Targeting GPUs with OpenMP Directives on Summit: A Simple and Effective Fortran Experience
Reuben D. Budiardja, Christian Y. Cardall

TL;DR
This paper demonstrates a simplified approach using OpenMP directives to effectively utilize GPUs on Summit, achieving significant speedups and scalable performance for astrophysics and fluid dynamics applications.
Contribution
It introduces a streamlined method for GPU offloading with OpenMP in Fortran, enhancing ease of use and performance on Summit supercomputer.
Findings
Achieved ~12x speedup with GPUs on Summit.
Demonstrated reasonable weak scaling up to 8000 GPUs.
Provided open-source code for GPU targeting with OpenMP.
Abstract
We use OpenMP to target hardware accelerators (GPUs) on Summit, a newly deployed supercomputer at the Oak Ridge Leadership Computing Facility (OLCF), demonstrating simplified access to GPU devices for users of our astrophysics code GenASiS and useful speedup on a sample fluid dynamics problem. We modify our workhorse class for data storage to include members and methods that significantly streamline the persistent allocation of and association to GPU memory. Users offload computational kernels with OpenMP target directives that are rather similar to constructs already familiar from multi-core parallelization. In this initial example we ask, "With a given number of Summit nodes, how fast can we compute with and without GPUs?", and find total wall time speedups of . We also find reasonable weak scaling up to 8000 GPUs (1334 Summit nodes). We make available the source…
Click any figure to enlarge with its caption.
