have been proposed to explain why networks are, in an informal sense, navigable. Some of the best-known models are described in [35, 13, 36, 37]. The original Watts-Strogatz (WS) model [20] generated random graphs in which pairs of nodes belonging to distant parts of the graph may be connected through random edges, called long-range weak ties. The WS model was thus effective in forcing the graph to be “small,” i.e., to assure the presence of paths consisting of few edges between any pair of nodes. Nevertheless, the WS model alone is unable to explain why people are capable of discovering such paths.
One class of approaches to search large networks relies on the notion of popularity. Adamic et al. [38] is perhaps the best-known approach in that category: here the search task is modelled as a random walk on the graph . In a specific step, if the walker occupies a node which is not the target one (and none of the neighbours of is the target one), then the walker chooses the unvisited neighbour with largest degree.
Another class of approaches – called similarity-based approaches – exploit homophily to speed up search tasks [13, 37]. Kleinberg [35] described a generalization of the WS model to explain why decentralized search is effective in real networks. In Kleinberg’s model, nodes of a social network are arranged to form a bi-dimensional grid (called a lattice); each node is connected to its neighbours in the lattice and, in particular, the distance between two nodes equals the number of grid steps separating them. As a result, each node is connected to its four local contacts (i.e., nodes at distance one from ). In addition, a random edge—called a long range edge—connecting with a node is generated with probability proportional to , being the so-called clustering exponent of the model. Kleinberg proved that if , then the performance of decentralized search is optimal, i.e. there exists an algorithm that, on average, is able to deliver a message from an arbitrary source node to an arbitrary target in time.
Another contribution is due to Watts et al. [37] who proposed a model to explain network navigability in which nodes aggregate into groups on the basis of some shared attributes such as job or geographic location. For each attribute, a population can be split into a hierarchical set of layers in which the top layer describes the entire population, while layers at increasing depth define a cognitive division of the population into more specific groups. Individuals can manage two kinds of information to decide to whom a message should be forwarded to: first, social distance, which accounts for the similarity of two nodes and, second, network distance, i.e., the number of network paths that can be detected by looking at the neighbors.
Social distance between two individuals and can be estimated by considering the groups and belong to and how distant these groups are in the layers of . As such, social distance is a kind of global metrics but, unfortunately, it is not a true distance in the sense that individuals belonging to close groups may be separated by long paths in the social network graph.
Network distance, on the other hand, is a true distance but a node only has access to a local portion of the network and, thus, it can correctly calculate network distances only for nodes which are separated from it by a few hops. By means of simulations [37] demonstrated that social distance is effective in approximating network distance and, thus, to successfully in directing messages across the network.
More recently Csimcsek et al. [24] suggest to combine popularity- and similarity-based methods and, to this end, they describe a graph search algorithm that, at each step, forwards a message from the current node to one of its neighbours, say , such that the product is maximum; here quantifies homophily between and .
Unlike the approaches above, which assume that some attributes are available at each node, our approach only makes use of connectivity patterns to calculate the centrality of a node.
3.2 Exogenous search approaches
Exogenous search is mostly related to search in information networks such as a collection of Web pages or Wikipedia.
One of the most common search strategies on the World Wide Web (WWW) is surfing, in which a user moves from a Web page to another one by following hyperlinks. Huberman et al. [39] introduced a probabilistic model to describe surfing. In this model, the sequence of Web pages a user visits is regarded as the realisation of a random process and each Web page is associated with a value to the user. A user will stop surfing if the estimated cost of accessing a new Web page is bigger than the expected value of the information the user may get from accessing it.