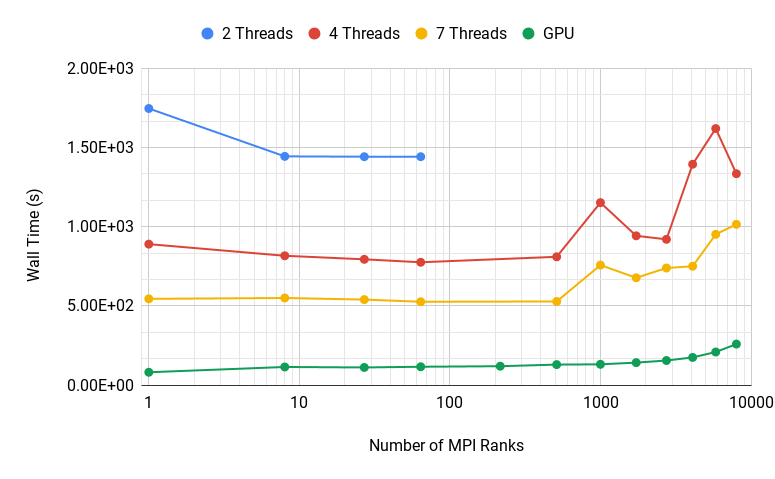 Figure 1
Figure 1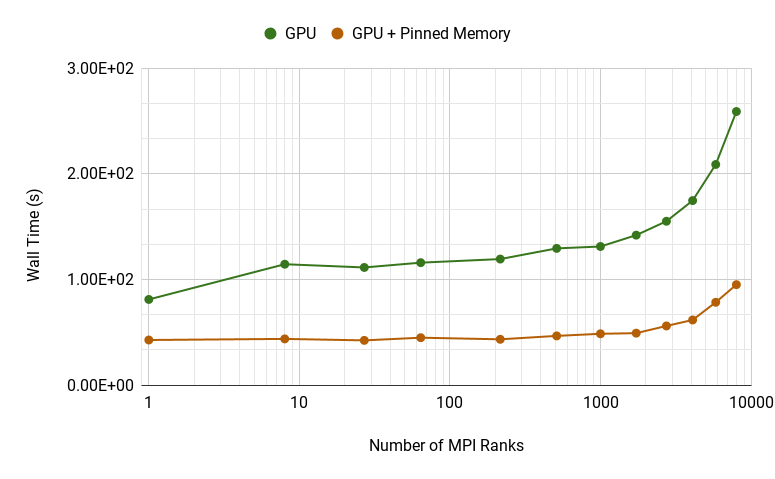 Figure 2
Figure 2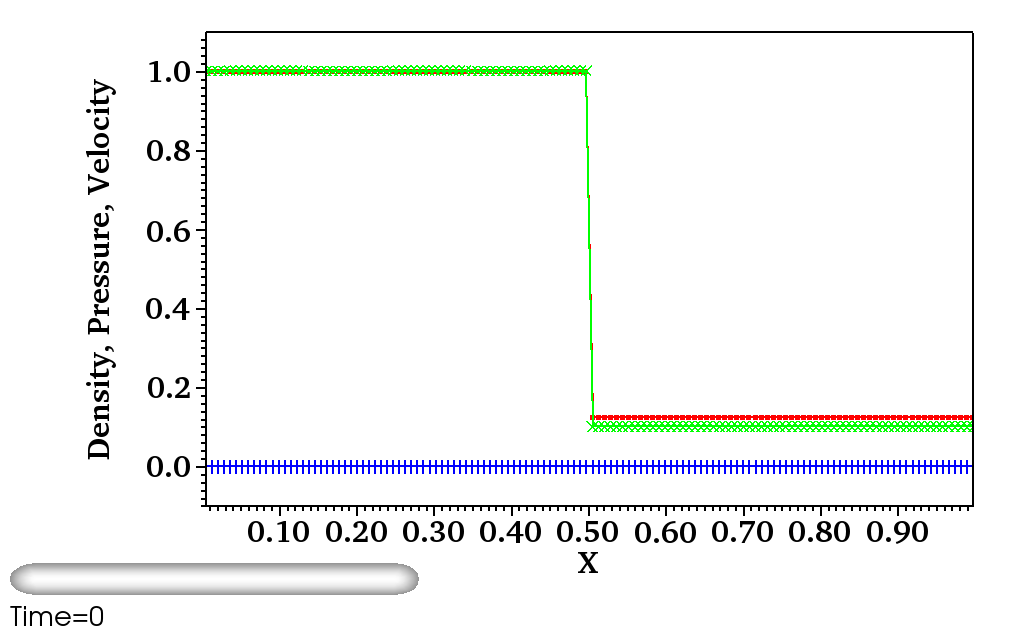 Figure 3
Figure 3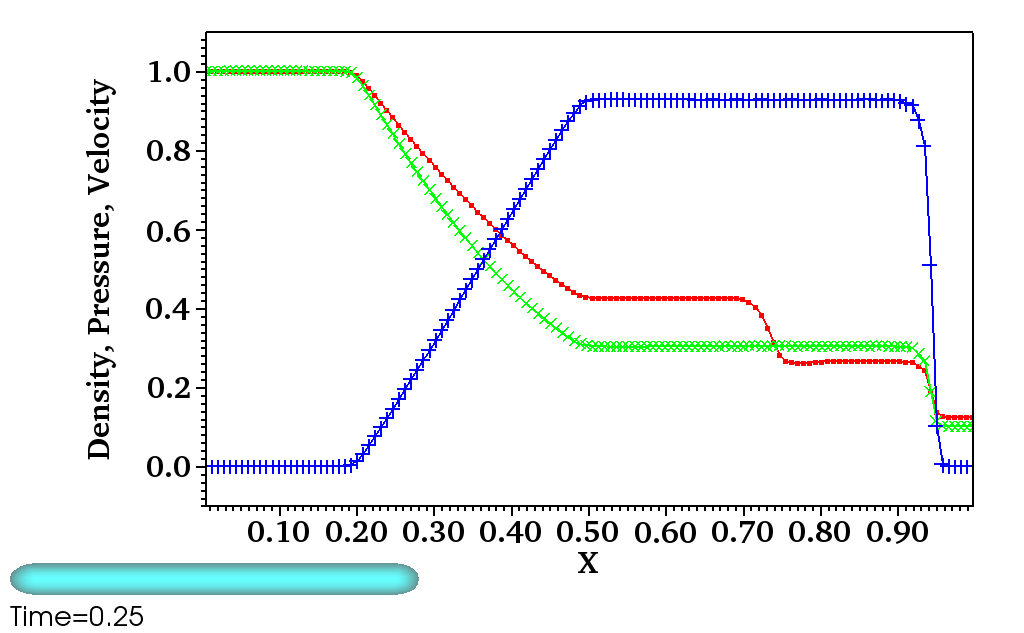 Figure 4
Figure 4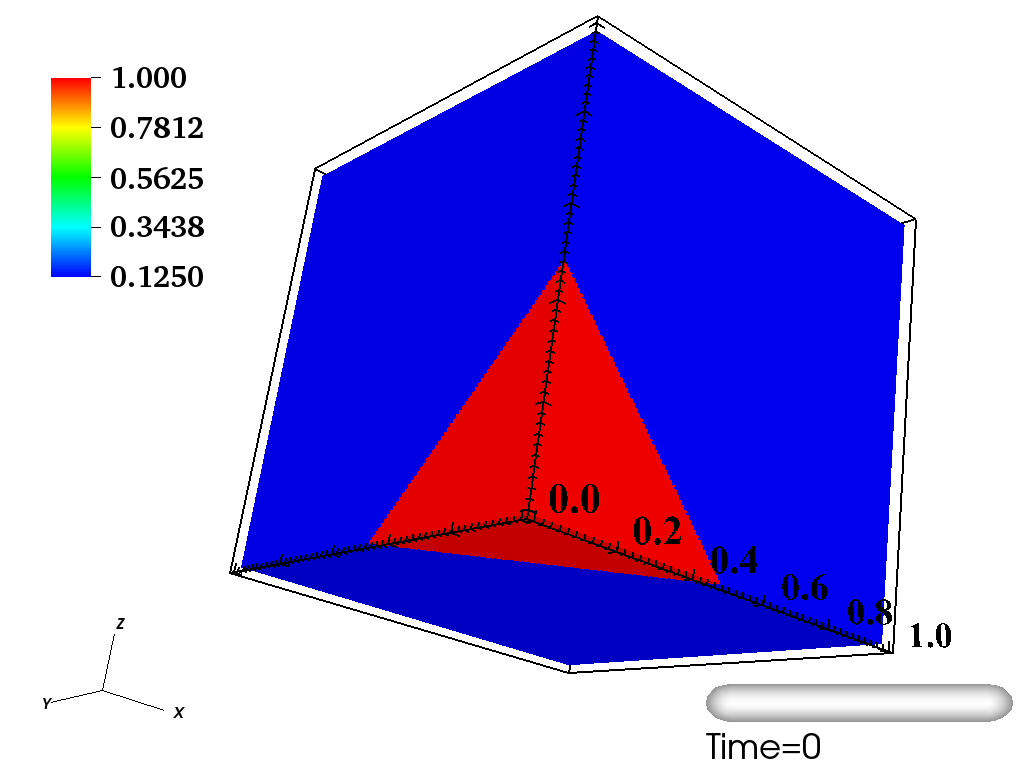 Figure 5
Figure 5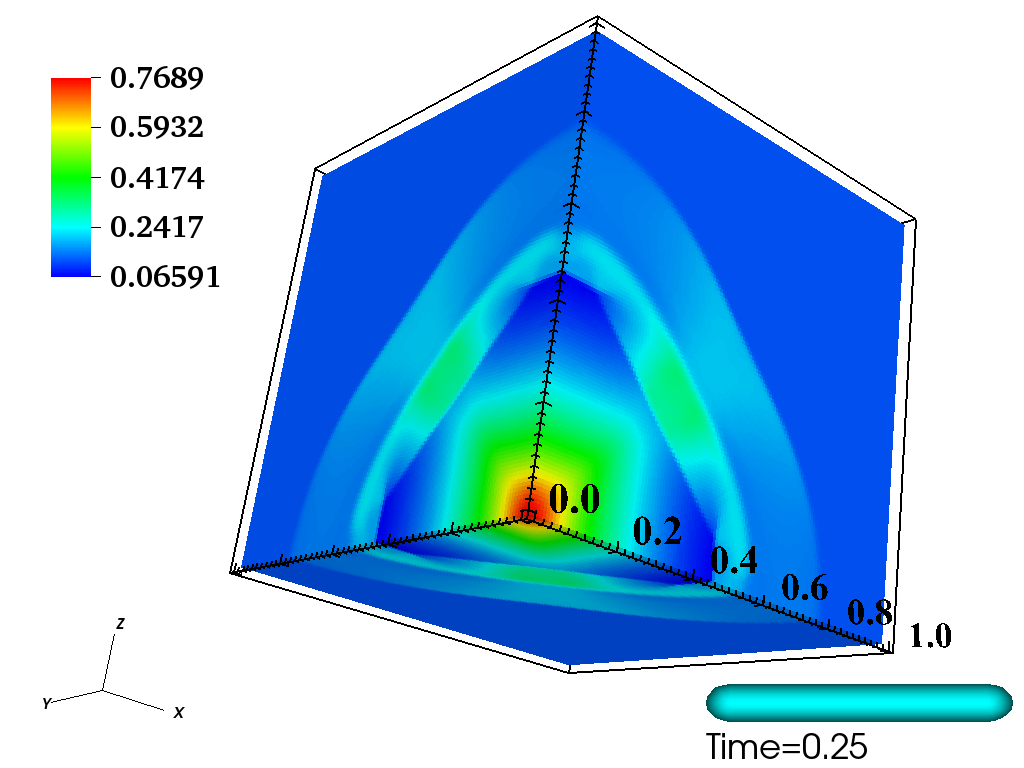 Figure 6
Figure 6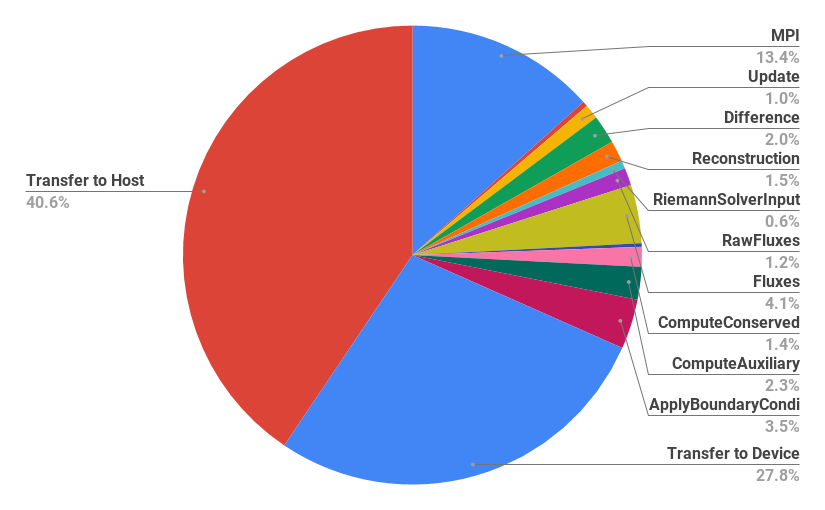 Figure 7
Figure 7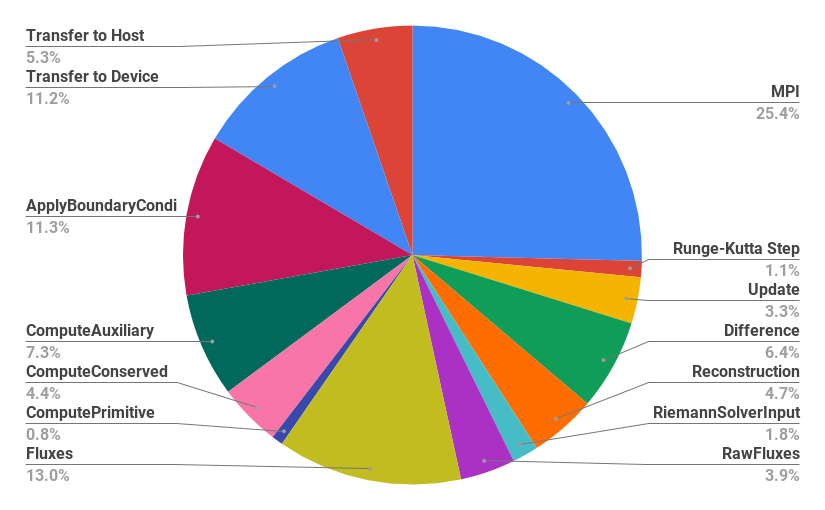 Figure 8
Figure 8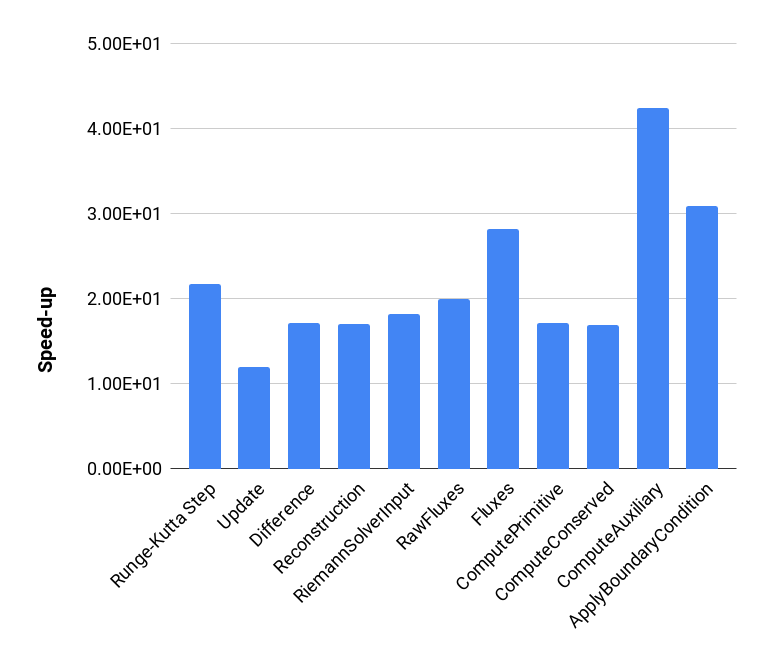 Figure 9
Figure 9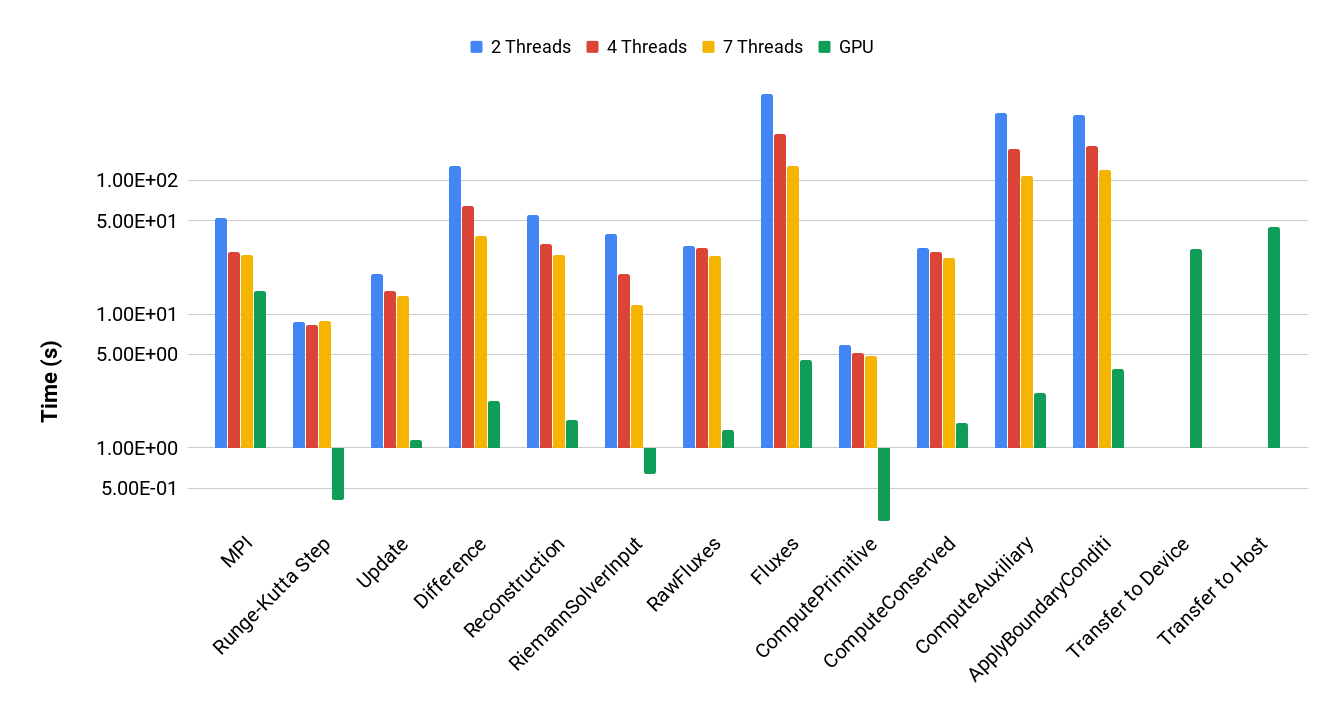 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Targeting GPUs with OpenMP Directives on Summit:
A Simple and Effective Fortran Experience
Reuben D. Budiardja
Christian Y. Cardall
National Center for Computational Sciences, Oak Ridge National Laboratory, Oak Ridge, TN 37831-6354, USA
Physics Division, Oak Ridge National Laboratory, Oak Ridge, TN 37831-6354, USA
Department of Physics and Astronomy, University of Tennessee, Knoxville, TN 37996-1200, USA
Abstract
We use OpenMP to target hardware accelerators (GPUs) on Summit, a newly deployed supercomputer at the Oak Ridge Leadership Computing Facility (OLCF), demonstrating simplified access to GPU devices for users of our astrophysics code GenASiS and useful speedup on a sample fluid dynamics problem. We modify our workhorse class for data storage to include members and methods that significantly streamline the persistent allocation of and association to GPU memory. Users offload computational kernels with OpenMP target directives that are rather similar to constructs already familiar from multi-core parallelization. In this initial example we ask, “With a given number of Summit nodes, how fast can we compute with and without GPUs?”, and find total wall time speedups of . We also find reasonable weak scaling up to 8000 GPUs (1334 Summit nodes). We make available the source code from this work at https://github.com/GenASiS/GenASiS_Basics.
††Notice of copyright: This manuscript has been authored by UT-Battelle, LLC under Contract No. DE-AC05-00OR22725 with the U.S. Department of Energy. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes. The Department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan (http://energy.gov/downloads/doe-public-access-plan).
1 Introduction
As of version 4.5, OpenMP provides an excellent opportunity to access the extraordinary computational power of the GPUs on machines like Summit at the Oak Ridge Leadership Computing Facility (OLCF). Most notably, the similarity to existing OpenMP multi- or many-core parallelization coding patterns allows relative ease of porting and minimizes divergence between versions of a code to be run with or without GPUs or other hardware acceleration devices.
That the programmer need not engage the CUDA programming model is particularly useful in Fortran applications. Given the broad acceptance and entrenched use of OpenMP, it can be expected that the facilities for devices now specified in its standard will receive wide support. This is in contrast for instance with CUDA Fortran, a non-standard Fortran extension provided by only two compiler vendors (PGI and IBM XL), excluding many widely-used compilers (e.g. GCC, Intel, and