More recently, West and Leskovec [40] analysed how people navigate an information network such as Wikipedia in order to reach a specific target. To this end, they used an online computation game, called Wikispeedia [25], in which Wikipedia information seekers are given two random articles and they are required to navigate from one to the other by clicking as few hyperlinks as possible. In a subsequent paper [26], they compared the accuracy of several decentralized search algorithms and benchmarked them against the human navigation paths. Such a study highlighted two main phases of human navigation in information networks: (i) Zoom-Out: here, users strives to reach the network core (or a hub in the network core); such a core consists of a Wikipedia page with many links to other pages in Wikipedia. In this step, humans would prefer pages with many outgoing links (high degree pages). (ii) Zoom-in, in which users leave the core to get closer to a topic. Specifically, if we think of segmenting Wikipedia pages into clusters on the basis of their topics, such a phase would consist of entering into a cluster. In the zoom-in phase, users prefer to look for similar nodes in order to orient their search.
A nice approach to combine decentralized search was described by Helic et al. [27] who applied decentralized search algorithms such as those described in [35] to model human navigation in information networks. They considered an online navigation game (called WikiGame); in this game, a user starts from a random Wikipedia page and navigates to a target page. More than 250,000 click paths were collected and studied to determine the factors influencing players’ decisions. The main finding in [27] is that two mechanisms regulate the way humans seek for information in large networks: i) exploitation, i.e., humans follow specific hyperlinks whenever they are confident enough that those will get them closer to the target they want, and ii) exploration, i.e., users navigate at random an information network, when their knowledge about how current links relates to a target Web page is insufficient. The quantitative analysis showed that exploration steps account, on average, for of collected links, while exploitation accounted for the remaining of collected links.
4 A model of network navigability
In this section we introduce our notion of network navigability, in Subsection 4.1 along with the Potential Gain as a new centrality measure and a new general framework that unifies many walk-based centrality indices and captures our notion of navigability. In Section 4.2 we describe two versions of the potential gain, called the geometric and the exponential potential gains. In Subsection 4.3 we compare the two versions of potential gain with other, well-known, centrality metrics from the literature. In Subsection 4.4 we investigate the relationship between the geometric and the exponential potential gain. Finally, 4.5 outlines our approach to calculating the geometric and exponential potential gain.
4.1 Network navigability and the potential gain
Starting from the Travers-Milgram’s experiment [12], several studies have sought to characterize under which conditions a graph is deemed navigable. According to Kleinberg [35], a graph is navigable if i) its diameter is bounded by a polynomial in (here is the number of nodes in ) and ii) it has a strongly-connected component which contains almost all of the nodes of . Kleimberg’s navigability is a property of the graph, whereas our purpose is to define the notion of navigability at the node level.
For navigability at the node level we leverage the main findings of Lamprecht et al. [41] on the navigability of a recommender network built on top of the Internet Movie Database (IMDB). Their work introduced some topological indices to quantify how difficult it is to navigate the recommender network. Specifically, they suggested to compute the eccentricity of each node , defined as the length of the longest shortest-path converging to from any other node belonging to the same connected component of . Thus, nodes with small eccentricity (also termed efficient reachability can be easily reached from any other node of the graph.
Eccentricity may seem a good starting point for the formalisation of network navigability but “suffers” from some known issues. First, the eccentricity is dominated by the distance, from to the farthest node: as a consequence, could have a large eccentricity even if it is close to almost all of nodes in . Second, any time the length of the shortest path connecting node to is above a threshold , the navigation from to is considered “hard,” regardless of the topology.
The starting point for our work is the framework proposed by Fenner et al. [21] who studied the problem of identifying “good pages” from which to start exploring the Web. They classify a page as a good starting point if it satisfies the following criteria: (1) it is relevant, i.e. the content of closely matches user’s information goals, (2) page is central, i.e., the distance of to other Web pages in the Web graph is as low as possible and (3) page is connected, in the sense that is able to reach a maximum number of other pages via its outlinks.
A key difference between Fenner et al. and our work is that they defined the navigability score of a page/a node as its ability to act as the source node for reaching all the other nodes. In our setting, instead, we consider the node as the target of search, as described next.