Cray). Moreover, OpenACC—an alternative directive-based approach—is currently actively supported only by the PGI compiler, and some ongoing efforts in GCC. On Summit in particular, excellent support for OpenMP 4.5 already exists with the IBM XL compiler. Our experience so far is that Fortran features and semantics such as multidimensional arrays, array sections, and pointer remapping (allowing for instance access to a given memory block as either a 3D or 1D array) are translated just as one would hope and expect.
We have recently begun using OpenMP to adapt our code GenASiS (General Astrophysical Simulation System) to the exploitation of GPUs on Summit. Aggressively deploying the features introduced in Fortran 2003 that facilitate an object-oriented approach, GenASiS is an extensible multiphysics simulation code aimed primarily at astrophysics applications [1]. Early versions have been used to study aspects of the post-bounce core-collapse supernova environment [2, 3, 4, 5, 6]. GenASiS is divided into three primary divisions: Basics, which includes utilitarian functionality generically needed by physics simulations on distributed-memory supercomputers [7, 8]; Mathematics, which encompasses implementations of manifolds (i.e. meshes), operations, and solvers [9]; and Physics, which comprises spaces governed by various theories of spacetime and gravity, specific forms of stress energy such as fluids and radiation, and the combination of these into universes. See Figures 1 and 2 of reference [7] for the overall structure of GenASiS and of GenASiS Basics, which is the basis of this work.
In this paper we report our initial explorations, which include implementation of GPU-related infrastructure in GenASiS Basics and its use in a simple fluid dynamics problem, the RiemannProblem example built only upon Basics classes. We assume throughout that the reader has some basic familiarity with OpenMP 4.5 device-related constructs.111For a thorough description of OpenMP target and device-related constructs, the reader is referred to the OpenMP 4.5 specification, reference guide, and examples available at https://www.openmp.org/specifications/. In Section 2 we describe the functionality we have added to GenASiS to streamline the use of GPUs. In Section 3 we introduce the RiemannProblem example and describe its porting to GPU-aware code. Section 4 reports the performance gains we obtain on Summit by exploiting its GPU resources. In Section 5 we show further performance gains that can be achieved when later OpenMP specifications adopt more advanced memory management. Section 6 offers some concluding thoughts on the state of OpenMP implementations vis-à-vis GPU usage. In what follows we use the term ‘host’ to refer to the set of cores assigned to a Message Passing Interface (MPI) process on the CPU, and ‘device’ to refer to the GPU available to the same MPI process. (In its current version, our code can only use one GPU per MPI process.)
We make available the source code from this work at https://github.com/GenASiS/GenASiS_Basics.
2 Using an Accelerator Device in GenASiS
In many cases (which may be opaque to or unexpected by the programmer), OpenMP directives enable the automatic transfer of data needed by offloaded kernels from the host to the device and back without intervention by the programmer; but because large data transfers incur significant overhead, it behooves applications to instead take affirmative control of significant data movement. In particular, it is possible to persistently allocate memory on the device for predictively repeated use; to flexibly associate Fortran variables with previously allocated memory locations on the device in a persistent manner; and to command the transfer of data between the host and device. When data is present on the device, and host variables are associated with device locations, a computational kernel expressed in terms of those host variables can be executed on the device by enclosing the kernel code with the OpenMP target directive and its corresponding end target exit directive.
In this section we distinguish between lower-level and higher-level functionality in GenASiS. Lower-level functionality consists of the most basic processes implemented as standalone routines. Higher-level functionality consists of the public methods of a class (using the type-bound procedure facility of the Fortran 2003 standard) for the convenience of programmers writing a GenASiS application.
2.1 Higher-level GenASiS Functionality
The primary way we have made device functionality available to GenASiS application programmers is by adding members and methods to our workhorse class StorageForm. This class includes members for both data and metadata; it is used to group together a set of related physical fields on a computational domain. Code for tasks like I/O, ghost cell exchange, prolongation and restriction on multilevel meshes, and so on are simplified and rendered more generic by use of this class.
The data member Value of StorageForm is a rank-2 array whose first dimension (rows)—that corresponds to contiguous storage in Fortran—indexes different values of a single physical field at different points in space, with the second dimension (columns) indexing different physical fields. Metadata members include such things as names and units associated with the several physical fields.
Prior to the addition of device functionality, the only method of StorageForm was an overloaded Initialize procedure. One mode of initialization entails allocation of the data member Value according to a specified shape; this is a ‘primary’ instance of StorageForm. A second mode initializes an ‘overlay’ instance of StorageForm, which does not allocate new storage; instead, it points its Value member to that of an existing instance, and includes an integer array member iaSelected222The prefix ia- in iaSelected is our shorthand for ‘index array.’ specifying a subset of physical fields—that is, the indices of selected columns of Value to be regarded as ‘active’ in the new instance. (The iaSelected member of a ‘primary’ instance of StorageForm automatically includes all columns of data.)
Adding just a handful of members and methods to our StorageForm class provides for the persistent allocation of device memory—and references thereto—in a manner that is simple to use, yet still quite generic and therefore powerful. A new method AllocateDevice() is used to allocate device memory in a manner that mirrors our usual access to physical fields in primary and overlay instances of StorageForm on the host. In the case of a primary instance, the method AllocateDevice() (a type-bound procedure of the class) calls the lower-level AllocateDevice() routine (a free-standing wrapper discussed in Section 2.2) to allocate a block of memory corresponding to the member Value of StorageForm. The sections of this array on the device are persistently associated with the corresponding individual physical fields (columns of the Value member) on the host by a call to the lower-level AssociateHost() routine (another free-standing wrapper discussed in Section 2.2). In this way, when individual physical fields are addressed inside an OpenMP target region as host variables, the correct device memory locations are referenced.
A call to AssociateHost() for each individual variable is needed following the memory allocation on the device for the following reason. Using an unstructured directive
!\
[TABLE]
OMP target enter data map ( alloc : Value )}
to associate the member Value on the host with its copy on the device would not allow us to address individual physical fields (columns of Value). Although the latter could have been accomplished by instead using the specified columns of Value as the argument to the directive, such as,
do iV = size ( Value, dim = 2 )
Variable => Value ( :, iV )
!\
[TABLE]
OMP target enter data map ( alloc : Variable )
end do
such code may result in memory allocation on the device that is non-contiguous from one column of Value to the next. By explicitly allocating memory on the device ourselves to the full size of Value (rows and columns), we ensure a contiguous memory allocation that facilitates flexibility in transferring data either in bulk or as individual columns, and in performing operations across multiple columns of Value that may be much more efficient with coalesced memory.
In the case of an overlay instance of StorageForm, a call to the AllocateDevice() method is neither needed nor appropriate, because persistent association of individual physical fields must be established by a call to the AllocateDevice() method of the primary instance.
Finally, the methods UpdateDevice() and UpdateHost() (which call the lower-level routines of corresponding name discussed in Section 2.2) allow all the selected fields of an instance of StorageForm to be transferred to or from the device en masse with a single call. Alternatively, individual fields can be specified for transfer.
2.2 Lower-level GenASiS functionality
In the previous section we explained why we need to use OpenMP runtime library routines for device memory management—such as the persistent allocation of memory on the device and for association of a host variable with previously allocated device memory—instead of target enter data directives. Because these routines are only provided in C, we use the C interoperability capabilities of Fortran 2003 to write simple Fortran wrappers to make this functionality available as standalone routines GenASiS.