Let us fix a source node and a target node and provide an estimate of how “easy” it will be for to be reached if we choose as source node. Intuitively, the larger the number of walks from to , the easier it would be to reach when starting from . In addition, assume that the task of exploring a graph is costly and such a cost increases as the length of the walks/paths we use for exploration purposes increases. Therefore, shorter walks should be preferred to longer ones. By combining the requirements above, we obtain:
[TABLE]
here is the number of walks of length going from to and the non-increasing function acts as penalty for longer walks. If we sum over all possible source nodes , we obtain a global centrality index for :
[TABLE]
In analogy to Fenner et al., let be the potential gain of .
In conclusion, the main differences between Potential Gain and Eccentricity are : i) the computation of PG is grounded on walks while the computation of the eccentricity is based on paths, ii) the potential gain consider all walks converging to a target node while the eccentricity consider only shortest paths reaching and, iii) in the potential gain, the contribution of a walk of length is penalized by a factor , while in the calculation of the eccentricity we take the length of the shortest path as is (i.e., with no penalization).
4.2 The geometric and exponential potential gain
Given the above specifications, we first define the potential gain in matrix notation. For the base case, consider walks of length k=1, i.e., direct connections. Only the neighbours of a node will contribute to the potential gain of which leads to the trivial conclusion that, at , nodes with the largest degree are also those ones with the largest potential gain.
We define the vector such that for every node :
[TABLE]
If we include walks of length two, then we have to consider the squared adjacency matrix . So, we add a contribution to the potential gain.
By induction, nodes capable of reaching from through walks of length up to provide a contribution to the potential gain equal to . By summing over all possible values of we get to the following expression for :
[TABLE]
To attenuate the effect of the walks’ length, we will consider two weighting functions, namely:
Geometric: with . So we define the geometric potential gain, :
[TABLE] 2. 2.
Exponential: . So we define the exponential potential gain, :
[TABLE]
4.3 Relation to centrality measures
The geometric and the exponential potential gain introduced above yield a ranking of network nodes and, therefore, it is instructive to compare them with popular centrality metrics. Recall that we defined the spectral radius of as the largest eigenvalue of .
As for the geometric potential gain, if we let , the following expansion holds:
[TABLE]
in which we make use of the Neuman series [28]:
[TABLE]
At this point, the term is exactly the Katz centrality score [9, 42], a popular centrality metric that defines the importance of a node as a function of its similarity with other nodes in Hence, we can say that the geometric potential gain combines two kind of contributions: popularity, as captured by node degree, and similarity as captured by Katz’s similarity score.
It is also instructive to consider what happens for extreme values of : if , then the geometric potential gain tends to , i.e., it coincides with degree. In contrast, if , then the Katz centrality score converges to eigenvector centrality [10], another popular metric adopted in Network Science. Boldi and Vigna [8] show that the Katz Centrality score is also strictly related to the PageRank. More specifically, the PageRank vector coincides with the Katz Centrality score provided that the adjacency matrix is replaced by its row-normalized version :
[TABLE]
Here, the parameter is the so-called PageRank damping factor. Let us now concentrate on the exponential potential gain. We rewrite Equation 6 as follows:
[TABLE]
where is the exponential of [43].
The exponential of a matrix has been used to introduce other centrality scores such as communicability or subgraph centrality [44, 10].
Specifically, measures how easy is to send a unit of flow from a node to a node and vice versa. Such a parameter is known as communicability and it can be regarded as a measure of similarity between a pair of nodes. Communicability has been successfully used to discover communities in networks [44]. The product yields a centrality metric which defines the importance of a node as function of its ability to communicate with all other nodes in the network. In turn, the diagonal entry of the matrix exponential defines a further centrality metric called subgraph centrality [23]. As a result of the rewriting above, we clearly see the exponential potential gain as dependent on two factors: popularity of (i.e., its degree) and similarity of with all other nodes in the network.
The computation of the geometric (resp., exponential) potential gain for all nodes in needs the specification of the full adjacency matrix ; in this sense, the geometric and the exponential potential gain should be considered as global centrality metrics, on par with the Katz centrality score and subgraph centrality.
4.4 The relation between the geometric and the exponential potential gain
In this section we present some guidelines on how to choose the factor discussed in the previous section.
A straightforward choice would be to set as in [9] or, in analogy with the Google PageRank damping factor, [22]. On the other hand, Foster et al. [45] suggested the following:
[TABLE]
where .
It is instructive to investigate the existence of a crossover point , i.e. to discover a value of at which the geometric and the exponential gain of a node coincide. To this end, we provide the following result.
Theorem 1**.**
Let be a graph with adjacency matrix and eigenvalues . For each node and for , the geometric and the exponential gains of coincide if and only if one of the following holds:
, or 2. 2.
, provided that .
Proof.
Recall that for sufficiently large values of , we can approximate the geometric and the exponential gain as follows:
[TABLE]
Recall that is a square and symmetric matrix. Thus, it admits the following eigendecomposition,
[TABLE]
where is a diagonal matrix storing the eigenvalues of and is an orthonormal matrix, whose columns coincide with the eigenvectors of .
Now recall [43] that, for any function , the matrix is still diagonalisable and, for any eigenvalue of we have that is an eigenvalue of . In addition, the matrices and share the same eigenvectors so we have .
Let us consider now the application of the two functions and to matrix . The eigenvalues of the matrix are
[TABLE]
whereas the eigenvalues of the matrix are
[TABLE]
Let us introduce and , the diagonal matrices storing the eigenvalues of the matrices and , respectively. Let us now compute the difference between the geometric and potential gain:
[TABLE]
We focus on the -th component of vector and observe that its value is given as:
[TABLE]
Here we used the fact that eigenvectors of form an orthonormal basis. If we assume that , then if and only if:
[TABLE]
which completes the proof. ∎
4.5 Calculation of geometric and exponential potential Gains
In this section we present our algorithm for the computation of the geometric potential and exponential potential gain.
Our algorithm can be implemented in few lines of code in any high-level programming language, since it applies the expansion series provided in Equations 7 and 10. Our approach provides insight on how the walk length affects the calculation of the geometric (resp., exponential) potential gain: indeed, if we stop the expansion of Equation 7 (resp. Eq. 10) after the first terms, then, we would only include the walks up to length in the calculation of the geometric (resp., exponential) potential gain.
Let us consider the computational complexity of our solution. We begin with the geometric potential gain and assume that we stop expanding the Neumann series after generating walks of length . In such a case, it is easy to see that cost will be in . In fact, for any such that , let us set and suppose that we have stored the sequence , with , .
Hence, the following recurrence holds:
[TABLE]
The last equality states that any term can be calculated as the product of a sparse matrix () by a vector (), already computed in the previous iteration. Such an operation takes steps which, in the case of sparse networks, is .
Similarly, given that can be expressed as , we conclude that the cost required to compute the geometric potential gain amounts is . As for space complexity, the cost for computing is .
The computation of the geometric potential gain requires to fix beforehand, which, in turn, requires to fix an approximation of the spectral radius . The literature on the estimation of provides some bounds on it [46, 47] but, available upper bounds are often not tight and, thus, uninformative; therefore, an alternate way to approximate is to rely on algorithms such as the Power Iteration Method [48]. On the other hand, if we target very large graphs, sampling techniques seem the best option [49].
Analogous results for both time and space complexity hold for the computation of the exponential potential gain as we show next. Define a sequence recursively as follows:
[TABLE]
Therefore, any term can be calculated as the product of a sparse matrix () by a vector (), which has been already computed in the previous iteration. Such an operation takes .
Given that can be expressed as , we can conclude that the (worst-case) time complexity for the calculation of the exponential potential gain is ; similarly the space complexity is , hence for sparse graphs both time and space complexity reduce to
5 Methods for computing the Geometric and Exponential Potential Gain
In this section we prove that our algorithm to calculate the geometric and the exponential potential gain is convergent, and we provide an upper bound on the rate of convergence.
Let be the true value of the geometric potential gain and let be the approximate value of geometric potential gain we would obtain by considering walks up to length . We wish to estimate:
[TABLE]
Analogously, the approximation error associated with the calculation of the exponential potential gain is given by
[TABLE]
The evaluation of and requires us to evaluate the norm of some matrices; here we will rely on the matrix norm (also known as the spectral norm), which, in case of symmetric matrices coincides exactly with [48].