In our code, the line
call AllocateDevice ( Value, D_Value )
allocates a memory region on the device corresponding to the size of the Fortran array Value previously allocated on the host, and sets the variable D_Value of type(c_ptr) to the memory location on the device. 333As might be guessed from the paired variable names Value and D_Value, our default approach is to mirror variables allocated in host memory on the device, using the prefix D_ to denote the device copy. Similarly, the command
call AssociateHost ( D_Value, Value )
causes references to a host variable Value appearing in an appropriate OpenMP directive to be interpreted as referring to the device memory location pointed to by D_Value. We have also provided the corresponding Fortran routines DeallocateDevice() (which frees memory on the device pointed to by an argument D_Value) and DisassociateHost() (which frees a host variable argument Value from its association with a memory location on the device). Under the hood, these wrappers call the OpenMP C functions omp_target_alloc(), omp_target_associate_ptr(), omp_target_free(), and omp_target_disassociate_ptr() respectively, making use of the Fortran 2003 bind attribute. In each case the function omp_get_default_device() is used to identify the device, which is all that is needed with our convention of only one device (i.e. GPU) per MPI process.
We also provide standalone Fortran wrappers in GenASiS to transfer data to and from the device, with the commands
call UpdateDevice ( Value, D_Value )
and
call UpdateHost ( D_Value, Value )
performing transfers from host to device and from device to host respectively. Similarly, under the hood these wrappers call the OpenMP C function omp_target_memcpy().
Although in implementing these lower-level routines we have used OpenMP runtime library routines under the hood, in principle they constitute a façade allowing implementation using other backends, such as the Nvidia CUDA or AMD ROCm libraries.
Normally, we expect that GenASiS application programmers will not need to use these lower-level routines, and therefore never have to deal with device pointers. Instead, we expect application programmers to use the methods of StorageForm for allocation of and association to device memory, and for transfers between host and device, as discussed in Section 2.1.
2.3 Offloading Computational Kernels in GenASiS
In contrast to the functionality added to our workhorse StorageForm class as discussed in Section 2.1—which shields application programmers from direct references to OpenMP—the offloading of computational kernels to the device requires OpenMP directives. This is to be expected given the inherent nature of computational kernels, defined as straightforward segments of code implementing repetitive basic operations, through which significant amounts of data are fed.
In line with common practice and in part for traditional purposes of modularity, our habit is to sequester computational kernels in dedicated subroutines, to which only a few changes are needed to achieve offloading. In GenASiS the sequestration of kernels in subroutines also serves—via arrays provided in argument lists—the additional purpose of exposing fundamental data types to both the programmer and the compiler. That is, instead of confronting a human or algorithmic parser with data buried in more complicated structures, such as array sections of the rank-2 pointer member Value of our StorageForm class, programmers and compilers see straightforward arrays of real variables.
Suppose for example we have an instance Fields of class StorageForm whose Value member contains three columns of data corresponding to three physical fields. Adding the line
call Fields % AllocateDevice ( )
to the program initialization allocates a block of contiguous device memory comprising the three fields, and associates the individual fields on the host with the appropriate addresses within the memory block on the device. Suppose further that we wish to set the third field to the sum of the first two fields by executing a routine AddKernel() on the device. The data is originally on the host, and is again needed on the host after the operation. The lines
call Fields % UpdateDevice ( )
call AddKernel &
( Fields % Value ( :, 1 ), &
Fields % Value ( :, 2 ), &
Fields % Value ( :, 3 ) )
call Fields % UpdateHost ( )
accomplish this task.
The computational kernel called here, shown in Listing 1, has only one element that distinguishes it from a kernel not intended for offloading to the device.444The parameters KDR in lines 3 and 5 and KDI in line 7 specify the Fortran kind of real and integer variable respectively.
The kernel loop in lines 8-12 is accessorized with an OpenMP target directive rather than a similar construct
!\
[TABLE]
OMP parallel do schedule ( static, 1 )
that would be used in a traditional CPU multithreading context. The target directive in line 8 tells OpenMP to offload the computational kernel (line 9-11) to the device. Because the host variables A, B, and C have been previously associated with the device memory location inside the method Fields % AllocateDevice ( ), the OpenMP runtime uses the corresponding device locations for those variables, avoiding any implicit data transfer. The teams distribute directive in the same line creates and distributes work to a league of teams of threads on the device. The manner in which the teams of threads are mapped to the device hardware is implementation-dependent.
It may be asked why the transfer of data to and from the device is not included in the kernel itself—perhaps even left to be done implicitly and automatically by the compiler—and the answer is important to the simple and effective porting of sophisticated codes. Because of the nontrivial overhead involved in data transfer to and from the device, it is highly desirable to keep data on the device for as long as possible. The above simple example involves only a single kernel, but realistic cases may involve calls to many separate kernels between necessary updates to the host. The persistent allocation and association of device memory allows data to be left on the device for extended operations involving multiple separate kernel calls without disrupting the existing structure of thoroughly modularized codes.
3 Porting a Fluid Dynamics Application: RiemannProblem
As a concrete working example of targeting GPUs with OpenMP directives, we use our implementation to solve a RiemannProblem using GenASiS Basics. RiemannProblem is an extension of the classic 1D Sod shock tube—a standard computational fluid dynamics test problem—to 2D and 3D. Figure 1 shows the initial and final state of 1D and 3D versions of RiemannProblem after being evolved to time at a resolution of cells in each dimension.
Pseudocode outlining the solution in RiemannProblem (and other simple fluid dynamics examples distributed with GenASiS Basics) is displayed in Algorithm 1.
Each iteration of the main loop enclosed by lines 4 and 23 is a second-order Runge-Kutta time step consisting of two substeps, each of which consists of several computational kernels (lines 8-12 and 16-20). Because the emphasis in the Basics examples as originally distributed [7, 8] was to demonstrate use of the utilitarian functionality provided by that division of the code, the kernels were written in the most simple-minded and compact manner possible, with essentially no regard for performance or even traditional OpenMP multi-core threading. Eschewing explicit loops and indexing, Fortran array syntax—whole-array operations, the where construct, the cshift() operation, and the like—had been used throughout. Therefore our first task, prior to beginning the porting required for exploitation of GPU devices, was to rewrite these kernels in terms of do loops over explicitly indexed arrays, accessorized with OpenMP directives implementing multi-core threading. This then constituted a code that provided a basis for a speedup comparison, with kernels readily adaptable to offloading via modification of the familiar OpenMP parallel do construct.