Since all matrix norms defined over a space of finite-dimension matrices are equivalent, our results generalize to other matrix norms; the only requirement is that the sub-multiplicative property holds, i.e., for any pair of matrices and .
5.1 Rate of convergence for the geometric potential gain
Regarding the assessment of , we note that the source of error in approximating the geometric potential gain depends on the early stopping of the Neumann series, i.e., on the approximation:
[TABLE]
Now, if we set , the error depends on:
[TABLE]
As we obtain:
[TABLE]
Moreover, as , converges to [29]. This result, however, is rather weak as it does not give us a realistic estimation of the number of iterations that are required to assure that , for any .
A more refined estimation of the rate of convergence of that applies to the general case of square complex matrices is due to Young [50], who provides a bound of the form ; it depends on , on the number k of iterations and, finally, on the size of .
Since we are dealing with symmetric matrices, we can derive simpler bounds that are independent of the matrix size, as proved below.
Theorem 2**.**
Let be a graph with adjacency matrix and let be its spectral radius; also let . Then with convergence rate .
Proof.
Recall that matrix is square and symmetric thus it admits the following eigendecomposition
[TABLE]
where is a diagonal matrix storing the eigenvalues of and is an orthonormal matrix, whose columns coincide with the eigenvectors of .
In the light of the eigendecomposition of we get:
[TABLE]
which can be further simplified by observing that, for any :
[TABLE]
Here we used the fact that and are orthonormal so their norm is equal to . In addition, has the same spectrum of hence its norm coincides with the spectral radius of . By putting together the previous results we obtain:
[TABLE]
as required.
∎
5.2 Rate of convergence for the exponential potential gain
The convergence result obtained with Theorem 2 above has a counterpart for the exponential potential gain. In Theorem 3 below we give an exponential convergence result for the exponential potential gain case.
Theorem 3**.**
Let be a graph with adjacency matrix and let be the spectral radius of . If is at least then
[TABLE]
is an upper bound for .
Proof.
Thanks to Equation 6 we can define:
[TABLE]
Next, we exploit the sub-multiplicativity property of the norm to obtain:
[TABLE]
with . Also, by repeated application of the triangle inequality we obtain:
[TABLE]
Recall that is undirected so its adjacency matrix is symmetric. Thus, the norm of coincides with its spectral radius. Also, for any , is still symmetric and, due to the sub-multiplicativity of the norm, we get , which allows us to simplify Equation 25 as follows:
[TABLE]
Now, since , we have that converges to the constant value .
The final step corresponds to applying Stirling’s formula [51], which states that, for sufficiently large values of , , which implies if . Therefore, after some simplifications, we obtain
[TABLE]
which completes the proof.
∎
5.3 Computational Analysis
Many previous studies focused on the problem of efficiently calculating the product where , and is an arbitrary function defined over the spectrum of [52].
In many applications is large and, thus, it is computationally prohibitive to first compute and, then, to form the product .
A clever strategy consists of projecting (resp., ) onto a matrix (resp., a vector ) of size (resp., ) belonging to a subspace such that is much smaller than : in this way, we estimate the product as which is much easier to compute.
The task of projecting and onto and is equivalent to constructing an orthonormal matrix whose columns span . If such a matrix is available, then is defined as and the vector is mapped onto the vector .
The procedure for calculating depends on both the spectral features of as well as on the approximation accuracy we plan to obtain; in practice, the size of could be very large and, thus, optimization techniques have been extensively studied to generate good approximations of .
One of the most popular techniques is the Krylov subspace [53, 48]
Definition 1** (Standard Krylov Subspace).**
Let matrix and let . The standard Krylov subspace of dimension associated with and is defined as the
[TABLE]
One could construct the standard Krylov subspace and identify an orthonormal basis for ; the vectors in such a basis constitute the columns of the matrix we would like to compute.
Since is symmetric the most efficient technique to find such an orthonormal basis for is the symmetric Lanczos algorithm [48]. Such an algorithm performs iterations and, at each iteration, the most time-expensive step consists of calculating the product of the matrix by a vector of size . If is large but sparse, the cost of each iteration is and the overall cost is which is equal to the asymptotic cost of our algorithm.
A further, computationally-appealing option is to approximate by means of a rational function defined as the ratio of two polynomials, and , of degree and , respectively [54, 52]. In this way, the problem of calculating is equivalent to evaluate which should be hopefully easier to calculate. If we denote as the poles of , i.e, the roots of , then we introduce the following definition:
Definition 2** (Rational Krylov Subspace).**
Let matrix and let . The rational Krylov subspace of dimension associated with and is defined as the
[TABLE]
Rational Krylov subspace methods are often more accurate than standard ones but they require to solve, at each iteration, a linear system; such a task is equivalent to computing terms of the form and such a procedure is usually much more expensive than standard Krylov methods.
Theorems 2 and 3 indicate that our procedure is capable of achieving an exponentially decay error: consequently, we are able to achieve the accuracy we wish with a relatively small number of iterations.
6 Experimental validation
In this section we report on the experiments we carried out to assess the effectiveness of geometric and exponential potential gain on real-world datasets. Our experiments aim at answering the following questions:
How sensitive are our approximations of the geometric and the exponential potential gain w.r.t. the length of walks? 2.
Do our algorithms scale up to real graphs? 3.
How do the geometric and exponential potential gain correlate with other, popular, centrality metrics such as Degree, Katz, PageRank and Eigenvector Centrality? Are the aforementioned centrality metrics good candidates for assessing the navigability of a node in the sense defined in this paper?
To answer these questions, we considered three large, real datasets, taken from [55], whose features are described in Table I. The first dataset – Facebook – is a sample of the Facebook user connections graph: in it, a node represents a Facebook user and an edge represents a friendship between two users. The second dataset, called DBLP, is a sample of the DBLP computer science bibliography: authors correspond to nodes and two nodes are linked by an edge if the corresponding authors have published at least one paper together. Finally, YouTube, is a sample of the friendship network between YouTube users.
We implemented our algorithms in Python (with the Scipy module) on a hardware platform with the following features: AMD Ryzen 5 1600 CPU, 16GB RAM and Ubuntu 17.10.
6.1 The impact of walk length on the approximation of geometric/exponential potential gains
The aim of this section is to answer question and, specifically, to study the quality of the approximation of the geometric and exponential potential gain in relation to walk length. Ideally, one would like geometric (resp., exponential) potential gain values to stabilize already for small values of . It would mean that, for any node , it suffices to consider nodes located a few hops away from to get a satisfactory approximation of its geometric (resp., exponential) potential gain.
To perform our study we experimentally studied the decrease of and as function of . We start by discussing the results for the geometric potential gain, in Figures 1, 2 and 3.
A notable feature of our algorithm is that convergence is very fast, independently of the size and nature of the dataset under investigation. For instance, with the YouTube dataset– the largest tested here – walks up to length are sufficient to achieve lesser than .
A further observation is that, for a fixed value of , the larger , the slower the convergence of to zero, and that our results perfectly agree with the statement of Theorem 2.
It is also instructive to study how varies across datasets: for any value of , for DBLP converges to zero faster than it does for Facebook, despite the fact that DBLP is about five times larger than Facebook (see Figures 2 and 3). It is also possible to appreciate small differences in the slopes of straight lines plotting as a function of .
The important finding described above is mirrored by a similar result for the exponential potential gain, as illustrated by Figure 4. Once again we notice that graph size has a small impact on the convergence of our algorithm. From Theorem 2, in fact, is the dominant parameter: the smaller , the faster the algorithm converges to the true value of the exponential potential gain. Notice also how the exponential potential gain needs walks that are longer than those needed for the geometric potential gain: we need walks up to length 169, 189 and 279 for DBLP, Facebook and YouTube, respectively.