Given the infrastructure and approach to accelerator devices described in Section 2, porting Algorithm 1 to its device-enabled counterpart in Algorithm 2 was both straightforward and effective.
Algorithm 2 differs from Algorithm 1 in its notation of whether steps are executed on the Host or Device, but otherwise matches almost line for line in this high-level perspective, the only additions being the Transfer operations explicitly commanded in lines 6, 15, 17, and 25. In the present state of our code these transfers are necessary to allow the host to exchange ghost data between MPI processes responsible for separate regions of the spatial domain. (Future exploitation of CUDA-aware MPI libraries with hardware-enabled GPUDirect technologies should allow this ghost exchange to proceed directly between devices.)
We emphasize that the basic structure of the code has been preserved, and that (with the exception of FluidCurrent) the data utilized by the several kernels is generated on the device and remains on the device throughout each of the Runge-Kutta substeps in lines 9-13 and 19-23 of Algorithm 2. Instances of our class StorageForm for FluidOld, Differences, Reconstruction, Fluxes and FluidUpdate are initialized as part of line 1 in both Algorithm 1 and Algorithm 2; and in the latter case, addition of a call to the AllocateDevice() method of each of these instances to enable use of the device is rather trivial from a programming perspective. Without such use of designated persistent device memory and controlled transfers, OpenMP by default ensures that data would—with blissful ignorance on the part of the programmer, but at the cost of debilitating wall time overhead—be automatically shipped back and forth between host and device between each of the several kernel calls.
It is worth noting a degree of flexibility available in the mapping of host program variables to device memory in computational kernels. As discussed in Section 2.1, we store the values of a physical field corresponding to different cells of a discretized computational domain in a column of a rank-2 Fortran array, the Value member of class StorageForm. However in our fluid dynamics problem (and as is of course the case in general), some of the kernels require knowledge of spatial relationships in the data, in particular, nearest-neighbor (or wider) stencils. In this Basics example problem a single-level rectangular mesh is employed, so that stencil relationships can be represented through appropriate indexing of rank-3 arrays embodying discretized 3D position space. Such 3D arrays can be obtained from a column of data with the Fortran pointer remapping facility. For instance, local rank-3 pointer variables V and dV declared as
real ( KDR ), dimension ( :, :, : ), pointer :: V, dV
can be used to remap (say) the iV-th data column of instances FluidCurrent and Differences of class StorageForm:
V ( -1:nX+2, -1:nY+2, -1:nZ+2 ) &
=> FluidCurrent % Value ( :, iV )
dV ( -1:nX+2, -1:nY+2, -1:nZ+2 ) &
=> Differences % Value ( :, iV )
where nX, nY, nZ are the numbers of ‘proper’ or active cells in each of the three dimensions of a subdomain assigned to an MPI task, and allowance is made for two layers of ghost cells. Now the rank-3 arrays V and dV can be sent to a kernel ComputeDifference_X shown in Listing 2.
Even though the associations between the host variables and device memory locations were originally set in connection with rank-1 arrays (single columns of a Value data array), the references in lines 16 and 17 to rank-3 aliases of these data columns work just as hoped and expected.
To compile our code, we use IBM XL Fortran, version 16.1.1 with -qsmp=omp -qoffload -Ofast flags. The invocation xlf2008_r is used to compile Fortran 2008 source files with thread-safe compilation. The MPI library is provided by IBM Spectrum MPI.
4 Performance Results
The test results described here were performed on Summit, a newly deployed supercomputer at the Oak Ridge Leadership Computing Facility (OLCF).555https://www.olcf.ornl.gov/for-users/system-user-guides/summit/ A compute node on Summit is an IBM Power System AC922, which consists of two IBM Power9 CPUs and six NVIDIA Volta V100 GPUs. Each Power9 CPU has 22 physical cores, one of which is reserved for the operating system tasks, leaving 42 physical cores on a Summit compute node available for running a user’s application. Three GPUs and a Power9 CPU are interconnected with NVLINK. The two Power9 CPUs are connected by an X-Bus. Summit nodes are interconnected in a non-blocking fat tree topology with a dual-rail EDR InfiniBand network.
Summit’s job launching system, jsrun, allows users to create logical abstractions of Summit nodes with the concept of a resource set. Here we create six resource sets per node, where each resource set has seven CPU cores (i.e. 1/6 of the 42 cores per node) and one GPU (i.e. 1/6 of the six GPUs per node). Each resource set is assigned to one MPI process. This allows for meaningful speedup measurements in ‘proportional resource tests’ that compare the performance of runs using either the GPUs or the CPU cores in the resource sets. In other words, we seek to answer the question “With a given number of Summit nodes, how fast can we compute with and without GPUs?”
In the test runs reported here, we use the GPU in exclusive mode by assigning one GPU to each MPI process. In each resource set (described in the preceding paragraph) we run one MPI process with either the GPU or up to seven OpenMP threads on the seven CPU cores assigned to the set. As alluded to in Section 3, the computational kernels in our code can run either with OpenMP threads on the CPU or with OpenMP target directives for the GPU, but not both simultaneously. The speedup results we report below compare these two modes of operation.
For the performance and scaling tests, we assign cells per MPI process for the 3D RiemannProblem to ensure that the problem size is large enough that each MPI process, whether utilizing the GPU or multiple OpenMP threads on the CPU, is not computationally starved. For a sense of comparison, in previous production simulations [5, 6] we assigned cells per MPI process to achieve reasonable time to solution per simulation.
Figure 2 shows the weak scaling of the 3D RiemannProblem for both versions of the code: with OpenMP threads on the CPU, and OpenMP target directives on the GPU. The figure demonstrates near-ideal speedup with increasing CPU thread counts, from 2 to 4 to 7; and from 7 CPU threads to the GPU, approximately another factor of 6 speedup is observed. This significant speedup is achieved even when the extra costs of data transfers between the host memory and GPU high-bandwidth memory are included.