The main results of our experimental validation can be now summarized as follows: (i) For the geometric potential gain, small values of should be used. Walks of length between 4 and 10 are sufficient to get a very good approximation. (ii) The time needed to compute the geometric and the exponential potential gain does not depend on the graph size but it only depends on : the larger the more dense/connected the graph is and, thus, a larger number of walks is needed to achieve a good approximation. (iii) Computing the exponential potential gain is slower than computing geometric potential gain and, experimentally, it might require walks whose length is ten times larger. This finding suggests that we should consider as future work to introduce a decay factor of the form to penalize long walks.
6.2 Scalability Analysis
In this section we address question by studying how our algorithms scale over Facebook, DBLP and YouTube. We measured the execution times as a function of the walk length . In particular, for the geometric potential gain we were concerned with understanding how affected the performance of our approach. The results we obtained are plotted in Figure 5.
Clearly, an increase of yields an increase in computational time. This is due to the fact that larger values of force our algorithm to explore the graph in more depth. Such effect can be clearly seen in Figure 5; the increase is approximately linear in so we can conclude that the computational impact of increasing is limited. Of course, larger datasets still require greater computational resources since we will have multiply the adjacency matrix by a vector. However, for sparse adjacency matrices the calculation is still fast, e.g., it takes less than one second for the three datasets considered here.
Table II reports the computation times of the exponential potential gain. Again we may notice how exponential potential gain is computationally more demanding than the geometric potential gain as we need many more iterations. In addition, notice how the computational time for DBLP is about three times slower than for Facebook despite the fact that the latter needed 20 iterations more. Such difference depends on the difference in size between the two datasets.
6.3 Relation with other centrality metrics
In this section we investigate how the geometric and the exponential potential gain are correlated with some popular centrality metrics. Specifically, we compared the Geometric (GPG) and the Exponential Potential Gain (EPG) with Degree Centrality (DEG), Eigenvector Centrality (EC), PageRank (PR) and Katz Centrality (Katz). As for PR, we fixed the damping factor equal to 0.85. For a fair comparison, we choose the same value of forGPG and Katz. We used Spearman’s coefficient to calculate the correlation between the ranked lists of nodes that each of these centrality metrics generates on the datasets above.
Let us now analyse how DEG, PR and EC correlate each other and how they are related with EPG. (EPG is discussed later as it does not depend on any parameter). The main findings of our analysis are plotted in Figures 6 - 8 and can be summarized as follows:
DEG and PR are strongly positively correlated: we found Spearman’s correlation coefficients ranging from (on YouTube) to (on Facebook). Such correlation is well-known in the literature because, in the case of undirected graphs, the PR scores of nodes are almost proportional to their degrees. 2. 2.
On Facebook EPG and EC are highly correlated while at the same time display a perfect negative correlation on the other two datasets. This result is related to the property that the EPG of a node is always proportional to its communicability, as we have shown in Section 4.2. When the spectral gap between the largest and the second-largest eigenvalue, i.e., , is large, then communicability is, up to a constant factor, exactly equal to EC; see [22] for a detailed proof. As a consequence, for graphs with a large spectral gap the EPG of a node is proportional to its EC; this explaining the large correlation values we observed in our tests. 3. 3.
The topological features of the given graph have a huge impact on : for instance, DEG and EC are positively correlated on Facebook () but they are negatively correlated on DBLP and YouTube. Analogously, EPG and PR are positively correlated on Facebook and YouTube ( = 0.64 and 0.44, respectively) but almost unrelated on DBLP.
Let us now consider the correlation between DEG, EC, PR and EPG and GPG; such correlation varies upon different choices of the parameter . Figures 9, 10 and 11, show how varies as function of , where . We can draw the following conclusions:
The GPG and Katz have an almost perfect correlation, as one would expect (red line). In fact, GPG and Katz differ by a multiplicative and constant factor given by the degree. 2. 2.