To better understand the computational costs of the different portions of our code, we heavily accessorize computational kernels and logical portions of the code with timers from our TimerForm class [8]. Figure 3 shows the timings for the computational kernels, MPI communication, and—for runs utilizing GPUs—data transfers to and from the GPUs. The figure shows that in almost all computational kernels the GPU runs outperform the CPU runs. We do not expect significant differences in the timing of the MPI communication portion of the code, which is single-threaded and only runs on the host. We therefore attribute the timing differences seen in Figure 3 for the MPI portion to system noise and general variability. (Similar effects of system noise and variability can be seen on the weak scaling plot on Figure 2 for runs with 1000 and more MPI processes.)
Figure 4 plots the speedup of the GPU runs over the CPU runs with 7 OpenMP threads for each computational kernel. Speedups of more than 10X-40X are achieved.
Are we getting the speedups we can reasonably expect from offloading our kernels to the GPU via OpenMP target directives? To answer that question, we note the following facts. In this example fluid dynamics problem most of the kernels are memory-bandwidth bound, since most of the work involves vector-like operations across all cells. Therefore we can at least expect performance improvements proportional to the ratio of the bandwidths of the GPU’s HBM2 memory to the CPU’s DDR4 main memory. Summit’s HBM2 theoretical peak bandwidth is GB/s,666https://www.olcf.ornl.gov/for-users/system-user-guides/summit/nvidia-v100-gpus/ while its DDR4 bandwidth is GB/s,777https://www.olcf.ornl.gov/for-users/system-user-guides/summit/system-overview/ implying a HBM2 to DDR4 bandwidth ratio of . Since most of the GPU offloaded kernels get speedups exceeding this ratio, it seems that we also benefit from the much higher computational power of the GPUs.
Figure 5 shows the timing proportions of the different portions of the GPU runs of the 3D RiemannProblem, revealing prime targets for further attention. Despite overall speedups of 6X and beyond, the data transfers between the GPU and host memory loom large in taking more wall time than anything else in our application. The primary cause of these data transfers is the need to move the fluid data for MPI communication (ghost exchanges and time step reduction) for every time step, since our MPI communication is done on the host CPU. In the next section we discuss how we have alleviated these costs.
5 Pinned Memory
Figure 5 suggests that further speedups can be achieved if we can reduce the time required for data transfers between host and device. Host data that are allocated on a page-locked memory—more commonly known as pinned memory—can be transferred between host and device much more efficiently than data allocated on pageable host memory. However, OpenMP 4.5 does not provide a mechanism to allocate host data on pinned memory. To do this we provide new Fortran routines AllocateHost() and DeallocateHost() as wrappers to the CUDA functions cudaHostAlloc() and cudaFreeHost(), respectively. We added an option to the initialization method of StorageForm to allocate the data member as pinned memory by calling the routine AllocateHost(), instead of using the the intrinsic Fortran statement allocate.
Figure 6 shows the weak scaling plot of the 3D RiemannProblem of the GPU runs with and without the use of pinned memory. In this figure, the line labeled “GPU” is the same as the one in Figure 2. The line labeled “GPU + Pinned Memory” shows the timings when FluidCurrent in Algorithm 2 is allocated on pinned memory. We observe speedups between when pinned memory is used, resulting overall speedups of relative to 7 CPU threads. We plot the timing distribution of the different computational kernels when pinned memory is used in Figure 7.
6 Conclusion
In this paper we describe our use of OpenMP 4.5 to implement GPU-related infrastructure in GenASiS Basics and port fluid dynamics kernels in the RiemannProblem example. This has proved to be simple and effective, yielding speedups of for our RiemannProblem. In section 5 we went beyond the current OpenMP 4.5 specification to achieve even further speedups to using pinned memory. These results further motivate the need for more advanced memory management with OpenMP, which is available in the new OpenMP 5.0 specification.
Acknowledgements
This material is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Nuclear Physics under contract number DE-AC05-00OR22725; the National Science Foundation under Grant No. 1535130. This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Christian Y. Cardall, Reuben D. Budiardja, Eirik Endeve, and Anthony Mezzacappa. Genasis: General astrophysical simulation system. i. refinable mesh and nonrelativistic hydrodynamics. The Astrophysical Journal Supplement Series , 210(2):17, 2014.
- 2[2] E. Endeve, C. Y. Cardall, R. D. Budiardja, and A. Mezzacappa. Generation of Magnetic Fields By the Stationary Accretion Shock Instability. The Astrophysical Journal , 713:1219–1243, April 2010.
- 3[3] E. Endeve, C. Y. Cardall, R. D. Budiardja, S. W. Beck, A. Bejnood, R. J. Toedte, A. Mezzacappa, and J. M. Blondin. Turbulent Magnetic Field Amplification from Spiral SASI Modes: Implications for Core-collapse Supernovae and Proto-neutron Star Magnetization. The Astrophysical Journal , 751:26, May 2012.
- 4[4] E. Endeve, C. Y. Cardall, R. D. Budiardja, A. Mezzacappa, and J. M. Blondin. Turbulence and magnetic field amplification from spiral SASI modes in core-collapse supernovae. Physica Scripta Volume T , 155(1):014022, July 2013.
- 5[5] Christian Y. Cardall and Reuben D. Budiardja. Stochasticity and efficiency in simplified models of core-collapse supernova explosions. The Astrophysical Journal Letters , 813(1):L 6, 2015.
- 6[6] Reuben D. Budiardja, Christian Y. Cardall, and Eirik Endeve. Accelerating our understanding of supernova explosion mechanism via simulations and visualizations with genasis. In Proceedings of the 2015 XSEDE Conference: Scientific Advancements Enabled by Enhanced Cyberinfrastructure , XSEDE ’15, pages 1:1–1:8, New York, NY, USA, 2015. ACM.
- 7[7] Christian Y. Cardall and Reuben D. Budiardja. Genasis basics: Object-oriented utilitarian functionality for large-scale physics simulations. Computer Physics Communications , 196:506 – 534, 2015.
- 8[8] Christian Y. Cardall and Reuben D. Budiardja. Genasis basics: Object-oriented utilitarian functionality for large-scale physics simulations (version 2). Computer Physics Communications , 214:247 – 248, 2017.