We note some interesting facts about the correlation of GPG and EPG (orange line). Firstly, if increases, then we generally have a (sometimes slight) increase in . The correlation coefficient is always positive but it ranges from in DBLP to 1 (on Facebook and YouTube).
To explain the differences emerging across our datasets we observe the difference of the geometric and the exponential potential gain of a node depends on (see Equation 13). Therefore, on the basis of the distribution of eigenvalues, we conclude that for some datasets GPG and EPG might be strongly and positively correlated while they are negatively correlated elsewhere. 3. 3.
As for the correlation between EC and GPG (green line), we find a positive correlation on Facebook and a negative correlation on DBLP and YouTube. In fact, for a fixed node, the GPG is proportional to the Katz score of that node; if , then the Katz score converges to EC and, in this case, the GPG of a node is proportional to its EC. Similar considerations hold for GPG and PR (magenta line). 4. 4.
Consider now DEG (see blue line). An increase in generally causes a decrease in , with the exception of the DBLP dataset where the correlation between DEG and GPG is almost perfect. As expected, when the GPG is well approximated by DEG. Vice versa, as increases, walks of length greater than one increasingly contribute to GPG, thus amplifying the difference between DEG and GPG.
The detailed analysis of the experimental results strongly suggests that the potential gain is a general framework, which unifies some of the main walk-based centralities.
7 Conclusions
We have introduced the potential gain, a general framework which captures the ability of a node to act as a target point for navigation within a graph and unifies several walk-based centrality indices in graphs. We have defined two variants of the potential gain, the geometric and exponential potential gain and proposed two iterative algorithms for each of them. The convergence of the algorithms was also proved; their scalability was tested against three real large datasets.
The present results provide a starting point to a better understanding of the theoretical properties of the potential gain. Previous research has sought to axiomatise centrality and its metrics, and it would be extremely interesting to study which of these axioms are satisfied by the Potential gain. For instance, Boldi and Vigna [8] proposed three axioms, called size, density and score monotonicity, which may play a role in axiomatising the Potential Gain itself.
Another topic for future work is investigation of the relationship between network robustness and network navigability. To this end, we intend to design an experiment in which graph nodes are ranked on the basis of their geometric/exponential potential gain and then are progressively removed from the graph. Basic properties about graph topology, such as the number and size of connected components shall be re-evaluated upon node deletion. We also plan to study how adding edges can increase the geometric/exponential potential gain of a target group of nodes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] L. Lü, D. Chen, X. Ren, Q. Zhang, Y. Zhang, and T. Zhou, “Vital nodes identification in complex networks,” Physics Reports , vol. 650, pp. 1–63, 2016.
- 2[2] F. Chung, P. Horn, and A. Tsiatas, “Distributing antidote using Pagerank vectors,” Internet Mathematics , vol. 6, no. 2, pp. 237–254, 2009.
- 3[3] J. Leskovec, L. Adamic, and B. Huberman, “The dynamics of viral marketing,” ACM Transactions on the Web , vol. 1, no. 1, p. 5, 2007.
- 4[4] S. Agreste, P. De Meo, E. Ferrara, S. Piccolo, and A. Provetti, “Trust Networks: Topology, Dynamics, and Measurements,” IEEE Internet Computing , vol. 19, no. 6, pp. 26–35, 2015. [Online]. Available: https://doi.org/10.1109/MIC.2015.93 · doi ↗
- 5[5] R. Alber, I. Albert, and G. Nakarado, “Structural vulnerability of the North American power grid,” Physical review E , vol. 69, no. 2, p. 025103, 2004.
- 6[6] S. Agreste, P. De Meo, E. Ferrara, S. Piccolo, and A. Provetti, “Analysis of a heterogeneous social network of humans and cultural objects,” IEEE Transactions on Systems, Man, and Cybernetics: Systems , vol. 45, no. 4, pp. 559–570, 2015.
- 7[7] M. Newman, Networks: an introduction . Oxford University Press, 2010.
- 8[8] P. Boldi and S. Vigna, “Axioms for centrality,” Internet Mathematics , vol. 10, no. 3-4, pp. 222–262, 2014.